
Abstract
In machine learning, a crucial task is feature selection in that the computational cost will be increased exponentially with increases in problem complexity. To reduce the dimensionality of medical datasets and reduce the computational cost, multi-objective optimization approaches are mainly utilized by researchers. Similarly, for improving the population diversity of the Flamingo Search Algorithm, the neighbourhood centroid opposition-based learning mutation is employed. In this paper, to improve the classification accuracy, enhance their exploration capability in the search space and reduce the computational cost while increasing the size of dataset, neighbourhood centroid opposition-based learning (NCOBL) is integrated into the multi-objective optimization based Flamingo Search Algorithm (MOFSA). The optimal selected datasets are classified by using the weighted K-Nearest Neighbour classifier. With the use of fifteen benchmark medical datasets, the efficacy of the suggested strategy is assessed in terms of recall, precision, accuracy, running time, F-measure, hamming loss, ranking loss, standard deviation, mean value error, and size of the selected features. Then the performance of the suggested feature selection technique is compared to that of the existing approaches. The suggested method produced a minimum mean value, standard deviation, mean hamming loss, and maximum accuracy of about 99%. The experimental findings demonstrate that the suggested method may enhance classification accuracy and also eliminate redundancy in huge datasets.
Keywords
Introduction
In machine learning, an important pre-processing step is the feature selection (FS) process because of the increase in the dimensions and volume of information [1]. Many times the original features in the dataset may contain redundant features that are not necessary for regression and classification tasks. If we consider these redundant features, the classification performance will decrease [2]. Without losing any useful information content of the data it can be eliminated by using the feature selection approach [3]. The major benefits of FS techniques are an improvement in the effectiveness of classification and a decrease in the complexity of the dataset as well as the cost of computation. In the field of medical diagnosis, the feature selection approach gets more attention due to the widespread data generation by medical establishments. Filter based and wrapper-based approaches are the two main types of FS approaches [4]. Without using any learning methods the inherent characteristics of data are analysed and ranked based on the relevance of features and subsets are selected by the filter-based algorithm. The additional attributes are selected and ranking attributes are involved in this approach. The relationship between the dataset features is considered by the wrapper-based algorithms [5]. For the generation of various subsets of properties, the optimization algorithm is employed by this approach based on the appropriateness of the sub-categories. When comparing the performance of filter-based feature selection approaches, the wrapper-based approach had shown better performance [6].
The wrapper-based FS technique seeks to minimise the number of features used while retaining accuracy [7]. To achieve this goal a suitable optimization algorithm should be chosen. The selected features by the traditional optimization approaches cannot be efficient and effective due to the high dimension search space. Recently, meta-heuristic optimization techniques have been used in FS problems because they can find optimal solutions by utilising some global search techniques. This has helped a wrapper strategy to identify optimal feature subsets. The differential evolution (DE), particle swarm optimization (PSO), memetic algorithm (MA), Flamingo Search Algorithm (FSA), ant colony optimization (ACO), and genetic algorithm (GA) are some meta-heuristic feature selection techniques [8–12] used for FS. Based on the objective function these optimization approaches are classified as single-objective optimization approaches and multi-objective optimization approaches. For satisfying the two goals of wrapper based feature selection approach, the multi-objective FS approaches are employed. The FSA is a popular optimization algorithm which is inspired by the foraging and migratory behaviour of flamingo birds [13]. In various optimization problems, FSA has been mainly utilized. When compared with existing algorithms the FSA have better convergence speed, search accuracy and stability. To improve the performance of FSA for high dimensional datasets, mutation operators such as opposition based learning (OBL), Levy flight mutation and Cauchy mutation can be applied. The neighbourhood centroid opposition based learning (NCOBL) mutation operator is used in this research to present the multi-objective FSA [14]. Consequently, the mutation operator increases the suggested approach’s convergence speed. Multi-Label Feature Selection Algorithm (MMFS) [15], Multi-Objective Artificial Bee Colony (B-MOABC) [16], and Multi-Objective Harris Hawks Optimisation and Fruitfly Optimisation Algorithm (MOHHOFOA) approach [17] are used to validate the performance of the suggested strategy.
The following list includes the article’s key contributions: A novel FS strategy called NCOBL-MOFSA is proposed as a remedy for the inferior solutions to premature convergence and attains well balanced trade-off between exploration and exploitation strategy. To improve the population diversity of the FSA, the neighbourhood centroid opposition-based learning mutation is employed. To classify the diseases, the weighted K-Nearest Neighbour (KNN) classifier makes use of the optimum features that are chosen using the suggested feature selection methodology. The effectiveness of the suggested FS strategy NCOBL-MOFSA is compared with four conventional approaches using fifteen benchmark medical datasets. The evaluation parameters utilized are precision, accuracy, recall, running time, F-measure, hamming loss, ranking loss, standard deviation, mean value error and size of selected features.
The remainder of the article is structured as follows. The related works are explained in Section 2. The suggested strategy is detailed in Section 3. A discussion of the experimental findings is included in Section 4. The report is finally concluded in Section 5 with information on future studies.
Related works
The sequential or random based search strategy is used in wrapper based FS methods. The features sequentially add or remove could lead to trapping in local optimum solutions. Utilising random search approaches based on metaheuristic algorithms and their many search strategies, including sequential backward search, sequential forward search, and floating search, might help solve local optimal issues [1]. Since they employ gradient-free methods, the metaheuristics are effective in obtaining global optimum values [2]. The researchers’ understanding of the wrapper-based FS is still hazy. The multiple inertia weight strategy based co-evolution binary particle swarm optimisation is developed in [3] to enhance the global search capacity and good variety by dividing the particle population into numerous species and different inertia weight schemes. In [4] proposed a binary version of ant lion optimizer (BALO) algorithm for feature selection by adaptively optimized search of features in the space with the required diversity in population and well balanced trade-off between exploration and exploitation strategy.
In [18] a multi-objective feature selection algorithm called MOFS-BDE is proposed based on self-learning and Binary Differential Evolution (BDE). The performance is improved with the new three operators. To generate fresh solutions, a probability difference based new binary mutation operator is proposed. In the population, the elite individuals are refined using purifying search of one-bit. The crowding distance idea is paired with non-dominated sorting to cut down on time consumption and choose the best parent people. The findings show that the suggested strategy may balance local exploitation and global exploration while combining binary mutation and OPS. The algorithm’s ability to directly handle continuous or categorical information is constrained by the binary representation. A multi-objective approach is recommended in [19] for the prediction of warfarin dosage. They also employ the multi-objective PSO (MOPSO) and the Non-dominated Sorting Genetic Algorithm-II (NSGA-II) in addition to the artificial neural network. On 553 patients the INR test was performed during 2013–2015. To predict the dosage, the identification of genetic and clinical features is involved. In the experimental results, the MOPSO obtained higher accuracy than NSGA-II.
In [20], a feature in hyperspectral imagery is chosen using the multi-objective algorithm called the discrete sine cosine algorithm (SCA). To reduce duplication and increase the significance of the chosen feature subset, the suggested method uses a novel and practical hyper spectral FS framework where the ratio between mutual information (MI) and Jeffries-Matusita (JM) is displayed. To increase the quantity of information and to address the problem of choosing discrete hyperspectral features, a different measurement known as variance has been used. The proposed discrete SCA broadens the options for choosing the optimum feature’s subcategories. Five hyperspectral image data sets, ten conventional UCI data sets, and an experiment employing these datasets have all been utilised to demonstrate the usefulness and efficiency of the proposed technique. In [21] provides a description of the two-archive Multi-Objective Artificial Bee Colony (MOABC) algorithm solution to the FS issue. For observer bees the diversity-guiding search and for employed bee’s the convergence-guiding search are the two new operators that have been presented to find a non-dominated group with convergence and distribution. The two archives that have been used to enhance the search capabilities of various types of bees are the external archive and the leader’s archive. The outcomes show that this approach outperforms the single-objective ABC algorithm.
Using the criteria of simultaneously minimising the makespan and overall cost, the multi-objective fruit fly optimization algorithm (MOFOA) is suggested in [22]. For order preference, a search method based on vision is also applied. The effect of the parameters is also investigated using a design-of-experiment approach. This model performed well when measured against a number of common benchmarks and when the results were compared to those of other optimization techniques. A cloud model is employed in [23] to simulate food circumstances, and the FOA is supplied to resolve problems that have multi-objective functions. There is also the use of a self-adaptive parameter strategy. To improve diversity, the nearest neighbour distance is normalised.
A multi-objective FOA technique is detailed in [24] to address the issue of test point selection. Fruit fly locations are indicated by the binary string. When compared to other algorithms, the performance data for this model demonstrates that it has performed in an acceptable manner. A new recombined model for predicting air pollution is described in [25] and is depend on the multi-objective Harris hawks optimization method. In order to forecast air pollution time series, an extreme learning machine (ELM) is also used. This study evaluates and tests an air pollutant concentration system in three Chinese cities using a variety of different criteria. In experiments, this model is found to work successfully. An optimization problem with multi-objective function has been presented in [26] for selecting the features based on DE to locate generally similar clusters without knowing in advance how many clusters will be found using less features in the data sets. Additionally, a number of real-world experiments have been carried out with numerous synthetic criteria utilising a variety of clustering algorithms in order to analyse the suggested methodology. Additionally, the outcomes imply that the strategy they propose can considerably enhance clustering performance while lowering dimensionality.
Ruiz and Stutzle, 2007 [5] proposed an Iterated Greedy (IG) based wrapper feature selection algorithm for efficiently finding the best subset from all existing features with well-balanced destruction and construction operations at each iteration based on pre-calculated filter scores. This method avoids exploring the entire search space. A simple and effective IG based novel wrapper feature selection algorithm that is strategically guided by their pre-calculated filter scores is proposed by Gokalp et al. 2020 [6] for developing an effective feature selection method with the best dimensionality reduction in a sentiment analysis framework. In [7], a greedy crossover technique is integrated into coronavirus herd immunity optimizer (CHIO) to improve their exploration capability in the search space as a remedy for the inferior solutions to premature convergence and when it is locked into a local optimum search space.
Two multi-objective functions for FS proposed in [27] used the artificial butterfly optimization technique. The objective of the first solution was maximizing the accuracy of classification, and the objective of the second solution was to reduce the number of characteristics. The suggested method outperforms the examined methods in experiments on eight data sets, and both solutions outperform single-objective methods. Because FS’s problem is continuing and the multi-objective Grey Wolf Optimizer(GWO) method was developed to address continuous optimization issues, FS is given this option in [28]. A deep learning network was utilised to assess the subset categorization of the chosen characteristics, and the binary form was given with the operator of the sigmoid transmission function. Fifteen benchmark data sets were utilised to compare and assess the performance of the suggested technique using the MOPSO and NSGA-II algorithms. Most of the time, reducing features and classification mistakes while using less processing power is preferable to most of the optimization problems with multi-objective functions.
Proposed feature selection strategy
The suggested framework consists of pre-processing, feature selection and classification. At first, the collected medical dataset is pre-processed to speed up the process. Then the pre-processed features are selected using the suggested feature selection strategy. At last, the optimal selected features are used by the weighted KNN classifier to classify the disease. The suggested strategy’s design is depicted in Fig. 1.
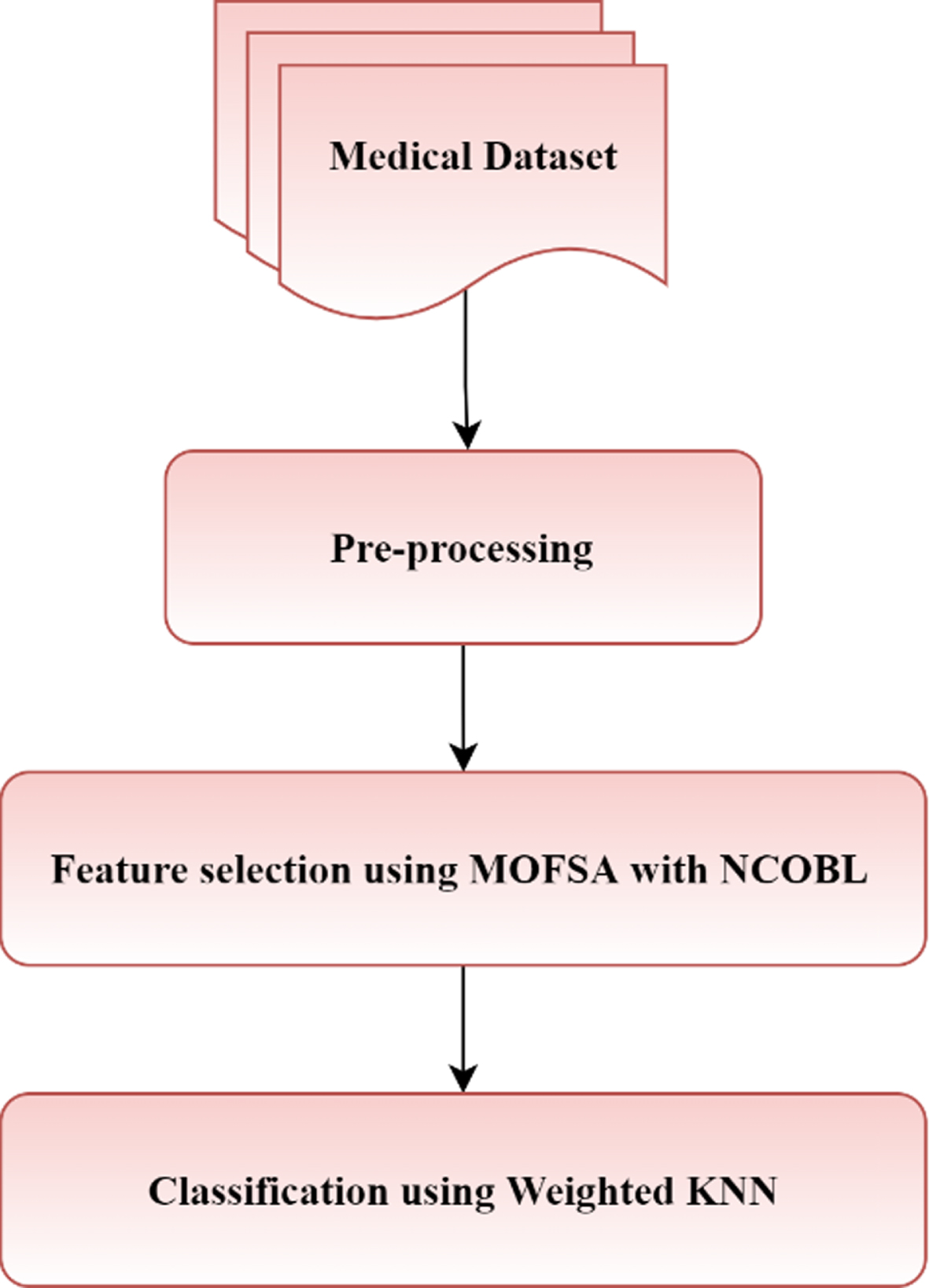
Framework of the suggested strategy.
To increase the quality of the dataset, cleaning is the first step in data pre-processing. In this stage, duplicates are eliminated, missing values are handled, and encoding is done. Only numeric data can be read by machines, however the dataset includes both nominal and numeric data. Therefore, encoding is used to transform the dataset’s character data into numeric values. Data scaling is the final pre-processing step done to speed up the procedure. The dataset’s characteristics exhibit significant range, magnitude, and unit variation. Scaling can normalise the dataset within the range [0, 1] because it is required to keep all the data in one format.
Feature Selection using NCOBL-MOFSA
The suggested strategy is used to choose the best features from the pre-processed dataset. The MO-FSA is combined with the neighbourhood centroid opposition learning based mutation operator. In the proposed approach multi-objective feature selection approach is proposed with a weighted KNN classifier. MOFSA is proposed with an NCOBL mutation operator. The flowchart of the suggested feature selection strategy is illustrated in Fig. 2. The proposed approaches main processes are discussed in this section.
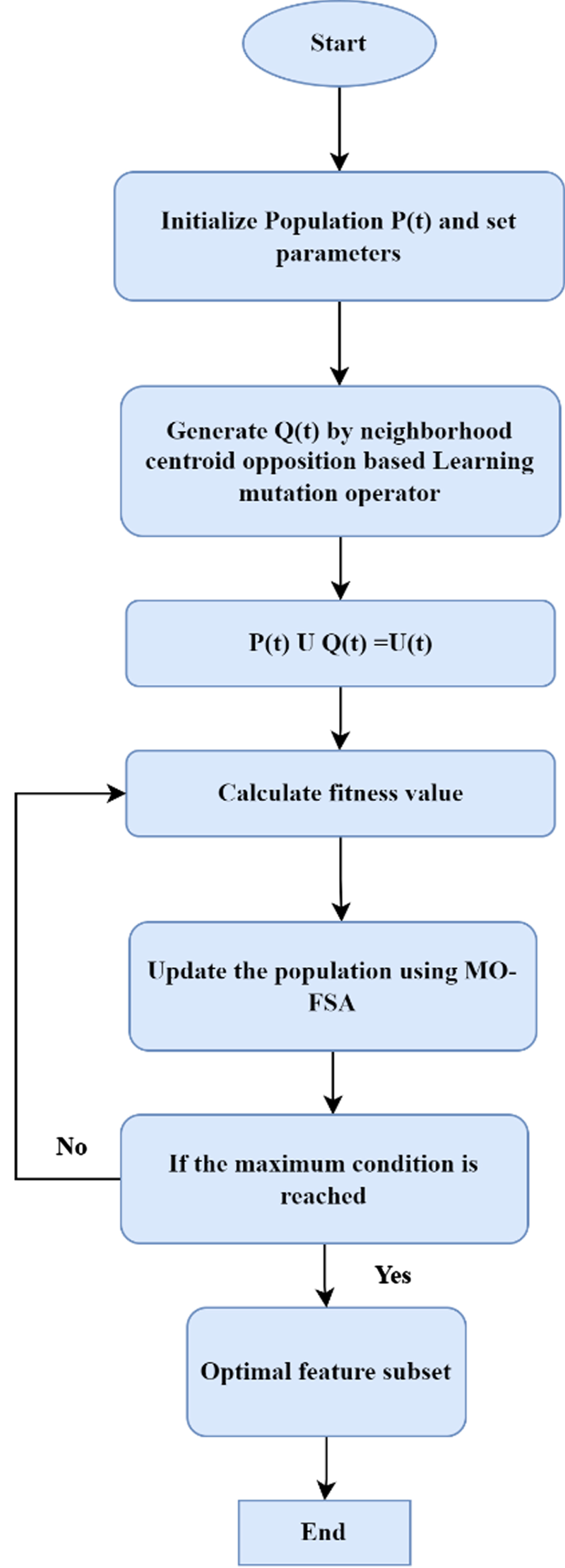
Flowchart of proposed feature selection approach.
Initially, the population P(t) is initialized and parameters are set. To mutate the population P(t), the neighbourhood centroid opposition learning based mutation operator is employed. The offspring population Q(t) is produced by the mutation operation. The joint population is obtained by combining the offspring population Q(t) and population P(t). Then the fitness function is calculated. Based on the fitness function, the position is updated based on the FSA. This process is repeated until the maximum iteration condition is achieved. The final output of this process is considered as the optimal selected features. This optimal feature subset is used to classify the diseases using a weighted KNN classifier. Then the performance is evaluated using various performance measures. The values are compared with existing approaches.
A random number among 0 and 1 is created using SN individuals, initialising the population as P. Initialization of the parameters is done, and each population’s size is decided. The first section makes the claim that flamingos are migrating, MP b . The maximum iteration is taken as Iter Max . In the i th iteration of population renewal, the number of foraging flamingos is MP r = rand [0, 1] ×P × (1 - MP b ). In the first part of the iteration, the number of migrating flamingos is MP0 = MP b × P. In the next section of the iteration, the number of migratory flamingos is MP t = P - MP0 - MP r . Based on the fitness value of flamingos, the population of flamingos is organized. The high fitness former flamingos MP b and low fitness former flamingos MP t are considered as migratory flamingos and others are considered as foraging flamingos. Equation (1) is used to modify the location of the flamingos’ foraging activities.
Where, (t + 1)
th
iteration in j
th
dimension i
th
flamingo is represented by
Where, t
th
iteration flamingo location is represented as
OBL’s objective is to simultaneously analyse the present and its reverse solution and choose the better one to increase search efficiency. The reverse points in OBL are computed using the maximum and minimum boundaries. OBL has the drawback of not fully utilizing population-wide search data, which is a drawback. The NCOBL operator is used by the FS strategy to change the optimal seagull location in order to escape the local optimum. It can be defined as follows
The search space is D-dimensional, with unit mass X = [x1, x2, …, x
n
] is considered to be n points; then, the total center of gravity can be explained as given in Equation (3)
The reverse point of X
i
can be defined as given in Equation (4)
where
In the proposed feature selection approach, two objectives are considered. The multi-objective function aims to increase classification accuracy while decreasing dataset size. Increasing classification accuracy is the first fitness function that is taken into account. For that, Equation (5) is used to calculate the classification error.
Where total instances are denoted by I
total
and I
e
represents the predicted instances. This function calculates the minimum error. The second fitness function considered is minimization of the feature size. This can be calculated using Equation (6).
Where the ith value of the feature set is denoted by x i . The dataset’s overall number of features is represented by F.
The K-nearest neighbours (KNN) approach has been applied in the feature selection techniques in recent years. The conventional KNN technique can be thought of as giving each nearest neighbour a weight of 1/K. In other words, K-nearest neighbour samples contribute equally to the prediction testing sample category, ignoring the possibility that the significance of various nearest neighbours may vary. The likelihood that two samples will fall into the same category increases with sample proximity, hence its significance should increase. Therefore, each of K neighbours should be given a weight based on how close it is to the testing sample, if it is a regression or classification task. The allotted weight of the neighbour increases with closer distance. As a result, the weighted KNN approach is utilised in this work to determine sample prediction.
According to the weighted KNN approach, which is based on KNN, different nearest neighbours may have varying degrees of importance. This is because it is assumed that the closer a neighbour is to the target variable, the more influence it will have on the target category’s prediction. As a result, each neighbour is given a distance weighting. Using the KNN, the class label
Where, the number of nearest neighbours is denoted K, and the nearest neighbours’ class labels are denoted by y
j
. After considering the distance weighting, the target variable
Between x j and x i the Euclidean distance is represented by d ij . A function of weighting of the distance d ij can be denoted by wd ij , and the value of w (d ij ) is between [0, 1].
Dataset details
The efficacy of the suggested feature selection strategy is evaluated using 18 benchmark datasets from the OpenML [29], including SpamBase, Sonar, Arrhythmia, Madelon, Isolet, Colon-cancer, Hepatitis, Iris, Lymphography, Primary-tumor, Breast-cancer, Lung-cancer, Liver-disorders, Dermatology, and Leukaemia. The dataset is described in Table 1 and includes the dataset name, the number of features, the number of data samples, and the number of classes.
Dataset details
Dataset details
Python programming is used to implement the suggested model in Google Colab [30]. A Jupyter-based environment called Google Colab runs in a web browser. Python code is able to be developed and run on this open-source platform. Datasets are stored in Google Drive and mounted on the Google Colab.
Parameter settings
The parameter setting of the proposed approach and existing approaches are illustrated in Table 2.
Parameter Setting
Parameter Setting
To assess the effectiveness of the suggested approach the performance metrics utilized are recall, precision, accuracy, ranking loss, hamming loss and F1 score. The way of computing these metrics is explained in the below section.
Where, the intersection among γ i and are denoted ∩ and φ i denotes the anticipated label list for i. Label count may be expressed as |L|. The multi-label dataset may be represented as s ={ (s i , γ i ) |1 ⩽ i ⩽ |s| }, Z i specifies a specific instance and its real label subset are indicated by γ i ∈ L. The symmetric variance among the predicted label subsets and true label is denoted by ⊕. P i denotes the set of labels predicted by the suggested classifier.
The suggested approach’s performance is contrasted with that of three well-known techniques, including MMFS, B-MOABC, and MOHHOFOA. The suggested technique is compared in terms of pareto front analysis in Fig. 3. A method used in multi-objective optimisation issues is Pareto front analysis, commonly referred to as Pareto front optimisation or Pareto front discovery. In order to find the optimum trade-offs among competing goals, it seeks to determine the set of ideal solutions. This comparison is made with various approaches currently in use using the Spambase dataset. The graph’s y-axis represents classification error, while its x-axis represents the size of the ideal feature collection. The feature size decreased along with the decrease in classification error. As a result, two objective functions remain in balance. According to the Pareto front results, the suggested NCOBL-MOFSA approach can reduce classification mistakes while also guaranteeing a decreased solution size for all 15 datasets.
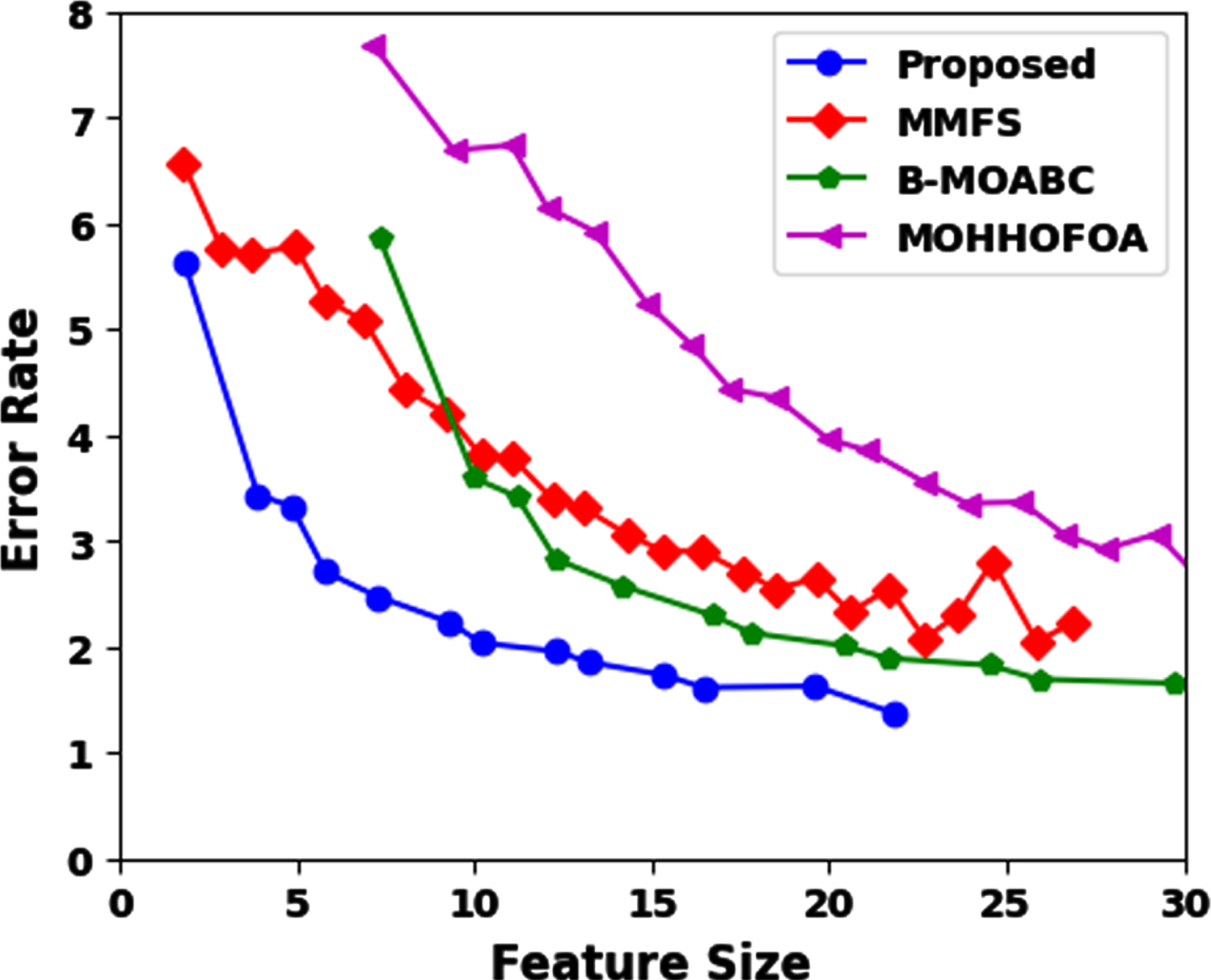
Pareto front analysis.
Figure 4 compares how well the suggested technique performs in terms of precision, accuracy, recall, F-measure, and specificity using boxplot analysis. Figure 4(a) compares the proposed approach’s accuracy to that of existing methodologies for all datasets using box plot analysis. The datasets used by Spambase for the suggested technique had a 99.3 accuracy rate. For the suggested strategy, the box plot’s top quartile is 99%. The greatest upper quartile values for current techniques like MMFS, BMOABC and MOHHOFOA algorithms are 94%, 93%, and 92%, respectively. As a consequence, the box plot of all known approaches demonstrates that the recommended strategy has the highest value of the upper quartile. In comparison to the already used ways, the recommended solution has a greater median line of the box. The accuracy, recall, F-measure, and specificity of the proposed technique are compared with those of existing approaches in box plot analysis, as shown in Figures 4(b), 4(c), and 4(d). The suggested methodology outperformed the other existing strategies. Since the average performance of all the strategies is higher, the box plot contains no potential outliers.

Comparison of performance (a) accuracy (b) Precision (c) Recall (d) F-measure (e) Specificity.
The size of the selected features is compared with existing approaches such as MMFS, B-MOABC and MOHHOFOA in Fig. 5. The strategy that uses a smaller set of features can shorten training time while increasing classifier accuracy. The suggested method needs to use fewer features that have been specifically chosen in order to increase accuracy. The suggested technique has fewer features that have been selected for all 15 datasets, as shown in Fig. 3. The proposed approach has the lowest feature size when compared with the existing approaches.

Selected features comparison.
Table 3 compares the average fitness values for several approaches across various datasets. On analysing the table it is observed that for all the 15 datasets, the suggested method achieves lower average fitness values compared to the other methods like MMFS, B-MOABC and MOHHOFOA. Lower fitness values generally indicate better performance or higher quality solutions. From the results, it can be known that the suggested NCOBL-MOFSA approach has better fitness value than the existing approaches.
Comparison of average fitness
Figure 6 shows the comparison of the hamming loss and ranking loss of the suggested feature selection with existing approaches. Hamming loss measures the fraction of incorrect labels for the suggested multi-label classification problem, where a lower value indicates better performance. Ranking loss, on the other hand, quantifies the inconsistency between the predicted rankings and the true rankings of labels. In the suggested approach the radar chart is used to compare the outcomes. On analysing the radar chart it is found that for most of the datasets, the hamming loss and ranking loss are lower than the existing MMFS, B-MOABC and MOHHOFOA strategies which specify that the suggested approach performs well in terms of both Hamming loss and Ranking loss compared to the other methods.
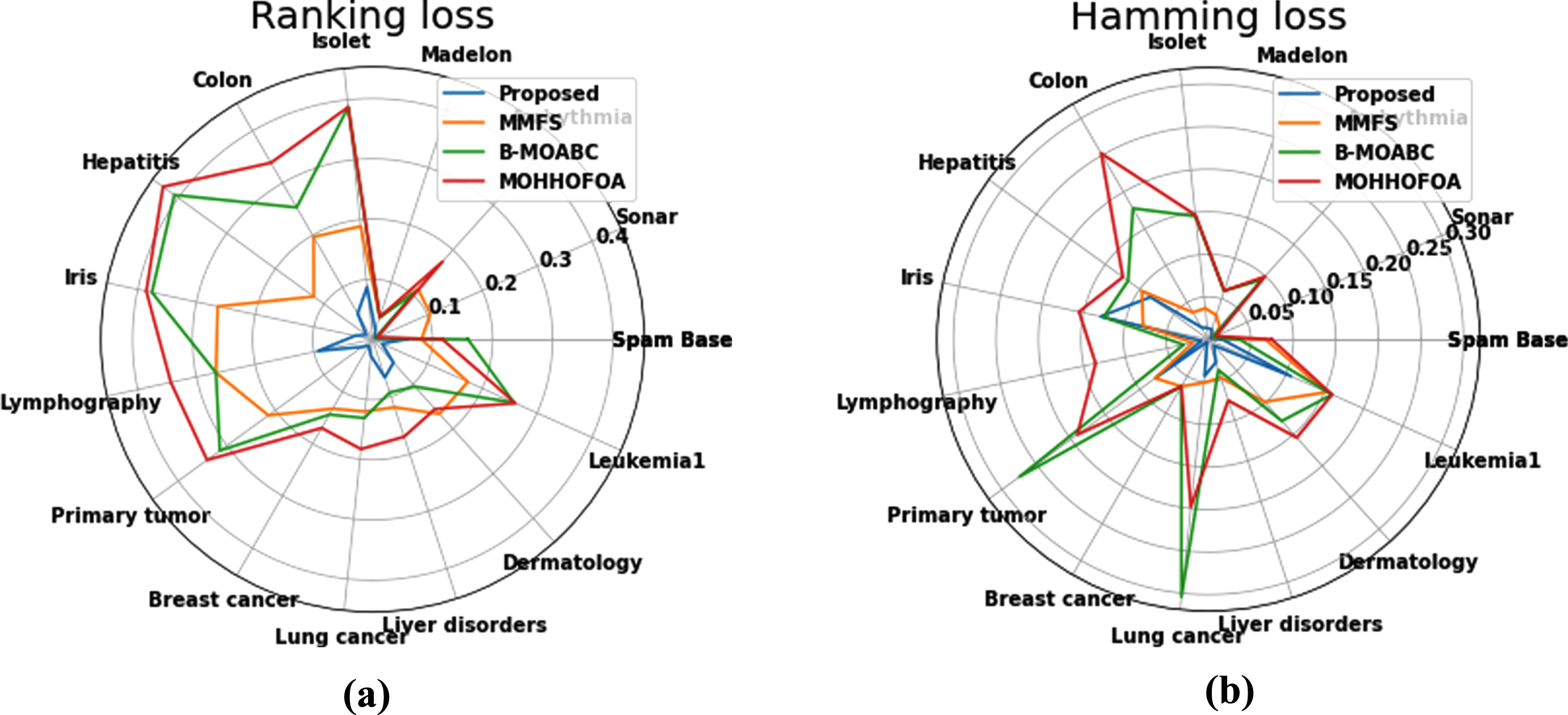
Comparison for (a) Ranking loss and (b) Hamming loss.
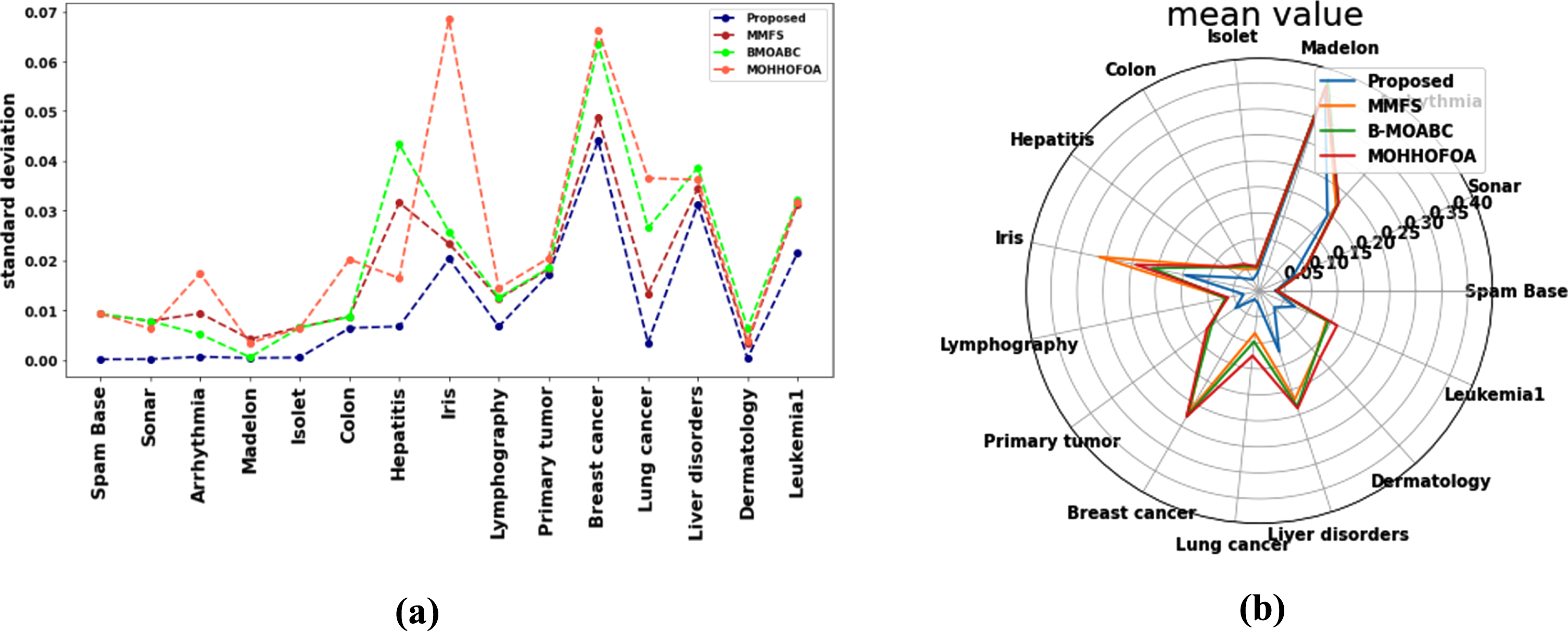
Error comparison (a) Standard deviation (b) Mean value.
In Fig. 4 mean value and standard deviation are represented as box plot analysis. This figure provides the standard deviation as a measure of variability or spreads in the results, while the mean represents the average value. Lower standard deviation values indicate less variability, which can be desirable in many cases. Higher mean values can suggest better performance, depending on the specific evaluation criteria and the nature of the problem. Based on the figure, the suggested method shows relatively lower variability (as indicated by the standard deviation) compared to the other methods in several datasets. This suggests that the suggested method may provide more stable and consistent results.
Figure 8 compares the suggested approach’s running time to that of the current techniques MMFS, B-MOABC, and MOHHOFOA. In the proposed approach lower runtimes generally indicate faster execution. On analysing the figure it is found that all 15 datasets take lower runtimes for the suggested strategy compared to the existing MMFS, B-MOABC and MOHHOFOA approaches. The findings show that the suggested method may retain greater accuracy even if feature size is reduced.
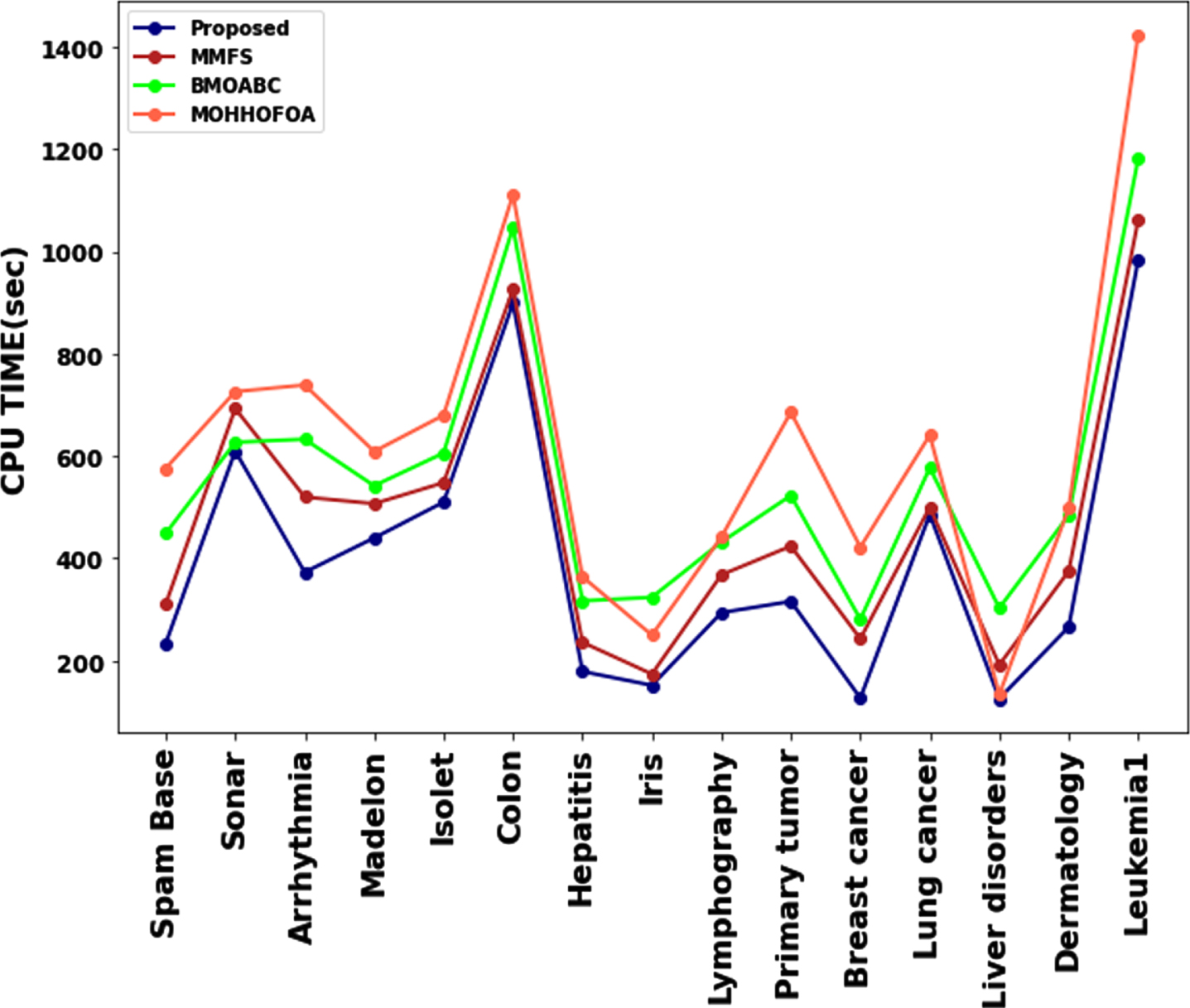
Running time comparison.
In order to categorise the medical datasets, a new multi-objective feature selection methodology is proposed in this study. In this study, the neighbourhood centroid opposition-based learning (NCOBL) is integrated into the multi-objective optimization-based Flamingo Search Algorithm (MOFSA) to increase the size of the dataset while reducing computational cost, improving exploration capability in the search space, and improving classification accuracy. The weighted K-Nearest Neighbour classifier is used to categorise the best-chosen datasets. With the use of fifteen benchmark medical datasets, the efficacy of the suggested strategy is assessed. The suggested feature selection technique’s performance is compared to that of existing methods in terms of precision, accuracy, recall, running time, F-measure, hamming loss, ranking loss, standard deviation, mean value error, and size of the selected features. According to the experimental findings, the suggested technique can choose the optimal features with a better degree of accuracy of 99%. Despite having good performance, the suggested solution does not employ a dataset balancing strategy. The performance of the suggested strategy will be enhanced by the use of dataset balancing techniques.