
Abstract
With the rise of group decision-making and the increasingly complex decision-making environment, preference modeling for decision makers has become more and more important, and many preference modeling methods have emerged. Based on the fuzzy theory, researchers have proposed a large number of preference models to express the subjective uncertainty of decision makers. These methods based on fuzzy theory are collectively referred to as fuzzy preference modeling methods. The fuzzy sets preference model is the first practice of fuzzy theory used in the field of preference modeling, and it is still widely used by researchers until now. Subsequently, based on fuzzy theory, the researchers also proposed linguistic term sets and cloud model. These methods have different representation domains, and are applicable to different decision-making environment. In this paper we give a review of classical fuzzy preference modeling methods and its latest extensions and variants. After the presentation of comparative analyses on the existing methods, we figure out some current challenges and possible future development directions in the field of fuzzy preference modeling.
Keywords
Introduction
As decision-making problems become more and more complex, it is difficult for human individual’s cognitive ability and decision-making ability to meet the requirements of complex decision-making problems. Therefore, Group decision-making (GDM) [27] is discovered as a more effective form of decision-making. Group decision-making refers to a process in which multiple decision makers participate in decision analysis, integrate individual judgments into group judgments, and then make decisions based on group information. Compared with the traditional single-person decision-making form, group decision-making reflects the scientific and democratic characteristics of the decision-making process, while ensuring the comprehensiveness, rationality and accuracy of the decision-making results.
However, the rapid development of group decision-making has brought many new demands and challenges to the decision-making process. Nowadays, the complexity of decision-making problems is not only reflected in the difficulty of modeling between multiple criteria and conflicting goals, the difficulty of handling a large number of alternatives, but also the lack of knowledge of decision makers, conflict of preferences and pressure of decision time. This means that the decision-making process contains more and more uncertainties, and decision makers always need to make decisions in a fuzzy environment. Therefore, expressing the subjective preference of decision-makers in a fuzzy environment, namely fuzzy preference modeling, is an important topic in the field of preference modeling, and it has become a prolific research area after Zadeh’s seminal fuzzy sets article in 1965 [68].
Since then, a variety of fuzzy preference modeling methods have emerged. According to the different representation domain, the mainstream fuzzy preference modeling methods can be summarized into 3 categories: fuzzy sets, linguistic term sets and cloud model [26]. These three methods are all extended from fuzzy theory, but they have different representation domains and use different models (fuzzy sets, linguistic variables, cloud models) to express the preferences of decision makers.
This paper is devoted to providing a systematic overview of the current fuzzy preference modeling techniques. After exploring the main idea of current techniques, we will present a brief discussion on each technique and highlight some current issues and challenges of fuzzy preference modeling. In order that, the rest part is organized as follows: Section 2 introduces the basic concepts of preference modeling. Section 3 introduces fuzzy preference modeling methods. Section 4 compares and analyzes the existing methods, and summarizes the development trend of preference modeling methods. Section 5 enunciates some concluding remarks.
Foundation of preference modeling
Normally, preference modeling refers to a decision-making process that represents and applies value judgments made by actors to different event states or alternatives according to their wishes. This model is built so that decision makers can better understand and express their preferences under given scenarios and problems. The established preference model is a formulaic expression of the object, which is expressed in an abstract language that includes both the structure of the object itself described and the corresponding calculation operation. This model is established for the purpose of calculation [3].
Some basic concepts of preference modeling are introduced as follows.
Structure of preference modeling
A classical group decision-making situation [17] is defined as a situation in which there is a problem to solve, a solution set of feasible alternatives, X = { x1, x2, …, x
n
} , (n ⩾ 2), and a group of decision makers, E = { e1, e2, …, e
m
} , (m ⩾ 2). The decision makers convey their preferences or opinions about the set of alternatives to achieve a common solution. In this case, the decision maker can express his/her preferences in the following two structures [24]: Non-pairwise comparisons. The preference of decision maker i about alternatives set X are described as n independent value judgements: P
i
={ pi1, pi2, …, p
in
} where p
ij
is the preference value of the i -th decision maker for the j -th alternative. Pairwise comparisons. In this case, the decision maker expresses his/her opinions by giving the preference relationship of any two alternatives in X, such as ‘x
a
≻ x
b
’ or ‘x
a
∼ x
b
’. The former can be interpreted as the preference degree of alternative x
a
over x
b
, and the latter means that the two alternatives have the same degree of preference. The symbol pr (x
a
, x
b
) is often used to indicate the quantified value of the degree of preference. Then, the preference of decision maker i about alternatives set X is a PRn×n:
It should be noted that consistency is a basic problem of preference relations (pairwise comparisons) [13]. For example, in aggregated preference relationship, alternative A “≻ ” alternative B, and alternative B “≻ ” alternative C, but alternative C “≻ ” alternative A, this is a typical inconsistency. It is obvious that consistent information, which does not imply any kind of contradiction, is more relevant or important than the information containing some contradictions [6]. However, due to the complexity of most GDM problems, experts’ preferences can be inconsistent. Fortunately, the lack of consistency can be quantified and monitored [25, 79].
Obviously, whether it is p ij in the non-pairwise comparisons structure or the pr (x i , x j ) in the pairwise comparisons structure, it may be vague and uncertain. Therefore, it is necessary to choose an appropriate fuzzy preference method to model them. In other words, p ij and pr (x i , x j ) can be represented by fuzzy sets, linguistic variables or cloud models.
Steps of preference modeling
The traditional decision-making process includes two main steps: aggregation and exploitation [47]. With the rise of group decision-making and the increased complexity of the decision-making environment, decision maker’s preference needs to be further processed, that is, preference modeling. In this way, the group decision-making process includes the following four steps, as shown in Fig. 1. The first two steps are preference modeling.

Group decision-making process.
At the beginning of
It can be found that preference modeling plays a vital role as the first step of group decision making. The quality of preference modeling directly affects the accuracy of consensus process and alternatives ranking, and even determines the success of group decision-making.
Fuzzy set is the basis of fuzzy preference modeling [16]. Linguistic term sets and cloud models are improved fuzzy preference technologies based on fuzzy theory [30, 51]. Linguistic term sets improve the accuracy of preference expression by introducing various forms of linguistic variables, while cloud model improves the computability of preferences by combining probability theory and fuzzy theory. Until now, these methods have been gradually improved, but there are still some shortcomings.
In order to systematically introduce the development of fuzzy preference modeling methodology, according to Kitchenum’s and Morente-Molinera’s guidelines [4, 38], the paper applies the following inclusion and exclusion criterion: only consider the development of novel fuzzy preference modeling methods (primary studies). Application articles were discarded.
The following will be introduced these methods.
Preference modeling based on fuzzy sets
Basic concepts of fuzzy sets
Traditional quantitative methods cannot measure the uncertainty of human behavior in the decision-making process [69]. Therefore, Zadeh [68] proposed the concept of Fuzzy Set in 1965. Its main argument points out that many decisions in the real world are made in an environment where the consequences of possible actions cannot be accurately known. According to the theory of Chan and Hwang [9], the rational decision-making process should take into account human subjectivity, rather than using probability to measure. As an effective tool for expressing human subjectivity, fuzzy sets have been widely used in the field of preference modeling and multi-criteria decision-making [17].
In the fuzzy sets proposed by Zadeh, membership is used to model the uncertainty. A simple membership function model is shown in Fig. 2. The abscissa x represents the variable value, and the ordinate u (u ∈ [0, 1]) represents the possibility of the corresponding x value.
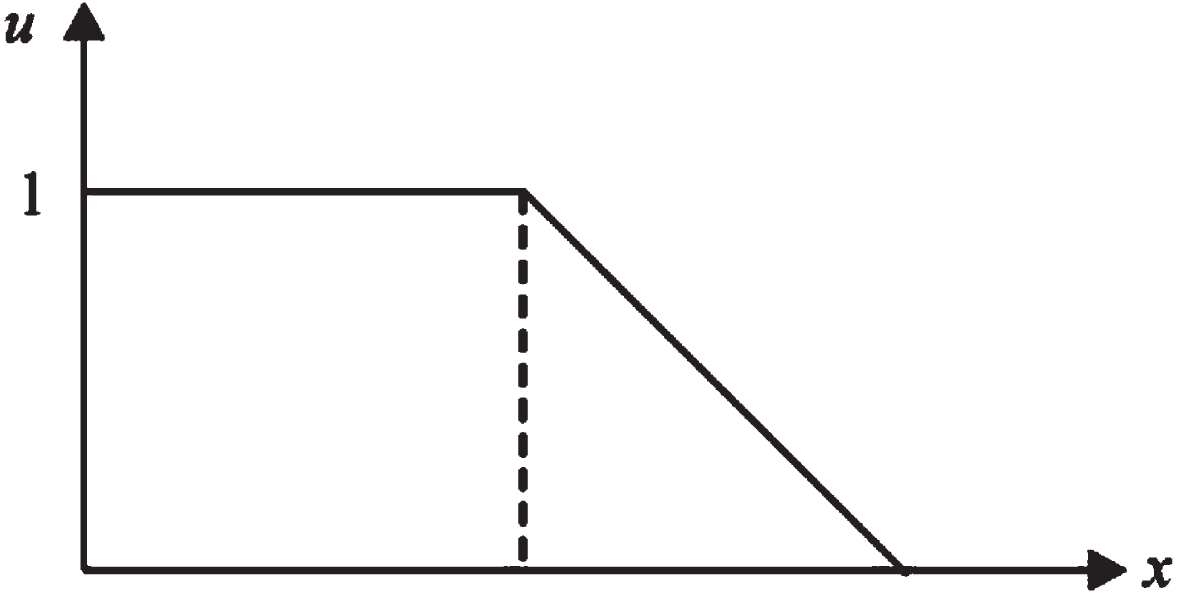
A membership function.
The membership function has always been the most important part of the fuzzy sets, which reflects the degree of ambiguity and the degree of hesitation. The basic definition of fuzzy sets is as follows:
Although the fuzzy sets open up a brand new field for group decision preference modeling, Atanassov [1] believes that the membership of traditional fuzzy sets can only be a unique number between 0-1, which still limits the subjective expression and cannot dig deeper into the degree of ambiguity in actual decision-making. Based on the above considerations, Atanassov proposed Intuitionistic Fuzzy Sets (IFSs). On the basis of membership, the concept of non-membership expressing negative semantics was added.
Because of its more flexible form of expression, it has received great attention in the field of fuzzy preference modeling. Many scholars have also made some extensions and improvements to intuitionistic fuzzy sets, Ren [45] studied interval-valued intuitionistic fuzzy sets. Zhao [77] studied type-2 intuitionistic fuzzy sets. Gau [18] studied Vague Sets similar to intuitionistic blur. There are also a large number of articles on the research of the operators of intuitionistic fuzzy sets. Liu [34] studied several basic aggregation operators of interval value intuitionistic fuzzy sets (IVIFSs) and applied them to group decision-making problems. Chen [10] studied the point operator of intuitionistic fuzzy sets, which was further extended to interval-valued intuitionistic fuzzy sets, and then proposed a multi-attribute decision-making method based on interval intuitionistic fuzzy sets. Some new arithmetic operations on Atanassov’s intuitionistic fuzzy sets that have good algebraic properties were proposed by Nguyen [39], such as intuitionistic fuzzy weighted arithmetic mean (IFWAM) and intuitionistic fuzzy weighted geometric mean operators (IFWGM).
In addition to providing fuzzy descriptions from different perspectives, there are studies that start from the membership itself, expand the dimension of the membership and enhancing the ability to express uncertainty. Mendel [36] introduced the concept of type-2 fuzzy sets, whose membership is no longer a value, but a fuzzy number on [0,1].
where x is a variable in X, u is the primary membership of x, μ
A
(x, u) is the secondary degree of membership for x and u, and
Scholars have successively extended the concept of fuzzy to “n-type” fuzzy sets that allow an element to belong to a set with a membership of n-1 type fuzzy sets [15]. Among them, the hesitant fuzzy sets (HFS) proposed by Torra and Narukawa [48] are the most widely used in multi-dimensional membership fuzzy sets.
HFS allows multiple memberships to exist simultaneously under the same attribute, which can better reflect the state of hesitation among different decision makers and is more in line with the actual situation in the field of complex group decision-making.
In terms of the HFS’s operators, Xia and Xu [59, 60] defined some algebraic operators for hesitant fuzzy elements based on the relationship between hesitant fuzzy sets (HFS) and intuitionistic fuzzy sets (IFS). Based on these algebraic operators, aggregation operators including hesitation fuzzy weighted average (HFWA), geometric hesitation fuzzy ordered weighted average (HFOWA) and hesitation fuzzy ordered weighted geometric operator (HFOWA) are defined. In terms of the extended model of hesitant fuzzy sets, Zhu and Qian [44, 80] combined hesitant fuzzy sets with intuitionistic fuzzy sets, and proposed dual hesitant fuzzy sets (DHFS) and generalized hesitant fuzzy sets (GHFS), respectively. Chen [8] combined hesitant fuzzy sets and interval-valued fuzzy sets, and proposed interval-valued hesitant fuzzy sets (IVHFS). Based on triangular fuzzy numbers, Wei [58] proposed a hesitant triangular fuzzy set (HTFS) and gave some aggregation methods for hesitant triangular fuzzy information. He [23] defined a hybrid model called hesitant fuzzy soft set by combining hesitant fuzzy set with soft set.
From the perspective of set relations, fuzzy sets emphasize the indistinguishability of the set boundary and the indistinguishability between objects, similar to the inclusion relationship. From the perspective of the objects studied, fuzzy sets study the membership of different objects in the same category. From the perspective of uncertainty assessment, the membership functions of fuzzy sets are mostly a priori functions given by experts based on experience, with strong subjectivity.
Fuzzy sets have been developed for 50 years, the most important application in the field of decision is fuzzy preference modeling [17]. Fuzzy sets and its extensions include: Intuitionistic Fuzzy Sets, Vague Sets, Hesitant Fuzzy Sets, Soft Sets, etc. These tools are designed to more fully express subjective ambiguity and uncertainty in order to better complete the group decision-making process. Due to the unique non-membership, there are more researches on intuitionistic fuzzy sets than other fuzzy sets, and it has become the focus of fuzzy preference modeling. In the field of fuzzy preference modeling, fuzzy sets still have irreplaceable importance, and new forms of fuzzy sets and corresponding similarity measure operators, entropy evaluation operators and aggregation operators may be more urgent research directions.
Basic concepts of linguistic term sets
The complexity and uncertainty of objective things and the ambiguity of human thoughts sometimes make it impossible to use precise numbers or mathematical models to express their preferences when obtaining the true will of decision makers. At this time, the evaluation information given by decision makers in natural language phrases is often closer to reality, especially for some complex decision-making problems that are difficult to quantify. In other words, the value of the variables is not a number, but a word or sentence in natural or artificial language.
The concept of linguistic decision was first proposed in 1975, Zadeh [69] proposed the concept of linguistic variable, and the basic linguistic term sets, S = very low, low, medium, high, very high. Then Zadeh combined fuzzy theory and linguistic variables establish a linguistic model, called fuzzy linguistic method. Subsequently, in order to further improve the computability of the linguistic preference model, the concept and method of computing with words (CWW) were proposed [71].
The representation of complex language that is a five-tuple form.
The three denotations, i.e., the name s, its semantics M (s) and its restriction R (s) can be used interchangeably [70]. Given a domain U, the set S is a fuzzy partition of the domain which also implies the granularity of uncertainty. Generally, a set of g + 1 linguistic terms, associated with their semantics, are denoted as:
The basic properties of linguistic term elements are as follows:
The set is ordered: s i > s j , if i > j.
There is a negation operator: neg (s i ) = st-i.
Generally, the semantics of linguistic terms are determined by practical issues. Therefore, linguistic terms may not be evenly distributed or symmetrical in the linguistic term sets [14].
With the introduction of the concept of linguistic variables, decision-making based on the linguistic environment has also developed rapidly. Based on the linguistic variables proposed by Zadeh, scholars have also proposed many variants of linguistic term sets [51] to express more complex uncertainties. At present, linguistic term models are generally divided into two categories: natural linguistic models that are more in line with human daily expressions and artificial linguistic models that express more accurately [51]. Natural linguistic models. It usually appears in the natural language of communication between people. For example, “between low and medium”, “medium”, “at least good”, “more or less medium”, “not good”. Artificial linguistic models. It adds additional information to linguistic variables to mine detailed personal opinions, and it is not entirely consistent with the way humans communicate daily. For example, “low or medium or good, furthermore, the possibility of low is 0.2, the possibility of medium is 0.5 and the possibility of good is 0.3”.
In recent years, a large number of linguistic term sets have emerged, for example, Uncertain Linguistic Sets (ULSs) [63], Hesitant Fuzzy Linguistic Term Sets (HFLTSs) [46], Extended Fuzzy Hesitant Linguistic Term Sets (EHFLTSs) [50], Probabilistic Linguistic Term Sets (PLTs) [40], Evidential Reasoning (ER) [65], Double Hierarchy Hesitant Fuzzy Linguistic Term Sets (DHHFLTSs) [22], Linguistic Hesitant Fuzzy Sets (LHFSs) [37], Interval Value Intuitionistic Uncertain Linguistic Sets (IVIULSs) [32], etc.
In these linguistic term sets, hesitant fuzzy linguistic term set (HFLTS), double hesitant fuzzy linguistic set (DHFLTS) belongs to the typical natural linguistic model. Their definition and examples are as follows:
The double hierarchy hesitant fuzzy linguistic term sets (DHFLTSs) has a finer granularity than HFLTSs, adding an emphasis on semantics.
Probabilistic linguistic term sets (PLTs) and linguistic hesitant fuzzy sets (LHFSs) are typical artificial linguistic models. Their definition and examples are as follows.
LHFSs that not only give the possible linguistic terms of a linguistic variable but also consider the possible membership degrees of each linguistic term.
With the improvement of the linguistic term sets, the corresponding operators have also attracted the attention of researchers [20]. The aggregation operators of linguistic term sets with excellent performance should reflect the opinions of all members of the decision-making group.
Xu [64] on the basis of fuzzy sets aggregation operators, proposed some new operators for linguistic term sets: linguistic geometric average (LGA), linguistic weighted geometric average (LWGA), linguistic ordered weighted geometric average (LOWGA), linguistic hybrid geometric average (LHGA), uncertain linguistic geometric average (ULGA), uncertain linguistic weighted geometric average (ULWGA), uncertain linguistic ordered weighted geometric (ULOWG).
The researchers also proposed some aggregation operators for the extended linguistic term sets and applied them to practical decision-making problems. For HFLTSs, some aggregation operators are proposed, including hesitant fuzzy linguistic weighted arithmetic average (HFLWA), hesitant fuzzy linguistic weighted geometric average (HFLWGA) [29] and hesitant fuzzy linguistic ordered weighted average (HFLOWA) [76]. Liu [32] proposed the interval value intuitionistic linguistic weighted arithmetic average operator (IVILWAA), interval value intuitionistic linguistic ordered weighted average (IVILOWA) and interval value intuitionistic linguistic hybrid average for IVIULS, and verified its effectiveness in examples. For DHHFLTSs, Liu [35] proposed the double hierarchy hesitant fuzzy linguistic generalized power aggregation (DHHFLGPA), the double hierarchy hesitant fuzzy linguistic generalized power geometric (DHHFLGPG), and their weighted forms. Probabilistic linguistic average (PLA), probabilistic linguistic geometric (PLG), probabilistic linguistic weighted average (PLWA), and probabilistic linguistic weighted geometric (PLWG) were proposed by Pang [40]. In order to further improve the performance of group decision making, Zhang [74] proposed probabilistic linguistic hybrid weight average (PLHWA) and probabilistic linguistic hybrid weight geometric (PLHWG). Meng [37] proposed four of LHFSs’ operators are called the generalized linguistic hesitant fuzzy hybrid weighted averaging (GLHFHWA) operator and the generalized linguistic hesitant fuzzy hybrid geometric mean (GLHFHGM).
From the perspective of language expression, natural linguistic models based linguistic term sets are easier to express personal views directly, while artificial linguistic model based linguistic term sets are only suitable for expressing group views due to their form restrictions. However, the linguistic term sets represented by artificial language model are more logical and easier to be accepted by computer programs, so it is more suitable for intelligent decision support systems.
Ideally, complex language expressions allows experts to express their views naturally and freely, but it also bring an exponential increase in computational complexity. Therefore, from the perspective of CWW, the calculation of linguistic term sets in natural language expressions is more complicated, and the linguistic term sets in artificial language expressions are easier to calculate because they contain more formulaic elements. However, as the complexity of linguistic term sets increases, both forms of linguistic term sets require efficient operators to support practical applications.
Natural linguistic models focus on specific types of linguistic expression, while artificial linguistic models focus on linguistic information in specific scenarios. The definition of each model has inherent limitations in the application. As the decision-making environment changes, these models have more or less certain defects, so combining the advantages of artificial language models and natural language models will be a new goal of fuzzy preference modeling.
Basic concepts of cloud model
Randomness and fuzziness are the two most common uncertainties in human cognition [31]. Probability theory is used to deal with randomness, and fuzzy sets also makes fuzziness better handled. However, the relationship between fuzzy and random should not be split, and the samples with greater membership should also have a greater probability of acquisition. Therefore, combining probability theory and fuzzy mathematics, Li [30] proposed a cloud model that can connect qualitative concepts and quantitative representations through uncertain relationships, and demonstrated that knowledge representation and reasoning methods based on cloud models can fully express uncertain fuzziness and randomness of knowledge. The cloud model is objective and can solve the problem of information loss in the process of information aggregation.
The normal cloud model is defined as follows:
The numerical characteristics of the cloud model are Expectation (Ex), Entropy (En), and Hyperentropy (He). Briefly, these three numerical characteristics are explained through a figure (see Fig. 3). In the figure, the ordinate represents the degree of membership, and the abscissa represents the attribute value in the actual problem. The cloud consists of many cloud drops. The overall shape of the cloud reflects the qualitative concept. Cloud drops are quantitative descriptions of qualitative concepts. The process of generating cloud drops represents an uncertain mapping between qualitative concepts and quantitative values.

Cloud numerical characteristics.
Ex is the central value of the data and represents qualitative data characteristic. En stands for a qualitative concept and represents the range that can be measured. He is the entropy of entropy, used to represent the uncertainty of entropy, it represents the randomness of the sample, that is, the degree of dispersion of cloud drops on the cloud model.
At present, more and more fuzzy preference expressions are involved in the processing of complex group decision-making. Traditional fuzzy mathematics has been unable to meet the needs of fuzzy preference modeling. The cloud model has received more attention from scholars due to its statistical nature and the completeness of calculation, simulation and reasoning, and it has been widely used in decision-making such as uncertain knowledge expression [67], multi-attribute decision-making research [49].
In recent years, preference modeling based on cloud models has become the main application of cloud model in decision-making, especially in the context of linguistic group decision-making. The cloud model can realize the uncertain conversion of qualitative linguistic terms and quantitative variables, and can better solve the problem of information loss during the aggregation process. Wang [49] used it to represent the linguistic evaluation information expressed by decision makers, and used the floating cloud model to aggregate preference, which was shortly after the cloud model was proposed. Subsequently, the concept of integrated cloud [52] was proposed to aggregate cloud models and applied to multi-criteria group decision-making methods based on uncertain linguistic term sets. Xu [62] proposed a large-scale group decision-making method based on the cloud model, and illustrated the practicability of the method with an example. Zhou [78] proposed the conversion method of HFLTSs to cloud models on the basis of cloud models and linguistic information mapping, and aggregated the cloud models with evidence theory. Peng [41] established the conversion method of Z-number and cloud model, and proposed lots of aggregation operators to deal with group preferences. There are also related studies that use the cloud model as a tool for fuzzy preference expression and apply it to other related multi-criteria decision-making methods, including TOPSIS [72], PROMETHEE [75], AHP [66], CPT [57] (cumulative prospect theory), etc.
In order to make the preference representation of cloud model better applied to practical decision-making, researchers have proposed efficient cloud model aggregation operators [33, 56]: cloud weighted arithmetic average (CWAA), cloud ordered weighted arithmetic average (COWA), cloud hybrid average (CHA), cloud maclaurin symmetric mean (CMSM).
In order to improve the performance of cloud model, a series of the extension normal cloud models such as interval cloud model [53], trapezium-cloud model [28], z-trapezium cloud model [41], intuitionistic normal cloud [55] have emerged gradually.
The cloud model was developed late, and related research mainly focused on the uncertain representation and conversion of linguistic variables. This model combines fuzziness and randomness, which can refine and digitize fuzzy preference information, while ensure the validity and completeness of the information, so as to achieve accurate ordering of solutions. The cloud model based on mathematical logic has efficient computing performance, and its computational efficiency is higher than fuzzy sets and linguistic variables. Therefore, the cloud model will be a powerful tool in the field of fuzzy preference modeling.
Research outlook
This section makes a comparative analysis of the fuzzy preference modeling methods introduced above, and summarizes the development trends and main challenges in the field of fuzzy preference modeling.
Comparative analysis
Search comparative
In order to compare the current research trends of these methods, the number of papers published in the field of group decision preference modeling by these methods was searched in the SCOPUS database, as shown in Fig. 4. The development of fuzzy sets was the earliest. The linguistic term sets were proposed ten years later, while the cloud model was not used for the first time in the field of decision-making until 2005. Obviously, fuzzy sets have the most related research papers. This is because fuzzy sets are very versatile and are reflected in other fuzzy preference modeling tools, including linguistic term sets HFLTSs and DHFLTSs. The cloud model started late, and there are few related research literatures. However, due to its fuzziness and randomness, the application potential is large. In recent years, in the field of fuzzy preference modeling, the number of literatures on cloud model has been increasing rapidly.
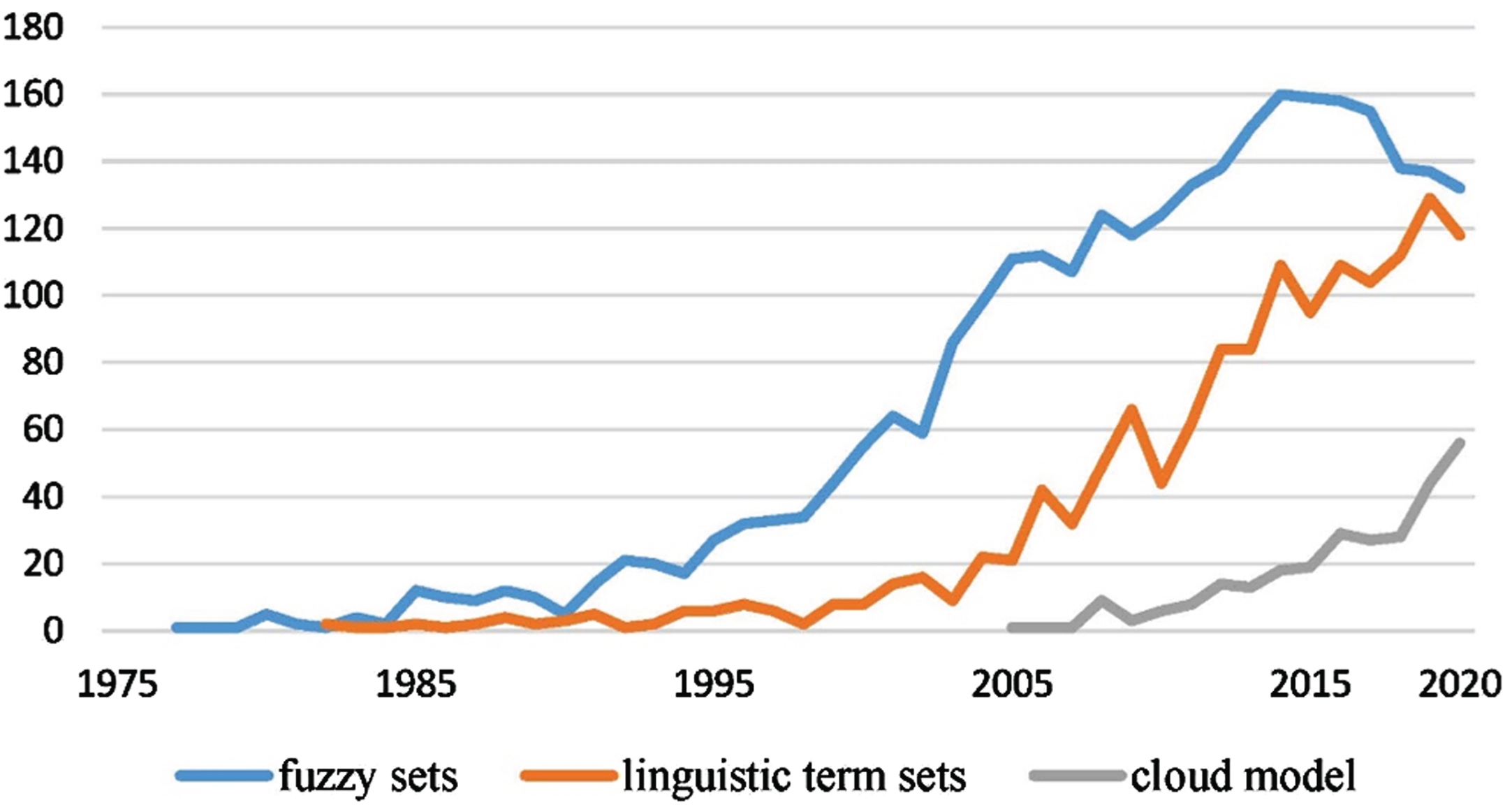
Search results of three preference modeling methods in SCOPUS.
The key of fuzzy sets is the establishment of membership function. Researchers have extended the fuzzy set in order to complete the membership function. In recent years, fuzzy sets, as a fuzzy preference modeling tool, are often used, including hesitant fuzzy sets and intuitionistic fuzzy sets, to express various aspects of ambiguity. The fuzzy set has good scalability, and can be combined with various other tools to improve the representation of uncertainty. Therefore, there are still many studies on fuzzy sets proposed in the 1960s.
Linguistic term sets is the most practical expression model for preferences. The core is to express fuzzy preferences in linguistic terms. Some linguistic term sets are extensions of the original linguistic term sets that combine with fuzzy sets and probability theory. Therefore, the development of linguistic term sets is often accompanied by the improvement of fuzzy sets. The calculation of linguistic term sets is complicated. Therefore, in addition to the high-performance operators, other tools, such as cloud models, are often considered to assist calculations. From the perspective of decision makers, this model is most consistent with natural expression. Therefore, in terms of preference expression, linguistic term elements have unparalleled advantages.
The latest development of the cloud model, as a fuzzy preference modeling tool that can express both fuzziness and randomness, has unique advantages, such as fewer parameters, simple calculation, and arbitrary conversion of qualitative and quantitative objects. In the field of fuzzy preference modeling, cloud models are often used as an intermediate in linguistic term sets to handle the process of preference expression and aggregation in group decision-making.
Different preference models have different forms, and their emphasis on expressing subjective preferences is also different. The same preference model also has different performances in different preference structures.
As introduced in section 2.1, preference modeling includes two structures: non-pairwise comparison and paired comparison, also known as utility value and preference relationship [11, 43].
When using the non-pairwise comparison structure to express preferences, decision makers express their views on each alternative separately and provide the utility value vector [12].
In the fuzzy sets environment, the preferences of decision makers are expressed by fuzzy numbers as follows:
In the context of linguistic term sets, decision makers can use
With the cloud model, the subjective preferences of decision makers are as follows:
Obviously, the same preference semantics has a completely different structure under the expression of these three methods. The preference represented by the fuzzy set is the most accurate and contains no ambiguity, but it requires a detailed definition of the membership function. The semantics of preferences expressed by linguistic term sets are very intuitive, and the relationship between preferences is clear, but the difference between different preferences is difficult to quantify. The preferences expressed by the cloud model can be directly calculated, but the corresponding fuzzy degree (membership function) is not intuitive and needs to be generated by the cloud generator.
When using the pairwise comparison structure to express preferences, the decision maker expresses the degree of preference for every two options in the set of alternatives [12].
In the fuzzy sets environment:
In the context of linguistic term sets:
In the context of cloud model:
In the preference structure of pairwise comparison, the amount of decision-makers’ subjective preference information is greatly increased, which is the square of number of alternatives. Therefore, the fuzzy set itself needs a complicated membership function to define, which makes it no longer suitable for the preference structure of pairwise comparison. The complete definition of a linguistic variable requires less information than the other two methods. Therefore, in a large group decision-making environment, linguistic term sets can greatly reduce the redundancy of decision-makers’ preference information. In this preference structure, due to its strong computability, the cloud model also plays an irreplaceable role, especially in the preference aggregation process.
With the increasing scale of group decision-making problems, the consensus reach process become very complicated [42]. In order to make preference modeling better serve the consensus reaching process, more and more researches are now focusing on the calculation performance of preference model.
Fuzzy sets calculations are usually performed directly on the set, such as ∪ and ∩, etc., which can retain the original information to the greatest extent, but the calculation efficiency is not high. When calculating linguistic term sets, two functions, g () and g () -1, are needed [21]. Firstly, linguistic terms are quantified by g (), and then the aggregation or other operations can be performed. After that, it needs to be converted into linguistic variables again by the inverse function g () -1. The cloud model can be calculated directly through parameters without any conversion operations, so it has the highest computing performance among these three models.
The performance of these models is summarized in Fig. 5.
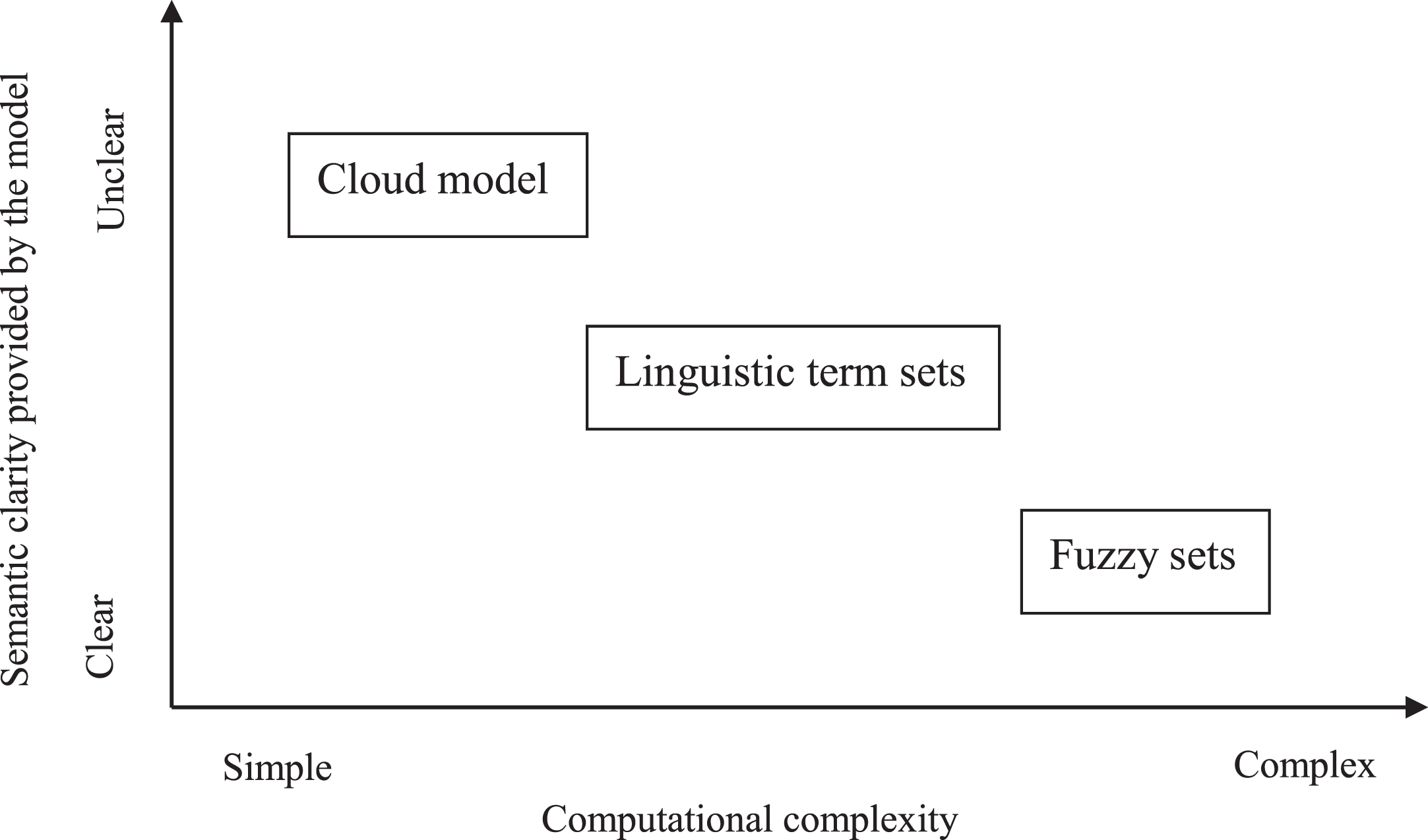
A graphical summary of the fuzzy preference modeling methods.
The characteristics, advantages and disadvantages of the three models are summarized, as shown in Table 1.
A summary table on three techniques
With the changes in the social and technical levels, group decision-making environments become more and more complex and uncertain, so a large number of experts are needed in some decision-making problems. This type of problem is called large group decision-making (LGDM) problem [61]. Obviously, the increase in the number of decision-makers makes the decision-makers’ preference modeling and preference aggregation more demanding.
As LGDM becomes more and more important, fuzzy preference modeling tools and methods also need to be improved. In order to better adapt to group decision preference modeling with a large number of decision makers, the existing fuzzy preference modeling methods have some challenges that need to be solved urgently. The extension of preference modeling methods should be strictly based on real-world application. By simply combining the idea of uncertainty processing tools and expanding the preference model theoretically, most of them may not be applicable or feasible in practical applications. According to the real-world application, the extended preference expression model is divided into two directions. Expansion of semantic range. At present, the types of basic elements (basic qualitative linguistic terms, fuzzy numbers, cloud model) that can be modeled are still limited. Therefore, how to expand the semantic range of preference model and increase the types of basic elements is a direction to be developed. Expansion of model granularity. Between successive preference variables, there is a more fine-grained preference representation, that is, preference hedges. For example, “more or less good” in linguistic expression. It is not a linguistic term adjacent to “good". Instead, it represents the uncertainty of using a single term “good". There is little research on preference hedges in linguistic term sets, and the other tools rarely involve preference hedges. So far, the field of group decision fuzzy preference modeling has not systematically studied the concept of preference hedges. Due to the necessity of dealing with uncertainty, preference modeling tools need to be extended to support preference hedges. Expand the group decision preference modeling process to deal with bounded rationality. Although there are many models for expressing preferences, the expansion of the preference modeling process is very limited, and few new ideas are introduced. The extension of existing methods focuses on the steps of uncertainty expression and preference modeling. However, the bounded rational behavior of decision makers also needs to be dealt with in the preference modeling process. It has been proved in practice that finding a satisfactory solution is often more reasonable than finding the solution with the highest performance. Therefore, how to expand and improve the existing group decision fuzzy preference modeling process to simulate the bounded rational behavior of decision makers is an urgent problem to be solved. Developing the hybrid preference model. The above three fuzzy preference models have their own advantages and disadvantages, and each model has inherent limitations in application. Obviously, problems in the real world may not match the ideal situation defined in any model. Therefore, how to combine multiple preference models to solve some practical problems and use hybrid preference models to make decisions is a difficult problem that needs to be solved. If a novel preference model can combine several advantages of existing models, it will be very meaningful. For example, the linguistic term set is closest to the natural language of the decision maker. If it can be combined with other tools to solve its computational complexity, the actual application effect of the linguistic term sets will be significantly improved. As a preference modeling tool that includes fuzziness and randomness, the cloud model can better handle different forms of preferences. If the cloud model is used as an intermediate, so that decision makers can make decisions in a heterogeneous environment with different granularity preferences, the subjective uncertainty can be more accurately expressed.
Conclusions
Because of the sharply increasing complexity of real-world decision-making problems, the traditional preference expression methods are often not enough to cope with uncertainties which come from multiple information sources. Therefore, the fuzzy preference modeling method has attracted the attention of researchers. So far, there have been a large number of fuzzy preference modeling methods, which can be divided into three types according to the representation domain: fuzzy sets, linguistic term sets and cloud model. These models provide the excited tools to enhance the capability of group decision-making.
This survey has been devoted to presenting a systematical review on these fuzzy preference models, especially on the focused preference expression and computing performance. The main contribution can be concluded as follows: The fuzzy preference modeling method is introduced based on the classification criteria of representation domain, including the definition of these methods and the development in recent years. The three methods are systematically compared, including the number of literatures, representation structure and computational performance. The major limitations of the existing models are figured out. Based on current challenges, it also explores some possible future development directions in the field of fuzzy preference modeling, including: expansion of preference model, preference hedges and hybrid preference model.
Footnotes
Acknowledgments
The authors appreciate the support from the National Key Technology Support Program (2018YFB1700905), the National Science Foundation of China (61672247, 61772247 and 61873236)