
Abstract
How to accurately model user preferences based on historical user behaviour and auxiliary information is of great importance in personalized recommendation tasks. Among all types of auxiliary information, knowledge graphs (KGs) are an emerging type of auxiliary information with nodes and edges that contain rich structural information and semantic information. Many studies prove that incorporating KG into personalized recommendation tasks can effectively improve the performance, rationality and interpretability of recommendations. However, existing methods either explore the independent meta-paths for user-item pairs in KGs or use a graph convolution network on all KGs to obtain embeddings for users and items separately. Although both types of methods have respective effects, the former cannot fully capture the structural information of user-item pairs in KGs, while the latter ignores the mutual effect between the target user and item during the embedding learning process. To alleviate the shortcomings of these methods, we design a graph convolution-based recommendation model called
Introduction
As one of the most effective technologies to solve information overload, personalized recommendation systems (RSs) are a practical internet product [39] for users. In a personalized recommendation system, user preferences for items (e.g., restaurants, movies, commodities) are modelled. Prior efforts in the field of recommendation systems (e.g., collaborative filtering-based (CF-based) [1, 43] methods and matrix factorization machines [2]) use historical interaction information (explicit or implicit feedback) between users and items as input; however, these methods are simple and only achieve limited effectiveness. However, because the interaction information between users and items is typically sparse, the risk of overfitting is typically high and leads to the cold start problem. Later, with the rapid development of social media, methods [3, 4] aimed to integrate various auxiliary information into the recommendation process to address these two issues and improve overall performance.
Many recent studies have introduced knowledge graphs [5–7] as auxiliary information to model user preference. A knowledge graph contains rich semantic associations between entities (items or item attributes) that provide auxiliary information for recommendation systems, which can successfully mitigate the problem of data sparsity. Different from other types of auxiliary information, a knowledge graph can reinforce recommendation results in the following ways: accuracy, diversity and interpretability. First, a knowledge graph introduces more semantic relationships for users and items and can deeply dig users’ preferences. Second, a knowledge graph provides different types of connections, which is conducive to the divergence of recommendation results and avoids limiting the recommendation results to a single type. Third, a knowledge graph can connect the users’ history and recommendation results to improve the users’ acceptance and satisfaction of the recommendation results and enhance the users’ trust in the recommendation system. Therefore, many approaches in the era of KG-based recommendation have been proposed to enrich representations of users and items to improve recommendation performance. Typically, these approaches can be divided into two groups: path-based and graph convolution network (GCN)-based methods.
While powerful, these methods also have limitations. The first group uses knowledge reasoning, which treats KG as a heterogeneous information network and introduces meta-paths to refine the similarities between users and items such as personalized entity recommendation (PER) [8] and factorization machine with group lasso (FMG) [9]. More recently, a study [38] proposed exploiting reinforcement learning to explore useful paths for recommendation. However, we argue that meta-paths are inefficient because they fail to automatically predict unseen connectivity patterns because mate paths require domain knowledge to be predefined. Most importantly, these path-based methods ignore rich structural information in KG. Another group of studies uses GCN to learn high-quality user and item embedding. Many GCN-based methods [20–25] yield the best results in feature learning with knowledge graphs. These methods use GCNs to learn the embedding of target users and items in their own original KG. Monti et al. proposed the first GCN-based method for recommendation systems [38]. In their approach, a GCN was used to aggregate information from two auxiliary user-user and item-item graphs, and thus failed to capture their mutual influence during the information aggregation procedure. RippleNet [26] takes advantage of the information propagation in KG to simulate the propagation of users’ potential preferences in KG and explore the level of users’ interests relative to KG. KGCN-LS [27] and KGAT [28] learn the embedding of the items by superimposing multiple GCN layers and use the randomly initialized user embedding to calculate the users’ weight on the relationships between item entities. The user profile is not considered when aggregating item neighbours in KG. Although this type of method improves the performance to certain extent, the relevance between the target user behaviour and the item is not considered in the embedding learning process; thus, it is easy to introduce invalid information when learning the embedding of the target item, which may impact recommendation performance.
In this study, inspired by graph convolutional networks, we extract the spatial features of topological graphs to mitigate the shortcomings of existing methods. We develop a new framework called CUIKG to jointly learn user embeddings and item embeddings from user-end KG and item-end KG. In terms of user embedding learning, we apply non-spectral domain graph convolution neural networks to aggregate neighbourhood information. Then, the generated user embedding is used to learn the corresponding user, item and relationship representations with the item-end KG. In terms of item embedding learning, we use a bias in aggregating neighbour information of a given item entity when calculating the representation of the item entity in the item-end KG. This bias is determined by the degree of preference in the user embedding to the relationship between item entities and their relative attribute entities. Our model fully considers the relationship between user attributes and item attributes, which describes why users consume items. As an example, when high-income people choose a hotel, they think more about the “star” level of the hotel, while low-income people consider the “price” more; this topic is discussed in more detail in Section 3. Compared to existing recommendation methods, the primary innovations of this study are summarized as follows: We design a recommendation model that combines user-end and item-end KG learning. The proposed model emphasizes the importance of aggregating neighbours by extending the respective field of each entity in the KG. We manage target item features with different neighbours by introducing user information that contains users’ profiles learned from user-end KG to consider the mutual influence between the target user and item. We perform extensive experiments on the public datasets MovieLens-20 M and Yelp to demonstrate the effectiveness of CUIKG and comprehensively analyse the influence of changes in the operation parameters on the proposed model.
The remainder of the paper is organized as follows. Section 2 introduces related work, including research methods based on GCNs and knowledge-aware recommendations. Section 3 elaborates on the details of the proposed model. First, in Section 3.1, we define the symbol set used in this paper and the rules for constructing the knowledge graph. Then, we describe the overall framework of the model in Section 3.2. Sections 3.3 and Section 3.4 explain the two most important components of the model, the combined layer and MLP layer, respectively. Section 4 describes the experiments performed, including dataset processing, experimental settings, baselines, evaluation metrics, experimental results and analysis. Finally, conclusions and recommendations for future work are discussed in Section 5.
Related work
In this section, we review two research topics that are related to this study: recommendation with GCNs and knowledge-aware recommendation. Then, we discuss the research gap between early and existing approaches.
Recommendation with GCNs
Because GCNs exhibit good performance in learning the representation of target nodes in higher-order graphs, many studies have investigated recommendation with GCNs. GCNs generalize the definition of convolution from a regular grid to an irregular grid, such as graph structures. The GCN framework generates node representations by a localized parameter-sharing operator, known as a graph aggregator. In general, there are two popular methods to extract spatial features from topological graphs: a spatial domain and a special domain. First, the spatial domain is intuitive and extracts spatial features from a topology graph; however, we must determine the neighbours of each vertex. Hamilton et al. [32] treat each neighbours equally with a mean-pooling operation when aggregating neighbours’ messages and performs well. Velickovic et al. [33] differentiate the importance of neighbours with an attention mechanism to improve recommendation performance. Wang et al. [27] uniformly sample a fixed size of neighbours for each entity as their receptive field instead of applying any simplification to the knowledge graph structure. Second, the spectral domain is the theoretical basis of GCN. A simple generalization is to study the properties of graphs using the eigenvalues and eigenvectors of Laplacian matrices of graphs [30], which describes the convolution operation on topological graphs with the help of graph theory. Because the operation of eigen decomposition yields a high computational cost, researchers use Chebyshev polynomials to calculate this approximation [31]. First, scholars in graph signal processing (GSP) defined the Fourier transformation on graphs and then defined the graph convolution. Finally, GCN was proposed in combination with deep learning. Due to GCN’s power to learn high-quality user and item embedding, the work in this paper is shown as a spatial domain approach to a particular type of graph (i.e., knowledge graph).
Knowledge-aware recommendation
Knowledge-aware recommendations are a novel research topic. An existing research topic investigates meta-paths to connect users and items on KG; however, we believe that this method is inefficient for modelling user-item interactions. Another research topic investigates embedding fashion. With the surge of Neural Network (NN) [10–12] models and inspired by Natural Language Processing (NLP) models, DeepWalk [13] was proposed as the first network embedding method that uses representation (or deep) learning. DeepWalk bridges the gap between network embeddings and word embeddings by treating nodes as words and generating short random walks as sentences. Then, neural language models such as Skip-gram [14] could be used on these random walks to obtain network embedding. Then, a host of models (e.g., LINE [15], node2vec [16], and doc2vec [17]), which extend from DeepWalk, have been proposed. However, these methods focus on local structure and thus ignore long-distance global relationships and fail to consider the importance of entity relations in transferring knowledge from KG. Knowledge graph embedding (KGE) is a subfield of network embedding. Because knowledge graphs contain special semantic information, feature learning of knowledge graphs must design a more detailed and targeted model than general network feature learning. KGE methods are primarily classified into two categories: translational distance models and semantic-based matching models. Regarding the former, Bordes and Liu leverage KGE techniques such as TransE [18] and TransR [19]. This type of model uses the distance-based scoring function
Because the interaction information between users and items can be considered to be a bipartite graph structure in essence, auxiliary information such as knowledge graphs and social networks naturally belongs to the graph structure. Therefore, various graph learning methods have been used to learn user and item embeddings. Among graph learning methods, GCN is currently popular. Recently, GCNs have yielded better performance than traditional graph learning methods (e.g., random walk and knowledge graph embedding). Although GCN-based methods [40–42] have achieved good results in KG learning, there are still drawbacks to these methods: (1) user and item embeddings are learned from two graphs separately and do not consider mutual influence between the target user and item during information aggregation; (2) many methods only capture item-item relatedness over KG and cannot integrate users well, even when reconstructing user-user graphs and item-item graphs into one graph, yielding noise and/or a complex structure in the unified graph; and (3) most previous studies of KG learning did not build user profiles based on user attributes.
Proposed method
Preliminaries
Based on the user-item interaction (e.g., rating, clicking or purchasing) data used in representative recommended scenarios, we use
A knowledge graph is a large directed semantic network whose nodes are entities ɛ and edges R denote their relations, which aims to describe the concept entity events of the objective world and the relationship between them. Formally, we define KG as kg = {(e h , e t , r) |e h , e t ∈ ɛ, r ∈ R}, and each triplet indicates that there is a relationship r from head entity e h to tail entity e t . For example, the triple (Sugar Factory, located, Chicago) indicates that the famous restaurant called “Sugar Factory” is located in the city of Chicago. In this study, we separately construct user-end associated attribute KG kg U = {(e h , e t , r u ) |e h , e t ∈ ɛ u , r u ∈ R u } and item-end associated attribute KG kg I = {(e h , e t , r i ) |e h , e t ∈ ɛ i , r i ∈ R i }. Each user u ∈ U or item i ∈ I corresponds to one entity e u ∈ ɛ u or e i ∈ ɛ i . Considering the same example, “Sugar Factory” will only appear in kg I as an entity with the same name, and the same process is performed for each user. In the movie dataset, r u represents the relationships (attributes) between entities in user KG with a total of 4 relationships: age, gender, occupation, location postcode, r i represents the relationships (attributes) between entities in item KG, with a total of 32 relationships: director, leading actor, subject, type, release time, etc. In the Yelp datasets, r u includes review_count, yelp_since_year, fans, and average_stars, while the relations r i of item entities are composed of 4 attributes: state, stars, WIFI, and Restaurants Price Range 2. All these description symbols are summarized in Table 1.
Set of symbols used in this paper
Set of symbols used in this paper
The CUIKG model, as shown in Fig. 1, has two important components. First, the combined layer is the key innovation point that combines user-end KG learning and item-end KG learning. Second, regarding the MLP layer, we concatenate the learned user and item embeddings from the combining layer and make it pass through the MLP layer to produce the final predictions. We will describe these two parts of the model in detail in the next subsection.
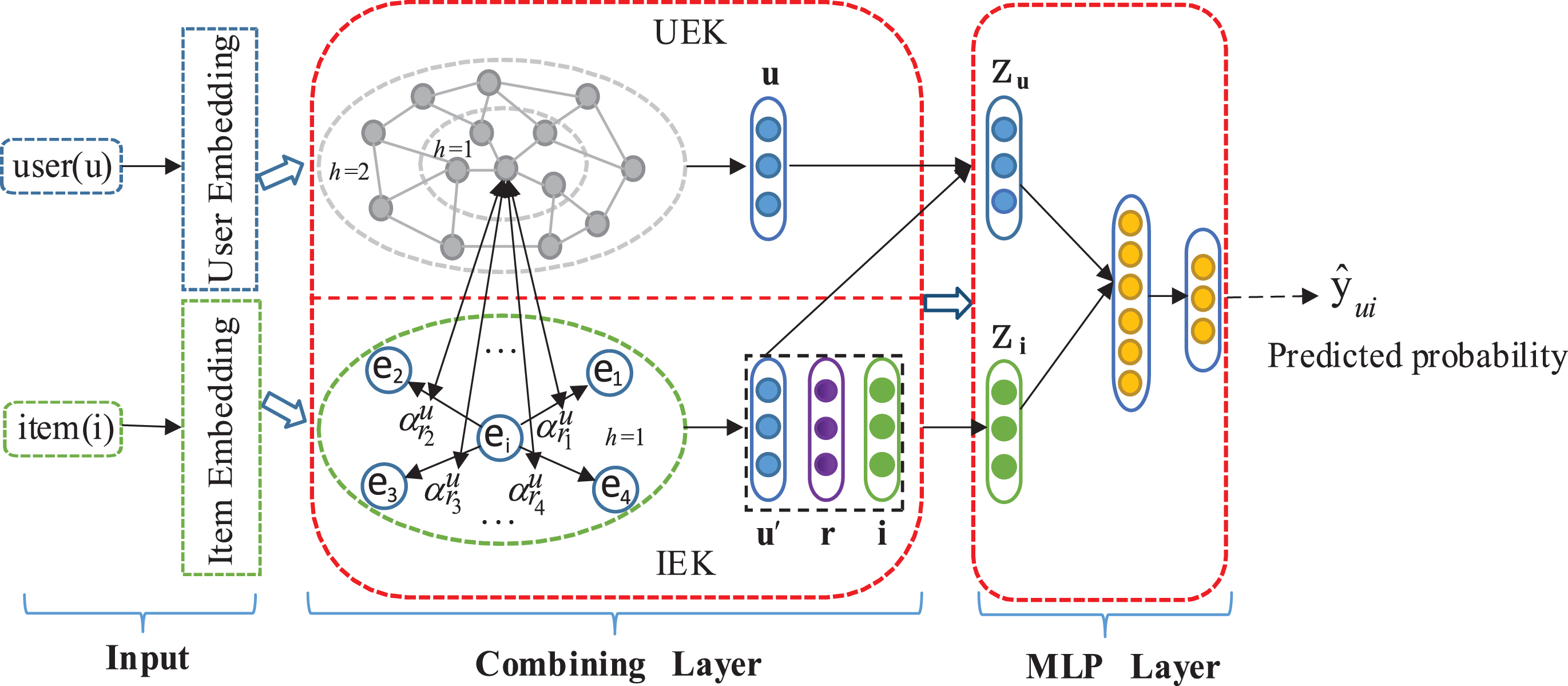
Overview of the proposed CUIKG. Overall, CUIKG consists of two key parts: a combined layer and an MLP layer.
Sample of user data in MovieLens-20 M
Sample of user data in MovieLens-20 M
In Table 2, userIDs are numbered from 1, with a total of 138159 users, and each user corresponds to a number. Gender is categorized as F for female and M for male. Age is the minimum value of each age range, and a total of 7 age ranges are divided into 1∼18, 18∼24, 25∼34, 35∼44, 45∼49, 50∼55, and 56+. Each number corresponds to an occupation, and there are 21 occupations in total, ranging from 0 to 20. Zip code represents the real zip code of the user’s location. Due to the large number of users, users with a movie score below 4 were filtered out during model building, while no threshold was set for Yelp. Each user was then renumbered, and an item and user knowledge graph was constructed based on the KG rule defined in Section 3.1. We performed the same method with the Yelp dataset and built the user-end KG.
After building the user-end KG, we removed the attribute relationship between entities because we only focus on learning the embedding of users; thus, we treat the KG as an undirected graph. Considering a candidate pair of user and item (u
l
, i
j
), in the UEK, as shown in the top half of combining layer, which yields an illustrative example of two-layer receptive field for a given user entity, we first obtain the user’s initial embedding
We use the currently popular rectified linear unit ReLU (x) = max(0, x) as the nonlinear activation function, where [;] represents concatenation, and
where the sigmoid function is defined as σ (x) = 1/(1 + exp(- x));
The advantage of this method is that we use embedding, which can capture the user’s profile to calculate the degree of preference for the relationship, to further mine the user’s potential interest and motivation. For example, in the movie recommendation scenario, a user may like the “Star” or the “director” of the movie. We think that by calculating the user’s score on the movie attribute, we can obtain the weight of aggregating the neighbour information of each item. However, there is a problem in this method. If the initial state of the user’s embedding is randomly initialized, it will lead to uncertainty in the score. In a real-world scenario, each user is described by a lot of attribute information, such as gender, age, and occupation, which constitute the user’s personal profile. Because each user’s profile is different, each user will have a different motivation for their movie preferences. For example, user A and user B score the same movie as 5 out of 10. User A may like the “type” of the movie, and the score calculated by user A for the “type” relationship will be significantly higher than that calculated by other relationships. However, user B may like the “Star” of the movie; thus, the score calculated by user B for the “Star” relationship will be significantly higher than that calculated by other relationships. Although the two users provide the same rating of the movie, we must more accurately mine the potential personalized preferences of users.
Under the input of the given formalization, we jointly train user-end KG and item-end KG. In terms of UEK, the ultimate output in the UEK section is
Once the final embedding of user u l and item i j are determined from the combining layer, we use several layers of a neural network that can fit any nonlinear function to deeply model the interactions among users and items. First, we merge the aforementioned user and item embeddings by embedding concatenation and feed them into a preference layer P that contains multiple feed-forward neural networks:
where the total number of hidden layers P is Q; the q-th hidden layer of P is denoted as p
q
(z); p0 (z) = z = [
The model parameters are trained by formulae (1) ∼ (12). Every time the minibatch samples are trained, the model parameters are updated, and the feature matrix of users and items is updated concurrently. During back propagation, the gradient of ∂L/∂
In this section, quantitative experiments on top-K recommendation and click-through rate (CTR)recommendation tasks are performed. For each recommendation task, the MovieLens-20 M and Yelp datasets are used to verify the performance of UIKG. Additionally, the control variable method is also used to analyse the influence of hyperparameters on the model to select the most appropriate parameters and make the model achieve better performance in the recommended application scenarios. All experimental code and datasets are located at https://github.com/xiaoliangshare/ACM-RecSys.git. We invite researchers to contact us for help in implementing this code.
Dataset
Two real datasets, MovieLens-20 M and Yelp, are used to evaluate the proposed model. These datasets are the most widely used public datasets in the field of machine learning algorithms and recommendation systems. For each dataset, because the rating data in the original dataset belong to explicit feedback, we transform the rating data into implicit feedback. During data processing, records with each user rating below 4 are filtered in MovieLens-20 M and no users are filtered in Yelp. After processing, each record is marked as 1, which indicates that the user rating of the item is positive. A non-interactive item collection is sampled for each user. Each record is marked as 0, indicating that the user rating of the item is negative. Also, the proportion of each user rating positive items to negative rating items is 1:1.
·
·
Based on user attribute information and item meta-data information stored in the two datasets, we use Microsoft Satori to build the user and item knowledge graphs, respectively. The basic statistical information of the datasets is shown in Table 3.
Basic statistics of dataset
Basic statistics of dataset
Python 3.7.3 and TensorFlow 1.14.0+ numpy1.14.3 are used in the experiment. The ratio of the training set, verification set and test set is 7:1:2. The initial values of the hyperparameters are set in the experiment without pretraining. For all models, we use the Adaptive Moment Estimation (Adma) and Adagrad as optimizers, and apply a grid search to the models to find the best settings for each task. The search range of learning rate η is {0.001, 0.002, 0.005, 0.01, 0.02}, and the coefficient of L2 regularization is {10–5, 10–4, 10–3, 10–2, 10–1, 0}. The weight factor θ of the user embedding output by UEK and IEK is set to 0.5, and the embedding of the end user is obtained by concatenation by default. The default value of the number of layers Q of preference layer P is set to 1, which is input layer ⟶hidden layer⟶output layer. For simplicity, the embedding dimension of users and items is set to d = du = di = 32, and the corresponding embedding dimension of each layer is 64⟶32⟶1. The number of iterations (epochs) of each experiment is set to 10, and the number of training samples (batch-size) is 65536. Each experiment was repeated three times, and mean results are reported. L2 regularization and dropout technology are used during training to prevent overfitting. The default depth H of the local receptive field is 3. The size of neighbours aggregated in each layer is S, and the default value is set to 8. The neighbour sampling strategy of each layer is described as follows. First, for a given entity in the user (item) knowledge graph, there may be multiple neighbours directly connected to the entity; if both are aggregated, the calculation efficiency is lower. To keep the computational pattern of each batch and the calculation efficiency fixed, we select S neighbours from all neighbours of the entity for aggregation. If the number of all neighbours of a given entity is greater than S, the S neighbours are randomly selected from all neighbours of the entity. If the number of all neighbours of a given entity is below S, there are only s (s < S) neighbours, and we randomly copy (S-s) neighbours from s to S. Because these experiments and a comparison method are based on the same dataset standard, the experimental parameters of a comparison methods are set to the default values given by their original papers.
Baselines
There are two types of representative comparison methods in this study: recommendation methods (SVD, libFM) without a knowledge graph, and recommendation methods (libFM+TransE, CKE, RippleNet, KGCN) that use a knowledge graph to learn the user (item) embedding. The following methods are compared to the proposed model:
Evaluation metrics
After several training iterations, we can determine whether model training is complete by observing the change in the loss function value. When its value is near 0 and tends to be flat, model training is considered complete. Then, the trained model is used for prediction. The same evaluation metrics are used to evaluate the proposed method and comparison methods in this paper. Based on different recommendation tasks, the evaluation metrics used in this experiment are as follows: In Top-K recommendation, for each given test user, all items that the user has interacted within the test set are considered to be the truth set ground_truth_items, and then the preference probabilities of the user with all items that the user has not interacted with are calculated. We sort the probability value and select the top_k item set with the highest probability recommended to users as a candidate set. Recall@K is used in this study to evaluate the recommendation performance of the model. Recall@K represents how many items in top_k belong to the ground_ truth_ items. The formula of Recall@K is as follows:
Finally, the average value of all users Recall@K is calculated as the final metric value. In CTR prediction, F1 and AUC are used to evaluate the performance of the model. F1 represents the mean value of the Precision@K and Recall@K of the model; Precision@K indicates how many items in the ground_ truth_ items belong to top_k; and AUC represents the area under the ROC curve which is a curve composed of false positive rate as abscissa and true positive rate as ordinate. Precision@K and F1 are calculated as follows:
Similarly, the average F1 of all users is calculated as the final metric value.
Experimental results recommended by Top-K
The result of the Top-K recommendation is shown in Fig. 2, which shows a comparison curve of the proposed method and comparison methods (CKE, libFM+TransE, RippleNet, KGCN). Because SVD and libFM directly calculate the score to represent the user’s preference for the item, their curves are not drawn. The abscissa of Fig. 2 represents the number of items in top_k, and the ordinate represents the recall@K corresponding to K. Figure 2 shows that CUIKG outperforms the baseline methods by 3.0% ∼20.5% under the metric of recall@K in Yelp but only increases by 2.5% ∼13.6% in MovieLens-20 M. By incorporating KG, CUIKG yields more promising improvements on Yelp than MovieLens-20 M, which implies that the knowledge graph is more helpful for sparse data. Figure 2 also shows that KGCN and RippleNet yield good performance on the two datasets primarily because they use GCN to model the items and users, respectively, on the knowledge graph. Due to their lack of consideration of the impact between users and items when generating their respective representations, their performance is not as good as UIKG. Lastly, Fig. 2 also shows that although libFM+TransE and CKE also introduce the knowledge graph as auxiliary information, their learning model of the knowledge graph is based on the translation distance model or semantic matching model, which is more suitable for link completion and link prediction of the knowledge graph. Therefore, the performance in the recommendation scenario is more general, which verifies that the method based on GCN can extract features of users and items more effectively.
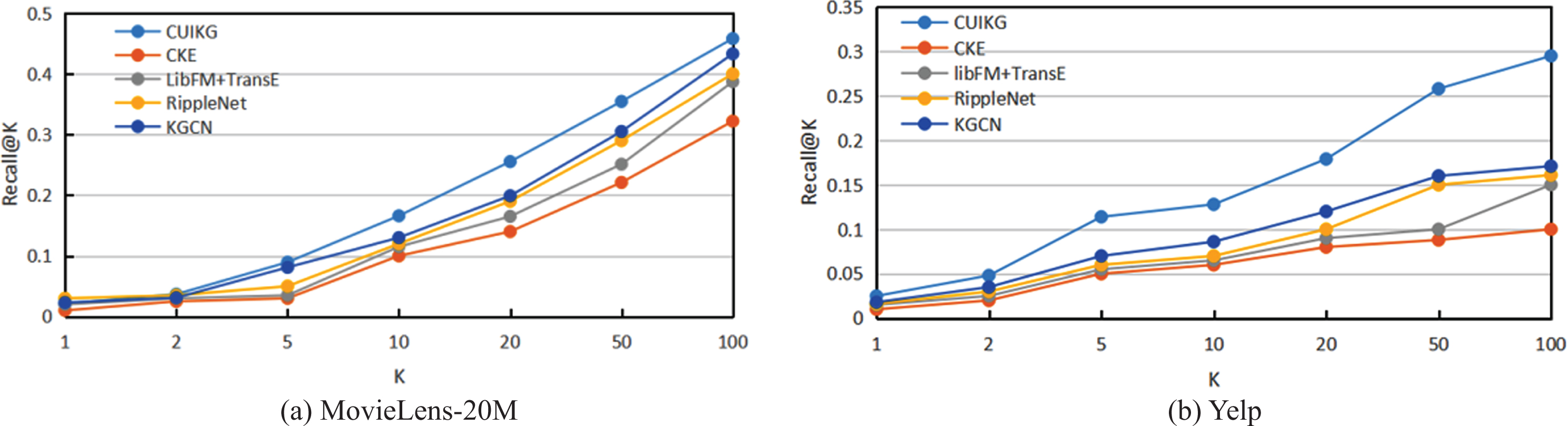
Recall@K in Top-K recommendation.
The AUC and F1 metric values under the CTR recommendation scenario are shown in Table 4. Results show that the performance of the proposed method is optimal on both datasets. Compared to the contrast methods, the performances of SVD and libFM without a knowledge graph are better than that of CKE, which indicates that the CKE method cannot make good use of the knowledge graph as auxiliary information for modelling. However, their performance is worse than that of RippleNet, KGCN and UIKG. This situation is similar to the Top-K recommended scenario, indicating that the GCN-based method can effectively model the interaction between users and items. Also, LibFM+TransE performs better than LibFM in most cases, which demonstrates that introducing a knowledge graph into the recommendation system can improve model performance. Lastly, compared to MovieLens-20 M, the proposed model performs better on Yelp, and the improvements are similar to those on Top-K recommendation.
AUC and F1 in CTR prediction
AUC and F1 in CTR prediction
The following section analyses the influence of hyperparameters on the experimental results. We only examine the influence of hyperparameters on the experimental results in the CTR recommendation scenario.
AUC and F1 result of CUIKG with different Q
AUC and F1 result of CUIKG with different Q
AUC and F1 result of CUIKG with different d
AUC and F1 result of CUIKG with different H
AUC and F1 result of CUIKG with different S
This paper describes the learning of user-end item-end knowledge graphs. The purpose of learning the user-end knowledge graph is to construct user profiles. Then, we introduce the learned embedding of the user into the item-end knowledge graph learning to mine the motivation behind the users’ engaging the item. The proposed model can capture the relevance between users and items, which shows user preferences for consuming items. The experimental results show that the CUIKG framework outperforms existing methods on the MovieLens-20 M and Yelp datasets by 2.5% ∼13.6% under the metric of recall@K and a 0.4% ∼11.9% increase in AUC and F1 indicators. These results show that the proposed method can enhance the representation of users and items, and model user preferences better than other personalized recommendation methods.
In the future, we plan to introduce more user attributes to improve the depth of user profiles. Due to the high computational complexity of knowledge graph training, optimizing the model and considering the application of the model in a real-world scenario will be studied in more detail. In real-world scenarios, users’ preferences can be interfered from social networks in real time. The method proposed in this paper is suitable for static knowledge graphs; however, if new knowledge is added, we will consider combining users’ social networks to capture their friends’ long-term preferences to capture users’ dynamic interest changes.
Footnotes
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (Nos. 62066010,61862016,61966009), the Natural Science Foundation of Guangxi Province (No. 2020GXNSFAA159055), and the Guangxi Innovation-Driven Development Grand Project (No. AA17202024).