
Abstract
Deep convolutional neural networks (DCNNs), with their complex network structure and powerful feature learning and feature expression capabilities, have been remarkable successes in many large-scale recognition tasks. However, with the expectation of memory overhead and response time, along with the increasing scale of data, DCNN faces three non-rival challenges in a big data environment: excessive network parameters, slow convergence, and inefficient parallelism. To tackle these three problems, this paper develops a deep convolutional neural networks optimization algorithm (PDCNNO) in the MapReduce framework. The proposed method first pruned the network to obtain a compressed network in order to effectively reduce redundant parameters. Next, a conjugate gradient method based on modified secant equation (CGMSE) is developed in the Map phase to further accelerate the convergence of the network. Finally, a load balancing strategy based on regulate load rate (LBRLA) is proposed in the Reduce phase to quickly achieve equal grouping of data and thus improving the parallel performance of the system. We compared the PDCNNO algorithm with other algorithms on three datasets, including SVHN, EMNIST Digits, and ISLVRC2012. The experimental results show that our algorithm not only reduces the space and time overhead of network training but also obtains a well-performing speed-up ratio in a big data environment.
Introduction
The past decade has witnessed considerable progress in image recognition work with deep learning, which is based on structured deep neural networks [1–3]. Deep convolutional neural network (DCNN) [4], one of the foremost families, embraces convolutional computation capable of downscaling a large number of parameters of an image and effectively preserving image features, which is virtually tailored for processing images. In particular, the advent of the big data era has opened the gateway for the rapid development of DCNNs. Many excellent deeper models have been proposed, the excellent AlexNet, VGG, GoogLeNet, ResNet and DenseNet [5–9]. The learning of large amount of training data allows models to achieve better generalization ability and function approximation capability. However, with the exponential growth of data, several issues cannot be ignored. Most DCNNs use some convolutional layers in image recognition work before the fully connected layers. Convolutional layers aim to diminish image dimensionality, but they are computationally tedious and there may be invalid kernels in the convolutional kernel, which do not significantly help image classification results but incur significant inference costs. In this way, the network must be reconstructed and adapted to take into account solutions working in big data. One research direction is to remove redundancy by pruning. The general procedure is to measure the importance of neurons, remove some of the unimportant neurons, and fine-tune the network. In this way, by modifying the bulky model, it is possible to reduce its memory and time cost while obtaining as much performance as possible from its original unmodified model.
Backpropagation (BP) [10] is one of the most widespread supervised learning algorithms in multilayer feedforward neural networks. There are two weight update modes in the BP algorithm: online mode and batch mode. The batch update mode is more suitable for some popular frameworks that deal with big data (such as MapReduce [11]), because all items in the training set can be used simultaneously. Unfortunately, the original BP algorithm converges slowly when executing parameter updates and tends to fall into local optima, which seriously affects the training time. In addition, the stochastic gradient descent method [12] in BP algorithm involves a great deal of manual tuning to optimize the parameters when distributed or parallelized using clusters of computers. Compared to this, the conjugate gradient method [13] offers special features that allow the gradient computation to be distributed over different machines, while the training is more stable and the convergence is easier to check, but it is usually slower. Therefore, it is worth pondering how to accelerate the convergence of conjugate gradient method. On the other hand, the single machine training model requires high memory and time efficiency, and the parallelization within DCNN does not consider load balancing, which may result in long response time and inefficient parallelization. As one of the most popular Big Data frameworks, MapReduce provides new ideas for solving this problem. As one of the most popular Big Data frameworks, MapReduce provides a reliable, fault-tolerant and resilient computational framework for storing and processing large data sets that scales well as the size of the data set continues to grow. This definitely provides new ideas to improve the parallelization efficiency of DCNN.
Based on the above analysis, a new parallelized deep convolutional neural network algorithm combined with MapReduce is proposed. The experimental results indicate that the algorithm demonstrates excellent performance when dealing with large-scale datasets. And it works even better as the computing nodes grow. The main contributions of this study are as follows: A feature map pruning (FMP) strategy was designed to effectively reduce redundant parameters. A conjugate gradient method based on modified secant equation (CGMSE) is obtained in the map phase to achieve fast convergence of the conjugate gradient method. To mitigate the effects of data skew in the reduce phase, a load balancing strategy based on regulate load rate (LBRLA) is developed to realize equal distribution of the data keys, thus ensuring the balance of computation completion time.
The rest of the paper is arranged as follows. Section 2 shows related work, and Section 3 introduces the DCNN and conjugate gradient methods. Then Section 4 describes the details of our proposed DCNN algorithm and analyzes its time complexity. After that, Section 5 shows our experimental design and comparison results; Finally, Section 6 concludes the paper.
Related Work
To assist readers, the relevant work mentioned in the manuscript is listed in Table 1. Substantial work has been done on reducing redundant parameters by pruning. Tung et al. [14] proposed the CLIP-Q method, which jointly performs weight pruning and weight quantification in parallel with fine-tuning. To some extent, it reduces the superfluous elements, but does not take into account the inter-layer differences in DCNN. Immediately afterwards, Lin et al. [15] combined two different regularizes for structured sparsity in the original filter pruning objective function to prune adaptively. By exerting structured sparsity and fully coordinating global output and local pruning operations, the number of filters and output feature mappings are simultaneously diminished, speeding up the computation. Unfortunately, this scheme is less efficient for pruning due to the structured sparsity that requires frequent access to memory. Yu et al. [16] assessed neuronal importance directly by back propagation weights. The importance-based criterion is extensively implemented for the purpose of reducing memory access. However, a drawback of this method is that its compression of high-dimensional information may degrade the accuracy.
Literature merits and demerits
Literature merits and demerits
Aiming to accelerate the rate of convergence, a spectral conjugate gradient algorithm by modifying the learning step-size and conjugate directions is described in research [17], which only adopts the gradient direction for each line search and guarantees global convergence using a non-monotonic strategy. There is no free lunch, and its strong dependence on many functions and gradients predisposes it to be more time-consuming. Jian et al. [18] proposed a new spectral parameter generation method (JC method) with a step size obtained from a strong Wolfe or generalized Wolfe line search. By introducing a new double truncation technique, both the sufficient descent property of the search direction and the bounded property of the spectral parameter sequence can be guaranteed. The algorithm achieves global convergence for uniformly convex functions, but does not work for convexity without an objective function. As a modified version of the JC method, Faramarzi et al. [19] proposed a new spectral conjugate gradient method for unconstrained optimization problems and proved that it is globally convergent without the assumption of convexity of the objective function. Despite the success, all the above schemes pose restrictions, such as the inability to secure generation of descent directions, thus requiring the typically inefficient restart process to ensure convergence, which leads to potentially significant time consumption. Consequently, how to make the conjugate gradient method converge quickly is an urgent issue.
To date, many studies have tried to implement the convolution neural network by MapReduce. Zhao et al. [20] proposed the convolution neural network based on MapReduce (CNN-MR) algorithm, which adopts a data-parallel strategy to partition the training samples to each computational node. However, the method simply distributed the training samples without considering the efficiency of the model and the loss of accuracy due to data segregation. In [21], the MapReduce-based deep convolution neural network algorithm (MR-DCNN), developed by Basit et al. in 2017, added elastic distortion to the input data. Despite the improved accuracy, the algorithm struggles to achieve a satisfying balance between accuracy and computational cost. The large amount of intermediate data generated in the MapReduce process causes frequent IO operations, which will consume a lot of time. In the literature [22], the polymorphic parallel convolution neural network (PP-CNN) algorithm, developed by Zeng et al. in 2019, introduced deconvolution layer and designs local polymorphic parallel neural network and many-to-many connections. Their method reduces the computational complexity marginally, but it should be noted that it relies on reliable performance metrics, so availability is a limitation. To overcome these issues, Banharnsakun et al. [23] proposed a distributed artificial bee colony (distributed CNN-ABC) algorithm, which combined with the artificial bee colony method to find the optimal parameters in parallel, thereby minimizing classification errors and reducing time complexity. However, the above scheme failed to take full advantage of the acceleration provided by parallelization, and the non-uniform distribution of keys induce imbalance in task completion time and delay in the execution of the overall work, so how to design and implement an efficient parallel DCNN is still an urgent problem to be solved.
DCNN
DCNN extracts advanced semantic features of the image by utilizing multiple convolutional layers and pooling layers. It reduces the dimensionality of the feature map and preserves important feature information while ensuring image rotation invariance and translation invariance. Its training process is divided into two stages: forward propagation and back propagation.
During forward propagation process, the feature map is calculated for each layer input as
where * denotes a convolutional operation, y l is the output of the lth convolutional layer, x(l-1) and b l are the input vector and the bias term of the l th layer. I is the set of input feature maps and f (x) is the activation function. The weights of the l th convolutional kernel of the rth level are denoted by I.
During back propagation process, let’s assume the dataset has M samples, and the forward propagation phase of the network will output predictions for each class by comparing the desired output of the network with the predicted outcome to adjust the weights. Define the final objective function of the network as
Here, L (p r ) is the loss function, and the classification error is reduced by iteratively training the network to reduce the loss function. p r is the output of the last level in Equation (1), where it represents the input to the back propagation. λ (w) is the regularization function and w indicates the weight in the network.
Here, i is the current iteration commonly denominated epoch, w0 ∈ R n indicates a given initial point, η i > 0 is the learning rate and d i is the descent search direction.
Use the following expressions to define the update parameter β
i
[25, 26] in Equation (4):
Here, g i = ∇ E (w i ), yi-1 = g i - gi-1, || · || represents the Euclidean norm.
In this section, we describe and analyze parallel deep convolutional neural networks optimization (PDCNNO) algorithm in detail. The structure of PDCNNO is shown in Fig. 1. Our algorithm has three kernels: model compression, obtaining local classification results, and obtaining global classification results. In the model compression phase, to achieve pruning of redundant parameters, the FMP strategy calculates the L a -norm of the feature map to obtain the L a -norm average of the convolutional kernel, and then pre-training the network to obtain the compressed model. In the phase of obtaining local classification results, the Split function is firstly applied to divide the entire dataset into file blocks of the same size and stored on each node; then CGMSE is used to update the parameters when a Map function is employed to train the network on each node. In the phase of obtaining global classification results, LBRLA is designed to improve the performance of the Reduce function in calculating the final weights of the network, so as to quickly obtain the global classification result.

PDCNN algorithm structure.
A DCNN usually contains many layers, each of which in turn contains many convolutional kernels. However, not all the weights in convolutional kernel are needed in predicting the network, so the network has a large number of redundant parameters. The traditional pruning method for redundant parameters is tocalculate the L1-norm for each convolutional kernel. On this basis, convolutional kernels larger than the L1-norm are considered significant, while those smaller than the L1-norm are insignificant. In practice, the convolution kernel shows the features of a dimension of the image (e.g. outline, color), and it has degrees of depth. For example, the VGG16 configuration is shown in Fig. 2, which has 16 layers (13 convolutional and 3 fully connected layers), and its convolutional layers are divided into 5 segments, with a maximum pooling after each segment convolution. The 3 × 3 small convolution kernel is used to reduce the parameters and improve the fitting ability of the network. The 2 × 2 maximum pooling separates the layers from each other and the ReLU function is used for the activation units of all hidden layers. For shallower convolutional layers, it can only extract simple edges and color blocks. With conv1-1 (the first convolutional layer of VGG16), as shown in Fig. 3. (a), we can clearly see the outline of the whole bird, which is the edge feature of the object. Unlike shallower convolutional layers, deeper convolutional layers can focus on extracting highly abstract image features. As shown in Fig. 3. (b), conv4-1 (the eighth convolutional layer of VGG16) obtained high-level features such as the head, wings, and tail of the bird. ConsideringL1-norm alone may face the problem of ignoring important convolutional kernels, so we proposed FMP to pre-train DCNN before using all the data for training.
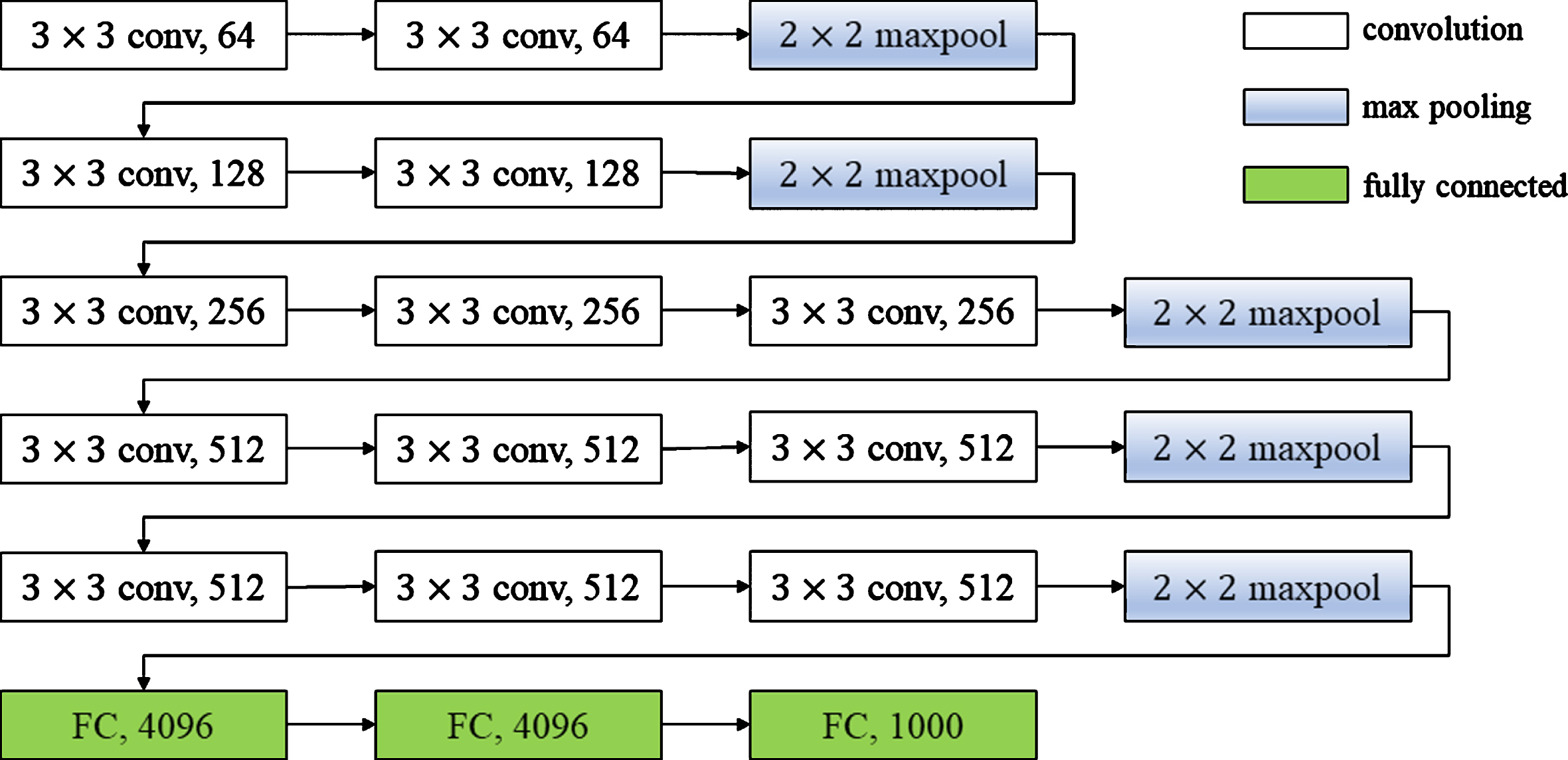
VGG16 Configuration.

Feature map of (a) VGG16 conv1-1 and (b) VGG16 conv4-1 output.
The FMP first randomly selects some training data to pre-train the DCNN, and evaluates the importance of the convolutional kernel using the L a -norm mean of the feature map. For each input sample x in the training dataset, the L a -norm for the output of the convolution kernel can be computed, and then the mean value of the L a -norm for all training samples is assigned to this kernel. The convolutional kernels are sorted by their corresponding mean values, and pruning is performed on those kernels having mean value less than a preset threshold. This pruning strategy can be repeated, recursively compressing the model and increasing computational speed.
Clearly, the use of FMP allows the removal of insignificant parameters and the retention of parameters that have an impact on the classification results. The pseudo code of model compression is shown in Algorithm 1.
The obtaining of partial classification results includes Split phase and Map phase. During the Split phase, divides the original dataset into blocks of the same size using Hadoop’s default file block policy. During the Map phase, the Map function is used to calculate the local variation of each network weight parameter, and then the weights are updated to obtain local classification results. Since the stochastic gradient descent method of updating weights in Map phase is very slow to converge in a big data environment, this paper proposes CGMSE to search for the optimal parameters based on the quadratic convergence of the conjugate gradient method. There are three main steps to CGMSE, detailed below.
The pseudo code for obtaining local classification results is shown in Algorithm 2.
In the previous phase, each node is trained to obtain the local weights of DCNN. At this stage, the key-value pairs <key = (a, b) , value = w> output by each Map node are transmitted to the reduce function to complete the final merge and obtain the final network weights (w is the weight, and (a, b) is the bth weight of the ath convolutional kernel). Taking into consideration the impact of load balancing on the efficiency of parallel algorithms, this paper proposes LBRLA. It maintains load balancing and enhances system resource utilization through load distribution rules and setting load thresholds. The LBRLA is described below.
Given a server composed of nodes, where node S
i
(i = 1, 2, . . . , n) has an inherent load of C
i
and a current load of L
i
, the following equation holds if the parallel system reaches load balancing.
Here, P
i
is the load rate of the ith node. Averaging the load rates of all nodes we get the current average load rate
However, according to fuzzy set theory [29], for each node of a parallel system, once the utilization of hardware resources (GPU, memory, network, disk) or parallel nodes exceed a certain percentage (such as 97%), the nodes can no longer handle the additional load. Accordingly, in the process of distributing load, it is necessary to evaluate the load by considering the following metrics: disk I/O usage, GPU usage, memory usage, network usage, parallel node usage, etc. Since they are all proportional to the load, we assign a weight to each metric, where disk I/O usage is D [i], GPU usage is G [i], memory usage is M [i], network usage is W [i], and node usage is N [i]. The combined node load rate is
Then, in practice, when the server reaches load balancing, we have
The parallel system calculates the difference between the average load and the load per node; the larger the difference, the smaller the node load and the higher the priority of the node to allocate the load; similarly, the smaller the difference, the larger the node load and the lower the priority of the node to allocate the load. Since the MapReduce chunking mechanism makes it difficult to get each node load exactly the same, when the node load reaches
In summary, LBRLA takes into account parallel node load rate and load weight as metrics based on real-time feedback from parallel nodes. By controlling the load rate, the data volume and distribution of each node is more balanced. It not only ensures the load balance of each compute node, but also enhances and upgrades the resource utilization of the parallel system.
The pseudo code for obtaining the global classification results is shown in Algorithm 3.
The time complexity of the PDCNNO algorithm is shown in Table 2 and it consists of the following three stage: Model compression stage: assume the network contains D convolutional layers, C
l
represents the number of convolutional cores in the lth convolutional layer, and M is the number of convolutional cores in each layer. The edge lengths of the output feature maps of the convolutional kernels, K represents the edge length of each convolutional kernel, and the number of pre-trained samples is m. Then the time complexity of the model compression using FMP is the sum of the feature map ordering time and the pruning time below the preset threshold weights, namely O (m log m) + O (m). The stage of obtaining local classification results: suppose the number of Map nodes is a. Since each iteration of the CGMSE requires a matrix-vector multiplication and some vector inner product calculations, the complexity is O (n3) after completing n iterations. Therefore, the time complexity of obtaining local classification results is The stage of obtaining global classification results: Assuming that the number of Reduce nodes is r, the time complexity of obtaining global classification results in Reduce stage is the quotient of the number of nodes and the total number of samples b, that is, O (b/r).
Time complexity
Time complexity
In conclusion, the time complexity of the PDCNNO algorithm is the sum of the above three stages, namely
In this section, we discuss the experimental setup, the experimental results and the corresponding analysis.
Experimental setup
We used the following three real datasets:
The SVHN [30] dataset contains color digital images from the real world, 32 × 32 pixels in size. The official dataset has 73257 images in the training set, 26,032 images in the test set, and 531,131 images for additional training. We segmented 6,000 images from the training set as a validation set and divided the pixel values by the 255, so their size is in the range [0,1], instead of using additional training images. The EMNIST Digits [31] dataset is all black and white images of 32 × 32 pixels. It provides a handwritten digital dataset that is directly compatible with the original MNIST dataset. The dataset has a total of 280,000 images, including 240,000 images for the training set and 40,000 images for the test set. The ISLVRC2012 [32] dataset contains 1,000 classes with 1,281,167 training images, 50,000 validation images, and 100,000 test images, each with multiple bounding boxes and corresponding class labels, and the entire dataset is approximately 150 G. Due to the inconsistency in image size, we cropped and scaled the images in the dataset to 224 × 224 and randomly selected 500 of these classes for the experiment.
Specific information about the dataset is shown in Table 3.
Experimental datasets
Experimental datasets
For the experimental hardware, we used 1 JobTracker node and 7 TaskTracker nodes. All nodes have an AMD Ryzen 7 CPU, 16GB RAM, with 8 processing units, a GPU of NVIDIA RTX2070 8 G, connected via 1Gb/s Ethernet. For software, the operating system installed in each node is Ubuntu 18.04, the MapReduce architecture is Apache Hadoop 2.7.4, and the software programming environment is java JDK 1.8.0. The specific configuration of the nodes is shown in Table 4.
The foundation configuration of each node in the experiment
To validate the performance of the PDCNNO algorithm, we conducted experimental comparisons by evaluating the algorithm running time, memory usage, and speed-up ratio.
Running time and memory usage
We perform experiments based on the SVHN, EMNIST Digits, ISLVRC2012 dataset to comprehensively compare the PDCNNO algorithm with the MR-DCNN [21] algorithm, PP-CNN [22] algorithm, distributed CNN-ABC [23] algorithm, and a variant of the PDCNNO algorithm without model compression (denoted by PDCNN below). The running time and memory usage of the five algorithms are shown in Fig. 4.
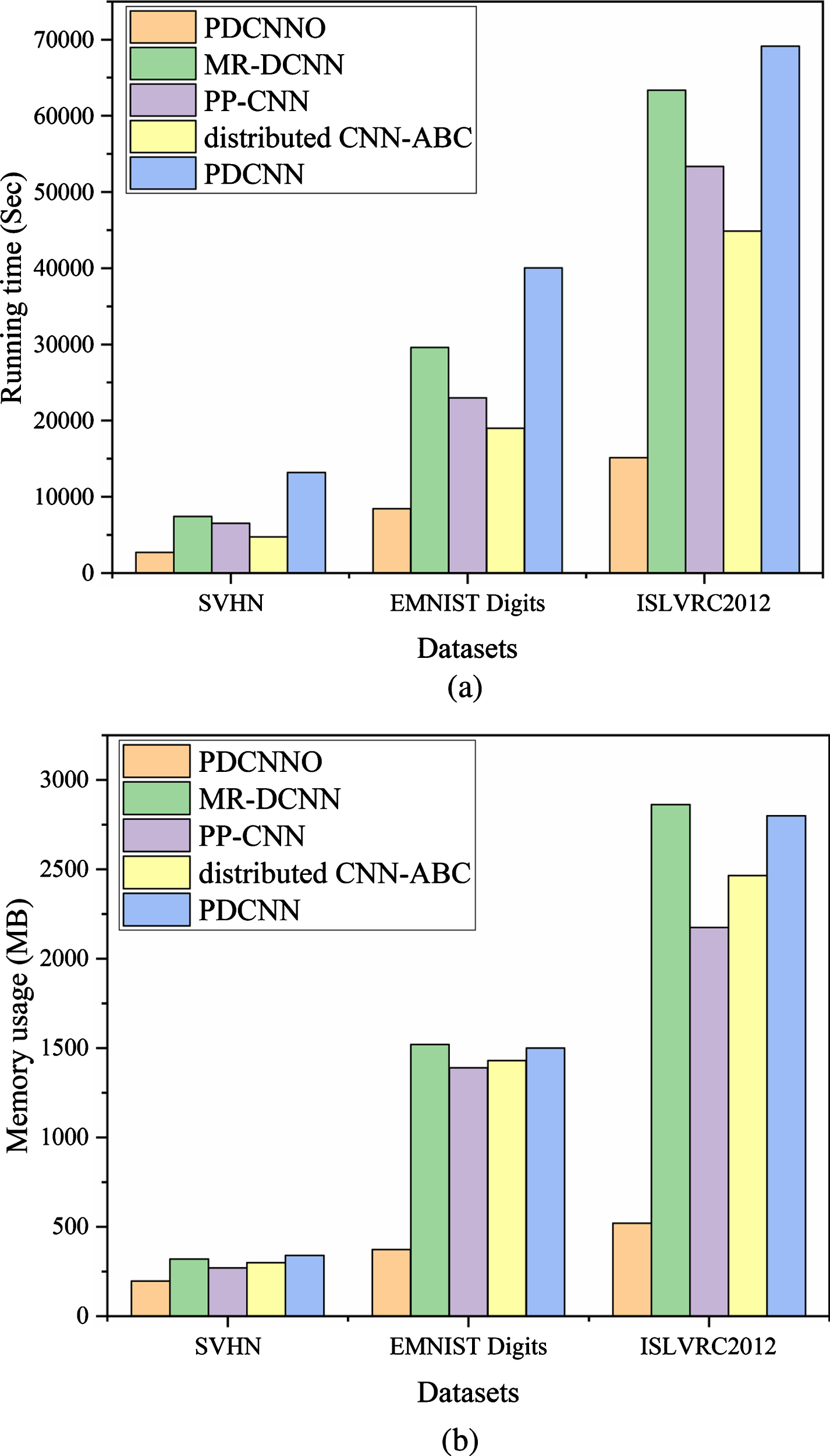
Comparison of (a) running time and (b) memory usage of each algorithm.
As shown in Fig. 4(a), the running time of the PDCNNO algorithm when processing the SVHN dataset is 36.31% of MR-DCNN, 41.25% of PP-CNN, 61.83% of distributed CNN-ABC, and 20.42% of PDCNN, respectively. Note that as the volume of data increases, the PDCNNO running time grows gently, while the other algorithms (including the PDCNN algorithm) increase geometrically. Especially when dealing with the largest dataset ISLVRC2012, the running time of the PDCNNO algorithm is 23.87% of MR-DCNN, 28.34% of PP-CNN, 41.47% of distributed CNN-ABC and 21.96% of PDCNN algorithm, respectively. The PDCNNO algorithm performs the best, while the ABC algorithm performs the second best. On the whole, there are three reasons for this result: firstly, since the pre-training time is much less relative to the algorithm running time, it has little impact on the overall performance of the PDCNNO algorithm; secondly, the distributed CNN-ABC algorithm manages to find the optimal initial weights, which improves time efficiency to some extent, but pruning of the network method in this study, directly led to a low-complexity network that accelerated model operation; finally, the use of CGMSE speeds up network convergence, thereby reducing running time better.
From a memory usage perspective (as shown in Fig. 4(b)), when processing the SVHN dataset, our algorithm is 53.23% of MR-DCNN,72.7% of PP-CNN, 57.65% of the distributed CNN-ABC and 57.65% of PDCNN, respectively. The superiority of the PDCNNO algorithm is becoming apparent when processing the latter two datasets. It can be noticed that the memory usage of the PDCNNO changes slightly, while the memory usage of the remaining algorithms increases sharply with larger datasets. Focusing on the comparison of the four algorithms it is revealed that they differ little on the first two datasets, except that the PP-CNN and distributed CNN-ABC algorithms perform slightly better on the dataset ISLVRC2012. This is attributed to the many-to-many connections used by the PP-CNN algorithm to guarantee continuous memory in the model. The more acceptable memory usage of the PDCNNO algorithm comes mainly from its pruning strategy. By pruning the redundant parameters via FMP, the number of parameters is substantially reduced, with a consequent reduction in running time and memory usage. Therefore, it can be concluded that the PDCNNO algorithm can significantly improve the training efficiency of DCNN in a big data environment and ensure the efficient operation of the model.
Speed-up ratio is typically used as a significant indicator to measure the parallelization performance of the algorithm. The speed-up ratio refers to the ratio of time, which is defined as
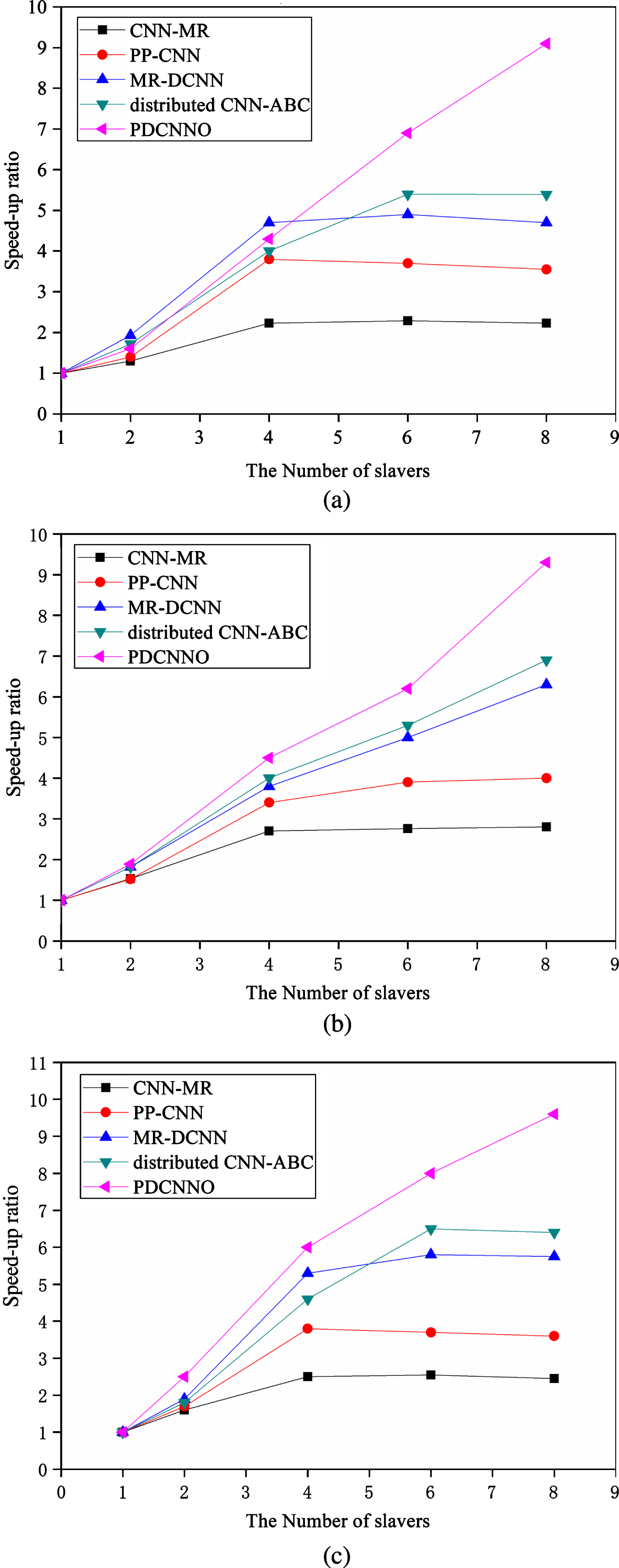
Speed-up ratios for each algorithm on (a) SVHN, (b) EMNIST Digits and (c) ISLVRC2012.
From Fig. 5, it can be seen that the speed-up ratio of each algorithm follows an increasing trend with the number of nodes. When the number of nodes is small, such as 2, the difference among the algorithms’ speed-up ratios on the three datasets is not significant, although the value is slightly larger using the ISLVRC2012 dataset. In other words, with fewer nodes, the PDCNNO algorithm incurs time overhead in cluster operation, task scheduling, node storage, and other aspects, which slow down the computation speed of the algorithm, so the parallel performance of the PDCNNO algorithm is not good in this case. However, as the number of nodes increases to 6, the speed-up ratio of the PDCNNO algorithm surpasses other algorithms, for instance, it is higher than the MR-DCNN, distributed CNN-ABC, PP-CNN, and CNN-MR algorithms by 2.0, 1.5, 3.2, and 3.9, using SVHN dataset. This difference becomes more pronounced with rising number of nodes, and as we see from the different datasets, the speed-up ratios of the four comparison algorithms eventually stabilize, whereas the speed-up ratios of the PDCNNO algorithm essentially increase linearly with increasing number of nodes. This is due to the fact that the PDCNNO algorithm distributes the classification results equally among the computing nodes using LBRLA, and the advantage of the algorithm to compute the classification results and update the weights in parallel is gradually amplified. From Fig. 5(c), we observe that the acceleration ratio of PDCNNO is consistently better than the other algorithms. This result further suggests that the PDCNNO algorithm is suitable for processing larger datasets, and the parallel performance of the algorithm is greatly improved while the number of computational nodes is increased.
To compensate for the shortcomings of the traditional DCNN algorithm in terms of redundant parameters, slow convergence, and inefficient parallel performance in a big data environment, this research proposes the PDCNNO algorithm and provides an in-depth exploration and evaluation of its parallel design and implementation. At first, pre-training a portion of the randomly selected data and designing an FMP to reduce redundant parameters in the network by comparing the average value of L a -norm. Next, we trained the network using the MapReduce model and propose CGMSE during parameter updates in the Map phase, which accelerates convergence by optimizing the search direction. Finally, we presented LBRLA in the Reduce phase to solve the problem of load imbalance across nodes in parallel systems and improve the parallel performance of the algorithm. Furthermore, in our experiments, the proposed algorithm and other techniques are compared in detail, including CNN-MR algorithm, MR-DCNN algorithm, PP-CNN algorithm, distributed CNN-ABC algorithm and PDCNN algorithm. Experimental results illustrated that our algorithm significantly outperforms the other compared algorithms in terms of running time, memory usage and speed-up ratio. And for larger datasets, the PDCNNO algorithm is more adaptable.
However, there remains room for improvement of the algorithm. For instance, pruning is limited by the width of the convolutional layer and the threshold for evaluating the L a -norm needs to be adjusted manually. A future effort is to design an adaptive pruning so that the parameters can be applied to more general cases. Moreover, another point to note is that the algorithm provides insignificant performance improvement or even performance drops when dealing with small data sets. As such, it will be our direction to explore in the future by further improving the resource utilization of Hadoop clusters.