
Abstract
Quality prediction plays an essential role in the business outcome of the product. Due to the business interest of the concept, it has extensively been studied in the last few years. Advancement in machine learning (ML) techniques and with the advent of robust and sophisticated ML algorithms, it is required to analyze the factors influencing the success of the movies. This paper presents a hybrid features prediction model based on pre-released and social media data features using multiple ML techniques to predict the quality of the pre-released movies for effective business resource planning. This study aims to integrate pre-released and social media data features to form a hybrid features-based movie quality prediction (MQP) model. The proposed model comprises of two different experimental models; (i) predict movies quality using the original set of features and (ii) develop a subset of features based on principle component analysis technique to predict movies success class. This work employ and implement different ML-based classification models, such as Decision Tree (DT), Support Vector Machines with the linear and quadratic kernel (L-SVM and Q-SVM), Logistic Regression (LR), Bagged Tree (BT) and Boosted Tree (BOT), to predict the quality of the movies. Different performance measures are utilized to evaluate the performance of the proposed ML-based classification models, such as Accuracy (AC), Precision (PR), Recall (RE), and F-Measure (FM). The experimental results reveal that BT and BOT classifiers performed accurately and produced high accuracy compared to other classifiers, such as DT, LR, LSVM, and Q-SVM. The BT and BOT classifiers achieved an accuracy of 90.1% and 89.7%, which shows an efficiency of the proposed MQP model compared to other state-of-art- techniques. The proposed work is also compared with existing prediction models, and experimental results indicate that the proposed MQP model performed slightly better compared to other models. The experimental results will help the movies industry to formulate business resources effectively, such as investment, number of screens, and release date planning, etc.
Keywords
Introduction
Background
The movie industry is a multi-billion dollar business worldwide [1]. Every year, movie production companies of the united states of America produces thousands of motion pictures of different categories, such as action, animation, comedy, horror, and war, etc. Hollywood is a multi-billion dollar movie industry which earned more money in the international movies market since 1920s [2]. According to the study [3], every year, the movie industry of America generate revenue up to 10 billion dollars. The worldwide revenue of box-office was 42.2 billion USD in 2019, which is increased from the previous year [4]. The movie industry is a big business [5], which can give profit in case of “hit” movie and loss in case of flop movie up to several million dollars. Movies production companies spend up to 100 million dollars on making a single movie.
However, still, there is a great deal of uncertainty that the high budget movie will do business or not. Therefore, movies quality prediction is considered a challenging task in the field of ML. Different researchers have developed different ML-based approaches to predict box-office revenue and theatre requirements [6–9]. The existing prediction ML-based prediction model is not too efficient and robust to make an accurate prediction to provide better support for movie investors to drive effective decisions. Therefore, our work aims to develop a robust ML-based prediction model to predict the success of the pre-released movie to provide accurate prediction and facilitate movie investors to drive better decisions to formulate resources effectively.
ML-based prediction algorithms are rapidly growing in different areas, such as classification and regression [10–13], pattern recognition [14, 15], computer vision [16], statistical learning [17], natural language processing [18], and business intelligence [19], to name of few. ML techniques are effective and robust to build reliable prediction models based on historical data to drive a conclusion or provide the best assessment of the future outcome. Traditional systems are not capable of processing, analyzing and evaluating a massive number of movies data to generate useful information and other hidden insights. In contrast, ML-based predictive analytics techniques are capable of extracting underlying patterns and hidden insights from a massive amount of data to develop a robust prediction model. The prediction model aims to make accurate predictions that are used to facilitate business management to drive better business decisions. Therefore, our work aims to utilize data and predictive analytics techniques to propose a robust MQP model based on hybrid features to predict movie success class, that will help investors to formulate business strategies and future decisions.
Problem statement and motivation
The predicting quality of the movie is dependent based on different factors such that how users rated the particular movie, box-office revenue, and other external factors, including release date, competing movie, and weather. All these factors directly influence the revenue of the movies. It is discussed in an earlier section that every year movie industry produces thousands of movies of different genres. The fact is that only 36% of movies had higher box-office revenue than the total amount of investment [1], which significantly shows the importance of prediction to make accurate investment decisions. It reveals that there is a great deal of uncertainty exist for investment in the movies business. In the last few years, different movies quality prediction models have proposed based on different features set, such as movie pre-released, post released, social media data, and static data features [20, 21]. To the best of our knowledge, very few authors have considered both pre-released and social media features for the prediction process, but they did not achieve accurate prediction results. The maximum accuracy achieved using both pre-released and social media is 58.53% [20], while using social media data features with others set of features is 88.8% [21], which is still improvable. Therefore, it is an open area for researchers to propose innovative techniques based on a various set of promising features that can enhance the performance of movie quality prediction models.
The process of making a motion picture is both an industry and an art [22]. Motion pictures are considered one of a great source of entertainment as well as multi-billion dollar business. Movies Industrialist invests a lot of money and time to make a single movie. Movies production companies don’t know about their upcoming movie performance at the box-office that whether it will succeed or not. As the movie industry is growing too fast over the last two decades, there are many online sources available such that Internet Movie Database (IMDb) [23], Rotten Tomatoes (RT) [24], Movielens [25], and Wikipedia [26], etc., to keep the record of the movies data. The availability of the massive amount of movies data makes it an exciting and challenging task in the field of ML. Therefore, our work aims to propose a robust ML-based MQP model to analyze pre-released and social media features of IMDb movies data to predict movie success class, which will help movie investors to devise effective business strategies.
Main contributions of the proposed MQP model
The main contributions of the proposed MQP model are listed as follow: Develop a prediction model based on integrating movie pre-released and social media data features using ML techniques to accurately predict movie success class, which facilitate investors to formulate effective business strategies. Preprocess, analyze and extract features from IMDb movies dataset to predict movie quality to reduce investments risk. Newly features are constructed, such as star power of movie actor, star power of movie director, star power of movie actor and director, significance of the movie release date, and competition factor. Features selection approach is employed to select only relevant and the most promising features to enhance the performance and reduce the computational complexity of the proposed model. Two different experimental models are developed; predict movie success class using the original set of features and a reduced set of features. The comparison analysis of the original and reduced set of features are given. Trained and tested the proposed model based on different ML algorithms and give a comparative analysis of the top six classifiers. Comparative analysis is given to demonstrate the effectiveness and significance of the proposed MQP model with state-of-art techniques.
Paper organization
This paper is organized as follow: Section 2 presents existing approaches related to MQP model. Section 3 presents the proposed methodology which includes the following steps: data acquisition from the IMDb, preprocessing acquired dataset, features engineering, labeling dataset, data normalization, selection of decision features, training and testing ML-based classification models, and performance evaluation. Section 4 presents implementation environment of the proposed MQP model. Section 5 discusses the experimental results. Section 6 presents a comparative analysis of the proposed MQP model with existing models. Finally, Section 7 presents a conclusion and possible future direction.
Related work
This section presents background information and related work for the movie prediction models. A large interest had started in predicting movie success when Netflix announced the Netflix Prize [20] in 2006. It is discussed in an earlier section that the movie industry is a multi-billion dollar business, which can give revenue in case of hit movie and loss in case of flop movie up to several million dollars. Therefore, different research studies attempted to develop predictions models based on a different set of features to predict movie success class. In [22], the authors used ML techniques to predict movie popularity based on standard movie online database IMDb. The proposed features of this work are rating, MPAA rating, genre, awards, screens, opening weekend, meta score, number of votes and budget. The authors achieved better prediction results using simple logistic and logistic regression of 84.34% and 84.15%, respectively. Assady et al. [27] designed an iterative approach to predict movie success. The author’s combined features from both structure and unstructured data to predict movie quality using different ML techniques, such as SVM, MLP and LR. Team J. Alexander et al. [28] proposed an artificial neural network (ANN) based prediction model to predict movie rating using following two parameters, such as ratings of crew members and actors of relevant movies. The authors presented a comparative analysis using different ML-classification models to predict movie success class [29]. A multi-class model was presented in [30] to predict movie box-office success. The authors considered pre-released and post released movie features to build a prediction model. In [31], the authors proposed a deep convolutional neural network (CNN) model to extract relevant features from movie posters and build a prediction model to predict box-office revenue. U. Ahmad et al. [32] proposed a multi-features based prediction model to predict movie success to reduces the investment risk.
Some of the researchers applied data mining techniques to predict movie success class [33–37]. In [34], the authors proposed auto-regression methods and an adaptive network of fuzzy inference system to predict movie performance. The proposed model produces a single output, which is a category of the movie, such as Disaster to All Time Blockbuster. In [35], the authors presented a prediction model based on the following techniques, such as NB, k-NN, and DT, to predict movie success. The authors concluded that that DT achieved the best accuracy of 83%. The NB produced an accuracy of 73%; whereas k-NN (3-NN) produced the prediction accuracy of 51%, which is relatively low. Another study presented in [35] proposed a prediction model based on movie pre-released features using DM techniques to predict movie success class. A comprehensive study is presented in [36] to analyze movies data to identify movie success class. Similarly, in [8], DM approaches were used to predict movie success and failure based on movie pre-released features to facilitate movie audience. There are different researchers suggested movie prediction models using web mining and text mining techniques [1, 37]. In [1, 37], the authors used text mining and social network analysis techniques to make early movie success predictions to support movies production companies decisions. Similarly, in [38], a text mining approach was used to predict movie success class based on sentiment features extracted from movie reviews data. The authors achieved an accuracy of 81.69%. Today, soft computing techniques are considered as a fundamental paradigm to develop effective and sustainable solutions to the existing problems. The soft computing techniques are divided into three different, such as ANN, fuzzy logic, and meta-heuristic approaches. These techniques are widely used in a different domain, such as safety [39, 40], predictive analytics [41, 42], decision making systems [43, 44], to name of few.
Some of the existing research studies used sentimental analysis to predict movie success class [45, 46]. In [45], the authors presented a prediction model to predict box-office revenue using movie trailer reviews posted by different users on social sites. In this work, movie trailer reviews are collected from social sites to predict movie sales performance, and then calculate rating and revenue using sentimental analysis. In [46], the authors proposed a model to predict the movie success class based on public sentiments analysis. The author’s considered dataset used by Mass et al. [47], which contains 50K movie reviews. The movie reviews are classified into two categories, such as positive and negative. The authors used features extraction techniques to extracted the following features such that Term Frequency and Inverse Document Frequency (TF-IDF), and polarity score.
Similarly, some of the existing prediction models attempted to used social media data features to analyze and predict the movie success class [48–50]. In [48] proposed a predictive model to analyze the role of different factors in predicting movie success. The proposed work was developed based on the integration of classical and social media factors to identify movie success and failure. The authors reported that multi-variate Linear Regression (LRE) achieved an accuracy of 70.57%, which still needs improvement to make an accurate prediction for investors to plan resources effectively. Another similar study presented in [49], the authors proposed a prediction model to demonstrate the role of social media contents towards predicting real-world outcomes. The authors reported that LRE produced accurate prediction results in terms of R2 score of 0.80. In [50], the authors presented a prediction model to predict movies popularity based on two different sets of features, such as conventional features (CF) and social media features (SMF). The authors reported that DT classifier produced the best prediction results for the movie rating and income of 77% and 61%, respectively. It can be observed that the performance of the studies mentioned above needs improvements by enhancing existing models to add more prominent features. Table 1 presents summary of the existing prediction models.
Summary of the existing prediction models
Summary of the existing prediction models
To best of the author’s knowledge, most of the afore-mentioned studies considered both static and pre-released movies data features to predict movie success class. It is evident that every research study has used pre-released movies features in their prediction models which show the importance of these features, while some authors have used movie static features along with movie post-released features, whereas very few have used social media data features to enhance the performance of the movie’s prediction models. To best of our knowledge, a very few researchers have considered both pre-released and social media features for the prediction process [21, 30], and [32] but they did not achieve accurate prediction results to facilitate investors to manage their future resources effectively. Therefore, it opens an area for researchers to propose innovative and effective solutions that can enhance the performance of movie quality prediction models. The proposed research study attempts to combine both movies pre-released features (with historical features) and social media data features to form a hybrid features model to build a robust and effective MQP model. The proposed MQP model aims to help the movie industry to plan their future resources effectively, such as investment, the number of screens, and release date planning, etc.
This section presents a methodology of the proposed MQP model. The proposed MQP model aims to predict movie quality to facilitate business industries to increase revenue and reduce investment risks. This work utilize ML-based classification techniques to predict movie quality based on IMDb data into two classes, such as high and low quality movies. Figure 1 presents the basic flow of the proposed MQP model.
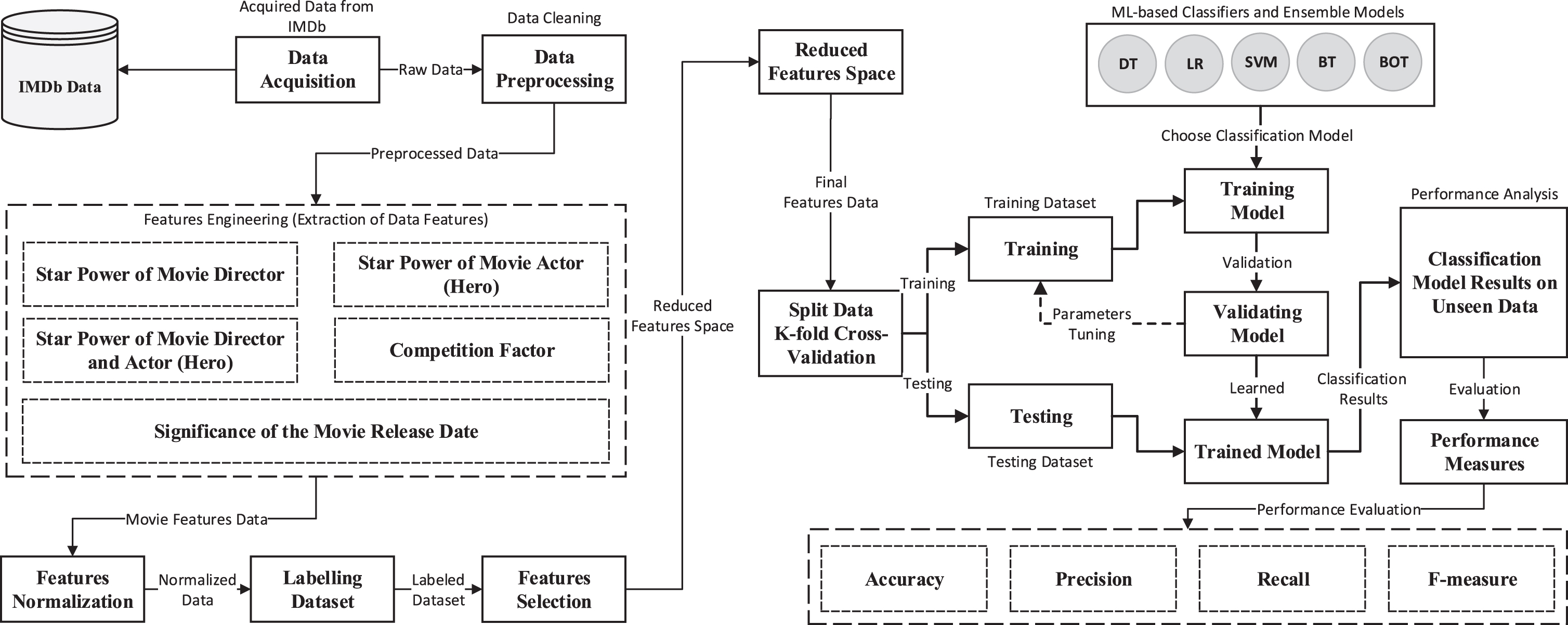
Basic flow diagram of the proposed MQP model.
The proposed methodology comprises the following steps: acquisition of movie data from the IMDb, preprocessing acquired dataset, data normalization and transformation, features computations, labeling dataset, selection of decision features, and train/test different ML classifiers. The most important steps of this research study are given below as follow: Acquisition of Movies Data from Online IMDb Data Pre-processing Features Engineering Data Normalization Labeling Dataset Selection of Decision Features Training/Testing ML Classifiers on Labeled Dataset Performance Evaluation
The IMDb is one of the largest movie datasets publicly available on the web which contains detailed information about movies. It is one of the most popular sources of movie data features such that title, actor, director, writer, genre, movie news, movie reviews, trailer, votes, show times and release date, to name of few. In this work, movies data are collected from an online available source known as Kaggle IMDb dataset, which is also used in [51]. The retrieved data is in JSON format that converted later into MS CSV format for further processing. The data acquired from Kaggle IMDb dataset contains 5000 movies samples. Each movie consists of the following features listed in Table 2.
Acquired movies features list
Acquired movies features list
Data Preprocessing is an important step to clean and transform raw data into a competent and reliable format. Therefore, it is essential to transform raw data into reliable format to increase the consistency and reliability of the dataset. After the acquisition of movie data, it is found that HTML entities strings are encoded to movie features and also found duplicate records for some movies. In the preprocessing step, all encoded HTML entities string, duplicate records and all other outliers from acquired data have identified and removed to increase the consistency of the dataset. All those movies records are removed which do not have any information about box-office details, such as movie budget and gross values. The missing values attributes are checked and resolve inconsistency issues in order to make sure that the information required is the same format for all attributes. This work uses a central tendency method (mean and median, etc.) as a standard to fill missing values attributes to resolve inconsistency issues. All other irrelevant data and static features that cannot process by learning model are removed to increase the efficiency of the dataset. Finally, only relevant data attributes are considered to perform features engineering to unearth hidden insights and useful knowledge from the historical movie dataset.
Features engineering
This subsection presents features engineering to extract features from existing preprocessed dataset. This technique is used to construct and add new data features from/to existing dataset. This work uses features engineering technique to extract the following hidden features from the prepared dataset. Star power of movie director Star power of movie first actor (movie hero) Star power of movie director and first actor (movie hero) Significance of the movie release date Competition factor
Star power of movie director
The first feature that is extracted known as “Star Power of the Movie Director” using existing dataset attributes such that a movie budget and a movie gross. The following Algorithm 1 is designed to extract new data feature based on the existing dataset features.
The star power of each director is calculated by summing up the budget and gross values of all movies done by that specific director during their career. After summation of the budget and gross values, the average value for the total budget and total gross is calculated. Thus, if the average value of the total gross is higher than the average value of the total budget, then the star power of a particular director is Hit; otherwise, it is a Flop.
Star power of movie first actor (movie hero)
Similarly, the second data feature is extracted known as “History of the movie first actor (movie hero)” using existing dataset features, such as movie budget and movie gross. The star power of movie actor is calculated by summing up the budget and gross values of all movies and counting all movies of the specific actor done during their career. Then the average values for the total budget and total gross are calculated. Thus, if the average value of the total gross is higher than the total budget, then the star power of the specific actor is denoted as “Hit”; otherwise, it denotes as “Flop”. The following Algorithm 2 is designed to compute the star power of movie actor based on the existing dataset features.
Star power of movie director and first actor (movie hero)
The third feature that is extracted from the prepared dataset known as “star power of the all common movies between a movie director and a movie first actor”. The star power for the movie director and actor is calculated as follow: Summing up the movie budget and movie gross for the all common movies of the specific movie director and movie actor done together during their careers, and Total number of movies of the specific director and actor done together during their careers Then the average values for the total budget and total gross of the common movies are calculated. Thus, if the average value of the total gross is higher than the total budget, then the star power of the specific director and actor is denoted as “Success”; otherwise, it is denoted as “Failure”.
The following Algorithm 3 is designed to compute the star power of movie director and movie actor based on the existing data features.
Figure 2 presents popularity analysis of the movie actors in terms of Fb likes. It demonstrate the social popularity of the movie actors. This research study reveals that the popularity score of the movie actors also significant impact towards movie success at theaters.

Popularity of Movie Actors in terms of Fb Likes.
This work uses a movie release date to check the significance of the movie release date. In this work, Canadian holiday and festival days are considered to shows the effectiveness of the release date of the month. The following Canadian holiday and festival days are considered, such as valentine day (February), St. Patrick’s Day (March), Victoria Day (May), Independence Day (July), Halloween Festival (October), Thanksgiving Day (November), and Christmas Festival (December). Thus, if a movie released in these days, then it will get a score of 1, otherwise it will get a score of 0.
Competition factor
In this work, a competition score is computed for each movie by counting all movies released within 2 weeks before or after the given movie release date. The inverse of the competition score calculates the competition factor. Thus, the competition factor is defined as follows in Equation 1:
In our preprocessed dataset, it is found that some of the movies feature cause skewness or bias, such as movie budget, movie gross, Fb likes, number of users reviews, number of voted users, to name of few. Therefore, it is essential to transform all these data features into some defined range, such as [0,1] to get uniformity among data features values. There are different data normalization techniques used to normalize features values in some specified range to avoid biases, such as min-max normalization, scaling decimal-based normalization, and z-score normalization, etc. In this work, the min-max normalization technique [52] is used to normalize all those data features which cause biases in their values. The min-max Normalization technique is used to fit the attribute values in the pre-defined range [0,1]. The basic min-max normalization formula is given in Equation 2:
A represents the attribute X
i
represents the i
th
value of the attribute A min represents the Minimum value of the attribute A max represents the Maximum value of the attribute A
Thus, the dataset is normalized using a min-max normalization technique and then stored in the MS CSV file separately.
After data normalization step, there are two different sets of data attributes, such as categorical and nominal features sets. The categorical features set consists of 8 features, whereas nominal features set consists of 12 features. Our prepared dataset contains 4,807 movies along with 20 data features. Table 3 presents all categorical features along with possible values for each feature.
List of categorical features
Whereas Table 4 presents all nominal features and their values range for each feature is scaled between 0 and 1.
List of nominal features
This subsection presents labeling prepared dataset to assign a class label to each movie. The prepared dataset is an unsupervised dataset, which data features have an unknown class label. The supervised classification models required a training dataset where all given dataset features are already associated with the known class label. Therefore, it is required to assign a label for each movie in advance, such as high or low. There are several methods available to unsupervised label datasets. This work uses a data labeling approach which is used in the following research study [21]. Thus, a class label is assigned to a normalized dataset that whether the class label is high or low for each movie data features. The existing method is used to assign a class label to all movies, whether it is a high-quality or low-quality movie. The proposed work uses existing work to label movie quality into high and low. The considered approach is reliable and heuristically produced the most promising results than a simple method of calculating movie profit. Based on the existing approach, the total revenue of the movie is divided by two in order to consider movie promotion costs as well as other distribution costs, which are not publically available. The given data labeling approach is implemented in Algorithm 4, which uses to label prepared dataset in two categories, such as high or low.
Features selection
Our proposed MQP model analyses prepared dataset to select the most promising features for the classification process to reduce a large number of features space. There are several techniques available for the features selection process. With the help of the features selection techniques, it is possible to identify the most promising features from the prepared dataset to enhance the performance of the ML models. It is used to eliminate irrelevant data features that do not have enough information to contribute towards the analysis process. It is also used to find out the weight of most contributed features for the analysis process and also find out those features, which contribute least. This work uses Principal Component Analysis (PCA) technique [53] to select decision features set from the original set of features shown in Tables 2 and 3. PCA is a dimension reduction method used to reduce decision features space from a larger number of features set to a smaller number of features set that still contains most of the features information in the large features space. It is used to select a subset of decision features from the larger number of features set based on those original features which have the highest correlations with the principal component. It is a very effective technique to reduce the training time and increase the overall performance of the classification models.
Applied ML-based algorithms
This subsection presents the applied algorithms for the proposed MQP model. The main focus of this work is to compare the performance of each ML classifier to predict whether each movie would be a high-quality or a low-quality. In this work, we are going to classify supervised data. For this, the following different linear and non-linear ML-based classification algorithms are implemented for the analysis process shown in Table 5.
List of trained classifiers on labeled dataset
List of trained classifiers on labeled dataset
Each of the implemented classifiers results tested against k-fold cross-validation method where the value of k is 10. Thus, the 10-fold cross-validation method is used to evaluate and compare results of the implemented classifiers. The prepared dataset is divided into k (where k = 10) equal parts by dividing the total number of movie samples to k. These k parts of the dataset are used to train each classifier k times in such a way that each time a different part of the dataset is used as a testing set and remaining k - 1 parts will be used as the training set. This execution of testing and training will overcome the probability of over-fitting and gives accurate classification results. This approach is very effective for each ML-based classification model because it gives results in a less biased as compared to other data splitting methods, such as train-test split, etc. The accuracy of each classifier is determined by dividing the total number of accurate classified instances by the total number of classifications made by the classifier.
The implemented ML-based algorithms, such as DT, LR, SVMs with a linear and quadratic kernel are applied to predict the quality of the movies. All these algorithms are based on supervised learning, where a training dataset is required for each algorithm to predict the class labels for the unseen instances correctly. The following performance measures are utilized, such as AC, PR, RE, and FM, to find out the best classifier among implemented classification algorithms.
Ensemble techniques are used to combine multiple models (decision trees) to increase the overall accuracy of the prediction models. The main idea of the ensemble model is to combine weak learners to form a robust learner. Typically, weak learners are simples classification rules which can be used to predict any instance of the dataset. This work uses the following ensemble techniques, such as BT and BOT, to increase the prediction accuracy by combining prediction results from multiple models.
BT technique is used to reduce the variance of a DT. In this work, the main idea behind the BT is to create several subsets of data randomly from a training dataset. After that, we have trained a DT for each subset of data. Next, decision trees for all subsets of data are combined in order to build a robust and effective learning model. Finally, an average value is calculated from the obtained prediction results of different decision trees as an output, which is more robust and effective than a single DT. Another ensemble technique is Boosting, which is used to create a collection of predictors. In this paper, with the help of boosting model (BOT), decision trees are computed sequentially with early decision trees, which are used to fit simple models for data and then data are analyzed for errors. BOT is used to find highly accurate classification rule by combining many weak classification rules, where each of a rule is moderately accurate.
This section presents the implementation process and environment of the proposed MQP model. Figure 3 shows the implementation steps of the classification process. The following implementation steps are carried out, including movies data acquisition from the IMDb, data preprocessing, features extraction, data normalization and labeling, features selection, and use of different ML classifiers. Data are acquired from the available online source, such as IMDb in order to predict movies quality. The acquired dataset is preprocessed in order to transform raw data into a reliable and understandable format. The proposed work uses a one-hot encoding approach to convert each categorical attribute value into a new column and assign binary notations, such as 1 or 0. This approach is more effective and flexible as compared to other label encoding approaches. It eliminates order issues faced by the label encoding scheme, but it causes to increase the size of the dataset by increasing more data columns. The next step is to extract features from the preprocessed data and add extracted features to the existing dataset. In the next step, all data features are normalized using a min-max normalization technique to avoid skewness among data features values. The prepared normalized dataset is labeled using an existing approach [21], to assign a label to each movie sample. Once the dataset is labeled, PCA is used as a standard feature selection technique to select most contributed features from the given features space and remove irrelevant features. Finally, our proposed work implemented the following ML-based classification algorithms, such as DT, L-SVM, Q-SVM, LR, BT, and BOT. In this work, each of the implemented algorithm results validated against k-fold cross-validation method where the value of k is 10. Thus, the 10-fold cross-validation method is used to validate results obtained from each of the applied algorithms. The following performance measures are utilized to evaluate the performance of the implemented classification algorithms, such as AC, RE, PR, and FM.
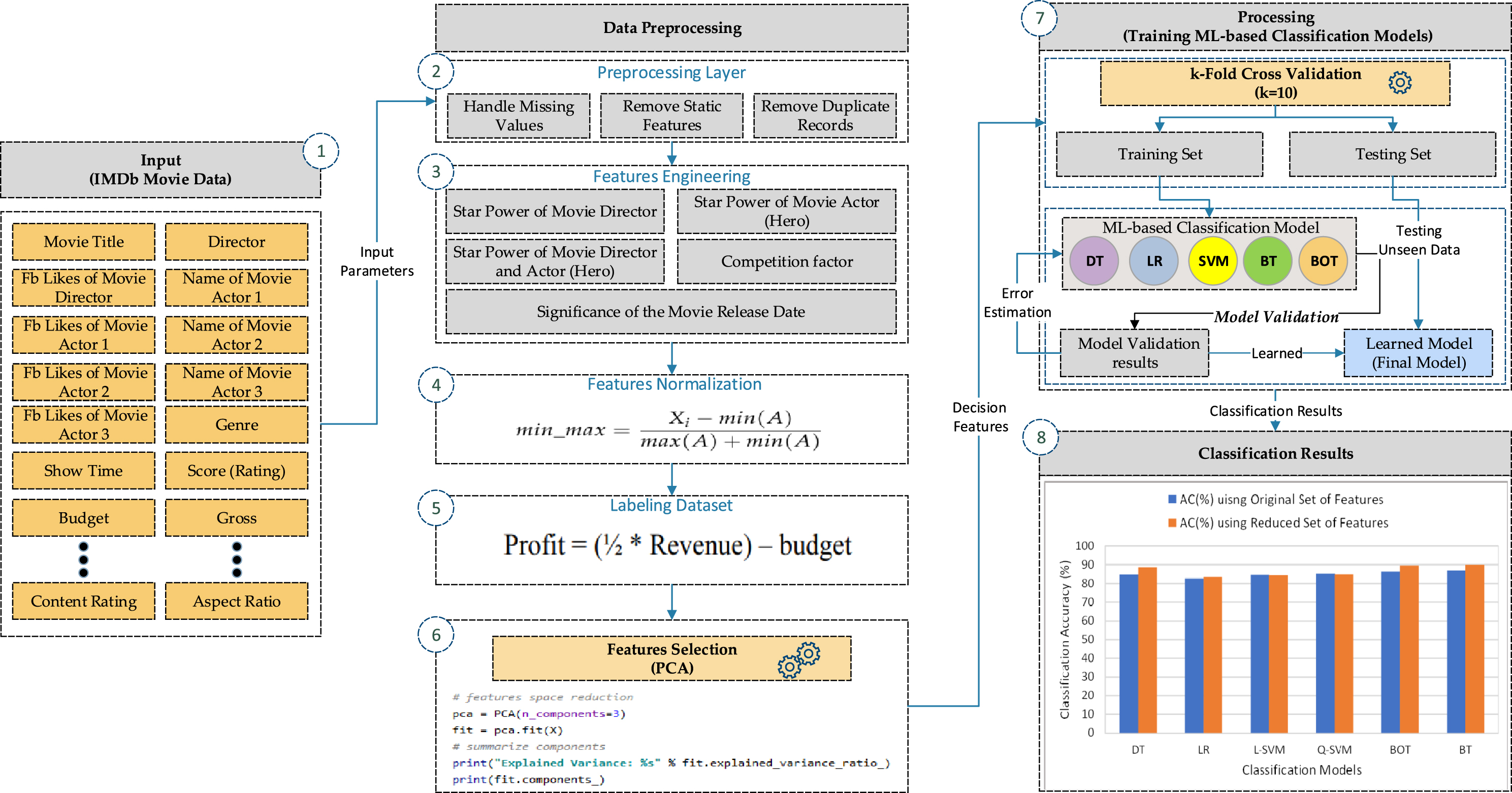
Implementation process of the proposed MQP model.
Table 6 summarizes the implementation environment for the proposed MQP model. In this paper, we used Python as a core programming language to conduct different experiments. This work uses a well-known library of ML known as sklearn. The sklearn is a prominent library for classification, preprocessing and filtering, clustering, regression and optimization problems.
Implementation setup of the proposed MQP model
This section presents the experimental results of the proposed MQP model. The proposed MQP model consists of two different experimentation models. First, an original set of decision features are utilized to predict movies box-office success. Second, we used the PCA technique to select the most promising features to predict movie box-office success. Figure 4 depicts the experimental results obtainted using the original set of features. It is evident that the correctly classified movies rates of the all implemented classifiers using the original set of features are higher than 82.6%. Hence, BT and BOT classifiers produced accurate prediction results compared to other classifiers. The prediction accuracy of BT and BOT models using the original set of features is 87% and 86.3%, respectively. Furthermore, other implemented classifiers, such as DT, L-SVM, Q-SVM, and LR, produced an accuracy of 84.7%, 84.5%, 85.2%, and 82.7%, respectively.

Movies quality prediction results using the original set of features.
Figure 5 depicts prediction results using ML models based on a reduced set of features. In this work, we use the PCA technique to select a subset of decision features to train/test ML models. It is an effective technique to reduce overfitting and complexity of the learning model. It also used to increase the overall performance of the predictive analytics model. Therefore, only relevant and essential data features are considered to report prediction results from the classification process. It is found that BT and BOT classifiers produced accurate prediction results compared to other implemented ML models. The prediction accuracy of BT and BOT classifiers is 90.1% and 89.7%, respectively. In contrast, other ML models, such as DT, LSVM and QSVM, produced an accuracy of 88.8%, 84.4%, and 84.8%, respectively. The LR classifier produced an accuracy of 83.4%, which is slightly low compared to other models.
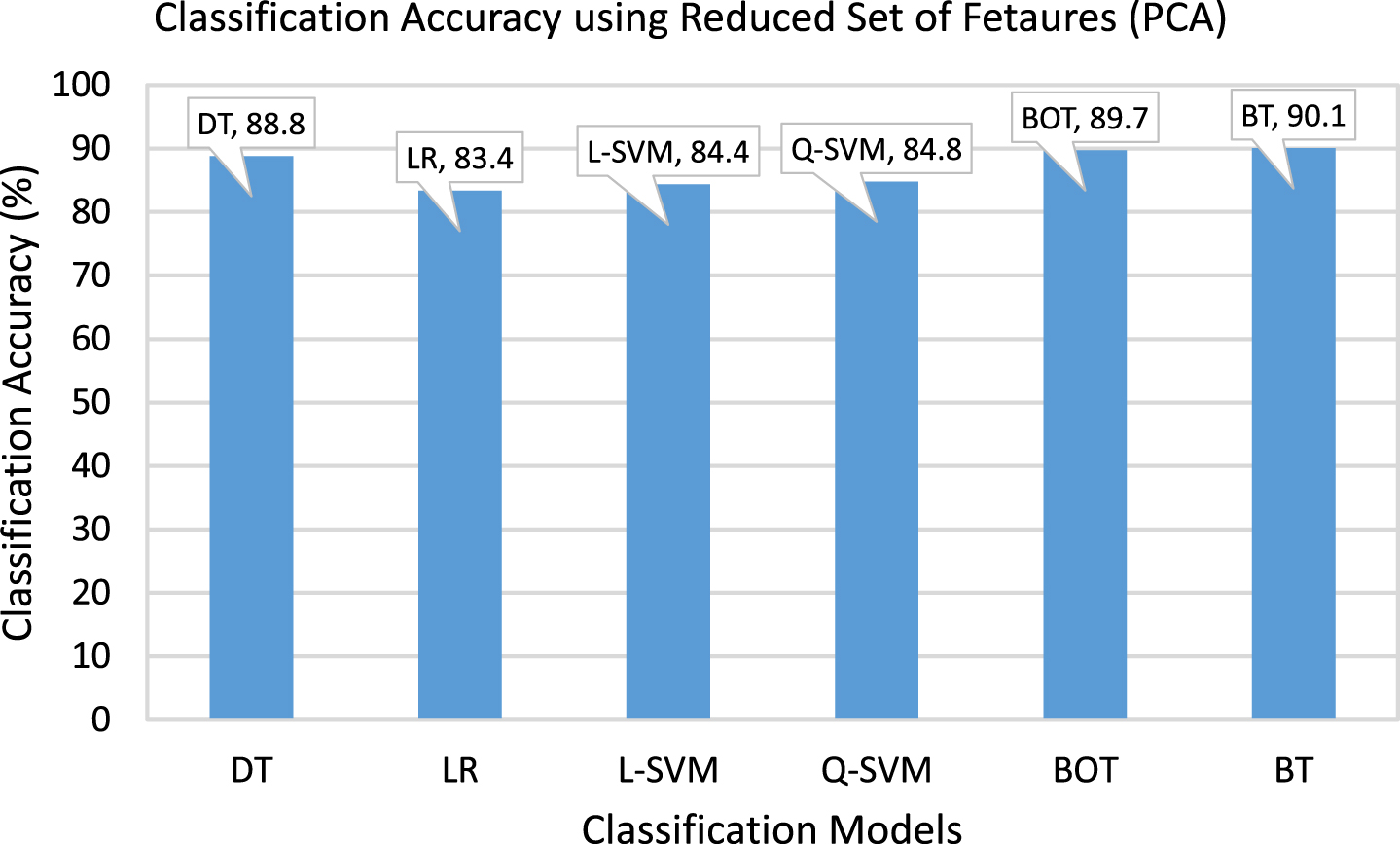
Movies quality prediction results using reduced set of features.
Furthermore, in Figure 6, we compare the accuracy of classification results of both experimental models to highlight the effectiveness of the feature selection technique. It can be observed that the classification models performed slightly better using a reduced set of features compared to the original set of features. It is evident that the classification accuracy of the BT classifier increases from 87% to 90.1%, which shows the significance of the PCA technique. Hence, PCA is an effective feature selection technique in order to reduce features space and increase the overall performance of the classification models.
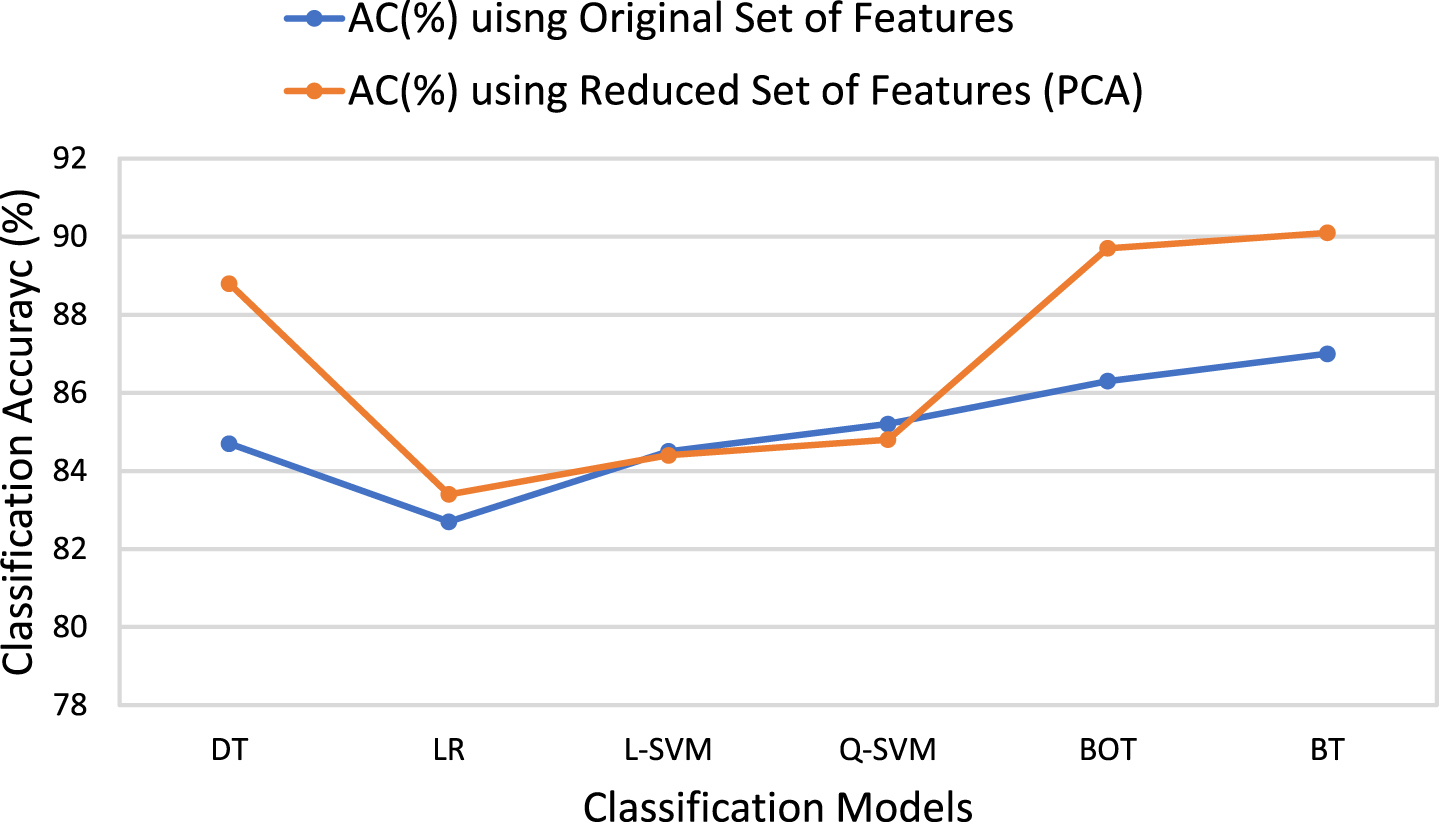
Comparative analysis of the classification models performance using original and PCA-based reduced set of features.
The proposed MQP model uses a confusion matrix for both experimentation models in order to find the accuracy and correctness of each model classifiers. The confusion matrix for the binary classification problem consists of four different combinations such as True positive (T p ), False positive (F p ), True negative (T n ), and False negative (F n ). Table 7 summarizes confusion matrix for the implemented classifiers using the original set of features. It is evident that BT classifier correctly classified 4,188 movies out of 4,807 for both class labels, such as High and Low. It is also evident that BOT classifier correctly classified 4,168 movies instances out of 4,807, which performs slightly lower than the BT classifier. Hence, the BT classifiers produced an accurate prediction accuracy compared to other implemented ML-based classification models using the original set of features.
Confusion matrix of the implemented classifiers (using original set of features)
Based on the confusion matrix analysis, it is found that BOT classifier produced the best prediction rate for the class label High; whereas the L-SVM performed well in the prediction process and produced high accuracy rate for the class label Low among the implemented classifiers using original features set. The DT and LR classifier produced high prediction error for the class label High and Low, respectively. Hence, BT classifier produced the most promising classification results using the original set of features compared to other implemented ML-based classification models.
In Table 8, it is evident that BT classifier correctly classified 2,024 movies out of 2,158 of the class label High, and 2,307 movies out of 2,649 of the class label Low. It is also found that BOT classifier correctly classified 2,041 and 2,273 movies for the class labels High and Low, respectively. Hence, the BT classifier produced an accurate prediction rate for the class label Low compared to BOT classifier. In contrast, BOT classifier achieved the best prediction rate for the class label High compared to BT classifier.
Confusion matrix of the implemented classifiers (using reduced set of features)
The results analysis demonstrate that the BOT classifier produced the best prediction rate using a reduced set of features for the class label High. In contrast, LSVM got the best prediction rate for the class label Low among all the implemented classifiers. The LR classifier produced a low prediction error for the class label High among all the implemented classifiers. The DT classifier also produced a low prediction error for the class label Low. Overall, BT classifier produced accurate prediction results using a reduced set of features for class labels High and Low of 2,024, and 2,307, respectively.
There are different performance measures [54] available for machine learning to evaluate the performance of the ML-based classification model. The proposed MQP model uses the following performance evaluation measures, such as accuracy (AC), precision (PR), recall (RE), and f-measure (FM), to evaluate the performance of the implemented classifiers for both experimental models.
The accuracy measure is used to evaluate the performance of the classifier. This is a very useful measure for the evaluation of the balanced data of target class labels. It should not be used in the case where target class labels data are unbalanced. In this case, it causes biases to favour the majority target class label. For the binary classification, the basic formula for the AC measure is expressed as follow in Equation 3:
T
p
(true positive) represents the correctly classified examples of the positive class. T
n
(true negative) represents the correctly classified examples of the negative class. F
p
(false positive) represents the examples of the negative class that are incorrectly classified into the positive class. F
n
(false negative) represents the examples of the positive class that are incorrectly classified into the negative class.
Precision (PR) is used to measure the percentage of movies labeled as the high quality that were accurately classified by the classification model. The PR measure is calculated as follow in Equation 4:
Table 9 summarises the performance analysis results of the implemented ML-based classification models using the original set of decision features. It is observed that the BT classifier determines relatively better prediction results in terms of AC and FM. In contrast, BOT classifier give us the best prediction results in terms of RE, Q-SVM produces the best results in terms of PR among implemented classifiers using original set of features. Hence, BT classifier achieved an accuracy of 87.0% using original set of features, which is slightly better compared to other classification models.
Performance evaluation of the classification models using original set of features
Similarly, Table 10 presents the performance evaluation results of the implemented classification models using a selected set of features. It is evident that BT classifier performed well in the classification process and produced the most promising results in terms of AC, PR, and FM as compare to other classification models. In contrast, BOT classifier produces the best classification results in terms of RE. Hence, BT classifier achieved an accuracy of 90.1% using the most promising set of data features to predict movie box-office success.
Performance evaluation of the classification models using a reduced set of features
Figures 7, 8 presents a comparative analysis of the implemented classifiers in terms of PR, RE, and FM for both experimental models. Figure 7 shows a comparative analysis of the implemented classifiers in terms of PR, RE, and FM using the original set of features to predict movie success class. It is evident that the BT classifier produces accurate classification results of 86.1% in terms of FM; whereas Q-SVM gives relatively better classification results of 84.2% in terms of PR and BOT classifier achieves accurate classification results of 91.4% in terms of RE. The BT and BOT classifiers produced the best classification results in term of FM of 86.1% and 85.7%, respectively; whereas prediction performance of the LR classifier in terms of FM is 80.4%, which is slightly low compared to other classification models.
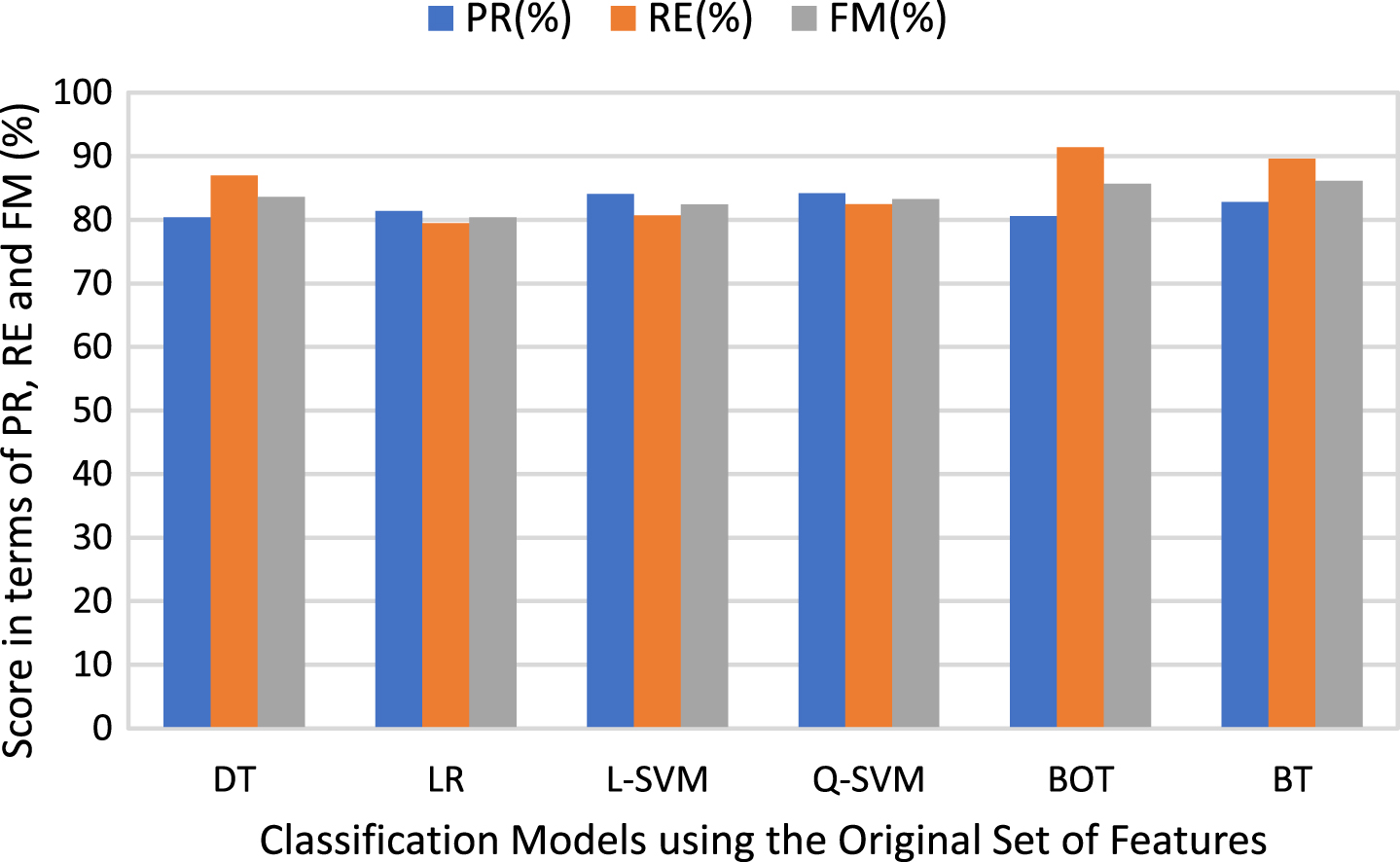
Comparative analysis of the classification models using the original set of features in terms of PR, RE, and FM.
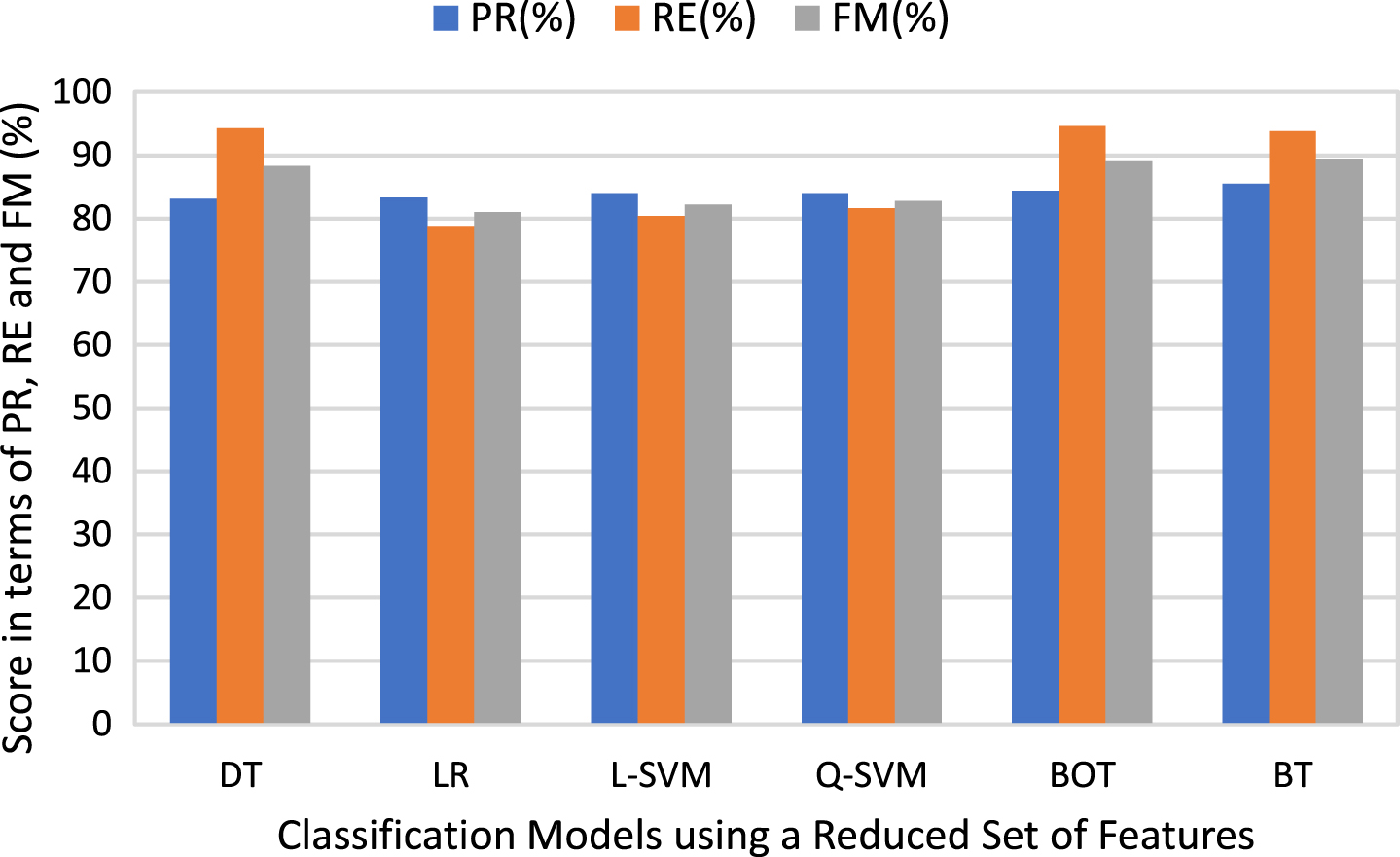
Comparative analysis of the classification models using the reduced set of features in terms of PR, RE, and FM.
Similarly, in Figure 8, It shows a comparative analysis of the classification models using a PCA-based selected set of features. Different performance analysis measures are utilized to compare and evaluate the performance of the implemented classifiers to analyze the significance of the classification models. It is found that the BT classifier performed well in the prediction process and achieved correctly prediction rate of 85.5% and 89.5%, which is slightly better in terms of PR and FM among all implemented classification models. In contrast, BOT classifier produces an accurate classification rate of 94.6% in terms of RE as compared to other implemented classification models using a reduced set of features. Furthermore, the LR model produces the classification performance of 83.3%, 78.8%, and 81%, in terms of PR, RE, and FM, respectively, which is slightly low compared to other classification models. Hence, it is found that BT and BOT classifiers produce the most promising and effective prediction results.
In this paper, we use the k-fold (k=10) cross-validation method to report prediction results. The experimental results of k-fold cross-validation method are summarized by taking an average (mean) of model skills scores. Therefore, we selected the top two classifiers to analyze performance score for each I the iteration. Figure 9 depicts the accuracy of BT and BOT classifiers using k-fold cross-validation method. It can be observed that the accuracy of BT classifier fluctuates between 89.2% and 91.7%. In contrast, the accuracy of BOT classifier is ranging from 86.1% to 88.2%.
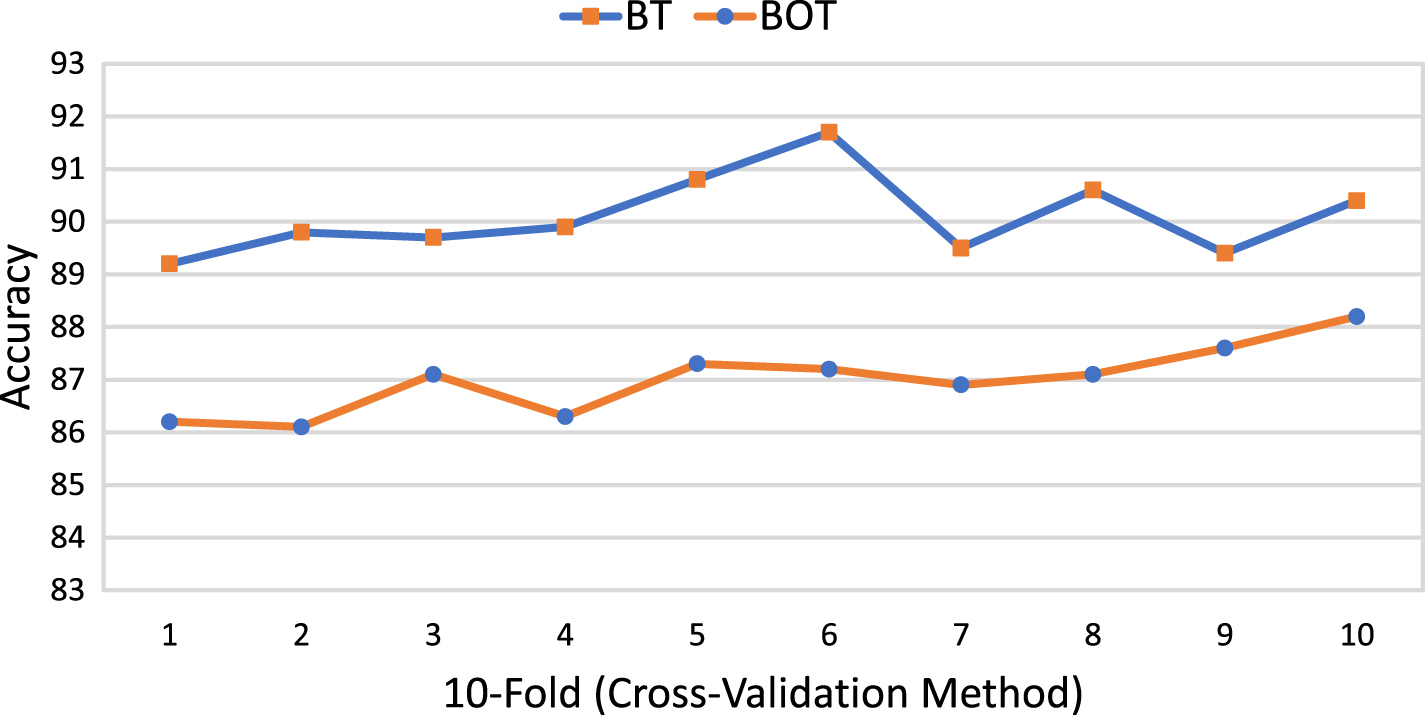
k-fold cross-validation based analysis of BT and BOT classifiers.
However, a statistical measure is required to compare the performance of BT and BOT classifiers to demonstrate the significance of the proposed classification models. Therefore, a t-test based approach is developed to compare the performance of the proposed models. Different steps are required to perform a t-test. First, a difference is calculated between models performance for each i
th
iteration. The following Equation 8 is used to calculate the difference.
Next, we compute mean and variance for computed differences as shown in equations 9 and 10.
In [55], the authors proved that independence t-test might cause problem of underestimation of the variance for the models score differences. Therefore, we modified variance to overcome the aforementioned problem. The Equation 11 is defined to modify variance.
Once we computed t statistic then p value can be computed and compared with significance level (5%) to reject or fail to discard the null hypothesis. If p value is smaller than defined significance level then null hypothesis can be rejected. If p value is greater than defined significance level then it conclude that the given models performed similarly. The p value for the given models is 1.89%, which is smaller then the defined significance level. Therefore, it statistically suggests that BT and BOT classifiers performed differently.
This section presents a comparative analysis of the proposed MQP model with the existing studies. In this work, we carried out a series of experiments in order to demonstrate the effectiveness and robustness of the proposed MQP model. There are different ML-based movie quality prediction models developed using different set fo data features. Table 11 summarizes the comparative analysis of the proposed MQP model and other state-of-art-techniques. The existing studies [22, 30] considered movie pre-released data features to predict movie success class; whereas some of the research studies [56, 57] considered movie pre-released features along with static movie features to predict movie success class. Some of the existing studies [1, 37] used an integrated model of the movie pre-release and post-release features to predict movie quality. Some research studies [21, 58] attempted to combine movie pre-released, static, and social data features to predict movie success class. All the aforementioned ML-based movie quality prediction uses a different set of features to predict movie success class, but they did not achieve accurate prediction results to help the movie industry in resource planning and managing, which is essential for the movie industry to plan and manage future resources for their upcoming movies. Therefore, our proposed MQP model attempts to integrate movies pre-released features along with historical features and social media data features to form a hybrid prediction model, which is more robust and reliable as compared to the existing models. It can be observed that the following research studies [21, 58] are the most similar to our proposed MQP model. Therefore, we consider these state-of-art-techniques to compare with our proposed MQP model to demonstrate the effectiveness and robustness of our model. In [58], the authors presented an integrated model to combine movie pre-released and social media features to predict movie popularity into three different classes, such as High, Medium, and Low. The authors reported an accuracy of 75.4% using SVM. In contrast, our work uses hybrid features model in order to combine movie pre-released along with historical features and social media features to predict movie success class. Our proposed model achieved an accuracy of 84.5% and 84.4% using L-SVM for original and reduced features set, respectively, which is significantly better than the classification performance reported in [58]. Similarly, in [21], the authors attempted to combine movie pre-released and social media features to predict movie success class. The authors reported an accuracy of 88.8% using NN model. Whereas, our proposed model achieved an accurate classification rate of 90.1%, 89.7% using BT, and BOT, respectively, which is slightly better than the classification results reported in [21]. In [50], the authors reported an accuracy of 61% using DT(J48) for integrated features model; whereas our MQP model achieved significantly better classification results with DT for both experimental models, such as 84.7%, 88.8%, respectively. Hence, our proposed MQP model produced the most promising results and outperformed all these state-of-art-techniques.
Comparative analysis of the proposed MQP model with the existing studies
Comparative analysis of the proposed MQP model with the existing studies
Other research studies, such as [1] used NN to predict movie box-office success. The authors achieved an accuracy of 83.40%, which is still improvable. In [22], the author’s utilized ML-based classification techniques, such as MLP, NB, LR, to name of few, to predict movies popularity based on IMDb data. The authors achieved an accurate classification rate of 84.34% with LR. Whereas the experimental results of proposed MQP model are much better, it is evident that BT classifier has produced the highest accuracy for both experimental models, such as 87.0% and 90.1%, respectively. In [30], the authors implemented seven different ML-based classification techniques, such as LR, SVM, RF, GNB, AdaBoost (AB), SGD, and MLP, to predict movie box-office success. The authors reported the highest accuracy with MLP of 58.53% and the least accuracy with SGD of 43.29%. In contrast, our proposed MQP model achieved the highest accuracy with BT of 87.0% (original features set) and 90.1% (using a reduced set of features) respectively and the least accuracy with LR of 82.7% and 83.4%, respectively for both experimental models. In [56], the authors suggested movies quality prediction model based on the following ML techniques, such as DT, NB, SVM and NN, to predict movie success. The authors reported the classification accuracy of 80% with DT. Whereas, our proposed MQP model achieved much higher accuracy with DT for both experimental models, such as 84.7%, 88.8%, respectively. Overall, it is found that our proposed MQP model outperformed the state-of-art-techniques. Furthermore, it is evident that our MQP model produced the most promising and accurate prediction results as compared to the existing prediction models, which will help movie makers to formulate resources for their upcoming movies effectively for their upcoming movies and also help to gain significant revenue over market competitors.
Table 12 presents a comparison of the proposed work and the existing model [21]. Different essential factors are considered to compare the proposed work with the baseline model. It can be observed that the existing method used a small dataset to predict movie success class, which cause an issue of a poor generalization (overfitting) of the learning model. In [21], 66 out of 375 movies are labelled as a flop, and remaining movies are labelled as a hit. It is evident that data instances are not equally distributed, which cause a data imbalance issue and report unsatisfactory prediction results. The authors used the hold-out method to split data into training and testing subsets, which is not an effective way to prevent overfitting issue during testing unseen data samples. In contrast, our proposed model uses 4,807 movie data to train and test the ML models to predict movie success. The proposed model used k-fold cross-validation method, which is used to produce an accurate approximation of model generalization for unseen data. It is an effective approach compared to the hold-out because it tunes model using multiple mini train-test splits to prevent overfitting and produce accurate results. Furthermore, we used different performance measures to evaluate the proposed MQP model; whereas the existing model used accuracy measure to report prediction results. In an earlier section, we discussed that accuracy measure is not a useful approach to evaluate the model’s performance in case of the data imbalance problem. The proposed model achieved an accuracy of 90.1
Comparative analysis of the proposed MQP model with T. G. Ree et al. [21]
The movie success class does not depend only on those features (such as movie pre-released, post released and static data features) that are related to movies. The social media features also play a vital role in a movie to become successful or unsuccessful at box-office. This paper presented an MQP model based on the integration of movie pre-released and social media data features using ML techniques to predict the box-office success of the upcoming movies. This paper utilized a benchmark IMDb movies dataset to predict movies quality that whether it is a high-quality or low-quality movie. The proposed MQP model presented two different experimental models; predict movies box-office success using the original and reduced set of features. First, all the decision features were considered to predict movie success class using six different ML-based classification models. Second, the PCA-based feature selection technique was used to select the most promising features to predict movie box-office success. The following ML-based classification models are implemented, such as DT, LSVM, and QSVM, LR, BT and BOT for both experimental models. The prediction results using original set of features show that BT classifier produced relatively better prediction results in terms of AC and FM, BOT classifier produced best prediction results in terms of RE and Q-SVM classifier produced best prediction results in terms of PR. In contrast, prediction results obtained using a reduced set of features show that BT classifier performed well in the classification process and produced relatively better prediction results in terms of AC, PR and FM, and BOT classifier produced best results in terms of RE. The proposed MQP model achieved an accuracy of 90.1%, f-measure of 89.5%, and ROC area of 96% with BT classifier, which show the significance of the proposed prediction model as compared to other ML models. The experimentation results revealed that both experimental models enhanced the overall accuracy of the classification models. The comparative analysis demonstrates the effectiveness and significance of the proposed MQP model with state of the art techniques. Furthermore, our proposed MQP model identified the most influential attributes from the prepared dataset, which includes IMDb rating, budget, user reviews, movie FB likes, critic reviews, the star power of movie director, and movie genre, which play a vital role while predicting a movie success class. The prediction results will facilitate movie investors to devise business strategies effectively to reduce investment risks and increase revenue at the box-office. The experimental results will help the movie industry to plan their resources for their upcoming movies effectively, for instance, investment, the total number of screens bookings, and release date planning, etc. Likewise, it will be helpful for a movie watcher to decide whether to book a ticket in advance or not to save precious time and money. Besides, our proposed MQP model demonstrate that predictive analytics is the most effective and reliable solution to plan and manage movie industry resources effectively to reduce the risk of investments.
For future work, this work can be enhanced by adding a few more features to our prepared datasets like sentiment and semantic features. The proposed MQP model can also be extended by adding Google search trends in order to improve the overall performance and to provide better prediction results for the movie industry. This work could easily be extended to other relevant fields, like identifying the quality of products and play store apps, etc.
Conflicts of interest
The authors declare no conflict of interest.
Footnotes
Acknowledgments
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education(2018R1D1A1A09082919), and this research was supported by Energy Cloud R&D Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT (2019M3F2A1073387), Any correspondence related to this paper should be addressed to DoHyeun Kim.