
Abstract
Application Traffic Identification is an imperative device for sorting out the system as it is the most popular approach to distinguish and characterize the network traffic created from different applications. The classification using conventional Port-based and Payload-based techniques has become counterproductive due to inconsistencies. However, in recent times, approaches with machine learning and statistical techniques have guaranteed higher accuracy. However, learning techniques are inadequate for solving problems with Time and Memory intricacies in vast datasets. Hence, the proposed paper presents a novel scheme of Statistical based traffic classification named Multi-Phased Statistical Based Classification methodology that renders Semi-supervised machines with advanced K-medoid clustering and C5.0 Classification algorithm. The proposed system displays a classic competence in observing the known and unknown application flows by statistical features utilization scheme that enhances the classification preciseness. Further, the trial results show that the proposed work outperforms previous approaches by achieving a higher granularity of 98–99% and reducing complexities. Ultimately, the new proposed work is evaluated on our campus traffic traces (AU-IDS). It is proven that the proposed approach accomplishes a higher exactness rate and thus encourages its implementation in real-time.
Keywords
Introduction
With the rise of the World Wide Web, the utilization of the Internet and the network traffic generated by them is growing exponentially. It is evolving as a hot area of research because of the newfangled encryption strategies and burrowing rising step by step, making traffic undetectable. This has led to a dire need to classify the traffic as it aids the network manager to impose various security policies and properly rank applications across the limited bandwidth. Network traffic classification is the initial phase, which is followed by monitoring and control in network management. It is done to enhance the network performance [1, 2]. Over the previous decades, Port-based techniques were used in classification,which neglected to get through the dynamic idea of ports [3–5]. This was superseded by a Payload based technique that suffered from heavy overload and hence fell short in classifying the encrypted traffic [6, 7]. As of late, dissecting the statistical boundaries, network flow has picked up significance because of its raised characterization exactness, adaptability, and light-weight. The statistical boundaries incorporate packet size measurements (Min/Max packet length), inter-arrival time, flow duration, bytes transferred, byte counts, and the number of packets, and so forth. [15, 16]. At first, traffic order dependent on flow measurements depended on unsupervised or supervised machine learning algorithms. The unsupervised algorithm operates by grouping the data samples with similar behavior into clusters, with no prior knowledge. However, mapping of numerous clusters for a few applications [17].
With no prior knowledge is a problematic task [18, 19]. The Supervised algorithm trains the classifier by examining the set of labeled training samples and classifying the traffic based on pre-classified classes built in the training phase [15, 16].
The multi-level cluster analysis (unsupervised), when used in conjunction with compound classification (supervised), promises higher accuracy and completeness in application identification [49–51]. To expand the stream characterization precision, fell grouping procedures utilizing a blend of calculations just as semisupervised ML approaches have been recently investigated.Utilizing various classifiers and choosing the ideal decision for characterizing each traffic flow through casting a ballot or, in any event, joining the outcomes for the last decision, in any case, doesn’t explicitly consider refining the ground-truth information to completely represent the different stream classes (per application) and their ensuing identification. Moreover, blending various occurrences of classifiers raises versatility issues concerning their ongoing execution.
The current traffic arrangement techniques experience the ill effects of lackluster showing in the essential circumstance where supervised data is deficient, and significant obscure flows are available. Especially, increasingly new/obscure applications are developing in the distributed computing based climate. Robust traffic characterization is a significant test in reality complex organizations. For example, as new applications rapidly build, we can gather and examine an uncompleted preparing informational index. Additionally, if the developing applications are scrambled, it is practically challenging to investigate adequate preparing tests through profound examination in a restricted time. These perceptions become the inspiration for our work.With the rapid evolution of modern internet technologies, new applications came into existence [26, 28]. This resulted in poor performance of traffic classification using the above approaches. In this paper, we mean to handle the issue of obscure flows in a semi-supervised methodology [53–55]. This work considers not many named preparing tests and examines flow connection in reality network climate, making it distinctive to past works.
Therefore, to address these challenges, we have achieved a semi-supervised methodology that initially clusters the data samples to make the best predictions followed by feeding this into classifier as training data to classify the new amorphous data efficiently.
The principal commitments of our work are as per the following: The Offline Phase imposes advanced k-Medoid clustering that adds one medoid at a time and utilizes each traffic flow as an optimal cluster candidate for the k-th medoid. The representative objects known as Medoids are utilized to follow the most halfway situated object in a cluster. An inventive capacity is characterized to locate the following new ideal medoid at every iterative advance. Once the cluster formation is determined, the models are constructed for each application traffic flow. Furthermore, these pre-labeled application models are retained as prior knowledge for online Classification. The advanced clustering algorithm considerably excels in reducing the computational effort for large datasets. In online Classification, the features are extracted, and flows (Session) are grouped based on 5-Tuple information. The clustered flows are fed to the Advanced C5.0 classifier to attain the maximum accuracy of Classification. If the classifier fails to identify the new applications (unknown), they can be recognized by 5-Tuple information, which provides more accuracy.
Besides, tests were completed to evaluate the proposed work’s exhibition in correlation with the other five distinctive machine learning algorithms that demonstrate that our work achieves higher accuracy. The residue of this manuscript is composed as follows. Section 2 elaborates on the current foundation work of traffic characterization. A new technique for application classification is briefed in Section 3. It is supplemented with test results and discussions about the suggested approach’s functioning and the existing ML algorithms of Section 4. Section 5 discusses the conclusion and future extension. Table 1 presents the applications involved in our work.
Traffic Collection in the Web Backbone
Traffic Collection in the Web Backbone
A few strategies have been proposed to classify network traffic. The research community’ s focus has exclusively moved towards complete surveys on traffic classification [15, 16], which indicates the interest in this domain. The accompanying subsection presents the cutting edge approaches in the sphere of traffic characterization.
Port-based traffic classification
The proper method for organizing traffic grouping utilized port numbers to identify the network application [3]. Though many applications use well-known ports defined by IANA, all applications need not have registered port numbers. Hence, this approach’s accuracy has seriously declined due to the evolution of applications like P2P, online gaming applications that don’ t have any registered port numbers but use random port numbers, thus categorizing using ports impossible. Simultaneously, port-based arrangement strategies are presently viewed as outdated, given the regular jumbling methods and dynamic scope of ports utilized by applications.
Payload-based traffic classification
It is an alternative strategy for the port-based procedure that examines the packet payload signatures to identify the network traffic [6–9]. It is implemented using Deep Packet Inspection (DPI) which promises high accuracy. However, it requires continuous updating of the signature with every update of the application, and it does not work well with encrypted traffic.
User-behavior based traffic classification
User Behavioral techniques are profoundly encouraging and give a lot of order precision with diminished overhead contrasted with payload review strategies. In any case, user behavioural techniques centre around end-point action and require boundaries from various streams to be gathered and investigated before effective application recognizable proof.The user-Behavior based technique analyses the network traffic based on host behavior. It works on three main levels: 1) Social level 2) Functional Level 3) Application Level to recognize the host’s conduct [10–12]. This method partners have conduct set up with at least one traffic applications and improves the meaning by heuristics and conduct separation. However, they require numerous flows to classify the traffic accurately, and they cannot handle traffic in different groups with similar behaviour.
IP-level traffic classification
Following the idea of port-based technique, the IP level traffic classification approach uses the evidence delivered by notable IP addresses to group the system traffic. The IP level classification technique studies the well-known IP addresses belonging to the popular internet application in an offline classification phase [13].
Service-based technique
It [14] studies the triplet features <IP Address, Port Number, protocol>of the traffic flows and equates them with labelled data set traffic flows in offline mode to classify the network traffic. However, a periodical update is required to maintain high accuracy.
Statistical flow feature-based approach
The statistical flow-based approach has gained momentum owing to its efficiency and scalability in classification. It exploits the traffic flow fingerprints to categorize and determine the classification model through data mining algorithms to classify individual traffic applications. Statistical flow-based methodologies misuse application variety and natural traffic impressions (stream boundaries) to portray traffic and determine order benchmarks through data mining procedures to recognize singular applications. Initially, it extracts the statistical features from a labelled dataset and generates different structures (e.g., Clusters, Classifiers, Decision Tree) as the output used to classify the new traffic flows. Ordinary statistical flow level characterization can be additionally partitioned dependent on the sort of Machine Learning calculation being utilized, that is, supervised or unsupervised.
Unsupervised machine learning approach
Unsupervised ML performs clustering that detects the hidden structures or patterns in applications. They categorize the unlabeled traffic records and construct clusters to learn more about their similar and dissimilar behaviours. Zander et al. [17] suggested the Auto Class grouping method for network traffic arrangement. L.Yingqiu et al. [18] evaluated the traffic flows by statistical features for traffic identification. McGregor et al. [19] suggested the Expectation-Maximization (EM) calculation to bunch the traffic flows into a few gatherings and assigned the application name to traffic groups by hand. Bernaille et al. [20] and J.Erman et al. [25] proposed the K-Means bunching calculation for gathering the traffic groups and doling out the application name payload investigation device. J.Erman et al. [21] proposed the DBSCAN grouping calculation, and D.Liu et al. [22] applied the Fuzzy C-Means bunching calculation for application recognizable proof. Y.Wang et al. [23] proposed statistical features for flow clustering and matching equivalent clusters with applications by the payload signature method. Finamore et al. [24] proposed to absorb the statistical element bunching and payload measurable component grouping. These approaches uncovered the exciting patterns hidden in the traffic.
Supervised machine learning approach
Supervised ML requires trained data samples to build the traffic classifier. Moore et al. [26] suggested a Naive Bayes calculation to examine the traffic for recognizing the application names for testing data sets of pre-marked preparing information tests. Kim et al. [27] and Este et al. [32] suggested the support vector machine (SVM) calculation for naming the network traffic application dependent on flow-based statistical highlights. Auld et al. [28] proposed a Bayesian Neural Network that used several statistical flow features for network traffic classification. Haffner et al. [29] proposed a machine learning technique for automated application signatures that combined different statistical characteristics. Bernaille et al. [30] proposed a supervised classification scheme by taking the first few statistical features packets. Bonfiglio et al. [31] suggested Naive Bayes and Pearson’s Chi-Square Test organize traffic arrangements. Crotti et al. [33] proposed Probability Density work (PDF) based convention fingerprints, and Valenti et al. [34] utilized Small time-Windows-based parcel mean allocating application names to the system traffic. J.But et al. [35] proposed five machine learning algorithms to construct the arrangement model and examine its exhibition. The offline phase of the traffic classification scheme is used to pre-process and generate training data for online classifiers as test cases in Chun-Nan Lu et al. [36]. T. Bujlow et al. [37] suggested the C4.5 managed calculation that utilizes a show, contents to relate packets, and flow records with application use. The supervised Machine learning approach for known applications outperforms classification accuracy. However, for new applications, it fails to do justice.
Semi-supervised machine learning approach
The multi-level cluster analysis (unsupervised), when used in conjunction with compound classification (supervised), promises higher accuracy and completeness in application identification. Valentin et al. [38] proposed Deep Packet Inspection (DPI) techniques for the system model and used C5.0 classifier for network traffic classification. Erman et al. [39] proposed the adequacy of administered Naive Bayes and the Auto class bunching calculation. The traffic characterization framework’s disconnected condition is utilized to pre-process and deliver preparing information for online classifiers of experiments in A. B. Mohammad et al. [40]. J. Zhang et al. [42] proposed the semi-supervised approach, focusing only on new applications. Erman et al. [43] proposed a probabilistic assignment of the unsupervised clustering algorithm for assigning application names to clusters. M.Hall et al. [44] applied the data mining tool (WEKA), combining unsupervised and supervised algorithms to estimate each Machine Learning algorithm’s efficiency.
Our proposed multi-phased statistical based classification approach
Our work is designed to handle even newer (new) application traffic in the University Campus Network with reduced complexities. This is attained through the proposed semi-supervised ML approach that promotes the traffic classification method. Our work’s processing is as follows: Our scheme contains two main segments: Offline Pre-Learning Phase and Online Classification Phase. Figure 1 portrays the overall idea of the proposed work. The disconnected characterization’s primary point is discovering the application models that must be unmistakable or separate from different applications. The similar 5-Tuple information of consecutive traffic packets are collected, and all the Statistical Dissemination (Table 3) are counted beneficial to find the differentiation between the applications. The valid number of Statistical Dissemination is taken for each different application to improve the classification accuracy. The invalid packets are omitted considering the size of the payload, and only legitimate packet counts are taken for each application to reduce the time and space complexity. Employing Statistical Dissemination and its proportion, the advanced K-Medoid Clustering algorithm clusters the similar flows with an innovative function (distance matrix), and the models (representatives) are created for each application. In the online classification phase, the continuous traffic flows are captured, and flows of the same sessions are grouped based on 5-Tuple information. The bunched application flows are then sent to cutting edge C5.0 classifier for preparing the classifier to demonstrate a decision tree capable of classifying the network traffic accurately based on prior knowledge of the application model. Every module of our proposed work is portrayed in the accompanying sections.
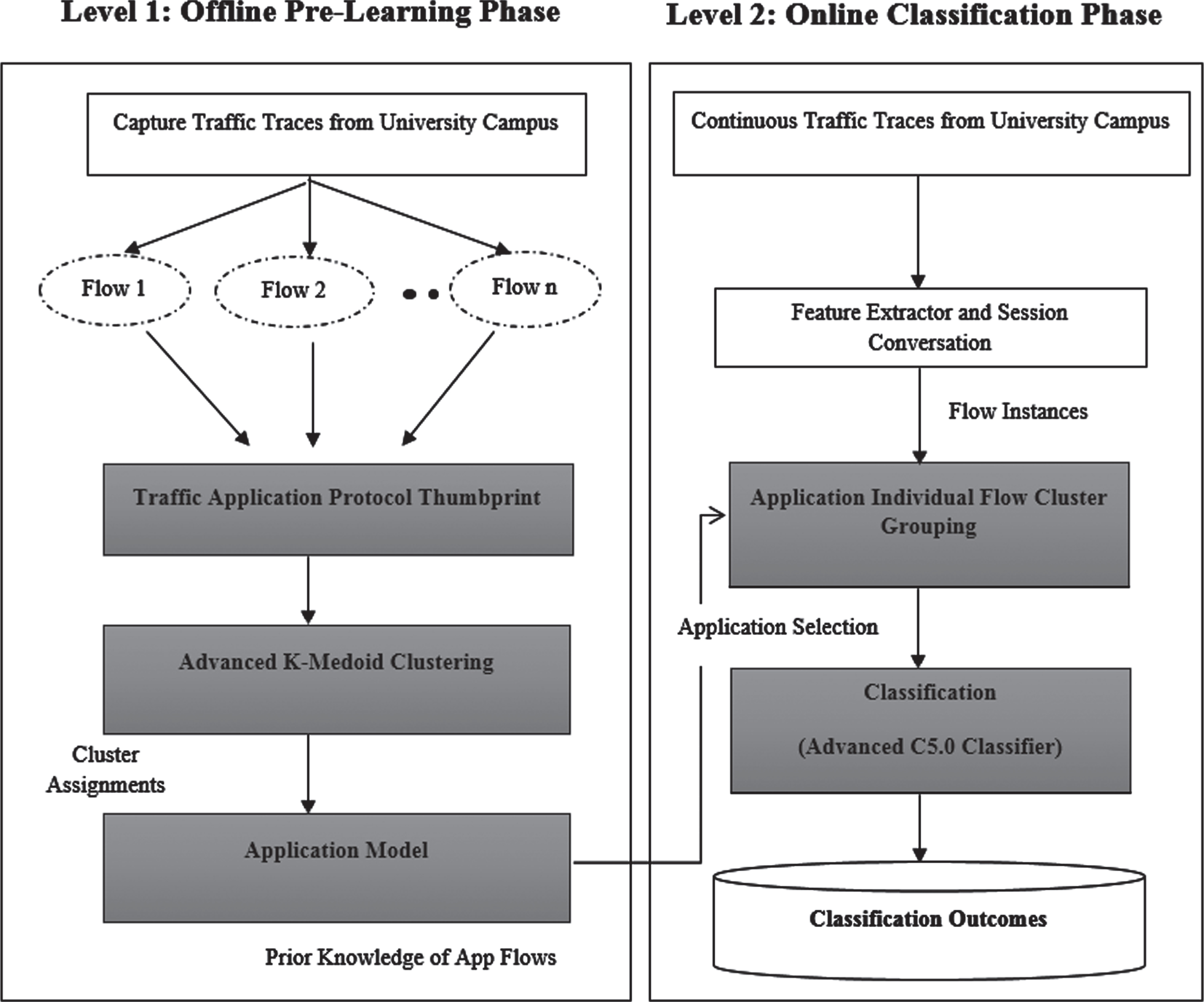
Framework architecture of multi-phased statistical classification scheme.
Traffic Classification begins with initial offline Pre-classification that contributes to two main modules: Traffic Application Protocol Thumbprint and advanced K-Medoid Clustering. The Online phase classification includes Session Grouping and Application Classification, using prior knowledge of pre-labeled traffic flows.The detailed process for Multi-Phased Statistical Classification Scheme is described in Algorithm 1 and 2.
Offline pre-classification phase
The accompanying subsections portray the procedure associated with offline pre-grouping.
Traffic Application Protocol Thumbprint
By watching the conduct of traffic, every application is separated from their Statistical Dissemination. The flows having a place with a similar application have comparative Statistical Dissemination even while indicating uniqueness between flows having a place with various applications. Each steady traffic flow is marked with Statistical Dissemination and its proportion (protocol Thumbprint). Still considering only the maximum availability of Statistical Dissemination and its proportion for each traffic flows to avoid large memory space consumption. The following equation illustrates the maximum availability of Statistical Dissemination and its proportion of Traffic Flows.
In our work, a new form of the advanced k-Medoid algorithm is proposed, whereas the K-means algorithm is complicated for selecting starting points and can only be used on trivial datasets. An innovative function is used to find the starting points for the next optimal cluster center to address this problem. The Proposed Clustering Algorithm leans to choose k most centrally positioned object as the initial medoid. The distance matrix is calculated once and is used for finding new clusters at each iterative step.
Suppose that n traffic flows having m Statistical Dissemination features should be grouped into k (k < n) clusters, where k is assumed to be given. Let us define j the Statistical Dissemination of traffic flow i as (i = 1...n ; j = 1...m). The distance metric (3) is utilized to gauge the degree of likeness between traffic flow i, and j is given by
Step 1: Choose Initial Medoid Figure the separation between each pair of all items dependent on the picked similarity measures. Calculate the Application Model AM
i
(4) for a traffic flow i as follows
Step 2: Renovate Medoid Find another Medoid of each Cluster, which is the article restricting the hard and fast partition to various things in its gathering. Remodel the Current Medoid in each gathering by superseding it with the new Medoid.
Step 3: Allocate items to Medoid Consign everything to the nearest Medoid and obtain the Clustering result. Figure the aggregate of the right ways from all things to their Medoids. If the whole is proportionate to the previous one, at that point, stop the calculation. If not, return to Step 2. The Advanced k-Medoid algorithm is preferred over other clustering methods because of its simplicity, less touchiness to outliers, and computational efficiency.
The application Model A ai for each application is structured in a table for online classification. Utilizing distinctive application models may cause entirely unexpected arrangement results. It ought to be noticed that Application Models may vacillate for various stages.
Online classification phase
The following subsections describe the methodology involved in the Online Classification.
Application individual flow cluster grouping
Initially, statistical features are utilized to assemble the individual traffic flows per application. The statistical flow features are scrutinized using packet header instead of the packet payload to avoid deep packet inspection, which leads to massive overhead. Each flow is managed by 5-Tuple Data, including Source IPAddress, Destination IPAddress, Source Port Number, Destination Port Number, and Protocols. The individual traffic flows are bunched by the statistical features of 5-tuple data caught from the IP packet header. On the off chance that the source IP address and goal IP address of two diverse individual flows are the same and their Source Port numbers are progressive, as the operating system assigns consecutive port numbers for connecting the remote host, the correlated flows will be grouped as clusters. The following equation asserts the allied flows for an application.
Grouping of individual flows using 5-Tuple Data
At this stage, the Advanced C5.0 classifier models a decision tree consuming pre-trained data samples and Application flow cluster grouping. The C4.5 [40] is the precursor of the C5.0 algorithm, which forecasts the dependent feature set to produce the most acceptable traffic classification. Initially, the Cardinality Set Information (CSI) maintains the statistics of independent feature sets separated and recorded from the college grounds, which is valuable in advancing the unmistakable choice tree. The clustered individual flow record is afterward served to Advanced C5.0 classifier for supervised knowledge to classify a decision tree. Table 3 recorded the independent flow feature set information (CSI). The accompanying condition speaks to the cardinality include set given to the Advanced C5.0 classifier.
a combined set of classifiers is used to predict the final traffic class by surveying each classifier’s vote sum.
Misclassification costs
pruning the branches of the decision tree that causes an error at each iteration.
Winnowing method
in sampling and cross-validation phase, the feature set is concentrated that has a low predictive ability in classification.
The following section portrays the trial aftereffects of the proposed work and the examination with other substitute Machine Learning Algorithms for traffic grouping.
Experimental outcomes and conversation
This section manages the trial handling of the proposed plan and its outcomes and conversations. The performance is then compared with existing approaches. The trial work’s framework necessities incorporate the standard framework Intel Core 3 Duo Processor 2.20GHz, 4.00 GB RAM, Microsoft Windows 13, and Linux Ubuntu 20.04 working framework to run the proposed plot. We tracked the R Data Mining Tool for the usage of the suggested approach.
Dataset collection
In this stage, the traffic follows from 17 well-known web applications like HTTP, FTP, DNS, eDonkey, Skype, SMTP, etc., that can allude from Figure 5. A traffic filter is used to extract the traffic flows automatically based on standard configurations that filter out irrelevant traffic [45–47]. The network traces are captured from AU-IDS using Wireshark, producing a total of 35GB of data. An equal proportion of network traffic flows are taken for Training and Testing Phase. A few feature sets with 20 Statistical Dissemination from each traffic flow listed in Table 3 are taken for evaluation. The system traffic is gathered utilizing packet sniffer instruments like Wireshark, and the 20 Statistical Dissemination highlights are removed utilizing our GCC program.
Feature Sets Utilized for the Advanced C5.0 Grouping Technique
Feature Sets Utilized for the Advanced C5.0 Grouping Technique
The real-time Anna University campus traffic traces (AU-IDS) are used to investigate the proposed algorithm’s performance. The AU-IDS dataset embraces 17 traffic Applications with almost 10T traffic flows in each application. Each steady traffic flow is marked with Statistical Dissemination and its proportion (protocol Thumbprint). It is considering only the maximum availability of Statistical Dissemination and its proportion for each traffic flow to avoid large memory space consumption. The steady traffic flows are examined for each specific application and are grouped with the respective traffic class based on the Clustering Algorithm.
Selection of initial medoid
The performance of selecting the initial medoid is compared with the other different methods like
Systematic selection (SS) method
Sort all Objects in the request for estimations of the Statistical Dissemination. Isolate the scope of qualities with equivalent stretches and Select K-objects haphazardly from every span.
Random selection (RS) method
Arbitrarily Select K-objects from all Traffic Applications
Outmost object (OO) selection method
Select the Outermost K-object from the cluster mean.
Sampling (SM) method
Discretionarily taking 25% (Sampling) from all applications as an example and playing out an underlying grouping on these examined applications utilizing the Advanced K-Medoid Clustering calculation. The resultant k medoid is utilized as the underlying medoid. Comparing the accuracy rate of different Selection of initial Medoids with the Proposed Method (PM) is depicted in Fig. 2. The four test cases taken for each algorithm is 1 × 105, 1.5 × 105, 2.5 × 105and3 × 105 traffic flows. Figure 2 shows that the accuracy rate of Selection of Initial Medoids by Method SS and OO seems to be inadequate compared with RS and SM. The accuracy rate of Test cases for different selection methods demonstrate the level of effectively perceived traffic application. The accuracy rate increases for higher test cases in each method. The accuracy rate of RS and SM is relatively equal but seems inferior to the Proposed Method. It may be concluded that the PM shows higher accuracy when compared with other methods for selecting the Initial Medoids.

Accuracy rate of test cases for different selection methods.
We operated the Proposed method with K=17 to the real-time data with known Traffic labels. The attributes (Set 3) specified in Table III are considered for clustering. The vector representation of traffic classes will be specified for each specific application. The Advanced K-Medoid algorithm is applied to the individual flows to map them to their respective traffic class, which is implemented using the R programming language. The flows having a place with a similar application have comparative Statistical Dissemination. At the same time, they show the divergence between flows having a place with the various applications, which are portrayed in Fig. 3 with the packet size and Fig. 4 with the inter-arrival time feature of Statistical Dissemination. Additionally, Fig. 5 shows the different applications have diverse packet sizes. The individual progressions of traffic are gathered into 17 (k) bunches of the particular class, and the grouping precision against the genuine classes is delineated in Fig. 6. The exactness is processed on the correctly classified Traffic Classes against the actual classes. It quantifies the exactness paces of session acknowledgments by isolating the number of effectively distinguished Traffic Classes by the all outnumber of Traffic Classes. The Clusters that will be narrowed within different flow classes generated are made for our future work. After grouping each flow with the respective traffic classes, each application is structured in a CSV file for online classification. The Advanced C5.0 classifier is fed all 17 internet traffic classes in equivalent extents (half) for training and testing stages.

Packet size distribution of SKYPE, FACEBOOK AND YOUTUBE traffic classes.
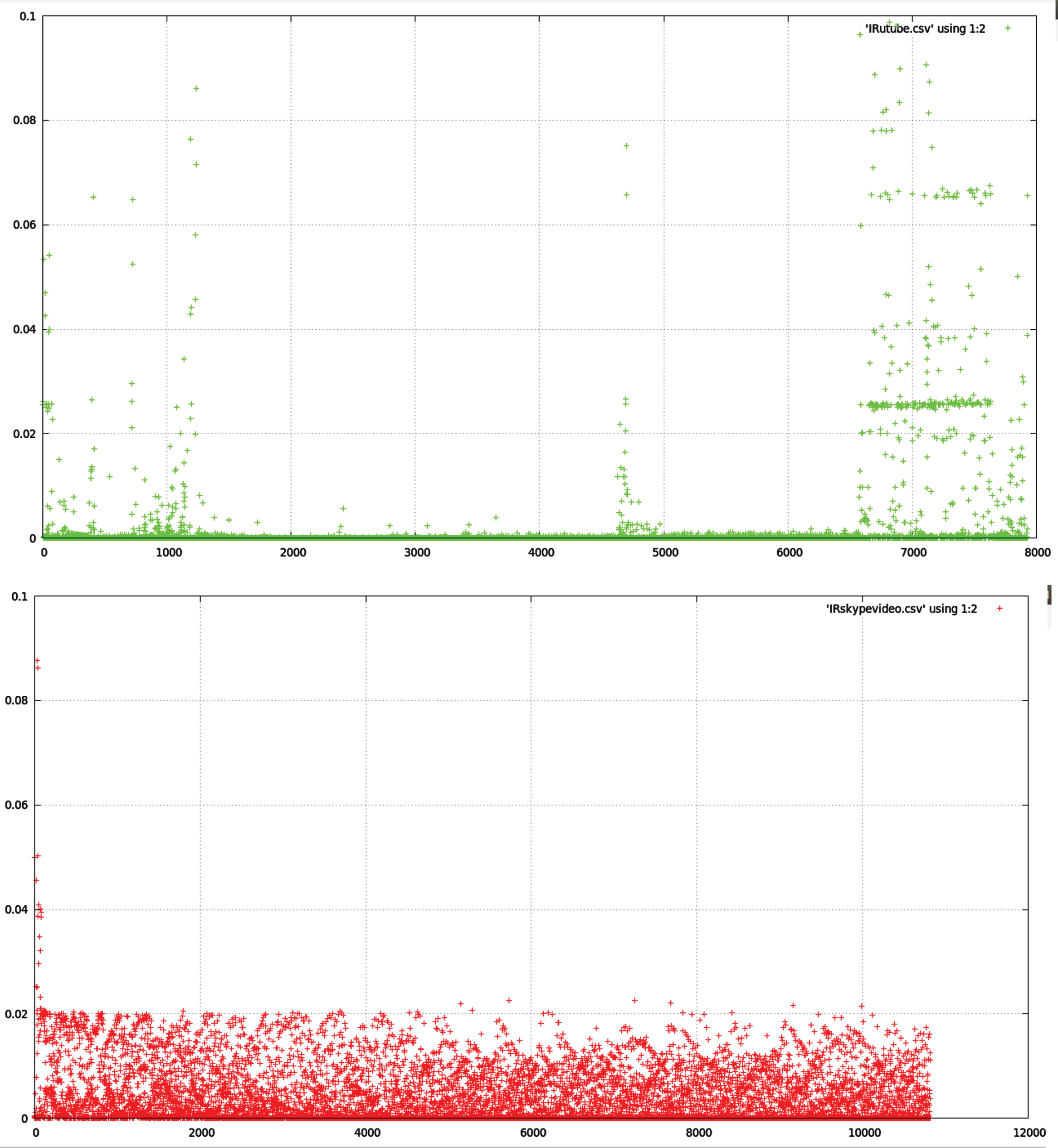
Inter arrival distribution of YOUTUBE AND SKYPE.
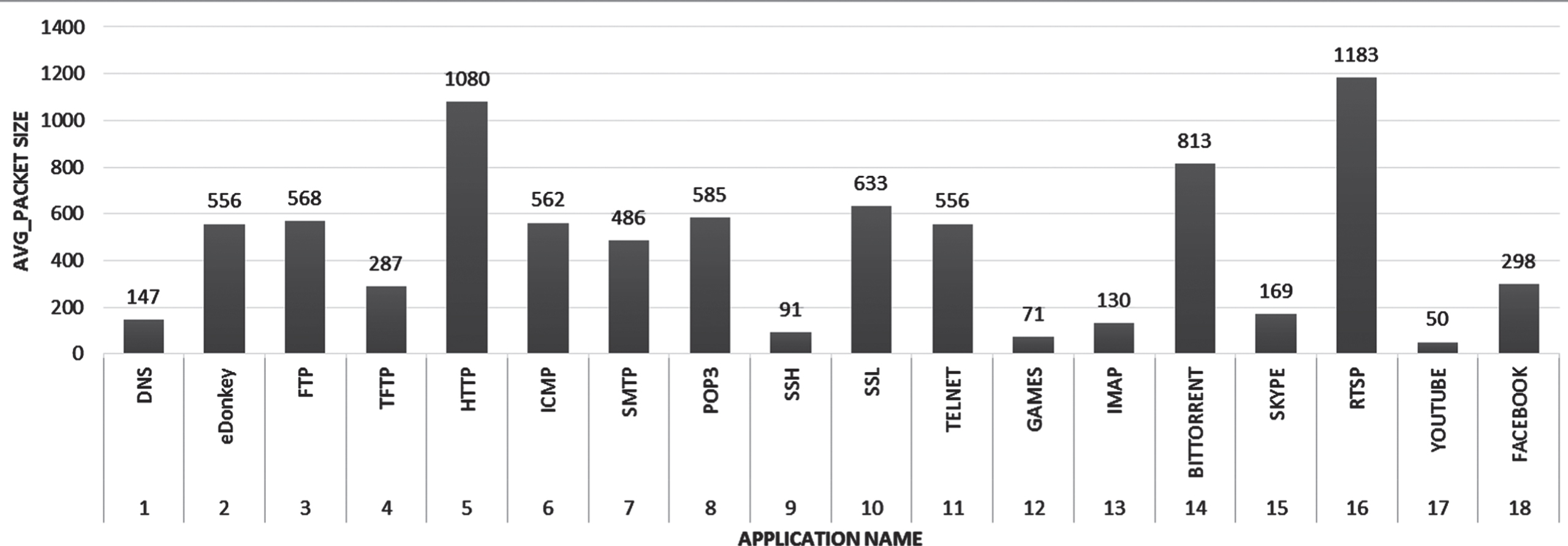
Normal Packet Size for various applications.
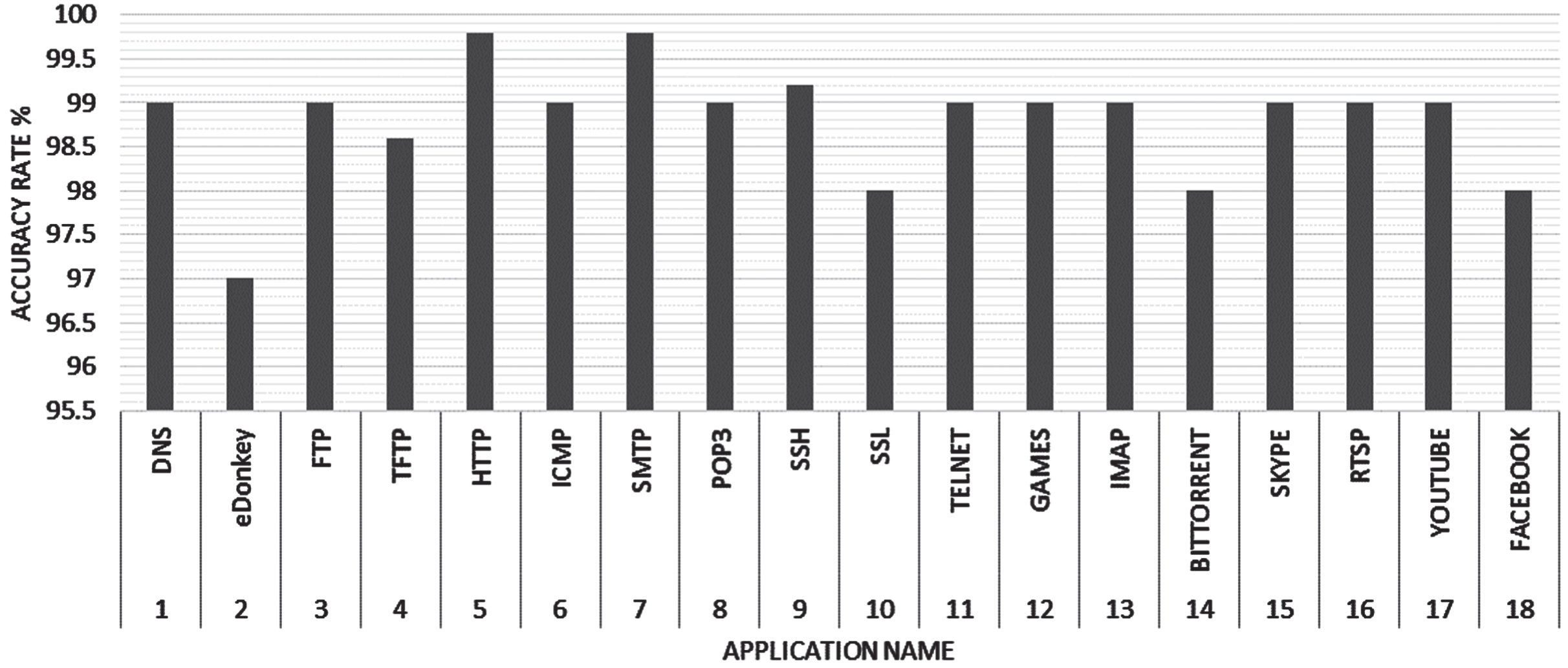
Accuracy Rate of Each Application by Advanced K-Medoid Algorithm.
Each correlated traffic flow is clustered based on 5- tuple information and grouped as similar individual flows. Based on statistical features (5-Tuple information), the operating system (Microsoft Windows 13, Linux Ubuntu 20.04, Microsoft Windows XP, Microsoft Windows, and Vista) assigns consecutive port numbers to the individual flows because of the speedy process of resource allocation to the requests given as shown in Fig. 7. This method is considered only for observing the partnership between enormous traffic flows. Our scheme’s strategic trace is to identify the similar flow records per application, which is used to train the classifier with a complete flow footprint of each application, thus classifying the network traffic efficiently.
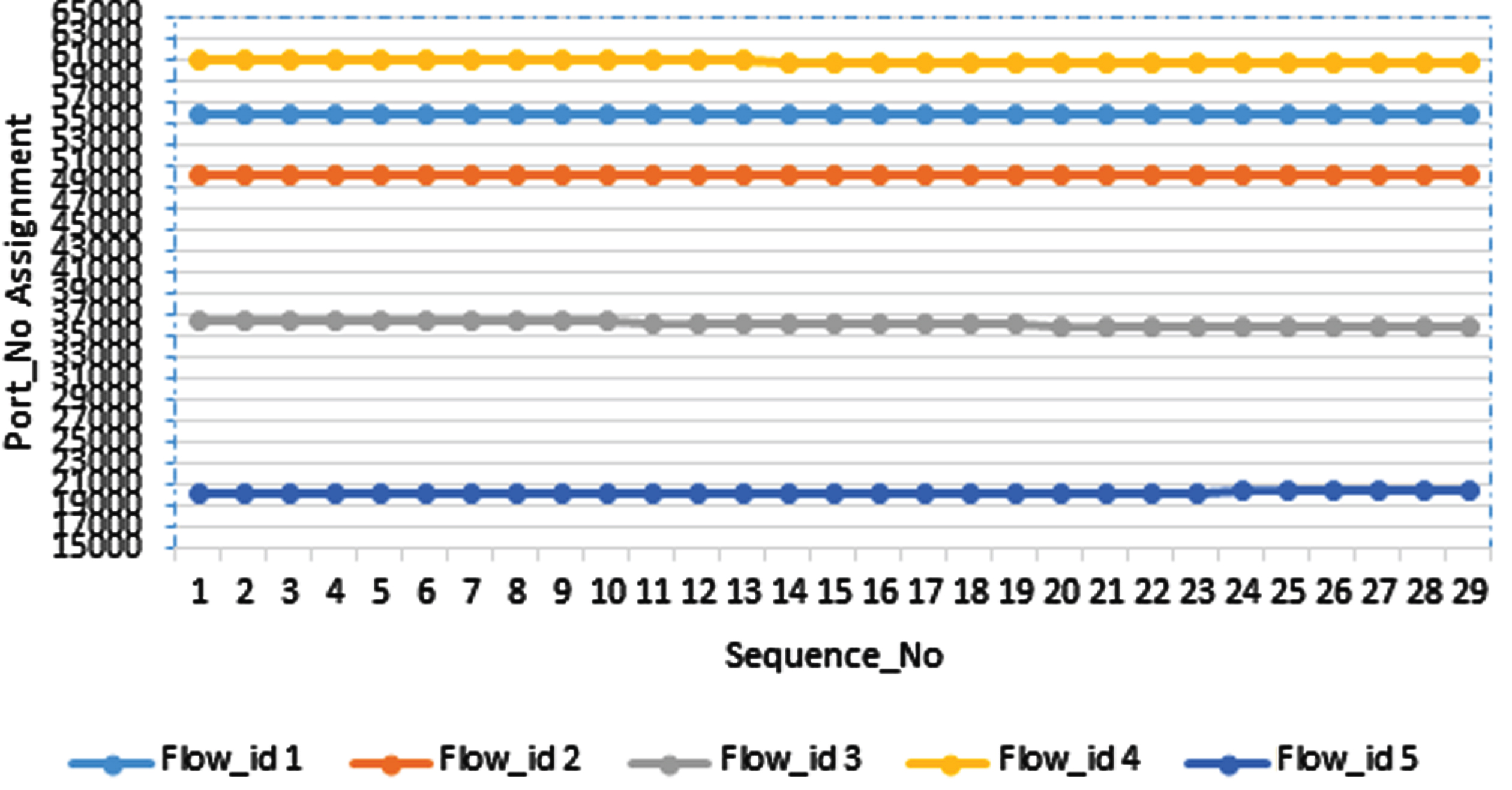
Identifying Consecutive Port Numbers used by the application.
The traffic flows marked with suitable traffic classes by Advanced K-Medoid clustering is fed to train the classifier. It repeats boosting and pruning; Advanced C5.0 models a decision tree for classification implemented in R that classifies the online traffic accurately during the testing phase. The attribute selection in classifier learning should be closely related to individual flows that distinguish dissimilar traffic flows and the Clustering algorithm that segregates traffic classes. As referenced in Table 3, Set 1 keeps up IP level traffic order (Source IP locations and Destination IP addresses), Set 2 keeps up Service-Based Traffic Identification (Source IP locations, Destination IP addresses, Source Port Number, Destination Port (0-1023 known, obscure >1023)Number, Protocols (TCP/UDP)) and Set 3 keeps up Statistical element based Information (Statistical flow properties). The Advanced C5.0 machine learning algorithm was prepared and tried with the list of capabilities 1 to 3.The list of capabilities 1 keeps up IP tends to bring about the precision of 79.5% alone, and the mistake rate, for this situation, is 20.5%.The list of capabilities 2 keeps up three distinctive flow characteristics bringing about the exactness of 82.13% higher than the precision pace of Set1, and the general blunder rate for this case is 17.86%. The component Set3 keeps up 15 distinctive flow characteristics bringing about a broad higher exactness pace of 98% contrasted and another list of capabilities choices, and the blunder rate for this case is 1.9%. The Evaluation time taken for experiments is around 5.0 to 7.9 seconds for each component determination. The precision rate can be improved by utilizing a few cases for preparing and testing stages. Figure 9 portrays the Classification table utilizing Feature Set 3 for preparing and arranging on the web traffic in R. The attribute usage for each feature set selection, error rate, and Accuracy rate is given in Table 4.
Comparison of Proposed Scheme With Other Algorithms.
Classification table for the Traffic’s Collected.
An Error Rate of Attribute Usage in Advanced C5.0 Classifier
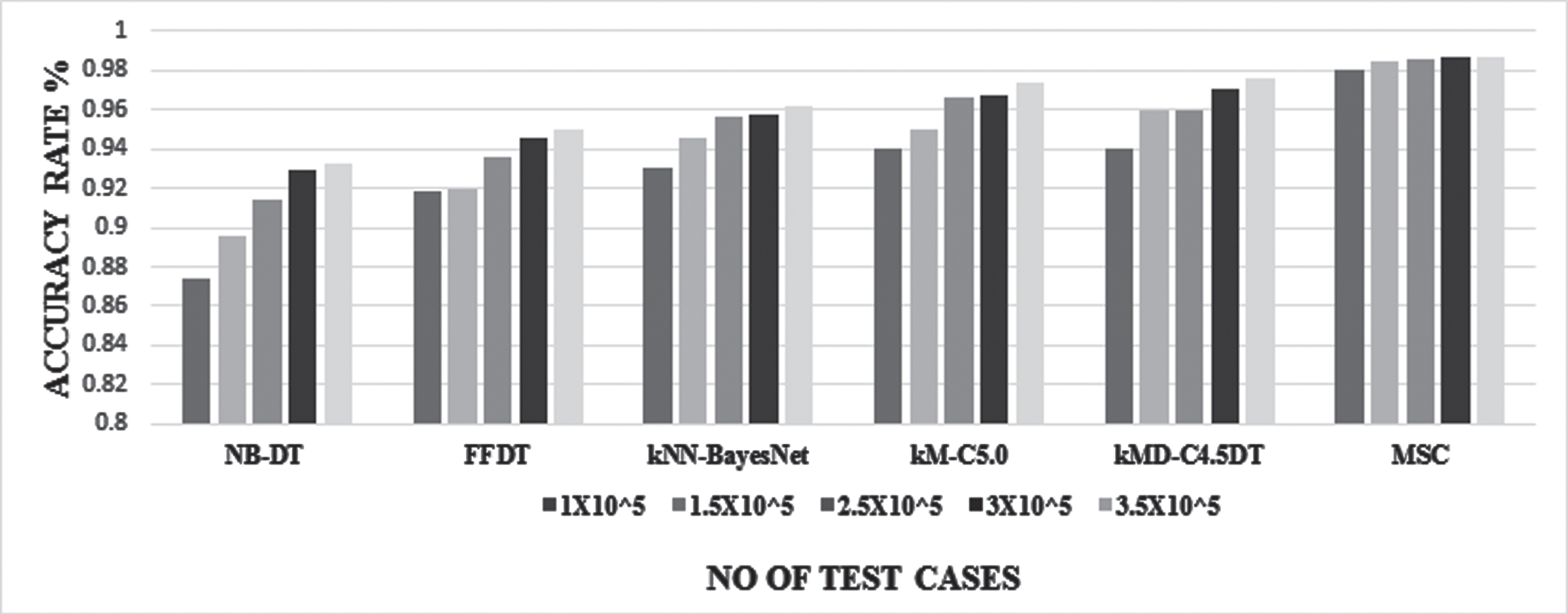
Our exploratory examination utilized 17 distinctive main flow of Internet traffic classes while the past methodologies manage just a couple. We sourced the Waikato Environment for Knowledge Analysis (WEKA) device, contrasting the suggested and current methodologies. Our staggered proposed conspire functions admirably because it groups all unique, measurable practices of a traffic class with a high precision rate, though different calculations distinguish one or different practices of a traffic class. The proposed traffic grouping plan is contrasted and, Naive Bayes+Decision Tree(NB-DT), Finest-first Decision Tree(FFDT), kNN+Bayesian Network(kNN-BayesNet), k-Means+C5.0(kM-C5.0) and K-Medoid+J48/C4.5(kMD-C4.5DT).
To attempt a completely subjective assessment of the Multi-Phased ML approach, we considered substitute ML classifiers and evaluated their reasonability for per-flow traffic characterization comparable to the proposed method. Weka suite was utilized to assess the five most ordinarily used machine learning algorithms in correlation with the proposed approach [48–55]. The classifiers utilized a similar proportion of preparing and testing informational index pools (set apart with individual application class). Half of the flows were utilized for preparing the separate classifier, and the staying half flows were utilized for testing purposes. We quickly portray the machine learning algorithms that were assessed as follows.
Naive Bayes+Decision Tree(NB-DT)
NB-DT is a half breed classifier which consolidates choice tables alongside naive Bayes and assesses the advantage of isolating accessible highlights into disjoint sets to be utilized by every calculation separately. Utilizing a forward determination search, the chose credits are demonstrated utilizing NB and choice table (contingent likelihood table), and at each progression, and superfluous credits are taken out from the last model. The joined model allegedly performed better than individual naive Bayes and choice tables and was executed with default boundaries.
Finest-first Decision Tree(FFDT)
The Finest-first choice tree (FFTree) utilizes paired parting for ostensible just as numeric credits and uses a top-down choice tree induction approach with the end goal that the best split is included at each progression. As opposed to profundity first request in every iterative tree generation step, the calculation grows hubs in the best-first request rather than a fixed request. Both addition and Gini record are used in figuring the best hub in the tree development stage. The calculation was executed utilizing post pruning empowered and with a default estimation of 5-fold in pruning to improve the subsequent classifier.
k-Nearest Neighbours+Bayesian Network(kNN-BayesNet)
k closest neighbors (kNN) calculation figures the separation (Euclidean) from each test to the k closest neighbors in the n-dimensional component space.The classifier chooses the main flow label class from the k closest neighbors also appoints it to the test model.Bayesian Network (BayesNet) is a non-cyclic coordinated chart that speaks to many highlights as its vertices and the probabilistic relationship among highlights as diagram edges.While utilizing Bayes’ standard for probabilistic derivation, under invalid contingent freedom suspicion (in naive Bayes), BayesNet may beat NB and yield better order precision. The default boundaries, that is, Simple Estimator, were utilized for assessing the contingent likelihood tables of BayesNet in the Weka execution of BayesNet on the preparation set.
k-Means+C5.0 Decision Tree(kM-C5.0)
The named information accessible is taken care of to K-Means grouping for gathering up of substance and helper flows of the application. Every application is again named with traffic that is genuinely application traffic and other strengthening flow inside it. These are the flows produced by the application. They speak to the complete information about every application.The C4.5 [40] is the C5.0 algorithm’s precursor, which forecasts the dependent feature set to produce the finest traffic classification. Initially, the Cardinality Set Information (CSI) maintains the statistics of independent feature sets separated and recorded from the college grounds, which is valuable in advancing the unmistakable choice tree. Afterward, the clustered individual flow record is served to C5.0 classifier for supervised knowledge to classify a decision tree.
K-Medoid + J48 / C4.5 Decision Tree (kMD-C4.5DT)
Employing Statistical Feature and its proportion, the K-Medoid Clustering algorithm clusters the similar flows with an innovative function (distance matrix), and the models (representatives) are created for each application. J48/C4.5 choice tree builds a tree structure, in which every hub speaks to statistical feature tests, each branch speaks to a result (output)of the test and each leaf hub speaks to a class name, that is, application flow name in the current work. To utilize a choice tree for Traffic Classification, guaranteed tuple (which requires class expectation) comparing to statistical features stroll through the choice tree from the root to a leaf. The name of the leaf hub is the Traffic Classification result. The calculation was empowered with default boundaries in the Weka Tool of the current test to improve the subsequent choice tree.
Besides, our proposed plot only beats another order calculation when new traffic classes exist. In comparison, the other arrangement calculation neglects to recognize more current applications to have a lower execution in the preparation stage. The comparison of the accuracy rate of different machine learning algorithms is depicted in Fig. 8. The four test cases taken for each algorithm are 1 × 105, 1.5 × 105, 2.5 × 105and3 × 105 traffic flows.The accuracy rate increases for higher test cases in each classification algorithm.
In general, the Multi-phased methodology accomplished better per-flow arrangement in examination with the substitute procedures, while for hardly any applications (flow types), the characterization precision was practically equivalent. For the game, set up flows, the precision is the most noteworthy. For game control flows, substitute methodologies, for example, kNN-BayesNet and kM-C5.0, give a superior level of accurately recognized flows. This was viewed as before while assessing a Multi-staged classifier’s affectability and was, for the most part, because of misclassification blunders (of game control) with the web perusing flows.kNN-BayesNet and kM-C5.0, nonetheless, give a lower exactness than Multi-staged ML for perusing and flowing flows. Also, for the flowing application level, kMD-C4.5DT based methodology yielded exceptionally exact outcomes similar to the Multi-staged machine learning approach while it yielded negligible exactness when the email level was analyzed. For the correspondence application flows, practically all classifiers except for FFDT (83%) gave the right arrangement results (93%). This was principal because of the prescient capacity of flow boundaries for this arrangement of utilizations. For deluge based flows, the choice tree alongside NB gave practically 90.99% flow recognizable proof capacity of downpour control flows because of confusing with game control and perusing flows. Consequently, while one methodology may be appropriate for distinguishing specific traffic flows, comparable high precision probably will not be acknowledged for an alternate application utilizing a similar classifier. Regarding generally precision, Multi-Phased ML gave a significantly more cognizant and material outcome at 98.466% effectively arranged records.
The NB-DT and FFDT calculation results with a precision of 90.9% and 93.38%. The kNN-BayesNet and kM-C5.0 calculation (SA) shows a higher precision than the over two calculations, which was 95% and 95.94%. Finally, the kMD-C4.5DT calculation results with a precision of 96.12%, and the proposed work (MSC) beat all above with (98.46%) exactness rate in rush hour gridlock grouping.
Discussions
We experimentally contemplated the predominant exhibition of the proposed strategy during countless trials on AU-IDS traffic datasets. Some significant perceptions and examinations on the trial results are as per the following.
The proposed technique beats past administered traffic characterization strategies when obscure applications are available in reality traffic datasets. The past Traffic Classification techniques would group obscure flows into pre-characterized known classes, which prompts low arrangement exhibitions, mainly when the number of obscure applications is enormous. In any case, the proposed strategy can recognize obscure flows and order known flows precisely.
The proposed approach is the Application Individual Flow Cluster Grouping, which is, essentially, an automatic naming technique dependent on the 5-tuple. The Application Individual Flow Cluster Grouping is one motivation behind why the proposed approach works so well when the truth is told; not many directed examples are accessible. The other explanation is of compound characterization, which can mutually group connected flows all the more precisely. Standard managed techniques perform gravely even without obscure traffic if the size of the regulated preparing set is excessively little. Since the flow name engendering is autonomous of characterization calculations, we can later utilize it as a pre-preparing venture with any managed strategies to build the regulated preparing set size. Be that as it may, it ought to be called attention that this paper’s critical worry is obscure traffic. The Application Individual Flow Cluster Grouping can not manage obscure traffic clear. We proposed a semi-supervised plot by joining the Offline and Online phase to deal with obscure traffic adequately. It ought to be brought up that this paper does not address traffic grouping across networks. In this work, all strategies are proposed to manage obscure applications on an organization.
Application Background
The current innovation identifies with the characterization of organization traffic for the reasons for investigation, announcing, and control and, more significantly, to strategies, mechanical assemblies, and frameworks that encourage the ID and order of web administrations network traffic.
Enterprises have gotten progressively reliant on PC network frameworks to offer types of assistance and achieve crucial errands. Undoubtedly, these organization frameworks’ exhibition, security, and proficiency have become basic as endeavors increment their dependence on distributed computing environments and wide area computer networks.
Web administrations networks are quickly developing innovation models permitting applications to take advantage of administrations’ assortment in an amazingly professional and savvy way. Web administrations empower practical and proficient joint effort among elements inside a venture or across undertakings. Web administrations are URL or IP addressable assets that trade information and execute measures. Web administrations are applications uncovered as administrations over a PC organization; furthermore, they are utilized by different applications utilizing Internet standard advancements, such as XML, SOAP, WSDL, and so forth. As needs are, Web applications can be rapidly and effectively gathered with administrations accessible inside an endeavor WAN or outer administrations accessible over open PC organizations, for example, the Web.
To be sure, an expanding number of organization applications utilize information pressure, encryption innovation, or potentially restrictive conventions that cloud or forestall recognizable proof of other application-explicit credits, regularly leaving significant port numbers as the main reason for the arrangement. Truth be told, as organized applications become progressively mind-boggling, information encryption or potential pressure has promoted security or improvement. Indeed, information encryption tends to worry about security and protection issues yet makes it significantly more challenging for the middle of the road network gadgets to recognize the applications that utilize them.
Considering the prior, a need for craftsmanship exists for expanding the productivity and execution of organization traffic arrangements. A need likewise exists in the craftsmanship for decreasing the asset prerequisites related to network traffic order. Exemplifications of the current innovation considerably satisfy these necessities.
Conclusion
In this manuscript, we offered a delegate key for recognizing and ordering various sorts of application traffic on the University Campus. The proposed technique presents a semi-supervised approach, incorporating both unsupervised cluster analysis (offline Pre-Learning Phase) and a compound supervised (Online Classification Phase) method. It attempts to order the system traffic prominently with the capacity to handle more current applications. Traffic information from 17 well-known web applications was gathered from the different servers of AU-IDS. The invalid packets were omitted in light of the size of the payload, and only legitimate packet counts were taken for each application to reduce time and space complexity. The disconnected Pre-Learning Phase is to discover the application models that must be unmistakable or separate from different applications. The steady traffic flows are segregated by advanced K-Medoid clustering into the respective application traffic class, which is used to train the advanced C5.0 classifier to classify new online traffic accurately. The experimental results show that our proposed strategy (MSC) can classify the 17 popular real-world traffic obtained in our University campus with an accuracy of 98%. The performance evaluation revealed that the proposed work outperforms the classification methods like Naive Bayes, Semi-Supervised, and C4.5. Our future work is to expand the suggested procedure for improving the ground truth data in real-world situations.