
Abstract
Word embeddings have been successfully applied in many natural language processing tasks due to its their effectiveness. However, the state-of-the-art algorithms for learning word representations from large amounts of text documents ignore emotional information, which is a significant research problem that must be addressed. To solve the above problem, we propose an emotional word embedding (EWE) model for sentiment analysis in this paper. This method first applies pre-trained word vectors to represent document features using two different linear weighting methods. Then, the resulting document vectors are input to a classification model and used to train a text sentiment classifier, which is based on a neural network. In this way, the emotional polarity of the text is propagated into the word vectors. The experimental results on three kinds of real-world data sets demonstrate that the proposed EWE model achieves superior performances on text sentiment prediction, text similarity calculation, and word emotional expression tasks compared to other state-of-the-art models.
Introduction
Sentiment analysis or opinion mining is the computational study of people’s opinions, sentiments, emotions, appraisals, and attitudes towards entities such as products, services, organizations,individuals, issues, events, topics, and their attributes [1]. Large amounts of emotional text data have been accumulated by social media platforms such as Twitter, Facebook, and WeChat and by shopping platforms such as Taobao, Jingdong, and Amazon. Analyzing the emotional tendency of these text data has both essential research significance and commercial value [2]. Moreover, sentiment analysis has grown to be one of the most active research areas in natural language processing (NLP). Existing research on sentiment analysis includes both supervised and unsupervised methods. In the supervised setting, the papers used all types of supervised machine learning methods (such as Support Vector Machines (SVM), Maximum Entropy, etc.) and feature combinations. Unsupervised methods include various methods that exploit sentiment lexicons, grammatical analysis, and syntactic patterns. Several survey books and papers have been published, which cover those early methods and applications extensively [3].
Distributed representation learning, as a new deep language analysis technology, has received increasing attention from researchers in the field of NLP. Many deep learning models in NLP need distributed representation results as input features [4]. Word embedding is a technique for language distributed representation learning, which transforms words in a vocabulary to vectors of continuous real numbers. Therefore, the representation of words has become the basis for the development of various tasks and in research. In a vector space, it is easy to quantify the distance between words by distance or angle. Thus, word representations (also known as word embeddings) have received increasing attention from researchers in the NLP field.
There are two main frameworks for training word representations: global matrix factorization methods, such as latent semantic analysis (LSA) [5, 6] and local neural network methods [7, 8], such as the word2vec model [9]. The former generates low-dimensional word representations by factorization matrices that capture global statistical information about a corpus. The latter uses a neural network framework to train word representations that are good at making predictions within local context windows. In these two main structures, most word representations are learned from extensive collections of document texts; however, they ignore the sentiment information in documents. Nevertheless, in real-world datasets, documents such as commodity review data may contain rich emotional information. This situation is suboptimal because it means that the emotional information in the documents is not being used when discovering word representations. In this paper, we focus on embed emotional information into word representations.
Recent efforts on sentiment detection take advantage of word representations embedded in semantic vector spaces [9, 10], which are learned based on neural networks or probabilistic models on large text corpora. The derived word embeddings have been shown to accurately capture the semantics and context of words. Simultaneously, using the resulting embeddings in a supervised classification setting (especially with neural network architectures) can improve the trained sentiment models, as shown by Le and Mikolov [11]. Severyn and Moschitti [12], Socher et al. [13] and Tang et al. [14] proposed learning sentiment specific word representations by applying sentiment labels (positive and negative). The results from the word representation embedding algorithm show that in addition to capturing precise syntactic and semantic information, the word embeddings obtained from these algorithms demonstrate a linear structure particularly well suited to performing analogy tasks. More researchers focus on the sentiment embedding from different perspectives. Fu et al. [15] propose an integrated sentiment embedding method to combine context and sentiment information using a dual-task learning algorithm to perform sentiment analysis. Sun et al. [16] propose solve the problem of text containing semantics, syntax, sentiment and other information. Kaibi et al. [17] focus on the comparison of three commonly used word embeddings techniques (Word2vec, Fasttext and Glove) on Twitter datasets for Sentiment Analysis. Mohamed et al. [18] propose an enhanced ensemble classifier framework which is based on lexicon-based method, bag-of-words, and pre-trained word embedding. Seyed et al. [19] propose a novel method, Improved Word Vectors (IWV), which increases the accuracy of pre-trained word embeddings in sentiment analysis. However, It is a challenging problem to integrate emotional information into the pre-trained word vectors and represent document sentiment features.
In this paper, we propose an emotional word embedding (EWE) model for sentiment analysis. This method first uses pre-trained word vectors to represent document features with two different linear weighting methods (EWE (1) and EWE (delta - idf)). Then, the document vectors are used as input to the classification model to train the text sentiment classifier, which is based on a neural network. The emotional polarity of the text is propagated into the word vectors. Our experimental results on three kinds of real-world data sets demonstrate that the proposed EWE achieves superior performances on text sentiment prediction, text similarity calculation, and word emotional expression tasks.
The contributions of this paper can be summarized as follows. We propose an emotional word embedding (EWE) model to encode both word level and emotion level sentiment information when learning sentiment-specific word embedding, which makes full use of existing sentiment lexicons. We present two different linear weighting methods (EWE (1) and EWE (delta - idf)) to pre-trained word vectors to represent document features. The document vectors are used as input to the classification model to train the text sentiment classifier, which is based on a neural network. The emotional polarity of the text is propagated into the word vectors. We conduct experiments on three standard datasets sentiment classification benchmarks. The proposed EWE model achieves superior performances on text sentiment prediction, text similarity calculation, and word emotional expression tasks compared to other state-of-the-art models.
The remainder of this paper is organized as follows. In Section 2, we briefly summarize the related works on sentiment analysis and word representations. Section 3, describes the proposed EWE model for incorporating emotional information into the word representations. Section 4 presents an experimental evaluation of the proposed model’s performances on text sentiment prediction, text similarity calculation, and word emotional expression tasks, and Section 5 concludes the paper.
Related Works
A vast amount of related work has been performed on word representations and sentiment analysis. In this section, we discuss the significant contributions from both areas.
Word vector representations
Word embedding is a popular method in NLP whose goal is to learn low-dimensional vector representations of words from large numbers of documents. This approach can capture both syntactic and semantic word relationships. The earliest vector representation of words was proposed by Harris [20] in 1954, who introduced a distributional structure in which the appearance of each word is related to that word in context. Subsequently, two main frameworks were developed for training word representations: local neural network methods and global matrix factorization methods.
Moreover, a logbilinear model was proposed by Botha and Blunsom [22], who exploited addition as a composition function to enhance word vector representations from morpheme vectors. Chen et al. [23] proposed a character-enhanced word embedding model. Yang and Sun [24] introduced a model to improve the learning of Chinese word embeddings by using semantic knowledge. The basic idea was to learn the word representations by considering the semantic information about words and their component characters when performing composition functions.
Document-level sentiment analysis
Document-level sentiment classification is the most popular and extensively studied topic in the field of sentiment analysis. The goal of this task is to classify a document (e.g., a product review) as expressing positive or negative sentiment. Document sentiment classification considers each document as a whole and ignores details such as, for example, who is expressing the sentiment or which product aspects are involved. The assumptions behind document sentiment analysis are that each document expresses an opinion regarding a single entity and that a single sentiment holder expresses those sentiments.
According to [31], the approaches for document sentiment classification can be grouped into supervised and unsupervised tasks. The lexicon-based approaches are types of the traditional approaches for sentiment analysis that use pre-compiled sentiment lexicons containing different words and their polarity to classify a given word into positive or negative sentiment class labels. The studies [3], [32] provide a detailed description of these approaches. Stone et al. [33] started the task of sentiment analysis using the lexicon method in 1966. Later, different lexicons were proposed such as WordNet, WordNet-Affect, SenticNet, MPQA, and SentiWordNet [34]. Among supervised approaches, Dyer et al. [35] was the first to adopt a supervised machine learning method to address the sentiment classification problem. Many previous works showed that feature engineering plays a crucial role in sentiment analysis tasks. The widely used one-hot word representation always serves as a baseline in sentiment analysis. Furthermore, Richard et al. [36] incorporated numerous manual features to build a state-of-art system for performing sentiment analysis on Twitter posts. The current state-of-the-art approaches to sentiment analysis rely on embedding-based feature extraction and deep learning architectures [37–39]. These approaches represent words as a function of their context, which enables machine learning algorithms to generalize across words with similar contextual representations.
Deep learning approaches is an emerging branch of machine learning algorithms, which is inspired by artificial neural networks.Word embeddings are types of word representation that aim at representing wordsa̧ŕ meaning in the form of vectors, they serve as first data processing layer in deep learning approaches [40]. There are heavily relies on the learned representations produced by word embedding methods for sentiment analysis. Fu et al. [15] propose an integrated sentiment embedding method to combine context and sentiment information using a dual-task learning algorithm to perform sentiment analysis. Sun et al. [16] propose solve the problem of text containing semantics, syntax, sentiment and other information. Kaibi et al. [17] focus on the comparison of three commonly used word embeddings techniques (Word2vec, Fasttext and Glove) on Twitter datasets for Sentiment Analysis. Mohamed et al. [18] propose an enhanced ensemble classifier framework which is based on lexicon-based method, bag-of-words, and pre-trained word embedding. Seyed et al. [19] propose a novel method, Improved Word Vectors (IWV), which increases the accuracy of pre-trained word embeddings in sentiment analysis.
In the main related works, most word representations are learned from large amounts of document texts, and they ignore the sentiment information in documents. In real-world datasets, documents such as commodity review data may capture rich emotional intelligence. The situation is suboptimal because the word representations ignore this sensitive information in the documents when discovering word representations. In this paper, we focus on how to incorporate this emotional information into word representations.
Emotional Word Embedding Model
In this section, we propose the Emotional Word Embedding model named EWE. First, we design two weighting methods (EWE (1) and EWE (delta - idf)) to construct the document features. Then, the emotional polarity of the text is propagated back to the word vector by a neural network classifier. In this way, we can generate word embeddings that include emotional characteristics are generated.
Problem description
It has been shown conclusively that unsupervised word vector learning methods can be used to estimate the probability distributions of words from a large-scale corpus [41]. These distributions are characterized by words with similar contexts, and the corresponding word vectors are similar concerning spatial distance. However, the words obtained by this method do not reflect the emotional polarity of the words, as shown in Table 1.
Similarity of word vectors for good vs bad and good vs great .
Similarity of word vectors for
In Table 1, although ’bad’ and ’good’ carry emotionally opposite sentiments, they are similar in both their usage scenarios and contexts; therefore, the resulting vectors are relatively close in space. In contrast, ’great’ and ’good’ have similar (both positive) emotional polarities. However, due to their contextual differences, the distance between the vectors of these two terms is relatively large. Therefore, the main research goal of this paper is to reduce the spatial distance for word vectors with the same emotional polarity and to increase the spatial distance for word vectors with opposite polarities. We want to obtain the maximum value between w1 and w2 if they are synonyms and the minimum value if they are antonyms.
We wish to learn word representations that capture the emotional information of words while maintaining predictive power for supervised tasks. Given a collection of documents d1, d2, . . . , d n with corresponding binary sentiments y1, y2, . . . , y n , the goal is to learn a set of emotional word vectors that are spatially close to other vectors with the same emotional polarity and spatially distant from vectors with a different emotional polarity. The overall goal is to train a classifier that, when given a previously unseen document d, can accurately estimate the sentiment of the document, and the notations used in this paper are shown in Table 2.
The notations used in this paper
We propose the EWE model, which has a 3-layer neural network structure, to train a classifier via a given set of documents d1, d2, . . . , d n and their corresponding emotion labels y1, y2, . . . , y n . Moreover, the model can learn the emotional polarity of the word while completing the emotional classification. The principle of the EWE model is to learn the emotional polarities of the words from the emotional label of the document. Moreover, the model identifies the emotional polarity of a sentence through the emotional words in the document. The architecture of EWE is shown in Fig. 1.
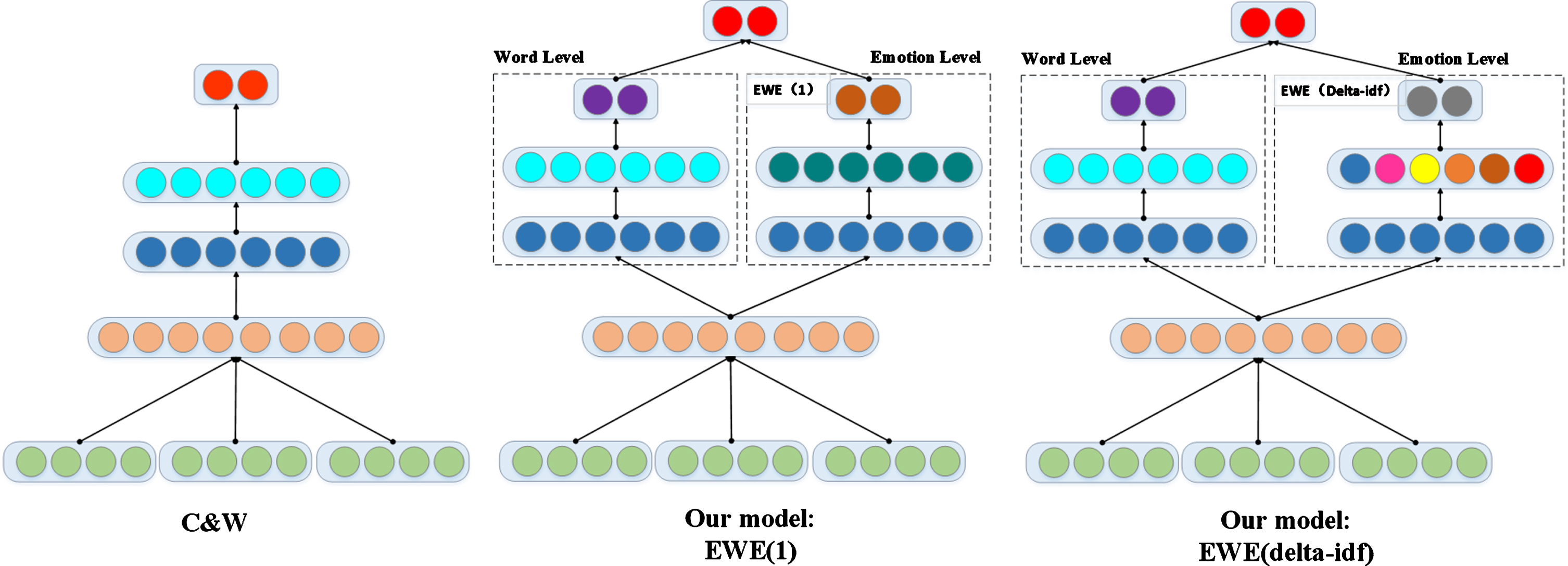
Architecture of Emotional Word Embedding(EWE) learning methods
Under the EWE model architecture, we set a linear weighting method to vectorize the document for each word vector w1, w2 . . . , w m in the document. In this paper, we propose two methods to set the word vector weighting to construct document vectors.
As shown in Formula 1, the weight for a word vector w
t
can be represented as α
t
. The first method of weighting is that all the word weights in the document are set to 1, corresponding to α
t
= 1. We call this first weighting method EWE (1). The second weighting method is
Based on the above two weighting methods, we perform weighted summation on each dimension to obtain the feature vector d
i
of the i - th document.
For the training samples, the input of the neural network is x = [d1, d2, . . . , dn]
The hidden layer is the same as in a common feedforward neural network, and is followed by a fully connected layer. We select the tanh function in Formula 3 as the activation function of the hidden layer.
Logistic regression models are widely used in a large body of classification tasks, such as sentiment analysis. In this section, we assume that the probability model of interest is the logistic model. Under this assumption, the calculation of the output layer is performed with a logistic regression model:
The parameters in the EWE model include the word vector W for each word and the neural network parameters H,U,b1 and b2. To learn the parameters, our paper defines the cost function J (H, U, b1, b2, w) as follows:
This optimization problem can now be written as a maximum likelihood estimation problem in which the goal is to find a set of parameters that minimizes the cost:
Therefore, we use minibatch gradient descent (MBGD) in our optimization method and use the backpropagation algorithm to calculate the gradient. The training process for the proposed EWE is shown in Algorithm 1.
Initialization word vector W by word2vec and related parameters by random;
Calculate the cost function value J (H, U, b1, b2, w);
Calculate the parameters of the gradient update classifier θ;
Calculate the word vector W that appears in the gradient update sentence;
return Word vector W and Classification model;
The time complexity of the learning algorithm is O (T · K · |N| · L), where T is the number of iterations until converge. N is the number of negative sampling. Number of dimension K indicates the length of representation vectors for each node, which meas that we need to learn O (K) parameters for each word. L is the maximum length of the document. Moreover, The space complexity of EWE is O (|W| · K), since we need to learn K-dimensional vectors for each word w ∈ W.
In this section, we demonstrate the efficacy and efficiency of the presented EWE (1) and EWE (delta - idf) models for learning emotional word representations. We evaluate the models empirically on three tasks: sentiment analysis, the similarity of the sentiment text, and sentiment word analysis. We perform the evaluation on three datasets: IMDB, Yelp, and Amazon. The implementation process of the EWE model is described in Fig. 2.
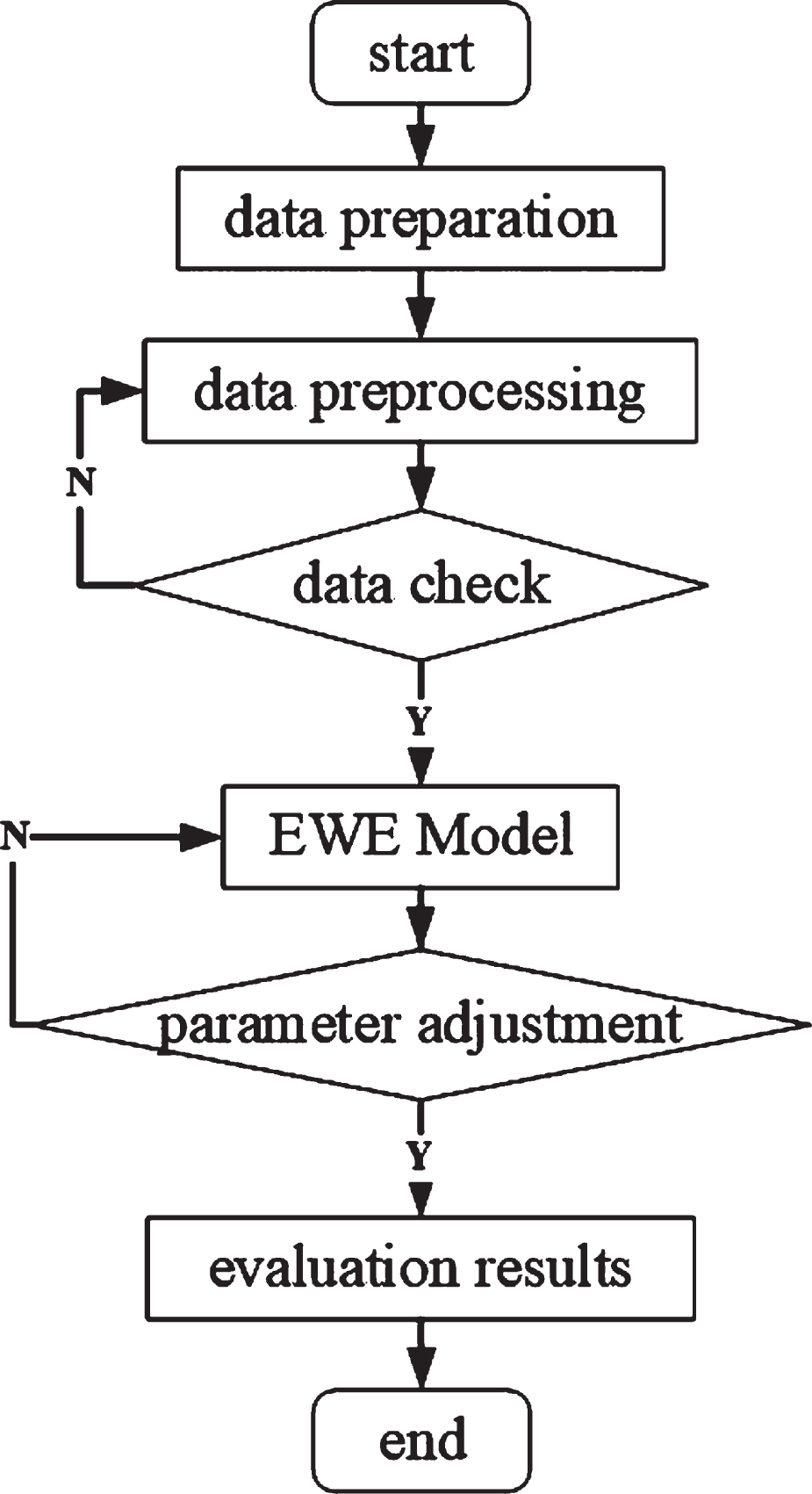
The flow chart for the implementation process of the EWE model.
To train EWE, we use three datasets that are used in our study. Among these, the IMDB dataset contains 1,000 movie reviews, the Yelp dataset includes 1,000 food reviews, and the Amazon dataset contains 1,000 product reviews. All three datasets were balanced to consist of 500 positive-emotion samples and 500 negative-emotion samples. All three datasets can be downloaded from the UCI repository 1 ; the sample content in the datasets is shown in Table 3.
Samples of IMDB, Yelp and Amazon
Samples of IMDB, Yelp and Amazon
Generally, English text data do not need word segmentation, nor is it necessary to consider the problem of coding conversion. However, in English, spelling is a crucial problem that must be considered. Because of the particular characteristics of the English language and grammatical considerations such as the grammatical case, singular and plural forms, and the grammatical person, words have different forms. If this aspect is not addressed, various forms of the same word may be mistakenly classified as different words, which greatly interferes with the results.
For the training datasets, this paper first uses the NLTK toolkit in Python to preprocess the English texts. The preprocessing operations include removing stop words, removing special symbols, changing uppercase to lowercase, restoring parts of speech, and so on. Then the stop word removal function removes words from the text that do not contribute relevant meaning. Part-of-speech restoration removes affixes from the words based on WordNet and extracts the main part of the word. An example is listed in Table 4.
Effect of data preprocessing in emotional word embedding
In this section, we first list the baselines that we compare with our method and describe the evaluation protocol; then, we provide an analysis of the results.
Baseline
To examine its effectiveness, we compared EWE against the following baselines:
Evaluation
The performances are assessed based on accuracy on the test set, and the metrics are defined as follows:
In this study, the experiments were performed using three data sets: IMDB, Yelp, and Amazon. We obtained average values by using 10-fold cross-validation. The number of iterations was determined experimentally, that is, when the change in the target function value was less than an absolute threshold (≤10-5), the iteration is terminated.
We compare the results of the proposed model with those of the benchmark models with regard to text emotion classification tasks, as shown in Table 5 to Table 8.
The result of text sentiment classification on IMDB
The result of text sentiment classification on IMDB
The result of text sentiment classification on Yelp
The result of text sentiment classification on Amazon
AUC of text sentiment classification
As the results show, compared with the other methods, the two EWE models achieve better results on the emotion classification task (PR,RE and F1). Moreover, the EWE (delta - idf) method is the most effective because the pre-trained word vector contains a wealth of emotional information, and the use of the linear weighting method more effectively combines semantic and emotional polarity. The average weighting method performs a greater degree of correction to the word vector itself, which may destroy the contained semantics, resulting in a slight decline in the results.
Another goal of this paper is to determine the similarity of emotional texts. This paper investigates the degree of similarity between sentences by calculating the similarity between text feature vectors. From the viewpoint of emotional similarity analysis, sentences highly similar to sentences with positive emotions should also contain positive emotions. In the same way, sentences highly similar to sentences with negative emotions should contain negative emotions.
In our paper, we used the cosine value to calculate the similarity of two sentence vectors. Because the cosine can be used to measure the difference between two vector directions. There are (x1, x2, . . . , x
N
) and (y1, y2, . . . , y
N
) represents the eigenvectors of two sentences, and N is the dimension of the feature vector.
In this paper, the three sentences with the highest similarity are calculated using the text characteristics obtained by EWE (1), EWE (delta - idf), and TwoStep(word2vec) to evaluate the method’s performance.
Taking the
Result of sentence similarity
The results show that the two weighting methods in EWE are used to calculate the text vector as the feature used in the text similarity calculation. Then, the three sentences with the highest similarity are obtained. We find that the emotional polarity of the sentences obtained by the EWE methods is consistent. However, the sentences obtained by the two-step method cannot distinguish the emotion polarity well. The text similarity calculation has similar results on the other data sets; the EWE model can incorporate the emotional polarity of the document into the word vector well, thus providing better features for sentiment analysis.
In this paper, by calculating the similarities between word vectors for synonyms and antonyms, we investigate the emotional polarity contained in word vectors and then examine whether this training method can distinguish words with similar context but opposite sentiment polarity.
We compare the word vector obtained after training or model with the word vector obtained by pre-training word2vec to investigate emotional polarity. The sentiment similarity calculation method is consistent with the sentence similarity calculation method; the angle reflects the similarity. Here, the cosine value of the two-dimensional spatial angle is used to calculate the corresponding two-dimensional angle.
As shown in Table 10, it is an antonym comparison: Taking the word ’bad’ as an example, the words ’good’, ’great’ and ’excellent’ are all words with opposite sentiment polarity to ’bad’. The table shows that the similarity between ’bad’ and these three words in the EWE (1) model is negative¡ªthe opposite of the result of the word vector calculation obtained by word2vec, indicating that the terms are further apart in vector space.
Antonyms of “bad”
By treating the similarity as the cosine value of a 2D angle, a mapping diagram of the word vector in 2D space can be visualized:
Figure 3 shows that the word vectors trained by the EWE (1) model can reveal words with similar contexts but opposite emotional polarities because they are further apart in vector space.
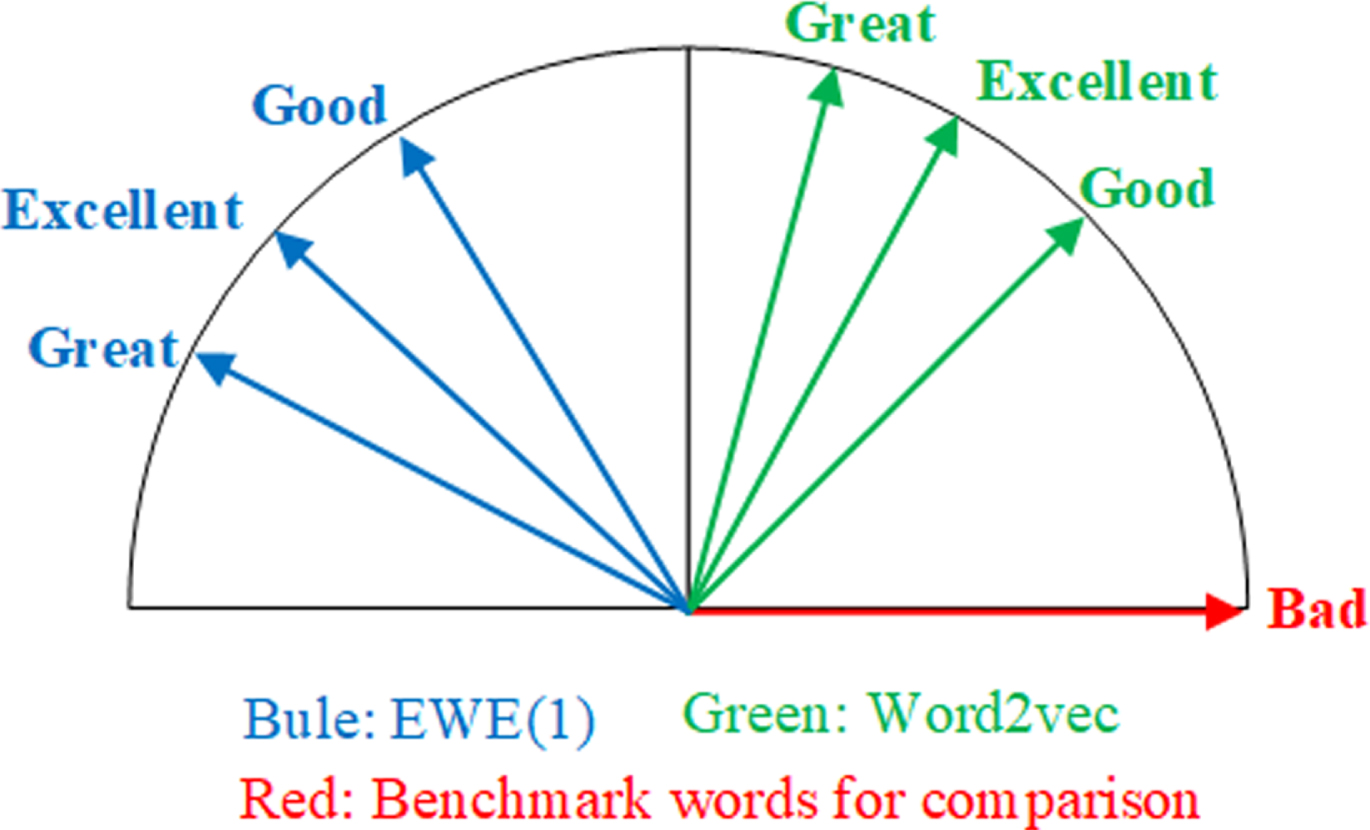
Similarity among good, excellent, great and the benchmark words: bad.
Table 11 presents a close-term comparison; taking the word “good” as an example, “good” and “fine” represent equivalent words in terms of positive emotional polarity. The similarity of “good” and other two words is relatively high in the EWE (1) model; the antonym results are combined to reveal that the model has successfully represented the emotional polarity of the text for each of the emotional words, which is reflected in the spatial distances of the word vectors.
Synonyms of “good”
Figure 4 shows that the EWE (1) model training causes the vectors of words with different contexts but similar emotional polarity to be closer in vector space. However, the word vectors obtained by the EWE (delta - idf) method are no different than the original pre-trained word vectors. The reasons may be as follows. (1) The emotional information of words was added to the word weight level to consider positive and negative emotion during the classification process effectively; thus, the word vector does not change much during the training process. (2) In EWE (1), the weight is initially set to 1; that is, the word vectors of each text are simply summed up. That approach does not convey precise emotional information; thus, the emotion of the text can be extended to vector form more effectively during the emotional classification training process, allowing the emotional word vector to be obtained.
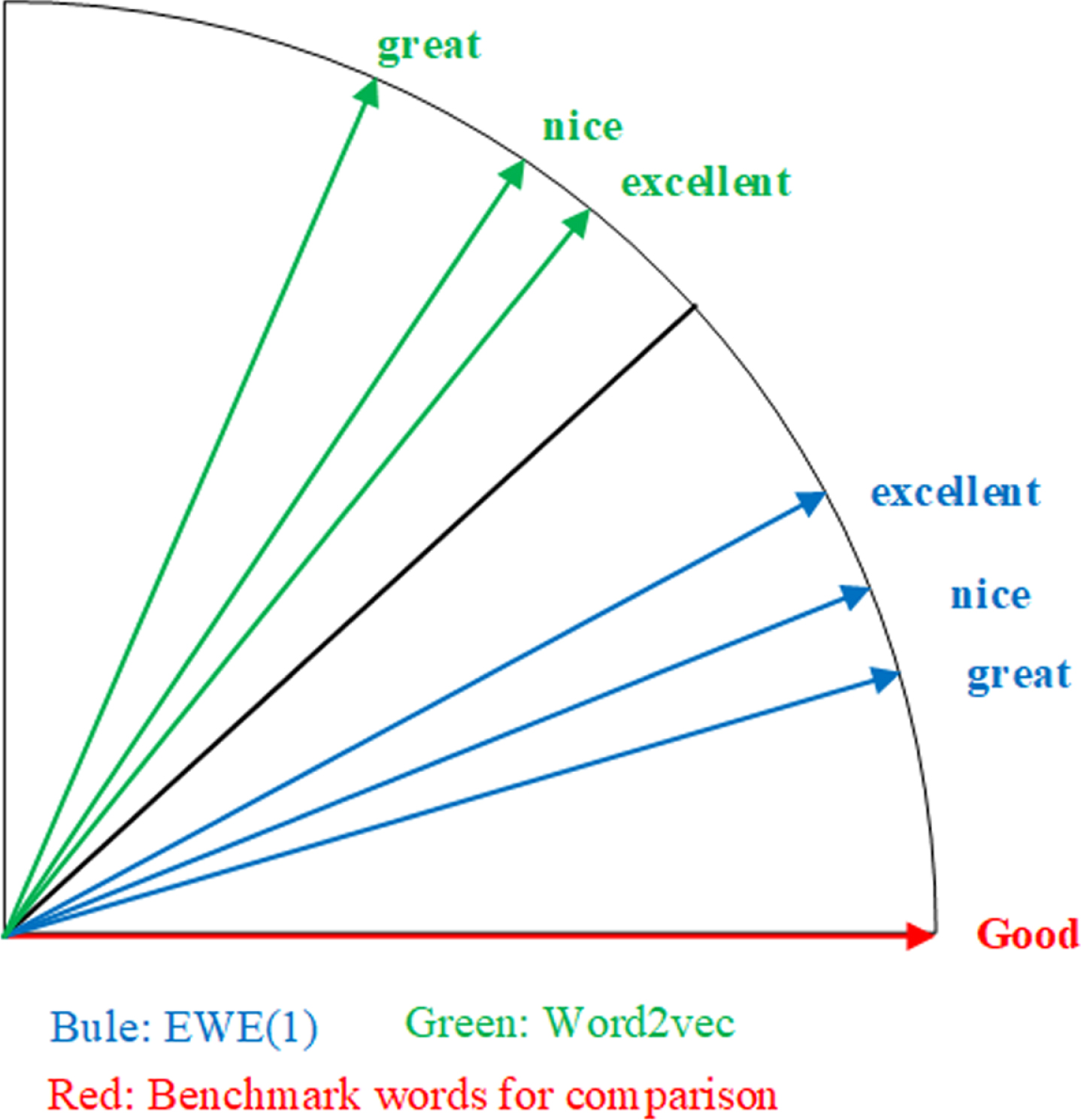
Similarity among good and great, excellent, nice.
In this paper, a word vector training method for text emotion classification is proposed. First, word2vec is used to pre-train the word vector, and the pre-trained word vector is modified by two weighted methods to obtain a document feature vector, which is used as the input to the classifier. Then, the training samples are used to train the classifiers, and the sensitive polarity of the text is transferred to the word vector through gradient descent and back-propagation. The experimental results reveal that the emotional word vector accomplishes the following goals. It achieves better results than do baseline models on the text emotion prediction task. That is, given a new, unseen sentence, the model can use the word vector with sensitive polarity to perform the emotional classification. In the sentence similarity calculation task, the emotional polarity of a sentence obtained by calculating sentence similarity remains consistent with the target. In the word emotional comparison task, words with similar contexts but opposite emotional polarity can be used as antonyms. After training, the spatial distances between these words is greater; this allows words with different contexts but similar emotional polarities to be spatially closer after training.
Moreover, there are still several open problems that should be investigated further: (1) In our models, we only consider the explicit sentiment documents. In many cases, there are also rich implicit sentiment documents. We will exploit implicit sentiment documents in word representation learning. (2) We may also explore topical word embedding model for the text analysis.
Footnotes
Acknowledgements
This research is supported by the National Natural Science Foundation of China (Grant No.62072288, 61303167, 61702306, U1931207), Shandong Provincial Natural Science Foundation, China (ZR2017BF015), SDUST Research Fund (2015TDJH102), the Humanities and Social Science Research Project of the Ministry of Education (18YJAZH017), the Taishan Scholar Program of Shandong Province (Grant No.ts20190936).