
Abstract
Aspect-Based Sentiment Analysis (ABSA) has become a trending research domain due to its ability to transform lives as well as the technical challenges involved in it. In this paper, a unique set of rules has been formulated to extract aspect-opinion phrases. It helps to reduce the average sentence length by 84% and the complexity of the text by 50%. A modified rank-based version of Term-Frequency - Inverse-Document-Frequency (TF-IDF) has been proposed to identify significant aspects. An innovative word representation technique has been applied for aspect categorization which identifies both local as well as global context of a word. For sentiment classification, pre-trained Bidirectional Encoder Representations from Transformers (BERT) has been applied as it helps to capture long-term dependencies and reduce the overhead of training the model from scratch. However, BERT has drawbacks like quadratic drop in efficiency with an increase in sequence length which is limited to 512 tokens. The proposed methodology mitigates these drawbacks of a typical BERT classifier accompanied by a rise in efficiency along with an improvement of 8% in its accuracy. Furthermore, it yields enhanced performance and efficiency compared to other state-of-the-art methods. The assertions have been established through extensive analysis upon movie reviews and Sentihood data-sets.
Introduction
Human beings tend to learn from the experience of others. Whenever we buy a new product, seek admission in an educational institution or take other important decisions in our life we seek the opinions of our relatives, peers and acquaintances. Establishments carry out product surveys to understand the taste of its consumers and even the Government conducts elections to understand the pulse of the voters while appointing leaders of the nation. Thus, opinions play a vital role in the life of human beings. In the present era, most of the opinions and emotions are expressed through the Internet. Therefore, analyzing the sentiments expressed through online platforms has become an important sector for research.
Sentiment Analysis is a domain concerned around sentiment evaluation, opinion appraisal and emotion assessment of expressions by people regarding a certain physical or abstract subject. The reference of term Sentiment Analysis can be traced back to Nasukawa and Yi [1] while Opinion Mining was coined by Dave et al. [2]. There are basically three levels of Sentiment Analysis –Document-Level, Sentence-Level and Aspect-Level or Aspect-Based. In Document-Level Sentiment Analysis sentiment evaluation is carried out upon the entire document as a whole [3]. It suffers from the drawback that there may be multiple sentences in a given document with conflicting sentiment polarities. Sentence-Level is an improvement over Document-Level Sentiment Analysis in which the document is decomposed into sentences and then sentiment evaluation is carried out [4]. But an impediment to this approach is that it fails to capture the sentiments associated with multiple aspects in a sentence. To redress all these issues Aspect-Based Sentiment Analysis (ABSA) was developed in which the sentiment associated with individual aspects are evaluated [5].
For quite a few years the chosen methods for aspect extraction were Conditional Random Field (CRF) [6], Recurrent Neural Network (RNN) [7, 8] and using semantic patterns and syntactic rules of grammar [9]. The limitation behind using CRF is that it requires huge data in order to give good results due to its linear nature [10]. For RNNs, the feedback nature makes it difficult to extract terms based upon the context [11]. Convolutional Neural Network (CNN) was developed to redress these issues whereby it can learn features by itself. CNN uses vector representation of words and thereby is able to map terms based upon semantics [12, 13]. Also, CNN’s have been used in combination with other methods such as Long Short Term Memory (LSTM) [14, 15] to improve the accuracy. But, this leads to additional overhead in terms of computation power and increasing complexity [11]. All these methods suffered from the drawback of training the model from inception and its inflexibility for application in various domains simultaneously. Rule-based approaches have been in use for quite some time due to its unsupervised nature, domain independence, efficiency with acceptable accuracy. Here, the efficacy is dependent upon the rules formulated to capture the grammatical construction of sentences [9, 16]. Also, rule-based approaches may be combined with neural-network-based models to boost the efficiency along with aiding in feature extraction [10]. Presently, transformer-based pre-trained models which employ advanced neural-network architectures like OpenAI’s Generative-Pre-trained Transformer (OpenAI GPT) [17] and Bidirectional Encoder Representations from Transformers (BERT) [18] are on the rise. These can be readily deployed in various domains with some fine-tuning as per the requirements. The above-mentioned developments pave the way towards the trend to design an approach which can provide high accuracy and at the same time is computationally efficient.
In this work, for a given data-set, the phrases containing aspects along with associated opinions have been extracted using a unique set of rules. Then, the phrases have been subjected to significant aspect extraction using a modified rank-based version of Term-Frequency - Inverse-Document-Frequency (TF - IDF). Following this, using similarity measures based on a unique embedded representation of words, the aspects have been grouped into respective aspect categories. After that, the compound aspects and other aspects related to the significant aspects have been extracted. Finally, the phrases belonging to each aspect category have been individually subjected to sentiment analysis using BERT classifier. It is noteworthy that BERT provides advanced features like bidirectional nature, multi-head attention and three-tier representation of text which make it a very robust method in the domain of Natural Language Processing (NLP). However, BERT has drawbacks like quadratic drop in efficiency with an increase in sequence length due to its attention mechanism [19] and limitations on the maximum sequence length [18]. This drawback can be mitigated using the proposed methodology as established through this paper. From the results obtained upon the movie reviews data-set and Sentihood data-set, it is evident that the proposed methodology is more efficient and accurate compared to a typical BERT classifier and other state-of-the-art methods.
The prime contribution of this paper is as follows: A unique set of rules has been formulated to extract the aspect-opinion phrases in order to reduce the average sentence length and complexity of the text. A modified rank-based version of TF - IDF has been proposed to identify significant aspects. The contributions listed above help to enhance the efficiency of BERT and mitigate its limitation on the maximum sequence length. Along with this, the proposed methodology gives 8% greater accuracy compared to a typical BERT classifier.
The organization of this paper is as follows- Section 2 briefs about the background and motivation behind the proposed methodology. Section 3 presents a detailed description of the steps in the proposed methodology. Section 4 enunciates the data-sets, libraries, hyperparameters and evaluation metrics used for the implementation of the proposed approach. Section 5 portrays the results obtained along with its analysis. Finally, inferences from the proposed methodology have been drawn in the conclusion section.
Background and motivation
In this section, the background and motivation behind the proposed methodology have been presented.
Aspect-based sentiment analysis (ABSA)
For a given piece of text, ABSA performs the task of determining the opinion-triplet
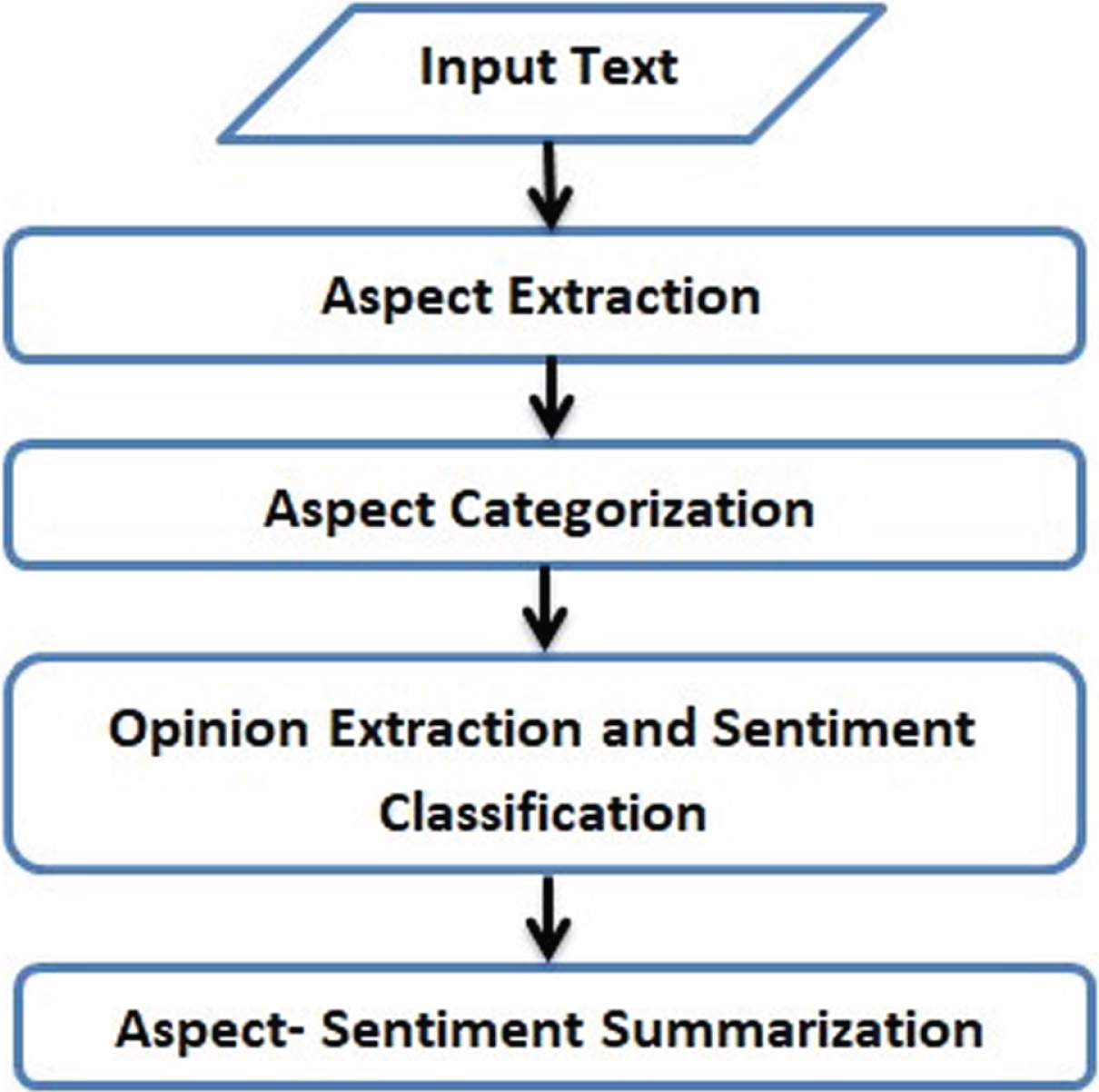
Basic steps to perform ABSA.
In Figure 1, the first step deals with extracting the aspects from a given text. This can be achieved in various ways such as finding the noun terms or noun-phrases which occur frequently, revealing the relations between opinion words and its associated target, application of supervised methods or modelling the topics present in the corpus. After this step, the related aspects are clustered into various categories. The next step deals with extracting the opinion phrases associated with the aspects and determining the sentiments. For this, various supervised techniques like CNN [12, 13], RNN [8], LSTM [14, 15], etc. as well as unsupervised techniques [21] and Lexicon based methods may be used [22–24]. Finally, the opinion triplet is generated and summarization of opinions either in structured or unstructured form is performed for analysis [20].
It is one of the most preferred methods deployed in the domain of topic modelling and for significant aspect extraction. Mathematically, it is the product of Term-Frequency (TF) and Inverse-Document-Frequency (IDF) where TF for a term p, TF p is the number of occurrences of a specific term in a corpus and IDF for a particular term p, IDF p is the logarithmic inverse ratio of the number of documents involving the term and the total number of documents in the corpus as depicted in the equation below:
Word embedding
The growth in the techniques for text processing led to the necessity for the effective representation of words present in a text. Bag-of-Words was one of the earliest methods for text representation proposed in an article by Harris [27]. It performed word representation in fixed-length format. The major drawbacks of fixed-length representations were the absence of ordinal and semantic information [27]. In order to address this issue, vector representation approaches were developed wherein the relationship between the context and target can be realized. Word2Vec is one such approach and was first proposed by Mikolov et al. [28, 29]. It consists of two architectures- Continuous Bag-of-Words (CBoW) and (Skip-Gram) SG both of which use shallow neural-network consisting of a hidden single-unit projection layer along with input and output layers. While CBoW estimates the target-term w n from the surrounding terms (wn-k to wn+k), SG estimates the surrounding terms (wn-k to wn+k), from the target-term w n . The pictorial representation of both the architectures has been depicted in Figure 2. For CBoW and SG, the objective is to maximize the average log-probability of a target term with respect to surrounding terms and vice versa respectively. A noticeable drawback in this approach is that for a given term, its vector representation is calculated depending only on its local context with no global context information [30].
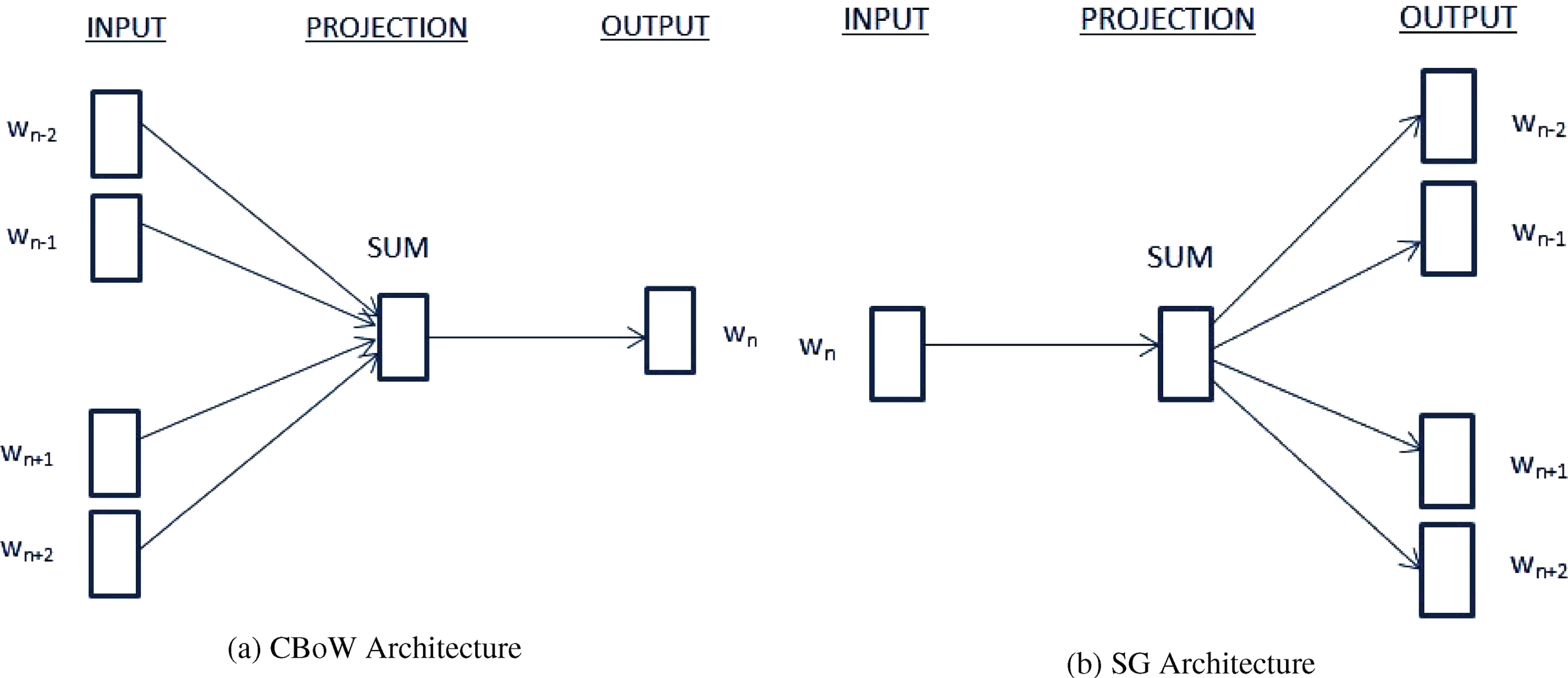
Representation of CBoW and SG architectures of Word2Vec.
Another unsupervised method- Global Vectors for Word Representation (GloVe) was proposed by Pennington et al. to address the local context limitation of Word2Vec [30]. It finds the occurrence of a word relative to a context on the basis of a word-context co-occurrence matrix using the concept of matrix factorization. As described in Figure 3, an approximation of the word-context co-occurrence matrix is initially formed by initializing the word-feature matrix and the feature-context matrix with some random weights. Now, using Stochastic Gradient Descent the error is calculated and minimized in further iterations. Finally, the matrix of word features is obtained which contains the words in embedded format. Here, the co-occurrence of words irrespective of its proximity of occurrence contributes to the vector representation of a term.

Implementation of GloVe Matrix Factorization.
BERT was developed by Google for pre-training in the domain of NLP. It employs transformer-based architecture, an advanced version of neural-network-based models. The advantage of using BERT lies in the fact that it is bidirectional which enables it to learn the word context from its both left and right surrounding words. This makes BERT superior to standard NLP methods which are unidirectional. Also, it is an unsupervised method for language representation. [18, 31]. Bidirectional LSTM models are unsuitable for parallel training due to its sequential nature [19]. Furthermore, transformers with attention mechanism are more potent in analyzing dependencies compared to recurrent models due to its ability to map the relationship among the tokens in an input sequence to the output [19]. The BERT model comprises of transformers with multi-head attention features and supports parallel training [18, 19]. All these features make BERT better than pre-trained LSTM based models like Embeddings from Language-Models (ELMo) [32], Universal Language Model Fine-tuning (ULMFit) [33] and even OpenAI GPT [17] which although uses transformer but follows unidirectional architecture [18]. The architecture, text representation and pre-training process of BERT has been elucidated as follows:
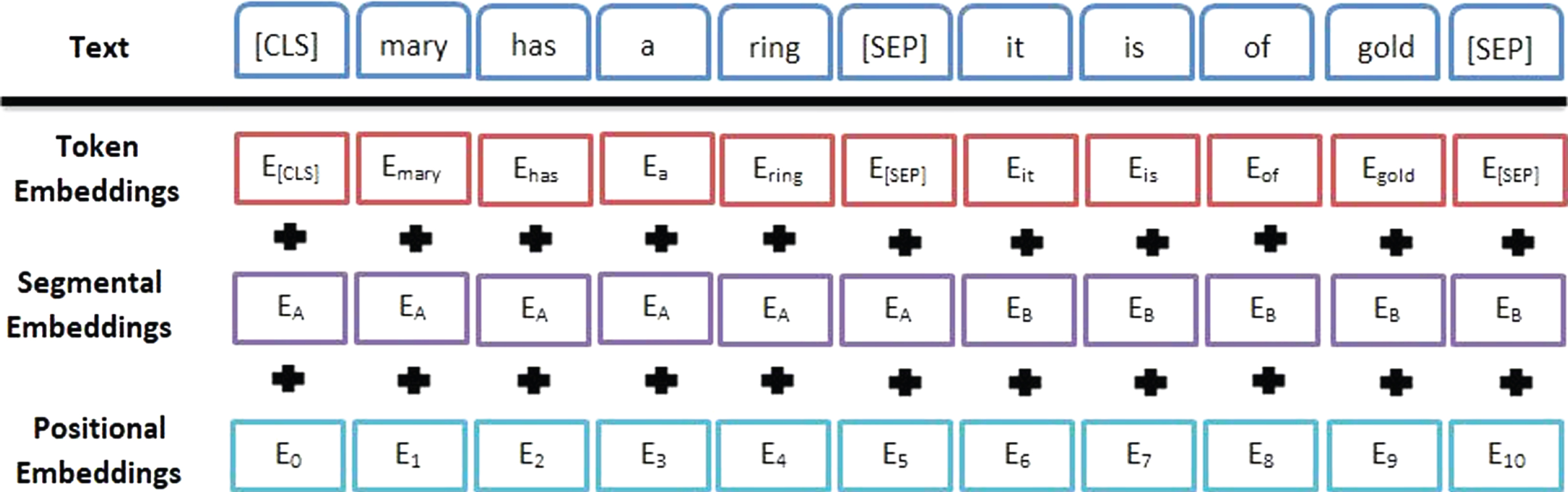
Representation of text using BERT.
The survey of the previous works and prevailing approaches as presented above and in Table 1 have served to be the stepping stone for the proposed methodology. For the task of ABSA, it can be noticed that earlier models like CRF needed huge data for being accurate [10]. LSTM models are superior to CNN and RNN for capturing long-term dependencies [19] with bidirectional versions having the ability to analyze a text in both directions [14]. But, it leads to additional overhead in terms of computation power and increasing complexity [11]. In this situation, pre-trained models like ELMo and ULMFit [32, 33] come to rescue with its ability to be deployed to a task without training from inception. Another point to ponder here is that all the above-mentioned models are sequential in nature which hinders parallel training [19]. To address this issue, transformer-based models with attention mechanism and support for parallel training like BERT [18, 31] and OpenAI GPT [17] can be applied. As OpenAI GPT follows unidirectional architecture, BERT with its bidirectional, pre-trained nature and multi-head attention becomes the apt choice for the proposed methodology. In spite of all this, BERT succumbs to longer input sequences due to its attention mechanism [19] and limitation on the maximum number of tokens allowed in a sequence [18]. On the other hand, rule-based approaches have been trusted for quite a few years due to its unsupervised nature, domain independence, high accuracy versus complexity trade-off with performance dependent upon the rules [9, 16]. Furthermore, rule-based approaches aid in feature extraction along with boosting the efficiency when combined with neural-network-based models [10]. This gives rise to the motivation to devise a methodology which incorporates rule-based aspect-extraction along with BERT to mitigate the drawbacks and at the same time improve the efficiency and performance of a typical BERT classifier.
A Study of the Works Related to the Given Task
A Study of the Works Related to the Given Task
Note- SVM: Support Vector Machine, ME: Maximum Entropy Classifier, CRF: Conditional Random Fields, CBoW: Continuous Bag-of-Words, SG: Skip-Gram, GloVe: Global Vectors for Word Representation, RNN: Recurrent Neural Networks, CNN: Convolutional Neural Networks, PCA: Principal Component Analysis, LSA: Latent Semantic Analysis, LSTM: Long Short Term Memory, Bi-LSTM: Bidirectional Long Short Term Memory.
For significant aspect extraction, TF - IDF has been a trusted method due to its simplicity and effectiveness [25]. However, it has been observed that some irrelevant terms may be selected due to undesirable spikes in TF - IDF value. Therefore, the need arises to refine TF - IDF using normalization and other smoothening approaches [26].
From the study on word embedding techniques, it has been observed that fixed-length representations suffered from drawbacks like the absence of ordinal and semantic information. This can be tackled using vector representations like Word2vec [28, 29] and GloVe [30]. While Word2Vec computes the vector representation based upon terms in the proximity of the target, GloVe uses co-occurrence of terms, irrespective of its proximity as its basis for the representation of a word. This leads to the contemplation to devise a technique capable to capture the local context like Word2Vec along with global information such as GloVe.
The proposed methodology has been designed to increase efficiency as well as performance for the task of ABSA using BERT through refined aspect extraction. In this methodology, the input text passes through a series of modules consisting of techniques required to perform the sub-tasks of ABSA. The output produced labels the aspect categories corresponding to the aspect terms along with its sentiment polarity. The flow-diagram representation of the proposed methodology has been presented in Figure 5.
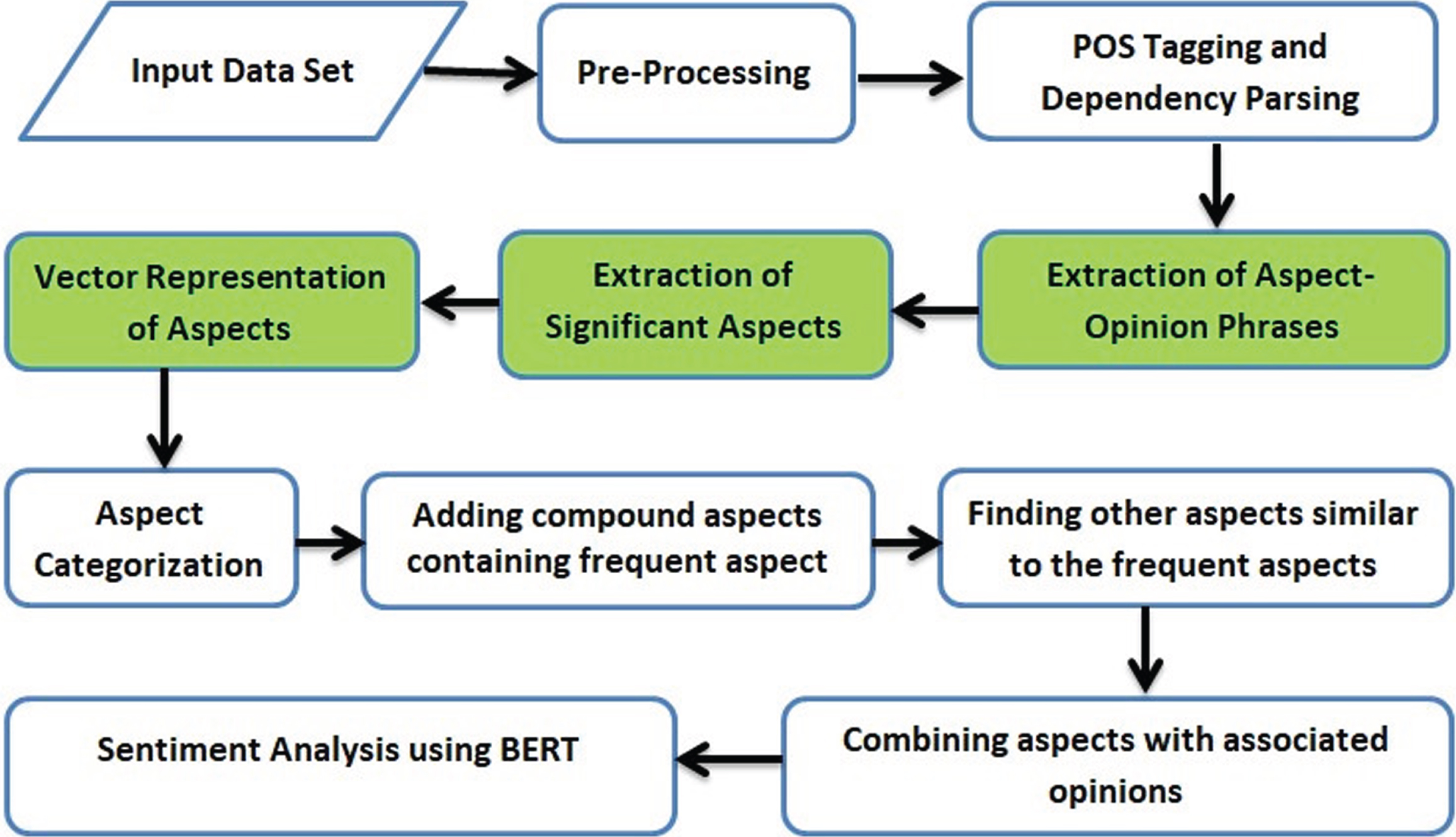
Illustration of the proposed methodology.
In Figure 5, the highlighted modules {i.e. “Extraction of Aspect-Opinion Phrases”, “Extraction of Significant Aspects” and “Vector Representation of Aspects”} accentuate our prime contribution in the proposed methodology. The other modules too play a vital role and have been tailored to boost the performance and efficiency of the proposed methodology. The modules in the proposed methodology have been enunciated as follows:
After loading the input data-set, the following pre-processing operations have been carried out to make it suitable for the application of the proposed methodology- Operations required to sanitize the text: Removal of line breaks and digits. Removal of URL patterns. Removal of non ASCII characters. Removal of punctuation marks. Standardization of white spaces. Conversion of alphabets into lowercase. Lemmatization of words to remove inflectional affixes. Removal of single as well as double character words. Removal of stop words. Also added additional stop words to further remove irrelevant words.
POS tagging and dependency parsing
After pre-processing the text as described above, a parts-of-speech (POS) tagger and a term-dependency parser has been deployed. The POS tagger helps to determine the parts-of-speech for each term in the text while the dependency parser helps to decipher the relation and influence of a term upon other terms in the sentence. Therefore, the combination helps to interpret both the syntactical as well as semantic relationships between terms present in the corpus.
Extraction of aspect-opinion phrases
For the purpose of extracting phrases containing aspects along with the associated opinions, an unprecedented Rule-Based approach has been designed. Using this approach, for a given text, only the aspect terms along with the associated opinions are extracted and all other irrelevant words are discarded. Although, various rules have been proposed in the previous works [9, 16], in this work the focus is upon extracting the entire aspect-opinion phrases compared to extracting only the aspect and opinion terms. This technique helps in a substantial reduction of irrelevant content from the input while at the same time keeps the aspect-opinion relationship intact. The set of rules have been mentioned below.
If a noun word considered as a probable aspect term is preceded by one or more adjectives or adverbs which modify the aspect term, then the aspect along with the adjective and the adverb modifiers are extracted. An illustration of such dependency has been provided in Figure 6. In Figure 6, the pair extracted is ‘not very good acting skills’ and ’acting skills’ has been classified as compound words.
If a probable aspect term has its verb associated with one or more adjective or adverb modifiers, then the phrase containing such dependency is extracted. An illustration of such dependency has been shown in Figure 7. In Figure 7, the pair extracted is ‘movie is fantastic’.
If conjunct dependency exists between two or more noun terms considered as probable aspects, then both aspect phrases are extracted separately along with their adjective, adverb or negative modifiers. An illustration of such dependency has been provided in Figure 8. In Figure 8, the conjunct pairs are [‘great music’, ‘great dialogue’].
If a noun term considered as a probable aspect has two or more opinions associated with it, then all such opinions are extracted in separate phrases along with its associated aspect. An illustration of such dependency has been provided in Figure 9. In Figure 9, the conjunct pairs are [‘film is entertaining’, ‘film is informative’].
If a preposition is preceded with a verb having its subject considered as a probable aspect and succeeded by a noun object with adjective or adverb modifiers such that the object of preposition qualifies the principal subject, then the phrase is extracted. An illustration of such dependency has been provided in Figure 10. In Figure 10, the extracted pair is ‘music composed with great care’
If an aspect term is found to co-occur with another noun term and have compound dependency among them, then such pairs are treated as compound words and extracted together. Examples of compound words are background-music, love-story, etc.
If negation words like not, neither, nor etc. modifying associated adjectives or adverbs are found, then such words are added to the extracted phrases.
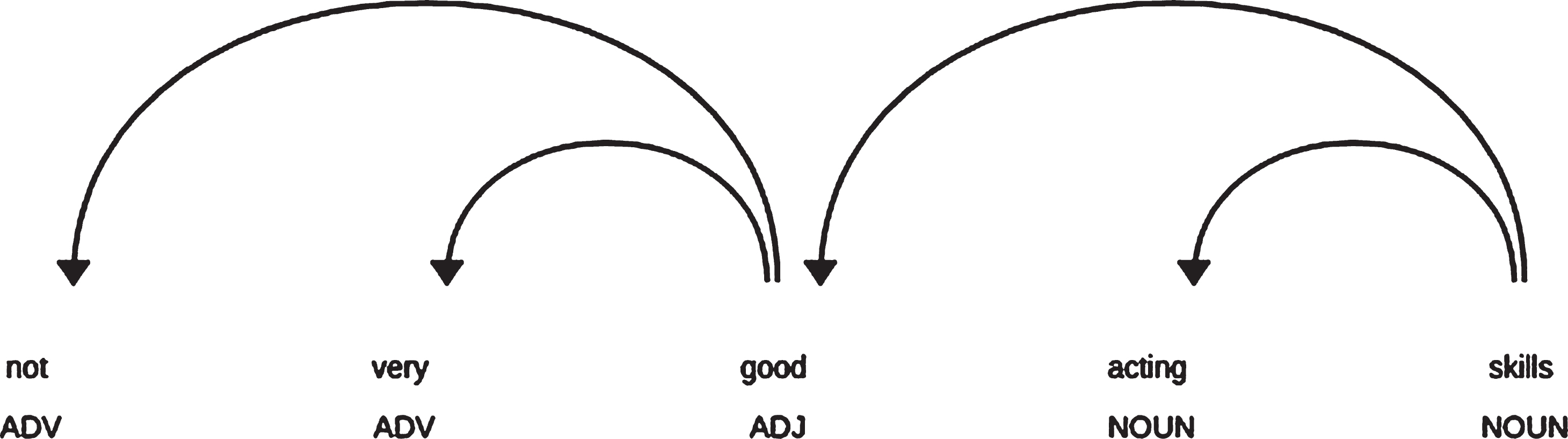
Dependency plot showing adjective and adverb modifiers in a sentence.

Dependency plot showing verbs with direct object in a sentence.

Dependency plot showing conjunct aspects in a sentence.
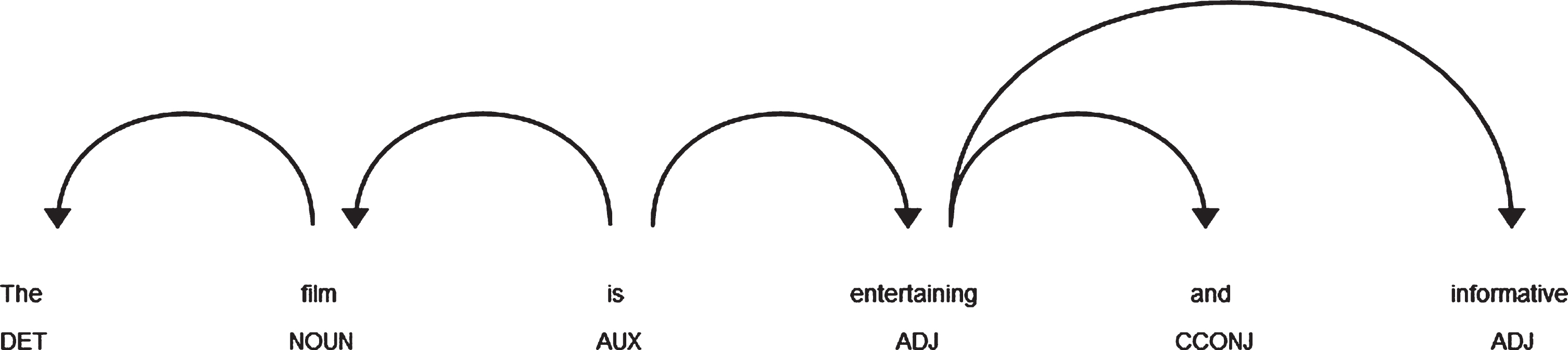
Dependency plot showing conjunct opinions in a sentence.

Dependency plot showing objects of prepositions in a sentence.
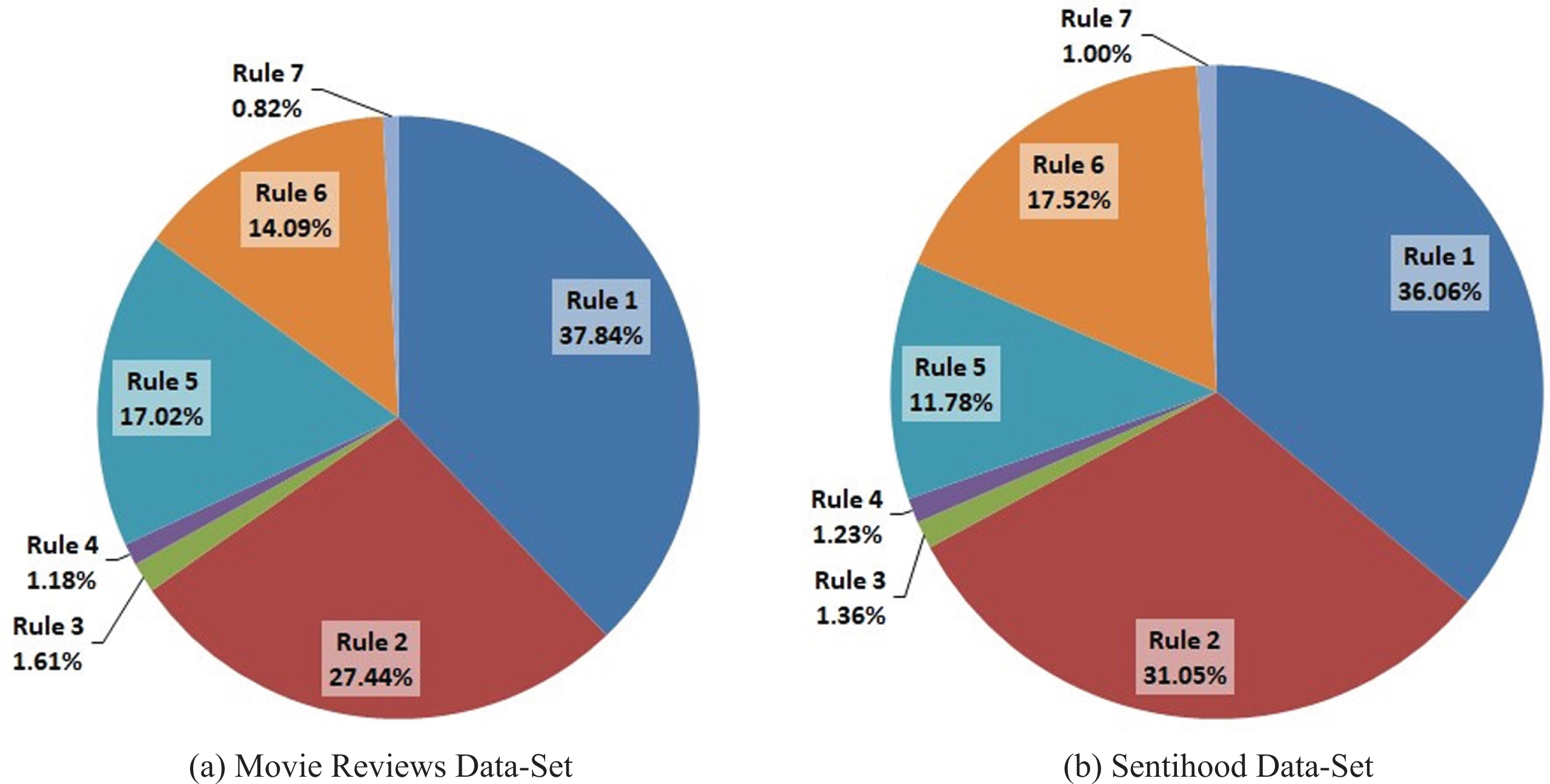
Pie Plot of percentage contribution of individual rules for extraction of aspect-opinion phrases.
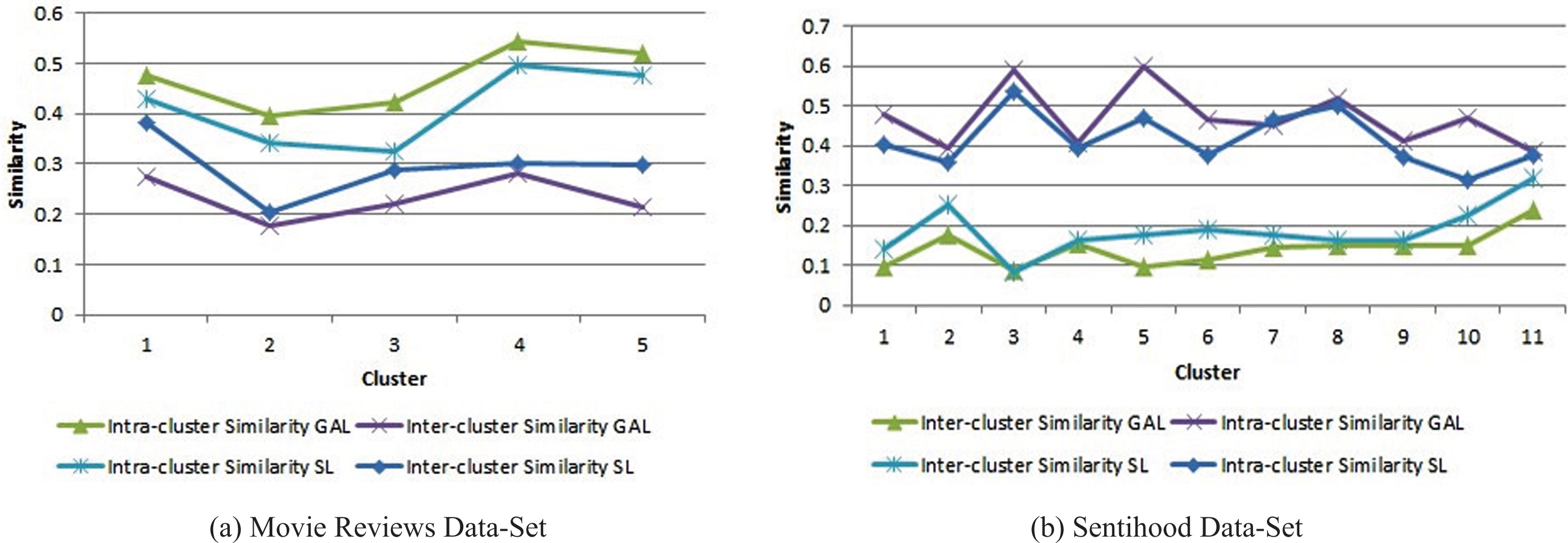
Line Plot of variation of intra-cluster distance with inter-cluster distance for GAL Clustering and SL Clustering.
The problem of significant aspect extraction is to extract the most defining and relevant aspects for the given data-set. Here, the points to ponder are that generally the significant aspects are less frequent and most frequent words are often irrelevant. The challenge here is to drop the meaningless frequent terms and instead find terms which define the document. For the task of significant aspect extraction, a modified rank-based version of TF - IDF (
where,
The rank (R) refers to the ordinal representation of terms based upon overall frequency i.e., the most frequent term is assigned a value of 1, the second most frequent term is assigned the value of 2 and so on.
By this approach, the average normalized value of TF is taken which ensures that the frequent terms are taken into account. The average normalized value of IDF supports the assumption that the infrequently occurring terms have a higher chance of occurring in relevant documents and should be considered more informative and important. R is inversely proportional to TF and therefore multiplying the expression by R c , where c < 1 helps to smoothen the effect of TF in the expression.
Vector representation of aspects
Vector representation of the aspects is essential for the effective representation of the aspect terms and to understand the lexical relationships between them. It is a vital step for the execution of various operations like finding similar aspect terms and aspect categorization. In the proposed methodology, each unique aspect term is represented in the form of a vector of finite dimension using an innovative word-embedding technique. Here, two different word embedding techniques with equal dimensions have been concatenated together into a unified representation. Using this approach, one technique captures the local context while the other captures the global context for a given term as described in Section 2.3 in order to produce a comprehensive word-vector representation. The specifications of the word embedding technique used have been mentioned in Section 4.2.
Aspect categorization
After obtaining the vector representation of aspects, the need arises for categorizing or grouping similar aspects together. This is essential as there may be several significant aspect terms in a given text while it may be observed that most of them are similar to each other or mean the same. For better comprehension, such similar aspects must be represented by a single category by grouping similar aspects together. In the proposed methodology, the significant aspects are categorized into aspect categories based upon similarity scores (cosine similarity). For this, two approaches of clustering have been adopted - Single-Linkage (SL) Clustering and Group-Average-Linkage (GAL) Clustering. In SL Clustering, an aspect is appended to an aspect category if there exists an aspect in that category for which its similarity is maximum. In GAL Clustering, the average similarity of the term with respect to all the aspects present in that aspect category is calculated. Finally, the term is placed in that aspect category which has the maximum group average similarity with respect to that term. Also, the clustering procedure has provision to form new groups or merge groups based upon the similarity of aspects.
Adding compound aspects containing frequent aspect
From the compound pairs list grouped compound aspects containing frequent aspect terms to its corresponding single-word aspect. Here, it needs to be noticed that for the aspect ‘film’, the compound word ‘detective film’ is grouped with ‘film’ but ‘film actor’ is omitted and rather grouped with the aspect ‘actor’. This problem is taken care of by the observation that if the aspect term occurs as the second word of the compound pair then it is to be grouped into the aspect category. This is because compound pairs are often descriptions or types of a single-word aspect.
Finding other aspects similar to the frequent aspects
In this step, the aspect terms other than the frequent aspects which are similar to the frequent aspects are appended to its appropriate aspect categories. For this, GAL clustering approach has been adopted. While calculating the average similarity of the term with respect to all the aspects present in the aspect category a threshold on similarity has been set in order to filter out irrelevant aspects. Finally, the term is placed in that aspect category which has the maximum group average similarity with respect to that term. While implementing this step it has to be taken care that duplicates are not appended to the list.
Combining aspects with associated opinions and performing sentiment analysis using BERT
After populating the aspect categories with similar aspect terms, the aspect-opinion phrases corresponding to the aspect terms are extracted separately for each aspect category. This step combines the aspect terms with its associated opinion phrases. Following this step, category-wise sentiment analysis is performed upon the phrases containing the aspects along with the opinion words. In order to perform sentiment analysis, a pre-trained BERT model was applied using some fine-tuning as specified in Section 4.3. For this task, the aspect-opinion phrases are fed into BERT separately for each aspect category. Here, BERT has been selected due to its potential to recognize both syntactic as well as semantic relationships in a text while at the same time save processing power for explicit training due to its pre-trained nature. After this step, the final results are obtained containing the sentiment-polarity for aspect terms belonging to each aspect-category.
Materials and methods
For the purpose of implementation of the proposed methodology presented in Section 3, the data-sets, libraries, BERT hyperparameters and the evaluation metrics used have been elucidated in this section.
Data-Sets
The proposed approach was implemented upon two data-sets tailored for the task of ABSA. In order to demonstrate the generic nature of the proposed methodology, the two data-sets have been selected differing from each other in terms of content-origin, the number of aspect categories, average text length and sentence complexity. A brief description of the data-sets is as follows:-
Libraries
In the proposed methodology, a few libraries were utilized for performing tasks like extraction of linguistic features and vector representation of text. A brief description of such libraries are as follows:
BERT hyperparameters
For the task of assigning sentiment polarities to aspect-opinion pairs, pre-trained BERT model 5 was deployed with some fine-tuning. The BERT model had 12 transformer units, 12 attention heads and 110,000,000 parameters [18]. During fine-tuning, the batch size was taken as 32, with learning rate as 2e-5, the number of epochs as 3 and warm-up proportion as 0.1.
Evaluation metrics
The efficiency of the proposed phrase extraction approach in reducing the text complexity, the effectiveness of the proposed rank-based version of TF - IDF along with GAL clustering in aspect identification has been evaluated with the help of following metrics:
Results and analysis
In this section, the contribution of the proposed phrase extraction approach and the rank-based version of TF - IDF along with GAL clustering and an innovative vector representation in the proposed approach has been highlighted. Based on the evaluation metrics described in Section 4.4, the superiority of the proposed methodology in terms of efficiency and the overall accuracy with respect to the state of the art methods has been demonstrated.
Demonstration of the proposed methodology
Table 2 demonstrates the effectiveness of the proposed rules in the task of aspect-opinion phrase extraction. For a given input text, it depicts the phrases extracted along with the rules applied for extracting the given phrase. For ease of understanding, the aspect terms have been underlined while the words extracted using Rule 6 and Rule 7 have been represented above using angle brackets 〈〉 and curly brackets { } respectively. From the extracted phrases, aspect terms such as “actors”, “acting”, “songs”, “story”, “action”, “dialogue”, “film” and “background music” have been obtained. These aspects have been subject to aspect categorization wherein depending upon the similarity between the vector representation of the given aspect terms aspect categories like (“actors”; “acting”), (“story”), (“song”; background music”), (“action”; “dialogue”) and (“film) have been formed. After this, the aspect-opinion phrases corresponding to each aspect category have been compiled together and fed into the BERT classifier for ABSA. From Table 2, it has been observed that the proposed technique reduces the overall text length by approximately 62% and the average number of words per sentence by 83%. It has been observed that the complexity of the attention mechanism in BERT is quadratically proportional to sequence length [19]. Therefore, the proposed technique helps to increase the efficiency of BERT and address its limitation on maximum sequence length [18].
Demonstration of Proposed Rules for Phrase Extraction
Demonstration of Proposed Rules for Phrase Extraction
Figure 11 plots the individual percentage contribution of each rule proposed in Section 3.3 for the extraction of phrases containing aspects along with the associated opinions. It has been observed that for both the data sets, Rule 1, Rule 2, Rule 5 and Rule 6 altogether extract nearly 96% of the phrases. Although, a low percentage of phrases could be extracted using Rule 3, Rule 4 and Rule 7, but it does not imply that these rules are insignificant especially for large and complex data sets.
Comparison of text complexity
Table 3 presents the comparison of the text complexity and readability of the original data-set with the result obtained after application of the proposed approach. It has been observed that the processed data-set contains 84% fewer words per sentence. The metrics used in Table 3 supports our assertion that the proposed approach for phrase extraction reduces the text complexity of the data-set by roughly 50%. This helps to increase the efficiency of BERT classifier which uses attention mechanism having complexity quadratically proportional to the sequence length [19]. This also addresses the limitation on maximum sequence length in BERT [18]. Also, it is observed that the complexity of the original movie reviews data-set is higher than the Sentihood data-set. This can be attributed to the fact that the movie reviews are lengthy and have a greater number of words per sentence compared to the Sentihood data-set.
Comparison of Text Complexity
Comparison of Text Complexity
Figure 12 illustrates the comparison of the effectiveness of GAL Clustering and SL Clustering for the process of aspect categorization. It plots the variation of intra-cluster distance formulated in equation (10) with average inter-cluster distance for a cluster with respect to all other clusters. It is observed that the extracted aspect terms have been categorized into 5 and 11 categories for the movie reviews and Sentihood data-set respectively. As cosine similarity has been used for the representation of similarity, a lower value of inter-cluster distance signifies better separation among clusters while a higher value of intra-cluster distance signifies better cohesion among the members of a cluster i.e., between terms present in the aspect categories [42]. From Figure 12a and Figure 12b it is evident that GAL Clustering outperforms SL Clustering in the task of aspect categorization for both the data-sets.
In Table 4, the values denote the cluster effectiveness values as formulated in equation (9). It can be observed that the clustering effectiveness for GAL Clustering outperforms SL Clustering for both movie reviews as well as Sentihood data-sets. This implies that the aspect categories formed using GAL Clustering are more cohesive while at the same time aspects of different clusters have greater separation among them.
Evaluation of accuracy
From the above-mentioned results, the potential of the proposed methodology in reducing the complexity of the text and effective aspect extraction as well as categorization can be assessed. In this subsection, a comparison of the overall accuracy of the proposed methodology with various conventional classifiers as well as state-of-the-art methods has been presented on the movie reviews and Sentihood data-sets. To interpret the accuracy of aspect identification the confusion matrix notation has been depicted in Table 5. While for sentiment classification, the confusion matrix notation has been illustrated in Table 6. From Table 7 it can be conceived that for the task of aspect identification, the proposed approach gives impressive accuracy. Also, with the same proposed aspect identification approach when sentiment analysis was performed, BERT provides far better performance compared to conventional classifiers. Due to the fact that BERT being a pre-trained model, it also reduces the overhead of training the model from the beginning. From Table 8, it can be deduced that the proposed approach fares appreciably well compared to the existing state-of-the-art methods with respect to both aspect identification as well as sentiment analysis. For aspect identification, the proposed methodology provides the highest accuracy among the given state-of-the art methods. Also, it is worth mentioning that using the proposed methodology, the accuracy of the BERT classifier has increased by 8% as can be observed from its comparison with the BERT-single model. Although, for sentiment analysis, the proposed approach marginally falls short of BERT-pair-QA-M and BERT-pair-QA-B. This is due to the fact that these approaches perform additional tasks which are outside the domain of application of the proposed methodology. In addition to it, based upon Table 7 and Table 8, it is observed that the proposed approach has similar accuracy for two different data-sets. This validates that the proposed approach provides stable performance irrespective of the data-set.
Comparison of Aspect Categories
Comparison of Aspect Categories
Confusion Matrix- Aspect Identification
The proposed phrase extraction method helps to extract the phrases containing opinion terms corresponding to an aspect and filter out all the irrelevant parts of the sentence. The individual percentage contribution of the rules in extracting the aspect-opinion phrases as depicted in Figure 11 implies that approximately 96% of the phrases can be extracted using four rules. Despite the fact that a few rules have a low quantitative contribution, they are vital to capture complex dependencies essential in determining the opinions related to the aspects. It has been observed from Table 3 that the average sentence length and text complexity of the data-set to be fed for ABSA is reduced by approximately 84% and 50% respectively. This helps to increase the efficiency of the BERT classifier which uses attention mechanism having complexity quadratically proportional to the sequence length [19]. Moreover, this mitigates the maximum sequence length limitation of BERT [18].
The proposed technique for significant aspect extraction is unprecedented and superior to vanilla TF - IDF due to the fact that both TF and IDF values are normalized and multiplying the expression by R c , where c < 1 helps to smoothen the effect of TF in the expression. This can be demonstrated through Figure 12 wherein high inter-cluster separation as well as high intra-cluster cohesion can be observed among the aspect categories for both the data-sets. From Table 4, it is observed that GAL Clustering yields better aspect categories compared to SL Clustering when evaluated on the basis of the ratio of inter-cluster distance to intra-cluster distance. For the task of vector representation of aspects, combining Word2Vec with GloVe seems to be an innovative strategy. It helps to capture both local as well as global context for a given term and leads to a comprehensive word vector representation.
Confusion Matrix- Sentiment Classification
In the proposed approach, the usage of BERT can be justified due to its bidirectional nature, multi-head attention mechanism and three-layered representation of text which helps to understand the context better compared to existing neural network models [18, 31]. This is also evident from Table 7, in which BERT exhibits better performance in comparison to conventional classifiers for the same aspect identification approach. Also, the proposed phrase extraction method with a dependency tagger along with BERT helps to capture long term dependencies in a sentence as opposed to the CNN and RNN [19].
Accuracy Results- Movie Reviews Data-Set
Based upon the accuracy results in Table 7 and Table 8, it has been observed that the proposed approach gives better accuracy in comparison to the existing state-of-the-art methods with respect to aspect identification. Furthermore, for the task of sentiment analysis, the proposed approach increases the accuracy of BERT by 8% as can be observed from its comparison with the BERT-single model. In addition to this, the proposed approach gives consistent accuracy for two different data-sets differing in context, words per sentence and sentence complexity. This affirms that the proposed approach is generic with consistent performance irrespective of the data-set.
Accuracy Results- Sentihood Data-Set
In future, the proposed work can be extended to increase efficiency and simultaneously reduce the complexity of other state-of-the-art models in the given domain. Also, further efforts may be focused on capturing implicit aspects. This work may also be converted into an API which can be installed on a mobile device so that even common people can obtain ABSA results of any set of reviews on the move.