
Abstract
Intuitionistic meta fuzzy forecast combination functions are introduced in the paper. There are two challenges in the forecast combination literature, determining the optimum weights and the methods to combine. Although there are a few studies on determining the methods, there are numerous studies on determining the optimum weights of the forecasting methods. In this sense, the questions like “What methods should we choose in the combination?” and “What combination function or the weights should we choose for the methods” are handled in the proposed method. Thus, the first two contributions that the paper aims to propose are to obtain the optimum weights and the proper forecasting methods in combination functions by employing meta fuzzy functions (MFFs). MFFs are recently introduced for aggregating different methods on a specific topic. Although meta-analysis aims to combine the findings of different primary studies, MFFs aim to aggregate different methods based on their performances on a specific topic. Thus, forecasting is selected as the specific topic to propose a novel forecast combination approach inspired by MFFs in this study. Another contribution of the paper is to improve the performance of MFFs by employing intuitionistic fuzzy c-means. 14 meteorological datasets are used to evaluate the performance of the proposed method. Results showed that the proposed method can be a handy tool for dealing with forecasting problems. The outstanding performance of the proposed method is verified in terms of RMSE and MAPE.
Keywords
Introduction
The concept of forecasting is defined as a planning tool for the future trends based mainly on data that were previously collected. Therefore, forecasting methods have been commonly used in variety fields, such as economics, meteorology, health sciences, consumption in all areas, and etc. Because the complex structure of a time series in real-life problems, there are hundreds of thousands forecasting methods in the literature that were proposed under different circumstances. While some of these methods are probabilistic, some of them are non-probabilistic. However, usually real-life time series datasets contain both probabilistic and non-probabilistic parts in them.
Probabilistic approaches have been introduced under strict assumptions, i.e. stationarity. Stationarity which requires that a time series dataset has a constant mean and covariance function is a strong assumption. Autoregressive Integrated Moving Average (ARIMA), which was organized by Box and Jenkins [19] to obtain the best ARIMA model parameters, is one of the most used traditional time series forecasting methods in probabilistic approaches. However, ARIMA models assume that there is a linear relationship between data. Because this is usually not the case in real life datasets, many researchers have studied alternative (non-probabilistic) methods for forecasting, such as Artificial Neural Networks (ANN), Fuzzy Inference Systems (FIS), and Fuzzy Time Series (FTS).
The first ANN method was proposed by McCulloch and Pitts [58]. It has been commonly studied topic by then. Recently, ANN method has been widely used for forecasting problems. Zhang [20] hybridized ARIMA and ANN in their studies. Yolcu et al. [54] took in consideration both linear and non-linear parts of a time series in their proposed ANN method. Gundogdu et al. [40] proposed multiplicative ANN based on Gaussian activation function. Li and Chan [44] proposed predictive time series modeling by adapting ANNs. Egrioglu et al. [15] introduced recurrent multiplicative neural network for non-linear time series forecasting. Khosravi et al. [1] used ANNs and support vector machines to predict wind speed and wind direction. Because, ANN based forecasting methods contribute the literature, multilayer perceptron ANN is included as a forecasting method in the study.
Another commonly used method for forecasting is FISs, which were first introduced by Zadeh [31]. He gave the definition of a linguistic variable and fuzzy systems in his study. Later, several researchers studied FISs by adapting the fuzzy set theory to the inference systems. Some of the well-known FISs, which are used in the forecasting literature, are proposed by Mamdani and Assillian [17], Takagi and Sugeno [53], Jang [25], and Turksen [21]. Sarica et al. [5] proposed adaptive fuzzy inference system (ANFIS) by employing autoregressive model for forecasting. Chen and Zhang [12] introduced ensembled time series prediction method based on ANFIS. Chang [4] used ANFIS resolving forecasting problems of overshoot and volatility clustering. Beyhan and Alci [47] used ARX model in fuzzy functions for nonlinear system identification. Tak et al. [37] proposed recurrent type-1 fuzzy functions for forecasting. Tak [34] adapted intuitionistic fuzzy c-means algorithm and grey wolf optimizer in recurrent type-1 fuzzy functions for time series forecasting. The studies in the literature have shown that FISs are outstanding options in the forecast literature. Therefore, time series fuzzy inference system is also included in the study.
FTS method, which is another power tool for forecasting, was firstly introduced by Song and Chissom [45]. There are three stages in FTS forecasting approaches: the fuzzification, fuzzy logical relationship determination and defuzzification stages. Because FTS does not make any assumption on a time series, they have been widely used in the recent literature. Chen and Chen [32], proposed a granular computing based FTS method for forecasting stock prices. Jiang et al. [43] introduced a framework for inbound tourism demand by using FTS and advanced optimization algorithm. Xian et al. [52] proposed a FTS method based on the improved artificial fish swarm optimization algorithm. Chen and Phuong [49] proposed optimal partitions of intervals and optimal weighting vectors based FTS method.
Because the complex structure of real-world time series problems, a time series usually contain both probabilistic and non-probabilistic structure. In other words, defining a time series has a pure linear or nonlinear structure almost impossible in real life problems. Thus, the combination of forecasting methods has been commonly used techniques by researchers [26, 42].
Two challenges arise in the forecast combination literature. The first challenge is to choose the forecasting methods to combine. The accuracy of forecasting performance in forecast combination can be improved by selecting various methods in the system. In this context, Makridakis and Winkler [50] pointed out that the forecasting accuracy is improved as the number of forecasting methods increase in the combination function although it is not always possible. Lemke and Gabrys [7] searched for the best individual forecasting method for a given time series at first, tried to improve the forecasting accuracy, later, by using different meta-learning approaches.
The other challenge is to determine the optimum weights in the combination. There are numerous combination techniques in the literature by using different combination weight functions. The combination of two forecasting methods were first introduced by Bates and Granger [26]. Later, Newbold and Granger [42] proposed another approach that aimed to combine three different forecasting methods by introducing three different combination weight functions. Eventually, both studies propose that combining forecasting methods had better performance accuracy. Later, Aladag et al. [10] used ANN to obtain the weights of the methods in the combination function in their paper. It has been common studied topic by researchers in terms of forecasting by then. Granger and Ramanathan [11] introduced an improved combination forecasting methods. They concluded that it is more accurate to add up the weights to one. Shamseldin et al. [3] used three forecast combination techniques for simulated river flows of different rainfall. Eliiott and Timmermann [18] proposed an optimal forecasting combination method under regime switching. Wang et al. [30] introduced neural network based optimal forecast combination method for time series forecasting. Safari and Davallou [2] proposed a hybrid model based on time-varying weights with Kalman filter. They concluded that time-varying weights outperformed the fixed weights based forecast combination methods.
Aforementioned studies have revealed that forecast combination methods are powerful tool in the time series forecasting literature. Thus, in this study, we propose a forecast combination method, which adjusts the weights of the methods in the functions based on the forecasting performances of the methods for a given time series. The proposed method adjusts the selected forecasting methods in functions based on their outcome performances for a given time series. In this sense, intuitionistic meta fuzzy forecast combination functions (MIFFs) contribute the selection of forecasting methods in the forecast combination literature.
Intuitionistic fuzzy c-means (IFCM) is employed in MFFs because it has been a powerful tool in forecasting literature. Hajek et al. [41] used intuitionistic fuzzy sets in cognitive maps for forecasting interval valued time series. Bisht and Kumar [27] proposed a forecasting method for financial time series based on hesitant fuzzy sets. Chao et al. [8] used intuitionistic fuzzy sets in recurrent neural networks for online learning and time series prediction. Fan et al. [59] introduced a long term intuitionistic fuzzy time series method for network traffic forecasting. Gupta and Kumar [28] proposed a probabilistic time series forecasting method based on hesitant fuzzy sets. Hassan et al. [48] designed an intuitionistic fuzzy forecasting model combined with information granules and weighted association reasoning. Kocak et al. [6] used intuitionistic fuzzy time series method in long-short term memory method to obtain accurate outcomes. The cited studies and many more have shown that intuitionistic fuzzy set-based forecasting methods had better outcomes than the classical fuzzy set-based methods. In this sense, IFCM is employed in MFFs to account for the hesitancy of an object belonging to a cluster.
To sum, the first contribution of the study is to give an outline to combine different forecasting methods that are proposed under different circumstances in functions. Another contribution of the paper is considering the hesitancy of a forecasting method that belongs to a cluster (function) with a degree of membership value. In this sense, the performance of MFFs is improved by adapting intuitionistic fuzzy c-means (IFCM) clustering algorithm.
The rest of the paper is organized as follows. Section 2 gives a brief introduction of the selected forecasting methods. Section 3 covers meta fuzzy functions and intuitionistic fuzzy c-means. The proposed method is discussed in Section 4. Section 5 evaluates the performance of meta intuitionistic fuzzy functions with 14 meteorological time series datasets. Some remarks and conclusions are argued in Section 6.
Selected forecasting methods
Six different forecasting methods are aggregated in functions in the proposed method; Multilayer Perceptron Artificial Neural Network (MLP-ANN) that is introduced by using ANN for forecasting problems, Fuzzy Time Series Network (FTS-N) that is introduced as an alternative FTS forecasting method, Time Series Fuzzy Inference System (TSFIS) that is introduced as an FIS forecasting method, and Seasonal Holt method (S-Holt), Winters Additive Exponential Smoothing (WA-ES) and Winters Multiplicative Exponential Smoothing (WM-ES) that are defined as classical forecasting methods. FTS-N, MLP-ANN, TSFIS, S-Holt, WA-ES, and WM-ES are briefly explained in this section.
To start with, FTS-N was proposed by [14]. A fuzzy time series method was firstly presented as a network structure in FTS-N. Fuzzy-time-series forecasting models can be successfully used for real-life time series that have linearity or nonlinearity. FTS-N is a hybrid forecasting method, it combines an autoregressive model and a fuzzy-time-series forecasting model based on a fuzzy approach, in a network structure. Besides, FTS-N is designed to forecast linear and nonlinear time series.
The second, the use of neural networks, and in particular the multilayer perceptron, has been shown to be effective alternatives to more traditional statistical techniques [46]. A multi-layer perceptron (MLP) has same structure of a single layer perceptron but it has one or more hidden layers different from single layer perceptron. MLP has an input layer that connects to the input variables, one or more hidden layers, and an output layer that produces the output variables. An important issue of MLP-ANN [13] is the determination of the number of inputs and hidden layer neurons. There are three main training algorithms for MLP-ANN in the literature as back propagation, Levenberg-Marquardt and Bayesian Rule algorithms. In the proposed method, Levenberg Marquardt training algorithm was used as learning algorithm.
The third, although classical FISs can produce good forecasting results, each of these classical fuzzy inference systems cannot employ probabilistic approaches and confidence intervals for forecasts. Unlike from these fuzzy inference systems, time series fuzzy inference system (TS-FIS) proposed by Yolcu et al. [56] can generate probabilistic results, produce confidence intervals and some possibilities for the forecasts. Moreover, TS-FIS has a superior forecasting performance. With these properties, TS-FIS filled an important gap of the fuzzy inference systems.
The fourth, Holt method has been widely used for the prediction of time series with trend component and the method was proposed by Holt [9]. In the Holt method, the predictions are obtained by updated trend and level of series. Updating of trend and the next level of series are determined via utilization of previous computed and real values. Although this method produces successful prediction results for time series with trend component, many encountered time series include seasonal component as well as trendy. From this point of view, Yolcu et al. [55] proposed a new model in Holt method that contains a seasonal component (Seasonal Holt Model). The seasonal Holt model has some new smoothing parameters regarding to seasonal component and these smoothing parameters of the seasonal Holt method are estimated by using particle swarm optimization.
Last, Winters exponential smoothing methods have been used if a time series have both trend and seasonality. Winters exponential smoothing methods are firstly applied to the level, slope and then seasonal component of the series. There are two types of Winters exponential smoothing methods as Winters additive exponential smoothing (WA-ES) and Winters multiplicative exponential smoothing (WM-ES) methods. WA-ES and WM-ES are used in series suitable for additive and multiplicative model respectively. Both WA-ES and WM-ES have level, slope and seasonality parameters. These parameters are updated by using certain update equations.
Preliminaries
Meta fuzzy functions
Meta fuzzy functions (MFFs) were proposed by Tak [33] to improve the outcomes of many methods by aggregating them in functions and to overcome the difficulties of choosing the right method for a purpose. MFFs was inspired by meta-analysis and carried out by looking at the outcomes of the methods However, Tak [33] improved the forecasting accuracy of recurrent type-1 fuzzy functions as an application in his study. Thus, he showed that it was possible to stabilize and increase the prediction accuracy of a method. Tak [35] used MFFs to aggregate different definitions of currency crisis and process capability indices. Tak and Gok [36] used meta fuzzy functions based on possibilistic fuzzy c-means clustering algorithm for indices to design an early warning system. The results show that meta fuzzy functions was capable of capturing more crisis than other compared methods. Aforementioned studies has shown that MFFs is a powerful tool in different domains. Thus, we aggregate 6 commonly used forecasting benchmarks in functions to obtain more reliable and accurate forecasting performance in this study.
There are three components in MFFs: functions, weights, and the best meta fuzzy function. Functions are defined as the linear combination of weights and the outputs of the selected methods. Weights are calculated from the membership grades that are obtained from FCM. The best meta fuzzy function is the function that has the best evaluation criteria. Meta fuzzy functions start with the construction of the input matrix as the outputs of selected methods for a purpose. Later, the input matrix is clustered by using FCM to discriminate the methods based on their prediction accuracy. Thus, each method will belong to a cluster with a membership grade. Then, the weights of the methods are calculated by using membership grades for each cluster. In this case, there will be as many functions as the number of clusters. However, we are looking for a function that has the best evaluation criteria. Thus, the function that has the best evaluation criteria is selected as the best meta fuzzy function, finally.
Intuitionistic FCM (IFCM)
Clustering is one of the commonly used unsupervised learning method to discriminate the objects that have different characteristics in different clusters while grouping the objects that have similar characteristics in the same cluster. Thus, clustering is used in many fields.
One of the commonly used clustering algorithms is k-means. K-means starts with initializing the number of clusters and the centers of the clusters. While there are some criteria to initialize the optimum number of clusters, the cluster centers are generally randomly generated. Next, the objects are assigned in a cluster based on a distance metric between cluster centers and the location of an object. Thus, an object can belong to one cluster or not. Finally, all cluster are assigned to a cluster and cluster centers are optimized based on the objective function of k-means clustering algorithm. However, in real life examples, it is not always case to assign an object to a cluster. In other words, there are uncertainty in some real-life examples, thus, it is fuzzy to assign an object to one cluster. In this sense, fuzzy c-means clustering algorithm was proposed by Bezdek [24] as the generalization of k-means clustering algorithm. FCM allows an object to be belong to more than one cluster with certain membership grades. Thus, FCM accounts for uncertainty of an object belonging to a cluster.
In order to obtain the membership grades and cluster centers accurately, there have been numerous studies in the literature. Because it accounts also for hesitancy of an object belonging to a cluster, intuitionistic FCM Atanassov [29], which is the generalization of FCM, is one way to obtain membership grades accurately. The main advantages of intuitionistic FCM are: [57] A vague classification problems are transformed to a precise and well defined optimization problem. The uncertainty of degree of memberships are controlled by intuitionistic FCM.
The detailed steps of IFCM is given in Step 5 of the proposed meta intuitionistic fuzzy functions.
The proposed meta intuitionistic fuzzy functions
There are 6 forecasting methods to reveal the prediction accuracy of the proposed method. Indeed, adding different forecasting methods would improve the accuracy of MIFFs. However, FTS-N is selected to capture both linearity and non-linearity in the time series data set. MLP-ANN used in the combination function because artificial neural networks have been recently famous for nonlinear time series forecasting literature. Besides, TS-FIS is added in the study because of its superior forecasting accuracy. In order to refer linear time series datasets, S-Holt and WM-ES are included in the proposed method to capture the seasonality and trend. Lastly, because seasonality is considered to be additive, WA-ES is also included in MIFFs.
The proposed method assumes that a forecasting method might have much/partial/ no information for a given time series dataset. In this sense, we are looking for the optimum weights of the forecasting methods in the combination function for a given time series. To aggregate the forecasting methods in different functions according to the amount of information they have, MIFFs are introduced in the paper. Thus, the forecasting methods are clustered based on their forecasting performances by using IFCM. The functions are composed of the linear combination of the weights, which are calculated by using IFCM, and the methods for all clusters. In this case, a function is represented by a cluster. Thus, the number of functions equal to the cluster numbers. While the methods that have better forecasting performances are represented by higher membership values in a function, the methods that have worse forecasting performances are represented by higher membership values in another function. Each function is a candidate for the best MIFF. The answer to the question “Which function should we select for the final forecasting model?” is the function that has the minimum RMSE or MAPE value is selected as MIFF best .
So, the proposed method is an adaptive method for forecast combination.
The algorithm and pseudo code of MIFFs are detailed step by step as below.
Determine the forecasting methods
Divide the time series dataset into two as Y train and Y test
Train the selected methods by using Y train
Obtain the forecasts from the trained methods for Y test
Use the forecasts of the forecasting methods as the input matrix (X) for MIFFs
Divide X as X training and X test
Use X training to obtain MIFFs
Initialize the number of clusters and fuzzy index parameter
Use IFCM to determine the weigths of the forecasting methods in functions
Obtain the MIFFs by using Equations 8–9
Calculate RMSE and MAPE values of MIFFs
j = j + 1
α = α + 0.1
Return the function (MIFF best ) that has the minimum RMSE/MAPE
Calculate the forecasts by using MIFF best
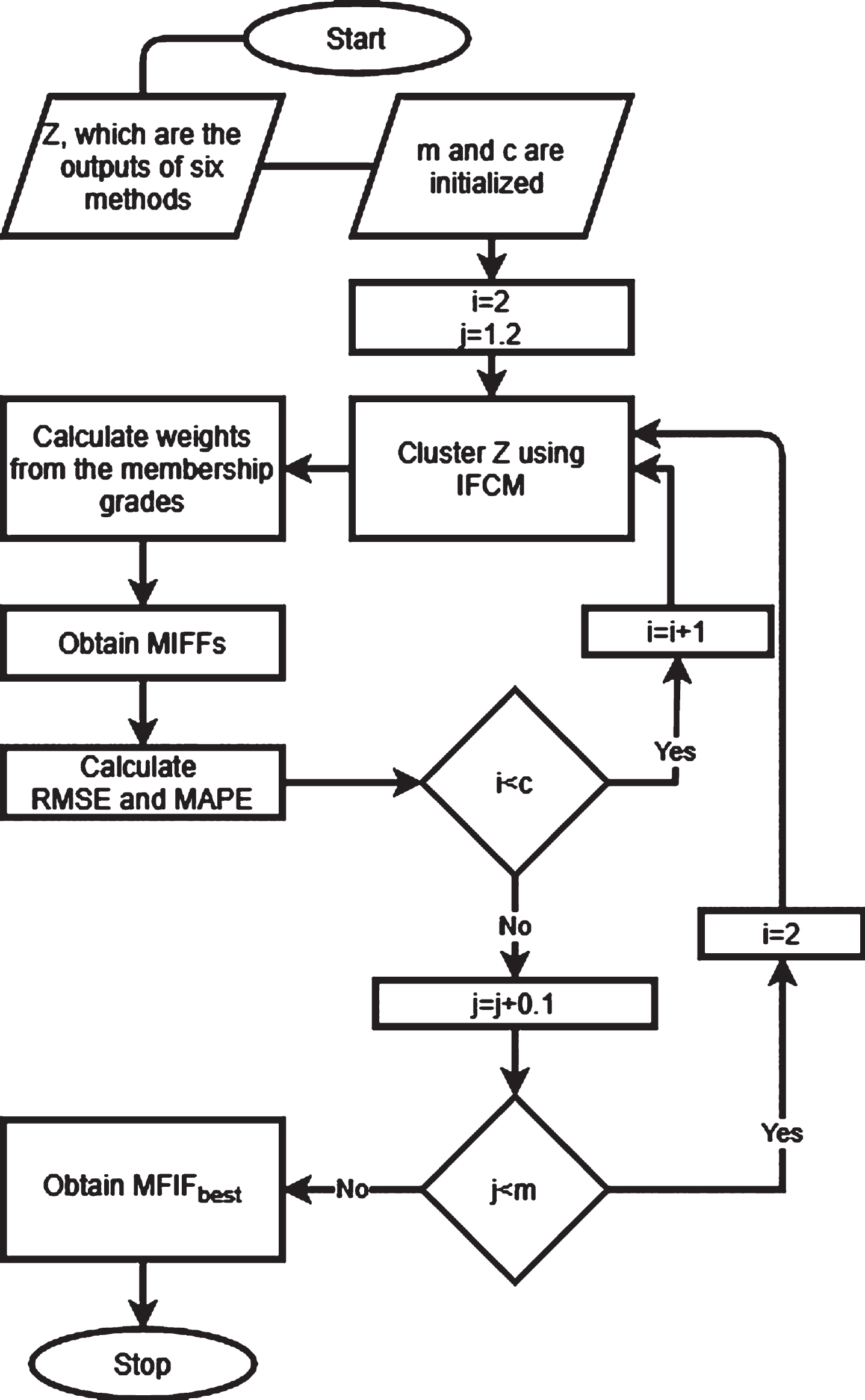
Flowchart of MIFFs.
Step 1. Parameters specification and methods selection. The lengths of training (ntrain) and test (ntest) datasets for a time series dataset(Y) are determined. The block structure is preferred to discriminate training (Y
train
) and test (Y
test
) data. Forecasting methods, the number of clusters, alpha - cut and fuzziness index values are determined. Step 2. Forecasting methods are applied to the training datasets. After training processes, the forecast values are obtained from each method for the test set. Moreover, if the forecast results are obtained from the literature, there is no need for the training processes. The proposed method only needs one step ahead forecasts from all methods for the test dataset. Step 3. The forecasts of the test dataset from all methods are used as the inputs (X) of MIFFs and divided into two datasets, X
train
and X
test
. The lengths of X
train
(ntrain1) and X
test
(ntest1) are determined by the user. X
train
is used to obtain the degrees of memberships and MIFFs. Then, the function that has the minimum MAPE value is determined as the MIFF
best
. X
test
is used to compare the performance of the proposed method with the other methods that are obtained from the literature. Step 4. Z
test
, which is standardized inputs of (X
test
) is calculated with the formula given in Equation 3, is used to obtain the weights of the methods in a MIFF.
Step 5. Z matrix is clustered by using IFCM. Using IFCM algorithm, the membership degrees for forecasting methods are calculated. In other words, the coefficients of forecasting methods in a function will be determined with the help of IFCM. Using the IFCM algorithm, cluster centers and the degrees of membership (μ (x)) and non-membership (u (x)) are obtained by considering α - cut. If μ (x) < α - cut, then μ (x) =0, and if u (x) < α - cut, then u (x) =0. Step 5.1. Initialize the number of clusters, the fuzziness index (f), and the centers of the clusters (v
i
) randomly. Step 5.2. Calculate the degrees of membership (μ) and non-membership (u) with the formulas given in Equation (5)–(6):
Step 5.3. Update the centers of the clusters by using Equation (7):
Step 5.4. Stop if the difference between two iterations drops under some threshold; otherwise, go to Step 4.2. Step 6. Using the degrees of memberships from IFCM, MIFFs are obtained with Equations 8–9.
Step 7. Forecasts of MIFFs (F
ij
; i = 1, 2, …, c ; j = 1, 2, …, ntrain1) are obtained for X
train
.j
is a vector, consisting of forecasts for j
th
data points from m methods.
Step 8. Determining the MIFF
best
.
Using the forecasts and actual values, evaluation criteria (RMSE, MAPE) are calculated. The one that has the minimum evaluation criteria is selected as MIFF
best
. Step 9. The forecasts for the best MIFF are calculated for X
test
. The forecasts for the best MIFF (MIFF
best
), Step 10. The evaluation criteria (RMSE, MAPE) is calculated for
The evaluation of MIFFs starts with training by using maximum temperature, monthly average temperature and rainfall datasets of Giresun, Turkey. Then, the forecasts that are obtained from the selected forecasting methods are used as the inputs (X) of MIFFs. Next, X is divided into two sets; X train and X test . The length of X train and X test are determined by the user. Then, the algorithm is applied to X train to calculate the weights of the forecasting methods in functions. MIFFs are calculated and the best function is selected as the MIFF best by using the weights. Further, the methods are evaluated according to RMSE and MAPE values, which are calculated in Equation 15-16 by using X test . Finally, the performance of MIFFs is validated by using Diebold-Marino and, Tukey post hoc tests.
14 practical time series datasets are used to evaluate the performance of the proposed method. The outcomes of the MIFFs are calculated in R. The first 12 datasets are maximum temperature datasets from Giresun, Turkey whose elements are daily observed from 2006 to 2017 year by year. The observations of the average temperature dataset of Giresun are collected monthly between January 1960 and December 2011. The rainfall dataset is observed monthly from 1960 to 2016 in Giresun, Turkey.
There are two parameters to be adjusted in the proposed method; the fuzziness parameter (m) and cluster numbers (c). Many studies in the literature have been conducted to determine the optimum value of fuzziness parameter by researchers. Pal and Bezdek [38] suggested that [1.5, 2.5] is the optimal value of m. Ozkan and Turksen [22], on the other side, proposed that the upper and lower values of m is varied between 1.4 and 2.6, respectively. Bezdek [23] identified that 2 is the optimum value of m. Because, there is no consensus on determining the optimal value of m, m is searched iteratively between 1.5 to 3 with an increase rate of 0.1 in the study. Optimum cluster numbers are also searched iteratively between 2 and 5. The optimum value of m and c are determined in terms of RMSE/MAPE for the training set.
As an application 6 different selected forecasting benchmarks are aggregated by using MIFFs to obtain more accurate results for temperature and rainfall datasets. Winters additive and multiplicative exponential smoothing methods (Method1 and Method2, respectively), seasonal Holt method (Method3), fuzzy time series network (Method4), time series fuzzy inference system (Method5), and multilayer perceptron artificial neural network (Method6) are trained for all datasets. Multiple inputs, one hidden layer and one output are used as the architecture of ANN and particle swarm optimization method is used to train ANN. The summary of the datasets and the optimum parameter specifications of the datasets for MIFFs are given in Table 1.
Summary and parameter determination of the datasets
“ntraining” in the Table 1 is the number of observations in the training dataset that is used to train the selected forecasting methods. By using the trained forecasting methods, rest of the observations are forecasted by using one-step ahead forecast for the given datasets. Then, the forecasts are used as the inputs (X) of MIFFs and divided into two sets by using the block partitioning structure. The first set (X training ) is used to train and calculate the weights of the selected forecasting methods in functions in MIFFs. The forecasts of MIFFs are obtained by using the weights of (X training ) and the second set (X test ). The length of X training and X test are represented as ntraining1 and ntest1 in Table 1. The optimum values of m and c are searched iteratively for all given datasets and determined as in Table 1.
The elements of the rainfall dataset were collected monthly from 1960 to 2016. There are 360 observations in the dataset. In order to train the 6 selected forecasting methods, the last 60 observations are left out of the sample. Thus, the methods are trained by using 300 observations and 60 future points are forecasted by using one-step-ahead forecast approach. Simple average (SimpleA) [26] method, variance covariance method (VCM) [51], artificial neural network (ANN) [10] and meta fuzzy functions (MFFs) [33] based forecast combination methods are used to evaluate the forecasting accuracy of the proposed method for rainfall dataset of Giresun in Table 5.
The forecasts from 6 methods are used as the inputs (X) of MIFFs. The last 12 observations are left out of X. So, the first 48 observations (X training ) are used to calculate the methods’ weights in functions. The weights of the 6 methods and the last 12 observations are used to calculate the forecasts of MIFFs. The weights of the methods for training dataset (X training ) and corresponding RMSE and MAPE values of X training are given in Table 2. Table 2 is used to determine the MIFF best by looking at the MAPE values of the functions. MIFFs for rainfall dataset are given in Equation 17-19. MIFF best that will be used for the future predictions is selected as the second function in terms of MAPE (see Table 3). Table 4 represents that MIFFs obtains more accurate forecasting accuracy by aggregating the selected forecasting benchmarks. Inspecting Table 5, it is clear that the proposed method outperformed some well-known forecast combination techniques in terms of RMSE and MAPE values.
Weights of the methods and RMSE values of the functions for the training set
Weights of the methods and RMSE values of the functions for the training set
Forecasts, RMSE and MAPE values of MIFFs
The comparison table of MIFF best and the existing methods and corresponding RMSE and MAPE values for the rainfall dataset
The comparison table of MIFF best and the existing forecast combination methods for the rainfall dataset
Diebold-Marino test, which aims to compare the forecasting accuracy of two methods, is used to compare the forecasting performance of MIFFs with other forecasting methods. Table 6 indicates that MIFFs are significantly different SimpleA and VCM although there is no significant difference between MSFE, ANN, MFFs and the MIFFs. However, RMSE and MAPE values of MIFFs, still, indicate a minor improvement on forecasting accuracy.
Diebold-Marino test results of the proposed method and other methods for rainfall dataset
DM denotes the test statistics value
*Denotes significance at 10%
**Denotes significance at 5%
***Denotes significance at 1%
There are 13 temperature datasets to evaluate the performance of the MIFFs in this section. The first dataset is monthly collected by observing the average temperature of Giresun, Turkey from January, 1960 to December, 2011. The next 12 datasets are daily collected by observing the maximum temperature of Giresun from 2006 to 2017. Each year is evaluated separately. The detailed tables (such as methods’ weights in functions and functions) are given for the first application. The performances of MIFFs of the rest of the datasets are given in comparison tables in terms of RMSE and MAPE values in Tables 12, 13, respectively.
Average temperature
There are 624 observations in average temperature dataset of Giresun, Turkey. The first 624 observations are used to train the selected 6 forecasting methods. The next 48 observations are forecasted by using the selected forecasting methods. The inputs (X) of MIFFs are obtained from the forecasts of 6 different methods. Then, X is divided into two as X training and X test . X training is used to obtain the methods’ weights in functions and to determine the MIFF best . X test is used to compare the forecasting performances of the proposed method with the existing ones. The weights of the methods are calculated by the membership degrees of the methods in each cluster and corresponding RMSE and MAPE values are given in Table 7. Table 8 gives the outcomes of 6 selected forecasting methods for X test and corresponding RMSE and MAPE values.
Weights of the methods and RMSE values of the functions for the training set
Weights of the methods and RMSE values of the functions for the training set
Forecasts, RMSE and MAPE values of MIFFs
It is clear from Table 7 that the best performances are obtained from the second function in terms of both RMSE and MAPE values. Therefore, the future forecasts are calculated by using the second function that is given in Equation 20. Four methods contribute the performance of the second function. Although the most contribution is carried out from the fifth method, the third, fourth and sixth methods also have some effect on the forecasting performances of MIFF2.
Table 8 represents the forecasting performances of the all functions and corresponding RMSE and MAPE values. Simple average (SimpleA) method, variance covariance method (VCM), artificial neural network (ANN) and meta fuzzy functions (MFFs) based forecast combination methods are used to evaluate the forecasting accuracy of the proposed method for average temperature of Giresun in Table 10. Results in Tables 9 and 10 show that MIFF
best
outperformed the other functions and the selected forecasting methods in terms of RMSE and MAPE values.
The comparison table of MIFF best and the existing methods and corresponding RMSE and MAPE values
The comparison table of MIFF best and the existing forecast combination methods
By comparing the forecasting results of the existing combination methods with MIFFs, MIFFs outperformed MSFE, VCM and ANN. In addition, DM tests (see Table 11) suggest that there is no significant difference between SimpleA, ANN and MIFFs.
Diebold-Marino test results for forecasted IEX using the proposed method and other methods
DM denotes the test statistics value.
*Denotes significance at 10%.
**Denotes significance at 5%.
***Denotes significance at 1%.
12 real-time series datasets are evaluated by using the outcomes of six different forecasting methods as the inputs of MIFFs in this section. The summary of the datasets, length of training and test datasets, the optimum value of m and optimum cluster numbers are given in Table 1. The search space for the optimum value of m and the cluster numbers are varied between 1.5 to 2.5 with an increment of 0.1 and between 2 to 5, respectively. The results of MIFF best and the selected forecasting methods in terms of RMSE and MAPE values are given in Tables 12 and 13, respectively.
RMSE values of the selected methods and MIFFs for Rainfall datasets of Giresun
RMSE values of the selected methods and MIFFs for Rainfall datasets of Giresun
MAPE values of the selected methods and MIFFs for Rainfall datasets of Giresun
The outcomes of MIFFs outperform the other methods in both tables by looking at the average of RMSE and MAPE values. Most of the time MIFFs approach improves the forecasting performances by aggregating different forecasting methods in functions. However, if the aggregation of the forecasting methods does not improve the forecasting performances, then, the proposed approach is able to determine the method that performs best in terms of MAPE values for a given dataset. Because Method 5 dominates the other five methods most of the time for temperature datasets of Giresun, Turkey, MIFF best contains Method 5 with higher effect size for almost all years.
The one way analysis of variance (ANOVA) test is applied to see the significant difference among the means of RMSE values for all methods. The obtained ANOVA table is given in Table 14. According to statistical analysis, there is a significant difference among the methods. To determine homogenous sub-groups, Tukey post hoc test is applied and the results are given in Table 15. According to Table 15, the proposed method is grouped with the Method5 (TS-FIS) and MFFs approach. Other methods can create different two sub-groups without contain the proposed MIFFs method.
The one way ANOVA results to compare performance of all methods for temperature datasets
The homogenous sub-grups according to post hoc test
Means for groups in homogeneous subsets are displayed.
Based on observed means.
The error term is Mean Square(Error) = 0.242.
a. Uses Harmonic Mean Sample Size = 12.
b. Alpha = 0.05.
A novel approach based on IFCM and MFFs is introduced to aggregate 6 selected forecasting methods in the study. The aim of the study is to combine the selected forecasting methods into functions by looking at their performances for a given time series dataset. In other words, collecting the methods, which perform better for a given dataset in terms of some evaluation criteria, in a cluster with higher degree of membership values is the focus of the paper. Some remarks of MIFFs are listed below. 6 different forecasting methods that were proposed under different circumstances are selected for the proposed method. Three of the selected forecasting methods are called as the classical time series approaches while the rest are called as non-classical time series forecasting methods. ANN, FISs, and FTS approaches are most used techniques as an alternative (non-classical) forecasting method in the literature. Thus, a method under each of these techniques is selected for the proposed method. IFCM is employed to improve the performance of the proposed by quantifying the hesitancy of an object in a cluster. The scope of the MIFFs is the aggregate the information of selected forecasting methods in functions by considering their forecasting performances for a given dataset. Therefore, MIFFs is an adaptive method that adjusts itself for a given dataset. For example, while method A can dominate the other methods for a dataset, method B can dominate method A for different datasets. Thus, while method A will be selected in the best function with higher weight, method B will be selected in the best function for different datasets. Although MIFFs are usually able to increase the forecasting accuracy of 6 different forecasting methods by aggregating them in functions, they, at least, guarantees to pick the best forecasting method in terms of MAPE/RMSE among 6 methods.
In the paper, we propose a naive way to combine different forecasting methods in functions to get more reliable forecasting results in terms of some evaluation criteria. We use 14 different meteorological datasets from Giresun, Turkey. From the results, we are able to claim that MIFFs have the ability to improve the forecasting accuracy by aggregating different forecasting methods. For some datasets, MIFFs produced the outcomes of the best forecasting method. For example, the performances of MFFs and MIFFs are almost identical for Tables 5 and 10 because TS-FIS has outstanding forecasting performance compared to other forecasting methods. Thus, TS-FIS stands alone in a cluster for both MFFs and MIFFs. Although, there is no significant difference between MFFs and MIFFs, there is still improvement on forecasting performance for the proposed method. However, MIFF, usually, produced better outcomes than the best method by aggregating more than one method in functions. It is possible to increase the number of forecasting methods in the proposed method. We believe that the more forecasting methods in the MIFFs will give the better forecasting accuracy.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.