
Abstract
Sentiment analysis is the field that analyzes sentiments, and opinions of people about entities such as products, businesses, and events. As opinions influence the people’s behaviors, it has numerous applications in real life such as marketing, politics, social media etc. Stance detection is the sub-field of sentiment analysis. The stance classification aims to automatically identify from the source text, whether the source is in favor, neutral, or opposed to the target. This research study proposed a framework to explore the performance of the conventional (NB, DT, SVM), ensemble learning (RF, AdaBoost) and deep learning-based (DBN, CNN-LSTM, and RNN) machine learning techniques. The proposed method is feature centric and extracted the (sentiment, content, tweet specific and part-of-speech) features from both datasets of SemEval2016 and SemEval2017. The proposed study has also explored the role of deep features such as GloVe and Word2Vec for stance classification which has not received attention yet for stance detection. Some base line features such as Bag of words, N-gram, TF-IDF are also extracted from both datasets to compare the proposed features along with deep features. The proposed features are ranked using feature ranking methods such as (information gain, gain ration and relief-f). Further, the results are evaluated using standard performance evaluation measures for stance classification with existing studies. The calculated results show that the proposed feature sets including sentiment, (part-of-speech, content, and tweet specific) are helpful for stance classification when applied with SVM and GloVe a deep feature has given the best results when applied with deep learning method RNN.
Introduction
Web 2.0 has revolutionized the way people interact. It allows people to create, upload, and publish their content using social media such as blogs, wikis, forums, social networking sites, etc. The rapid growth of the social web has given birth to new communities in all fields of life from business to academia and research. To get this information from the raw data, new research domains such as sentiment analysis [1, 2], collaborative filtering-based recommender systems [3], community detection [4], social network analysis and mining [5, 6]. Sentiment analysis has emerged as one of the active research domains. It identifies and classifies sentiments, emotions, and opinions expressed in user-generated content with positive, negative, and neutral polarities. It has numerous application areas such as product recommendation [7], reviews helpfulness [8], social issues analysis [9], detection of users’ behavior analysis based on stance, and antisocial behavior predictions [10]. The stance is a person’s belief, claim, opinion, or stand towards an event.
Stance classification is sub problem of sentiment analysis and detects the stance of author towards any subject. Stance is a person’s (belief, claim, opinion, or stand) towards an event. Form linguistic point of view the definition of stance is “Stance is a public act by a social actor, achieved dialogically through overt communicative means, of simultaneously evaluating objects, positioning subjects (self and others), and aligning with other subjects, with respect to any salient dimension of the socio-cultural field” [11]. Stance predicts the person opinion’s like “favor” or “against” towards any target as shown in Table 1.
Sample Tweets explaining Stance classification (taken from Climate Change is a Real Concern from SemEval2016 Dataset)
Sample Tweets explaining Stance classification (taken from Climate Change is a Real Concern from SemEval2016 Dataset)
Sentiment analysis computes the sentiments in text while stance computes the polarity of sentiments in a text. Sentiment analysis alone does not address the issues of subjectivity and polarity calculation of opinions. Stance Classification also used to detect the emotions, perspective identification / subjective evaluation of text of author, sarcasm detection, argument mining and biased language detection to predict the inclination of perspective in a text. There are diverse application areas of stance classification discussed here. Stance classification is carried out on online text content on various topics including politics, social arguments, product reviews, and elections. Stance classification can help forecast the latest trends in the market. Stance classification is also helpful for recommender systems; by analyzing the stance, recommender systems can give more personalized recommendations to customers. Stance detection is implemented in public health [12], topic-based stance classification for twitter [13], social media political debates [14], predicting electoral issues [15], and analyzing public opinion regarding a certain social issue [16].
The relevant literature reports two approaches commonly used for stance classification [17]. The first approach takes classification as a typical problem and exploits only textual information such as sentiment-lexicons and syntactic-patterns to gather the stance information. Whereas the second approach claims that textual information could not provide enough information for stance classification. Thus, the proponents of the second approach propose models, exploiting the relationship between posts or users for stance classification. It concludes that the earlier research studies utilize complex linguistic features which require additional resources [18]. Hence, it urges to explore diverse feature sets that do not need additional resources and intend to analyze their significance for stance classification. In the field of sentiment analysis accuracy is an important parameter.
To address the above-mentioned accuracy problem, the proposed research study aims to investigate different features and techniques and optimizes the accuracy of the result for stance classification. In this regard a framework each for stance classification is proposed which follows the five steps; 1) data pre-processing, 2) feature extraction, 3) feature selection, 4) application of algorithms, and 5) results evaluation, to analyze content for the classification of stance in tweets. This research contributes as follows: To perform the task of stance classification on tweets SemEval2016 and SemEval2017 data sets are selected. This research study has proposed a set of feature sets including sentiment, part-of-speech, content, and tweet specific as well as deep features including GloVe and Word2vec. Baseline features such as BoW, N-gram and TF-IDF also extracted to compare the performance of the proposed feature sets. Feature selection techniques are applied to find the usefulness of the proposed feature sets. Investigated the role of the machine learning techniques including 1) Conventional machine learning techniques – Naïve Bayes (NB), Decision Tree (DT), Support Vector Machine (SVM), 2) ensemble learning techniques such as AdaBoost and Random Forest, 3) and Deep learning techniques such as Recurrent Neural Network (RNN), Deep Belief Network (DBN), Convolutional Neural Network (CNN). Comparison of computed results for stance classification is evaluated using four standard performance evaluation measures including accuracy, precision, recall, and F-measures. The computed results for stance classification outperformed the results of baseline approaches.
This section briefly describes the frameworks proposed, data pre-processing and feature engineering for the stance classification.
The proposed framework
The proposed framework defines the steps followed for stance classification. Firstly, data pre-processing techniques are used to clean the datasets of SemEval2016 and SemEval2017. Then the proposed feature sets such as (sentiment, tweet specific, part-of-speech and content) based features are computed from the pre-processed dataset through Python libraries.
Some baseline features such as TF-IDF, N-gram and Bag of Words are also extracted from the selected datasets to perform the comparison with the proposed feature sets. Deep features including GloVe and Word2Vec are not explored for the stance classification. To explore the effectiveness of these famous deep features GloVe and Word2Vec are also extracted from the selected datasets.
After computing features to find the useful features and remove the redundant or irrelevant features feature ranking machine learning algorithms such as Information Gain (IG), Gain Ratio (GR) and Relief-F are applied. Then, these features are fed into various machine learning classifiers of three types including conventional machine learning techniques: (SVM, NB, DT), ensemble learning methods: (RF, AdaBoost) and deep learning algorithms such as (DBN, RNN, CNN-LSTM). In the last step, the performance evaluation measures are applied to evaluate the classification ability of applied algorithms for stance classification of tweets. The proposed framework along with complete definition of steps, datasets used, and algorithms applied is shown in Fig. 1.
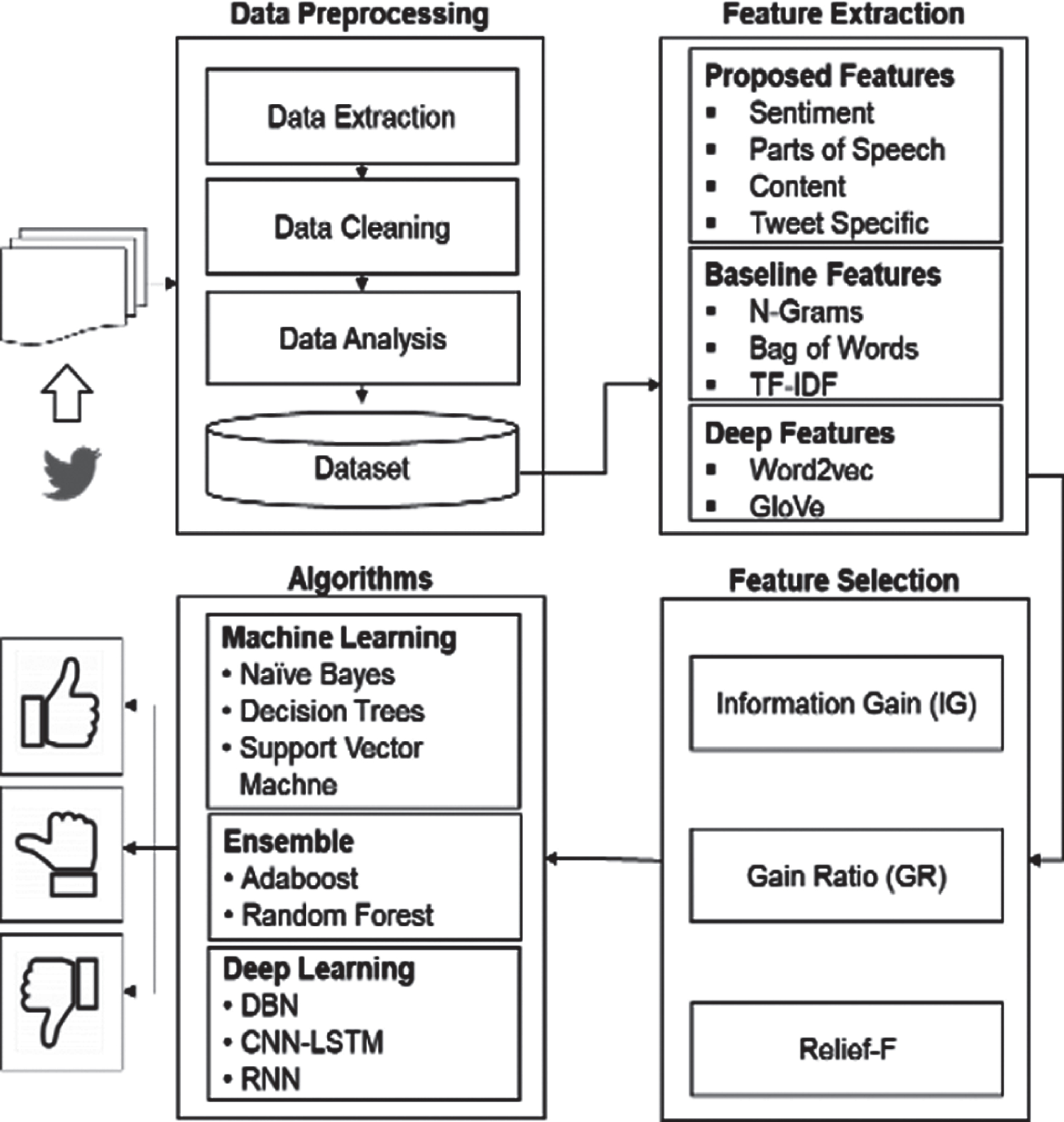
The proposed framework for stance classification.
Features represents any quality or aspect of an attribute. To complete he feature based research task features are extracted based on various categories. Then, these features are selected according to their ranking using famous feature selection algorithms. Features are ranked to find the correlation between them and find the more effective features from the proposed feature sets.
Diverse features are computed from the selected datasets SemEval2016 and SemEval2017 to increase the effectiveness of the proposed model. These diverse features are based on sentiment, tweet specific, content and part-of-speech as shown in Table 2. Since selection of features plays important role in removing the irrelevant and redundant attributes to perform this task feature selection process is carried out as described in section 2.4. The sub-sections cover discussion on feature sets including proposed features, baseline features for comparison and deep features used for stance classification for first time. It also presents the selection and ranking techniques of the features for finding the relevant features.
Proposed features sets
Proposed features sets
The stance classification and sentiment quantification are directly linked with the overall field of sentiment analysis; therefore, sentiment related features are considered. For sentiment score computation, Python-based standard library Natural Language Took Kit (NLTK) has been exploited which contains standard Vader lexicon [19, 20] which is widely used in many existing studies, in the relevant literature [19, 22]. Also, this standard lexicon is considered for sentiment analysis to find the count of positive and negative words. Since various social media platforms allow to add emoticons and these emoticons can be used to predict the sentiments or emotions, this research also consider emoticons as features.
Linguistic features play important role in understanding the overall nature of the content; therefore, part of speech tagging is used. Considering, any standard content of English language it tags each word as a verb, noun, adjective, etc. Since nouns helps to identify the entity under discussion, thus it has been taken as a feature. Another, part of speech, a verb carries information about action or behavior of the entity, is used in the features. Also, adjectives count is taken as an important feature because adjectives depict the positive, negative and sense of the characteristics. For the tagging of part of speech, Python NLTK tagger is used.
Content features exploit the text within the given social media source such as a post or a tweet. As the linguistic characteristics of the content are covered in part of the speech set of features and sentiment aspects of the features are covered in sentiment feature set, therefore, in this content-based feature set, the focus is the diverse nature of content within the tweet content. For instance, the use of WH words along with the use of question mark is taken as important because both features are related to check, whether a question has been raised in the content or not. Thus, it is assumed that in sentiment or stance, questions have been asked in conversations. Similarly, exclamation mark character and special characters are considered as a feature since the use of exclamation character represents that someone seeking attention. It is proposed that the addition of such factors is more likely to be part of sentiment-based content rather than objective content. The concept of a retweet is also considered as the political or social related subjective content is likely to be re-tweeted more as compared to factual content containing facts and figures. The use of quoted words helps to detect whether a tweet contains a discussion about a topic as the quoted contents are used to cite existing tweet content. The use of capital case is considered for shouting or emphasis. Thus, it has also been considered as a feature.
Social media platforms provide different functionality; therefore, nature of feature may vary for different target social medias. Since this research considers Twitter social media, thus Twitter specific features are considered. We assume that a tweet that is retweeted more is highly related to some sentiment related concept. As in subjective content, there is more chance of conversation discussions having a thread where replies are shared, therefore mention feature is considered which is used to add someone in the discussion or directly mention specific users within the content. Moreover, the existence of URL in the content is taken because the users are likely to mention the URL in the content to emphasize their point of view by sharing proof of some webpage in content such as video on YouTube, a post of Facebook, etc. As the hashtags depict the topic of content, therefore this feature is taken assuming that an opinionative content is likely to have more hashtags. Also, the use of capitalized case hashtags is considered as a feature. The following feature set is proposed for stance classification and sentiment quantification as shown in Table 2.
Some other conventional features are also proposed along with some new features includes N-Gram, TF-IDF, Word2Vec, and GloVe.
The evaluation of supervised learning models is tricky. Following the standard procedure, the data is split into two sets: training and testing. The training set is used to learn the model whereas the testing set is used to evaluate the learning of the model. Then, the performance evaluation metrics such as accuracy, precision, recall, f-measure are applied for evaluation. This method is called holdout method and is not reliable as the accuracy obtained for one test set can be very different to that of another test set. K-fold cross validation provides a solution to this problem. In this method, a given dataset is split into a k number of where each fold is used as a testing set once. Let us take the scenario of 10-fold cross validation, where the data is split into 10 folds. In the first iteration, the first fold is used to test the model and the rest are used to train the model. In the second iteration, second fold is used as the testing set while the rest serve as the training set. This process is repeated until each fold has been used as the testing set. For our empirical analysis, 10-fold cross validation is used.
Baseline features
Besides the proposed features, this research also considers baseline features for comparison with the proposed feature sets discussed in the following sections.
A. N-Gram
N-gram is a series of n words based on probabilities of word embedding. N-gram is divided into three categories: 1) N-gram/uni-gram, 2) bi-gram, and 3) trigram. The example of uni-gram, bi-gram, and trigram are “standup”, “standup slowly”, and “she stood up”, respectively.
B. Bag of Words
The bag-of-words (BoW) model is a simplifying representation used in natural language processing and information Retrieval (IR). In this model, a text (such as a sentence or a document) is represented as the bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity. The bag-of-words model is commonly used in methods of document classification where the (frequency of) occurrence of each word is used as a feature for training a classifier.
C. TF-IDF
An enhanced version of Bag of Words (BoW) is Term Frequency-Inverse Document Frequency (TF-IDF). TF-IDF finds word’s frequency in a text. While document-frequency is the ratio of word frequency in a document over the total number of documents. TF-IDF represents all the words in the list and then assigns it to all the documents.
If there are 300 words list, a one-row vector and 300 columns for each document will exist. Where rows are consisting of the calculated frequency of terms and columns consists of words. The document frequency is calculated by the given formula in Equation (1).
Where N is the number of documents containing a given word. So, in the end, the TF - IDF value can easily be obtained by multiplying TF and IDF values.
In addition to the proposed and baseline features, deep features are also considered and discussed in the following sections.
A. Word2vec
Text-based documents are represented in vectors using Word2vec, a technique of word embedding. Wordv2vec finds the words ‘semantics and syntactic similarity between words. Word2vec converts an input of texts into a large vector.
B. GloVe
GloVe is another approach used for word representation. GloVe is based on unsupervised learning in which the same words make a cluster and different words repel. GloVe puts words into vector space to make clusters of similar words. Apart from statistics generated locally, GloVe finds the consistency of words to get the vectors of words. GloVe gathers local and global statistics to make vectors of words.
Feature selection
Feature selection plays an important role in finding the highly correlated, and redundant attributes from the dataset. To find the redundant and irrelevant attributes from the proposed feature sets famous feature ranking techniques are applied. Negative and lowest value of information gain makes an attribute irrelevant and high correlation up to 0.9% or above it makes an attribute dependent and redundant. Among the proposed features no attribute has lowest (-ve) value of the information gain and no attribute is highly correlated with the other attribute. Therefore, from the proposed feature there was no attribute which is irrelevant, or redundant. Further, feature ranking algorithms are applied to rank the attributes according to their score as shown in Table 3. The details of the ranked attributes are also mentioned in section 2.4.4.
Information gain (IG)
Information Gain is also known as “Mutual Information”. IG decreases the biasness of attributes that have multiple values. For this purpose, IG selects the attribute on basis of its total branches and their size. ML methods widely use IG for predicting class information gain and compute the results in bits. Information Gain is used for the selection of important attributes from the dataset. Information gain is computed by decreasing overall entropy value and accessing the impact of feature’s inclusion. E is the entropy in given Equation (3).
Where k is number of class and p
i
is the probability of any attribute. Class C
i
obtained as
For attributes A∈ { a1, a2, …, a
v
} would be in v partitions E∈ { E1, E2, …, E
v
} Equation (4) is used to compute the entropy information.
Where |Ej|/|E| is the weight of the jth partition and entropy of Ej is defined as info (E
j
). IG by separate on A is:
Attributes with a top value of IG are used to classify the document in the provided class.
Gain Ratio uses a repetitive process to select the small feature set by using the score of GR. GR is used widely for dimension reduction. GR calculates the inequality of features. The Top-score of GR defines the feature’s usefulness. The normalization value depicts the split value of information. The training document is split into v partitions, respective to v output on feature F.
Here high splitinfoA shows information is low and consistent. Few partitions keep peak values. GR is calculated as:
Relief-F selects the arbitrary elements and calculates the closest neighbors of features, Relief-F is another approach used for attributes that have multiple values. Relief-F sets the final feature weighting vector. Features with high importance separate the instances from neighboring classes. It calculates the best estimate from giving probabilities to calculate the weight for each dimension.
The number of features in each feature set was proposed and analyzed for finding whether the features is relevant and plays its role in the prediction of the target class. For this, feature selection has been carried out using standard feature selection and all those features which were not relevant or have negative influence towards target class prediction have been omitted from our feature list and the only those features are selected which play significant roles in target class prediction.
In addition to feature selection, we have also applied the features selection algorithms to compute the ranking of each features within each feature set. This ranking helps us to identify top features within each category of features and then investigate their significance with respect to target class prediction. Based on three standard feature selection and ranking algorithms, we have computed the ranking of the features as shown in Table 3.
The Table 3 presents that for the sentiment-based features, the sentiment score is important as compared to count of sentiment based polar words whether positive or negative. It is also interesting to note that the negative words play more significant role in classification as compared to positive words, this observation is consistent with existing research studies [23]. Then the emoticons are ranked and again the use of negative ones are ranked higher as compared to positive emoticons. Part of Speech tags are also important and use of adverbs and adjectives are found to be important as these are the top two features in POS feature set and it is understandable as these two part of speech tags are used to refer to merit or demerit of any action or about an entity. Being more specific, adverbs modify verbs, adjectives and other adverbs whereas adjectives modify nouns and pronouns. Then verbs are ranked higher than nouns as the verbs are related to actions, behavior and functionalities and noun are related to entities and their characteristics. So, all these POS tags are important for prediction of classes annotated for social media content.
In addition to POS tags which are relevant to content, content features are also important as well. The presence of WH words and question marks shows that the subjective content contains questions raised by discussion and conversation regarding certain actions or entities. Then, quoted and repetitive content is ranked high which shows that the opinionative content contains double quoted words referring to existing content shared by some social media users. This feature shows the dialog or conversation nature of the content which is common in sentiment related classes [24]. Then use of special characters is ranked which is followed by the use of exclamation sign which is another special character. Among the tweet specific features, mention is at top as this shows the dialog or discussions within content. Then retweet count is also ranked high. The existence of URLs is higher in sentiment as the users shares links to other content in web pages to emphasize their point of views. Hashtag are ranked low as these are related to topics which are important both in objective content as well as opinionative content. The retweet capability of content is ranked lower which is understandable as any objective content containing facts and figures can also be retweeted more which does not contain any sentiment or stance in both our cases.
Among the existing baseline features, tf-idf is ranked higher as this is directly linked to content band then n-gram is ranked higher than bag-of-words as these do not contain the sequence or words. Among deep feature, GloVe are ranked higher as compared to word2vec as the former are easier to train over more data as compared to the later. In addition, GloVe combines the benefits of the word2vec based skip gram model in the word analogy tasks such as sentiment analysis and stance classification.
The Table 3 presents that for the sentiment-based features, the sentiment score is important as compared to count of sentiment based polar words whether positive or negative. It is also interesting to note that the negative words play more significant role in classification as compared to positive words, this observation is consistent with existing research studies [23]. Then the emoticons are ranked and again the use of negative ones are ranked higher as compared to positive emoticons. Part of Speech tags are also important and use of adverbs and adjectives are found to be important as these are the top two features in POS feature set and it is understandable as these two part of speech tags are used to refer to merit or demerit of any action or about an entity. Being more specific, adverbs modify verbs, adjectives, and other adverbs whereas adjectives modify nouns and pronouns. Then verbs are ranked higher than nouns as the verbs are related to actions, behavior and functionalities and noun are related to entities and their characteristics. So, all these POS tags are important for prediction of classes annotated for social media content.
Feature ranking
Feature ranking
In addition to POS tags which are relevant to content, content features are also important as well. The presence of WH words and question marks shows that the subjective content contains questions raised by discussion and conversation regarding certain actions or entities. Then, quoted, and repetitive content is ranked high which shows that the opinionative content contains double quoted words referring to existing content shared by some social media users. This feature shows the dialog or conversation nature of the content which is common in sentiment related classes [24]. Then use of special characters is ranked which is followed by the use of exclamation sign which is another special character. Among the tweet specific features, mention is at top as this shows the dialog or discussions within content. Then retweet count is also ranked high. The existence of URLs is higher in sentiment as the users shares links to other content in web pages to emphasize their point of views. Hashtag are ranked low as these are related to topics which are important both in objective content as well as opinionative content. The retweet capability of content is ranked lower which is understandable as any objective content containing facts and figures can also be retweeted more which does not contain any sentiment or stance in both our cases.
Among the existing baseline features, tf-idf is ranked higher as this is directly linked to content band then n-gram is ranked higher than bag-of-words as these do not contain the sequence or words. Among deep feature, GloVe are ranked higher as compared to word2vec as the former are easier to train over more data as compared to the later. In addition, GloVe combines the benefits of the word2vec based skip gram model in the word analogy tasks such as sentiment analysis and stance classification.
This section describes the dataset, machine learning approaches and performance evaluation measures for stance classification.
Datasets
This section covers discussion on standard datasets considered in this research work for both stance classification and sentiment quantification.
Two standard datasets SemEval2016 and SemEval2017 used for the stance classification are discussed in the following sub-sections.
SemEval2016
SemEval2016 is a standard dataset used for classification and quantification purposes. SemEval2016 contains tweets divided into 5 targets: Abortion (933 tweets), Feminist Movement (949 tweets), Legalization of, Hillary Clinton (984 tweets), and Atheism (733 tweets), Climate Change (564 tweets). Each topic contains many tweets with a stance class that can have a label from the set FAVOR, AGAINST, NONE. The details of the dataset are shown in Table 4. This dataset has been used in earlier studies [25].
Statistics of SemEval2016 & SemEval2017
Statistics of SemEval2016 & SemEval2017
SemEval2017 is a standard multi-lingual dataset. SemEval2017 contains tweets in English and Arabic. But more tweets are in English only 19% tweets are in Arabic. The dataset contains 50,333 training and 12,284 testing tweets in English, and 3,355 training and 6100 testing tweets in Arabic. The details of the dataset are shown in Table 4. The dataset has been used in earlier studies [26, 27].
Conventional machine learning techniques
Naïve Bayes (NB)
Naïve Bayes (NB) is a traditional machine learning classifier grounded on conditional probability and Byes rule. NB Bayes rule formula is given in Equation (9). Where w is an event and Y is the evidence. While P(w) is the probability of an event before the evidence is seen, and P(Y|w) is the probability of an event after the evidence is seen.
By using Equation (10), we can find the maximum probability of class w.
Where P(w) is the probability of class and P ((y
m
|W) is a conditional probability.
NB gives better performance for categorical data rather than numerical data.
Support Vector Machine (SVM) technique is based on linear regression. SVM is applied for text classification and text processing. SVM is also used to apply for high dimensional data. SVM separates positive and negative instances with high margins. SVM acquire an optimal boundary between the classes. SVM optimization is calculated through the given formula shown in Equations (12) and (13).
Where x is the number of training, e is a linear combination of training inputs, q is the training output and m is the cost function, and k and p measure the similarity of the dot product of m. SVM performance is not favorable for noisy data when applied for large datasets, as SVM needs more execution time for the training process.
DT is an inductive learning algorithm grounded on the principle of data decision. In this method, at internal node questions appear. DT algorithm makes a decision tree by applying entropy and Information Gain (IG) principles. The entropy technique helps in the reduction of execution time for pre-processing. DT easily carries out missing values without effecting the decision tree, which only requires more execution time. The entropy is calculated using the given formula in Equation (14).
Where P is the probability of an attribute belongs to class m. To process the information in bits the log function is used. While En(X) is the required time to find the class label. En(X) is also known as Entropy. Information Gain is the difference between the original and expected information required to classify the rows in the dataset.
AdaBoost
AdaBoost combines the week classifiers to give a strong prediction for misclassified instances. All predicted values are combined for the final value. AdaBoost learners assign a weight to each element in the training sample. The very first weight is adjusted as shown in Equation (16):
Where X counts the number of training elements by E
i
as training elements. Miss-classified prediction rate is computed as shown in Equation (17).
AdaBoost enhances the classification accuracy of classifiers, but not a suitable technique for imbalanced data, as needs more execution time.
RF is an ensemble learner grounded on the regression method. RF build deep trees to give a strong prediction for irregular patterns. RF decreases the variation of values by taking an average. RF take votes of data D = d1, d2, … . . , d
n
with responses R = r1, r2, … . . , r
n
by applying bagging for N times. For N =1... n: A regression tree is trained using formula given in Equation (18).
In this research following deep learning techniques are used for stance classification and sentiment quantification.
The third type of techniques used for stance classification and sentiment quantification are deep learning techniques which are discussed in the following sub-sections.
Deep Belief Networks (DBN)
Deep Belief Networks (DBN) is a type of deep neural networks. DBN is grounded on statistics and probability concepts. DBN process several layers consisting of hidden blocks. These layers are interconnected with each other, but hidden blocks are separated from each other. DBN is now the latest trend to use for sentiment analysis. The three layers’ architecture is shown in Fig. 2 [28]. X is the input and h1 is the hidden layer which is training the DBN classifier using divergence method. While hd is the total number of hidden layers and w is the weight of layers. The next layers include three layers the lower layers are “sigmoid layer” and upper layers are “Restricted Boltzmann Machine” (RBM) use to freeze the weights. The DBN mathematical model is given in Equation (19) [28].
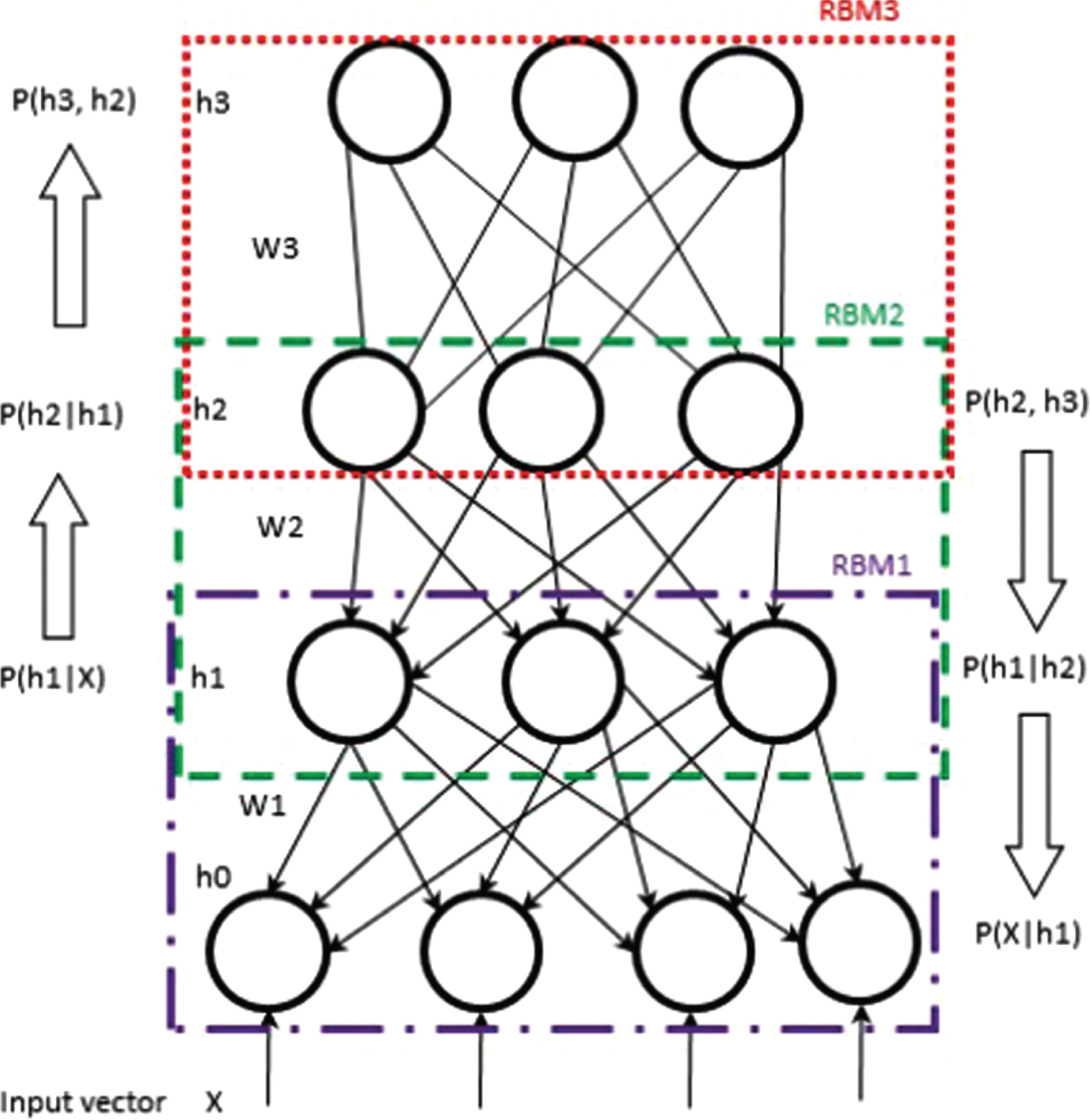
Architecture of DBN.
CNN (Convolutional Neural Network) a deep learning approach is unable to catch long-distance dependency. To address this issue LSTM (Long Short-Term) is applied in sequential text modeling for sentiment analysis in sentences. The CNN-LSTM architecture extract features from given input using CNN architecture and combines them with LSTM to acquire sequence prediction. The CNN based on LSTM architecture is shown in Fig. 3 [29].
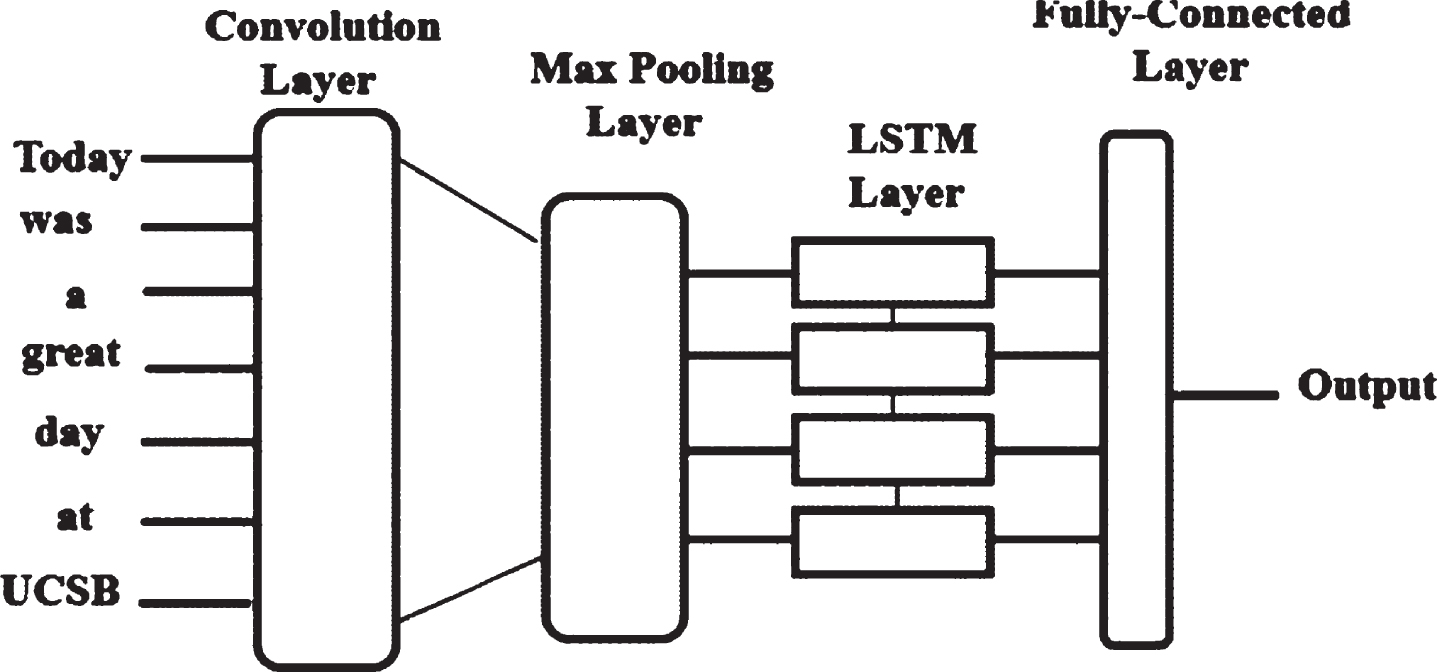
Architecture of CNN-LSTM.
RNN is the type of ANN used for speech a handwriting recognition. RNN saves memory learned from former input generated in the output phase and training phase. RNN is dependent on weights of input along with hidden vector representation knowledge. RNN acquire input {x0… . . x
t
}. where h
t
is a hidden vector. RNN acquire input till x
t
and update hidden vector to h
t
as shown in Fig. 4 [30]. RNN activation function is calculated from the given formula in Equation (20).
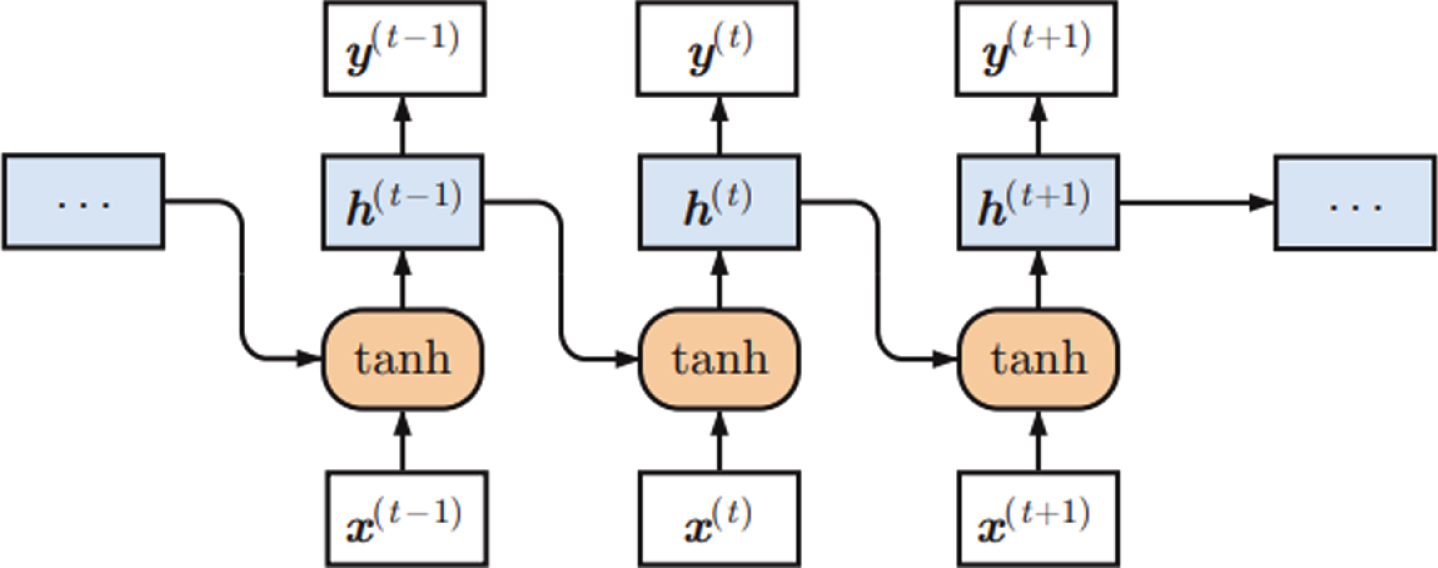
Processing of RNN.
To evaluate the accuracy of classifiers for stance classification, following four performance evaluation measures are used.
Accuracy
Accuracy is metrics of performance evaluation measures used to apply in fields of information retrieval and data mining. Accuracy is by the given formula in Equation (12).
Here FP, FN, TN, and TP, stand for False Positive, False Negative, True Negative, and True Positive, respectively.
Precision is another metric of performance evaluation measure. Performance evaluation measures calculate the ratio of classified positive attributes to the actual positive attributes divided by the classified positive attributes.
The recall is also known as the sensitivity is the ratio of positive instances that are classified to the actual positive.
The f-measure also is known as F-score. F-score is the harmonic mean of precision and recall. F-score is calculated from the given formula given in Equation (24).
Results are computed on a core i7 10th generation with 16 Gb RAM and 1 TB HDD. For conventional and ensemble-based machine learning techniques default parameter settings are used in Jupiter Notebook using Python. While for the deep learning algorithms Rectifier, maxout and tanh are used with and without dropout value. The dropout value is set to be 0.5 and 50 hidden layers are used in these models.
Results and discussions
This chapter covers a detailed discussion on the computed results for stance classification and sentiment quantification. The discussion starts with single feature set based classification to multiple feature-based classification and concludes with optimal feature sets using conventional, ensemble based and deep learning-based techniques.
Single features set based classification
To present the detailed analysis, we have performed various experiments on selected datasets for stance classification. For this purpose, a single feature set of proposed features and different combinations of proposed features are selected from SemEval2016 & SemEval2017. To accomplish this experimentation, diverse features including, sentiment, part of speech, content, and tweet specific features were extracted from both selected datasets, and machine learning approaches including, Naïve Bayes (NB), Support Vector Machine (SVM), Decision Tree (DT), an ensemble-learners Random Forest (RF) and AdaBoost were applied on single features set. According to the computed results, part-of-speech (POS) features are found more effective in the detection of stance, when applied with an ensemble-learner AdaBoost. The highest accuracy of 69.61% and 70.90% with AdaBoost is recorded for SemEval2016 and SemEval2017 respectively and outperformed other approaches due to the ensemble nature of techniques as shown in Table 7.
Combination of features set based classification
Further experiments were carried out on the combination of proposed features groups. These combinations include sentiment+POS, sentiment+ content, sentiment+tweet specific, POS+content, POS+tweet specific, content+tweet specific, sentiment+POS+content, sentiment+content+tweet specific, sentiment+POS+tweet specific, POS+ content+tweet specific and all features group. All features set (sentiment+content+POS+ tweet specific) proved to be more effective when applied with SVM classifier which is widely used for text classification due to its effectiveness for high dimensional data. The computed results show that SVM has superseded all other applied approaches and the baseline methods [31, 32] with an accuracy of 79.30% and F-score 75.11% for SemEval2016 as shown in Table 8.
The same experiments were performed on the SemEval2017 dataset. According to the results, the sentiment+content+POS+tweet-based features group is found more effective when applied with SVM. Also, SVM has dominated all other applied approaches as well as the baseline methods [33–35] with the accuracy of 80.10% and F-score 75.87% for SemEval2017 as shown in Table 9.
Discussion of optimal features set
The proposed feature sets are fed to conventional machine learning algorithms such as NB, DT and SVM and ensemble learning algorithms such as RF and AdaBoost. The proposed feature sets are fed alone and then as group of features to find the optimal results. After applying all the algorithms on single feature set their average is calculated for each single feature set. According to the computed results, Part-of-speech (POS) proved to be a promising single feature set, when applied with SVM for both datasets of SemEval2016 & SemEval2017 as shown in Fig. 5.
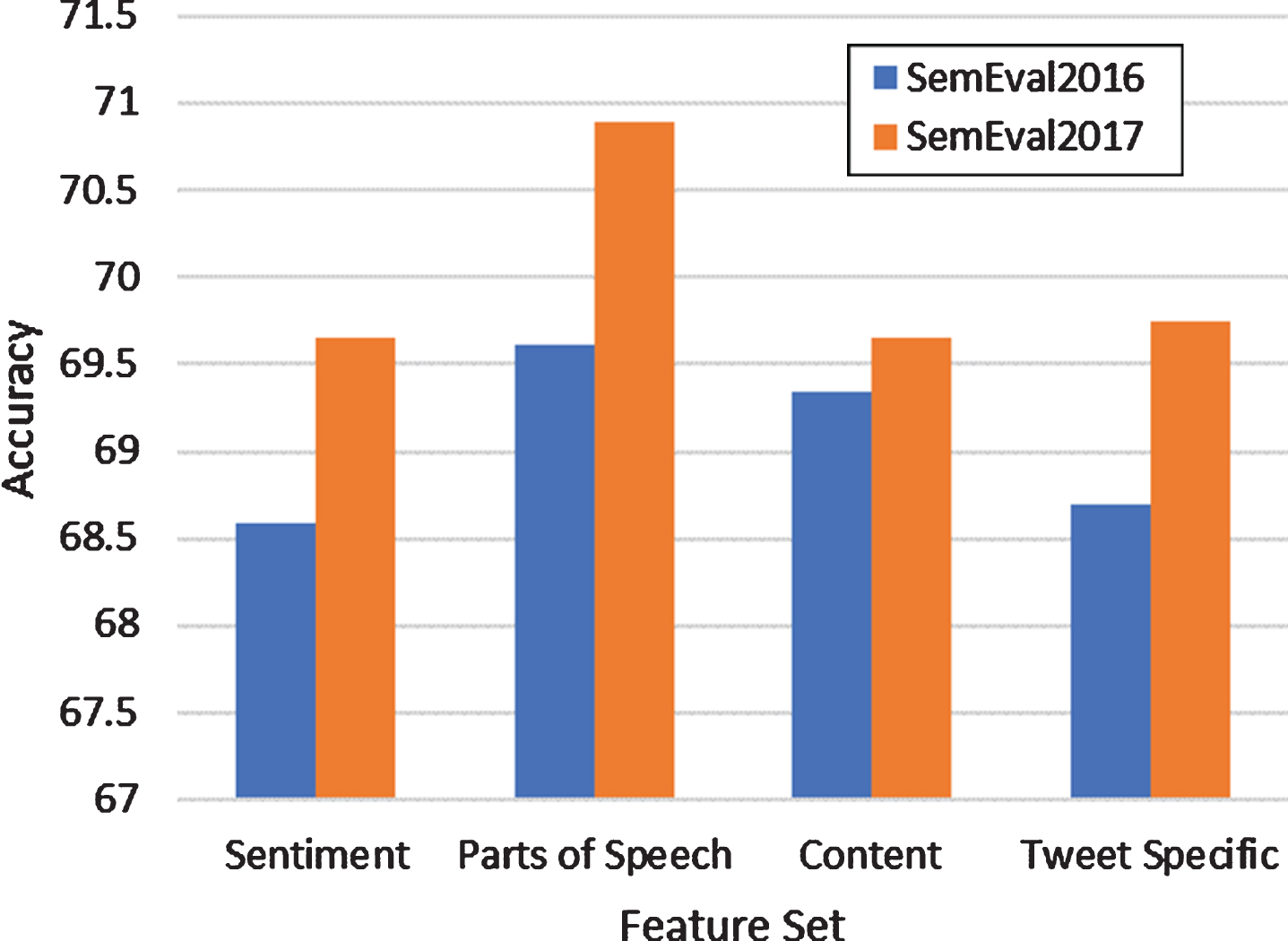
Comparison of Optimal Results using Single Feature Set for Stance Classification based on all ML classifiers.
Further analysis is performed on various combination of feature sets fed into the above-mentioned classifiers. The average results of all the combinations are calculated for each applied classifier. The computed results show that (sentiment+POS+content+tweet specific) feature group is more effective when applied with SVM and given the highest accuracy and F-score values as shown in Fig. 6 for both dataset of SemEval2015 and SemEval2017.
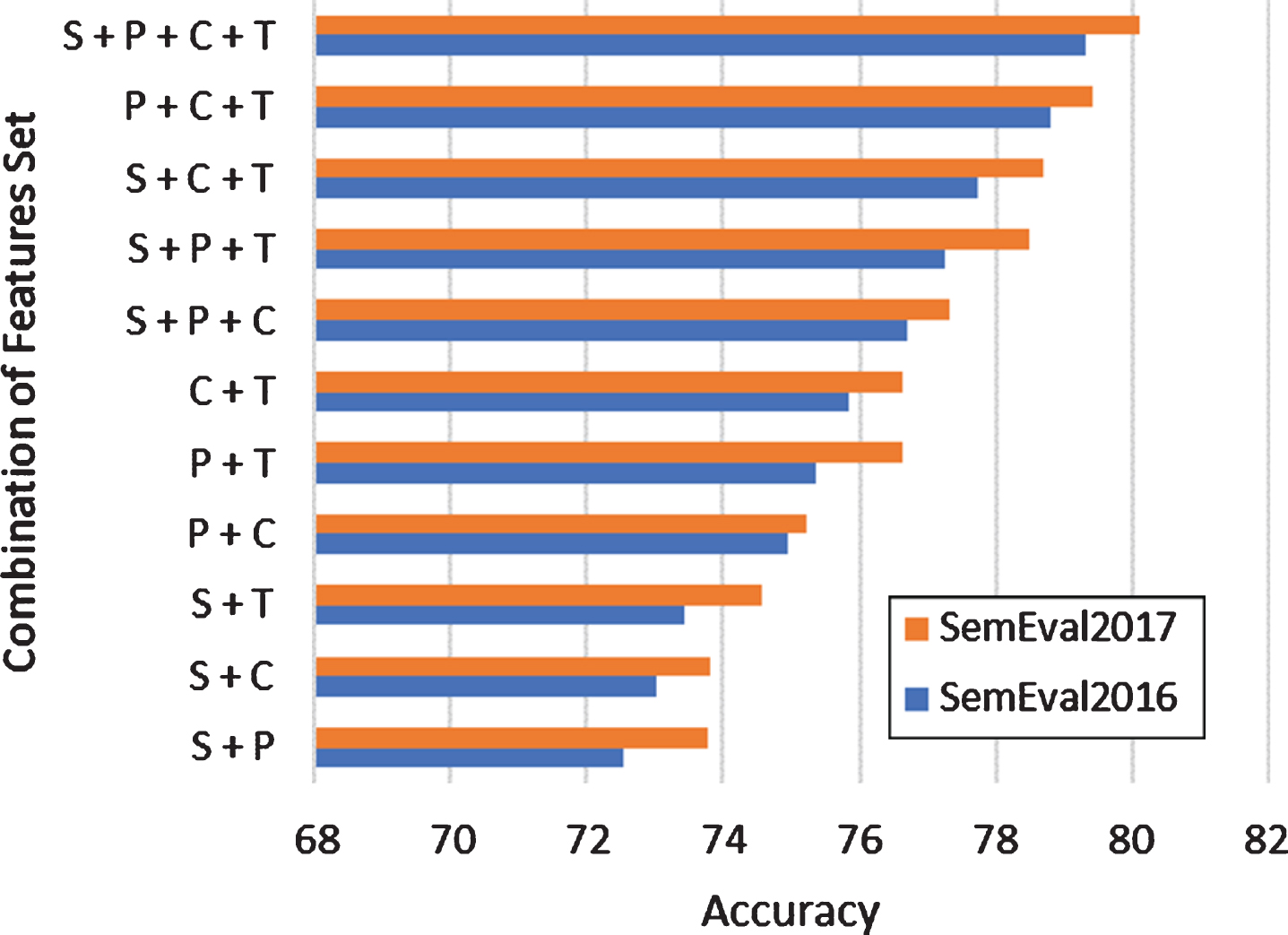
Comparison of Optimal Results using Feature Sets Combination for Stance Classification based on all ML classifiers.
In addition to the proposed feature sets: sentiment, content, tweet specific and part of speech, some baseline and deep features are also included in this research study. To compare our proposed features the baseline features such as BoW and N-gram are also extracted from the selected datasets. Then, deep features are not explored for the stance classification task till now. To explore the effectiveness of deep features, GloVe and Word2Vec are also extracted from both datasets SemEval2016 and SemEval2017. Deep features are applied with deep learning algorithms. Along with deep features the deep learning algorithms are also applied due to effectiveness and reliability for the unstructured and un labelled data. Deep features such as GloVe and Word2Vec are extracted from SemEval2016 and SemEval2017 datasets and compared with N-gram and Bag of Words features. The deep features are then fed to deep learning classifiers including Deep Belief Network (DBN), Convolutional Neural Network (CNN) based Long Short-Term Memory (LSTM) and Recurrent Neural Network (RNN) for stance classification. GloVe feature is more effective when applied with RNN and outperformed other deep learning techniques when applied with other deep features. According to the computed results, RNN have achieved the highest accuracy of 86.02% with f-score of 83.28% on SemEval2016 dataset and accuracy of 83.18% with f-score of 78.8% on SemEval2017 as presented in Table 5.
Deep features based stance classification results
Deep features based stance classification results
The best results of the combination and single feature sets are shown in Table 6. The mentioned feature sets have given best performance with the different machine learning and deep learning classifiers. According to the empirical analysis-based results, the deep learning models outperformed the traditional machine learning classifiers when applied on deep features extracted from both data sets. Deep learning has outperformed the other machine learning approaches due to their complex nature and advantage of the current context as shown in Table 6. Same with the case of proposed features and deep features, the proposed features are more effective when applied with traditional classifiers and deep features have given more promising results when applied with deep learning approaches. When compared the overall performance the deep learning technique RNN model outperformed all other machine learning classifiers when applied on a deep feature GloVe and achieved the highest accuracy of 86.02% and 83.18% for SemEval2016 and SemEval2017 datasets, respectively. While for traditional and ensemble classifiers, SVM outperformed all other techniques when applied on the group of (sentiment, content, part-of-speech, and tweet specific) features. The results of best combinations of features for different algorithms are given in Table 6. GloVe a deep feature and (sentiment, content, part-of-speech, and tweet specific) remained dominant for the deep learning and conventional machine learning techniques, respectively. According to the results RNN outperformed CNN-LSTM, DBN deep learning methods for both datasets whereas, in the case of machine learning, the SVM model outperformed other machine learning classifier with group of all the proposed feature sets. as shown in Table 6.
Comparison of optimal results for stance classification using feature sets combination
The proposed method for stance classification is found efficient when applied with the proposed features set and it outperformed the baseline approaches for selected datasets of SemEval2016 and SemEval2017 as presented in Table 10.
Comparison of single feature set using ML classifiers for stance classification
Comparison of single feature set using ML classifiers for stance classification
Comparison of feature sets combination using ML classifiers on SemEval2016 for stance classification
Comparison of feature sets combination using ML classifiers on SemEval2017 for stance classification
This section presents the review of existing studies for stance classification based on feature, ensemble, and deep learning-based approaches.
Categorization of existing studies of stance classification
This section discusses the earlier research studies carried out for stance classification-based on machine learning approaches. The earlier work is divided into three categories: feature-based, deep learning-based, and ensemble-based machine learning techniques.
Feature-based approaches
Diverse machine learning approaches consists of feature set are applied in the field of stance classification are discussed here. Support Vector Machine (SVM) is widely used as a feature-based technique for stance classification. SVM was used as a baseline classifier for comparison with other techniques. Saif et al., targeted the tweets to perform sentiment analysis and stance detection. SemEval-2016 was selected to carry out the experiments. Word embedding technique used to improve the stance classification [31, 37]. SVM studies include the following feature set for stance classification: n-grams and character gram, syntactic n-grams, target transfer features syntactic and positional features, word embedding, word-length, number-of-words, number-of-hashtags, number-of-words starting with capital letters, parts of speech, and bag of words features. Further to address the problem of target-training dataset for SemEval-2016, a new approach is introduced based on Bag-of-words to represent the features of tweets. Logistic Regression is used to classify the labelled tweets and achieved optimal results for sub tasks of SemEval-2016 [38].
Comparison of Performance with Existing Techniques for Stance Classification
Comparison of Performance with Existing Techniques for Stance Classification
Another approach is presented to predict the voting intentions of twitter people based on stance detection. A semi-supervised approach is selected along with additional features of sensitive text and network information. The proposed approach is tested on real time environment and achieved effective and robust results [39]. Logistic Regression studies include the following feature set: Linguistic, topic model, word vector, similarity, sentiment, and tweet-specific features [40], headlines features, claim-headline features, domain-independent features, pattern around prior-situation/effect features [41, 42]. Naïve Bayes (NB)is the third frequently used traditional classifier for stance detection. Addawood et al., [43] investigated users stance in debate. The proposed method used lexical, twitter specific and syntactic features for classifying stance. The models trained on these features achieved significant accuracy. Another approach is proposed [44] for stance classification based on sentiment polarity and target information. Target-specific features are useful for stance classification. NB based studies used following features set: content-based features, sentiment-based (AFINN, Hu & Liu, LIWC, DAL), structural features (Hashtags, punctuation marks), context-based (target of interest mentioned by name, target by pronouns, target party, target party colleagues, target oppositions, nobody) [45].
Various other classifiers employed for stance classification based on feature-based techniques are cited here. Artificial Neural Network (ANN) related studies-based on feature set: TF-IDF [46]. Corpus Quantitative and computational based features, adjective frequency, adverb frequency, character number/sentence, Word number/sentence, Commas frequency, conjugation frequency, Digitals frequency, full stops frequency, Pronouns frequency, nouns frequency. These features have improved the performance of stance classification for following categories including necessity, prediction, source, uncertainty and source of knowledge. The experimental results showed that stance formation is highly correlated with these features and can be effective in automatic stance classification [47]. Another framework is proposed to find the stance in news articles. The proposed approach calculated the correlation between headline and body of news. Deep learning is applied to extract the features. Bidirectional LSTM achieved the highest accuracy [48, 49]. Decision Tree (DT) related studies used feature set: n-grams, explicit stance predicted, explicit stance oracle, majority class baseline [50]. K Nearest Neighbor (kNN) [51]. Maximum Entropy method based on feature set: Handcrafted features, lexical features, Sentiment-based features, and topic features [52] used for stance classification. To detect stance in topics, a method is proposed based on factorization machine. Factorization machines are applied for recommendations of users’ preferences. The proposed approach achieved best results for predicting stance of silent users [53], active learning with SVM [54], and active learning with logistic regression [55].
Ensemble learners combine more than one classifier to achieve the desired output. The ensemble learners include majority voting technique is used to detect the stance in tweets. The proposed technique used a part-of-speech method and hashtag segmentation for tweets representation in form of trees. Majority voting method is more efficient for stance classification while applied on SemEval-2016 dataset. The proposed method is compared with the state of the art methods and proved to be more effective for stance identification [56]. Combined Long Short Term Memory (LSTM) and Convolutional Neural Network (CNN) employed for stance detection in debates [57]. Some other related studies-based on the ensemble based approach include a semi-supervised learning approach [58], stance detection in fake news based on LSTM and GRU [59]. To contribute in field of stance detection, a new approach is presented by Yiwei et al. [60]. The proposed approach presented the tweets in form of vectors. The vectors are constructed with respect of target regardless of fact that if target is mentioned or not mentioned in a tweet. The proposed approach based on CNN and GRU focused on the target information with vector representation of tweets. Bi-directional GRU based CNN is applied that deals tweets on semantics. The proposed model collects the useful information about target-based stance from informative tokens. The proposed approach builds conditional vectors of tweets with respect to target. The experiments are carried out on the SemEval-2016 dataset. The empirical results demonstrated that the proposed approach have outperformed many baseline techniques based on token level method, GRU and SVM classifiers.
To detect the stance in tweets with respect to target information the conventional methods used the attention-based approaches. These approaches combine the target information with tweets but lacks in better performance due to the usage of a information repeatedly. To address this issue, another technique is introduced to detect the stance in tweets based on target information. The proposed method collects the better information of target content. The proposed model learns the vector representation of tweets with respect to target information. After collecting the enough information, the model runs the iterative process to extract the critical information of target. This critical information about the target is gathered through multiple interaction of target with tweets words. The proposed model is tested on SemEval-2016 and dominated the state of the art methods which cannot express the opinions in tweets explicitly [61].Some other ensemble-based related studies are based on features cited here. SVM, Random Forest based on feature set: character and word level feature, character N-grams, Word N-grams, stance indicative takers [62]. For consumers’ health related queries, a new ensemble-based technique is presented. The proposed model is tested on consumer’s health information query-based dataset. The dataset contains stance-based query results and helps researchers in proper decision making. Apart from Bag of Words the linguistic characteristics are used for the consumers health dataset. Diverse features are extracted based on medical semantics, stance vector and sentiment polarity. SVM and Neural Network based ensemble technique is used to find the impact of the proposed features for stance classification. The proposed features are more effective than the BoW features and outperformed other state of the art methods [63]. Tomás Hercig et al., introduced a method to detect stance in online discussions. The proposed method detects whether an author is in against, favor or neutral towards the given target. The proposed method based on SVM, Maximum Entropy and CNN and extracted n-gram, BoW, bag of adverb, bag of adjectives, negative emoticon, word shape, n-gram, text length feature set to detect stance in online discussions. The proposed approach is efficient then state of the art methods [64]. SVM, Logistic Regression, Naïve Bayes, Decision Trees, Random Forest model-based on Hashtag, sentiment, quantitative, emoji’s, orthographic, long words, stop words, onomatopoeia, slang, POS tag, character unigram, character bigram, character trigram, word unigram, word bigram, word trigram, skip character n-gram, skip word n-gram [65]. Ensemble learner methods less applied than traditional approaches; due to the performance of ensemble learners, they can be applied more in the future to improve the performance of stance detection [66].
Deep learning approaches
Deep Neural Network is used for stance classification alone and along with some other traditional approaches. Isabelle Augenstein et al., [67] proposed a model based on Long Short-Term Memory (LSTM) with conditional encoding for stance classification. The proposed model addresses the problem of missing targets and training data. The proposed model builds a tree of tweets based on target. Bi-directional method conditional encoding increased the performance of LSTM. The experiments are carried out on SemEval-2016 and has given efficient results for semi-labelled data based on target function. Another method is introduced to detect stance in topics. The proposed model is based on two phases. The first phase calculates the subjectivity of tweets with respect to topic. In second phase, the sentiment analysis is performed on tweets. LSTM is used on every stage with attention model. SemEval 2016 is selected to carry out the experiments. The proposed method outperformed the other deep learning methods with 60.2% accuracy [13]. Qingying SUN et al., improved the sentiment analysis for detection of stance. The proposed model is based on neural network to predict the sentiment and stance of a post. Neural network approach aids in learning the representations of sentiment and stance collectively. The stacking approach helps in detection of sentiments for stance classification [68]. Mavrin et al., proposed a model based on LSTM and soft attention model to detect stance of tweets with respect to news. The experiments are carried out on publicly available dataset and outperformed other state of the art method [69]. To detect the stance in documents a neural network-based approach is presented. The proposed approach makes a model of words to learn representation of documents. The proposed technique computes the linguistic features of documents to detect the stance. A hierarchy-based attention model learns the relation between documents and linguistic information. The empirical analysis is applied on the two datasets and outperformed other attention based models in terms of accuracy [70]. To contribute in field of stance detection, a new approach is presented by Yiwei et al. The proposed approach presented the tweets in form of vectors. The vectors are constructed with respect of target regardless of fact that if target is mentioned or not mentioned in a tweet. The proposed approach based on CNN and GRU focused on the target information with vector representation of tweets. Bi-directional GRU based CNN is applied that deals tweets on semantics. The proposed model collects the useful information about target-based stance from informative tokens. The proposed approach builds conditional vectors of tweets with respect to target. The experiments are carried out on the SemEval-2016 dataset. The results demonstrated that the proposed approach have outperformed many baseline techniques based on token level method, GRU and SVM classifiers [60]. Deep learning approaches used word vectors features, word embedding, and character gram based on sentiment lexicon [66]. By employing the neural networks techniques improved the stance classification [13, 69]. Problem Statement.
In the literature, various feature sets have been exploited using machine learning techniques to improve the results; however, still, there is a need to investigate those feature sets for emerging domains of stance classification to further improve accuracy because of sensitive nature of sentiment in opinion seeking process. The problem statement for stance classification is formally described as: A twitter user u i belongs to U can share his views and opinions by creating a new tweet (t i belongs to T) using the Twitter microblog where U is the set of m users, such that U ={ u1, u2, u3, …, u m }. It may be a reply of a user u i to the tweet by any other user u j belongs to U in the Twitter social network. A user can express his views or opinions in Favor, Against or Neutral (neither favor nor against).
Formally, a tweet t∈ T = { t1, t2, t3, …, t n } is a sequence of words wεW, our task is to classify each, by a user u j U ={ u1, u2, u3, …, u m } into one of the stance class c k ∈ C = { c1, c2, c3 }.
Conclusion
The proposed research study contributes to the field of sentiment analysis in general and to the research domains of stance classification. Following the main objective to improve the accuracy of classifiers for stance classification. The proposed study explores a variant of features including the proposed features (content, sentiment, tweet specific, part-of-speech) and deep features such as (GloVe and Word2Vec). Some base line features (Bag of Words, N-Gram and TF-IDF) are also computed form the selected datasets to compare the performance of our proposed approach. Feature Selection techniques are applied to find the relevant attributes including (IG, GR and Relief-F).
For investigating the likelihood of machine learning techniques, conventional, ensemble-based, deep learning-based techniques are investigated. In conventional machine learning techniques, three methods including Naïve Bayes (NB), Decision Tree (DT), and Support Vector Machine (SVM) are used. AdaBoost and Random Forest are used in the case of ensemble-based techniques. Recurrent Neural Network (RNN), Deep Belief Network (DBN) and Convolutional Neural Network (CNN-LSTM) are exploited in deep learning category of techniques. The computed results show that deep features which are still not explored for the stance classification have given the best results. GloVe a deep feature outperformed other deep learning techniques when applied with RNN for both datasets SemEval2016 and semEval2017. In case of the proposed feature sets, the combination of all feature sets (sentiment, Part of speech, content, and tweet) has outperformed the other machine learning techniques when applied with SVM for both datasets. Thus, in general the combination of all proposed feature sets (sentiment, Part of speech, content, and tweet) and GloVe a deep feature have given the best results for the task of stance classification for tweets.