
Abstract
The segmentation and extraction of the purple soil region from purple soil color image can effectively avoid the influence of background on recognition of soil types. A scale weighted fuzzy c-means clustering algorithm(SWFCM) is proposed for effective segmentation of purple soil color image. The main work is to establish the maximum difference optimization model with the mean of Gaussian distance between each pixel and each peak of the image histogram, and optimize the clustering number and the initial clustering centers. Then, the compactness of each class is defined to weight the Euclidean distance between the pixel and the clustering center and improve the optimization model of FCM for raising its clustering performance. Aiming at the problem of removing scattered small soil blocks in the background and filling holes in the purple soil region, the algorithm of extracting the boundary of the purple soil region and the algorithm of filling the purple soil region are proposed. Finally, the normal and robust experiments are carried out on the normal sample set and robust sample set. And the performances of relative algorithms are compared, which involves the previously released FCM algorithms and some methods for the segmentation of purple soil color image and our proposed algorithm. Experimental results show that performance of SWFCM is better and it can provide a high reference for adaptive segmentation of purple soil color images. Especially for robust experiment images, its average segmentation accuracy is improved by 6 . 64% ∼ 8 . 25 % compared with other purple soil segmentation algorithms.
Introduction
The cultivation of most crops is inseparable from soil and the high yield of crops is closely related to soil. With development of agricultural automation technologies, it is possible to recognize soil types by machine vision technology. Soil identification based on soil classification system is the basis of soil resources utilization and improvement, and it can provide scientific and technical support for improving soil fertility and formulating crop cultivation measures, so as to achieve the scientific development of agricultural production. But The classification of soil is complex, and traditional soil species identification is artificial identification of soil structure on natural soil faults, which only depends on the professional skills of soil experts. It even causes that many of ordinary agricultural scientists and technicians can not meet the requirements of accurately identifying soil types, and it is more difficult for ordinary agricultural practitioners [1]. In order to spread the technology of identifying soil types to farmers at the grass-roots level and realize more scientific agricultural production, the technology recognized soil types by machine vision has wide application and research value.
Purple soil is a kind of special soil and is widely distributed in Southwest China and there are rich nutrients in it. Under natural conditions in the field, a purple soil image obtained by machine vision inevitably contains complex backgrounds such as planted crops, mosses and weeds, which will interfere with the recognition of purple soil type. Therefore, segmenting and extracting the purple soil region image from the purple soil color image is the basic work for further identifying the purple soil types and analyzing the attribute value of the purple soil, and it is also the primary problem for studying the identification of purple soil types.
The segmentation of purple soil color image is a process of extracting an image of natural soil fault with intact soil structure. Accurate segmentation of purple soil color image is a challenging task due to the existence of shadows and the complex background and similar topsoil in it.
There are very few soil image processing documents that can be retrieved in nearly 10 kinds of mainstream Chinese and foreign literature databases. In the published literatures, threshold approaches and clustering approaches are mostly used. For the first time, Cheng(2019) [1] used normal distribution to fit the ’H’ component histogram of soil image and obtained the confidence interval of the ’H’ color component with 95% confidence as the segmentation threshold, but it is rather farfetched and the segmentation effect is poor due to poor fitting accuracy. In order to further improve the segmentation accuracy, the soil image was segmented by the improved simple linear iterative clustering algorithm (SLIC,2019) [2], and then the super-pixels belonging to the soil were merged. However, the disadvantage of this method is that it is unable to perform adaptive segmentation. Subsequently, Zeng(2019) [3] established an optimization model with the maximum ratio of inter-class variance and intra-class variance between soil and impurities in the purple soil region to optimize the confidence probability, and used Chebyshev inequality to acquire the segmentation threshold adaptively. It realizes the adaptive segmentation of soil image, but its segmentation accuracy needs to be improved.
To further improve the segmentation accuracy of purple soil color image, image segmentation algorithms in other fields are referenced. At present, neural network and deep learning are wildly used in the image segmentation and other field. However, because these algorithms require a large amount of data for training and it is expensive to collect soil images and number of the collected soil images is limited not to satisfy requirement of deep learning samples, they are not suitable for soil image segmentation. Fuzzy c-means clustering(FCM) has attracted our attention for segmenting soil image and it would be improved.
The rest of this paper is organized as follows. Section 2 reviews the FCM algorithms. SWFCM is described in Section 3. Section 4 shows the segmentation of purple soil color image. Experimental results are given in Section 5 and Conclusion of this paper is in Section 6.
Work related to FCM algorithm
FCM [4, 5] is a classical algorithm used in image segmentation because of its advantages such as better fault tolerance and retaining more original image information than hard clustering [6]. It was widely used in the segmentation of natural images [7–9], medical images [10, 11] and remote sensing images [12, 13]. For the dataset X ={ x1, x2, . . . , x
n
}, the FCM objective function is shown as Eq. (1).
Since FCM is sensitive to noise, some scholars integrate spatial neighborhood information into FCM to make it have better anti-noise capability [14], but it also brings high computational complexity at the same time. Then, FCM_S1 pre-integrates spatial neighborhood information into FCM by using average or median filtering to reduce time complexity [15]. The enhanced FCM algorithm (EnFCM) uses gray level instead of pixel to perform clustering, which further reduces the time complexity [16]. The EnFCM objective function is shown as Eqs.(2) and (3).
On the basis of EnFCM algorithm, the fast generalized FCM algorithm (FGFCM) [17] puts forward a new neighborhood information weighting method. The FGFCM objective function is shown as Eqs.(4)- (9).
To further improve anti-noise capacity, the neighbor weighted FCM algorithm (NWFCM) had defined the neighborhood-weighted distance to replace the Euclidean distance in the objective function of FCM based on image patches and local statistics [18]. NWFCM is able to provide better segmentation results for images corrupted by Salt & Pepper and Uniform noise, but it is sensitive to Gaussian noise. The NWFCM objective function is shown as Eqs.(10)- (14).
The fast and robust FCM algorithm (FRFCM) is more robust to different noise than NWFCM because it incorporates the local spatial information of an image into FCM by introducing morphological reconstruction operation [19]. The FRFCM objective function is shown as Eqs.(11) and (12).
Aiming at its poor segmentation effect for purple soil color image and initializing manually the clustering centers, FCM algorithm will be improved. The FCM improvements based our works include two parts: 1) Initializing adaptively the clustering centers. 2) Considering the influence of the clustering compactness on the effective classification of boundary points, a clustering compactness measure is defined and integrated into the traditional FCM algorithm by weighting.
Initializing the clustering centers
Initializing a suitable clustering centers not only helps to speed up the stability of the clustering centers, but also provides a better result for data classification. Therefore, an algorithm for initializing the clustering centers is designed. Due to the high density of the main peak of data histogram and the data points distributed around it, main peaks of the data histogram are usually initialized as the clustering centers [20]. By observing the ’a’ component histogram of 60 color images of purple soil, it is found that the main peaks have the following characteristics.
1) the density of the main peak and its surrounding distribution points is high.
2) There is a certain distance between two main peaks.
To meet the first characteristic mentioned above, the mean of the Gaussian distance (MGD) is introduced to reflect the density of the main peak and its surrounding points. Before calculating the MGD, all the peaks in histogram are first calculated, as shown in Eqs.(13)-(15).
Then, the calculation of MGD j depends on the average difference between all points and the peak, as shown below.
In the process of initializing clustering centers, the number of initial clustering centers is determined by the parameter ɛ. While ɛ is set to be larger, some main peaks in the set peak will be deleted. On the contrary, some pseudo peaks in the set peak can not be effectively deleted. In order to get a reasonable parameter ɛ, the maximum difference optimization model is raised. From the description in section 3.1, we know that compared with the MGD value of the main peak, the MGD value of the pseudo peak is very small. Therefore, the parameter ɛ can be obtained by maximizing the inter-class difference between the main peak set and the pseudo peak set. The specific steps are as follows. The mean value of all elements in the set MGD is first calculated, then delete the pseudo peaks whose MGD value is less than the mean value and keep the peaks whose MGD value is greater than the mean value from the set peak, and repeat the above steps. When the MDG mean difference of all elements in the set peak before and after deletion is the largest, the inter-class difference between the main peak set and the pseudo peak set can be maximized. At this time, the MDG mean value before deletion is set as the parameter ɛ. For the data D ={ MGD1, . . . , MGD
P
}, the mathematical model of the above optimization algorithm is shown as Eqs.(19) and (20).
The procedure of getting parameter ɛ is summarized as Algorithm 1.
1: Compute the mean value avg0 of the set D.
2: Delete the peaks whose MGD value is less than avg0 from peak.
3: Set D1 ={ MGD k |MGD k ≥ avg0, MGD k ∈ D }, t = 1, mind = 0.
4:
5: Compute the mean value avg t of the set D t .
6: Delete the peaks whose MGD value is less than avg t from peak.
7: Compute d = |avgt+1 - avg t |.
8:
9: Set mind = d and ɛ = avg t .
10:
11: Update Dt+1 ={ MGD k |MGD ≥ avg t , MGD k ∈ D t }.
12: Set t = t + 1.
13:
In FCM, the classification of point x i is simply determined by the distance between x i and each center. This strategy is effective for the classification of the points close to one clustering center and far away from other clustering centers, but it can not provide a good effect for the classification of the points at the junction of two clusters.
For example, as shown in Figure 1, there are two clusters with different dispersions, and there is an unlabeled red point at the junction of the two clusters. According to the FCM algorithm, the probability of the red point belonging to the cluster A is higher, because it is closer to the center of the cluster A. However, it has a greater impact on the intra-class variance of the cluster A than that of the cluster B, which obviously violates the clustering criterion of minimizing the intra-class variance and maximizing the inter-class variance.
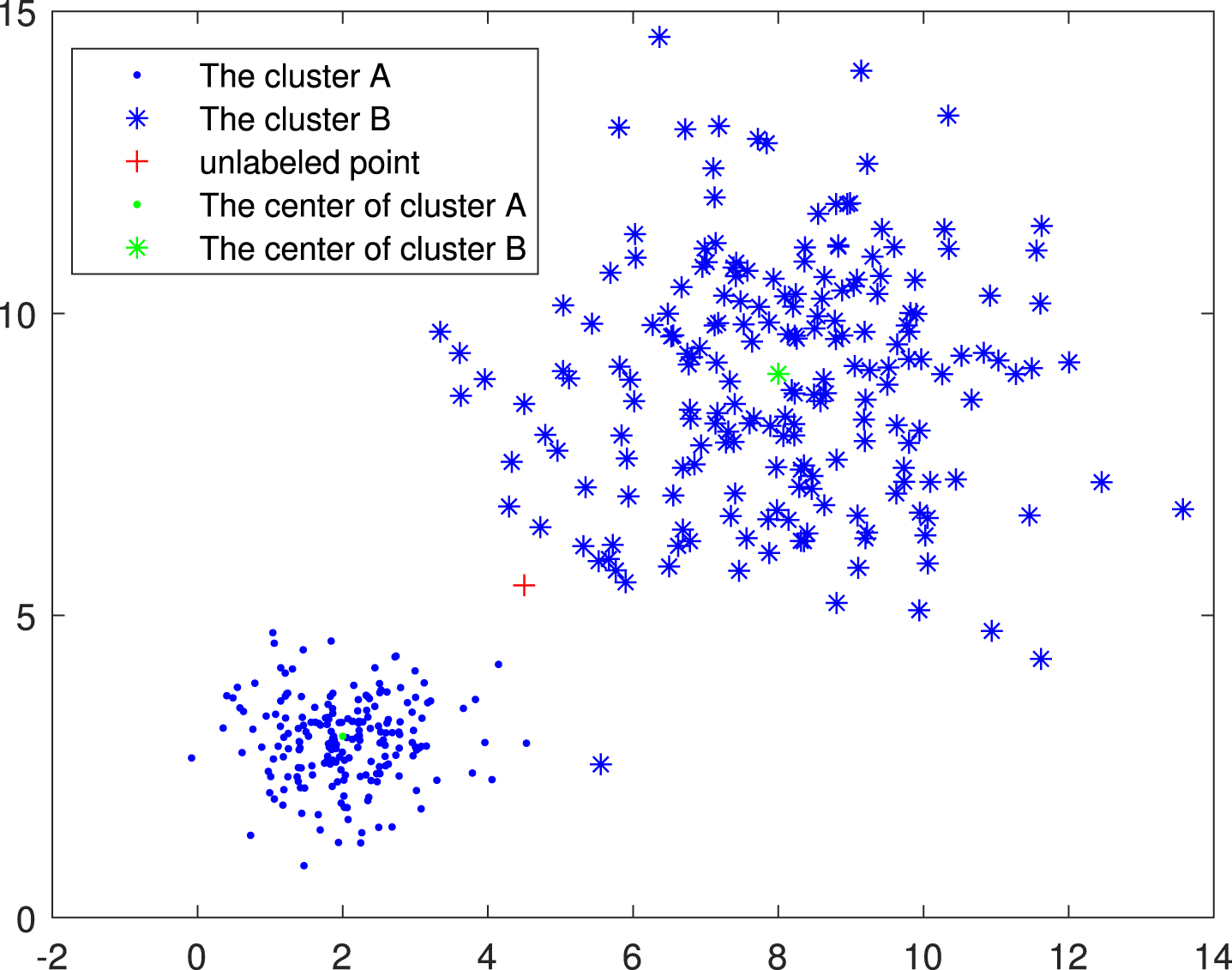
The scatter diagram of two clusters.
Aiming at the defect that FCM can not provide a good performance for the classification of the points at the junction of two clusters, the compactness of clusters is defined to weigh the Euclidean distance between point and the clustering center, so that the points at the junction of two clusters are more likely to belong to the cluster with smaller compactness. The objective function of the improved FCM is shown in Eq. (21).
The compactness ω j is defined by calculating the reciprocal of the dispersion σ j of the j th cluster, and then normalize it to [0,1]. The mathematical expression of ω j is shown in Eq. (22).
Using Lagrange multiplier method [21], the objective function of SWFCM is equivalently transformed to Eq. (25).
According to the above description, the procedure of the SWFCM algorithm is summarized as Algorithm 2.
1: Set ψ = 1,m = 2,δ = 0.5,T = 100.
2: Calculate the set peak of imgA by Eqs.(13)-(15).
3: Compute the set D by Eq. (16).
4: Getting ɛ using algorithm 1.
5: Initialize V(0) and C by Eqs.(17) and (18).
6: Initialize Δ(0) = { σ i } 1×C, σ i = 1/C and W(0) = { ω i } 1×C, ω i = C, i = 1, . . . , C.
7: Set t = 1.
8:
9: Update U(t) using V(t-1) and W(t-1) by Eq. (26).
10: Update V(t) using U(t) by Eq. (27).
11: Update Δ(t) using V(t) and Δ(t-1) by Eq. (23).
12: Update W(t) using Δ(t) by Eq. (22).
13: Set t = t + 1;
14:
The time complexity of SWFCM is composed of two main parts. One is the initialization of clustering numbers and centers and its most time-consuming step is to count the peak, which needs to traverse all the pixels in the image. Its time complexity is O (M × N). The other is the clustering part. Its most time-consuming step is to update the membership matrix U. Iteration is executed T times in the worst case (the maximum number of iterations is T) and the distances between all pixels in the image and different clustering centers are calculated in each iteration. The iteration is executed once in the best case. So the average time complexity of the clustering part is O (T × M × N × C). Based on the analysis above, the average time complexity of SWFCM is O (M × N + T × M × N × C).
The time complexity of different algorithms is given in Table 1. Where M × N is the size of an image. C represents the clustering number. G denotes the gray levels of an image. S is the size of the filtering window. According to Table 1, EnFCM, FGFCM and FRFCM have low time complexity at the clustering part because G is much less than M × N. However, the time complexity of preprocessing (such as determining the optimal classification number) is lower than comparative algorithms (smoothing filtering, etc.)
Time complexity of six improved FCM algorithms
Time complexity of six improved FCM algorithms
In this section, the segmentation of purple soil color image is introduced. It includes three steps: 1) Initial segmentation based on SWFCM. 2) Extracting boundary of the purple soil region. 3) Filling the purple soil region. Among them, the first step is used to extract purple soil region, and the last two steps are post-processing, mainly to ensure the integrity of purple soil region and removes impurities in the background. Figure 2 is a process result diagram of purple soil segmentation.

Example of segmentation result. (a) A purple soil color image. (b) Segmentation result of Figure 2(a) with SWFCM. (c) The result of boundary extraction. (d) The result of Filling purple soil region.
In previous research on segmentation of purple soil color image, Cheng and Zeng used the ’H’ color component to segment. Through histogram analysis, it is found that the ’H’ component of purple soil is distributed at both ends of the histogram for some purple soil color images (as shown in the Figure 3(d)). The reason is that the distribution model of ’H’ color component is a closed circle, and its value range is [0,360], while the ’H’ component of purple soil in some images is distributed in the range of [0,90] and [270,360] (as shown in the Figure 3(a)). Therefore, the ’H’ component is not suitable to segment all purple soil color images.

In order to segment purple soil color image more effectively, the color components with significant differences between the background and the purple soil are selected through histogram analysis in different color space. A result of analysing the histogram of sixty images shows that there is the difference distribution between the purple soil region and the background on the ’a’ component (show in Figure 3(e)). Thus, we select the ’a’ component as the color feature of purple soil color image for segmentation. The procedure of segmenting purple soil color image based on SWFCM is summarized as Algorithm 3.
1: Set a zero matrix matB with size (M + 2) × (N + 2).
2: Compute the ’a’ color component matA of imgA;
3: Getting V and U using matA by Algorithm 2.
4: Randomly capture five 50×50 windows from the 100×100 window centered on the center of matA, then remove the windows with maximum and minimum ’a’ component mean, and finally calculate the ’a’ component mean avgA of the remaining three windows.
5: The class element whose cluster center is closest to avgA is extracted, and the pixel value at the corresponding position in matB is set to 1.
The boundary extraction of purple soil region can be realized by obtaining the boundary which has the largest area enclosed by it and contains the center of image. As shown in Figure 4(a), it is a binary matrix matB that simulates the image result after initial segmentation. The pixels with value of 1 represent purple soil, and the pixels with value of 0 represent background. Figure 4(b) shows the process of purple soil boundary extraction. Firstly, keeping the center of matB unchanged, the size of matB is expanded from M × N to (M + 2) × (N + 2). The pixel value of expanded part of imgB is set to 0. Secondly, starting from the center point of matB, the point with value of 0 is searched towards the right as the boundary starting point bsp. Thirdly, bsp is initialized as the current point cp and its left neighborhood point is initialized as the initial search neighborhood point isnp. In the four neighborhood points of cp, the first point fp with a value of 0 is searched counterclockwise starting from isnp (If there is no point with value of 0 in the four neighborhoods of cp, so the point cp is an isolated point, and then we search for the next boundary starting point starting form bsp). Then, isnp is updated with cp, and cp is updated with fp. According to the above rules, isnp and cp are updated repeatedly, and the coordinate position of cp is recorded in the matrix edg until cp returns to the position of bsp. Finally, it is judged whether the boundary formed by all current points contains the center of image. If so, this boundary is the boundary of purple soil, otherwise, the next boundary starting point is searched. The algorithm of extracting the boundary of the purple soil region is shown as Algorithm 4.
1: Initialize a zero matrix edg with size (M + 2) × (N + 2), dx ={ 0, 1, 0, - 1 } and dy ={ - 1, 0, 1, 0 }.
2: Keeping the center of imgB unchanged, imgB is expanded from M × N to (M + 2) × (N + 2). where the pixel value of expanded part of imgB is set to 0.
3: Set the center point of imgB to the current point (x, y).
4:
5: Set y = y + 1.
6:
7: execute step 5.
8:
9: execute step 11.
10:
11: Set up = low = M/2, right = left = N/2, tx = x, ty = y, edg (tx, ty) = 1, i = 0 and initialize an empty stack stackA, push the current point (x, y) into it.
12:
13: Initialize flag = 4.
14:
15: Set i = (i + 1) % 4.
16:
17: Set flag = flag - 1.
18:
19: Set flag = 0.
20:
21:
22: Set tx = tx + dx (i) and ty = ty + dy (i)
23: Set edg (tx, ty) = 1 and push (tx, ty) into stackA.
24:
25: Set i = (i + 2) % 4.
26:
27: Set i = i + 2.
28:
29:
30: Set up = tx.
31:
32: Set low = tx.
33:
34:
35: Set left = ty.
36:
37: Set right = ty.
38:
39:
40:
41: Pop all element (tx, ty) from stackA and set edg (tx, ty) = 0
42:
43:
Filling purple soil region
Figure 4(c) shows the process of filling purple soil region. The center of matrix edg is pushed into stackA. Starting from a point popped from stackA, horizontal search in edg is done along the left and right directions until a point with value of 1 is found at each direction. In the horizontal search, the points with value of 0 are pushed into stackB and their values in edg are set to 1. Then, starting from a point popped from stackB, longitudinal search in edg is done along the top and bottom directions until a point with value of 1 is found at each direction. In the longitudinal search, the points with value of 0 are pushed into stackA and their values in edg are set to 1. These two steps are repeated until both stackA and stackB are empty and the work of filling the purple soil region is finished. The algorithm of filling the purple soil region is shown as Algorithm 5.
1: Initialize a zero matrix matC and two empty stack stackA and stackB.
2: Push the center point of matrix edg into stackA.
3:
4:
5: Pop an element from stackA as the current point (x, y).
6: Set na = y - 1, nb = y + 1, edg (x, y) = 1 and matC (x - 1, y - 1) = 1.
7:
8:
9: Set matC (x - 1, na - 1) = 1, edg (x, na) = 1 and push (x, na) into stackB.
10:
11:
12: Set matC (x - 1, nb - 1) = 1, edg (x, nb) = 1 and push (x, nb) into stackB.
13:
14: Set na = na - 1 and nb = nb + 1.
15:
16:
17:
18: Pop an element from stackB as the current point (x, y).
19: Set na = x - 1, nb = x + 1, edg (x, y) = 1 and matC (x - 1, y - 1) = 1.
20:
21:
22: Set matC (na - 1, y - 1) = 1, edg (na, y) = 1, push (na, y) into stackA.
23:
24:
25: Set matC (nb - 1, y - 1) = 1, edg (nb, y) = 1 and push (nb, y) into stackA.
26:
27: Set na = na - 1 and nb = nb + 1.
28:
29:
30:
31: The result of Hadamard product between matrix matC and the RGB three channels of imgA is the purple soil region.

Example of post-processing algorithms. (a) The matrix matB. (b) Boundary extraction. (c) Filling purple soil region
The initial segmentation of purple soil color image is based on SWFCM, so its time complexity is the same as SWFCM. The most time-consuming step of algorithm 4 is to traverse the boundary of the purple soil region, and it needs to traverse the boundary pixels of the purple soil region image and its four neighborhoods in the worst case. Thus its time complexity is O (M × N). The main step of algorithm 5 is to traverse the pixels in the purple soil region, which needs to traverse the whole image in the worst case. So its time complexity is O (M × N).
Experiments
Three experiments were done to verify the effectiveness of the proposed algorithm. Experiments include: 1) Evaluating the effectiveness of initializing the clustering centers. 2) Comparison of segmentation results with different FCM algorithms. 3) Comparison of segmentation results with other algorithms for the segmentation of purple soil color image.
Experimental environment is a graphic workstation with Intel(R) Xeon(R) CPU E5-2687W v2 @ 3.40GHz(2 CPU), 64 GB RAM and NVIDIA Quadro K5000 graphic card, and Visual Studio 2017.
Acquiring images
According to classification and code for Chongqing soil [DB50 / T 796-2017] [22], there are four soil genus and 34 soil types of purple soil at Chongqing, China. The natural fault of purple soil (core soil) is obtained by a spade in 0-25cm tillage soil, and it keeps the original features of purple soil. In order to extract purple soil conveniently, all purple soil color images can meet the requirement that the natural fault of purple soil is located in the center of image. The experimental data in this paper include 15 groups of normal images and 15 groups of robust images, which cover all purple soil types.
45 purple soil color images are randomly selected to compose 15 normal sample groups of normal images, which features are as follows: 1) There is no large shadow in the purple soil region. 2) There is no large scattered purple soil whose structure has been destroyed in the background. The images of No. 4 Group are shown in Figure 5.

Images of Normal No. 4 Group.
15 robust sample groups are composed of 45 robust images that are artificially selected and there are the characteristics of big shadow in the purple soil area and structure damage purple soil in the background. The images of No. 6 Group are shown in Figure 6.

Images of Robust No. 6 Group.
Eq. (28) is the mathematical function of Jaccard index [23], which is used to evaluate the segmentation performance of related algorithms in this paper. The larger the Jaccard index is, the better the segmentation accuracy (SA) is.
To test the effectiveness of initializing the clustering centers, the segmenting accuracy of SWFCM with different clustering numbers is tested on normal images (No. 4 Group) and robust images (No. 6 Group). Table 2 gives the clustering centers obtained by our proposed algorithm, and Figure 7 shows the segmentation accuracy of SWFCM under different clustering numbers. In Table 2 and Figure 7, SWFCM provides better segmentation accuracy for Normal No. 4 Group and the Robust No. 6 Group when the clustering centers are obtained by our proposed algorithm. This reflects that our proposed algorithm is effective for the initialization of the clustering center.
The clustering centers obtained by our proposed algorithm
The clustering centers obtained by our proposed algorithm

Segmentation accuracy using SWFCM with Normal No. 4 Group and Robust No. 6 Group.
To test and verify advantage of SWFCM on segmentation accuracy, five improved FCM algorithms, such as EnFCM, FGFCM, NWFCM, FRFCM and SWFCM, are used to test segmenting accuracy for Normal No. 4 Group and the Robust No. 6 Group. Figure 8 shows the image results of five improved FCM algorithms, and their post-processing results are shown in Figure 9. Table 3 and Table 4 give the segmentation accuracy and execution time of the image results in Figure 8 and Figure 9.
The evaluation index of the image results given in Figure 8
The evaluation index of the image results given in Figure 8
The evaluation index of the image results given in Figure 9 after post-processing
In the experiment, all FCM algorithms use the ’a’ color component to cluster. A fixed 3 × 3 window is used to filter in the FCM algorithm involving filtering for fair comparison. Common parameters of all FCM algorithms are ψ = 1,m = 2,δ = 0.5,T = 100. In addition, α is used to control the effect of the neighbor term in EnFCM and NWFCM, experientially, α = 1. In FGFCM, the spatial scale factor and the gray-level scale factor are λ s = 3 and λ g = 0.5, respectively.
Figure 8 shows SWFCM obtains a better visual effect than other FCM algorithms. Such as Normal No. 4 Group (c), SWFCM is able to remove the surface soil and white labels, which indicates that it can help the classification of the points at the junction of two clusters. In addition, as can be seen from the image results of Robust No. 6 Group (b) that it is not sensitive to shadow. The possible reason is that the selected color feature is not affected by the shadow. In Table 3, compared with EnFCM, FGFCM, NWFCM and FRFCM, the average segmentation accuracy of normal experimental samples with SWFCM is improved by 5.32%, 5.37%, 6.36% and 5.81% respectively, and the average segmentation accuracy of robust experimental samples is improved by 3.24%, 9.38%, 0.03% and 13.93% respectively. Compared with EnFCM and FGFCM, the average executing time of SWFCM is larger. The reason is that both EnFCM and FGFCM are based on gray level for clustering, while SWFCM is based on pixels. Obviously, the gray level of an image is much smaller than the number of pixels. The average executing time of SWFCM algorithm is less than that of NWFCM and FRFCM. Although FRFCM is based on gray level for clustering, its pre-processing costs are large. While SWFCM has no pre-processing. It can be seen in Figure 9 that the image results are closer to the Ground Truth after post-processing. Table 4 shows that the segmentation accuracy of the image in Figure 9 has greatly increased after post-processing algorithms. This reflects that the post-processing algorithms in this paper are able to remove holes and scattered impurities. In addition, its execution time is fast.

Segmentation results of Normal No. 4 Group and the Robust No. 6 Group using the five FCM algorithms. (a)EnFCM. (b)FGFCM. (c)NWFCM. (d)FRFCM. (e)SWFCM.

The post-processing results of the image given in Figure 8. (a) EnFCM. (b) FGFCM. (c)NWFCM. (d) FRFCM. (e) SWFCM. (f) Ground truth.
To verify the effectiveness of SWFCM for the segmentation of purple soil color image, 15 groups of normal image examples and 15 groups of robust image examples are used to test segmenting accuracy and execution time with different algorithms which are SWFCM, threshold segmentation algorithm [1] and Improved SLIC algorithm [2]. Figure 10 shows the image results of three algorithms. Table 5 gives the segmentation accuracy and execution time of the image results in Figure 10. Table 6 gives the segmenting accuracy and executing time of 15 groups of normal image examples and 15 groups of robust image examples.

Segmentation results of Normal No. 4 Group and the Robust No. 6 Group using the relative algorithms. (a) threshold segmentation algorithm (TS). (b) Improved SLIC algorithm(ISLIC). (c) SWFCM.
Figure 10 shows that the segmentation result of the purple soil image with threshold segmentation algorithm is incomplete. Such as Normal No. 4 Group (a), threshold segmentation algorithm divides part of the soil into the background. The reason may be that the fitting effect of normal distribution on h-component histogram of soil is not ideal. In addition, as can be seen from the image results of Robust No. 6 Group (c) that threshold segmentation algorithm failed to correctly classify the topsoil that was similar in color to the purple soil but whose structure had been damaged. Again, improved SLIC algorithm has the same problem. Compared with the improved SLIC algorithm, SWFCM is more accurate for the segmentation of the detailed information of the purple soil boundary.
Table 5 shows that compared with threshold segmentation algorithm and improved SLIC algorithm, the average segmentation accuracy of robust experimental samples with SWFCM is improved by 16.57% and 19.37% respectively.
The evaluation index of the image given in Figure 10
In terms of time cost, threshold segmentation algorithm only uses one threshold to realize image segmentation, which costs less time. Compared with improved SLIC algorithm, SWFCM takes less time to execute, because improved SLIC algorithm spends more time on super-pixel merging. These are also validated by the experimental results of all image sample groups in the Table 6.
The evaluation index of 15 groups of normal image examples and 15 groups of robust image examples
In this paper, An adaptive scale weighted fuzzy c-means clustering for the segmentation of purple soil color image has been proposed to improve the segmentation quality. The following conclusions are drawn.
(1) The maximum difference optimization model is established with the mean of the Gaussian distance to optimize the parameter ɛ. Then, this parameter ɛ is used to adaptively initialize the clustering centers of FCM algorithm. The experimental results show that this model is helpful to initializing the clustering centers.
(2) The objective function of FCM is reconstructed by weighting the Euclidean distance between the pixel and the clustering center with the compactness of each cluster. Experimental results show that the SWFCM algorithm is effective in improving the segmentation accuracy of purple soil images.
(3) Aiming at the problem of removing scattered impurities and filling holes, the algorithm of extracting the boundary of the purple soil region and the algorithm of filling the purple soil region are proposed. The experimental results show that the post-processing algorithms are effective and their executing time is fast.
Although the effectiveness of the proposed algorithms is promising, some open issues remain to be resolved in the future. Firstly, there is much room for improving the segmentation accuracy of robust images. Secondly, it is necessary to reduce the time cost of SWFCM algorithm so that it can be applied to high-resolution soil images.
Footnotes
Acknowledgments
This work supported by the Key Science and Technology Research Program (No.KJZD-K201900505) and Chongqing University Innovation Research Group funding (No.CXQT20015) of Chongqing Municipal Education Commission, China.