
Abstract
There are three contributions in this paper. (1) A tensor version of LLE (short for Local Linear Embedding algorithm) is deduced and presented. LLE is the most famous manifold learning algorithm. Since its proposal, various improvements to LLE have kept emerging without interruption. However, all these achievements are only suitable for vector data, not tensor data. The proposed tensor LLE can also be used a bridge for various improvements to LLE to transfer from vector data to tensor data. (2) A framework of tensor dimensionality reduction based on tensor mode product is proposed, in which the mode matrices can be determined according to specific criteria. (3) A novel dimensionality reduction algorithm for tensor data based on LLE and mode product (LLEMP-TDR) is proposed, in which LLE is used as a criterion to determine the mode matrices. Benefiting from local LLE and global mode product, the proposed LLEMP-TDR can preserve both local and global features of high-dimensional tenser data during dimensionality reduction. The experimental results on data clustering and classification tasks demonstrate that our method performs better than 5 other related algorithms published recently in top academic journals.
Introduction
In the current era of big data, high-dimensional data learning has become a serious “dimensional disaster” for machine learning. For example, text analysis and feature extraction are based on high-dimensional data. However, most of the current algorithms deal with high-dimensional data by converting them to vectors, and the algorithms of vector data are further used to process these converted data. This method makes people want to describe things from various aspects in vain. Therefore, this paper proposes a dimensionality reduction method that can consider the different features of each dimension of multidimensional data.
Tensor algebra is a powerful mathematical tool. Tensor models can handle multi-dimensional data with index sets. Therefore, when describing actual problems, compared with the matrix model, it is closer to the properties of the actual problems, so it can better describe the actual problems. However, most current machine learning algorithms do not target tensor, so researching tensor is an urgent research task. In the past, there were some widely used tensor decomposition models, such as Canonical Polyadic (CP) [1] and Tucker decomposition [2, 3]. According to the actual application needs, by adding different constraints, these two basic forms can be derived from a variety of tensor decomposition forms, namely non-negative tensor factorization applied to hyperspectral separation [4, 5] and optimization algorithm based on non-negative tensor decomposition [6], non-negative Tucker factorization [7, 8], orthonormal Tucker factorization, higher-order singular value decomposition (HOSVD) [9], etc. Recently, the method of tensor decomposition has been greatly developed, and many methods have emerged. Sun et al. [10] used the advantages of orthogonal and non-negative constraints to propose a Tucker decomposition form based on polynomial manifold tensor clustering. Li et al. [11] introduced the manifold regularization non-negative Tucker decomposition (MR-NTD) in 2017, and merged the manifold regularization into the kernel tensor to maintain the nearest neighbor relationship of the data points. In order to achieve a more robust and regular effect, Jiang et al. [12] proposed an algorithm called graph-Laplacian tensor decomposition (GLTD) for short, which simultaneously considered the attributes of the graph and the pairwise similar information.
Local linear embedding (LLE), as a classic manifold learning algorithm, is used to maintain the local linear structure of data. It has been a hot research topic. In recent years, improved algorithms based on LLE have continuously emerged and are widely used in various fields such as data mining, image processing, pattern recognition, and error detection. The work very close to this paper, such as locality perserving projections algorithm for hyperspectral image dimensionality reduction (LPP-DR) proposed by Wang et al. [13], an image representation method using Laplacian regularized non-negative tensor factorization (LRNTF) proposed by Wang et al. [14] etc, are used in vector data. This paper proposes an improved algorithm for LLE in the case of tensor, that is, combining LLE with tensor decomposition to reduce dimensionality.
This paper combines the classic manifold learning algorithm of local linear embedding to maintain the local linear structure of the data. Moreover, based on the knowledge of tensor decomposition, we seek a set of matrices that form a projection subspace, so the mode product of the high-dimensional tensor and the projection matrix reduces the tensor’s dimensions globally.In other words, this paper develops a reduced dimensionality method for Tensor data based on local linear embedding and mode product. The algorithm has three contributions, as follows:
(1) Local Linear Embedding (LLE) is the most famous manifold learning algorithm for dimensionality reduction. Since LLE was proposed, various improvements to LLE have been continuous. However, they are all applied to vector data and cannot be directly applied to tensor data. Therefore, this paper develops the tensor version of LLE, which also provides a bridge for various improvements to LLE to transfer from vector data to tensor data.
(2) Inspired by the mode product of tensors and matrices that can change the size of any one-dimensional tensor, this paper proposes a dimensionality reduction scheme for tensor data, where the dimension-reduced tensor is the mode product of the high-dimensional tensor and different matrices. As long as the sizes of these matrices meet the requirements of dimensionality reduction, they can be used to carry out the required dimensionality reduction. The elements of matrices are determined according to specific criteria.
(3) Finally, a new dimensionality reduction algorithm for tensor data combining LLE and mode product is proposed, called LLEMP-TDR for short, in which LLE is used as a criterion to determine the elements of matrices in the mode product. So far, it seems that no similar algorithm has been reported. Since LLE is a local preserving algorithm while mode product is a global preserving algorithm, LLEMP-TDR can maintain both local and global features during the dimensionality reduction process.
The structure of the rest of this paper is as follows: In Section 2, we will introduce some preliminary knowledge. The latest works related to ours are introduced in Section 3. Section 4 mainly includes the derivation, solution, complexity analysis of LLEMP-TDR and comparison with contrast algorithms. In Section 5, we use MATLAB for implementation and verify the performance of LLEMP-TDR through sufficient experiments. Finally, the conclusion of this paper is presented in Section 6.
Preliminaries
Symbols
In this paper, we use lowercase letter x as a scalar, bold lowercase letter
Basic operators
Basic operators
In mathematics, tensor is a multi-linear functional. In the application of data processing, we usually represent a tensor as a multi-index data set. Tensor is a set of real numbers. For example,
From the perspective of data processing, an N-order tensor
Tensors can be represented by matrices [15]. For example, the mode-n of a tensor
bfDefinition: Mode product of a tensor and a matrix: With a tensor Alter the order of the tensor. if A
n
is full rank of the column, using the mode-n product, there is:
associative law: suppose commutative law: suppose
The following Lemma will be used in this paper.
bfLemma [15]: Suppose
LLE
Local linear embedding (LLE) [16] is known as the first algorithm for manifold learning, and it is a dimensionality reduction method for nonlinear data. The low-dimensional data after processing can maintain the original topological relationship. In recent years, LLE is widely employed in the classification and clustering of image data, character recognition, visualization of multi-dimensional data, bioinformatics and other fields. N. Jain et al. proposed patch based LLE for node localization in sensor networks [17], which is able to localize nodes in dense nodes accurately. In order to extract the global and local characteristic of the observation data more accurately, Y. Zhang et al. proposed a novel modified kernel semi-supervised LLE named MK-SSLLE [18]. C. Yao et al. proposed the LLE score [19], which is a new filter-based feature selection method. In addition, Hessian Local Linear Embedding (HLLE) [20] and Adaptive Local Linear Embedding (ALLE) [21] had been used to solve localization problem. H. Rajaguru et al. [22] used LLE and HLLE to implement Epilepsy Classification from EEG signals.
Tensor decomposition
More and more algorithms consider adding manifold learning algorithms to the dimensionality reduction model, which is usually used as a regular term to preserve the internal geometric information of the data during the dimensionality reduction process. In this regard, the algorithm called graph regularized non-negative matrix factorization (GNMF) [23] was proposed, in which a manifold regularization term based on non-negative matrix factorization was added, and the neighborhood information was learned through Laplace regularization terms, so local geometric information of high-dimensional data could be retained in the new subspace. Subsequently, Zhang et al. proposed the method of low-rank matrix approximation with manifold regularization (MMF) [24]. It considers the neighborhood information of the data while seeking low-rank factorization, and learns the geometric information of the data through undirected graphs.
Recently, researchers have done in-depth research on the Tucker decomposition of tensor in the field of machine learning. Let
The research of Tucker decomposition mainly focuses on the orthogonal or non-negative constraints as well as the addition of various regularization terms. For example, non-negative Tucker decomposition (NTD) [25] also adds non-negative conditions. Zhang et al. [2] proposed a new model for tensor decomposition–low-rank regularized heterogeneous tensor decomposition for subspace clustering (LRR-HTD). For all modes except the last mode, LRR-HTD aims to seek a series of orthogonal projection matrices that can project the original tensor data to a low-dimensional subspace. And for the last mode, we can get the lowest-rank representation under the condition of satisfying the low-rank constraint, which reveals the overall structure of the sample. In 2017, Li et al. [11] proposed a unique algorithm called manifold regularization non-negative Tucker decomposition for tensor data dimension reduction and representation (MR-NTD). Under non-negative constraints, a method for Tucker decomposition of multiple tensor objects is showed. At the same time, the manifold structure of the data is considered, and the geometric relationship of the core tensor is introduced into the objective function to maintain the geometry of the tensor before and after dimensionality reduction. Then, a more efficient algorithm called the graph-Laplacian tensor decomposition (GLTD) [12] is proposed in 2019. This method also studies the characteristics and similarities between pictures. In addition, the addition of LE regular items improves the robustness of occlusion or abnormal image processing.
Tensor representation of tensor datasets
Since dimensionality reduction algorithms have to make use of the relationship between data, unlike many similar algorithms, multidimensional datasets are presented in the form of tensor, not a singular data in this paper. Here,
In order to explain the dimensionality reduction of tensor data more clearly, for example, given a tensor
Local linear embedding is an important idea for manifold learning. The so-called local linear embedding is to first decompose the high-dimensional data set into several parts, then calculate the linear pattern of each part, and finally solve the reduced dimensional dataset according to the criteria maintained by the local linear pattern. This paper applies the idea of local linear embedding to the dimension-reduced of high-dimensional datasets.
Local linear approximation
For any high-dimensional data
We let
This paper proposes to use the mode product of Tensor to achieve dimensionality reduction of tensor data. The matrix here is the projection matrix. Given a high-dimensional tensor data and the dimensionality reduction requirements of each order, the dimensionality reduction algorithm (referred to as MP-TDR) proposed in this paper is: as mentioned above, for a original tensor
The above dimensionality reduction algorithm has three characteristics: This algorithm is global. It does not decompose This algorithm is subspace-dependent and is an algorithm constructed based on subspace A1, ⋯ , AN-1, so we call it a subspace-based dimensionality reduction algorithm; Any vector in the subspace spanW is a high-dimensional vector of
It must be pointed out that as long as the number of rows and columns of these matrices meet the specified dimensionality reduction requirements, the specific values of the matrix elements are open. Therefore, MP-TDR is not so much an algorithm as it is an algorithm framework. Any specific method for determining the mode product matrix will transform this framework into a specific algorithm. A natural and intuitive subspace selection method is to minimize the distance between high-dimensional tensor data and its projection in the subspace, that is:
The propsed algorithm
There are two categories of dimensionality reduction algorithms, one is locally preserved dimensionality reduction algorithms, and the other is global preserving dimensionality reduction algorithms, such as PCA and LDA. LLE has two characteristics: one is partial, in which the dataset is decomposed into one by one, and then each part is constructed separately for dimensionality reduction algorithm; The other is that there is no clear relationship between high-dimensional tensor datasets and reduced dimension tensor datasets, so the out-of-sample problem cannot be solved. And MP-TDR also has two characteristics: one is global, it does not decompose the tensor dataset into one part when MP-TDR constructs the dimensionality reduction algorithm, the entire tensor dataset is unified to consider the construction of the dimensionality reduction algorithm; The other is that the high-dimensional tensor dataset has a clear relationship with the reduced dimension tensor dataset in MP-TDR, that is, the reduced dimension tensor is the mode product of the high-dimensional tensor. At present, the standard of a good data dimensionality reduction algorithm should be: reduced dimension dataset can not only maintain some global features of the high-dimensional dataset, but also maintain some local features of the high-dimensional dataset. In other words, the data dimensionality reduction algorithm is preferably an algorithm that maintains certain global and local features of a high-dimensional dataset at the same time. Besides, it is better to establish a clear relationship between high-dimensional data and reduced dimension data in order to solve the problem of insufficient samples. From the analysis of LLE and MP-TDR in this paper, it can be seen that LLE and MP-TDR can complement each other in these two aspects. Therefore, this paper proposes a combination of LLE and MP-TDR, referred to as LLEMP-TDR. The method of LLEMP-TDR determines the matrix in the light of the locally linear embedding criterion derived in Section 4.2 of this paper, that is:
LLEMP-TDR not only considers the properties of local preservation but also the properties of global preservation. Therefore, LLEMP-TDR is the dimensionality reduction of tensor data with local and global attributes. The local preservation of LLEMP-TDR refers to the preservation of the local linear approximation patterns, while the global preservation refers to the preservation of the minimum distance between the high-dimensional tensor data and its subspace projection.
Since
The algorithm flow of LLEMP-TDR in the table Algorithm 1.
Complexity analysis
The computational complexity of LLEMP-TDR mainly consists of the calculation of Π and
Compared with comparison algorithms (such as GLTD [12], etc.), our algorithm does not require iterative solution, and according to the complexity analysis of the algorithm we proposed above, it can be seen that the complexity of our algorithm is roughly the same as or even lower than most similar algorithms.
Comparison with other the state-of-the-art related works
In this section, we will introduce some of the latest works published in top journals that are most relevant to our work, and explain the difference between them and our work.
Matrix is actually a kind of second-order tensor, so the famous non-negative factorization of matrix is a special kind of Tucker decomposition for tensor. In [23], an algorithm of graph regularized non-negative matrix factorization (GNMF) is as follows:
Zhang et al. proposed an algorithm called Low-Rank Matrix Approximation with Manifold Regularization (MMF) [24]. MMF is a low-rank decomposition model, which considers the neighborhood information of the data while seeking low-rank factorization, and learns the geometric information of the data through undirected graphs. The objective function of the algorithm is as follows:
Orthographically constrained Tucker decomposition is another research topic of Tucker decomposition. In 2018, Zhang et al. proposed an algorithm of low-Rank regularized heterogeneous tensor decomposition for subspace clustering (LRR-HTD) [2]. LRR-HTD seeks a set of orthogonal projection matrices to map the original tensor data to a low-dimensional subspace, but for the last mode, the low-rank constraint needs to be satisfied, to obtain a lowest-rank representation that reveals the overall structure of the sample. The model of LRR-HTD is as follows:
In [24], an algorithm of manifold regularization non-negative Tucker decomposition (MRNTD) is proposed as follows:
Recently, a relatively novel dimensionality reduction algorithm for tensor has been proposed by Jiang et al. It is called an image representation and learning method based on graph-Laplacian tensor decomposition (GLTD) [12]. The difference between this method and other algorithms is that the properties and resemblances between the images are considered, and the LE regular term is addded to improve the robustness of occlusion or abnormal image processing. The objective function is shown in Equation 23.
The algorithm proposed in this paper not only maintains global and local information in dimensionality reduction, but also takes into account lower computational complexity. Therefore, the algorithm in this paper has a slight advantage over the above algorithms. The experimental results between our algorithm and these algorithms are presented in Section 5 Experimental Results.
In the experiment, we use the PC as the tool, and its configuration is as follows:
(1) Hardware: CPU: Inter Core i5-6200U @2.30GHz; Memory (RAM): 4.00GB; Operating system: Windows 7, 64 bit;
(2) Software: MATLAB R2019a.
At present, there is no unified and widely-recognized criterion for evaluating various algorithms of dimensionality reduction. The evaluation of various dimensionality reduction algorithms is mainly indirect. After dimensionality reduction, classification or clustering experiments are carried out to see which algorithm can get the highest accuracy.
This section presents the experimental results of the LLEMP-TDR proposed in this paper and the other five related algorithms published in the top journal in recent years on five common datasets. The theoretical analysis of these five related algorithms has been given in Section 3. The performance of the LLEMP-TDR is fully demonstrated by evaluating the clustering accuracy, classification accuracy and normalized mutual information (NMI) on five standard data sets (Faces94 male, ETH80, ORL, Olivetti, USPS). In addition, this section also provides the influence of the embedding dimension on the performance of LLEMP-TDR.
Datasets
(1) bfETH80-1: ETH80 [26] is a multi-vision image dataset, including eight categories such as apples, cars, cows, etc,which is shown in Fig. 1. Each category is composed of 10 pictures, each picture is represented by 41 images from different angles, in which the original picture size is 128 × 128, and the size of each image is adjusted to 32 × 32 in our experiments. This experiment selected the image of the first item in each category, a total of 328 images.

The example picture of ETH-80 dataset.
(2)bf ORL: As a face dataset, ORL [22] contains 400 images of 40 different people, varying in light, angle, facial expression, and whether wearing glasses. The original image size is 92 × 112. In this experiment, we adjust the size of each picture to 32 × 32. The ORL dataset is shown in Fig. 2.

The example picture of ORL dataset.
(3) bfOlivetti Faces: The dataset of Olivetti Faces consists of 40 people, with a total of 400 faces, each of which has 10 face pictures, including front face, side face, and different expressions. And the size of each picture is adjusted to 64 × 64.
(4) bfFaces 94 male: Faces 94 male [12] contains 113 male subjects. Each subject was sitting in front of the camera and was asked to speak while taking 20 images. The speech was intended to introduce changes in facial expressions. The original image size is 20 × 180. In our experiment, each image was adjusted to 50 × 45. We selected 30 subjects for a total of 600 images.
(5) bfUSPS: USPS (United States Postal Service) [27] is a handwritten dataset shown in Fig. 3. The dataset contains ten types of handwritten images from 0 to 9, and each type has 1100 sample images. The size of each example image is 16 × 16. In this paper, we randomly select 200 images in each category for a total of 2000 images.

The example picture of USPS dataset.
The above five datasets use K-Means method of Euclidean distance metric to perform clustering experiments on the embedding results, and use KNN classifiers to perform classification experiments on the embedding results. At the same time, we evaluate the performance of the LLEMP-TDR and other algorithms by using three indicators of clustering accuracy, NMI, and classification accuracy to verify the effectiveness of LLEMP-TDR.
The parameters selection of all algorithms are set as follows: the neighbor number of all methods is set to 8; the LLE regular coefficient λ of LLEMP-TDR is set to 10; the number of cycles of GNMF [10] is set to 500; For MMF [23], the number of outer and internal loops is set to 40 and 25 respectively; the parameter γ of LRR-HTD [24] is 1; the parameter setting of MR-NTD [11] refers to [11]; the maximum number of iterations of NTD [28] is 50, and the maximum number of iterations of GLTD [12] is 50, too.
This paper uses five common datasets to verify the performance of the algorithm. The main statistical parameters are shown in Table 3.
Abbreviation
Abbreviation
Statistical parameters of datasets
There are usually two processing methods for datasets: clustering and classification. In the clustering experiment, the dimensions of the five high-dimensional datasets are first reduced to a certain dimension using the dimensionality reduction algorithm mentioned in the paper (LLEMP-TDR, GNMF, MMF, LRR-HTD, MR-NTD, NTD, and GLTD). Then, the K-means method of Euclidean distance measure is used to cluster the dimensionality-reduced datasets. The number of clusters is the same as the number of categories of the datasets. Since the algorithm of K-means is sensitive to the initial number of clusters, we set different initial value and repeat it 50 times in each clustering experiment. Then, the average of these results for the 50 tests is used as the final result.
Finally, the clustering accuracy and normalized mutual information (NMI) of each dimension-reduced dataset [29] are calculated to indirectly judge the performance of each algorithm of dimensionality reduction.
The calculation of NMI is as follows: Let θ
i
be the probability of the i-th class of the original-dimensional tensor dataset
Here, we perform clustering experiments on a subset of the number of different classes divided by the above five datasets. LLEMP-TDR proposed in this paper has good performance in the clustering accuracy and the clustering NMI performance for different types of sub-datasets for the ETH80 dataset (see Figs. 4 and 5). The performance of LLEMP-TDR is far superior to GNMF and GLTD. The performance of MMF, MR-NTD and NTD on this dataset is also lower than that of LLEMP-TDR. In addition, the clustering accuracy and clustering NMI of LLEMP-TDR decrease as the number of classes in this dataset increases. This result may be caused by the similar authentic structure of different types of datasets, which makes the algorithm produce similarity errors in the learning process. Other comparison algorithms have similar trends.

Clustering Accuracy on subsets of ETH80.

Clustering NMI on subsets of ETH80.
On the ORL dataset (see Figs. 6 and 7), we can see that the experimental results of LLEMP-TDR and other comparison algorithms are both lower than 75% in clustering accuracy and clustering NMI. However, it can be clearly seen that the LLEMP-TDR outperformance other algorithms, and it is 6% -20% higher than other algorithms in all categories. Especially for NTD and MR-NTD, our algorithm is 23% higher than them. In addition, the curve fluctuation of LLEMP-TDR is smaller than other algorithms, which indicates that the algorithm is more robust than other algorithms.
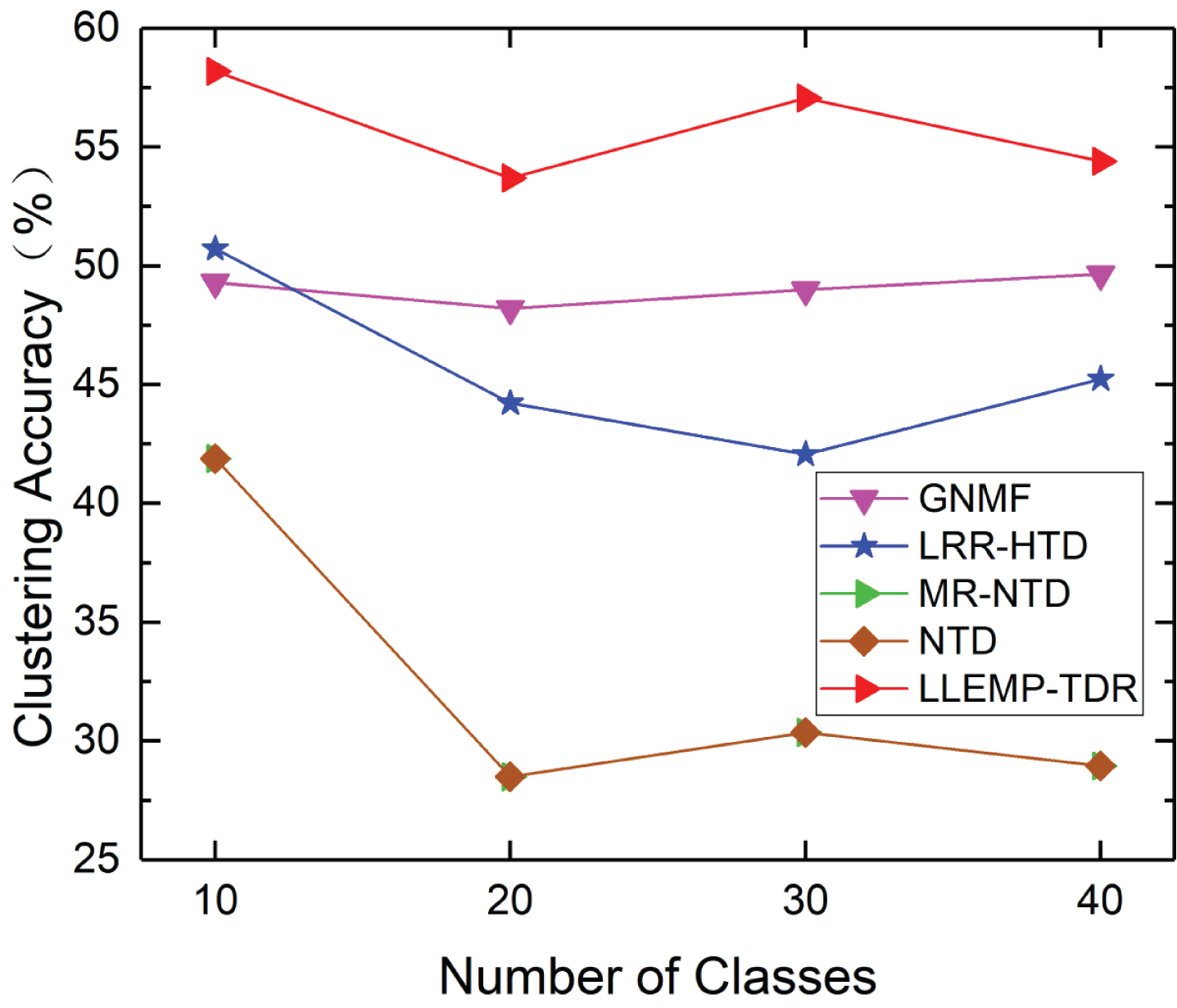
Clustering Accuracy on subsets of ORL
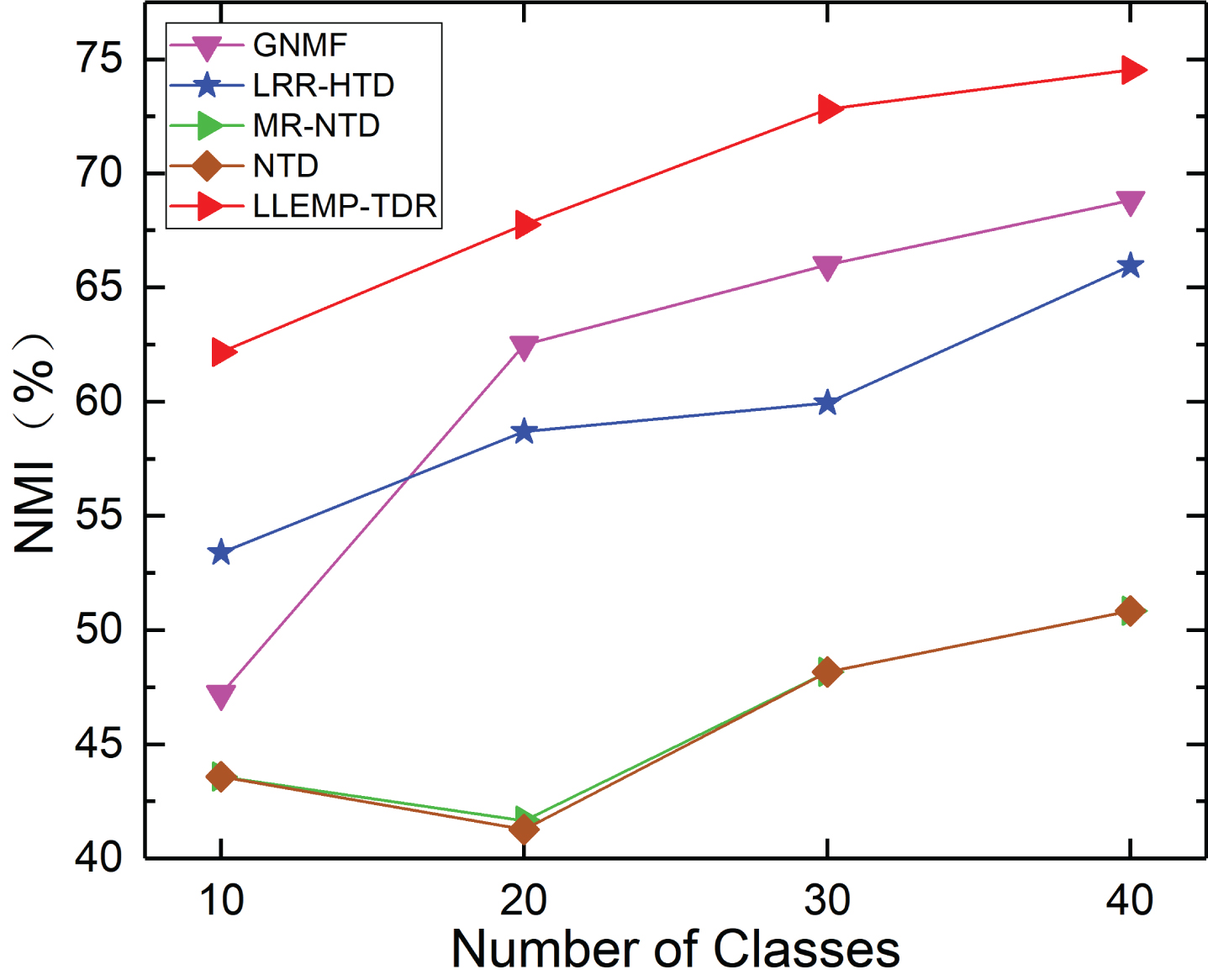
Clustering NMI on subsets of ORL
The effect of LLEMP-TDR for the Olivetti dataset (see Figs. 8 and 9) is comparable to the ORL dataset. LLEMP-TDR obtains the best clustering effect on both clustering accuracy and clustering NMI, and it obviously outperforms other algorithms.
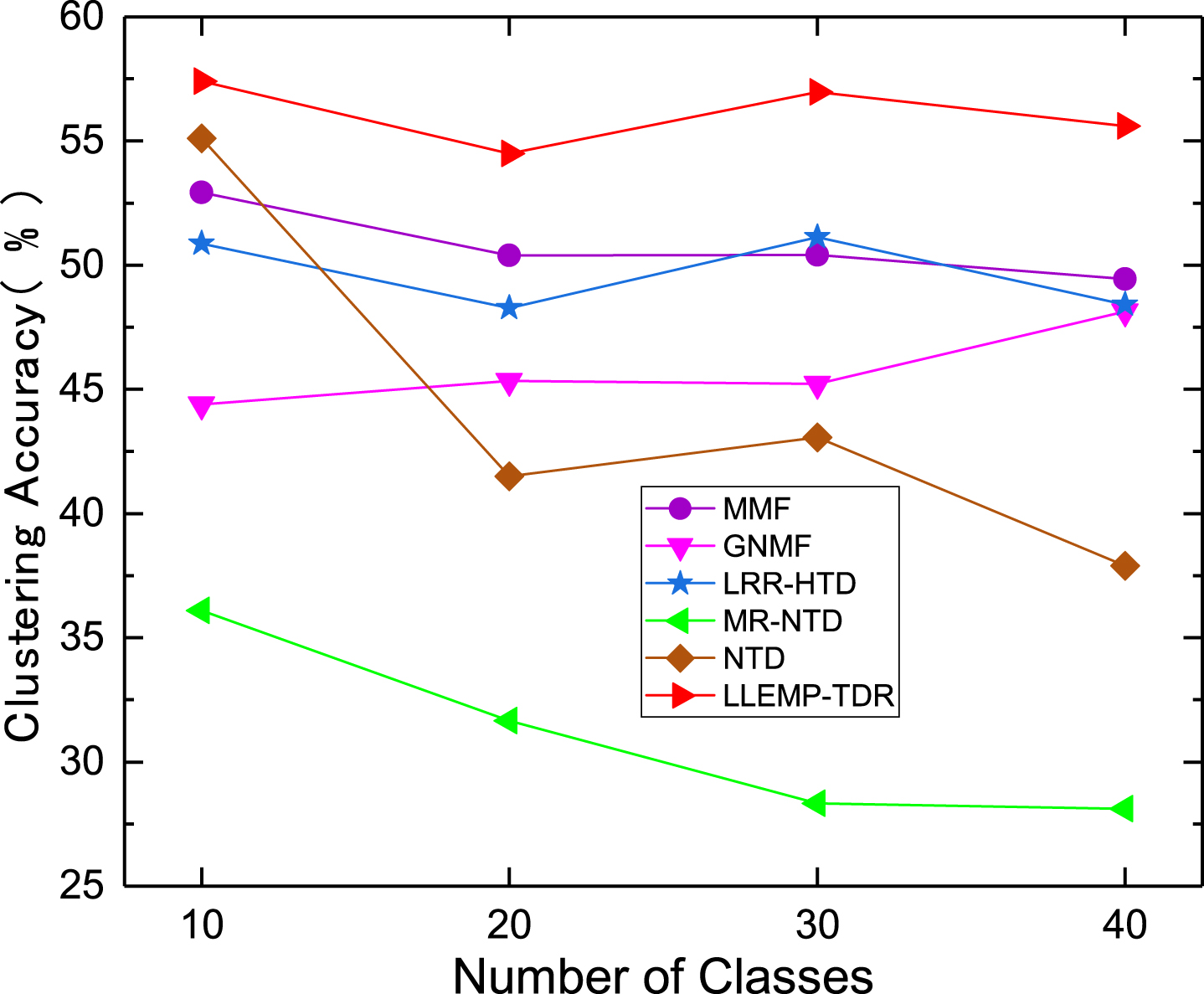
Clustering Accuracy on subsets of Olivetti.

Clustering NMI on subsets of Olivetti.
On the Faces 94 male dataset (see Figs. 10 and 11), LLEMP-TDR performs well on a subset of the dataset in each category, which is significantly better than MMF and MR-NTD. LLEMP-TDR, GNMF, NTD and GLTD all maintain high clustering accuracy and clustering NMI. Among them, LLEMP-TDR achieves the best results. Moreover, it can be seen from the clustering graph shown in the figure that the performance of LLEMP-TDR is relatively stable, which indicates that the algorithm has strong robustness to the dataset.

Clustering Accuracy on subsets of Faces 94 male.
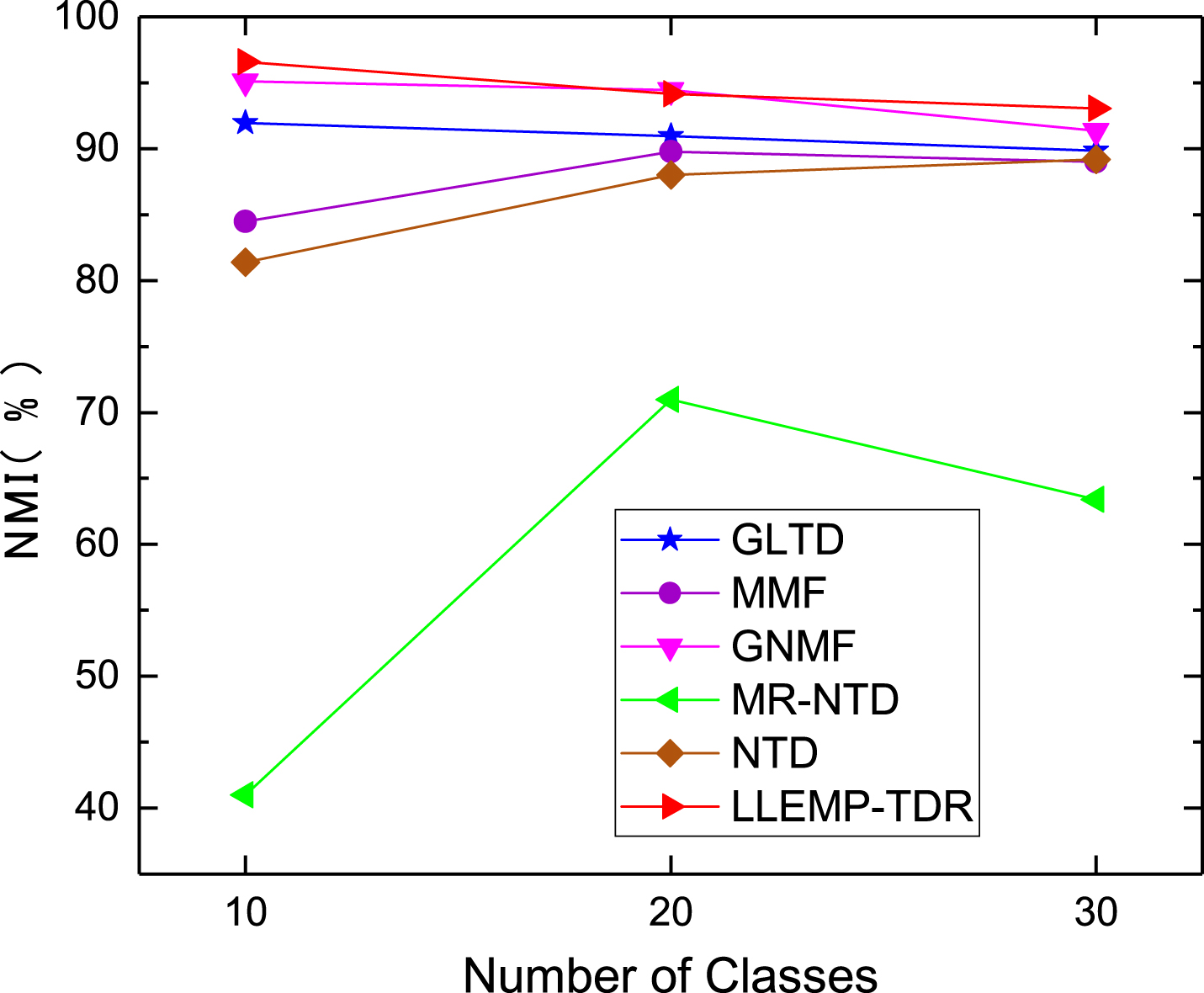
Clustering NMI on subsets of Faces 94 male.
For the USPS dataset (see Figs. 12 and 13), the clustering results of NTD, MR-NTD and LRR-HTD on different types of sub-datasets show large fluctuations, so their accuracy is usually not high. And they are lower than LLEMP-TDR in clustering accuracy and clustering NMI. The clustering performance of LLEMP-TDR decreases as the increase of the number of classes. The performance of clustering accuracy is slightly lower than that of GLTD, but the performance of clustering NMI is better than GLTD. This may be due to the similar geometric structure of different classes of datasets, which makes the LLEMP-TDR cause similar errors in the learning process.

Clustering Accuracy on subsets of USPS.

Clustering NMI on subsets of USPS.
Tables 4 and 5 summarize the average clustering results of the algorithm on different subsets of the same datasets, and the highest precision value of the average clustering result of each dataset is indicated in red bold. As can be seen from the table, LLEMP-TDR performs better than other algorithms in most cases.
Average clustering accuracy on subsets of each dataset
Average clustering NMI on subsets of each dataset
In this paper, we use the classical KNN with K = 8 to test the reduced-dimensional data, and use cross-validation to randomly select 80% of the dimension-reduced data as the training set, and use the remaining 20% as the test set, in which each dataset is tested 10 times, and the average of the classification accuracy is used as the classification accuracy of the dataset. We compare the experimental results with GNMF, MMF, LRR-HTD, MR-NTD, and NTD. The algorithm parameter settings in the classification experiment are consistent with those described in 5.2. The results of the experiment are shown in the Figs. 14 to 18.

Classification Results on subsets of Faces94 male.
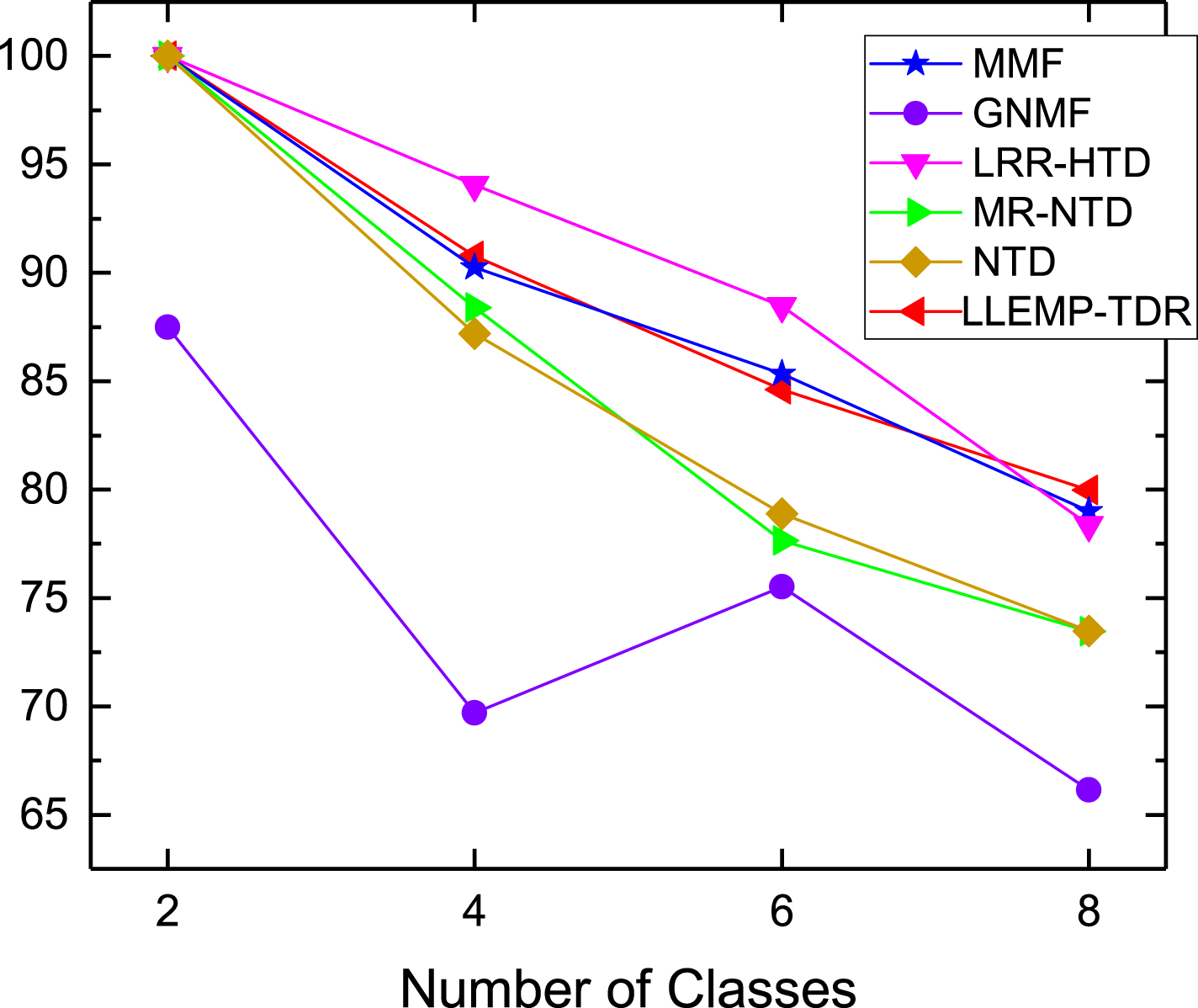
Classification Results on subsets of ETH80.

Classification Results on subsets of ORL.

Classification Results on subsets of Olivetti.
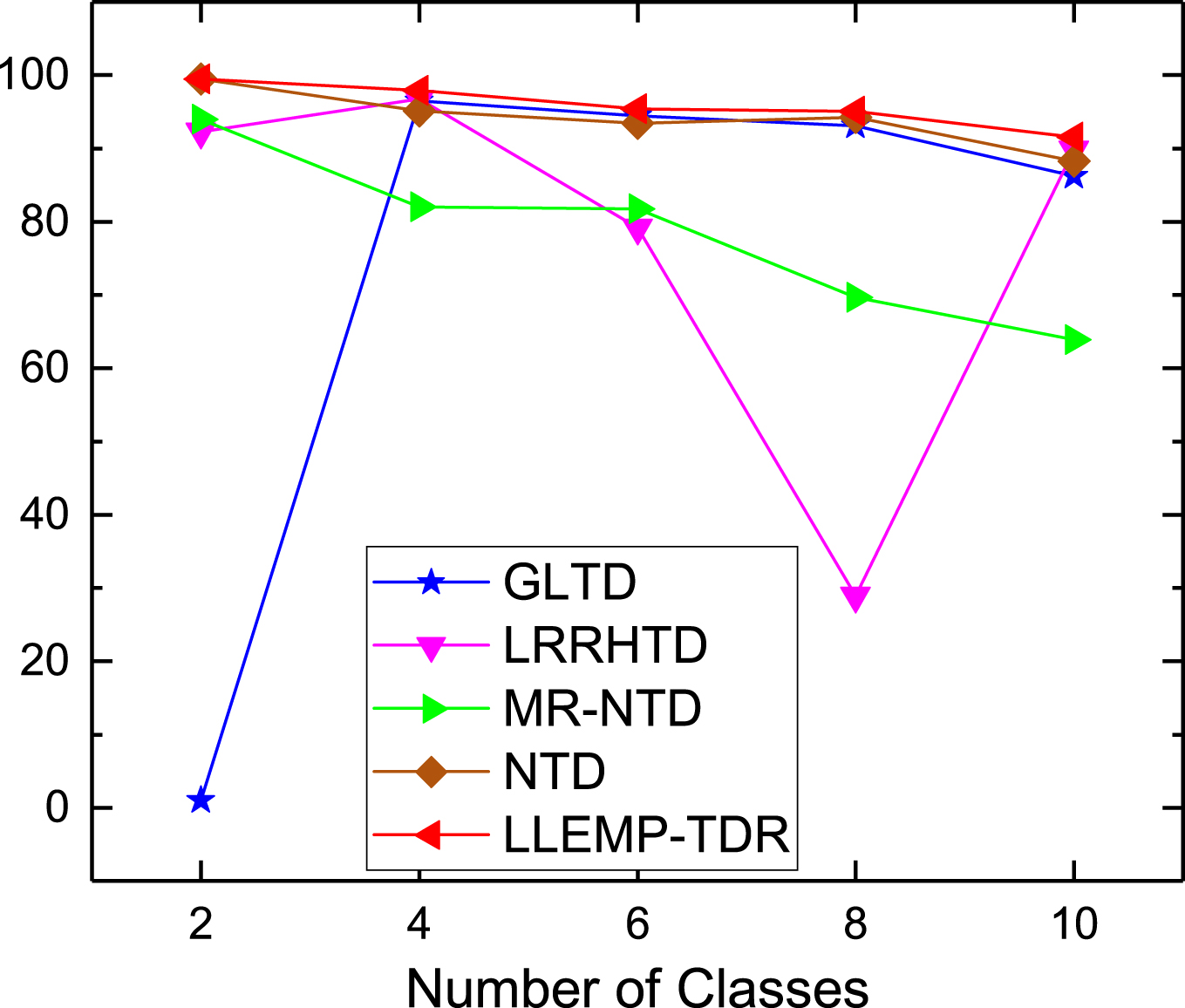
Classification Results on subsets of USPS.
As can be seen from Figs. 14 to 18, LLEMP-TDR shows relatively optimal classification results in the number of categories on the five datasets, especially for the datasets of Faces94 male, ORL and Olivetti, the classification accuracy of LLEMP-TDR is much better than other comparison algorithms, which can reach up to 100%, and the classification accuracy of more than 90% is maintained on the ETH80 and USPS datasets. In general, LLEMP-TDR not only has the best classification effect on the five datasets, but also has strong robustness.
Table 6 summarizes the average of classification results for the algorithm on different subsets of the same datasets, where the highest accuracy of the average of classification results on each dataset is indicated in red bold. According to the table, the LLEMP-TDR proposed in this paper performs better than other algorithms in most cases.
Average classification accuracy on subsets of each dataset
In this section, we analyze the accuracy of LLEMP-TDR in different embedding dimensions n × n of the test dataset. The experimental results are shown in Figs. 19–21, the performance of the USPS dataset in the clustering experiment is poor, and the performance in the classification experiment is better, that may be because the dataset is more suitable for classification tasks. On the Faces 94 male dataset, the performance of LLEMP-TDR in clustering and classification experiments is basically not affected by the embedding dimension and shows strong robustness, which indicates that our algorithm has strong robustness. Overall, LLEMP-TDR is robust to different embedding dimensions.
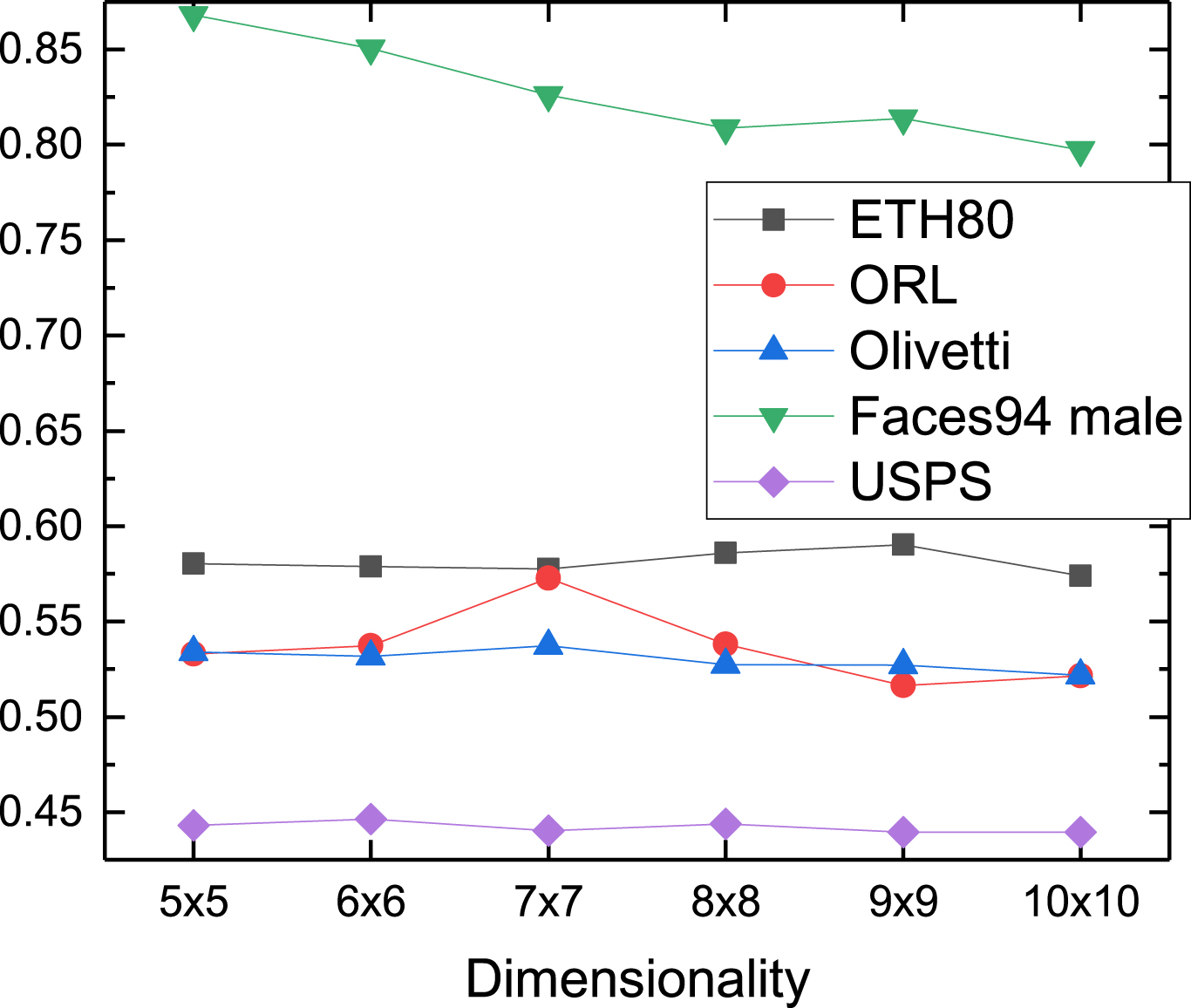
Embedding dimensionality analysis results on Clustering Accuracy
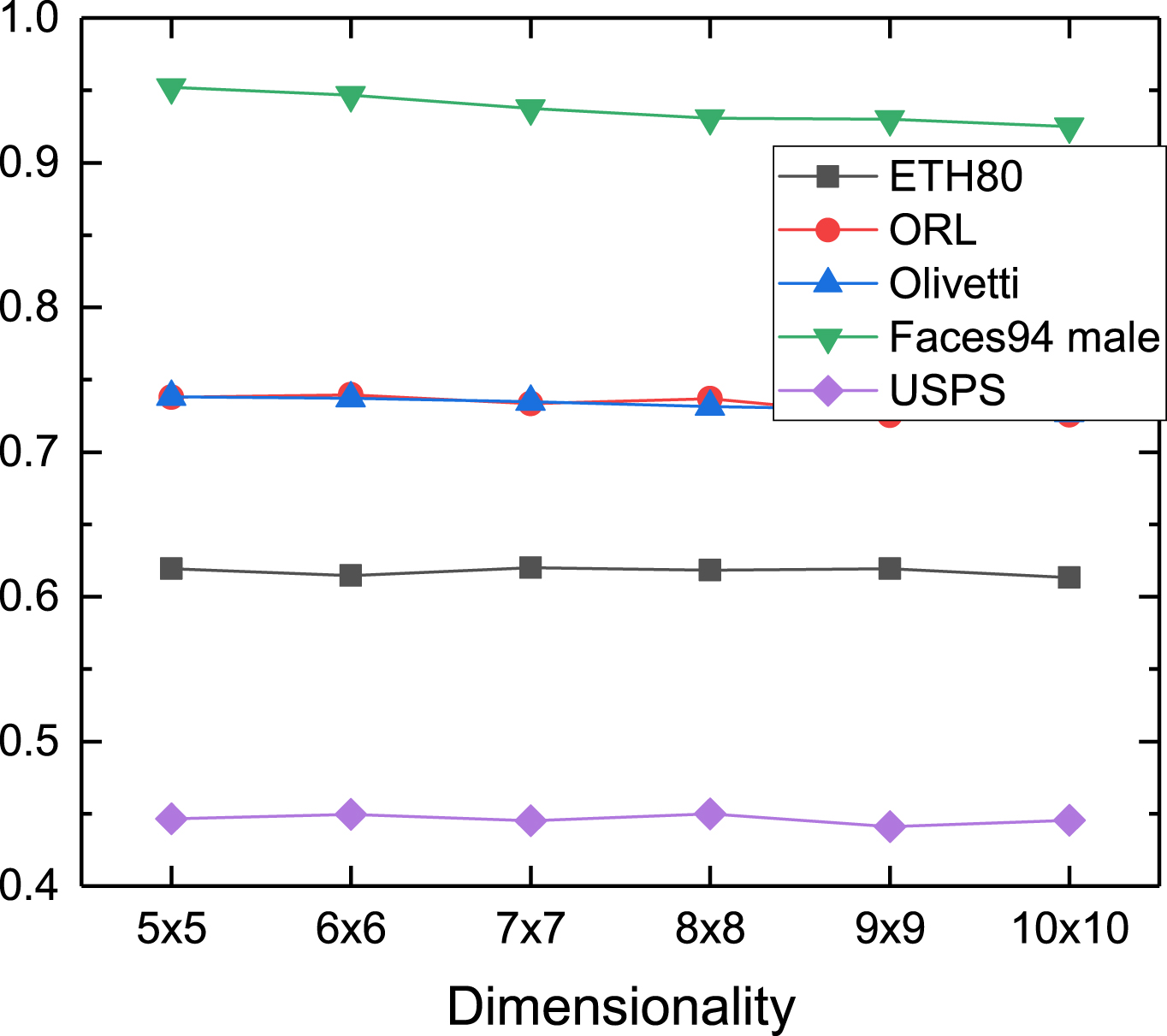
Embedding dimensionality analysis results on Clustering NMI.

Embedding dimensionality analysis results on Classification Accuracy.
This paper proposes a new dimensionality reduction algorithm for tensor data. A dimensionality reduction algorithm of tensor data based on LLE is proposed. Although LLE is popular in the dimensionality reduction of vector data, it is not suitable for tensor data. In the deduction of tenser LLE, some special skills such as the expression of tensor datasets are exploited. A dimensionality reduction framework of tensor data based on tensor mode product is proposed. Tensor mode product is an operation in tensor algebra, in which a tensor is expressed as the mode product of another tensor and a number of matrices. Careful selection of the number of rows and columns of matrices can achieve the effect of tensor dimension reduction. A new algorithm of tensor dimensionality reduction based on LLE and mode product is proposed in our manuscript, in which the matrices in mode product are determined based on LLE criterion. This algorithm is new and has the characteristics of preserving both local and global properties of high-dimensional tensor data while dimensionality reduction.
Footnotes
Acknowledgments
This work was supported in part by Science and Technology Program of Guangzhou, China under Grant 68000-42050001 and National Natural Science Foundation of China under Grant 61773022.