
Abstract
Locally Linear Embedding (LLE) is honored as the first algorithm of manifold learning. Generally speaking, the relation between a data and its nearest neighbors is nonlinear and LLE only extracts its linear part. Therefore, local nonlinear embedding is an important direction of improvement to LLE. However, any attempt in this direction may lead to a significant increase in computational complexity. In this paper, a novel algorithm called local quasi-linear embedding (LQLE) is proposed. In our LQLE, each high-dimensional data vector is first expanded by using Kronecker product. The expanded vector contains not only the components of the original vector, but also the polynomials of its components. Then, each expanded vector of high dimensional data is linearly approximated with the expanded vectors of its nearest neighbors. In this way, the proposed LQLE achieves a certain degree of local nonlinearity and learns the data dimensionality reduction results under the principle of keeping local nonlinearity unchanged. More importantly, LQLE does not increase computation complexity by only replacing the data vectors with their Kronecker product expansions in the original LLE program. Experimental results between our proposed methods and four comparison algorithms on various datasets demonstrate the well performance of the proposed methods.
Introduction
Machine learning is a hot topic in artificial intelligence research, and also has been increasingly and successfully developed in various engineering problems, such as materials engineering [1], satellite control system [36], supply chain networks [3, 8], Bioengineering [5], social engineering [6], energy vehicle [4], cloud model [2] and so on. Researches on machine learning [9, 37] usually face with a huge amount of high-dimensional data to be processed. Although the high-dimensional data could be contain plenty data information, it also includes a large amount of invalid or disturbing information, even causing the curse of dimensionality. Therefore, data dimensionality reduction is getting more and more attention. The task of data dimensionality reduction is to effectively transform the given high-dimensional data set into a meaningful low-dimensional data set. Roughly speaking, the algorithms of dimensionality reduction can be divided into two kinds: linear and nonlinear. Most of traditional algorithms of dimensionality reduction are linear, such as Principal Component Analysis (PCA) [10], Linear Discriminant Analysis (LDA) [11–13] and so on, while the emerging manifold learning algorithms are nonlinear, such as LLE [14], LE [15], HLLE [16], LTSA [17], ISOMAP [18] and so on.
LLE (acronym for Local Linear Embedding), published in Science in 2000, is honored as the first algorithm for manifold learning. LLE claims to be a locally linear but globally nonlinear algorithm, in which each high-dimensional data is linearly approximated with its nearest neighbors. The approximation coefficients are called local learning patterns. LLE keeps the local linear patterns unchanged during dimensionality reduction. Since the core of local feature preservation is intuitive and effective, LLE is developed in many applications and methods [1–35]. However, with the development of manifold learning, the defects of LLE have been exposed. For example, the original LLE is strict for local selection (neighborhood selection). If the neighborhood is too small, the local geometry structure of manifold cannot be well preserved. If the neighborhood is too large, the local reconstruction error will be too large, causing the algorithm fail. In order to solve this problem, a series of algorithms are proposed, [20–23]. The learning of local linear patterns of LLE is actually a local reconstruction process. The local reconstruction process may cause a relatively large error when the local curvature of the original data is too large. And when the center data of neighborhood is far away from the plane composed of neighbors, the local geometric information also will be lost. Therefore, the improvements of the local reconstruction process focus on finding more reasonable methods to reconstruction weights (approximation coefficients) [26]. LLE linearly reconstructs a high-dimensional data by utilizing its neighborhood data and corresponding reconstruction weights for learning the local features of the high-dimensional data set. It is the first and critical step in LLE. But actually, most of the linear reconstruction is difficult to completely. In other words, the original high-dimensional cannot be linearly reconstructed by its neighbors in some cases. To solve this problem, we propose a local quasi-linear embedding method.
In theory, local linear patterns are just an approximation to local nonlinear patterns and therefore local nonlinear embedding is an intuitive improvement. Inspired by it, we propose a novel nonlinear dimensionality reduction algorithm, named local quasi-linear embedding (LQLE). LQLE utilizes Kronnecker product to nonlinearly expand each high-dimensional data vector, and learns the local geometry structure of data by using the merits of LLE. The novelty of our method can be summarized as follows:1) the proposed method can learn an effective low-dimensional embedded representation for high-dimensional data; 2) the proposed method achieves some form of local nonlinear patterns data and keeps the local nonlinear patterns unchanged during the process of dimensionality reduction; 3) the proposed method does not increase computation complexity by only replacing the data vectors with their Kronecker product expansions in the original LLE program; 4) the proposed method can be easily transplanted to the application fields of LLE.
The remaining part of the paper is organized as follows. In the Section 2, some related works are introduced. Our mainly work are proposed in Section 3, including the extended vectors of data vectors, the local quasi-linearity for high-dimensional data, and the novel LQLE. Section 4 demonstrates the experimental results and analysis. Finally, Section 5 gives the summary of our work.
Related work
LLE has been concerned by researchers since it was proposed. It has a high value in research and application. Since it has been proposed, the improvement algorithms on it have emerged in an endless stream. Besides, researches have made detailed overviews of it [19].
Local linear embedding
The main idea of LLE is to approximate the data point with linear weight of its neighbors and preserve the linear weight in low-dimensional space. Let X = {x1, ⋯ , x N } ⊆ R D be the N points high-dimensional data set of D dimensions. The purpose of LLE is to find the low-dimensional embedding of X in the embedding space R d , (d ⪡ D). We denote the N points low-dimensional embedding by Y = {y1, ⋯ , y N } ⊆ R d .
LLE firstly find the k-nearest neighbors for each data point x i , i = 1, ⋯ , N. The neighbor set is defined as N i = {xi1, ⋯ , x ik }. For each sample x i , the linear weight {w ij , j = 1, ⋯ , k} can be computed by solving the following problem:
After the linear weight W = {w ij , j = 1, ⋯ , k, i = 1, ⋯ , N} is learned, the low-dimensional embedding can be found, which best preserves the geometric properties of the original space. That is to minimize:
LLE reduces the dimension of data by preserving the relationship between data point and neighborhood locally, so the selection of neighborhood plays an important role in the performance of the algorithm. The Euclidean distance is used directly in the original LLE to find the neighbors. Some later works attempt to introduce other method to measure the distance for selecting neighbors.
Kernel Local Linear Embedding (KLLE) [20] proposed by Dennis Deste finds the k-nearest neighbor point with kernel distance (linear kernel) instead of Euclidean distance in original LLE algorithm. The KLLE proved the feasibility of substituting Euclidean distance with kernel distance. Varini believed that selecting neighbor points with Euclidean distance would make two points with short Euclidean distance but long geodesic distance select as neighborhood points. To avoid this situation, LLE with geodesic distance (ISO-LLE) [21] was proposed, which searches for the neighbor points with geodesic distance. Experiments show that ISO-LLE can solve the above situation effectively. Weighted Local Linear Embedding (WLLE) [22] adjusts the LLE algorithm based on weighted distance [23], which gives the original data with high density a smaller weight scaling while those with low density a larger weight scaling. WLLE works well in preventing the selected neighbor points from being over congregating in uneven distributed locality. Rank-Order Distance [24] was proposed to solve the problem that different sparsity in different clusters leads to inaccurate image classification in face recognition. Rank-Order Distance was applied in the selection of neighbors in LLE. Similar to the before algorithm, LLE based on Rank-Order Distance [25] was proposed, and the application of Rank- Order Distance also solve the problem of uneven density to some extend.
Some work focus on use different reconstruction weights to improve LLE. As the weight matrix is set, one direction of improvement is to find more reasonable methods to reconstruction weights. Nonlinear Embedding Preserving Multiple Local-Linearities (NEML) [26] proposed a nonlinear pattern with multiple weights and proved that multiple sets of local construction weights that are approximately optimal and can be used to improve the stability of LLE which can improve the performance of it.
Out-of-sample extension of LLE
The Original algorithm of LLE didn’t provide an effective solution to out-of-sample problem. To solve this problem, NPE [27], NPP [28] and ONPP [29] are proposed. These algorithms tried to match the result of LLE with linear projection from high-dimensional space to low-dimensional space. Given the high-dimensional data set X ⊆ R
D
, these algorithm attempt to find out its low-dimensional embedding Y ⊆ R
d
and the explicit projection from R
D
to R
d
at the same time. That is to find a projection matrix V ∈ RD×d that satisfy Y = V
T
X. To solve this problem, the optimization problem 2 should be transformed:
After training, the out-of-sample points x o can be directly projected into low-dimensional space by y o = V T x o .
Based on these work, Hong Qiao proposed a non-linear projection method NPPE and its simplified algorithm SNPPE [23], which expanded the projection coefficients to vector polynomials. The coefficients of y
i
are not simply linear combination of coefficients of x
i
but a polynomial instead. The form of projection y
i
= V
T
x
i
can be rewritten as
In recent years, besides the improvements to LLE algorithm, the development of LLE mostly lies in the application of the algorithm [24, 31]. Proposed a sparse linear embedding based on LLE and ONPP. Besides manifold learning itself, another important branch of LLE application is image processing, such as feature extraction [25, 32]. Moreover, the value of LLE algorithm is not limited in algorithm research, but also showed in various engineering problems, which had proved its practicability [1, 33– 35].
Given the high-dimensional dataset X = [x1 ⋯ x N ] ∈ RD×N, the task of dimensionality reduction is to get a low-dimensional dataset Y = [y1 ⋯ y N ] ∈ Rd×N, where y n is the low-dimensional representation of x N and n = 1, ⋯ , N, (d ⪡ D). In this paper, we proposed a local quasi-linear embedding (preserving) algorithm for data dimensionality reduction. Note: In the section, the dataset is represented by a matrix, and each column of it represents a data vector.
The extended vectors of data vectors
Let x = [x(1) ⋯ x(D)]
T
∈ R
D
denotes a data vector, in which x(i) represents the ith component of x, i = 1, ⋯ , D, then
The p-order extended vector x p of x is then defined as
For all x
n
, let xn1, ⋯ , x
nK
be its K nearest neighbors in the given data set, and then
The derivation of w n is as follows:
LQLE takes into consideration the fitting relationship between the high order component, so the computed W in LQLE is different from the weights matrix in LLE.
Corresponding to the local data x n and {xn1, ⋯ , x nK } in high-dimensional space, the dimension-reduced data in low-dimensional space are y n and {yn1, ⋯ , y nK }. LQLE proposed in this paper preserves the same locally linear pattern w n between y n and {yn1, ⋯ , y nK }, i.e.,
Making further derivation,
In this section, we verify the effectiveness of the proposed algorithm by conducting the dimensionality reduction experiments and classification experiments with LLE [14], WLLE [22], and ONPP [29] algorithms on both toy and real-world data sets. Among these algorithms, LLE [14] is the classical local linear embedding algorithm, WLLE [22] is the representative improved LLE algorithm based on neighborhood selection, and ONPP [29] is the typical out-of-sample extension of LLE.
Datasets description and experimental setting
Toy datasets: two data sets are generated by randomly selecting 2000 data samples from the Swiss Roll and Swiss Hole, respectively.
USPS [38]: a famous handwritten digit dataset (Fig. 1), contains handwritten images of 10 classes corresponding to the digits 0 to 9, with 1100 sample images per class. The size of each sample image is 16×16. We randomly select 200 images from each class to construct the experimental dataset with a total of 2000 images.
Binary Alphadigits [39]: another handwritten dataset (Fig. 2), contains binary 20×16 digits of 0 through 9 and capital A through Z, 39 examples of each class. We only use the capital A through Z, and randomly select 30 images from each class to construct the experimental data set with a total of 780 images.

Partial data of USPS data set.

Partial data of Binary Alphadigits data set.
COIL20 [40]: an object data set (Fig. 3), contains 20 objects taken from different angles, and 72 images per object. Each image is uniformly processed as the size of 32×32.

Partial data of COIL20 data set.
Table 1 lists the parameter settings of the three real-world datasets in the experiments.
Parameters settings of data sets
We first compare the LQLE algorithm with the LLE algorithms on two toy data sets. The number of neighbor is set to be K = 10 and the polynomial order is set to be p = 2. The experiment results are showed in Fig. 4. It can be seen that the LLE algorithm has a poor performance when K = 10. But the proposed LQLE would achieve a better result. It means that our LQLE introduces more local information to data dimensionality reduction.
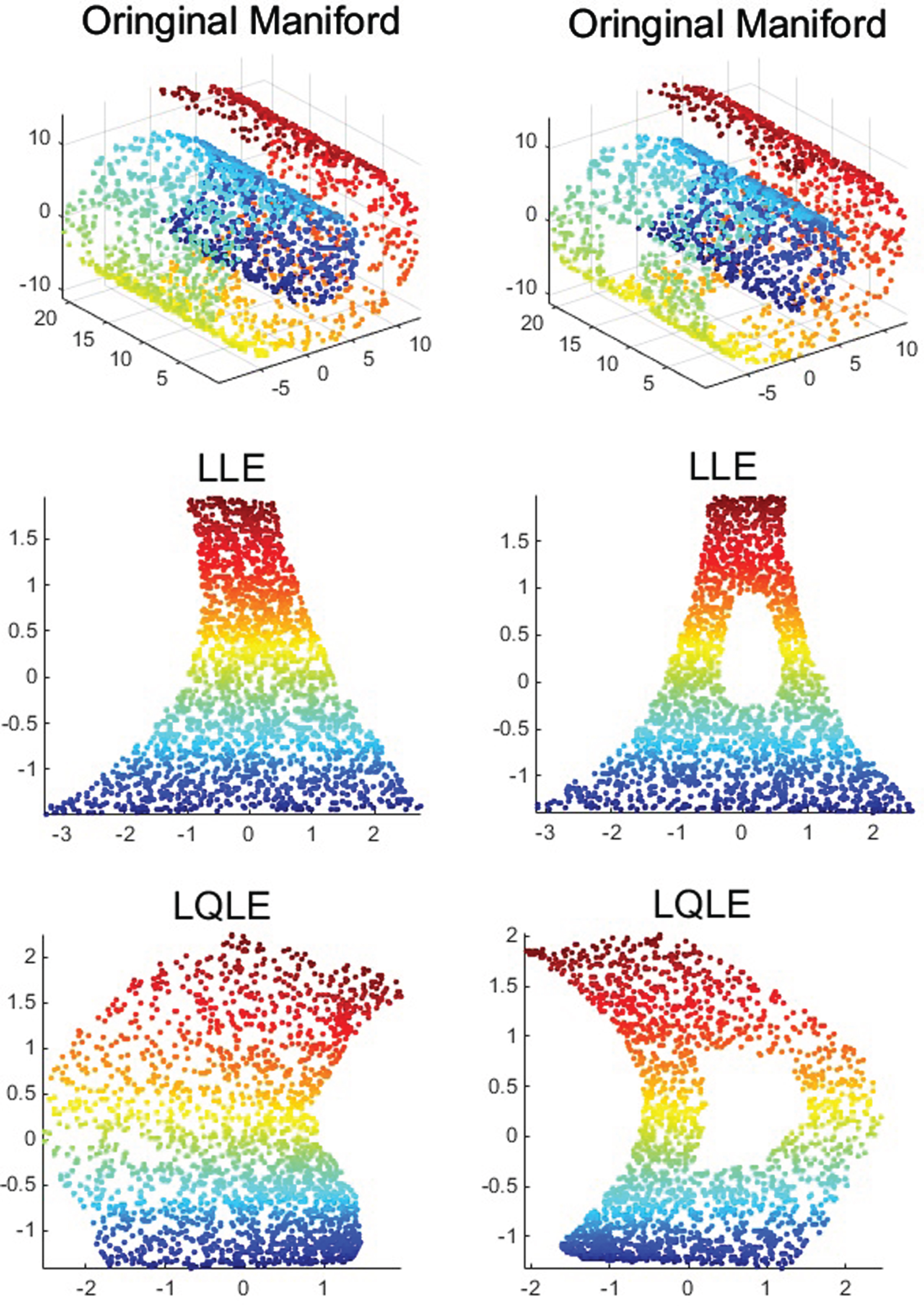
The dimensionality reduction results of LLE and LQLE on toy dataset.
In the classification experiments, we adopt the KNN classifier with K = 8 on reduced-dimensional data sets, and use the cross-validation method for computing the classification accuracy. We randomly select 50% of the dimensionality reduced data from each category of the data set as the training set, and the remaining 50% as the test set. Each process repeats 5 times and the average of the classification accuracy of the 5 tests is used as the final. Generally, the number of neighborhood points for each compared algorithm is selected according to the principle that the number of neighborhood points is about 1% of the number of data in the corresponding data set. Dim . denotes the dimension of the dimensionality reduction results. The value of Dim . is setting from 2 to 100 on USPS and Binary Alphadigits data sets, and is setting from 2 to 200 on COIL20 data set. The polynomial order in LQLE is set to be p = 2.
Table 2 lists the average classification results of four comparison algorithms on the USPS data set. In order to show more direct observation, the average classification results of all experiments on USPS data set are also shown in Fig. 5 for visualization. Seen from them, when Dim. is less than 60, ONPP has the worst performances on USPS, which maybe caused by strict global linear constraints. In most cases, WLLE has the best results, our LQLE is second, and the last is LLE. But when Dim. is less than 15, our method works better than WLLE. When the dimension of dimensionality reduction is less than 50, the performance of all the algorithms almost become better as the Dim. increasing. Overall, the performances of our LQLE are better than LLE. It proves that the proposed method is an improvement to LLE. And with increasing of the dimension, the performances of LQLE maintain a certain degree of stability. It means that our algorithm is robust.
The average classification results of four compared algorithms on USPS data set. The classification performances of four compared algorithms versus different dimension (Dim .) on USPS data set are shown here. LQLE is the proposed algorithm
The average classification results of four compared algorithms on USPS data set. The classification performances of four compared algorithms versus different dimension (Dim .) on USPS data set are shown here. LQLE is the proposed algorithm

The average classification results of four compared algorithms on USPS data set. LQLE is the proposed algorithm.
Table 3 exhibits the average classification results of the four comparison algorithms on the Binary Alphadigits data set when the dimension of the dimensionality reduction is changing. Fig. 6 shows the classification performances of all compared methods on Binary Alphadigits data set. Obviously, when the dimension of dimensionality reduction is less than 60, WLLE has the worst performances on Binary Alphadigits. It means that on this data set, using weighted distance in WLLE cannot improve the performance of LLE. When Dim. is less than 10, ONPP works worse than LLE and our LQLE. And when Dim. is larger than 40, LQLE works better than LLE. And overall, with increasing of the dimension, LQLE still maintains better performances. And all the average results of the four compared methods reported in the last column of Table 3 further illustrate the robustness of our algorithm.
The average classification results of four compared algorithms on Binary Alphadigits data set. The classification performances of four compared algorithms versus different dimension (Dim .) on Binary Alphadigits data set are shown here. LQLE is the proposed algorithm
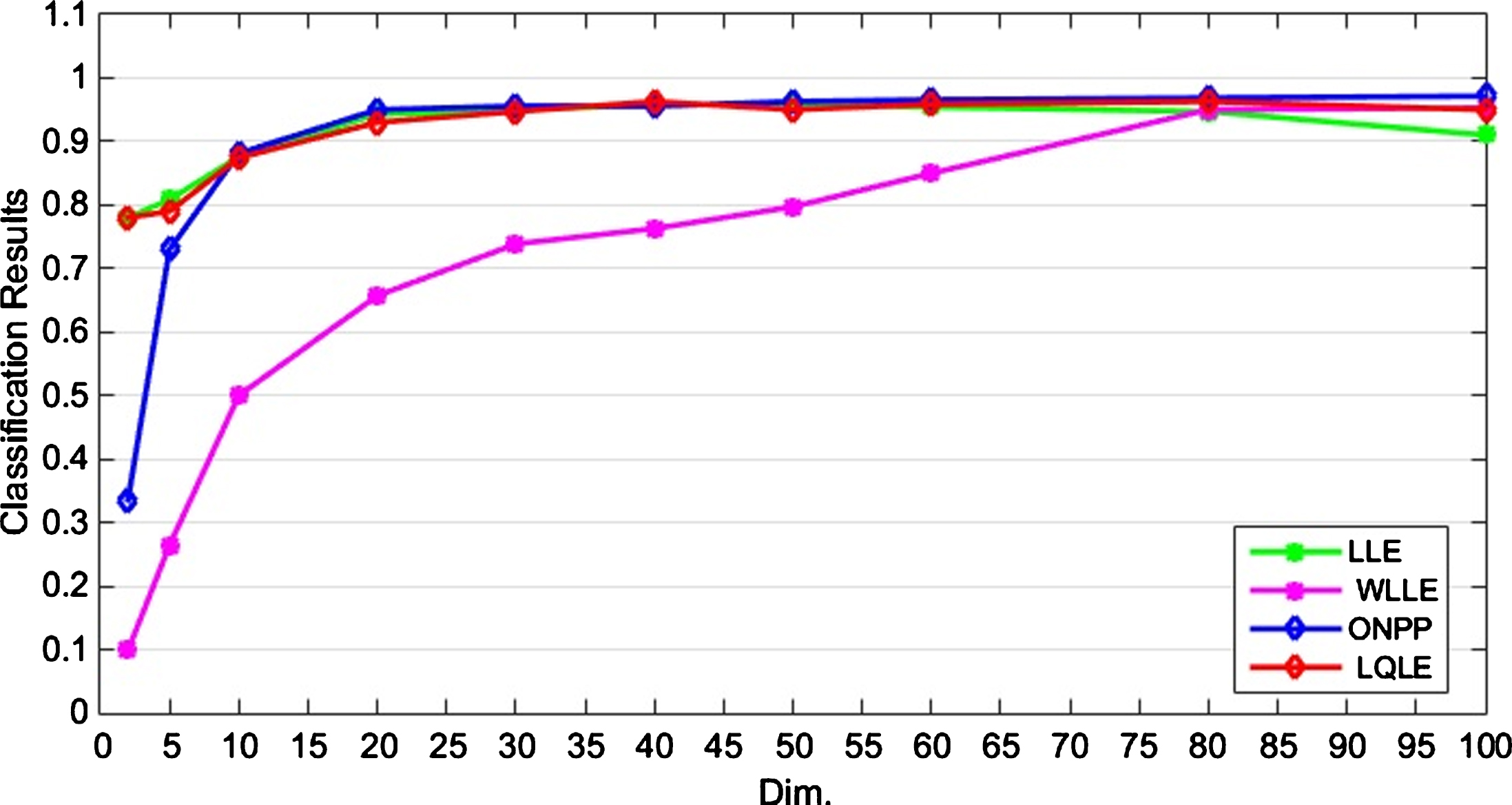
The average classification results of four compared algorithms on Binary Alphadigits data set. LQLE is the proposed algorithm.
Table 4 lists the average classification results of the four comparison algorithms on the COIL20 data set when the dimension of the dimensionality reduction is changing. And Fig. 7 shows the classification performances of all compared algorithms on COIL20. From them, we can observed that different from the results on the Binary Alphadigits, when Dim. is less than 70, WLLE almost has the best performances. Follow it, our algorithm also works well on COIL20 data set. But the performances of WLLE are not stable as the Dim. increasing. Overall, the performances of the proposed LQLE are better than LLE in most cases. And LQLE still maintains better performances on COIL20 as the Dim. increasing. Furthermore, the total average results of the four compared methods reported in the last column of Table 4 show that our algorithm has the best result. To sum up, our LQLE algorithm can maintain better performance on three different data sets. It further proves that the proposed algorithm has good robustness.

The average classification results of four compared algorithms on COIL20 data set. LQLE is the proposed algorithm.
The average classification results of four compared algorithms on COIL20 data set. The classification performances of four compared algorithms versus different dimension (Dim .) on COIL20 data set are shown here. LQLE is the proposed algorithm
In the paper, we propose a novel nonlinear dimensionality reduction, named local quasi-linear embedding (LQLE). The proposed method nonlinearly expands each data vector by using Kronecker product and then performs local linear embedding for these nonlinearly-expanded data vectors. LQLE explores the local nonlinear structure of data and learns an effective low-dimensional embedded representation for the high-dimensional data. In general, the nonlinear improvement to the local linear patterns of LLE may lead to a significant complexity. Compared with LLE, LQLE hardly increases any computational complexity and inherits the merits of LLE. Therefore, it can be easily transplanted to the application fields of LLE. We also conduct the dimensionality reduction and classification experiments on both toy and real-world data sets to demonstrate the effectiveness of the proposed method.
Footnotes
Acknowledgment
This work is supported in part by the Guangdong Basic and Applied Basic Research Foundation under Grant 2019A1515111143 and by the Natural Science Foundation of China under Grant 62006042.