
Abstract
In practice, the class imbalance is prevalent in sentiment classification tasks, which is harmful to classifiers. Recently, over-sampling strategies based on data augmentation techniques have caught the eyes of researchers. They generate new samples by rewriting the original samples. Nevertheless, the samples to be rewritten are usually selected randomly, which means that useless samples may be selected, thus adding this type of samples. Based on this observation, we propose a novel balancing strategy for text sentiment classification. Our approach takes word replacement as foundation and can be divided into two stages, which not only can balance the class distribution of training set, but also can modify noisy data. In the first stage, we perform word replacement on specific samples instead of random samples to obtain new samples. According to the noise detection, the second stage revises the sentiment of noisy samples. Toward this aim, we propose an improved term weighting called TF-IGM-CW for imbalanced text datasets, which contributes to extracting the target rewritten samples and feature words. We conduct experiments on four public sentiment datasets. Results suggest that our method outperforms several other resampling methods and can be integrated with various classification algorithms easily.
Keywords
Introduction
With the development of social networks and e-commerce, users have generated a large amount of text data. In actual applications, it is necessary to mine the subjective tendencies of these opinioned texts so that we can provide valuable information for practitioners and assist them with better decisions [1]. As a fundamental task of natural language processing, sentiment classification is utilized to predict the sentiment polarity of a text. Nevertheless, most existing text classification algorithms assume that the number of samples in different categories is balanced. On the contrary, the class distribution of the dataset is usually skewed in real scenarios, where the sample size in one class is much larger than the other one. As the problem of imbalance gets exacerbated, the performance of classifiers drops dramatically [2]. Such kind of sentiment classification is known as imbalanced text sentiment classification. The class with larger sample size is called the majority class and the class with smaller sample size is called the minority class.
Many methods have been proposed to solve this problem and can be generally divided into two types: data preprocessing and algorithm-level methods [3]. On the one hand, data preprocessing mainly refers to resampling methods, including over-sampling and under-sampling. Over-sampling methods generate new minority class samples, whereas under-sampling methods eliminate majority class samples to balance the dataset. On the other hand, algorithm-level methods mainly include cost-sensitive learning [4] and ensemble learning [5]. Cost-sensitive learning assigns different misclassification costs for different classes. The class easy to be misclassified will have more cost. Ensemble learning under-samples the majority class to obtain several balanced subsets and then train a classifier for each one. Finally, all classifiers work together to predict the label of new data.
Compared with algorithm-level methods, data preprocessing strategies are more universal. They are conducted before the training stage and can be easily integrated with different classification algorithms [6]. While various data preprocessing strategies are outstanding in numerical data applications, most of them are not suitable for text sentiment classification since text is not structured data. The basic units of texts are words rather than numbers [7]. Although we can utilize term weighting to represent the text as a vector, there are so many words in a corpus that the vector will be high-dimensional and sparse. In addition, if we perform numerical resampling directly in vector space, the semantics of the text will be ignored. A popular scheme is employing data augmentation techniques to over-sampling, including generation-based methods and replacement-based methods [8]. Generation-based methods depend on deep learning models to generate samples, but the quality of new sample cannot be guaranteed because of the limited capability of model [9]. Replacement-based methods generate new samples by replacing words in original samples with synonyms or antonyms [10]. However, most existing replacement-based methods have a shortcoming in common. The samples to be replaced are randomly selected, which means noisy data with vague or wrong sentiment may be selected. Therefore, noisy data will increase, bringing challenges to the classifier.
To this end, we propose a novel balancing strategy for imbalanced sentiment datasets. The approach is based on word replacement and is divided into two stages: over-sampling and noise modification. In the over-sampling stage, we extract representative data whose sentiment polarity is explicit according to the data distribution in vector space. Then we generate new samples to balance the dataset by replacing feature words of the representative data. The second stage performs noise detection to find noisy data whose sentiment polarity is vague or wrong. After that, we modify these noisy data with the right feature words. The whole process is illustrated in Fig. 1. In short, the main contributions of our study are 4-fold: Inspired by TF-IGM, we propose a novel term weighting scheme called TF-IGM-CW for the two-stage strategy. The weighting can be used to extract feature words and separate different classes in vector space. The concept of sentiment centroid is developed to extract representative data and noisy data in the two stages. Sentiment centroid is the centroid vector of all text vectors in a class, which represents the class effectively. We propose a two-stage balancing strategy, which not only can balance the class distribution of the training set but also can modify the sentiment polarity of noisy data. We conduct experiments on four public sentiment datasets. Results show that our method is superior to several other resampling methods. Both the over-sampling stage and the noise modification stage can improve the performances of classifiers.
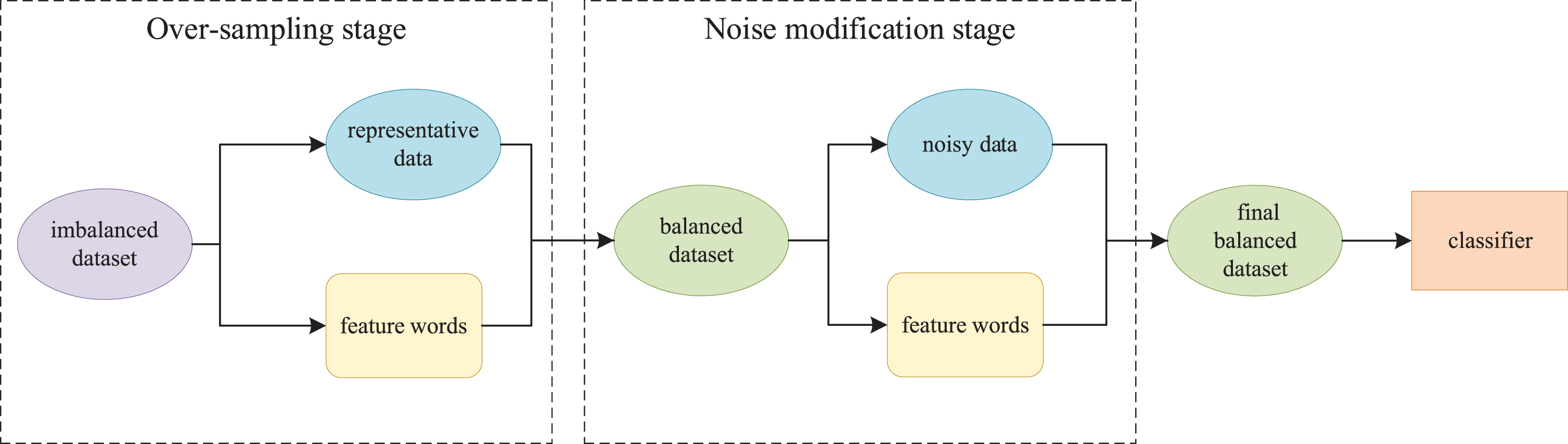
Overview of our two-stage balancing strategy.
The remainder of this paper is organized as follows. In Section 2, related works are summarized. The proposed term weighting and balancing strategy are explained in Section 3 and Section 4. Experimental results and analyses are presented in Section 5. Section 6 concludes the paper.
In this section, we review the issue of imbalanced sentiment classification and existing main solutions.
The issue of imbalanced sentiment classification
Skewed data distribution is very prevalent in sentiment datasets. Taking product reviews as an example, generally, positive reviews are the majority and negative reviews are the minority. Businesses are more interested in the latter because they can make improvements to the product by analyzing negative reviews. Nevertheless, the issue of imbalanced datasets does damage to the performances of classifiers. We can measure the severity of imbalance problem according to imbalance ratio (IR) [11], which is defined as the relationship between the sample size of majority class and minority class, by the expression:
In a general way, imbalanced text sentiment datasets mainly have three characteristics and the caused problems are as follows: Imbalanced size: It refers to the large gap of sample size between the majority class and the minority class. To pursue high accuracy, the classifier ignores the minority class and prefers the majority class [12]. We consider an extreme case in the binary classification task. When IR = 9.9, the accuracy can be 99% even if the classifier predicts all samples as the majority class. Small disjuncts [13]: Since the sample size is relatively small, the minority class has much fewer features. Consequently, minority class samples are distributed in numerous feature spaces [14] and surrounded by majority class samples, as shown in Fig. 2(a). This results in great difficulty for classifiers to learn the features of minority class. Class overlapping [15]: In imbalanced datasets, samples belonging to different classes may overlap, especially for the minority class, as shown in Fig. 2(b). The sentiment of these samples occurring in other class area is vague. They are disadvantageous to classifiers and called noisy data.
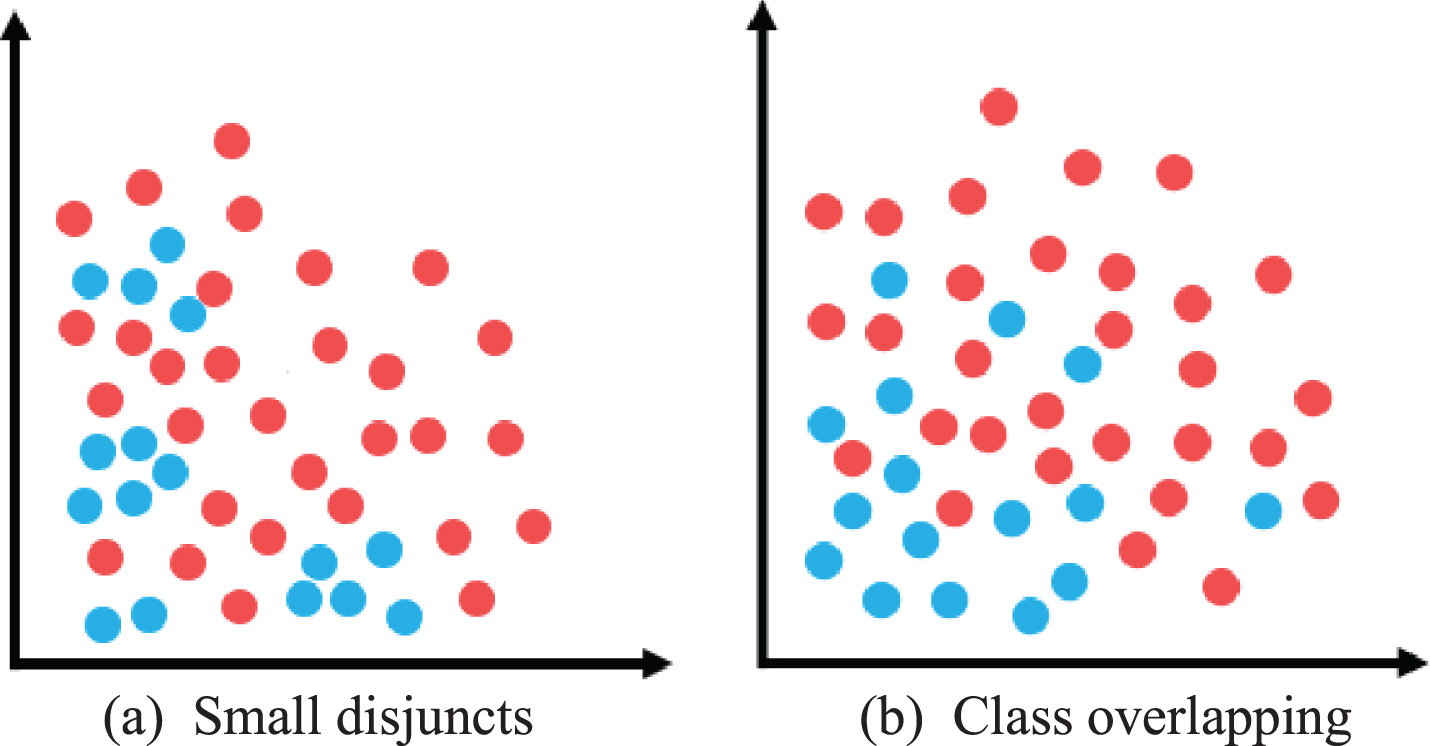
Examples of imbalanced dataset: (a) small disjuncts and (b) class overlapping. The red points are the samples of majority class and the blue points are the samples of minority class.
The existing solutions for imbalanced sentiment classification consist of data preprocessing methods and algorithm-level methods.
Data preprocessing methods include over-sampling and under-sampling, while there are few related studies focused on text sentiment classification. Li et al. [2] propose a clustering-based under-sampling framework, which groups the majority class into serval clusters and only retains the representative samples in each cluster. Prusa et al. [16] discard majority class samples with random under-sampling (RUS) to balance the class distribution of Twitter datasets. Wang et al. [17] propose the BRC algorithm to cutting majority class samples in the dense boundary region. However, under-sampling methods may lose many features of the majority class. In the aspect of over-sampling, the basic strategy is random over-sampling (ROS), which augments the minority class by randomly duplicating minority class samples, but it suffers from the problem of over-fitting.
In regard to the above problem, researchers employ data augmentation techniques to over-sample, mainly including generation-based methods and replacement-based methods. Generation-based methods address imbalance problems with generative models. Hu et al. [18] generate controlled text with an auto-encoder backbone. Luo et al. [19] utilize sequence generative adversarial networks to add minority samples. Nevertheless, the quality of the sentence generated by these models is always poor. Replacement-based methods generate new sentences by replacing some words in the original sentences. Zhang et al. [20] extract replaceable words from the text firstly, and then randomly select some of them to replace with synonyms. Fadaee et al. [21] pay attention to the rare words and replace only these words in a sentence. Wei et al. [22] present a set of easy data augmentation (EDA) techniques for text classification tasks, including synonym replacement, random insertion, random swap, and random deletion. The above replacement-based methods show high effectiveness in imbalanced text classification. However, they have a drawback in common. The processed sentences are random, which means data contributing nothing to the classifier may be selected. As a result, this type of data easily misclassified by the classifier increase. In this paper, we address this disadvantage and propose a non-random replacement-based method for imbalanced sentiment classification. The sentiment polarity of new samples can be controlled to a large extent.
The algorithm-level method is another solution. Since they are not the focus of our paper, we only give a brief introduction to them. Madabushi et al. [23] combine cost-sensitivity with BERT to improve the performance of classifier for imbalanced text datasets. Wang et al. [24] study the effectiveness of ensemble learning for imbalanced text sentiment classification.
Proposed term weighting scheme
In our method, we extract representative data and noisy data based on the class distribution of text datasets in vector space. Toward this aim, we improve TF-IGM weighting which is described in Section 3.1 and propose a novel term weighting called TF-IGM-CW in Section 3.2. Moreover, feature words of different classes are extracted respectively, which is explained in Section 3.3.
Overview to TF-IGM weighting
Generally, we utilize term weighting schemes (TWS) to represent a word as a number and transform texts into vectors. In this way, we can mine the deep relationships between texts, such as similarity. Besides, term weighting can measure the class distinguishing power of a word [25], which can be used to extract feature words. A term weighting usually consists of local factor and global factor. Term frequency (TF) is generally used as local factor, which refers to the frequency of a term in a document. Global factor reflects the occurrences of a specific term in the entire corpus, which can be utilized to extract feature words.
In this subsection, we review a recently proposed term weighting scheme called TF-IGM (term frequency & inverse gravity moment) [26], which can precisely measure the class distinguishing power of a term. The formula of TF-IGM is as follows:
In this formula, TF (t i , d k ) is the term frequency of term t i in document d k . M represents the number of classes in the dataset. f ir is the number of documents containing the term t i in the r - th class, which are sorted in descending order with r being the rank. λ is the balance coefficient.
The core of TF-IGM is a statistical model called “Inverse Gravity Moment” (IGM). IGM is a global factor, which can show the class distinguishing power of a term by considering the inter-class distribution. For term t i , IGM sorts all classes in descending order according to the number of documents containing t i , and finally weights them. λ is used to balance local factor and global factor. In the related literature [26], its value range is set to be 5.0–9.0 and the default is 7.0, which is appropriate for different datasets. By calculating the IGM value of each word, we can extract feature words that can distinguish the class effectively in the dataset. The word with a larger IGM value has a stronger ability to distinguish classes.
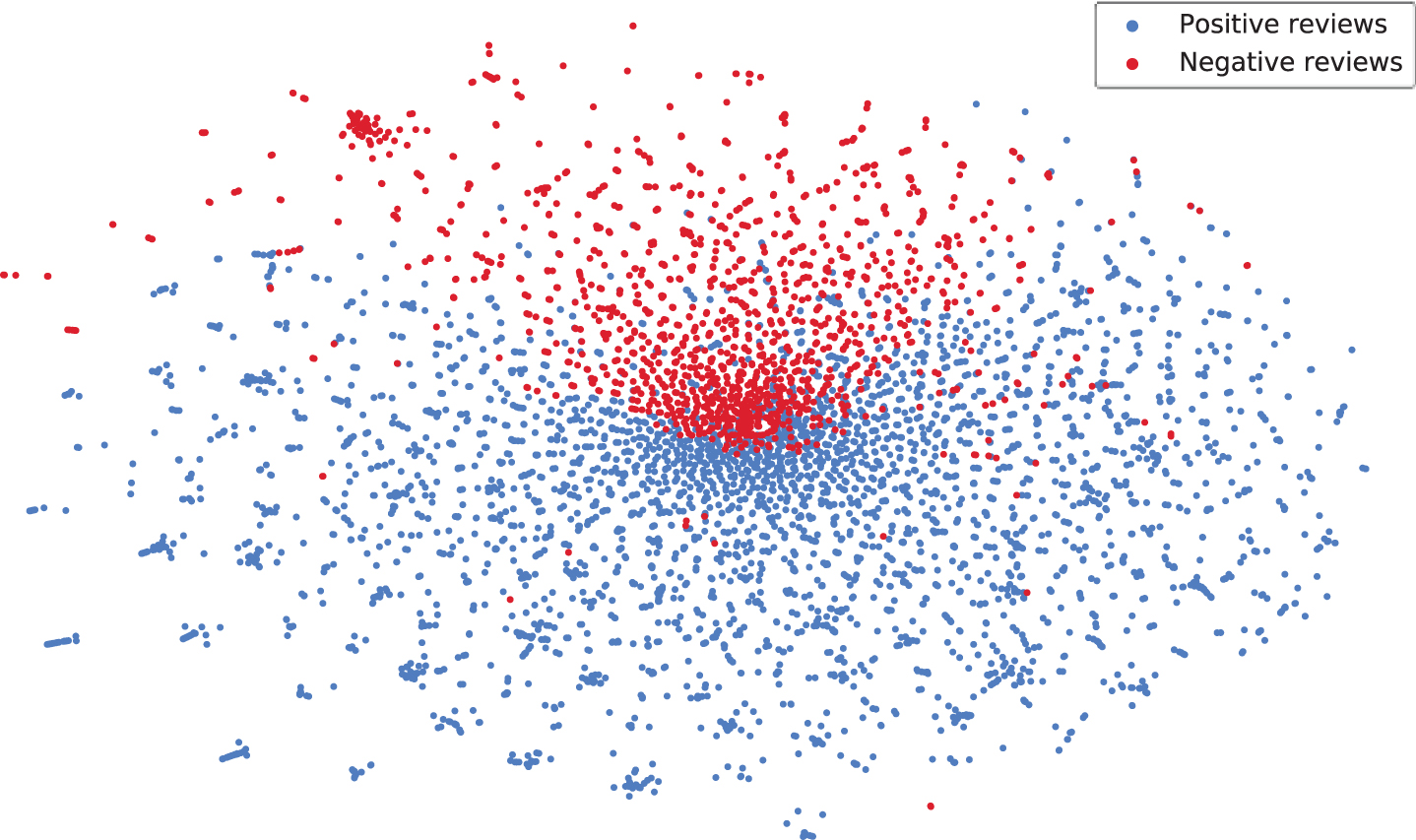
Due to the full use of inter-class distribution information, the term weighting TF-IGM can accurately measure the class distinguishing power of words. And the related literature [26] proves that TF-IGM has an excellent performance in text classification tasks. However, TF-IGM has two drawbacks: (a) By means of IGM, we can only find the feature words of the entire dataset rather than feature words belonging to different classes; (b) Since each word shares the same IGM value in different classes, after the vectorization of text data with TF-IGM, the data of different classes will be mixed in vector space. Taking the binary-class dataset Movie Review Data (MR) [27] as an example, we select 4,265 positive and 1,705 negative movie reviews, so positive reviews are the majority class and negative reviews are the minority class. Particularly, the imbalance ratio is 2.5. We use TF-IGM to vectorize sentences. The dimensionality of sentence vector is equal to the number of words in the corpus, and each word corresponds to a dimension. The value of each dimension is the TF-IGM value of the corresponding word in the sentence. Then we apply t-SNE [28] to these vectors and plot their 2-D representations, as shown in Fig. 3. The data points of the majority class and the minority class are mixed in vector space, so the useful information available to us is quite limited. Similar problems also exist in many popular term weighting schemes, such as TF-IDF.

Distribution of MR dataset in vector space based on TF-IGM.
In order to solve the above problems, we propose a class-specific factor called class weighting (CW). CW considers the intra-class distribution of a term and can measure the representative power of a term in a specific class. The CW values of each term in different classes are independent, which can be formulated as in the following equation:
Formula (3) indicates that CW (t
ij
) depends on the intra-class distribution of term t
i
in the dataset. CW (t
ij
) will be assigned a larger value when term t
i
frequently occurs in class C
j
and occasionally occurs in other classes. The word with better representative power will have a larger CW value. The minimum value of CW (t
ij
) is 0 when t
i
never occurs in class C
j
, and the maximum value is log(1 + D) when t
i
occurs only in class C
j
. To unify the distribution of CW values in different classes, CW value can be transformed to fall in the interval [0, 1.0] by applying Min-Max normalization:
We incorporating the class-specific factor CW into TF-IGM and achieve an improved term weighting called TF-IGM-CW:
where TF - IGM - CW (t ij ) represents the TF-IGM-CW value of term t i in class C j and λ in TF - IGM (t i ) is set to the default value of 7. We visualize the selected MR data with TF-IGM-CW in the same way, as shown in Fig. 4. As thus, data points belonging to different classes are separated in vector space. We can extract the representative data and noisy data depending on the class distribution.
Distribution of MR dataset in vector space based on TF-IGM-CW.
Word replacement is one of the most popular data augmentation techniques for imbalanced sentiment classification. In previous studies [20–22], the word to be replaced is usually randomly selected or selected based on its part of speech and occurrence frequency. Taking a different approach, we replace feature words in a target text with synonyms or antonyms, which can alleviate the problem of imbalanced features. Generally, the global factor of a term weighting can be used to extract feature words. In this study, in order to extract feature words of different classes respectively, we use the combination of global factor IGM and class-specific factor CW in TF-IGM-CW. Due to the combination of inter-class and intra-class information, IGM-CW not only can measure the class distinguishing power, but also can measure the representative power of a term for a specific class. The IGM-CW value of term t
i
in class C
j
(j = Ma, Mi) can be expressed by the following equation:
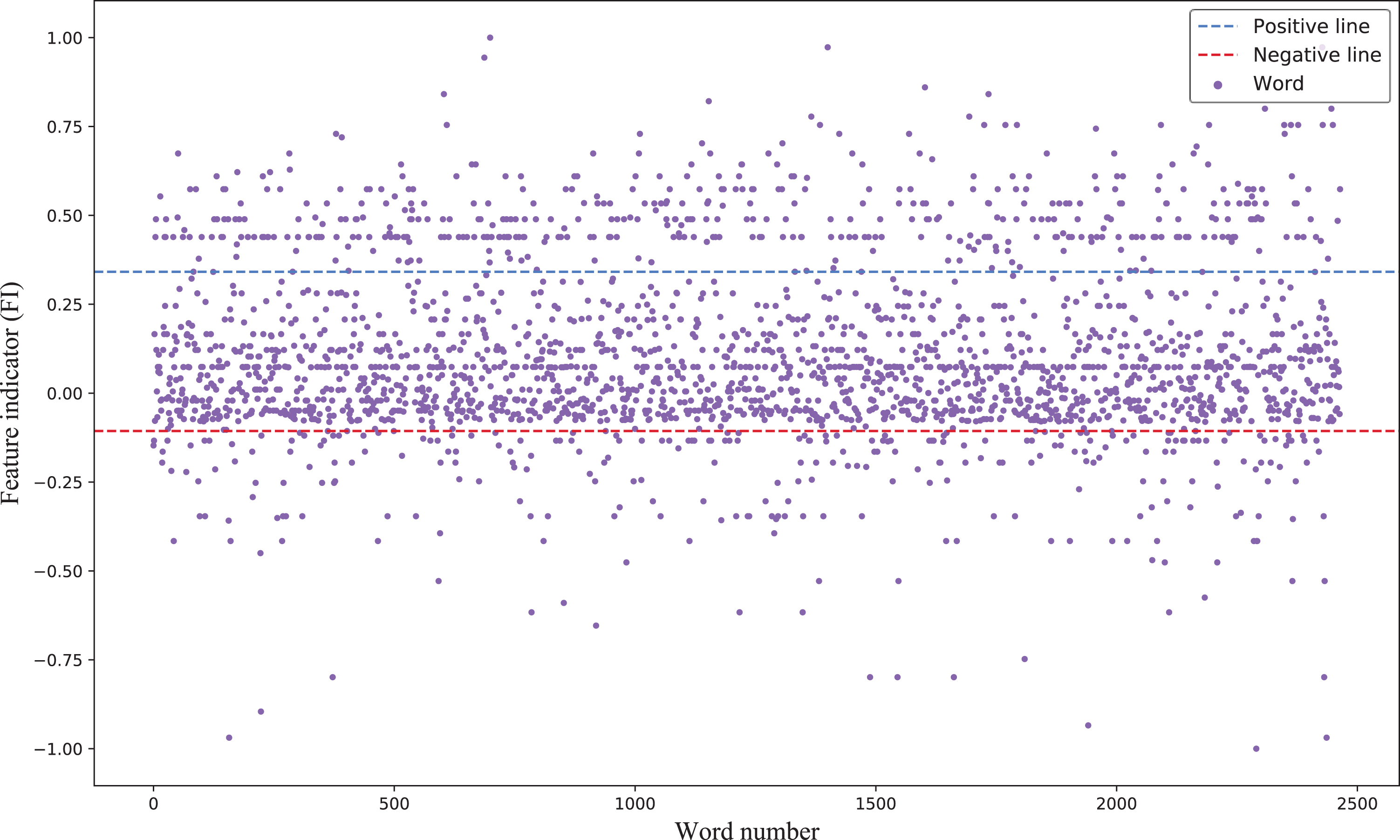
The FI values of words in MR dataset.
In addition, we further divide all words into ordinary words, feature words of the majority class and the minority class in the light of threshold K (0 < K < 1): Feature words of the majority class: According to the descending order of FI value, we select majority class words with a ratio of K as feature words of the majority class. These words have a much higher frequency of occurrence in the majority class than in the minority class. They can effectively represent the majority class and sparsely distributed on the top of coordinate axis. Feature words of the minority class: According to the ascending order of FI value, we select minority class words with a ratio of K as feature words of the minority class. These words have a much higher frequency of occurrence in the minority class. They can represent the minority class and sparsely distributed on the bottom of coordinate axis. Ordinary words: Excluding all feature words, the rest are ordinary words. These words have an approximate frequency of occurrence in both two classes. The class representative power of them is quite weak and they are densely distributed on both sides of FI = 0.
The value of K determines the number of feature words, so we show the effect of K on classification performance in the experimental section. In order to demonstrate the effectiveness of our method for extracting feature words, we set K to 30% and thus get two boundaries in Fig. 5. Words above the blue dotted line are feature words of the majority class, and words below the red dotted line are feature words of the minority class. We utilize WordCloud 1 to visualize some feature words according to the FI value, as shown in Fig. 6. Most feature words in the majority class can express a positive sentiment, such as ‘wonderfully’ and ‘entertainment’. And most feature words in the minority class are negative, such as ‘unfunny’ and ‘badly’.

Word cloud of feature words in MR.
There is great randomness in most of the existing over-sampling strategies based on word replacement. Specifically speaking, the data to be replaced may have no contribution to the classifier or even bring interference to it, such as noisy data whose sentiment polarity is wrong. Thus, this type of data may be added after over-sampling. Our non-random two-stage strategy mitigates the weakness by performing word replacement on some specific data. In this part, sentiment centroid is developed to extract these specific data, which is explained in Section 4.1. Then details of the over-sampling stage and the noise modification stage are introduced in Section 4.2 and Section 4.3.
Sentiment centroid
In Section 3, we show TF-IGM-CW can vectorize the text data and separate different classes in vector space. In this subsection, we propose the concept of sentiment centroid (SC). For text sentiment datasets, sentiment centroid is the centroid of all sentence vectors in a class. According to the distance between the sentence vector and the sentiment centroid, we can identify whether a sentence is representative data or noisy data. Generally, to obtain the centroid of a group of vectors, we calculate the average value of the corresponding dimensions of all vectors, and the resulting vector is the centroid. However, from our perspective, the significances of sentences are unequal in sentiment datasets. The sentence with stronger class distinguishing power should be assigned a greater weight when we calculate the centroid.
Since IGM-CW can measure the class distinguishing power and the class representative power of a word, we calculate the average IGM-CW value of all words in a sentence to identify its importance. The obtained average value is the weight of the sentence, which can be defined as the following equation:
The reason for averaging is to avoid extreme scenarios. For example, a long sentence with all ordinary words and a short sentence with all feature words, in this case, the latter should be assigned a greater weight than the former. Finally, we calculate the weighted average value of corresponding dimensions of all sentence vectors:
In the over-sampling stage, we replace feature words in the representative data with the external knowledge base WordNet 2 , which not only can generate new samples with explicit sentiment label, but also can alleviate the problem of imbalanced features to some extent. Representative data refers to the data with strong class representative power, and they are not easy to be misclassified.
Since sentiment centroid is the centroid vector of all sentence vectors in a category, we can extract representative data according to the Euclidean distance between data and their centroids. Data with stronger class representative power will have a smaller distance. Taking the selected MR data as an example, we present some representative data based on the ascending order of distance, as shown in Table 1.
Representative data in MR dataset
Representative data in MR dataset
Sentiment words are shown in bold italics. The sentiment label of majority class is positive and minority class is negative.
Table 1 shows that representative data have the following characteristics: explicit sentiment tendency, less redundant information, and containing sentiment words. Sentiment word refers to the word that has a great contribution to the sentiment polarity of sentences, such as ‘funny’, ‘terrific’, ‘entertaining’ in positive data and ‘Letdown’, ‘hopelessly’, ‘incomprehensible’ in negative data. These words rarely occur in another category, so most of them are feature words. By the use of knowledge base, we replace feature words with synonyms or antonyms to generate new minority class samples, as a result of which features of the minority class can be added.
In binary classification tasks, assuming that the difference between the sample sizes of two classes is N and the value of imbalance ratio is IR, we extract representative data in the majority class and minority class with the number of
Suppose the sentence length is l, we select words with the number of α • l to replace where parameter α (0 < α < 1) means the percent of words in a sentence. The specific process is as follows:
After the over-sampling stage, the dataset becomes balanced. Nevertheless, the dataset still has the problem of class overlapping. Some samples from one class may occur in the area of another class in the feature space, which is disadvantageous for classifiers to learn class features. These samples are called noisy data whose sentiment polarity is vague or even wrong. Part of these samples come from the original dataset and part from the generated samples in the over-sampling stage. Thus, it is necessary to extract these noisy data and modify their sentiment polarity.
Similarly, we identify noisy data based on the class distribution in vector space. The sentence having a farther Euclidean distance to its sentiment centroid than to another centroid is defined as noisy data. In this way, we perform noise detection on the selected MR data mentioned in Section 3.1and present some of the noisy samples in Table 2.
Noisy data in MR dataset
Noisy data in MR dataset
Sentiment words of the other class are shown in bold italics.
Table 2 shows that noisy data mainly have two types: (a) containing no sentiment tendency or just expounding an objective fact, such as the first noisy positive data; (b) possessing sentiment words of the other class, such as ‘uncomfortable’, ‘messy’ in the noisy positive data and ‘faultlessly’, ‘impressive’ in the noisy negative data. Most of these sentiment words are feature words that contribute to the vague or wrong sentiment polarity of a sentence.
We modify the two types of noisy data by replacing feature words. The specific process is:
In this section, we present the details of our experiments. In Section 5.1, we briefly introduce the experimental settings and in Section 5.2, results and analysis are shown.
Experimental setting
We conduct experiments on four public sentimental review datasets. All of them are binary classification dataset, consisting of positive reviews and negative reviews. We process the training sets of four datasets in the same way: holding the full set of positive samples as the majority class and randomly selecting some negative reviews as the minority class with IR = 2.5. The four adopted datasets are as follows: MR [27]: Movie Review Data (MR) collected by Pang and Lee including 5,331 positive and 5,331 negative reviews. We extract 80% of them as the training set and remain 20% as the testing set.
We compare our method with three popular random resampling strategies for imbalanced text sentiment classification, all of the dataset settings are:
To validate the effectiveness of our method integrated with different classification algorithms, we consider four basic models: logistic regression (LR), naive bayes (NB), convolutional neural network (CNN), recurrent neural network (RNN) and two state-of-the-art deep learning models: ACNN and AC-BiLSTM. The specific settings of them are introduced below:
In addition, we utilize Accuracy (Acc) to evaluate the performance of each classification algorithm.
Results and analysis
The effectiveness of our two-stage balancing method
We conduct experiments on four imbalanced datasets with different combinations of balancing strategies and classification algorithms. Threshold K is set to 30% and parameter α is set to 10%.
The comparison results depicted in Table 3 indicate that our method outperforms all of the three considered random resampling methods. Compared to raw imbalanced datasets, the average improvement of OSRD is 2.1% and more 0.9% of improvement can be achieved after implementing RND. It should be noted that the average improvement of OSRD and RND on the two state-of-the-art models are 0.3% and 0.1% lower than on the four basic models respectively, which probably because the two state-of-the-art models are better at learning the characteristics of raw imbalanced datasets. Consequently, the proposed method has a slightly lower improvement on the two state-of-the-art deep learning models. We also observe that under-sampling method RUS has the lowest improvement, because feature information may be lost during the under-sampling process, especially for small imbalanced datasets. But RUS has an average improvement of 1.1% on IMDB dataset, as models can possess good generalization ability even if the large dataset loses some data. Moreover, among over-sampling strategies, the performance of RSR is better than ROS, which may be attributed to the improvement of over-fitting to some extent. Our over-sampling stage has the best performance as we reduce the increase of useless data. And by modifying the noisy data, RND improves the performance of OSRD, which demonstrates the necessity of addressing noisy data. In short, our method has great performance both in two stages and can be effectively integrated with different classification algorithms.
Performances (%) of the different combinations on four datasets
Performances (%) of the different combinations on four datasets
In Section 3.2, we select feature words with threshold K. The value of K affects the number of feature words to be replaced in the over-sampling stage and noise modification stage. Since our method has coincident performance on the six classification algorithms, we take RNN and ACNN as examples, setting the parameter α to 10% and testing the effect of different K between 5% and 50%. The results are shown in Figs. 7(a) and 8(a). It turns out that the highest classification accuracy is around at K = 30%. The performance of OSRD is similar to RSR at small K because only few feature words are identified. And the classification accuracy will be stable and slightly decreased at K> 30 %. It may be attributed to the limited number of replaced words. Specifically speaking, too many feature words will exist in a sentence at large K, which is far more than the words needing to be replaced. Additionally, when the value of K is too large, many words with weak class distinguishing power will be identified as feature words. These words are called pseudo-feature words in this paper. Consequently, in the over-sampling stage, pseudo-feature words instead of true feature words may be replaced in the majority class sample. And the generated sample would not be a new minority class sample, bringing interference to the classifier. Thus, taking the four datasets into account, the optimal value of K for OSRD is 30%.
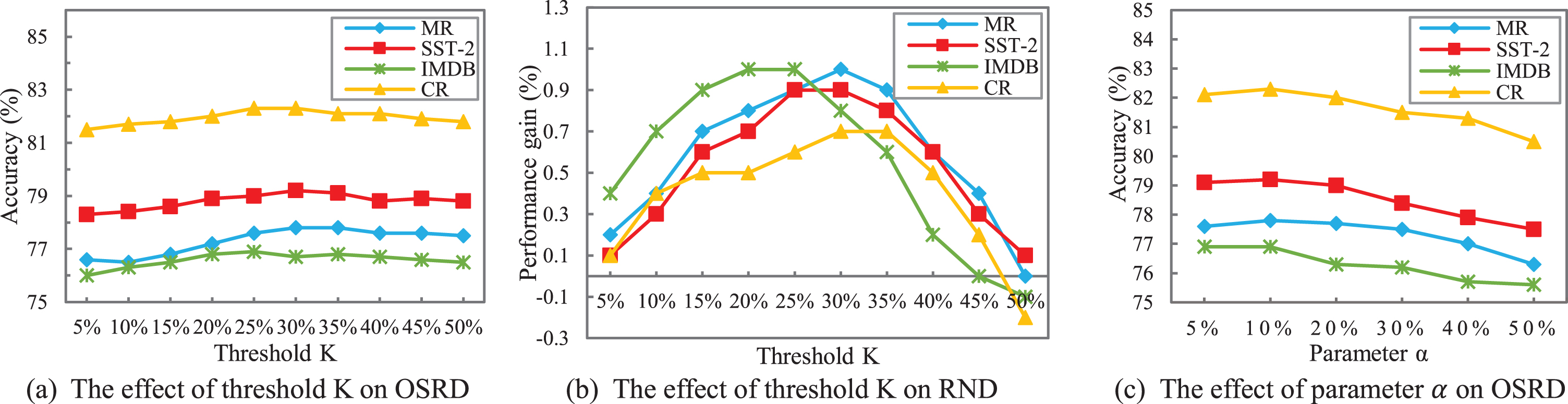
The effects of threshold K and parameter α on the proposed method with RNN.
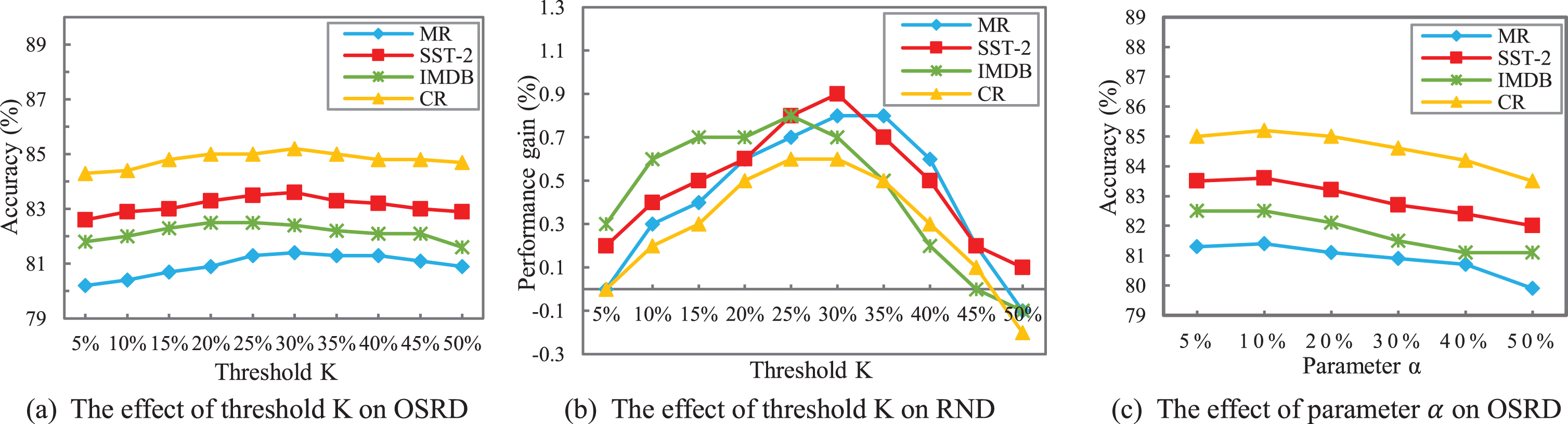
The effects of threshold K and parameter α on the proposed method with ACNN.
In the noise modification stage, we replace feature words belonging to the other class in the noisy data, so the value of K also influences the performance of RND. We test the performance gain of RND compared to OSRD at different K, the experimental results are shown in Figs. 7(b) and 8(b). It is obvious that the highest accuracies of the four datasets are at K = 25% or K = 30%. And the performance gain decreases significantly at K> 35 %, even leading to a negative optimization. This might be attributed to the increase of pseudo-feature words, as a result of which too many words in noisy data will be replaced. In this case, most of these replaced words are pseudo-feature words, possibly changing the identity of a sentence. Furthermore, the best performance of the large dataset IMDB is at 20% or 25%. Since IMDB has a large vocabulary, feature words with strong class distinguishing power can be extracted at small K. On the other hand, the problem of pseudo-feature words is devastating at large K, which can be observed in Figs. 7(b) and 8(b).
In conclusion, considering OSRD and RND, we suggest setting K to 30% which is an optimal solution across the board.
In the over-sampling stage, we select a certain number of words for replacement according to the ratio α. The number of replaced words can affect the quality of a new sample. We set K to the optimal value of 30%, and study the effect of different α between 5% and 50% on the performances of classifiers. Similarly, we take RNN and ACNN as examples and results are shown in Figs. 7(c) and 8(c). It is found that accuracies are high for small α, especially for large dataset IMDB. As α increases, the classification performance begins to decrease, likely because replacing too many words destroys the sentence structure and generates unintelligible sentences. Thus, the suggested value of α is 10%, which is appropriate for different datasets according to our experiments.
Conclusion
This paper proposes a two-stage balancing strategy for imbalanced text sentiment classification. Our approach is based on word replacement but removes the problem of randomness in conventional approaches. By means of the improved weighting TF-IGM-CW, the over-sampling stage generates new samples with explicit sentiment via rewriting representative data. And we can obtain a relatively clean dataset in the noise modification stage, where the sentiment polarity of noisy data is modified. Finally, experimental results indicate that our approach outperforms several previous resampling strategies, and can be easily integrated with different classification algorithms. Compared to raw imbalanced datasets, the total average improvement of the proposed two-stage balancing strategy is 3.0%. Specifically, the average improvement of OSRD is 2.1% and RND is 0.9%.
In this work, we only study the imbalanced binary sentiment classification problem. In fact, it is also worthy to consider the imbalanced multi-class classification problem in text sentiment classification. For instance, the sentiment dataset has the label of neutral sentiment except positive and negative sentiment. Therefore, future work focuses on the research of developing suitable term weighting schemes to study the class distribution of the multi-class dataset and investigating corresponding balancing strategies.