
Abstract
Metaphor plays an indispensable role in human life. Although sequence tagging models took advantage of linguistic theories of metaphor identification, the usage of metaphor in common words is not considered, when choosing the literal meaning of the target verbs. We present a novel approach to express the literal meaning subtly, combining the common usage and the inherent visualizability properties of words, termed GloVe embedding and visual embedding. Meanwhile, we import position information of the target verbs to gain the contextual meaning more accurately. Both two DNN models use these embeddings as inputs in this paper, which are inspired by two human metaphor identification procedures augmented with contextualized word representations (ELMo embedding). By testing on two public datasets, the results show improvement over previous state-of-the-art approaches. In addition, we also verify the universality of the approach by testing the examples that the target words were adjectives, adverbs, and nouns, and the results show the approach is applicable to the above three parts of speech.
Keywords
Introduction
Metaphor expressions are widely used in our daily conversations to help us organize, construct and express knowledge vividly, comprehensively and clearl [1] (Lakoff and Johnson, 1980: Metaphors we live by). Unlike commonly used similes, "like" and "as" do not appear in metaphors, while relatively obscure comparisons are made. A metaphor appears every three sentences in daily life,and we are accustomed to express our perception and imagination of the object by describing another one. As a result, the use of metaphor can help us strengthen our understanding of abstract object, which leads to verb metaphors appear frequently. When directly translating verb metaphorical sentences, the real meaning that the author wants to express may not be obtained. On the other hand, it is likely to hinder the completion of natural language processing tasks. As the basic work of metaphor processing, metaphor detection has attracted more and more attention from scholars. In addition, verb metaphors appear frequently in texts, so they deserve more attention.
(1) Tom answers the telephone.
(2) The steering of my new car answers to the slightest touch.
The explanation of “answer” is to say, write or do something as a reaction to a question or situation. Therefore, the actor of answering is inclined to an animate agent. We can easily get the meaning of (1), while we may be confused about the meaning of (2) if we use the literal sense of answer directly because the car is not animate. The implication of answer in (2) should be in response to an action, and can be interpreted as rotation. We can conclude that verbs are likely to cause metaphors in some collocations from these two sentences. We will not be able to get an accurate explanation, if we choose the literal sense of verb directly in verb metaphorical sentences.As a result, it will be more difficult for us to understand the meaning of the sentences and carry out the next natural language processing task.
At present, metaphor detection can generally be divided into two categories: the first is detecting in a single sentence [4, 6], and the other is in the discourse [7–9]. There are two common task formulations for metaphor detect of verbs [11] in the first case: (1) Sequence Labeling:input a single sentence and output multiple tags(a sequence of binary labels are predicted to indicate the metaphoricity of each word in the sentence), (2) Classification: input a single sentence and output a binary label to indicate the metaphoricity of the target verb. And our approach is based on the first task formulation.
As we all know, metaphor is a special language behavior. However the most previous approaches [10, 11] adopt standard sequence tagging models which do not explicitly take advantage of linguistic theories of metaphor identification and the most commonly used model is BiLSTM(Bi-directional Long Short-Term Memory) [12]. In a word, the verbal metaphor detection task has no character compared with other sequence tagging task such as Named Entity Recognition (NER). In a nutshell, the linguistic features of metaphor detection are ignored.
The most recent approaches [13] considered the linguistic theories in the verbal metaphor detection task. Metaphor Identification Procedure (MIP) detects metaphors at the lexical unit by comparing the contextual meaning contrasts with the literal meaning [18, 19]. And SPV [20] proposes that a metaphoric word could violate selectional preferences. Fundamentally, the two models are similar, metaphors can be identified by identifying the semantic conflict between literal meaning and contextual meaning of target verbs. The sentence will be predicted as metaphorical if the literal meaning in conflict with the contextual meaning of the target verb. And the GloVe Embedding 1 [14] (trained on the common-crawl data set which is very large that is crawled on the Internet, so that it can well express the words meaning in the source domain) is respectively regarded as the literal meaning. The contextual meaning of the target verb is got from the hidden state of the RNN model with GloVe Embedding and ELMo Embedding [15]. However, there is a general phenomenon that people tend to use a metaphorical sentence to express their views, which may lead the model to mistakenly treat the metaphorical representation as a literal representation.For example,the sentence “Time proves everything.” is metaphorical as the subject of the word “proves ” is often human.The source domain “people” makes the target domain “time” easier to understand.
For the reason given above, we add the inherent visualizability properties of words which are gained from the image datasets to make the literal meaning of the target words more precise. More specifically, we combined GloVe Embedding with the information obtained from the visual language datasets visual embedding we term visual embedding as the literal meaning of the target verb. It makes the literal meaning of the target verb more accurate, so that better comparing with its contextual meaning. In addition, we also fully consider the position information of the target verb in the sentence to make the contextual meaning of the target verb more accurate as far as possible.
We used two end-to-end metaphor identification models RNN_HG and RNN_MHCA which are proposed by Mao et al. [13]. for experimentation:RNN_HG is a simple DNN model inspired by MIP linguistic theory, using BiLSTM the network structure. It performs metaphor detection based on the comparison between the contextual meaning and literal meaning of the target word. And RNN_MHCA is inspired by SPV linguistic theory and adopts a network structure combining multi-head attention mechanism and BiLSTM. It uses the window mechanism and pays attention to the important information of the hidden layer of the BiLSTM model to obtain the contextual meaning of the target word comprehensively. The embeddings composed of ELMo Embedding, GloVe Embedding, Visual Embedding and Pos Embedding are respectively input into two neural networks, and the experimental results are obtained after a series of calculations.
The contribution of our work can be summarized as follows:
(1) We have further explored and improved the method of linguistic theories (MIP and SPV) as the direct information of the deep neural network(DNN): combining the visual visibility of words and the word vectors of the language model training and the position information of words as the input of the DNN model enables the model to more accurately capture the context meaning and text meaning of the target word.
(2) We experience in two datasets and the result shows that our method outperforms the baseline with 2.04% improvement and 2.4% improvement in F1 score on the two datasets. As a result, our approach is superior to the state-of-the-art baseline.
The rest of the article is organized as follows: Section 2 reviews related works, Section 3 outlines our idea and describes the model in detail, Section 4 presents experimental results and analysis to show the effectiveness of our proposals, and the last section summarizes the article and future direction.
Related work
The traditional approach is to divide the metaphor detection task into two parts: feature engineering and classifier (e.g., Support Vector Machines) [2]. They used semantic and syntactic feature such as abstractness, imageability, supersenses and so on [3–5]. The subsequent approaches took the supervised machine learning for binary classification [16] by using Logistic Regression [8], Random Forest [6], Linear Support Vector Classifier, which was the first to investigate the effectiveness of semantic generalizations/classifications for verbal metaphor detection. However, this approach requires a lot of manual feature engineering, a large amount of corpus resources and more professional domain knowledge, while its text representation is high-dimensional and sparse and the feature expression ability is very weak which neural networks are not good at dealing with.
On account of the above situation, end-to-end neural model got proposed to metaphor detection which was independent of any external linguistic knowledge resources [17]. Su et al. [23] believed that metaphors were rich in cultural connotations, understood metaphors from the cultural level, and proposed a culture-related layered semantic model to detect metaphors. Gao et al. [10] first proposed a model that concatenated GloVe and ELMo representations and then encoded by BiLSTM. However, he did not consider interactions between either contextual and literal meanings. Mao et al. [13] are the first to explore using linguistic theories (MIP and SPV) to directly inform the design of Deep Neural Networks (DNN) for end-to-end sequential metaphor identification. They used the second classification method, inputting a complete sequence of sentences to predict whether the target verb was metaphorical or not. Their innovation is comparing literal meaning and contextual meaning of target words with linguistic theories to output classification results by judging their differences. In particular, the MIP based model with a simple DNN architecture, outperforms the baseline with an average of 2.2% improvement in F1 score, whereas the SPV based model with a novel multi-head contextual attention mechanism achieves an even higher gain of 2.5% against the baseline while the author uses experimental results of Gao et al. [10] as a baseline.
There are several ways to get the literal meaning of the target word. Subconsciously, the most common meaning of a word is its literal meaning as we hold the opinion that sentences without metaphor are used more frequently than sentences with metaphor in our daily life. The first approach is to present the literal meaning with GloVe embedding which is trained on the common-crawl data set which is very large that is crawled on the Internet, so that it can express the words meaning in the source domain well. However basic meanings is probably not the most frequent meanings of the lexical unit [18] such as “Time is money”. All of us know “time” is a so abstract concept that we use numerous sayings, proverbs to perceive it. The sayings and proverbs are colloquial and their structure is regular, while most of them use metaphor for visualize and conciseness. Another approach [21, 22] takes advantage of the inherent visualizability properties of words in visual corpora (the textual components of vision-language datasets) to compute concreteness scores for words in metaphor detection tasks. The concreteness score of the word can be obtained through the artificial annotation and the representation of the word in the picture (the visibility of the word). And the visibility of the word usually refers to the textual part of vision-language datasets. The words are divided into two groups according to whether the words are in a given corpus. Determine whether the target word is concrete or abstract by calculating the difference between the average specific score of each group and the two averages normalized by the score range of the list (Diff/Range%). We can get the specificity of the target verb (the literal meaning of the target word) more accurately compared with the simple GloVe embeddings.
Methodology
We adopt the first task formulation for the verbal metaphor detection, and treat metaphor detection as a sequence labeling task. Given the target verb and the sentence containing the target verb and its index of the position in the sentence, predict whether target verb is metaphorical or not. Other words in the sentence can provide the context information of the target verb.
The encoding embedding
Most of the machine learning and deep learning algorithms we use cannot directly handle strings and plain text. These techniques require that we must convert text data to numbers before we can perform any tasks (such as regression and classification). Simply, word embedding is to convert blocks of text into numbers for performing natural language processing tasks. The word embedding format usually attempts to use a dictionary to map words to vectors.In this paper, we make full use of visual linguistic information and linguistic theory to maximize the information expression of the data set. We created four inputs for the neural network: GloVe Embedding, ELMo Embedding, Visual Embedding and Pos Embedding.
GloVe embedding
GloVe (Global Vectors for Word Representation) [15] is an unsupervised learning algorithm that can get a vector representation of words proposed by Stanford University. It can get rare but related words beyond the daily vocabulary through Euclidean distance. The aggregated global word-word co-occurrence statistics from the corpus are trained, and the resulting representation shows an interesting linear substructure of the word vector space. In this article, we use the pre-trained word vectors with 840B tokens provided by GloVe trained on Common Crawl.
ELMo embedding
ELMo (Embeddings from Language Models) [16] is a context word vector (dynamic word vector) pre-trained language model.ELMo is a deep word vector representation method, which is based on deep bidirectional language model (deep bidirectional language model, referred to as biLM) training. During training, vectors and a pair of language models derived from bidirectional LSTM are used, similar to word2vec, which is performed on a large number of corpora. Each word will only be trained to get one word vector, and the problem that polysemy words cannot be expressed accurately in the previous pre-training model. ELMo has made improvements, for each input sentence will output a different representation of the word, so it has a good representation of polysemy.
Visual embedding
Visibility Embeddings is created in a simple way by the Big Visual Corpus (BVC) [22] consists of the Visual Genome, MSCOCO, Flickr30K, and ImageNet, and contains over 98K lowercaesd (but otherwise non-normalized) terms. Firstly, check whether the target words are in the visual corpus. Next divide the words (words contained in the corpus and words not contained in the corpus) into two non-overlapping sets according to the list of specificity scores (usually the 40K or MRC), and then calculate the specificity score of each list, as well as the difference of the two averages normalized by the score range of the list (‘Diff/Range%’). Based on the visual corpus BVC, we assign values (0, 1, -1) to each word in the sentence in the metaphor datasets, where -1 aims to represent abstractness and 1 aims to represent concreteness.
Pos embedding
Pos embeddings is used to indicate the position of the target verb in the sentence. We regard the sentence as a sequence whose length is set to the number of words.We assign a binary indicator to the sequence, the target verb is assigned a value of 1, and the rest are 0. Then we use the index embedding dictionary to map the sequence markers into real finger vectors, which are randomly initialized and fixed during training. In this paper, pos embedding is set to (2, 50).
Model
Our experiment is based on RNN_HG (Recurrent Neural Network Hidden-GloVe) and RNN_MHCA [13] (Recurrent Neural Network Multi-Head Contextual Attention) two models. However, the processing procedures of the two models are roughly similar because MIP and SPV are basically detecting the conflict between the word representation of the target word and the context. We detect metaphor via computing the distance of the different representations of the target word in vector space.
Figure 1 shows the model flow diagram. The left model in is RNN_HG model based on MIP. As we all know, the performer of the bind action is generally a person, and the executed party is a thing. The general paradigm is person binds thing. As a result, “bind” has literal embedding which is embedded by words in domains of “person” and “thing” in GloVe Embedding and Visual Embedding. The contextual meaning of “bind” is encoded by “hydrogen”, “oxygen” and itself in BiLSTM. The two different vectors for “bind” are concatenated and input in classifier 1. Then classifier 1 detect whether two vectors represent similar meaning (indicating literal) or different meaning(indicating metaphor).
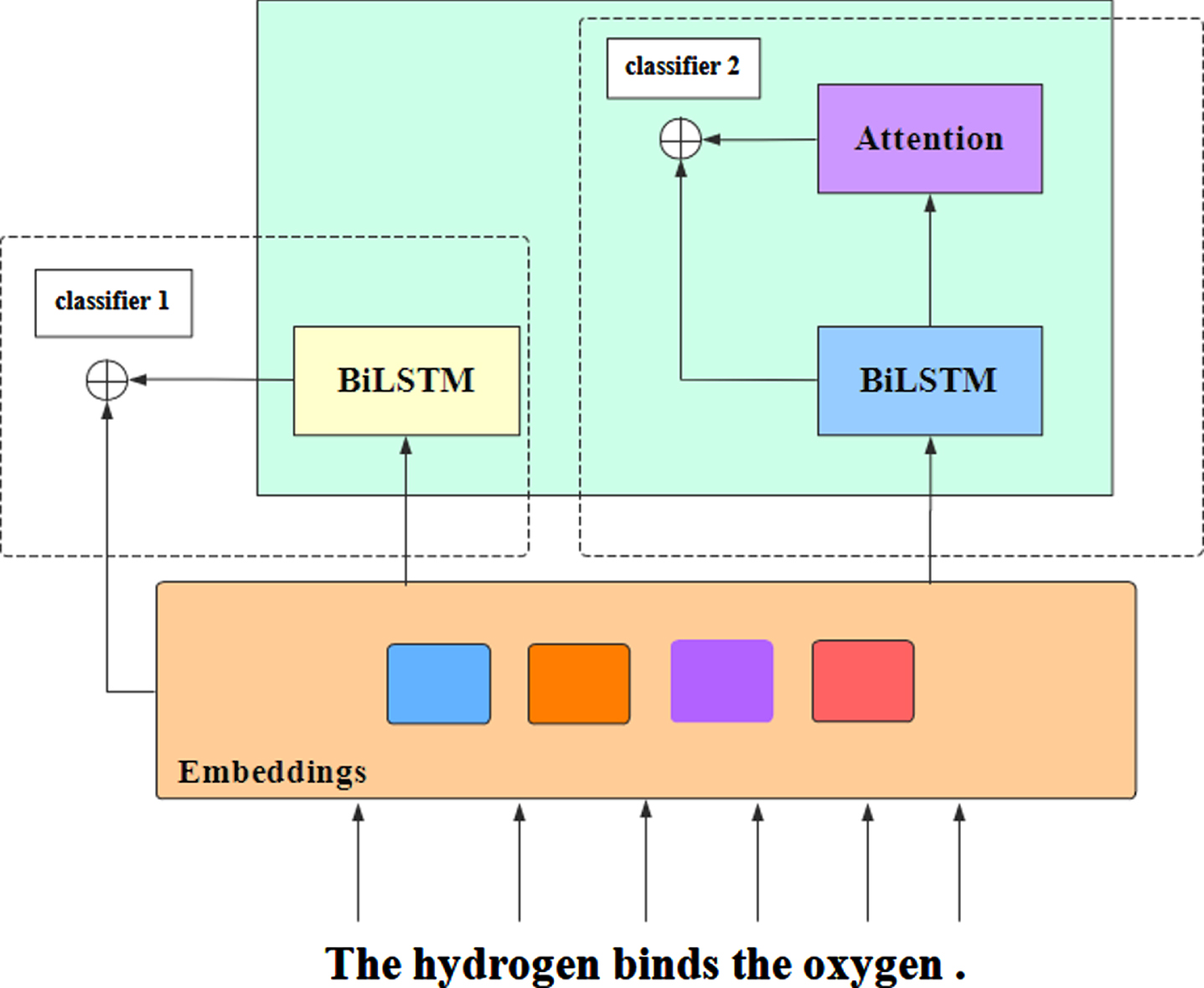
Model flow diagram, ⊕ denotes concatenating tensors along the last dimension, classifier 1 is RNN_HG model flow diagram and classifier 2 is RNN_MHCA model flow diagram.
The right moedl is RNN_MHCA model based on SPV. “Hydrogen”, “bind” and “oxygen” are encoded in the BiLSTM network to get the “bind” vector. On the other hand, “hydrogen” and “oxygen” are encoded from left to right and right to left, respectively and concatenated to form the context. The individual “hydrogen” vector and “oxygen” vector are still closer than “bind” vector, because “bind” vector had its own literal meaning in the encoding process. Classifier 2 learns to recognise the contrast between word representation of “bind” and its context. Below we will give a detailed introduction to these two models.
RNN_HG (Fig. 2) was designed inspired by MIP which regards that metaphorical expressions of words are contrast to literal expressions. In our work, the word vectors trained by the GloVe pre-training model are static, and the embedding of each word is fixed after training. In other words, they will not change dynamically due to different contexts in the sentence. Therefore, GloVe Embedding and Visual Embedding are considered literal meanings mentioned in MIP linguist theory. Connect all embeddings as the input of the BiLSTM model, then the neural network encodes the target word and its context to get the hidden state. We take the hidden state of words as the contextual meaning mentioned in MIP. Finally, the Softmax classifier compares the literal meaning and the contextual meaning to obtain the label prediction of the target word at position t:
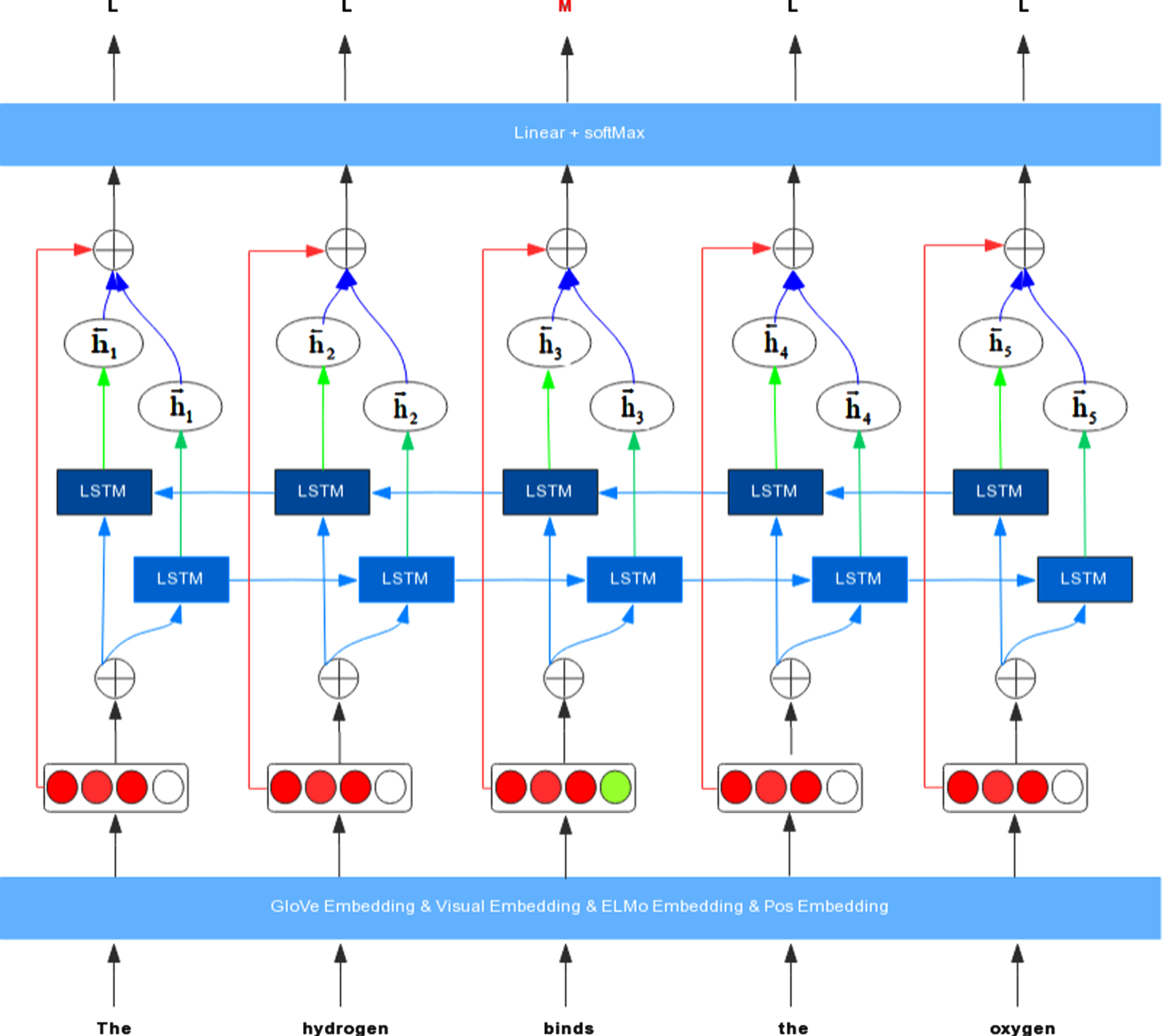
RNN_HG model framework, ⊕denotes concatenating tensors along the last dimension.
RNN_MHCA (Fig. 3) was designed inspired by SPV which proposes that a metaphoric word could violate selectional preferences.This model compares the target word representation h
t
with its context c
t
.The model mainly consists of three main layers: (1) BiLSTM layer, all embeddings are connected as the input of BiLSTM, and the forward and backward hidden states are regarded as the target word representation. (2) Attention layer, the input is the hidden state of BiLSTM, and the context of the target word is composed of left-side (
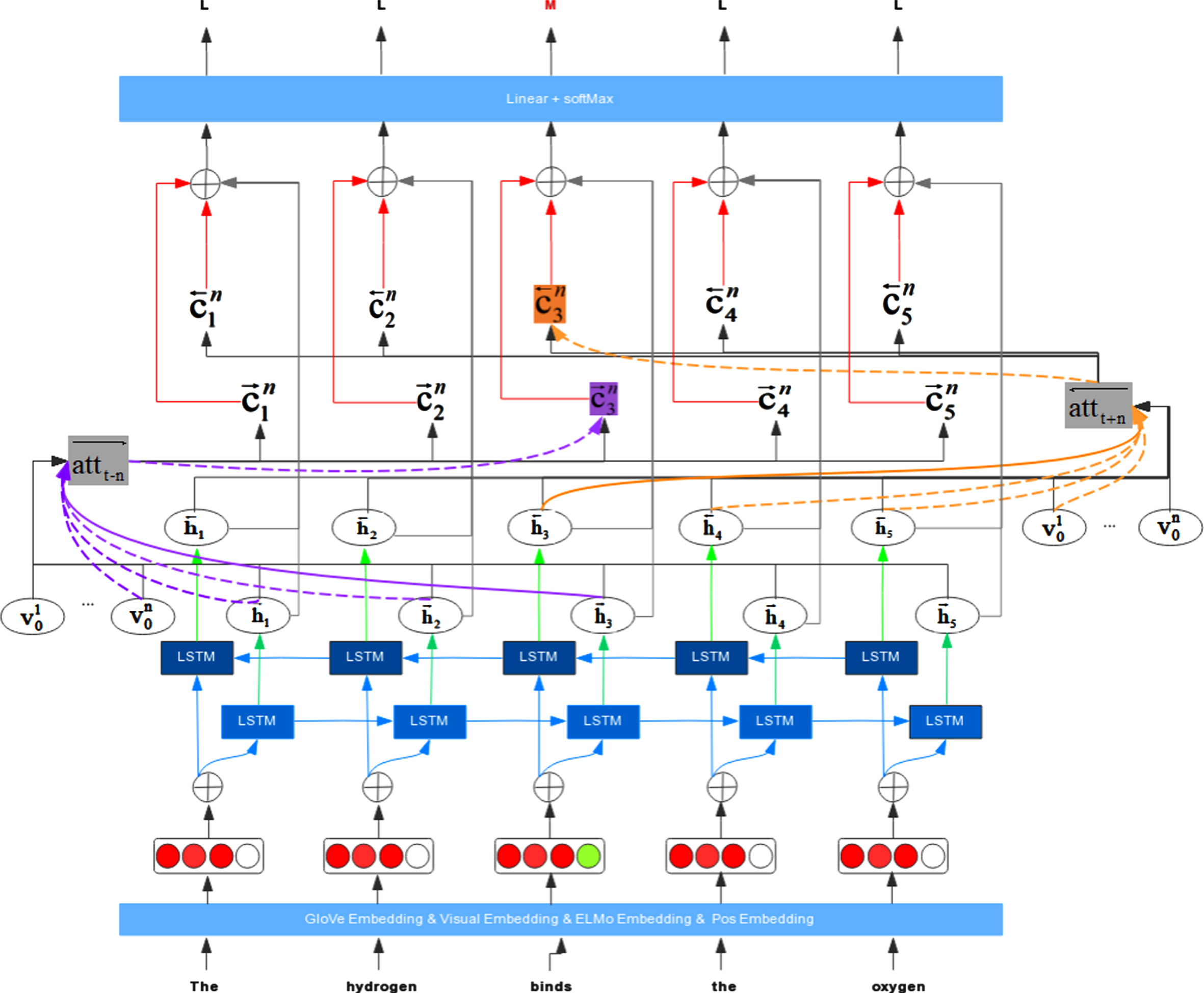
RNN_MHCA model framework, attt±n is the window of n context words in attention mechanisms. We define that the window size is 3. The context
Datasets
We used two widely used public datasets: MOH-X and VUA. The size of datasets can be viewed in Table 1.
The datasets information. Target token is the number of target tokens whose metaphoricity is to be identified. % Metaphor is the percentage of metaphoric tokens among target tokens
The datasets information. Target token is the number of target tokens whose metaphoricity is to be identified. % Metaphor is the percentage of metaphoric tokens among target tokens
MOH-X [24] is a corpus made by Mohammad. There are simple sentences in WordNet, and only one target verb is marked in each sentence. MOH-X is a subset of MOH, discarding examples where there is no mapping in the MOH data set. The data set contains the verb and the words matched with the verb, whether it contains metaphors, and syntactic structure.
VUA 3
VUA [20] is composed of 117 fragments, and the samples come from four genres in the British country: academic, news, conversation and novel. Although the number of texts varies greatly, each type is represented by approximately the same number of tags, with news archives having the largest number of texts. This corpus represents the largest public evaluation dataset for metaphor detection that is used by the NAACL-2018 Metaphor Shared Task [25]. The corpus is divided into VUA_train, VUA_val, VUA_test as training dataset, validation dataset and test dataset.
Implementation details
We further build on the model proposed by Mao et al. (2019) by adding the Visual Embeddings and the pos embeddings to the set of embeddings mapped to each word in a given sentence. As shown in Fig. 4, the ELMo dimension is 1024, the GloVe dimension is 300 and we set the visual dimension and pos dimension to 50. As a result, the whole embedding dimension is 1424. We also separately arranged and combined these kinds of embedding and input them into the model to test the effect of various combinations in the experiment.

The model input dimension.
We adopt 10-fold cross validation since this data set is relatively small.To accommodate the new embeddings, we changed the learning rates and number of epochs, but kept the structure and all the other parameters of RNN_HG and RNN_MHCA, and the parameters are shown in Table 2. In addition, we use RNN_HG and RNN_MHCA models of Mao et al. [13] and experimental data from Kehat et al. [22] as the baselines for this paper.
Parameter settings
In this paper, we use Accuracy, Recall, Precision and F1 score to evaluate the effectiveness of our model. Accuracy is the proportion of correct predicted target token in total token. In the MOH-X dataset, we only consider the verbs as the target token in the sentence. For VUA dataset, we consider the verb and all tokens as the target token separately.
As we can see in Table 3 and Fig. 5, we separately arranged and combined these kinds of embedding on MOH-X dataset. Our methods are top in the four evaluation indicators compared with three baselines. Specially, RNN_HG+GloVe_ELMo_visual achieves the best performance on the precision which gains 3.8% than RNN_HG getting 79.9%, and RNN_HG+GloVe_ELMo_pos gains 2.1% to the Recall than RNN_MHCA which gets 83.1%. RNN_MHCA+ELMo_pos_visual reached 82.5% on F1-score, which is 2.04% higher than the model of Kehat et al, and gains 3% on accuracy than RNN_MHCA model achieving 79.8%.
Performance comparison of MOH-X dataset under different models (%), and all means we put the four embeddings into the model, E means ELMo Embedding, G means GloVe Embedding, V means Visual Embedding
Performance comparison of MOH-X dataset under different models (%), and all means we put the four embeddings into the model, E means ELMo Embedding, G means GloVe Embedding, V means Visual Embedding
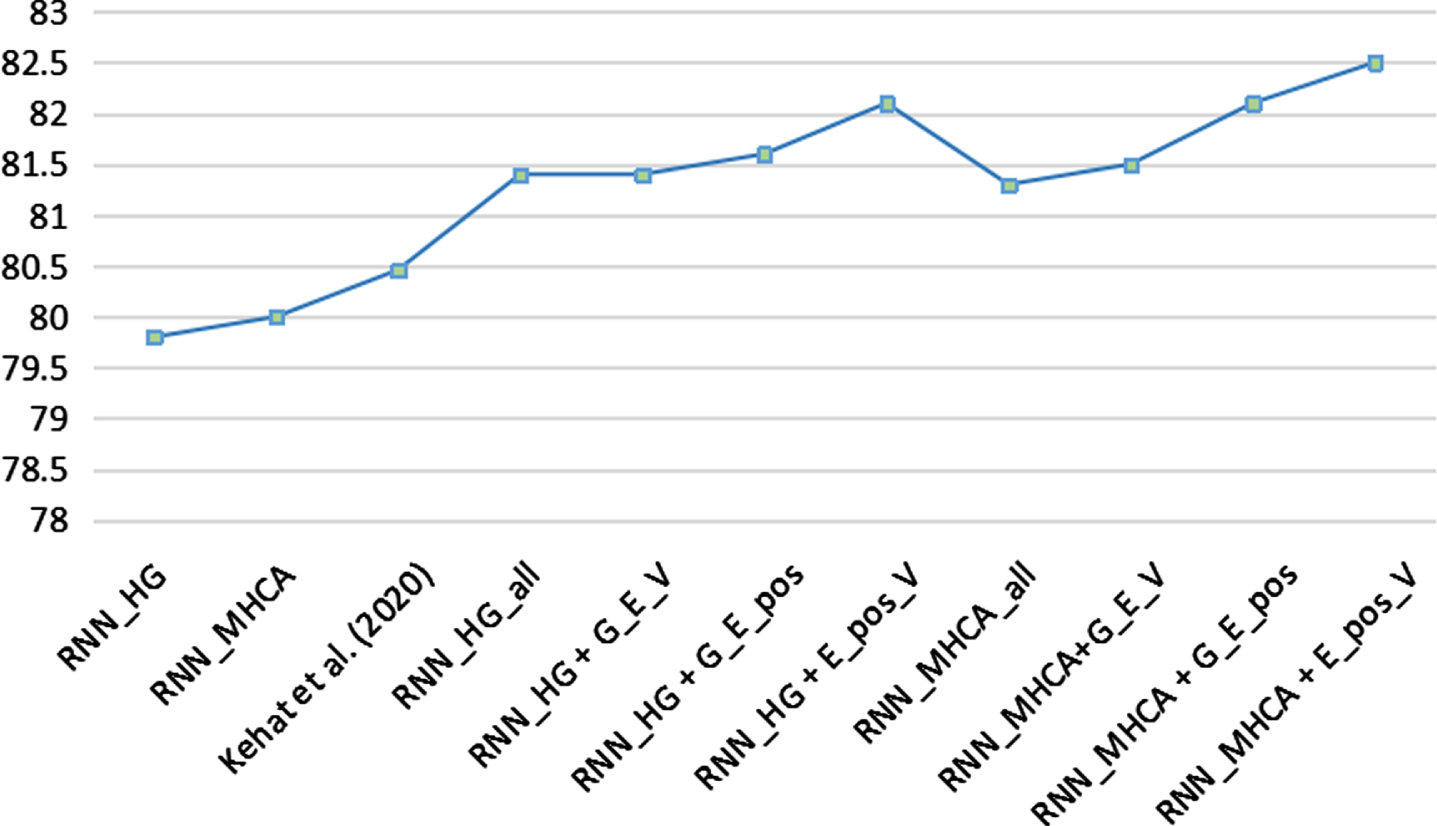
F1-score of MOH-X dataset under different models (%) and E means ELMo Embedding, G means GloVe Embedding, V means Visual Embedding.and all means we put the four embeddings into the model.
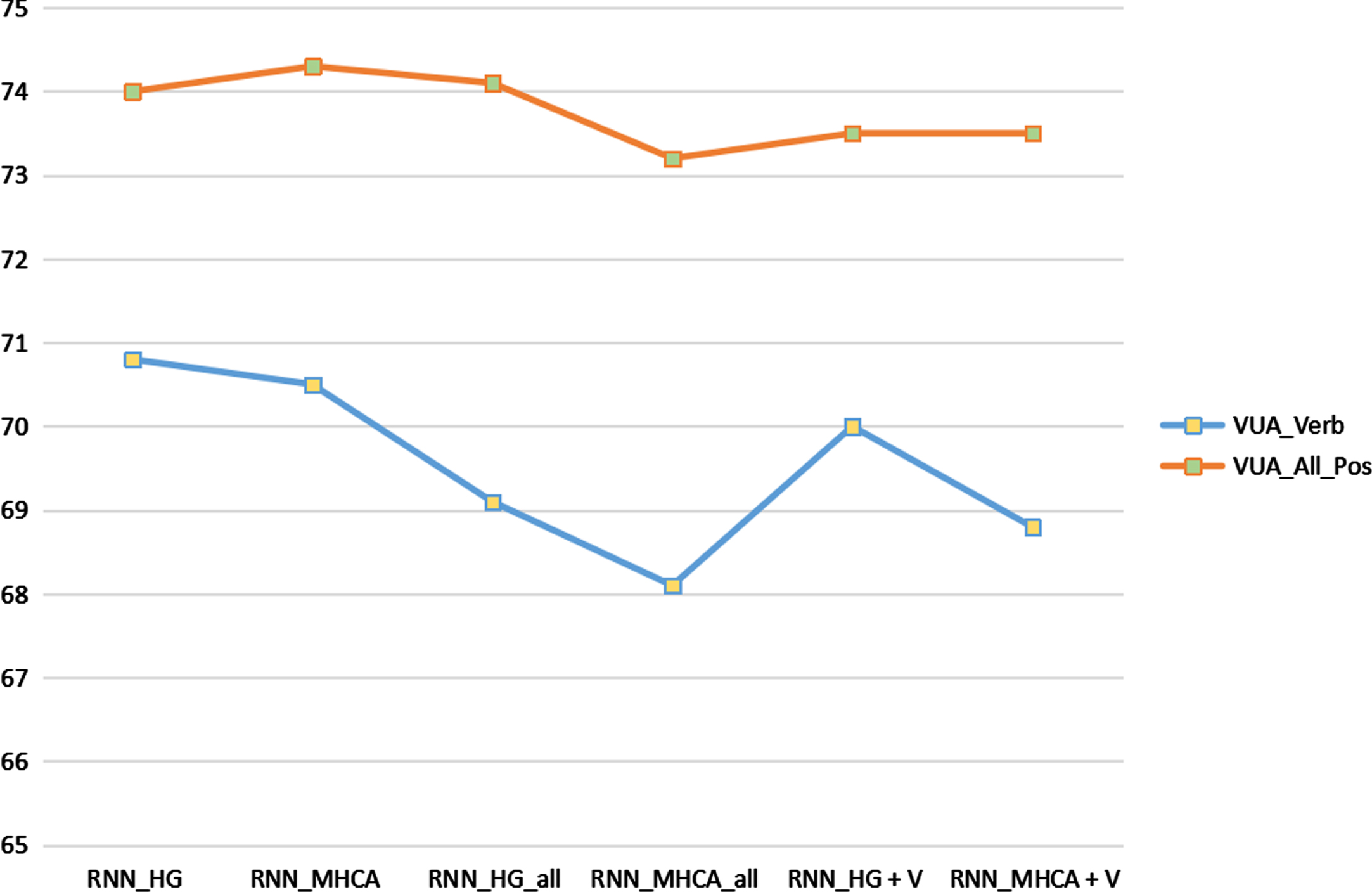
F1-score of VUA dataset under different models (%). And all means we put the four embeddings into the model, V means Visual Embedding.
We measure the performance of the model when the target word in the VUA dataset is a verb or all parts of speech, and the results show that our models are the best as shown in Table 4 and Fig. 6. For verbal target words in VUA, it is worth noting that RNN_MHCA_all_embeddings model gains 3% to the precision than RNN_HG model getting 69.3%. Meanwhile, RNN_HG_all_embeddings gains 0.3% to the accuracy than RNN_HG model. As for all parts of speech in VUA, RNN_MHCA_all_embeddings of reach 79.9% and 93.9% gaining 5.3% and 0.1% than the baseline RNN_MHCA model which gets 73.0% and 93.8%.
Performance comparison of VUA dataset under different models (%), AUA_Verb is the representation of the target word in the dataset when the target word is only a Verb and AUA_ALL_POS is the representation of the target word in the data set with all parts of speech. And all means we put the four embeddings into the model, V means Visual Embedding
In order to verify the versatility of our method, we experienced not only the validity of verbs on the VUA dataset, but also the metaphoricity of other parts of speech (verbs, adjectives, nouns and adverbs) in the sentence. The results are shown in the Table 5. It is worth noting that the RNN_HG_all model gains 2.4% to F1-Score than 63.8% of RNN_HG model for adverb. In addition, considering the construction source of the VUA dataset, we also conducted experiments on the four text genres (academic, conversation, fiction, and news) in Table 6 and our model still achieved good performance. In the source of academic, the RNN_HG_all gets 80.6% on F1-score gaining 0.8% than RNN_MHCA model. And in fiction, RNN_HG + V gains 0.7% on on F1-score than 67.7% of RNN_MHCA model.
The model performance on different types of words in VUA dataset (%). And all means we put the four embeddings into the model, V means Visual Embedding
The model performance on different types of genres in VUA_ALL POS (%). And all means we put the four embeddings into the model, V means Visual Embedding
At present, most metaphor detections are regarded as sequence labeling tasks. Although the contextual information of the target word is well preserved, it fails to realize that the problem of metaphor is fundamentally a linguistic problem. On the basis of Mao et al., we further explore and develop how the linguistic theory MIP and SPV are applied to deep neural networks. Aiming at the problem of using normalized metaphors, we propose a solution that combines the visual visibility of words with language pre-training word vectors which make the deep neural model can better capture the literal meaning of the target word. The experimental results show that our approach achieve state-of-the-art performance on two public datasets. Specially, in MOH-X dataset, RNN_HG + GloVe_ELMo_Visual reaches 83.5% on Precision and gains 3.8% than the baseline, RNN_HG + GloVe_ELMo_pos gains 2.1% to the Recall, and RNN_MHCA + ELMo_pos_visual reaches 82.5% on Fi-score and gains 2.04% and 3% to the F1-Score and Accuracy. And in VUA dataset, the results show that our method is worth noting that RNN_MHCA_all_embeddings gains 3% to the Precision and RNN_HG_all_embeddings gains 0.3% to the Accuracy. As for VUA all pos, the Precision and accuracy of RNN_MHCA_all_embeddings reach 79.9% and 93.9% where are 5.3% and 0.1% than the baselines. We also tested the universality of the method. We found that our method can not only obtain good results in the recognition of verb metaphors, but also apply to the situation where the target word is of other part of speech. And our method still achieves the best performance when the target words are adverbs, nouns, and adjectives. In addition, we find that our method can achieve good performance in a simple model, which will save resources. In the future, we will continue to proceed from the perspective of linguistic theory, consider the impact of cultural factors on metaphors, try to improve the model to better obtain contextual information and word representation. And an interesting direction is to use graph convolutional neural networks (GCN) to more accurately obtain the contextual collocation of target words [26].
Footnotes
Acknowledgements
This work is supported by National Natural Science Foundation of China, Grant/Award Number: 61962057; Key Program of National Natural Science Foundation of China, Grant/Award Number: U2003208; Major science and technology projects of autonomous region, Grant/Award Number: 2020A03004-4.