
Abstract
Context-Aware Recommender System (CARS) suggests more relevant services by adapting them to the user’s specific context situation. Nevertheless, the use of many contextual factors can increase data sparsity while few context parameters fail to introduce the contextual effects in recommendations. Moreover, several CARSs are based on similarity algorithms, such as cosine and Pearson correlation coefficients. These methods are not very effective in the sparse datasets. This paper presents a context-aware model to integrate contextual factors into prediction process when there are insufficient co-rated items. The proposed algorithm uses Latent Dirichlet Allocation (LDA) to learn the latent interests of users from the textual descriptions of items. Then, it integrates both the explicit contextual factors and their degree of importance in the prediction process by introducing a weighting function. Indeed, the PSO algorithm is employed to learn and optimize weights of these features. The results on the Movielens 1 M dataset show that the proposed model can achieve an F-measure of 45.51% with precision as 68.64%. Furthermore, the enhancement in MAE and RMSE can respectively reach 41.63% and 39.69% compared with the state-of-the-art techniques.
Introduction
With the advent of the World Wide Web and big data, recommender systems (RSs) are becoming more and more popular [1, 2]. The purpose of these systems is to suggest different services to different users. In the existing literature, researchers have presented numerous recommendation approaches such as collaborative filtering (CF), content-based filtering (CBF) and hybrid techniques. Collaborative filtering is one of the most popular methods. It is based on the rating histories to calculate the similarities between users or items [3]. It suggests similar objects to those favored by the user in the past, or items which have been liked by similar users. The most popular technique in CF is the nearest neighbor, where a subset of k suitable users (or items) is chosen based on their similarities to the target one [4]. Then, a weighted aggregate of ratings is used to produce predictions for the active customer. The content-based algorithms are relying on the content of items [5]. They propose objects that are similar to those previously chosen by the user. On the other hand, the hybrid techniques are able to integrate the power of different algorithms and methods to create a more robust recommender system [6].
Furthermore, many researchers have shown that incorporating context in the recommendation process seems one of the promising approaches to improve prediction accuracy [7–9]. Context-aware recommender system (CARS) has emerged as an efficient tool for enhancing the recommendations by exploiting contextual information in order to recommend items that are relevant to evolving customer needs [10]. However, the notion of context is complex and not easily integrated into recommendation process [11]. Moreover, there are several challenges to be resolved in CARSs, including the sparsity problem, which refers to situations where insufficient data are available for inferring similar users or items [12]. Therefore, the sparsity problem becomes more severe when user preferences are filtered with contextual factors [13]. In fact, using many contextual parameters increases the data sparsity and few context factors in recommendations fail to bring the contextual impact [12].
This study proposes a hybrid method for alleviating the sparsity problem in CARS by considering the latent properties of items to calculate the similarity scores, and by directly incorporating context into the prediction process instead removing items that are irrelevant in a given context. Thus, a context-aware recommender model which is called Topic Modeling and Particle Swarm Optimization based Collaborative Filtering algorithm (TMPSO-CF) is proposed. It combines latent interests and explicit contextual features using Latent Dirichlet Allocation (LDA) and Particle Swarm Optimization (PSO). Firstly, the dimensionality space is reduced by extracting the latent properties from the unstructured texts describing the items. The latent context is modeled as numeric vectors that are automatically learned through the application of LDA, which is probably the most common topic model suitable for low dimensional representation [14]. LDA is an unsupervised technique with proper underlying generative probabilistic semantics that makes sense for the type of data that it models [15]. Then, a weighting function is proposed to integrate explicit contextual factors (numerical and/or categorical data), such as user’s age, user’s occupation, movie’s runtime, etc., with their degree of importance in the prediction scores calculation. Specially, the time evaluation is introduced into the proposed weighting function in order to increase the importance of the most recently accessed items because the user’s interests change over the time [16]. Usually, objects which have recently been consumed by the user play a greater role in generating future recommendations than items with early access [17]. In addition to that, TMPSO-CF uses a particle swarm optimization algorithm for assigning suitable weights to different contextual features. PSO have been commonly applied in many optimization problems having very satisfactory results [18]. In most cases, it outperforms many other approaches applied to the same optimization problems [19]. It has also shown a faster convergence rate than other evolutionary algorithms on some problems [20]. Moreover, PSO has very few parameters to adjust, which makes it particularly easy to implement.
The main contributions of this paper are summarized as follows: A novel hybrid context-aware recommender system, which is called TMPSO-CF, is proposed. It combines collaborative filtering algorithm and content based method in order to enhance the prediction accuracy, alleviate the sparsity problem in the sparse datasets and handle the contextual sparsity issue in CARS. It considers also the influence of individual contextual features during the recommendation process. An application of TMPSO-CF for the Movielens 1 M dataset. The performance of the proposed model on the Top-N Recommendations at the optimal neighborhood size (k) is evaluated. A comparison of TMPSO-CF with other well-known methods.
The remainder of this paper is organized as follows: Section 2 reviews related works in context-aware recommender system and the use of LDA and PSO in these systems. In Section 3, the proposed TMPSO-FC model with a detailed description of how the system employs the LDA and PSO is provided. Section 4 introduces the dataset and the evaluation metrics. It also discusses the results of the experiments. Section 5 presents the performance of TMPSO-CF at optimal neighborhood. Finally, section 6 provides conclusion and future work.
Background and related works
Context-aware recommender system
Context-aware recommender systems (CARSs) are promising way of generating more relevant services to users. They produce personalized recommendations in accordance with users’ current context [21]. Consequently, the rating function is modeled in a multi-dimensional space as R: Users×Items×Contexts ⟶ Ratings [22]. Several context-aware recommendation algorithms have been proposed and developed [10, 16]. They explore various ways in which contextual factors such as time, location, companion, etc. can be integrated into the recommendation models in order to enhance the prediction quality [23]. The temporal factor has a major impact on people’s desires and allows tracking the evolution of user preferences over time [17, 24]. Lin and Chen [8] proposed a probabilistic method to capture the time dynamics of recommender systems. Essentially, the model differentiates between the recent and early data. In the hidden Markov model, the recent ratings are used to capture the change of the preferences of both the users and items over time. However, the early ratings are used to produce the overall prior distribution of the random variable of both users and items.
Based on the fact that only relevant contextual information should be taken into consideration in a recommender system, Braunhofer and Ricci [25] presented a model which predicts the contextual factors influencing customers when evaluating an item, in order to use only relevant contextual information in the recommendation process. In their research work, Zhou et al. [26] selected the optimal features based on the similarity between a feature and a set of other ones to remove the redundancy. Thus, a content-context interaction graph model that completely fuses and captures the interactions between content and contexts is presented. Tensor Factorization (TF) can also be used to model the context [10, 27]. It extends the traditional two-dimensional Matrix Factorization problem into a n-dimensional version by integrating contextual information [28].
Latent Dirichlet allocation in CARS
Latent Dirichlet allocation (LDA) is a generative probabilistic and statistical modeling method to extract topics from a text corpus [15]. The basic idea behind LDA is that the groups of terms which are contextually similar constitute different topics. LDA models each document as a random mixture of latent topics, and it defines each topic by a word distributions. It generates the probability distributions of topics p (t|d) for each document d. Each topic t (t ∈{1,..., T}) is composed of the word probabilities p(w j |t) for words w j , j = 1,...,V. Where V is the size of the vocabulary and T is the pre-defined number of topics. The topic density in the model is controlled by Dirichlet hyperparameters α and β, which play an important role in learning accurate topics. In fact, LDA’s popularity is due to its simplicity and modularity [29].
Given N items with a textual description of the item i (i ∈{1,..., n}) having V i words, the generative process is as follow [15]:
The variables θi are item-level variables, sampled when per item. zj, wj are word-level variables. They are sampled when for each word in each text description item.
In fact, latent context is very useful in increasing the efficiency of recommender systems. Hence, unsupervised tools such as LDA have been used to learn the latent characteristics in RS [29, 30]. Yan et al. [31] presented a unified video recommendation solution for YouTube by transferring and incorporating the social and content information of users through Twitter network. So, LDA model is applied by considering users as documents and their hashtags as words. Lin et al. [30] used user reviews from the Airbnb platform for deriving the features of the products and creating customer preferences. The authors implemented the LDA technique to infer both the features and preferences.
Particle swarm optimization in CARS
Particle swarm optimization (PSO) is a population based technique firstly developed in 1995 by Kennedy and Eberhart [32]. In the PSO algorithm, a swarm is a group of particles which represent candidate solutions. For a d-dimensional space, the particles correspond to d-dimensional vectors. The position and velocity of the ith particle are represented by X i = (xi1, xi2,..., x id ) and V i = (vi1, vi2,..., v id ), respectively. At each time step, each particle i keeps the information about its personal best position (pbest P i (t)) and the swarm best position (gbest g i (t)). The particles move throughout the search space by updating their velocities and their positions according to Equations (1) and (2), respectively. For every particle, i∈{1, 2, ... ., N}.
Where N is the number of particles in the swarm. c1 and c2 are positive acceleration constants. c1 expresses the confidence of a particle in itself, while c2 expresses the confidence of a particle in its neighbors. r1 and r2 are random numbers within the range [0, 1]. The inertia weight w is an important parameter to strike a better balance between global and local exploitation. The linear decreasing inertia weight has been widely used to update the value of w according to Equation (3) [33].
Where Nb max is the maximum number of iterations, tr is the iteration index, w start and w end are the maximum and minimum values of the inertia weight, respectively.
PSO has been used by many researchers to select the features or assign weights to different factors in the recommender systems [34, 35]. The work of Ujjin and Bentley [36] applied the PSO to learn users’ personal preferences and provide the recommendations based on the adjusted Euclidean distance. Katarya and Verma [37] combined k-means clustering algorithm with Fuzzy c-means and PSO to classify the types of movies according to users. Firstly, k-means is employed to provide initial parameters to the PSO algorithm, and then PSO is used to optimize Fuzzy c-means clustering. Sumathi et al. [32] combined particle swarm optimization with user access based ranking algorithm for the new user recommendation. The authors referred each user as a particle and applied PSO to find similar users for an active one.
It is observed by surveying the existing literature that collaborative filtering approaches and content-based recommendations were tried numerously in the context-aware recommender system area. However, most studies have mainly focused on improving the measure of similarity; with relatively little research on prediction score models, although it is extremely important to improve the accuracy of the recommendations [38]. Moreover, collaborative methods are among the most widely used and successful techniques [17]. Unfortunately, their success is based on the availability of a sufficient number of available ratings. In fact, when the data are too sparse, the information that can be used in exploring similar users or items is too little to make a recommendation. Thus, several works in CARS focused on using the unitary context because multidimensional contexts will aggravate the sparsity problem. There is also a lot of research that claims to improve the quality of recommendations through the combination of content based methods and collaborative information. The greatest advantage of the hybrid approach is that it can overcome the drawbacks of both methods and benefit from their advantages. However, it will also make the final model more complicated. Therefore, the method of mixing needs to be analyzed according to the actual situation. This is the setting for the proposal presented in this study, i.e. the design of a hybrid recommendation system with the aim of solving the sparsity problem in CARS, especially when more than one kind of context is used. This paper proposes a mixed model combining the item-based k nearest neighbor algorithm with content based enhancements via LDA for improving the accuracy of the recommendations. The proposed approach also takes advantage of the PSO algorithm to estimate the contribution of contextual information instead of context selection.
The proposed system aims to enhance the prediction accuracy, alleviate the sparsity problem in the sparse datasets and handle the contextual sparsity issue in CARS. It exploits the hidden properties of items, from their textual description, and directly integrates context in the prediction process by introducing a weighting function, which combines contextual information with their degree of importance.
TMPSO-CF algorithm
Figure 1 illustrates the complete system flow. The textual descriptions of items are passed to the preprocessing unit before the LDA training, in order to filter out noisy data and non-informative words that do not add any distinctive character in the objects (removal of stop words and punctuations, Lemmatization tokenization, stemming, etc.). Then, the LDA algorithm is applied to determine the optimal number of topics and represent each item in the latent topic space using the item-topic distributions as its feature vector. In the other hand, the PSO algorithm is employed to learn and optimize weights of different contextual features in order to control their contribution in the recommendation process. In fact, the contextual data in numeric form are directly normalized. However, the categorical features must be converted into numeric values before the normalization. Finally, when the predefined number of iterations is reached, we get the optimal weights of features, which will be used to calculate the predictions.
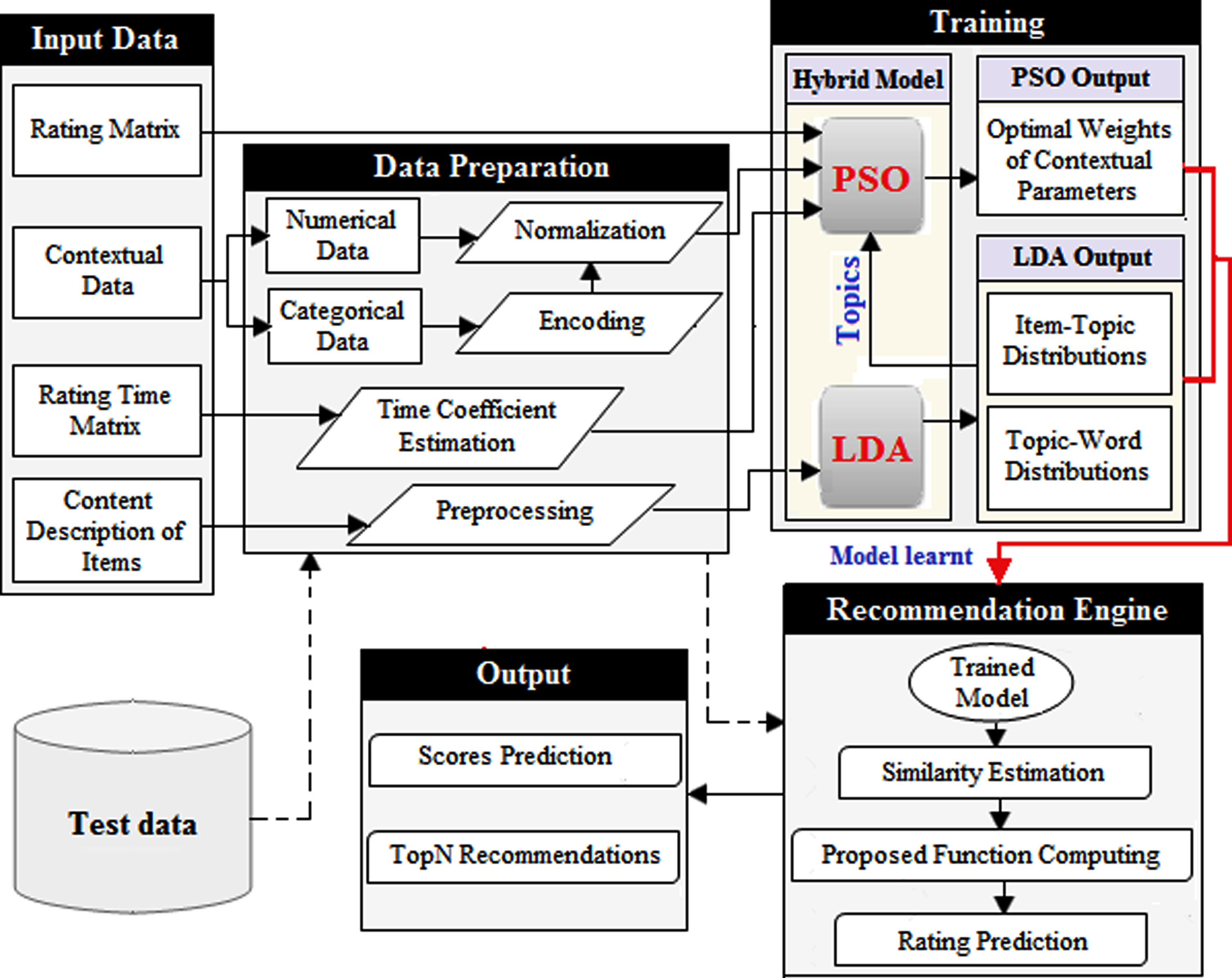
General workflow of TMPSO-CF model.
The following pseudo-code will describe the proposed model in details.
The users set: U = {u1, ... ., u
m
}, where m is the number of users. The items set: I = {i1, ... ., i
n
}, where n is the number of items. The rating histories: R = {Ru,i| u ∈ U; i ∈ I}. The rating time matrix. The content information of items. The topic-word distributions. The item-topic distributions. The contextual features set: P = P
n
∪ P
c
= {P
n
1, ... ., P
n
ln
} ∪ {P
c
1, ... ., P
c
lc
}, where ln is the number of numerical features and lc is the number of categorical features. The neighborhood size (k). The optimal weights of contextual parameters: w
t
and w
i
( List of TopN items.
Where, T is the number of topics, i h and j h are the probability distributions of the items i and j, respectively, over the topic h. The Hellinger distance varies from 0 to 1. The upper bound 1 (i.e. sim(i, j) = 0) means the distance is maximal and thus the two items are very different. The lower bound 0 means the two items are very similar. So, they share the same topic distributions.
Where, w t represents the weight of the time evaluation. t A is the time of the latest evaluation given by the user u to an item sharing at least one genre or one topic with the item j. t B represents the time of the latest evaluated item by the user u. Δt corresponds to the average duration between each two successive ratings of user u.
x p is the value of the feature p (the value of a numerical feature or the numerical value of a categorical feature). Δp is the interval of variation of the feature p. min(p) is the minimum value of the feature p.
x
p
represents the value of the contextual feature p about the user u or the item j. w
t
and w
k
represent the weight of the time evaluation and the weight of the feature p, respectively, and satisfying the condition,
Where, Ru,j is the rating of user u on item j. k is the neighborhood size of the item i.
Illustrative examples of the data normalization and the parameter λ calculation are presented respectively in Table 1 and Fig. 2. Given five users u1, u2, u3, u4 and u5 to whom we want to recommend movies 7, 5, 3, 1 and 2, respectively. The data in Table 1 include the duration of movies (r), occupation (o) and age (g) of the users, with age Î [7, 73] and runtime Î [24, 238]. Firstly, each occupation is represented by a unique integer number between 1 and 21, such as 1 for “other”, 2 for “academic/educator”, 3 for “artist”, etc. Then, the values of age, occupation and runtime are normalized according to Equation (7) in order to calculate the function f(u, j). In the other hand, Fig. 2 describes the movies evaluated by the target user in the past. According to Equation (6):
An illustrative example of data normalization.
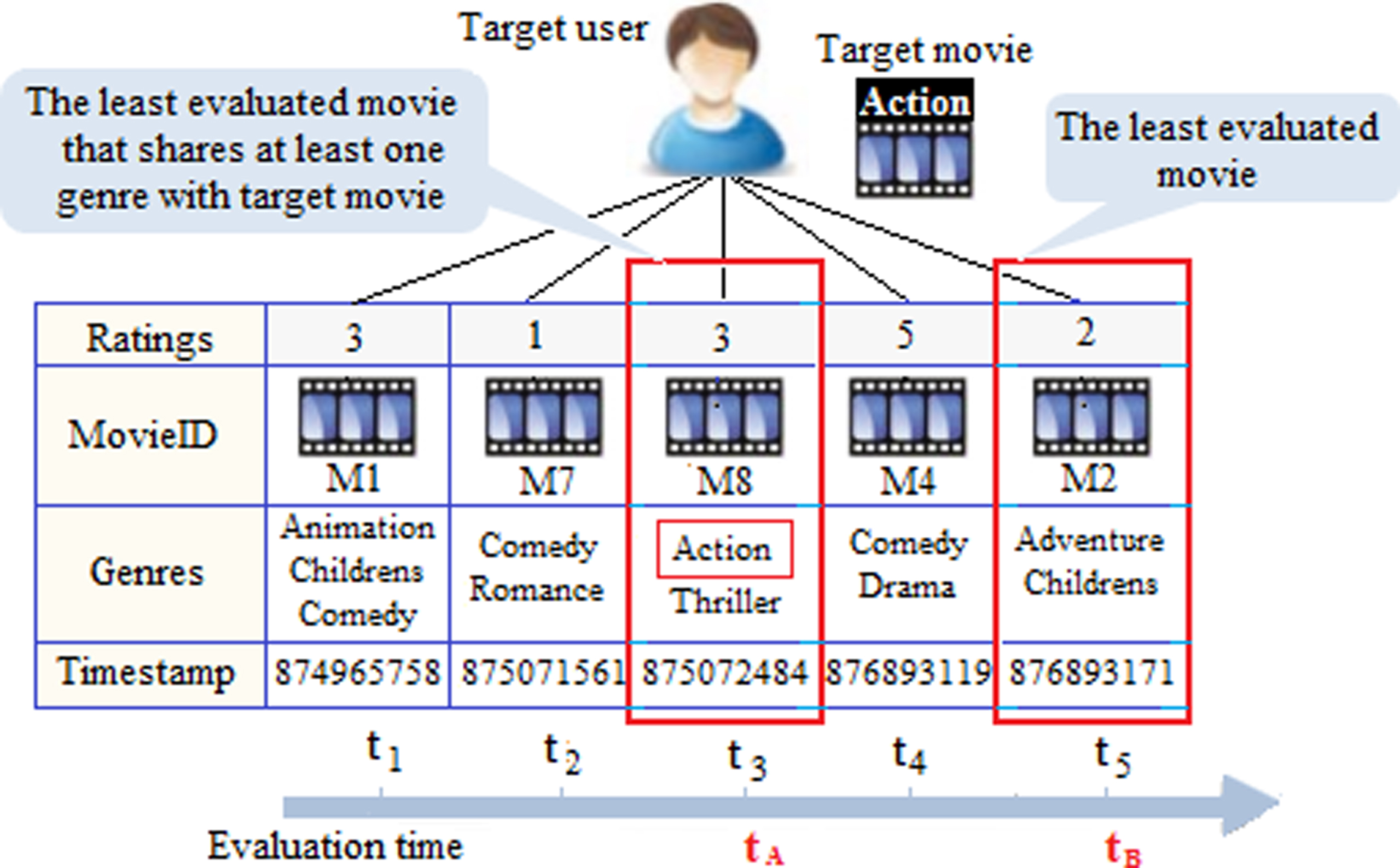
An illustrative example of parameter λ calculation.
In this paper, the position of each particle represents the weight vector of l contextual features (w1, w2, ... .., w
p
, ... .., w
l
), where w
p
(0 < wp≤1) is the weight of the feature p and
|Q| is the cardinality of the training set. P’u,i and Pu,i are real rating and predicted rating, respectively. The predictions calculation is based on the proposed weighting function defined in Equation (8).
To demonstrate the effectiveness of the proposed model, several experiments have been conducted on the Movielens 1 dataset and CMU Movie Summary 2 Corpus. The experiments use a five-fold cross validation scheme to randomly splitting Movielens dataset into training and testing, where 80% of the data are used for training and 20% are used for testing. All the experiments are repeated five times, and the evaluation outcome is the aggregated result from all folds.
Dataset
Movielens is widely used to evaluate recommender systems. This dataset is provided by the University of American Minnesota GroupLens project group. The ML-1M dataset consists of 6,040 users, 3,900 movies and 1,000,209 ratings [39]. The sparsity of the ML-1M dataset is 95.754%. The CMU Movie Summary Corpus is also used in this paper. It contains plot summaries for 42,306 movies and metadata for 81,741 movies such as genre, release date, runtime, languages, etc. Each movie is indexed by a Wikipedia Movie ID.
Methods compared
The following algorithms are compared in our experiments:
Parameter setting
For all experiments with the LDA model, the number of topics T is fixed to 25, the parameters α and β are set to 0.01 and 0.02, respectively. The training of the LDA is based on the Gibbs sampling method to estimate the latent parameters θ and ϕ. For the PSO algorithm, the inertia weight w is linearly decreasing from 0.9 to 0.4. c1 and c2 are selected as 1.4945, and the maximum number of iterations is 80.
Evaluation Metrics
The proposed model is evaluated from two differ-ent perspectives: predictive accuracy and classifica-tion accuracy. Predictive accuracy measures the accuracy of a prediction value on a target item. The Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are the frequently used metrics in predictive accuracy [40]. MAE represents the average of the absolute difference between the predicted ratings and real ratings. The formulas for RMSE and MAE are defined in Equations (11) and (12), respectively.
|Q| is the cardinality of a training set. P’u,i and Pu,i are real rating and predicted rating, respectively.
Classification accuracy evaluates the rate of cor-rect predictions. Precision, recall and F-measure are the three popular metrics for classification accuracy. Precision is a percentage of recommended items that are relevant while recall is a percentage of the rele-vant item that is recommended [40]. Precision, recall and F-measure are defined in equations Equation (13), Equations (14) and (15), respectively:
In this section, each user is considered to be an active user and the item ratings for each of them are predicted. The recommendation algorithms are evaluated by comparing the predicted ratings with the actual ratings. Since a different neighborhood size k leads to different recommendation results, the impact of k is also considered in this experiment. So, recommendation results are calculated and compared under the condition of different k.
Figures 3 and 4 illustrate the evolution of the MAE and RMSE through the neighborhood size. It can be seen that the errors in metrics MAE and RMSE decrease as the number of neighbors increases for Item-CF approach. However, for the other methods, the error starts with a relatively high value and then it reaches the lowest points at k = 40. The MAE and the RMSE of TMPSO-CF are 0.7043 and 0.9071, respectively. It is also observed that the values of MAE and RMSE increase with the increase of the neighborhood size in the range of 40–100. This can be explained by the fact that these methods achieve a better prediction quality when more similar items are taken into account. Among all the methods, TMPSO-CF always has the best MAE and RMSE no matter how the number of neighbors changes, which means that the predicted scores by TMPSO-CF are closer to the original scores. It is also obvious from Figs. 3 and 4 that the methods which consider the degree of importance of contextual information (i.e. TMPSO-CF and PSO-CF) perform better than the other methods. Furthermore, compared with the closest competitor (PSO-CF), TMPSO-CF has a 3.55% advantage for MAE and 5.55% for RMSE. The main reason is that TMPSO-CF also considers hidden context, which is conducive to the improvement of prediction performance.
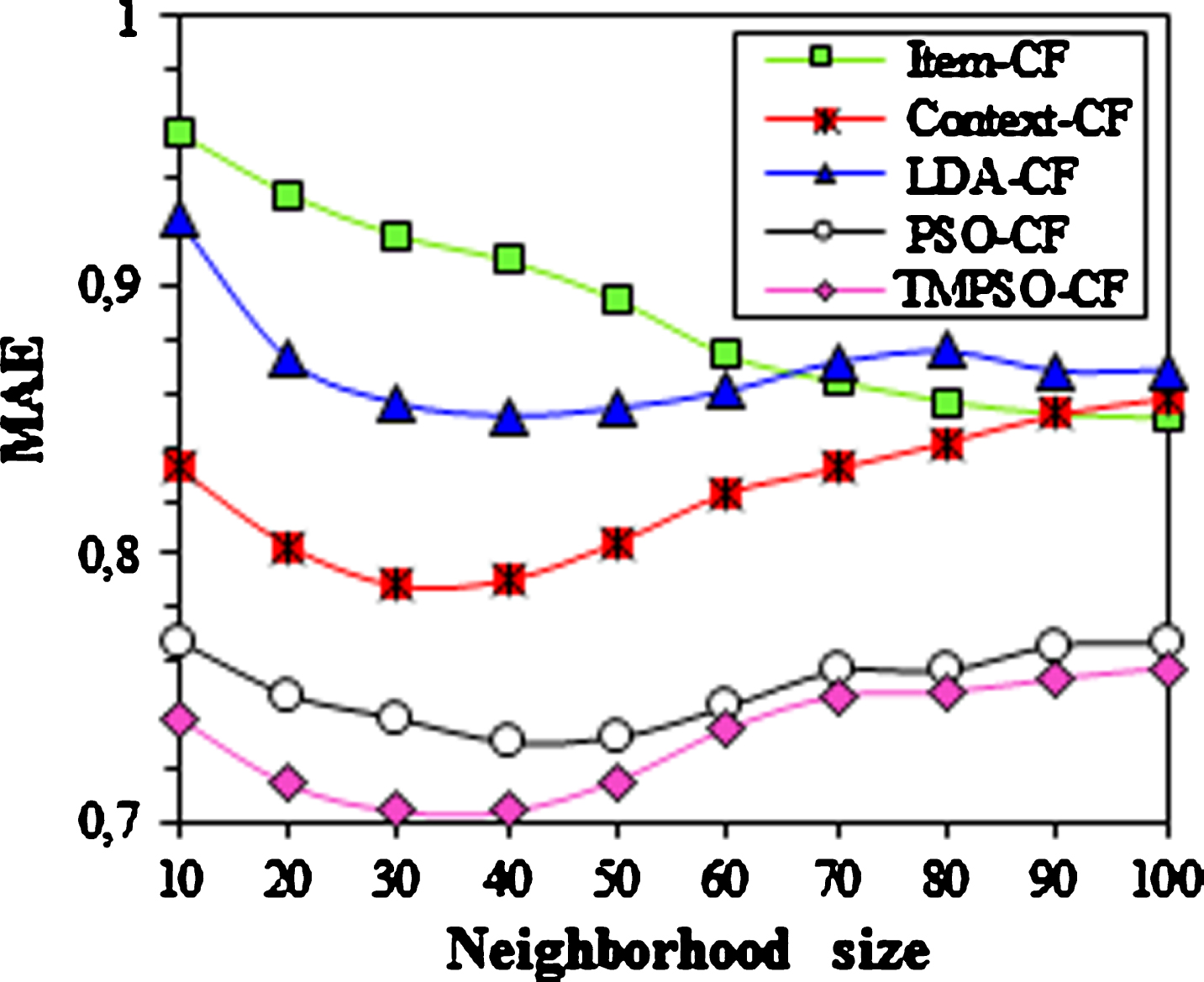
MAE with different neighborhood size.
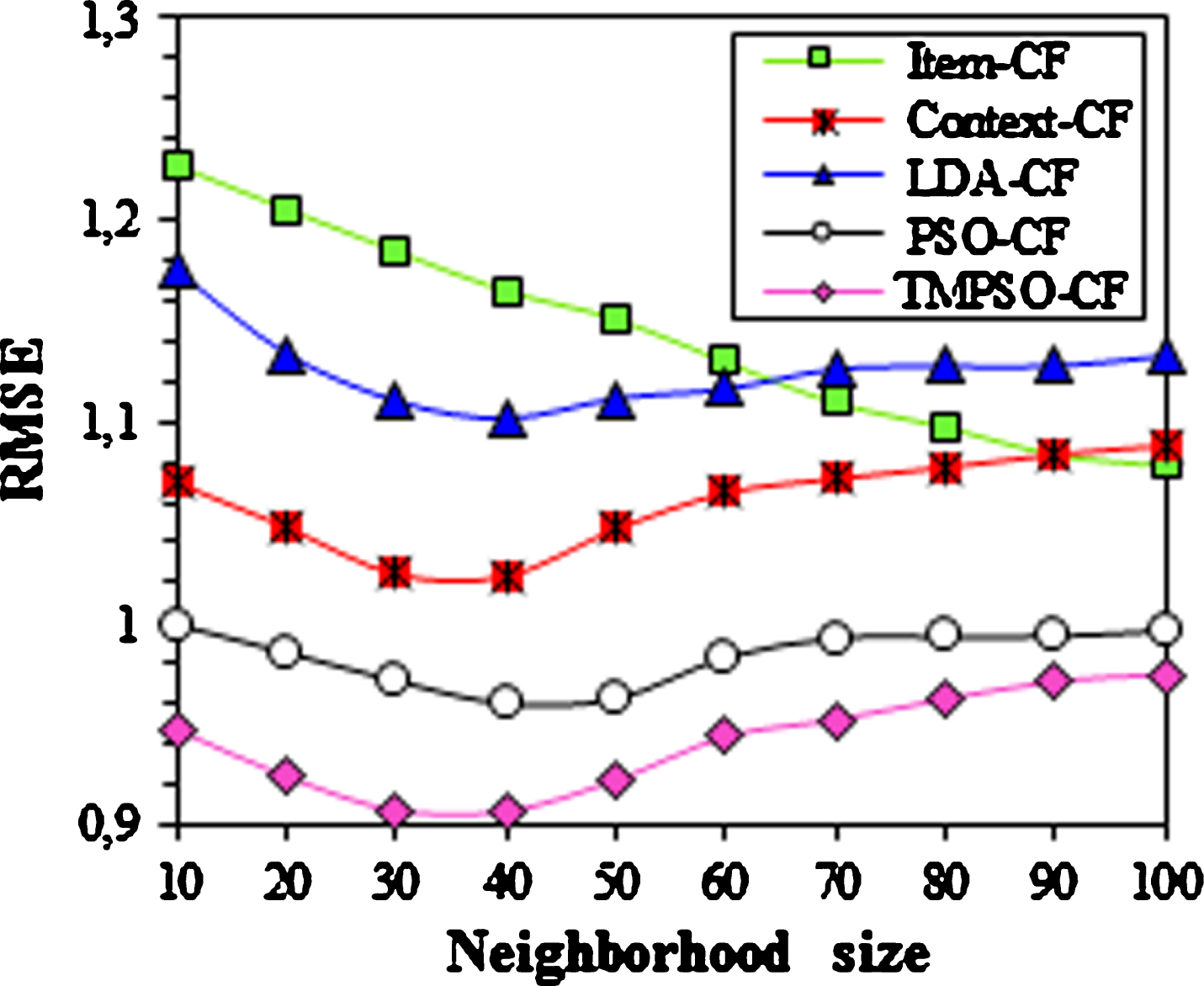
RMSE with different neighborhood size.
Overall, the results of these experiments confirm that the model which combines the latent interests and explicit features with their degree of importance performs better than the other CF algorithms. On one hand, latent factors have a real meaning for recommendations. So, getting only several interest information about the target user allows discovering the possible items that this user may like, through the item–interest relationship [41]. On the other hand, the ratings produced at different times and in different context situations have different impacts on the prediction process [22, 42].
Figure 5 outlines the evolution of precision through the neighborhood size. The results indicate that the precision of all methods decrease when the number of neighbors increases. This means that the number of the relevant objects increases when more similar items are considered. Moreover, TMPSO-CF mimics PSO-CF, under different neighborhood size, and both perform significantly better compared with the remaining methods. The proposed TMPSO-CF enhances precision by 4.49% and 22.50% compared with PSO-CF and item-CF, respectively.
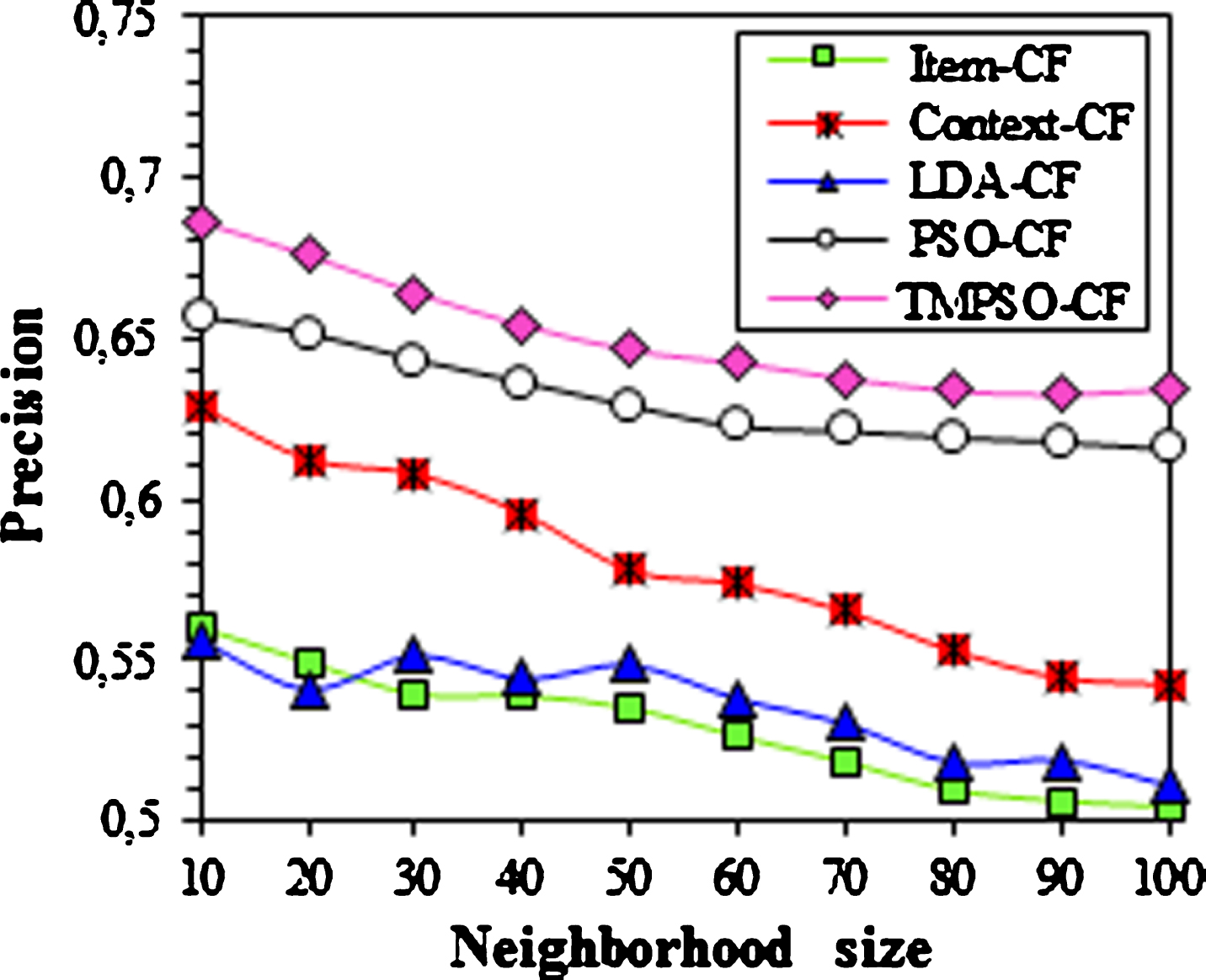
Precision with different neighborhood size.
Figure 6 illustrates the evolution of recall through the neighborhood size. It can be seen that, the recall values of all methods become better as the number of neighbors increases. The results also confirm that TMPSO-CF exceeds the Item-CF, Context-CF and LDA-CF in recall by more than 17%. To sum up, the experiments verify that the TMPSO-CF enhance the prediction performance. This is beneficial to find the proper trade-off between efficiency and performance.
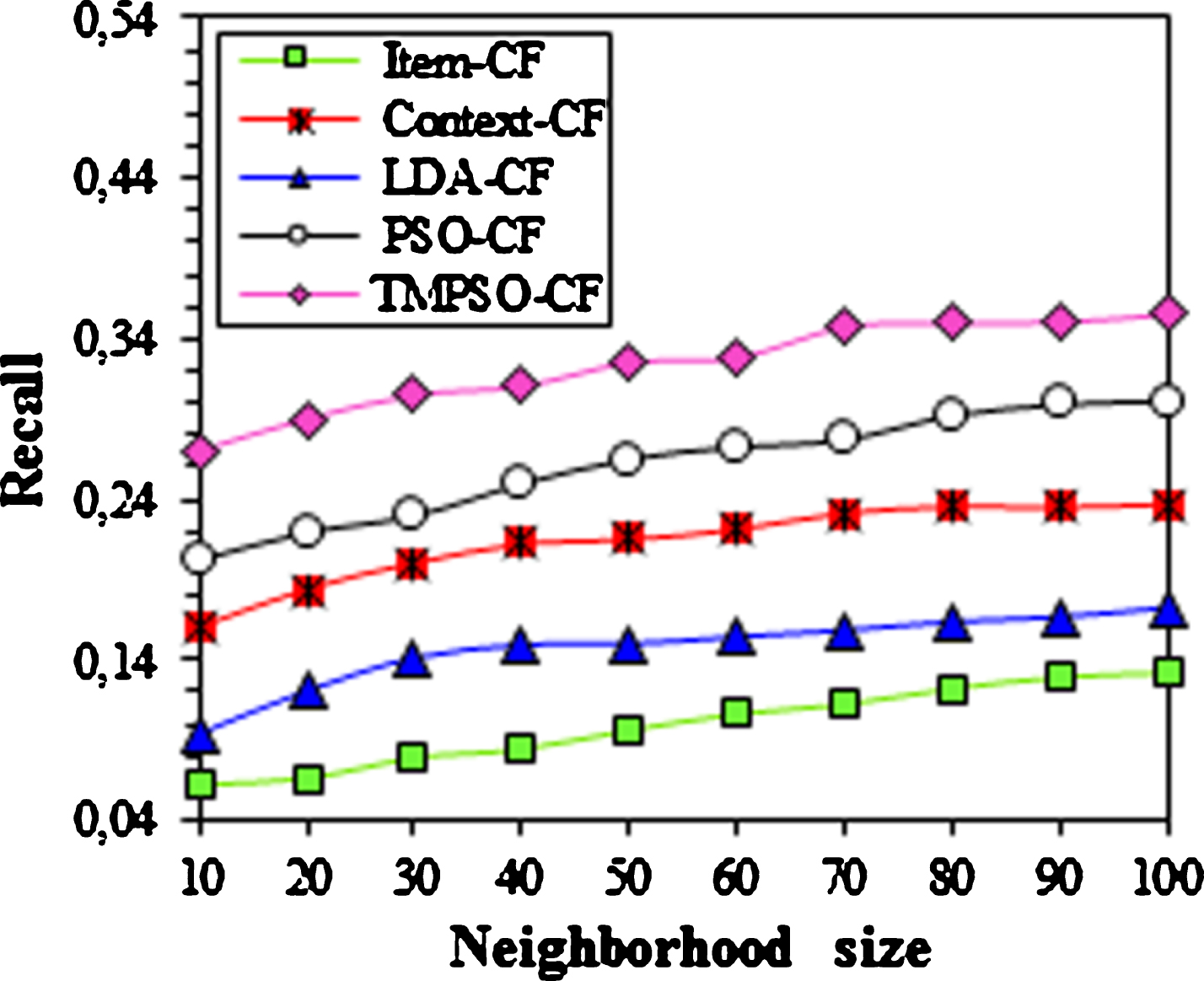
Recall with different neighborhood size.
Figure 7 shows the evolution of F-measure through the neighborhood size. It is clear that the F-measure of all methods changes slightly with different numbers of neighbours. This means that these models perform stably in F-measure. Furthermore, the presented TMPSO-CF has better F-measure values than the other CF models. It achieves an F-measure value close to 0.45. Compared with the closest competitor PSO-CF, the TMPSO-CF has 12.54% advantage. However, the advantage of TMPSO-CF is more apparent compared to the other CFs discussed here. It exceeds 37%.
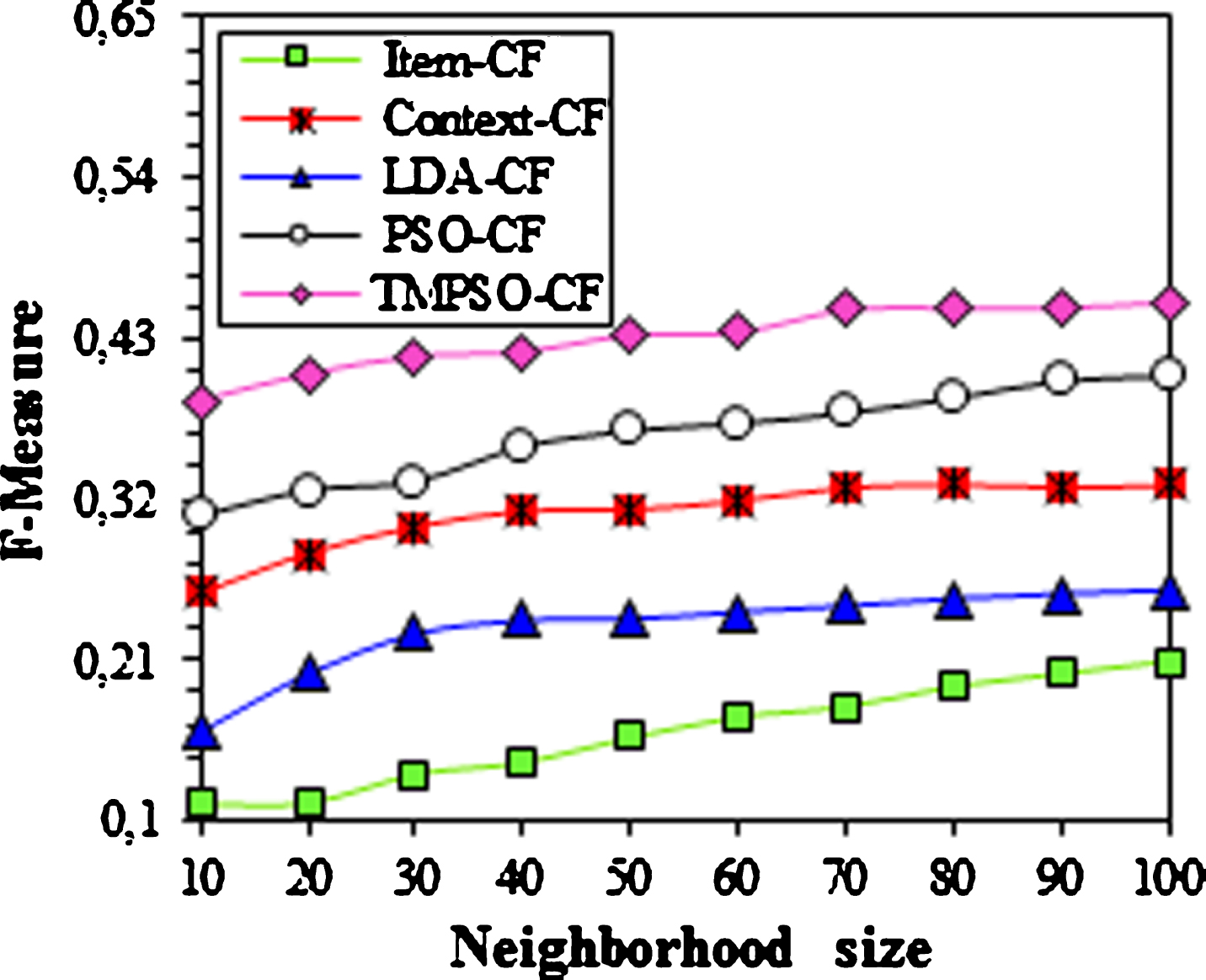
F-Measure with different neighborhood size.
Overall, the results of this experiment confirm that TMPSO-CF has better performance in both successful and perfect predictions. It can identify the indirect correlations between the movies. Thus, it considers movies in the latent space to discover the hidden interests and utilizes the contextual factors with their degree of importance when computing predictions. This was an important reason why the TMPSO-CF performed better than the other models.
In order to verify the difference between the results of TMPSO-CF and the four competing methods over the five evaluation metrics, a paired t-test is computed. This statistical analysis was performed for a confidence level of 95%. The results of paired t-tests for the TMPSO-CF model are summarized in Table 2. For all the paired t-tests results, the p-values are less than the value of the significance level (i.e. less than 0.05), which proof the robust performance of the TMPSO-CF method. Consequently, the null hypothesis of mean equality is rejected and significant differences in prediction and classification accuracy of the proposed model are proven against the competing methods.
Statistical significance of TMPSO-CF results using paired t-test
Statistical significance of TMPSO-CF results using paired t-test
In brief, the results are very promising, showing the advantage of combining the hidden and explicit contexts for movie recommendation system. However, the performance of the proposed model strongly depends on the neighborhood size. Herlocker et al. [4] studied the size of neighborhood in detail, and reached a conclusion that the size of the neighborhood have a significant impact on recommender system’s efficiency. So, it is crucial to select the optimal value of the neighborhood size in order to obtain the best trade-off between the efficiency and performance of the TMPSO-CF proposed model on Movielens 1 M dataset.
The computational complexity of the proposed algorithm depends on the time complexity of model construction, and the time required to generate recommendations using this model. The former is performed offline, whereas the latter is accomplished online. The time complexity of training phase consists of two parts: including the time required to build both the LDA and PSO algorithms. The overall time complexity of LDA is O(I1TnS), where I1 is the iteration number of Gibbs sampling, T is the number of latent topics, n denotes the number of items and S is the average number of words.
In the next phase, the PSO is applied to find the weights for the contextual features. The time complexity of the PSO algorithm is O(I2Cfk), with I2 is the number of iterations, C denotes the number of particles and fk represents the fitness calculation complexity. For the fitness function, the similarity scores between items should be computed. The complexity of this step is O(Tn2). Furthermore, the time of O(nlogn) is spent for choosing the k nearest neighbors. Additionally, the time required to compute the proposed weighting function defined in Equation (8) is O(klm), where l is the size of the particles (i.e., the number of contextual features) and m is the number of users. Finally, the computational cost of the error function is about O(km). Thus, the complexity of training PSO is O(I2 C(Tn2 + nlogn + klm + km)) ≅ O(I2 C(Tn2 + m)). Therefore, the total computational complexity of the proposed model during the offline phase becomes approximately O(I1TnS + I2 C(Tn2 + m)). In the online phase, the time complexity of the proposed model is O(k) for one rating prediction and O(n) for ranking the items and making recommendations.
Performance of TMPSO-CF at optimal neighborhood
Optimization of neighborhood size
The desirability function approach has been used for multiple evaluation metrics optimization of TMPSO-CF using the Design Expert Software. This approach involves specification of the individual desirability function (di) for each evaluation metric (Yi) by assigning to the estimated values a score ranging from 0 (very undesirable) to 1 (very desirable). The optimization module searches for a neighborhood size (k) in the range of 10–100 that simultaneously satisfies the requirements placed on the evaluation metrics. During the optimization process, the aim was to find the optimal value of neighborhood size (k) in order to produce the lowest values of MAE and RMSE with the maximal values of precision, recall and F-measure. The constraints used during the optimization process are summarized in Table 3 and the optimal solution is reported in Table 4.
Constraints for optimization of neighborhood size (k)
Constraints for optimization of neighborhood size (k)
Optimal solution
For clear assessment, desirability value of each individual factor and responses associated with the modeling are shown in Fig. 8. The MAE and RMSE are found to be more desirable with 0.97109 and 0.97056, respectively. It can be said that the TMPSO-CF achieves the best compromise between the efficiency and performance with a neighborhood size equal to 37. Similar results were reported in [4], where Herlocker et al. suggest that, in the real-world situations, a neighborhood of 20–60 neighbors is reasonable to be used for making predictions.

Bar chart of the desirability optimization.
To further check the performance of the proposed algorithm, Figs. 9 and 10 illustrate the comparisons between the used models in different number of recommendations (TopN). In these experiments, the neighborhood size is fixed to 37. As can be seen from Fig. 9, the precision results of TMPSO-CF significantly outperform the others in returning relevant movies for all TopN values. In fact, compared with the Item-CF algorithm, the TMPSO-CF has a remarkable improvement; it is about 28% when the TopN is 5. The average improvement of TMPSO-CF compared with the Item-CF, LDA-CF, Context-CF and PSO-CF is 29.67%, 27.10%, 17.28% and 5.7%, respectively. This is because the TMPSO-CF is able to remove movies that are less related to the target one. Furthermore, it is established that the precision decreases as the number of recommendations increases. Figure 10 compares the recall rates of user interesting movies. Contrary to the precision results, the recall values increase smoothly as the TopN increases. It’s also apparently that TMPSO-CF still provides greater recall rates with each value in the number of recommendations. Compared with PSO-CF algorithm, the TMPSO-CF can improve 6.86% when the TopN is 25. Moreover, the average improvement of TMPSO-CF compared with Context-CF and PSO-CF is 43.37% and 11.83%, respectively.
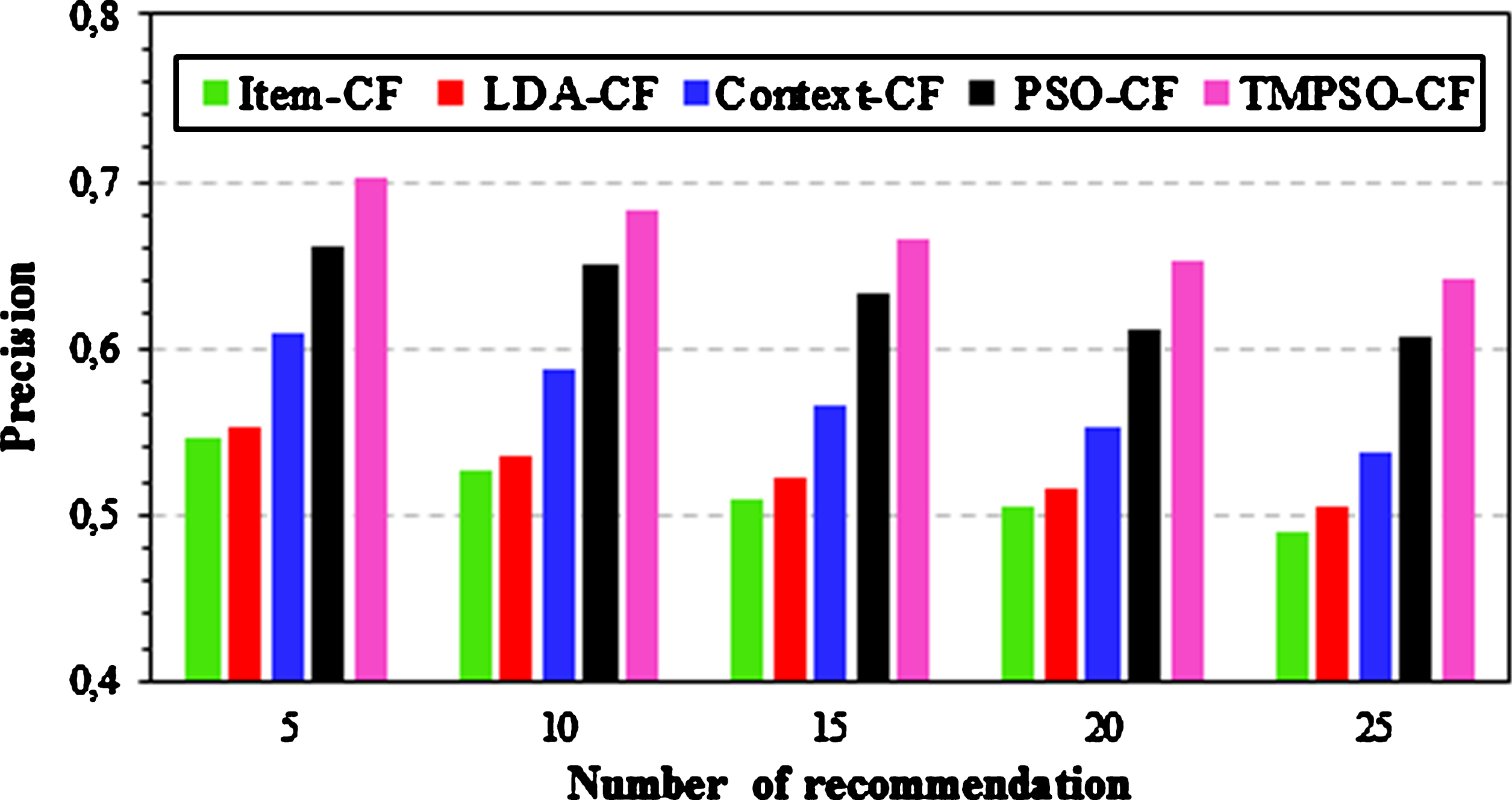
Precision performance with different TopN.
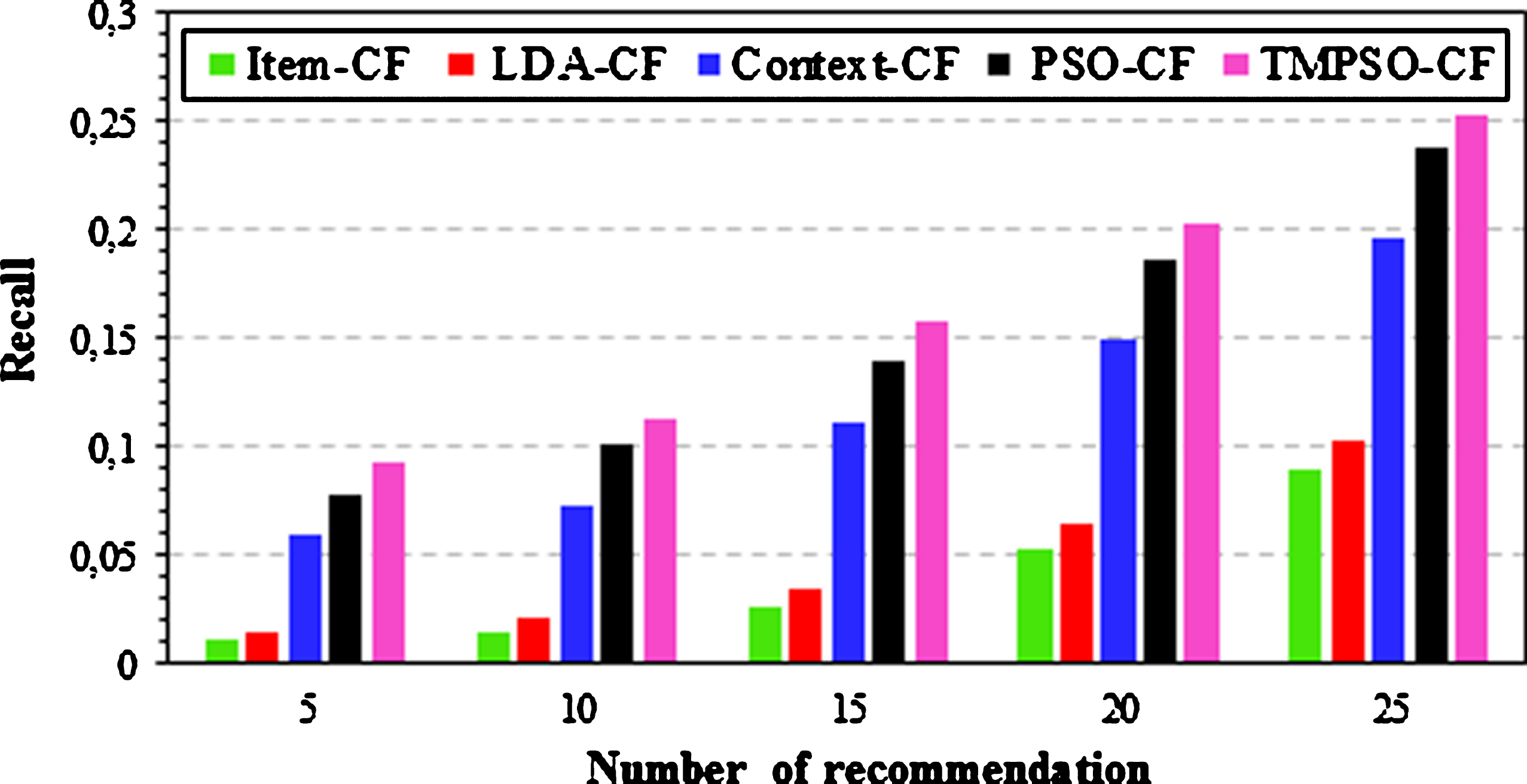
Recall performance with different TopN.
Furthermore, Table 5 reports comparison results of the proposed model with the best results of the state-of-the-art RS’s methods [43–45] in MovieLens 1 M. It is clear that TMPSO-CF produces significant improvement in terms of MAE by 14.36%, 4.48% and 41.63% for GA + GELS, BiUCF and Random method, respectively. Moreover, the enhancement of TMPSO-CF in RMSE compared with GA + GELS, BiUCF and Random method is 13.87%, 12.7% and 39.69%, respectively. However, the percentage error between TMPSO-CF and NMF, SlopeOne, K-NN, Centered K-NN, Co-Clustering and Baseline is insignificant for both MAE and RMSE. In fact, the performances of these methods are close, and they all have good application potential.
Performance of TMPSO-CF compared with state-of-the-art methods
To sum up, this study provides a new way to combine the collaborative filtering algorithm and the content based method to alleviate the data sparsity in CARS. The proposed model is tested on MovieLens 1 M dataset, which contains sparse ratings. It can be concluded from different tests conducted in this work that TMPSO-CF performs better with respect to five metrics.
Consequently, it can identify the users’ needs and suggest relevant resources for the customers. This is due to the topic analysis method, which can analyze the item themes those users are interested in, and the weighting function which consider the change of user’s interest over context. These encouraging results clearly confirm that the context is an important criterion in recommendation systems. Moreover, the combination of hidden and explicit features with their degree of importance is a promising way to improve the quality of prediction and recommendation.
This study proposes a context-aware recommender system based on Latent Dirichlet Allocation (LDA) and Particles Swarm Optimization (PSO) to make recommendations that consist not only of items that are popular in the community, but also those that are similar in content and in context. The main aim is to alleviate the sparsity problem and improve the quality of recommendations. The LDA algorithm is used to learn latent properties of objects in order to compute the similarity scores between items through the hidden context. Furthermore, a weighting function is introduced to directly integrate explicit context in the recommendation process. It exploits contextual factors and their degree of importance, which are computed based on the PSO algorithm in order to detect user’s interest drifts. The effectiveness of the proposed method was evaluated experimentally using data from the Movielens 1 M dataset and CMU Movie Summary Corpus. The experiments indicated that the developed model alleviated the sparsity problem and achieved significantly better recommendation quality than the baseline methods. It also achieves the best trade-off between the efficiency and performance. In a future work, we plan to incorporate some other useful information obtained from social networking sites. We will also propose a dynamic context weighting mechanism for further performance enhancement.