
Abstract
Facial expression recognition (FER) has been one of the research focuses in recent years due to its significance in human-computer interactions. However, there are still challenges in the field of FER caused by the diversity and variation of facial expressions in real scenes, the singleness of feature type and the lack of enough discriminant features cannot effectively improve the recognition performance. To solve these problems, we propose a Multi-feature Fusion Network (MFNet) with dual-branch based on deep learning. Firstly, the MFNet uses the pyramid parallel multiscale residual network structure with progressive max-pooling of channel attention to extract multi-level facial features and enhance the discrimination of features; In the meantime, a shallow Gabor convolutional network is designed to enhance the adaptation of learned features to the orientation and scale changes and improve the ability to capture local details features; Finally, the maximum expression features obtained by the above two networks are fused to make more effective expression recognition. Experiments on three public large-scale wild FER datasets (RAF-DB, FERPlus, and AffectNet) show that our MFNet has a superior recognition performance than other recognition methods.
Introduction
As the most direct and vital way of expressing human emotions, facial expressions play an important role in the transmission and understanding of emotions in interpersonal communication. With the continuous development of computer vision, the automatic recognition and analysis of facial expressions in human-computer interaction, automatic driving, medical diagnosis and treatment, mental health analysis, criminal investigation, psychological assessment, polygraph, public safety, and intelligent assistance are constantly being applied. We call the research on the emotional state of facial expressions (neutral, happy, angry, sad, fear, disgust, surprise, contempt, etc.) as facial expression recognition (FER).
With the continuous development of machine learning and deep learning in recent years, FER has made significant progress [1, 2]. The recognition of facial expressions taken in the laboratory (in the lab) under controlled conditions (correct posture, unobstructed view, simple background, etc.) with clear, accurate, and uniform data has achieved excellent performance through various algorithms [3, 4], and such expression datasets include JAFFE [5], CK+ [6], and Oulu-CASIA [7]. However, the large-scale facial expression datasets in recent years from the real scenes that we called in the wild datasets bring new challenges to researchers due to noise, pose, occlusion, illumination, and some other variations, such as RAF-DB [8], FERPlus [9], and AffectNet [10] expression datasets. Many scholars have carried out many studies on such datasets based on Convolutional Neural Network (CNN) [11, 12]. To extract more effective expression features, exploring the correlation between multiple features has also received further attention. Zeng et al. [13] explored the relationship between manual features and deep features and embedded manual features in the network structure to improve facial expression recognition accuracy. Xu et al. [14] combined LBP and CNN to extract features separately through two branches, then merged these two features and reduced the dimensionality by PCA to improve the identification performance of FER. The recent proposal of the attention mechanism can make the model have the ability to focus on specific features [15] and be helpful for the extraction of facial expression features in real scenes. The above methods have laid a good foundation for the research of facial expression recognition in real scenes, but there are still the following problems: 1) Due to the spontaneity and variability of facial expressions in real scenes, and complicated situations such as occlusion, posture, and illumination, features extracted by using a single type of kernel and a single space size, such as the standard convolution, may not be the optimal solution. Especially for the wild facial expressions with more changes in direction and scale, the capture of detailed features needs to be further enhanced; 2) The expression focus area is not concentrated enough, and the most expressive features are insufficient.
To address above issues, we propose an effective Multi-feature Fusion Network (MFNet) method, which further focuses on the core regions of interest in facial expressions and extracts effective facial features from multiple levels and different perspectives to enhance the discrimination ability of wild expressions. The MFNet is composed of Max-pooling Pyramid Residual Network with 40 layers (MPResNet-40) and Gabor Convolutional Network (GBCN) dual-branch network through feature maximization fusion. The MPResNet-40 network consists of progressively embedded Max-pooling Efficient Channel Attention (MECA) and Pyramid Residual Network with 40 layers (PyResNet-40). First, the PyResNet-40 network is used to extract multi-level expression features by pyramidal convolution, and meanwhile, the feature weights are redistributed by progressive stage MECA attention to further focus the range of expression region; In addition, we design the shallow GBCN network by combining Gabor orientation filters (GoFs), so that the convolution filters have powerful spatial localization, orientation selectivity and spatial frequency selectivity to capture essential features of detail changes for further enhancing the robustness of recognition. Finally, we carry out the maximum selection of features for the above two branches and fuse the two types of features to conduct the final recognition analysis.
The contributions of this article are summarized as follows: We propose a novel end-to-end MFNet method to perform FER, which takes an effective fusion of MPResNet-40 and GBCN branches. The MPResNet-40 extracts multi-level features from the region of interest under the progressive stage attention. The shallow GBCN captures the key detail features by great texture representation ability in the meantime. The fusion features obtained at last are used for expression recognition. We visualize the low-level features of two types of network and the effects of attention, and further analyze their respective mechanisms. We validate the MFNet on large-scale wild FER datasets (RAF-DB, FERPlus, and AffectNet), and achieve accuracy of 88.53%, 89.18% and 60.38% respectively, which show competitive recognition capability and good generalization performance.
Related work
FER in the wild
Generally, a FER system includes three parts: face detection, feature extraction, and expression recognition. In the face detection stage, Dlib [16], MTCNN [17], and more deep face detection models [18] are proposed and used to locate faces in various scenes and do further face alignment. In the feature extraction stage, the type of features can be divided into engineered features and learned features. For engineered features, they can be divided into texture features and geometric features, and the texture features mainly include HOG [19], LBP [20], and Gabor wavelet [21] and geometric features depend primarily on the landmark points from the region of eyes, mouths, and noses. These features are used for final facial expression recognition by selecting classifiers such as support vector machines (SVM).
With the continuous development of deep learning technology and the introduction of large-scale datasets in facial expression competitions such as FER2013 [22] and EmotiW [23] based on real scenes, deep learning methods based on learned features have gradually become the mainstream technology in the field of FER, and features extraction and classification recognition are unified into a joint model.
To recognize facial expressions in the wild, Barsoum et al. [9] used the Probabilistic Label Drawing (PLD) strategy to extract and classify features in the VGG model by constructing a more realistic label distribution. Zeng et al. [24] developed an end-to-end Inconsistent Pseudo Annotations to Latent Truth (IPA2LT) model for the inconsistency of labels in real scene datasets, which learned potential associations from inconsistent labels and then output real labels for recognition. Acharya et al. [25] introduced covariance pooling into the Symmetric Positive Definite Manifold Network (SPDNet) to establish a second-order feature manifold network that can better capture the distortion of facial features. Siqueira et al. [26] designed different network structure integration models according to the dataset type (in the lab or in the wild) to improve the recognition effect. Wang et al. [27] proposed a Self-Cure Network (SCN) for dynamic adjustments labels during the training process to improve the recognition effect in view of the uncertain factors in the current large-scale facial expression dataset, such as low image quality and labeling errors. Farzaneh et al. [28, 29] respectively constructed Discriminant Distribution-Agnostic (DDA) loss and Deep Attentive Center Loss (DACL) models for the imbalance between classes to adjust the distance of intra-class and inter-class to enhance the discrimination ability of the classes. Shi et al. [30] proposed Amend Representation Module (ARM) to reduce the weight of eroded features by reconstructing the feature distribution and strengthen the feature representation ability. Zhao et al. [31] utilized the EfficientFace method to extract local and global features through a local-feature extractor and a channel-spatial modulator for expression classification.
Attention-based FER
The attentional mechanism can select the focus position and produce more discernible feature representation, which is conducive to the further recognition of facial expression. Li et al. [15, 32] proposed robust global-local based Attention-CNN (gA-CNN) and Patch-Gated Convolution Neural Network (PG-CNN) for the partial occlusion and pose problems of real scene expression datasets, which through the attention to perform sub-regional weight reconstruction for further improving the overall recognition rate. Albanie [33] applied Squeeze-and-Excitation Networks (SENet) to use channel attention for feature reconstruction to improve the learning ability of expression features. Fan et al. [34] proposed a Deeply-Supervised Attention Network (DSAN) that adopts the attention block to highlight the essential local facial characteristics for better automatic facial expression recognition by capturing the regions of interest. Wang et al. [35] proposed Region Attention Networks (RAN) to capture critical regions of occluded and pose-transformed images to enhance the robust recognition of wild expressions. Li et al. [36] designed the Local Binary Attention Network and Islets Loss (LBAN-IL) model, which prevents excessive sparseness of feature maps and enhances expression feature’s discrimination by increasing the amplitude of vectors.
FER based on feature fusion
Multi-feature fusion has been widely used in computer vision, such as image classification and semantic segmentation. The fusion of different feature maps can enrich the overall performance and effectively improve generalization ability and recognition performance. Chen et al. [37] proposed a multiple feature fusion method for acoustic features, dynamic textures, and geometric features to tackle wild FER. Huang [38] trained the two network models of ResNet and VGG separately and conducted fusion research at different stages. Georgescu et al. [39] further enhanced the recognition performance by combining multiple CNN network learning features and manual bag-of-visual-words (BOVW) features. Shao et al. [40] proposed a dual branch CNN to extract LBP features and deep features in parallel and fused these feature maps by concatenation for FER. Ma et al. [41] developed the Convolutional Visual Transformers (CVT) method to fuse attention-focused LBP features and CNN features information through two-branch CNNs for further improving the discrimination of features. We propose a Multi-feature Fusion Network (MFNet) that combines Gabor convolution features and multi-scale CNN features embedded with attention to enhances the ability of feature extraction in regions of interest and improves the performance of facial expression recognition in real scenes.
Proposed model
In this part, we first briefly introduce the MFNet, and then further describe the two branch networks and their detailed components.
Multi-feature fusion network (MFNet)
The proposed MFNet is a dual-branch fusion network that consists of a parallel pyramid convolution network with an attention mechanism and a shallow Gabor convolution network. The detailed structure is shown in Fig. 1. The branch network MPResNet-40 uses the 4-stage pyramid parallel residual network PyResNet-40 to extract abundant multi-level facial expression features, and progressive stage MECA attention embedded in the front of each stage to aggregate the energy of key regions to further enhance the discrimination of expression features. The branch of GBCN takes full advantage of Gabor convolution in different directions and scales to capture the local detail variation features. The GBCN model is composed of a 4-stage shallow network, and each stage uses two 3×3 Gabor convolutions for feature extraction. Then we perform the maximum selection mechanism on the differential features extracted from the two branches to select highly discriminative features, conduct multi-feature fusion through concatenation, and finally classify them.
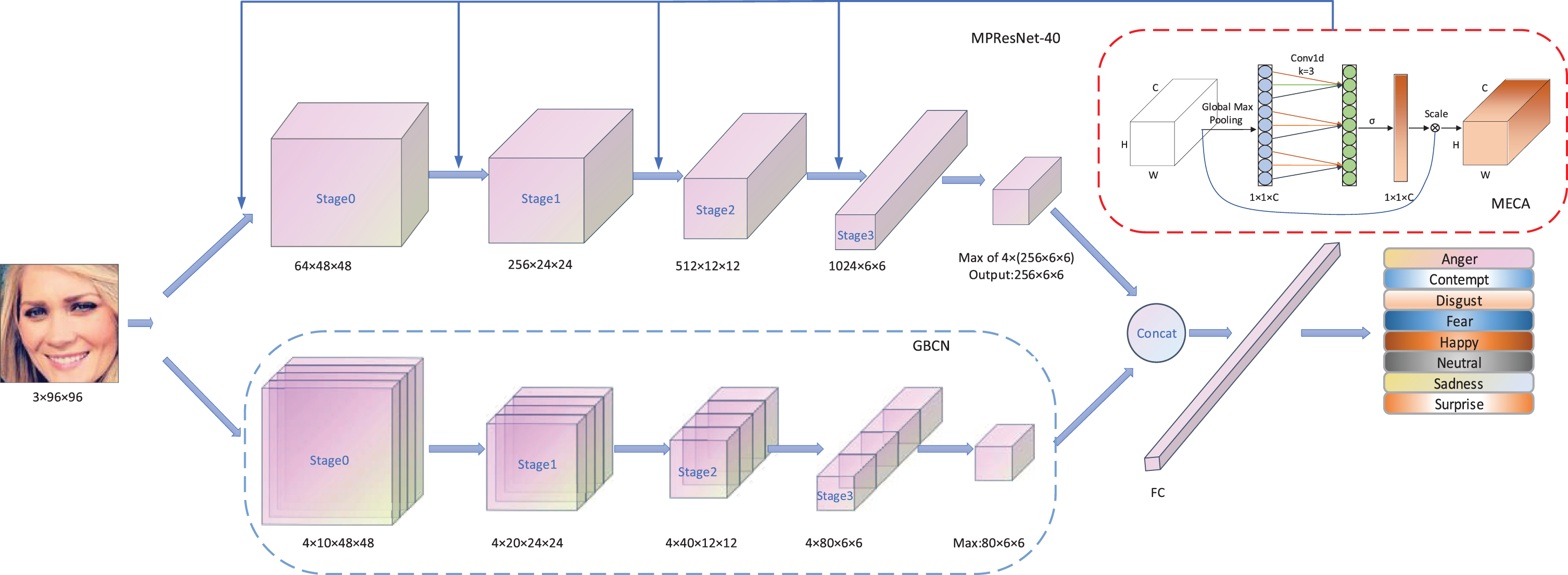
The framework of our Multi-feature Fusion Network. The facial expression image enters two networks simultaneously to extract features and MECA attention module is embedded in front of 4 stages of MPResNet-40 respectively.
Figure 2 shows examples of low-level feature maps of two branch networks. It can be seen that the feature maps of PyResNet-40 presents rich multiscale feature information, and the feature maps of GBCN has a better response to the local texture features of key regions.

An example of low-level feature maps extracted by two branches. (a) show the feature maps first pass PyConv of PyResNet-40, and (b) show the feature maps first pass GConv of GBCN.
The MPResNet-40 model in this paper is based on the ResNet50 model which applies pyramid convolution (PyConv) [42]. In order to further lighten the network and improve the efficiency of the network, part of the convolutional layer is reduced to design a 40-layer pyramid parallel multiscale residuals network structure while focusing on the extraction of more effective deep expression features. In addition, this model continuously aggregates feature channel information and enhances the interaction between channels by adding the progressive MECA module to improve the feature expression ability of the core area. MPResNet-40 is formed by stacking blocks of similar structure, and the detailed structure is shown in the right column of Table 1.
The details of model structure for GBCN and MPResNet-40
The details of model structure for GBCN and MPResNet-40
To extract multi-level feature information in the expression region, the pyramid convolution of each stage in MPResNet-40 varies in depth and size. First, the input features of each stage are mapped by 1×1 convolution after preliminary 7×7 convolution and attention feature reconstruction, then PyConv is used for feature extraction under parallel multiscale, after adjusting the number of feature channels under 1×1 convolution, additive operations with the initial input features are executed, next the feature information of the channels is input into the MECA module for reaching cross-channel interaction without dimensionality reduction, and enter the next stage after channel information aggregation. After the last stage, we sequentially select the maximum activation information in each of the four channels from 1,024 channels, and finally, 256 expression feature maps with the maximum activation information are obtained to perform the following fusion, which provides more discriminating features and reduces the number of parameters.
Based on the deep residual network, the PyResNet-40 network uses PyConv to further improve the feature extraction ability. Different from improving the receptive field by adjusting the resolution of the image, PyConv makes full use of the capability of parallel multiscale feature extraction by adjusting the size of multiple convolution kernels, which can extract multi-level facial features and provide more abundant information. Meanwhile, it can be flexibly expanded to construct a better network structure to adapt to many visual tasks. The PyConv structure is shown in Fig. 3. For each input feature map FM i , kernels of different sizes can be applied, and convolution kernels of different depths FM oi for each stage can be used for group convolution processing simultaneously, and finally get the output of the parallel features.

Pyramid convolution model.
Finally, we built a 4-stage pyramid residual network PyResNet-40 based on PyConv for facial expression feature extraction and recognition.
In order to make the network pay more attention to the core area of expressions and improve the feature representation ability and recognition accuracy, we have added the max-pooling channel attention module MECA to the pyramid parallel network in stages, which is inspired by ECA [43] and applies Global Max Pooling (GMP) to capture cross-channel interactions without reducing the dimensionality, so that the network can better focus on the aggregation of image channel features and strengthen the network’s attention to effective channels, which will be very helpful to enhance the feature’s representation of key areas. It is illustrated in Fig. 4.

MECA module example (inserted after Stage 0).
MECA is mainly constituted by GMP, Conv1d, and Scale. GMP compresses the input features of size W×H×C into the global max-pooling information of 1×1×C in the spatial dimension and takes advantage of the channel size adaptive function ψ(C) to solve the number of adjacent channels k which participate in the channel weight calculation. ψ(C) is given by Equation (1).
Where C is the number of channels, the parameters b and γ are set to 1 and 2 respectively, and the adjacent odd numbers are taken after calculation, and we get k = 3 at last. Conv1d solves the local cross-channel weight value ω for adjacent k channels, and the feature map with channel weight is ultimately obtained as Equation (2). Finally, the scale is used to multiply the weight value to weight the previous feature.
Where σ is the activation function, α is the channel sharing parameter, and
Since the usual deep learning network does not have the ability to decompose the direction and scale of features, in order to enhance adaptability for direction and scale changes and the ability to capture these local detail changes, we employ the Gabor orientation filter (GoF) [44] to form Gabor convolution (GConv) and design a lightweight Gabor Convolution Network (GBCN) to extract local detailed expression features, especially with changes in direction and scale. It consists of 4 stages, each stage adopts two small 3×3 GConv to enhance the sense of vision and increase the non-linear ability of the network while reducing the number of parameters, and further realize the extraction of fine-grained details of expressions. Meanwhile, we add batch normalization (BN) and ReLU activation function after each GConv to speed up the model’s convergence and overcome the gradient’s disappearance or explosion. After each stage, we use the 2×2 convolution kernel to perform the max-pooling convolution operation, which reduces the parameters while retaining the key features and maintains the invariance of the original space of the features. The structure details are shown under the column “GBCN” of Table 1.
GoF is a filter with adjustable parameters, which performs the learning of convolution filters through the Gabor filter bank to generate enhanced feature maps. GoFs encode the direction information into the learned filters and embed the scale information into different layers meanwhile. A GoF is attained based on a modulated process using Gabor filters of U directions on the learned filters under a given scale v. The modulation process of the Gabor filter is given by Equation (3).
Where G(u,v) denotes u directions and K×K kernel Gabor filter under v scales, Ci,o is a learned filter with the size of U×K×K, ∘ represents element-by-element product operation.
From the Equation (4), we can see that the ith GoF
Through GoFs, the feature map obtained by the GBCN network and the process is defined as Equation (5).
The Equation (5) represents that the input feature map F is convolved with the ith GoF C
i
to obtain the output map
Where (n) is the nth channel of F and Ci,u, and
Implementation details
Our MFNet uses MPResNet-40 and GBCN as the dual backbone network for feature fusion, and PyResNet-40 is pre-trained based on ImageNet [45]. We perform face detection and alignment through MTCNN [17] and further resize face images to 106×106 pixels. Then we augment these input images by random crop (96×96 pixels), random rotation, random horizontal flip, and normalization on the fly to prevent over-fitting and enhance generalization. In model training, the stochastic gradient descent (SGD) with momentum optimizer is used for optimization, where the momentum parameter is 0.9 and a weight decay of 5e-4. We fix the mini-batch size to 64, and cross-entropy loss is adopted as the loss function. The model is trained for 250 epochs, the initial learning rate is 0.03, and it is attenuated by 0.9 times every 10 cycles. All the experiments in this article are programmed and implemented in Python under the PyTorch framework on Ubuntu16.04, 32 G RAM by using NVIDIA RTX 2060 SUPER GPU with 8 G RAM for training.
Datasets
In order to verify the effectiveness of the model proposed in this paper, we have conducted experiments on wild FER datasets with RAF-DB, FERPlus, and AffectNet. These datasets cover different data scales and image challenges. Figure 5 shows some expression sample images of the above three datasets.

Sample images on RAF-DB (The first row), FERPlus (The second row) and AffectNet (The third row).
RAF-DB [8] is an emotional dataset containing 29,672 facial expression images in real scenes. The dataset comes from the Internet, which is divided into a basic dataset containing seven types of basic expression labels and a composite dataset containing twelve types of composite expression labels. The experiment selects the basic expression dataset for evaluation, including 12,271 training samples and 3,068 test samples, and conducts experimental measurement on the test set.
FERPlus [9] is a wild expression dataset obtained by relabeling on the FER2013 [22] dataset. It contains 28,709 training images, 3,589 verification images, and 3,589 test images with a size of 48×48 pixels, which have been relabeled as ten classes of extremely unbalanced expressions. The experiment adds contempt to the basic seven expressions (neutral, happiness, surprise, sadness, anger, disgust, fear) for a more comprehensive assessment and performs accuracy measurement on the test set containing eight basic expressions.
AffectNet [10] is the largest wild facial expression dataset to date, containing 450,000 tagged facial expression images with manual annotations which are collected from the Internet by querying three major search engines. The dataset includes people of different races, background changes, lighting, postures, etc., and the category data is very uneven. The experimental selection includes eight expressions: anger, disgust, fear, happiness, neutral, sadness, surprise, and contempt for evaluation. There are 287,651 images as training data with very uneven categories (The category with the most images is more than 35 times in image numbers than that with the least one) and 500 images for each class as a validation set. We report the accuracy of the validation set for experimental evaluation.
To show the effectiveness and rationality of the module combination in the network, we conduct ablation studies on RAF-DB, FERPlus, and AffectNet datasets respectively to evaluate the performance.
1) The influence of MECA in MPResNet-40: To further evaluate the effectiveness of the MECA method in the MPResNet-40 model, we conduct the ablation study for the MECA module in the MPResNet-40 model. As shown in Table 2, when the MECA attention module is not added, MPResNet-40 achieves the accuracy of 87.48%, 87.94%, and 59.30% on the RAF-DB, FERPlus, and AffectNet datasets which only PyResNet-40 is used. When the MECA is added, the accuracy rates are increased by 0.26%, 0.51%, and 0.55%, respectively. The results show that the progressive stage attention can further improve recognition accuracy based on the original model.
Evaluation of MECA module in MPResNet-40 (%)
Evaluation of MECA module in MPResNet-40 (%)
We also discuss the location of MECA. As shown in Fig. 1, we define the position added before stage0 in the MPResNet-40 network branch as 0#, and the following positions are numbered sequentially. Table 3 shows that the model has a slight improvement when MECA is added at 0# position. When attention is added at 1# and 2# positions, the model’s recognition ability has a rapid improvement. After the 3# location continues to be added, there is still a small performance improvement. As shown in Fig. 6, this embedding pattern of progressive attention is very helpful for the MPResNet-40 network to gradually focus on the facial expression area and weaken the influence of the rest of the background, and finally have a cumulative performance improvement. At the same time, we calculate the running time of the model after adding different positions of MECA on the RAF-DB dataset. It takes 0.33 s, 1.20 s, 1.95 s, and 2.88 s training time respectively after adding one MECA, two MECA, three MECA, and four MECA sequentially. We can see that this lightweight attention has little impact on the network operation and is more efficient.
Evaluation of locations for MECA in MPResNet-40 (%)

Attention maps (From left to right: original image, result of MECA added at 0#, MECA added at 0# and 1#, MECA added at 0# to 2#, MECA added at 0# to 3#).
2) The influence of MPResNet-40 and GBCN in MFNet: We perform ablation experiments on MPResNet-40, GBCN, and the fusion of the two models, respectively. As shown in Table 4, when we only use GBCN, the algorithm shows a good recognition performance with accuracy rates of 87.03%, 87.97%, and 59.35% on the RAF-DB, FERPlus, and AffectNet datasets, respectively. When only using MPResNet-40, the model achieves 87.74%, 88.45%, and 59.85% accuracies on the three datasets that shows a strong recognition ability. Compared with the MPResNet-40 and GBCN branch separately, the MFNet’s accuracy is increased by 0.79% and 1.50% on RAF-DB, 0.73% and 1.21% on FERPlus, and 0.53% and 1.03% in AffectNet. Therefore, the final fusion model shows a competitive recognition ability.
Evaluation of GBCN and MPResNet-40 modules in MFNet (%)
3) The influence of the Mini-Batch Size N: N is the mini-batch size for facial expressions directly related to the model’s performance. We study the influence of different N values from 16 to 128 on RAF-DB, FERPlus, and AffectNet. As shown in Fig. 7, When N is set to 64, the model achieves the best classification performance. The smaller the value of N, the slower the model converges and the worse the recognition performance. When the value of N increases to a certain degree, the performance has begun to decline. With limited GPU memory, our method uses a moderate batch size to achieve better recognition performance.
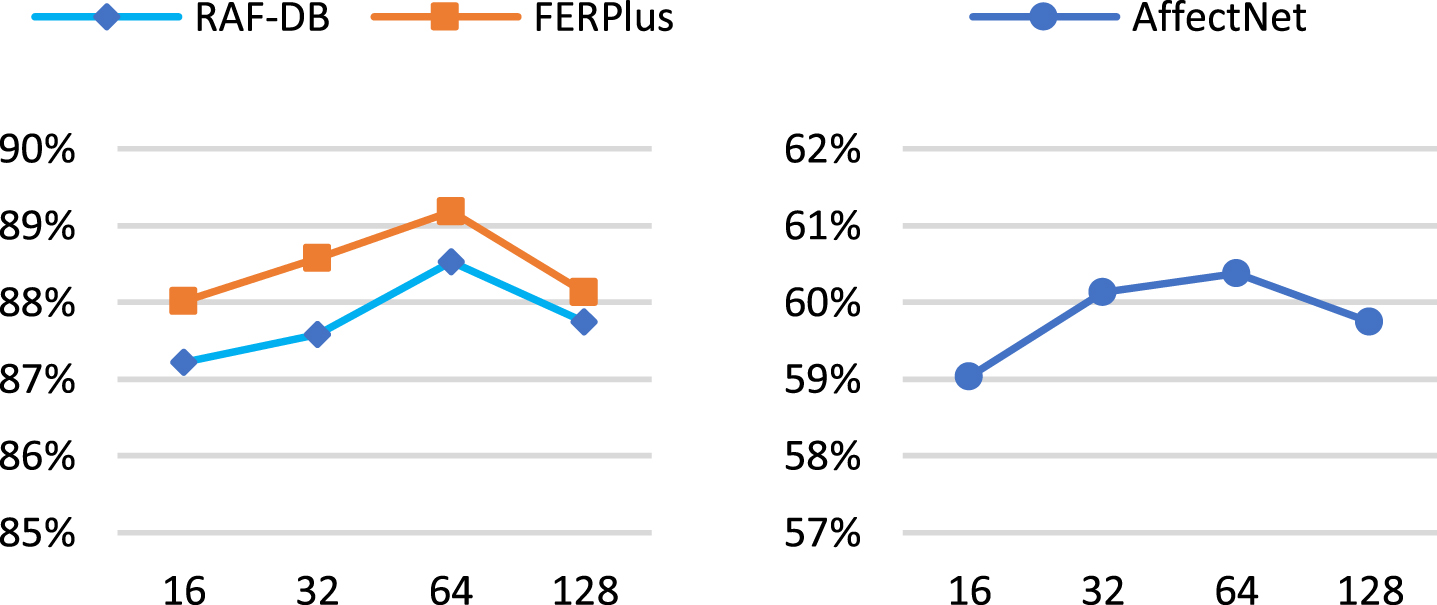
Evaluation of the mini-batch size N on RAF-DB, FERPlus and AffectNet.
To show the superiority of the MECA attention for the network feature extraction, we use Gradcam [46] to visualize the features after stage3 of the MPResNet-40 for some images of wild datasets shown in Fig. 8. The first line in the figure is the original image, and the second line shows feature maps which does not use the MECA model. It seems that the feature weights under parallel multiscale extraction have been close to the core areas of expressions, but some of the focus points have been shifted, and the focus area of expression is large. The third line shows the energy maps of feature weight after adding the MECA model. As we can see, the focus area is more concentrated after adding MECA, especially the key areas of the eyes, eyebrows, nose, and mouth areas that receive much weight. Meanwhile, the weight of the background area irrelevant to the expression is further weakened. Therefore, this will facilitate the further extraction of key features of the region of interest.

Visualization with PyResNet-40 (without MECA) in the second line and MPResNet-40 (with MECA) in the third line.
To illustrate the effectiveness of the MFNet, we compare the currently popular algorithms on RAF-DB, FERPlus, and AffectNet wild datasets, and the overall sample accuracy is used for evaluation.
1) Results on RAF-DB: From Table 5, we can see that our MFNet achieves an accuracy of 88.53%, which is the best result compared with other methods. Compared with the attention-based methods gA-CNN [32], RAN [35], and LBAN-IL [36], we outperform the best-performing RAN by 1.63%. Compared with the IPA2LT [24] and SCN [27] ways for label improvement, our method exceeds 1.50% of the SCN which has a better result. For DDA [28] and DACL [29] based on the loss function method, our model exceeds the best result of DACL by 0.75%. It is also 1.53% higher than the SPDNet [25] method based on manifold network. We further analyze the results in the confusion matrix. As shown in Fig. 9 (a), except for disgust which makes it easy to recognize the expressions with small amplitude as neutral, the other categories have achieved high recognition rates.
RAF-DB accuracy comparison
RAF-DB accuracy comparison
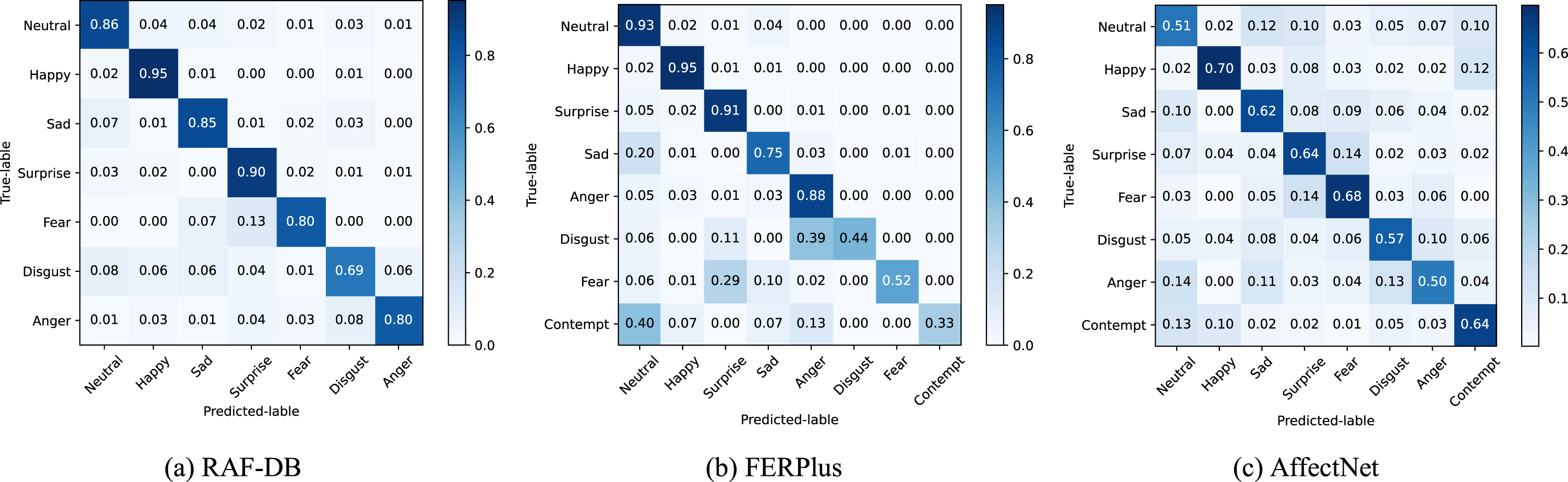
Confusion matrix of RAF-DB (a), FERPlus (b) and AffectNet (c).
2) Results on FERPlus: Table 6 shows that our method achieves the best accuracy of 89.18%. Compared with the attention-based method SENet [33] and RAN [35], our method is 0.38% higher than the better result of SENet. Compared with the label improved PLD [9] and SCN [27] methods, it is 1.17% higher than SCN. At the same time, compared with fusion networks for feature extraction, our method is 0.37% higher than the best performing CVT [41]. From the confusion matrix in Fig. 9 (b), it is clear that the recognition rates for minority classes are low for disgust, fear, and contempt expressions, which have a very small number of image training and are easy to be confused with other categories, and the rest such as happy, surprise and other categories have achieved better recognition ability.
FERPlus accuracy comparison
3) Results on AffectNet: Table 7 shows that our MFNet achieves the best recognition accuracy of 60.38% on the AffectNet with 8 classes. Compared to attention-based PG-CNN [15], gA-CNN [32] and RAN+ [35], our method outperforms the best RAN+ by 0.88%. It is also 3.07% higher than IPA2LT [24] based on label distribution. At the same time, compared with ESRs [26], ARM+ [30], Efficient Face [31] networks for feature extraction, we outperform the best performing EfficientFace by 0.49%. As can be seen from the confusion matrix in Fig. 9 (c), due to the large scale and difficulty of the dataset, the variations of different expression categories are small and easy to misjudge. However, our model has a more comprehensive recognition of class samples with different difficulties, and the recognition performance differences are small among different categories, so our method can perform well in this type of dataset.
AffectNet accuracy comparison (8 classes)
+denotes oversampling is used, †denotes random resampling is used, and * denotes Imbanaced dataset sampler1 is used to efficiently rebalance the distribution between classes, because the AffectNet dataset is very imbalanced.
This paper proposes a dual-branch Multi-feature Fusion Network (MFNet) that combines the pyramid parallel multiscale network with the max-pooling channel attention mechanism and the shallow Gabor convolutional network. The MPResNet-40 branch obtains abundant multi-level expression features through multiscale feature extraction and focuses on the region of interest by embedding the progressive stage MECA attention. The GBCN branch makes full use of Gabor convolution’s good detail representation ability to capture the details of local expression features. The MFNet finally integrates the above two networks to further improve the recognition accuracy. The experimental results on three open wild large-scale datasets demonstrate the effectiveness and robustness of our MFNet model. In the next step, we will focus on building a more efficient and lightweight network structure and designing more optimized loss function to further improve the comprehensive performance of expression recognition in real scenes.
Footnotes
Acknowledgments
This research was supported by the National Science Foundation of China under Grant 61966035 and U1803261, by the Autonomous Region Science and Technology Department International Cooperation Project (2020E01023), and by Autonomous Region Graduate Innovation Project (XJ2019G071).