
Abstract
Identification/recognition of assault, fighting, shooting, and vandalism from video sequence using deep 2D and 3D convolutional neural networks (CNNs) is explored in this paper. Recent wave of extensive unrestricted urbanization has not only uplifted the standard of living, but has also threatened the safety of a common man leading to an extraordinary rise in crime rate. Although Closed-circuit television (CCTV) footage provides a monitoring framework, yet, it’s useless without an auto volume crime detection system. The system proposed in this work is an effort to eradicate volume crimes through accurate detection in real-time. Firstly, a fine-grained annotated dataset including instance and activity information has been developed for real-world volume crimes. Secondly, a comparison between 3D CNN and 2D CNN network has been presented to identify the malicious event from the video sequence. This is carried out to explore the significance of spatial and temporal information present in the video for event recognition. It has been observed that 2D CNN even with lesser parameters achieved a promising classification accuracy of 91.2%and Area under the curve (AUC) of 95.2%on four classes. The system also reduces false alarm rate in comparison to state-of-the-art approaches.
Keywords
Introduction
Global urbanization is elevating at an expeditious pace due to frequent immigration of people from rural to urban areas. Urban population was one third of the global population in 1964 which has increased to 54%by 2014 and is expected to progress to two thirds of the global population by 2050. Even though urbanization provided us with significant economic and social transformation, it was on the expense of certain unanticipated consequences e.g. inadequate housing, water and sanitation, transport, health care services, and safety & security [36].
Among all others repercussions, security of the citizens is considered significant in shaping the society. Safer countries attract considerably progressive economies. For ensuring citizen security, various initiatives have been taken to mitigate crimes usually through establishment of efficient security measure. Recently safe-city concept has been introduced to maintain law and order situation throughout urban areas. To cover the entire locality, CCTV cameras are installed at decisive locations across the city. In order to reduce the impact of crimes recorded by CCTV cameras, timely detection of the activity is needed for prompt actions by the concerned authorities. The network of CCTV cameras is monitored through a central control room operated round-the-clock by human observers. However, firstly a large expert task force is required to monitor these hundreds of video streams. Secondly, the probability of detecting anomalous activities decreases with increase in number of video streams and the time of attention. According to [1] an operator may efficiently monitor a video stream for about 12 minutes continuously, after which he may miss upto 45%of screen activity. After 22 minutes this miss-rate may even elevate to 95%. Thus, to improve the efficiency of surveillance systems an autonomous technological solution is required to continuously analyze the CCTV recordings.
Researchers extensively started to explore the area of abnormal behavior detection recently. Initially, various definitions of abnormalities were proposed through expert systems to address the solution-oriented technicalities of the problem. Abnormal events were identified as the presence of prohibited entities (car, bicycle, skateboard) in public walkways by Amraee et al. [2, 8]. Liu et al. considered throwing objects and walking in the wrong direction as an abnormal behavior [7, 24]. Furthermore, [38–40] recognized running, chasing, and loitering as an abnormal event. Also, [30, 46] has focused on the detection of crowd and considered the presence of crowd in scene as an abnormality. The discussed actions are although normal daily life routine activities, however, if performed in a prohibited premises then they are considered as an anomalous activity. Such actions are identified as abnormal by their context of performance. For instance, bicycling is a normal action unless and until it’s performed in the public walkways. Similarly, while running in the playground is normal, it’s nonetheless a serious offense in the parade ground. In order to make the city surveillance system more effective. it is desired to detect real-world abnormalities.
Considering the importance of detecting real-world anomalies, Nieto et al. considered violence in a crowd and purse snatching as abnormality [33]. This study only targeted crowd behavior analysis. A group of researchers focused on the detection of person-on-person attack [46] as an anomalous behavior. The mentioned approach is suitable only for detecting fights among two persons only and cannot be generalized for different types of fights among a group of individuals. Similarly, [47] identified abuse, accident, and fighting as an abnormality. In this case, although the author tried to cover multiple abnormalities, yet it lacks the concept that an accident detection system needs to be deployed on highways. Whereas, fighting and abuse are the activities least expected on highways. So, a unified system for detecting such abnormalities lacks the utility of a system in terms of deployment. The maximum numbers of real-world anomalies are reported in [21, 44] listing 13 real-world anomalies including: arrest, arson, assault, fighting, shooting, vandalism, burglary, accident, explosion, abuse, robbery, stealing, and shoplifting. The proposed setting contains a very diverse set of classes and failed to achieve a promising detection accuracy. In this paper, we have exploited a subset of volume crimes (assault, fight, shooting, vandalism) which can be of the obvious threat to the life and property of the population. Some of these examples are illustrated in Fig. 1. These are common abnormalities that occurs in the streets of an urban area. A unified system is desired to address the selected subset of volume crimes.
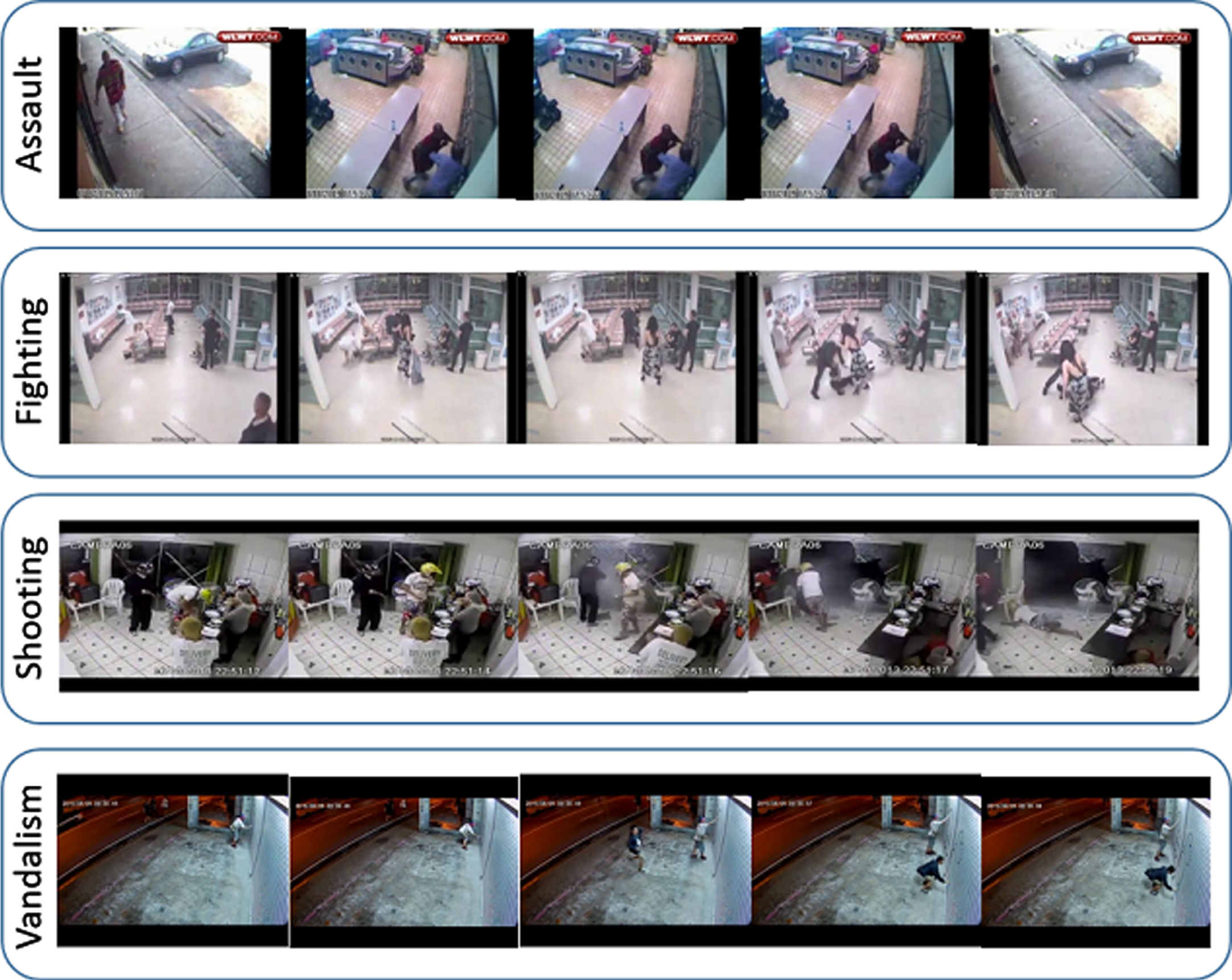
Sequence of frames taken from video stream can related to different malicious events e.g Assault, Fighting, Shooting, and Vandalism.
Various approaches have been entertained to develop a system for automatic detection of abnormal behaviors in CCTV recording. The initial studies in abnormal event detection were focused on object tracking [4, 50], where a moving object is considered as abnormal if its trajectory doesn’t follow the fitted model during the training period. Trajectory analysis can perform well in case of an individual moving object in a scene but is less effective for complex and crowded scenes. Such efforts are less effective in tracking the motion of abnormal shapes. Handcrafted feature extraction techniques are also exploited for anomaly detection [49, 51]. The fundamental problem with the mentioned approach is the selection of efficacious features which was resolved through deep features by Gong et al. [15]. They have used unsupervised deep learning-based features for addressing anomaly detection. Usually, deviation from the normal is considered as an anomaly in unsupervised learning; however, this may not be the case due to the existence of a fine line between normal and abnormal behaviors, which results in a large number of false alarms. The strongest approach used so far is supervised deep learning algorithms. In supervised deep learning techniques, various labeled datasets are used for detection of a particular group of activities[47]. The latest approach used by Sultani et al. is Multiple Instance Learning (MIL) for real-world anomaly detection. They introduced an assorted dataset of 13 real-world malicious activities. They managed to achieve a classification accuracy of 28%. The developed dataset contains a very diverse set of classes. Nevertheless, class labels are assigned to whole videos while only a part of these videos contained the occurrence of the actual event. This causes MIL to perform poorly leading to low classification accuracy.
The work presented here provide a mechanism where a properly labeled dataset is developed in which each video instance is labeled based on the type of activity present in it to make it suitable for supervised learning methodology. In addition to properly arranging the training datasets, the most effective concept of intermediate frame fusion and early frame fusion for Spatio-temporal analysis of videos has been adopted and deployed using basic 2D, and 3D CNN.
This research work has three tier contributions including: Development of dataset for malicious instance recognition problem. 3D-CNN and 2D-CNN based models developed for recognition of anomalous instances in real-time CCTV recording. Ablative study to compare the efficiency of proposed models for optimal performance.
The best performance achieved a promising accuracy of 91.2%. It is also observed that the models are capable of processing above 1000 frames per second, thus could be employed in real-time application easily.
The remainder of this paper is organized as follows: Section 2 reviews the related work in anomalous activity detection. Section 3 presents the architectures of the proposed models including problem formulation and its implementation details. 4 explains the experimental setup including dataset while section 5 provides the results and analysis. Section 6 concludes the paper.
In this section, we will be discussing various approaches entertained in past for malicious activity detection using Spatio-temporal CNNs. Generally, malicious activities are anomalous parts of the video sequence; however, it could be observed in the literature that maliciousness of the activity in the given video sequence has been contextually specified according to the target application. According to [50], the definition of malicious activities changes with the scenario. It is a complicated task to differentiate the malicious event from the rest of the video recording at the given instance. Some of the malicious events identified in CCTV footages have been shown in Fig. 1. The following subsections present the overview of various approaches used for the detection of context-sensitive anomalies and established anomalies.
Context sensitive anomalies
Object tracking as abnormal motion. Motion in restricted areas, running, and loitering are often considered as an anomaly in a sensitive environment. Such type of movements in a video sequence are detected by various trajectory analysis techniques [19, 50]. Calderara et al. considered inter node transition pattern in a graph as trajectory for abnormal motion detection [4] while Morris et al. found the inter resting node using Gaussian Mixture Model and then Hidden Markov Model for the same purpose [29]. Moreover, techniques based on low level local features have been used for detection of abnormal motion [3, 51]. Ermis et al. constructed a probabilistic model for abnormal motion detection by generating behaviour cluster derived from behaviour profile [12]. Reddy et al. exploited ground truth segmentation in combination with the motion and size feature modeled by kernel density estimation [41]. This approach claims its effectiveness in detecting abnormal object in crowded scenes. Xiao et al. used hybrid combination of sparse semi non-generative matrix factorization (SSMF) and histogram of non-negative coefficient (HNC) for anomaly detection in surveillance videos [51]. In their work only normal data is used for parameter tuning and deviation from normal motion is considered as an anomaly. Li et al. [22] proposed a spatio-temporal model for anomaly detection in complex and crowded scene. Dynamic texture model in combination is used for considering both dynamics and appearance information. In proposed model spatial saliency score is computed using a center-surround discriminant. Whereas, temporal saliency score is produced using a model of normal behaviour learned from data. Although, all of these techniques performed well for abnormal motion detection such as running in a scene and walking in the wrong direction, however, they are specifically designed for tracking objects in image sequence.
Falling object as abnormal motion. A more complicated scenario considering the safety of aged citizen would be tracking the human fall. Autonomous systems are developed for timely detection of human’ fall in hospitals, homes and old age facilities. Based on the type of hardware used for human fall detection the methods used can be broadly divided into two classes: wearable sensor based system and ambient sensor (camera) bases systems. Wearable sensor based system is non-scalable as it need sensors (accelerometer, barometric pressure sensor, tilt switch, and gyroscope) to be installed on body of each individual [18, 35]. Considering the scalability of ambient sensor based system. Various approaches have been used for human fall detection from videos. Various handcrafted feature based techniques and deep-neural framework have been used [26, 53]. Zhang et al. proposed to use deformation of the joint and subject height as feature and then used k-nearest neighbours (KNN) in combination with support vector machine (SVM) [53]. Similarly, Ma et al. used a bag of curvature scale space of human silhouette followed by extreme learning machine (ELM) [27]. Stone et al. proposed a technique based on use of prominent features (vertical velocity, vertical acceleration, frame to frame vertical velocity) and ensemble decision trees [42]. Furthermore, considering the issue of choice of handcrafted features, Lu et al. [26] proposed the use of spatio-temporal feature learned in a training process followed by LSTM. Similarly, Chen et al. in [6] proposed a framework for fall detection in complex environment. The proposed framework uses mask RCNN for the extraction of moving object from complex environment and then Bi-directional LSTM is used for fall event detection [6]. All these approaches have been specifically designed for fall-detection which may have important utilities in indoor situations e.g. smart homes, old-age houses, and patient monitoring. However, they contribute least towards outdoor activities considered anomalous.
Violence detection. Violence either detected indoor or outdoor is generally regarded as malicious and is mostly harmful. Violence may be verbal or physical therefore, it could be detected through audio, visual or both features. Jeho et al. proposed the use of visual features for detection of flame, blood, and explosion for characterizing violent and non-violent scenes [31]. Others have used low-level visual, auditory features and high-level audio effects for detecting violence in movies [13, 52]. Karan et al. has considered person on person attack and crazy crowd as violence [14, 43]. Various approaches based on use of low level-feature, trajectory tracking and deep neural network have been used for violence detection. Nguyen et al. has used the motion and limb orientation for trajectory tracking [32]. Hierarchical hidden markov model (HMM), violent flow descriptor in combination with support vector machine (SVM) has also been used for violence detection [17, 28]. Furthermore, [5, 34] has proposed various spatio-temporal descriptors (space time interest point, scale invariant feature transform (SIFT), and motion SIFT) for effective detection of violent activities. Football hooliganism is detected using deep learning through bidirectional LSTM [14]. Ullah et al. [46] proposed a spatio-temporal convolutional neural network for detecting violence in crowded scene as well as person on person attack. The mentioned approaches used for violence detection are limited to detect violence in crowd and person on person attacks. To generalize the detection process researchers focused on the area of abnormal human behaviour detection.
Established anomalies
Anomaly detection remained in focus for the last decade to detect the abnormal human behaviour in surveillance videos. A group of researchers working in the area of ensuring safety of pedestrian walkways focused on the detection of non-pedestrian entities in public walkways [22, 45]. Li et al. [22] proposed the use of spatio-temporal information. Center-surround discriminant saliency detector and normal behaviour model for extracting spatial and temporal saliency score respectively, for the categorization of pedestrian abnormalities. Tahboub et al. [45] used local binary pattern in combination with random forest for detecting pedestrian anomalies. Ravan et al. [39] used generative adversarial network for learning normal pattern of public walkways and deviation from the learned pattern is considered as an abnormality. Ameer et al. [2] proposed combination of connected component analysis, histogram of oriented gradient and Gaussian mixture model for non-pedestrian object detection. Khan et al. [21] used Gaussian discriminant model in combination with k-means clustering for classification of events recorded in surveillance videos installed in pedestrian walkways.
Various applications of the anomaly detection have been previously validated with certain benchmark dataset listed in Table 1. These include some of the prominent datasets of UCSD (PED1, PED2), Avenue, Subway Entrance, Subway Exit, and UMN. Most of these datasets have been developed for identification of a particular set of anomalies in specific environments e.g. UCSD is used to identify non-pedestrian entities and walking across walkways, Subway dataset is for identifying walking in wrong direction, non-payments, and loitering, while Avenue, UMN, Hockey Fight, and The Movies datasets have been used for identification of single activity mostly fighting. Moreover, these datasets have been developed with the help of actors and does not provide any real life situation in any of their videos [44].
Existing Datasets for Malicious Activity Detection
Existing Datasets for Malicious Activity Detection
We can conclude that the approaches discussed in the previous section mainly targeted contextual anomalies tested over fabricated datasets in which anomalous scenes are acted by the actors.
Considering the importance of detecting real-world anomalies recorded in real-time CCTV footage to assist security agencies. Sultani [44] introduced UCF crimes dataset incorporating 13 real-world anomalies, and proposed multiple instance learning (MIL) for the classification of abnormal activities. The dataset is developed by downloading videos of CCTV recordings from liveleaks and youtube. Each video is labeled according to the type of anomaly recorded in that video. According to sultani the developed dataset is weekly annotated. The proposed algorithm achieved a classification accuracy of 28%, thus, a state of the art solution for detecting real-world abnormality in CCTV recording is still a dream.
Spatio-temporal analysis is usually desired for identification of a function between spatial and temporal data to affect the performance of any process. While it defines a relation between GPS coordinates and its time instance for activity recognition in [48] and a relation between location and time of the day for prediction of criminal activity in [11], it links the spatial information of each frame of a video sequence to its temporal distribution in [54]. Extraction of useful information from a video sequence relies not only on the visual information spread spatially in each static frame but also on the complex motion information distributed along the continuous sequence of frames. Previously, hand-crafted features are used for obtaining appearance and motion information from video streams [20, 22]. However, these hand-crafted features contain less discriminant information and recent deep supervised and unsupervised features are employed for different applications [44]. More advanced, spatio-temporal convolutional neural networks (CNN) are introduced to learn appearance as well as motion information in video stream [54] which previously gained popularity in area of action recognition [23] and hand gesture recognition [16].
Inspired from the popularity of spatio-temporal CNNs, we in this research propose the use of a similar CNN modified for malicious activity detection.
In this research, we have developed a dataset specifically to identify malicious events in a video stream. For this purpose videos are taken from UCF crimes dataset and are annotated for instance recognition task. Followed by a convolutional neural network used to classify the respective abnormalities. Since the colour information plays the least significant role in instance recognition we have employed gray-scale versions of videos with 2D-CNN networks and achieved better results.
Proposed framework
Instance recognition in videos demands analysis of the information spread across spatial and temporal domains of video sequence. We can acquire semantic information of the scene from spatially distributed objects in a single frame, while sequence of such consecutive frames provides the positional changes of objects, hence enabling us to understand the overall activity in the video stream. To perform this task through CNNs, we have designed a framework that takes in samples of the video stream and outputs the activity performed in each sample. The overall architecture has been divided into the modular phases of video pre-processing, feature extraction, and instance recognition. The overall architecture is presented in Fig. 2.
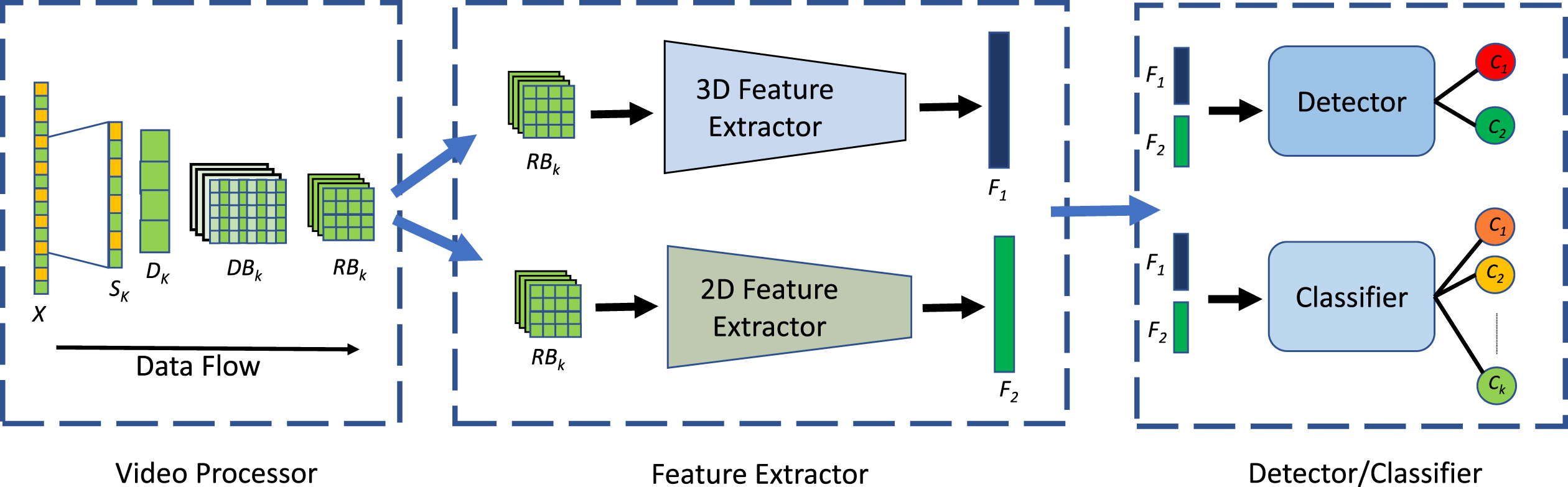
Overall architectural diagram of the framework developed for malicious instance recognition.
Videos consist of a sequence of stationary image frames. For the interpretation of useful information through convolutional neural network from these videos, we divide them in to blocks of l images. These blocks usually consist of frames that are semantically similar in the context of a single scene in the video. We have used l = 64 in this work and further down-sampled the block by 2 to avoid redundant information. Moreover, for the given input video with spatial resolution of 320 × 240 × 3 we have resized the frames of each block to 212 × 212 × 3, whereas the third dimension points towards the number of channels in each frame. The whole process of block formation could be expressed mathematically in Equation 2. Considering the sequence of discrete frames from video expressed as X [n] we can present the kth block of frames as:
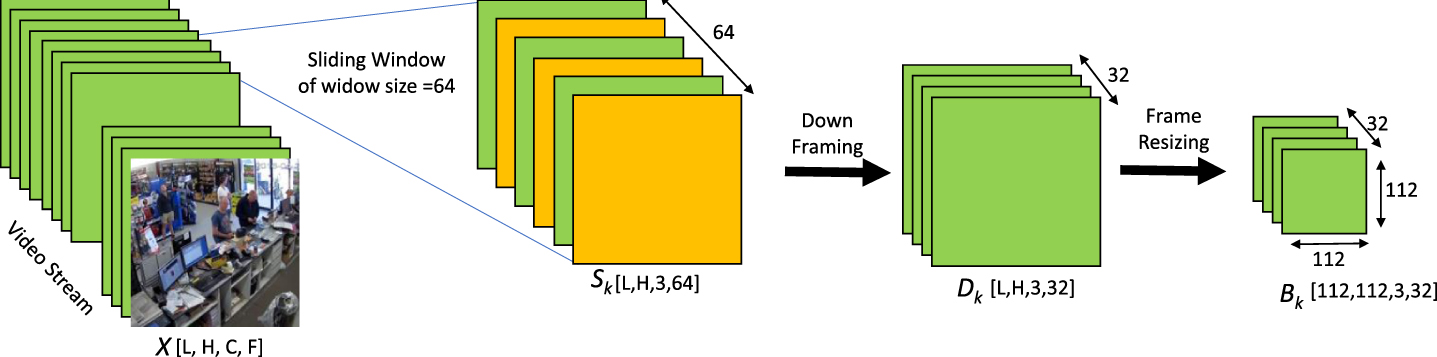
Video Preprocessor Block.
Deep CNNs have been extensively used for feature extraction in various image domains. They proved to extract much more representative features from images compare to previous hand-crafted approaches that relied mostly on local features in images. We have explored two types of deep learning architectures for extracting features from the given block of video stream. Both of these networks have been developed in such a way that take the block of video and extract a single dimensional feature.
3D CNN based Feature Extractor. We believe motion information of the objects to be equally important for instance recognition in addition to the spatial distribution of objects in a given frame. For this purpose, we developed a CNN network comprising of 3D convolution layers that could learn spatial as well as temporal features from the given block of the video sequence. The proposed model is obtained by removing a few convolution layers from the standard C3D network to reduce the network complexity. Our 3D CNN feature extractor uses 5 tiered 3D convolution layers followed by 2 fully connected layers to learn a single-dimensional feature vector. Each 3D convolution layer is followed by a Max-pooling layer with stride 2 × 2 ×2 to transform the object and motion information from spatial and temporal dimension to depth. This transformation leaves us with a frame size of 4 × 4 ×2 × 256. Recently, 3D-CNN gained popularity in the area of action recognition [9, 25]. Inspired by the performance of 3D-CNN in the field of action recognition, we developed the model in Fig. 5.
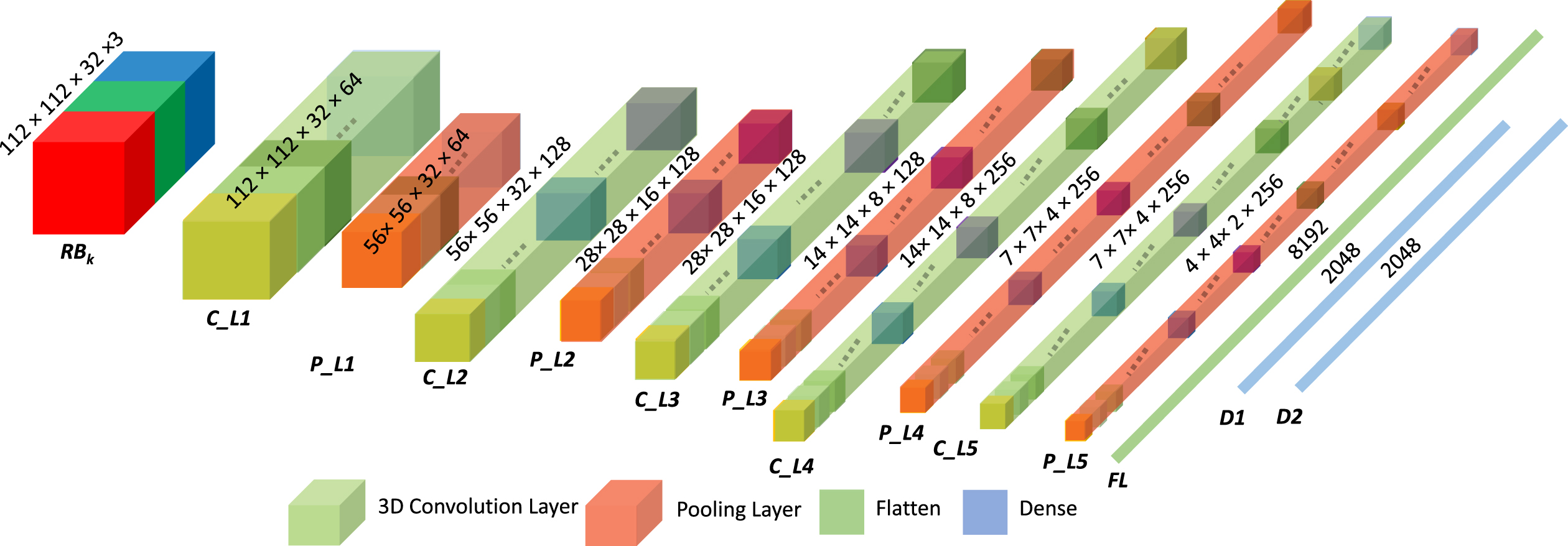
3D Convolutional Neural Network.
2D CNN based Feature Extractor. Network parameters of proposed system are 24,109,437. In order to reduce the network parameter the dimensions of input block is reduced from (112 × 112 × 3 ×32) to (112 × 112 × 32) by converting each frame to gray-scale. Conversion to gray-scale doesn’t affect the system performance in case of activity detection due to the fact that activity detection procedure is not sensitive to the color tone in video frames. The gray-scale block is then fed to 2D CNN of same number of convolution layers and dense layers. Thus reducing the network parameters to 13,722,437. Block diagram of the proposed system based on 2D-CNN is given in Fig. 4. In the figure, the last layer represent the feature vector. The feature vector is then fed to two fully connected layers and an output layer. The number of neurons in fully connected layers and dense layer are same as that in 3D-CNN. For instance S is the block of 32 gray-scale frames of a video, S
k
is the kth frame of block S, h is the 2D filter of dimension L × M. The mathematical process for considering temporal as well as special information are shown in Equation 4.
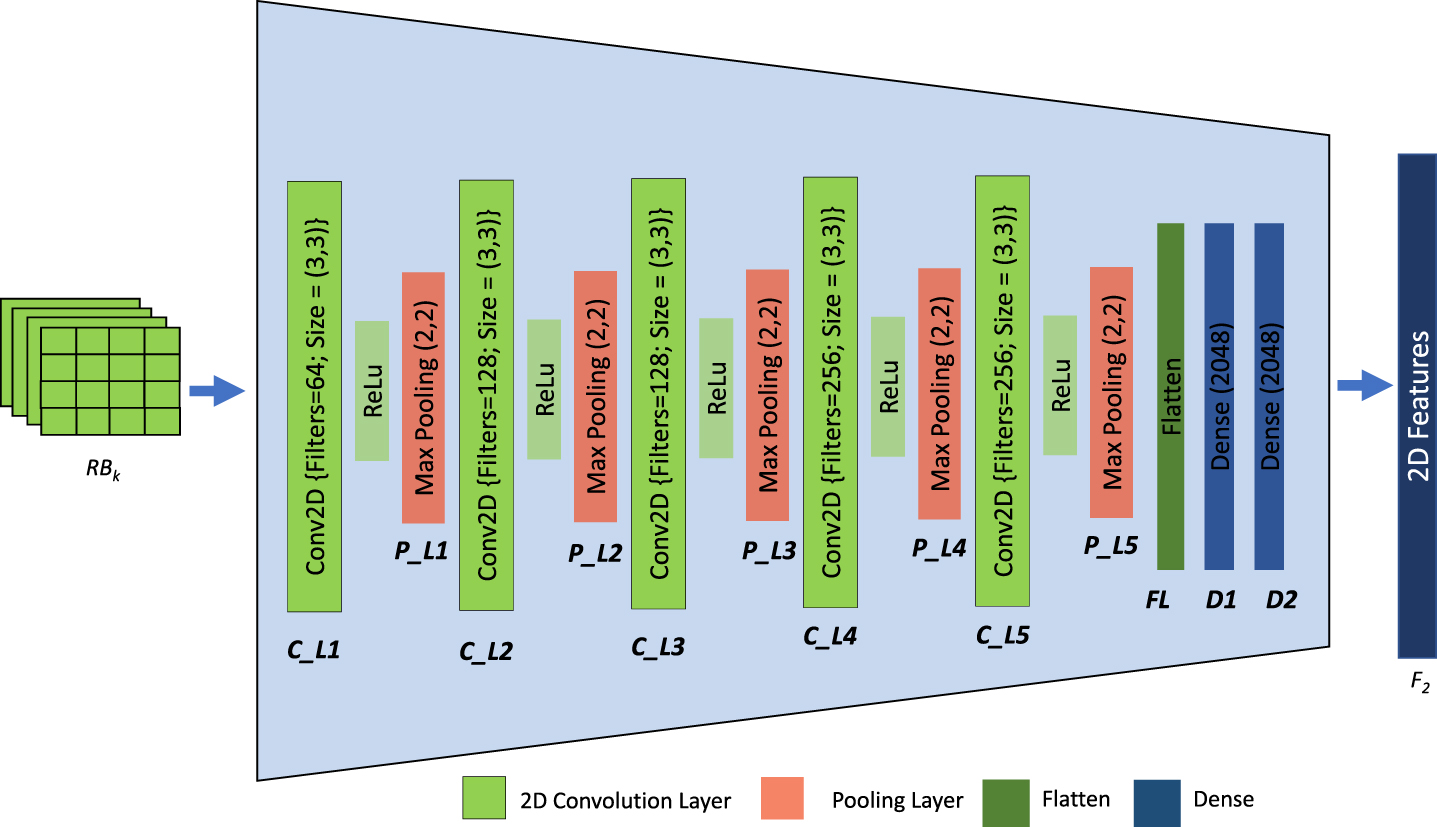
2D Convolutional Neural Network.
The objective of the research is to detect the combination of frames in a video stream with one of the categories of the volume crimes mentioned earlier on. For this purpose, features of the block acquired in section 3.2 are classified through various classification algorithms including Naive Bays, Decision Tree, Support Vector Machine (SVM), k-Nearest Neighbour, and Softmax. All these classifier are developed in such a way to address both instance detection (binary classification) and instance classification (multi-class classification).
Among all these, softmax classifier has been designed with softmax activation optimizing the binary cross entropy loss and categorical cross entropy loss with detection and classification, respectively. Both of these losses are mathematically presented as:
We have developed a unified framework for the tasks of detection and classification. For the case of instance detection the block is identified as a normal or anomalous event. This is similar to the concept introduced in [15] which considered everything that doesn’t look normal as anomaly. In classification, on the other hand the specific type of activity associated with each of volume crime is identified. Technically, detection performs a binary classification task (0, 1) while in classification we perform a multi-class classification task (0, 1, 2, 3, 4) with the same framework given in Fig. 2. Both of these task have been validated through the dataset developed specially for malicious instance recognition.
Dataset
This research work is focused on the anomaly detection in safe-city environment, this is why the subset of a very recent dataset (UCF crimes) developed for real-world anomaly detection in surveillance videos has been considered. The dataset consists of CCTV footage’s of real world anomalies from Liveleaks, and Youtube including 13 real-world anomalies containing 1900 videos spanned over 128 hours. For this research a subset of four most crucial anomalies (shooting, assault, fighting, and vandalism) are annotated for in-video event recognition. This is carried out by specifically separating normal frames from the ones that contain anomalous activity. The process has been demonstrated in Fig. 6. Previously, it was very difficult to use the video labelled as assault, it was observed that videos labeled as (Assault 039) contain (
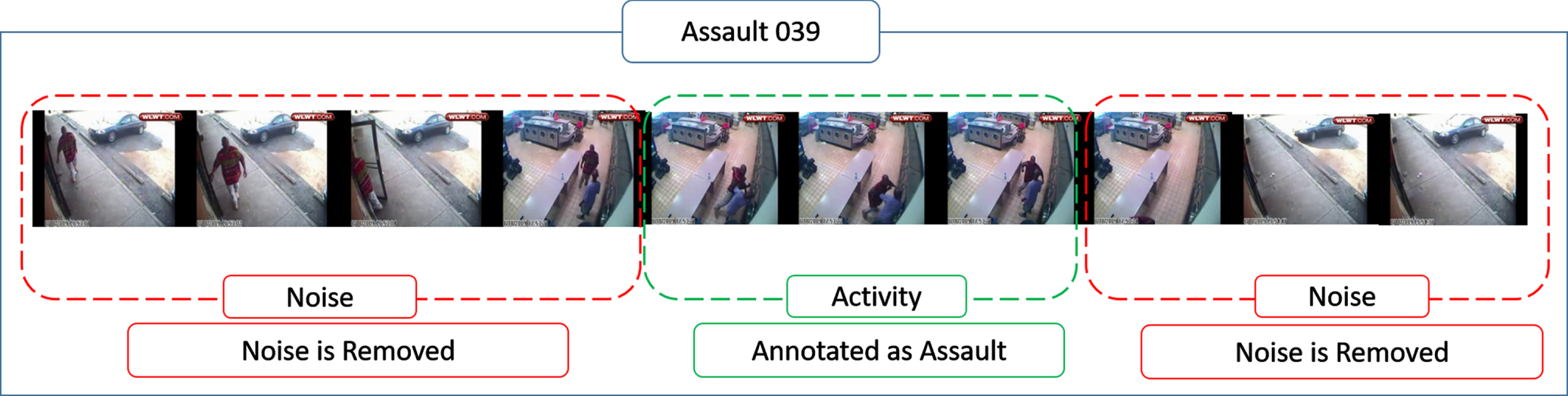
Annotation of video sample labeled as Assault in original dataset.
We have conducted experiments for detection and classification using 3D-CNN and 2D-CNN features with various classifiers explained in section 3.3. Hyper parameters setting for 2D and 3D CNNs are listed in Table 2. We have performed our experiments on Intel Core-i5 with 8 Gb RAM and NVidia GTX 1050Ti Graphical Processing Unit. In each experiment Stochastic Gradient Descent optimizer is used for learning weights.
Hyper parameter choice for 2D-CNN and 3D-CNN
Hyper parameter choice for 2D-CNN and 3D-CNN
result
We have conducted numerous experiments for detection and classification using features extracted from 2D and 3D-CNNs. The performance of the mentioned model is evaluated based on the performance metric like AUC, accuracy, and false-positive rate. This section provides a performance comparison of our proposed system. Table 3 summarizes the results.
Comparison of the features from 2D CNN and 3D CNN with other classifiers
Comparison of the features from 2D CNN and 3D CNN with other classifiers
From the results on event detection using different features it was observed that 2D CNN outperforms 3D CNN achieving the overall detection accuracy of 91.24%. Although, all the classifiers equally performed well for both type of features, however, Softmax classifier outperforms the rest in detecting malicious video events as shown in Table 3. Similar patterns have been observed in confusion matrices and t-SNE plots of the detection process as shown in Fig. 7 8.
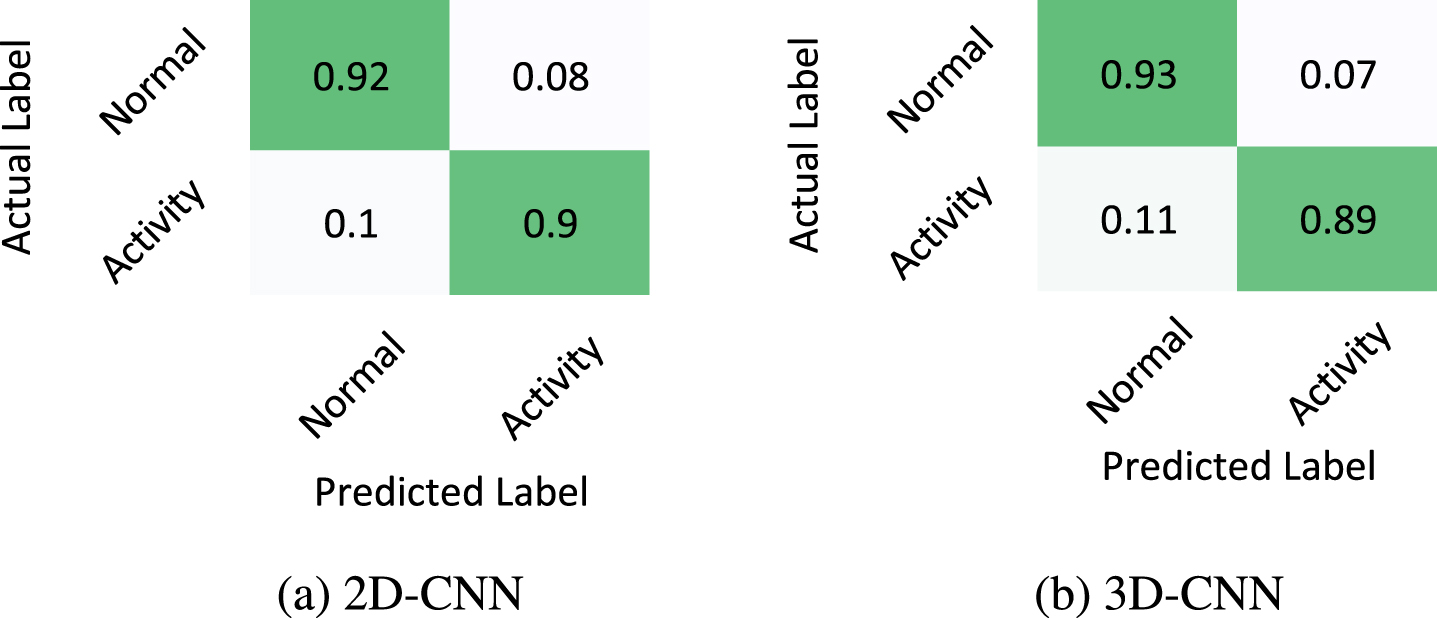
Confusion Matrix for 2D features and 3D features using Softmax classifier.
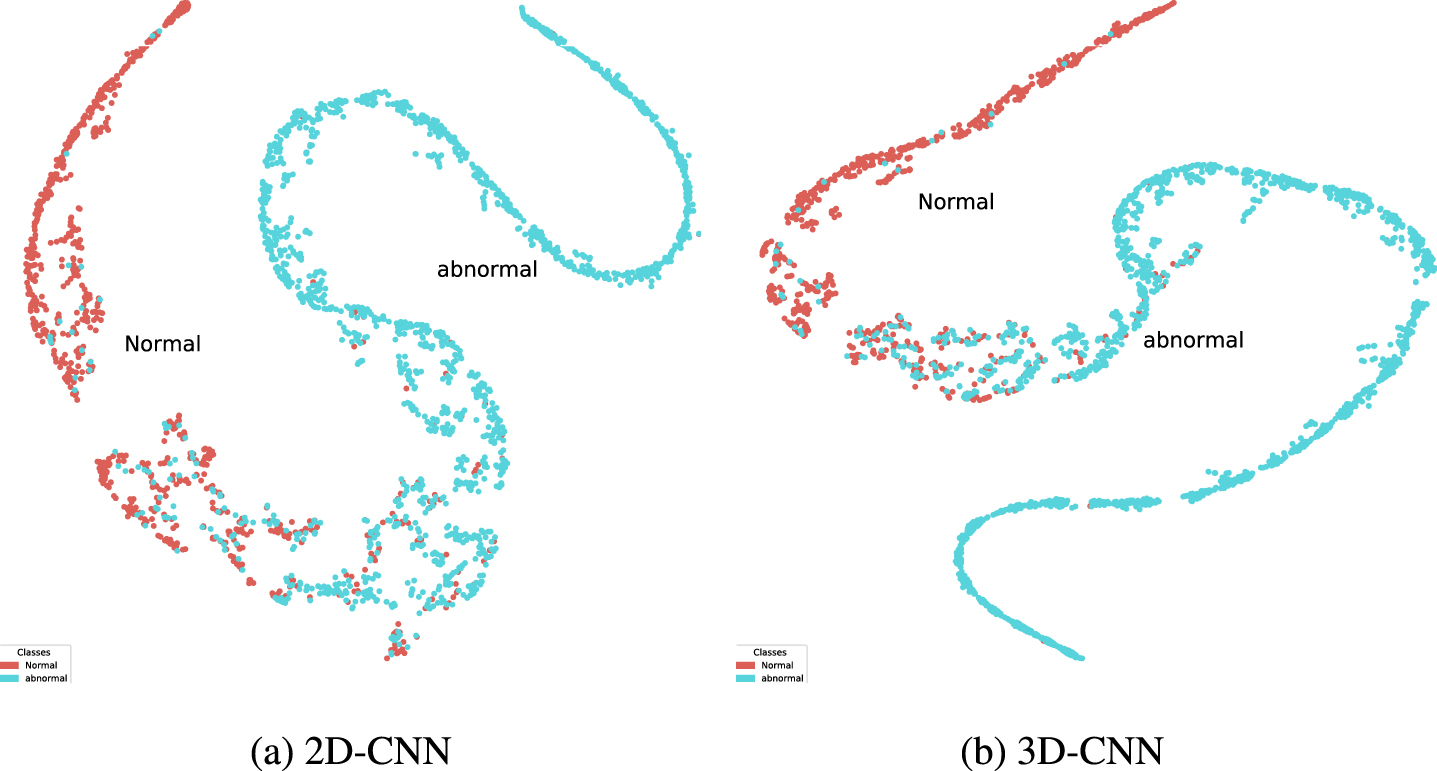
t-SNE plots for 2D features and 3D features using Softmax classifier.
Extended analysis on Anomalous Event Classification
For classification of the event among one of assault, fighting, shooting, vandalism, and normal, the features from 2D and 3D CNN have been extracted in similar manner and evaluated with various classifiers as described in Section 3.3. It is observed that the performance of Softmax classifier combined with 2D features is much better in comparison to the rest of classifiers. Overall classification accuracy of 91.73%has been achieved for this specific task. Even though, 3D features also performed well in classification; however, the number of network parameters in 2D CNN are much less as compared to 3D-CNN.
Extended analysis on anomalous event classification
We also presented the results in terms of detail performance metrics including Precision, Recall, and F1-Score for each class of anomalous events. Upon observation of Table 6, we came to the conclusion that 2D-CNN performs better for each class in comparison to the 3D-CNN. A similar phenomenon could be observed in the recall score for the shooting as 0.846 and 0.916 for 3D-CNN and 2D-CNN, respectively.
Table 5 contain confusion matrices, whereas Fig. 9 shows the t-SNE plots for event classification using 2D and 3D features with Softmax classifier. It should be noted that visibly separable clusters could be seen in t-SNE plots which validates the accuracy achieved for the given task of classification.
Confusion Matrix for 2D features and 3D features using Softmax classifier
Confusion Matrix for 2D features and 3D features using Softmax classifier
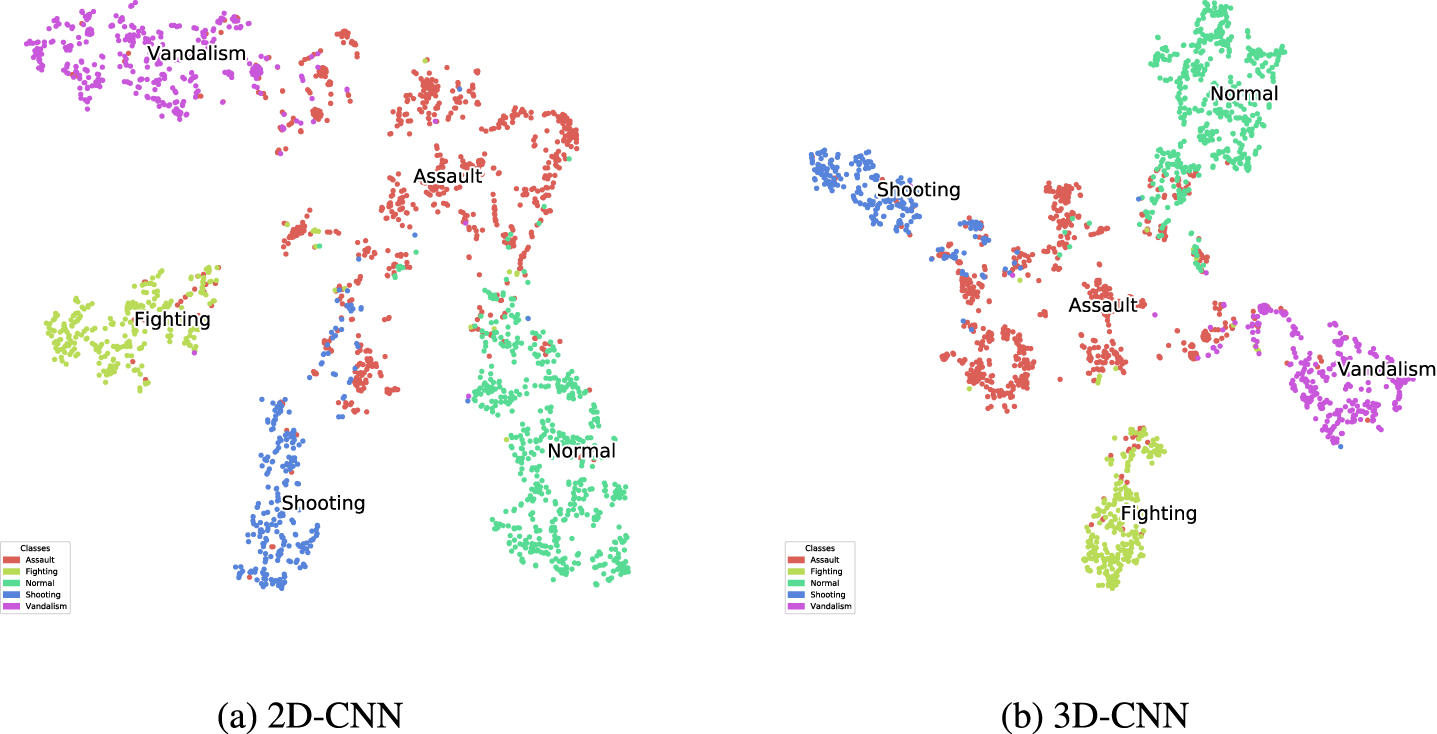
t-SNE plots for Classification Task for 2D features and 3D features using Softmax classifier.
We have also compared our approaches with the state-of-the-art techniques using 14 UCF crimes dataset. It is observed from Table 4 that our approach is performing far better on 5 classes as compared to the rest of the techniques using MIL and GDA techniques. Moreover, our approach achieves the least false positive rate of 7%for our 3D CNN.
Comparison with state-of-the-art techniques
Comparison with state-of-the-art techniques
It is observed that the proposed 2D model outperforms the performance of 3D model in case of the activity detection and manage to achieve false positive rate of 0.8. Furthermore, the model is suitable for real time application due to its low false positive rate and high frame processing rate that is 1000 frames/sec.
Lack of implementable software solutions for identification of real-world malicious activities from video streams in safe city environment require blend of computer vision and machine learning algorithms. In this regard an optimal solution for the analysis of temporal frames extracted from CCTV recordings is proposed. Our proposed models managed to achieve high accuracy for not only the identification of malicious events but also classification of real world volume crimes including assault, fighting, shooting, and vandalism in a video sequence. Furthermore, Our models are also suitable for real-time applications due to their high frame processing rate and low false alarm rate, with high classification accuracy of 91.2%and AUC of 95.2%on five classes.
The system can further be modified for other classes of crimes including but not limited to burglary, riots, attempted murder, arson, explosion, robbery, theft, and arrest etc. In order to get a unified framework for the detection of multiple malicious activities recorded by a CCTV camera, we need to train the same system with the data for the above mentioned events.