
Abstract
The use of probabilistic linguistic preference relations (PLPRs) in pairwise comparisons enhances the flexibility of quantitative decision making. To promote the application of probabilistic linguistic term sets (PLTSs) and PLPRs, this paper introduces the consistency and consensus measures and adjustment strategies to guarantee the rationality of preference information utilized in the group decision making process. First of all, a novel entropy-based similarity measure is developed with PLTSs. Hereafter an improved consistency measure is defined on the basis of the proposed similarity measure, and a convergent algorithm is constructed to deal with the consistency improving process. Furthermore, a similarity-based consensus measure is developed in a given PLPR, and the consensus reaching process is presented to deal with the unacceptable consensus degree. The proposed consistency improving and consensus reaching processes follow a principle of minimum information loss, called a local adjustment strategy. In particular, the presented methods not only overcome the deficiencies in existing studies but also enhance the interpretation and reduce the complexity of the group decision making process. Finally, the proposed consistency measure and improving process, as well as consensus measure and reaching process are verified through a numerical example for the medical plan selection issue. The result and in-depth comparison analysis validate the feasibility and effectiveness of the proposed methods.
Introduction
Group decision making (GDM) approaches have been broadly applied to varied fields [1–4], in which several relevant experts are invited to express their opinions and reach a unanimous proposal to solve a complicated problem. For example, the medical plan selection can also be considered a GDM process. Numerous optional alternatives can be selected for the treatment of a disease. In a GDM process, the invited experts typically express their preferences for distinct alternatives by pairwise comparison values. It is usually the perception derived from a finite semantic scale with qualitative description such as linguistic terms sets (LTSs) rather than numerical values [5]. In detail, experts utilize ‘bad’, ‘slightly bad’, ‘good’ and ‘slightly good’ to express their preferences for the medical treatment alternatives. However, these linguistic terms are inherently incalculable and cannot be directly employed for quantitative decision-making process.
To obtain a quantitative outcome, some conceptions are proposed in light of computing with words (CWW). Those CWW conceptions involve 2-tuple fuzzy linguistic preference relations [6–8], neutrosophic linguistic term sets [9, 10], linguistic Z-numbers [11], hesitant fuzzy linguistic terms sets [12–15], and hesitant fuzzy linguistic preference relations [16–18]. They are influential and can reveal the uncertainness and fuzziness in the linguistic terms and preference relations. However, the inadequacy of those conceptions has also been verified when dealing with complex subjective information [19]. One obvious limitation is that all linguistic terms are regarded to have the same importance in the linguistic term set. Nonetheless, this assumption cannot always be feasible in practice because experts may comment on the respective linguistic terms along with varying degrees of importance. For example, an expert may label one alternative as ‘bad’ and ‘slightly good’. However, he/she deems that the importance degree of the label ‘bad’ is 70 percent and the label ‘slightly good’ is 30 percent. This instance demonstrates that differentiating the importance degree of various linguistic terms is beneficial, but the aforementioned conceptions fail to highlight this trait. To press closer to real-life application, Zhang et al. [20] proposed a popular concept of distribution assessments in a linguistic term set. Symbolic proportions were assigned to all the linguistic terms, which can be interpreted as probabilistic distribution. Wu et al. [21] generalized this definition to the decision making process. However, obtaining the complete information of probabilistic distribution is generally difficult. Then Dong et al. [22] proposed the concept of unbalanced linguistic distribution assessments with interval symbolic proportions. Li et al. [23] subsequently considered a consistency-driven methodology to manage linguistic distribution preference relations (LDPRs) with personalized individual semantics, which estimated the ignorance elements in incomplete linguistic distribution assessments in the form of numerical scales. Similarly, the concepts of multigranular linguistic distribution assessments [24], multigranular hesitant linguistic distribution [25], proportional interval type-2 hesitant fuzzy linguistic term sets [26], proportional hesitant fuzzy linguistic term set [27] are also proposed to deal with linguistic assessments with completely known probabilistic distribution. On the basis of these ideas, Pang et al. [28] proposed a similar concept called probabilistic linguistic term sets (PLTSs) by adding probabilities without loss of any original linguistic information provided by the DMs. Specifically, the PLTS enables the DMs to express even incomplete probabilistic distributions, i.e., partial ignorance is acceptable. Thus, the proposed PLTS can be seen as an extension of the existing techniques.
In particular, the preference relations with PLTSs are defined as probabilistic linguistic preference relations (PLPRs). These definitions completely consider the possible importance degrees of the set of linguistic values and can process partially incomplete assessments [29]. As for practical scenario applications, PLTSs and PLPRs have been widely employed for solving GDM issues. Mao et al. [30] introduced the application to the selection of financial technologies with a new method for PLTSs. In addition, Xiao and Wang introduced an application of site selection for solar power plants with PLTSs [31]. With respect to emergency scenarios, the incomplete PLPRs and related methods were employed for public health emergency decision-making process [32]. Moreover, Liang et al. [33] advanced a nonlinear optimization model and fuzzy cooperative games with PLPRs to solve a GDM-based physician selection issue. Additional applicability of the real scenario with probabilistic linguistic information can be explored in [34–36]. Referring to these studies, this paper also proposes some novel methods applied for the GDM-based favorable medical plans selection issue with PLPRs.
In the resolution process of GDM problem with PLPRs, considering both consistency and consensus for the preference information plays a central role. Consistent PLPRs are to ensure that the preference information provided by each DM is neither random or contradictory [37]. In addition, consensus is to guarantee that the preference information among the DMs is generally agreed [38]. Inconsistent preference information and non-consensus can lead to an inaccurate outcome [39]. Thus, several studies have taken insight into the research of consistency and consensus measure methods. Consistency measure aims to gauge the rationality degree of the preference information for an individual decision maker. Consensus measure is to measure the agreement degree among collective DMs. In particular, consistency and consensus measures can employ the same basic similarity or distance measure. Li et al. [40] reviewed additive consistency measurements of various reciprocal preference relations and proposed some open problems on consistency of reciprocal preference relations, which also can be considered and referred in the consistency measure for PLPRs. Zhang et al. [41] proposed a distance-based consistent index measure and a Euclidean distance-based consensus measure with PLPRs. The consistent measure suggested by Krishankumar et al. [42] has a similar distance measure trait. Liao et al. [43] defined one inconsistent index and consistent index to measure the consistency degree, which was based on the calculation between the proposed probabilistic truth degree. Xie et al. [44] and Li et al. [45] introduced transformation functions to derive expected transformed additive PLPRs for consistent measure. Furthermore, Luo et al. [46] and Zhao et al. [19] proposed similarity-based consistency and consensus measure. Luo et al. introduced a cosine-based similarity measure with PLPRs [46] for both consistency and consensus measure. Whilst a complement operation for distance measure was used for calculating the similarity degree, and the proposed possibility degree computed from similarity degree was provided for consensus measure in [19]. Liu et al. [47] introduced the similarity degree and deviation degree for consensus measure for PLPRs. The core idea of [47] is similar to [19], but the probabilities of LTSs in PLTSs are considered. Moreover, Nie and Wang [48] applied prospect theory regarding risk preference and psychological behavior for constructing a novel consistent index with multiplicative PLPRs. These studies offer us a deep insight of the methods for measuring consistency and consensus with PLPRs.
However, limitations are also detected in the current studies. The distance-based consistency and consensus measures have a counter-intuitive problem when faced with some specific values in [41] and [42]. For example, when two PLTSs have the same linguistic terms, the distance between these two sets is directly computed as zero regardless of the corresponding probabilities. It obviously overlooks the benefit of probabilities in PLTSs, which will result in a serious deviation when measuring the consistency and consensus level. A similar problem is also discovered in [19]. Additionally, the transformation functions in [44] and [45] create difficulty in understanding the outputs, and the unique characteristic of PLTSs is lost. In addition, the operation law of PLTSs in [46] was deemed inefficient owing to an oversight to the benefits of probabilities. Faced with these flaws, we therefore attempt to advance a novel consistency and consensus measure on the strength of a similarity measure. An entropy-based similarity measure is proposed with PLPRs. It is firstly discussed in [49] with Atanassov’s intuitionistic fuzzy sets (IFSs). After fully recognizing the inner meaning of Atanassov’s IFSs, we extend the similarity measure into PLPRs. It can effectively deal with the aforementioned shortcomings and create a useful similarity method for consistency and consensus measure.
Expecting completely consistent PLPRs is unrealistic. When reaching a certain index degree, the consistency and thus the consensus are deemed to be acceptable. When the consistency or consensus level is judged to be unacceptable, it should take actions to adjust the original preference information to make it acceptable.
With regard to the consistency improving strategy, the above discussed studies provided certain references. Zhang et al. [41] suggested an iteration algorithm which was to conduct a convex operation using the inconsistent PLPR and standard consistent PLPR. This algorithm works but runs in a low efficiency. The complex computation not only costs excessive time but also brings high risk of large-scale loss of initial preference information. Raghunathan et al. [42] and Li et al. [45] also employed the iteration algorithm on the basis of addition operation for consistency improving process. In particular, Raghunathan et al. [42] added a preference parameter on the basis of the formula in [41]. A virtually transformed term for the element in the PLTS is used for iterative addition operation, and exponential calculation and priority weights are considered in [45]. The complex calculation problem also occurs in the above discussed studies. A linear programming function was constructed to achieve an acceptable consistent PLPR in [39], but the output was not the form of PLTSs. Luo et al. [46] and Nie and Wang [48] recommended a subjective adjustment of PLPRs based on the experience and professional knowledge from experts. It can be one solution in some ‘soft’ situation. However, under a strict environment, a concise and reasonable quantitative algorithm or model is preferable.
With respect to the consensus reaching process, the related studies for PLPRs are not flourishing. Zhang et al. [50, 51] introduced the consensus reaching process by considering both the bounded confidence levels and minimum adjustment of decision makers’ linguistic assessments. Moreover, Zhang et al. [52] introduced an overview on feedback mechanisms with minimum adjustment or cost in consensus reaching in group decision making, and proposed some open problems. Those studies can be regarded as reference techniques for PLPRs’ consensus reaching process. The consensus reaching process in [41] also followed the feedback mechanism. It considered a local adjustment of the elements which caused the most negative effect on the consensus degree. This mechanism capitalizes on the maintenance of the original PLPRs. However, the distance measure included in that mechanism fails to deal with some specific values, which has been discussed above. Zhao et al. [19] indicated a specific change in the smallest possibility degree with PLPRs which was measured to be less than the predetermined level, but experts subjectively decided the adjusted value. Instead of subjectively replacing the specific position value, Liu et al. [47] suggested the position selected for modification by aggregating global relevant PLTSs using Probabilistic linguistic weighted aggregation (PLWA) operator.
Considering the time-consuming and counter-intuitive distance or similarity measure in the consistency improving and consensus reaching processes, this paper develops a novel entropy-based similarity measure as the core of the adjustment strategy. For the consistency improving algorithm, we introduce a local adjustment strategy rather than the global change in light of convex operation. By constructing a transitional matrix, the local adjustment strategy directly replaces the maximum value in the matrix with the value in the corresponding position of the standard consistent PLPR as discussed in Ref [53]. This operation can quickly reach an acceptable consistent degree. For the consensus reaching algorithm, we also follow the feedback mechanism. Rather than the distance-based measure or possibility degree, the picked-out position is determined by the proposed similarity measure. It completely considers the unique characteristic of the PLTS, and well solves the counter-intuitive issue. Both consistency improving and consensus reaching processes string along the merit of retaining the initial preference information in the largest scale possibility. In addition, the bounded confidence level of decision makers in the consensus reaching process will be learned in our future study.
After making the consistency and consensus degree acceptable, steps are taken to aggregate all PLPRs to derive a sort result. PLWA operator is adopted to transform the group PLPR matrix into a collective expected value in the GDM process. Finally, a medical plan selection problem is applied to verify the practical applicability of the proposed methods. In general, the main motivation and contributions of this study are summarized as below.
(1) Given the characteristic of PLTSs, utilizing them to describe probabilistic linguistic assessments of decision makers’ preference relations is convenient and dependable. Considering the existing limitation of the distanced-based consistency measurement for PLPRs, new consistency and consensus measurements are defined on the basis of the proposed entropy-based similarity measure. The advantage of the new entropy-based similarity measure is that it can overcome the counter-intuitive issue in some special situations and largely deal with the uncertainty in the assessments. In addition, it takes full advantages of the characteristics of PLTSs, and avoids the virtual form transformation, which is efficient for a more concise computation process.
(2) In many cases, the adjustment strategy for the unacceptable consistency or consensus level overlooks the information loss and computation complexity. Considering the shortcomings in the existing techniques, new local adjustment strategies are introduced to complete the consistency improving and consensus reaching processes. The advantage of the proposed adjustment strategies is that it ensures both the minimum information loss and the concise computation by modifying part of elements rather than all elements with the proposed similarity measurement.
(3) A resolution framework is designed to solve the GDM issue. On the basis of the PLWA operator, a mathematical process is introduced to select the best alternatives with the probabilistic linguistic assessments. The effectiveness and feasibility of the proposed methods are certified and improved with the numerical example illustration. Furthermore, the comparative analysis with the latest researches validates the rationality of the proposed model for solving GDM problems.
The rest of the study is organized as follows. Section 2 introduces the related definitions and operation rules used in the paper. Section 3 exhibits the proposed consistency measure and adjustment methods. Section 4 elaborates the proposed consensus measure and adjustment methods. Section 5 introduces the resolution process of the GDM problem. Section 6 provides the numerical example illustration and comparison analysis. Finally, we make a summary in Section 7.
Preliminaries
This section introduces some basic concepts of PLTSs and PLPRs.
Then the comparison law between two PLTSs L (p) 1 and L (p) 2 can be denoted as
if E (L (p) 1) > E (L (p) 2), then L (p) 1 ≻ L (p) 2; if E (L (p) 1) < E (L (p) 2), then L1 (p) ≺ L2 (p); if E (L (p) 1) = E (L (p) 2), then, if deva (L (p) 1) > deva (L (p) 2), then L1 (p) ≺ L2 (p); if deva (L (p) 1) < deva (L (p) 2), then L (p) 1 ≻ L (p) 2; if deva (L (p) 1) = deva (L (p) 2), then L (p) 1 ∼ L (p) 2.
when the subscripts r(l) (l = 1, 2, . . . , # L (p)) are varied, then, the PLEs in a PLTS with the same values of r(l)p(l) are ranked by the values of r(l) (l = 1, 2, . . . , # L (p)) in descending order; when the subscripts r(l) (l = 1, 2, . . . , # L (p)) are identical or incomplete, then, the PLEs in a PLTS with the same value of r(l)p(l) are ranked by the values of p(l) (l = 1, 2, . . . , # L (p)) in descending order.
The operation laws related to the linguistic terms in PLTSs satisfy (1) s α ⊕ s β = s α+β; (2)λs α = sλα, where λ ∈ [0, 1].
In certain situations, the linguistic terms calculated by the above operations lie beyond the linguistic term evaluation scales [s-τ, s
τ]. Then, a transformation function is suggested to deal with the extreme values:
In many GDM problems, pairwise comparisons are employed to reveal the preference of one alternative over another. The preference relation displayed by PLTSs is named PLPR. For a finite set of alternatives, X = {x1, x2, . . . , x n } (n ≥ 2), the PLPR is defined over the linguistic evaluation scale S = {s α|α = - τ, . . . , -1, 0, 1, . . . , τ}.
In particular, the PLPR is called normalized PLPR (NPLPR), if the PLTSs in the PLPR are normalized by Definition 2.2 and denoted as
This section introduces a novel consistency measure on the basis of a similarity measure for PLPRs, and then proposes a consistency improving process to construct an acceptable consistent PLPR.
Consistency measure of PLPRs
Consistency is a significant feature of PLPRs, as inconsistent PLPRs will result in contradictories and excessive problems during the decision-making process.
Through computation in Equation (5), if
Then, the PLEs in the
To calculate the consistent index named CI (B) of the PLPR B, we construct a consistency measure for PLPRs on the basis of a novel similarity measure, which is an extension of IFSs, an entropy-based similarity measure [49].
Generalized from [49], a novel similarity measure is provided with PLTSs. The definition is shown as follows.
We here extend the entropy-based similarity measure to the PLSTs shown in Equation (6).
(S1). 0 ≤ SIM (L (p) 1, L (p) 2) ≤1;
(S2). SIM (L (p) 1, L (p) 2) = SIM (L (p) 2, L (p) 1);
(S3). SIM (L (p) 1, L (p) 2) =1 if and only if L (p) 1 ∼ L (p) 2.
The proof of these properties can be checked in Proof 1.
The proof of the properties defined above is shown as follows:
(S1): Given that T represents the number of the linguistic terms in the linguistic scale S = {s
α|α = - τ, . . . , -1, 0, 1, . . . , τ}, T > r. Then, we obtain
Then,
Thus,
(S2): As
thus SIM (L (p) 1, L (p) 2) = SIM (L (p) 2, L (p) 1). S2 is proven.
(S3): When SIM (L (p) 1, L (p) 2) =1, it means
However,
In other word,
This is,
Let
Then, Equation (10) can also be represented as:
The ideal value of consistent index is CI (B) =1, which means a perfect consistency. However, achieving perfect situation is difficult in practice, but reaching such extreme value is not too critical. Commonly, a threshold δ is given to determine the consistency level. If CI (B) ≥ δ, the PLPR B is judged to be acceptably consistent. Otherwise, if CI (B) < δ, it is considered to be an inconsistent PLPR B. An unacceptable PLPR should be improved before the next decision-making process, which will be discussed in the next part.
When CI (B) < δ, the consistency of the PLPR matrix B is assumed to be unacceptable. Necessarily adjusting the preference relation expressed by experts is demanded to meet the condition CI (B) ≥ δ. Meanwhile, we expect a narrow deviation of the newly obtained PLPR B′ from the initial one B. If a huge distinction exists between the adjusted and the original PLPRs, the information expressed by experts is seriously lost. That is, the cost of achieving a consistent PLPR is excessively high, which deviates from the prime purpose of obtaining a reasonable decision.
To minimize modifying the prime preference information and avoid complex computation, this paper then proposes a local adjustment strategy for PLPRs to improve the consistency. In the process, whilst going through the PLPR matrix, only the most influential PLTSs contributing to the inconsistent PLPR will be adjusted, instead of modifying the overall elements in the matrix to reach a consistent PLPR. Algorithm 1 is developed to reveal the improving process in detail.
This algorithm achieves a consistent PLPR. The consistency measure for PLPRs interprets the inner meaning of those PLEs. In Step 4, if several elements d ij obtains the same maximum value in the upper triangular part of D, the element with a minimum i1 + j1 will be selected. Alternatively, the decision maker can choose to modify more than one element in each round if a speed requirement exists. Through this local adjustment for certain elements rather than global adjustment for all elements in the matrix, it is beneficial to retain the original preference information to the greatest extent, whilst achieving a consistent PLPR.
Consensus measure and reaching process
Consensus measure of PLPRs
After the adjustment to make each PLPR consistent, the next step is to measure to the consensus, which aims to find out whether the preference relations among experts are in a collective agreement. In practice, achieving an ideal and unanimous consensus is impossible. In other words, a loose consensus degree requirement among experts often plays a part in the fuzzy and uncertain environment. Distance measure and similarity measure are applied to gauge the consensus degree among experts [41, 56]. This paper develops an entropy-based similarity measure to estimate the consensus degree.
On the basis of the similarity measure between two PLTSs in Equation (6), the comparison of the preference relations of each pair of experts e
f
, e
k
is denoted as SM
fk
. The similarity matrix
Then, the consensus degree of two experts e f , e k is
Thus, the consensus degree CS of the expert group is computed as
Once the consensus degree of the expert group is estimated, the consensus degree CS is then compared with the predefined consensus threshold value ϑ. Even if detecting whether the threshold is scientific or not is nearly nonviable, such a threshold is very critical and worthwhile in numerous GDM problems [46]. If CS ≥ ϑ, conducting a consensus reaching process is unnecessary; otherwise, a new iteration process based on feedback mechanism is significant, which concludes two phases:
(1) Identify the specific expert who needs to modify his/her preference values. The minimum actual consensus degree computed by the similarity measure between two experts represents the most distant value from all other experts. The two experts contributing to minimum consensus degree is denoted as:
To decide which expert needs to modify his preference values, two new groups are constructed as
(2) Modify the PLPR of the identified expert. To fully retain the PLPR of the specified expert to a maximum extent, the reaching process also follows a local adjustment mechanism.
Determine the position of
(b) Improve
The detailed algorithm of the consensus reaching process is depicted as Algorithm 2.
This section discusses a resolution process the GDM problem with PLPRs. The main steps include viz., measuring consistency and consensus degree, adjusting inconsistent PLPRs and non-consensus preference information, aggregating process. The details are displayed as follows:
Figure 1 illustrates the resolution process.
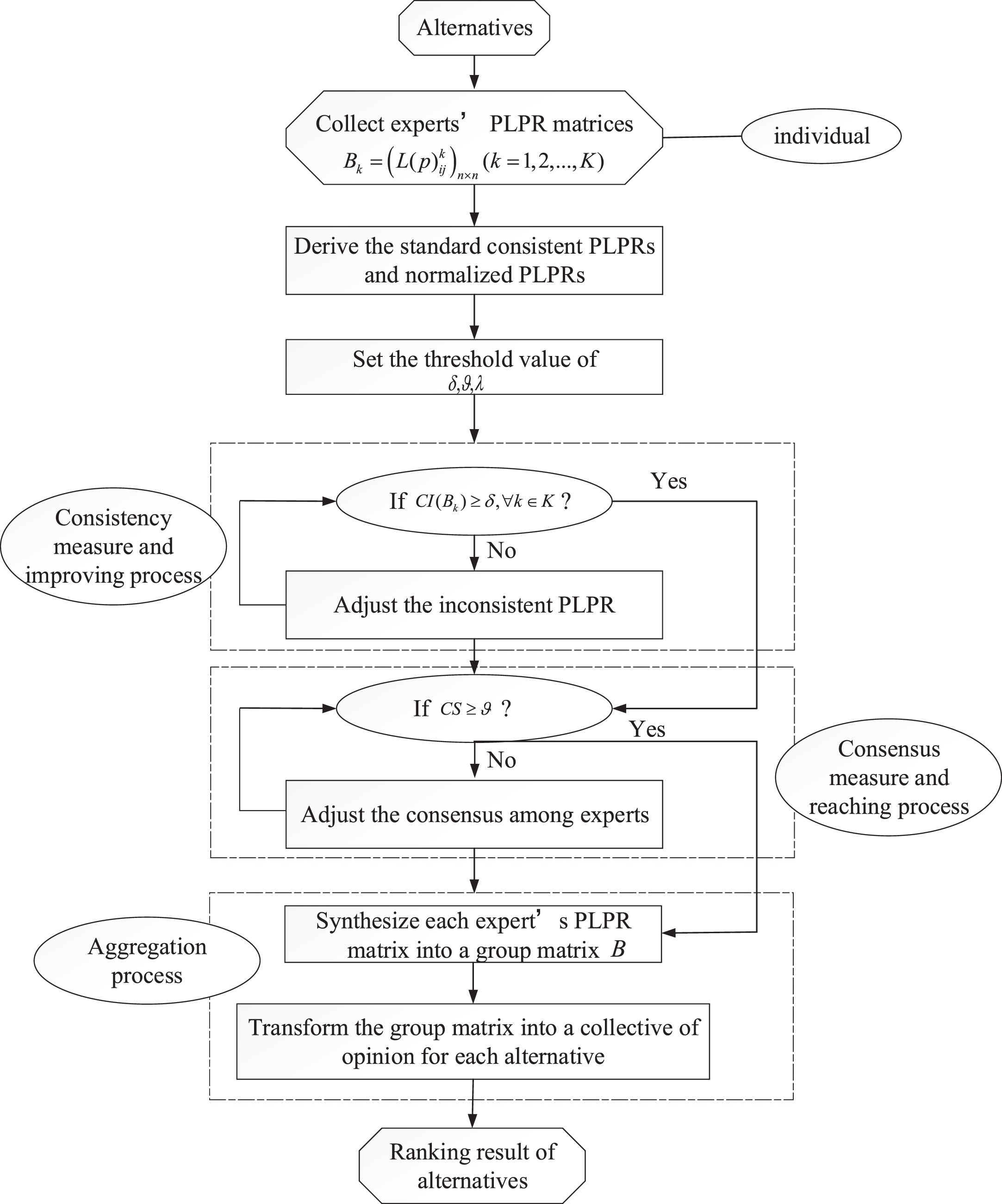
Complete process for managing the GDM problem.
This section cites an example of a medical plan selection issue to verify the effectiveness and feasibility of the proposed methods.
Description of the illustrated problem
The issue of medical plan selection problem can also be regarded as a group decision making process. Several candidate medical alternatives or plans are available, and the experts in corresponding fields are asked to express their preference of alternative x i over alternative x j . Typically, linguistic values are utilized as the expression tool. Fuzziness and uncertainties exist during the discussion process. Considering the specific characteristic dealing with linguistic values, PLTSs and PLPRs can be employed for evaluation. However, inconsistency and non-consensus in the PLPRs can be latent hazards, which will lead to a contradictory result. The measure and improving process are essential before conducting the next decision. After obtaining acceptable consistency and consensus degree, the next step is to choose the best medical plan. Through aggregating all individuals’ preference information and ranking the expected values of alternatives, a favorable plan with the largest value will be selected.
Let us consider that four candidate medical alternatives are waiting to be chosen. Let x
i
(i = 1, 2, 3, 4) denote the four alternatives. Physicians or experts express their opinions on these candidate alternatives, denoted by.e
f
(f = 1, 2, 3, 4). These experts apply PLTSs to express their preference on the linguistic term set S = {s-4, . . . , s-1, s0, s1, . . . , s4},(s-4 = very bad,s-3 = bad,s-2 = a little bad,s-1 = slightly bad, s0 = medium,s1 = slightly good,s2 = a little good,s3 = good,s4 = very good). In terms of expressing the preference of one medical alternative over another, they use one or more than one linguistic label with related probabilities. For example, as for e2, he/she thinks that the preference degree of x1 over x2 may be s-4 or s-3. If he/she maintains 30 percent probability that the preference of x1 over x2 is s-4, and the probability of the preference s-4 for x1 over x2 is 30 percent, then, the remaining 40 percent probability is that he/she cannot give a linguistic label. Thus, his/her opinion is denoted as
Firstly, the normalization process in Definition 2.2 of these PLPRs must be completed before measuring consistency. Meanwhile, the ideal and acceptable consistent NPLPR
By the proposed consistent measure in Equation (11), we can derive the consistent degree of each PLPR:
According to Ref [46] and a substantial discussion with a group of experts, we set the threshold δ = 0.85. Thus, we obtain CI (B1) < δ and CI (B2) < δ, whilst CI (B3) > δ and CI (B4) > δ. Therefore, the preference relations expressed by experts e1 and e2, named B1 and B2, are judged to be inconsistent. Before the next step, an improving process for the unacceptable PLPRs is required.
Then, the proposed local adjustment strategy for obtaining a consistent PLPR is applied. By running Algorithm 1, in the first round, we obtain the following:
Thus, the maximum value in D1 is max { dij,1 } = d24 = 0.344. As
By the same token, the PLPR
According to Equations (13, 14), the similarity matrix of each pair of experts is shown as follows:
By Equation (15), we can obtain cs12 = 0.81, cs13 = 0.68, cs14 = 0.70, cs23 = 0.85, cs24 = 0.72, cs34 = 0.85.
By Equation (16), the consensus degree of the group is
Set ϑ = 0.85, as CS < ϑ, the consensus degree of the group is deemed unacceptable. Therefore, the consensus reaching process for adjusting the unacceptable consensus degree is necessary.
By running Algorithm 2, firstly, one expert is chosen from e1 and e3 to be the target being modified. Based on the above computation, the new consensus degrees of the group E ∖ e1 and E ∖ e2 are:
As CSE∖e1 > CSE∖e3, after choosing e1, the similarity degree of the new group is improved; thus e1 is thought to contribute less to the group consensus and e1 is identified for adjustment. Then, the specific position to be adjusted is determined. By Equation (19), pos (i*, j*) = (1, 2) = (2, 3). In terms of the speed of the reaching process, the local adjustment of the positions (1, 2) and (2, 3) are conducted together.
Set λ = 0.5 and use Equation (20), we have:
Through the iteration of the first round h = 0, the modified
Based on Equations (13–16), we obtain cs12 = 0.87, cs13 = 0.86 and cs14 = 0.80. Then, the revised consensus degree of the group is
As
The modified
Based on Equations (13–16), we obtain cs14 = 0.80, cs24 = 0.76 and cs34 = 0.85. Thus, the new consensus degree of the group changed to
Iteration process for achieving an acceptable consensus degree
Iteration process for achieving an acceptable consensus degree
After five times of iteration, the consensus degree of the group is acceptable, which is CS = 0.85 = ϑ. The PLPR
After measuring and improving the consistency and consensus of all PLPRs, the next step is to aggregate all individual PLPRs into a group PLPR and rank the alternatives.
The weight of experts is set as
The next phase is aggregating the preference values in the collective PLPR B
N
. By Equation (22), each weight vector of each element is set as
By Equation (2), the expected values of alternatives are E (C x 1 ) = -0.35, E (C x 2 ) = -0.64,E (C x 3 ) =1.22,E (C x 4 ) = -0.34. Therefore, the ranking result of the four alternatives is x3 ≻ x4 ≻ x1 ≻ x2. Thus, in this case of selecting the best medical plan, the alternative x4 is in the priority.
From now on, studies conducted to deal with consistency and consensus problems are not bustling for PLPRs, but they all have their own characteristics. These methods must be acknowledged to achieve their goals in their specific background. In practice, no generally admitted approach is judged to be the best. In general, we conduct a comparison analysis with some latest studies to prove the feasibility of the proposed methods in the context of selecting the best medical plan.
Comparison on the consistency measure and improving process
Each consistency model displays different characteristics during the consistent measure and adjustment process. Comparison analysis with the proposed method is constructed as follows:
(1) Comparison with [41, 42]: [41] and [42] are distance-based consistency measures shown as Equations (23, 24), where a counter-intuitive problem exists. Suppose we have two PLTSs, whose subscripts are the same but the related probabilities are distinct such as
(2) Comparison with [46]: Ref [46] proposes a cosine-based similarity measure for consistency measure. We both applied the similarity measure for the consistency measure. However, [46] adopts an equivalent transformation function, which transforms a PLTS into HFLE. This operation laws change the expression of a PLTS and a linguistic term, and the corresponding probability is transformed into an abstract expression. Such operation law causes the uniqueness of PLPTs to be missed compared with normal linguistic term sets. A virtual term is used to represent each PLE in the cosine-based similarity formula. The method is shown as follows:
In a practice setting, it may lead to an issue of difficulty understanding. Regarding the consistency improving process, [46] recommends a subjective improving process following group’s feedback and discussion. It is one approach to comply the aim in some highly tolerant environments. Compared with the consistency measure, we retain the expression of PLTS during the operation, and less information is lost. In addition, understanding the computation forms is easier in the similarity measure method. Furthermore, we propose a local adjustment strategy based on objective calculation, which appears to be more accurate.
(3) Comparison with [48]: it proposes a novel consistency measure and a consistency improving process for multiplicative PLPRs (MPLPRs) in [48]. The same transformation issue occurs, which transforms the MPLPRs into certain linguistic terms. The virtual terms in the consistency measure formula causes difficulty in understanding. In terms of the consistency improving strategy, it puts forwards a prospect theory-based consistency modification method, which separates DMs into risk seeking and risk aversion and comes up with different methods for different risk types. It is one of the innovative ideas which consider psychological behaviors and can serve as one useful method in some practical backgrounds. However, it also a global change, which renders all elements adjusted to reach an acceptable consistent level. Differently, we take advantages of the local adjustment strategy to improve the elements which causes the highest influence in the inconsistency.
Overall, the proposed methods in this paper are valuable. On the one hand, the similarity-based consistency measure solves the counter-intuitive problem in existing study and is more understandable. On the other hand, the local adjustment strategy retains the largest original information of DM’s preference. It also balances the computation complexity and practical implications than those studies.
Different consensus measure and reaching mechanisms contribute to different consensus models. However, only handful papers study about consensus measure and reaching under PLPRs. Comparison analysis with the relevant consensus models is addressed as follows:
(1) Comparison with [41]: Ref [41] proposes a distance-based consensus measure. Through the complementary relation property between distance and similarity measure, the distance measure transforms into a similarity-based measure to gauge the consensus degree. However, as mentioned in section 6.2.1, the distance-based measure in [41] presents a counter-intuitive flaw, which can also cause a negative influence through the similarity transformation in consensus measure. Compared with the distance-based consensus measure, this paper proposes an entropy-based similarity measure method, which overcomes the flaws existing in the [41]. Moreover, the formula form is relatively concise. Related to the consensus reaching process, both encourage a local adjustment for the unacceptable PLPRs. Therefore, only a very small portion of the preference information which contributes to the deadliest influence in consensus degree will be modified in the decision-making process.
(2) Comparison with [46]: Ref [46] employs the same consistency measure called consistency/consensus index to gauge the consensus degree. As discussed in 6.2.1, the distinct and limit have been compared, and there is no further discussion for the consensus measure. For the improvement of the non-consensus PLPRs, it also suggests a subjective adjustment based on the groups’ feedback, discussion, or particular circumstances. Compared with this abstractive reaching process, the local consensus adjustment strategy proposed in this paper is more direct and interpretable. Considering no consensus measure and reaching process are given in [48], we no longer make further comparison.
(3) Comparison with [19]: it defines a consensus measure on the basis of possibility between two PLTSs, and the possibility degree function is constructed by the similarity degree. It computes the similarity degree through finding the maximum and minimum subscript of linguistic terms and performing the calculation. However, it overlooks the probabilities of the linguistic terms during the computing, and only the linguistic terms are considered. Such method fails to satisfy the definition of PLTSs, whose characteristic is that probabilities are reflecting the importance degree of linguistic terms. The similarity degree measure in [19] does not directly display the meaning of the corresponding probabilities of linguistic terms. Moreover, no clear explanation of transformation function exists for linguistic terms in the formula, which is very difficult to understand in the real implication scenario. Compared with this method, the consensus measure method proposed in our paper is reasonable and can display each role of the component of PLTSs. Regarding the consensus reaching process, Ref [19] only gives a very brief introduction which is to determine the smallest similarity degree in the PLTSs and adjust it by experts when the PLPR is determined to be an unacceptable consensus level. This adjustment strategy is subjective and uncertain. Nevertheless, compared with [46], it adds the step to determine the smallest similarity degree and suggests to replace the specific position value with a quantitative computing result, which is more reasonable.
In general, we construct the consensus measure by the proposed entropy-based similarity measure. It fully considers the relationship of linguistic terms and related probabilities. In addition, it overcomes the flaws existing in the published studies and is proven to be valuable. Furthermore, as for the local adjustment strategy for the non-consensus PLPRs, it is advantageous for largely retaining the original preference information and deriving the modified PLPR by quantitative calculation. It is verified to be feasible and beneficial.
Rationality of the proposed GDM model
First of all, we wish to compare the two similar concepts of the PLPR and the LDPR using the above numerical example. The main difference between these two concepts is the normalization process when the linguistic probability is incomplete. The normalization for the PLPR is computed by Definition 2.2, whilst the normalization for the LDPR is processed by [23] using the collective personalized semantics model. It is to add the ignored linguistic terms and their probabilities for the incomplete LDPR by maximizing the overall consistency of the supposed complete DLPRs. Firstly, it should transform the linguistic term into a numerical index using the function NS
c
: S → R. To make the collective personalized semantics model adapt to the linguistic scale S = {s
α|α = - τ, . . . , -1, 0, 1, . . . , τ}, we set the range of NS
c
(s
α) as
By using the collective personalized semantics model in [23], the ignored linguistic terms and probabilities of B1, B2, B3, B4 are completed. The detailed normalization results for B2, B3, B4 are omitted here, only taking the normalized
Probabilistic information
After normalization, the proposed consistency and consensus measures are conducted, and unsatisfied preference relations are modified to make them acceptable. Processed by the proposed GDM framework, the final ranking result of those two concepts is shown in Table 3.
It shows that both concepts with different normalization processes obtain a similar ranking result. The normalization method applied for LDPR takes advantages of retaining the original preference relation and complementing the ignored probabilities for linguistic terms. Each linguistic term will be assigned a certain probability. However, most linguistic terms are assigned a very small probability, which contributes little positive effect to showing the preference information, but the sum of their small probabilities cannot be ignored. This scenario makes following calculations more complicated. Moreover, although the normalization process in [23] is conducted by maximizing the overall consistency of all preference relations, the consistency index values measured by Equation (10) for the LDPR B1 and B2 remain unacceptable and the further modification process is needed. Hereafter the preference information in the normalized DLPR also has to be adjusted to reach an acceptable consistent level. The normalization for PLPR in Definition 2.2 is to redistribute the ignore probabilities to the initial linguistic terms. It may change the original information but the importance ratio of those linguistic terms stays the same. Through the consistency measure and improving process, the preference information contained in the normalized PLPR is adjusted to an acceptable level, which is just the aim that Ref. [23] hopes to achieve. This result shows that even if the normalization methods are different, the consistency improving and consensus reaching processes adjust the different expression to the similar preference information. Therefore, similar ranking results are obtained. In addition, proposing more optimized normalization methods for both concepts is one of our future directions.
Comparison on the final ranking result
To examine the rationality of the proposed GDM model, we compare the final ranking result on the basis of the above example illustration through the comparison with or without consistency and consensus reaching process. Through computing, the comparison result is shown as Table 4 and Fig. 2.
Ranking result of two similar concepts with different normalization methods
Using the numerical example data in Section 6.1, the final ranking result derived by Zhang et al. [41] is a little different with the proposed model. From the aforementioned discussion, a natural limit of the suggested distance measure for consistency and consensus exists. When special data characteristics exist, slight deviations will be reflected in the final result. As the data used in the example is almost general, the two final results generated by the two different models are very similar. Only the positions of x1 and x2 at the back are different, but the superior recommended medical plan is the same. Then, the proposed GDM model in this paper can be judged to be reasonable. To show the importance and necessity of the consistency measure and improving process, we compare the final result without the consistency process. The preference information expressed by expert e1 and e2 is inconsistent. Without the consistency improving process, contradictory preference information is brought into the next calculation. Therefore, the superior alterative is ignored. Computed with Zhao et al. [19], two ranking results are almost completely opposite. Apart from the contradictory preference information existing in the calculation process, overlooking the probability in the suggested similarity measure of Zhao et al. [19] is also responsible. In Luo et al. [46], they suggested a subjective modification process for the unacceptable consistency. We therefore assume that it is no quantified calculation for the consistency improving process. As reflected from the final result, only the most and second recommended alternatives are in different positions. No concrete consistency adjustment exists, but the consensus is thought to be workable. Then, the final result by Luo et al. [46] reflects a little difference. To investigate the impact of the consensus reaching process for the unacceptable consensus level, two comparison calculations were conducted without consensus reaching process. The group consensus level mentioned above is known to be unacceptable. Thus, the preference expression of certain expert need be modified to reach a unanimous opinion. Alternatively, the final result will be assumed to be non-representative. As reflected from the results of Krishankumar et al. [42] and Nie et al. [48], the final ranking results are almost totally different from the proposed model because controversial opinion exists in the group decision making process. Moreover, operation problems exist in [42]. Then, a final ranking result without the consensus reaching process is not feasible and representative.
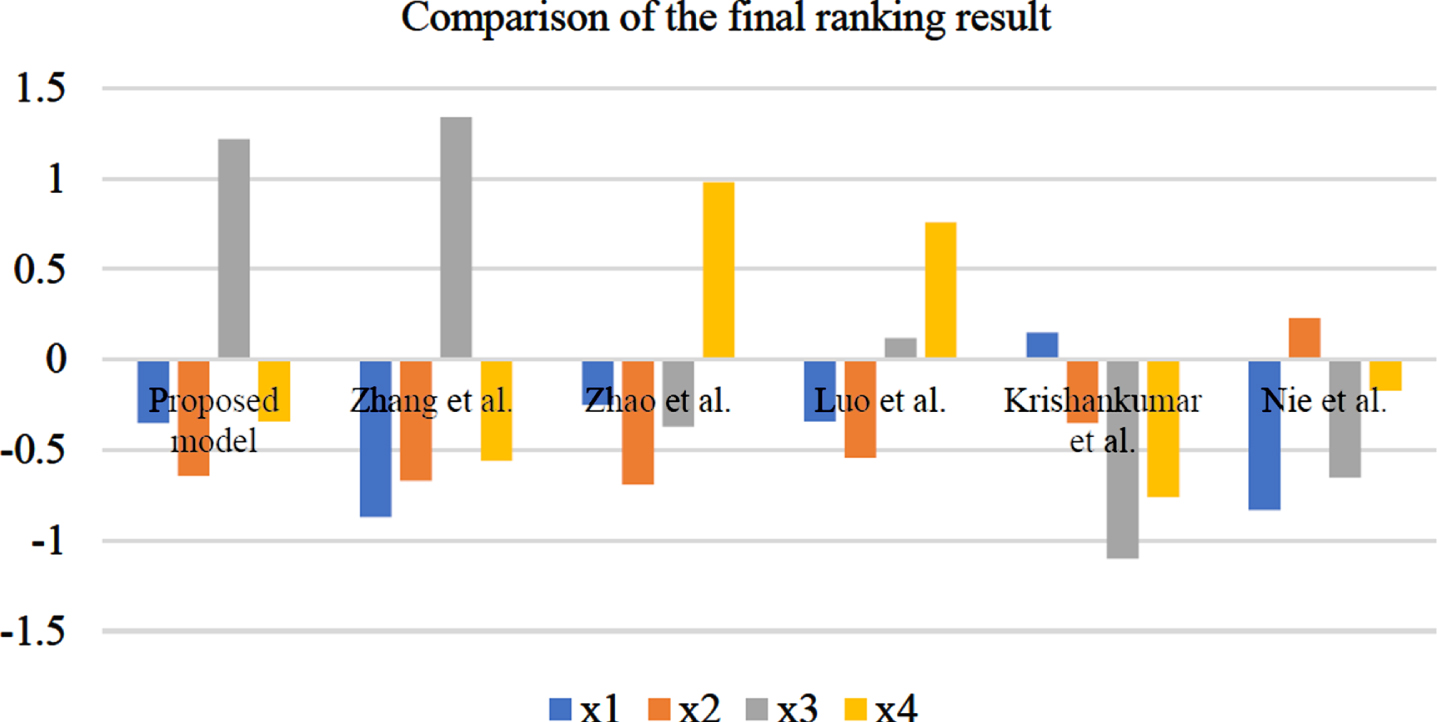
Comparison on the final ranking result.
Overall, the proposed model for solving the GDM problem is verified to be beneficial and effective. Moreover, the adjustment strategy for improving the unacceptable consistency and consensus levels is also demonstrated to be very significant.
Making use of the PLPRs, in which the pairwise comparisons are described by PLTSs, the
uncertainty of the preference information expressed by decision makers can be depicted more quantitatively and flexibly. Considering that both consistency and consensus create a central impact on GDM with PLPRs, this paper focuses on processing three issues: similarity measure, consistency measure and improving process, consensus measure and reaching process. First of all, this paper proposes a novel entropy-based similarity measure for PLTSs. It is proven to meet all the properties and has a relatively laconic computation form. Furthermore, a novel consistent measure index and a consensus measure index are presented on the basis the proposed entropy-based similarity measure. Both calculations overcome the shortcomings existing in recent studies. Moreover, the similarity-based consistency and consensus measure are more understandable and reasonable. Thirdly, with regard to the unacceptable consistency improving and consensus reaching processes, a local adjustment strategy is suggested. It follows the desire of minimum adjustment in the original preference information. Only the element or position which leads to the largest negative influence on the acceptable consistency or consensus degree will be improved rather than the overall elements in the PLPR matrix. Then, it presents dominance of preserving the initial PLPRs on a large scale. Finally, a numerical example illustration of selecting superior medical plan is put forward to verify the effectiveness and practical implications for the proposed GDM model. Over and above, the comparison analysis demonstrates the favorable performance and benefits of the proposed methods.
Furthermore, this study contains one limitation. The normalization process for incomplete PLTSs proposed by Pang et al. [28] sometimes cannot work well, even if it can be adjusted to be workable through the consistency improving process. Moreover, the flexible linguistic expressions proposed by Wu et al [59, 60] are learned to be general and significant in recent studies. Thence, our future study will focus on: (1) normalization methods for incomplete PLTSs; (2) group decision making applied in medical diagnosis with flexible linguistic expressions; (3) considering the bounded confidence level in the consistency improving and consensus reaching processes; (4) applying the proposed GDM framework to the application of high-speed rail, bid evaluation, among others.
Author contributions
conceptualization, P. L. and J. H.; methodology, P. L.; software, P. L.; validation, J. H.; formal analysis, P. L. and J. H.; investigation, P.L.; resources, P. L. and J. H.; data curation, P. L.; writing-original draft preparation, P. L.; writing-review and editing, P. L., J. H. and K.C.; visualization, J. H.; supervision, J. H. and K.C.; project administration, J. H. and K.C.; funding acquisition, J. H.
Conflicts of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Funding
This work is supported by the National Natural Science Foundation of China (Grant numbers: 71871229 and 71771219).