
Abstract
Aiming at the low effectiveness of short texts feature extraction, this paper proposes a short texts classification model based on the improved Wasserstein-Latent Dirichlet Allocation (W-LDA), which is a neural network topic model based on the Wasserstein Auto-Encoder (WAE) framework. The improvements of W-LDA are as follows: Firstly, the Bag of Words (BOW) input in the W-LDA is preprocessed by Term Frequency–Inverse Document Frequency (TF-IDF); Subsequently, the prior distribution of potential topics in W-LDA is replaced from the Dirichlet distribution to the Gaussian mixture distribution, which is based on the Variational Bayesian inference; And then the sparsemax function layer is introduced after the hidden layer inferred by the encoder network to generate a sparse document-topic distribution with better topic relevance, the improved W-LDA is named the Sparse Wasserstein-Variational Bayesian Gaussian mixture model (SW-VBGMM); Finally, the document-topic distribution generated by SW-VBGMM is input to BiGRU (Bidirectional Gating Recurrent Unit) for the deep feature extraction and the short texts classification. Experiments on three Chinese short texts datasets and one English dataset represent that our model is better than some common topic models and neural network models in the four evaluation indexes (accuracy, precision, recall, F1 value) of text classification.
Keywords
Introduction
With the continuous development of intelligent technology, text has become more and more important as the main carrier of information. Nowadays, short texts have gradually become the focus of text processing, and it plays a significant role in information search [1], social comments [2], interest recommendation [3]. Short texts refer to the text form within 160 characters in length, such as news headlines, comments information and document abstracts.
Short texts have the characteristics of sparse content, fast update speed, more abbreviations, and fewer words with practical meaning, so it is difficult to extract key features. Therefore, the key of short texts classification is to achieve effective feature extraction. At present, the methods of text feature extraction are mainly based on three types of models, including Vector Space Model (VSM), topic model and neural network. The VSM [4] extracts the features in the document and then simplifies it into vector operations in the vector space. Although the vector dimension of VSM has a clear meaning, the sparsity of the vector is very high when the amount of data is large. At the same time, VSM does not consider the relevance of text features. The topic model introduces the concept of “topic”, which has certain practical significance. Topic model assumes that the potential topics and words in the document should obey a certain probability distribution, so that the topic distribution representation of the document can be obtained after training. The most popular topic model is the Latent Dirichlet Allocation (LDA) proposed by Blei [5]. The text representation method based on neural network has developed rapidly since the emergence of the word2vec [6] algorithm. This method converts text into vectors at the word, sentence, or longer text level. At the same time, many neural network models have been proposed to extract the features of texts, such as Long Short-Term Memory (LSTM) [7] and Convolutional Neural Networks (CNN) [8].
Since short texts have fewer feature words, the generated topics are not clear and the relevance is poor when traditional topic models are applied to short texts. Therefore, many scholars have proposed different ideas to improve the effectiveness of traditional topic models when applied to short texts. Yan et al. [9] proposed the Biterm Topic Model (BTM), which improves the effectiveness of the LDA topic model when applied to short texts by extracting word pairs in the document, but it ignores the connection between multiple words. Lv et al. [10] expanded the content of the short texts by extracting appropriate words from the topic-word distribution matrix obtained by training the LDA topic model, and finally combined Support Vector Machine (SVM) for classification. Pang et al. [11] considered the relationship between Chinese microblog documents, and realized the effective application of the LDA topic model in the microblog short texts by aggregating multiple Chinese microblogs into one microblog document. Hu et al. [12] used external resources to expand short texts information to reduce the sparseness of short texts, and then selected representative topics from the topic distribution trained by online BTM as short texts features to complete classification. However, this method requires relatively high quality of external resources.
With the continuous development of deep learning technology, especially the successful application of the Variational Auto-Encoder (VAE) [13], the neural network topic model has developed rapidly. The main advantage of these neural network topic models is that they can be easily inference through the forward pass of the neural network, without the need to use Gibbs sampling or Variational Bayesian (VB) algorithm to perform complex iterative reasoning for topic of each word like traditional topic models. Miao et al. [14] first used VAE to construct the Neural Variational Document Model (NVDM). The NVDM assumes that the prior distribution of potential topics of the document obeys the Gaussian distribution, and the document-topic distribution is generated by an encoder network composed of a Multi-Layer Perceptron (MLP). Ding et al. [15] used pre-trained word vectors to measure the semantic similarity between words on the basis of NVDM, and the method is used as a part of the NVDM optimization function, thereby improving the consistency of the topic generated by the model. Dieng et al. [16] proposed embedded topic model (ETM) on the basis of VAE, which introduced word embedding and established topic vector distribution for each topic. ETM assumes that the potential topics of the document follow the logistic-normal distribution, and the topic-word distribution is the product of topic vectors and word vectors, which improves the interpretability of the topics generated by the model.
However, the Kullback-Leibler (KL) divergence in VAE causes prior probability distribution of all samples to match its posterior probability distribution, which makes the output and input of the VAE encoder very different. This problem is called posterior collapse [17]. Wasserstein distance solves the problem of KL divergence well, so the Wasserstein Auto-Encoder (WAE) [18] was born. Nan et al. [19] first proposed the neural network topic model Wasserstein-Latent Dirichlet Allocation (W-LDA) on the basis of WAE. W-LDA uses Dirichlet distribution as the prior distribution of potential topics and uses Maximum Mean Discrepancy (MMD) to match the high dimensional Dirichlet distribution. W-LDA avoids the problem of posterior collapse, and obtains more consistent topics.
In practice, although Dirichlet distribution is good at capturing sparse topics from document, the relevance of the obtained topics is often low. At the same time, W-LDA obtains the document-topic distribution through the softmax activation function after the hidden layer inferred by the encoder network, but the distribution generated by softmax is dense. In fact, there are not many hidden topics in the short texts, and the dense distribution is often contains many unclear topic features. In response to the above problems, this paper proposes a neural network topic model, Sparse Wasserstein-Variational Bayesian Gaussian mixture model (SW-VBGMM), suitable for feature extraction of short texts on the basis of W-LDA, and we combine SW-VBGMM with BiGRU to achieve effective short texts classification. The contributions in this paper are summarized as follows: The Bag of Words (BOW) input to W-LDA is preprocessed by the Term Frequency-Inverse Document Frequency (TF-IDF) [20] to highlight the weight of keywords in the document, so that W-LDA can generate higher quality topic features. On the basis of W-LDA, the prior distribution of potential topics in the model is replaced from the Dirichlet distribution to the Variational Bayesian Gaussian Mixture Model (VBGMM) [21]. Due to the multi-apex of VBGMM, more relevant topic features are obtained. The sparsemax function layer [22] is introduced after the hidden layer inferred by the W-LDA encoder network to replace the softmax function layer to generate a document-topic distribution suitable for sparse features of short texts. The sparse document-topic feature distribution generated by SW-VBGMM is input to BiGRU (Bidirectional Gating Recurrent Unit) [23] for deep feature extraction, and finally the softmax layer is used for classification, so as to obtain better short texts classification effect.
The remainder of this paper is organized as follows: The second section introduces the technologies and models related to this research. The third section introduces the proposed SW-VBGMM in this paper, and the process of completing short text classification. The fourth section presents the experimental results and discusses the results. The fifth section concludes the paper.
Related work
Wasserstein auto-encoder (WAE)
WAE was proposed by Google in 2018 [18]. It uses Wasserstein distance instead of KL divergence to measure the difference between the true distribution of the sample and the fitted distribution generated by the decoder network. Since Wasserstein distance can measure the distance between any two distributions, WAE can learn more complex data distributions, and the quality of samples generated by WAE is significantly higher than that of VAE.
WAE assumes that each sample in the training data S is generated by a latent variable L in the latent space. WAE first samples L from a prior distribution P L in the encoder network, and then generates the fitted distribution P t of the training data S by the decoder network. In order to minimize the optimal transport distance between the fitted distribution P t and the true distribution P s of the training data S, WAE needs to minimize the following objective function:
There are two different forms for the regularization term D L (Q L , P L ). The first is based on Generative Adversarial Networks (GAN) [24], which uses Jensen-Shannon (JS) divergence to measure the distance between distributions. The second is based on MMD [25], where D L (Q L , P L ) ≜ MMD Z (Q L , P L ), MMD uses a kernel function to map Q L and P L to a high-dimensional space and sample to obtain the expected values of the two distributions. The upper bound of the difference between all expected values of the two distributions is defined as the MMD distance. For the reproducing kernel function Z : L × L → R [18], the definition of MMD is as follows:
Similar to other neural network topic models, W-LDA obtains the document-topic distribution from the input BOW through the inference of the encoder network. Decoder network samples the output of the encoder network to get the topic-word distribution, thereby completing the reconstruction of the input BOW.
The encoder network of the model is a Multi-Layer Perceptron (MLP), which maps the input BOW to the output layer with N neurons through the hidden layer, and then adds a softmax layer to obtain the document-topic distribution
W-LDA uses the MMD-based regularization term D L (Q L , P L ), MMD needs to match the Dirichlet distribution and the Dirichlet distribution is a high-dimensional continuous probability distribution with positive simplex as the support set. Therefore, MMD uses the information diffusion kernel function [26]. The equation is as follows:
MMD distance is an unbiased estimator in theory, so f samples of Equation (6) can be used for unbiased estimation of MMD in Equation (2):
Gated Recurrent Unit (GRU) reduces a gated unit on the basis of LSTM [27], which not only retains the advantages of LSTM with long-term memory but also greatly reduces the number of parameters and effectively preventing over-fitting. Set the text input at GRU k time as x k , and the input at the previous time and the accumulated historical information are respectively xk-1, ck-1. Then the output at the current moment is c k , as shown in Equation (7):
BiGRU is equivalent to two GRUs training from opposite directions, and finally the training results of the two GRUs are connected. It obtains clearer semantics by predicting the text information inputted in the past and in the future. The structure of BiGRU is shown in Fig. 1.

BiGRU neural network structure.
Sparsemax is the sparse form of the softmax activation function [28], as shown in Equation (11):
The projection method is to find the point closest to the simplex through the Euclidean distance, so the projection point probably falls on the boundary of the simplex, resulting in the effect of output sparsity.
The Gaussian Mixture Model (GMM) can be considered as the probability distribution of the linear superposition of a finite number of Gaussian distributions, the Equation is as follows:
VBGMM is the GMM obtained by Variational Bayesian inference. The Variational Bayesian inference process of GMM is as follows: For each sample value x n input in GMM corresponds to a latent variable a n (a nm represents the latent variable of the m - th Gaussian distribution in the mixed distribution). Set the input N sample data as X ={ x1,⋯,x N }, set the latent variable as A ={ α1,⋯, α N }, the joint probability distribution of sample data X and latent variable A is:
The optimal estimation of each parameter in the above equation are obtained by Variational Bayesian inference, and the optimal estimation q* (A) of q (A, π, μ, Λ) under parameter A is as follows:
The optimal estimation q* (π) and q* (μ m , Λ m ) of q (A, π, μ, Λ) under parameters π, μ and Λ are respectively shown in Equations (19):
Then continue to updata the parameters of the q (π) and q (μ, Λ) distributions until the Evidence Lower Bound (ELBO) of the Variational Bayesian inference of GMM converges. The ELBO of the Variational Bayesian inference of GMM is shown in Equation (20):
Short texts preprocessing
The process of preprocessing the short texts in this paper is as follows: Firstly, the Chinese short texts dataset are segmented with JIEBA [29], the stop words and low-frequency words in the dataset are filtered; Secondly, the low-frequency words and stop words in the English dataset are deleted through the natural language Toolkit (NLTK); Subsequently, the word frequency of the processed dataset is counted, and BOW is established to realize the vectorization of the text; Finally, the weight of word frequency in the BOW is modified by TF-IDF, highlight the weight of important feature words. Then it’s used as the input of the SW-VBGMM.
Sparse Wasserstein-Variational Bayesian Gaussian mixture model (SW-VBGMM)
W-LDA takes the Dirichlet distribution as the prior distribution of potential topics in the model. Although Dirichlet distribution well captures the rule that documents usually belong to sparse topic subsets [19], the weak relevance among the components of the random vector in the Dirichlet distribution makes the obtained potential topics almost irrelevant, which is not consistent with many practical problems. The Gaussian mixture distribution can fit any distribution through multiple Gaussian distributions. At the same time, due to the multi-apex of the Gaussian mixture distribution, it can better fit the data to obtain the more consistent topics [32]. VBGMM improves the generalization ability of the model and effectively prevents the occurrence of data over-fitting compared to GMM obtained by Expectation Maximization (EM) inference [30]. Therefore, we use VBGMM [21] as the prior distribution of W-LDA’s potential topics, and VBGMM continuously fits the potential topics during the model training process.
The encoder network of the SW-VBGMM is still a MLP. The input of the encoder network is b
T
, which is the BOW pre-processed by TF-IDF. VBGMM is used as the prior distribution of potential topics, where the number of Gaussian distributions in VBGMM is consistent with the number of topics preset by the model. When the MLP maps b
T
to the output layer with N neurons, VBGMM continuously fits the potential topics. Then add a sparsemax layer after the output layer of the MLP to obtain the sparse document-topic distribution
Then the sparse document-topic distribution φ1 is used as the input of the decoder network, where the decoder network is still composed of a single-layer neural network. The decoder network samples φ1, and adds the sparsemax layer to the weight matrix generated by the decoder network to obtain the sparse topic-word distribution β1. At the same time, the word probability distribution
In this paper, in order to match the VBGMM, we replace the information diffusion kernel function with the Radial Basis Function (RBF) kernel [31] suitable for Gaussian distribution. The mathematical form is as follows:
Similarly, use f samples of Equation (6) to estimate the MMD in Equation (2) unbiasedly to obtain the MMD distance.
The process of short texts classification by the short texts classification model proposed in this paper is shown in Fig. 2. Firstly, the preprocessed corpus is converted to BOW, and TF-IDF is used to preprocess it to generate b T . Subsequently, b T is input into SW-VBGMM encoder network to generate the document-topic distribution φ1, which is used as the input of BiGRU; Then, BiGRU neural network deeply extracts the features of φ1; Finally, the softmax function layer classifies the final extracted features.
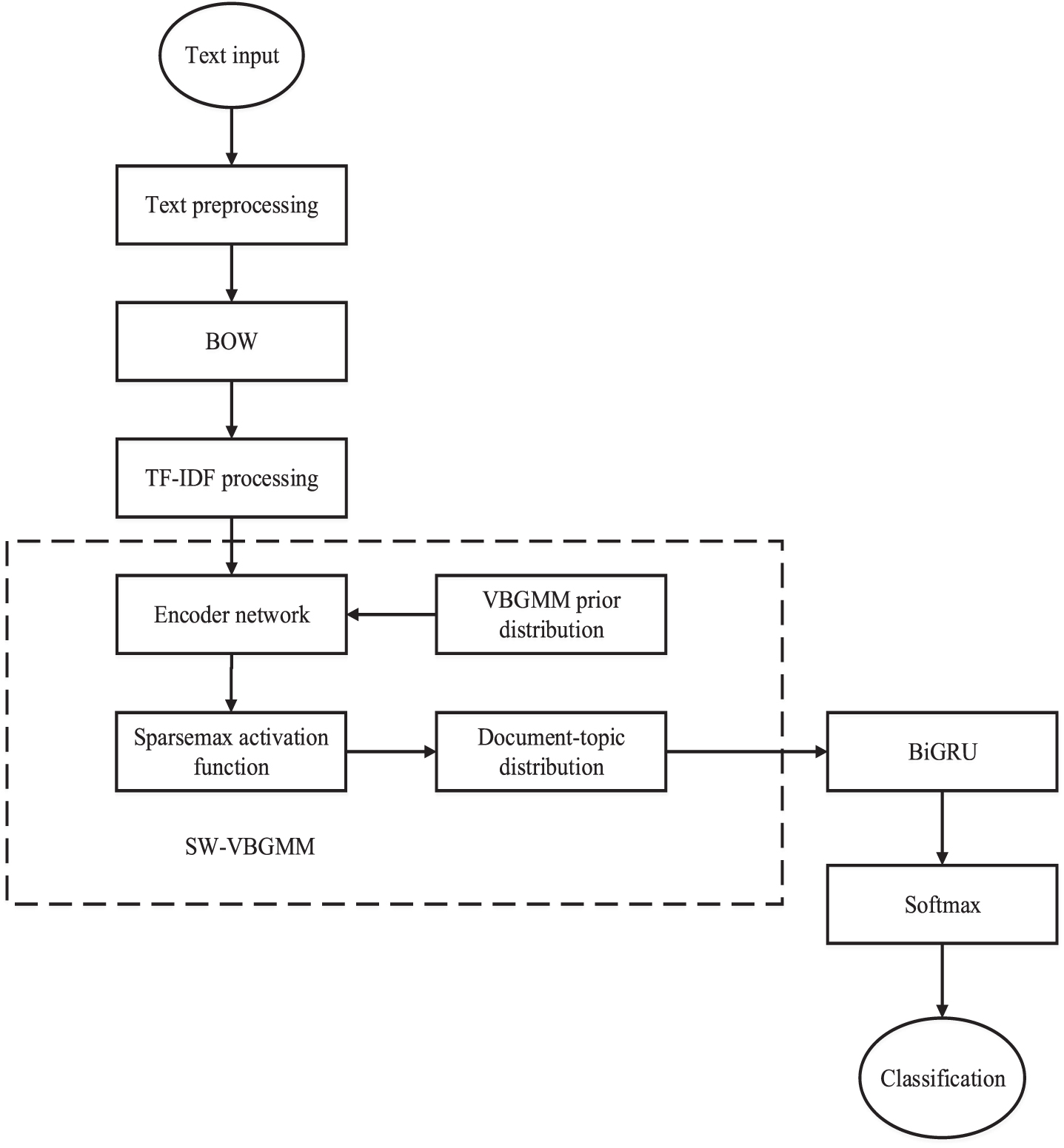
Short texts classification flow chart.
Experimental datasets
The experimental dataset includes Tan Songbo hotel review dataset, Takeout review dataset, THUCNews news headline dataset and AGNews dataset. The Tan Songbo hotel review dataset (3000 positive and 6000 negative) and the Takeout review dataset (4000 positive and 8000 negative) are both two-category Chinese datasets. The THUCNews news headline dataset includes ten categories of finance, real estate, stocks, education, technology, society, current affairs, sports, games, and entertainment. we extract 900 documents from each category in its training set to form a training set containing 9000 documents, and extract 300 documents from each category in its validation set and test set to form a validation set and a test set containing 3000 documents. AGNews is an English short news dataset, including four categories: world, sports, business and technology. It has 120,000 documents in the training set and 7,600 documents in the test set, we extracted 24,000 documents from the training set as the validation set. The data distribution is shown in Table 1.
Data distribution
Data distribution
The experimental operating environment used in this paper was all carried out on a Windows Intel (R) Core (TM) i7-9750 CPU @ 2.60 GHz, 16 GB RAM. The experimental code was built on the basis of the Pytorch framework, and the experimental language was Python 3.6. The parameter settings in this paper are shown in Table 2, except for the number of Gaussian distributions in SW-VBGMM and the number of hidden layers in BiGRU, other parameter settings are shared.
Parameter settings
Parameter settings
The quality of text classification is usually measured by precision (P), recall (R), F1 value (F1) and accuracy (ACC). The mathematical forms are as follows:
Determine the optimal number of topics
In order to determine the optimal number of topics, we set the number of topics of the SW-VBGMM from 2 to 10 on the datasets of Tan Songbo hotel review and Takeout review, and use the F1 value to select the optimal number of topics. Since AGNews is a four-category dataset, we set the number of topics of the SW-VBGMM from 4 to 10 for experiments. As shown in Fig. 3, the optimal number of topics for the Takeout review dataset is 3, the F1 value is 96.62%; the optimal number of topics for the Tan Songbo hotel review dataset is 5, the F1 value is 95.78%; the optimal number of topics for the AGNews dataset is 7, the F1 value is 91.28%.
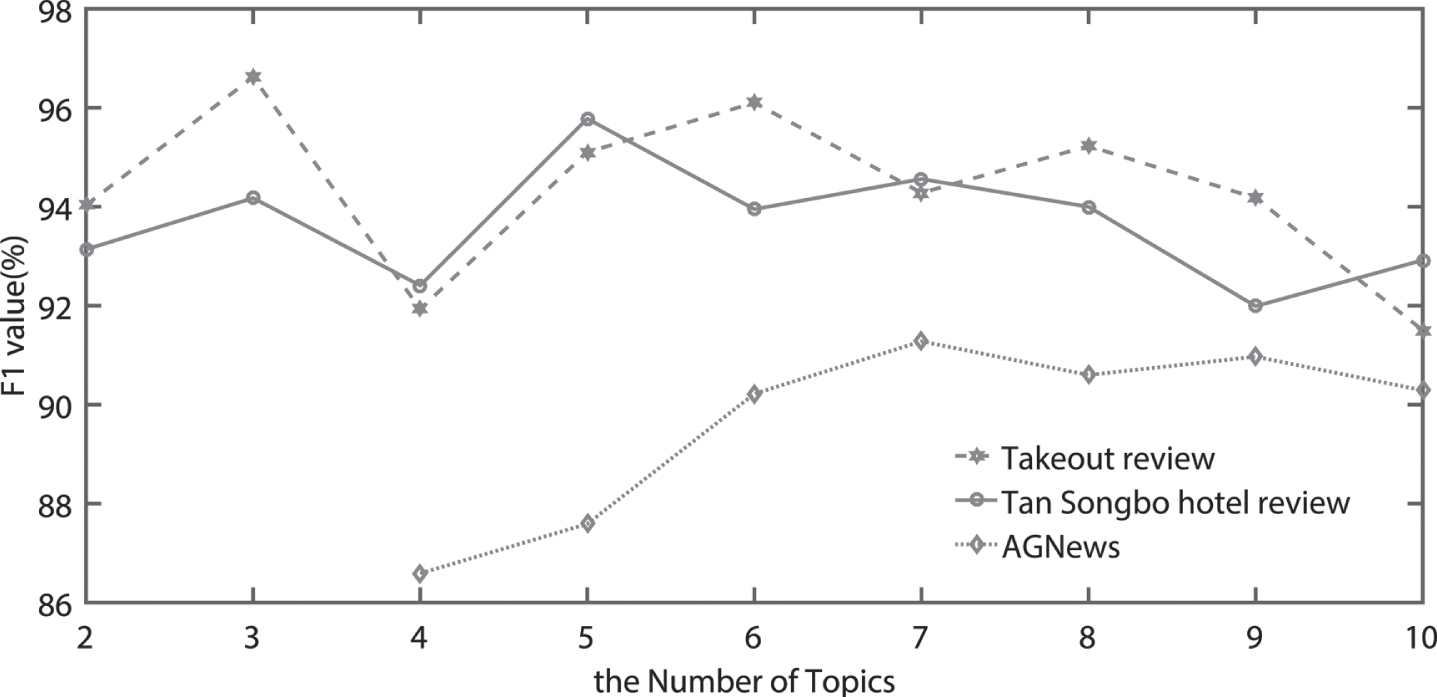
F1 value of the two-category Chinese dataset and AGNews dataset under different topics.
For the THUCNews news headline dataset, we set the number of topics of SW-VBGMM from 10 to 50, and conduct experiments at intervals of 5. As shown in Fig. 4, the optimal number of topics for the dataset is 25, the F1 value is 93.61%.
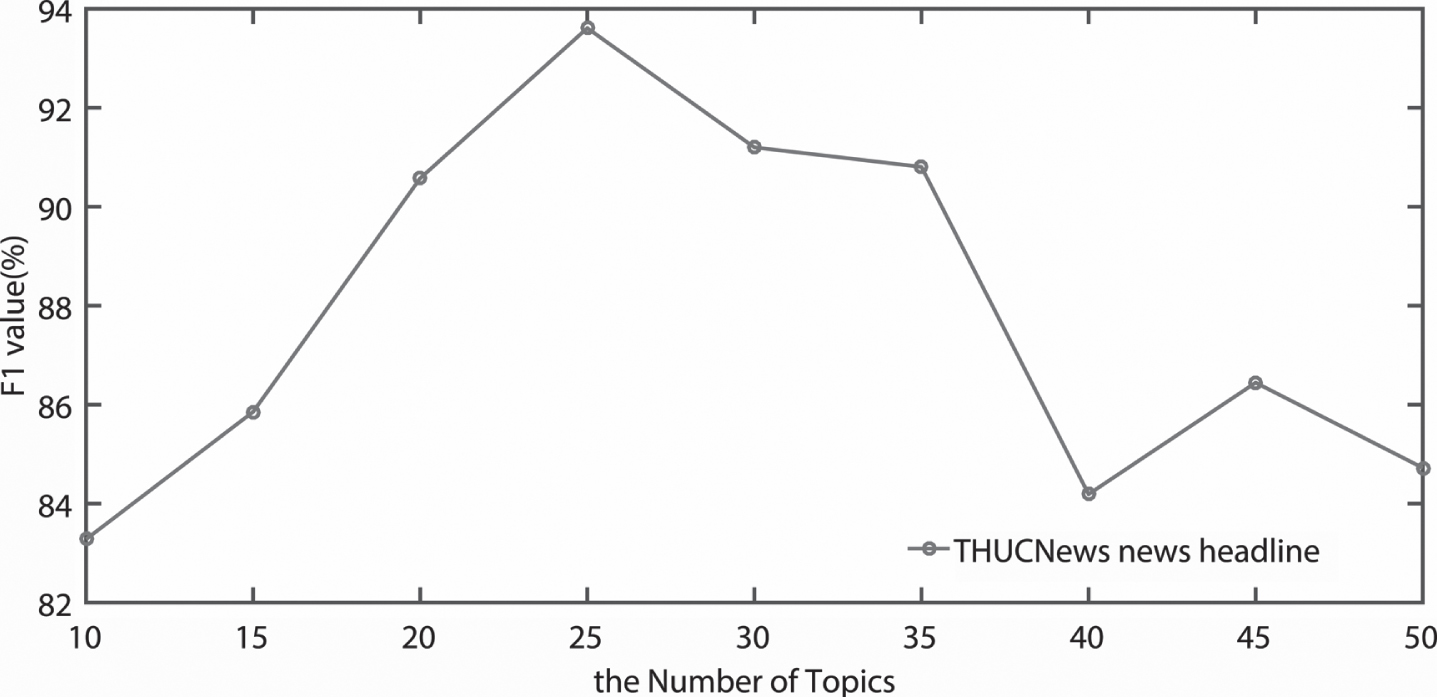
F1 value of the THUCNews news headline dataset under different topics.
In order to verify that BiGRU can effectively extract the features of the document-topic distribution φ1 generated by the SW-VBGMM and perform classification, we input φ1 into different classifiers for comparison experiments. These classifiers contain SVM, Decision Tree (DT), K-Nearest Neighbor (KNN), Logistic Regression (LR), CNN and LSTM.
For classifiers based on machine learning (SVM, DT, KNN, LR), we combine the training set and the validation set of the dataset into a training set. In the SVM, we use the Gaussian kernel function RBF; In the DT, we set the feature selection method as information gain; The k value of KNN is selected as 5; The regularization parameter of LR is selected as L2 regularization. For the neural network (CNN, LSTM), we divide the training set, validation set and test set according to the data distribution ratio in Table 1. The validation set is used to adjust the hyperparameters to prevent the neural network from overfitting. The convolution window size of CNN is set as (3, 4, 5), the number of filters is set as 100, and the dropout value is set as 0.6; LSTM parameter settings same as the BiGRU. The experimental results of the Takeout review dataset and the Tan Songbo hotel review dataset are shown in Table 3, the experimental results of the THUCNews news headline dataset and the AGNews dataset are shown in Table 4.
Comparison of different classifiers on Takeout review and Tan Songbo hotel review
Comparison of different classifiers on Takeout review and Tan Songbo hotel review
Comparison of different classifiers on THUCNews news headline and AGNews
It can be seen from the experimental results in Tables 3 4 that this paper combines the sparse document-topic feature matrix φ1 generated by the SW-VBGMM with BiGRU for classification and has achieved good results. Especially on the multi-categorized news headline dataset, the neural network as the classifier is significantly better than the traditional classifier. On the Takeout review dataset, the F1 value of BiGRU as the classifier for short texts classification is about 0.92% higher than CNN, and higher than SVM about 1.73%; on the Tan Songbo hotel review dataset, the F1 value of BiGRU as the classifier for short texts classification is about 1.57% higher than CNN, and higher than SVM about 2.79%; on the THUCNews news headline dataset, the F1 value of BiGRU as the classifier for short texts classification is about 1.61% higher than CNN, and higher than SVM about 5.19%; on the AGNews, the F1 value of BiGRU as the classifier for short texts classification is about 0.45% higher than CNN, and higher than SVM about 2.8%.
It can be seen from the experimental results that BiGRU is better than other classifiers (SVM, DT, KNN, LR, CNN, LSTM) in short texts classification. This is because that SVM and DT are very sensitive to missing features, so they are not suitable for sparse features; Both KNN and LR are difficult to deal with the problem of sample imbalance; Compared with CNN, BiGRU can extract the feature information of the context at the same time; Compared with LSTM, BiGRU reduces the number of parameters and effectively prevents over fitting. Therefore, BiGRU has got the best short texts classification effect among all comparison classifiers.
In order to verify the advantages of the proposed model compared with other topic models, we compared the SW-VBGMM with topic models such as LDA [5], W-LDA [19], NVDM [14], ETM [16]. The hyperparameter settings of the LDA topic model are consistent with the work of Blei [5], and the number of Gibbs sampling iterations is 2000; the parameter settings of the neural network topic model (W-LDA, NVDM, ETM) are consistent with the model proposed by this paper, the output of the encoder network is used as the feature of short texts classification, the topic vector dimension of ETM is set to 500, and the Dirichlet parameter of W-LDA is set to 0.1. The input of these comparative topic models is BOW, and the classifier is BiGRU. At the same time, we directly used the BOW processed by TF-IDF as the input of CNN [8] and BiGRU [23] for comparative experiments. The experimental results of the Takeout review dataset and the Tan Songbo hotel review dataset are shown in Table 5, the experimental results of the THUCNews news headline dataset and the AGNews dataset are shown in Table 6.
Comparison of different models on Takeout review and Tan Songbo hotel review
Comparison of different models on Takeout review and Tan Songbo hotel review
Comparison of different models on THUCNews news headline and AGNews
It can be seen from the experimental results in Tables 5 6, that the model proposed in this paper has obvious advantages over the traditional LDA topic model in the short texts classification effect. At the same time, it is better than the neural network topic models (W-LDA, NVDM, ETM) and neural network (CNN, BiGRU) compared in this paper. BiGRU as the classifier for all topic models, the F1 value of the SW-VBGMM when used for short texts classification is about 3.69% higher than W-LDA in the Takeout review dataset, higher than W-LDA about 4.21% in the Tan Songbo hotel review dataset, higher than W-LDA about 6.81% in the THUCNews news headline dataset, and higher than W-LDA about 5.29% in the AGNews dataset. The proposed model in this paper achieves the best results compared with other comparison models on the three Chinese datasets and the AGNews dataset, which proves the effectiveness of the combination of SW-VBGMM and BiGRU for short texts classification.
Compared with other topic models (LDA, W-LDA, NVDM, ETM), SW-VBGMM is more suitable for short texts feature extraction. This is because that LDA and W-LDA use the Dirichlet distribution as the prior distribution of the model’s potential topic features. However, the Dirichlet prior distribution can not generate topic features with strong relevance. Although NVDM and ETM use Gaussian distribution and logistic-normal distribution respectively as the prior distribution of the model’s potential topic features, SW-VBGMM uses a more complex Variational Bayesian Gaussian mixture prior distribution, which can continuously fit potential topic features in the process of model training through multiple Gaussian distributions to generate more consistent topic features. At the same time, the input of SW-VBGMM is BOW processed by TF-IDF and sparsemax activation function is introduced, which makes the SW-VBGMM more suitable for extracting sparse features of short texts. Compared with CNN and BiGRU, the combination of SW-VBGMM and BiGRU can not only use SW-VBGMM to extract sparse topic features with better relevance, but also use BiGRU to further extract the generated topic features globally, thereby achieving a better short texts classification effect.
SW-VBGMM is improved on the basis of W-LDA. In order to verify the effectiveness of the various improved methods proposed in this paper for W-LDA, we conducted ablation experiments on four datasets. The experimental results of the Takeout review dataset and the Tan Songbo hotel review dataset are shown in Table 7, the experimental results of the THUCNews news headline dataset and the AGNews dataset are shown in Table 8.
Comparison of different improved methods for W-LDA on Takeout review and Tan Songbo hotel review
Comparison of different improved methods for W-LDA on Takeout review and Tan Songbo hotel review
Comparison of different improved methods for W-LDA on THUCNews news headline and AGNews
It can be seen from Tables 7 8 that the three methods proposed in this paper to improve W-LDA are effective whether used alone or in combination with each other. In particular, using VBGMM as the prior distribution of potential topics in W-LDA plays the most significant role in improving the quality and relevance of topic features generated by the model. On the basis of keeping BiGRU as the topic features classifier, the results of the ablation experiment are analyzed as follows: using only VBGMM as the prior distribution of potential topics in W-LDA, the F1 value of the classification is higher than W-LDA about 2.38% in the Takeout review dataset, higher than W-LDA about 2.51% in the Tan Songbo review dataset, higher than W-LDA about 4.48% in the THUCNews news headline dataset, and higher than W-LDA about 3.04% in the AGNews dataset. It can be seen from the experimental results that when VBGMM replaces the Dirichlet distribution as the prior distribution of potential topics in W-LDA, the effect of short texts classification is significantly improved. This is because that the weak relevance between the components of the random vector in the Dirichlet distribution makes the relevance between the topic features generated by the model not strong. However, VBGMM continuously fits the potential topic features through multiple Gaussian distributions in the process of model training. In this way, the relevance of the topic features finally generated by the model is improved, and better classification results are obtained by using the topic features with higher relevance.
On the basis of VBGMM as the prior distribution of potential topics in W-LDA, using the sparsemax activation function instead of the softmax activation function on the output layer of the encoder network, the F1 value of the classification is higher than W-LDA about 3.11% in the Takeout review dataset, higher than W-LDA about 3.18% in the Tan Songbo review dataset, higher than W-LDA about 5.49% in the THUCNews news headline dataset, and higher than W-LDA about 4.17% in the AGNews dataset. It can be seen from the experimental results that the sparsemax activation function is more suitable for short texts features than the softmax activation function. This is because that the features of short texts are sparse, but the feature distribution generated by the softmax activation function is dense. Therefore, when softmax activation function is applied to short texts, many features in the generated dense feature distribution are ambiguous. The sparse feature distribution generated by the sparsemax activation function is more in line with the characteristics of short texts, and thus a better short texts classification effect is obtained.
On the basis of the previous two improved methods, using TF-IDF to preprocess the BOW input by the model, the F1 value of the classification is higher than W-LDA about 3.69% in the Takeout review dataset, higher than W-LDA about 4.21% in the Tan Songbo review dataset, higher than W-LDA about 6.81% in the THUCNews news headline dataset, and higher than W-LDA about 5.29% in the AGNews dataset. It can be seen from the experimental results that the classification effect is improved after preprocessing the BOW input by the model with TF-IDF. This is because that TF-IDF modifies the weight of the features in the BOW and improves the weight of the key features in the BOW, so that the model can generate more accurate topic features.
This paper proposes a neural network topic model SW-VBGMM, which can effectively extract the topic features of short texts. SW-VBGMM uses the BOW preprocessed by TF-IDF as the input of the model, and uses VBGMM as the prior distribution of potential topics in the model, so the quality and relevance of the topic features generated by the model are better. At the same time, SW-VBGMM adds the sparsemax activation function to the output layer of the encoder network to generate a document-topic feature distribution, which is more suitable for the sparse short texts features. Then the document-topic feature distribution is input to BiGRU for deep feature extraction. Finally the softmax layer is used to achieve effective short texts classification. Experiments show that the short texts classification effect of the proposed model is better than the topic models (LDA, ETM, NVDM, W-LDA) and neural network models (CNN, BiGRU) compared in this paper.
In the future, we consider inputting word embedding to SW-VBGMM instead of BOW to obtain a more consistent topic features. At the same time, we consider adding the sparsity constraint of topic-word in the SW-VBGMM training process to improve its topic extraction ability.
Footnotes
Acknowledgments
This work was supported by the Postdoctoral Science Foundation of China (2016M592894XB), the National Natural Science Foundation of China (61866020) and (11773012), the General Program of Yunnan Provincial Department of Science and Technology (2019FB082), and the General Program of basic research in Yunnan Province (202001AT070047).