
Abstract
The volume of short text data increases rapidly these years. Data examples include tweets and online Q&A pairs. It is essential to organize and summarize these data automatically. Topic model is one of the effective approaches, whose application domains include text mining, personalized recommendation and so on. Conventional models like pLSA and LDA are designed for long text data. However, these models may suffer from the sparsity problem brought by lacking words in short text scenarios. Recent studies such as BTM show that using word co-occurrent pairs is effective to relieve the sparsity problem. However, both BTM and extended models ignore the quantifiable relationship between words. From our perspectives, two more related words should occur in the same topic. Based on this idea, we introduce a model named RIBS, which makes use of RNN to learn relationship. By using the learned relationship, we introduce a model named RIBS-Bigrams, which can display topics with bigrams. Through experiments on two open-source and real-world datasets, RIBS achieves better coherence in topic discovery, and RIBS-Bigrams achieves better readability in topic display. In the document characterization task, the document representation of RIBS can lead better purity and entropy in clustering, higher accuracy in classification.
Introduction
With the development of the Internet, expressing opinions through the social network or asking and answering questions online have become more and more popular. These daily behaviors may produce huge volume of short text data. That is why short text, also named micro text [7], has attracted much attention from researchers. These massive data emerging everyday are of great value, but we can hardly analyse them directly. Therefore, we need a tool like topic model to help us organize and summarize text data automatically. Topic model can represent each document with a distribution over topics and describe each topic with a distribution over words. It is widely applied to many interesting domains such as text mining [15, 18], question retrieval [6, 12] and personalized recommendation [4, 13].
Researches on topic model have been carried out for years. Conventional topic models include probabilistic Latent Semantic Analysis (pLSA) [10] and Latent Dirichlet Allocation (LDA) [3], which are widely used for discovering hidden topics from text corpus. Most following works focus on relaxing model assumptions [26], applying to different types of collections [23] and so on. These models are designed for long text documents, which consist of many words, and have shown great effectiveness in long text scenarios. However, nowadays we have to deal with short text data more often. Different from long text data, the sparsity of short text content brings challenges to conventional topic models, because the document-word matrix is quite sparse so that we have few words to learn and analyse from original corpus.
There exist various strategies to address the sparsity problem, which have been introduced in recent years. One intuitive strategy is to extend the original short text corpus into longer ones by aggregating similar texts [14, 28] based on certain rules. The shortcoming of this strategy is obvious because these methods over rely on auxiliary data, which may be unavailable or hard to get in some cases. For example, if we get a dataset without author information or we can find little suitable knowledge from the Internet, the effectiveness of this kind of methods will be greatly weakened. The second strategy is to add restrictions to model assumptions. For example, there is only one topic in each document, known as Dirichlet Multinomial Mixture (DMM) [31]. This kind of solution alleviates the sparsity problem to some extent but the restriction is too strong, because the topic number of each document depends on the given corpus. Another creative strategy alleviates the problem by constructing word pairs or word groups to represent the original texts. One of those representative work is Biterm Topic Model (BTM), which uses word co-occurrence relationship from original corpus to learn topics [30]. For Word Network Topic Model (WNTM), it constructs pseudo documents with word groups learned from the word network [33] to alleviate the sparsity problem. These models indeed have a superior performance to conventional methods. However, it is worth noting that they both ignore the quantifiable relationship between words. For instance, if there is a document, which consists of words {iPhone, iPad, house}, BTM would model biterms (iPhone, iPad) and (iPhone, house) equally for learning topics. But according to our knowledge, iPad may have a higher probability to appear in the same topic with iPhone than with house. This means we can not ignore the prior knowledge of relationship between words. Detailed examples from the Online Questions Dataset, which will be introduced later, are as Table 1 shows.
Examples of biterms extracted from the Online Questions Dataset
Examples of biterms extracted from the Online Questions Dataset
We can find that even two biterms are with similar co-occurrence, the relationship between words is quite different. So it is essential to take this into account. There are various evaluation metrics for relationship between words. For example, Chen and associates [5] use Pointwise Mutual Information (PMI) to describe this relationship. Unfortunately, PMI is simply based on statistics. For example, if (A, B) co-occurs as many times as (A, C) does, PMI will fail to distinguish the different influence caused by the distance between word A and B, and between word A and C. So we prefer to learn this relationship by training Recurrent Neural Network (RNN) for its successful application in language model. At the same time, to filter high-frequency words, we apply classic Inverse Document Frequency (IDF) [24] on each word. We call this model as RNN-IDF based Biterm Short-text Topic Model (RIBS). What’s more, we also introduce an extended model named RIBS-Bigrams, which can improve the readability of topics with bigrams. The main contributions include:
We propose an effective RNN-IDF based Biterm Short-text Topic Model to take into consideration the quantifiable relationship between words. In RIBS, the relationship is determined by training RNN on the whole corpus and using IDF of words. In this way, we can have a better description on biterms. We introduce a simple, fast and effective method RIBS-Bigrams to extend RIBS for displaying topics with bigrams. In RIBS-Bigrams, the generation of each bigram is determined by considering the topical information and the closeness of two words at the same time. In this way, we can have a better readability on topics. On two open-source and real-world short text datasets, we evaluate the proposed models by conducting topic quality, topic display and document characterization experiments. Experimental results demonstrate the effectiveness of proposed models.
This paper will be organized as follows. Section 2 will show related researches. Sections 3 and 4 will present our topic models RIBS and RIBS-Bigrams. Section 5 will contain the experiments and finally Section 6 will have a conclusion.
Topic model has developed for years. Especially, there have been many researches on topic model in long text scenarios [3, 10, 20]. In this section, we focus on recent work in short text scenarios and give a brief summarization.
With the explosive growth of short text data and high value of applications like text categorization [27] and news clustering [29], topic model in short text scenarios has become a promising research field. More and more researchers have shown interests in it. The main challenge brought by short text lies in the lack of words, which may cause the document-word matrix seriously sparse. This kind of phenomenon is harmful for topic discovery because we can hardly describe topics with only few words. Most models are proposed based on the following strategies. One strategy in early years was document aggregation. For example, Hong and associates aggregated tweets, which shared the same key words before using LDA [11], Weng and associates [28] aggregated texts, which were posted by the same author, Jin and associates extended short texts with auxiliary related texts [14]. These models need extra text data, which may be limited or hard to get. Some other researchers developed their models with additional strong assumptions. For example, Zhao and associates assumed that each document would only contain one topic [32], similar to this idea, Lin and associates assumed that each document would contain the most related subset of topics and each topic could be composed by limited words [18]. These restrictions are too strong and the rationality of assumptions over depends on the content of given corpus, which make these models limited. Another novel idea in recent years is constructing word groups or word pairs. Using word groups to construct pseudo document is feasible because semantic related word groups can stand for the same topic, work like WNTM [33] is based on this idea. Using word pairs is also popular, Yan and associates proposed a novel topic model named BTM [30] which could learn topics by modeling the generation of word co-occurrence patterns directly. Following work like d-BTM [29] extended BTM by deleting some redundant biterms, as shown in Fig. 1.
For doc1 {Google Map for IOS}, we can see BTM extracts every co-occurrent word pair from the same document to form a biterm, while d-BTM tries to exclude some unimportant biterms. It labels each word as a topic term (T), general term (G) and document specific term (D) respectively, biterms which don’t contain topic terms will be deleted. For example, Map is a document specific term and for is a general term, so biterm Map-for will be deleted.
From the illustration of Fig. 1, we find both BTM and extended models can relieve the sparsity problem without using auxiliary texts. It is more suitable and universal in short text scenarios, so we do research on this basis. However, BTM ignores the different relationship between words, and d-BTM tries to filter some useless biterms simply by deleting them, which may result in the loss of information. From our perspectives, it is more rational to bring in prior knowledge to describe the relationship between words. In our early work [19], we utilized RNN, instead of using word2vec [16, 21], to learn this kind of prior knowledge so as to solve these two deficiencies at the same time. We think training word2vec requires to make use of auxiliary texts and has the probability to bring in noise. However, RNN only uses original corpus for training and has been successfully applied to many text processing tasks [1, 25]. So, we introduce a RIBS topic model to enhance topic discovery in short text scenarios. Furthermore, benefiting from the prior knowledge learned in RIBS, we extend the RIBS topic model by introducing a method to display topics with bigrams, leading to the RIBS-Bigrams topic model.
RIBS topic model
In this section, we will give the problem setting of short text topic model at first. Then we will give detailed descriptions of how RIBS works. Table 2 lists some annotations, which we will use.
Annotations
Annotations
A simple illustration for biterm extraction of BTM and d-BTM.
Topic model uses observed words to discover latent topics, which is really helpful in text mining. The problem setting is as Definition 1 shows.
Model description
RIBS utilizes prior knowledge to measure the quantifiable relationship between words. If two words are more related, they are more likely to belong to the same topic. Different from BTM’s generative process, we assume that two words in a biterm are drawn from a topic probabilistically based on their relationship, whereas a topic is still sampled from a topic mixture over the whole corpus. The generative process is shown in Fig. 2 and described as follows:
For each word Draw For each topic
draw draw For each biterm
draw draw draw
where
Graphical representation of RIBS.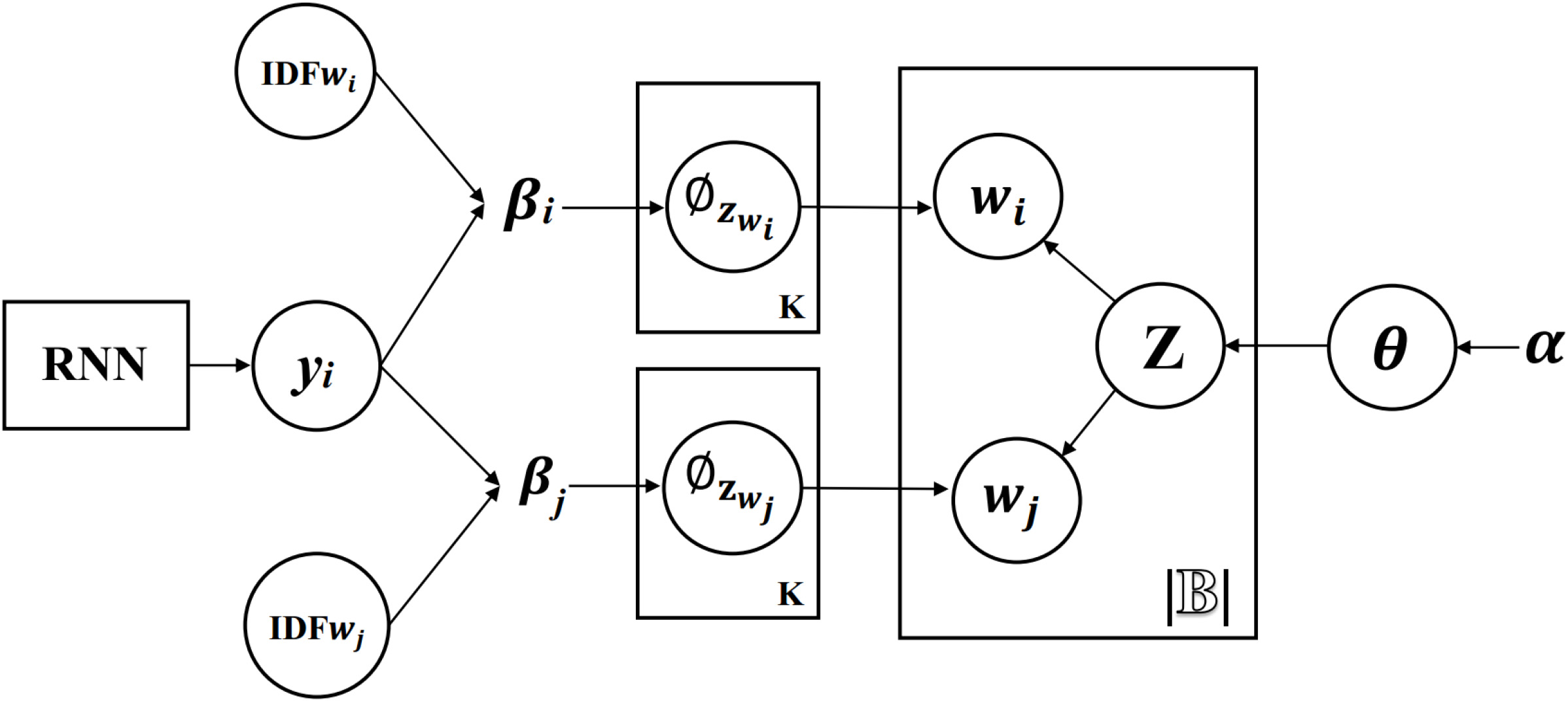
Most short text topic models like BTM and d-BTM ignore the quantifiable relationship between words. However, this kind of relationship is very important because if two words are more related, they may have a higher probability to occur in the same topic. We think the prior knowledge should satisfy the following properties:
If two words are more likely to appear in the same generative sentence, they are more related. Instead, if two words are far away from each other in the same sentence, the relationship between them shall be weakened. The order of two words should be taken into account for learning relationship, which means, for example, we encourage to generate bigram white house instead of house white. If a word appears in many documents, it may contain less topical information, whose probability of representing topics should be weaken.
We bring in two kinds of prior knowledge and combine them together to satisfy these properties and give detailed description respectively.
Artificial neural networks have been found quite effective in learning relationship between words for sentence generation [2, 25]. We find that RNN is a good choice, which satisfies the first and second property for the following reasons:
The conditional probability learned by RNN can quantify word The learning process of RNN can guarantee that the earlier a word is observed, the less influence it will have on current learning word. Words trained by RNN appear in sequence, so the learned quantifiable relationship can help generate readable phrases and bigrams for further research.
Encouraged by recent work [2], which utilized RNN for short text representation, we use a simple recurrent neural network called Elman [8] to learn relationship between words. We can also choose LSTM [9], which is known for preserving information observed long ago. However, the long-time memory ability of LSTM might build unexpected strong relationship between two far apart words and bring in some noise. Detailed analysis will be discussed in the experiment section. In this section, we will show the learning process of relationship between words with Elman network. The Elman network is as Fig. 3 shows.
A simple Elman recurrent neural network.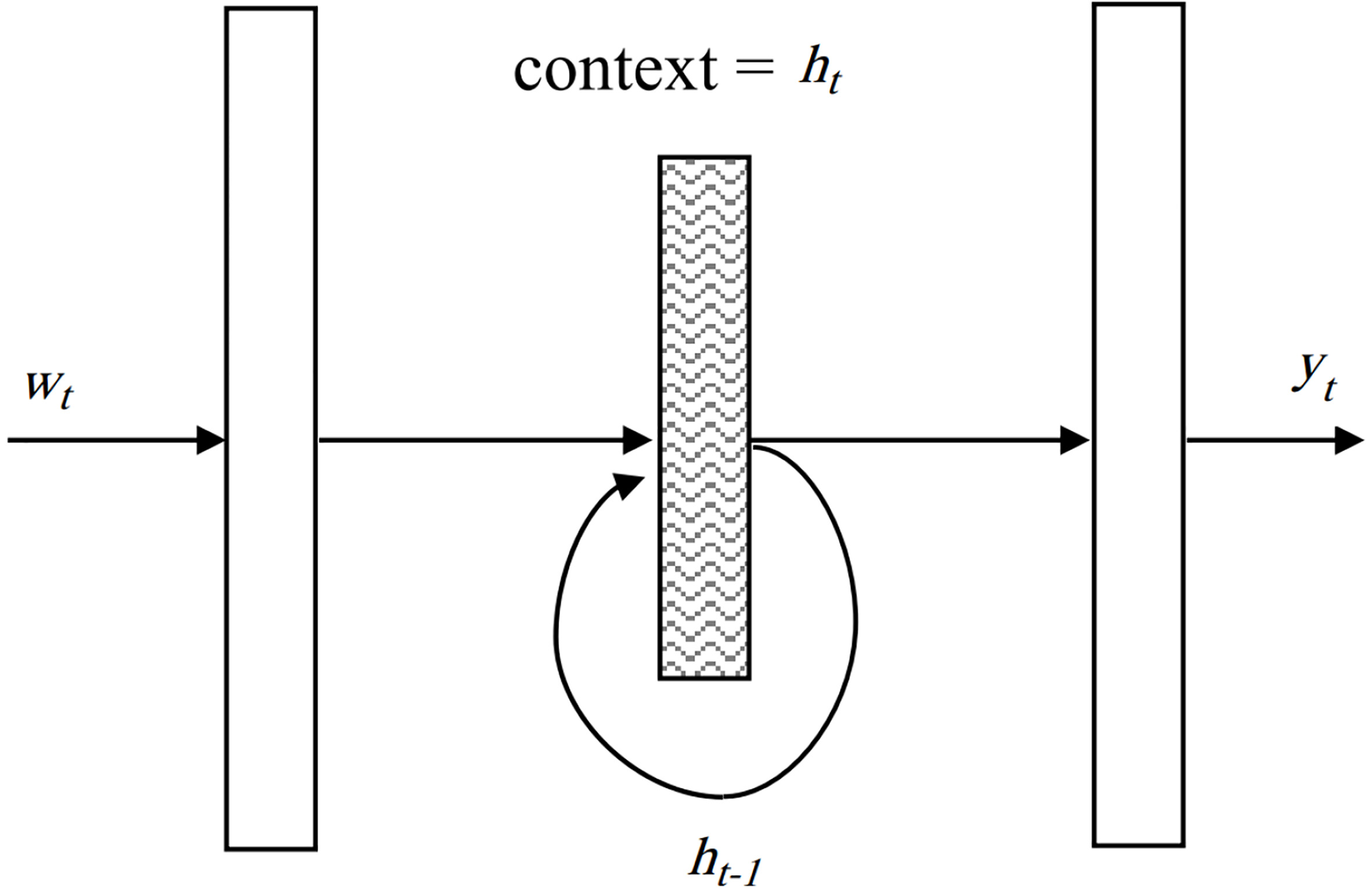
In Fig. 3,
Since the hidden layers
The input layer
where
Once we have learned the conditional probability, we can give the definition of the relationship between
What’s more, to satisfy the third property, work like d-BTM just deletes some topic-irrelevant biterms. Since we are already short of words, deleting biterms may cause further information loss. So we decide to utilize Inverse Document Frequency (IDF) for measuring each word as follows:
where
Now we can give the final definition of prior knowledge
where
After learning prior knowledge, we can introduce biterm construction. RIBS constructs biterms by using any two distinct words in a single document, which means we can generate
When scanning the whole corpus, biterm-construction process is executed at the same time.
We employ Gibbs sampling for learning parameters like BTM by taking prior knowledge into consideration. According to the chain rule on the joint probability of the corpus, we acquire the following conditional probability equation:
where
for word
The Gibbs sampling procedure is as Algorithm 1 shows.
[h] Gibbs sampling algorithm for RIBStopic number
According to the definition of Eqs (9) and (10), we can denote
Because RIBS models topics on biterms, we have to infer the topic distributions over documents by utilizing knowledge learned by Gibbs sampling. Deriving topic
We assume the topic of
We can calculate
where
As to calculate
where
Outputs of RIBS are a
When we are reading texts, bigrams are usually much easier to understand and contain more information than single word. Most topic models, no matter they are designed for long text or for short text, such as LDA [3], pLSA [10], d-BTM [29], BTM [30], and WNTM [33]. When coming to topic display, they all use a set of single words to describe a learned topic. This will make difficulty for reading, which is one of the deficiencies of most topic models. For example, if we read two words captain and America separately, they are with quite low semantic similarity. In fact, we find they would often occur in the same words set for describing topic about movie. However, when we treat these two words as bigrams captain America, then they become the name of a popular movie, and have more specific topical information. So, we believe it is necessary to describe topics with bigrams for the following reasons:
Using bigrams to display topics can improve readability and reduce ambiguity, which can reduce the reading and summarizing time by human. When the number of words or bigrams for displaying topics is fixed, using bigrams can contain more information.
We believe every bigram to be generated for topic description should satisfy the following two properties, given words
To satisfy the first property, we can use a simple strategy: For every topic
Benefiting from the training procedure of RNN, we input words into the network in order. So we can satisfy the second property by directly utilizing the quantifiable relationship between words.
[h] Bigrams generation algorithm for topic displaytopic number
We propose a simple and effective bigrams generation algorithm for topic display, details are as Algorithm 2 shows. This work is an extension of RIBS, which aims to improve the readability of topics. Benefiting from the learning procedure of RNN in RIBS topic model, we do not need to spend additional time and learn additional knowledge for generating bigrams. We can utilize the prior knowledge learned in RIBS to improve the quality of topic discovery and topic readability in short text scenarios at the same time. We name this model as RIBS-Bigrams.
The bigrams generation algorithm is extendable and flexible because the most important knowledge we utlize in the algorithm is the relationship between words. This can be discovered and replaced by other NLP algorithms and techniques.
In this section, we conduct experiments to show RIBS outperforms the state-of-the-art topic models in short text scenarios. We evaluate the performance in terms of topic quality and document characterization respectively. We also conduct topic display experiments to compare RIBS-Bigrams with other unigram models. The experimental results show that our proposed model RIBS is more effective and RIBS-Bigrams can describe topics much better than other models.
Datasets
We use two open-source and real-world short text datasets for experiments:
Online Questions:2
Online News:3
The preprocessing for both datasets is according to the following three steps: Firstly, we lowercase all the capital letters to reduce the vocabulary size without any information loss. Secondly, we delete all the stop words based on the common stop words list for English. Finally, we delete documents containing less than 3 words.
We compare RIBS with four topic models:
LDA is a famous topic model which performs really well in regular text scenario. We use a standard open source LDA4
BTM is a popular topic model for short text. We do experiments with the standard code provided by BTM authors.5
d-BTM is extended from BTM by deleting some topic-irrelevant biterms. We implement this model based on BTM source code.
RIBS-LSTM uses LSTM cells to learn prior knowledge for RIBS topic model. We compare this model with other models to show that LSTM is not suitable for topic discovery in short text scenarios.
Parameter settings are as follows.
For training RNN: we implement the network training with tensorflow (version 1.2):6
For training topic models: we set
For learning prior knowledge of RIBS: we set
For RIBS-Bigrams: we set the threshold
Topic discovery performance with the change of parameter 
Better topic discovery ability of RIBS
Topic model is designed for topic discovery, so topic quality is a significant judgement of model performance. This experiment aims to show RIBS has a better performance in topic discovery than baselines. We choose coherence [22] as the evaluation metric. The main idea of coherence is that a good topic should consist of words in cohesive semantic similarity. It is calculated as follows:
where
In Tables 4 and 4, all four short text topic models outperform LDA on both datasets, which means LDA is really unsuitable for short texts because the document-word matrix is too sparse. Results of BTM and d-BTM show that biterm construction is good for short text topic discovery. But d-BTM achieves worse coherence than BTM does, we think this is caused by deleting biterms in d-BTM. It will lead to information loss when the text is quite short. For RIBS-LSTM, we find its performance is similar with BTM and has improvement in few cases. This indicates the quantifiable relationship learned by LSTM is not as suitable as which learned by Elman. No matter what value
This experiment aims to show the improvement of topic’s readability by displaying topics discovered by different topic models. Most topic models describe topics with a set of single words. This is one of
| K |
K |
K |
|||||||
|---|---|---|---|---|---|---|---|---|---|
| M |
M |
M |
M |
M |
M |
M |
M |
M |
|
| LDA | 217.1 6.5 | 1174.1 21.1 | 5702.9 32.4 | 94.3 3.2 | 514.6 13.7 | 2625.0 24.3 | 60.2 2.2 | 314.7 6.5 | 1627.5 27.2 |
| BTM | 20.3 2.2 | 104.2 8.1 | 535.9 13.5 | 22.2 0.9 | 113.8 2.5 | 581.4 17.9 | 21.8 1.2 | 117.5 2.4 | 607.2 8.4 |
| d-BTM | 22.3 2.8 | 107.4 5.4 | 540.8 16.6 | 23.2 1.2 | 115.8 2.4 | 589.7 10.7 | 23.0 1.1 | 118.7 1.3 | 616.1 7.3 |
| RIBS-LSTM | 23.4 2.4 | 111.4 6.5 | 546.3 7.7 | 20.5 0.5 | 114.1 2.6 | 593.1 13.8 | 21.0 0.6 | 119.1 2.5 | 612.3 5.8 |
| RIBS |
|
|
|
|
|
|
|
|
|
| K 20 | K 25 | K 30 | |||||||
| M 5 | M 10 | M 20 | M 5 | M 10 | M 20 | M 5 | M 10 | M 20 | |
| LDA | 41.6 1.3 | 223.8 5.9 | 1153.8 12.0 | 31.4 1.3 | 172.6 1.6 | 897.9 11.0 | 25.4 0.9 | 139.2 2.6 | 727.3 10.8 |
| BTM | 21.4 0.9 | 117.6 2.0 | 623.2 9.0 | 20.5 0.8 | 118.0 1.6 | 629.6 11.0 | 21.4 0.8 | 121.1 1.4 | 640.6 5.7 |
| d-BTM | 22.9 0.6 | 119.4 1.5 | 623.9 6.6 | 21.8 0.4 | 121.0 1.4 | 634.2 6.6 | 22.2 0.4 | 122.3 2.1 | 644.7 6.6 |
| RIBS-LSTM | 20.1 1.0 | 117.6 1.7 | 615.5 4.3 | 20.4 0.8 | 117.3 2.9 | 621.1 7.3 | 20.7 0.7 | 119.6 1.3 | 636.2 5.0 |
| RIBS |
|
|
|
|
|
|
|
|
|
Topic coherence on Online News Dataset (the best results are in boldface)
the deficiency of topic models. In RIBS, the relationship between words learned by RNN can not only describe biterms better but also help generate bigrams for displaying topics. So, we introduce a bigrams short text topic model named RIBS-Bigrams extended from RIBS. The comparison between BTM and RIBS-Bigrams for both datasets are exhibited in Tables 5 and 6.
Topic display on Online Questions Dataset
Topic display on Online News Dataset
Take Topic about TV and Movies in Table 6 for example. Word box and word office almost have little correlation with tv and movies. However, when they appear together, box office indicates “a place at a theater or other arts establishment where tickets are bought or reserved”, which is a common phrase in the movie industry. What’s more, using bigrams can have a more specific meaning for describing topics. Take the Topic about Entertainment in Table 6 for example: there are many first names or second names discovered by BTM, such as justin. But there exist many men who are named ‘justin’. We can hardly figure out which field this ‘justin’ might belong to. RIBS-Bigrams can solve this deficiency by generating bigrams justin bieber. With this phrase, we can figure out this is a name of a popular singer, not a manager or other else. And this name may have higher probability to describe topic about entertainment. There is another advantage of using bigrams, which we can list more related topical information when given fixed number of words or bigrams. We can still look at Topic about Entertainment. Compared with BTM, RIBS-Bigrams has discovered five new topical bigrams (baby north, selena gomez, chris martin, seth rogen, photo), which are all closely related to this topic.
Document characterization is a common application of topic model, so we conduct clustering and classification experiments to show the advantage of RIBS from another perspective.
Clustering aims to gather unlabeled documents into several clusters, each of which contains semantic similarly documents. This is an effective method to measure topic quality. For fair comparison, we use the same clustering method as BTM does. We take each topic as a cluster, and assign each document
Purity calculates the ratio of dominant category in each cluster, where a larger value indicates a better performance. Formally:
Entropy is used for measuring chaos in a set of data so that a smaller entropy indicates a better performance. Formally:
We compute the purity and entropy with average results of ten-times experiments. We set
We have the following observations. Although d-BTM indeed improves BTM in clustering in most cases on the Online Question Dataset, when it comes to the Online News Dataset, the performance of d-BTM is even worse than BTM in some cases. We think deleting some biterms may reduce several topic-irrelevant ones, but will also lose some word-topic information at the same time. Experimental results in both four figures show the better performance of RIBS-LSTM and RIBS than other models on both datasets. The reason is that, different from d-BTM, RIBS utilizes probabilistic knowledge learned from IDF to elimiate high-frequency words which can remain word-topic information as much as possible. We think it is useful for achieving better topic representations. We also find that the performance of RIBS-LSTM in clustering task is not quite stable, which is better than LDA, BTM, d-BTM in most cases but may fail in few cases. This phenomenon shows the effectiveness of bringing in prior knowledge but using LSTM is not as good as using Elman.
Classification aims to annotate each document a label by learning from label-observable documents. We use topic distributions over documents
We have the following observations from Tables 8 and 8. Firstly, on both datasets, our RIBS-LSTM and RIBS models significantly outperform existing models in most cases. This observation shows that the improvement benefits from involving quantifiable relationship between biterms for short text topic modeling. Secondly, on the online news dataset, RIBS-LSTM and RIBS achieve the quite similar performance. This may lie in the average length of the online news dataset, which is longer than the online question dataset. So, the noise of remembering irrelevant words brought by LSTM might reduce and RIBS-LSTM can have similar performance with RIBS.
In summary, through the topic discovery experiments, the RIBS topic model can discover more coherent topics and RIBS-Bigrams can select more suitable bigrams with higherexperiment1-1 probability to represent topics. Through both the clustering and classification experiments, we can conclude RIBS has a better performance than other baselines in document characterization tasks.
Classification accuracy on Online Questions Dataset (the best results are in boldface)
Classification accuracy on Online News Dataset (the best results are in boldface)
Clustering performance on Online Question and Online News Datasets. Subfigures (a) and (b) are purity and entropy performance on Online Question Dataset respectively. Subfigures (c) and (d) are purity and entropy performance on Online News Dataset respectively.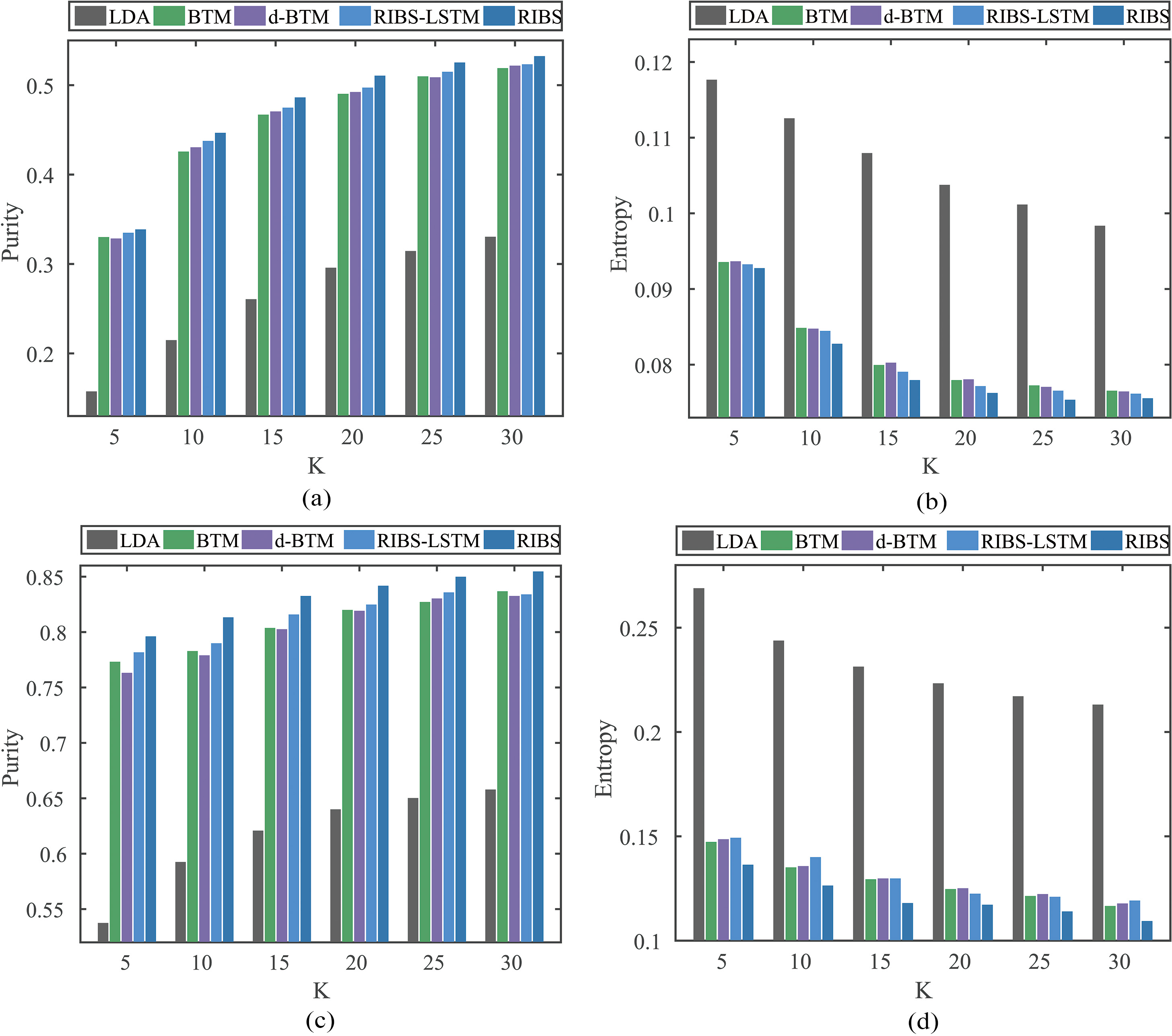
Topic model is widely accepted as an effective tool for organizing and summarizing digital data automatically. With the explosive growth of social network on the Internet, topic model for short text has become a promising research field. Analysing short text data will suffer from the sparsity problem. In this paper, we introduce a novel short text topic model named RIBS which brings prior knowledge learned from RNN and IDF for describing biterms. We also introduce a bigrams display topic model RIBS-Bigrams extended from RIBS. To the best of our knowledge, few topic models have taken solving sparsity problem and better displaying topics into consideration at the same time. Experimental results based on two open-source and real-world datasets show that this kind of prior knowledge is quite important and useful for short text topic discovery, also show the effectiveness of RIBS and RIBS-Bigrams. As for future work, since most short text data are emerging continuously, we would like to extend RIBS into an online model and apply it into practice.
Footnotes
Acknowledgments
This paper is supported by the National Key Research and Development Program of China (grant no. 2016YFB1001102) and the National Natural Science Foundation of China (grant no. 61375069, 61403156, 61502227), this research is supported by the Collaborative Innovation Center of Novel Software Technology and Industrialization, Nanjing University. We also would like to thank machine learning repository of UCI and Yahoo! Research for the datasets.