
Abstract
Classification of vehicle types using surveillance images is a challenging task in Intelligent Transportation Systems (ITS). In this paper, Convolutional Neural Networks for Vehicle types classification are comparatively studied. Firstly, GoogLeNet, ResNet50 and InceptionV4 are exploited as baselines for comparison. Secondly, we proposed a new network architecture based on GoogLeNet, ResNet50 and InceptionV4, named Fused Deep Convolutional Neural Networks (FDCNN), to take advantage of the ‘Inception’ module on parameter optimization and ‘Residual’ module on avoiding gradient vanishing, and applied the model to vehicle types classification. Thirdly, we created a vehicle dataset under the conditions of complicated and varied weather and lighting conditions, and conducted comparative experiments using the SEU vehicle dataset. Experimental results show much better performance of the proposed FDCNN with RMSprop optimizer on recognizing vehicle types. Specifically, the average classification accuracies of six vehicle types, such as truck, coach, sedan, minivan, pickup and SUV, are over 96.8%. Among the six classes of vehicle types, sedan is the most difficult to classify and the proposed FDCNN achieved over 93.81% accuracy in comparative experiments.
Keywords
Introduction
The type of vehicles such as car, bus, truck, etc. is of great significance to the determination of highway toll, the management of large parking lot and the monitoring and control of highway traffic. Vehicle type classification based on images from surveillance cameras is an important aspect of intelligent transportation, which can improve the efficiency of many related works, including toll collection system, vehicle related crime stopping, traffic monitoring, traffic control and management [5, 29]. Many researches have been carried out in recent years, and the advantages of image-based vehicle type classification comparing the traditional loop detector are generally recognized [25, 26].
In the field of image-based vehicle recognition, the traditional machine learning method is mainly based on the appearance features of vehicles. The commonly used vehicle frontal feature extraction methods, such as vehicle geometric features [6, 31], HOG [1, 28], fast Fourier transform [10], SURF [7], share the common disadvantages of low precision, complex calculation and low recognizability. Laopracha [18] proposed to use Gabor features of images, combined with SVM classifier and neural network classifier for classification, demonstrating better performance. Wen x et al. [27] exploited Haar-like features and AdaBoost classifier and proposed a fast-training scheme. Tungkastan [4] proposed an approach using the Hausdorff distance between the Harris corner point between the vehicle to be identified and the ground-truth samples of vehicle. The vehicle with the smallest distance is judged to be the same type. The disadvantage of minimum distance matching is that it is greatly affected by the random noise of samples, especially when the samples overlap in the feature space. Zhou [32] applied hidden Markov model (HMM) to classify vehicle types, training class-specific HMM models for each vehicle type. To sum up, the traditional machine learning methods for vehicle recognition extract features using some hand-designed algorithms followed by appropriate classification approach. The feature extraction, either geometric features or algebraic features, are heuristic in nature and suboptimal in characterizing different image invariances caused by illumination, scaling, translation and rotation.
Compared with traditional machine learning methods, deep learning technology has excellent performance in computer vision. As pointed out by Hinton [2], deep learning technology is more powerful in feature extraction and discrimination functions. Deep Convolution Neural Network (DCNN) is the most popular deep model which has been extensively applied. Some works have been reported of applying CNNs for vehicle type classification. Sasongko et al. [3, 23] used pre-trained ResNet models, including ResNet34, ResNet50 and ResNet 101, to classify toll station vehicle types, and have enhanced its accuracy over 95% using ResNet101. Lee et al. [24] has successfully applied AlexNet to vehicle plate recognition, also reaching a high accuracy. VGG-16 and AlexNet are both utilized by Seng et al. [8] for vehicle types classification in traffic videos. Xue et al. [14] have tested ZFNet performance and proposed a fused network designed especially for the low-resolution images. Several popular networks, such as ResNet, Inception-ResnetV2, InceptionV3 and NASNet were tested and compared by Ali et al. [15] for vehicle recognition while Inception-ResnetV2 has shown the best performance. Rong et al. [11] proposed an automatic sparse encoder to obtain a deep network for vehicle type classification, using the convolution kernel to generate features. Dong et al. [30] proposed a semi-supervised convolutional neural network based on the front image of vehicles, and introduced a sparse Laplacian filter to learn from unlabeled data. In 2017, Wang et al. [13] used transfer learning and established a convolutional neural network to classify vehicle images.
The transfer learning or semi-supervised learning by combining DNNs and filters do not achieve much higher accuracy on the classification of vehicle types, due to the similarity of vehicle front face and windshield. Some networks go deeper at architectures but with the cost of higher computation resources. Some researchers have studied feature fusion of different transfer learning networks and achieved better performance. Ali and Ragb [22] fused Densenet201, Resnet50, and their proposed model as three approaches. The output of each network gives a vote in the classification process. The experimental results show that the proposed approach has better performance than the networks used in the fusion process when they act individually. Banik et al. [20] proposed a fused convolutional neural network (CNN) model to classify the images of white blood cells and fuse the feature maps of two convolutional layers by using the operation of max-pooling to give input to the fully-connected neural network layer. The results show that the fused model trains faster than CNN-RNN model. The prior researches showed that fused models may have some superiorities, with improved performance or computing time.
In this paper, we aim to design a new scheme of Convolutional Neural Network to meet the high reliability requirements of vehicle types classification. A Fused Deep Convolutional Neural Network for Vehicle Types Classification (FDCNN-VTC) is proposed. To acquire the particular one-dimensional feature matrix from every single network, each deep neural network’s fully connected layer or global average pooling layer has been removed, which means only the feature extraction without classifier in the FDCNN-VTC. Then, a separate network is used to extract features of vehicle frontal image. The feature matrices are fused using parallel fusion strategies, and then retrained and reclassified by a global average-pooling layer. Eventually an N-dimensional vector is generated, where N is the number of classification results and the vector represents the possibility of each class.
The remainder of this paper is organized as follows. Section 2 briefly introduces the structure of proposed GoogLeNet, ResNet, InceptionV4 for vehicle type classification, and how they are adjusted to fit the input data and output categories. Section 3 introduces the whole structure of FDCNN-VTC, and expounds the process from input vehicle front images to single vehicle type classification models. Section 4 illustrates the experiment of proposed single vehicle type classification models, and compares the performance of each model, optimizers and classifiers. Meanwhile, the performance of proposed FDCNN-VTC and the top three single models are also compared to prove superiority of the fused model. Section 5 concludes the paper and attaches the acknowledgement.
Convolutional neural networks for vehicle types classification
GoogLeNet for vehicle types classification
The proposed structure of GoogLeNet-VTC
The proposed structure of GoogLeNet-VTC
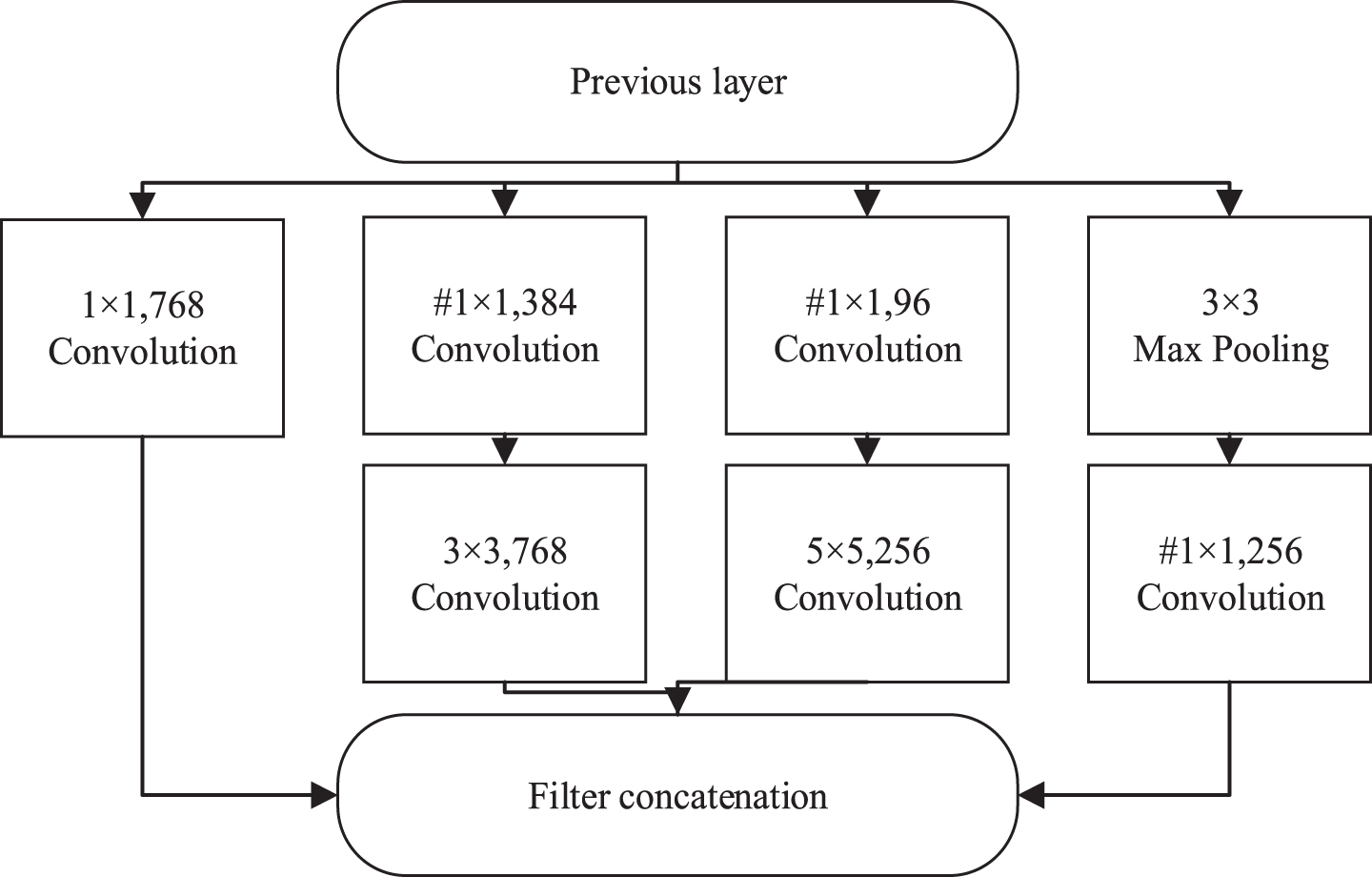
The adjusted module in Inception (5b*) in GoogLeNet-VTC
The proposed structure of ResNet50 for Vehicle Type Classification (ResNet50 -VTC), the core of which is residual learning, is shown in Table 2. In the conventional network, the objective function is the optimal solution mapping H (x) when solving parameters at each layer. For the residual network, it does not directly match the optimal solution mapping H (x), but matches the residual map as in Equation (5). The residual mapping process is shown in Fig. 2. The optimal solution of the original map can be changed to F (x) + x, and the gradient of Loss is shown as Equation (6).
The proposed structure of ResNet50-VTC
The proposed structure of ResNet50-VTC

The residual mapping processes
where x
l
represents the matrix in previous layer, and x
L
represents the results after the residual. When the residual module
For instance, as is shown in Fig. 3, the maximum parameter of this module, where the input has gone through 3 convolution kernels, is calculated as:

The Structure of Conv2_x
In the residual process, where the input has been convoluted once by conv (1×1, 256), the parameter
can be optimized and calculated as:
The ResNet50-VTC uses the main residual module to optimize parameters and operations, and removes the last fully connected layer with a global average-pooling layer. Finally, the ResNet50-VTC outputs a 1×1×2048 array, which represents the results of this no-top model.
The proposed structure of InceptionV4 for Vehicle Type Classification (InceptionV4 -VTC) combining the core of Inception and Residual module is shown in Table 3 where 1×1 blocks are used for parameter optimization and residual blocks are used to avoid gradient vanishing. The Inception-resnet modules of InceptionV4 -VTC contain 1×1, 3×3, 1×7 and 1×3 blocks, which are formed as in Fig. 4, one channel for combined #1×1 linear extraction, one for 1×1 extraction and one for 1×n extraction. The InceptionV4-VTC has changed the linear block dimension in the final module Inception-resnet-C to 2048, and then has an output array (1,1,2048) after an average pooling 8×8.
The proposed structure of InceptionV4-VTC
The proposed structure of InceptionV4-VTC

The structure of Inception-Resnet-A module
As the module ‘Inception’ shows great performance on parameter optimization, and the ‘Residual’ module of convolutional neural networks shows great improvement on avoiding gradient vanishing, an innovative Fused Deep Convolutional Neural Networks for Vehicle Types Classification (FDCNN-VTC), based on the GoogLeNet-VTC, ResNet50-VTC and InceptionV4-VTC, is proposed in this paper to improve the performance of single convolutional neural network. The proposed structure of the FDCNN-VTC, consisting of Resnet50-VTC, GoogLeNet-VTC and InceptionV4-VTC, is shown in Fig. 5. The single vehicle type classification models, such as GoogLeNet-VTC, ResNet50-VTC and InceptionV4-VTC, have regulated the final module structure in order to fit the output size (1,1,2048), and three 2048-dimensional arrays are generated in parallel as a (1,3,2048) array in the output layer. As to evaluate combination weights, a fully connected layer is then used with a dropout rate 0.5, which is set as the norm of single deep convolutional neural networks.

The Structure of Fused Deep Convolutional Neural Networks for Vehicle Types Classification (FDCNN-VTC)
For Resnet50-VTC in the structure of FDCNN-VTC, the input vehicle image is 224×224×3, which consists of 3 conv2_x units, 4 conv3_x units, 6 conv4_x units, and 3 conv5_x units. The first layer of Resnet50-VTC in the structure of FDCNN-VTC is a 7×7 convolution, and the last layer is a fully connected layer, where conv2_x unit, conv3_x unit, conv4_x unit and conv5_x unit all include 3 convolutional layers, the convolution operators are 1×1, 3×3 and 1×1, respectively. Finally, the output characteristics of 1×2048 dimensions are obtained. For InceptionV4-VTC, the input vehicle image size is 229×229×3 (Padding = SAME), using the structure of layer-convolution and layer-pooling in Stem module. After Stem module, 5 Inception-resnet-A units, 1 Reduction-A unit, 10 Inception-resnet-B units, a Reduction B unit, 5 Inception-resnet-C units and an average pooling layer are connected respectively, and finally an array of 2048-dimensional characteristics is obtained. For GoogLeNet -VTC, the input vehicle image size is 224×224×3. The first stage performs two convolutions of 7×7, stride = 2, max pooling of 3×3, stride = 2, then with a convolution of 3×3, stride = 1, max pooling of 3×3, stride = 2, which aims to improve the nonlinearity through the activation function. The deep separable convolution operation units are then contacted, where each operation unit contains a #1×1 convolution operation, a 3×3 convolution operation after 1×1 linear operation, a 5×5 convolution operation after 1×1 linear operation and a maximum pooling operation with ReLU activation function. Two softmax activation functions with a small weight (0.5) relating to the results are attached between modules Inception 3, 4 and 4, 5 as an auxiliary classifier. After the average-pooling layer, a 2048-dimensional output is obtained.
In the structure of FDCNN-VTC, the middle Inception, ResNet, and Inception-resnet modules consist of several deep separable convolution operation units, including a 3×n depth separable convolution operation with ReLU activation function, and continuous convolution operation units. The continuous convolution operation units contain n times 1×1 depth convolution operation with ReLU activation function, sub-convolution operation and maximum pooling, followed by m times 3×3 depth convolution operation with ReLU activation function, respectively. Each single pre-model obtains 2048-dimensional output characteristics (m, n is decided by back propagation). The three pre-models output the 3×2048-dimensional features, and then use a dropout layer with rate 0.5. Finally, a fully connected layer is connected to the output node with the softmax function, and the 6-dimensional vector is output. The classification of vehicle type corresponding to the largest component in the vector is the final result.
In this section, we evaluate the performance of Convolutional Neural Networks for vehicle types classification on SEU vehicle dataset, which is provided by Jiangsu Transportation Science Research Institute. The SEU vehicle dataset contains 9,665 raw (with blurred, sombre or multi-vehicle congested) vehicle images with sizes of 1600×1200 and 1920×1080 captured from cameras at different time and places in Jiangsu expressway. The images in SEU vehicle dataset contain changes in the illumination condition, the scale, the surface colour of vehicles, and the viewpoint, and the images contain frontal views of a single vehicle captured from variable distances. The vehicle front-face dataset contains six types of vehicles: Truck, Coach, Sedan, Mini-Van, Pickup, and SUV. Examples of SEU vehicle dataset are shown in Fig. 6.

Examples of SEU vehicle dataset. (a) Truck. (b) Coach. (c) Sedan. (d) Minivan. (e) Pickup. (f) SUV.
This section describes the measurement strategy for Region of Interests (ROI) of vehicle frontal image. Specifically, the license plate is firstly segmented by finding a rectangle using the Maximally Stable External Regions (MSER) method [16, 21]. Based on MSER method, the characters in an image which are under the length of 7 (the length of Chinese number plate) are recognized as the license plate area, and are covered with a gray bounding rectangle. The left and
right lower edges of the license plate area are edges of the vehicle frontal part area, and the upper edge height is located 2×h above the license plate (h is the height of the license plate), as shown in Fig. 7. In addition, the SEU dataset of vehicle frontal part includes images not only on different light conditions, such as strong light, normal light, and low light, but on different weathers such as sunny, foggy and cloudy days, which are shown in Fig. 8. This section describes the measurement strategy for Region of Interests (ROI) of vehicle frontal image. Specifically, the license plate is firstly segmented by finding a rectangle using the Maximally Stable External Regions (MSER) method [29, 30]. Based on MSER method, the characters in an image which are under the length of 7 (the length of Chinese number plate) are recognized as the license plate area, and are covered with a gray bounding rectangle. The left and right lower edges of the license plate area are edges of the vehicle frontal part area, and the upper edge height is located 2×h above the license plate (h is the height of the license plate), as shown in Fig. 7. In addition, the SEU dataset of vehicle frontal part includes images not only on different light conditions, such as strong light, normal light, and low light, but on different weathers such as sunny, foggy and cloudy days, which are shown in Fig. 8.

The ROI of vehicle frontal image. (a) The height of license plate. (b) The height of vehicle frontal part.

Vehicle frontal part image under different weather and illumination conditions. (a) Strong light. (b) Foggy. (c) Normal light. (d) Sunny. (e) Low light. (f) Cloudy.
The following experiments are conducted on conditions of Jupyter Notebook (Ipython), based on Python 3.6, Keras deep-learning packages (Tensorflow as backend). The CPU of experimental computer servers is Intel Core i7-10700 2.6 GHz. The GPU is NVIDIA GeForce Titan 1080 s with 8 G memory and the overall RAM is 32 GB. In the following experiments, 3500 images in SEU dataset which contain clear and single vehicle per image are finally adopted, 60% of which are used as training data, 20% as validation data, and the rest 20% as testing data. Among the 3500 images, 6 types of vehicles are included, which are Coach, Minivan, Pickup, Sedan, SUV and Truck, with number of samples 500, 500, 500, 1000, 500, 500, respectively.
In the following experiments, Convolutional Neural Networks are tested in a fixed batch size 64, determined by the best computing capacity of the sever GPU. While the batch size does not affect the ACC and ROC values as well as Adam and RMSprop optimizers, which are required in the next fusion experiment, batch size scales are not discussed in this section. The convergence curves of Convolutional Neural Networks for vehicle types classification with optimizer Adam are shown in Fig. 9, and the convergence curves of Convolutional Neural Networks for vehicle types classification with optimizer RMSprop are shown in Fig. 10. As are illustrated in Fig. 9(a) and Fig. 10(a), the vertical axis represents cost function values of each single network, while the horizontal axis represents the epochs. In Fig. 9(b) and Fig. 10(b), the vertical represents accuracy. After 20 times of epochs, the curve of cost function value continues to decrease as epoch grows, while the curve of accuracy continues to increase, suggesting that the single networks basically fit the dataset. At about epoch 12, the RMSprop optimizer has a more convergence performance than the Adam optimizer, achieving more efficiency and adaptability towards SEU vehicle dataset.
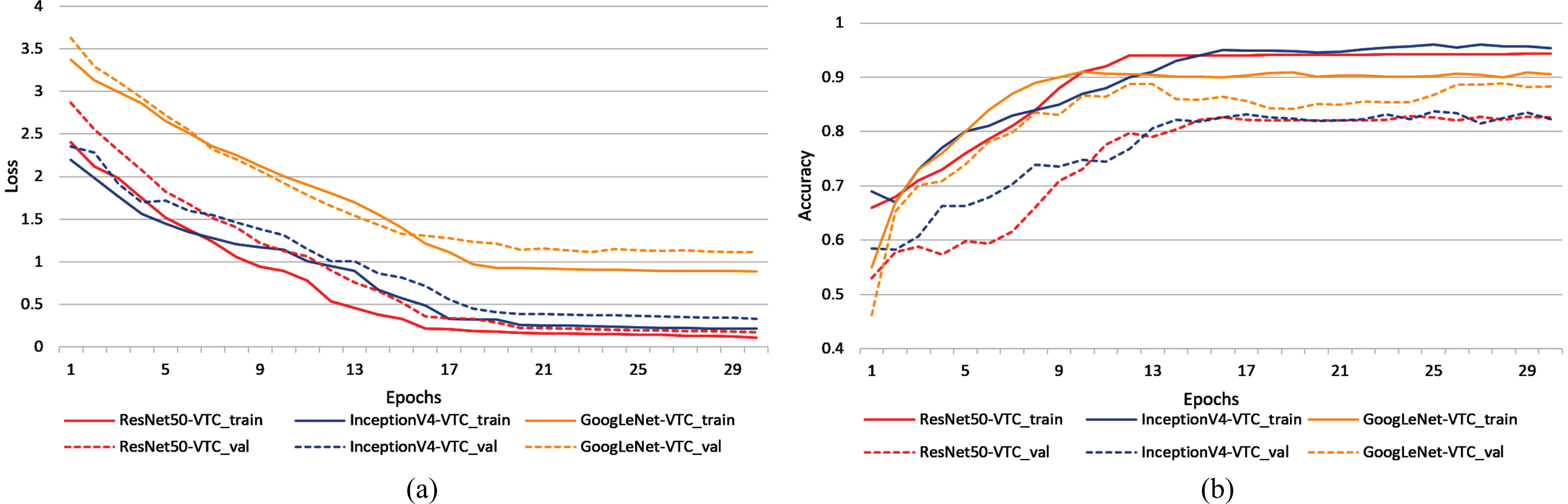
The training and validation convergence curve (optimizer = Adam). (a) The training and validation loss. (b) The training and validation accuracy
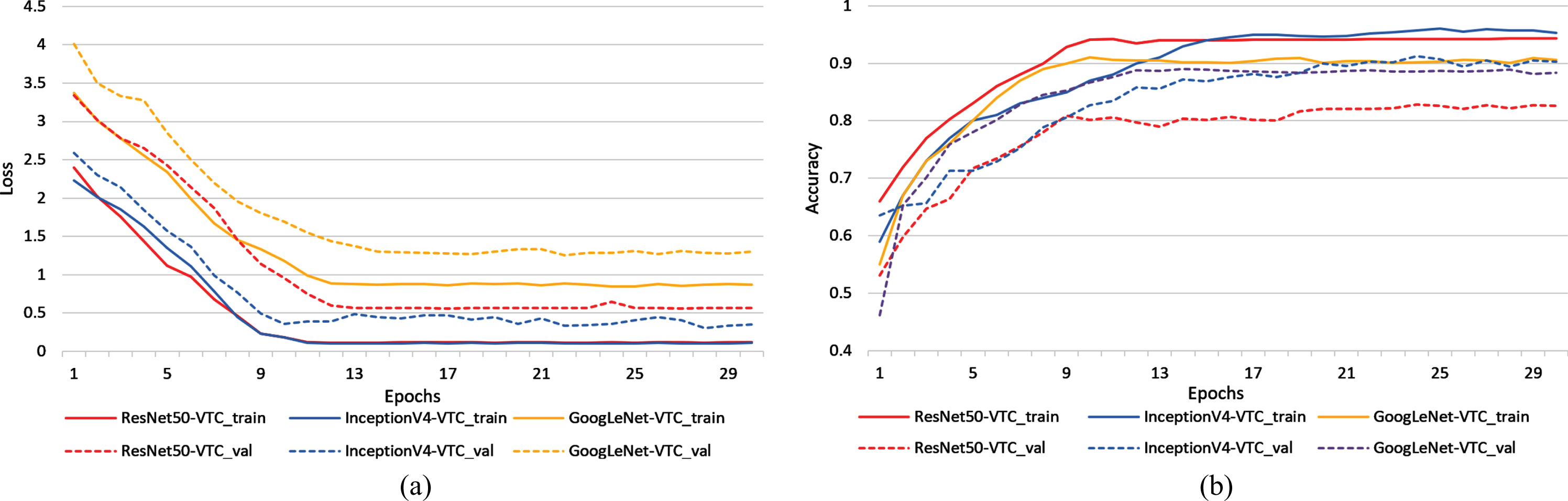
The training and validation convergence curve (optimizer = RMSprop). (a) The training and validation loss. (b) The training and validation accuracy
Table 4 shows the accuracy list of GoogLeNet for vehicle types classification (GoogLeNet-VTC), InceptionV4 (InceptionV4-VTC), and ResNet50 (ResNet50-VTC), compared with ZFNet (ZFNet-VTC), AlexNet (AlexNet-VTC), ResNet101 (ResNet101-VTC), VGG16 (VGG16-VTC) under the two optimizers. In terms of the average training and validation accuracy, the Adam optimizer exceeds in training accuracy at about 1% but lags in validation accuracy more than 5%, revealing a higher possibility of overfitting on the validation dataset. Compared to Adam optimizer, the results above show that RMSprop optimizer has a smaller
Accuracy of different single networks
variance between training and validation accuracies (about 5% compared to 11%), and a greater average accuracy on the top 3 single networks (1% on training and 6% on validation). RMSprop leads to a better performance and can be applied as the optimizer of fused deep neural network.
In order to test the stability and robustness of the above seven Convolutional Neural Networks, such as GoogLeNet-VTC, InceptionV4-VTC, ResNet50-VTC, ZFNet-VTC, AlexNet-VTC, ResNet101-VTC and VGG16-VTC, the 100 cross-validation test experiments are performed. Each experiment randomly extracts 1800 images from the test set, and calculates accuracies of the seven Convolutional Neural Networks. Bar plots of top classification accuracy and box plots of classification rates are shown in Fig. 11 (a). The graph illustrates that AlexNet-VTC, VGG-16-VTC and ZFNet-VTC share the lowest accuracy and variance. As epoch grows, ResNet101-VTC overfits due to the contradiction that training accuracy increases while validation and testing accuracy decrease. The Area Under Receiver Operating Characteristic (AUROC) values for abnormality detection in the vehicle frontal part testing dataset are shown in Fig. 11(b). The AUROC is designed to comprehensively evaluate the True Positive Rate (TPR) and False Positive Rate (FPR) values for abnormality detection. According to AUROC values, ResNet50-VTC, InceptionV4-VTC and GoogLeNet-VTC perform comprehensively better than ZFNet-VTC, AlexNet-VTC, ResNet101-VTC and VGG16-VTC on this testing dataset.

The accuracies of the seven Convolutional Neural Networks. (a) The box plot of networks accuracy. (b) The bar plot of AUROC values.
In this experiment, 3500 images in SEU vehicle dataset are adopted, 60% of which are used as training data, 20% as validation data, and the rest 20% as testing data. Categories are: Coach, Pickup, Minivan, Sedan, SUV and Truck. Due to the complex structure and layers of fused network, a large batch size could be very challenging in terms of the server computing capacity. A smaller batch size (24), about one third of the previous one (64), is adopted in the following experiment, which leads to the extension of epoch convergence. The training and validation rates are illustrated in Fig. 12. On optimizer RMSprop, the accuracy convergence curves start to flatten at about epoch 50, which is about three times of the converging epochs on single networks. Table 5 is the confusion matrix of the FDNN-VTC model. Each row of the confusion matrix represents the predicted class, and each column represents the true class. The diagonal indicates the rate of correctly classified samples. From Table 5, it can be seen that the correct classification rates of Coach, Truck and Pickup are the highest, and the correct classification rate of Sedan and SUV

The convergence curve of FDCNN-VTC. (a) train-loss. (b) train accuracy. (c) validation-loss. (d) validation accuracy.
The confusion matrix of FDCNN-VTC (%)
with a large number of samples is slightly worse. Due to the high consistency of the frontal part information of SUV and Sedan, a small number of SUV and Sedan appear misclassification. The Recall and Precision Rates in multi-class classification should be regarded as a binary classification that, samples belonging to one specific class against samples belonging to the other classes.
Figure 13 shows the Recall and Precision Rates of FDCNN-VTC, compared with top-3 models ResNet50-VTC, InceptionV4-VTC, GoogLeNet-VTC, and the latest proposed architecture [33] ResNet152(no-top) on SEU vehicle dataset. There are no clear improvements (about 2%) on categories of the highest accuracy (Coach, Pickup and Truck), while the SUV and Sedan show a great increase (about 8% in average) in Recall and Precision. In terms of AUROC in Fig. 14, the FDCNN-VTC achieves the largest area and performs better on the True Positive Rates (TPR).

The recalls and precision rates of FDCNN-VTC, compared with ResNet50-VTC, InceptionV4-VTC, GoogLeNet-VTC and Butt et al. [33]. (a) Recalls. (b) Precisions.

AUROC of FDCNN-VTC, compared with ResNet50-VTC, InceptionV4-VTC, GoogLeNet-VTC and Butt et al. [33].
With the purpose of accurate and robust classification of vehicle types from surveillance images, a fused deep convolutional neural network is studied in this paper. Firstly, with transfer learning, some existing DNNs have been studied for the performance comparison on vehicle front face dataset. Secondly, by using parallel fusion strategies on output features, a new scheme of Fused Deep Convolutional Neural Networks (FDCNN) based on GoogLeNet for vehicle types classification, ResNet50 for vehicle types classification and InceptionV4 for vehicle types classification, has been proposed. Finally, the comparative experiments have been carried out based on SEU vehicle dataset under the conditions of complicated and changeable weather and lighting. The experimental results show that the proposed FDCNN for vehicle types classification with RMSprop optimizer is more capable of recognizing vehicle types and shows greater performance, especially on undistinguishable classes, which is an 8% increase on similar samples (SUV and Sedan).
Footnotes
Acknowledgment
The authors would like to thank Key Science and Technology Projects of Transportation Industry of Ministry of Communications (Grant No. 2020-MS5-134), Transportation Science and Technology Plan Project of Shandong Province (Grant No. 2020B36) and Science and Technology Project of Shandong High Speed Group Co., Ltd (Grant No. (2020) SDHS-GSGF-09). Their assistances are gratefully acknowledged.