
Abstract
Recently, many pre-trained text embedding models have been applied to effectively extract latent features from texts and achieve remarkable performance in various downstream tasks of sentiment analysis domain. However, these pre-trained text embedding models also encounter limitations related to the capability preserving the syntactical structure as well as the global long-range dependent relationships of words. Thus, they might fail to recognize the relevant syntactical features of words as valuable evidences for analyzing sentiment aspects. To overcome these limitations, we proposed a novel deep semantic contextual embedding technique for sentiment analysis, called as: SE4SA. Our proposed SE4SA is a multi-level text embedding model which enables to jointly exploit the long-range syntactical and sequential representations of texts. Then, these achieved rich semantic textual representations can support to have a better understanding on the sentiment aspects of the given text corpus, thereby resulting the better performance on sentiment analysis task. Extensive experiments in several benchmark datasets demonstrate the effectiveness or our proposed SE4SA model in comparing with recent state-of-the-art model.
Introduction
In recent years, along with the rapid growth and popularization of Internet, e-commerce has become the mainstream for customers to purchase their desired products or services. As a primitive task of natural language processing (NLP) domain, the sentiment analysis [1–4] is an automatic computational evaluation of customers’ opinions and attitudes, towards their purchased products and services. In fact, sentiment analysis not only effectively supports for organizations/companies on e-commerce platforms to improve the quality of their products/services and consumer satisfaction but also provide useful references for the customers about their wanted goods. In general, the automatic sentiment analysis systems are designed to identify the sentiment polarities of aspects related to products/services which are explicitly presented in customer’s reviews/comments. The sentiment tendencies of consumers about products/services might be varying but can be generally categorized as positive, negative and neutral opinions. Thus, the sentiment analysis problem is formulated as a sentiment polarity prediction/classification task of a given text (reviews, comments, etc.). Traditionally, the sentiment classification is frequently regarded as a special case of text classification. By considering sentiment analysis as a classification task, textual representation plays an important role which enables to capture the original information that is conveyed by words/sentences/phrases in a given document. In the past, related sentiment tendency evaluation problems are mainly tackled by applying textual hand-crafted feature engineering-based techniques, such as bag-of-words (BOW) based representations (word frequency, TF-IDF, etc.) and out-of-the-shelf classification algorithms to categorize the polarities of user’s opinions. However, the hand-crafted feature engineering-based models encounter limitations related to the sparsity of short texts and unable to preserve the complex semantic relationships of words. Among early attempts for overcoming shortages of BOW-based textual representation approach, neural network-based word embedding techniques, such as: Word2Vec [1], GloVe [2] etc. were proposed to effectively generate dense and rich-semantic embedding vectors for word representation. Then, these learnt word embedding vectors are combined with non-neural classification algorithms, such as: Logistic Regression (LR), Support Vector Machine (SVM), etc. to obtain better results in sentiment classification task. Latterly, the emergence of deep learning has provided powerful techniques for textual representation learning problem and produced state-of-the-art performances in primitive tasks of NLP area, such as sentiment analysis. The development of text representation learning approach which is combined with advanced deep neural network-based archiectures, such as Convolutional Neural Network (CNN) [3–5] and Long Short-Term Memory (LSTM) [6, 7] have leveraged the performance of the sentiment analysis task. However, deep neural network-based models also have several drawbacks related to sufficiently capture the surrounding local context of words in separated sentences to categorize the emotional polarity of the given sentences. In recent time, with the raises of sequence-to-sequence (seq2seq) [8] and attention-based transformer [9] in textual representation learning approach, many pre-trained text embedding techniques, such as: ELMo [10], GPT [11], BERT [12], etc. have been utilized to efficiently capture the rich-semantic contextual information from large-scale text corpora, thereby achieve significant performances in NLP’s downstream problems. Similar to the traditional approach, the sentiment analysis is basically considered as a text classification problem. Thus, many attention-based pre-trained language models [10, 12] have been applied to encode the contextual relationships of words/sentences and explore the latent feature representations for sentiment polarity categorization at the decoding steps.
Recent achievements & existing limitations
Recently, with the tremendous emergences of advanced deep neural network architectures in NLP domain like as seq2seq [12], attention mechanism [13] and transformer [14–16], there are notable models have been proposed recently to deal with multiple challenging SA tasks. Despite great achievements of previous deep neural network/transformer-based models, there are limitations regarded to the neglect of extra linguistic knowledge integration as well as structural syntactical relationship evaluation during the process of textual embedding for sentiment analysis task. Most of recent designed pre-trained based models, like as: BERT-PT [17], ABSA-BERT [18] and DAPT/TAPT [19] for sentiment analysis task majorly focus on modelling the semantic sequential relatedness between contextual words and sentimental aspects of sentences. Hence, they are considered as insufficient to preserve the global syntactical dependencies of given texts. Moreover, the sequence-based textual embedding models can only preserve the multi-word latent features as consecutive terms with the recurrent neural network-based learning operation over sentences. Thus, with the problem of identifying sentiment polarity, they are inadequate to determine emotional expressions which are depicted by multiple words/compound words that are not continuous to each other. Therefore, these transformer-based models are limited to achieve better performance in multiple complex SA tasks like as the aspect-based.
Recently, there is a remarkable work of Ke, P. et al., called as: SentiLARE [20] which is a BERT-based sentiment-aware model for effectively acquiring the emotional polarities from texts. The proposed SentiLARE model utilizes multiple linguistic pre-knowledge resources to leverage the performance of sentiment analysis with custom label-aware masked text representation learning processes. However, proposed SentiLARE model is also categorized as sequence-based textual embedding approach which fail to fully capture the global contextual and syntactical structures of given texts.
Our motivations & contributions
To overcome above listed limitations, we proposed a novel pre-trained syntactical textual embedding model called: SE4SA which enables to jointly learn the sequential and global syntactical representations of the given text corpus. First of all, to acquire the structural syntactic latent features of words in each sentence, we apply a self-attention-based mechanism to capture the of co-reference relationships between words. Then the archived latent co-reference relatedness embedding vectors are fused into the latent syntactical word-sentence/document relationship representations by using a multi-layered GCN-based encoder [17]. In our approach, we use a multi-layered GCN architecture to encode the syntactical relationships between words and a given document which are represented as a grammatical dependency tree. By referring to the parsed syntactical dependency tree of each document via Stanford CoreNLP, a GCN encoder is sufficiently capable of preserving the syntactically relevant words to the target different sentimental aspects, and exploiting the long-range dependent relations of words which are not next to each other. The final syntactical representations of words in each document are then used to feed into a label-aware masked BERT-based encoder to jointly integrate with the latent continuous representations of words. To acquire the sequential semantic representations of words in a document, we applied the pre-trained BERT encoder with masked language mechanism. In this step, mainly inherited from previous studies of Ke, P. et al. in SentiLARE model, we incorporate the sequential textual embedding process with the external SentiWordNet [18] as the pre-knowledge source for the sentiment-oriented representation learning task. In order to deal with the sentiment analysis task in different types of documents, including: short (contain only one sentence) and long (few sentences or a completed paragraph/microblog) documents, we utilize a Bi-LSM encoder at the output layer of the given masked language BERT-based embedding architecture to learn the overall representations of each document.
Figure 1 illustrates the overall architecture and main components of our proposed SE4SA model. To sum up, our contributions in this paper can be summarized as three folds, which are: First of all, we propose a novel approach of preserving the co-reference and syntactical dependency relationships between words of each document. We name this proposed textual embedding strategy as: CoSynEmb process. For the co-reference relationships of words, we apply the self-attention-based neural mechanism on the contextual dependent co-reference relatedness between words/phrases to efficiently capture the co-referencing representations. Then, the achieved co-referencing representations in previous step are merged into the structural syntactical representations of words which are preserved from the dependency tree/graph of a given document by using a multi-layered GCN-based encoder. To handle the word representation merging task, we use a custom personalized non-linear fusion function to effectively map the co-referencing embedding vector of words into the long-range syntactical dependency latent representation space. After the merging process, we can perceive the final unified rich-semantic embedding vectors of all words in a given document which are then used as the inputs for the label-aware masked BERT-based encoder in the next process. Secondly, to incorporate word embedding vectors which are achieved in previous CoSynEmb process with the task-specific sentiment analysis, we integrate them with the emotional senses which are referred from the SentiWordNet dictionary as the external pre-knowledge resource. By doing this, we can inject latent linguistic knowledge features for the given word representations which enables to sufficiently derive the global sentiment polarities of a whole document. Then, these enriched sentiment-aware word embedding vectors are fed into a BERT-based embedding architecture to directly capture the sequential latent representations of words with the masked label-aware mechanism. Then, for sentence’s embedding vectors of the given BERT-based architecture, we use a Bi-LSTM encoder at the output layer to combine and generate a final unified sentiment-aware representation of a given document. At the last stage, to handle the sentiment categorization task, we use a full-connected multi-layered perception (MLP) with the softmax normalization layer at the end to conduct the classification task. Finally, to evaluate the effectiveness of our proposed SE4SA model, we conduct extensive experiments in multiple benchmark datasets, including: Stanford Sentiment Treebank (SST), Amazon Reviews (AR), Movie Reviews (MR), IMDb, and Yelp. Experimental outputs demonstrate the outperformances of our proposed SE4SA model in comparing with recent state-of-the-art sentiment analysis baselines.

Illustration of overall architecture of our proposed SE4SA model.
The left parts of our paper are organized into four sections. In the second section, we briefly present recent studies in sentiment analysis domain as well as discuss about pros/cons of each model. Next, we formally describe about related background concepts and notations which are used in this paper in the third section. In the fourth section, we present detailed descriptions about our main ideas, methodology of the proposed SE4SA model and implementation. Then, we demonstrate our extensive experiments with multiple benchmark datasets in the fifth section. In this section, we also provide studies related to comparative baseline, experimental result discussions and parameter sensitivity of our proposed SE4SA model. In the last section, we conclude about our achievements in this paper as well as highlight some possible improvements for the future works.
In this literature review section, we formally present recent studies related to the traditional, deep learning-based and advanced pre-trained text embedding approaches for sentiment analysis task.
Traditional approach for sentiment analysis
Considering as a primitive task in NLP domain, sentiment analysis/classification have been popularly studied in decades due to its potential applications in multiple disciplines. From the past, several language-specific analyzing methods have been proposed to effectively model the sentiment from the type-varied text corpora, such as: product’s reviews in e-commerce platforms, comments/microblogs in social networks, etc. Traditional sentiment analysis models can be categorized as two main trends. The first trend is opinion-aware language technique which mainly focus on identifying emotional aspects of occurring words in a given document to fulfill the sentiment classification task. The models [19, 20] in this trend are mainly focus on the use of the expert knowledge/lexical resources (e.g., SentiWordNet [18, 21] for sentimental references. The second trend mainly concentrates on developing textual analysis methods (e.g., BOW, n-grams, etc.) to learn the representations of given documents for the sentiment categorization process by using binary-class/multi-class classification algorithms [22, 23]. Although the traditional methods of both lexicon-based and textual analysis-based approaches can automatically extract sentimental aspects from given text corpora, they often rely on expert-based/hand-crafted feature engineering process to ensure the quality of model’s outputs. To release the dependences on pre-knowledge resources as and high efforts on the manual feature engineering tasks, the deep learning-based models have been proposed.
Deep learning-based approach for sentiment analysis
Deep learning-based models for sentiment analysis task have a common advantage that they don’t or less require expert knowledge intervention to automatically extract latent emotional aspects from texts to leverage the performance of sentiment classification. In existing deep learning-based techniques, the sentiment analysis task is frequently formulated as a joint three-way prediction problem with trained sentiment classifiers to predict a given document as positive, neural, and negative. The sentiment classifiers might be out-of-the-shelf classification algorithms (e.g., SVM, LR) or neural network-based mechanism (e.g., MLP), are fed by latent embedding vectors of given documents which are achieved by common deep neural network-based architectures, like as recurrent neural network (RNN) (e.g.,: GRU, LSTM, Bi-LSTM etc.) and convolutional neural network (CNN) [28].
RNN-based approach for SA task
RNN is considered as the most popular deep neural architecture which is used in multiple tasks of NLP domain, including sentiment classification. In order to preserve the sequential relations of words in a given document for leverage the emotional polarity. Among early attempts, there are notable works like as the proposals of Chen, T. et al. in Bi-LSTM-CRF [28], Balikas, G. et al. in Bi-LSTM + Multitask [29] which proposed modified Bi-LSTM based architecture to facilitate the sequential representation learning process of texts in which can support to leverage the performances of SA task. Recently, Ma, Y. proposed a novel LSTM-based model, called as SenticLSTM [7] which is a combination between the LSTM-based textual encoder and the recurrent additive network that support to directly detect the target-dependent sentiment aspects for the aspect-based polarity classification task. In the recurrent neural network (RNN) based approach, there are also studies of Wen, S. et al. in the proposed MLSTM model [30] which proposed a memristor-based LSTM architecture to fasten the text embedding process for sentiment analysis task, which is similar to recent works [31, 32]. However, most of RNN-based SA models still suffered limitations related to the capability of capturing rich contextual information from texts to facilitate the sentiment classification-driven training process.
CNN-based approach for SA task
In recent years, there are notable efforts in the utilization of CNN-based architecture to assist the representation learning process for better textual understanding and fine-tuning for multiple complex SA tasks. Such as the well-known study of Santos D. et al. [3] in applying deep convolutional neural network for jointly exploring the word-based and sentence-based latent representations to conduct the sentiment analysis of short texts. Similar to that, there are works of Jianqiang Z. et al. [4] which used a multi-layered CNN-based encoder to effectively learn the contextual semantic features and the co-occurrence relationships between words. Then, the learnt latent representations of texts via CNN-based encoder are used to support for identifying the sentiment polarity. Inherited from successes of previous CNN-based techniques, Fan, C. et al. [8] proposed a memory-based CNN text representation learning method to effectively preserve the latent features of both words and multi-words expressions in texts for the aspect-based specific sentiment analysis task. To specifically target emotional expression words in texts, Hyun, D. et al. [36] proposed a novel target-dependent CNN-based textual representation learning technique to capture the distance relationships between the target emotional words and their surrounding contextual words. Or recent well-known works of Abid, F. et al. [37] and Piryani, R. et al. [38] which proposed an integration between CNN and LSTM architecture to assist the sentiment-aware textual embedding process in which can support to leverage the accuracy performance of the sentiment analysis task.
Sequential pre-trained language model for sentiment analysis
With the raises of Seq2Seq [11] and attention-based transformer [12] in textual representation, several advanced sequential text embedding baselines have been proposed, such as: ELMo [13], GPT [14], ULMFit [39], BERT [15], etc. These sequential pre-trained language model have demonstrated significant performances in acquiring the rich semantic contextual representations of texts which then effectively leverage the accuracy results of multiple NLP’s tasks, including sentiment classification. Among common pre-trained language models, BERT [15] is considered as the most popular one due to its flexibility in various NLP-based pre-training tasks, including the masked language mechanism for general text classification task. An early work of Xu, H. et al. [16] in the proposed BERT-PT model which applies the pre-trained BERT-based textual embedding technique to benefit the aspect-based sentiment classification. The success of BERT-PT model has demonstrated the potential application of pre-trained language models in sentiment analysis task. Similar to the proposed TransBERT [22] which integrates the supervised transferable knowledge with the fine-tuning process of BERT to effectively handle multiple NLP’s tasks. Recent famous study of Gururangan, S. et al. [18] which specified the possibility of using a unified pre-trained language model for multiple NLP-specific tasks via the different pre/post-training processes. Following the pre/post-training strategy, there are recent proposed models, such as DomBERT [40] and SentiBERT [23] have integrated the training process with relevant domains and multilevel attention-based mechanism to improve the performance of aspect-based sentiment analysis. To enrich the semantic meanings of word embedding vectors for the task-specific sentiment analysis, recently proposals of Ke, P. et al. [19] in using the integration of sentiment-related linguistic pre-knowledge lexicon, such as SentiWordNet and pre-trained BERT-based textual embedding mechanism to benefit the wide-range of primitive tasks in the sentiment analysis area, called as SentiLARE model.
However, there is a major limitation of proposed sentiment-driven pre-trained language models is that they only mostly focus on preserving the contineous latent representations from a given document to identify the sentiment polarities of words in different sequential contexts. Thus, they might be unable to capture the latent syntactical structure of overall word-document relations which enable to recognize the global relatedness contextual words as important clues for identifying sentimental aspects. Majorly inherited from the existing works on utilizing pre-trained language embedding model for sentiment analysis task. In this paper, we propose a combination of GCN-based and masked language BERT-based encoding mechanisms to jointly learn the sequential and syntactical dependency structures of texts for dealing with wide-range of downstream tasks in sentiment analysis domain.
Preliminaries & problem formulation
In this section, we briefly present about background concepts of BERT textual embedding, mask language model and the GCN architecture. The ultimate goal of the proposed SE4SA model is to learn the representations of given documents for identifying sentiment polarities. In more details, our proposed SE4SA is a textual embedding (definition 1) model which is designed for task-specific sentiment analysis. Considering sentiment analysis task as a textual classification problem (definition 2), the learnt sentiment-aware text of documents via text embedding techniques used to train the classifier to predict the distribution of sentiment polarities. In previous studies of using textual embedding for sentiment analysis, several sequential text embedding (definition 3) methods, such as: BERT [12] is majorly used to capture the contextualized vector representation of each word in a given sentence/document. In fact, BERT is one of the important innovations in the recent advances of contextualized representation learning area. For sentiment analysis, pre-trained BERT can be adopted different fine-tuning approaches to meet specific architectures for different end tasks, such as general sentiment classification, sentiment aspect extraction, etc. This BERT’s advantage enables to minimize the requirements of prior human/expert knowledge for the data modelling process.
However, most of recent pre-trained models for sentiment analysis have a common limitation of unable to fully exploit the long-range multi-word relationships as well as the overall syntactical information structure within a whole document. Thus, sequential pre-trained based models might fail to determine the important sentiment aspects which are represented by multiple words/compound words that are not contineous occurring with each other. To overcome this limitation, a novel proposal of using GCN (definition 4) to effectively exploit the long-range dependent relationships between words. GCN is commonly used for multiple unstructured data embedding, including texts in forms of graph-based structures. Table 1 shows common notations which are used in our paper.
List of used notations & descriptions
List of used notations & descriptions
In this section, we formally introduce the approach of our proposed SE4SA model which is a sentiment-aware masked text embedding model. Our proposed SE4SA enables to jointly learn the semantic sequential and structural syntactical representations of documents for sentiment polarity identification. First of all, each document will be passed through the CoSynEmb-based embedding mechanism to fully learn both co-referencing and syntactical contextual relationships between words by using the self-attention-based mechanism with the multi-layered GCN-based dependent text graph encoder. Then, the achieved CoSynEmb-based embedding matrix for words are used to feed into a masked pre-trained BERT encoder to learn the sequential representations of all words in a given document at the local context level. Through separated masked label-aware pre/post training steps, we achieve the unified embedding vectors of words which are then accumulated into a final representation of a given document by using a Bi-LSTM encoder at the output layer. Finally, having obtained the final representation of a target document, we feed it into a full-connected MLP layer to conduct the sentiment classification.
CoSynEmb: co-referencing and syntactical text representation learning
Textual syntactical structure representation learning via GCN
Given a n-word document, as: ={ 𝓌1, 𝓌2, …, 𝓌n }, we firstly applied the pre-trained Word2Vec model [1] to learn the local contextual representations of words, denoted as:
Then, a k-layered GCN architecture is utilized to capture the syntactical representation of word nodes in a given dependency text graph G
𝒹
(as illustrated in Fig. 2). Taking the initial word embedding vectors of
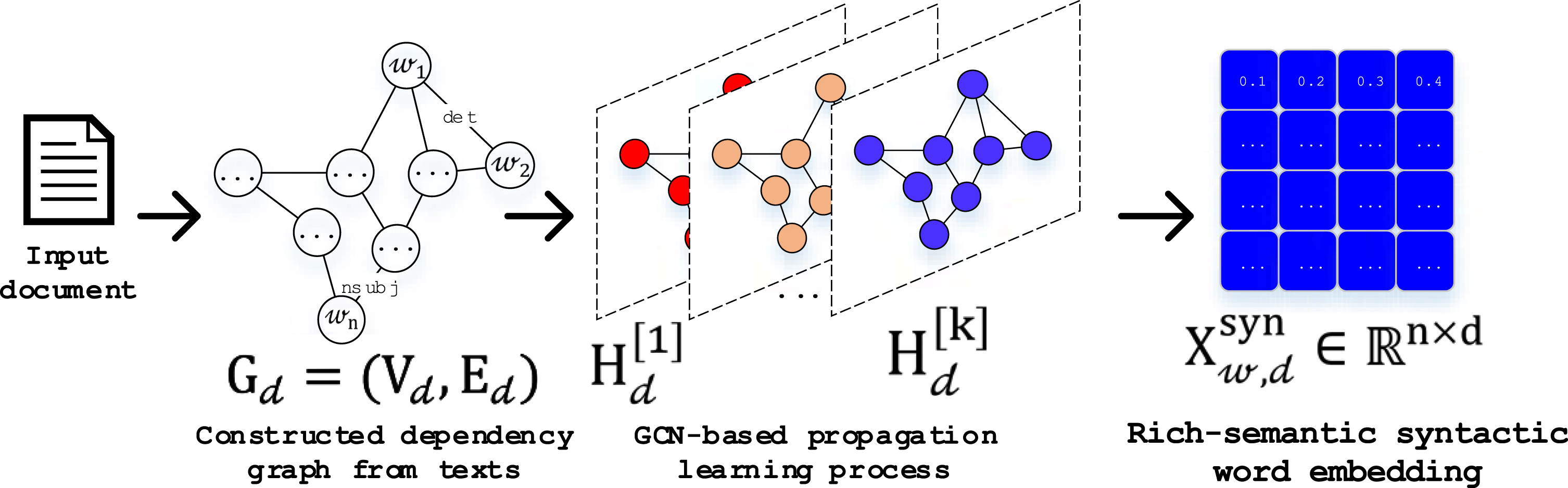
The illustration of syntactical structure representation learning via GCN for each document.
Where: fact (.), is the activation function of a given GCN-based architecture, in this case we used the ReLU (.) function. H[t], W[t] and b[t], are the hidden state, weighting parameter and bias matrices at the tth layer of a given GCN-based architecture.
After the propagation learning process, at the kth layer of the given GCN-based architecture we can achieve the syntactical representation of words in a given document, as last hidden state matrix, denoted as:
Next, to learn the co-referencing relationships between words in a given document (𝒹), we applied the self-attention mechanism with Bi-LSTM encoder to learn the contextual co-referencing spans from co-referencing word clusters. To extract co-referencing relatedness of words, we use the syntactic co-reference parser of the Stanford CoreNLP [33] library. Beginning with a Bi-LSTM based encoder, similar to the syntactical structure representation learning via GCN in previous approach, we also take the word embedding vectors of the given document (𝒹) as the inputs for a given Bi-LSTM architecture (as illustrated in Fig. 3). To learn the sequential representations of words over each co-referencing span, denoted as: (ℊ), we encode a given set of continuous word embedding vectors, as:
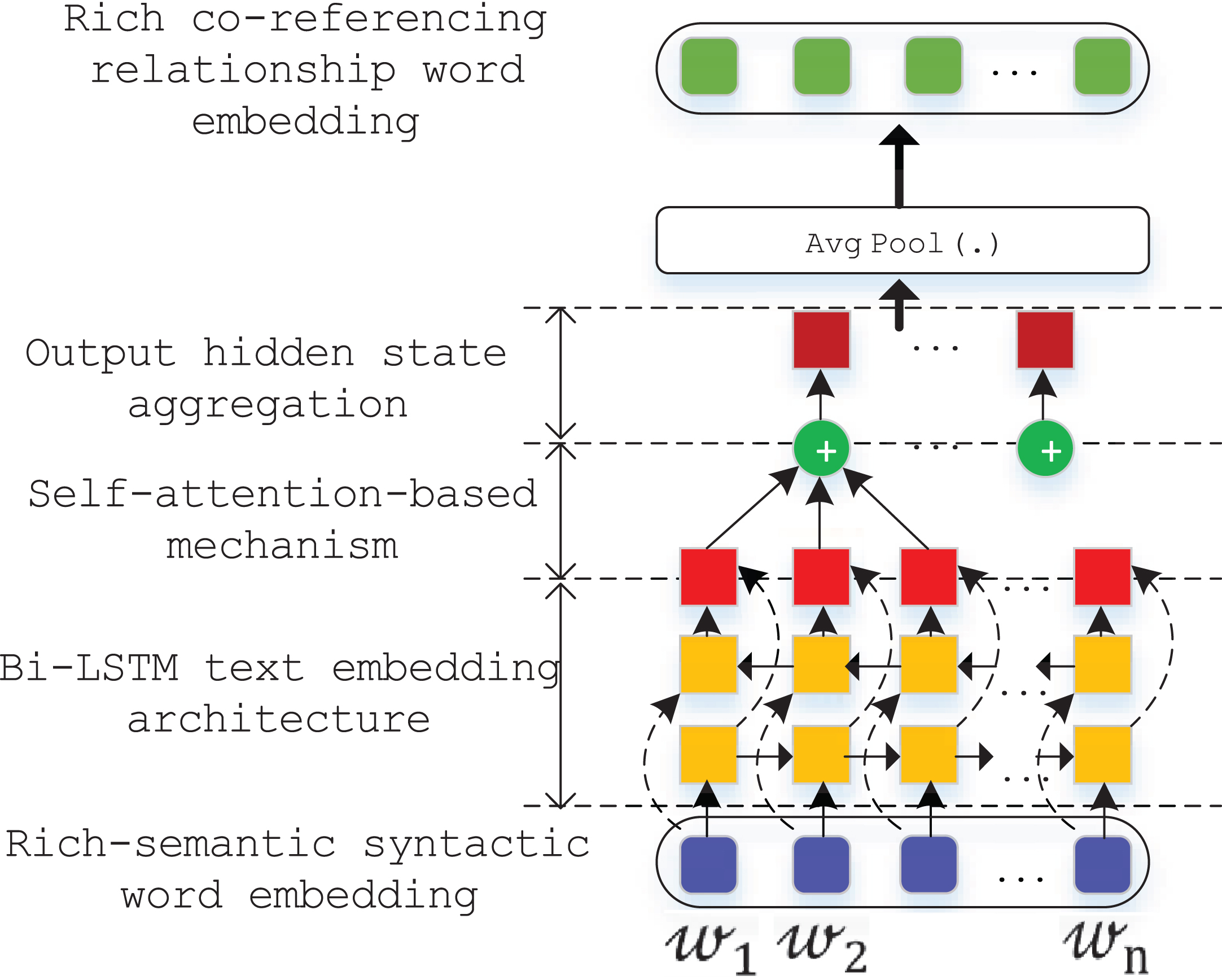
The illustration of co-referencing relationship representation learning via Bi-LSTM with attention based mechanism for each document.
Where: σ (.), is the sigmoid function.
U and b, are the weighting parameter and bias metrices of a given Bi-LSTM architecture.
The use of a Bi-LSTM encoder enables us to fully capture the contextual information of the co-referencing relationships between words which also is the surrounding external and internal structure within each span (ℊi). Then, we attach the co-referencing relatedness representation learning process with the self-attention mechanism to align it with the syntactic structure of occurring words inside each span. The overall task-specific co-referencing relation embedding task with the attention-based mechanism is formulated as the following (as shown in Equation 3a and 3b):
Where:
Z
γ
and W
γ
, are the weighting parameter metrices of a given self-attention-based mechanism for aligning the span representation with its occurring word embedding vectors.
Finally, to efficiently integrate the achieved co-referencing relationship representation with separated word embedding vectors at the global document context level, we applying the average pool strategy to softly arrange extracted latent features of different representations into a single unified embedding space. Let
Where:
From these enriched word embedding vectors with the co-referencing relationship contextual information, we form a new word embedding matrix, denoted as:
At this stage, we have achieved separated embedding matrices of words in a document (𝒹), which are the syntactic structure-based embedding matrix, denoted as:
Where: σ (.), is the defined non-linear function for our proposed word embedding fusion mechanism –in this case is the sigmoid function. Unl, Wnl and bnl, are the weighting parameter and bias matrices of a given fusion function.
The ultimate purpose of using a non-linear fusion mechanism to merge different types of word embedding vectors into a single unified representation space is to flexibly model the complex syntactical and co-referencing relationships between words. To optimize need-to-update parameters of our defined fusion function, we apply the traditional stochastic gradient descent (SGD) strategy with the pre-defined learning rate: η and calculated gradients for each parameter corresponding with the given word embedding vectors, as:
From the previous achieved unified word embedding vectors, we apply the previous approach of Ke, P. et al. in SentiLARE model [16] with pre-knowledge injection for each word embedding vector via the SentiWordNet [18] lexicon. In the first step, for each word in a given document (𝒹), we apply the Stanford CoreNLP [31] tool to extract the part-of-speech (POS) label. To obtain the sentiment polarity label of each word in the given document (𝒹) by calculating the sentiment polarity score between each ith word (𝓌i) and its related labelled POS: pi with different sentiment context-gloss senses (
Where: fAvg-CoSynEmb (.), is the average embedding vector of a given text by using the proposed CoSynEmb-based strategy as a mapping function (described in 0).
λ, is the normalized parameter for approximating the impact of each sense within overall existing senses in
After identifying the sentiment polarity score of each word-POS pair 〈𝓌i|pi〉 in a given document (𝒹) which supports to indicate the sentiment label, as: ℓ
i
(sp (〈𝓌i|pi〉, 𝒹) > 0: positive, sp (〈𝓌i|pi〉, 𝒹) = 0: neutral otherwise: negative) of each word-POS pair following its surrounding contextual representation, we utilize pre-trained BERT-based architecture with masked language mechanism. We define a set of training set for our BERT-based sequential embedding model, as:
Where:
BERT (.), is the pre-trained BERT-based sentence-level embedding model with specific several masked word positions.
Inherited from previous work of Ke, P. et al. [16], we utilize the sentiment-aware masked language training strategy with the configurations which let the given BERT-based encoder to predict the masked word (𝓌) with its associated POS tag (p) and the assigned sentiment label (ℓ). Hence, the loss function with the desired learning objective for the output layer of pre-trained BERT model is defined as the following (as shown in Equation 7).
Where: f
j
(.), is the indicator function which return vae [1] if the (ith) word is masked, otherwise is [0]. logProb (. | .), is the logarithmic probability of given masked word which is calculated upon the corresponding sentence-level hidden state.
After the model training process, we will achieve a set of sentence-level embedding vector of a given document (𝒹) which carry out sequential contextual information of words. Then, to produce the final representation of a given document (𝒹), as:
Where:
Finally, after having the final rich-semantic sentiment-aware representation of a given document (𝒹), as:
Where: Mclass and bclass, are the weighting parameter and bias matrices of a given MLP architecture.
To train the given sentiment classification model, we apply the standard SGD with cross-entropy loss and the L2-regularization strategy (is generally formulated in Equation 10b).
In this section, we conduct extensive experiments to demonstrate the effectiveness of our proposed SE4SA model in comparing with recent state-of-the-art baselines for sentiment analysis.
Experimental dataset usage & settings
Dataset usage descriptions
Our experiments are conducted in six benchmark datasets, include: Stanford Sentiment Treebank (SST), Amazon Reviews (AR), Movie Reviews (MR), IMDb, Yelp and SemEval2014/2016. Below is the detailed information of each dataset: SemEval2014 (Task 4) [43]: is a well-known dataset for aspect-level sentiment analysis task. In this dataset, we selected two categories: laptop (Laptop14) and restaurant (Resta14) for the aspect-based sentiment analysis. This dataset can be directly downloaded at this repository
6
. SemEval2016 (Task 5) [44]: similar to SemEval2014 dataset, in this dataset we also selected the restaurant domain (Resta16) for the experiments in aspect-based sentiment analysis. This dataset can be downloaded at this repository
7
.
For textual contents in each dataset, we applied some simple text pre-processing steps, such as special character removal, word stemming and tokenization, sentence segmentation, etc. For complex textual processing tasks, such as: extracting POS tag for each word and constructing dependency tree for text documents, we the mainly used the Stanford CoreNLP library 8 . Tables 2 and 3 show general statistics of datasets which are used for our document/sentence-level and aspect-level experiments after pre-processing steps, respectively.
General statistics of datasets which are used for document/sentence-level experiments
General statistics of datasets which are used for document/sentence-level experiments
General statistics of datasets which are used for aspect-level experiments
To evaluate the accuracy performance of each sentiment analysis models, all the experimental outputs are evaluated by the accuracy (Acc.) and F1 metric. For all datasets in our experiments, we applied the out-of-the-box pre-trained Word2Vec 300-dimensional embedding model 9 to initialize and achieve word embedding vectors of each document. For the pre-trained BERT implementation, we used the original large and uncased version 10 for the initial setup and fine-tuning processes. Table 4 shows general setting parameters of our proposed SE4SA which are used in all experiments of our paper.
General settings for our proposed SE4SA model
General settings for our proposed SE4SA model
To demonstrate the effectiveness of our proposed SE4SA model, we also implemented several well-known sentiment analysis baselines for comparative studies, which are:
For general configurations of above listed models, we applied the same settings which are presented in Table 4. For specified parameters of each model, we used the same configurations which are described in the original works where these models achieved the highest accuracy performance.
Experimental outputs & discussions
Sentence/document-level sentiment classification task
We firstly evaluated the accuracy performances of different sentiment analysis models in sentence/document-level based task. Tables 5 and 6 show the experimental outputs of sentiment analysis task via different techniques in terms of Precision, Recall (R) and F1 standard metrics within benchmark datasets. We can definitely observe from the experimental results that our proposed SE4SA model performs better than recent state-of-the-art baselines on the sentence/document-level sentiment classification task, thus indicating the effectiveness of our proposals in this paper. In more details, our proposed SE4SA model significantly outperforms averagely 14.12% (general pre-trained BERT), 12.55% (TransBERT), 8.55% (BERT-PT) and 6.46% (SentiBERT) in all benchmark datasets. For our main competitors, which are: ASGCN and SentiLARE, our proposed SE4SA also slightly achieves better performance approximately 4.71% and 1.66%, respectively.
Experimental outputs for the sentence/document-level sentiment analysis task via different models in terms of Precision (P), Recall (R) and F1 metrics within SST, AR and MR datasets
Experimental outputs for the sentence/document-level sentiment analysis task via different models in terms of Precision (P), Recall (R) and F1 metrics within SST, AR and MR datasets
Experimental outputs for the sentence/document-level sentiment analysis task via different models in terms of Precision (P), Recall (R) and F1 metrics within Yelp and IMDb datasets
For experiments related to the aspect-level sentiment analysis, we conducted four main downstream subtasks, which are: aspect term extract (ATE), aspect term sentiment classification (ATSC), aspect category detection (ACD) and aspect category sentiment classification (ACSC). In general, Table 7 shows general statistics of SemEval2014 (Laptop14 and Resta14) and SemEval2016 (Resta16) datasets which are used for multiple downstream subtasks of aspect-level sentiment analysis tasks via different textual embedding methods.
General dataset statistics for different aspect-level sentiment analysis subtasks with different models
General dataset statistics for different aspect-level sentiment analysis subtasks with different models
Tables 8 and 9 present the experimental results for different aspect-level sentiment analysis subtasks in terms of accuracy and F1 metrics. The experimental outputs present the outperformance of our proposed SE4SA model in comparing with recent text embedding baselines for multiple aspect-level sentiment analysis subtasks, including: ATE, ATSC, ACD and ACSC. In general, for the aspect-specific term analysis related subtasks (ATE and ATSC) about proposed SE4SA remarkably outperforms about 8.74%, 8.22%, 4.55% and 2.94% in comparing with the general pre-trained BERT, BERT-PT, TransBERT and SentiBERT in terms of F1 accuracy metric for both Laptop14 and Resta14 datasets. For the category aspect related subtasks (ACD and ACSC), our proposed model also achieves better performance about 12.73% (general pre-trained BERT), 12.59% (BERT-PT), 7.45% (TransBERT) and 9.32% (SentiBERT). In comparing with our main competitors in this paper which are ASGCN and SentiLARE, the proposed SE4SA also performs better about 3.77% /3.72% (term-specific/category-specific term tasks) and 2.16% /1.72% (term-specific/category-specific term tasks) in terms of F1 evaluation metric for all datasets, respectively.
Experimental outputs for aspect-level sentiment analysis subtasks: ATE and ATSC via different models in terms of Accuracy (Acc), Precision (P), Recall (R) and F1 metrics
Experimental outputs for aspect-level sentiment analysis subtasks: ACD and ACSC via different models in terms of Accuracy (Acc), Precision (P), Recall (R) and F1 metrics
In overall, experimental results in both sentence/document-level and aspect-level sentiment analysis tasks demonstrate the effectiveness of our proposed SE4SA model which prove the potential application of the combination between the sequential and syntactical structure representation learning in textual embedding approach for sentiment analysis.
In this section, we present extensive empirical studies related to the setup parameters’ sensitivity of our proposed SE4SA model, including the dimensionality of embedding vector (d), number of LSTM-based cells in Bi-LSTM encoders (h), number of training epochs and number of layers for the GCN-based syntactical encoder in our CoSynEmb-based text embedding strategy. To conduct experiments related to model’s parameter sensitivity, we selected two large-scale datasets, include: Amazon Reviews (AR) and Yelp which have > 500 K documents. Our proposed SE4SA is implemented to conduct sentiment analysis task in these two large-scale datasets with different values of evaluated parameter while fixing the others.
As shown from the experimental outputs in Figs. 4 and 5, our proposed SE4SA model is quite insensitive with the dimensional embedding size and number of used LSTM-based cells for Bi-LSTM architectures. In more details, for different sizes of datass, the value of (d) needs about > 200 to achieve the highest accuracy performance in terms of F1 metric for both AR and Yelp datasets. Similar to that, we varied the value of (h) from 10 to 300 and observed the changes in accuracy performance of our proposed model. It is shown from experimental outputs that the proposed SE4SA model is definitely insensitive with the number of used LSTM-based cells. With value of (h) parameter is over 250, the performance of SE4SA model becomes stably balanced for both AR and Yelp datasets. We can assume from these experimental outputs that the value of (d) and (h) parameters should be aligned with the size of evaluated dataset in order to sufficiently capture latent features from texts. Figure 6 shows our extended experimental studies on the number of training epochs and number of GCN-based layers which are initially configured for our SE4SA model. For different datasets, our proposed SE4SA model need different amount of epochs for the convergence which is > 250 for AR dataset and > 200 for Yelp. It indicates the fact that our model needs more number of training epochs to reach the convergence point for larger dataset size. In contrast, the increase in number of used GCN-based layer for the syntactical embedding shows the opposite results. As shown from Fig. 6, our proposed model gains the highest accuracy performance with number of GCN-based layers is set from range [5, 6] for AR dataset and [3–5] for Yelp dataset. For both datasets, the increase of this parameter over 6 leads to the significantly downgrades of overall SE4SA model’s accuracy performance in terms of F1 metric. Thus, it presents that the SE4SA model is quite sensitive with the setup number of GCN-based layers which are used for the CoSynEmb-based word embedding strategy.
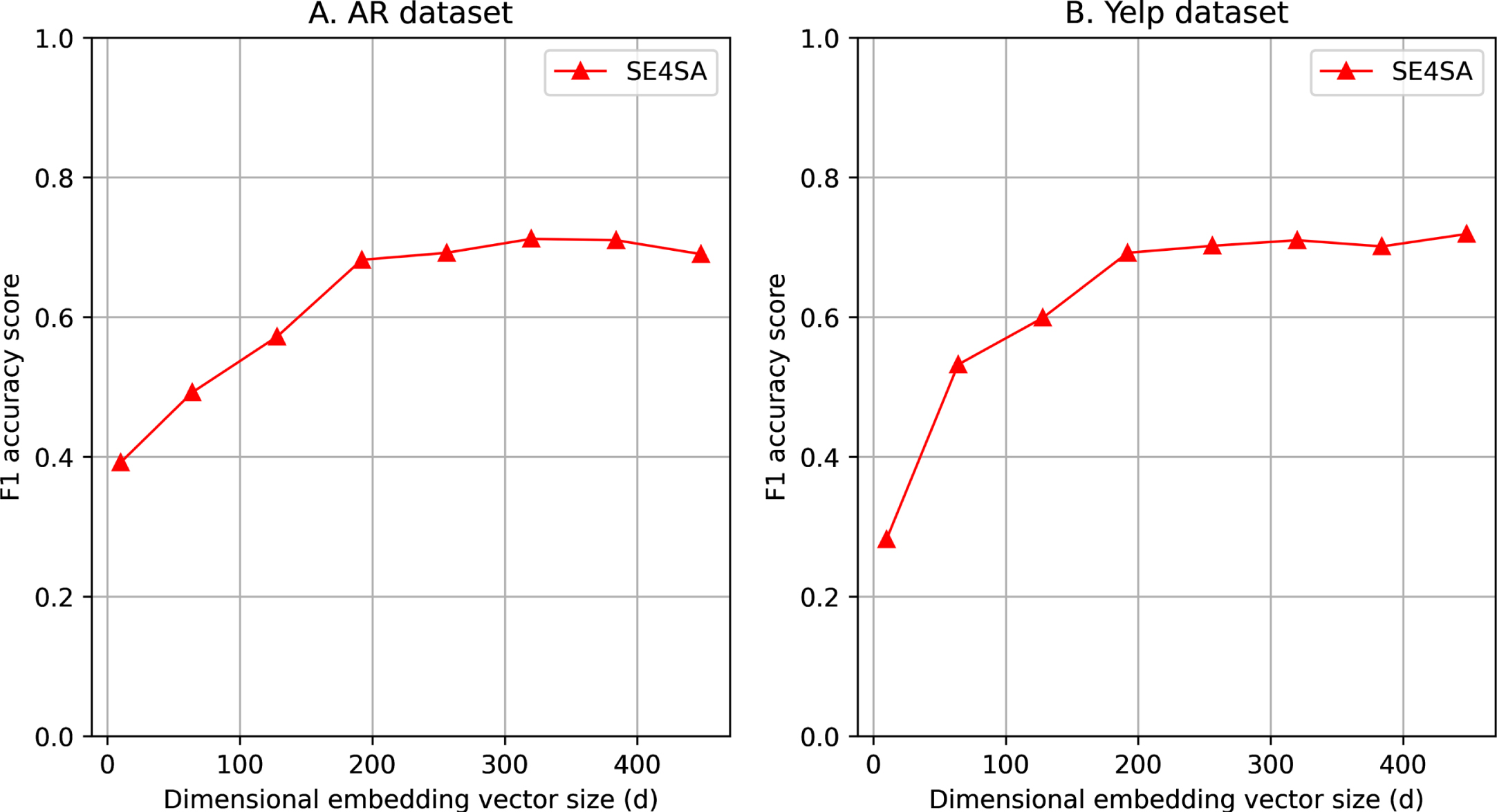
The effect of the dimensionality of embedding vector (d) in the overall accuracy performance of our proposed SE4SA model.
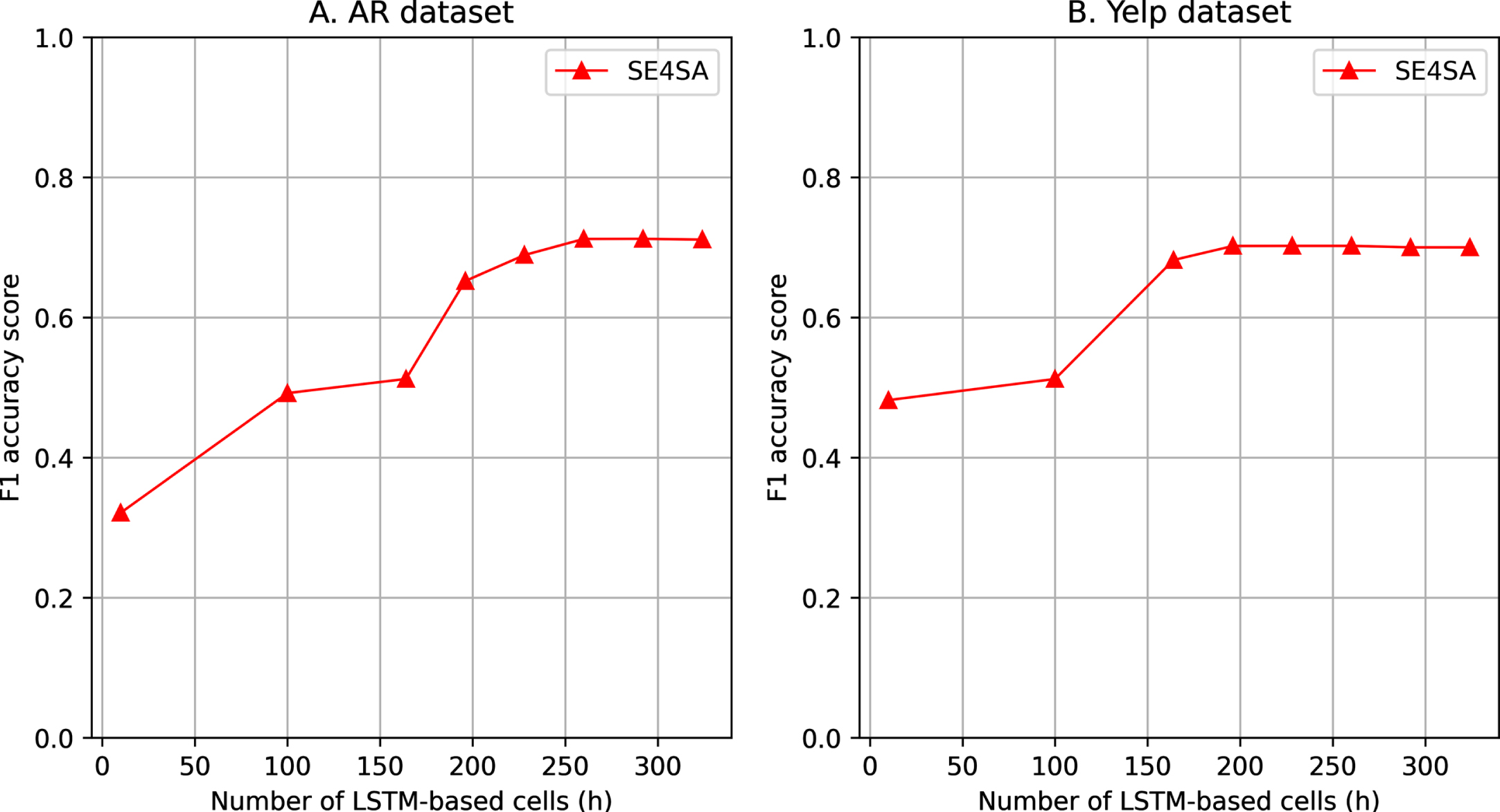
The effect of the number of LSTM-based cells (h) of Bi-LSTM encoder in the overall accuracy performance of our proposed SE4SA model.

The influences of number of training epochs and used GCN-based layers in the overall accuracy performance of our proposed SE4SA model.
In this paper, we formally present a novel approach, called SE4SA which is an integration of graph convolutional network with pre-trained BERT model for jointly capturing the sequential semantic and syntactical structural representations of text which enables to leverage the accuracy performance of multiple downstream tasks in sentiment analysis area. In our proposed SE4SA model, we firstly proposed a novel GCN-based textual embedding technique, called as: CoSynEmb which supports to preserve both global syntactical structure and contextual co-referencing relationships of words in a given document. Then, the rich-semantic CoSynEmb-based word representations are used to feed into a pre-trained BERT-based sentence-level encoder with masked language mechanism to effectively learn the continuous representations of words and sentences. Inspired from previous models, our proposed SE4SA is also able to integrate with external sentiment lexicons such as SentiWordNet to leverage the sentiment polarity capability through pre-training tasks with BERT-based architecture. Extensive experiments in benchmark datasets demonstrates the effectiveness of our proposed model in comparing with recent state-of-the-art baselines. For future improvement of our works, we intend to integrate the semantic representations of texts with other information sources, such as social network structure in order to improve the accuracy performance of sentiment analysis task.
Declarations
This study was funded by Thu Dau Mot University, Binh Duong, Vietnam.
Footnotes
Acknowledgments
This research is funded by Thu Dau Mot University, Binh Duong, Vietnam.
Conflict of interest
This research is funded by Thu Dau Mot University, Binh Duong, Vietnam.