
Abstract
The purpose of aspect-based sentiment analysis is to predict the sentiment polarity of different aspects in a text. In previous work, while attention has been paid to the use of Graph Convolutional Networks (GCN) to encode syntactic dependencies in order to exploit syntactic information, previous models have tended to confuse opinion words from different aspects due to the complexity of language and the diversity of aspects. On the other hand, the effect of word lexicality on aspects’ sentiment polarity judgments has not been considered in previous studies. In this paper, we propose lexical attention and aspect-oriented GCN to solve the above problems. First, we construct an aspect-oriented dependency-parsed tree by analyzing and pruning the dependency-parsed tree of the sentence, then use the lexical attention mechanism to focus on the features of the lexical properties that play a key role in determining the sentiment polarity, and finally extract the aspect-oriented lexical weighted features by a GCN.Extensive experimental results on three benchmark datasets demonstrate the effectiveness of our approach.
Introduction
Traditional sentiment analysis focuses on inferring the sentiment polarity of an entire sentence. In contrast to traditional methods, aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task intended to identify the sentiment polarity (e.g., negative, neutral, or positive) of the given aspect. A sentence may contain several different aspects, each of which may have a different sentiment polarity. Aspect-based sentiment analysis has many practical applications, for example, aspect-based sentiment analysis for product reviews can extract users’ attitudes towards different aspects of a product, providing a more granular reference for manufacturers to further improve their products. For example, given a sentence like “I love Windows 7 which is a vast improvement over Vista.” the aspect of the sentence is usually an entity, so the aspect of the sentence is “Windows 7” and “Vista”, whose sentiment polarity is positive and negative, respectively.
Intuitively, the key to the task is to relate aspects to their respective opinion words in order to infer the sentiment polarity of the aspect. In recent years, deep learning has been widely used in ABSA tasks, especially in Recurrent Neural Networks(RNN) and Convolutional Neural Networks (CNN). Tang et al. [1] used two LSTMs to extract the features on the left and right of the aspect, and finally splices the implied vectors of the two LSTMs into a softmax classifier for classification.Xue et al. [2], on the other hand, used the CNN. Also, the Attention mechanism is widely used in ABSA tasks, Tang et al.; Wang et al.; Li et al.; Fan et al.; Du et al. [3–7] all by using the attention mechanism to achieve aspect sentiment classification. However, these methods largely ignore the grammatical structure of the sentence and tend to use non-opinion words as a feature to judge the sentiment polarity of that aspect. Therefore, in recent years, graph neural networks have been widely used in ABSA tasks, where researchers used the dependency-parsed tree of sentences to obtain the adjacency matrix of sentences and then extracted features by GCN [8]. Bai et al. [9] designed a relational graph attention network that integrates typed syntactic dependency information.
Most graph neural network-based aspect sentiment analysis tasks encode a dependency-parsed tree for the entire sentence, and few researchers have converted it into an aspect-oriented dependency-parsed tree. In addition, since the existing dependency parsers do not have aspect-oriented specific parsers, the parser tends to confuse the opinion words of different aspects when there are two or more aspects in a sentence. For example, a sentence like this: “The price is so expensive but the service is timely and abundant.”, the dependency-parsed tree of the sentence after parsing by the parser is shown in Figure Figure 1., where the subscript of each word is its lexical property. It is easy to see from this that the dependency tree incorrectly connects the aspect word “price” with the opinion words of the aspect word “service”.In addition to this, to our knowledge, the lexical properties of each word has not been introduced as a basis for judging aspectual sentiment polarity in previous studies.

The dependency-parsed tree for “The price is so expensive but the service is timely and abundant.”
By analyzing the lexical properties of the words in the dataset, we found that most of the aspects’ opinion words belonged to verbs, adverbs and adjectives. Table 1 shows the corresponding lexical properties of each word in the sentence. To further argue for the sentiment polarity of the decision aspect the opinion word consists mainly of verbs, adverbs and adjectives, the constituent elements include { JJ,JJR,JJS,RB,RBR,RBS,VB,VBD,VBG,VBN,VBP, V BZ}, we randomly selected 100 data items from the Restaurant and Laptop datasets [10], respectively, and recorded the number of lexical occurrences of the constituent elements of the opinion words, and the results are shown in Table 2. From this we can see that although there are a few other lexical forms that make up opinion words, verbs, adverbs and adjectives still make up the majority. So we can infer that the word of opinion, which determines the sentiment polarity of the aspect, consists mainly of verbs, adverbs and adjectives.
Examples of sentences and their corresponding lexical properties
The number of lexical occurrences of opinion words in 100 sentences extracted from the Restaurant and Laptop datasets, respectively
In this paper, we propose a lexical attention and aspect-oriented GCN for aspect-based sentiment analysis. First we use Biaffine Parser [11] to obtain the dependency-parsed tree of the sentences and, of course, the lexical properties of each word. The original dependency-parsed tree has been restructured to better relate aspects to opinion terms, and an aspect-oriented dependency-parsed tree can better focus on the connection between aspects and potential opinion words. The lexical attention mechanism focuses on verbs, adjectives and adverbs, and the GCN is used to encode new dependency-parsed tree with lexical attention. Finally, the global features and aspect-oriented features are fused using a multi-headed self-attention mechanism. We have named this model LA-GCN and extensive experimental results on three benchmark datasets demonstrate the effectiveness of LA-GCN.
The contributions of this work include: In this paper,we propose a new aspect-oriented parse tree to reduce the impact of non-opinion words on aspects by pruning the nodes. We propose lexical attention mechanisms to focus on features that play a key role in sentiment polarity judgments. Experiments on the ablated LA-GCN design model were conducted to assess the significance and effectiveness of the LA-GCN design architecture.
In recent years, a variety of approaches have been cited to deal with the ABSA task, and most researchers have based their learning of features on deep learning methods. In this section, we will focus on the work related to aspect-level sentiment analysis from the perspective of deep learning.
Since neural network-based approaches do not require artificially crafted features and can be trained by the network to obtain semantic information about the text, they have received increasing attention from scholars studying natural language processing, including, of course,the ABSA task. Dong et al. [12] proposed Adaptive Recurrent Neural Network (AdaRNN) for target-related Twitter sentiment classification. Ada-RNN adaptively communicates the emotions of words to aspects based on the context and the syntactic relationships between them. Tang et al. [1] proposed two models, TD-LSTM and TC-LSTM, in order to obtain the relationship between aspects and contextual features. TD-LSTM used two LSTMs to model the aspect and left context and the aspect and right context respectively, and finally the implicit vectors of the two LSTMs are spliced and fed into a softmax classifier for classification. TC-LSTM splices the average of the aspect word vectors with the word vectors of each word in the sentence and then performs the same operation as TD-LSTM. Nguyen et al.; Wang et al.; Ma et al. [13–15] all used RNN to implement the ABSA task. Cheng et al. [16] employed a multi-attentional mechanism to capture emotionally distant features, resulting in greater robustness to irrelevant information. Xue et al. [2] proposed a model based on CNN and the electron pass mechanism.
Since the introduction of Transformer [17] in 2017, Transformer-based pre-training models GPT [18], GPT-2 [19], GPT-3 [20], BERT [21], and XLNet [22] have been widely used in natural language processing tasks, among which BERT has become a research hotspot for ABSA and has achieved good results. Xu et al. [23] explored a novel post-training method on the popular language model BERT to improve the fine-tuning performance of BERT on Reviewed Reading Comprehension (RRC), which can also be adapted to aspect-based sentiment analysis. Song et al. [24] proposed an attentional encoder network (AEN) that eschews recursion and used an attention-based encoder for context and aspect-to-subset modeling, and also applied a pre-trained BERT to this task. BERT was also used in the Category Name Embedding network (CNE-net) proposed by Dai et al. [25]. LCF-BERT was also a BERT-based post-training method [26].
In recent years, GCN combined with dependency trees have shown attractive effectiveness in ABSA tasks. Zhang et al.;Sun et al.; Chen et al. [8, 28] proposed to build a GCN on the dependency tree of sentences to exploit syntactic information and word dependencies. Tang et al. [29] proposed a dependency graph enhanced dual-transformer network (named DGEDT). Liang et al. [30] were able to leverage syntactic knowledge (dependencies and types) by using well-designed dependency embedded graph convolutional networks (DREGCN). However, these approaches usually ignore the lexical properties of words and the construction of an aspect-oriented dependency trees.
Preliminary
Dependency parsing
The syntactic structure of a sentence can be revealed by dependency parsing. The result of the dependency parsing of the sentence “The mushroom was rather over cooked and dried but the chicken was fine.” is shown in Figure 2., where the label under each word indicates its lexical properties. It is easy to see that the dependency tree is not rooted with the aspect, moreover, when the number of aspects in a sentence is greater than or equal to 2, the general dependency parsers tend to confuse the connection of opinion words of multiple aspects. We found by observation that most of the false connections start from root to the node farthest away from root. The dependency-parsed tree for this sentence is incorrectly connected in the aspect sentiment analysis scenario: cooked→fine.

The dependency-parsed tree for “The mushroom was rather over cooked and dried but the chicken was fine.”
Based on the above observations, we propose a method for constructing aspect-oriented dependency trees. By pruning the incorrect connections and reshaping the original dependency tree, only the nodes that are linked to that aspect as well as the lexical properties are retained.
Algorithm 1 describes the pruning process. Given an aspect
The results of pruning the sentence “The mushroom was rather over cooked and dried but the chicken was fine.” are shown in Figure 3. and Fig.4

Results after pruning of aspect “mushroom”.

Results after pruning of aspect “chicken”.
Pruning of the original dependency tree allowed the model to focus more quickly and accurately on the relationship between aspects and opinion words. The lexical properties of the retained words are also used as important factors in determining the sentiment polarity of aspects.
Given a context sequence
The network architecture of our proposed LA-GCN is shown in Figure Fig.5. The network mainly consists of an embedding layer, a lexical attention layer, a graph convolutional network layer, a feature fusion layer, and an output layer. For a given input text, we first utilize BERT as the aspect-based encoder to extract the hidden contextual representations. Then a mask operation is performed through the lexical attention layer for the purpose of focusing on opinion words, and the GCN aggregates the feature vectors of the nodes adjacent to the aspect. Finally feature fusion layer to fuse local features and global features between the aspect and the context.
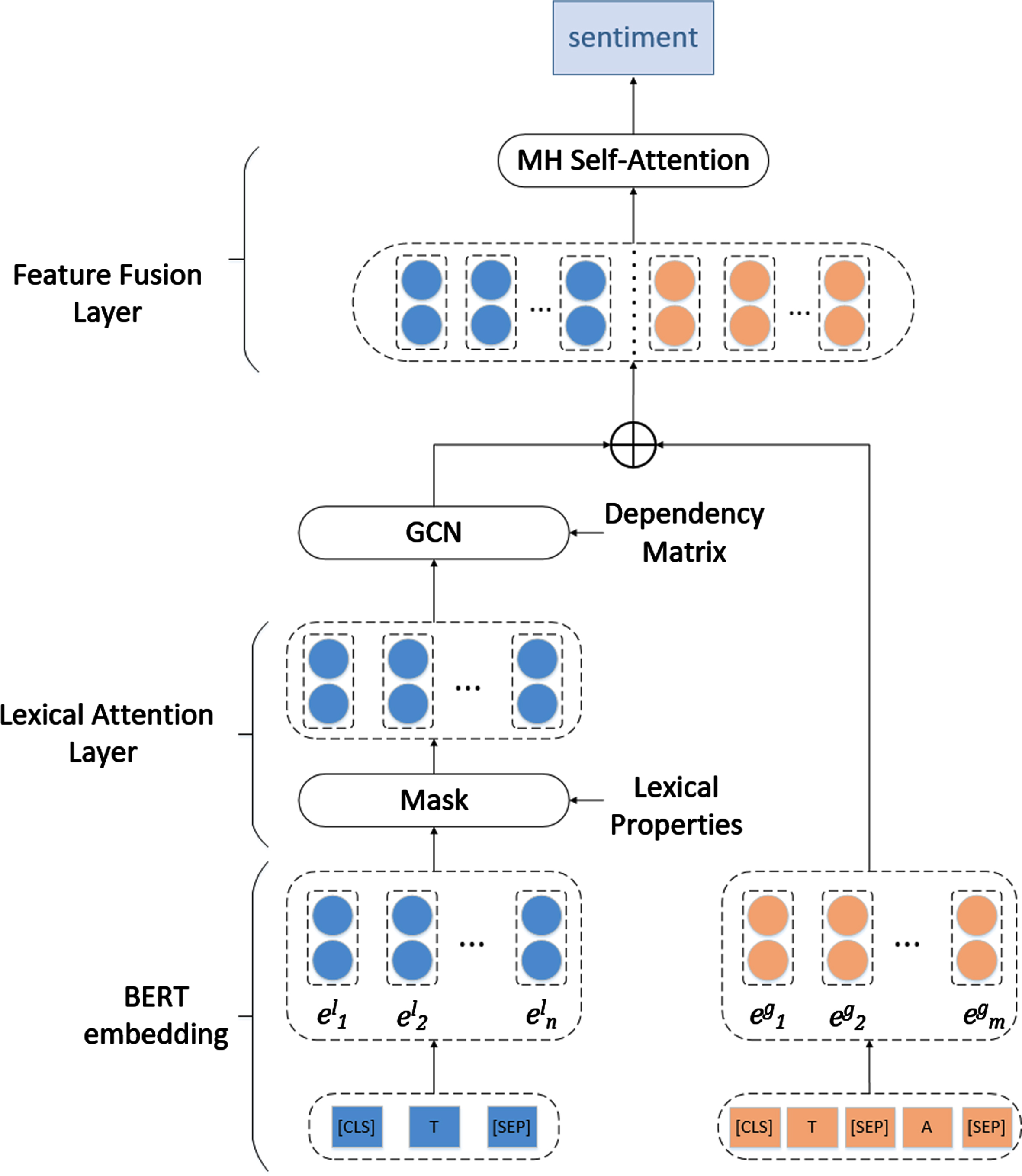
Overall architecture of LA-GCN design.
The embedding layer uses pre-trained BERT to generate word vectors for the sequences. The input format for obtaining global features is [CLS]+T+[SEP]+A+[SEP]. The format of the input for obtaining aspect-oriented local features is [CLS]+T+[SEP].
For the input of local context and global context representations T
l
and T
g
, respectively, we have
BERT l and BERT g are the corresponding BERT-shared layer modeling for local context and global context, respectively. The global feature e g represents the semantic relationship between the aspect and the contextual sentence. The aspect-oriented local feature e l represents the interaction between the context and the aspect.
The lexical attention layer focuses on the characteristics of words that play a key role in the sentiment polarity judgments. Since most opinion words are made up of adjectives, verbs, or adverbs, the lexicality to focus on M = {JJ,JJR,JJS,RB,RBR,RBS,VB,VBD,VBG, VBN,VBP,VBZ}. We classify the node lexicality into {major, other, non}. Where “major” means that the node has a dependency on the aspect and the lexical property of the node belongs to M,“other” indicates a dependent relationship with the aspect, but the lexical property of the node is not that of M, “non” indicates the lexical properties of a node that has no dependency on the aspect.
The lexical attention layer assigns weights to local features e l by lexicality, which is obtained by dependency pruning. If the lexical property belongs to “major”, the features are fully preserved, and if the lexical property belongs to “other”, the decay is enhanced by the relative distance from the aspect, focusing mainly on features that are closer to the aspect. The features with lexical “non” are masked, and the masked features are set as zero vectors.
Given a local feature e
l
, the aspect A. The vector o
la
after performing lexical attention is:
Where
The GCN aggregates the feature vectors of neighboring nodes and propagates the information of a node to its first-order neighbor nodes. The graph convolutional network layer takes the lexically weighted features and passes them through the GCN to obtain new features. For a dependency tree with n nodes, an n×n adjacency matrix A can be generated. We took the pruned dependency tree and generated an n×n adjacency matrix adj according to its dependencies, where we added a self-loop for each node, i.e., adj
ij
=adj
ji
=1. Then, the GCN layer can convolve the features of neighboring nodes to obtain new node features by the following functions:
Where
The attention function used in this paper is Scaled Dot Product Attention, and the attention fraction is calculated as follows:
where o is the input word vector representation, Q, K, V are obtained by multiplying o by their respective weight matrices w q ∈ Rd h ×d q , w k ∈ Rd h ×d k ,w v ∈ Rd h ×d v , d h is the hidden layer dimension, and h is the number of attention heads, which is set to 6 in this paper.
Assuming that H
i
is a learned representation for each self-attentional head, then there is:
where “;” denotes a vector connection and w mhsa ∈ Rhd v ×d h is a learnable parameter.
Feature Fusion Layer (FFL) is designed to interactively learn aspect-oriented local features and global features between aspects and contexts. If only local information is considered, some useful information will be overlooked, so the MSAH operation is performed after connecting local features with global features.
where o gcn is the output of the graph convolutional network layer, e g is the text pair consisting of the context sentence T and the aspect term A obtained by pre-trained BERT, and “;” denotes the vector connection.
In the output layer, the output vector O
all
of the feature fusion layer is passed through the fully connected layer to obtain the vector
where C is the sentimental polarity class, y is the sentimental polarity predicted by the model, and W ∈ R1×d h and b ∈ R d h are learnable parameters.
We use the L2-regularized cross-entropy loss as a loss function to adjust the LA-GCN model parameters, and the loss function is defined as follows:
Dataset
We conducted experiments on three datasets: the SemEval-2014 Task consisting of Restaurant reviews and Laptop reviews [10], and the ACL 14 Twitter dataset collected by Dong et al. [12].All aspects of the above dataset were labeled with three types of sentiment polarity: positive, neutral, and negative. Statistics for the three datasets are shown in Table 3.
Statistics of the three datasets
Statistics of the three datasets
We use BERT-base English version, which contains 12 hidden layers and 768 hidden units for each layer. The vocab size of BERT is 30,522. We use Adam [31] as the optimizer for the model, with the initial value of the learning rate set to 2×10-5 and the L2 regularization is set to 1×10-5. Batch shuffling is applied to the training set. The batch size of all model is set as 16. We train our model up to 10 epochs and conduct the same experiment for 10 times with random initialization. The dependency-parsed tree is obtained using Biaffine Parser 1
Model comparisons
To fully evaluate the performance of the LA-GCN
2
model, we evaluated it on three experimental data and compared it with several baseline models, including: TD-LSTM [1] uses two LSTMs to model the aspect and left context and the aspect and right context, respectively, and then splices the last hidden vector of the two LSTMs into a softmax classifier for classification. ATAE-LSTM [4] splices the embedding of each word with the embedding of the aspect at the embedding level to get a representation of the word associated with the aspect. The final representation is then obtained and classified using LSTM and attention. MGAN [6] uses fine-grained and coarse-grained attention to capture word-level interactions between aspects and sentences. BERT-PT [23] explored a novel post-training method on the popular language model BERT to improve BERT’s fine-tuning performance on Reviewed Reading Comprehension (RRC), which can also be adapted to aspect-based sentiment analysis. AEN-BERT [24] eschews recursion and uses an attention-based encoder to model between the context and the target. LCF-BERT [26] proposes a Local Context Focusing (LCF) mechanism for aspect-based sentiment classification based on Multiple Head Self-Attention (MHSA), which focuses on contextual local features. The mechanism utilizes contextual feature dynamic masking (CDM) and contextual feature dynamic weighting (CDW) layers to focus more on local contextual words. ASGCN [8] extracts aspect-related features from the data by performing dependency parsing on the data and then using a GCN. TD-GAT [32] uses the new Target-Dependent Graph Attention Network (TD-GAT) for aspect-level sentiment classification, which explicitly exploits dependency relationships between words. Use a dependency tree, which propagates affective features directly from the syntactic context of the aspect target. R-GAT [9] considered dependency labeling information and proposed a new relational graph attention network which integrates typed syntactic dependency information.
Results and analysis
Main results
Table 4 shows the overall performance of all models. According to the experimental data, we can observe that the LA-GCN model outperforms most of the baseline models. Compared with the graph neural network-based ASGCN, TD-GAT and RGAT, the overall performance of our model is substantially improved, illustrating the effectiveness of lexical attention-based and aspect-oriented GCN design. By assigning higher weights to potential opinion words through a lexical attention mechanism, the aspect-oriented GCN aggregates features of words with grammatical connections to aspects, thus improving the overall performance of the model. Among them, the performance improvement of LA-GCN model is larger in Restaurant and Laptop datasets, but limited in Twitter dataset because the sentences in Twitter dataset are less grammatical, which limits the efficacy. Furthermore we can find that the BERT-based baseline model has surpassed most of the current ABSA models, which proves the usefulness of the BERT-based pre-trained model in aspect-based sentiment analysis tasks. After combining BERT with our proposed model, the overall performance is further improved and reaches a new level.
Model comparison results (%).The results of models we reproduced by following the methodology published in the paper are indicated by asterisk (#)
Model comparison results (%).The results of models we reproduced by following the methodology published in the paper are indicated by asterisk (#)
To further examine the contribution made by each component of LA-GCN to the overall performance, an ablation study was performed on LA-GCN. The results are shown in Table 5.
Ablation study results (%). “w/o” means “without”
Ablation study results (%). “w/o” means “without”
We first investigate the impact of the dependent pruning (DP) mechanism on the overall model. It was found through experiments that the Restaurant dataset and the Laptop dataset were more affected when the model was trained on the unpruned dependency parse tree, both in terms of accuracy and F1 values, which were much lower. The main reason is that both lexical attention and aspect-oriented GCN designs are based on dependency-parsed tree implementations. If the dependency tree is not pruned, there is a high chance that the lexical attention mechanism will give high weight to opinion words from other aspects, and the graph convolutional neural network will also extract other wrong information when extracting features, which will have a greater impact on the performance of the model. The impact on the Twitter dataset is smaller in comparison, mainly because the sentences in the Twitter dataset are less grammatical, so the performance is not degraded too much.
Next we investigated the effect of the lexical attention layer (LAL). The role of the lexical attention mechanism is to focus on the features of words that play a key role in the sentimental polarity judgments. We found that the overall performance of the model without LAL is smaller than that of LA-GCN, which indicates that LAL is important for LA-GCN design, and also shows that the word lexicality is useful for sentiment classification.
We then investigate the impact of the graph convolutional network layer (GCN). This layer mainly extracts new features on the output of the lexical attention layer. From the experimental data we can find that the overall performance of the model decreases, but the effect on the model is smaller compared to the effect of the lexical attention layer. Because the lexical attention layer has already acquired the opinion word features, this layer is also based on the lexical attention layer for feature extraction, so the overall impact on the model is less than that of the lexical attention layer.
Finally we investigate the effect of the feature fusion layer (FFL) on the model. In studying the significance of the FFL, we only took aspect-oriented local features for classification and did not fuse global features. Although the experimental results are much worse compared to LA-GCN, the performance on Restaurant and Laptop datasets is still much improved compared to ASGCN, TD-GAT, RGAT, which are graph convolutional neural network-based models. On the one hand, this illustrates the effectiveness of lexical attention and aspect-oriented GCN design. On the other hand it also directly illustrates the importance of the feature fusion layer for the model.
In this section, we select a sample for case study analysis.The results of the sample-dependent pruning are illustrated in Figures Fig.6. and Fig.7., and LA-GCN outputs correct predictions for both aspects of the sample, ’food’ and ’perks’. Figures Fig.8. and Fig.9. show a visualizations of the lexical attention process for each of the two aspects.

Results of dependency pruning and LA-GCN prediction for the aspect “food”.

Results of dependency pruning and LA-GCN prediction for the aspect “perks”.

The process of lexical attention to aspect “food”. Darker cell color indicates higher attention value and white indicates that the feature will be masked.

The process of lexical attention to aspect “perks”. Darker cell color indicates higher attention value and white indicates that the feature will be masked.
Dependency pruning reduces linking errors and enhances the connection between aspects and opinion words.LA-GCN introduces a lexical attention mechanism that allows for better prediction of aspect sentiment polarity by focusing on features that play a key role in aspect sentiment polarity judgments through grammatical information, while suppressing interference from opinion words in other aspects.
In this paper, we propose an approach based on lexical attention and aspect-oriented GCN. Firstly, by pruning the dependency-parsed tree, reconstructing an aspect-oriented dependency-parsed tree can better link aspects and opinion words, and then introducing a lexical attention mechanism to focus on potential opinion words that have dependency relationships with aspects, and afterwards aggregating the feature vectors of aspect-adjacent nodes by GCN. After obtaining aspect-oriented local features, to avoid missing useful information, we stitch the global features with the local features, then fuse the features through a multi-headed self-attentive mechanism, and finally perform classification. This method not only allows direct attention to the characteristics of the opinion words, but also reduces the incorrectness introduced by the parser. We also conducted an ablation study to verify the usefulness of the structural design of the LA-GCN layers for the model. Experimental results on three public datasets show that the method is able to better associate aspects with opinion words, which significantly improves the performance of the model.
Acknowledgements
This work is supported by the Science & Technology project (41008114, 41011215, and 41014117).