
Abstract
Intent detection and slot filling are recognized as two very important tasks in a spoken language understanding (SLU) system. In order to model these two tasks at the same time, many joint models based on deep neural networks have been proposed recently and archived excellent results. In addition, graph neural network has made good achievements in the field of vision. Therefore, we combine these two advantages and propose a new joint model with a wheel-graph attention network (Wheel-GAT), which is able to model interrelated connections directly for single intent detection and slot filling. To construct a graph structure for utterances, we create intent nodes, slot nodes, and directed edges. Intent nodes can provide utterance-level semantic information for slot filling, while slot nodes can also provide local keyword information for intent detection. The two tasks promote each other and carry out end-to-end training at the same time. Experiments show that our proposed approach is superior to multiple baselines on ATIS and SNIPS datasets. Besides, we also demonstrate that using bi-directional encoder representation from transformer (BERT) model further boosts the performance of the SLU task.
Introduction
Apart from the voice part, the task-oriented dialog system mainly consists of four parts: spoken language understanding (SLU), dialogue state tracking (DST), dialogue policy optimization (DPO), and natural language generation (NLG) [1]. As the beginning part, the quality of SLU module directly affects the performance of the whole dialog system. Its main responsibility is to take the user utterance as input and perform the following three tasks: domain determination, intent detection, and slot filling [2]. Among them, the purpose of the first two tasks is to identify the domain and intent in the utterance, both of which are classification problems and are usually combined for modeling. The latter is generally considered to be a sequence tagging problem [3]. For instance, the utterance “play techno on lastfm” randomly sampled in the SNIPS dataset, as shown in the Table 1. It adopts BIO annotation method. As you can see, each word in the utterance corresponds to a slot tag, and the whole utterance corresponds to a specific intent.
A sample example contains: intent label PlayMusic and slot label (BIO annotation format)
A sample example contains: intent label PlayMusic and slot label (BIO annotation format)
In early research, slot filling and intent detection tasks were usually modeled separately from two tasks, which is called pipelining methods. Intent detection is considered to be an utterance classification problem to predict an intent label, which can be modeled using traditional classifiers, including logic regression, support vector machine (SVM) [4], Adaboost [5] or recurrent neural network (RNN) [6]. The slot filling task can be framed as a sequence labeling problem. At present, there are two better performance methods: conditional random field (CRF) [7] and recurrent neural network (RNN) [8]. However, traditional machine learning methods need to extract features by hand, and RNN often has the problem of gradient vanishing when dealing with long sentence sequences.
Considering these two tasks often occur simultaneously and are related to each other, the tendency is to model the two tasks at the same time and develop a series of joint models [9–12]. However, these models only implicitly apply the joint loss function to the relationship between the two tasks. [2] proposed a RNN-LSTM model that does not establish an explicit relationship between intent and slots. Considering that the correct identification of the intent in the sentence is helpful to the slot filling task. [13, 14], and [15] designed a gate/mask mechanism, which integrates the intent information into the slot vector, and further combines the intent information to slot filling, which can filter out some non-entity slots. [16] adopts the token-level intent detection for the stack-propagation framework, using the output vector of the intent directly as input to slot filling. Recently, some researchers have also begun to study the use of slot information to predict intent tag, explicitly constructing a bi-directional interrelated relationship between two tasks. [17] proposed a capsule-based neural network model, which constructs intent capsules, slot capsules and word capsules, and accomplishes slot filling and intent detection via a dynamic routing-by-agreement schema. [18] proposed a SF-ID neural network structure. It uses ID subnet and SF subnet to establish direct connections between the two tasks to help them promote each other mutually. This approach adopts an iterative method in training, which needs to set the number of iterations manually, so it is difficult to optimize.
We apply the proposed approach to the single intent ATIS and SNIPS public datasets from [19] and [13], separately. Our experimental results show that our approach outperforms multiple baseline models. We further verified that using the pre-trained BERT representations [20] can greatly improve performance. The main contributions of this paper can be summarized as follows: (1) We propose a novel joint model with a wheel-graph attention network, which is able to model interrelated connections directly for single intent detection and slot filling tasks. (2) Establishing the interrelated mechanism explicitly among intent nodes and slot nodes in an utterance by a graph attention neural network (GAT) structure. (3) The graph structure can better learn the weight values of the edges of intent and slot nodes, and make our joint model more interpretable. (4) Our method is proved to be more effective on two popular datasets. (5) We investigated and explained the performance improvement after introducing pre-trained BERT into SLU tasks.
For easy reproduction, the source code of our implementation is publicly stored in https://github.com/gumowangfei/WheelGraph-SLU.
In current section, we will introduce the related research progress of SLU and GNN in detail.
Spoken language understanding
Graph neural networks
Applying graph neural networks (GNN) to solve some problems has been a popular approach recently in social network analysis [27], knowledge graphs [28], urban computing, and many other research areas [29, 30]. GNN is very suitable for modeling non-Euclidean sample problems, but traditional neural network methods can only deal with regular data. [31] proposed a simplified model of graph neural network, called graph convolutional network (GCN). GCN is a multi-layer neural network that relies on graph structure to determine update weights. It operates directly on the graph and summarizes the node’s embedded vector based on its neighborhood nodes.
Unlike previously discussed many joint models methods, our proposed approach explicitly establishes direct connections among intent nodes and slots nodes by GAT [29], which uses weighted neighbor features with feature dependent and structure-free normalization, in the style of attention. GAT is an improvement of GCN on neighbor weight assignment. Attention is learned through Multi-head Attention, which makes more sense than the GCN’s update weights, which rely solely on the graph structure. Analogous to multiple channels in ConvNet [32], GAT introduces a multi-head attention [33], which increases the parameters of the model, but improves the learning ability of the model, and can learn more types of attention features. Unlike other models [17, 18], our model does not need to set the number of iterations during training. We have also established a wheel graph structure to learn context-aware information in an utterance better.
Proposed approaches
In this section, we will introduce our wheel-graph graph attention model for SLU tasks. The detailed network architecture of the entire model is shown in Figure 1. First, we show how to uses a text encoder to encode an utterance, so that can gain the shared knowledge between two tasks. Second, we introduce the graph attention network (GAT) user weighted neighbor features with feature dependent and structure-free normalization, in the style of attention. Next, the wheel-graph attention network performs an interrelation connection fusion learning of the intent nodes and slot nodes. Finally, intent detection and slot filling are optimized simultaneously via a joint learning schema. Finally, the end-to-end joint learning schema is used to optimize intent detection and slot filling tasks simultaneously.
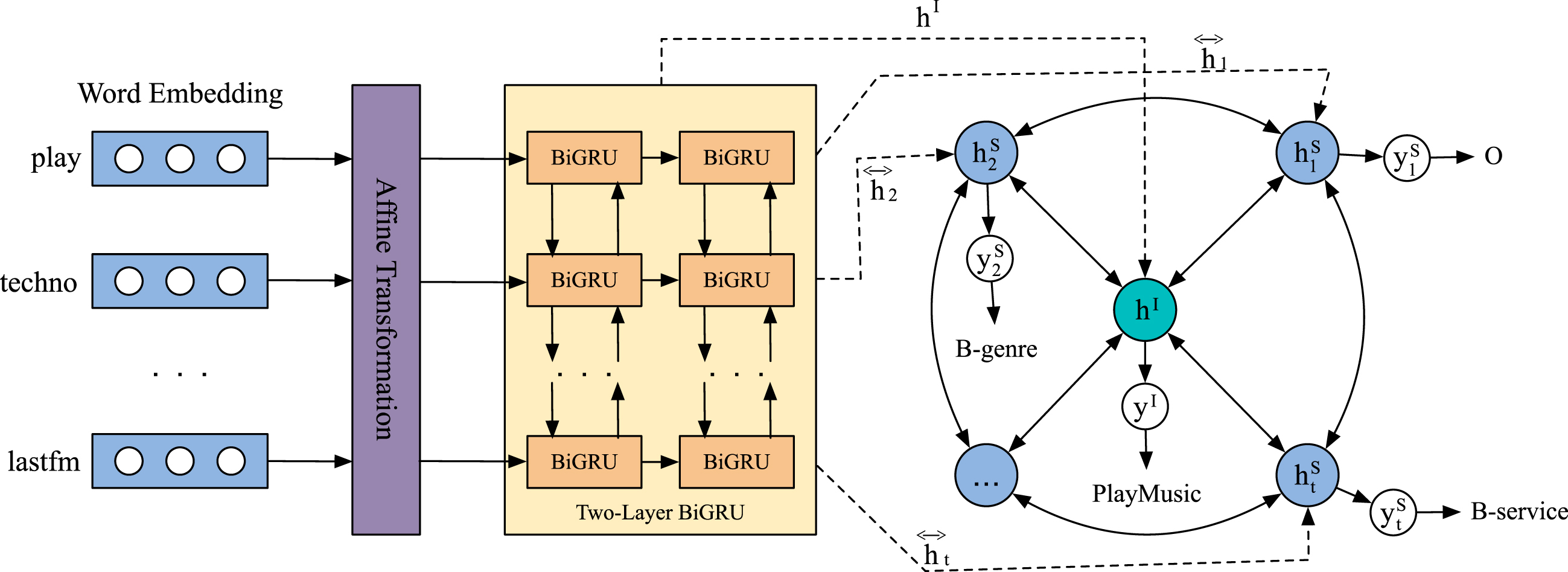
The overall architecture of the proposed model based on Wheel-Graph attention networks.
In order to take into account both past and future information. Consequently, we will exploit a two-Layer bidirectional GRU (BiGRU) to learn the utterance representations at each time step. The BiGRU, a modification of the GRU, consists of a forward and a backward GRU. The layer reads the affine transformed output vectors [
In summary, to get more fine-grained sequence information, we use a two-layer BiGRU to encode input information. The representation is defined as:
The graph attention network (GAT) [29] is a variant structure of graph neural network [36] and is an important module in our proposed approach. It propagates the intent or slot information from a one-hop neighborhood. Given a dependency graph with N nodes, where each node is associated with a local hidden vector
GAT exploits the attention mechanism as a substitute for the statically normalized convolution operation. Below are the equations to compute the node embedding
In the SLU task, there is a strong correlation between intent detection and slot filling. To make full use of the correlation between intent and slot, we constructed a wheel-graph structure. In Figure 1, this wheel-graph structure contains an intent node and slot nodes.
For the node representation, we use the output of the previous two-layer BiGRU, and the formula is expressed as:
For the edge, we created a bidirectional connection between the intent node and the slot nodes. To make better use of the context information of the utterance, we created a bidirectional connection between the slot nodes and connected the head and tail of the utterance to form a loop.
All in all, the feedforward process of our proposed wheel-graph attention network can be written as follows:
The last layer is the output layer. We adopt a joint learning method. The softmax function is applied to output representations with a linear transformation matrix to give the probability distribution
Then we define loss function for our model. We use
The loss function of intent is a cross-entropy cost function.
Similarly, the loss function for a slot label sequence is formulated as:
The training objective of the model is minimizing a united loss function:
In this section, we describe our experimental setup and report our experimental results.
Experimental setup
For the experiment, we adopt two popular datasets, including ATIS [38] and SNIPS [19], which is collected by Snips personal voice assistant in 2018. They are two public benchmark single-intent datasets, which are widely used as benchmarks in SLU researches. Compared to the single-domain ATIS dataset, SNIPS is more complicated, mainly due to the intent diversity and large vocabulary. Both datasets used in our paper follows the same format and partition as in [16]. The statistics of two datasets are shown in Table 2.
Datasets overview
Datasets overview
In order to verify the effectiveness of our approach, we compare it with the following baseline approaches. It is worth noting that the metrics of some approaches are obtained directly from [16].
In our experiments, the dimensionalities of the word embedding are 1024 for the ATIS dataset and SNIPS dataset. All model weights are initialized with uniform distribution. The number of hidden units of the BiGRU encoder is set as 512. The number of layers of the GAT model is set to 1. Graph node representation is set to 1024. The weight factor α is set to 0.1. We use the Adam optimizer [39] with an initial learning rate of 10-3, and L2 weight decay is set to 10-6. The model is trained on all the training data with a mini-batch size of 64. In order to enhance our model to generalize well, the maximum norm of gradient clipping is set to 1.0. We also apply the dropout ratio is 0.2 for reducing overfit.
We implemented our model using PyTorch 1 and DGL 2 on a Linux machine with Quadro p5000 GPUs. For all the experiments, We select the model that works best on the validation set and evaluate it on the test set.
Experimental results
As with Qin et al [16], we used three evaluation metrics in our experiment of the SLU tasks. For intent detection tasks, the accuracy is used. For slot fill tasks, the f1-score is utilized. F1-score combines two metrics of precision rate and recall rate, which can better evaluate the model. In addition, in order to evaluate the overall performance of the sentence, the sentence accuracy was used to represent the overall performance of the two tasks. Specifically, the percentage of samples when intent detection and slot filling are both correctly predicted across the corpus. Table 3 shows the experimental results of the proposed model on single-intent ATIS and SNIPS datasets.
Comparison results of different methods using Wheel-GAN on ATIS and SNIPS datasets. The metrics with* show that the improvement of our approach on all baselines is statistically significant with p < 0.05 under t-test
Comparison results of different methods using Wheel-GAN on ATIS and SNIPS datasets. The metrics with* show that the improvement of our approach on all baselines is statistically significant with p < 0.05 under t-test
We note that the results of unidirectional related joint models are better than implicit joint models like Joint Seq [2] and Attention BiRNN [11], and the results of interrelated joint models are better than unidirectional related joint models like Slot-Gated Full Atten. [13] and Self-Attentive Model [15]. That is likely due to the strong correlation between the two tasks. The intent representations apply slot information to intent detection task while the slot representations use intent information in slot filling task. The bi-directional interrelated model helps the two tasks to promote each other mutually.
We also find that our graph-based Wheel-GAT model performs better than the best prior joint model Stack-Propagation Framework. In ATIS dataset, our model achieve 0.6%improvement on Intent (Acc), 0.1%improvement on Slot (F1-score) and 0.7%improvement on Sentence (Acc). In the SNIPS dataset, our model achieve 0.4%improvement on Intent (Acc), 0.6%improvement on Slot (F1-score), and 0.5%improvement on Sentence (Acc). This indicates the effectiveness of our Wheel-GAT model. In the previously proposed model, the iteration mechanism used to set the number of iterations is not flexible on training, and the token-level intent detection increases the output load when the utterance is very long. While our model employed graph-based attention network, which uses weighted neighbor features with feature dependent and structure-free normalization, in the style of attention, and directly takes the explicit intent information and slot information further help grasp the relationship between the two tasks and improve the SLU performance.
In this section, to further examine the level of benefit that each component of Wheel-GAT brings to the performance, an ablation study is performed on our model. The ablation study is a more general method, which is performed to evaluate whether and how each part of the model contributes to the full model. We ablate four important components and conduct different approaches in this experiment. Note that all the variants are based on joint learning method with joint loss. Wheel-GAT w/o intent → slot, where no directed edge connection is added from the intent node to the slot node. The intent information is not explicitly applied to the slot filling task on the graph layer. Wheel-GAT w/o slot → intent, where no directed edge connection is applied from the slot node to the intent node. The slot information is not explicitly utilized to the intent detection task on the graph layer. Wheel-GAT w/o head ↔ tail, where no bidirectional edge connection is used between the intent node and the slot node. We only use joint loss for joint model, rather than explicitly establishing the transmission of information between the two tasks. Wheel-GAT w/o GAT, where no graph attention mechanism is performed in our model. The message propagation is computed via GCN instead of GAT. GCN introduces the statically normalized convolution operation as a substitute for the attention mechanism.
Table 4 shows the joint learning performance of the ablated model on ATIS and SNIPS datasets. We find that all variants of our much model perform well based on our graph structure except Wheel-GAT w/o GAT. As listed in the table, all features contribute to both intent detection and slot filling tasks.
Ablation Study on ATIS and SNIPS datasets. → indicates that the intent node points to the edge of the slot node. ← indicates that the slot node points to the edge of the intent node. ↔ indicates the edge where the head and tail word nodes are connected in an utterance
Ablation Study on ATIS and SNIPS datasets. → indicates that the intent node points to the edge of the slot node. ← indicates that the slot node points to the edge of the intent node. ↔ indicates the edge where the head and tail word nodes are connected in an utterance
If we remove the intent → slot edge from the holistic model, the slot performance drops 0.5%and 1.3%respectively on two datasets. Similarly, we remove the slot → intent edge from the holistic model, the intent performance down a lot respectively on two datasets. The result can be interpreted that intent information and slot information are stimulative mutually with each other. We can see that the added edge does improve performance a lot to a certain extent, which is consistent with the findings of previous work [13, 18].
If we remove the head ↔ tail edge from the holistic model, we see 0.4%drop in terms of F1-score in ATIS and 0.8%drop in terms of F1-score in SNIPS. We attribute it to the fact that head ↔ tail structure can better model context-aware information in an utterance.
To verify the effectiveness of the attention mechanism, we remove the GAT and use GCN instead. For GCN, a graph convolution operation produces the normalized sum of the node feature of neighbors. The result shows that the intent performance drops 1.3%and 1.7%, the slot performance drops 1.0%and 4.0%, and the sentence accuracy drops 2.9%and 9.8%respectively on ATIS and SNIPS datasets. We attribute it to the fact that GAT uses weighting neighbor features with feature dependent and structure-free normalization, in the style of attention.
In this section, to better understand what the wheel-graph attention structure has learned, we visualize the attention weights of slot → intent and each slot node, which is shown in Figure 2.
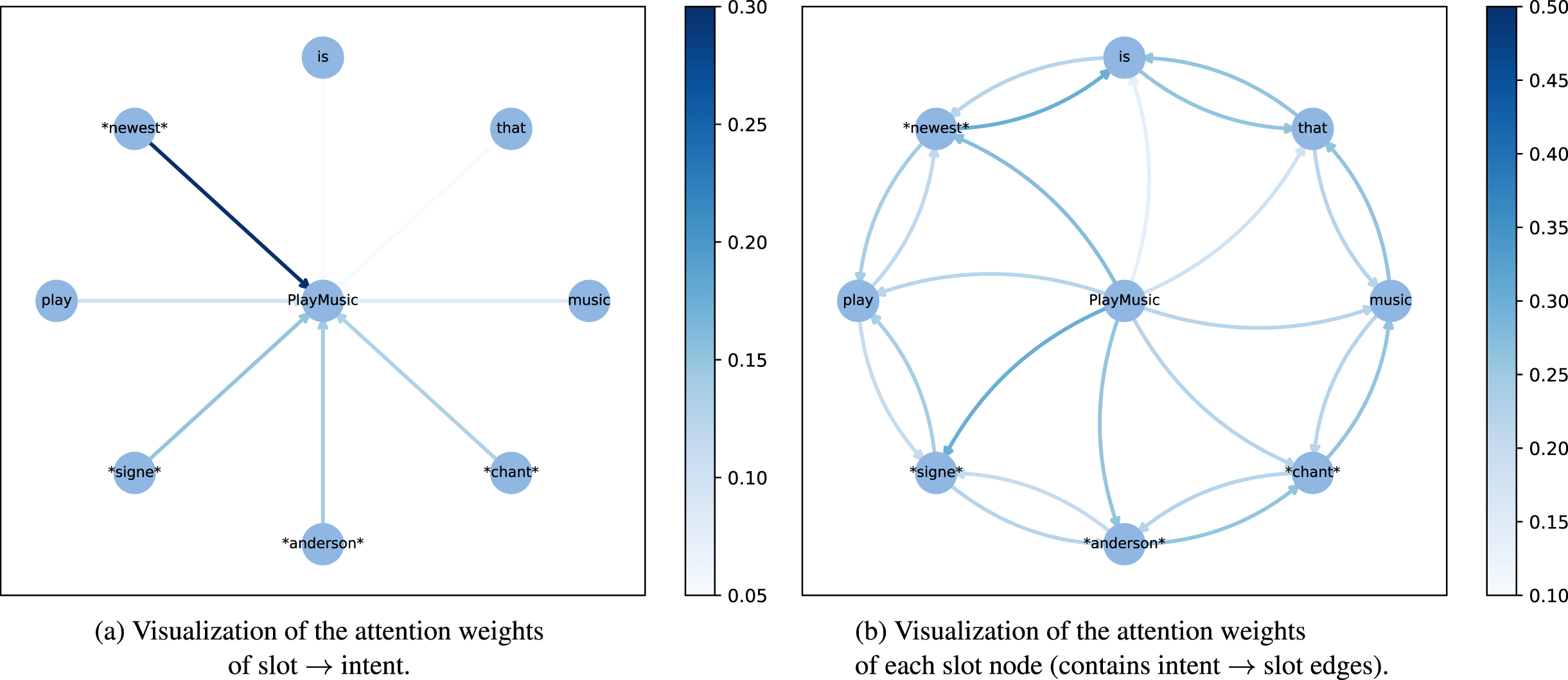
The central node is intent token and slot tokens are enclosed by *. For each edge, the darker the color is, it means that this corresponding of the two nodes is more relevant. It aggregates more information from this source node features.
Based on the utterance “play signe anderson chant music that is newest”, the intent “
In this section, we also experiment with a pre-trained BERT-based [20] model instead of the Embedding layer, and use the fine-tuning approach to boost SLU task performance and keep other components the same as with our model.
From Table 5, it can be seen that the Stack-Propagation + BERT [16] joint approach achieves a new state-of-the-art (SOTA) result than another without a BERT-based model, which indicates the effectiveness of a powerful pre-trained model in SLU tasks. We attribute it to the fact that pre-trained models can provide rich semantic features, which can help improve the performance of SLU tasks. Wheel-GAT + BERT outperforms the Stack-Propagation + BERT. That is likely due to we adopt explicit interaction between intent detection and slot filling in two datasets. This demonstrates that our proposed model is reasonable.
The SLU experimental results on BERT-based model on ATIS and SNIPS datasets
The SLU experimental results on BERT-based model on ATIS and SNIPS datasets
In this paper, we first apply the graph network to the SLU tasks. And we propose a new wheel-graph attention network (Wheel-GAT) model, which provides a bidirectional interrelated mechanism for intent detection and slot filling tasks. Compared with the previous model, our model has explicit modeling intent detection task and slot filling task. Where the intent node and the slot node construct an explicit bidirectional interrelated edge. This graph propagation mechanism can better learn the weight of the associated edge, further provide fine-grained semantic information integration for token-level slot filling to predict the slot label correctly, and it can also provide specific slot information integration for sentence-level intent detection to predict the intent label correctly. Experimental results show that the bidirectional interrelated model helps the two tasks promote performance each other mutually. Although this explicit way of constructing bidirectional interrelated relationship increases the complexity of the model, the performance of the whole model is greatly improved compared with the implicit method.
We discuss the network details of the proposed model, and do some experiments with some benchmark models to verify the effectiveness of our model. In addition, in order to further explore the advantages of our model, some ablation experiments were performed. Specifically, we first conduct experiments on ATIS and SNIPS single intent datasets. The experimental results show that the method of our model outperforms all baseline methods on all evaluation metrics. Then, in order to further investigate the effectiveness of the wheel-gat components for correlation intent detection and slot filling, we also report the ablation test results in Table 4. Since we are using the attention mechanism, so we visualize and analyze the slot → intent and the attention weight of each slot node. Finally, we also discuss and analyze the effect of adding pre-trained BERT model to SLU tasks. The results show that the proposed model achieves the state-of-the-art performance.
In future works, our plan can be summarized as follows: (1) We plan to increase the scale of our dataset and explore the efficacy of combining external knowledge with our proposed model. (2) Collecting multi-intent datasets and expanding our proposed model to multi-intent datasets to explore its adaptive capabilities. (3) We plan to introduce reinforcement learning on the basis of our proposed model, and use the reward mechanism of reinforcement learning to improve the performance of the model. (4) Intent detection and slot filling are usually used together, and any task prediction error will have a great impact on subsequent dialog state tracking (DST). How to improve the accuracy of the two tasks while ensuring the stable improvement of the overall evaluation metrics (Sentence accuracy) still needs to be further explored.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant No.61876043, National Natural Science Foundation of Guangdong Province under Grant No.2018A030313868 and Major Industry-University Research Project of Guangdong Province under Grant No.2016B010108004. The corresponding author of this paper is Bi Zeng.