
Abstract
Since small objects occupy less pixels in the image and are difficult to recognize. Small object detection has always been a research difficulty in the field of computer vision. Aiming at the problems of low sensitivity and poor detection performance of YOLOv3 for small objects. AFYOLO, which is more sensitive to small objects detection was proposed in this paper. Firstly, the DenseNet module is introduced into the low-level layers of backbone to enhance the transmission ability of objects information. At the same time, a new mechanism combining channel attention and spatial attention is introduced to improve the feature extraction ability of the backbone. Secondly, a new feature pyramid network (FPN) is proposed to better obtain the features of small objects. Finally, ablation studies on ImageNet classification task and MS-COCO object detection task verify the effectiveness of the proposed attention module and FPN. The results on Wider Face datasets show that the AP of the proposed method is 11.89%higher than that of YOLOv3 and 8.59%higher than that of YOLOv4. All of results show that AFYOLO has better ability for small object detection.
Introduction
Object detection is a basic problem in the field of computer vision. It is also a hot topic of theoretical research in recent years. It is widely used in many applications, such as face detection [1], mask detection [2], automatic driving [3], etc. The main task is to accurately locate and identify various objects in images or video. In recent years, with the rapid development of deep learning, convolutional neural networks (CNNs) have been applied more and more in computer vision, and achieved great success. Meanwhile, it has injected new vitality into object detection. Object detection based on deep learning is mainly divided into two categories. The first one is two-stage detector. The representative two-stage detector is R-CNN [4], proposed by Girshick et al., which firstly uses the CNNs to extract the region of interests (RoIs), and then performs classification and regression. Fast R-CNN [5] and Faster R-CNN [6] also belong to this pipeline. The accuracy of the two-stage detectors is relatively high, but the inference speed is slow. The other one is one-stage detector. One of the more influential one-stage detectors is YOLOv3 [7], an end-to-end detector. It can directly predict the locations and categories of the objects in the image or video. The one-stage detectors have fast inference speed and good real-time performance. But the accuracy is always slightly lower than two-stage detectors.
YOLO series methods, such asYOLOv2 [8] and YOLOv3, are known for their detection speed. Among them, the more influential YOLOv3 adopts a new backbone, namely DarkNet-53. It uses the idea of ResNet [9] for reference to improve the accuracy and efficiency of the detector. YOLOv3 uses fixed-size images as input, and uses regression to directly predict the locations and categories of the bounding boxes. Although YOLOv3 has a fast inference speed, its detection performance has not been completely explored, especially for small objects. The proposed method aims at solving the problem that YOLOv3 is not sensitive to small objects and is easy to miss-detection.
AFYOLO, a YOLOv3-based detector is proposed in this paper. Firstly, the parts of the ResNet in the Darknet53 are replaced by DenseNet [10]. And a new attention module was added into backbone. Then, in order to further enhance the features of small objects, a novel feature pyramid network (FPN) is introduced. Among the letters of AFYOLO, A stands for attention mechanism and FPN is F. Compared with YOLOv3, AFYOLO has achieved excellent performance on Wider Face [11] and MS COCO [12] benchmark. Before that, we used ImageNet [13] to verify the effectiveness of the attention module. Moreover, other baseline models are used on the MS COCO val set to evaluate and compare with ours. All of the baselines with our modules have achieved better results.
There are three contributions in this paper. (1) An attention module with better performance by effectively combining ECA channel attention and spatial attention have been proposed. It can be conveniently embedded into other CNNs (2) To solve the problem of poor detection performance of small objects, a Feature Enhancement Layer (FEL) is proposed and embedded in FPN. Better performance was achieved on the MS COCO val set with a small number of additional parameters. (3) Our proposed module (Attention module and FPN) is effective on ImageNet and MS COCO benchmarks. The improved YOLOv3-based detector, AFYOLO, is also proposed to achieve competitive results at Wider Face benchmark.
Related works
Small objects detection
In the field of object detection, large objects are usually easier to be detected because of their large area and rich features. Small object detection, such as UAV remote crowd detection [14] and satellite remote sensing image detection [15], are always difficult tasks. Small object detection has been a difficult and hot research topic in the computer vision field.
Small objects contain fewer pixels and carry less information, which often leads to miss detection and false detection. The detection accuracy of some methods for small objects is far lower than that for large objects [6, 16]. In view of the above problems, many scholars have carried out a variety of studies. Rabbi J et al. [17] used an edge-enhanced super-resolution GAN [18] (EESRGAN) to improve the quality of remote sensing images and achieved good performance on satellite data sets. BYLA et al. [19] designed a multi-block SSD [16], which divides the original image into several patches, inputs them into SSD separately, and finally merges them. Compared with the traditional SSD, accuracy is improved by 9.2%. Zhang et al. [20] used deconvolution to recover the lost information in convolution, and achieved good performance on several data sets. Meng et al. [21] also input the image patches into CNNs, and achieved good performance on the relevant data sets by a data enhancement strategy. Wei et al. [22] proposed a CNN composed of a multi-scale object proposal network and a multi-scale object detection network. The mean average precision (mAP) on aviation and remote sensing data sets reaches 89.6%. Hu et al. [23] proposed a scale-insensitive CNN (SINET), which is a two-stage detector, to address the scale-sensitive problem of existing CNNs. It uses context-aware RoI pooling to generate fixed-size feature vectors for each proposal, and then inputs them to a multi-branch decision network for classification and regression. The method achieves state-of-the-art performance on KITTI [24]. Liu et al. [25] introduced MobileNetV2 [26] as the backbone of YOLOv3, and designed a new feature fusion method to improve the performance of small object detection.
In our work, to make better use of the features extracted from the backbone to improve the detection performance, a feature enhancement layer is added to the backbone to enhance the ability of feature extraction, and connected to FPN through residual connections.
Attention mechanism
Many recent works have proposed to use channel attention [27], spatial attention, or both [28] of them to improve the feature extraction performance of CNNs. By explicitly establishing the dependencies between channels or spatial information, the feature representation generated by the convolutional layer can be improved. The intuition behind the attention mechanism is to enable the network to learn where to focus, and further focus on what the importance is.
One of the most outstanding methods is Squeeze-and-Excitation Networks (SENet [27]). It first used an adaptive average pooling on the input features to generate the channel statistic Cs with the dimension of the channel number. Then, two fully connected layers are used in turn to generate channel attention weights. To reduce the number of parameters and the complexity of the model, the dimension of channel statistic Cs is reduced in the fully connected layer, and then restored to its original size.
Recently, Wang et al. [29] proposed ECA-Net, which was inspired by SENet. Since SENet uses channel dimension reduction to decrease model complexity, the correspondence relationship between channels and their weights is broken. In other words, SENet successively reduces and increases the dimensions of channels, so that the generated channel attention weights and channels are no longer a direct one-to-one correspondence. In ECA-Net, adaptive average pooling is used to generate channel attention weights just like SENet. The difference is that ECA-Net does not use channel dimension reduction, but adopt a simple one-dimensional convolution to obtain the channel attention weights. In this way, the parameters in ECA-Net are only the size of convolution kernel. On the other hand, because ECA-Net uses one dimension convolution, it also has the ability of cross-channel interaction. It effectively preserves the dependency between channels, rather than abandoning the relationship to calculate independently.
In our work, a cascade ECA module was proposed and used in series with spatial attention. CNNs can obtain stronger feature extraction capabilities with a small amount of memory by this method.
Proposed methods
Proposed attention module
To capture contextual information, we proposed a combination of a cascade ECA module and a spatial attention module. Cascade just means two process paths of ECA module which will capture more context feature. Inspired by SKNet [30], this path uses dilated group convolution to transform the input feature X, as shown in Fig. 1. In this way, less memory cost is introduced and the receptive field is expanded. Then it is fed to ECA module to extract the channel attention weights W C 1 , and this process is mathematically expressed in Equation (1).

Channel attention module.
Where, 1Dk=3 indicates the convolution with dimension of 1 and kernel size of 3. The purpose of dilated group convolution is mainly to increase the receptive field. There is no significant change in the information. Therefore, the convolution with different kernel sizes are adopted to prevent similar calculation results with the other path. The detailed ablations will be conducted for verification in section 4.3.3. P avg is a global average pooling operator. C dg means the dilated group convolution layer, the group numbers keep the same setting with SKNet, i.e. 32. σ is the Sigmoid function. The other process path is the standard ECA module, which is illustrated by:
In this way, the channel attention feature map X C can be calculated by:
After the channel attention, we designed a serial structure with spatial attention, which is shown in Fig. 2. Followed by channel attention, similar to CBAM, a max pooling and an average pooling for X C are utilized to generate two spatial statistics. Then, a convolution layer is used to get the spatial attention weight W S :
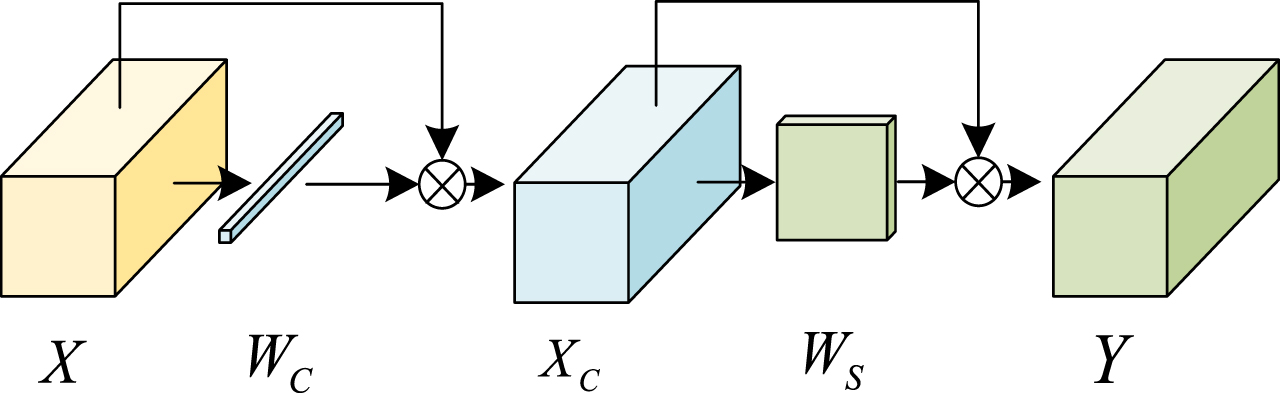
Proposed attention module.
Where f
M
, f
A
indicates max pooling and average pooling, respectively. Then a two-dimension convolution (
The proposed attention module can be easily embedded into the classical CNNs. Fig. 3(a) shows a residual unit of Darknet-53, the backbone of YOLOv3, which contains 1×1 convolution and 3×3 convolution. Each layer is followed by Batch Normalization and ReLU activation. Fig. 3(b) is the architecture of residual unit with proposed attention module. The feature map output by convolution was successively sent to channel attention (CA) and spatial attention (SA), and ReLU activation followed them.

(a) Original convolution block. (b) Convolution block with proposed attention module
Feature Enhancement Layer
Recently, Chen et al. [31] proved that C5, which is the output feature of the last residual block in backbone, contains the strongest information, and the mAP of only using C5(SiMo, single input and multiple output, Fig. 4(b)) was only 0.9%lower than that of the traditional method(MiMo, multiple input and multiple output, Fig. 4(a)). Inspired by their work, we designed a feature enhancement layer(FEL) to better utilize the features extracted from the backbone. Moreover, we also use the outputs of other stages, namely {C2, C3, C4, C5}, to obtain better results. FEL consists of three parts, which are pyramid pooling module(PPM), adaptive spatial fusion module (ASF) and double-ECA module (DEM).

MiMo(a) and SiMo(b) detection.

PPM, Pyramid pooling module.
On the other hand, using a larger kernel in a smaller feature map will result in a larger receptive field. This will further result in a large number of small objects after being mapped back to the original image, and reduce the performance of the detector. Secondly, after transforming in CNNs, the resolution of the feature map will become very small. Small objects, edges, textures, and other low-level features gradually become less or even disappear. Therefore, we use sub-pixel convolution [33] as up-sample operator to get four new feature maps:
Where, X is the input tensor with the shape of (H,W,C). P indicates the pyramid pooling with kernels. C1×1 and C sp is 1×1 convolution and sub-pixel convolution, respectively. {r1, r2, r3, r4} is the set of output feature maps with the shape of (H,W,d). C is four times as much as d. In this way, the high-resolution information of the image can be obtained. At the same time, it can contain more low-level object information.

ASF, Diagram of adaptive spatial fusion module.
Then X is split into two sub-tensors with the shape of (H, W, 1/2C). The 1×1 convolution is used to reduce the dimension to r (r < C) by a ratio of 0.5, and expand the features which have been refined by 3×3 convolution. Sigmoid function is used to normalize the output of convolutions. Accordingly, the feature maps can be computed as:
Where, G1,2 indicate the feature maps of two groups. X Split is the sub-tensor of input X. C1 and C3 indicate the 1×1 and 3×3 convolution, respectively. σ is sigmoid function. Note that each convolution is followed by batch normalization and LeakyReLU activation. Finally, the shape will be changed by concatenating X, G1 and G2 to H×W×2C. It will be split and summed to obtain the final context feature, that is:
Where, ASF (X) is the final output, and will be fed to the FPN through the residual connection.

DEM, Double-ECA module.
Where, Pmax is the global max pooling operator.
FPN [35] effectively combines the spatial location information, texture, and other features of the low-level layers with the semantic features of the high-level layers. PANet [36] adds a bottom-up path next to the original FPN to further improve the feature representation. Similar to PANet, a bottom-up path is added next to the original top-down path. The features from the backbone are up-sampled and pooled by the two paths, respectively. The new feature pyramid structure is shown in Fig. 8. In addition, our work also includes a residual connection from the backbone to the FPN, that is, the feature enhancement layer. It is fused with the feature map of FPN through element-wise addition, and then sent to the detection head.

Overall architecture of AFYOLO.
In this section, we first use the proposed attention module to perform image classification on ImageNet benchmark to verify its better classification performance than other modules such as ECA. Secondly, using the proposed attention module and FPN which are used to modify Faster R-CNN and other detectors to perform object detection task on MS COCO benchmark to prove the superiority of our method. Then in the next part, after conducting related ablation studies, use Wider Face val set to verify the detection performance of AFYOLO on small objects.
Image classification on ImageNet
We compare our modules with the SE, CBAM and ECA using CNNs, i.e., ResNet-50(R50), ResNet-101(R101) and MobileNetV2 (MV2) on ImageNet, with the same computing resource (Linux OS, 4 GeForce RTX 2080Ti GPUs). For training ResNet-50/-101 with our attention module, we adopt the same hyper-parameter Settings as [29] and directly copy the results. Specifically, the input images are randomly cropped and randomly flipped horizontally.
The stochastic gradient descent (SGD) is used as optimizer, with weight decay of 1e-4, momentum of 0.9 and batch size of 256 (32 images per GPU). Both of two models are trained 100 epochs with the initial learning rate of 0.1, which is decreased by a factor of 10 at 30, 60 and 90 epoch, respectively. For training MobileNet with our attention module, it is trained within 400 epochs using SGD optimizer with weight decay of 4e-5, momentum of 0.9 and batch size of 96 (12 images per GPU). Initial learning rate is 0.045, which adjusted by linear schedule with decay rate of 0.98.
The results given in Table 1 show that the proposed module has improved Top-1 accuracy by 2.39%and 1.93%than the original ResNet-50 and ResNet-101, respectively. Our method is also effective in lightweight CNN. The performance of MobileNetV2 combined with our attention module is better than that of SENet and ECA-Net. Compared with SENet and ECA-Net, our method also obtains competitive results. In summary, the image classification results on ImageNet verify the effectiveness of our proposed attention module.
Image classification results of different methods on ImageNet
Image classification results of different methods on ImageNet
In order to further evaluate our attention module and FPN on object detection task, we use Faster R-CNN, Mask R-CNN [37] and RetinaNet [38] as basic detectors to verify the effectiveness of our proposed modules. We compared the performance of our methods with ResNet, SENet and ECA-Net, respectively. And shows the detection result of each detector using the FPN proposed. All of backbones are pretrained on ImageNet and transferred to MS COCO through fine-tuning. Running at Linux with 4 GeForce RTX 2080Ti GPUs, all detectors are implemented by MMDetection toolkit [39]. For training, adopting 1333×800 as the size of input images. We use SGD as optimizer with weight decay of 1e-4, momentum of 0.9 and batch size of 8 (2 images per GPU). All detectors are trained for schedule 1x, i.e. 12 epochs. The learning rate is initialized to 0.01, which is decreased by a factor of 10 at 8 and 11 epoch, respectively. The evaluation results are shown in Table 2.
Object detection results of different methods on MS COCO
Object detection results of different methods on MS COCO
In general, the performance of our method is better than that of other methods mentioned above. This shows that our attention module and FPN are conducive to the improvement of object detection performance.
In order to verify the performance of AFYOLO on small objects, Wider Face is used for training and testing. The training set contains a total of 12,877 images, belonging to 61 activity categories, such as parades, conferences, festivals, etc. It contains 159,424 faces, and 95,818 faces are seriously blurred, most of which are small objects. There are 1,845 exaggerated faces, 8,134 highly exposed faces, and 2,399 partially blurred faces. This data set has many dense small faces. We have selected several example pictures to show in Fig. 9.

The sample images of Wider Face.
Before training AFYOLO, the number of training samples is expanded by using random horizontal mirror images and changing contrast to enhance the original image. The parameters of data augmentation are saturation = 1.5, and exposure = 1.5. In all the experiments, the detectors were trained for 100 epochs. The pretrained model is utilized to accelerate the convergence, and some parameters are frozen in the first 50 epochs, to protect the classification performance obtained by pretraining. In the last 50 epochs, all the parameters are trained together. In the training, the subdivision is set to 16, and batch-size is set to 8. SGD was used to optimize the network parameters with decay as 0.0005, momentum as 0.9, and the initial learning rate as 0.001. In the 50th epoch, the learning rate was reduced to 0.1 times of the original, i.e., 0.0001.
We use the ECA module and the proposed attention module on YOLOv3 for comparison. Table 3 shows the results. The same training hyper-parameters were set in two methods for a fair comparison.
Comparison on Wider Face Val Set
Comparison on Wider Face Val Set
The IoU threshold was set at 0.5 during the test. It can be seen from the results that the performance of the detector is obviously improved by adding the spatial attention module, at the cost of slightly reduced speed and a few more parameters.
Showing the difference between three-scale and four-scale, we conducted an ablation study. More specifically, we used YOLOv3 as the baseline to compare the performance of three-scale and four-scale. The results are shown in Table 4. Both methods were trained 50 epochs, and the confidence threshold was set at 0.3, and the IoU threshold was 0.5 during the test. It can be found that although the Recall of four-scale prediction is higher, AP and Precision of three-scale prediction is better. Besides, the inference speed is faster than that of four-scale prediction.
Comparison of three-scale and four-scale prediction
Comparison of three-scale and four-scale prediction
We use ECA Moudle in the backbone to propose a channel attention containing a cascade structure. The dilated group convolution is used for one of the branches. This part will prove its validity. As shown in Table 5, let Single indicate the use of a single original ECA Module. Cascade means that two original ECA Modules are directly cascaded with no other operation. Cascade† represents the cascade with dilated convolution mapping proposed in this paper. All of models were trained 50 epochs on AFYOLO. The IoU threshold was 0.5 during the test.
Ablations of proposed attention module
Ablations of proposed attention module
Obviously, the gain of directly cascade is very low, only 0.2%. So it can be inferred that directly cascade does have feature overlap, resulting in redundant cascade. Our method obtained a gain of 1.7%by using dilated convolution mapping, and were able to improve the receptive field.
This paper proposes a new attention module, a new FPN structure, and other optimization tricks for small object detection. These methods are added to the baseline one by one for comparative study. Table 6 shows the results of them. For a fair comparison, the IoU threshold was set to 0.5 in all experiments.
Results of proposed modules and method. √ means that the corresponding method is adopted. 104 is the larger scale. D represents whether the Res block is replaced with the Dense block; R is the connection mode from backbone to FPN, Iden and FEL represents identity mapping and employment of FEL, respectively. A represents our proposed attention module
It can be seen that original YOLOv3 (Row 2 of Table 6) has the lowest AP value with the least inference time. At the same time, it can also be noted that when the proposed methods were added to YOLOv3, the accuracy became higher. The AP value of AFYOLO (Last row of Table 6) is the highest, which proves the effectiveness of the proposed method. It is worth mentioning that although the number of parameters increases slightly, the performance has been greatly improved.
AFYOLO and YOLOv3 were used to evaluate the performance of tiny face detection on WiderFace, and the predicted results are shown in Fig. 10. The images on the left (a, c, e) are the predicted results of AFYOLO, and others belong to YOLOv3.

Detection results of YOLOv3 and AFYOLO.
In order to more clearly observe the performance of the proposed method, especially for small objects, we visualized the Precision-Recall(P-R) curves of the proposed module used on baseline, as shown in Fig. 11. Among them, mostly small faces or occluded objects are difficult to detect and the corresponding precision is lower. However, it can be seen from Fig. 11 that the accuracy of AFYOLO on each task is improved, especially in the hard task. The AFYOLO achieves the highest precision, which is higher than classic YOLOv3. The results prove that AFYOLO is effective for detecting small and occluded objects.
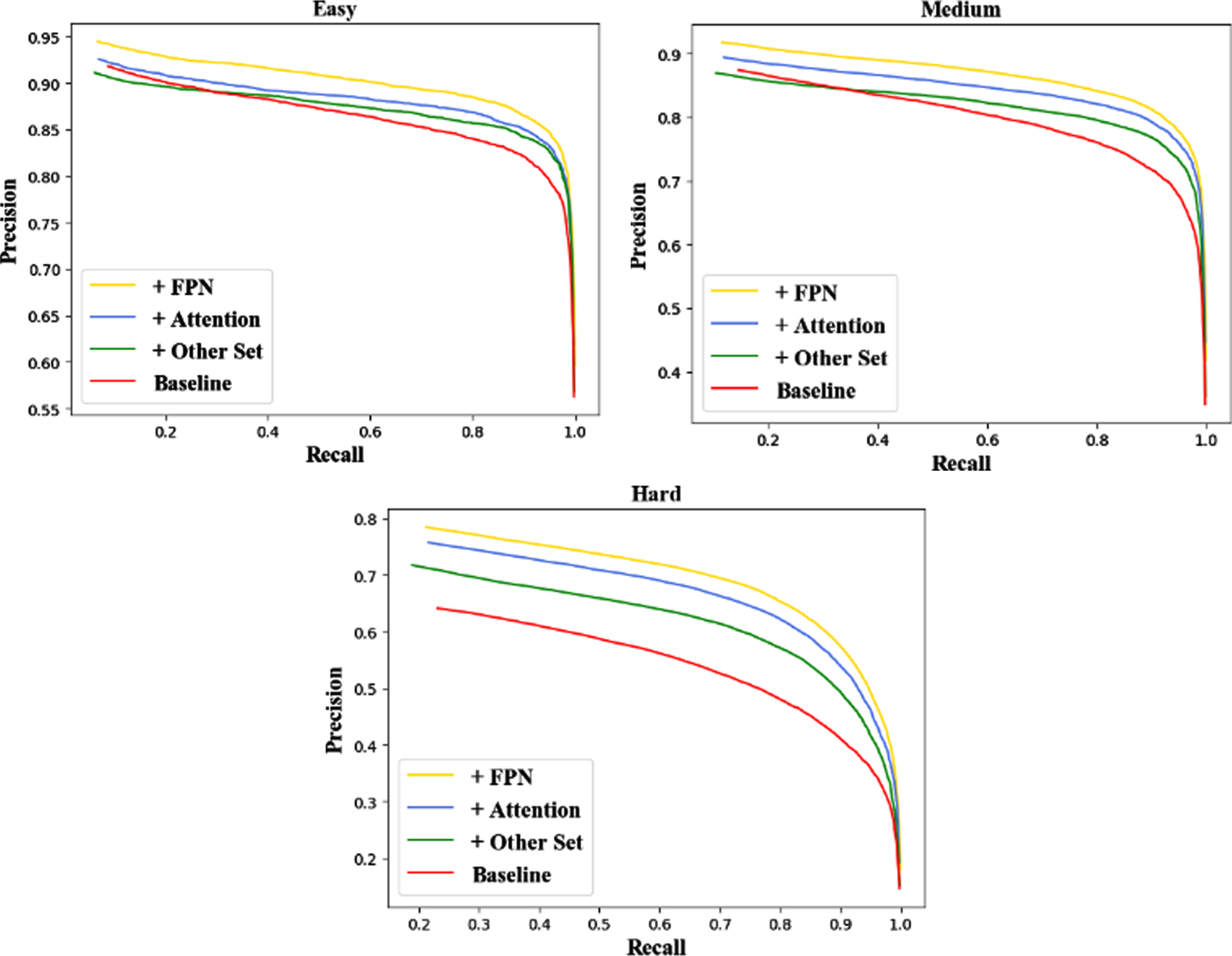
Visualization of P-R curves for various difficult tasks.
We also used YOLOv4 [40] for training and testing on Wider Face. Table 7 shows the results on the validation set. It can be seen that the method in this paper achieved the highest AP50 of 58.86%, which is much better than that of YOLOv4 and YOLOv3.
Comparison of YOLO series methods on Wider Face Val Set
Aiming at the problems of small object detection difficulty and low detection accuracy, this paper proposes an improved method, AFYOLO, based on YOLOv3. AFYOLO combines the classic YOLOv3 with our proposed attention module, a new FPN and other tricks for small object detection. Ablation experiments and object detection experiments were carried out on different datasets. The results show that the performance of ImageNet and MSCOCO benchmark can be improved by adding the proposed attention module or FPN to some popular networks. The AP of AFYOLO at small object detection task on Wider Face val set is better than that of YOLOv3 and YOLOv4. Experimental results verify the effectiveness of the proposed attention module and FPN, and the effectiveness of the proposed detection network in small object detection.
Footnotes
Acknowledgments
This work is supported by the National Nature Science Foundation of China (51209167), the Nature Science Foundation of Shaanxi Province (2019JM-474), the Science and technology project of Xi’an (2020KJRC0055), the Funding of Shaanxi Key Laboratory of Geotechnical and Underground Space Engineering (YT202004).