
Abstract
Accurate segmentation of fractures in coal rock CT images is important for the development of coalbed methane. However, due to the large variation of fracture scale and the similarity of gray values between weak fractures and the surrounding matrix, it remains a challenging task. And there is no published dataset of coal rock, which make the task even harder. In this paper, a novel adaptive multi-scale feature fusion method based on U-net (AMSFF-U-net) is proposed for fracture segmentation in coal rock CT images. Specifically, encoder and decoder path consist of residual blocks (ReBlock), respectively. The attention skip concatenation (ASC) module is proposed to capture more representative and distinguishing features by combining the high-level and low-level features of adjacent layers. The adaptive multi-scale feature fusion (AMSFF) module is presented to adaptively fuse different scale feature maps of encoder path; it can effectively capture rich multi-scale features. In response to the lack of coal rock fractures training data, we applied a set of comprehensive data augmentation operations to increase the diversity of training samples. These extensive experiments are conducted via seven state-of-the-art methods (i.e., FCEM, U-net, Res-Unet, Unet++, MSN-Net, WRAU-Net and ours). The experiment results demonstrate that the proposed AMSFF-U-net can achieve better segmentation performance in our works, particularly for weak fractures and tiny scale fractures.
Keywords
Abbreviations
Computed Tomography
Convolutional neural network
Adaptive multi-scale feature fusion based U-net
Adaptive multi-scale feature fusion
Batch normalized
Rectified Linear Unit
Residual block
Adaptive moment estimation
Introduction
The coal rock fracture network is the adsorption and seepage channels for gas and groundwater. The initiation and expansion of fractures are likely to cause the leakage of gas and groundwater when the underground mining activities cause the stress response of coal rock. Therefore, the accurately expressing characteristics of fracture network is of great significance for coal seam fracturing and gas extraction. Due to industrial CT (Computed Tomography) technology is a nondestructive scanning method to detect the internal structure of coal rock, we currently research coal rock fractures by coal rock CT images. However, coal rock CT images have the following features. Firstly, the scale and shape of coal rock fractures vary greatly. The large-scale fractures are found throughout the section of coal rock CT image, while small-scale fractures have only 1–5 pixels. Second, the low-contrast makes it difficult to segment fractures. In particular, the gray values between weak fractures and their surrounding coal matrix are very similar. Third, lacking coal rock CT image samples is also a problem. As a result, it is a challenging task for fracture segmentation in coal rock CT images.
Traditional segmentation schemes mainly based on threshold [1, 2], edge detection [3], region growth [4] and contour evolution [6]. These traditional methods need to design the hand-craft feature representation for a new target segmentation [7]. Because the shape and location of coal rock fractures are unfixed, which makes it difficult to define the coal rock fracture features manually. Therefore, the traditional segmentation methods are not suitable for the fracture of coal rock.
Recently, CNN (Convolutional Neural Network) is widely applied in the image segmentation because of its powerful feature extraction ability. U-net [8] was proposed to segment cell boundaries on 30 cell training samples, which achieved great success. Due to limited coal rock fracture data, this paper attempts to segment coal rock fractures based on U-net architecture. U-net is a typical encoder-decoder architecture (namely U-shape architecture), which is widely used in image segmentation [9–11]. However, the simple feature fusion method will lead to poor ability of feature extraction of network; especially, the weak-tiny fractures can be easily ignored by original U-net. In addition, it is easy to cause the disparity between encoder and decoder features with simple skip connections of the U-net architecture [12], which cannot extract more representative features.
To solve these limitations of U-net, on the one hand, some methods proposed to embed residual block in the U-net for improving the ability of feature extraction of the network, such as Res-Unet [13] and Residual U-net [14]. Further, some multi-scale fusion strategies were used [15–19] to aggregate multi-scale context information to improve the segmentation accuracy. Spatial pyramid pooling [15] and GRANet [16] leveraged spatial pyramid and dilated convolution to capture multi-scale information. Multi-scale information was obtained using inception modules [17–19]. Although the higher segmentation results were obtained, these methods were easy to generate mis-segmentation results on weak-tiny targets because of directly using the simple skip connection in U-shape architecture. On the other hand, some works [12, 21] designed new skip connections to capture the representative feature information. A skip connection employing High-Resolution pathway with residual dilated blocks was proposed [20]. U-net++ [21] designed the densely connection to improve segmentation performance. However, the relation between high-level features and low-level features was not considered in these methods.
Considering the characteristics of coal rock fractures and motivated by above discussion, we propose a novel adaptive multi-scale feature fusion based U-net (be called AMSFF-U-net) for fracture segmentation in coal rock CT images. First, we use ResBlock (residual block) to structure encoder and decoder path to boost the feature learning ability of network. Then, attention skip concatenate (ASC) module is proposed to obtain more distinguishable information for precise restoration in decoder, particularly for weak fractures. Finally, we propose the multi-scale features fusion (MSFF) module to efficiently aggregate multi-scale features by adaptively fusing different scale feature maps of encoder path.
The main contributions of our work are summarized below: An ASC module is presented to combine rich semantic information and spatial information between adjacent layers, which can capture the representative features. The MSFF module is proposed to fuse different scale feature maps of encoder path to extract rich multi-scale context information. It can improve the ability of AMSSFU-net in handling the various size of coal rock fractures. To prevent over-fitting, a set of comprehensive data augmentation methods is implemented to obtain the diversity training samples.
The remaining content of the paper is structured as follows: an overview of related works is presented in Section 2. Section 3 describes the methodology of our proposed approach in detail. Section 4 introduces the datasets creation, data pre-processing and the data augmentation. Section 5 reports the experimental results and comparisons. Finally, our works is concluded in Section 6.
Related work
Traditional segmentation methods mostly focus on the specific images. For example, the dynamic threshold method and entropy were used to segment fractures of the road image [1]. An efficient multilevel thresholding segmentation method (MCET-HHO) based on the Harris Hawks Optimization algorithm and the minimum cross-entropy was proposed [2]. It used a hybrid edge-based technique for renal lesions segmentation [3]. A multi-pass fast watershed method was introduced to segment nucleus [4]. Because the above methods only considered 2D features, they were easy to produce mis-segmentation results for weak-tiny fractures. The multiscale Hessian fracture filtering technique was used to segment load fractures from a 3D image dataset [5]. A coal rock fracture segmentation method based on the consistency of contour evolution and gradient direction consistency [6]. However, the segmentation results were still poor at the weak boundaries where the gradient change is not obvious.
No literature method so far copes with fractures of coal rock CT images based on multi-scale fusion methods. Here, the late works based on U-net for image segmentation are reviewed. The U-Net [8] is one of the typical encoder-decoder architectures with skip connections fusion feature information of encoder and decoder path. In order to strengthen feature learning ability, residual blocks [13, 14] were used to alleviate gradient vanishing problem when the network is deeper. A new type of residual block (BSE Blocks) structure [22] was incorporated into ResU-Net to boost the blood vessel segmentation accuracy. In addition, many works thought about improving the design of skip connections of U-net. Res-path [12] was used to instead of the ordinary skip connections. A densely connections was designed [20] between encoder and decoder path. MSN-Net [23] redesigned a novel skip connection with multi-scale context Fusion block and densely connections.
Multi-scale information can provide rich semantic features for image segmentation. These methods [23, 24] captured multi-scale context information by pooling operations. However, due to reduce the resolution of feature maps, the pooling layers are easy to lose spatial and semantic information. Without reducing the resolution of feature maps, dilated convolution can better understand the global context information by increasing the receptive field [26]. In some methods [27, 28], the ordinary convolution layers were replaced with dilated convolution with different dilated rates to obtain rich multi-scale information. Although DCU-Net was a multi-scale U-Net network to improve the accuracy of tumor boundary segmentation [29], the fusion mechanism of it was simple. In order to solve the problem of the target component information cannot be fully utilized, a multiscale convolutional neural network (CNN) based on component analysis was proposed to realize synthetic aperture radar automatic target recognition [30]. The method [31] proposed a multi-scale feature fusion pyramid network for object detection. In this method, different levels features were fused by the enhanced multi-scale feature fusion module, and the weight of different scale features were adjusted by predictor optimization module. Furthermore, a host of works [32, 33] introduced the attention mechanism to capture long-range contextual information. RefineU-Net [32] embedded global refinement module and local refinement module with residual attention gate into U-net. HDA-ResUNet [33] employed channel attention mechanism and dilated convolution based on U-net for medical image segmentation.
However, most of these existing methods cannot achieve better performance for coal rock fracture segmentation. To effectively segment coal rock fractures, the AMSFF-U-net is proposed to disentangle fractures from the coal rock CT images with complex semantic information. Note that the proposed AMSFF-U-net is different from the methods mentioned above.
Methods
In this section, we firstly give a brief introduction of the overall structure. Then, the details of attention skip concatenate (ASC) module, adaptive multi-scale feature fusion (AMSFF) module and loss function are described, respectively. The precise overall structure is shown in Fig. 1.

Our proposed approach which comprises ResBlock module, AMSFF module and ASC module. 1) Encoder and decoder path consists of four ResBlocks, respectively. 2) The size of the feature map is represented by the number below each rectangle such as 32 × 32.
The residual learning framework can prevent the gradient disappearing and improve the performance of training when network deepens [34]. Therefore, replacing all ordinary convolution layers with the ResBlocks on the path of encoder and decoder can strengthen the feature learning ability of the network. Encoder path mainly focuses on learning fracture features and reducing the resolution of coal rock CT images gradually; except for the first ResBlock, each ResBlock uses a stride 2 in the first convolution layer to reduce the size of feature map instead of pooling operation. Decoder path gradually up-samples the feature maps by up-sampling with 2 × 2, which restores the resolution to the level of its original image in the end. Finally, a 1 × 1 convolution and activation function is to obtain accurate pixel-level binary coal rock fracture segmentation results.
ASC instead of the simple skip concatenation of original U-net, which progressively combines feature maps of adjacent levels to capture rich semantic information and spatial information (the specific description can be seen in Section 3.1). AMSFF module is at the bottom of AMSFF-U-net, which fuses the different scale feature maps of encoder path. And it can efficiently aggregate multi-scale features so that AMSFF-U-net can handle the larger scale variations coal rock fractures (the specific description can be seen in Section 3.2).
Original U-net and many of its variants directly concatenate encoder and decoder path in each stage. However, the grayscale values of the weak fracture boundaries are close to those of the coal matrix. The simple skip concatenation can easily lead to a semantic gap and make it difficult to distinguish weak fractures from the surrounding coal matrix. It is well known that the high-level features from the deep layer have rich semantic information, while it lacks of abundant spatial information. On the contrary, the low-level features obtained from shallow layer have necessary spatial information. However, the low-level features are difficult to identify the target objects due to the lack of rich semantic information. According to the discussion above, the high-level features with rich semantic information and low-level features with abundant spatial information are complementary to each other in functionality from a global perspective. Inspired by this, an attention skip concatenation (ASC) module is proposed to fuse high-level features and low-level features between adjacent layers, which can strengthen segmentation accuracy of weak fractures. The total architecture of ASC is depicted in Fig. 2.
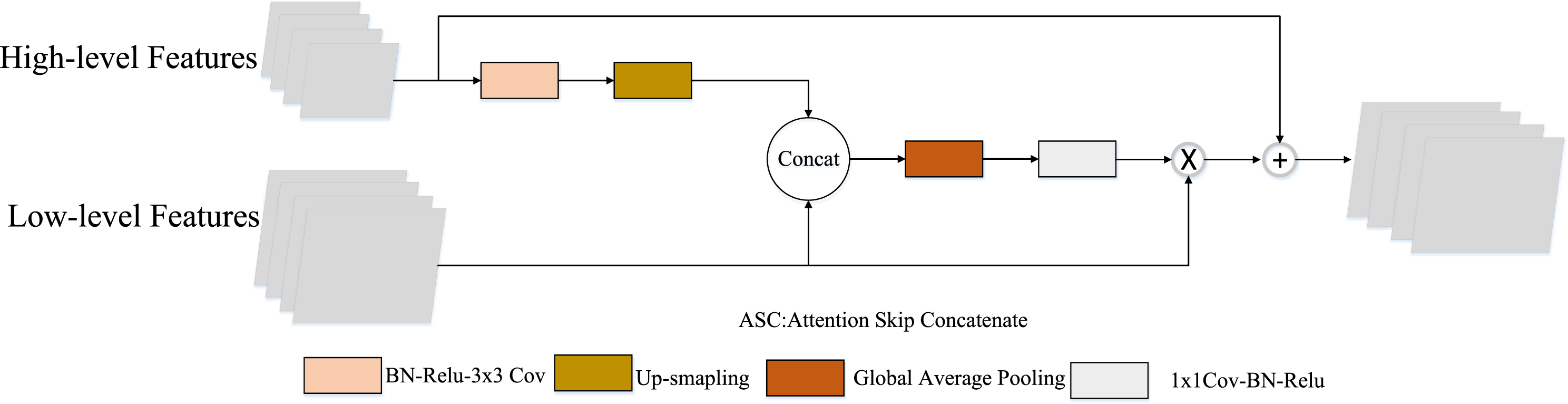
Schematic diagram of the proposed ASC module.
In detail, the high-level features are firstly performed 3 × 3 ordinary convolution and up-sampling, which is used to reduce channels of feature maps and ascend dimension of feature maps. Then, the feature maps of adjacent layers are concatenated; the concatenation process is defined by:
Where t is the current feature map layer; F represents the corresponding layer output;
Where C1×1 is the 1×1 convolution with batch normalization and ReLU; ⊕ denotes the element-wise sum, and ⊗ means the element-wise multiplication. The proposed ASC module can suppress the interference of coal matrix and preserve more fracture feature information for fracture localization.
Due to large scale variations of coal rock fractures, it is easy to loss the tiny fracture information in encoder process. In principle, loss of tiny fracture information of encoder path is difficult to reconstruct precise details. Reusing the feature maps from the earlier layers can capture rich multi-scale semantic information and spatial information [35]. Hybird dilation convolution (HDC) [36] was proposed to effectively extract concealed multi-scale context information by hybrid dilation rates. Motivated by this and the shallow features with rich spatial information, AMSFF module is presented to fuse the different scale feature maps of encoder path. AMSFF module is unlike the FDNet [35] and the HDC [36], which is shown in Fig. 3.
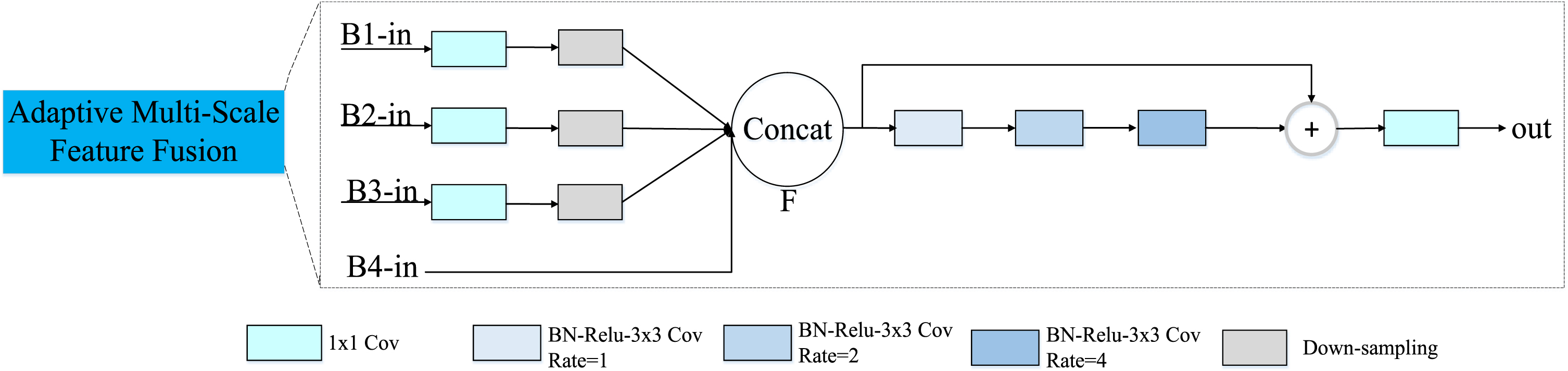
Structure of MSFF: 1) Firstly, the input feature maps (B1, B2, B3) undergo a 1 × 1 convolution layer to reduce parameters calculation; then they reduce the dimension by convolutions with strides 2 to obtain the same size; 2) The input feature map B4 directly is concatenated because of its dimensions are the same as the feature map F; 3) The merged feature map F undergo a residual dilated convolution.
We express the feature maps of the encoder path as B1, B2, B3, B4, respectively. Obviously, the dimensions and sizes of these feature maps (B1, B2, B3, B4) are different. Therefore, we must ensure them have the same spatial resolution and the number of channels before fusion operation. Specifically, firstly, B4 can be concatenated directly. Then, in order to reduce parameters calculation to increase processing speed, the B1, B2, B3 firstly undergo a 1 × 1 convolution layer, then the dimension is adaptive reduced by convolutions with strides 2 for obtaining the same size. Finally, the fusion feature maps F is produced by concatenation operation; the whole process can be clearly expressed as follows:
Where ⊙ denotes the concatenation; B
n
is feature map of n
th
layer in encoder path;
After the fusion, a set hybrid dilated convolutions with different dilated ratios (1,2,4) are utilized to generate abundant multi-scale information; and a residual connection is used to aggregate these multi-scale feature maps; the process can be simply described as follows:
Where C1×1 is 1 × 1 convolution layer is used to control the output channels;
The coal rock CT images fall under the imbalance of samples, i.e., there is large background proportion and small target proportion. Dice coefficient loss [37] is effective when data is unbalanced. We use the Dice coefficient loss as the segmentation loss function of coal rock fractures segmentation. Dice coefficient represents the similarity between the ground truth and the prediction result. The higher similarity is, the more accurate the model segmentation is. It is defined as follows:
Where, X i and Y i represent the ground truth and predicted value, respectively; N denotes pixels of coal rock training samples; ɛ ∈ [0, 1] is a smoothing factor to avoid denominator is 0. Furthermore, due to the limited samples of coal rock fractures, we construct our loss function with the L2 regularization to avoid over-fitting; it is shown in Equation (6):
Where ɛ = 0.02; ω represents the network parameters and the weight decay and the weight decay λ = 0.001 is the best performance in our experiments.
In order to complement the previous description, we describe the whole algorithm flow chart is presented in Algorithm 1.
Datasets creation
The experimental coal rock CT images are collected from State Key Laboratory Coal Resources and Safe Mining, China University of Mining & Technology (Beijing). Images labeled by staff of the laboratory who have been engaged in coal rock fracture labeling for many years ensure the authenticity and reliability of the annotated images of coal rock fractures. In this experiment, these coal rock samples are collected from five different regions. 1000 frames coal rock CT images are obtained from each region sample. Because the fractures of adjacent frames are very similar, and one frame is extracted out of 40 frames on each sample for labeling to prevent over-fitting. The total of 120 frames coal rock CT images are obtained from 5 different region samples. There are 6070 frames are generated via data-augmentation operations (the specific description can be seen in Section 4.3), eventually. In our works, we select 6050 frames as training dataset; 20%of the training data is selected as the verification dataset; the training parameters are updated iteratively according to each validation result. We select 20 frames, which include 5 coal rock samples, from the original samples as the test dataset.
Data pre-processing
As coal rock is a natural body, coal rock CT images are low-contrast and uneven gray. It is difficult to identify fractures without pre-processing. Here, we use globally CLAHE (contrast limited adaptive histogram equalization) to improve the contrast of the original images and maintain global information and enhance the contrast of the edges of coal rock fractures. Figure 4 shows an example of data pre-processing.
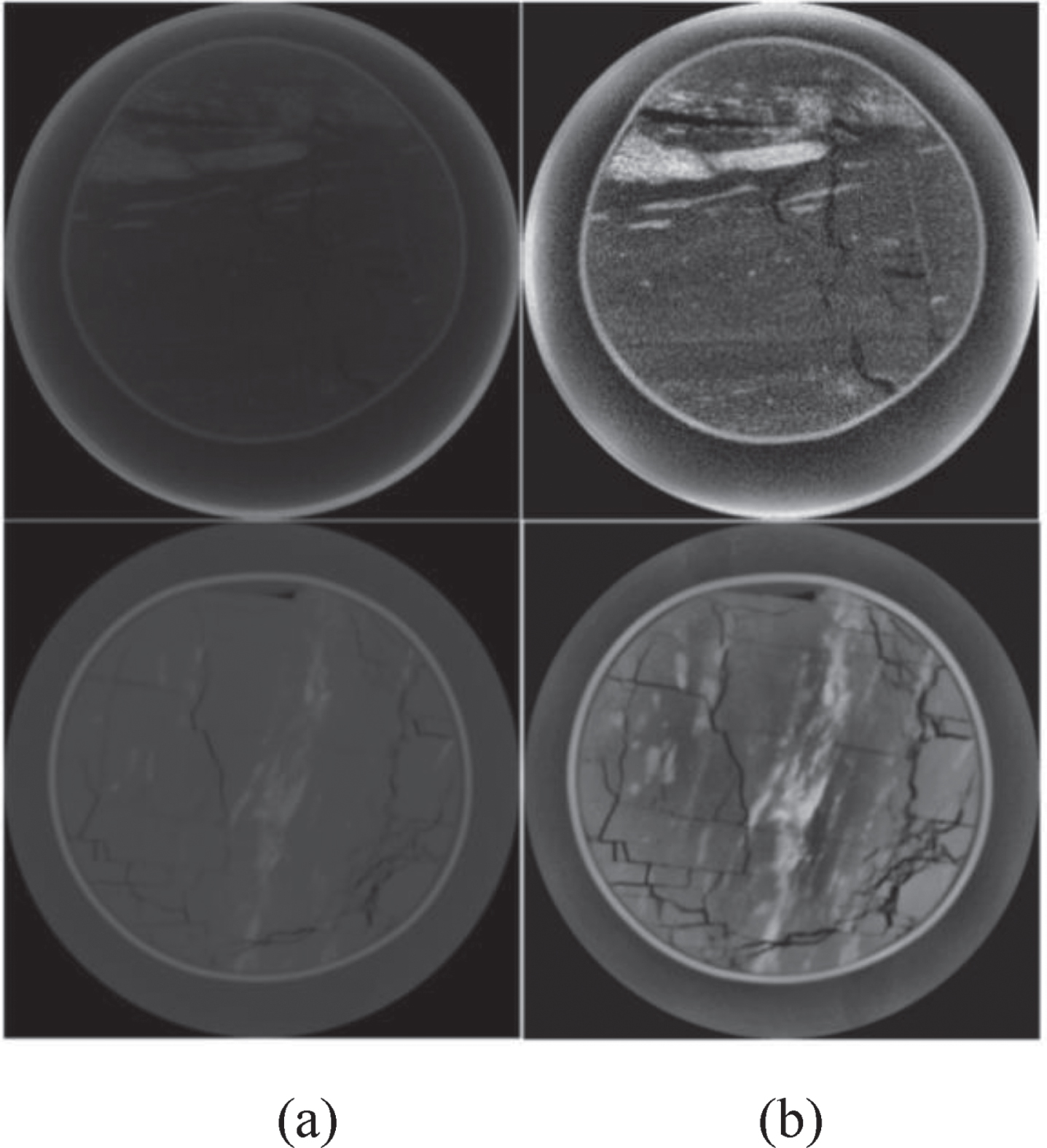
Examples of data pre-processing. (a) original image. (b) after globally CLAHE operation.
It can be seen from Fig. 4 that the contrast between the fractures and the coal matrix is significantly improved after globally CLAHE operation.
At present, there is no published dataset of coal rock CT images. However, manual label of coal rock fracture images is time-consuming and expensive. In order to overcome the limitation, we perform data augmentation on the original coal rock CT images and the corresponding label images to increase the diversity of training samples. It can avoid over-fitting and improve the generalization of the model. In this paper, we applied a set of comprehensive data augmentation methods, which is summarized in Table 1.
Summary of implementation data augmentation methods. B represents the factor of brightness; α and σ control the degree of the elastic distortion; β represents the weight of the image superposition
Summary of implementation data augmentation methods. B represents the factor of brightness; α and σ control the degree of the elastic distortion; β represents the weight of the image superposition
Basic data augmentation methods: random rotation, horizontal-flip, width-shift-range and contrast factor. Owing to the characteristics of sparse target of coal rock fracture images, these basic data augmentation methods are not sufficient to increase the diversity of fracture samples. These methods of image superposition and elastic transformation [38] are employed to generate diversity and reasonable training data. The mathematical representation of image superposition means that two images are superposed together according to a certain linear relationship while the image size is kept unchanged. Then, the elastic deformation operation is performed on the superimposed image. σ is a Gaussian of standard deviation, and it convolves with the displacement field. α is a scale factor which controls the intensity of the deformation. First, A is obtained by the original displacement field convolved with σ. Then, the elastic deformation displacement field is obtained by multiplying displacement field A and α. Finally, the elastic deformation displacement field is applied to the image, which is processed by affine transformation; it generates the final elastic deformation images. An example of data augmentation process is shown in Fig. 5.
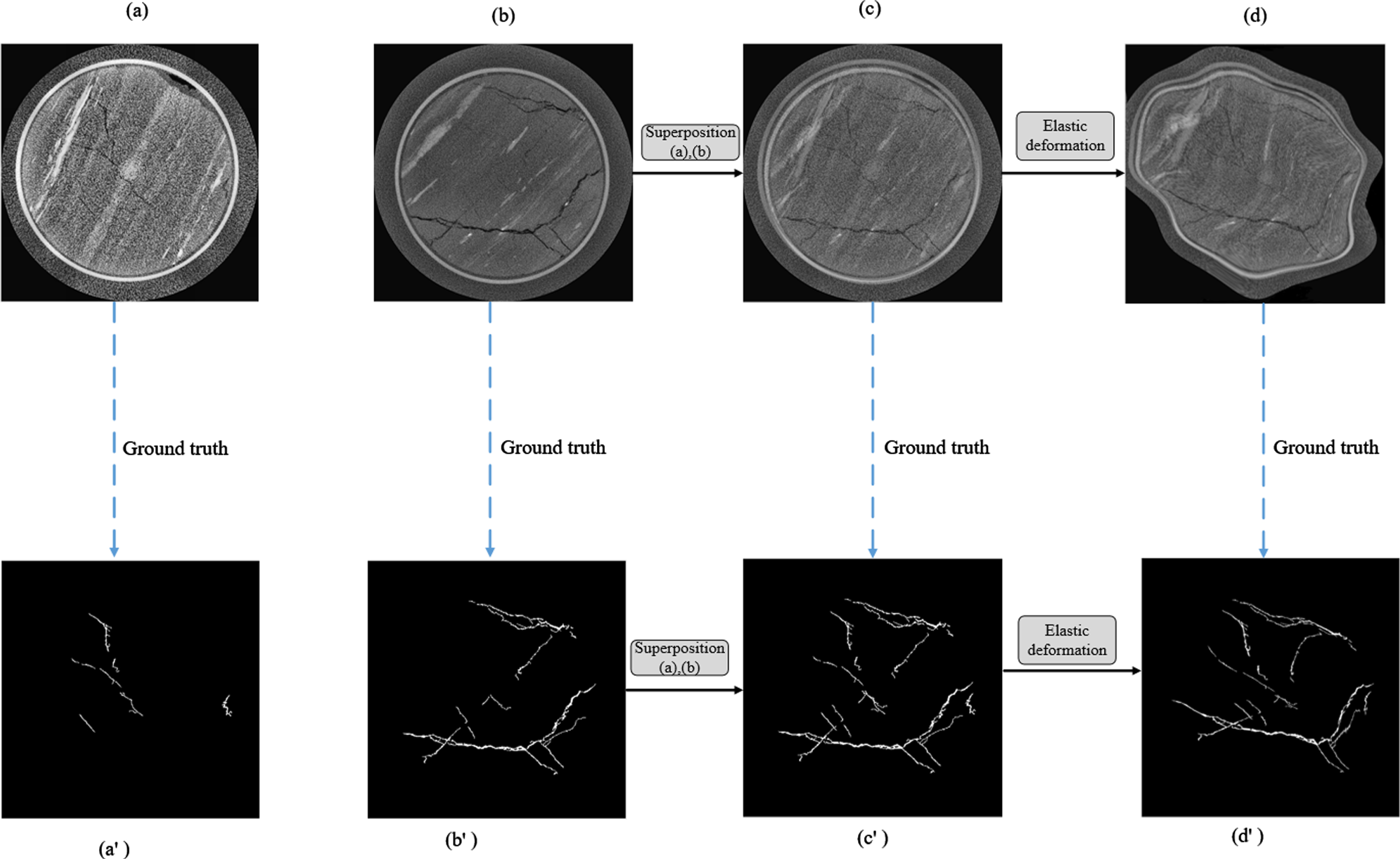
An example of data augmentation process. (a), (b) are the original coal rock CT images. (a′), (b′) are the ground truth of (a) and (b), respectively. (c) is the result of superimposing (a) on (b). (c′) is the ground truth of (c). (d) is the result of (c) by elastic deformation. (d′) is the ground truth of (d).
Implementation details
Our proposed model is implemented on Keras framework and is optimized by Adam (Adaptive moment estimation) optimizer. The network was trained on 2 G GPU and 128 G memory of Ubuntu 16.04. Data augmentation is used to alleviate the problem of lacking data samples (detailed in 3.3) during training. In this paper, coal rock CT images with a 512 × 512 resolution.
We employ the “poly” learning rate policy is shown below:
Where the initial learning rate is 0.0001; power is 0.9. The training epoch and batch size are set to 100 and 2, respectively; the validation set will be evaluated every 5 epochs.
To quantitatively evaluate the performance of the AMSFF-U-net, we use Dice (Dice similarity coefficient), Precision, IOU (Intersection over Union) and Accuracy as evaluation indicators, which commonly used evaluation indicators for semantic segmentation. The higher values are, the better the segmentation results are. The detailed description is as follows:
Where 1) TP: the numbers of correctly segmented fracture pixels; 2) TN: the number of correctly segmented background pixels; 3) FN: the number of fracture pixels is incorrectly predicted as background pixels; 4) FP: the number of background pixels is incorrectly predicted as fracture pixels.
To prove the effectiveness of the proposed AMSFF-U-net for coal rock fracture segmentation. The ablation study is performed to validate the effect of each component of AMSFF-U-net. To this end, U-net serves as the baseline in our ablation experiments; we compare AMSFF-U-net with six different architectures base on the baseline (namely U-net,U-net+ASC,U-net+AMSFF,U-net+ReBlock+ASC, U-net+ReBlock+AMSFF and U-net+ASC+AMSFF). The same training environments for all models. The comparison results are shown in Table 2.
Quantitative comparison of ablation studies with different architectures base on the baseline
Quantitative comparison of ablation studies with different architectures base on the baseline
As can be seen from Table 2, the proposed method achieves better quantitative evaluation values for coal rock fractures. Compared with U-net, both U-net+ASC and U-net+AMSFF improve the performance. Furthermore, U-net+ASC+AMSFF improves the Dice by 0.0435, the Precision by 0.0624, the IOU by 0.0643 and the Accuracy by 0.0428, respectively. It indicates that the representative features and multi-scale features extraction is necessary to improve the segmentation accuracy. We can also see that the performance of U-net+ReBlock+ASC and U-net+ReBlock+AMSFF is better than the baseline, which demonstrates that the ReBlock is important for boosting learning ability of network. Our experiment results can clearly infer that the effectiveness of the ASC and AMSFF for coal rock fractures segmentation.

Qualitative comparisons of segmentation results with different methods on our test dataset.
Two rectangles of different colors are used to mark two representative fracture locations. We can see from Fig. 6 that the traditional segmentation algorithm FCEM has a serious mis-segmentation phenomenon. It is unable to accurately separate the fractures in the case of the similar grayscale between the fractures and the surrounding matrix. Obviously, the fracture segmentation results of AMSFF-U-net are closer to ground truth compared with the other six methods. Especially, the weak-tiny fractures segmentation results of AMSFF-U-net on the column 3 and the column 5 are superior to other methods. Due to the lack of sufficient multi-scale information fusion mechanism, it is obvious that U-net and Res-U-net cannot segment tiny fractures very well. In contrast, the proposed AMSSFF-U-net can accurately segment tiny coal rock fractures because of the help of AMSFF module. As can be seen from the sixth and seventh row in Fig. 6, although the segmentation results of Unet++and MSN-Net are better for weak-tiny coal rock fractures, some boundaries of weak fracture are still blurry due to the lack of essential semantic information. WRAU-Net uses a wide-range channel-wise attention mechanism in encoder path to extract necessary semantic information, but the phenomenon of blurry boundaries of weak fractures still exists. Our AMSFF-U-net can extract more necessary semantic information and suppress many irrelevant matrix information by utilizing the global context information, which is the contribution of ASC module. According to the experimental results, the superiority of the proposed AMSFF-U-net in coal rock fracture segmentation task is clearly verified.
However, there are still unsatisfied case in coal rock fracture segmentation experiments, as shown in Fig. 7.
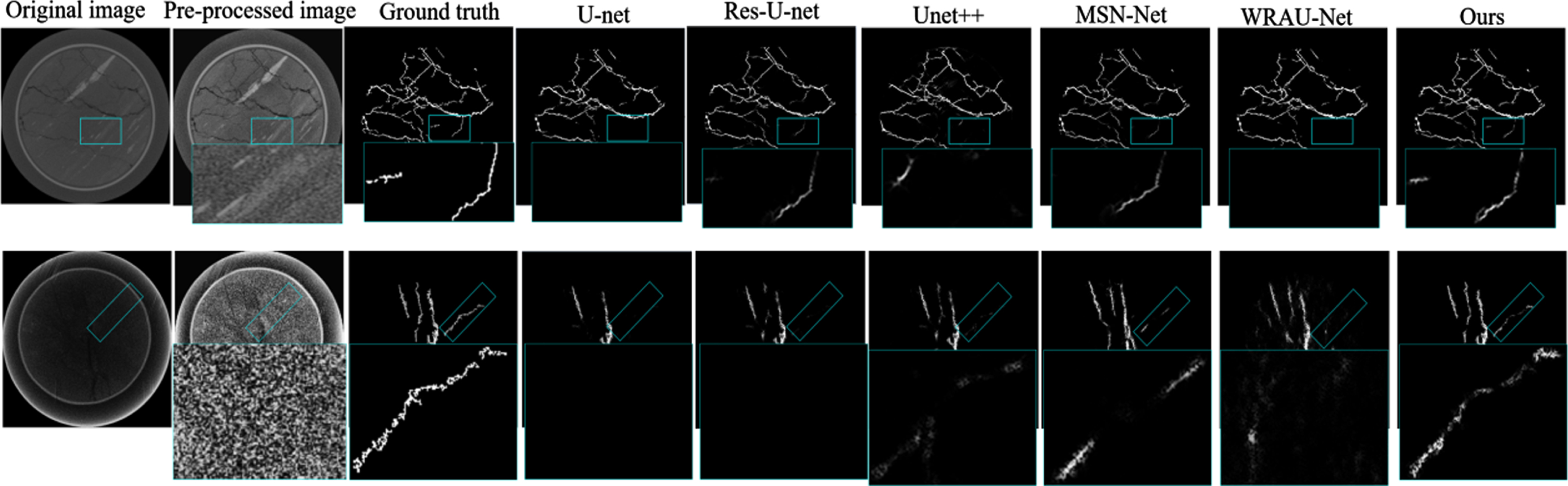
Visual comparisons of the unsatisfied cases with state-of-the-art methods.
As shown in the first row of Fig. 7, when the gray values between the fractures and the surrounding matrix is extremely similarity, like most methods, our method is also difficult to accurately identify the weak fractures. Furthermore, when the background noise is severe, our proposed method may lose some fracture features (see the second row of Fig. 7). However, compared with other methods, the proposed AMSFF-U-net still achieves the considerate segmentation performance; our segmentation results are also closer to ground truth.
The quantitative evaluations of different methods for coal rock fracture segmentation
As illustrated in Table 3, although the values of the traditional method FCEM in terms of the four evaluation indicators are the lowest, its computational time is the fastest. Compared with Unet++ and MSN-Net, values of U-net and Res-U-net in terms of the four evaluation indicators are the lower because of the lack of ability to capture rich semantic information. The values of U-Net++ and MSN-Net are similar due to their similar network architecture. Due to the simple skip connections, the values of WRAU-Net are lower than U-Net++ and MSN-Net. On the one hand, we can clearly see that the proposed method achieves the highest accuracy of 0.9815, the highest Precision of 0.8975, the highest IOU of 0.9154 and the highest Dice coefficient of 0.9254, respectively. On the other hand, compared with other competitors, our method achieves better performance in term of consumption time.
To further observe the performance of the proposed AMSFF-U-net, we compare the P-R(Precision-Recall) curve of our method with those of other five architectures, which is shown in Fig. 8. Obviously, the areas under the P-R curve of the other methods are smaller than those of our proposed method.
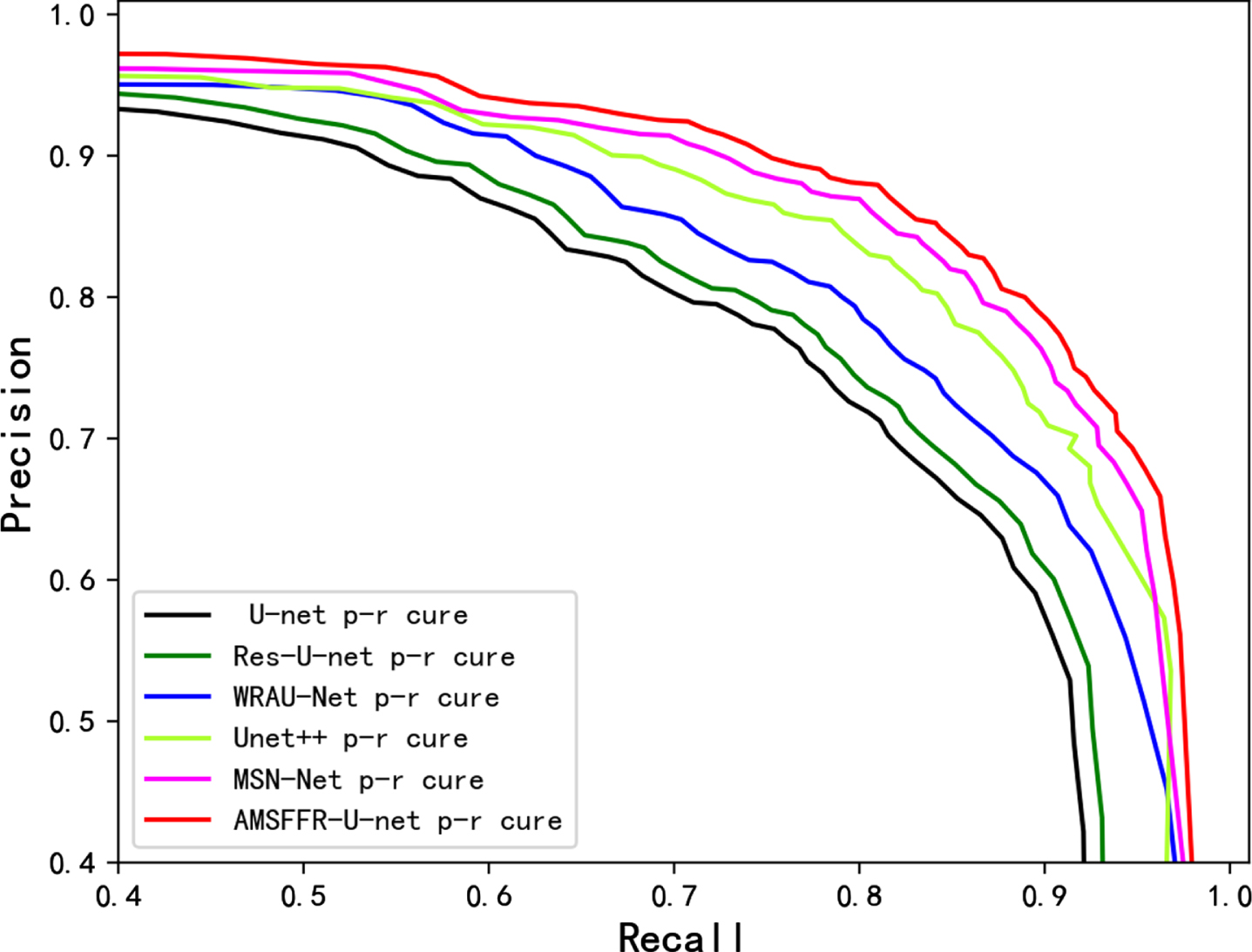
Precision-Recall curves of various methods.
Moreover, the accuracy and loss metrics during training and validation are presented to evaluate the performance of different methods, as shown in Fig. 9.
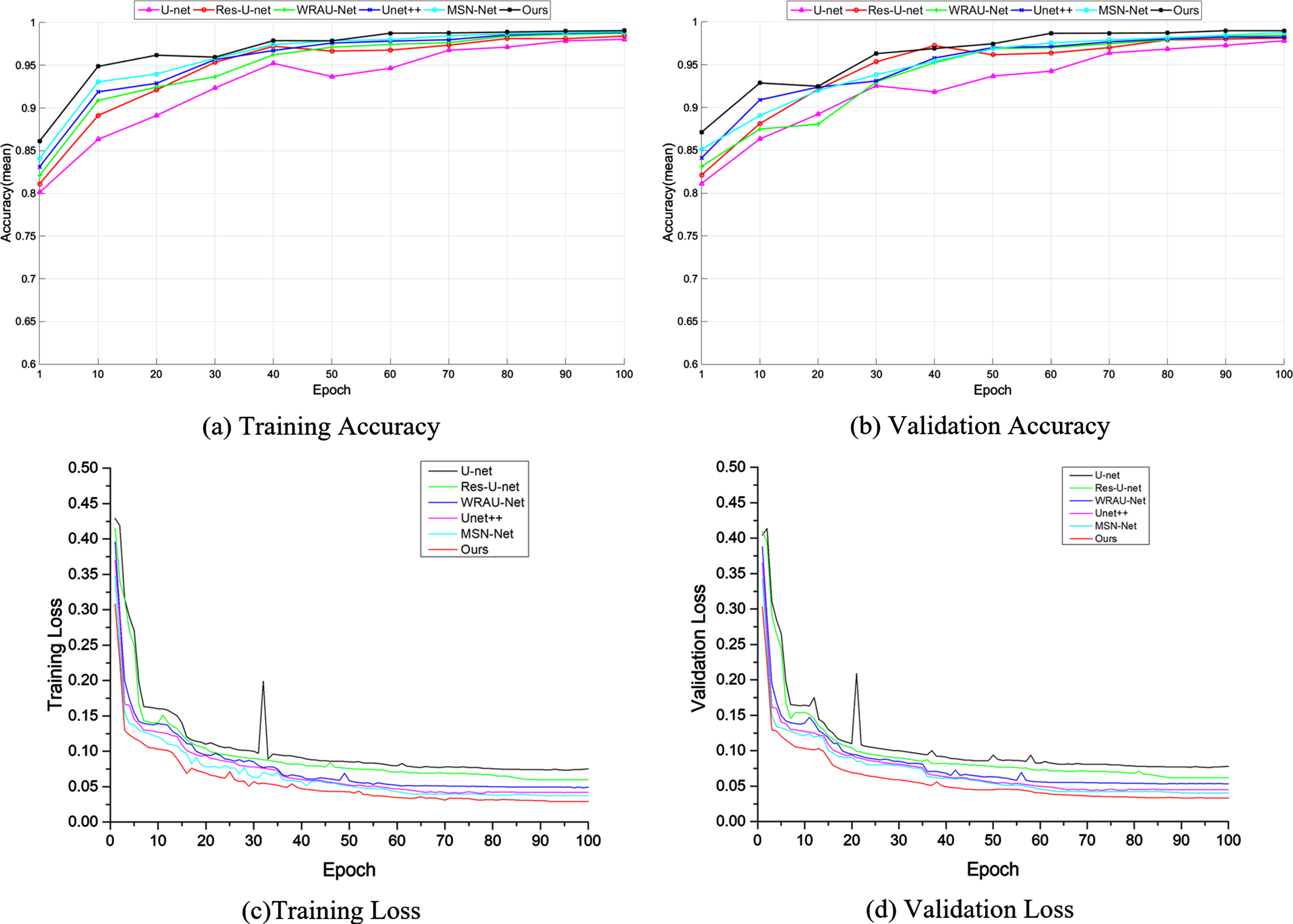
The accuracy and loss curves of different methods for coal rock fracture segmentation.
The training and the validation accuracy for different models are shown in Fig. 9(a-b). Compared with other methods, we can see that our proposed model presents the highest accuracy values. Meanwhile, Fig. 9(c-d) shows the training and validation loss curves of each epoch. It can be clearly observed that the loss values of our proposed method are lower than those of all competitors, and the convergence rate of AMSSFF-U-net is the fastest.
As with the above analysis, it indicates that our method can obtain better coal rock segmentation performance. That’s enough to prove the superior fracture segmentation performance of AMSFF-U-net for coal rock CT images.
In this paper, AMSFF-U-net is proposed for coal rock fracture segmentation task, which obtains superior performance. Two core modules (i.e., ASC and AMSFF) are proposed. ASC module can obtain rich semantic and spatial information to suppress the background noise to improve the ability of fracture feature identification by combining features between two adjacent layers. AMFF module adaptively fuse different scale feature maps of encoder path; then these multi-scale features are aggregated by a set residual hybrid dilated convolution to capture rich multi-scale context information. In addition, a set of comprehensive data augmentation is applied to increase the diversity of training samples to prevent over-fitting during training. The experimental results show that AMSFF-U-net outperforms state-of-the-art algorithms in coal rock CT images.
The 3D spatial information of coal rock CT images is important for accuracy coal rock fracture segmentation. However, the AMSFF-U-net currently does not take advantage of 3D information of coal rock CT images. In the future, we will further consider the 3D information and the connectivity of fracture among the coal rock CT images.
Availability of data and material
Our data is not shared temporarily. But, if you have any requirement, please feel free to contact us.
Competing interests
The authors declare no conflicts of interest.
Funding
This work was supported by the National Natural Science Foundation of China (GrantNo. U1704242).
Authors’ contributions
Data curation, Fengli Lu, Chengcai Fu, Guoying Zhang and Jie Shi; Formal analysis, Chengcai Fu; Methodology, Fengli Lu; Project administration, Guoying Zhang; Resources, Guoying Zhang; Software, Fengli Lu and Jie Shi; Validation, Chengcai Fu and Guoying Zhang; Writing – original draft, Fengli Lu; Writing – review & editing, Fengli Lu.
Footnotes
Acknowledgments
The author thanks the State Key Laboratory of Coal Resources and Safe Mining of China University of Mining and Technology (Beijing) for its help.