
Abstract
Deep learning-based image semantic segmentation approaches heavily rely on large-scale training datasets with dense annotations and often suffer from scarce semantic labels for unseen categories. This limitation has spurred a research trend in Few-shot image Semantic Segmentation (FSS), which makes it possible to segment objects of new categories using only a few labeled samples. Although more and more FSS methods are emerging and gradually integrated into practical applications, a deep understanding of its achievements and issues is still missing. In this survey, we focus on the recent developments of FSS, specifically on FSS methods based on meta-learning. According to different network architectures, we summarize the related research into three classes, that are Convolutional Neural Network-based (CNN-based) models, Graph Neural Network-based (GNN-based) models, and Transformer-based models. Then, we explore the specific implementations of these models, including parameter-based methods, metric-based methods, attention-based methods, and optimization-based methods. Furthermore, we illustrate datasets and analyze the experimental results of various kinds of methods. Toward the end of the paper, we discuss the limitations of FSS and present its applications and challenges to provide further research directions.
Introduction
Recently, deep learning has witnessed great success in semantic segmentation, but it depends on a large number of annotated datasets [1, 2]. In real life, especially in medicine and security fields, labeled data is not enough [3]. Semi-supervised and weakly supervised image semantic segmentation learning methods [4, 5] may reduce the dependence on large amounts of pixel-level labeled data. However, they still require a lot of weakly annotated training images. Furthermore, millions of parameters must often be trained to match the model as network layer depth increases [6]. Once the amount of data is scarce, even if the training effect is good, the generalization ability for new samples is still poor.
Human beings can pick up knowledge from a limited number of examples, integrate it, draw conclusions, and use it in a variety of situations [7]. The ultimate goal of artificial intelligence is to achieve human-like thinking and reasoning [8]. It is challenging to bridge the gap between artificial intelligence and human learning. Few-Shot Learning (FSL) [9] has been presented as a solution to this problem, which can reduce the burden of collecting large-scale supervision information by mining knowledge from a small number of samples. In recent years, FSL has demonstrated strong performance in image semantic segmentation. Few-shot image Semantic Segmentation (FSS) is regarded as a pixel-level extension of few-shot image classification [10–12]. The traditional FSS scheme simply fine-tunes the parameters of the pre-trained network through labeled data sets [13]. However, it is easy to overfit millions of parameters during the update process. To address this issue, Meta-learning [14], also known as the ‘learn to learn’ approach, offers a new learning paradigm for FSS. Meta-learning can help FSS improve the performance of the new task by leveraging the provided datasets and extracting meta-knowledge acrosstasks.
Recent review papers [15–17] summarize and analyze meta-learning-based FSS algorithms and make different classifications. However, review papers [15, 16] only focused on the metric-based meta-learning methods but ignored other methods, and literature [17] mainly discussed open challenges that few/zero-shot learning brings to visual semantic segmentation. Unlike earlier review papers, this paper makes a comprehensive summary of meta-learning-based FSS algorithms and classifies them according to their neural network architectures. Summaries of state-of-the-art FSS methods and the timeline of different network architectures in recent years are shown in Fig. 1. It is obvious that Convolutional Neural Network-based (CNN-based) models have been the core of FSS research since the appearance of One-Shot Learning for Semantic Segmentation (OSLSM) [18]. Graph Neural Network-based (GNN-based) models have emerged since Pyramid Graph Networks (PGNet) [19], and Classifier Weight Transformer (CWT) [20] opened a new chapter of Transformer-based models.
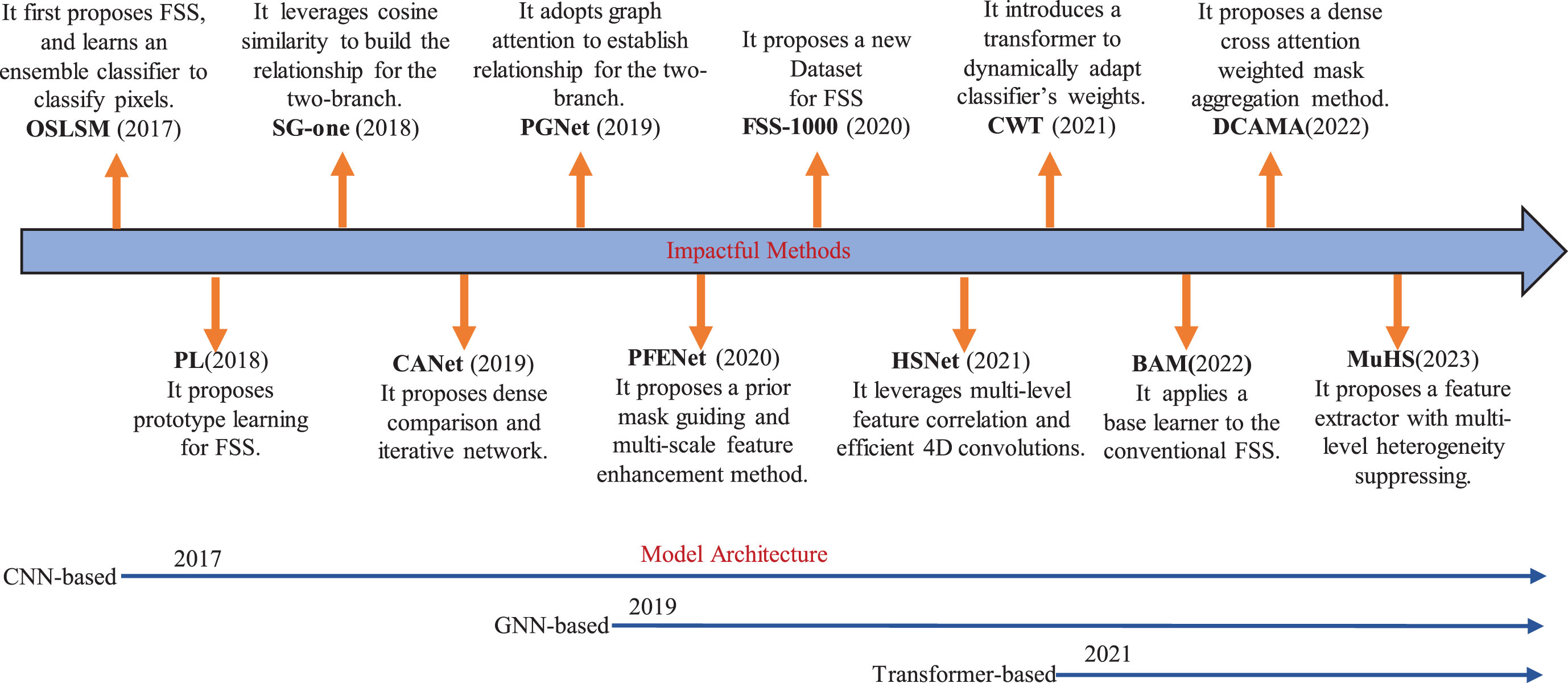
Summaries of state-of-the-art methods and the timelines of different network architectures for FSS in recent years.
Thus, from the perspective of network architecture, this paper synthesizes pertinent research based on meta-learning and divides FSS algorithms into three categories: CNN-based models, GNN-based models, and Transformer-based models. Furthermore, the meta-learning-based FSS algorithms are categorized into parameter-based, metric-based, attention-based, and optimization-based approaches based on their implementations. Parameter-based methods use a trainable set of parameters to learn the classifier. Metric-based methods measure the similarity between the support set and the query set using distance metrics. Attention-based methods incorporate attention mechanisms to selectively emphasize or suppress certain features in the support set or query set. Optimization-based methods develop an optimization strategy to optimize the weights of the network. Additionally, this paper summarizes the advantages and disadvantages of each type of approach, lists their applications in different fields (medical images, 3D point clouds, etc.), and discusses future trends.
The main contributions of this paper are as follows: A systematic review of Few-shot image Semantic Segmentation (FSS) algorithms based on meta-learning is presented, covering the description of the FSS task and development of FSS methods. the categorizations of FSS methods are provided according to their network architectures or implementations. The strengths and limitations of each type of method are analyzed, and the applications and research trends are discussed.
The rest of the paper is organized as follows. The task description of meta-learning-based FSS is given in Section 2. The FSS methods are classified and illustrated in Section 3. The main datasets and evaluation metrics are introduced and experimental results are analyzed in Section 4. The discussion and outlook are presented in section 5. In Section 6, we conclude the whole work.
The goal of FSS is to make pixel-level segmentation for new categories of the query image using one or a few labeled support images. By leveraging meta-learning, FSS models can learn and generalize concepts from a diverse set of tasks, and then apply the meta-knowledge to unseen tasks. As illustrated in Fig. 2, the meta-learning-based FSS is implemented by scenario-based training. The FSS task often boils down to the N-way K-shot task, where N refers to the number of new categories in the query image and K refers to the number of labeled images of the support set. The existing FSS algorithms are more often considered for N as 1, i.e. the 1-way K-shottask.

The conventional settings of the FSS based on meta-learning. The meta-learning-based FSS models adopt scenario-based training, which divides samples into different episodes. Once training is finished on the training set, the models are evaluated on the test set.
Specifically, given a training set
According to the different neural network architectures, we classify FSS algorithms into CNN-based models, GNN-based models, and Transformer-based models. The FSS algorithms mainly adopt a meta-learning paradigm with four implementations, namely parameter-based, metric-based, attention-based, and optimization-based methods. Next, detailed implementations for each kind of model are described.
CNN-based models
The CNN-based FSS models typically use a CNN encoder and construct convolutional algorithm units to learn transferable semantic information from the labeled support images to the query image. The implementations of the CNN-based models are parameter-based, metric-based, attention-based, and optimization-based methods. The metric-based methods can be classified into prototype-based linear metrics and dense matching-based non-linear metrics, and the attention-based methods can be classified into convolutional attention-based and cross-attention-based methods.
Parameter-based methods
The parameter-based methods often use a shared encoder to extract features for two branches, and then learn a parameter generator to update the classifier parameters. The general framework of such models is shown in Fig. 3, where a parameter generator is devised to predict the neural weights of the prediction layer for cross-class adaption. After training on base categories, the segmentation ability of the classifier on new categories can be quickly enhanced.
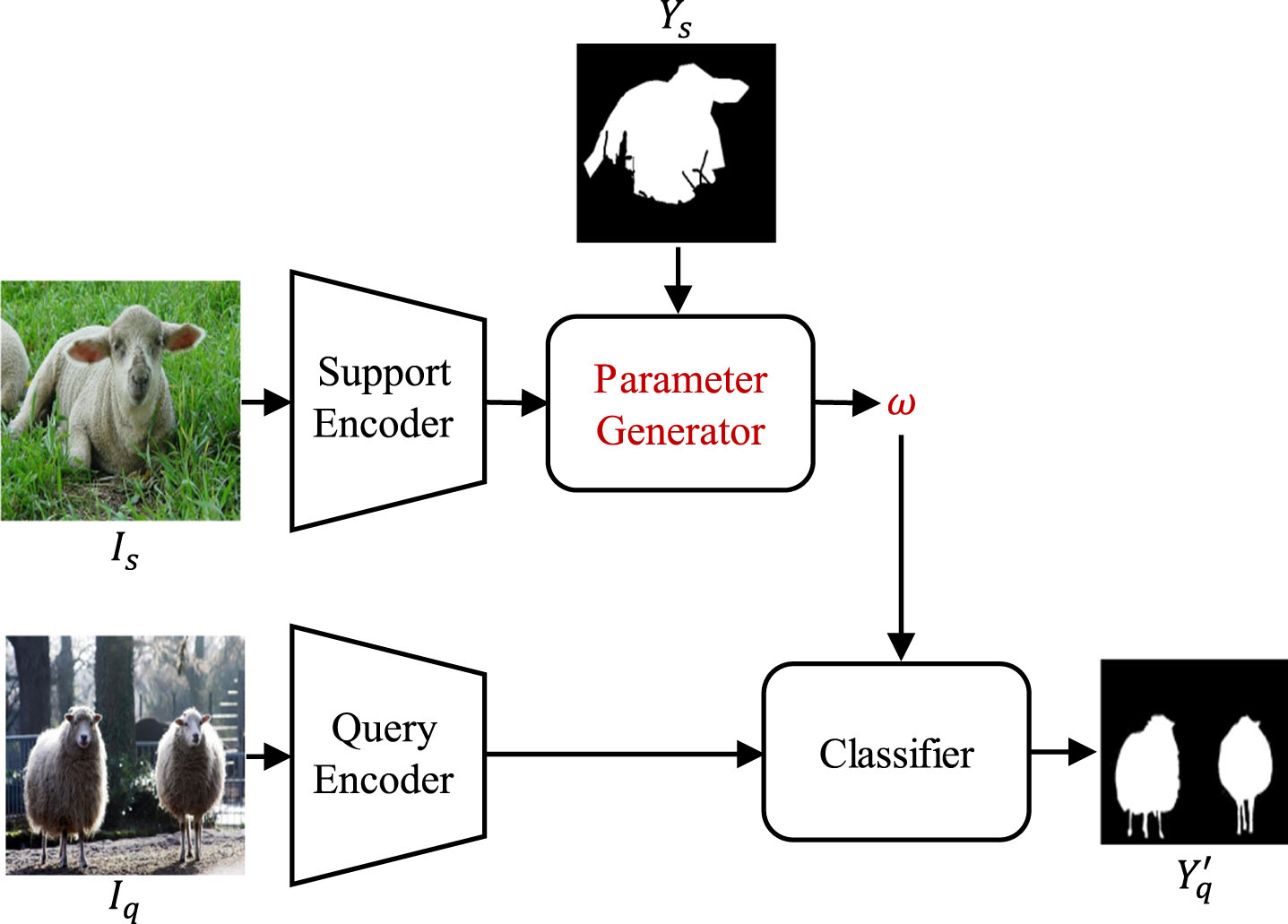
Framework of parameter-based FSS methods.
Shaban et al. [18] used a conditional branch to learn prediction weights and replaced the parameters of the classifier with logistic regression layers. Unlike direct and simple replacement of classifier parameters, dynamic update strategies [21, 22] can provide more potential for parameter-based methods. Dynamic Reasoning Network (DRNet) [21] is proposed to adaptively generate the parameters of predicting layers and infer the segmentation mask for each unseen category. By leveraging the knowledge from the base classes, the model [22] can dynamically construct and maintain a classifier for the novel class.
Remarks: The parameter-based methods use a direct and efficient way to update the classifier of the model, however, it is difficult for the parameter generator to estimate the parameters of the large-scale model.
The metric-based methods are dominant and effective FSS algorithms [15, 16]. These algorithms usually map feature representations to a metric space and use distance functions to measure the similarity among the samples. We classify the metric-based FSS methods into two types: prototype-based linear metrics methods and dense matching-based non-linear metrics methods, depending on whether the distance function is linear or not.
(1) Prototype-Based Methods
Prototype-based methods often use Mask Averaging Pooling (MAP) [23] to obtain prototype vectors. Then, the distance between the query features and the prototype vectors is measured using a cosine similarity or Euclidean distance function.Figure 4 displays the framework of the prototype-based methods.
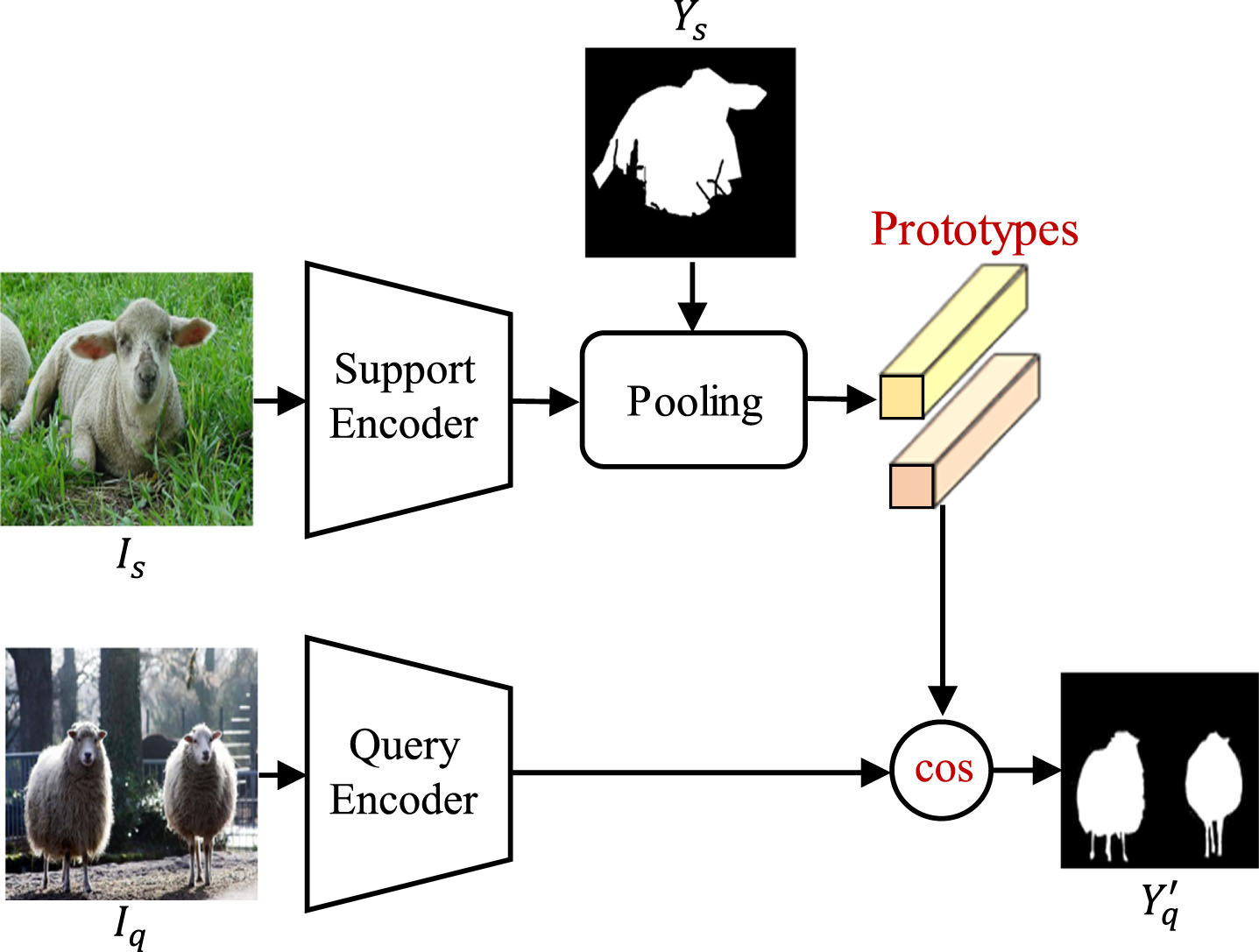
Framework of prototype-based FSS methods.
The Prototype Learning (PL) [24] model employs a prototype learner to obtain prototype vectors and uses a non-parametric weighted nearest neighbor classifier to classify semantics. The model is complex and unable to directly obtain segmentation results. Further research focused on addressing the limitations of the PL model. For instance, Wang et al. [25] developed a simplistic yet effective Prototype Alignment Network (PANet) that utilizes query prototypes to make backward predictions of support images. Some algorithms [26, 27] try to produce representative prototypes to reduce prototype bias brought on by data scarcity and intra-class heterogeneity. However, the aforementioned strategies are constrained by global representation.
Multi-prototype techniques attempt to address prototype bias by learning multiple prototypes. For instance, the Part-aware Prototype Network (PPNet) [28] uses the Simple Linear Iterative Clustering (SLIC) [29] strategy to convert a single prototype into multiple local prototypes. The Prototype Mixture Model (PMM) [30] strengthens prototype semantic descriptions by using the expectation estimation maximization (EM) algorithms. Except for extracting various prototypes from the support set, the potential new classes during training can also aid in fine-tuning prototypes [31]. Additionally, self-support prototypes (SSP) [32] of the query image can be employed to reduce the uncertainty resulting from intra-class diversity.
(2) Dense Comparison-based methods
Unlike linear metrics, dense comparison-based methods use a ‘concatenation + convolution’ operation to learn transferable category information, which is flexible and easy to integrate with other methods. As illustrated in Fig. 5, the general model first concatenates the query feature with the category feature learned from the labeled support image. Then, the model uses the convolutional layer to make a dense comparison. Finally, with a decoder, the target information can be segmented.
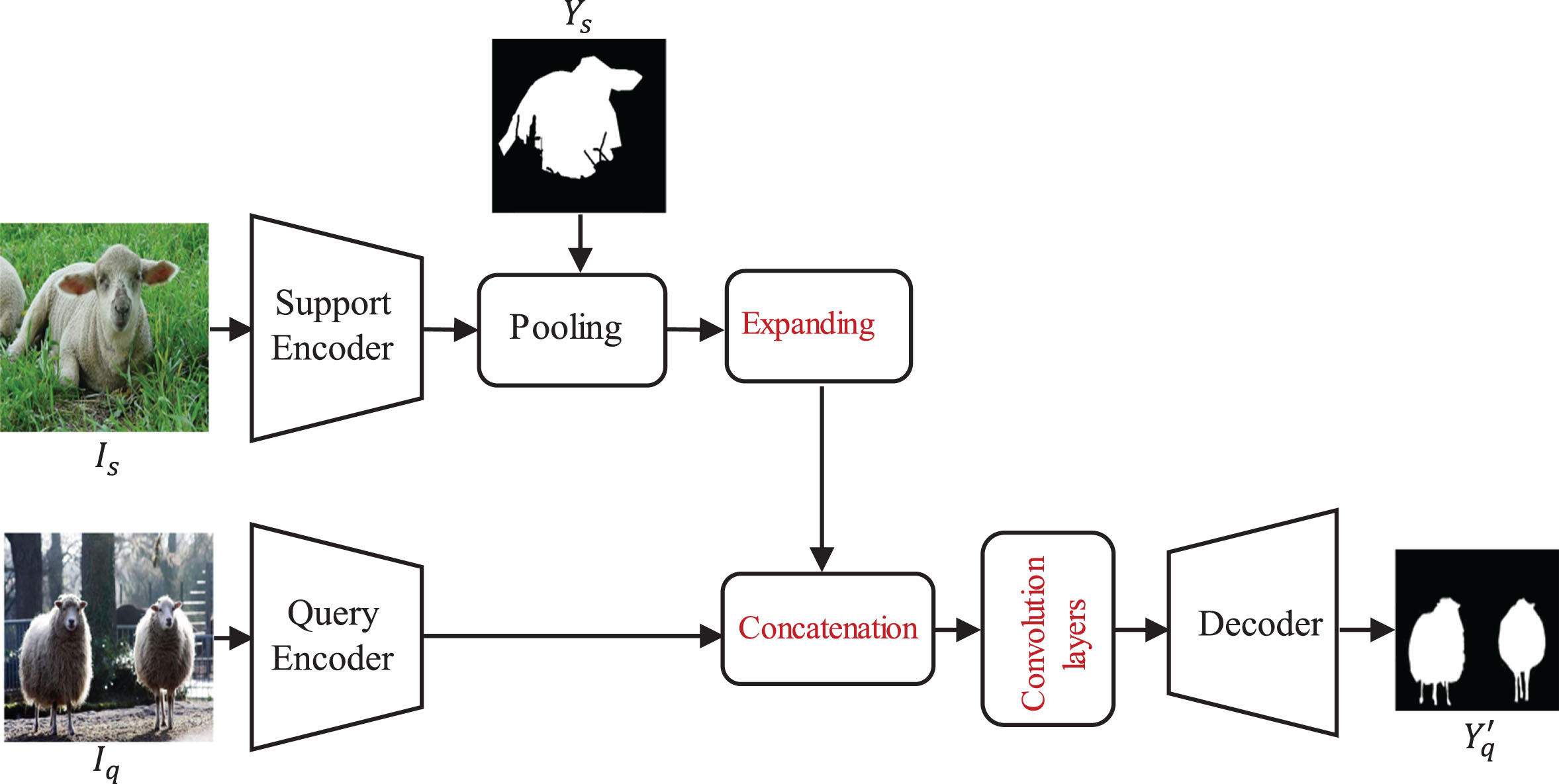
Framework of dense comparison-based FSS methods.
The idea of dense comparison derived from the Relation Network [33] was first introduced by the model [34], where two convolutional layers are used to embed the relationship between the support features and query features. Nonetheless, there is an alignment issue of spatial semantic information when making comparisons for local features. To address this issue, Class-Agnostic Segmentation Networks (CANet) [35] employ MAP to obtain a global category vector. Then, each position of the query feature is intensively compared with the vector. Following CANet [35], the Prior Guided Feature Enrichment Network (PFENet) [36] adds a prior mask generated from high-level features in a train-free manner to improve performance. Although PFENet has exceeded the previous algorithms, it still suffers from inadequate use of guidance information or a lack of spatial information on the global category feature.
To address these problems, some algorithms have embarked on enriching category features [37–39] or introducing memory units [40]. Self-guided learning strategy [37] enhances the segmentation results by aggregating the missing key information to the main category features. The superpixel-guided clustering and adaptive allocation-based algorithm is used to replace the global category feature with multiple local category features [38]. The dynamic convolution strategy [39] transfers more semantic information by acquiring dynamic category features. The recurrent memory network [40] is introduced to obtain rich category information from all resolution features in a cyclic manner.
The aforementioned works have endeavored to optimize the category feature but do not consider the impact of the base categories. Therefore, some algorithms [41–43] made use of the base categories. Literature [41] integrates base category prototypes with the new category prototypes to match each region in the query image. Literature [42] introduces a set of learnable memory embeddings to record meta-information. Divide-and-conquer proxies (DCP) [44] integrate a series of support-induced proxies derived from the coarse segmentation mask of the annotated support image to boost discrimination. The Base and Meta (BAM) network [43] adaptively integrates the coarse segmentation results of the base categories and the new categories to produce accurate segmentation predictions.
Remarks: Metric-based methods play a vital role in handling the FSS task. Prototype-based methods are stable and easy to implement but often suffer from the issue of prototype bias. Dense comparison-based methods are easy to combine with other methods. Learning discriminative category feature representations becomes the state-of-the-art solution for dense comparison-based methods.
The attention mechanism aims to focus its attention on relevant information while disregarding extraneous information [45]. In recent years, the attention mechanism has significantly advanced the performance of computer vision tasks [46]. Given the limited number of support samples provided by the FSS task, it is crucial to concentrate on the details of the target category. The attention mechanism can improve the interpretability and performance of FSS models. The attention techniques adopted in CNN-based FSS models consist of Convolutional Attention [47–49], Self-Attention [50], and Cross-Attention [51]. Since the Multi-Head Attention (MHA) of the Transformer-based models is comprised of numerous self-attention modules, here we only elaborate on the approaches that rely on Convolutional Attention and Cross-Attention.
(1) Convolutional Attention-based methods
The convolutional attention-based methods construct convolutional layers to learn a spatial or channel weight vector to weigh features. To capture the multi-layer contextual information from the labeled support images, the Attention-based Multi-context Guiding (A-MCG) network [52] uses a modified residual attention module (RAM) [47] as the feature selector. Furthermore, a comparative analysis is conducted in ablation experiments using channel attention Squeeze-and-Excitation Networks (SENet) [49]. Attention-based Refinement Network (ARNet) [53] does modest changes and uses RAM to concentrate effective information. To improve the performance of the K-shot FSS task, CANet employs a parallel attention mechanism inspired by spatial attention [47] to fuse segmentation results from different support images.
(2) Cross-Attention -based methods
The cross-attention-based FSS methods usually adopt a symmetrical structure that enhances the common semantic information by exploring correlation across support and query features. Typically, the structure (depicted in Fig. 6) involves the simultaneous segmentation of support and query images.
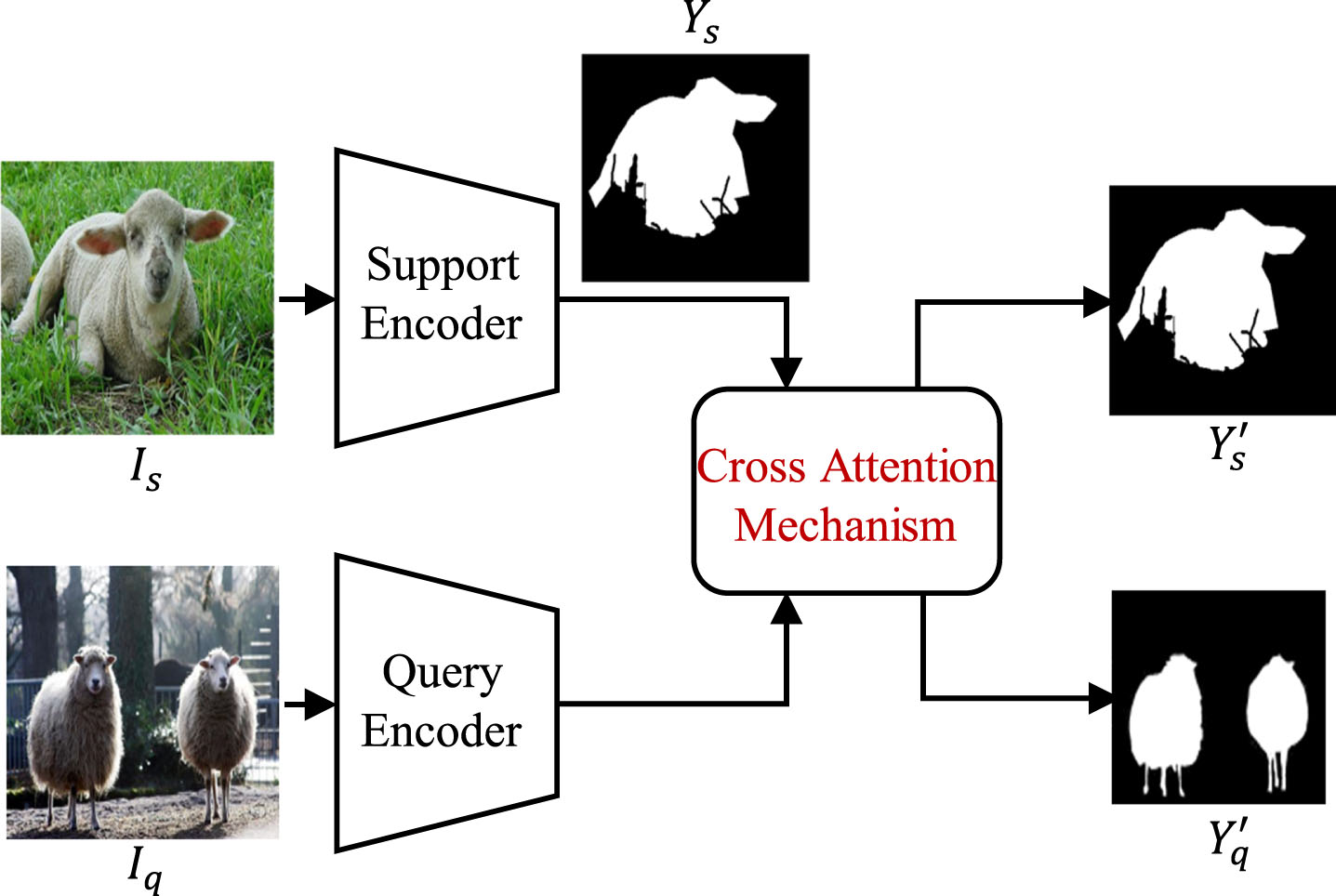
Framework of the cross-attention-based FSS methods.
Cross-Reference Networks (CRNet) [54] use a two-branch squeeze-and-excitation module to mine co-occurrent features in two images and generate updated representations. However, CRNet neglects the correlation of spatial information. To address this issue, some algorithms [41, 55–59] further learn the correlation between the two branches. Cross-Reference and Region Global Conditional Networks (CRCNet) [55] make an extension of CRNet, which can learn both local and global common information. Literature [56] computes the relationship matrix between query and support based on Cosine distance. Holistic Prototype Activation (HPA) [41] devises a feature interaction weighting scheme to model the inter-dependence and self-dependence of low-level features by matrix multiplication. To learn more common information, long-range dependences on both channel and spatial dimensions are explored [57, 59], and literature [58] incorporates foreground and background attention to the model.
Remarks: Attention-based methods are often used in conjunction with other methods in FSS models, such as metric-based methods, to achieve optimal segmentation performance. While it works well for learning local features, convolution-based attention is not as good at modeling long-range dependencies. Matrix multiplication-based cross-attention can capture long-range dependencies, but it often suffers from high computational complexity.
The optimization-based methods aim to make the model easy to fine-tune for new categories by learning a good initialization network. Feature Weighting and Boosting (FWB) [27] draws inspiration from the optimization concept and utilizes the pre-segmentation of support images to provide an initialization value for a segmentation model. Similarly, several works [37, 57] have utilized this optimization approach to train their models. Differing from above, Tian et al. [60] redefined the FSS task as an optimization-based pixel classification problem. To this end, they developed an embedding module that utilizes both a global and local feature branch to extract appropriate meta-knowledge for the meta-segmentation network. To learn a generalization meta-learning framework, Cao et al. [61] presented a network with a meta-learner and a base learner. The meta-learner can learn good initialization and parameter updating strategies for the FSS task. The base learner theoretically can be arbitrary semantic segmentation models, and the parameters can be updated quickly with the guidance of the meta-learner. To achieve adaptive tuning, Zhu et al. [62] designed the base learner as an inner-loop task and used an optimization-based learner as an outer-loop to progressively refine the segmentation results.
Remarks: The optimization-based methods often change the training strategy to iteratively update the model’s parameters, so that the model can quickly adapt to new category tasks. However, these methods often require a more complex experimental setup, such as setting separate training steps or using an inner-outer-loop framework. It makes the optimization-based approaches less flexible than other approaches.
GNN-based models
The GNN-based models use structured representations, i.e., graphs, to represent the inputs and propagate category information from the support graph to the query graph in terms of graphical reasoning. To reason about the potential relationships between query nodes and labeled support nodes, graph attention networks are often introduced. The graph attention modules [63] apply an attention mechanism of gridded structure to learn the weights among the nodes’ connections and highlight the significance of the nodes. As shown in Fig. 7, existing GNN-based methods first learn graph representations for the features extracted from the CNN encoder. Then, the label information is propagated from the support image to the unlabeled query image by modeling the relationship between the support and query graphs.
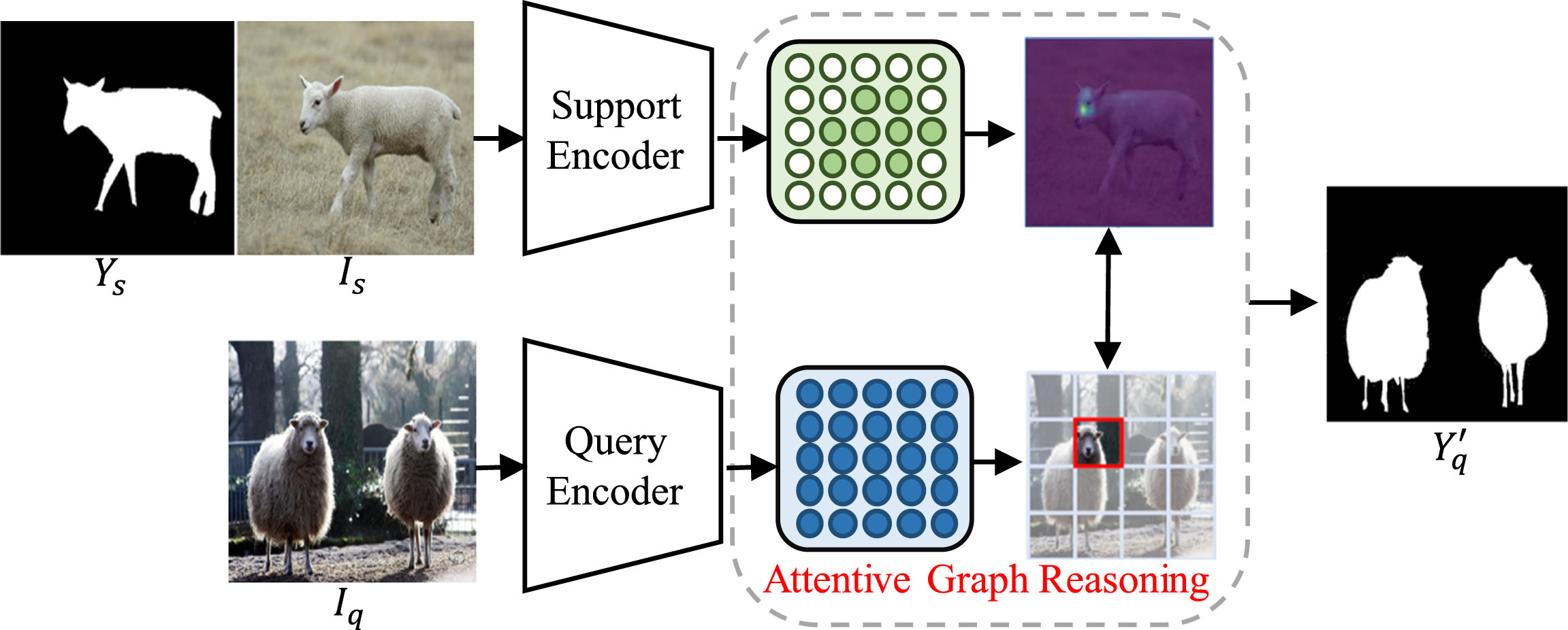
Framework of the graph-attention-based FSS methods.
The first GNN-based method, entitled Pyramid Graph Networks (PGNet) [19], employs the graph attention mechanism to construct a pyramid graph structure. To effectively propagate label information from the support images to the query image, subsequent algorithms aim to construct more optimal graph attention networks. For example, the Democratic Attention Network (DAN) [64] propagates guided information to the query image by rescaling the activated regions of objects in the support image. Scale-Aware Graph Neural Network (SAGNN) [65] interprets the cross-scale interactions between the support and query images in a structure-to-structure manner. However, the aforementioned weight adjustment strategies may not be reasonable and could introduce noisy pixels, which would ultimately lead to incorrect query image segmentation. To address this issue, the Mutually Supervised Graph Attention Network (MSGA) [66] constructs a bipartite graph attention module, which can improve performance through mutual guidance.
Remarks: The GNN-based models can reveal the linkages between intra-graphs or inter-graphs through various graph attention modules, and the visualization of the weights in their modules can provide interpretability of links. However, their computational efficiency is greatly impacted by the size and dimensions of the input samples.
The Transformer architecture has made significant progress in computer vision due to its powerful representational capabilities [67]. Inspired by this, researchers have begun exploring its potential applicability in the FSS task. Current transformer-based FSS methods usually take the form of ‘CNN + Transformer’ or ‘Pure Transformer’. As shown in Fig. 8, these methods extract features either from the CNN or Transformer encoder and design transformer-based modules to propagate the semantic information of the target categories within a global receptive field.
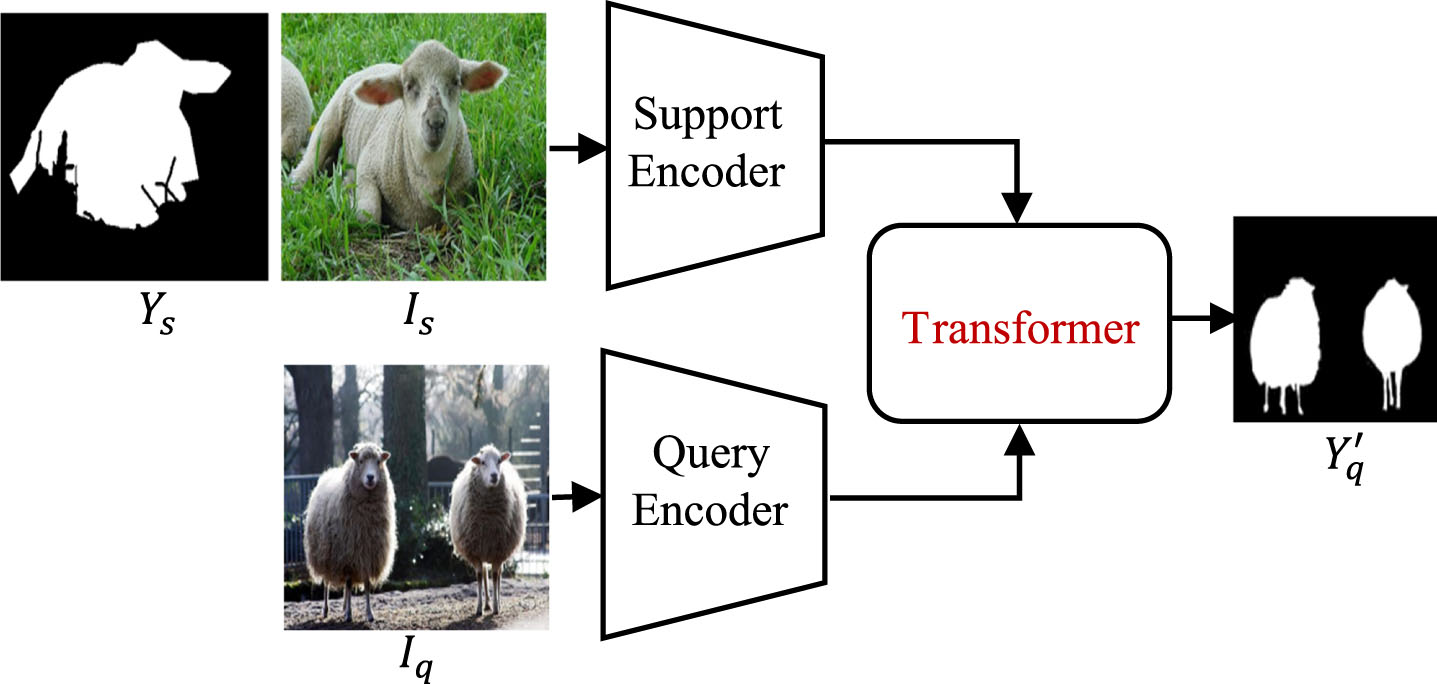
The Framework of the Transformer-based FSS methods.
The Transformer model is a new neural network architecture based on the self-attention mechanism. The model involves alternating MHA and Multi-Layer Perception (MLP), which achieves aggregation of relevant mappings by paying attention to the global receptive field [50]. The first transformer-based FSS algorithm [20] proposed a novel meta-learning framework that employs a Classifier Weight Transformer (CWT) to dynamically adapt to the classifier weights.
To filter out potentially harmful support features, the Cycle-Consistent Transformer (CyCTR) [68] uses self-alignment and cross-alignment transformer blocks to aggregate the context information within query images or across support and query images. The Context and Affinity Transformer (CATrans) [69] propagates contextual information using a relation-guided context Transformer and generates a reliable cross-affinity map by a relation-guided affinity Transformer. To ensure the purity of the sequential features and consistency of pattern matching, Hierarchically Decoupled Matching Network (HDMNet) [70] proposes a new hierarchically matching structure that utilizes self-attention modules and transformer-based matching modules to mine multi-scale pixel-level correlations. To address spurious matches in affinity learning methods, the Adaptive Buoys Correlation (ABC) network [71] rectifies direct pairwise pixel-level correlation by mining buoys and adaptive correlations. To reduce high computational complexity, Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA) [72] aggregates multi-level pixel correlation information between matched query and support features with the support masks. To learn a specialized feature extractor for the FSS task, Multi-level Heterogeneity Suppressing (MuHS) [73] enhances attention/interaction between different samples (query and support), different regions, and neighboring patches, respectively.
Remarks: The transformer architecture can leverage pixel-wise alignment to capture global information for the FSS task, which transcends the limitation of semantic-level prototypes. By allowing for fine-grained analysis and considering long-range dependencies, transformers have proven to be a powerful tool for achieving state-of-the-art performance in the FSS task. However, the computational complexity of the aggregation process still hinders their adaptability.
Datasets and evaluation
The popular benchmark datasets used for the FSS task primarily include PASCAL-5i, COCO-20i, and FSS-1000, which encompass 20, 80, and 1,000 categories, respectively. The first two datasets are derived from commonly used image semantic segmentation datasets redefined according to the concept of few-shot learning, while the third dataset is a distinct collection specifically created for the FSS task. Dataset PASCAL-5i was first introduced in OSLSM [18], which is composed of images and semantic labels from PASCAL VOC 2012 [74] and the extended set SDS [75]. 20 categories of PASCAL-5i are divided into 4 folds when treating 5 categories as the test set, the remaining 15 categories are formed the train set. Dataset COCO-20i was first introduced in FWB [27], which is composed of images and semantic labels from MSCOCO [76]. 80 categories of COCO-20i are divided into 4 folds, when 20 categories are treated as the test set, the remaining 60 categories are treated as the training set. Dataset FSS-1000 [34] is specifically designed to tackle the problem of few-shot segmentation for general objects. FSS-1000 comprises 1,000 categories and emphasizes the number of categories rather than the number of images. Each category contains 10 images and corresponding category labels, thereby making FSS-1000 highly scalable. The train/validation/test split used in the experiments consists of 5,200/2,400/2,400 image and label pairs.
Mean Intersection over Union (mIoU), Foreground-Background IoU (FBIoU), inferring time, and the learnable parameters are employed as the FSS assessment metrics. The
Ideally, an FSS model should be evaluated in multiple respects, such as quantitative accuracy (mIoU, FBIoU), speed (inferring time), and storage requirements (learnable parameters). However, most FSS methods focus on metrics for quantifying model accuracy, and only a few make a comparison with the learnable parameters and inferring time. Thus, we compare and analyze the performance of the FSS methods under the most popular mIoU and FBIoU metrics.
Performance and analysis
In this section, we compare and analyze the experimental results of FSS methods on the datasets PASCAL-5i, COCO-20i, and FSS-1000. We list the performance of meta-learning-based FSS methods on these three datasets with models, solutions, backbones, mIoU (%), and FBIoU (%), respectively. Table 1 presents the experimental results of various methods on datasets PASCAL-5i and COCO-20i. Table 2 displays the experimental results of several methods on the FSS-1000 dataset.
Segmentation performance of various methods FSS on datasets PASCAL-5i and COCO-20i
Segmentation performance of various methods FSS on datasets PASCAL-5i and COCO-20i
Segmentation performance of several FSS methods on dataset FSS-1000
We conduct a comprehensive analysis of the aspects of the datasets, backbones, and methods. It can be seen that almost all methods are evaluated on the dataset PASCAL-5i and the performance on the dataset FSS-1000 is superior to the other two and there remains significant room for improvement on the dataset COCO-20i. Thus, the scene diversity of the dataset has a great impact on FSS models. The CNN-based and GNN-based methods utilize the primary backbones of the VGG [77] and ResNet [78], while the Transformer-based techniques adopt additional backbones such as Swin [79] and DeiT [80]. Several methods [69, 73] evaluate their algorithms using both CNN and Transformer backbone architectures. It has been observed that the methods employing the Transformer backbone exhibit enhanced generalization capabilities compared to employing the CNN backbone. Thus, the discrimination of extracted features from the backbone affects the performance of FSS methods. The number of CNN-based methods is the highest, followed by Transformer-based methods, and the least prevalent are GNN-based methods. The metric-based CNN methods are the most widely used and have demonstrated promising performances. The attention-based methods in different models are often combined with metric-based methods. The attention-based Transformer methods have proven especially effective, achieving the best performance on all three datasets. Thus, both the metric-based and attention-based methods play important roles in FSS research.
In this section, we first summarize the state-of-the-art techniques with their merits, drawbacks, and applicability. Then, we discuss the limitations of FSS. After that, we present the applications in current FSS research. Last but not least, we show challenges to provide further research for the FSS task.
Discussion
FSS algorithms are primarily classified into CNN-based, GNN-based, and Transformer-based methodologies based on their architectures. The majority of FSS algorithms are CNN-based, the minority are GNN-based, and Transformer-based approaches exhibit a growing trend. The framework of these methodologies is changing from ‘Pure CNN’, ‘CNN + Graph’, and ‘CNN + Transformer’ to a more advanced approach with a ‘Pure Transformer’ configuration. In addition, different architectures are implemented in different ways. A discussion of these implementations, along with their merits, drawbacks, and applicability, is presented in Table 3.
Discussion of FSS techniques with merits, drawbacks, and applicability
Discussion of FSS techniques with merits, drawbacks, and applicability
In general, the research on the FSS task has made great progress, but several issues of different methods in different models still need to be addressed. In CNN-based models: Parameter-based methods directly modify the classifier’s parameters to suit new category segmentation, but adapting them to large-scale models can be challenging. Metric-based methods are straightforward to implement and can transfer meta-knowledge in meta-learning frameworks, but they still cannot fully address intra-class diversity. Metric-based methods often require significant effort to learn optimal prototype representations or discriminative category features. Attention-based methods can improve feature representation, but it is essential to strike a balance between computational complexity and performance. Optimization-based ideas are often exploited by other methods but often bring more complex experimental setups. In GNN-based models: Graph Attention-based methods can provide strong interpretability for the model, but they need to deal with complex computations. In Transformer-based models: Parameter-based methods can use a transformer structure to adapt the classifier, but cannot classify the images with extreme viewpoint differences. Attention-based methods can learn correlations in a global receptive for self- or cross-samples, but it is easy to produce high aggregation costs and overfitting.
Compared with traditional semantic segmentation algorithms, FSS algorithms have more obvious application advantages, which can greatly alleviate the problem caused by data scarcity, and provide a flexible solution for fast cross-class adaptation. Recent FSS has spurred intensive research efforts to apply it to various fields, such as medical images, 3D point clouds, etc.
Compared to natural images, medical images are considerably more challenging to collect and require expert manual labeling. Several FSS algorithms have been developed for medical images, including few-shot organ segmentation [81–83], few-shot skin lesion segmentation [84, 85], few-shot brain CT segmentation [86–90], and few-shot COVID-19 pneumonia diagnosis [91–94]. These methods are highly valuable to society and can improve medical diagnosis and promote medical research.
3D point clouds are complex, multidimensional data collections with intricate labeling requirements. Few-shot 3D point cloud segmentation methods [95–97] can use only a few labeled point cloud data to segment the new point cloud data. These methods hold great practical value and can benefit various applications, including autonomous driving, robotics, and augmented and virtual reality.
Besides that, FSS has also achieved breakthroughs in some other real-world segmentation tasks, including texture segmentation [98], logo segmentation [99], metal generic surface defect segmentation [100], and document layout segmentation [101]. In short, FSS plays a positive role in real scenes and makes life more intelligent and autonomous.
Challenges
Few-shot image semantic segmentation is gradually extending to more challenging tasks, such as Generalized Few-shot Semantic Segmentation (GFSS) tasks, weakly supervised FSS tasks, and cross-domain FSS tasks. These advancements create a strong basis for future research and application by significantly expanding its theoretical knowledge and application possibilities. GFSS. The commonly mentioned FSS is the narrowly defined FSS task, which uses a few labeled support images to segment new categories in the query image. But this specific task neglects base categories contained in query samples. Therefore, evaluating generalization performance only on new categories falls short of addressing real-world FSS scenarios. BAM [43] leverages segmentation information from base categories to facilitate the segmentation of novel categories, while also enabling the segmentation of base categories present in the query image. However, it still conforms to the strict narrow task setting which demands the support set to entail the categories present in the query sample. To overcome the drawbacks of the intricate narrow FSS setting and poor generalization over base categories, GFSS is proposed. GFSS methods [102–104] can simultaneously segment both base categories and new categories in the query image without prior knowledge of the specific categories. Weakly Supervised FSS. The label information contained in the support set in the FSS task typically refers to pixel-level labels, which are labor-intensive to produce. Consequently, some methodologies adopt weak labels [35, 105–108] (bounding boxes, dot annotations, etc.), image-level labels [109, 110], or even leverage self-supervised learning to generate labels [111]. These approaches help address the reliance on label information, further reducing its necessity. Cross-domain FSS. The FSS task often refers to the single-domain task, where generalization to new categories is achieved by learning segmentation models of base categories on the same dataset. It is far from being a genuine generalization. Some approaches [20, 112–114] emphasize cross-domain implementation across natural data, like COCO⟶PASCAL, PASCAL⟶COCO, and so on. And others [115] span from natural datasets to medical datasets. In addition to being more realistic, the cross-domain FSS challenge is also more difficult, allowing the trained model to be used in previously unexplored domains with distinct data distributions.
Conclusion
FSS can segment new categories only with a few labeled samples, which mitigates the reliance on labeled datasets and demonstrates generalization capabilities for new categories. In this paper, we survey FSS algorithms based on meta-learning and present the research trajectory. Specifically, we group them into architectural categories such as CNN-based, GNN-based, and Transformer-based models and explore their techniques such as parameter-based, metric-based, attention-based, and optimization-based methods. Moreover, we analyze the merits and drawbacks of existing FSS methods and discuss the limitations of current FSS research. To inspire future research in FSS, we also illustrate its applications and challenging tasks.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 62102129 and Grant 62276088, the Natural Science Foundation of Hebei Province under Grant F2021202030, Grant F2019202381 and Grant F2019202464.