
Abstract
It has been shown that the performance of neural machine translation (NMT) drops starkly in low-resource conditions. Thai-Lao is a typical low-resource language pair of tiny parallel corpus, leading to suboptimal NMT performance on it. However, Thai and Lao have considerable similarities in linguistic morphology and have bilingual lexicon which is relatively easy to obtain. To use this feature, we first build a bilingual similarity lexicon composed of pairs of similar words. Then we propose a novel NMT architecture to leverage the similarity between Thai and Lao. Specifically, besides the prevailing sentence encoder, we introduce an extra similarity lexicon encoder into the conventional encoder-decoder architecture, by which the semantic information carried by the similarity lexicon can be represented. We further provide a simple mechanism in the decoder to balance the information representations delivered from the input sentence and the similarity lexicon. Our approach can fully exploit linguistic similarity carried by the similarity lexicon to improve translation quality. Experimental results demonstrate that our approach achieves significant improvements over the state-of-the-art Transformer baseline system and previous similar works.
Introduction
Low-resource NMT has attracted lots of attention in recent years [1], some approaches have been proposed to improve the translation quality by data augmentation [2, 3], unsupervised learning [4, 5], transfer learning [6, 7], structure improving [8, 9], etc. Thai-Lao NMT is a typical low-resource NMT, however, influenced by language family and language processing tools, the research on Thai-Lao NMT in the past decade is not widespread. The bulk of researches on Thai-Lao NMT have to focus on language model training and named entity recognition [10, 11] etc. With the rapid development of the global economy, the demand for translation of Thai-Lao has been increasing. Therefore, it is important to investigate how to design an effective and suited model on the small scale of parallel corpus to improve the translation performance of Thai-Lao NMT.
Limited by parallel corpus and basic language processing tools, dominant low-resource NMT approaches show suboptimal performances on Thai-Lao language pair. However, as the languages both belong to the same Tai-Kadai language family, Thai and Lao have considerable cross-lingual similarities [12], the pronunciation and spelling of amounts of words are close or even identical. The similarities between Thai and Lao make them mutually intelligible for human communication, but there is still a lack of enough approaches to apply it to NMT. Intuitively, for using the cross-lingual similarity, the following preconditions need to be met: (1) accessible similarity representation: the similarity between two languages should be represented explicit and is easier to obtain than parallel sentences; and (2) improved NMT architecture: an efficient and suited model should be designed to receive the extra similarity information and balance the weight between the similarity information and the conventional sentence input. To tackle the above problems, we use bilingual similarity lexicon as the similarity information container and design a novel architecture to process the information flow. Our main contributions are as follows:
We investigate the cross-lingual similarities between Thai and Lao in the perspective of linguistic morphology and discuss the feasibility that chooses Thai-Lao similarity lexicon as an extra semantic information representation. Similarity lexicon is composed of pairs of Thai-Lao words, such as <  ,
, > (corresponding English: to), in which the Thai word “
> (corresponding English: to), in which the Thai word “ ” and Lao word “
” and Lao word “  ” are similar in linguistic morphology and have identical semantic.
” are similar in linguistic morphology and have identical semantic.
For utilizing the linguistic similarity carried by lexicon, we propose a novel framework that introduces an extra similarity encoder into the conventional encoder-decoder architecture, which allows linguistic similarity to be infused into the transformation from the source language to the target language. In the decoding side, we further provide a simple balance mechanism, the central idea is to balance the flow of information representations which are delivered from the input sentence and the similarity lexicon.
The remaining of the paper is arranged as following: In Section 2, we introduce the linguistic similarity between Thai and Lao. In Section 3, we describe the architecture of our proposed model. In Section 4 we report the experiment settings and results. Section 5 concludes the paper and provides our future work.
Linguistic similarity of thai and lao
Thai and Lao are both tonal languages from the Tai-Kadai language family, their pronunciation and writing are highly similar. Basically, spoken Thai and Lao are mutually intelligible. The two languages share a large amount of etymologically related words and have similar head-initial syntactic structures. For writing, Thai and Lao are both written with abugida scripts, slightly different from each other but are similar in basic morphological structure [12]. As the example shown in Table 1, it can be observed the similarity in the shape of tokens.
Thai-Lao linguistic similarity in writing
Thai-Lao linguistic similarity in writing
Besides token shape, we investigate the similarity of syntactic structure. We use GIZA++ tool [13] to obtain word alignment over the 20 K Thai-Lao portion of the publicly available ALT dataset [14]. Based on the alignment, we calculate Kendall’s τ according to the previous work of Isozaki [15]. Similar to editing distance, Kendall’s τ mainly focuses on the cost of adjusting the words in the parallel sentence pairs to the same order based on word alignment. As illustrated in Fig. 1, Thai-Lao language pair shows a relatively similar order with an average τ around 0.73, while the average τ for Thai-Chinese is about 0.25. The result demonstrates the considerable similarity in the syntactic structure between Thai and Lao, which is also consistent with the conclusion of the work [12].
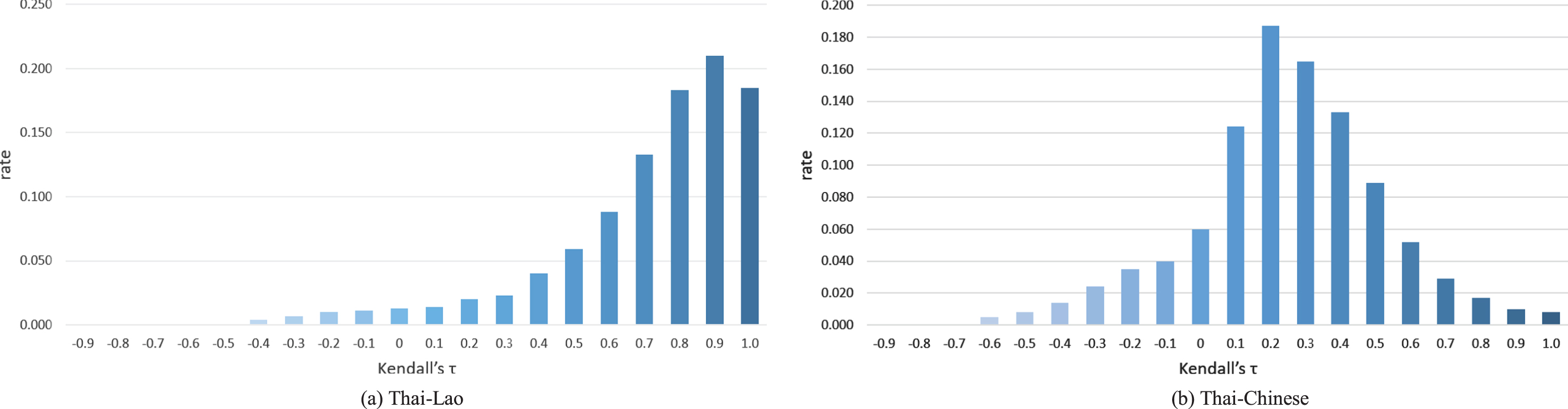
Distribution of Kendall’s τ on Thai-to-Lao (a) and Thai-Chinese (b).
According to the above analysis, Thai-Lao language pair has considerable cross-lingual similarity in either token shape or syntactic structure. Parallel sentence pairs with similarity are the best representation of those characteristics, however, they are difficult to obtain. Therefore, we choose the more accessible similarity lexicon for similarity representation, which can be obtained from the bilingual lexicon with a small number of manual modifications.
Despite some works have been done on language model and statistical machine translation (SMT) [16] over Thai-Lao language pair, there have been few works that focus on the impact of using an extra representation of similarity information in machine translation. To the best of our knowledge, there is no existing work on bilingual similarity lexicon integration for Thai-Lao NMT by designing a customized architecture. We argue that the similarity carried by the similarity lexicon will bring more adequate information from Thai to Lao and improve the accuracy of the translation.
In this section, we will elaborate the detail of our proposed model. Our goal is to achieve a customed Thai-Lao NMT model that can integrate an extra similarity lexicon encoder and guide the information flow in the decoder.
Overall framework
Given a source language sentence x ={ x1, x2, …, x
m
} and a target language sentence y ={ y1, y2, …, y
n
}, we use P (y|x, θ) to denote a standard attention-based NMT model:
To integrate similarity sequence into efficient encoder-decoder architecture and inspired by the multi-source NMT works [17, 18], we choose Transformer [19] as benchmark model and apply structural modifications on it. As shown in Fig. 2, we first add an extra encoder component into the conventional Transformer. Furthermore, to adjust the extra input generated by the similarity encoder, we improve the structure of the decoder by applying a simple mechanism in the encoder-decoder attention layer to balance the information flow. In the following subsections, we will elaborate the components of our proposed model and show how they are adapted to the Transformer architecture.
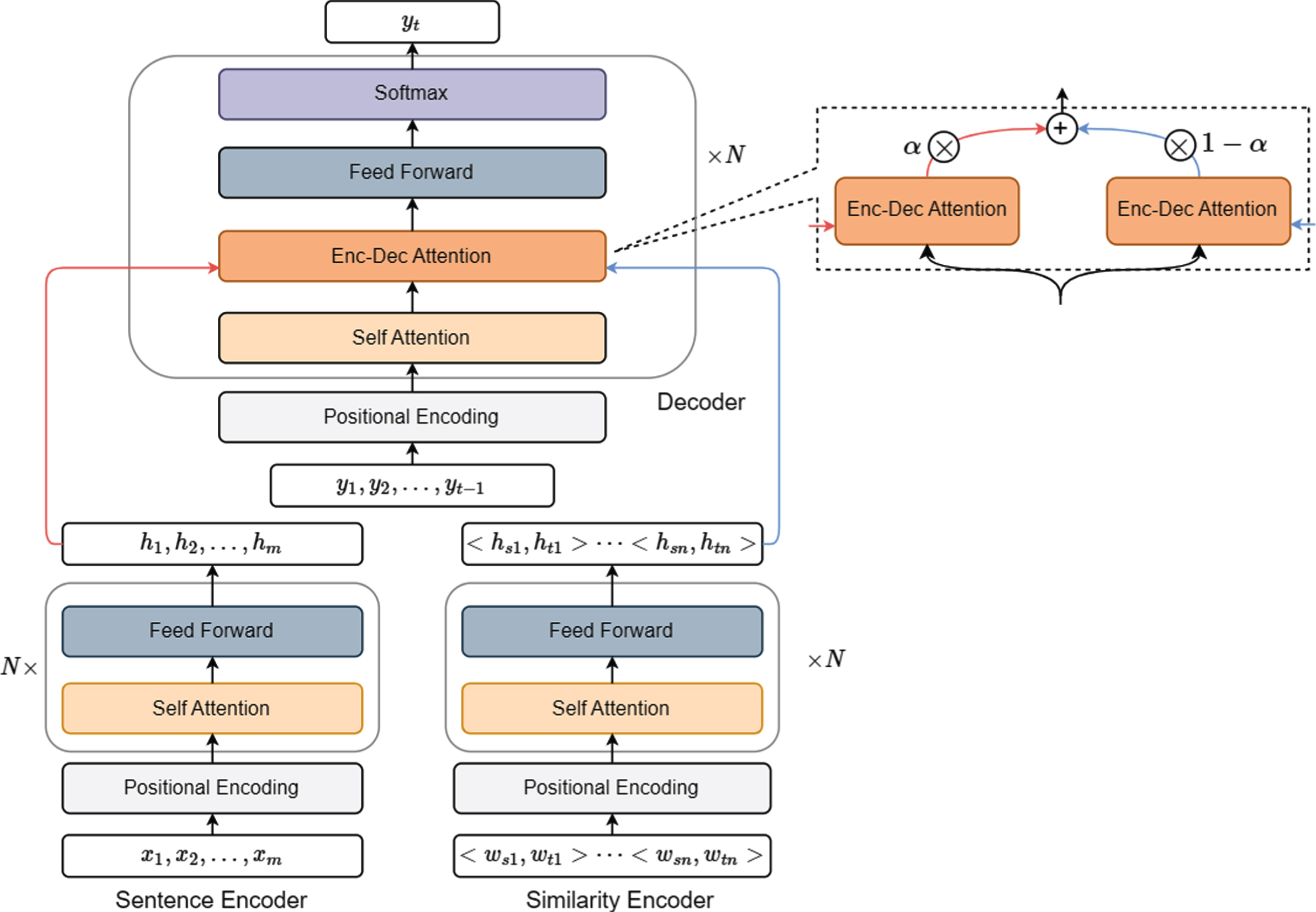
Illustration of the Thai-Lao NMT model based on modified Transformer. For simplicity, we assume that input sentence x matching only one pair of similarity words (ws1, wt1).
As illustrated in the left of Fig. 2, all N sentence encoder is standard Transformer encoders and are all identical in structure. The encoders use a stacked structure and each encoder comprises two sub-layers: a multi-head self-attention layer and a position-wise feed-forward network layer. For each sub-layer, residual connection and layer normalization mechanism are adopted. When given an input sentence x ={ x1, x2, …, x m }, the sentence encoder transforms x into a hidden state sequence h sen ={ h1, h2, …, h m }, where h i is the hidden state of x i .
Similarity encoder
For the input x ={ x1, x2, …, x m } of sentence encoder, we traverse it and get matched similarity sequence w ={ w1, w2, …, w l }, where l is the number of word pairs, for any i ∈ l, w i is a word pair 〈w si , w ti 〉 and comprises source word w si and its corresponding target word w ti in the similarity lexicon. Note that if x matches nothing in the similarity lexicon, we feed w with a special token pair 〈None, None〉.
As illustrated in the right of Fig. 2, the similarity encoder is identical in structure to the sentence encoder, which use a stacked structure and each encoder comprises two sub-layers: a multi-head self-attention layer and a position-wise feed-forward network layer. For the sake of simplicity, we omit the introduction of Transformer layers and give an input-output introduction here. Given similarity sequence w ={ w1, w2, …, w l }, the similarity encoder transform it into a hidden state sequence h sim ={ h1, h2, …, h l } by self-attention mechanism, where for i ∈ l, h i = 〈h si , h ti 〉, then the hidden state h sim and the sentence hidden state h sen will be transferred together (see the blue line and the red line) to the improved encoder-decoder attention layer in the decoder.
Decoder
As there is extra similarity information that flows to the decoder, the prevailing Transformer decoder needs to be modified to accommodate the new input. Furthermore, for balancing the weight between sentence information and similarity information, a dynamic mechanism needs to be adopted to get the optimal information flow. Specifically, in order to process the additional similarity input besides normal sentence input of the encoder-decoder attention layer, we split the layer into two components for different information accommodating and keep other source-independent layers unchanged. The modified Transformer decoder has three sub-layers: (1) a masked multi-head attention sub-layer, (2) a modified encoder-decoder attention sub-layer which is composed of sentence encoder-decoder attention component and similarity encoder-decoder attention component, and (3) a position-wise fully connected feed-forward network sub-layer.
The detail of the modified encoder-decoder attention sub-layer is illustrated in the upper part of Fig. 2. Given the output s
self
of the masked multi-head self-attention layer at position t and the representation h
sen
of input sentence, the sentence encoder-decoder attention is calculated as:
Inspired by the works [9, 21] that adopt balancing mechanism to control the information flow, we concatenate s
sen
and s
sim
for the calculation of the balancing coefficient α
t
, note when s
sim
is null vector, α
t
is set to 1 directly:
As illustrated in the upper part of Fig. 2. Then senc_dec is transferred to the position-wise fully connected feed-forward network:
In the conventional NMT, in order to actuate the model to predict the target sequence, maximum likelihood estimation (MLE) loss function is used to update the model parameter by maximizing the log likelihood of translation. The MLE loss function can be described as:
We assume that the conventional MLE loss function makes the translation approximate to the true distribution, while the similarity-integrated loss function guides the translation procedure in the perspective of semantic. In practice, we find that synthetically using two objectives can make training procedure easier and get a better translation performance.
In this section, we present empirical studies for the proposed approach on the publicly NMT dataset. We also conduct multiple studies to thoroughly analyze the effect of the proposed approach, including translation quality, inference efficiency, the effect of similarity, and case study.
Experimental setup
Moses: The dominant phrase-based SMT system with the default configuration and a 4-gram language model. We train the model on the entire training data and use the lexicon to constraint the word alignment result generated by GIZA++. We choose phrase-based SMT system as a baseline model because in low resource settings, SMT tends to achieve better performance than NMT [25]. Transformer: The dominant NMT approach that obtained the state-of-the-art performance on machine translation and predicts target sentence from left to right relying on self-attention. Song et al. [26]: A data augmentation approach that uses replace strategy for term lexicon introducing. For each source-target word, randomly sampling k1 matching sentences to replace a source-side word with its target-side word. For each combination of two source-target word pairs, the sampling hyper-parameter is set to k2 and both source-side matching words are replaced with their target translations. We follow the empirically set of Song et al. [26], in which k1 is set to 100, k2 is set to 30. Georgiana et al. [27]: A data augmentation approach that utilizes external term lexicon on the generic NMT architecture. The approach provides two strategies: append and replace for data augmentation. For append, the target words in term lexicon are append to the corresponding source words. For replace, the words in source sentences are replaced by the corresponding words in term lexicon. We compare our approach to the append strategy which performs better according to the conclusion of their work. Post et al. [28]: A constrained decoding approach, which uses a dynamic beam allocation (DBA) technique to reduce the computational overhead to a constant factor at the procedure of term integration.
Experimental results
Results on ALT Thai⟶Lao, Chinese translations (BLEU score). Significance tests are conducted based on the best BLEU results by using bootstrap resampling (p < 0.05). “bt” denotes back-translation
Results on ALT Thai⟶Lao, Chinese translations (BLEU score). Significance tests are conducted based on the best BLEU results by using bootstrap resampling (p < 0.05). “bt” denotes back-translation
Decoding overhead. “Inference time” is measured as the total decoding time on one P100 GPU for Thai-Lao test set (1018 sentences). “Type” column indicates that whether the model is structure-independent
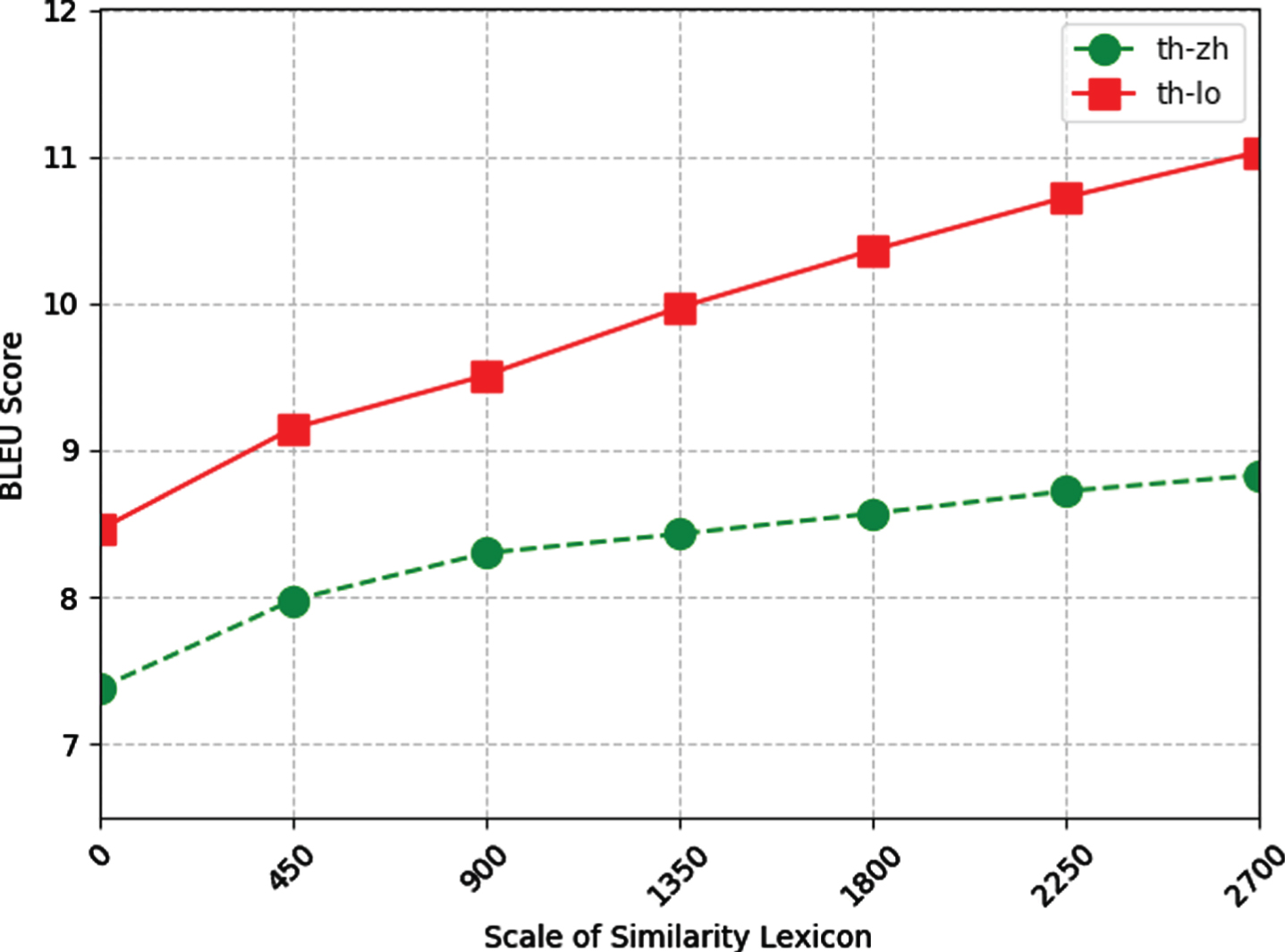
Performance on our proposed approach when infusing different amount of similarity word pairs.
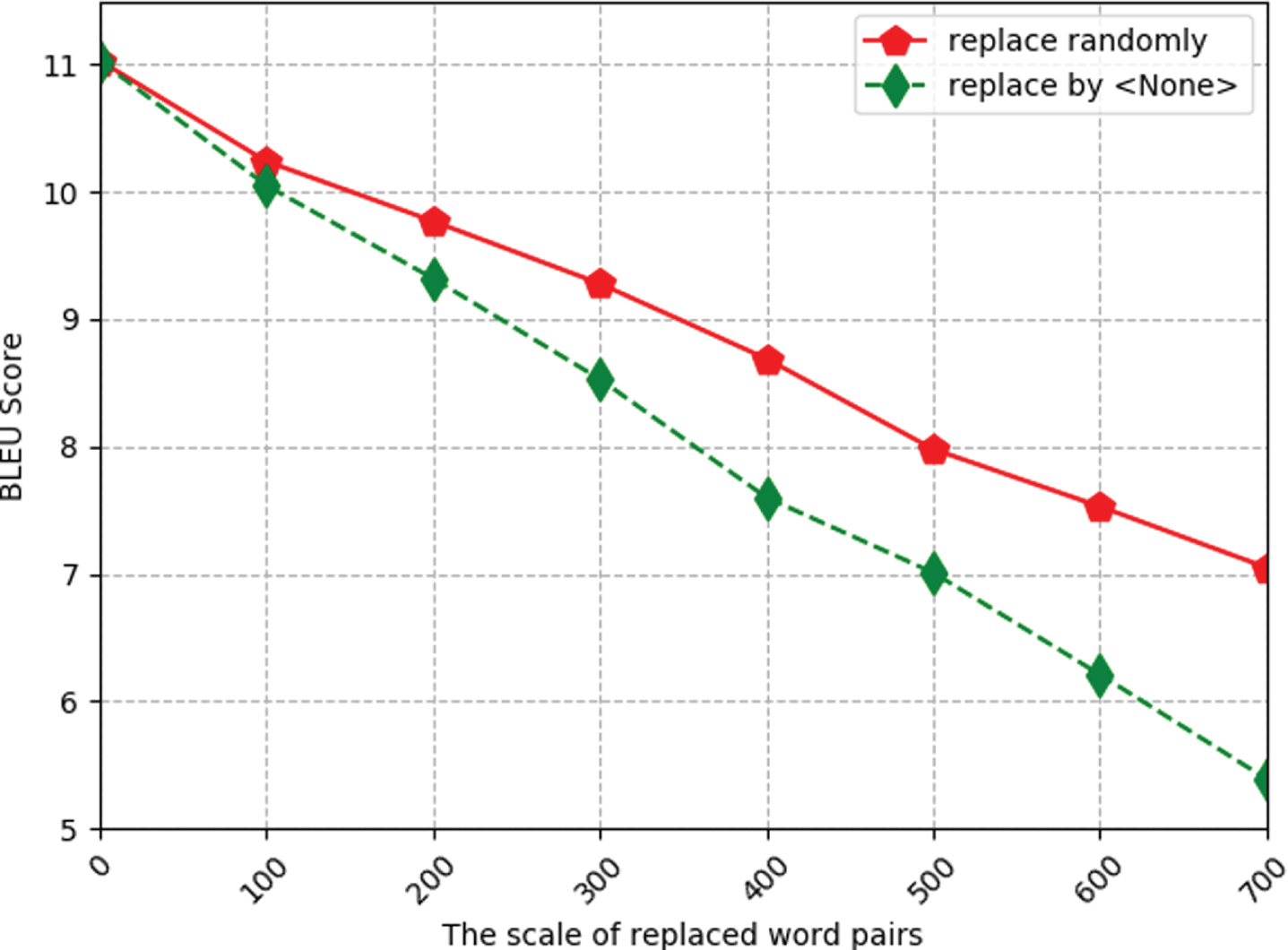
Performance decline on our proposed approach when using different corrosion strategies (on Thai-Lao translation task).
As shown in Fig. 5, when the β switches from 0.4 to 0.6, our model gets better performance than the intervals [0.1,0.3] and [0.7,0.9]. The results show that we can set the hyper-parameter β in a reasonable interval ([0.4,0.6]) to keep the balance between source text and similarity input.
The influence of hyper-parameter β on the model. Note we conduct the evaluation on the validation set and then validate the conclusion on the test set.
 ” (I) and “
” (I) and “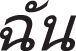 ” (go/to/leave) are translated correctly in our approach. We argue that one of the main reasons is that the similarity encoder delivers more information for the translation process. Because “
” (go/to/leave) are translated correctly in our approach. We argue that one of the main reasons is that the similarity encoder delivers more information for the translation process. Because “ 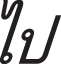 ” (I go/to/leave) in Thai is similar in morphology with “
” (I go/to/leave) in Thai is similar in morphology with “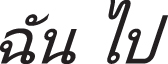 ”(I go/leave) in Lao and both of them can be found in the similarity lexicon.
”(I go/leave) in Lao and both of them can be found in the similarity lexicon.
Example of Thai-Lao translation
 (I will go abroad next week)
(I will go abroad next week)We propose a novel neural machine translation (NMT) approach focusing on language pair Thai-Lao which has extremely limited amount of parallel corpus but is cross-lingual similar. We first investigate the cross-lingual similarity of Thai-Lao language pair. Then for utilizing the cross-lingual similarity we propose a new end-to-end NMT model, in which a similarity encoder and a modified encoder-decoder attention layer in the decoder are designed for similarity receiving and fusion respectively. We further conduct contrast experiments, as the results reported, our approach achieves significant BLEU improvement on Thai-Lao task using tiny parallel corpus, compared to the strong SMT and NMT baseline models.
An interesting direction is to apply our approach to other low-resource NMT tasks in the future, with the feature that the source language is similar to the target language, such as Malay-Indonesian, etc.