
Abstract
Purpose:
at present, more and more deep learning algorithms are used to detect and segment lesions from spinal CT (Computed Tomography) images. But these algorithms usually require computers with high performance and occupy large resources, so they are not suitable for the clinical embedded and mobile devices, which only have limited computational resources and also expect a relative good performance in detecting and segmenting lesions.
Methods:
in this paper, we present a model based on Yolov3-tiny to detect three spinal fracture lesions, cfracture (cervical fracture), tfracture (thoracic fracture), and lfracture (lumbar fracture) with a small size model. We construct this novel model by replacing the traditional convolutional layers in YoloV3-tiny with fire modules from SqueezeNet, so as to reduce the parameters and model size, meanwhile get accurate lesions detection. Then we remove the batch normalization layers in the fire modules after the comparative experiments, though the overall performance of fire module without batch normalization layers is slightly improved, we can reduce computation complexity and low occupations of computer resources for fast lesions detection.
Results:
the experiments show that the shrank model only has a size of 13 MB (almost a third of Yolov3-tiny), while the mAP (mean Average Precsion) is 91.3%, and IOU (intersection over union) is 90.7. The detection time is 0.015 second per CT image, and BFLOP/s (Billion Floating Point Operations per Second) value is less than Yolov3-tiny.
Conclusion:
the model we presented can be deployed in clinical embedded and mobile devices, meanwhile has a relative accurate and rapid real-time lesions detection.
Introduction
Many deep learning algorithms are applied in reading spinal CT images, which is a very common and effective method in diagnosing spinal diseases. We can consider spinal fracture lesions detection as the some concrete kind of object detection, while spinal lesions has different coordinates and different categories in every CT image. So the state of art object detection algorithms, such as Faster-RCNN [1, 2], SSD (Single Shot MultiBox Detector) [3–5], SPPNet [6, 7], Yolo (You Only Look Once) [8], YoloV2 [9], YoloV3 [10] can be used in detecting spinal fracture lesions. Most of the algorithms mentioned above have a relative good performance in spinal lesions detection, but they are all running in computers with high configuration and large memory, and the training models of these algorithms are too large to clinical embedded devices, which only have low configurations and small computational resources, meanwhile expect a accurately real-time spinal lesions detection.
Yolov3-tiny [10] is the simplified network of Yolov3, which has less convolutional layers than Yolov3 and does not need many computational resources, so it has a small size model and can be ran in clinical embedded devices. Yolov3-tiny has a quickly detection velocity at the cost of losing detection accuracy, means the spinal lesions detection accuracy and overall performance of Yolov3-tiny does not meet the real-time demands for clinical embedded devices.
Inspired by the fire modules in the SqueezeNet [11] and in order to meet the demands of clinical embed devices, we propose a shrank model for detecting spinal lesions based on Yolov3-tiny by reducing the parameter number of training model, which has a small size model (almost a third of Yolov3-tiny) and accurate spinal lesions detection in this paper. The proposed model can detect spinal lesions rapidly and meet for real-time lesions detection in clinically. The contributions in this paper are as follow:
a. We introduce the fire modules in SqueezeNet into Yolov3-tiny to construct a novel frame for detecting spinal fracture lesions, which has a small size model and accurate lesions detection.
b. We remove the batch normalization layer in fire modules to reduce computation complexity and occupation of computer resources, so as to detect lesions rapidly.
c. We utilize the soft-NMS (Non-Maximum Suppression) instead of the original NMS to avoid the missed detection of overlapped spinal lesions in CT images.
This paper is organized as follows: In section 2, we depict the deep learning algorithms emerged in diagnosing spinal diseases. In section 3, we describe the data set and methodology in this paper, which includes CT images used in training and testing, combines the fire modules in Yolov3-tiny, and removes the batch normalization layer in fire module. In section 4, we describe the experiments and compare to other state of the art algorithms. Finally we give a conclusion of our work and next target in future.
Related work
Deep learning algorithms in spinal diseases
In recent years, deep learning algorithms have made great progresses in diagnosing spinal diseases. These algorithms present the objective and effective assistance to both doctors and patients. Badhe [12] develops an automated algorithm for thoracic vertebral segmentation on chest radiography using deep learning. Y Li [13] evaluates the performance of deep learning using ResNet50 in differentiation of benign and malignant vertebral fracture on CT Deng, Y [14] introduces a large-scale spine CT dataset, called CTSpine1K, and conducts several spinal vertebrae segmentation experiments to set the first benchmark based on this data set. Liebl, H [15] develops a method for fully automated radiological image analysis in spine imaging. Jakubicek [16] gives an approach for spine centerline determination based on CNN (Convolutional Neural Network). Wang [17] attempts to segment the intervertebral automatically. Liu [18] utilizes two stage of deep learning networks to segment and recognize vertebrae. Alberto A. Perez [19] proposes a simple graphical technique for CT-MR image overlay, for use in the surgical planning of spinal decompression and guidance of intraoperative resection Fang [20] uses FCN (Fully Convolutional Neural Network) and MC (Marching Cubes) to segment and reconstruct vertebrae. Kumthekar [21] proposes an inception U-Net architecture for automating cloud detection in multi-spectral images. Upadhyay [22] gives a new method to diagnose the Spinal stenosis by deep learning. Chen [23] presents a AEC-Net (Adaptive Error Correction Net) to estimate the Cobb angles from spinal X-rays. Alkafri [24] proposes a method to detect lumbar spinal stenosis from MRI (magnetic resonance imaging) scans of lumbar. Chuang [25] gives an vertebrae segmentation model, which can segment cervical, thoracic, and lumbar vertebrae. Liao [26] gives a vertebrae identification and localization system that can incorporate both the short-range and long-range contextual information in a supervised manner. BakaWang, H [27] applies a modified CapsNet to recognise 3D vertebral images by introducing an RNN module into CapsNet to further enhance its learning ability. Paugam [28] presents an open-source pipeline to train neural networks to segment structures of interest from MRI data. Lu [29] develops an efficient methodology to leverage the subject-matter-expertise stored in large-scale archival reporting and image data for a deep-learning approach to fully-automated lumbar spinal stenosis grading.
Most of the algorithms mentioned above have a accurate spinal lesions detection and real-time performance, but they require high configuration computers with complex computation ability and large memories, so they are not suitable for clinical embedded devices which only have limited computation resources. So we should compress the training network models to meet the requirements of clinical embedded devices.
Neural network model compression
Building a tiny and effective neural network model for embedded devices and mobile terminals in clinically is very urgent. We can reduce the model size by network pruning [30] and network quantization [31–33], and other methods. Network pruning is to clip network connections in a way that retains the original precision. After the initial training phase, all the links whose weights are lower than the threshold are deleted. This pruning converts dense fully connected layers to sparse layers. In this stage, we learn the topology of the network, so as to delete the unimportant ones. Then, we retrain the sparse network so that the remaining connections can compensate for the deleted connections. Network quantization is to convert the floating point weight value of most operations in neural network into fixed-point integer representation, and replaces operations with which can perform similar fixed-point integer operation. Therefore, most of the floating-point operations in the network can be replaced by fixed-point integer calculation, which can improve computing speed, reduce power consumption, and reduce storage consumption.
The methods mentioned above mainly modify the model in training stage. Another method is to design a compact and tiny network to build a small model while has the similar detection accuracy and performance with the traditional neural network model. The SqueezeNet [11] is proposed by UC Berkeley and Stanford researchers in 2016, which introduces the fire modules to reduce the model size by utilize less parameters in convolutional layers. The fire module use 1*1 convolutional layers to cut down the dimension of feature maps for reducing parameters. The accuracy of objective detection on ImageNet by SqueezeNet is almost same as AlexNet [34], but the model size is almost 500 times smaller than the model of AlexNet. ShuffleNet v1 [35] is proposed by Face++ in 2018 and is deployed on mobile terminals. The ShuffleNet mainly adopts two operations, one is point wise group convolution and the other is channel shuffle, to keep detection accuracy while reduce the amount of calculation greatly. The core design concept of shufflenet is to shuffle different channels to solve the disadvantages brought by group revolution. ShuffleNetv2 [36] proposes a new type operation of channel split, which divides the input channels of module into two parts, one is passed down directly, the other is calculated backward. So the information exchanging between channels in ShuffleNetv2 are fast and effective.
In this paper, we introduce the fire modules in SqueezeNet to reduce parameters of convolutional layers for constructing a small size model while has accuracy spinal lesions detection.
Materials and methods
In this section, we describe the CT images for training and testing, then depict the improvements of proposed model in detail.
Materials
We collect spinal fracture CT images from Xijing Hospital (Military Medical University of Air Force) and other hospitals. We label spinal fracture lesions in every CT image, and classify as cfracture (cervical fracture), tfracture (thoracic fracture), lfracture (lumbar fracture), with the assistance of orthopedic residents in Xijing Hospital, by the software LabelImg, which is a graphical image annotation tool and saves label annotation as XML files in Pascal VOC [37] format.
Data preprocess
Usually, there are some interferences in spinal CT images, so we preprocess CT images of spinal lesions for training and testing.
The format of spinal CT images is DICOM (Digital Imaging and Communications in Medicine), which includes a lot information of lesions. first, we input the original CT images to make equalization due to image pixels are scanned by CT equipments with different thick layers. Second, HU (Hounsfield Unit) value is used to represent density of a tissue or a organ of human body, which can be used to measure lesions size. Usually, HU value of air is -1000 and HU value of dense bone is +1000. HU value and pixel of spinal CT images can be mapped as a linear relationship and are switched to each other. In this paper, we choose HU value above 400, and make HU value between [400, 2000] normalized as [0,1]. Third, the Gauss Filter is used to reduce and remove noises in CT images for training. Finally, we extract and achieve the ROI (Region of Interest) of spinal lesions by binary segmentation and mathematical morphology.
Label spinal lesions in CT image
Every kind of spinal fracture lesions has two files after we labeled lesions in CT image, one is labeled CT image, the other is XML file which save the annotations, indicating the location and category of spinal lesions.
With help of doctors in Xijing Hospital, we label lesions in every CT image by labelImg, we randomly select three series sample of CT images, which are labelled as cfracture, tfracture and lfracture respectively. In Fig. 1, as we can see, (a) is original cervical CT image, (b) is cfracture labelled by labelImg, (c) is original thoracic CT image, (d) is tfracture labelled by labelImg, (e) is original lumbar CT image, (f) is lfracture labelled by labelImg.
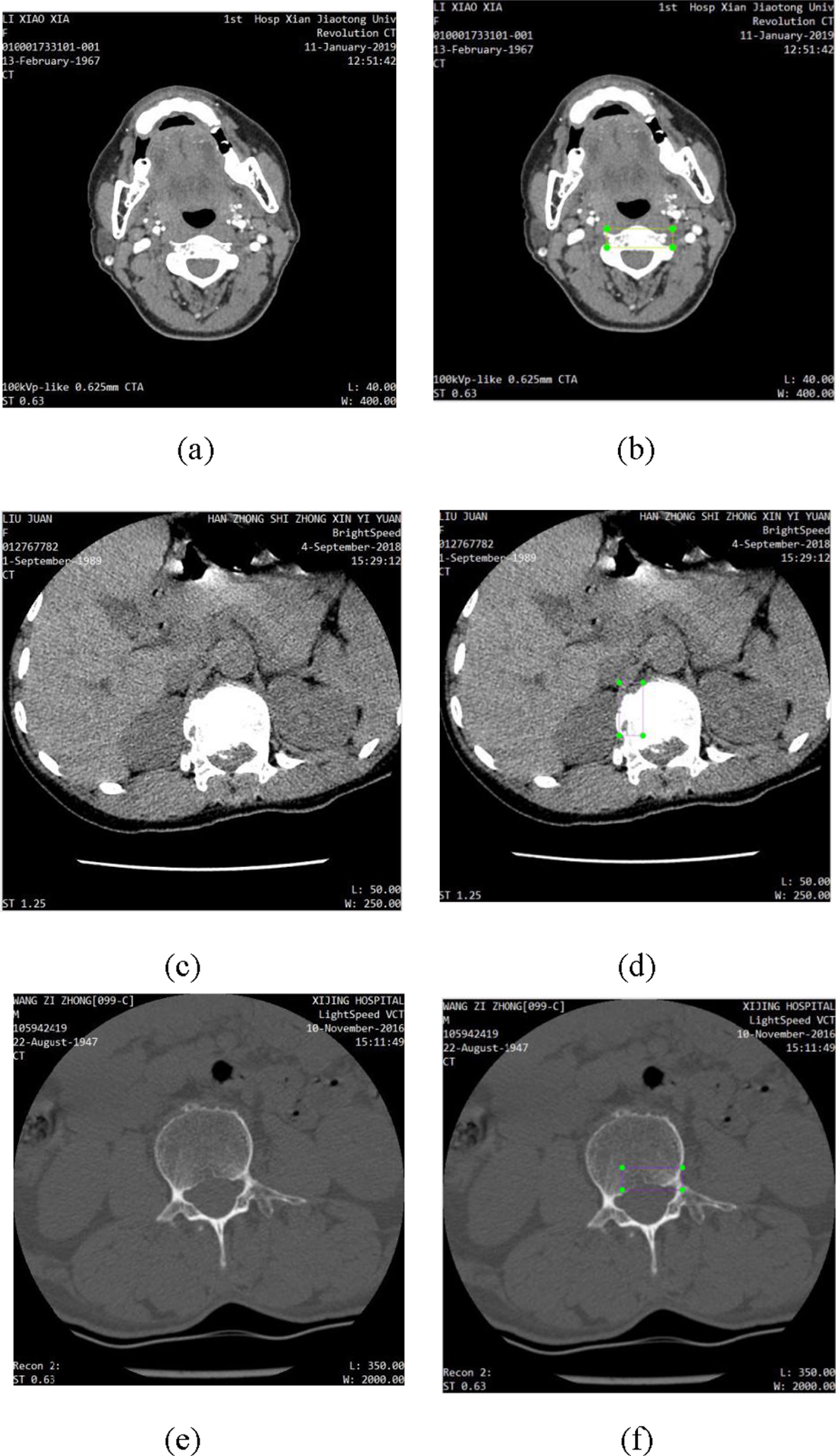
label fracture lesions: (a) original cervical CT image, (b) cfracture labelled by labelImg, (c) original thoracic CT image, (d) tfracture labelled by labelImg, (e) original lumbar CT image, (f) lfracture labelled by labelImg.
We select 40 series of spinal fracture CT images, which consists of 5134 images. Since deep learning algorithm needs a large amount of data, we augment data set by data enhancement, which includes rotating the CT image 90 degrees, 180 degrees, 270 degrees, horizontal flip, vertical flip.
Figures 2 to 4 are selected sample groups of CT images after data augmentation. In Fig. 2 to 4, the spinal fracture (cfracture, tfracture, lfracture) lesions are not obvious and hard to detect correctly, we can get clear information about lesions after data augmentation, for we can observe lesions from different views, so as to get accurate fracture lesions detection. After we rotate and flip the CT images, we do not change the sizes and shapes of spinal lesions, but we change directions of spinal lesions, which is critical and important to training network. The spinal fracture lesions with different directions are viewed as different lesions in training network.
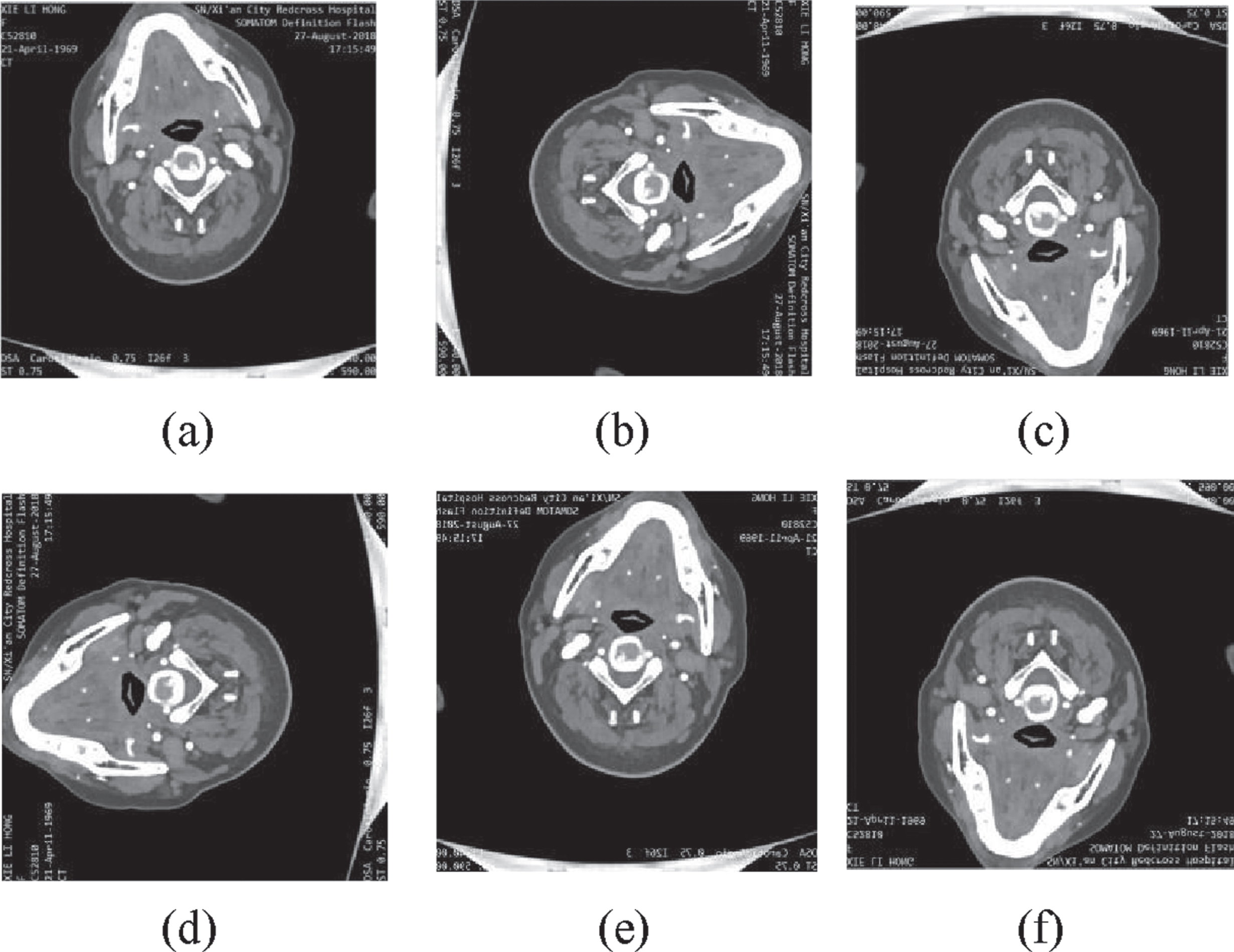
The augmentation of cfracture lesions. (a) Original CT images. (b) Rotating 90 degrees. (c) Rotating 180 degrees. (d) Rotating 270 degrees. (e) Horizontal flip. (f) Vertical flip.
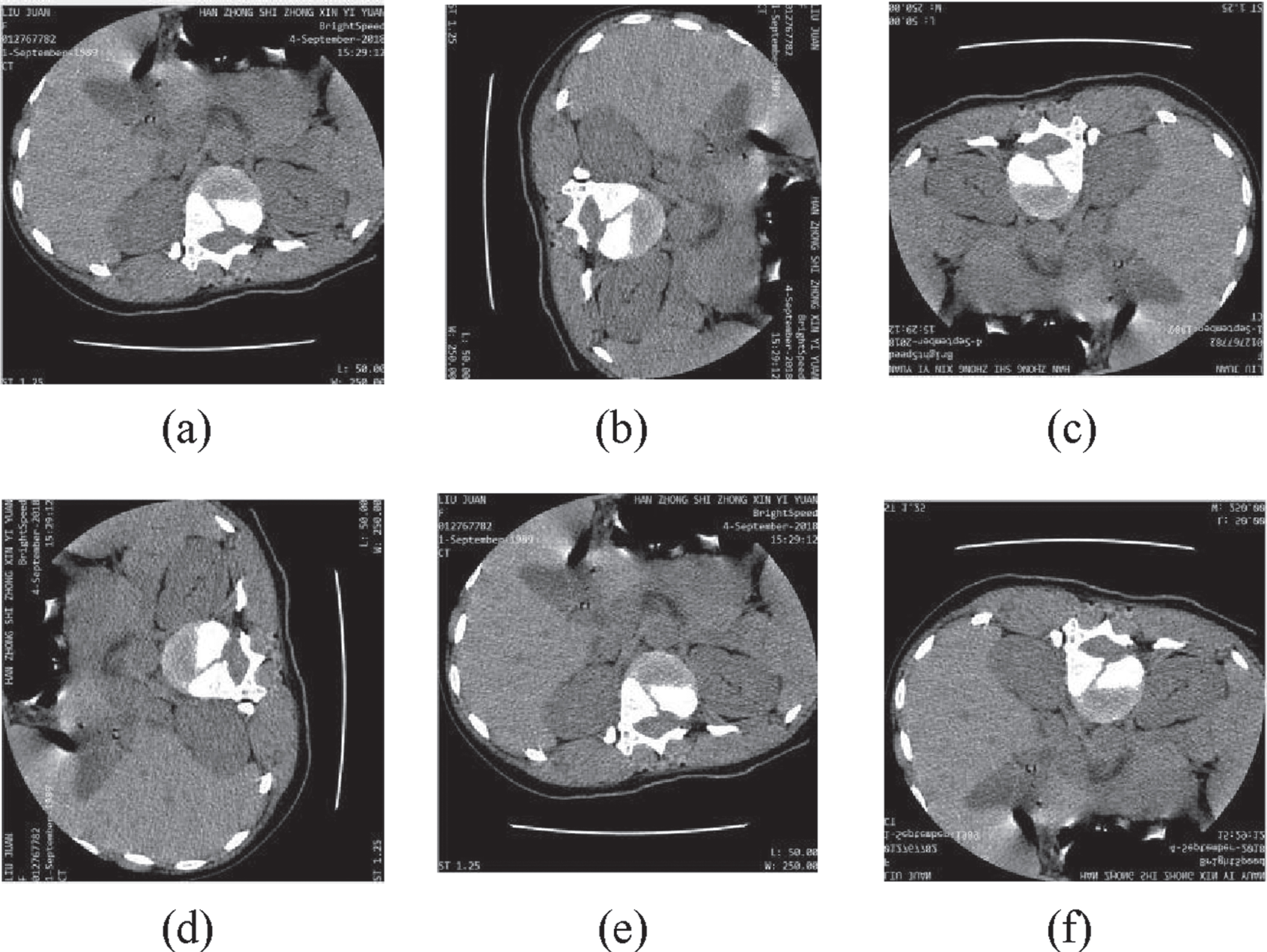
The augmentation of tfracture lesions. (a) Original CT images. (b) Rotating 90 degrees. (c) Rotating 180 degrees. (d) Rotating 270 degrees. (e) Horizontal flip. (f) Vertical flip.
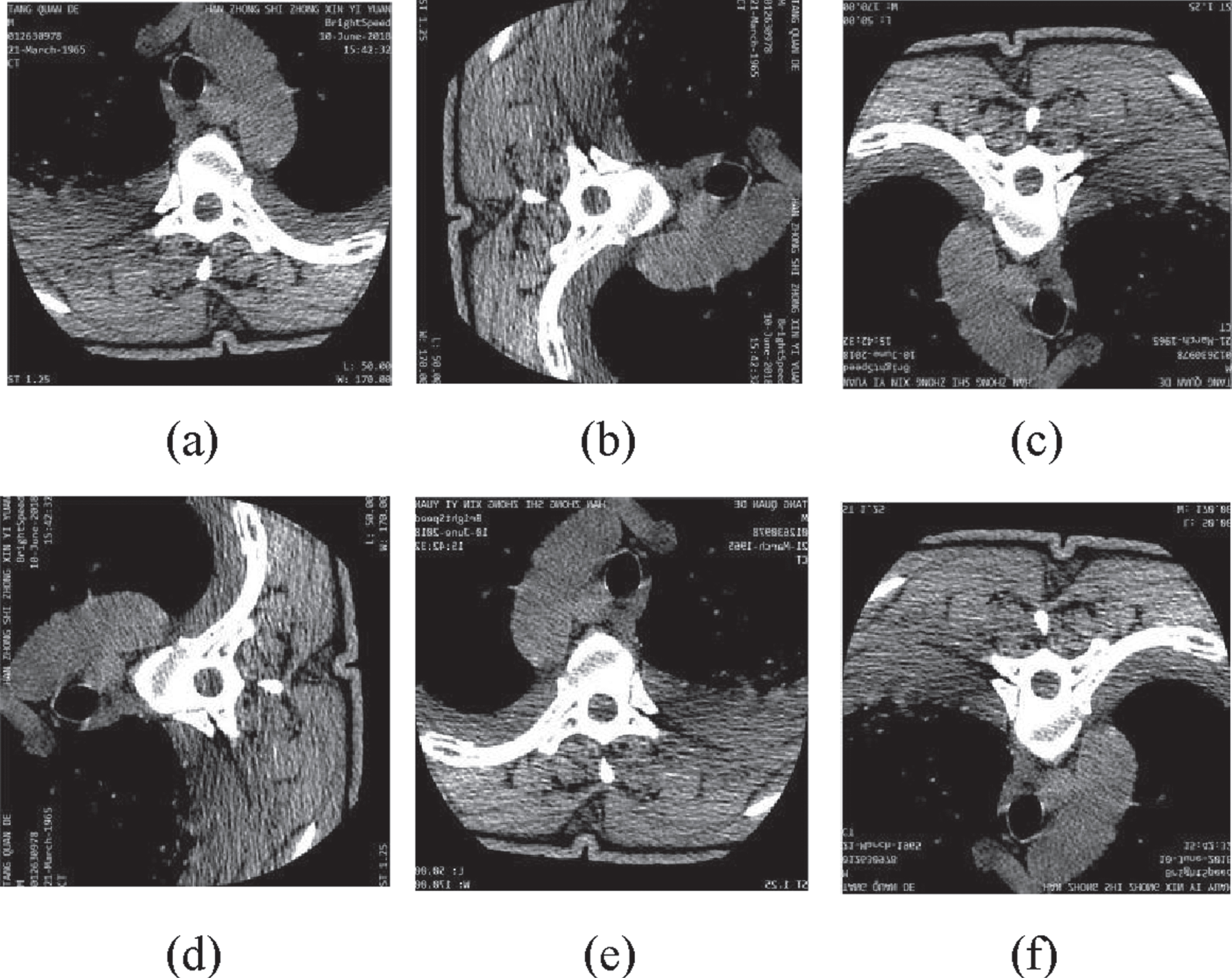
The augmentation of lfracture lesions. (a) Original CT images. (b) Rotating 90 degrees. (c) Rotating 180 degrees. (d) Rotating 270 degrees. (e) Horizontal flip. (f) Vertical flip.
After data augmentation, the data set of spinal lesions are augmented to 10268 CT images, the image pixel is 256*256. We randomly split train set and test set in the ratio of 4:1, 80% is used in training, and the other 20% is used in testing and verification. So 8216 CT images are used for training, 1027 CT images are used for testing, and 1027 CT images are used for verification.
Figure 5 is the network architecture of Yolov3-tiny, and there are seven convolutional layers and six maxpoolings in main feature extracting network then followed by two detection layers. The concrete architecture of Yolov3-tiny is shown in Table 1, we suppose the input CT images are with pixel 480*480. We can see in Table 1, there are two 512 and one 1024 filters in Yolov3-tiny, which cause a great number of parameters in computation and require a large memory in embedded devices, while the lesions detection costs a lot of time.
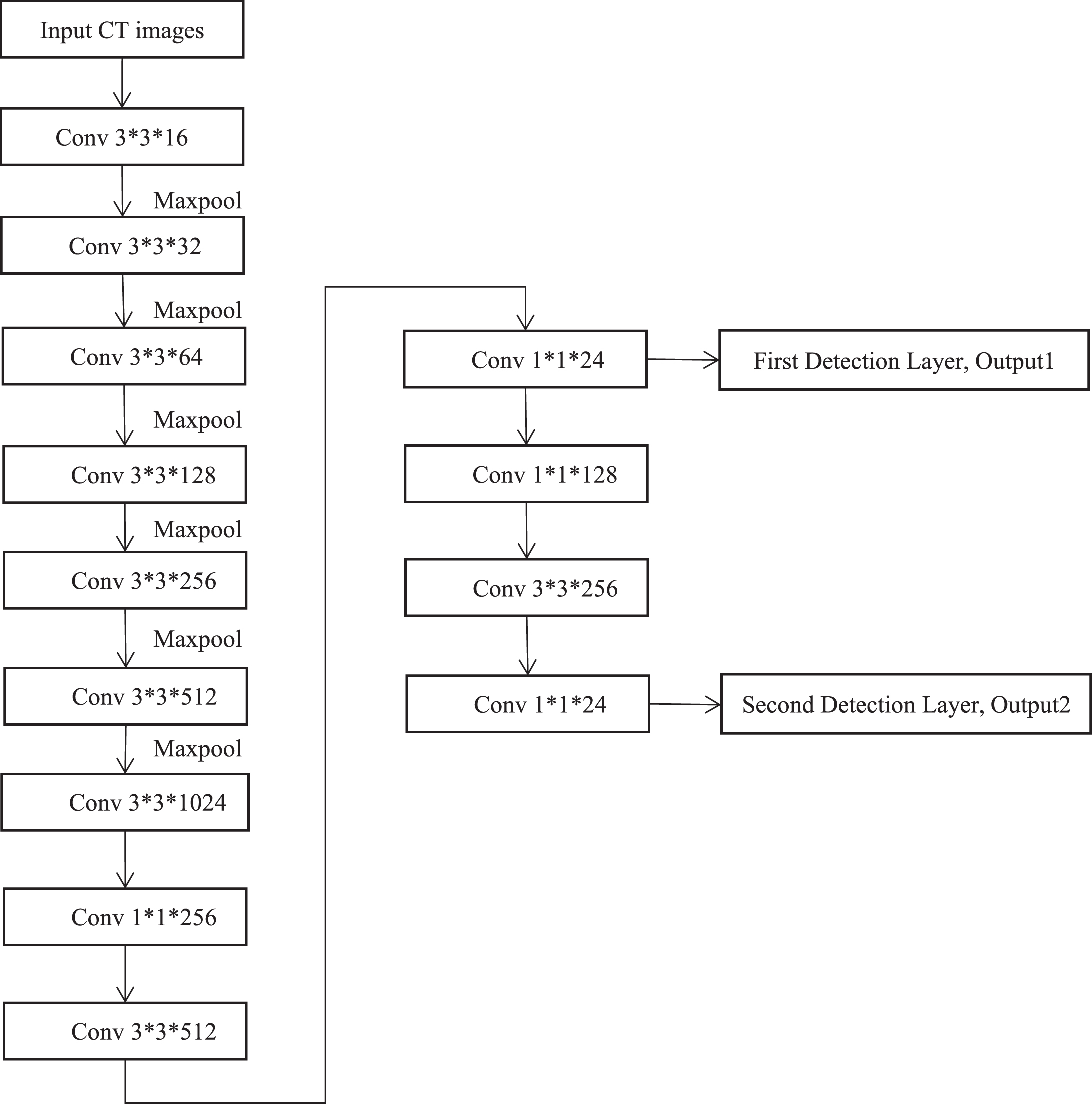
The network architecture of Yolov3-tiny.
The network architecture of Yolov3-tiny
In this paper, we propose a shrank model based on Yolov3-tiny to solve this problem, which has small size, fast and accurate lesions detection, and can be deployed in clinical embedded devices. Due to the 512 and 1024 convolutional layers in Yolov3-tiny produce a large number of parameters, we utilize fire module to replace the 512 and 1024 convolutional layers to reduce parameters for building a tiny model, while keeps the spinal lesions detection accuracy and real-time lesions detection.
In this paper, we introduce fire modules into Yolov3-tiny to cut down the parameters of training model and deepen the training network for accurate lesions detection. The fire module contains squeeze part and expand part, which is shown in Fig. 6. The squeeze part utilizes one convolutional kernel with 1×1, which is proposed by NIN (Network in Network) [38] and can cut down the parameters of training model effectively, while maintain lesions detection accuracy. The expand part utilizes both convolutional kernel with 1×1 and convolutional kernel with 3×3, then concatenate the outputs.
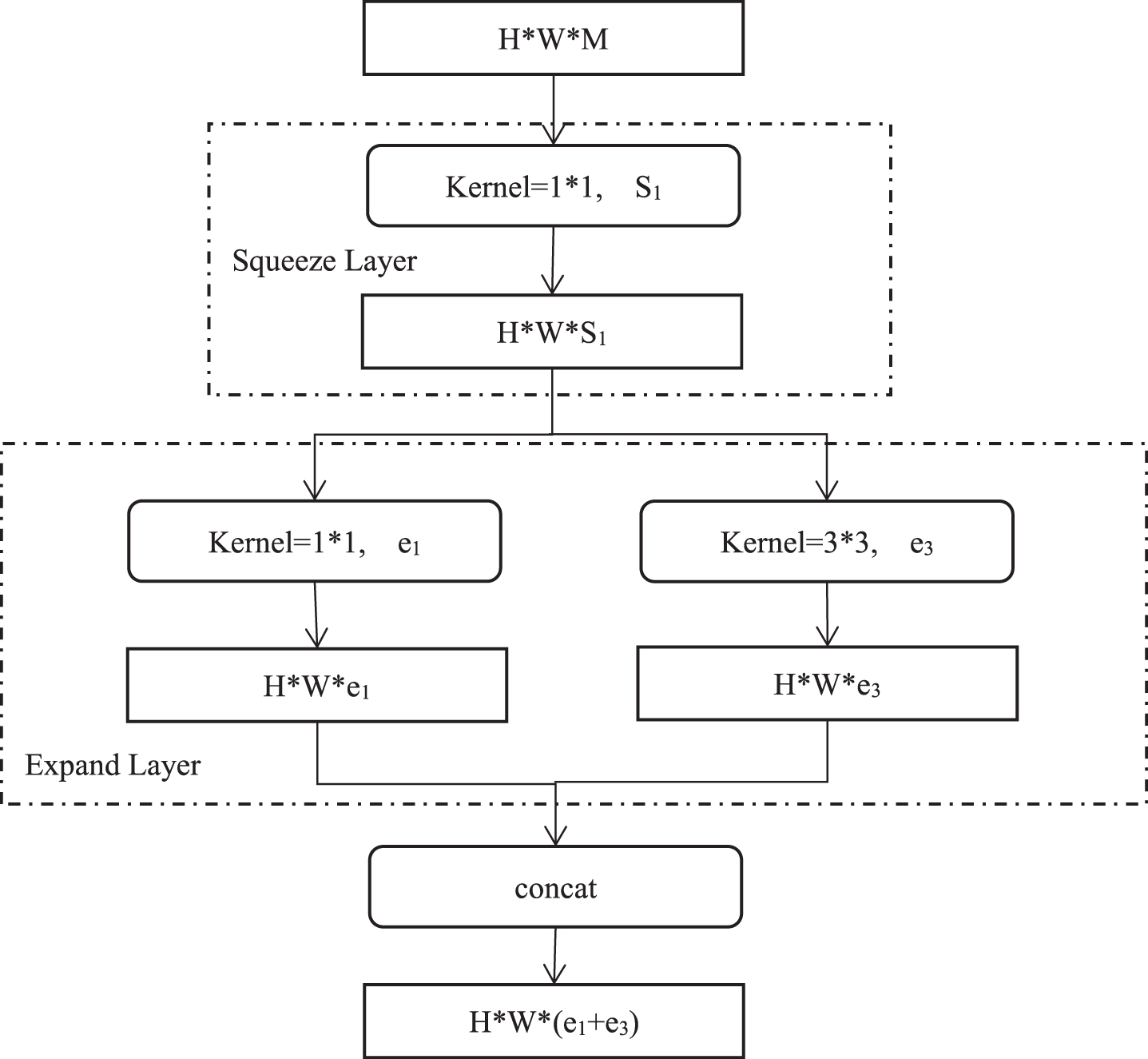
The Structure of Fire Module.
The parameters P of traditional convolutional layer are computed in Equation 1,
Here c i is the number of input channels in traditional convolutional network, k is the kernel size, c o is the number of output channels.
As we can see in Fig. 6, in fire module, the input CT image first goes through squeeze layer and gets S1 feature maps, then goes through the expand layer and gets e1 and e3 feature maps respectively, the final number of feature maps is e1 + e3. In Fig. 6, the input channels number of squeeze layer are M, the output channel number of squeeze layer are S1, the input channels number of expand part are S1, the output channels number of expand part are e1 and e3, we use Ks1 means the kernel size in squeeze layer, while Ke1 and Ke3 means the kernel size in expand layer, so the parameters in fire module are described in Equation 2, here, e1 is equal e3, and e1 and e3 means four times S1.
We present the comparison of different parameters between Yolov3-tiny and proposed model which contains fire modules in Table 2. We can see that the parameters of corresponding convolutional layers in Yolov3-tiny and the proposed model are obviously reduced.
The parameters in original Yolov3-tiny and proposed model
The architecture of proposed model is shown in Fig. 7, there are six fire modules in our proposed model, which are highlighted in blue. We utilize the first three fire modules are to replace 512 and 1024 filters in the sixth and seventh convolutional layer in Yolov3-tiny, then we utilize a fire module instead of the 512 filters before first detection, finally we utilize two fire modules instead of the 256 filters before the second detection. We present the concrete configuration about our proposed model in Table 3, which displays the detailed configurations of six fire modules.
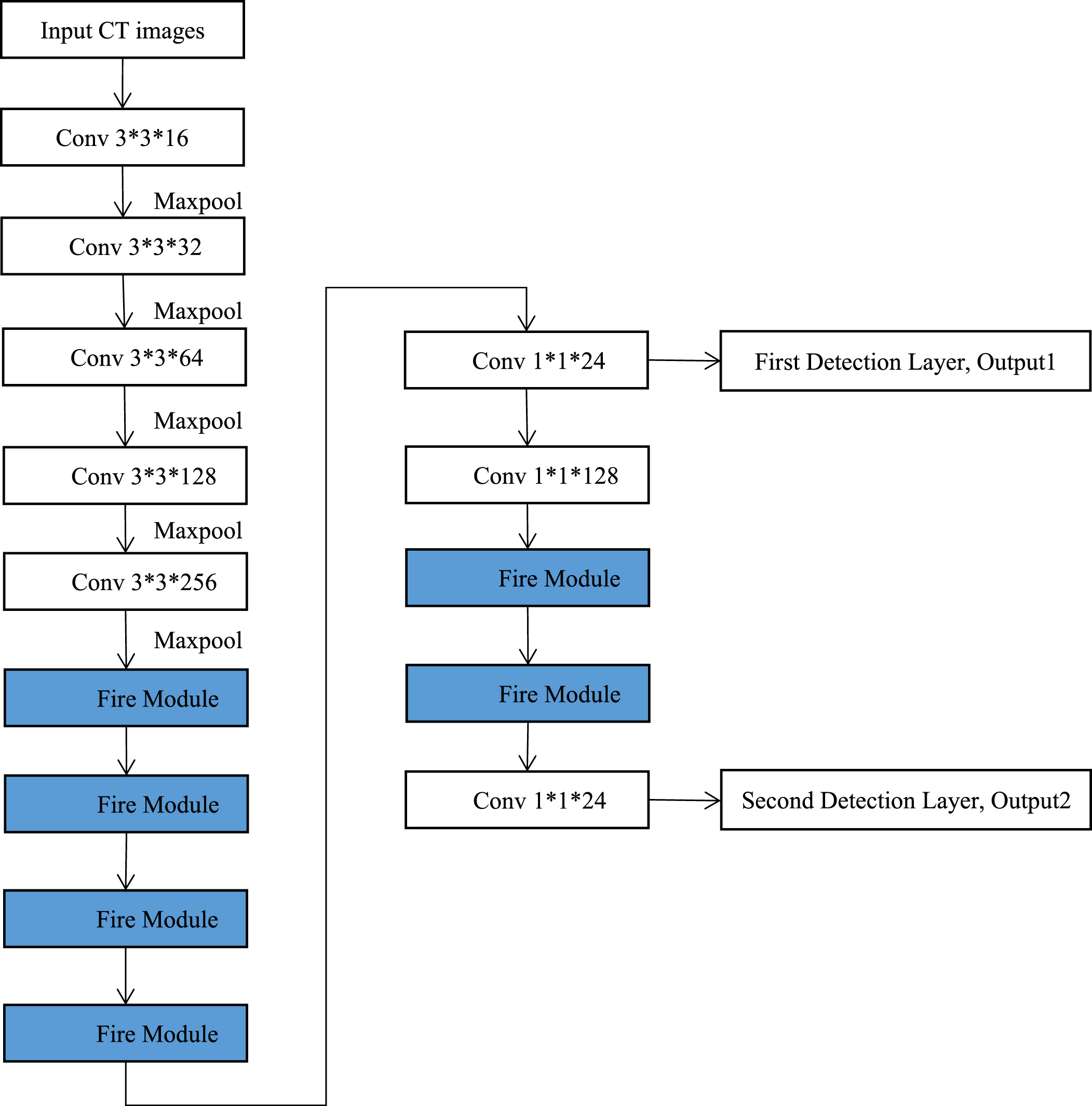
The network architecture of proposed model.
The network architecture of proposed model
If we replace all of the filters with fire modules in Yolov3-tiny, we can not get accurate lesions detection or cause other training problems, such as ’can not allocate memory in training’, after the experiments. we also find that if we replace the filters less than 256 in the main training network of Yolov3-tiny with fire modules, the accuracy of lesions detection and model size are only slightly improved, so we introduce six fire modules into Yolov3-tiny to replace the convolutional layers with large number filters for a fast lesions detection with a small model.
The common method to compress the convolutional neural network is to delete the unimportant convolutional layers, while the performance of modified network can not meet the performance of the original network [39]. The detection performance can grow greatly after deepening the network [40], as we can see in Tables 1 and 3, after we introduce six fire modules in Yolov3-tiny, the depth of network is increased 11 layers, and the lesions detection accuracy can be improved effectively. Meanwhile, the value of BFLOP/s in Tables 1 and 3 is decreased from 5.817 to 4.022. The BFLOP/s means the number of billion floating-point operations of the convolutional layer, it is usually to add all the BFLOP/s of each convolutional layer to evaluate the computation complexity of the training model. So the computation complexity is decreased after we introduce six fire modules in Yolov3-tiny, so we can get a small size model for clinical embeded devices and get fast spinal lesions detection.
In traditional convolutional layers, we use BN (Batch Normalization) layer to solve the problem that the different inputs in every convolutional layers. But the computation complexity is increased by almost 30% after the BN layer is utilized and is adjusted the different variance of every convolutional layer in training [41].
There are also BN layer in every fire module of out proposed model, so we try to remove the BN layer to decrease the computation complexity of our proposed model. In Fig. 8, we present the comparison of the PR curves of three spinal fracture lesions and the average loss curves in fire modules with BN layer and fire modules without BN layer, we use spinal CT images with 416 × 416 as input images. The three PR curves of fire modules without BN layer are slightly closer to top right with the coordinate of (1,1) than the PR of fire modules with BN layer, and the average loss curves of fire modules without BN layer are slightly closer to 0.3 than loss curves of fire modules with BN layer, so the performance of our proposed model is improved after we delete the BN layer in fire modules.
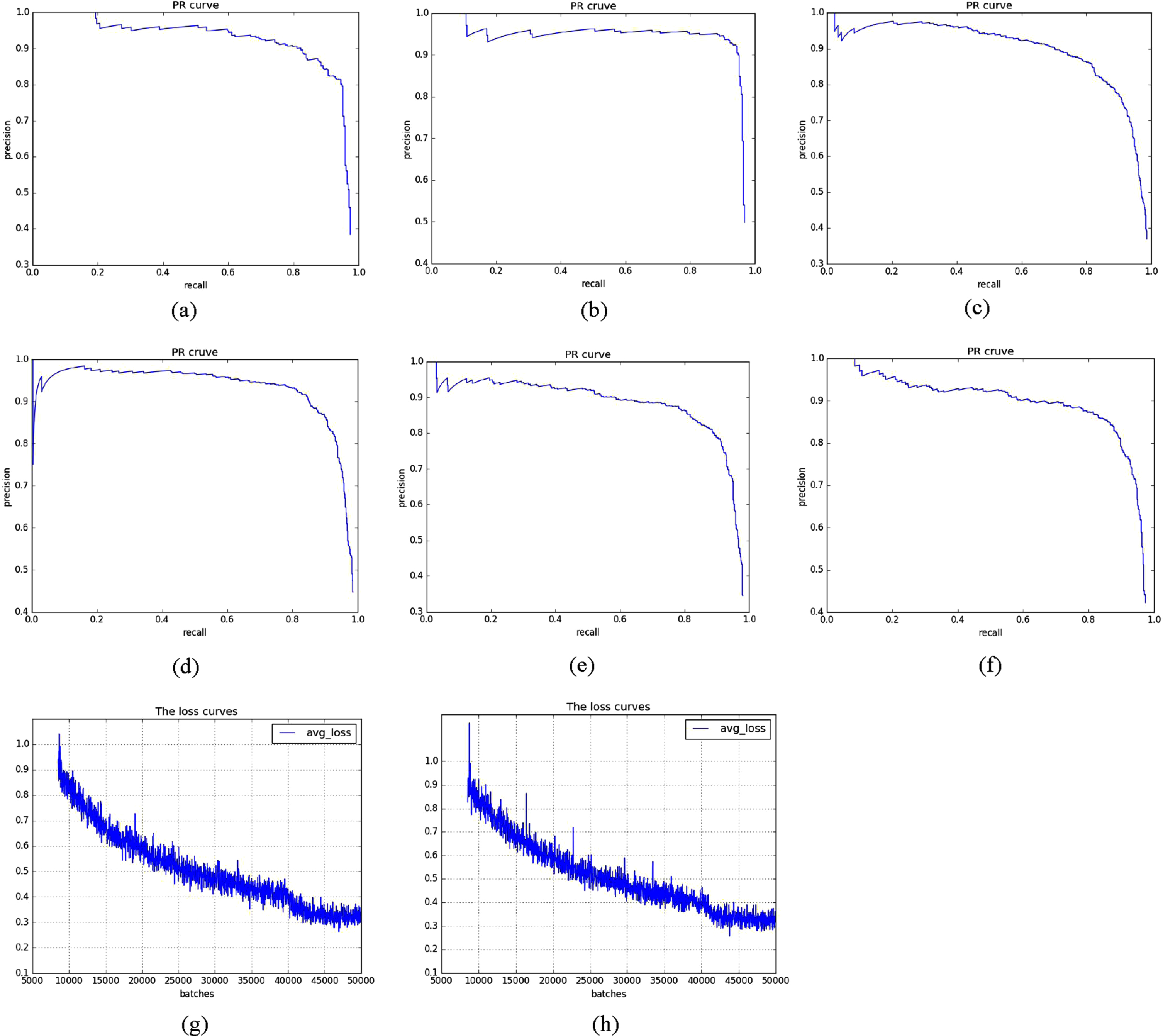
The PR and avg-loss of BN and NoBN, (a) is the cfracture PR curve of 416 with BN, (b) is the cfracture PR curve without BN, (c) is the tfracture PR curve of 416 with BN, (d) is the tfracture PR curve without BN, (e) is the lfracture PR curve of 416 with BN, (f) is the lfracture PR curve without BN, (g) is the avg-loss curve of 416 with BN, (h) is the avg-loss curve of 416 without BN.
In Table 4, we present the mAP(mean average precision), IOU(Intersection of Union), model size and lesions detection time T per each CT image. we can see that the performance is also slightly improved after remove the BN in fire modules of proposed model.
The comparison of fire module with and without BN
NMS(Non-maximum suppression) is a important and effective method in target detection algorithms, which sequences scores of proposal boxes of spinal lesions, selects the largest one (e.g. M), and computes overlapped IOU(Intersection over Union) between lesions proposal boxes(e.g. N). The proposal box will be saved, if the overlapped IOU is higher than the value(usually 0.7), and other proposal boxes are removed. NMS will iterate the computation operation until achieving the suitable lesions proposal box. The expression of overlapped IOU between lesion proposal box A and lesion proposal box B is in Equation 3:
Here S
I
the overlapped regions of A and B, S
A
is the region of A, S
B
is the region of B. Then the NMS is expressed in Equation 4,
Here S i is score of lesion proposal box, M is proposal box which has largest score, b is the set of lesions proposal box, while b i is the ith proposal box in b, IOU(M, b i ) is overlapped regions between b i and M, N t is presupposed threshold value(usually 0.7). Though the overlapped value of proposal box (e.g. L) between M is highest or is bigger than the presupposed threshold value, NMS will also remove L because NMS will directly and rudely set the highest score of lesion proposal box and the lesion proposal with IOU greater than the presupposed threshold value to zero, which generates missed detection of spinal lesions.
The soft-NMS is proposed by Navaneeth Bodla [42] to solve the problem for avoiding missed detection, which simply modified the original NMS, by replacing the original score with a slightly smaller one, not directly sets it roughly to zero, the soft-NMS is expressed in Equation 5:
We multiply the score of current proposal box by a weight function, which will attenuate the score of adjacent proposal box overlapped with the proposal box M of highest score. The higher the proposal box overlapped with the highest score proposal box M, the more serious the score will attenuate. Usually, we choose Gaussian function as the weight function to modify the rule of deleting proposal box in NMS. The Gaussian weight function is in Equation 6:
In this paper, we utilize soft-NMS to replace original NMS in proposed model to avoid missed detection of spinal lesions and improve the performance of lesions detection.
We transform the sizes of input CT images from 352 × 352, 416 × 416, 480 × 480, 512 × 512, 544 × 544 to 608 × 608 to train proposed model, which is shown in Equation 7:
Here, S is input CT image size, n is a random value from 0 to 12.
The training environment is Intel Core i7-6700 @3.40GHz × 8, memory 32G, GPU GTX1070, Ubuntu 16.04, Caffe, Cuda8.0 and Cudnn6.0, and the training super parameters: learning rate:0.0001, momentum:0.9, decay: 0.0005, batch size:32, subdivisons:8, steps: 40000,45000, max_batches:50200.
Evaluation metrics
In this paper, we use AP(Average Precision), mAP(mean Average Precision), IOU(Intersection of Union), and T to evaluate the performance of proposed model. T is the time to detect lesions per each CT image, which are shown as follows:
Here, TP is true positive means the correctly detection lesions number. TN is true negative means detection number of not spinal fracture lesions. FP is false positive means the not spinal lesions number. FN is false negative means the number of lesions detected not correctly. sensitivity means the percent of accurately spinal lesions prediction, itemize as spinal fracture lesions. specificity means the proportion of correctly non-spinal lesions prediction results. accuracy means the correction rate of detected spinal lesions to the global CT image.
The (Dice similarity coefficient) f1 value is the average of the precision and recall which can represent the accuracy of spinal lesions detection, and it is defined as follow:
Figure 9 are randomly selected three groups of predicted lesions by proposed model, (a) to (c) are the predicted cfracture lesions, (d) to (f) are the predicted tfracture lesions, (g) to (h) are the predicted lfracture lesions. The predicted results of proposed model are effective and accurate, which can provide a reference and assistance to treat spinal fracture diseases for doctors clinically.
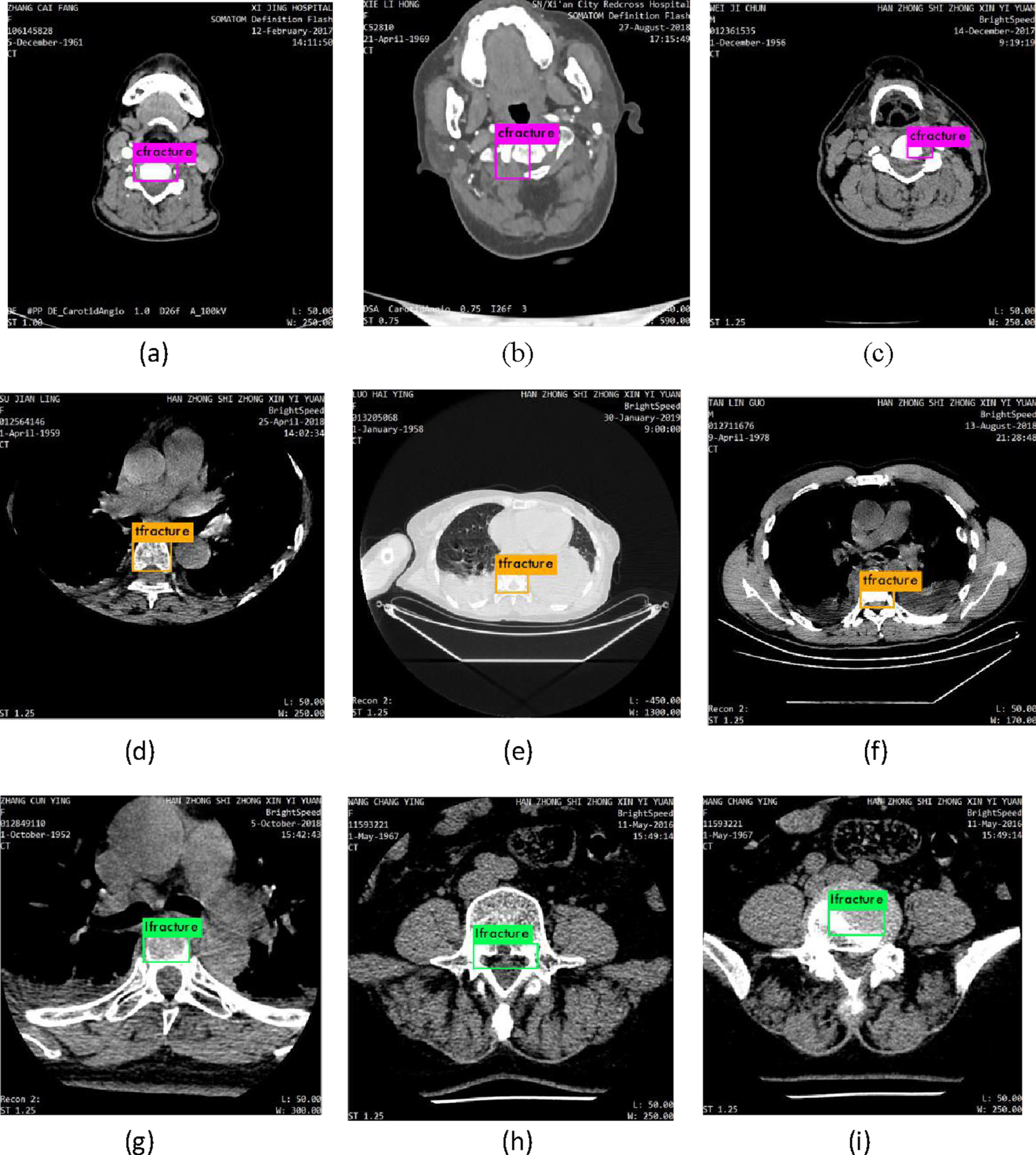
The samples of predicted three spinal fracture lesions, (a) to (c) are the predicted cfracture lesions, (d) to (f) are the predicted tfracture lesions, (g) to (h) are the predicted lfracture lesions.
Comparison of PR curves between Yolov3-tiny and proposed model
Figures 10 to 11 are the cfracture PR curves of Yolov3-tiny and proposed model with input size of 352 × 352 to 608 × 608, Figs. 12 to 13 are the tfracture PR curves of Yolov3-tiny and proposed model with input size of 352 × 352 to 608 × 608, and Figs. 14 to 15 are the lfracture PR curves of Yolov3-tiny and proposed model with input size of 352 × 352 to 608 × 608.

The cfracture PR curve: (a) is the PR curve of Yolov3-tiny-352, (b) is the PR curve of proposed-352, (c) is the PR curve of Yolov3-tiny-416, (d) is the PR curve of proposed-416, (e) is the PR curve of Yolov3-tiny-480, (f) is the PR curve of proposed-480.
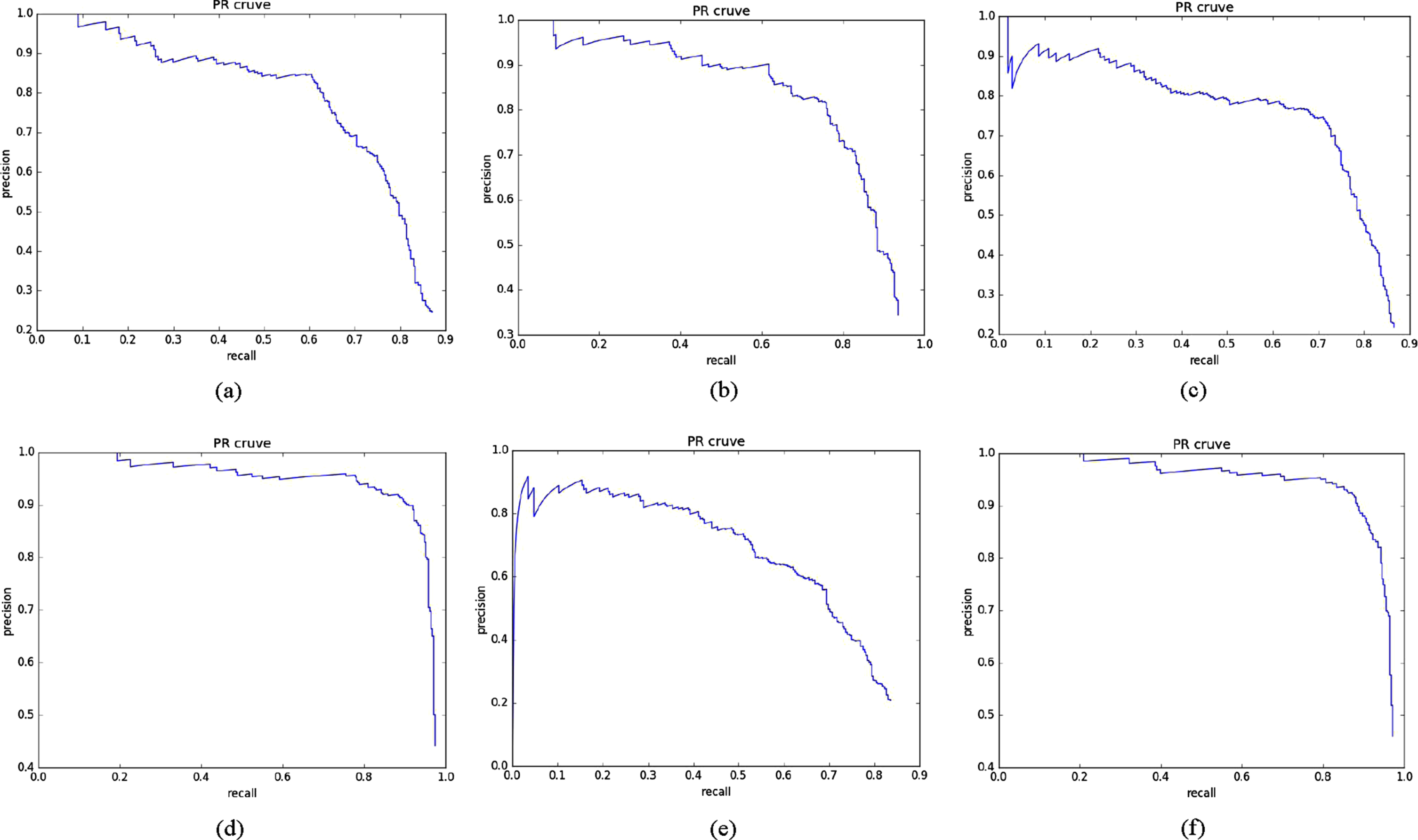
The cfracture PR curve: (a) is the PR curve of Yolov3-tiny-512, (b) is the PR curve of proposed-512, (c) is the PR curve of Yolov3-tiny-544, (d) is the PR curve of proposed-544, (e) is the PR curve of Yolov3-tiny-608, (f) is the PR curve of proposed-608.

The tfracture PR curve: (a) is the PR curve of Yolov3-tiny-352, (b) is the PR curve of proposed-352, (c) is the PR curve of Yolov3-tiny-416, (d) is the PR curve of proposed-416, (e) is the PR curve of Yolov3-tiny-480, (f) is the PR curve of proposed-480.
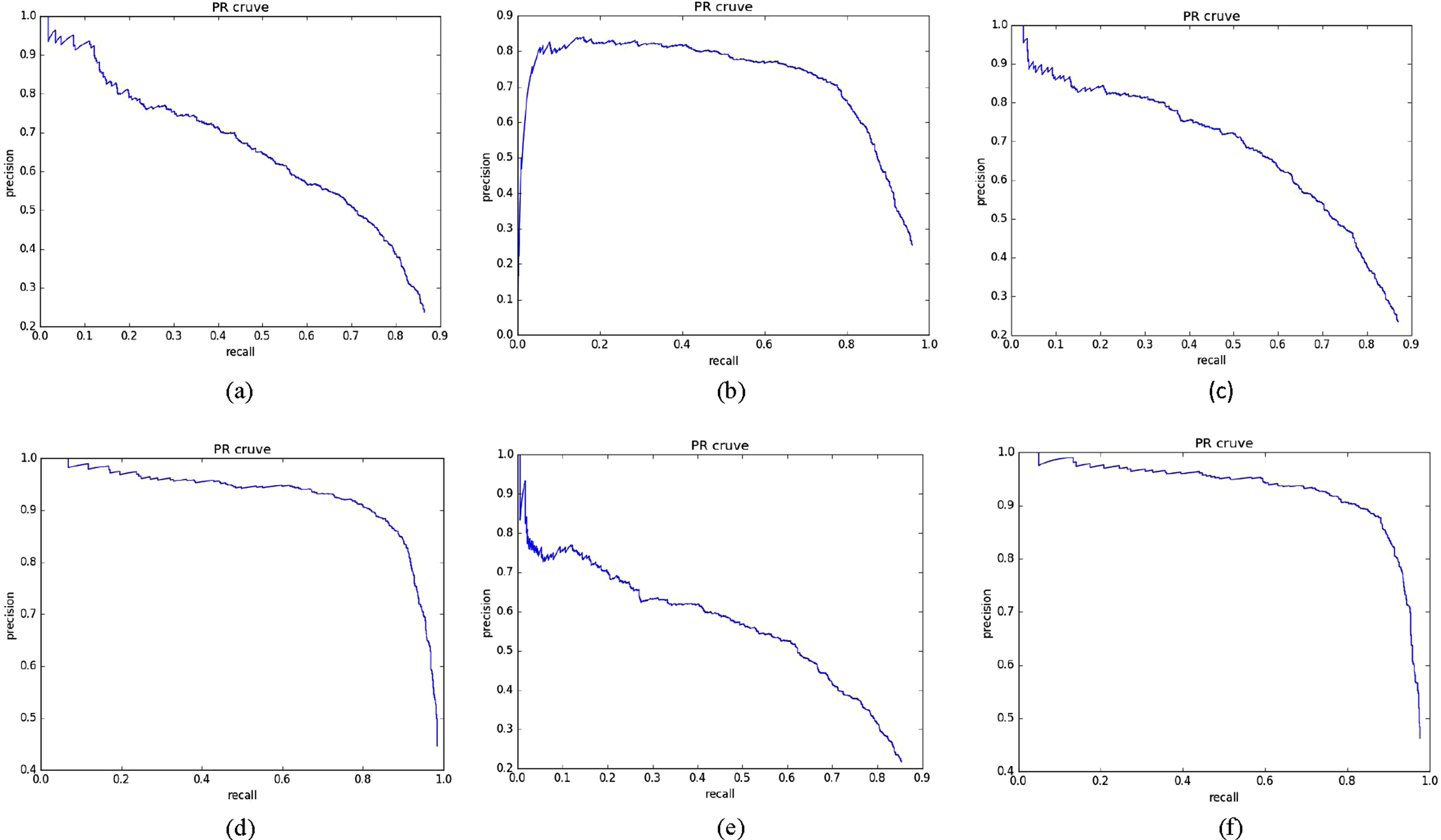
The tfracture PR curve: (a) is the PR curve of Yolov3-tiny-512, (b) is the PR curve of proposed-512, (c) is the PR curve of Yolov3-tiny-544, (d) is the PR curve of proposed-544, (e) is the PR curve of Yolov3-tiny-608, (f) is the PR curve of proposed-608.

The lfracture PR curve: (a) is the PR curve of Yolov3-tiny-352, (b) is the PR curve of proposed-352, (c) is the PR curve of Yolov3-tiny-416, (d) is the PR curve of proposed-416, (e) is the PR curve of Yolov3-tiny-480, (f) is the PR curve of proposed-480.

The lfracture PR curve: (a) is the PR curve of Yolov3-tiny-512, (b) is the PR curve of proposed-512, (c) is the PR curve of Yolov3-tiny-544, (d) is the PR curve of proposed-544, (e) is the PR curve of Yolov3-tiny-608, (f) is the PR curve of proposed-608.
Usually, we use two ways to evaluate the performance of PR curves, one is to compare the area covered by the PR curve, the other is compare the value of BEP(Break Even Point) of PR curves. As we can see, all of the PR curves of proposed model cover more bigger area than the PR curves of Yolov3-tiny, and the PR curves of proposed model are more closer to the top right point with coordinate (1,1) than the PR curves of Yolov3-tiny, which means the BEP value of proposed are bigger than the BEP value of Yolov3-tiny. So, we can achieve a better performance of lesions detection by proposed model.
Figures 16 to 17 are the average loss curves of Yolov3-tiny and proposed model with different input size of CT images from 352 × 352 to 608 × 608, we can see that almost all of the average losses of Yolov3-tiny are 0.5, while almost all of the average losses of proposed model are less than 0.4, and the average loss with input size of 608 × 608 is almost 0.3. The average losses are decreased by 0.1 after we use fire modules to replace the traditional convolutional layers, so we can get accurate spinal fracture lesions detection by proposed model.

The average loss curve: (a) is the avg-loss of Yolov3-tiny-352, (b) is the avg-loss of proposed-352, (c) is the avg-loss of Yolov3-tiny-416, (d) is the avg-loss of proposed-416, (e) is the avg-loss of Yolov3-tiny-480, (f) is the avg-loss of proposed-480.
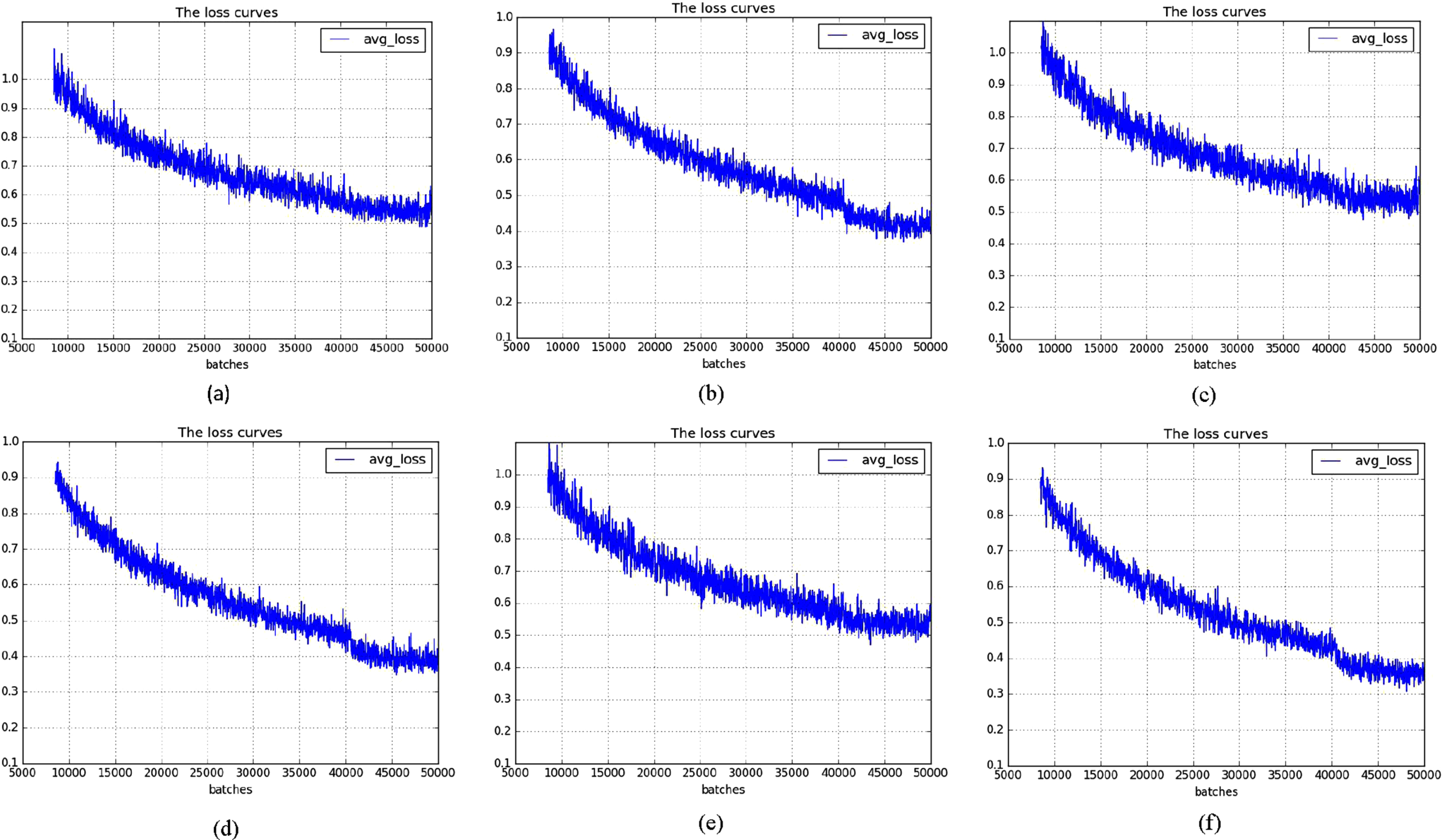
The average loss curve: (a) is the avg-loss of Yolov3-tiny-512, (b) is the avg-loss of proposed-512, (c) is the avg-loss of Yolov3-tiny-544, (d) is the avg-loss of proposed-544, (e) is the avg-loss of Yolov3-tiny-608, (f) is the avg-loss of proposed-608.
The reason is that we increase the depth of training network by 11 layers, after we introduce the fire modules into Yolov3-tiny, so we can achieve more lesions feature information to improve segmentation accuracy and reduce prediction errors.
In Table 5, we can see the lesions detection accuracy is increased by 0.005 after replacing the original NMS with soft-NMS, from 0.908 to 0.913, the sensitivity is increased by 0.006 after using soft-NMS in proposed model, from 0.916 to 0.922, meanwhile the specificity is increased by 0.005, from 0.907 to 0.912, the f1 increased by 0.004, from 0.921 to 0.925, respectively. So we can avoid the missed detection of the overlapped lesions to improve the performance of spinal fracture lesions detection. In this paper, our experiments are based on proposed model with soft-NMS.
Comparison of performance between proposed model with and without soft-NMS
Comparison of performance between proposed model with and without soft-NMS
The reason is that we keep the proposal boxes with the scores are bigger than threshold value (usually, 0.7), which are adjacent and overlapped the proposal boxes with highest score, after we utilize soft-NMS to replace the original NMS, so as to avoid missed lesions detection.
We train the spinal CT images with six different input sizes from 352 × 352 to 608 × 608 in Yolov3-tiny and proposed model, we can see in Table 6, the mAP and IOU are increased as the size of input CT images increases. The mAP, and IOU value of Yolov3-tiny-416 are 2.6%, 1.4% higher than Yolov3-tiny-352, the mAP, and IOU value of Yolov3-tiny-480 are 0.7%, 0.7% higher than Yolov3-tiny-416, the mAP, and IOU value of Yolov3-tiny-512 are 1.2%, 0.6% higher than Yolov3-tiny-480, the mAP, and IOU value of Yolov3-tiny-544 are 0.8%, 0.4% higher than Yolov3-tiny-512, the mAP, and IOU value of Yolov3-tiny-608 are 0.9%, 1.2% higher than Yolov3-tiny-544. But the detection time is also increased as the increase of input CT image size.
The detection performance of Yolov3-tiny
The detection performance of Yolov3-tiny
It is obvious in Table 7 that the AP, mAP and IOU are increased after we introduce fire modules into Yolov3-tiny, While, the mAP, and IOU value of proposed-352 are 1.4%, 0.9% higher than Yolov3-tiny-352, the mAP, and IOU value of proposed-416 are 2.1%, 1.6% higher than Yolov3-tiny-416, the mAP, and IOU value of proposed-480 are 2.5%, 1.4% higher than Yolov3-tiny-480, the mAP, and IOU value of proposed-512 are 3.1%, 1.4% higher than Yolov3-tiny-512, the mAP, and IOU value of proposed-544 are 3.1%, 2.3% higher than Yolov3-tiny-544, the mAP, and IOU value of proposed-608 are 2.9%, 3.2% higher than Yolov3-tiny-608.
The detection performance of proposed model
As we can see, the lesion detection time per CT image by proposed model is also less than the detection time by Yolov3-tiny. The reason is that we replace the convolutional layers, which have filters of 512 and 1024, with the fire modules which have filters less than 256, so as to reduce the computation complexity and the occupation of computer resources, and improve the detection efficiency of spinal lesions.
We compare the performances between our proposed model and the state of art lightweight models in Table 8, as we can see that our proposed model has a better performance in model size, mAP, BFLOP/s and detection time than other lightweight models, such as Yolov2-tiny, Yolov3-tiny, SqueezeNetSSD, MobileNetSSD. The model size of our proposed model is almost a third of Yolov3-tiny and half of MobileNetSSD. The BFLOP/s of our proposed is almost less a third than Yolov2-tiny, and lesions detection time of every CT image is the shortest than other lightweight models.
Comparison between other lightweight models and proposed model
Comparison between other lightweight models and proposed model
The reason is that we accelerate the lesions detection speed and reduce the occupation of computer resources, after we combine fire modules in Yolov3-tiny, so our proposed model has a fast lesions detection, low computation complexity and small model size, which means our proposed model is a appropriate model for clinical embedded and mobile devices.
In this paper, we present a shrank model for clinical embedded and mobile devices based on Yolov3-tiny to detect spinal fracture lesions from CT images. We introduce six fire modules into Yolov3-tiny to reduce the parameters of convolutional layers for achieving a small size model, meanwhile increasing the depth of training network in proposed model to detect spinal fracture lesions accurately and effectively. Then we remove the batch normalization layer in fire modules to reduce the computation complexity for fast spinal lesions detection. The experiments show that the mAP of proposed model is 91.3, IOU is 90.7 and detecting time is 0.015 seconds per CT image. The BFLOP/s is also decreased from 5.817 to 4.022, which can detect spinal lesions quickly.
Our next target is to detect spinal lesions from three-dimensional CT images.
Declarations
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Authors contributions
Junsheng Wu contributed to the conception of the study; Gang Sha performed the experiment, contributed significantly to analysis and manuscript preparation and the data analyses and wrote the manuscript; Bin Yu helped perform the analysis with constructive discussions
Funding
The project in this paper is supported by Biomechanical Modeling of Lumbosacral Spine and Surgical Evaluation System”, Fund Number 61172147.
Conflicts of interest/competing interests
The authors declare that they have no conflicts of interest.