
Abstract
Knowledge graph link prediction uses known fact links to infer the missing link information in the knowledge graph, which is of great significance to the completion of the knowledge graph. Generating low-dimensional embeddings of entities and relations which are used to make inferences is a popular way for such link prediction problems. This paper proposes a knowledge graph link prediction method called Complex-InversE in the complex space, which maps entities and relations into the complex space. The composition of complex embeddings can handle a large variety of binary relations, among them symmetric and antisymmetric relations. The Complex-InversE effectively captures the antisymmetric relations and introduces Dropout and Early-Stopping technologies into deal with the problem of small numbers of relationships and entities, thus effectively alleviates the model’s overfitting. The results of comparison experiment on the public knowledge graph datasets show that the Complex-InversE achieves good results on multiple benchmark evaluation indicators and outperforms previous methods. Complex-InversE’s code is available on GitHub at https://github.com/ZeyuMiao97/Complex-InversE.
Introduction
Knowledge graphs (KGs) consist of a large number of facts, where each fact is represented as a triplet (e s , r, e o ), which e s and e o represent subject and object entities and r represent a relation. At present, knowledge graphs have been applied to many artificial intelligence fields such as recommender systems [1], information retrieval [2] and natural language processing [3] and are important data sources for artificial intelligence applications such as Freebase [4], Yago [5], WordNet [6].
Most of the existing knowledge graph link prediction methods use entities, relations or graph features to perform link prediction. For a given knowledge graph learning a low-dimensional representation for all entities and relations, we usually define a score function to predict the missing links. Sun et al. [7] proposed RotatE, which defines each relation as a rotation from the source entity to the target entity in the complex vector space and propose a novel self-adversarial negative sampling technique for efficiently and effectively training their model. Vashishth et al. [8] proposed InteractE, which uses three key ideas – feature permutation, a novel feature reshaping, and circular convolution for link prediction. Zhang et al. [9] proposed QuatE, which models relations as rotations in the quaternion space.
Binary relations in KGs exhibit various types of patterns: inversion, symmetry/antisymmetry and composition. In the real world, marriage is a symmetrical relation while the relation of filiation is antisymmetric; some relations are the inverse of other relations (e.g., hypernym and hyponym); and some relations can be composed by others (e.g., my father’s wife is my mother). Under ideal circumstances, embedding models applied to link prediction should be able to learn all combinations of these properties. The keystone of embedding models is to find a balance between expressiveness and parameter space size. One popular composition function for embedding models is dot product. Dot products of embeddings perform well in scale and can naturally handle both symmetry and reflflexivity of relations, even enable transitivity with an appropriate loss function. Meanwhile, the standard dot product between embeddings can be a very effective composition function if the right representation is used. However, when dot products are used to deal with the antisymmetric relationship, the parameter space of the model will inevitably expand and implied an explosion of the number of parameters, making models prone to overfifitting.
Kazemi et al. [10] proposed a knowledge graph embedding method SimplE for knowledge graph link prediction. After generating head embedding and tail embedding for each entity and scoring the triple through score function, SimplE swaps the position of head embedding and tail embedding and score the triple again, then get the average of the two scores as the final score. However, the above methods only consider the mapping of entities and relations in real space, which could cause explosive growth of model parameters and may lead to overfitting of the model. At the same time, due to the data-driven nature of entity and relation vectorization methods, if the number of a certain type of relation or entity in the training set is too small, the vector score function of this type of entity and relation may also lead to overfitting of the model.
In response to the above problems, this paper proposes a knowledge graph link prediction method in complex space, Complex-InversE. In order to alleviate the problem that dot products cannot effectively handle the antisymmetric relations, Complex-InversE maps entities and relations to both real space and complex space. When using complex vectors to model entity and relation embeddings, facts about antisymmetric relations can receive different scores depending on the ordering of the entities involved. Thus complex vectors can control the parameter scale of the model within an acceptable range while retaining the efficiency advantage of the dot product, thereby alleviating the problem that dot products cannot effectively deal with the antisymmetric relations. At the same time, for the problem of small numbers of a certain type of relation or entity, Complex-InversE introduces Dropout and Early-Stopping to avoid overfitting of the model.
Our contributions are summarized as follows: By mapping relations and entities into complex space, Complex-InversE effectively captures antisymmetric relations while improving the dot product efficiency of the model, and avoids the explosion of the number of parameters We introduce a new score function in complex space. By integrating the performance of Complex-InversE in real space and complex space, the score function in complex space can effectively optimize the accuracy of Complex-InversE. Complex-InversE can effectively alleviate the overfitting of the model caused by the small number of a certain type of relation or entity by applying Dropout. The mechanism of Early-Stopping introduced enables Complex-InversE to accurately find the most suitable number of training iterations.
The rest of this article is structured as follows: we summarize related efforts in Section 2. Then we present the Complex-InversE model and introduce three key ideas complex embedding vectors, Dropout, and Early-Stopping in Section 3. We report on the experiments in Section 4 before concluding.
Related work
Complex-InversE
Model framework
The overall architecture of the model is shown in Fig. 1. n represents the number of training triples, m represents the number of entities or relations, d represents the embedding dimension and s1, s2, …, s
n
represents the triples read from datasets which contain three parts: head, tail and relation. The overall process of Complex-InversE is as follows: The model stores the true triples in real-world datasets in the form of (h, r, t), where h represents the head entity, r represents the relation, and t represents the tail entity. Bn generator generates corrupted triples by corrupting true triples and shuffles true triples and corrupted triples as training triples. The head entities, tail entities and relations are taken out separately and combined into entity and relation vectors. By defining an m×d embedding matrix in complex space, the model combines the entity and relation vectors with the embedding matrix to generate embedding vectors for training and mapping them into complex space. The model uses Dropout to process embedding vectors to alleviate overfitting. By defining an appropriate score function, true triples will get higher scores than corrupted triples.

Overview of our model.
CP and SimplE defined two vectors
Figure 2 shows the embedding vectors generated in real space, Fig. 3 shows the embedding vectors generated in the complex space. Complex-InversE uses the same function as in real space to generate the embedding vectors in complex space. In this way, Complex-InversE use

The embedding vectors generated by the original model in real space.
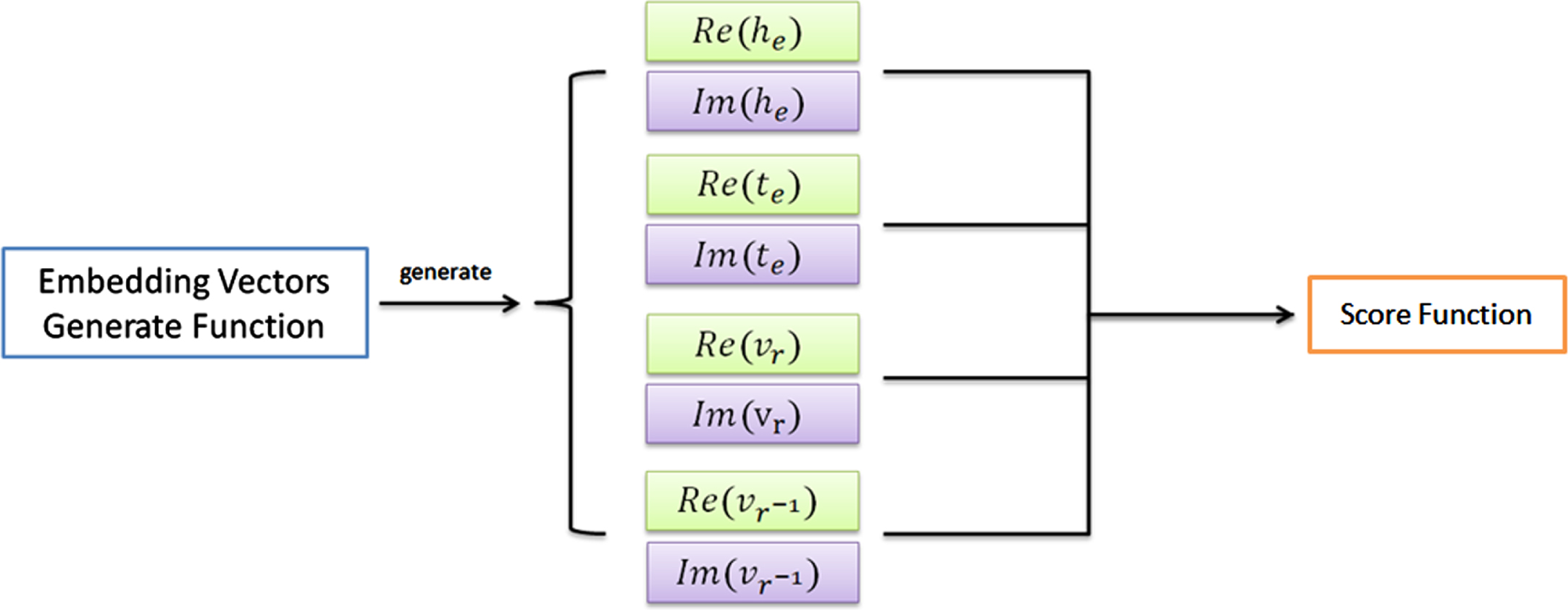
Embedding vectors after mapping into complex space, where Re(x) represents the real part of x, Im(x) represents the imaginary part of x.
In SimplE,
Therefore, the score function ψ (e i , r, e j ) in complex space for a triple (e i , r, e j ) of our method is:
According to the rules of complex number operations, the final score function is
Compared with batch gradient descent (BGD) using all data to calculate the gradient at once, stochastic gradient descent (SGD) updates the gradient for each sample every time it is updated. In our method, we use SGD with mini-batch for learning. Complex-InversE select n triples from the dataset as the positive batch then use the positive batch to generate negative batch by corrupting positive triples.
Figure 4 shows the process of corrupting a triple in Complex-InversE. For a positive triple (h, r, t), we randomly choose the head or tail to corrupt. If the head is chosen, we replace h with ɛ -{ h } where ɛ represents the collection of all entities. If the tail is chosen, we replace t with ɛ -{ t }. We define the label l, for positive triples, l is set to+1 and for negative triples, l is set to -1. Based on Trouillon and Nickel [19], Complex-InversE uses log-likelihood loss function to alleviate overfitting problem. This method choose the L2 regularized negative log-likelihood to optimize:

The process of corrupting a triple, where ɛ represents the collection of all entities.
Based on Hinton and Srivastava [20], we know that dropout can effectively alleviate overfitting and achieve regularization to a certain extent. The idea of dropout can be summarized as letting the activation value of a neuron stop working with a certain probability p during the process of forward propagation in order to make the model more general. When dot products are used to deal with the antisymmetric relationship, the parameter space of the model will inevitably expand and implied an explosion of the number of parameters, making models prone to overfifitting. Complex-InversE aims to improve the accuracy of link predictions by alleviating the overfitting that occurs when dealing with antisymmetric relations. Meanwhile, Dropout can also handle the problem of overfitting and enhance the effect of the model.
Algorithm 1 shows the process of Dropout in Complex-InversE.
Early stopping
Early stopping method is a widely used method, which performs better than the regularization method in many cases. By calculating the performance of the model on the valid dataset during training, we can stop training when the model’s performance on the valid dataset begins to decline in order to avoid overfitting due to continued training.
Algorithm 2 shows the process of Early-Stopping in Complex-InversE.
Time and space complexity analysis
This section compares the scoring function, time complexity and space complexity of Complex-InversE with other link prediction methods. Complex-InversE improves the accuracy of the model while restricting the time complexity and space complexity within a reasonable range. The details are shown in Table 1.
Scoring functions of state-of-the-art link prediction models, the dimensionality of their relation parameters, and significant terms of their time and space complexity. d
e
and d
r
are the dimensionalities of entity and relation embeddings, while n
e
and n
r
denote the number of entities and relations respectively.
are the head and tail entity embedding of entity e
s
, and
is the embedding of relation r-1 (which is the inverse of relation r). 〈 . 〉 denotes the generalized dot product,
denotes conjugate of complex vectors and ★ denotes the circular correlation operation
Scoring functions of state-of-the-art link prediction models, the dimensionality of their relation parameters, and significant terms of their time and space complexity. d
e
and d
r
are the dimensionalities of entity and relation embeddings, while n
e
and n
r
denote the number of entities and relations respectively.
Datasets
We conducted experiments on four widely used datasets. The overview of our datasets is in Table 2.
The overview of used datasets which include the number of entities and relations
The overview of used datasets which include the number of entities and relations
Based on [11], Complex-InversE use the filtered setting. While evaluating on test triples, we filter out all the valid triples from the candidate set, which is generated by either corrupting the head or tail entity of a triple. Complex-InversE use two classic evaluation indicators to judge the performance of our model on the data set:
Baselines
In our experiments, we compared our model with several baselines, which can be divided into Neural and Non-neural. Neural represents methods that involve neural networks in the modeling process, like ConvE [13] and R-GCN [22]. Non-neural represents methods that do not involve neural networks in the modeling process, like DistMult [14], ComplEx [19] and SimplE [10].
Implementation
We fixed the maximum number of iterations to 1500 and the batch size to 100 on Complex-InversE. We set the learning rate for WN18 and WN18RR to 0.1 and for FB15k and FB15k-237 to 0.05 and used adagrad to update the learning rate after each batch. Based on our research in Section 4.7 and 4.8, we set the dropout rate to 0.2 and generated one negative example per positive example for WN18 and WN18RR and 25 negative examples per positive example in FB15k and FB15k-237. We computed the filtered MRR of our model over the validation set every 50 iterations for WN18 and WN18RR and every 100 iterations for FB15k and FB15k-237 and selected the iteration that resulted in the best validation filtered MRR. The best embedding size and λ values for WN18 and WN18RR were 200 and 0.03, for FB15k and FB15k-237 were 200 and 0.1.
Results
Figure 5 Accuracy comparison between other benchmark methods and Complex-InversE, where a positive value indicates that the accuracy of Complex-InversE in this evaluation metric is higher than this model, and a negative value indicates that the accuracy of Complex-InversE in this evaluation index is lower than this model. All accuracy comparisons are expressed as percentages.

(a) Accuracy comparison between other benchmark methods and Complex-InversE on FB15K.

(b) Accuracy comparison between other benchmark methods and Complex-InversE on WN18.

(c) Accuracy comparison between other benchmark methods and Complex-InversE on FB15K-237.

(d) Accuracy comparison between other benchmark methods and Complex-InversE on WN18RR.
We compare the results of Complex-InversE with other baseline methods to prove the effectiveness of Complex-InversE. The results on the four link prediction datasets are summarized in Table 3 and Table 4. Figure 5 shows the accuracy comparison between other benchmark methods and Complex-InversE in percentage terms. We can see that Complex-InversE achieved better results on the three datasets compared to the existing baselines in the same datasets.
Results on WN18 and FB15k. Best results are in bold
Results on WN18RR and FB15k-237. Best results are in bold
On FB15K, Complex-InversE outperforms the baseline methods on four evaluation metrics.On WN18, Complex-InversE outperforms the baseline methods on three evaluation metrics, but the increase of accuracy compared to the original model is not significant. We believe that since the main relation patterns in FB15K and WN18 are symmetry/antisymmetry and inversion, and the model of entities and relations in complex space can effectively handle antisymmetric relations, Complex-InversE performs satisfactorily on FB15K and WN18. For most triples in FB15K, the types of head and tail entities are different, while almost all entities in WN18 are words and belong to the same entity type. Since Complex-InversE can deal with the problem of a small number of relations and entities to effectively improve model performance, we believe that this is the key for Complex-InversE to effectively deal with the problem of more triple types and less number of each type in FB15K to improve the model performance.
For the same reason, Complex-InversE performs better on FB15K-237 than on WN18RR. On FB15K-237, Complex-InversE performed satisfactorily, while on WN18RR, Complex-InversE performed worse than baseline methods. Complex-InversE significantly improves the accuracy of the original model SimplE on both FB15K-237 and WN18RR. Since the main relation pattern in FB15K-237 and WN18RR is composition and the original model SimplE is not good at handling the composition relation pattern, the results on FB15K-237 and WN18RR are worse than on FB15K and WN18, although the accuracy has been significantly improved compared to the original model SimplE. Specially, since WN18RR has both two unfavorable factors for Complex-InversE, i.e. the single entity type with large quantity and containing composition relation pattern, Complex-InversE performed worse than baseline methods on WN18RR.
In this section, we conduct ablation experiments on Complex-InversE to prove that our ideas are indeed effective. The experimental results are shown in Table 5.
Ablation experiment on FB15K
Ablation experiment on FB15K
From Table 5, we can see that the complex vector embedding, Dropout, and Early-Stopping all contribute to the accuracy improvement of the original model SimplE. At the same time, the lack of any improvement will reduce the performance of Complex-InversE, which proves that every improvement is effective. Complex vectors can effectively capture antisymmetric relations, Dropout and Early-Stopping can deal with the problem of a small number of relations and entities to alleviate overfitting.
We investigated the influence of dropout rate in the process of Dropout. Dropout rate represents the proportion of neurons temporarily deleted during the process of Dropout. For example, if dropout rate = 0.5, half of the neurons will be temporarily deleted during the process of Dropout. We focused on FB15K and let dropout rate vary in {0.1, 0.2, 0.3, 0.4, 0.5}.
Figure 6 shows the effect of dropout rate on the performance of Complex-InversE on FB15K. If the dropout rate is too large, too many neurons are temporarily deleted during training, and the model changes from overfitting to underfitting, which reduces the accuracy of the model. If dropout rate is too small, too few neurons are temporarily deleted during training, which cannot effectively alleviate overfitting. When dropout rate = 0.2, MRR and Hit@1 reach the highest value. When dropout rate = 0.3, Hit@3 and Hit@10 reach the highest value. Since MRR and Hit@1 can better show the accuracy of a link prediction method, we set the best dropout rate to 0.2.

Influence of dropout rate on the filtered test MRR. The number of negative triples generated per positive training example is 10.
We further investigated the influence of the number of negatives generated per positive training sample. We focused on FB15K, with the best hyper-parameters, obtained from the previous experiment. We then let η vary in {1, 5, 10, 15, 20, 25}.
Figure 7 shows the influence of the number of generated negatives per positive training triple on the performance of our model on FB15K. Generating more negatives clearly improves the results, but also increases training time. We choose 20 negatives a good trade-off between accuracy and training time.

Influence of the number of negative triples generated per positive training example on the filtered test MRR and on training time to convergence on FB15K for Complex-InversE.
This paper proposes Complex-InversE, a knowledge graph link prediction method in complex space. Complex-InversE uses three key ideas to improve the model performance, complex embedding vectors, Dropout, and Early-Stopping. Through experiments, we demonstrate that Complex-InversE achieves a consistent improvement on link prediction performance on multiple datasets. We also theoretically analyze the effectiveness of the components of Complex-InversE, and provide empirical validation of our hypothesis that mapping embedding vectors to complex space is beneficial for link prediction on bilinear models.