
Abstract
A drive-by download is a method of hackers planting the Web Trojan, which exploits browser vulnerabilities to execute malicious software. Because people usually access web pages with various browsers daily, drive-by downloads have become one of the most common threats in recent years. Most previous studies utilize the abstract syntax tree(AST) with deep learning methods to detect such attacks, which achieved high accuracy but are time-consuming and challenging to explain. Also, some methods use dynamic analysis, which needs a specific environment and is time-consuming with the complex operation. In order to solve these problems, the paper proposes DDIML, an explainable machine learning model based on novel features with static analysis. These features are extracted from five aspects: code obfuscation, URL redirection, special behaviors, encoding characters, and CSS attributes. The most popular machine learning algorithm, Random forest, is applied for building the classifier detection model. In addition, we use both local and global explanations to improve the model and prove that the proposed model could be trusted. The Experimental results show that our proposed model can efficiently detect drive-by downloads with a detection precision of 0.983 and a recall of 0.980. The average detection time for each sample is only 16.07ms in total.
Introduction
With the popularity of computers and the maturity of computer technologies, web applications have become an indispensable part of social life and work. They bring convenience to people’s lives, work and study, but they have potential risks. By now, network attacks aimed at web applications are still increasing. The most common one is the drive-by download attack, which is difficult to detect and easily causes severe threats because of its high concealment and flexibility.
Data published by The European Union Agency for Network and Information Security(ENISA) in 2018 shows that web-based attacks ranked second [1]. Based on the security report of Tencent Anti-Virus Lab in the Q3 quarter of 2018, the PC side has intercepted 1.2 billion viruses with an average of 133 million Trojans every month. The trojan is the first class of virus, which accounts for 57.57% of the total number of viruses [2]. According to the 117th CNCERT Internet Security Threat Report in September 2020, more than 1.18 million hosts corresponding to IP addresses in China are controlled by Trojans or bots [3].
Drive-by downloads specifically refer to installing malicious programs to users’ devices without their knowledge or consent. The attack infects users’ computers with vulnerability automatically and silently. Hackers invade insecure websites to plant malicious scripts on some pages. When a user accesses the infected website, the malicious script may install malicious programs on the user’s device or redirect the victim to other sites that attackers control. In many cases, attackers obfuscate malicious scripts, making them more difficult to detect by network security researchers. Many latest works apply AST with deep learning methods to detect the attack. These methods can achieve high accuracy, but they are time-consuming and error-prone in the actual application. Also, some dynamic analysis methods are time-consuming with the complex operation. In order to improve efficiency and ensure the accuracy of the detection, our paper combines feature engineering with the machine learning method for detection. The paper makes the following contributions: This paper manually extracts features from five aspects: code obfuscation, URL redirection, special behaviors, encoding characters, and CSS attributes. Among static analysis methods, the feature types we extracted are relatively comprehensive. The model DDIML is interpretable. We give local explanations and global explanations to the model. Local explanations focus on the impact of each feature in the sample on its prediction result. Moreover, global explanations express the feature importance and the relationship between feature values and prediction results. Local and global explanations help to understand the prediction better and improve the transparency of the model. Compared with other methods, DDIML has higher accuracy and is less time-consuming. The accuracy of our model reaches 0.982, and the average detection time of each sample is only 16.07ms.
The rest of the work is organized as follows. Section 2 briefly introduces the related work about malicious JavaScript detection. Section 3 discusses features, the Random forest algorithm, and the explanation method in detail. Section 4 provides experiment design, analyzes the experiment results, and visualizes the interpretation of the model. Section 5 provides conclusions and future work.
Related work
The drive-by download is the most common attack method, which causes a severe threat to people’s information privacy and tenure security. Network security researchers have paid close attention to it. With machine learning and deep learning development, researchers have made many contributions to detecting malicious JavaScript codes. In general, we divide the research methods into static, dynamic, and semi-dynamic analysis according to whether JavaScript codes are executed.
Static analysis
The static analysis focuses on extracting static features from JavaScript codes. Likarish et al. extract 65 features, but 50 are from JavaScript keywords and symbols. The extracted feature types are not comprehensive enough [4]. Curtsinger et al. propose Zozzle, which extracts hierarchical features from the JavaScript abstract syntax tree and hooks into a browser’s JavaScript engine to solve the deobfuscation [5]. In paper [6], Canali et al. design a filter named Prophiler, extracting HTML features, JavaScript features, URL, and host-based features to construct three different feature sets. They trained three models with different feature sets to get the best effect. Also, the method has less overload than dynamic analysis methods. Nayeem et al. present an interceptor between browser and server, which extracts features and uses the wrapper method for feature selection. The interceptor leads to high accuracy [7].
Static analysis methods can quickly detect most samples for some malicious scripts, but they lack semantic information. To solve this problem, some researchers use AST to extract semantic features [8–11]. Also, some researchers leverage AST to build Graphs to extract features based graph information [12, 13]. These approaches provide better accuracy and performance than conventional approaches. Furthermore, to detect obfuscated JavaScript codes, Morishige et al. reconstruct the divided URL to improve the detection effectiveness [14]. Stokes et al. propose the ScriptNet system, which contains Pre-Informant Learning to process JavaScript files as byte sequences [15]. Guo et al. propose GAN, which can achieve high accuracy with small labeled samples [16].
Dynamic analysis
The dynamic analysis mainly relies on client honeypot technology, which simulates the communication between the browser and the target station in a virtual environment. It distinguishes normal JavaScript codes from malicious by monitoring system behaviors.
Wang et al. design the Strider HoneyMonkey, which generates an XML report containing executable files, process creation, vulnerabilities, etc. HoneyMonkey successfully detects the javaprxy.dll vulnerability [17]. Mitsuaki et al. [18] mainly extract features from exploiting phases, multiple crawler processing, tracking of malware distribution networks, and malware infection prevention. They implement a new client honeypot to detect drive-by downloads, detecting and investigating various malicious websites. Jayasinghe et al. extract opcode feature with dynamic analysis to detect drive-by download attacks [19]. The method is efficient and has low resource consumption. Xue et al. combine data dependency analysis, defense rules, and replay mechanisms to classify JavaScript codes as normal or malicious [20]. Their method is scalable and efficient but consumes more time and resources.
Semi-dynamic analysis
The semi-dynamic analysis combines static analysis and dynamic analysis. Cova et al. propose an approach named JSAND, which uses HtmlUnit emulation to execute codes and extracts ten features from redirection, deobfuscation, environment preparation, and exploitation [21]. It can detect attacks that have not occurred before and reduce the false-positive rate but low speed. Rieck et al. present a system named Cujo, which uses ADSandbox and SpiderMonkey for dynamic analysis. The System detects 95% of drive-by downloads with few false positives and an average run time of 500ms per sample [22]. JSDC et al. design the tool named JSDC, which extracts features from the text, program structures, and risky function calls to detect malicious JavaScript codes [23]. Compared with other tools, JSDC gives low false-positive and false-negative rates. He et al. [24] implement a browser plugin called MJDetector, which conducts syntax analysis and dynamic instrumentation to extract features. The plugin can detect obfuscated malicious JavaScript and has high accuracy.
Although dynamic analysis has high accuracy, it has a heavy overhead and is time-consuming. This paper extracts 49 features statically, including 26 features proposed in other papers and 23 new features. As our experiments demonstrate, these new features significantly contribute to high accuracy for detection. Also, it is faster to implement detection than dynamic approaches.
Proposed method
In this paper, our goal is to classify JavaScript codes as either malicious or benign, as likely to have a drive-by download attack or not. To implement the classification, we analyze features in kinds of literature [7, 24–26] and extract 26 valuable features. Also, we extract 23 novel features by analyzing our samples. The overview of our model is depicted in Fig. 1. In the following, we first describe the features and then introduce the Random forest algorithm. Finally, we describe the specific definition of SHAP and why we choose SHAP to explain our model.

Overview of DDIML architecture.
We have extracted different features from malicious and benign JavaScript files in the feature extraction. We have written a feature extractor with regular matching in python, which takes a JavaScript file as input and the feature matrix as output. Malicious JavaScript codes are generally transformed, encoded, and encrypted to conceal attackers’ purpose and intention. We manually analyze samples and extract features from five aspects as follows.
We describe the specific features in the tables, where the reused features are illustrated in Table 1, and the new features we extracted are shown in Table 2.
Reused features extraction in our model
Reused features extraction in our model
New features extraction in our model
Random forest is a supervised learning algorithm composed of many decision trees, and there is no correlation between each tree. When building each decision tree, it needs to pay attention to random sampling and complete splitting. The specific process for constructing each decision tree is as follows: N represents the number of training samples. M represents the number of features. Row sampling, using random sampling with replacement sampling N times from N training samples to form a training set. There may be repeated samples in the new training set. Column sampling, randomly selecting m(m ⪡ M) from M features and then selecting an optimal feature from m features to divide the left and right subtrees of the decision tree. This enhances the generalization ability of the model. Then, the method uses completely splitting to build a decision tree. Because building a tree is random, there is no need for pruning and no over-fitting. When inputting a new sample, the category with the most significant number of votes is the final result among the classification results of decision trees.
The Random forest can handle high-dimensional data without feature selection compared with other machine learning algorithms. Moreover, the training speed is fast. Also, it can easily measure the importance of features.
Explanation method
The purpose of DDIML is to detect whether the JavaScript code is normal or malicious. Understanding why the model predicts some JavaScript codes to be benign and some malicious. The goal is to assess whether we can trust the learned model. In order to achieve the goal, this paper mainly uses SHAP [27] to make a reasonable interpretation on the prediction of the DDIML model.
Using the feature importance API of Random forest to calculate the importance of features, we can initiate the importance ranking of features in the model. The features of the top 20 are shown in Fig. 2. Among the top 20 features, our new features account for over half, fully showing the usefulness and importance of new features to the model prediction. However, feature importance only tells which feature is essential. Hence we do not know how features affect the prediction results and how much influence they have. Simply, we can use PDP (Partial Dependency Plots), and LIME (Local Interpretable Model-agnostic Explanations) [28] to explain the effect of the features on the model prediction. PDP needs to satisfy the independence of features. If there is a correlation between the features, the desired results are unreasonable. However, LIME ignores the feature correlation. We use the Pearson correlation coefficient to calculate the correlation among features, as shown in Fig. 3. It can be seen from the figure that no feature is entirely independent of others. So we choose to use SHAP to explain the model to deal with the problem.
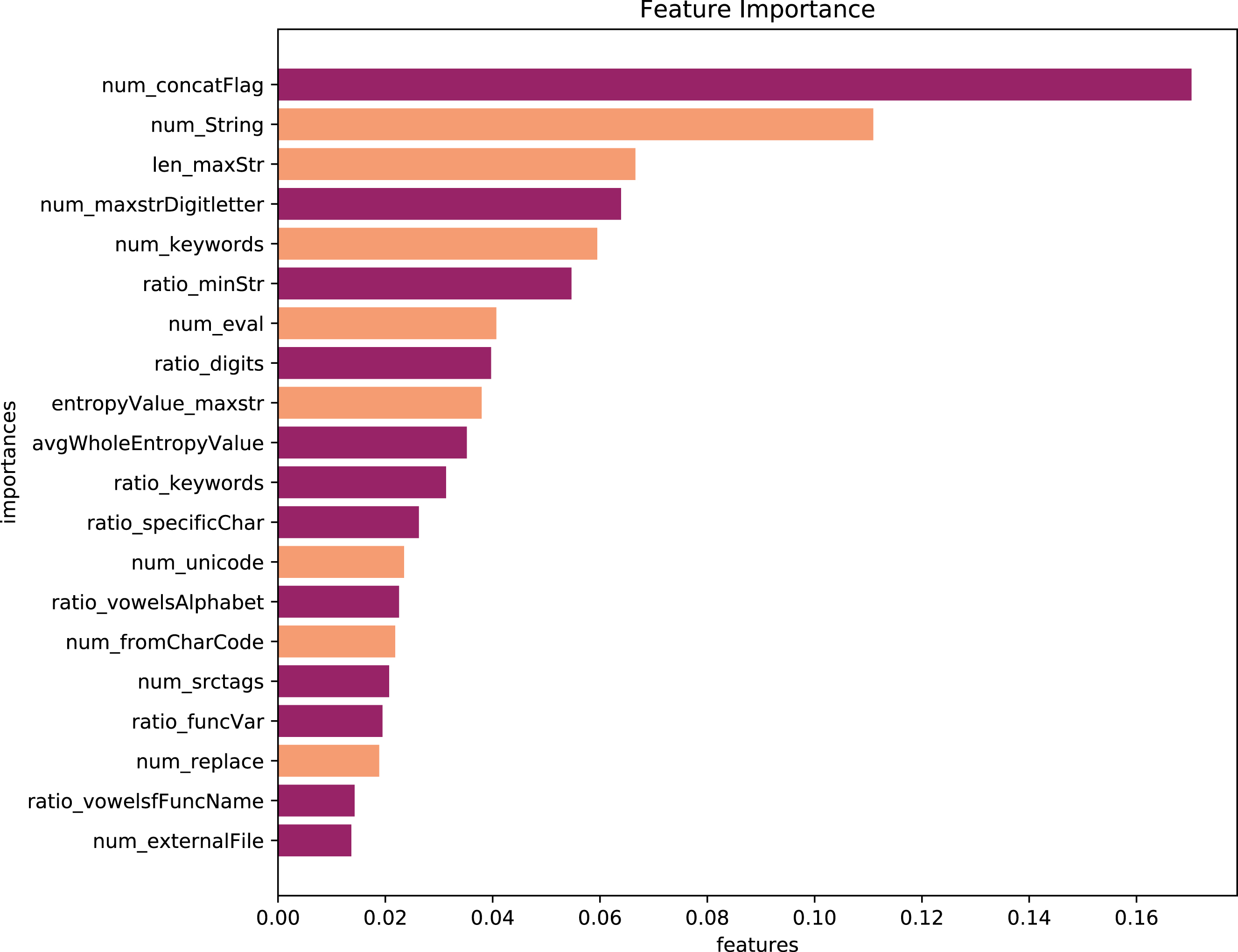
Feature importance.
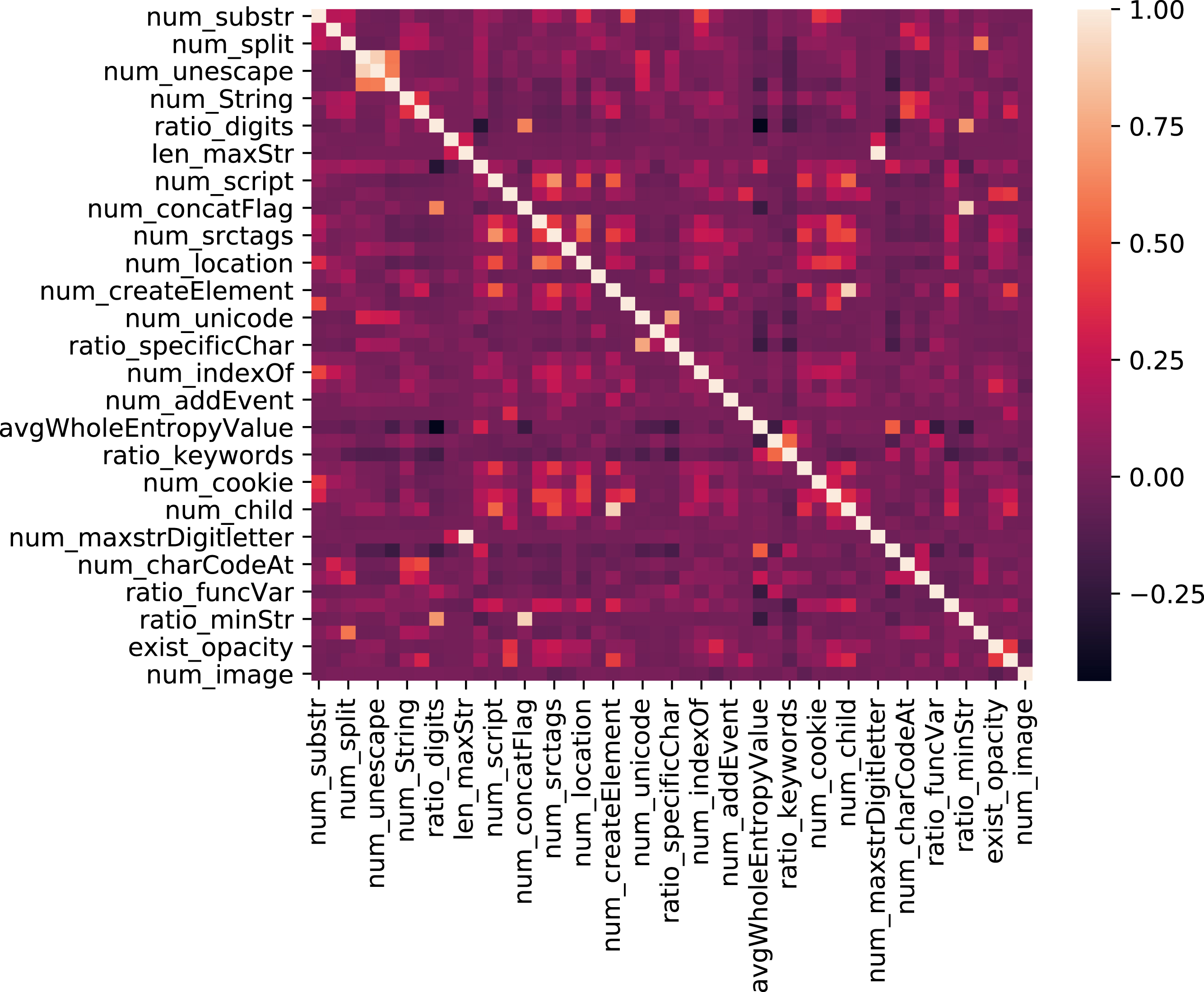
Feature interaction.
SHAP (SHapely Additive exPlanation) can interpret the output of any machine learning model. Inspired by cooperative game theory, SHAP constructs an additive explanatory model in which all features are contributors. The SHAP value is the contribution degree of each feature in a sample, which can be correctly estimated even if the features are correlated. Assuming that the ith sample is x
i
, the jth feature of the ith sample is x
ij
, the model predicts y
i
for this sample. y
base
represents the mean value of the predicted results of all samples. The SHAP value obeys equation 1.
Where f (x ij ) is the SHAP value of x ij , and the most significant advantage of SHAP value is that SHAP can reflect the influence of each feature of the sample on the prediction result. The influence also shows positive and negative.
Experimental setup
This paper studies the detection of drive-by download attacks based on static analysis. We use regular matching to extract features and optimize regular expressions to make the features more optimal and less time-consuming. Moreover, we use scikit-learn to implement machine learning algorithms. The specific experimental configuration is described in Table 3.
Experimental environment configuration
Experimental environment configuration
Results in experiment I and II
Results in experiment III
Results in experiment IV
The paper regards normal JavaScript codes as negative samples and malicious as positive samples. We adopt five evaluation metrics: accuracy, precision, recall, F1-score, and AUC to evaluate the prediction results. Accuracy represents the proportion of samples that are predicted correctly in all samples, as shown in Formula 2.
Where TP indicates the number of correct predictions of positive samples. TN represents the number of correct predictions for negative samples. FP represents the number of negative samples predicted as positive samples. FN is the number of positive samples predicted as negative samples.
Precision is the proportion of positive samples with correct prediction in all positive samples and is defined as Formula 3.
We can see from Formula 4 that Recall is the proportion of the correct positive samples predicted by the classifier to all positive samples.
F1-score is used to measure the weighted harmonic means of Precision and Recall, as shown in Formula 5.
AUC indicates the area under the ROC curve. The ROC curve represents the relationship between FPR(x-axis) and TPR(y-axis), where FPR is the proportion of negative samples that the classifier predicts incorrectly to all negative samples, as shown in Formula 6, and TPR is equal to Recall.
Detection results analysis
Model interpretability analysis
In Experiment V, we apply the SHAP method to perform the model’s local and global explanations.
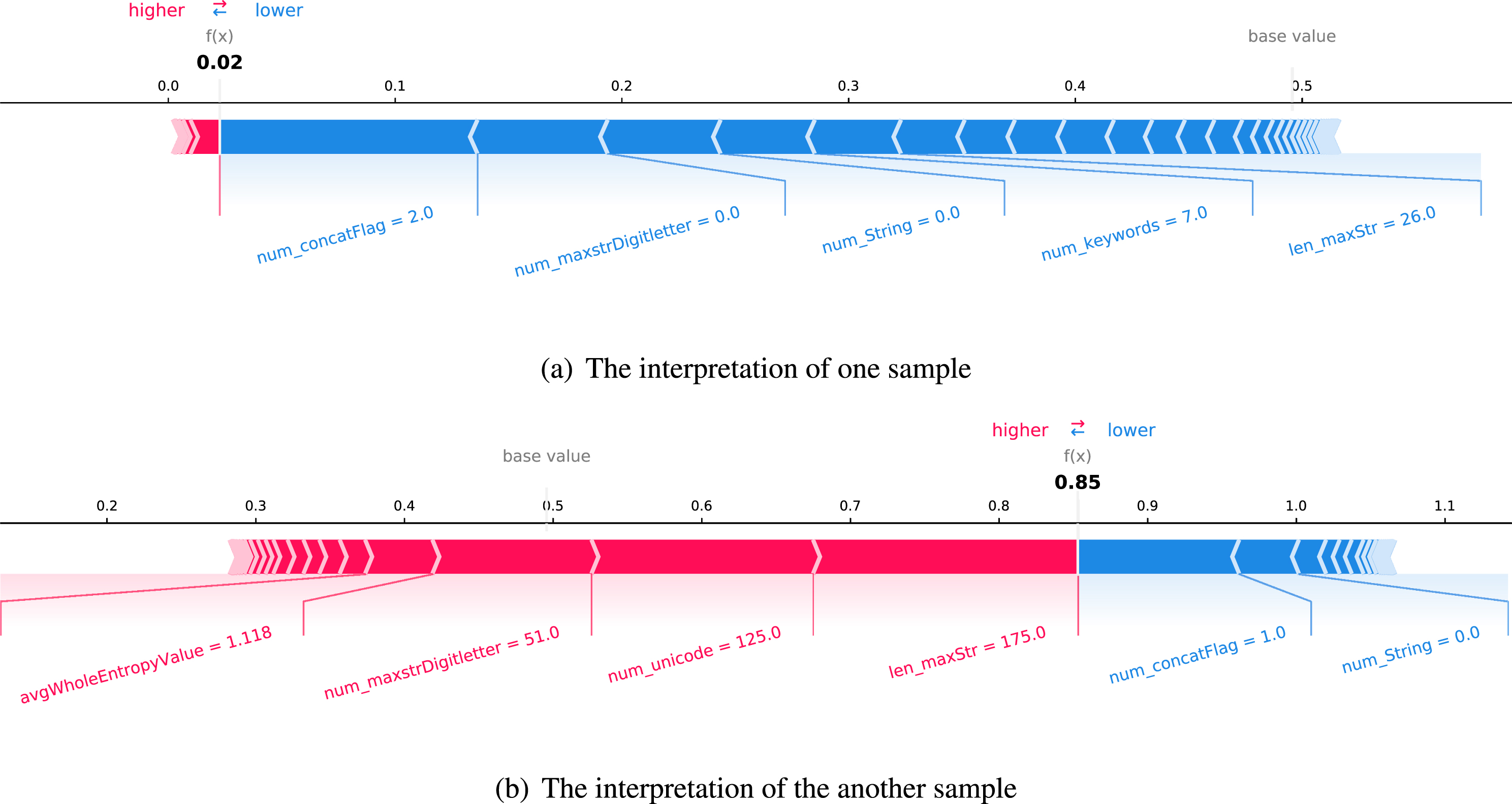
The interpretation of two randomly selected samples in the model.
Similarly, in Fig. 4(b), the bold value is higher than the base value, which shows that our model has an 85% certainty that the sample is malicious. As depicted in Fig. 4(b), there are many Unicode characters, the length of the longest string is up to 175, the number and letter alternately appear 51 times in the longest string, and the average entropy value of the whole file is equal to 1.118, etc. These features increase our model’s probability of predicting that the sample has a drive-by download attack. Finally, under the influence of all features, the model predicts that the sample has a 0.85 probability of being malicious. At the same time, these features shown in Fig. 4 are also in the top 20 of features ranking.
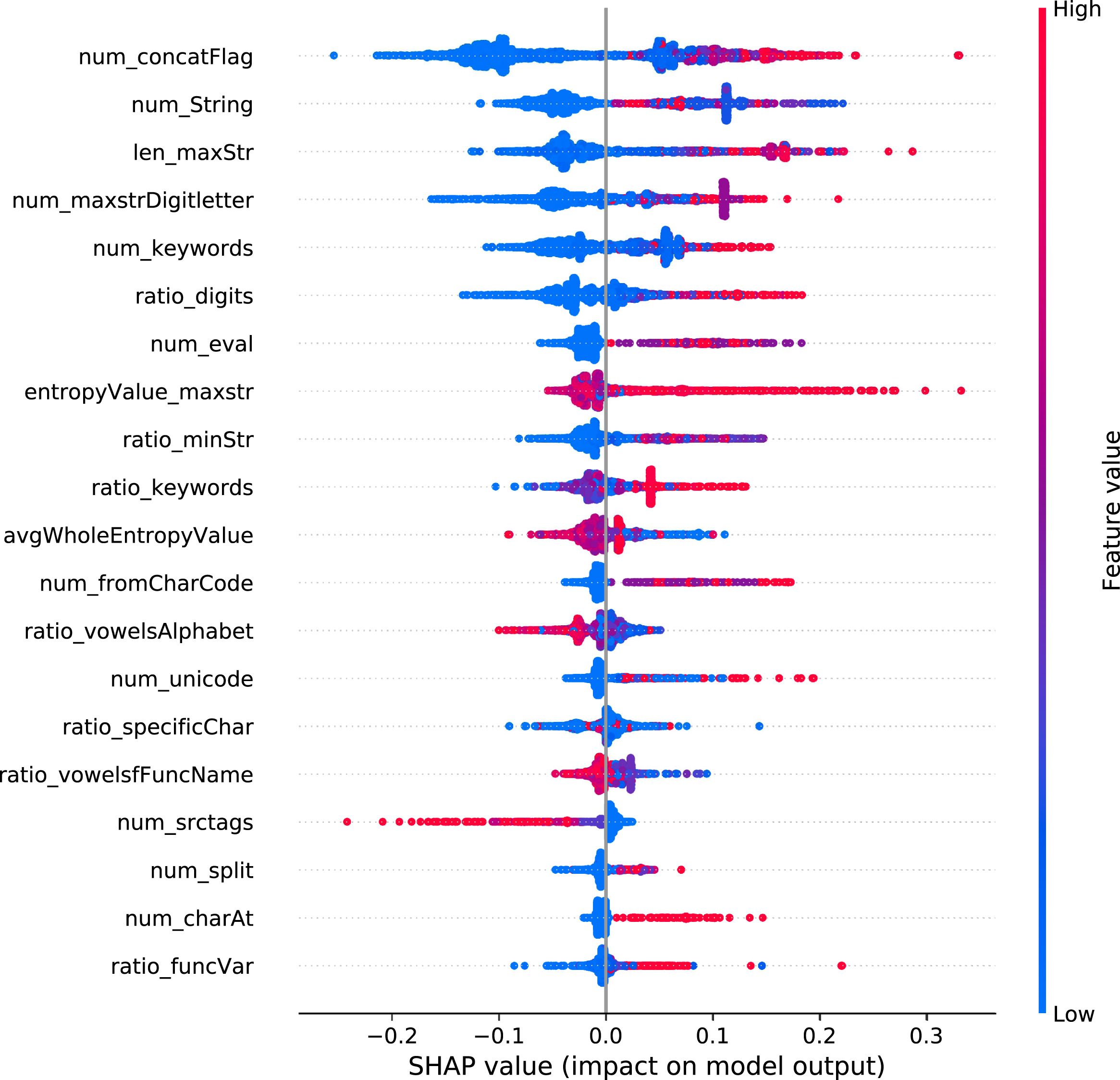
Summary plot of the model.
In Fig. 5, we can see the relationship between the feature values and the prediction impact on the whole, but the relationship is not definite. We specifically analyze the impact of the single feature value on the prediction by drawing the SHAP dependency plot. We choose some features as examples, such as num_concatFlag, num_maxstrDigitletter, entropyValue_maxstr, and ratio_digits. As depicted in Fig. 6, the x-axis represents the value of a certain feature, and the y-axis represents the SHAP value. The overall tendency for all plots is that as the feature value increases, the SHAP value increases. When attackers split malicious codes and then splice them, many connectors in samples may appear. Alternating numbers and letters in the longest string frequently appear, which may cause poor readability of the code. And as the entropy value of the largest string increases, the degree of code confusion increases. When there are many digits in a sample, code obfuscation may occur. These features positively affect the model, which predicts a sample is malicious. Moreover, it can be seen from Fig. 6 that some sample points are scattered, and this is because these features interact with other features.

Dependence plots about the effect of a single feature on prediction.
According to Fig. 3, we select the closely related features to the features in Fig. 6, where num_concatFlag is most relevant to ratio_minStr, num_maxstrDigitletter is most relevant to len_maxStr, entropyValue_maxstr is most relevant to ratio_vowels-Alphabet and ratio_digits is most relevant to ratio_minStr. The influence of two highly related features on prediction is shown in Fig. 7. In Fig. 7(a), x-axis is denoted as num_concatFlag, and y-axis on the right is denoted as ratio_minStr. It can be observed from Fig. 7(a) that as the connector increases, the number of short strings increases(the color turns red). Perhaps it is because attackers use connectors to splice short strings to generate malicious code. In Fig. 7(b), with the increase of the number of alternating digits and letters in the largest strings, the length of the largest string in samples becomes larger and larger. This could lead to code obfuscation in the longest string for some samples. In Fig. 7(c), when the ratio of vowels to letters in the largest string exceeds 0.5, the entropy value of the largest string is generally less than 5, which has a positive effect on predicting that a sample is benign. As you can see from Fig. 7(d), as the number of short strings increases, the number of digits in some samples also increases. It indicates that some digits are in the form of strings.
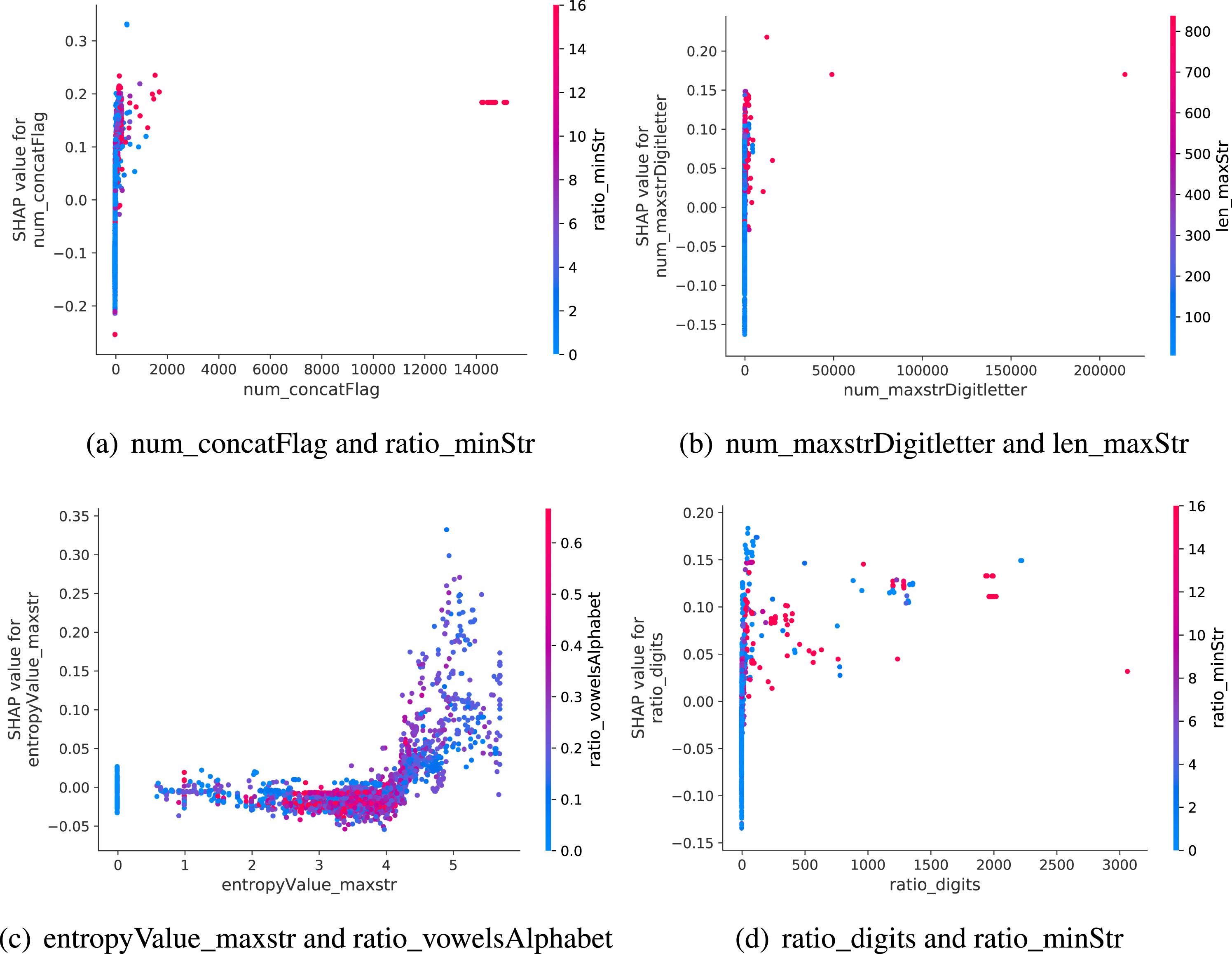
Dependence plots about the effect of two related features on prediction.
In summary, we explain the model by analyzing the feature importance, the feature correlation, the contribution of each feature in a single sample, and the relationship between feature values and SHAP values. The analysis shows that the new features significantly impact the model prediction, and these new features are feasible for detecting drive-by download attacks.
This paper proposes DDIML, an interpretable machine learning model based on novel features. Explaining the model proves that the features we extracted are reasonable, and our model can be trusted. In our dataset, compared with other machine learning methods and previous works, our model gives relatively good results, with a precision of 0.983, a recall rate of 0.980, and the average detection time for each sample is only 16.07ms. The model takes much less time than the abstract syntax tree and deep learning methods. However, the recall rate is only 0.965 with 10-fold cross-validation. Our model still needs to be improved. We will focus on distinguishing benign confusion and malicious obfuscation in future work. We could extract multiple feature sets and integrate multiple classifiers to detect drive-by download attacks. Also, we will try more methods to explain our model better to increase transparency and credibility.
Footnotes
Acknowledgment
This paper is supported in part by National Natural Science Foundation of China (U20B2045). We thank the Reviewer for their positive comment and careful review, which helped improve the manuscript.