
Abstract
A Neural Network is one of the techniques by which we classify data. In this paper, we have proposed an effectively stacked autoencoder with the help of a modified sigmoid activation function. We have made a two-layer stacked autoencoder with a modified sigmoid activation function. We have compared our autoencoder to the existing autoencoder technique. In the existing autoencoder technique, we generally use the logsigmoid activation function. But in multiple cases using this technique, we cannot achieve better results. In that case, we may use our technique for achieving better results. Our proposed autoencoder may achieve better results compared to this existing autoencoder technique. The reason behind this is that our modified sigmoid activation function gives more variations for different input values. We have tested our proposed autoencoder on the iris, glass, wine, ovarian, and digit image datasets for comparison propose. The existing autoencoder technique has achieved 96% accuracy on the iris, 91% accuracy on wine, 95.4% accuracy on ovarian, 96.3% accuracy on glass, and 98.7% accuracy on digit (image) dataset. Our proposed autoencoder has achieved 100% accuracy on the iris, wine, ovarian, and glass, and 99.4% accuracy on digit (image) datasets. For more verification of the effeteness of our proposed autoencoder, we have taken three more datasets. They are abalone, thyroid, and chemical datasets. Our proposed autoencoder has achieved 100% accuracy on the abalone and chemical, and 96% accuracy on thyroid datasets.
Keywords
Introduction
Machine learning techniques are used for the training of the data. We can train the data with the help of three types of learning processes. They are supervised, reinforcement, and unsupervised learning processes. If the input and output or targets values are given then we use a supervised learning process. This process is also called the classification technique. Some classification techniques are Decision Trees [1], Bayesian Classifiers [2], Neural Networks [3], K-Nearest Neighbour [4], Support Vector Machines [5], linear regression [6], and Logistic Regression [7]. Time series classification, dummy query sequence (for mobile users), Back-propagation (BP) neural network, Stochastic Neural Network, and linguistics-based stacking approach are some modern techniques of classification. Time series classification is a supervised learning process. A set of time series is achieved using a class label. Symbolic Aggregate approXimation (SAX) is a very famous method for the reduction of the dimension of time series, but BingBai et al. [8] used multi-feature dictionary representation and ensemble learning for time series classification. Using this method, the authors first extract mean features, second construct multiple single classifiers, and finally build an ensemble classifier to improve classification performance [8]. For protecting users’ privacy in the case of locally based services (LBS), Zongda Wu et al. [9] constructed a group of dummy query sequences. Using this method they successfully remove the problems on personal privacy i.e. location privacy and query privacy. Siyuan Tang and Feifei Yu [10] achieved better accuracy of retina vessel segmentation using a retinal segmentation algorithm. This algorithm is based on BP neural network. On the DRIVE library, they achieved 94.77% accuracy and on the STARE library, they achieved 94.98% accuracy. Danni Lu [11] provided a detailed study related to the exponential synchronization problem of stochastic neural networks. They proposed a dynamic model of master-slave neural networks which contains time-varying delays and Levy noises [11]. Yuwei Zeng et al. [12] used vogers to classify ISP-level DNS traffic into disposable and normal types of domains. They achieved a true positive rate of 98.98%, which is 0.41% more than the Y. Chen et al. methods. The authors have taken 12 basic linguistic features. They are Length, Label Level, Average Label Length, (Vowel Ratin, Consonant Ratio, and Digit Ratio), (Consecutive Consonants Ratio, Consecutive Digit Ratio), Character Cardinality, Inner digits number, Word ratio, and Entropy [12]. Classification of innovation input and innovation outputs are used in intelligent manufacturing. In the manufacturing process for the optimization of real data analysis, we use intelligent manufacturing. Measuring fiscal policies and innovation environment is known as innovation input and the results of these innovative activities within the economy are known as innovation output. Limeng Ying showed that intelligent manufacturing can promote both innovation input and innovation output of the enterprises [13]. Jing Feng et al. [14] proposed a sliding force prediction model based on Belief Rule-Based (BRB) inferential methodology. Using this method, authors accurately predict the slope of landslides and achieve early learning for landslide disasters. Losses to the lives and property of people are avoided by using this information. With the help of rock mass classification techniques, we classify rock mass into groups or classes. Fei Song et al. [15] have represented the post-failure behavior and time-dependent behavior of rock masses using the ViscoElastic-ViscoPlastic Strain-Softening (VEVP-SS) model. Area coverage classification is very useful in the mobile robot field. A mobile robot moves in the surrounding using area coverage classification techniques. Sheng Feng defines three coverage areas [16]. They proposed the Optimal k-coverage WSN deployment problem (OLXWDP) model. Using this model authors achieved average rates of nearly 100% for 1-coverage, 91.34% for 2- coverage, and 89.00% for 3- coverage. A neural network is a branch of machine learning [17]. Clustering, classification, recognition, etc. are major areas of Artificial Neural Network (ANN) [17-20]. There are many techniques of neural networks. Time Delay Neural Network [21], Multilayer feed-forward neural network, Self Organization Map, Convolutional neural network, Deep network, and autoencoder are some techniques of neural network.
Some classification applications based on stacked autoencoder are: Hyperspectral image classification [22], Network traffic classification [23], Electricity theft defection [24], Alzheimer’s disease classification [25], Cervical cancer predication and classification [26], Early gastric cancer classification [27], COVID-19 diagnosis [28], ECG beat classification [29], Brain Tumor Detection and Classification [30], Fault Diagnosis of permanent Magnet Synchronous Motor [31], Cross-domain fault diagnosis [32], Real-time radio technology and modulation classification [33], Weld defect classification [34] and Heart Sound classification [35]. Hinton and the PDP group proposed the first Autoencoder in 1980 (Rumelhart et al., 1986) [41]. An autoencoder is one of the networks of unsupervised learning algorithms. Better performance of the autoencoder is obtained by using a stacked autoencoder [42]. Generative Adversarial Network with Autoencoder (GAN-AE), Sparse Autoencoder, Variational autoencoder, Stacked Sparse Autoencoder (SSAE), Locality-Constraint Sparse Autoencoder (LSAE), Weight-Clustering Sparse Autoencoder (WCSAE), and Stacked Pruning Sparse Autoencoder (SPSAE) are some representations of stacked autoencoder models. Ian Goodfellow and his colleagues proposed GAN in June 2014. This is an unsupervised learning technique and therefore these networks create their own training data. Stephanic Ger et al. [43] proposed a noval GAN with autoencode (GAN-AE). In this model, the authors developed a GAN architecture with an additional autoencoder component. In order to generate synthetic data in this model, the authors used a recurrent neural network (RNN). In Sparse Autoencoder, the output is achieved using the sparsity method. The result of the loss function also depends on the sparsity regularization value [see equation (3)]. In the Variational autoencoder (VAE), the output values are obtained using probabilistic manners. Its loss function depends upon the reconstruction loss value and the Kullback-Leibler divergence value. In the SSAE, each hidden layer is made of the hidden layer of an individually trained Sparse Autoencoder [44]. The main properties of this autoencoder are that input values of each sparse autoencoder are obtained from the output value of the previous sparse autoencoder. During the experiment on CIFAR-10, STL-10, and Caltech-101 datasets, Luo et al. [45] proposed LSAE. They used the logistic sigmoid activation function in this network. The authors found a local subspace of training data using this proposed SAE. Fan et al. [46] proposed a novel approach for change detection using weight-clustering sparse autoencoders (WCSAE) combined object-oriented classification with difference images (DIs). The authors also introduced L1/2 regularization to extract more sparse features and avoid over-fitting. Using diagnosing bearing faults, Haiping Zhu et al. [47] proposed an SPSAE model. In this model, the input of each layer comes from the output of all the previous layers and the feature information of previous layers can be shared with subsequent layers.∥The activation function is one of the important parts of the autoencoder. We may increase the power of the autoencoder if we take a better activation function. Table [1] has some generally used activation functions. Some activation functions use exponential formulas in their functions. The logsigmoid, Hexpo, RelTanh, and tansigmoid are some activation use exponential formulas in their functions (Table 1). The purelin and satlin do not use the exponential functions. The exponential function is more useful for nonlinear complex datasets. So purelin and satline do not achieve the better result as compared with logsigmoid and tansigmoid activation function (AF) in maximum cases. The ReLU does not use the exponential or trigonometric functions. The ReLU suffers from a dying ReLU problem. This function is mainly used in CNN and very deep neural networks. In the case of ReLU AF, the neurons will be deactivated if the output of the linear transformation is less than 0 (i.e. for the negative value). The equation of a RelTanh AF is shown in Table 1, at serial number 8. This RelTanh AF is an improved AF of tanh. Xin Wang et al. achieved 96.15% testing accuracy with the help of RelTanh on the faulty dataset of CWRU [38]. The ReLU and its variants are mainly used in very deep layers and CNN networks. For an autoencoder generally ReLU and its variations AF is not used. So we compare our proposed autoencoder with purelin, satlin, tansigmoid, and logsigmoid AFs. In Table 2, we have shown comparisons of three other techniques and their results with our proposed autoencoder technique and our results.
Different activation function, their mathematical equations, derivatives and range
Different activation function, their mathematical equations, derivatives and range
Comparison of three other techniques and experiment with our proposed autoencoder
Our main aims in this paper are to propose an effective autoencoder technique that should be able to achieve better results compare to the existing autoencoder technique. Especially, the contribution of this paper is to change the activation function of an autoencoder.
For achieving this aim, firstly, we have taken some datasets. We have taken eight different types of datasets whose attributes and targets are different. Secondly, based on these datasets, now, we have decided to classify these datasets. Autoencoder is one of the best deep learning techniques. Therefore, we have taken an existing autoencoder technique. We have classified these datasets using this network or technique. But, we have found that these datasets do not achieve a better result. The accuracy of an autoencoder depends upon the size of hidden nodes, Epochs, L2 regularization, L2 Weight regularization, Sparsity Proportion, Sparsity regularization, training algorithm, and activation functions. Now our main contribution starts, we have decided to change the activation formula (AF) which is used in the existing technique. Therefore, we have proposed a new AF. Using this AF, we have proposed a new autoencoder. Finally, using this autoencoder, we have again analyzed these datasets on the same configuration. In multiple cases, we have achieved at par or better results as compared with the existing autoencoder technique. In the discussion section, we have presented full details of why our autoencoder gives better results using this modified AF.
Autoencoder
An autoencoder has the same number of neurons in the input layer and output layer. With the help of an autoencoder, we reduce the dimensions of the data [41]. Its main work is to copy its input to its output. There are two types of autoencoders. The first is a sparse autoencoder, and the second is a stacked autoencoder. There are three layers of the autoencoder. First is input, second is code (hidden), and third is the output layer. There are two main processes or components of the autoencoder. They are encoder and decoder (Fig. 1a.).

(a) Autoencoder, (b) stacked autoencoder.
Encoder process: The output value of this process is calculated with the help of equation (1). Suppose, ni is the value of the output of ith neuron, then
Where wj is a weight value of jth neuron, xj is a input value of jth neuron, b is a bias value, m is total number of inputs, and f(.) denotes an activation function of the encoder.
Decoder process: The output value of this process is calculated with the help of Equation (2). Suppose, nni is the value of the output of ith neuron, then
Where wj is a weight value of jth neuron, nj is a input value (or ouput value of encoder) of jth neuron, bb is a bias value, mm is total number of inputs, and g(.) denotes an activation function of the decoder.
On the encoder and decoder place, if we use the best activation then we may get the best results. But if our activation is not best then we may not get the best result. So in this paper, we use some modified activation functions for getting the best results.
During the design of an autoencoder, we calculate the Loss function. This Loss function (L (yij,
Where yij is the target value, yij’ is a predicted value, n is a number of input values and m is a number of variables or classes.
A number of the hidden nodes, Epochs, L2 regularization, L2 Weight regularization, Sparsity Proportion, Sparsity regularization are some parameters used during the training of the autoencoder. Hidden neurons (or nodes) work as a feature detector. So, with the help of the hidden neurons, we find out the features of the network. To get high accuracy, we run the network many times. So epochs are used to show how many times we run the network. L2 Weight regularization is also known as ridge regression or Tikhonov regularization. L2 Weight regularizer is used for weight decay only. It is not used for bias control. Regularized objective function J’ is calculated with the Equation (5).
Where J is an objective function, θ is the size of the parameter, α is a hyperparameter, x is an input value, and y is a target value.
In the above equation if we put
Now if we calculate the gradient of the above equation with respect to weight then we get Equation (7).
Now, we update the weight by using Equation (8).
Where, η is learning rate parameters.
To get better accuracy of the result of the wnew, we minimize the value of Δw J (w; x, y). So, we typically put its value as quite small.
In Equation (3), β * Ψ(n) is added to the loss function. Its main work is to control the sparsity. We generally take a low value of β so that we get a high degree of sparsity. It is also known as Sparsity Proportion. Sparsity regularization is calculated with the help of the Kullback_Leibler divergence [41] function, which is defined as under Equation (9).
If we want the range of the input data to match with the range of the transfer function for the decoder, then we use scale data. We maximize or minimize the value of any function with the help of optimization algorithms. There are two classes of maximum and minimum value. They are local maxima and local minima, and global maxima and global minima. Optimization algorithms are used during the calculation of new weights and biases. Losses are reduced with the help of these optimization algorithms. SCG, Adagrad, RMSprop, Adam are some famous optimization algorithms. The scaled conjugate gradient (SCG) algorithm is based on conjugate directions. SCG is used for finding out the local minima of a differentiable function. Whenever derivative of weight, input, and transfer functions are given in the network, then the SCG method may be used for training a network.
In the SCG case, the parameter of each training set is updated by the Equation (11).
SCG is used by many researchers. Upadhyay et al. (2019) had used SCG in violation prediction in Cloud Computing [51]. Jyotiprakash et al. had used LM, SCG, and BR for the prediction of water quality index in the ANN [52]. S.O. Sada had used LM and SCG for the prediction of accuracy in a mild steel turning operation [53]. Abdollahi et al. had proposed a new conjugate gradient method that was based on SCG and was used for solving an optimization problem [54]. Sujatha et al. had used BR, SCG, and LM for analysis of Bitcoin Trends [55]. SCG is used for large networks. SCG is a faster algorithm and can be also used during online training. Due to these uses and properties of SCG, we test our proposed autoencoder on SCG.
If we make a network by stacking more than one autoencoder together with the softmax layer, then it is called a Stacked Autoencoder (Fig. 1b.).
We may solve classification problems with the help of the neural network technique. There are a number of types of neural network techniques. An autoencoder is one of those techniques. In this paper, we have proposed an effectively stacked autoencoder with the help of a modified sigmoid activation function. We have proposed a two-layer stacked autoencoder, with a modified sigmoid activation function. After that, we have compared our autoencoder to the existing autoencoder technique. Authors of papers [41, 58-65] had used the existing autoencoder technique. In the existing autoencoder technique, we generally use the logsigmoid activation function. Therefore here, first of all, we have discussed logsigmoid Activation Function (AF) and its properties and after that, we have discussed our modified Activation Function (AF) and its properties and lastly, we have explained why our autoencoder achieved better results.
A) logsigmoid Activation Function (AF) and its properties
Equation (12) is a log sigmoid function. Figure 2 is a plot of this AF.
The plot of logsigmoid and modified sigmoid activation functions. This graph clearly shows the range of logsigmoid is [0, 1] and the range of our modified sigmoid is [-1, 1].
Where ‘n’ is input and f (n) is output.
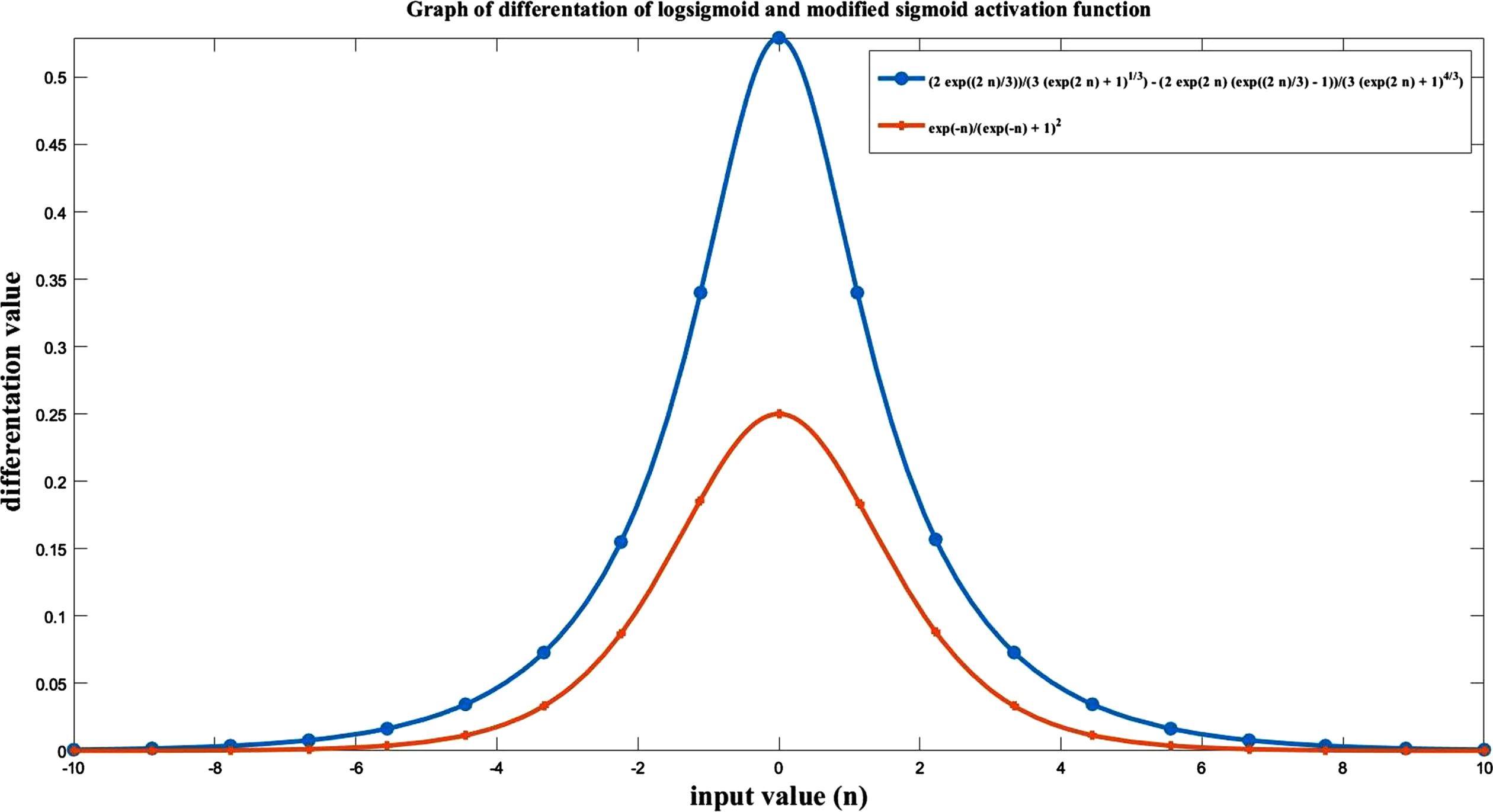
This AF has the following properties: Nonlinear: The logsigmoid activation function uses the exponential function. Therefore, this activation function is also used for solving nonlinear problems. Range and Shape: The range of this activation function is (0, 1). This range is a finite range. Therefore, in the case of pattern recognition and classification, this activation function will show more stability. The shape of this activation function is ‘S’ (Fig. 2). Continuously Differentiable: This AF is a continuously differentiable function (Fig. 3). Its differentiation is given in equation (13). Therefore, we may use this AF in the gradient-based Optimization method.
The plot of differentiation of logsigmoid and our modified sigmoid activation function. Zero-Centered: This AF is not a zero-centered activation function.
B) Modified Sigmoid Activation Function and its properties
Equation (14) is our modified AF. Figure 2 is a plot of this AF.
Our modified AF has the following properties: Nonlinear: Our modified AF uses an exponential function like logsig AF. Therefore, we can use our AF for solving nonlinear problems. Due to this reason, our AF gives better results compared to the purelin and satlin AFs. Range and Shape: The range of our AF is (-1, 1). This range is a finite range. Therefore, in the case of pattern recognition and classification, our AF will show more stability. The shape of this activation function is ‘S’ (Fig. 2). Continuously Differentiable: Our AF is a continuously differentiable function (Fig. 3). Its differentiation is given in Equation (15). Therefore, we may use our AF in the gradient-based Optimization method.
Zero-Centered: Our AF is a zero-centered activation function.
As compared with logsigmoid AF, our activation gives more variations for different input values (Table 3). So we can get more accuracy for different input values with the help of our AF. As with logsigmoid AF, our modified activation function (AF) also allows backpropagation, because our AF is a differential function. Our modified AF has zero centered but logsigmoid is not zero centered AF. Therefore, our AF works better than logsigmoid. The logsigmoid is not symmetric around zero, but our AF is symmetric around zero. Due to this reason, we may use this AF for solving very complex problems (Non-linear problems); such as audio, images, or any high dimensionality problems.
The output value of logsigmoid and modified sigmoid on different input values
As with logsigmoid, there are two limitations of our AF. Our AF has a finite range, due to this reason for the very high or very low value of input; there is almost no change to prediction. This problem is also called the vanishing gradient problem. Our AF may be performing slow convergence.
We have done this experiment on Intel core i7, window 10, and MATLAB 2021a [56]. In this research, we have proposed a Stacked Autoencoder. In this Stacked Autoencoder, we have taken one input layer, two autoencoder layers, a softmax layer, and an output layer. We have taken 5-datasets from the MATLAB software. These datasets are the iris, glass, wine, ovarian, and digit (image) datasets for comparison propose. After taking all these datasets, we have taken the values of regularizers.
Iris dataset: The iris dataset has 150 samples of three flowers. This dataset has four attributes and three targets. We have taken 150 samples for training and 150 samples for the testing purposes of this dataset. We have taken the values of the Hidden neuron size is to 4, Maximum epochs is to 400, L2WeightRegularization is to 0.001, SparsityRegularization is to 4, SparsityProportion is to 0.05, Decoder Transfer Function is to logsigmoid/‘our formula’ of autoencoder 1. And set values of the Hidden neuron size is to 50, the Maximum epochs is to 400, L2WeightRegularization is to 0.0015, SparsityRegularization is to 4, and SparsityProportion is to 0.05 of autoencoder 2. In this dataset, we have put our modified activation formula on autoencoder 1 at decoder place.
Wine, ovarian, and glass dataset: The wine dataset has 178 samples of wine data. This dataset has 13-attributes and 3-targets. We have taken 178 samples for training and 178 samples for the testing purposes of this dataset. The ovarian dataset has 216 samples of ovarian data. This dataset has 100-attributes and 2-targets. We have taken 216 samples for training and 216 samples for testing purposes of this dataset. The glass dataset has 214 samples of glass values. This dataset has 9-attributes and 2-targets. We have taken 214 samples for training and 214 samples for the testing purposes of this dataset. We have taken the values of the Hidden neuron size is to 10, Maximum epochs is to 400, L2WeightRegularization is to 0.001, SparsityRegularization is to 4, SparsityProportion is to 0.05, and Decoder Transfer Function is to logsigmoid/‘our formula’ of autoencoder 1. And set values of the Hidden neuron size is to 50, Maximum epochs is to 400, L2WeightRegularization is to 0.0015, SparsityRegularization is to 4, and SparsityProportion is to 0.05 of autoencoder 2. In these datasets, we put our modified activation formula on autoencoder 1 at decoder place.
Digit dataset: This dataset consists of 5000 training images and 5000 testing images with the size of 28-by-28 pixels. We have taken the values of the Hidden neuron size is to 100, Maximum epochs is to 400, L2WeightRegularization is to 0.004, SparsityRegularization is to 4, and SparsityProportion is to 0.15 of autoencoder 1. And set values of the Hidden neuron size is to 50, Maximum epochs is to 100, L2WeightRegularization is to 0.002, SparsityRegularization is to 4, SparsityProportion is to 0.1, and Decoder Transfer Function is to logsigmoid/‘our formula’ of autoencoder 2. In this dataset, we have checked our modified activation formula into autoencoder 2. In Fig. 4.b we have shown our modified sigmoid position. We have put our modified sigmoid at the decoder place.

Detail of autoencoder made by digit datasets. (a) is the first autoencoder. (b) is a second autoencoder. In the second autoencoder, we have put our modified sigmoid on the decoder place. (c) is a softmax layer, and (d) is a stacked network made by stacking of (a), (b), and (c).
All the parameter setting values are presented in Table 4 of autoencoder 1 and Table 5 of autoencoder 2. If we take all these values of the regularizer, then we can achieve better results (above 90%). When we change these values, then our accuracy result reduces. So for testing our network, we have taken all these values of the regularizer. After setting all the above regularization values, we have taken a softmax layer. During the training of the softmax layer, we have taken a cross-entropy loss function; because in multi-class classification problems cross-entropy loss function (Equation (16)) gives a better result as compared with the mean squared error (Equation (4)) loss function [57].
Parameter values of autoencoder 1
Parameter values of autoencoder 2
Where yij is the target value, y’ij is a predicted value and n is a number of input values.
In the Softmax, Soft means softmax is continuous and differentiable [17]. The Softmax function is now mostly used in the output layer of the classifier [17]. In this softmax function, if n is an input then output (a) is obtained with the help of Equation (17).
First of all, we have trained our autoencoder in an unsupervised manner up to the softmax layer, after that, we add all these networks. This joined network is known as stacked autoencoder. Figure 4.d is a stacked autoencoder made by stacking of Fig. 4.a, 4.b and 4.c (MATLAB generated images). At last, we have trained this stacked autoencoder in a supervised manner for getting high accuracy. We have to repeat this process until we don’t get stopping criteria. After completing these processes, we have achieved the exact weight and bias of the network of both layers. Figure 5 is an example of the weight image of the first autoencoder in the case of a digit dataset. After that, we have calculated errors, accuracy with the help of a confusion matrix. We have shown all confusion matrixes in Fig. 6.

Weight of the first autoencoder in the case of digit dataset.
Confusion matrix obtained from all eight datasets. The first column is obtained from the existing autoencoder technique. The second column is obtained from Our proposed autoencoder technique. Fig. ‘a.1’ and ‘a.2’ are iris, ‘b.1’ and ‘b.2’ are wine, ‘c.1’ and ‘c.2’ are ovarian, ‘d.1’ and ‘d.2’ are glass, ‘e.1’ and ‘e.2’ are digit, ‘f.1’ and ‘f.2’ are abalone, ‘g.1’ and ‘g.2’ are thyroid, and ‘h.1’ and ‘h.2’ are chemical confusion matrix.
For more verification of the effeteness of our proposed autoencoder, we have taken three more datasets. They are abalone, thyroid, and chemical datasets. The abalone dataset has 4177 samples of abalone shell rings. This dataset has 8-attributes and 1-targets. We have taken 4177 samples for training and 4177 samples for the testing purposes of this dataset. The thyroid dataset has 7200 samples of thyroid patients. This dataset has 21-attributes and 3-targets. We have taken 7200 samples for training and 7200 samples for the testing purposes of this dataset. The chemical dataset has 498 samples of chemical sensors. This dataset has 8-attributes and 1-targets. We have taken 498 samples for training and 498 samples for the testing purposes of this dataset. The parameter setting values of these datasets are presented in Table 4 of autoencoder 1 and Table 5 of autoencoder 2.
After completing the training process of this network, we have achieved confusion matrixes. In this research, we have taken eight datasets for comparison purposes. So, we have found 16 confusion matrixes. In all these confusion matrixes, the value of the output class (row) is known as a predicated class and the target class (columns) is known as true class. Diagonal values of these matrixes are correctly classified values and other values are incorrectly classified values. The upper and lower values of the last column are the percentage value of all the true classified values (or positive predictive value of precision value) and false discovery rate values (or incorrectly classified value) respectively. The upper and lower value of the last row (or bottom) values are the percentage of all example values (or recall values or true positive rate values) and false negative rate values respectively. The last right value of these matrixes is the overall accuracy value. The confusion matrixes of Fig. 6.a.1, 6.b.1 6.c.1, 6.d.1, 6.e.1, 6.f.1, 6.g.1 and 6.h.1 have been found with the help of the existing autoencoder technique and the confusion matrixes of Fig. 6a.2, 6.b.2, 6.c.2, 6.d.2, 6.e.2, 6.f.2, 6.g.2 and 6.h.2. have been found with the help of our proposed autoencoder technique. Figure 6a.1 and 6.a.2 .have been obtained by training of iris datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of iris datasets, we have achieved 96.0% accuracy with the help of the existing autoencoder technique and 100.0% accuracy with the help of our proposed autoencoder technique. Figure 6.b.1 and 6.b.2 have been obtained by training of wine datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of wine datasets, we have achieved 91.0% accuracy with the help of the existing autoencoder technique and 100.0% accuracy with the help of our proposed autoencoder technique. Figure 6.c.1 and 6.c.2 have been obtained by training of ovarian datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of ovarian datasets, we have achieved 95.4% accuracy with the help of the existing autoencoder technique and 100.0% accuracy with the help of our proposed autoencoder technique.
Figure 6.d.1 and 6.d.2 have been obtained by training of glass datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of glass datasets, we have achieved 96.3% accuracy with the help of the existing autoencoder technique and 100.0% accuracy with the help of our proposed autoencoder technique. Figure 6.e.1 and 6.e.2 have been obtained by training of digit datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of digit datasets, we have achieved 98.7% accuracy with the help of the existing autoencoder technique and 99.4% accuracy with the help of our proposed autoencoder technique. Figure 6.f.1 and 6.f.2 have been obtained by training of abalone datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of abalone datasets, we have achieved 100% accuracy with the help of the existing autoencoder technique and with the help of our proposed autoencoder technique. Figure 6.g.1 and 6.g.2 have been obtained by training of thyroid datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of thyroid datasets, we have achieved 95% accuracy with the help of the existing autoencoder technique and 96% accuracy with the help of our proposed autoencoder technique. Figure 6.h.1 and 6.h.2 have been obtained by training of chemical datasets on existing autoencoder technique and on our proposed autoencoder technique respectively. In the case of chemical datasets, we have achieved 100% accuracy with the help of the existing autoencoder technique and with the help of our proposed autoencoder technique.
We have compared the performance of our modified AF with purelin, satlin, and tansigmoid AF on the autoencoder. In multiple cases, our proposed autoencoder has achieved at par or better results (Table 6).
Comparisons of accuracy on different activation function (AF) on two layer autoencoder
Comparisons of accuracy on different activation function (AF) on two layer autoencoder
We have also checked the effectiveness of our proposed autoencoder on two more hidden layers (3 and 4) of stack autoencoder. In all these layers our proposed autoencoder has achieved acceptable results (Table 7).
Accuracy value of different datasets on different number of layers of stack autoencoder
From all the above results, we can say that in multiple cases our proposed autoencoder technique shows very effective performance and can achieve at par or better results compare to existing autoencoder techniques.
For checking the overfitting problems of the proposed autoencoder, we have divided our datasets into two different numbers of training and testing samples. In Table 8, we have shown these different training and testing samples. In this table, we have also shown the training and testing accuracy. These accuracies have been achieved using 2 layers of our proposed autoencoder. All these accuracies are acceptable accuracy.
Training samples, testing samples, total samples, training accuracy and testing accuracy on different datasets
Csaha Brunner et al. [48] achieved 73.2% accuracy from SAE-SNN, 74.26% accuracy from AE-SNN, and 77.25% accuracy from SNN on the NSL-KDD dataset. S. F. Qadri et al. [49] achieved 91.53% precision from SVeg on the MICCAI dataset. In Table 9, we have presented some other autoencoder, techniques, and their result. We have compared our techniques and our results with them. Serial no1 autoencoder is proposed by Jinling Zhao et al. based on a combination of SAE and 3 DDRN networks. Serial no 2 autoencoder is proposed by Yongming Li et al. based on ESGSAE. Serial no 3 autoencoder is proposed by R. Dhanuka et al. and based on A Semi-supervised autoencoder-based approach. Serial no 4 autoencoder is proposed by O Aouedi et al. based on a novel federated semi-supervised learning scheme. Serial no 5 autoencoder is our proposed autoencoder.
Comparison of three other techniques with our proposed autoencoder
Figure 7, shows the performance analysis of three AFs. This analysis has obtained with the help of the SCG training algorithm and on the glass dataset. We have trained these networks upto 10000 epochs. We have achieved the best training performance is 4.9753e-16 at epoch 2469 with the help of our proposed activation function. We have achieved the best training performance is 1.8993e-15 at epoch 9468 with the help of tanh. We have achieved the best training performance is 7.922e-16 at epoch 6478 with the help of losgmoid. Thus we say that on the basis of performance analysis, for the same training samples, algorithms, and the same configurations, our proposed activation function gives better performance.
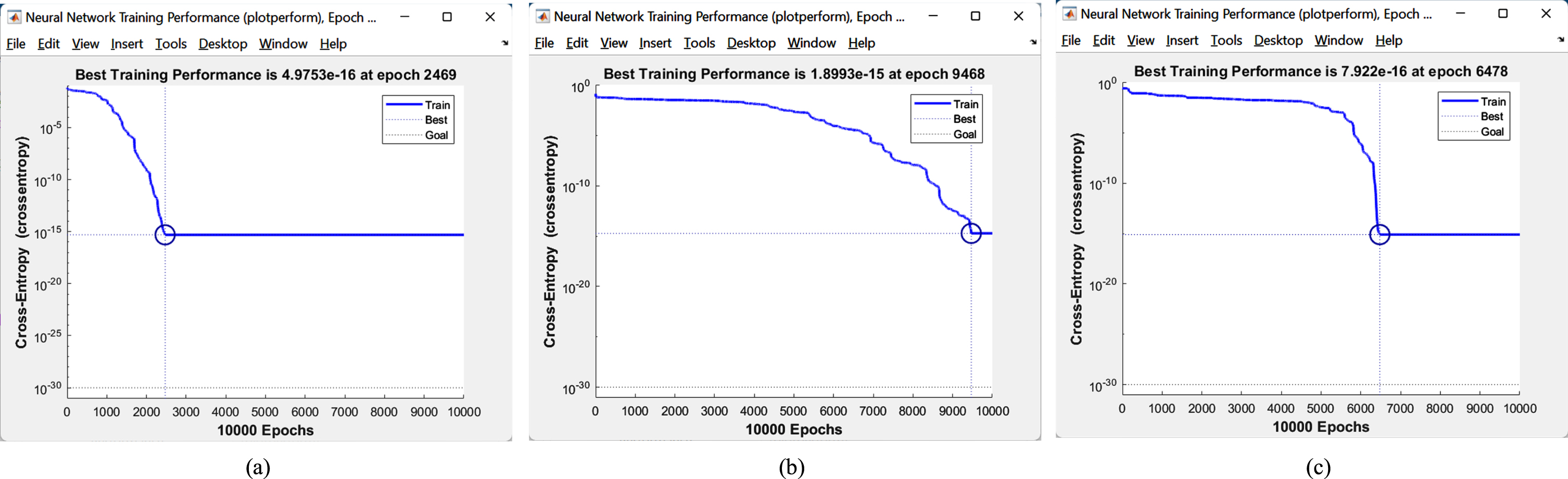
Cross-Entropy value on 10000 epochs. Figures (a), (b), and (c) have been obtained from our proposed activation function, tansigmoid, and logsigmoid respectively.
In this paper, we have explained our proposed effective stacked autoencoder with the help of a modified sigmoid activation function. Our modified sigmoid activation function is a smooth S-shape, bounded range (-1, 1), continuously differentiable, and zero centered function. Vanishing gradient and slow convergence are two limitations of our modified sigmoid activation function. We have compared our proposed stacked autoencoder with the presently used autoencoder technique. We have tested our proposed autoencoder on the iris, glass, wine, ovarian, and digit image datasets for comparison propose. The existing autoencoder technique has given 96% accuracy on the iris, 91% accuracy on wine, 95.4% accuracy on ovarian, 96.3% accuracy on glass, 98.7% accuracy on digit (image) dataset. Our proposed autoencoder has given 100% accuracy on the iris, wine, ovarian, and glass, and 99.4% accuracy on digit (image) datasets. In the discussion part, we have explained why our proposed stacked autoencoder is so effective and gave better results as compared with the existing autoencoder technique. The accuracy achieved with our proposed autoencoder is more than 4% on the iris, 9% on wine, 4.6% on ovarian, 3.7% on glass, and 0.6% on digit datasets as compared with the existing autoencoder technique. For more verification of the effeteness of our proposed autoencoder, we have taken three more datasets. They are abalone, thyroid and chemical datasets. Our proposed autoencoder has achieved 100% accuracy on the abalone and chemical, and 96% accuracy on the thyroid datasets.
Therefore in the future, we may consider our proposed stacked autoencoder in the neural network for getting better accuracy.