
Abstract
Conversational recommender systems use natural language conversations to elicit user preferences and recommend items proactively. Existing methods based on graph neural networks have been proven to be effective in exploiting knowledge graphs. However, node positions are often treated as constants, which leads to the neglect of graph connectivity due to fuzzy processing. In addition, although the transformer has significant advantages in understanding the text, its secondary computational complexity may be incapable when dealing with long texts. In order to solve these problems, we propose an additive positional conversational recommender model called APCR. This model converts the pair product of transformer into a linear operation, and uses the Laplacian eigenvector to build a location graph. The extended graph neural network captures the topology structure of the location knowledge graph. Specifically, we design an encoder based on additive attention to break through the bottleneck of long text. Furthermore, we develop a recommendation model based on a positional graph neural network to match items with dialogue context, thereby capturing the graph topology. Extensive experiments on the REDIAL dataset show significant improvements in our proposed model over the state-of-the-art methods in recommendation and dialogue generation evaluations.
Introduction
The convenience brought by intelligent assistants to people’s daily lives is obvious; assisting users in filtering information or completing specific tasks, such as product recommendations, hotel reservations, etc., has substantial commercial potential. According to Sales-force’s research, the adoption rate of chat bots in the travel, transportation, and hospitality industries is projected to increase by 241% by 2020. Many branded hotels, airlines, and online travel agencies (OTA) have already employed chat bots on their websites, during information editing, and through Facebook Messenger to engage in communication with their customers. Zingle, a B2C information solution provider collaborating with multiple hotel clients, conducted a survey among over 1,400 consumers to gather their perspectives on chat bots and human assistance. The majority of respondents (66%) stated that they have engaged in service interactions with chat-bots or digital assistants in the past few months. However, users are more willing to use chat-bots if they believe it can save them time. Therefore, researchers focus on conversational recommender systems (CRS), which interact with users to capture interests and preferences, effectively alleviating the cold start problem of traditional recommendation systems. The CRS usually consists of three components: the user interaction module, the dialogue strategy management module, and the recommendation engine.
Most existing CRSs focus on supplementing dialogue with external information and bridging the gap between recommender and dialogue systems. Traditionally, researchers examine a suite of neural architectures for sub-problems of conversational recommendation making to investigate the fundamental algorithmic elements of conversational recommendation systems. Moreover, the conversational recommender system with adversarial learning (CRSAL) [7] leverages an entirely statistical dialogue state tracker coupled with a neural policy agent to precisely capture each user’s intent from limited dialogue data and generate conversational recommendation actions. With the development of reinforcement learning [25, 26], the learning conversational recommendation policies are widely adopted to determine what attributes to ask for, what items to recommend, and when to ask or recommend at each conversation turn. The unified conversational recommendation policy learning via graph-based reinforcement learning (UNICORN) utilizes a dynamic weighted graph-based RL method to learn a policy to select the action at each conversation turn, either asking an attribute or recommending items. Recently, a popular trend has been to add knowledge graphs to conversational recommender systems. For example, unlike previous conversational recommendation systems, the knowledge-based question generation sys- tem (KBQG) models user preferences at a finer granularity by identifying the most relevant relationships from a structured knowledge graph. To improve recommendation performance, the knowledge-based recommender dialogue system (KBRD) uses the triples in the knowledge graph as input to the encoder along with the dialogue. To give full play to the unique advantages of Graph Neural Networks (GNN) [28, 29] in extracting graph structure data, some knowledge-based CRSs employ the graph convolutional neural network(GCN), the relation-graph convolutional neural network (R-GCN) [30, 31] and the Graph Attention Network (GAT) to learn graph information. In the interactive scene, the machine generates various read- able statements, which can bring users a better experience. Neural Templates for Recommender Dialogue System (NTRD) draws on traditional “slot filling” mechanisms and modern natural language generation techniques, enabling the system to generate text in a controllable manner like the Question Answering(QA) model [32, 33], and generate natural and fluent language like the KG based Semantic Fusion approach (KGSF).
However, these existing methods suffer from two issues. First of all, the CRSs based on knowledge graphs utilize graph neural networks to aggregate the feature information of nodes in the graph. Never the less, GNNs have two drawbacks. Firstly, they are not sensitive to node location information. They forget to consider node location information, whether GCN or GAT. It is worth noting that nearby nodes have similar location features, while more distant nodes have different location features. Secondly, they ignore the global connectivity of the graph. GCNs, in particular, assign the same weights to neighbors in the same order neighborhood. Furthermore, the attention based models (such as GAT), where attention is a function of local neighborhood connectivity rather than full graph connectivity. What is more, although the CRS based on transformers performs well on Natural Language Understanding (NLU) tasks, its quadratic complexity for the length of the input sequence makes it struggle when dealing with long sequences. Whether the text is complete or not determines whether it is semantically coherent or not, which will have a positive or negative impact on the subsequent Natural Language Understanding (NLU) tasks.
To address these two issues, we notice that graph transformers cleverly consider using location information to enhance the expressiveness of graphs. The GraphTransformer leverages Laplacian eigenvectors for positional encoding for each node in the graph, which naturally generalizes the sinusoidal positional encodings often used in Natural Language Processing (NLP). So it makes sure that each node has unique location information. Since graphstructured data is not sequence data, it selects batch normalization instead of layer normalization, which improves the model’s training speed and generalization ability. In addition, we also observe that the additive attention mechanism used in FastTransformer solves the problem that the number of parameters of a traditional transformer increases as the input sequence grows, which cannot be ignored for text modelling. Instead of modelling the pair wise interactions between tokens, additive attention mechanisms are used to model global contexts, and then each token representation is trans formed based on its interaction with the global context representation.
In this paper, we propose a novel model called the additive positional conversational recommender model (APCR). APCR is a neural method that generates responses incorporating recommended items via a position-aware knowledge graph. With slotfilling technology, items are inserted exactly where they fit in the sentence. The item recommender chooses the highestranked item for the slot and uses a Graph Transformer to incorporate external knowledge into the conversation. Our model is deployed in an end-to-end manner. The APCR has both the controllability of traditional slotfilling models and the flexibility of neural language models. In addition, our model takes into account the inefficiency of text modelling caused by the quadratic complexity of the input sequence when the transformer is dealing with long sequences. It converts a quadratic dot product operation to a linear sum operation. The advantage of the APCR model is that it reduces the high computational complexity of the traditional transformer while maximizing the memorization of the dependencies of each part of the sentence.
To sum up, the major contributions of this work are as follows: We developed a machine generates various read able statements in the interactive scene, which can given transformer model for graphs and adds location information to node features, thereby converting local attention to global attention, effectively alleviating the limited receptive field. We design an encoder-decoder network that integrates Fast former and Transformer to improve the long-text modelling efficiency of Transformer and save computational overhead in the processing of long sequences. We conduct extensive experiments on the redial dataset to evaluate comparatively, demonstrating that our proposed method outperforms state-of-the-art methods.
The remaining sections of this paper are structured as follows: Firstly, in the related work section, we introduce the dialogue systems and conversational recommendation systems that are relevant to this work. Secondly, in Section 3, we describe the organizational structure of the model and discuss the training cost. Then, in Section 4, we provide a brief overview of the experimental setup and analyze the performance of the model, as well as its strengths and weaknesses, based on experimental data. In addition, we analyze the computational complexity of the model and its online deployment. Finally, in the conclusion section, we summarize our work.
Related work
In this section, we first introduce the related work on task-oriented dialogue systems. Then we review the existing literature on attribute-based CRS. Finally, we will review the development of chit-chat-based CRS.
Task-oriented dialogue systems
The task-oriented dialogue system is designed to accurately process user information and assist users in completing tasks such as reservation and purchase.
Therefore, a task-oriented dialogue system can be implemented in a pipeline and end-to-end manner. This section will focus on reviewing deep learning based task-based dialogue systems. For example, Lei et al. [1] proposed a novel, holistic, extendable framework based on a single sequence-to-sequence (seq2seq) model to reduce systems’ architectural complexity and reinforce dialogue systems’ fragile. Subsequently, Wu et al. [2] leveraged the copy mechanism to generate dialogue states from utterances. In addition, benefiting from the pre-train language model, Budzianowski and Vulic [3] utilized the Generative Pre-Training(GPT) [27] to solve the data scarcity problem of task-oriented dialogue systems in multi-topic scenarios. As researchers show increasing interest in personalization research on task-oriented dialogue systems, Pei et al. [4] designed a cooperative memory net work (CoMemNN) with a novel mechanism to gradually enrich user profiles as dialogues progress and to improve response selection based on the enriched profiles simultaneously. To make better use of con text and effectively solve the long-term dependency problem, Qun et al. [5] combined bidirectional LSTM and self attention mechanism and propose an end-to-end dialogue model bidirectional LSTM and self attention mechanism net(B&Anet). Although the task oriented dialogue system has good performance in specific tasks, it needs to be more competent in the task of capturing users’ short term preferences in the task of recommending items. Hence, researchers turn their attention to dialogue recommendation systems.
Attribute-based CRS
The attribute-based dialogue recommendation system is more built for the policy module, hoping to achieve the most accurate recommendation in the shortest number of conversations. Attribute-based CRS use a fixed template with slots to populate recommended results. In recent years, some researchers have achieved success in recommendation strategies. For example, Different from capturing users’ interest in items, the question based recommendation method (Qrec) [9] utilized a novel matrix factorization to perceive user preferences for item features. This method not only outperforms traditional matrix factorization but also increases interpretability. Li et al. [10] proposed the conversational Thompson sampling model (ConTS), which modeled recommendation action heterogeneity by seamlessly unifying at tributes and items and Sampson sampling in the same arm space. To learn the profiles of potential users, a knowledge based model, the knowledge based question generation system (KBQG) [11] leveraged structured knowledge graphs to improve the modelling granularity of user preferences. Different types of feedback information (e.g., attribute level and item level) are usually treated; equally, Xu et al. [12] designed two gating modules, respectively, to adapt the original user embedding and item level feedback. Al though these works have succeeded, templated responses are limited in linguistic diversity. In the actual user experience, the user experience is not good. In order to solve these problems, many researchers concentrate on the chit-chat-based CRS, which uses a generative language model to solve the problem of a single sentence and poor flexibility.
Chit-chat-based CRS
In recent years, researchers have actively explored the introduction of external knowledge and user preference modeling in chit-chat-based CRS. Knowledge graphs dominate the coverage of specific types of knowledge and the structured process of knowledge. Chen et al. [13] pioneered the addition of knowledge graphs to a chit-chat-based CRS. The model introduces use rrelevant information to improve recommendation performance and improves dialogue generation quality by sensing lexical bias. Yu et al. [14] proposed using semantic fusion to bridge the semantic gap between natural language expressions and item level user preferences and employ mutual information to maximize the alignment of word level and entity level semantic spaces. Hu et al. [15] combined the slot filling method and neural natural language generation technology to make the recommendation item accurately embedded in the correct position of the re ply to improve the readability of the sentence. How ever, these methods need to pay more attention to users’ important role in the overall system. Li et al. [16] proposed a User Centric Conversational Recommendation (UCCR) model, which used historical conversational learners to perceive user preferences from knowledge, semantics, etc. Ren et al. [17] leveraged an end-to-end variational inference approach to accomplish the task of conversational recommendation. Liang et al. [18] proposed the framework of learning Neural Templates for Recommender Dialogue system (NTRD), which combines the widely used slot filling method with deep learning-based natural language generation.
Together, these works leverage knowledge graphs to model items and user interests. The node distribution of the knowledge graph has aggregation and symmetry, and the location characteristics of nodes cannot be perceived through the adjacency matrix and the degree matrix. When the topological order of the graph is essential and not encoded into the node features, the inductive bias of the connectivity of the graph is not considered, resulting in poor performance. By adding the location embedding to the node embedding, the model can perceive important spatial information, and during aggregation, nodes with similar locations will be aggregated. Furthermore, we use an additive attention mechanism to encode the dialogue context, which can solve the performance bottleneck caused by the quadratic time complexity characteristic of the Trans former when the sequence length increases.
The proposed model: APCR
In this section, we present our framework APCR. It integrates an additive attention mechanism and a graph transformer. We will first illustrate how the additive attention mechanism encodes the dialogue con text. We then demonstrate how to process knowledge graphs with the Graph Transformer and how to build a response generation module. Finally, we describe the training objectives and the testing process. The architecture of APCR is as Fig. 1.
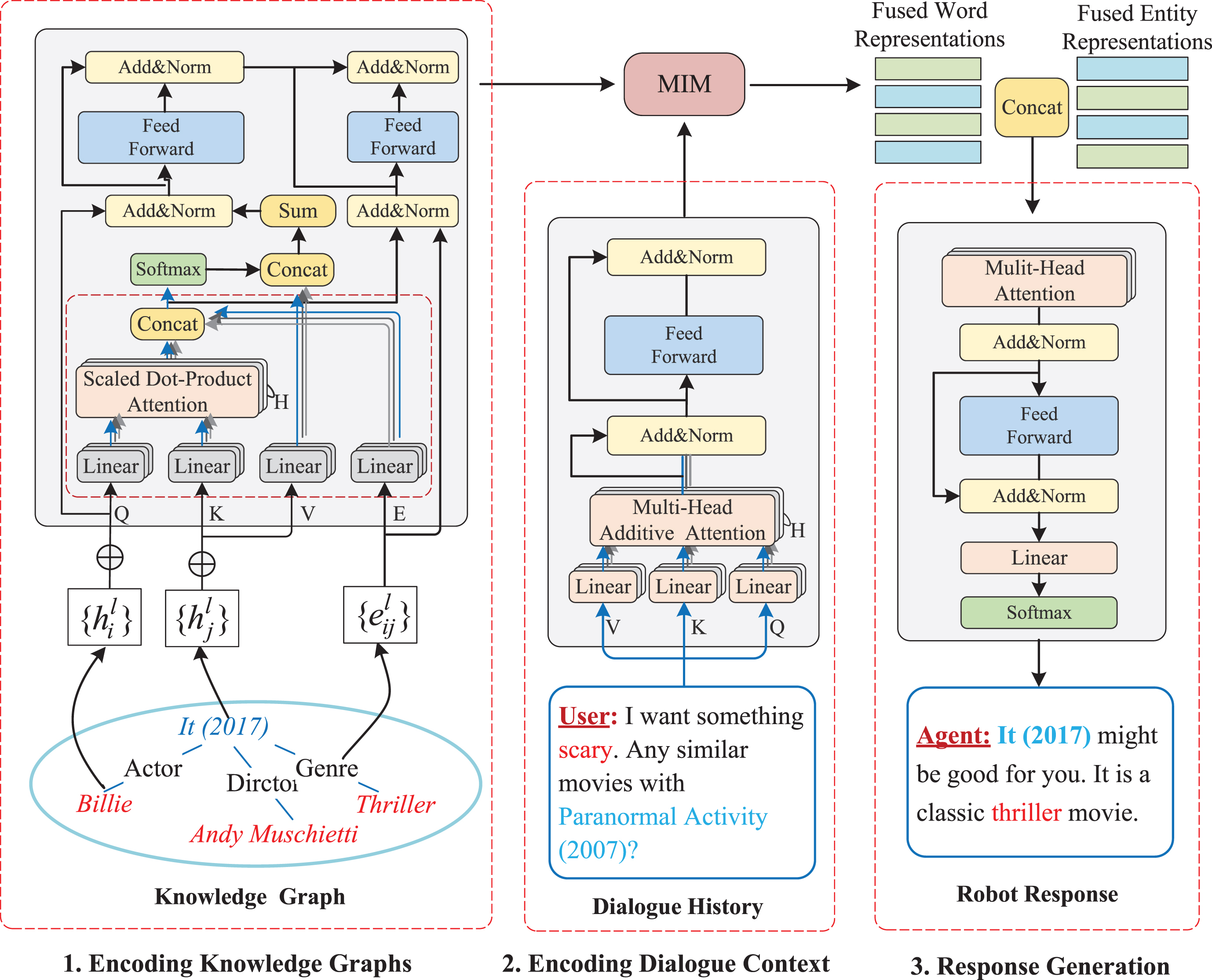
The proposed APCR model consists of three components. The upper part of the graph is an additive attention based encoder module, which uses an additive attention mechanism to learn historical dialogue information. The bottom half of the graph is the positionaware GNNbased recommender module, which is used to match items and contexts. These two parts present the recommended results to users through the templated response module.
To obtain the global context vector, we utilize trans formers as the model’s backbone. Specifically, we consider a dialogue as a sequence of n utterances D = {U1, U2,..., U
n
}, and each U
n
Next, the key to modelling the Transformer class architecture is the interaction between queries, keys, and values to model the contextual information of the input sequence. This is a commonly used method to model the interaction between query and key by the scaled attention mechanism. Unfortunately, as the input sequence grows, the quadratic complexity of the dot product between the query and the key reduces the performance of the transformer model. The additive attention mechanism neatly solves this problem. Specifically, additive attention is used to summarize the query into a global query vector
We use the element wise product between the global query vector and each key vector to model their interactions and combine them into a global context aware key matrix.
The inner product is then applied to the sub-vectors of the global query vector and the key vector. The sub-vectors obtained by each operation are arranged in rows to form the global context-aware key vector. In a similar way, we apply the additive attention mechanism to get the global key matrix. The additive attention weight of its i-th vector is computed as follows:
Afterwards, similar to the query-key interaction modelling, we also leverage the inner dot product to aggregate the global key and attention value. We use u = {u1, u2,..., u
n
} to denote key-value interaction vectors. To learn its hidden states, we perform a linear transformation on key-value interaction vectors. Finally, we add the original attention query and the global context-aware attention value to form the final output. The output matrix is denoted as
To enhance the representation of contextual semantic information, we utilize the graph neural network to model the external knowledge graph. Concretely, we follow [19] to leverage the widely used ConceptNet [20]. It is a large-scale multilingual semantic graph that depicts general human knowledge in natural language. ConceptNet stores a semantic triple as <w1, r, w2>, where w 1 ,w 2
The Graph Transformer is closely the same trans former architecture initially proposed in [21]. We now proceed to define the node update equations for a layer l.
Where
The encoder-decoder framework we develop here is based on the transformer, allowing us to generate a reply utterance in CRS. As we have already established, our encoder is a standard Transformer architec ture. Here we will focus on the decoder.
Given the context c and the knowledge graph g, we use the transformer and the graph transformer as en coders to input c and g into the network, respectively. The context embedding E(c) and graph embedding E(g) are obtained:
As explained previously, information is progressively introduced into the decoding step, beginning with the original context and progressing to related entity information in KG. The generation is finished by processing the decoder output S
t
through a softmax operation to foretell the token distribution. Given the predicted subsequence y1,. . .y
i
–1, The following to ken’s generation probability y
i
can be calculated as follows:
While the conventional framework typically consists of two stages, it is possible to train the two modules simultaneously in an end-to-end manner.
While the loss function for the item selector is calculated as:
We combine the template generation loss and the slot selecting loss as:
Where λ is a weighted hyperparameter.
In this subsection, we analyze the actual training cost of our proposed APCR model in terms of hard ware requirements, data acquisition, and training time. Specifically, APCR was trained for 30 epochs on an NVIDIA GeForce RTX 3090 24G graphics card, taking approximately 24 hours to complete. Additionally, we employed mutual information maximization techniques to align the semantic space of entity embed dings and word embeddings during the pre-training phase for three epochs. The movie dialogue dataset Redial, the movie knowledge graph DBpedia, and the common sense knowledge graph ConceptNet can all be obtained through online network resources.
Experiment
In this section, we conducted extensive experiments aimed at answering the following research questions:
Experimental settings
Datasets
A popular dataset of real-world dialogues about offering movie suggestions is called REDIAL [6]. It is automatically collected and constructed by Amazon Mechanical Turk (AMT). In REDIAL, there are 10,021 talks about 64,362 movies that are divided into training, validation, and test sets in an 8 : 1:1 ratio.
Evaluation protocols
Our APCR method is composed of a language generation module and a recommendation module, so we use BLEU n-gram, Recall, Distinct n-gram and Perplexity as evaluation metrics to evaluate the performance of our model.
Baselines
The baselines for the experiment are illustrated in the following:
Training setups
The models are implemented in PyTorch and trained on one NIVIDA GeForce 3090 Ti card. We utilize Deep Graph Library (DGL) to construct the graph from the edges set and assign features to each node and edge separately. The item’s embedding size and the node’s positional embedding size are set to 300 and 25, respectively. The maximum lengths of context and response are set to 256 and 30. For GraphTransformer, all hidden sizes are set to 128. We set the number of layers of the network to 1 and the number of heads to 2. During the training, the batch size is 128. Following KGSF’s practice, we leverage MIM loss to pretrain the knowledge graph for 3 epochs. We select Adam optimizer. The learning rate is 0.0005.
Experiment results
Experiment results and analysis (RQ1)
For the recommendation task, we adopt Recall@k-(k = 1,10,50) for evaluation. Table 1. shows the performance of our APCR method with other methods on the REDIAL dataset. As seen in the results reported in Table 1, our approach obtains 3.85% Recall@1, 18.36% Recall@10, and 36.62% Recall@50, which is the state of the art performance and surpasses all competitive baselines. Specifically, our method APCR improves Recall@1 by 57.1%, 23.4%, 0.5%, and 30.5% compared with Redial, KBRD, KGSF, and NTRD methods, respectively. For Recall@10, our approach outperforms all competitors and improves 29.2%, 18.8%, 4.7% and 21.9%. For Recall@50, our method APCR achieves the best result of 0.3662 in all conversational recommendation models. In comparison to NTRD, APCR makes significant improvements by increasing by approximately10%. This shows that the integration network in NTRD is unable to accurately generate appropriate responses with recalled items. It doesn’t match the gist of a chit-chat-based conversational recommendation system, which utilises natural language to provide users with accurate product recommendations. According to our observation, a strucured knowledge graph is helpful for entity representation, but by introducing location information into the knowledge graph can help the graph neural network to perceive global information (i.e., the attention score is not a location attention score but a global attention score obtained from the Laplacian matrix). It proves that incorporating positional features is a beneficial way to enhance the performance of the CRS. However, using Laplacian eigenmaps as node position representations can lead to the following issues. Firstly, the process of computing Laplacian eigenmaps involves eigenvalue decomposition of the entire graph, which is computationally expensive and resource intensive, especially for large scale graphs. Therefore, using Laplacian eigenmaps as node position representations for large scale graphs may face efficiency challenges. Secondly, Laplacian eigenmaps are computed based on the static structure of the graph, making them unable to adapt well to the temporal changes in dynamic graphs. This limitation can result in inaccurate node position representations for dynamic graphs. Lastly, Laplacian eigenvectors are derived from the structural properties of the graph and do not have direct semantic meaning. Consequently, they may not effectively capture the semantic information of nodes, limiting their suitability as node positional representations.
Results on the recommendation task. Best results are in bold
Results on the recommendation task. Best results are in bold
Table 2 reports the automatic evaluation results of models on the dialogue generation task on the RE DIAL dataset. We can notice that our APCR is obviously better on most automatic metrics compared to baseline models. As we can see, all of the Dist n scores are significantly higher when compared to NTRD, specifically + 0.016 for Dist2, + 0.382 for Dist 3 and+0.562 for Dist4, demonstrating that our approach is excellent at generating diverse utterances. Besides, our method APCR achieves the third best score of 9.91 on the PPL. The lower PPL score means more fluent responses. Regarding the model not per forming well on PPL, we infer that using additive attention to compress the query matrix and the key matrix into the global query vector and the global key vector is not well modelled context information in the approximation. But on the other hand, additive attention effectively reduces the time complexity of the encoder based on the transformer structure, breaking through the bottleneck of the transformer in processing long texts. However, there are some limitations in the interaction between the global query and key vectors in the additive attention mechanism. Summing the query vectors of different parts of a sentence to compute the global query vector ignores the temporal information of the sentence, as the position information of different parts of the query vectors in the sentence is unique. In contrast to using inner product to model the interaction, the global query vector blends the position information together, which can be questionable.
Results on the conversation task. Best results are in bold
We build an ablation study based on two variants of our complete model to show the contributions of each component to the conversation task and the recommendation task: APCR(GT) by removing the Graph Transformer from the recommendation module and APCR(FT) by removing the additive attention mechanism from the transformer encoder. As shown in Table 3, we can observe that the performance degrades after removing the Graph Transformer. It is because once it was removed, the model couldn’t perceive distance aware information(i.e., Nearby nodes have similar positional characteristics, while further nodes have dissimilar positional characteristics). Besides, as illustrated in Table 4, the additive attention mechanism seems to play an important role in the utterances’ diversity. One of the possible explanations is that better interaction with the global query vector is modeled by element wise product, as is the interaction of the global key vector with the value matrix. In conclusion, it shows that two components help improve the performance of the conversational recommender system.
Ablation study on the recommendation task
Ablation study on the recommendation task
Ablation study on the conversation task
Figures 3 and 4 show the performance of our method APCR with the different dimensions of positional embedding ranging from 1 to 30 and the number of heads ranging from 1 to 25, respectively. We can observe that when the dimension of the positional embedding is changed from 1 to 5, all Recall metrics increase dramatically, indicating that adding location in formation to feature information is a viable method for improving the model’s recommendation performance.
However, when the dimensions expand, all Recalls appear to fluctuate with a narrow range. We speculate that since the information carried by the location is limited, mapping the location to a high-latitude space may no longer have an effect on the feature representation in one or several dimensions. From Fig. 3. It is not difficult to find that different attention heads will have an impact on Dist, which shows that compared with single heads, each attention mechanism of multiple heads optimizes different feature parts of each word, so as to balance the possible deviations of the same attention mechanism, so that the semantic of the word may have more diverse expressions. Some polysemous words will affect the expression of the sentence as a whole. The results show that the combination of the additive attention mechanism and multi head attention mechanism is an effective scheme to re duce algorithm complexity and improve the diversity of generated sentences.
The complexity analysis (RQ3)
In this section, we will provide a detailed explanation of the time and memory consumption of the additive attention networks. Specifically, the learning cost for the global query and key vectors in the additive attention mechanism is O (N · d). Compared to the exponential time complexity of the traditional attention mechanism, the additive attention mechanism is more efficient. Similarly, the parameters of the two attention networks will not be of the same order of magnitude. Additionally, in the transformer-based graph neural network with positional encoding, the learning cost between the main node and other nodes is O (hd2), and the computational cost of the decoder is also O (hd2). Therefore, the computational complexity of the proposed model is O (hd2).
The global attention analysis
Designing unique node positions in graphs is difficult due to symmetries that preclude canonical node positional information. Therefore, for example, graph neural networks such as GCN, GAT, etc., learn on the knowledge graph just to aggregate the features of nodes in the first order domain of the host node, and the attention in GAT is local attention, not global attention. Luckily, In recent GNN efforts, the problem of positional embeddings has been with the aim of learning positional features. Specifically, [24] pre-compute Laplacian eigenvectors and use them as nodes’ positional information by making use of the graph structure. The calculation of Laplacian eigenvectors are as follows:
For encoding knowledge graphs, TransE, TransR are the usually used methods. TransE is an effective knowledge graph embedding technology, which embeds entities and relationships in the knowledge graph into the continuous vector space. However, the vector representation ability of the TransE is relatively weak. It only represents the association between entities and relationships through simple vector offsets, ignoring more complex semantic and grammatical fea tures. TransR distinguishes between entity space and relationship space based on TransE, but under the same relationship r, the head and tail entities share the same projection matrix. However, the types or attributes of the head and tail entities in a relationship may differ significantly. GraphTransformer utilizes the same se mantic space to represent both the head and tail entities. Transformer has strong representation ability and can fully represent the semantic information of words in high latitude space. In addition, it also considers embedding relationships as edge features, and integrating Laplacian feature vectors as position information into nodes to perceive the spatial features of the knowledge graph.
To demonstrate how our model actually operates, as seen in Fig. 2. For straightforward reading, we highlight all the mentioned items in red and the user preferences in blue. The conversation begins with pleasantries between the user (seeker) and the recommender(robot), who proactively inquire about the user’s preferences by inquiring what sort of movies the user enjoys. The recommenders offer a few potential movie choices because the user prefers explicitly “romantic” movies. The recommender based on the graph transformer utilizes global attention to give different attention weights to adjacent and adjacent nodes. It realizes the interaction between the host node and all other nodes through the inner product between the node feature matrices.

A sampler case between a real user as a seeker, and the dialogue agents(APCR) as recommenders. Items mentioned are marked in the red color, while the user preferences in user’s turn are marked in the blue color.

Performance (i.e., Dist-2, Dist-3 and Dist-4) of the conversational recommendation method with respect to the different number of head.
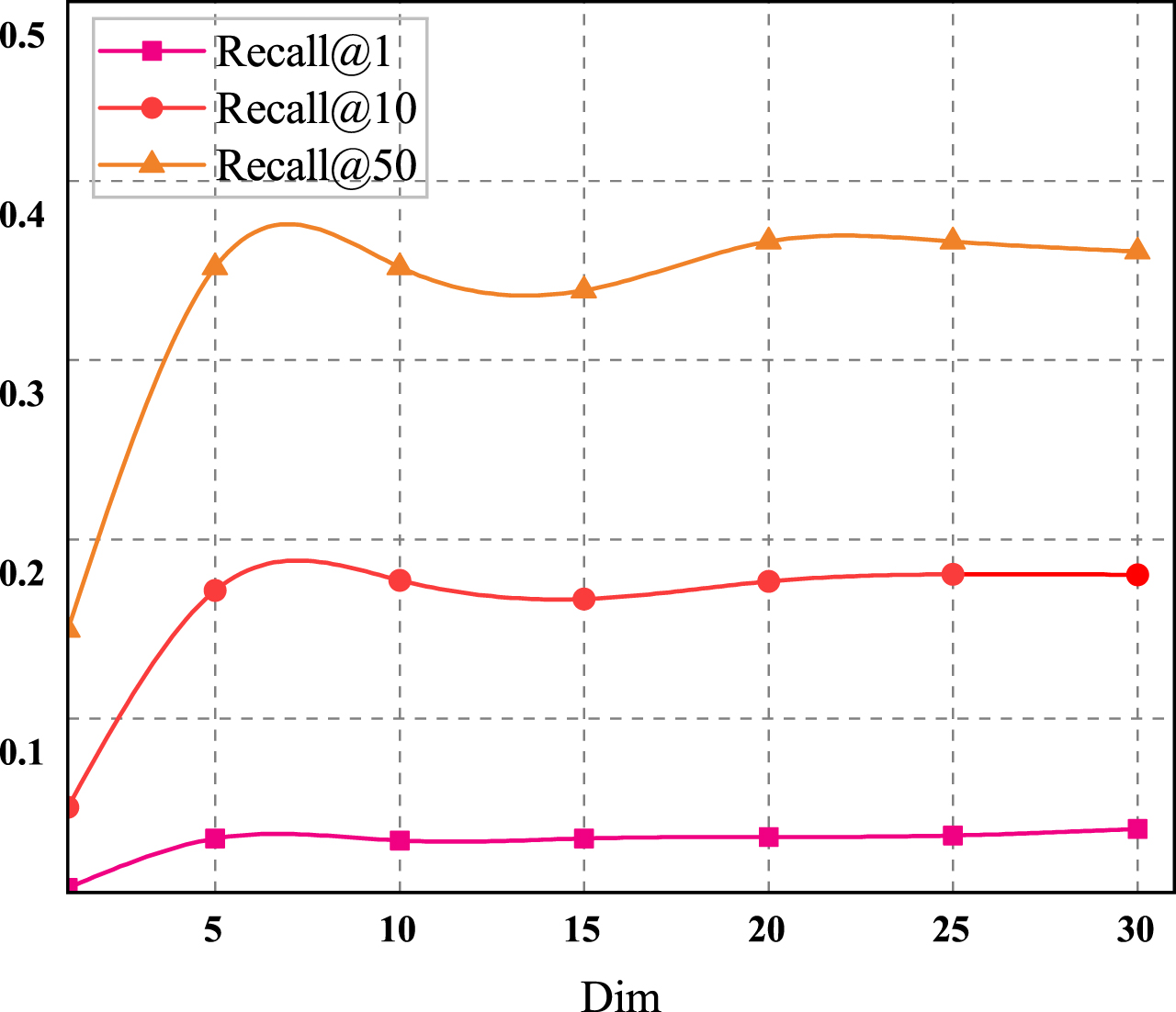
Performance (i.e., Recall@1, Recall@10 and Recall@50) of the conversational recommendation method with respect to the different number of dimension of positional emedding.
The real-time capability of a conversational recommendation system depends on several factors, including the volume of data, computational resources, and algorithm complexity. In certain scenarios, a conversational recommendation system can be implemented in real-time or near real-time to meet the users’ im mediate needs. For instance, when the system deals with relatively small amounts of data and employs simple algorithm designs, real-time performance can be achieved through fast data processing and real time recommendation algorithms. However, real-time performance may face challenges when dealing with large-scale conversation data and complex recommendation algorithms. Processing large-scale datasets may require more computational resources and time, while complex recommendation algorithms may involve additional computational and optimization steps. Furthermore, the real-time capability also depends on the overall system architecture and the supporting infrastructure. Therefore, the ability to achieve real-time or near real-time performance in a conversational recommendation system is determined by the specific application scenario and system design. Through appropriate algorithm optimizations, allocation of computational resources, and thoughtful system architecture, real-time or near real-time conversational recommendation services can be achieved.
Conclusion
In this paper, we develop a conversational recommender system based on additive attention and graph transformer. We design an additive attention model, which helps CRS learn correlations between memories and alleviates long-term dependency. Moreover, we develop a recommendation model based on a graph transformer to match items with dialogue context, thereby transforming local attention into global attention. Extensive experiments on the travel dialogue dataset show that our APCR method outperforms other state-of-the-art methods in both the evaluations of recommendation and dialogue generation.