
Abstract
The investigation on brain magnetic resonance imaging (MRI) of cerebral small vessel disease (CSVD) classification algorithm based on deep learning is particularly important in medical image analyses and has not been reported. This paper proposes an MRI classification algorithm based on convolutional neural network (MRINet), for accurately classifying CSVD and improving the classification performance. The working method includes five main stages: fabricating dataset, designing network model, configuring the training options, training model and testing performance. The actual training and testing datasets of MRI of CSVD are fabricated, the MRINet model is designed for extracting more detailedly features, a smooth categorical-cross-entropy loss function and Adam optimization algorithm are adopted, and the appropriate training parameters are set. The network model is trained and tested in the fabricated datasets, and the classification performance of CSVD is fully investigated. Experimental results show that the loss and accuracy curves demonstrate the better classification performance in the training process. The confusion matrices confirm that the designed network model demonstrates the better classification results, especially for luminal infarction. The average classification accuracy of MRINet is up to 80.95% when classifying MRI of CSVD, which demonstrates the superior classification performance over others. This work provides a sound experimental foundation for further improving the classification accuracy and enhancing the actual application in medical image analyses.
Keywords
Introduction
With the rapid development of medical imaging technology in recent years, it has become an indispensable tool for classifying various diseases [1, 2]. Because of its noninvasive, cheap and convenient characteristics, magnetic resonance imaging (MRI) is widely used in various medical image analyses, which help the doctors evaluate and diagnose the abnormal symptoms in the early stage, such as, cancer, tumor and osteonecrosis [3]. Moreover, MRI is also the preferred imaging tool for diagnosing the brain diseases, which can early detect the potential brain diseases, such as, cerebral small vessel disease (CSVD), and get timely treatment for the patients. In recent years, the incidence rates of CSVD and lesion have been increasing significantly, and it is a long and complicated process to diagnose the diseases in the clinic.
Deep learning, as an important branch of machine learning and possesses its powerful feature extraction and learning ability, has made significant progress in the fields of medical image segmentation [4, 5], image detection [6, 7], image generation and enhancement [8], image registration [9], computer-aided diagnosis and prognosis [10, 11]. Many researches have been carried out early disease detection and diagnosis based on deep learning [12–14]. Litjens et al. [15] applied deep convolution neural network to medical image analyses, which played an important role in breast cancer [16, 17], tumor screening [18, 19], lung nodule classification [20, 21], diagnosis of congenital heart disease [22, 23], and brain image classification [24–26]. Sriporn et al. [27] classified the lung disease based on convolutional neural network, and the accuracy rate was up to 98.97%. Gao et al. [28] constructed a convolutional neural network to segment and identify brain tumors, and the algorithm model has certain validity. Because the brain image contains a lot of noise and the resolution is relatively low compared with the images of liver and gallbladder, it is difficult to extract the relevant features, resulting in the low classification accuracy. Therefore, it is very important to extract the features with high resolution in the brain image, so as to early screen the brain diseases and improve the classification performance.
In order to help the doctors early find the abnormal symptoms in the brain of patients and reduce the variability of manual diagnosis, some scholars have proposed a number of automatic classification methods for medical images. Tang et al. [29] proposed a new classification method for CT pathological image analyses of brain and chest to extract image features and classify types. Talo et al. [30] proposed an approach ResNet34 that used deep transfer learning to automatically classify normal and abnormal brain MRI, and achieved 5-fold classification accuracy of 100% on 613 MRI. Swati et al. [31] used the pre-trained deep CNN model and proposed a block-wise fine-tuning strategy based on transfer learning, which can achieve the average accuracy of 94.82% under five-fold cross-validation. The proposed method outperformed state-of-the-art classification on the contrast-enhanced magnetic resonance images (CE-MRI) dataset. Li et al. [32] proposed a brain MRI classification algorithm combined with transfer learning and support vector machine (SVM), and the classification accuracy can achieve 100%, and the classification time was only 26 seconds. Kang et al. [33] proposed a method for brain tumor classification using an ensemble of deep features and machine learning classifiers. The experimental results demonstrated that an ensemble of deep features can improve the classification performance significantly, and SVM with radial basis function (RBF) kernel outperformed other machine learning classifiers, especially for large datasets. Fu et al. [34] proposed a classification method by analyzing a full slice of brain CT images, and F1 score can reach to 92.62% and 86.50% on two public datasets CQ500 and RSNA, respectively.
As can be seen from the above review, some improved methods based on deep learning to classify a number of diseases in medical image analyses have been proposed. However, to the best of our knowledge, the investigation on MRI feature of CSVD classification method based on deep learning has not been documented in the open literature to date, and the exact pathological mechanism is still unclear. It is particularly important to classify three types of brain MRI of white matter hyperintensity (WMH), lacunar infarction and normal, for investigating CSVD and improving the classification performance.
Therefore, this paper proposes an MRI feature of CSVD classification algorithm (MRINet) based on CNN, for improving the classification accuracy. The contributions of this paper are as follows: (1) the pre-processing brain MRI data are actually obtained by the radiologists, and the actual training and testing datasets are fabricated; (2) the MRINet model to extract the features of brain MRI is designed; (3) the transfer learning, Adam optimization algorithm and smooth cross-entropy loss function are adopted for improving the classification performance; (4) the average classification accuracy of the proposed network model is up to 80.95%, which provides an important foundation for further improving the classification accuracy in medical image analyses.
The structure of this paper is organized as follows: the overall framework of the CSVD classification algorithm MRINet is designed in Section 2, which consists of brain MRI data pre-processing, features extraction, and brain MRI classification. Wherein, Pre-processing brain MRI data are obtained, and the actual training and testing datasets are fabricated, MRINet model for classifying MRI features of CSVD is designed, and the transfer learning, Adam optimization algorithm and smooth cross-entropy loss function are adopted. The classification performance of the proposed model is fully investigated by the experiment in Section 3. The conclusions of this work are drawn in Section 4.
Materials and methods
To improve the classification accuracy of brain MRI of CSVD and enhance the robustness, a novel brain MRI features classification approach (MRINet) based on CNN is proposed in this paper. The proposed system framework for brain MRI features classification is illustrated in Fig. 1. The classification system framework mainly consists of brain MRI data pre-processing, features extraction, and brain MRI classification.

System framework based on CNN for brain MRI classification.
As can be known from Fig. 1 that the brain MRI is actually obtained by the radiologists, and expanded by the data augmentation technology in the first part. Using data augmentation technology can improve the generalization ability of the network model by increasing the amount of training dataset. Moreover, noise data are added to improve the robustness of the model. The training and testing datasets are fabricated by pre-processing brain MRI. In the second part, the MRINet model is proposed for features extraction and type classification of brain MRI of CSVD. In order to accelerate and optimize the learning efficiency of the proposed model that without learning from scratch as before, the transfer learning and Adam optimization are employed to share the learned parameters with the proposed model. The VGG is first pre-training by using ImageNet, and the obtained pre-training parameters are saved. Then, the fabricated training dataset is input into the designed MRINet model to extract brain MRI features by means of using the pre-training parameters. The extracted features are eventually sent into the Softmax classifier, and three types of brain MRI of CSVD classification results can be obtained accurately.
Since there is no public brain MRI dataset, we build our own brain MRI of CSVD dataset for training and testing the proposed network model. The dataset comes from the fourth affiliated hospital of Harbin Medical University, including WMH, luminal infarction and normal, and each image is accurately screened by the radiologists. The number of MRI is 2772, which is not enough to train the network model and not obtained the better classification performance. In order to ensure the convergence of the proposed MRINet in the training process, data augmentation technology is used in the paper for expanding the training dataset. It can reduce the risk of overfitting and improve the generalization performance of the model. According to the reference [35, 36], the rotation, shift, zoom and shear values are set as 30, 0.1, 0.1 and 0.1, respectively. The horizontal flip method is also used to reduce the overfitting phenomenon caused by the insufficient dataset. Because the data augmentation parameters for each batch of training samples are randomly sampled, each batch of samples after data augmentation is different, therefore, theoretically, the number of samples after data augmentation is infinite [36]. Figure 2 illustrates the brain MRI of WMH, luminal infarction and normal after data augmentation.
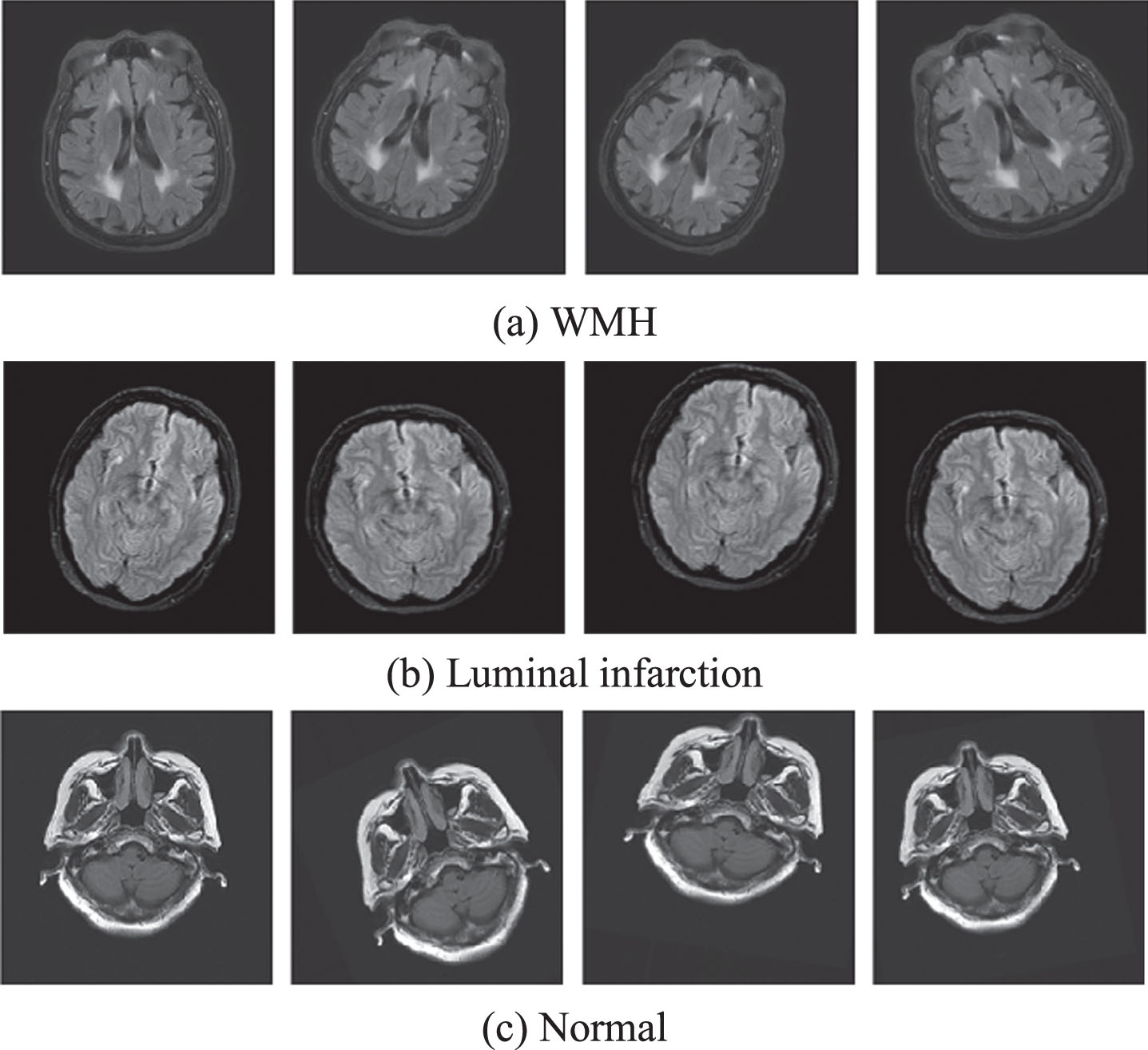
Brain MRI of WMH, luminal infarction and normal after data augmentation.
As can be known from Fig. 2 that WMH refers to the varied size abnormal signals in the white matter region of the brain MRI. Luminal infarction represents a round or ovoid fluid-filled cavity with similar to cerebrospinal fluid located in the subcortical and 3–15 mm in diameter. Adopting the data augmentation, WMH is obtained after rotation, shift, zoom and shear processing in Fig. 2.
Inspired by Simonyan et al. [37], the MRINet model is proposed for extracting brain MRI features of CSVD and classifying the types. In order to speed up and optimize the learning efficiency of the proposed model that without learning from scratch as before, the transfer learning and Adam optimization algorithm are adopted to pre-train and optimize the network parameters.
Figure 3 illustrates the proposed MRINet model, for extracting more detailedly features of brain MRI of CSVD and improving the classification performance. The model is optimized by weighting the classification performance and network parameters, which possesses the competitive advantages in alleviating the vanishing-gradient problem, strengthening the feature propagation, encouraging the feature reuse, extracting the detailed feature, substantially reducing the parameters, and thus improving the recognition performance of brain MRI.
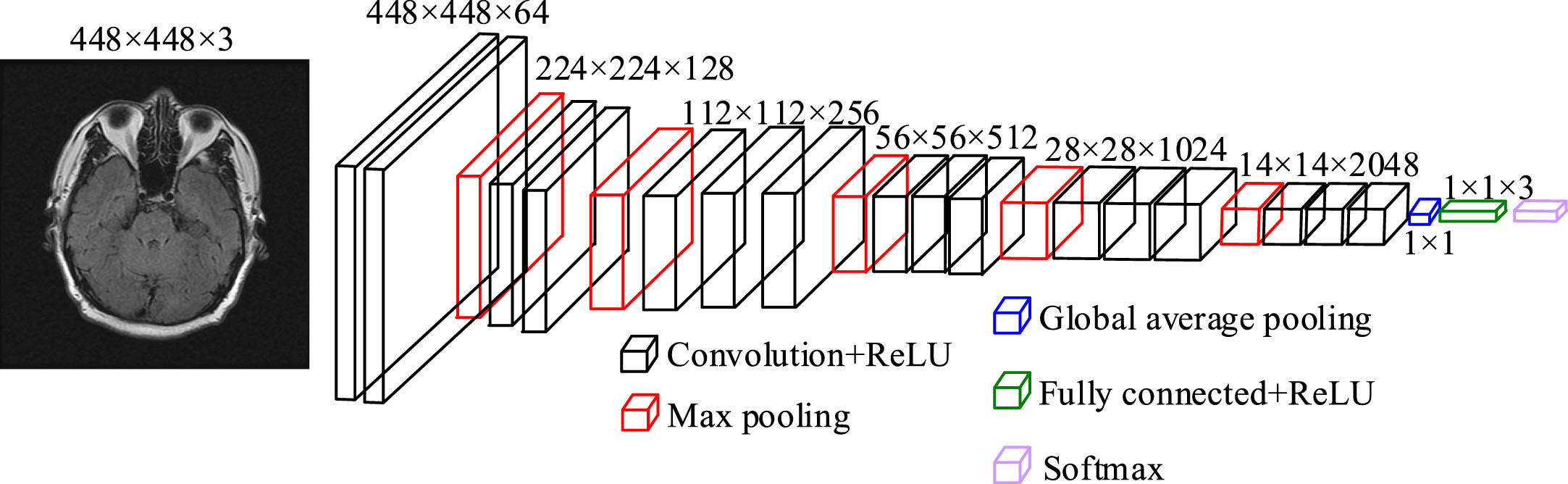
MRINet model framework.
It can be known from Fig. 3 that the proposed MRINet model includes 16 convolutional layers, 17 ReLU layers, 5 max pooling layers, 1 global average pooling layer, 1 fully connected layer and 1 Softmax classifier. The fabricated training dataset is first input into the convolutional layer with the kernel size of 3×3 for features extraction. The extracted features are input into the max pooling layer with the kernel size of 2×2, for reducing the dimension of the feature maps. Therein, the max pooling layer possesses the ability to take full advantage of the learned feature maps and decreasing the unnecessary external noise without using zero padding. Finally, the eventual features are input into the classification layer, which includes a global average pooling layer with a filter size of 1×1, a 3-dimension (3-D) fully connected layer, and a Softmax classifier, for classifying the brain MRI. The detailed parameters of the proposed MRINet are shown in Table 1.
Network parameters of the MRINet
In this paper, the VGG is pre-training on the ImageNet dataset, and the obtained pre-trained parameters are saved to later train the MRINet model in the brain MRI dataset.
Adam optimization algorithm adopts the initialization bias to correct the parameters, which is derived from the second-order moment estimation. Now we initialize the exponential moving mean v0 is equal to zero vector, and the updated exponential moving mean in all the previous time steps can be expressed as follows
In order to understand how the expected value E of the exponential moving mean at time step t is related to the real second moment E[g
t
2], the deviation between the two quantities can be corrected. Expect both the left and right sides of Equation (1) is expressed as follows
If the real second moment E[g t 2] is static, then ζ is equal to 0. Otherwise, ζ keeps a very small value. This is because the exponential decay rate β2 should be chosen, so that the exponential moving average assigns a small weight to the gradient. Therefore, initializing the mean to zero, the (1-β2t) term is only leaved.
Softmax regression model is a generalization of logistic regression model on multi classification problems. In the multi classification problem, the class label y can take more than two values. Suppose the training dataset consists of m labeled samples: (x1, y1), ⋯, (xm, ym). Since this paper focusses on three types of MRI classification, the type label y
i
is set to 0, 1, 2. The function is defined as
If the function could output a k-dimensional vector to represent the k estimated probability values, the function h θ (x) is rewritten as follows
where,
Dataset and parameter settings
By weighting the training convergence and the classification performance, the preprocessed datasets are divided into the training and testing datasets, accounting for 90% and 10%, respectively. The fabricated datasets statistics are listed in Table 2.
Datasets statistics
Datasets statistics
In order to evaluate the classification performance of the MRINet, this paper adopts the commonly used indicator to evaluate quantitatively the experimental results, such as accuracy, which is defined as
where, TP refers to the number of true positive predicted as positive classes, TN is the number of true negative predicted as negative classes, FP refers to the number of false positive predicted as positive classes, FN is the number of false negative predicted as negative classes.
In the experiment of brain MRI classification, the adopted hyper-parameters of the training model include the sample size, iteration step and learning rate. For obtaining the better network parameters and classification performance, the comparative analyses and discussions on the hyper-parameters should be given. The learning rates are adopted for conducting the comparative analyses, and set as 0.01, 0.001, and 0.0001, respectively. Table 3 lists the comparative analyses of classification accuracy for various learning rates.
Classification accuracies for various learning rates
As can be known from Table 3 that when the learning rate is set as 0.001, the classification accuracy, 80.95%, is higher than others. That is because the network model for classifying MRI is not convergent at the learning rate of 0.01. In addition, the network model falls into the point of local minimum at 0.0001. Therefore, the optimum learning rate of 0.001 is obtained.
The optimum hyper-parameters are as follows: the model is trained by mini-batch of samples; the sample size of mini-batch is set as 32; the iteration is set as 30000; the learning rate is set as 0.001. Dropout is adopted for preventing the overfitting, and set as 0.3. All models are implemented on Keras, and trained on the computer with core i9-10900k CPU and two RTX 3090 graphics cards.
To clearly demonstrate the convergence performance of the training network and express the training results of the proposed MRINet model, the loss and accuracy curves of the training process are adopted in this paper, as illustrated in Figs. 4 5.
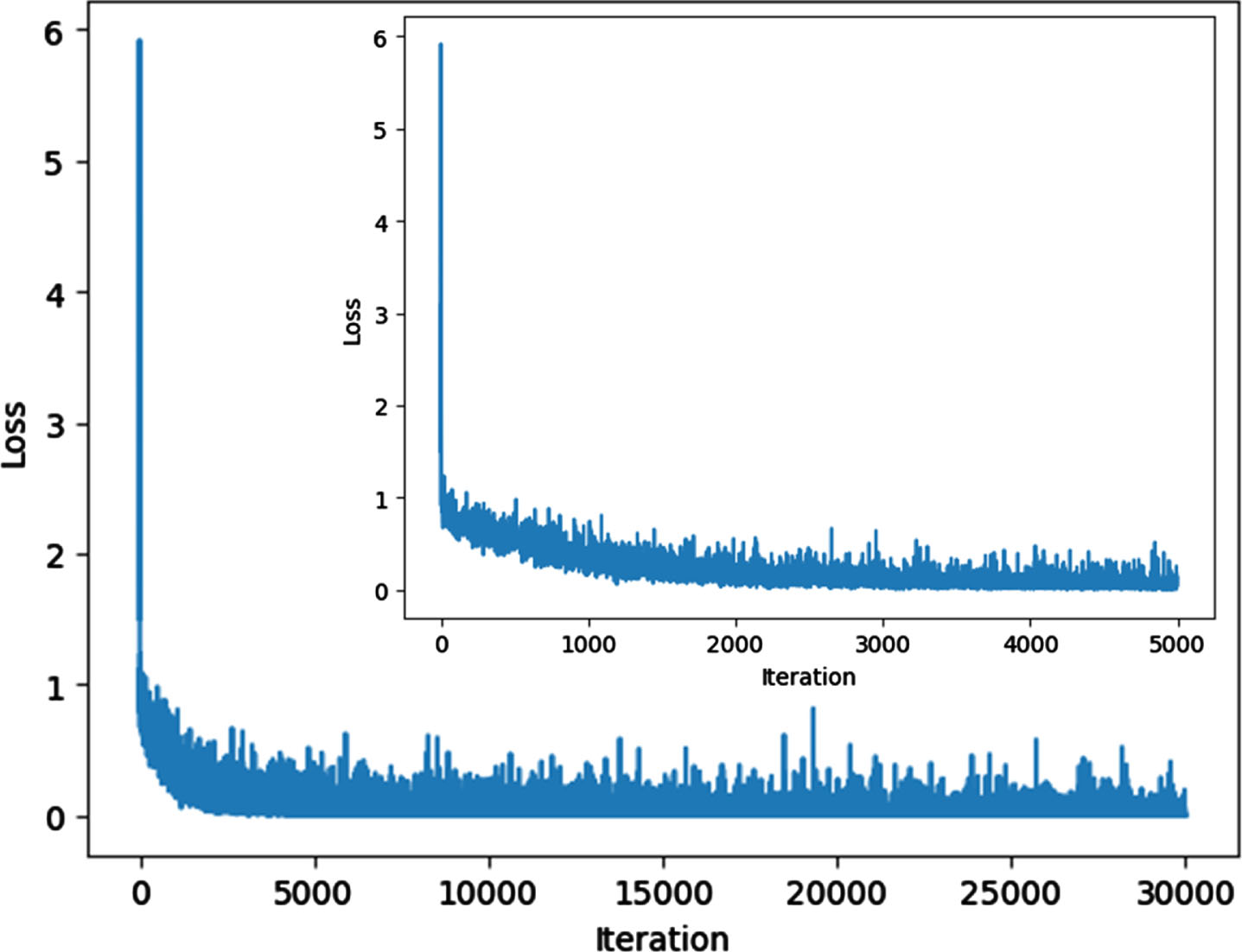
Loss curve of the training process.
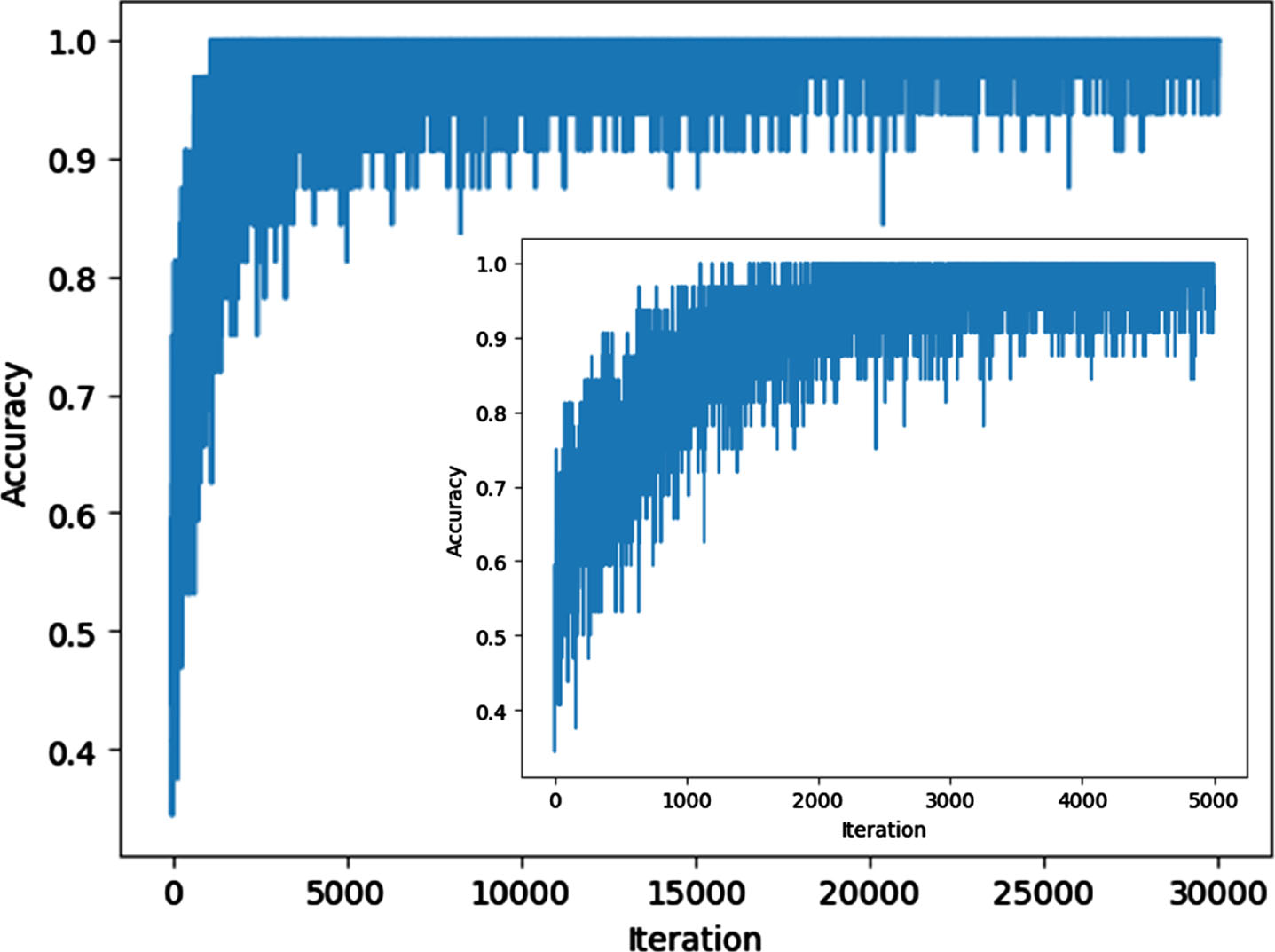
Accuracy curve of the training process.
As can be known from Fig. 4 that an increase of iteration results in the decrease of loss values, and loss values decrease obviously at the lesser iteration, especially less than 100. When the iterations are more than 1500, the loss values little change, and are almost smooth and close to zero. It means that the training tends to converge, and it can obtain the better network parameters and possess the generalization ability.
It is known from Fig. 5 that the accuracy values increase rapidly and then level off with the increase of the iteration. It is worth pointing out that the increase of accuracy values is more obvious in the first one hundred iterations. While, the accuracy value is almost close to one when the iterations are more than 1500. Therefore, the training process demonstrates the excellent results and the MRINet model can obtain the better network parameters.
For clearly demonstrating the classification accuracy and evaluating the proposed model, Fig. 6 illustrates the confusion matrices of experimental results.

Confusion matrices of experimental results.
As illustrating from Fig. 6 that the total number of MRI of WMH is 117, 88 images are correctly classified, 1 image is wrongly identified as normal, and 28 images are incorrectly classified as luminal infarction. It is worth pointing out that WMH is easily misclassified as luminal infarction. For 12 normal MRI, 10 images are correctly classified. Noted that the accuracy of classifying normal MRI is relatively higher. In the 165 luminal infarction MRI, 140 images are correctly classified. It can be known that the luminal infarction is easily misclassified as WMH.
To obtain a better insight of how the MRI classification performance of the proposed MRINet, VGG [37] and residual neural network (ResNet) [38] are adopted for comparative analyses. The comparison results of MRI classification accuracy for different methods are illustrated in Table 4.
Classification accuracies of MRI for different methods
As can be known from Table 4 that the average classification accuracy of the proposed MRINet is 80.95%, which is higher than 70.40% for VGG and 72.59% for ResNet. In addition, for the MRINet model, the classification accuracies of WMH, normal and luminal infarction are up to 75.21%, 83.33% and 84.85%, respectively. Therefore, the proposed method demonstrates the better classification performance over others. This provides an important experimental foundation for improving the classification performance in medical images analyses.
For automatically classifying MRI of CSVD and reducing the misjudgment of manual diagnosis, a brain MRI classification method (MRINet) was proposed. The actual MRI was first acquired, and the training and testing datasets were fabricated. The MRINet model was then designed for extracting more detailedly features. Transfer learning and Adam optimization were adopted for optimizing the network parameters. The experimental investigation on the classification accuracy of MRI was finally conducted in the fabricated datasets. The experimental results shown that the loss and accuracy demonstrated the better results in the training processes. The confusion matrices demonstrated that the proposed model can correctly classify the MRI types of CSVD. The average classification accuracy of the designed network model was up to 80.95%, which demonstrated the superior classification performance over others. This work provided a useful guidance for further improving classification accuracy and enhancing the actual application in brain MRI analyses.
Footnotes
Acknowledgments
This work was financially supported in part by the National Natural Science Foundation of China (Grant No. 61671168 and 61801143), in part by the National Natural Science Foundation of Heilongjiang Province (Grant No. JJ2019LH1760 and LH2020F019), in part by the Aeronautical Science Foundation of China (Grant No. 2019010P6001 and 2019010P6002), and in part by the Fundamental Research Funds for the Central Universities (Grant No. HEUCFJ180801).