
Abstract
Boosting methods are known to increase performance outcomes by using multiple learners connected sequentially. In particular, Adaptive boosting (AdaBoost) has been widely used owing to its comparatively improved predictive results for hard-to-learn samples based on misclassification costs. Each weak learner minimizes the expected risk by assigning high misclassification costs to suspect samples. The performance of AdaBoost depends on the distribution of noise samples because the algorithm tends to overfit noisy samples. Various studies have been conducted to address the noise sensitivity issue. Noise-filtering methods used in AdaBoost remove samples defined as noise based on the degree of misclassification to prevent overfitting to noisy samples. However, if the difference in the classification difficulty between classes is considerable, it is easy for samples from classes that are difficult to classify to be defined as noise. This situation is common with imbalanced datasets and can adversely affect performance outcomes. To solve this problem, this study proposes a new noise detection algorithm for AdaBoost that considers differences in the classification difficulty of classes and the characteristics of iteratively recalculated sample weight distributions. Experimental results on ten imbalanced datasets with various degrees of imbalanced ratios demonstrate that the proposed method defines noisy samples properly and improves the overall performance of AdaBoost.
Introduction
Boosting methods are known to obtain improved predictive results by sequentially combining multiple learners that are interconnected [1]. In particular, adaptive boosting (AdaBoost) has shown improved performance on hard-to-learn samples given its use of adaptive learning [2–5]. An individual learner focuses on suspect samples that are frequently misclassified. This can lead to adaptation to hard-to-learn samples. However, AdaBoost has a critical drawback in that it tends to overfit noisy samples. Base learners treat noisy samples as more important than hard-to-learn samples because noisy samples are misclassified continuously regardless of the progress of adaptive learning, which increases the weights of noisy samples [6–8]. Noisy samples with an excessively large weights degrades the performance of base learners, which in turn corrupt the performance of the ensemble model [8].
Many studies have sought to improve AdaBoost to make it more robust to noise. Algorithm-level methods have been designed to decrease the degree of adaptivity over suspect samples using a robust loss function or with an updating scheme [9, 10]. Data-level methods limit the effect of noisy samples for future learning after detecting them based on recalculated sample weights or margins representing the tendencies found in previous learning sessions [11–13]. Data-level approaches can be divided according to whether or not noisy samples are preserved. The noise-filtering method removes them for future boosting rounds by setting the sample weight to zero [11, 14], but the noise-correcting approach preserves them by either decreasing the sample weight or changing the labels of noisy samples [6, 15–17].
Noise-filtering methods are commonly used because the process of implementation and tuning the parameters is simple compared to algorithm-level methods [18–20]. However, noise-filtering methods not only clean the data, but can also result in information loss due to discriminating excessive samples, including informative samples, as noise [14, 21]. This problem is particularly important when dealing with imbalanced data, where the numbers of samples of certain classes are significantly higher than the numbers of other types. Classification with imbalanced data is a serious problem because learners tend to be biased toward the majority class 1 . Even if the minority samples are ignored, low errors are achievable such that it becomes easy to induce learning bias towards majority classes, which implies better prediction performance in the minority class.
AdaBoost is a cost-sensitive learning method that solves this problem by preventing base learners from becoming biased to the majority class. Usually, minority samples are assigned high sample weights owing to the high frequency of misclassifications, causing base learners to focus on minority samples rather than majority samples. However, adaptivity to minority samples of AdaBoost tends to degrade the classification performance, as minority samples tend to be eliminated at an excessive rate [9, 22]. Ignoring the stronger tendency toward misclassification of the minority class causes this problem.
To address this issue, in this paper we propose a new AdaBoost algorithm with an improved noise-filtering algorithm that considers that classification difficulties differ depending on the class in imbalanced data.
The remainder of this paper is organized as follows. A brief review of noise-filtering methods used in AdaBoost is provided in Section 2. The proposed method is explained in detail in Section 3. The experimental procedures and results are presented in Section 4. The conclusions and future work are provided in Section 5.
Related work
Many methods have been the goal of decreasing the degree of noise sensitivity in AdaBoost algorithms. The importance weight for each sample can increase rapidly, as it is calculated using the exponential loss function. As mentioned in Section 1, these methods are divided into two types: (1) algorithm-level and (2) data-level methods. The methodologies in the algorithm-level approach intend to decrease the degree of adaptivity over suspect samples by using either a robust loss function or an updating scheme. This approach is expected to increase the importance weight smoothly by using robust loss functions. Accordingly, alternative functions such as the logistic function mathematically demonstrated as smooth [8], the normalized sigmoid cost function [23] and the nonconvex function [24] are used. In addition, methods to regularize the distribution of the sample weights have been proposed. Noisy samples still tend to be assigned relatively high sample weight values, though it could be better to limit the contribution of a specific sample for training. These methods are divided into two types: those that set bounded ranges [25, 26] and those that prevent skewness of the sample weights [27, 28].
Data-level methods intend to limit the contribution for the training of noisy samples that are detected considering certain trends during classification, such as sample weights and margins that are updated sequentially. One of the simplest ways to limit the influence of noise is to eliminate it, and this is done using a noise-filtering method. Noise-filtering methods remove noisy samples by setting their importance weights to zero. Two typical methods that use sample weights to detect noise are ORBoost [11] and RUSBoostWO [13]. They use a common noise-filtering framework; however, one difference is that RUSBoostWO applies a noise-filtering method to a balanced dataset obtained by random undersampling [29]. The noisy samples are defined when the value of the sample weight exceeds than threshold, d. This is defined as follows:
Noise-correcting methods repair noisy samples either by penalizing the sample weights or swapping the labels to minimize the loss [6, 15–17]. Noise-correcting methods that use the margins to detect noisy samples, as typical noise-correcting methods, define noisy samples after sufficient results are collected and require additional information, such as the neighborhood for noise detection. The margin of each sample is calculated according to the weighted average of the predictions of the individual classifiers. This is done as follows:
However, noise-filtering is typically faster than noise correction because noisy samples are removed once they are defined as containing noise. It is also necessary to tune only the parameters associated with noise detection [18–20], whereas noise-correcting methods are necessary properly to correct noisy samples after noise detection, as noisy samples are continuously used for learning. In summary, the strengths of noise-filtering methods are usability and simplicity.
However, noise-filtering methods have several drawbacks. First, an excessive number of samples can be removed unless the number of noisy samples is bounded [32–35], which decreases the performance [21]. Second, informative samples could be defined as noisy [14]. These two problems are particularly critical for imbalanced data, as informative minority samples are likely to be removed. The elimination of informative minority samples is highly detrimental to the classification performance outcome [22]. Usually, boosting methods focus on samples that are misclassified frequently. For imbalanced data, minority samples tend to be misclassified frequently; therefore, excessively biased learning for the majority can be prevented. However, when the noise-filtering method is applied, minority samples are prone to be defined as containing noise. If the classification complexity differs for each class, which is frequently observed when handling imbalanced data, previous noise-filtering methods for AdaBoost are not appropriate for detecting noisy samples. When using these methods, a large number of minority samples are prone to be defined as noise, and removing minority informative samples may be as harmful as reserving minority samples containing noise. To address this problem, in this paper, an improved noise-filtering algorithm for AdaBoost is proposed to define noisy samples properly by considering differences when classifying different classes.
This study proposes a new noise-filtering method using the sample weights of AdaBoost for imbalanced data. The key point of the proposed noise-filtering method is to set different thresholds to detect noisy samples for each class. The first method (called Case 1) to obtain the thresholds utilizes the mean of the sample weights for each class, similar to ORBoost and RUSBoostWO. However, the mean may not be sufficient to represent the characteristics of the distribution of the sample weights because it does not consider deviation and skewness in the distributions. Therefore, this study additionally proposes a second method to set the thresholds considering the distribution of the sample weights for each class using a boxplot (called Case 2).
Case 1
The threshold value for noise detection is greatly affected by the classification complexity of the majority class in the case of imbalanced data. Considering that the minority class is more difficult to correctly classify than the majority class [36], many minority samples can have much higher sample weights than the threshold value. Figure 1 shows this problematic tendency with Abalone data as an example. In this figure, the boxplots show the distribution of the sample weights depending on the number of iterations, and the red line refers to the threshold values at each iteration. In addition, the green line represents the ratio of the noisy samples for each class at each iteration. As shown in Figure 1, the proportion of samples defined as noisy increased rapidly as the learning progressed.
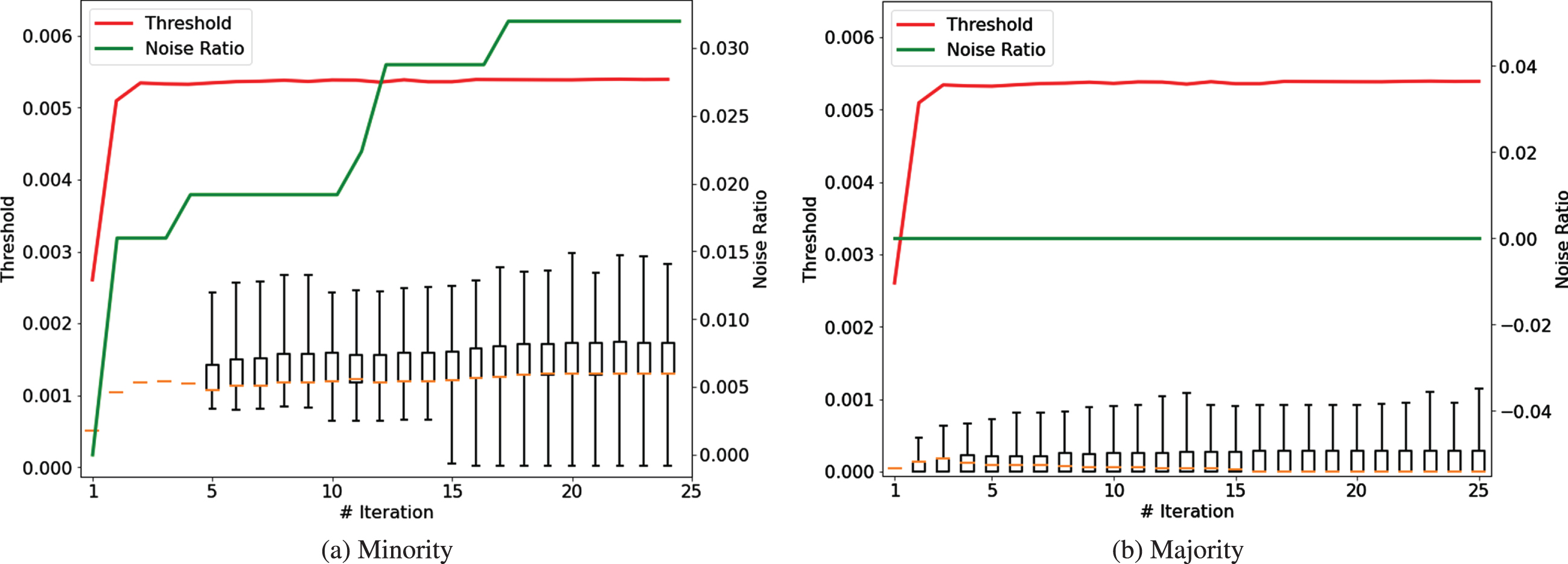
Distributions of sample weights, thresholds for noise detection, and the proportions of noise samples for the majority and minority classes
Unless noise-filtering methods are applied separately to each class, an excessively large number of minority samples can be defined as noise owing to the relatively high classification difficulty compared to the majority class. To solve this problem, the threshold to define noise should be set differently for each class. Case 1 sets different threshold values depending on class while continuing to use the same approach to obtain the thresholds of ORBoost and RUSBoostWO. The threshold values of Case 1 are defined as follows:
To consider not only the centrality of the distributions of the sample weights but also other characteristics of the distributions, such as deviation and skewness, the second approach to obtain the thresholds utilizes a boxplot. A boxplot is commonly used to depict the distribution of data graphically using quartiles [37]. In a boxplot, a box represents the centrality range, and fences represent the upper and lower limits. Typically, they are defined through quartiles to divide the data, ordering the dataset in an ascending order into quarters. The interquartile range (IQR) is defined between the first quartile (Q1) and the third quartile (Q3) to depict the box. The two fences, the lower fence (f L ) and the upper fence (f U ), are defined as follows:
To consider the skewness of the distributions of the sample weights for noise-filtering, Case 2 uses an adjusted boxplot for skewed data. In many studies related to improved boxplots, the degree of skewness is calculated based on two sub-elements [38–41]; semi-interquartile-range from upper quartile (SIQR U ) and semi-interquartile-range from lower quartile (SIQR L ) that are split at the median, where SIQR represents the semi-interquartile range. SIQR U and SIQR L are defined as follows:
Using SIQR U and SIQR L , the adjusted boxplots for skewed data generally use a longer distance from the box when setting the fences compared to that in the ordinary boxplot. One typical method is to use Bowley’s coefficient(B c ) [39], which is defined as follows:
B c is expected to be 0 for a symmetrical distribution and -1 or 1 for absolutely skewed distributions. The value of B c is applied differently to calculate the lower and upper fences, which are defined as follows:
In addition, the sample weights are iteratively recalculated only based on whether they are correctly classified or not. Therefore, the large number of samples tends to have similar or even identical values of the sample weights at the early stage of AdaBoost. In this case, the values for Q1, Q2, and Q3 could be identical, and in such a case, B
c
cannot be defined. Therefore, Case 2 defines the fences using a broader range of centrality than IQR to avoid the situation in which Q1, Q2, and Q3 have identical values. For Case 2, P15 and P85 are used instead of Q1 and Q3, respectively, where P
x
represents the xth percentile. Using these values, the centrality range (CR) and the two sub-elements of SCR
U
and SCR
L
are defined as follows:
Instead of using IQR, SIQR
U
and SIQR
L
, Case 2 uses the improved indicator (I
U
), which represents the ratio of SCR
U
from half of CR, compared to B
c
. I
U
is defined as follows:
Figure 2 shows the change of the threshold values versus number of iterations. Figures 2-(a) and (b) shows the results using ORBoost and RUSBoostWo, respectively. In this figure, the blue and green lines refer to the threshold values obtained using Case 1 and Case 2, and the solid and dotted lines refer to the threshold values of the minority and majority classes, respectively. In addition, the black line shows the threshold values obtained by the original noise-filtering method of ORBoost and RUSBoostWO. As shown in Figure 2, the threshold values for the minority class are much higher than those for the majority class when the proposed noise-filtering algorithm is used for ORBoost and RUSBoostWO.

The change of the threshold values according to number of iterations
Data
Several benchmark imbalanced datasets were selected for the experiments. Seven datasets were obtained from the machine learning repository of the University of California at Irvine [42]. KC1 and PC1 are software engineering datasets for predicting software defects, obtained from the NASA IV&V Facility Metrics Data Program repository 2 . The Oil dataset for predicting oil spills from satellite images was provided by [43]. Credit Card dataset for predicting fraud transactions was obtained from the revolution analytics repository 3 . Multiclass datasets were converted to binary class datasets by assigning the selected labels as the positive class (minority class) and the others as the negative class (majority class), according to previous studies. Additionally, categorical variables were excluded, and each numerical variable was standardized to prevent performance degradation due to the heterogeneous feature scale. Table 1 includes the details, specifically the number of samples, the features, and the imbalance ratio. The labels of the positive classes are enclosed in parentheses under “Data” column for multiclass datasets.
Dataset characteristics
Dataset characteristics
We used the AdaBoost algorithm combined with sample-weight-based noise-filtering methods, such as ORBoost and RUSBoostWO, as comparison methods, to prove the importance of a proper threshold for each class 4 . The proposed noise-filtering method was applied to ORBoost and RUSBoostWO instead of the original noise-filtering method of them and compared with the original ORBoost and RUSBoostWO. In addition, we conducted experiments using the original AdaBoost algorithm without noise-filtering to validate the effectiveness of noise-filtering on several imbalanced datasets.
The parameters α and β, used to calculate the thresholds for Case 1 and Case 2, respectively, were selected from the range of 3 to 20, and the best parameters were determined by five-fold stratified cross-validation. For RUSBoostWO, the size of the majority class after random undersampling was set to four times the size of the minority class, except for KC1 (two times). The imbalance ratio of KC1 is less than four.
The base classifier selected for AdaBoost was selected as the classification and regression tree (CART) classifier. The maximum depth of each base classifier was set to 1 to obtain weak learners. The number of base classifiers for each ensemble model was set to 50. The performances of different models were compared using the area under the receiver operating characteristic (AUROC), as this metric is broadly applicable to the validation of classification performances with imbalanced data. Owing to the limitation of page length, the experimental results for other evaluation metrics widely used for imbalanced data, such as precision, recall, F1, and G-mean, are provided in Sections S1 and S2 of the supplementary material. Five-fold stratified cross-validation was repeated 30 times.
In addition to the original datasets, experiments were also conducted on noise-injected data. In general, noise-injection methods are divided into two categories: those that swap the labels of selected samples and those that synthesize noisy samples using original data [11, 13].
In general, noisy samples are defined as those located within an area of the opposite class of a classification problem. Therefore, many related studies have tended to use the label-swapping method which swaps classes of randomly selected samples to inject noise. However, [44] pointed out that noisy samples injected using label-swapping are not realistic, because they are generated randomly rather than considering the characteristics of data. In addition, when applying label-swapping to imbalanced data, the noise level for each class should be set to be different to maintain the imbalance ratio of the given imbalanced data. Therefore, this study injects noisy samples by synthesizing samples rather than swapping labels.
This study utilizes the process of synthesizing samples used for SMOTE in which a sample is synthesized by linear interpolation between a randomly selected sample and one of its nearest samples from the same class [45]. However, we used weighted sampling instead of uniform sampling, and the label of the synthesized sample is defined as the opposite class to that of the sample used in synthesizing samples.
The sampling probability value is calculated based on the ratio of the intra/inter class nearest neighbor distance (dNN) [46], similar to a method in earlier work [44]. dNN for each sample is defined as follows:
The second case defines the sampling probability as inversely proportional to dNN, as follows:
Figure 3 visualize where the injected noise samples are mainly located according to the different sampling probabilities. This figure was obtained by reducing the dimension of the Satimage data to two dimensions using t-SNE after noise injection at a noise level of 20 %. Figures 3-(a) and -(b) show the visualization results of the noise-injected data using the direct and inverse sampling probabilities, respectively. As previously explained, it can be observed that the noise locations different depending on the sampling probabilities. In Figures 3-(a), the synthesized samples tend to be scattered at the boundary areas between two classes, whereas the synthesized samples tend to be located at areas far from the classes of the synthesized samples in Figure 3-(b).
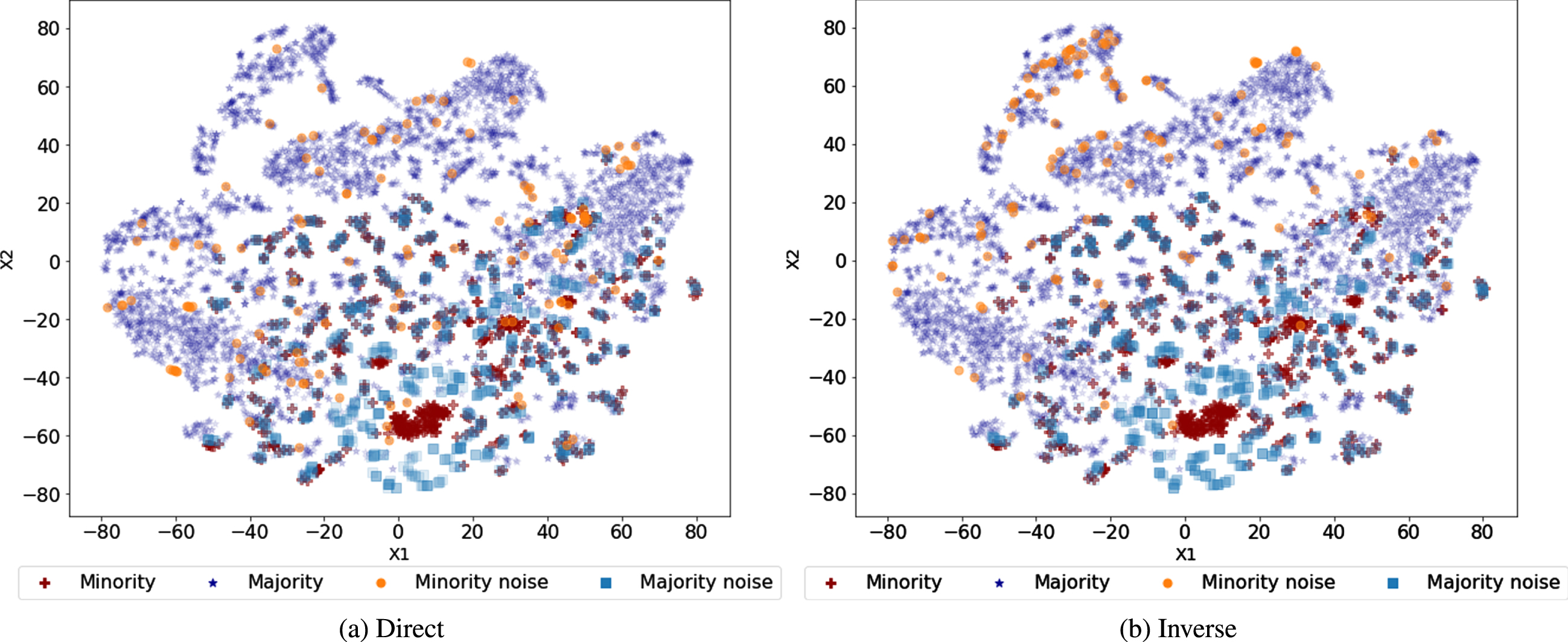
Distribution of noise injected dataset
For each dataset, noise-injected data were generated by varying the sampling probability to determine the sampling weight and noise level. In this study, the noise level was set from 10 % to 40 % with 10 % intervals.
Noise-filtering results
The excessive elimination of samples in the minority class is one of the main problems arising when using AdaBoost algorithms combined with noise-filtering for imbalanced data. Therefore, before comparing the classification performances of the different noise-filtering methods, we checked the proportion of the samples defined as containing noise for each method. Tables 2 and 3 correspondingly show the differences in the percentages of noisy samples between the noise-filtering methods compared here and the proposed noise-filtering method with different cases for the original data based on ORBoost and RUSBoostWO. Here, negative values denote an increase in the number of noisy samples when using the proposed method.
Difference in the percentage of the noisy samples between the proposed and comparison noise-filtering methods: ORBoost
Difference in the percentage of the noisy samples between the proposed and comparison noise-filtering methods: ORBoost
Difference in the percentage of the noisy samples between the proposed and comparison noise-filtering methods: RUSBoostWO
In Table 2, the difference in the percentage of the noisy minority samples between the proposed and comparison noise-filtering methods is considerably larger than the difference in the percentage of the noisy majority samples, and the percentage of the noisy samples in the minority class by the proposed method is smaller than that by the comparison method. For some datasets such as Oil, Wine Quality, Mammography, and PC1, the difference in the percentage of minority noisy samples was more than 90 %. This is because most of the samples defined as noise by Base are in the minority class, in contrast to the proposed method. In particular, in the datasets in which the weights of most minority samples are larger than those of the majority samples, the probability that the minority sample is discriminated as noise increases, and the difference in the proportion of the noisy minority samples between the proposed and comparison methods increases. For some datasets, the proportion of the noisy samples by the proposed method increased compared to that by the comparison method, but not by much. The difference between Case 1 and Case 2 is not significant.
Comparing Table 3 with Table 2, the difference in the percentage of the noisy samples between the proposed and comparison methods decreases when using RUSBoostWO compared to ORBoost. The difference in the percentage of minority noisy samples did not exceeds 50 %. For PC1, the difference decreases from 100 % to 0.30 %. This may be because RUSBoostWO detects noisy samples after the size of the majority class is reduced through under-sampling. In conclusion, when considering the characteristics of imbalanced data, where typically the degree of classification complexity for each class differs, the number of minority noisy samples decreases. In other words, the proposed noise-filtering method effectively prevents the excessive elimination of minority samples. It can also be expected to decrease the computation time if the number of majority noisy samples increases. Moreover, the similar conclusion can be drawn from the results for the noise-injected datasets, which are presented in Section S2.1 of the supplementary material.
Table 4 shows the average AUROC values when using the different base models (ORBoost and RUSBoostWO) for each dataset. Here, the “Base” and “AdaBoost” columns show the results using ORBoost or RUSBoostWO and AdaBoost, respectively. The best case for each base model is shown in bold. The standard deviation was calculated from the average AUROC values for each five-fold cross-validation. We also validated the performance of the proposed method using pairwise t-tests. The information about significantly better or worse performance compared to the AdaBoost and Base models at a significance level of 0.05 is represented by ↑ (better) and ↓ (worse) as superscripts for each average AUROC value of the proposed method. If the results of the t-tests are insignificant, •is used as the superscript. Among the two superscripts, the first represents the result of thet-test with AdaBoost and the second represents the result of the t-test with Base. The detailed results of the pairwise t-tests for the original datasets are provided in Section S1 of the supplementary material which also includes the results of the pairwise t-tests in terms of other classification metrics such as precision, recall, F1, and G-mean.
Evaluation results for the original datasets in terms of AUROC
Evaluation results for the original datasets in terms of AUROC
In Table 4, it is shown that the AdaBoost algorithms with noise-filtering always perform better than AdaBoost. In approximately half of the datasets, ORBoost and RUSBoostWO showed lower AUROC values than AdaBoost. ORBoost and RUSBoostWO perform the noise-filtering process regardless of whether noise exists in the dataset. Because the datasets used in this study were selected from among the well-known imbalanced datasets, the classification performance may be lowered by removing the samples defined as noise, if noise is not included in the datasets. However, when the propose noise-filtering method was used, the classification performance became better than that of Adaboost, even for the datasets where the performance of ORBoost or RUBBoostWO was lower than that of Adaboost.
The proposed method generally provides improved classification performance for ORBoost. It is demonstrated that the improved classification performance was observed for several datasets such as Ecoli, Satimage, Abalone, US Crime, Credit Card, Oil, Wine Quality, Mammography, and PC1. These datasets commonly have high IR values such that minority samples are likely to be defined as noise. Therefore, the effect of the prevention of the excessive elimination of minority samples as noise is considerable in these datasets, which improves the classification performance. However, less of an improvement was observed for the results of RUSBoostWO. The number of significantly improved cases decrease; in particular, this value decreases from 8 to 1 of Case 2. The classification performance of Base increases because the degree of IR is lessened via under-sampling before the noise-filtering method is applied.
The proposed method could not improve the classification performance of KC1. In this case, the IR value is smaller than those in the other datasets and the proposed noise-filtering method decreased the number of noisy samples for both minority and majority classes. When comparing the base models, the result of RUSBoostWO for KC1 was better than the result of ORBoost. Therefore it can be inferred that when the degree of IR is low, a decreased number of minority noisy samples cannot lead to an improvement in the classification performance.
Tables 5 and 7 show the evaluation results for the noise-injected datasets with different noise levels in terms of AUROC according to ORBoost and RUSBoost, based on the type of sampling probability, respectively. In these tables, the “Base” and “AdaBoost” columns show the results using ORBoost or RUSBoostWO and AdaBoost, respectively. The best cases for each noise level and type of base model are shown in bold. The information about significantly better or worse performance compared to the AdaBoost and Base models at a significance level of 0.05 is represented in the same way used for Table 4.
Evaluation results for the noise-injected datasets in terms of AUROC: using p (x
i
)
direct
Evaluation results for the noise-injected datasets in terms of AUROC: using p (x i ) direct
Evaluation results for the noise-injected datasets in terms of AUROC: using p (x i ) inverse
In Tables 5 and 7, ORBoost and RUSBoostWO generally outperformed AdaBoost as the noise level increases, except for Wine Quality, Mammography, and PC1. These results imply that noise-filtering is effective in improvement of classification performance for noisy data. In addition, the classification performance for the noisy datasets generated using the direct sampling probability was generally better than than for the noisy datasets generated using the inverse sampling probability and the number of the noise-injected datasets that ORBoost or RUSBoostWO outperformed AdaBoost was greater when the direct sampling probability was used than when the inverse sampling probability was used, comparing Tables 5 and 7. The noisy samples injected by the direct method tend to be located at the borderline areas between two classes, so it is hard to remove noise generated using the direct method by the noise-filtering method.
When comparing the proposed method with the comparison noise-filtering method used in ORBoost and RUSBoost, it generally outperforms the comparison method except for KC1, Satimage, and Abalone. Especially the best case is the using Case 1 based on the ORBoost. Case 1 usually outperformed RUSBoostWO on more datasets regardless of type of the sampling probability, and the number of datasets for which Case 1 performs significantly better than RUSBoostWO increased as the noise level was increased. On the other hand, Case 2 with RUSBoostWO hardly improved the performance of RUSBoostWO, likely because the noise-filtering process could not proceed when the values of P15 and P85 are identical. This could occur not only at the early stage but also during the later iterations, after some of the noisy samples were eliminated. In this case, a few noisy samples could be preserved and degrade the classification performance.
We additionally validated the performance of the proposed methods using a pairwise t-test. Case 1 with ORBoost shows significantly better performance for more than five datasets when the noise level is less than or equal to 40 %. Similarly, Case 2 with ORBoost, when the noise level is less than or equal to 30 %, shows more than five datasets with better performance than the original ORBoost. However the number of significantly worse performance is more than Case 1 as much as two or three. Moreover, the proposed method achieved significantly better performance than AdaBoost for the more number of the noise-injected datasets compared with the comparison results against ORBoost and RUSBoostWO. The detailed results of the pairwise t-tests are provided in Section S2.3 of the supplementary material due to the limitation of page lengths.
As the noise level was increased, the trends in the performance improvement by the proposed noise-filtering method differed from those of the base models. For ORBoost, the performance difference between the base model and the proposed models decreased, whereas it increased for RUSBoostWO. In the case of ORBoost, the ratio of the injected noise samples for both majority and minority classes increased for higher noise levels, whereas the synthesized noisy samples in the majority class can be removed by under-sampling in RUSBoostWO. This makes the difference between the original and synthesized samples larger than the difference between minority and majority classes, for which the proposed method is designed to solve.
In addition, the proposed noise-filtering method showed superior performance on the noise-injected datasets even using p (x i ) direct compared to the datasets using p (x i ) inverse . Because noisy samples generated by p (x i ) direct are more difficult to be classified correctly than those generated by p (x i ) inverse , it is an advantage of the proposed method to show good results on noise-injected datasets using p (x i ) direct .
This study proposed a new noise-filtering method for AdaBoost to enhance classification performance outcomes and increase noise robustness with imbalanced data. The proposed noise-filtering method solves the problem in the existing AdaBoost approach with noise-filtering in which an excessive number of minority samples are eliminated when they are defined as noisy. It does this by setting an appropriate threshold value to detect noisy samples for each class. The proposed noise-filtering method suggests two different threshold setting approaches: (1) one that considers only the average sample weight and (2) another that considers the spread and skewness of the distribution of the sample weights. The main contributions of this study are summarized below. This study proposes a new noise-filtering method that considers differences in classification difficulty levels between classes when processing imbalanced data. This study proposes two different thresholds setting methods depending on the statistics of distribution of the sample weights used to obtain the threshold values. A new noise injection framework is designed to increase the number of noisy samples while maintaining the degree of IR in the imbalanced data. The superiority of the proposed noise-filtering method is validated on 11 imbalanced datasets with various IR values and on noise-injected datasets with different noise levels.
In the experiments, the proposed noise-filtering method replaced the noise-filtering step of ORBoost and RUSBoostWO and the performance outcomes of the new AdaBoost algorithms were compared to the original ORBoost and RUSBoostWO on the original and noise-injected imbalanced datasets. As a result, it was observed that the number of noisy samples tended to decrease for the minority class. This confirms that for original dataset, the proposed noise-filtering method effectively prevents the excessive elimination of minority samples during noise-filtering in AdaBoost.
For the noise-injected datasets, the proposed method significantly enhanced the performance of ORBoost, whereas Case 1 showed an effective improvement in the performance when the proposed method was combined with RUSBoostWO. Interestingly, it was demonstrated that a noise level of 10 % could improve the classification performance, which may be because synthesized minority samples could be eliminated instead of the original minority samples by minimizing the number of synthesized majority samples. Moreover, it was shown that the proposed method was effective on not only noise-injective datasets by p (x i ) inverse but also those by p (x i ) direct , which implies that the proposed method works well on datasets including noisy samples difficult to be determined as noise.
In conclusion, the proposed method improves the classification performance by preserving informative minority samples for both original and noise-injected imbalanced datasets. When we compared the proposed methods, Case 1 generally outperformed Case 2.
In future work, we will improve Case 2 to prevent the problem in which the noise-filtering process could not proceed at the later stage of iterations by considering the spread of the sample weight distribution. In addition, we will improve margin-based noise-filtering methods so that they perform well with imbalanced datasets. These methods are also associated with the excessive elimination of noisy samples because the same threshold value is defined for the classes. These improvements are expected to be helpful for enhancing the classification performance by assigning the proper threshold value for each class by considering the characteristics of imbalanced datasets. In addition, it is easy to apply the proposed methods to multi-class imbalanced datasets because the key idea of the proposed noise-filtering process is to set a threshold value that defines noisy samples for each class. Therefore, we will evaluate the performance of a variant of the proposed method for multiclass classification problems. However, in Case 2, it was observed that it was difficult to obtain an appropriate threshold value when the class size was small. Therefore, caution should be exercised when applying the proposed noise-filtering method with Case 2 for a multi-class datasets with even one small class. Regardless of the number of target classes, Case 2 must be studied further to improve its performance.
Footnotes
Acknowledgment
This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. 2020R1F1A1054496).
This paper covers only binary classification problems with the majority class (negative class) and the minority class (positive class).
This paper used the AdaBoost algorithm implemented in the scikit-learn library of Python.