
Abstract
Distance measures of fuzzy sets have been developed for feature selection and finding redundant features in the fields of decision-making, prediction, and classification problems. Terms commonly used in the definition of fuzzy sets are normal and convex fuzzy sets. This paper extends the general fuzzy set definitions to subnormal and non-convex fuzzy sets that are more precise when implementing uncertain knowledge representations by weighing fuzzy membership functions. A distance measure method for subnormal and non-convex fuzzy sets is proposed for embedded feature selection. Constructing fuzzy membership functions and extracting fuzzy rules play a critical role in fuzzy classification systems. The weighted fuzzy membership functions prevent the combinatorial explosion of fuzzy rules in multiple fuzzy rule-based systems. The proposed method was validated by a comparison with two other methods. Our proposed method demonstrated higher accuracies in training and test, with scores of 97.95% and 93.98%, respectively, compared to the other two methods.
Keywords
Introduction
Decision-making, prediction, and classification problems dealing with uncertainty in nature are complex and hard to define at the human cognitive level. Fuzzy sets, introduced by Zadeh [1] to characterize the vagueness of uncertain knowledge, enable humans to interface with computers. A fuzzy set uses linguistic variables (LVs) and membership functions to define input–output attributes for inference of logical reasoning. The construction methods of fuzzy membership functions determine the fuzzy logic system’s performance by tuning parameters or linguistic hedges of the fuzzy membership functions. A fuzzy logic system can initially be designed by experts directly constructing fuzzy membership functions of LVs. However, methods to optimize fuzzy membership functions for the automatic tuning of fuzzy models are required. Neuro-fuzzy systems have been suggested for developing fuzzy logic systems as an alternative to neural network systems because they are powerful in automatic learning with high-performance gains without loss of readability.
The adaptive network-based fuzzy inference system [2] and Kosko’s adaptive fuzzy associative memory [19] are neuro-fuzzy approaches to approximate the automatic formation of the linguistic rule base. Zadeh [3] introduced powering modifiers called linguistic hedges that emphasize the importance of fuzzy sets. The linguistic hedges were applied to an adaptive neuro-fuzzy classifier that simplifies the characteristics of overlapping classes with feature selection using the scaled conjugate gradient algorithm [4, 5].
Feature selection approach [6, 7] is another major area wherein computational complexity can be reduced and discriminating ability of fuzzy logic systems can be increased by decreasing the feature vector dimensionality when redundant or irrelevant features exist. The selected features that preserve the original meaning are required to represent knowledge in fuzzy systems. The filter, wrapper, and embedded methods were the three types of feature selection that were categorized [6]. In contrast to the filter and wrapper methods, without consideration of the machine learning classifiers in the preprocessing step, the embedded methods perform feature selection while the machine learning classifiers are processing the classification procedure. The embedded methods are less computationally intensive than the wrapper methods and have greater interaction with the classifier than the filter methods [8].
To discriminate between fuzzy sets for feature evaluation, distance measures have been applied to select features in the machine learning preprocessing step [9, 10]. Decision-making or inference to formalize human reasoning has been emulated by fuzzy sets that are implicitly normal and convex LVs in a triangular or trapezoidal shape or other types of curve, including linguistic hedges. The subnormal and non-convex fuzzy sets imply rich aggregated information of LVs and are appropriate for modeling at a human cognitive level in fuzzy sets. The ways of distance measures of subnormal and non-convex fuzzy sets have been based on the traditional α-cut [11] or vertical slice approaches [9]; the more appropriate methods are required later for accurate assessment. This paper proposes a distance measure method to select the most salient features for supervised learning in classification problems.
Generally, inter-class distance measures for evaluating feature selection for learning perform better than probabilistic measures [12]. This paper introduces a new embedded feature selection method called distance–difference ratio (DDR) that efficiently measures distances between subnormal and non-convex membership functions learned from a neuro-fuzzy classifier.
A low temperature is not of much interest in the summer. Therefore, the maximum value of the low-temperature variable does not need to be a fuzzy value. However, the feverish temperature in the summer is significant and requires a higher weight for the high-temperature linguistic variable. This example shows that the subnormal LVs may contain more information than normal LVs. The subnormal LVs for an attribute in accordance with the suprema are represented by the weighted fuzzy membership functions (WFMs) [13]. The bounded sum of WFMs (BSWFMs) that combines the sub-normal LVs into one by bounded sum operation in fuzzy set theory forming convex or non-convex fuzzy sets was introduced in the neural network with weighted membership function (NEWFM) model [13]. As the BSWFM merges all WFMs into one for each attribute, when more attributes are added to a system, the high complexity of the fuzzy rules can be reduced to a linear number for efficient inference, resulting in greater accuracy. The simplicity of BSWFM with good interpretability and accuracy overcomes the weaknesses of fuzzy modeling in the Principle of Incompatibility [14] that interpretability and accuracy are conflicting attributes, and one overrides the other. Consequently, ranking the features by the distance measure by DDR between BSWFMs of features contributes to the selection of features for better accuracy or decision-making.
This paper verifies the concept of WFM in computational aspects for fuzzy classification systems. In addition, the new approach of a feature selection method based on the BSWFM is suggested. Parkinson’s disease classification tasks using the proposed feature selection in this paper are demonstrated. The results show that the proposed feature selection approach achieves an accuracy comparable to or better than that of state-of-the-art techniques, with a reduced computation time for the embedded method.
Definitions for BSWFM
Fuzzy sets introduced by Zadeh [1] have been extended in many fields with advanced notions and operations. Regular fuzzy sets overlook the inferencing of human reasoning. On the contrary, the subnormal and non-convex BSWFMs can emulate human reasoning by as they reflect a flexible human cognitive level. The main purpose of this paper is to demonstrate that the BSWFMs have powerful feature selection characteristics. The definitions and operations of fuzzy sets for explaining BSWFM are as follows:
(1) Subnormal
Let
A fuzzy set A is said to be subnormal if
(2) Convex and Non-convex
A fuzzy set A is convex only when the sets Γα, defined by
(3) Bounded Sum of Subnormal Fuzzy Sets
The bounded sum [15] of subnormal fuzzy sets A, B, ... , and N with membership functions is the fuzzy set whose membership function is given by
(4) Weighted Fuzzy Membership Functions (WFMs)
Fuzzy membership functions learned by NEWFM are said to be WFMs that are subnormal and convex in triangular shapes. The height of a WFM
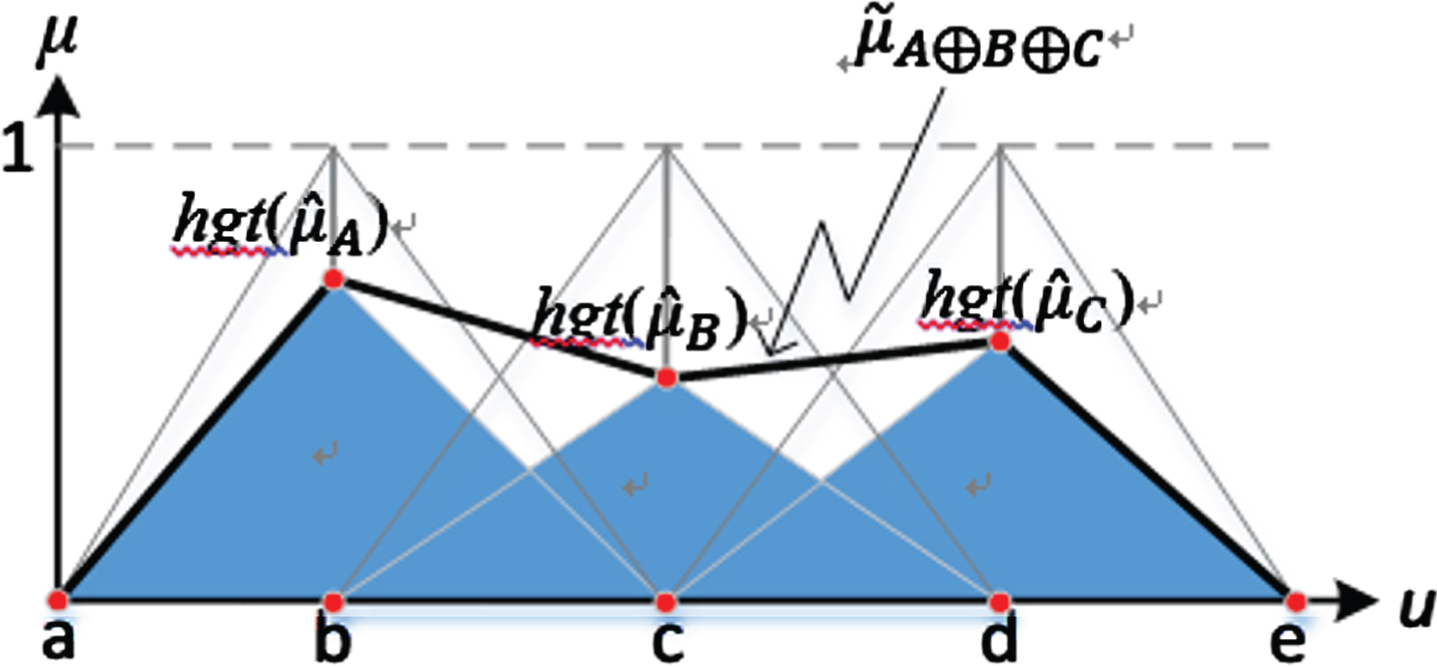
An example of a BSWFM
(5) Bounded Sum of Weighted Fuzzy Membership Functions (BSWFMs)
A feature is represented by WFMs (usually 5± 2) according to their LVs. Through the operation of bounded sum of subnormal fuzzy sets, the WFMs are combined into one fuzzy membership function such that
A BSWFM constructed by three WFMs
–BSWFM is subnormal and either convex or non-convex:
Assuming that there are three WFMs, (
(6) Bounded Difference [11]
The difference of a pair
(7) Bounded Distance
An operator ø for the bounded distance of a pair
(8) Bounded Intersection [1]
The bounded intersection of two BSWFMs
Decision-making or inference to formalize human reasoning has been emulated by fuzzy sets that are implicitly normal and convex LVs in a triangular or trapezoidal shape or even as types of curves, including linguistic hedges. Subnormal and non-convex BSWFMs imply rich aggregated information of LVs and are appropriate for modeling at a human cognitive level in fuzzy sets. The ways of distance measure of subnormal and non-convex fuzzy sets have been based on the traditional α-cut [11] or vertical slice approaches [9], and more appropriate methods are then required for accurate assessment. This paper proposes a distance measure method to select the most salient features in classification problems.
Distance-difference ratio (DDR) method for feature selection
Classification performance with respect to accuracy and speed in learning systems is significantly affected by the selection of salient features. This paper suggests a feature selection method, named DDR, that measures a distance using bounded distance and bounded difference of a pair of BSWFMs. The purpose of the DDR method is to find the distinguishing features among all input features that have the strongest power of classification.
Let
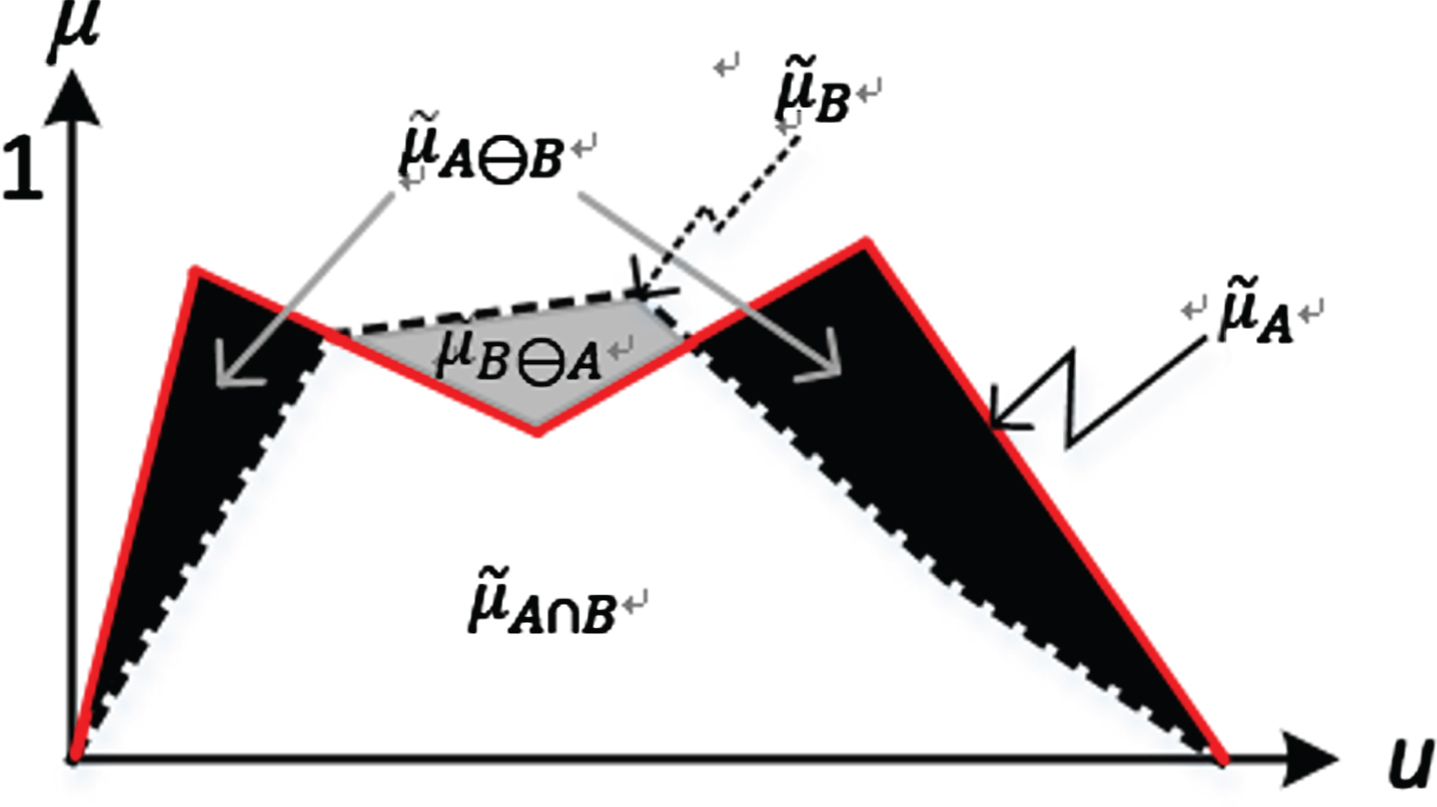
Example of
For a pair of
This paper asserts that the DDR feature selection method for supervised learning problems can be achieved on the distance measure between a pair of BSWFMs with the following hypothesis.
A salient feature for a pair of BSWFMs high value of low value of
The evaluation of the above properties is accomplished by the DDR evaluating the value of feature sets.
DDR feature selection is an embedded method that integrates with the training process in NEWFM. The method is based on backward selection by deleting the feature with the smallest DDR value in each iteration until the classification accuracy does not improve.
// Let
where c = 1 or 2.
// GCA: global classification accuracy
{
// DA: predefined desired accuracy by user, decrease when it falls into an infinite loop
LMCA = 0
// LMCA: local maximum classification accuracy
Besti = 0
// Besti: accumulated best cases of fi
Worsti = 0
// Worsti: accumulated worst cases of fi
}
LCA = 0
// LCA: local classification accuracy
// store greater LCA into LMCA
}
// update GCA by LMCA
Bestb = Bestb+1 such that fb has the highest
Worstw = Worstw+1 such that fw has the lowest
}
}
Experimental results
Dataset
The dataset used in the experiment was obtained from the UCI repository of machine learning databases [16]. The dataset was composed of 195 sustained vowel phonations from 31 subjects. Twenty-three of 31 subjects were Parkinson’s disease (PD) patients. Some patients with Parkinson’s disease had been diagnosed for less than one year while others had been diagnosed as long as 28 years. The patients were between 45 and 85 years of age. Each patient recorded an average of 6 times. The length of each recording ranged from 1 to 36 s, and the phonations were recorded as described in [17].
Experiment
The dataset was normalized in the range [0, 1] through three steps. In the first step, the normalization equation was as follows.
NEWFM, which is a neuro-fuzzy learning algorithm, was used as the classifier distinguishing between normal and PD. The feature selection method using DDR was embedded in NEWFM. We performed experiments by removing features one by one according to the result of DDR for each iteration. Initially, all 22 features were used for classification, resulting in 22 DDRs being obtained. Figure 3(a) and 3(b) represent the BSWFMs with the best and worst DDRs, respectively.

The example of DDRs(x axis means range of ri,j, y axis means result of weighted fuzzy membership function).
In Fig. 3(a), a pair of BSWFMs has the best DDR. It has a higher value of
The results of training and test after selecting features for the experiment
Our experimental results compared with [17] and [18] are shown in Table 2. The result of the comparison demonstrates that the degree of accuracy in the proposed method was higher than those obtained for the other methods.
Comparison of accuracy for DDR and the other two methods
These results demonstrated that the features selected by DDR have a greater effect on accuracy than the removed features, thereby demonstrating that DDR works well for feature selection. DDRs are automatically generated from BSWFMs in NEWFM during testing. They provide a logical and mathematical basis for automatically extracting features. Moreover, DDR is based on subnormal and non-convex fuzzy functions. There have been no previous experiments with subnormal and non-convex fuzzy functions. The experiment in [17] was performed based on data distribution using probabilities. However, experiments in this paper demonstrate results based on real data through learning rather than from the statistical method. The experimental results are significant as the use of actual data for classification improves accuracy by reflecting real meaning of data. The non-convex fuzzy function is similar to the graph drawn by the probability density function, but it may be more finely and nonlinearly adjusted by learning.
In this paper, we propose DDR for feature selection that is a distance measure method of subnormal and non-convex BSWFMs. After each iteration, DDRs were calculated from the overlapped BSWFMs generated for each feature, and the features were then ranked according to those DDR values. Some features were removed by their rank, and the next iteration was then performed on the remaining features. The iterations were repeated until the accuracy did not improve.
The proposed feature selection method was compared with two other methods, one based on probability density and the other on genetic programming.
The results of the experiment demonstrated that 97.95% training accuracy was maintained even if the features were reduced. The accuracy of the test set was 93.98%, which was highest when using 19 features. Moreover, compared with the other method, the method using DDR demonstrated higher accuracies for training and test of 97.95% and 93.98%, respectively.
We observed that the accuracy was maintained even though the features were reduced in our experiment, indicating that valid features were selected using feature selection via DDR. The neuro-fuzzy classifier, NEWFM, which generates a linear number of fuzzy rules, produces the same number of BSWFMs as the number of classes per feature. This is the subnormal and non-convex fuzzy set resulting from the experimentation. The subnormal and non-convex fuzzy set can include more information and are more natural than the convex fuzzy set because it can be adjusted more finely and linearly by learning enough to reflect the precise distribution of the actual data. Specifically, this means that there is a reduction in error through natural adjustment. The concept of difference area and distance area that are generated from BSWFMs of classes is based on the distribution of data included in each class. Therefore, it is very reasonable and logical that these concepts can be used for selecting the features and classifying data. We believe that we have demonstrated this via experimentation.
This study may impact the study of automatic feature extraction techniques that reflect the characteristics of the data itself within various types of datasets. It can be implied that the experiment proved the effect on the accuracy of the non-convex fuzzy set containing rich aggregated information.
Footnotes
Acknowledgments
This research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2021-2017-0-01630) supervised by the IITP (Institute for Information & communications Technology Promotion).
This research was supported by the Bio & Medical Technology Development Program of the National Research Foundation (NRF) funded by the Ministry of Science & ICT (2017M3A9E2072689).