
Abstract
Deep learning methods have led to the state-of-the-art medical applications, such as image classification and segmentation. The data-driven deep learning application can help stakeholders for further collaboration. However, limited labeled data set limits the deep learning algorithms to be generalized for one domain into another. To handle the problem, meta-learning helps to solve this issue especially it can learn from a small set of data. We proposed a meta-learning-based image segmentation model that combines the learning of the state-of-the-art models and then used it to achieve domain adoption and high accuracy. Also, we proposed a prepossessing algorithm to increase the usability of the segment part and remove noise from the new test images. The proposed model can achieve 0.94 precision and 0.92 recall. The ability is to increase 3.3% among the state-of-the-art algorithms.
Introduction
Deep learning (DL) algorithms have been adopted in the medical domain recently. Primarily methods are used for many medical images related tasks [26]. The methods result in outperforming the experts [11]. The architecture based extensions are proposed for recurrent neural networks (RNN), convolutional neural networks (CNN), and generative adversarial networks (GAN) [1]. However, the model generalization issue still exists, as no model performs on all problems, and new data sets with tune parameters are being developed. Deep learning models are often hard to be generalized on the new dataset [1]. In biomedical images, data points are often high dimensional, resulting in the non-linear manifold which is not a trivial task for model generalization.
The segmentation algorithms failure in transfer learning methods can be significant based on the statistical distribution of the datasets. The dataset generalization depends mostly on patient modalities, image acquisitions methods and protocols, the population of the sampling, and personal patient records [2]. The purpose of domain adaptation and domain-based generalization is to reduce the covariate shift between the training, validation, and test distribution of extracted features [2, 4]. The transfer feature representation should be non-correlated and discriminative enough for the learning mechanism. The adoption of the feature to the new domain can be unsupervised or semi-supervised. The method to generalize medical data is relatively less studied area; models use various sources to build feature representation and then combine for the target distribution during training. Using the method of few-shot learning, the model can be adapted to new distribution with very limited labeled training examples [5].
Motivation
Data are deemed one of the significant assets of various organizations from medical, education, and news. Pattern recognition is the process employed to explore a large amount of data and extract hidden knowledge and patterns from the data. It utilizes the past behaviors of the data and predicts different facts for the future. In the real world, patients with medical problems visit doctors, and then the doctor (if required) orders different scans (CT/MRI). The ordered scans are sent to the technologist whose jobs are to vet the study. The vetting method requires at least a week before it is scheduled. The analysis of radiologist described and assigned the protocols to be conducted on the patient. The radiologist marks the potential abnormal region. The biopsy is time taking and requires to be processed more efficiently. In case of patient rescheduling of appointment and even elderly person, it is difficult to get the slot for the technologist and radiologist. The wrong identification of an abnormal region could result in wasting valuable patient time and hospital resources. A system is needed that can help radiologists identify correct protocols using a limited set of medical images. This system may help in the reduction of hospital costs, patient time, as well as early detection of diseases. The contactless method also helps increase the pandemic scenario to recognize patient conditions and quickly separate them from healthy ones. The reduction in wrong protocol selection during any vetting process can help patients and any healthcare system reduce costs and time used.
The requirement of a vetting tool and automatic screening tool is the need of time. The problem of limited data can be solved using the meta-learning method. The proposed framework can process, detect, and fine-grained classify the medical image segments. The radiologist could find the relevant information with the operation and then vet the results (expert knowledge) for the protocol recommendations. This process is very less time-consuming and requires less time than the screening of the entire set of the medical centre. The proposed method enables the health system to develop a segmentation tool to decrease healthcare costs for patient data processing.
Related work
Meta learning-based applications have been developed recently [7]. The purpose is to adapt to the new small instances. The regression-based meta-learner was used to predict the multi-layer perceptron networks. The compressed feature representation is used as meta-feature [1]. The meta learner learns the relationship between meta-features and prior information. Doan et al. used the prediction based model to predict the training time of the algorithms [8]. Soares et al. used meta-learning methods to predict the outcome of clustering algorithms [30]. The parameter optimization is also done for support vector machine using the meta-learning method [12]. The method of meta-learning has been applied to a few medical imaging. Campos etal. [3] predict the segmentation scores for wound photos. Cheplygina et al. [6] used the statistical classifier to apply on meta-features space. Stacking-based medical pixel prediction has not been proposed using the meta-learning methods to the best of our knowledge.
In medical-based applications, some studies focus on domain adaptation and a few short learning. The problem becomes more challenging in image segmentation [9]; therefore, supervised [15] and unsupervised [14] both learning mechanisms are adopted recently. In particular, the segmentation of intravascular ultrasound tissues is also applied by using decision forest and vector-based images [21]. A few short network [22] segmentation is also performed to segment the MR into multiple organs. However, a test domain required a priori knowledge to be generalized. The generalization required a certain preprocessing mechanism that will focus on the research. The medical image segmentation mostly depends on the synthesis of data augmentation tasks to achieve generalization. Different data augmentation methods are applied to the heart segmentation problem [24]. The prime purpose is to mimic the distribution of the new test domain. Another research used the dynamic ensemble selection [32] and applied it to the classification problem. In work by Tajbakhsh et al. [31] as well as Shin et al. [29], the transfer learning method greatly improves the performance of the model. However, some fine-tunings are still required to transfer model weight on a different task. The quality of the model is still required to be assessed after training and validation.
The methods mentioned above have several limitations; the first is that training data are heavily augmented, which is not a general case. For instance, in the COVID-19 case, the goal is to extract useful information from the provided data, as the data are limited for domain generalization. The mentioned methods are not tested on majority diseased instances or a healthy population. The testing on real data signifies the methodology. When data augmentation is used as a prime source, then the training and testing set contains a set of similar instances or anatomies. In [27], the domain labeled data are used as additional information as it is challenging to curate it by radiologists. The patient data extracted from the same data centres cannot be considered a different domain as train, and test sets have similar statistical distribution.
Meta-learning methods are also another potential solution [35]. It is due to the complexity of the data or the little difference between datasets. Another issue is data availability; model performance significantly improved with the addition of the data. However, the limited instance of labeled medical data makes it a more challenging task. Therefore, there is a need of generalization from the previous experience whenever we are required to study a new medical imaging problem [23].
The authors addressed the negligence of the structure-based information in the classification task [34]. Also, they proposed the fully associative ensemble learning model, used the multi-variable regression with l1 norm regularization. The model was applied to image annotation and gene function prediction datasets. The discriminated information is also used to place similar data points close together [28]. The distance learning method is used to classify the data points by the probabilistic framework via ensemble learning [28]. Zheng et al. [36] classify the EEG signals by using ensemble networks. The model utilizes the bagging theory method to generalize the learning. The model can achieve 90.16% accuracy.
Methodology
The proposed meta-learner can solve three goals: (1) design and develop a semantic improved preprocessing algorithm to increase the unstructured radiologist data (raw images) as the computable representation. (2) increase the segmentation performance by using the meta-learning based classifier. (3) adopt and help in early detection of new vital signs of the patients.
Dataset
The dataset and cases are available from https://www.sirm.org/category/senza-categoria/covid-19/. The sample of the dataset with normal and two COVID segmentation cases are mentioned in Fig. 1. We convert the data from the DICOM to JPG. We normalized the image by using the Hounsfield Unit scale. The image is rescaled to NIFTI-file (512 x 512 x 110). The radiologist based segmentation is performed using http://medicalsegmentation.com/covid19/. Each pixel value was used to have ground class, consolidations and pleural effusions.
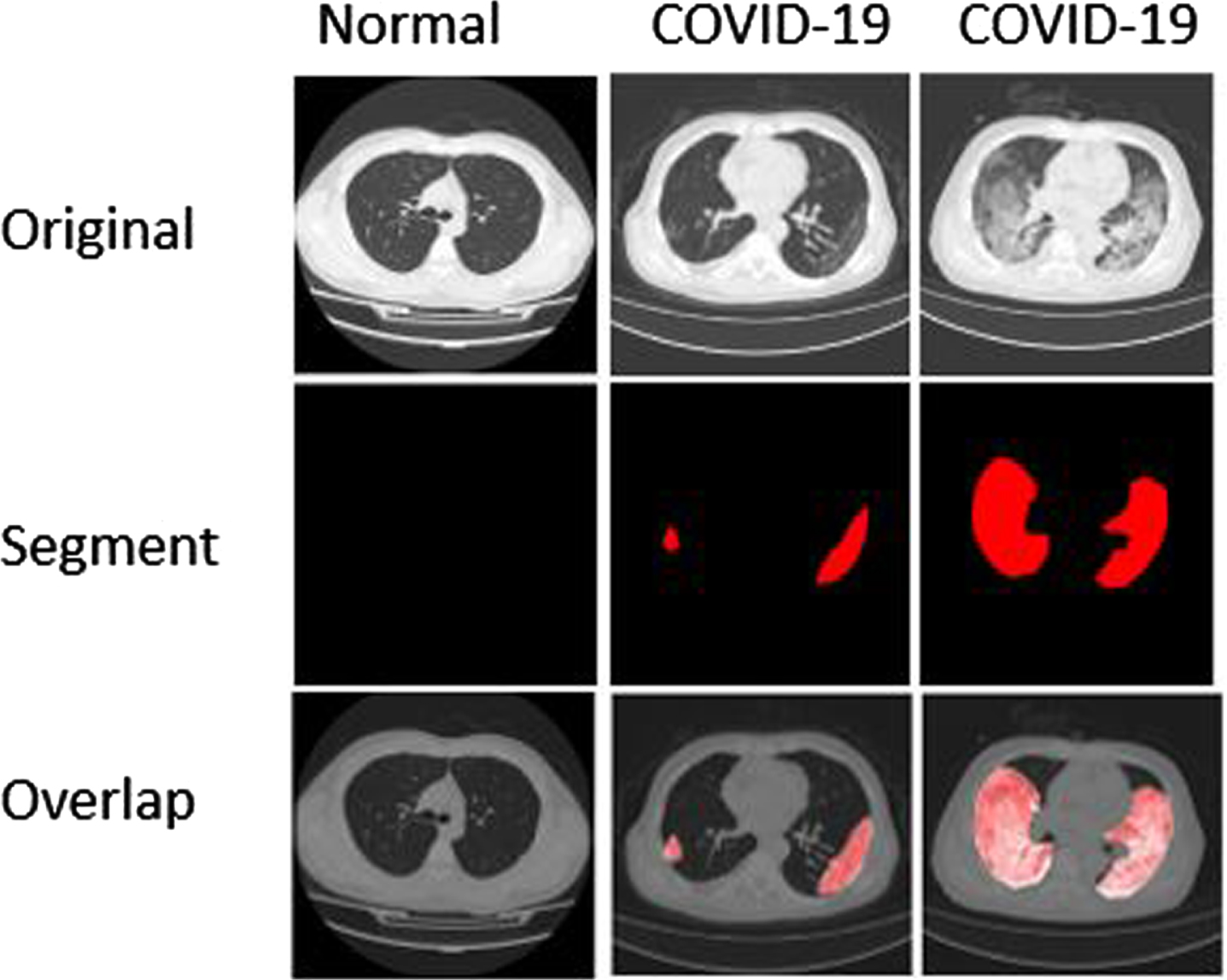
Sample dataset.
After the analysis of the dataset, we removed some regions of the image as it contains artefact at some pixels required to be enhanced as distortion results in miss classification. The flow of the method is described in Fig. 2. The 1% region data from the top and bottom are removed. The region was selected by calculating the percentage of the input image height. Then we convert the image into a binary image. After that, histogram equalization is performed to increase the bright spot in the image (Algorithm 1, lines 1 to 2). The median filter is used to handle noise issues, and morphological operations are applied to increase the image quality. The pixel segments are extracted by using the component that is connected (Algorithm 1, line 4). We apply the Savitsky Golay algorithm to smooth the edges as it helps in extracting distinct relevant parts (Algorithm 1, line 5). The smooth edges help to create the boundary. Then binary mark is used to extract the segments from the raw image (Algorithm 1, lines 6 and 7). The preprocessed image is then passed to imageNet feature extractor. These features are used by the learning network as shown in Fig. 3.
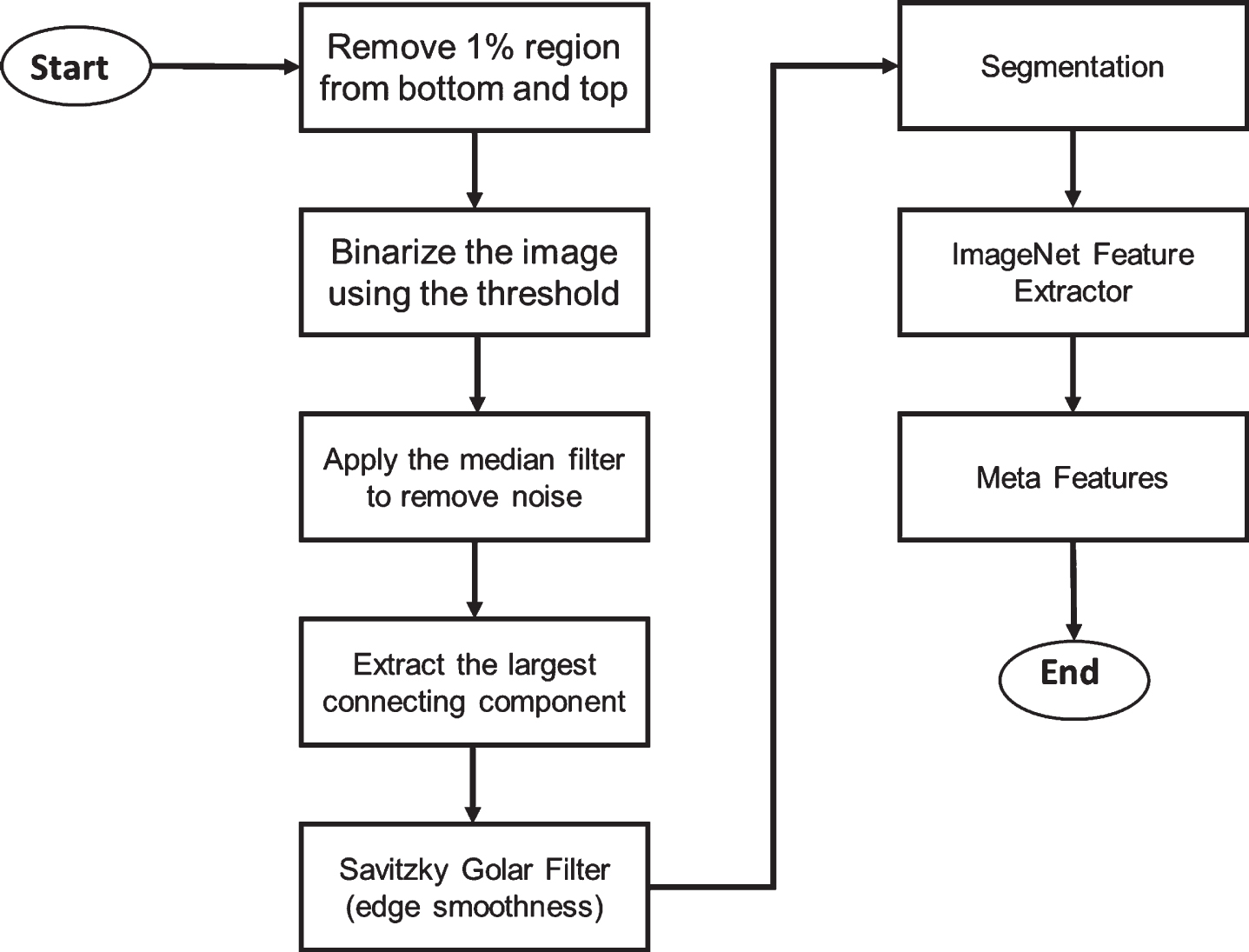
The flowchart of the proposed model.
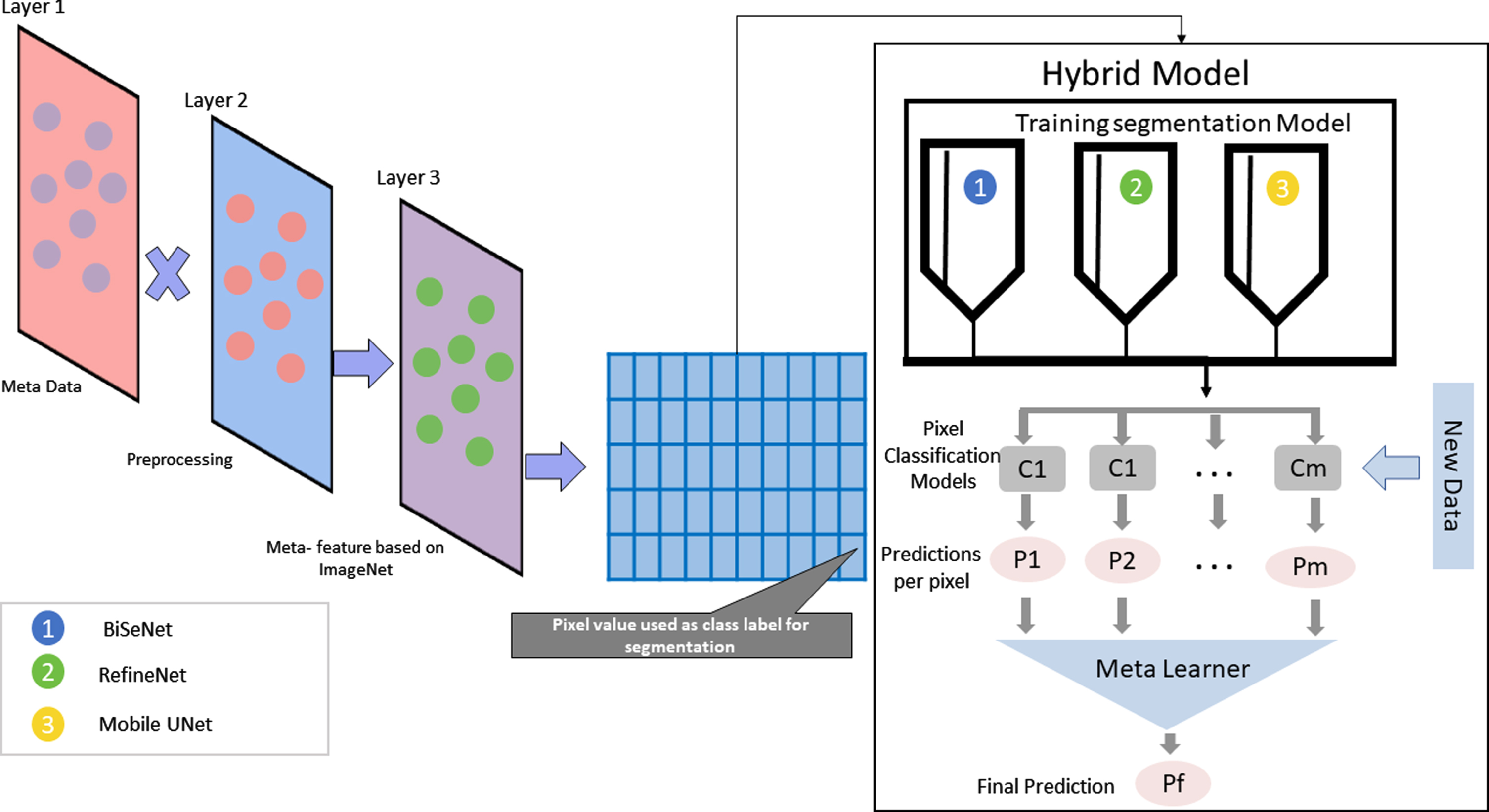
The developed methodology.
1: I ←Load_Image();
2: J ←ImBinarize(I);
3: J ←Median(J);
4: Blob ←ELCC(J);
5: Blob ←SGF(Blob);
6: Binary(mask) ←Convert(mask)(Blob);
7: extracted breast ←
Crop_image(I, Binary(mask));
8.
In the research, three frameworks have been deployed, i.e., BiSeNet [33], RefineNet [25], and Mobile UNet [16] for semantic segmentation publicly available in TensorFlow. In this research, we used the pre-trained network Imagenet [20] that was trained on 1.2 million RGB images. The transfer learning method is adopted by changing the first and last layers of the networks. The connected convolutional layers were used to extract different feature dimensions from the images. The deep networks were utilized in the field image classification to achieve high performance. The pre-trained network helps to extract features. The network weights help to generalize quickly on the new unseen data without modifying the architecture. The custom fully connected layer is added in the first layer, and the last layer is kept similar for the segmentation task. The back-propagation model can reduce loss and optimize the weights. We used this approach as it reduced the over-fitting.
Meta-learning
The method diagram is mentioned in Fig. 3. After prepossessing and image net-based feature extraction, the three frameworks are trained. The meta-learning model intents to learn an optimal method by combining the prediction P produced by the deep learning segmentation model C. The function f(C1, C2, …, C S ;θ) is required to be optimized to reduce loss for the prediction of each pixel. We combine the probabilistic model by using the hypercolumn formulation [13]. The training set with X images and segmentation set Y, the proposed model tried to optimize the function mentioned in the equation 1. A single layer regression network is used as meta-learning that takes the prediction of the deep network for each class, as mentioned in Fig. 3.
The networks BiSeNet [33], RefineNet [25], and Mobile UNet [16] are used for the experimentation. We trained them via Stochastic Gradient Descent using mentum. Fixed 1e-10 learning rate and 0.99 momentum are respectively set for three networks [19]. The model first and the last layer are changed for successive fine-tune. Also, we added random dropouts on the hidden layer to learn more complex representation. The model is trained by using the early stopping method to avoid over-fitting. After that, a meta learner that uses the learning output of the models and aggregates uses the network’s output as input features. We used a soft voting method. For instance, the model gives the probability (0.45, 0.45, 0.90) for the single-pixel as segments of illness [19]. The hard voting favours the majority rule (1 against and 2 in favour) [37]. As a result, the hybrid model will classify it as a negative or benign pixel whereas soft voting takes the average probabilities, i.e., 0.6, and classifies it as a segment with illness (positive). These pixel values are learned by the meta learner and used as knowledge. The regression network with a fixed learning rate is used as meta learner. We used IOU (intersection over union) as mentioned in equation 2 and Dice metrics as mentioned in equation 3 as performance measure [2, 10].
We used the pre-trained ImageNet as a meta learner by employing the preprocessing method. The proposed meta learner is compared with the traditional meta learner methods. Hard and soft voting based learning is used. In Table 1, it represents the overlapping region, and if the method has a higher value of dice and IoU, then the designed model can extract the region effectively. The prediction segments region if overlap with the ground truth then bounding boxes have higher scores than the less overlapping one. The soft voting based learning improves the dice and IoU by 0.68 and 0.61 values as shown in Table 1. At the same time, the method achieves 0.94 precision and 0.92 recall.
Sensitivity and Specificity of classification model under 25 threshold value
Sensitivity and Specificity of classification model under 25 threshold value
Precision is used to describe the exactness of predicted labels. The correct prediction results in an increased percentage of the classification model. In our case, 0.94 precision is represented in Table 2, which means a more robust prediction for the soft probability voting based meta learner. This higher number also shows that the method correctly classifies the positive and negative samples.
Dice and IoU of the compared models
The recall gives information about completeness. The higher values show the correct classification of the pixel type. In our case, 0.92 is represented in Table 2 that shows the classification model can predict the pixel belonging to the same class. The lower values show that the classifier is not sure about the co-located pixels.
In this research, we proposed the preprocessing method to increase the instance for the image segmentation problem. The proposed method used the meta feature extractor and combined the output of the state-of-the-art segmentation problem to learn the meta-representation. Then, by using the limited set, the learning model can achieve high accuracy. Each ensemble model uses the transfer learning method to adapt to the new distribution of the data points. Then, it uses the pre-train weights and updates the parameter. After that, we proposed the meta-learning model that uses the ensemble learner’s output and combines with the probabilistic approach to adapt and learn the new data point using the soft voting method. The voting mechanism helps to adopt the domain to achieve generalization and better accuracy. In comparison with unique architecture, the proposed model increases performance. The fine-tuned model architecture and voting mechanism help the meta learned to increase the hybrid approach’s performance. Although the model could achieve higher accuracy, we must perform domain segmentation with the different datasets for different applications. The methods should also consider the usage of the deep data augmentation concept for various segmentation problems. The proposed model can also apply to other segmentation-based problems in computer vision since classifying pixels is the same. In the future, we will work on the neural architecture search for domain adoption with meta-learning. We will first search for the best architecture for the problem by investigating the dataset characteristic and its correlation with meta neural architecture. Then apply the proposed method to tune architecture. It is also possible to apply some tunning model for the developed architecture, thus achieving better performance regarding precision and recall.