
Abstract
The primary objective is to identify and segments the multiple, partly occluded objects in the image. The subsequent stage carry out our approach, primarily start with frame conversion. Next in the preprocessing stage, the Gaussian filter is employed for image smoothening. Then from the preprocessed image, Multi objects are segmented through modified ontology-based segmentation, and the edge is detected from the segmented images. After that, from the edge detected frames area is extracted, which results in object detected frames. In the feature extraction stage, attributes such as area, contrast, correlation, energy, homogeneity, color, perimeter, circularity are extorted from the detected objects. The objects are categorized as human or other objects (bat/ball) through the feed-forward back propagation neural network classifier (FFBNN) based upon the extracted attributes.
Keywords
Introduction
Video segmentation is a huge concern in several applications that identify the object in the temporal image series for the next process like tracking, editing, reconstruction or identification [1]. The Video Object Segmentation (V.O.S.) aims to extort the front objects from the back scenario in a video [2]. Video object segmentation is a must for several sophisticated vision applications, including video understanding, object recognition and vision object replacements (cut and paste the video objects). In image and video processing, image segmentation is a challenging task and is one of the vital operations during processing [3]. The segmentation depends on the image’s dimensions, and it may be grey content, depth, texture, colour, or motion [4]. Every pixel in a region is comparable with respect to a few traits or computed properties like colour, intensity or texture. The adjacent regions fluctuate concerning similar characteristics [5].
Two circumstances occur with the changeable segmentation scales, namely, a) Under segmentation and b) Over segmentation [6, 7]. Under segmentation arises when segmentation limits the parameter like heterogeneity, band count, and resolution, resulting in higher segments than the actual attributes [8]. Over segmentation arise when the segmentation strictures generate lower than the actual attributes [9]. Under and over, segmentation makes a considerable change in the classification accuracy; however, under segmentation holds a much worse consequence [10].
Image segmentation is employed in several applications like biomedical image analysis, character detection and target identification [11]. In general, the image segmentation techniques are broadly classified into three types, namely, a) Boundary-based techniques, b) Region-based techniques, and c) Hybrid techniques [12, 13]. Several completely automated techniques and supervised techniques for segmenting the objects have been developed like histogram-based, edge-based, region-based and Markov-random field-based approaches [14]. Image processing is a burgeoning region in the arena of computer science. Its escalation has been occupied by the technological advancement in computer processing, digital imaging and huge storage devices [15]. Image processing generally begins with the edge detection technique, which is then followed by the feature extraction [16]. The edge detection is one of the most common practices in digital image processing. Image segmentation could be carried out through several edge detection methods like Sobel, Prewitt, EM algorithm, OSTU, Roberts, Canny, LoG, and Genetic Algorithm [17]. Image and video object detection face a protracted-standing challenge for computer vision, and the problem complexity is mainly based on the constriction and the limits enforced on the data [18]. The advantages of digital image processing are low-cost processing, reliably high image quality and the capability to control every view of the process. [19]. The most outstanding factor is the performance gap amid at the recent video object segmentation approaches, which experiences significant growth nowadays [20].
This manuscript’s sketch is designed as follows: Section 2 investigates the related problem regarding the proposed approach. Section 3 comprises a concise discussion related to the proposed method; Section 4 analyses the experimental outcomes, and section 5 concludes the work.
Related work
Ying pings Huang et al. [21] have projected a new method for the concurrent detection and categorization of the multiple class impediments such as automobiles, pedestrians and others. That technique incorporates stereovision-based obstacle recognition and the dynamic contour models. The stereovision is employed to build a depth map. Thus, many impediments got separated from the congested background based upon their locations. The dynamic contour prototypes are implemented for mining contour. The geometrical attributes such as aspect, area ratio and height are included for categorizing various objects including automobiles, pedestrians and others.
Mohini Deokar et al. [22] have projected an innovative technique for shot boundary detection through Block based histogram Comparison to deal with the concern in the video segmentation process. Initially, they flash videos depending upon the color and motion attributes offered for the cricket videos. A group of videos spin prominent interpretation regarding the affair department approaches normally fail because of the absence of visual dissimilarity amid the space and time. They confined a precedent-setting computationally smarter to find out the abrupt and gradual variations. In this approach, the frame traits such as color and motion features have been employed to attain the constant variation for the dissimilarities in illumination.
Jayanthh et al. [23] have projected the vision-based object recognition algorithms to mechanize the video frame abstraction with the sports action in a different view. In the preprocessing, filtered the frames with a scene of cricket area, where the cricket field made a region, by removing the frames which include an outlook of the viewers, close shots of the particular actors, ads, etc. The subpart of frames comprising the cricket region was then subjected to the Statistical Model of Grayscale histogram (SMoG). As the SMoG would not exploit the color or domain precise data, they develop anotherComponent Quantization-based RoI Extraction (i.e., CQRE) for pitch frame abstraction.
Mojtaba Seyedhossein et al. [24] have introduced a contextual structure known as the Contextual Hierarchical Model (i.e., C.H.M.) ascertains the related information in a hierarchical structure for semantic separation. It integrates the resultant multiresolution contextual data into a classifier to fragment the input image at a unique resolution. That the practices permit for the optimized joint posterior likelihood at several resolutions via the priority order. Contextual classified model merely depends upon the input image spots and did not utilize any segmented or the outline instances. Therefore, these were appropriate to several problems like object segmentation and edge detection.
Chi-Man Pun et al. [25] have introduced an innovative on-line video object segmentation approach which depends upon the light invariant color surface feature abstraction and indication likelihood. The developed object marker prediction approach comprises approximating the consumer quantified markers and positioning the object of interest in the subsequent existing frame through the superpixel motion prediction through, illumination invariant optical flow, marker superpixel applicant production short-termsuperpixel similarity, and maximum likelihood calculation using the long tenure superpixel similarity.
Zuoyong Li et al. [26] have projected a well-built mixture single body object image separation technique by developing the salient shift region. This technique initially employs local difficulty and native variance to recognize the changeover areas of an image. After that, the changeover region with manypixels was preferred as the salient changeover region. Next, a gray level detail was ascertained through transition regions and image information. One gray level of the interval was established as the segmentation threshold through the prominent changeover region. Lastly, the image thresholding consequence is processed as the final segmentation outcome through the salient transition region to confiscate the object’s phoney regions.
In the emergence of Deep Neural Networks (D.N.N.s) [29], a more significant benefit is obtained with the initiation of special Regions in association with CNN features (R-CNN) which have deeper architectures along with the capacity to learn more complex features than the shallow ones. This training algorithm is a robust one as it performs classification and bounding box regression tasks in an optimized way. Thus, D.N.N. outperforms over the primary CNN and makes it real-time and accurate object detection more achievable. “You just look once” - YOLO is an advanced real-time object detection system created by Joseph Redmon and Ali Farhadi from the University of Washington. Their algorithm applies a neural network to partitions the picture into a grid and uses one forward propagation to detect all objects in an image.
Augmented reality (A.R.) andvirtual reality (V.R.), one of the hottest topics in technology today. More to that, mixing these two techniques is still challenging and very potential to be studied. Some researchers started reviewing the techniques that mainly focus on vision-based techniques. Their general principles organized the methods. Strengths and weaknesses for these principles were also explored [30]. Thus, it enhances the quality of experience and quality of service of reality applications to improve users’ everyday lives. On the other hand, mobile Augmented Reality (A.R.) frameworks can continuously track a camera’s pose within the scene. They can estimate the environment’s correct scale by using Visual-Inertial Odometry (V.I.O.) [31].
Proposed methodology
In this manuscript, a novel method has been introduced a method to efficiently classify the multi objects and categorize the objects in sports videos. Originally the input video will be brought from the data catalogue, and that fetched video will be split into some frames. To simplify the segmentation process and the accurate detection of a human object, both forward and backward tracking will be supported out on the projected method. During the forward tracking, the order of frames will be considered from first to end. Initially, Preprocessing is implemented for every frame for eliminating the noise. In preprocessing level Gaussian filter is utilized for eliminating the noise. Then for each preprocessed frame, modified ontology-based segmentation is applied to segment the objects.
Meanwhile, backward tracking can also be executed. Here, the order of the frames will be from end to first. The same process carried out in the forward tracking will be repeated in backward tracking. Then the outcome of both forward plus backward tracking will be intersected for obtaining the segmentation result. Then the edge is detected from the segmented objects. Finally, the objects are detected by mean of the extraction of the edge detected frames. Attributes such as contrast, color, area, perimeter circularity, homogeneity, energy, and correlation are extorted from the detected objects. Depending upon the extracted attributes, the objects are perfectly categorized as human or bat or ball through the FFBNN classifier. Block diagram of our intended multi objects detection and classification approach is illustrated below.
Preprocessing
Let us assume a database I (D) containing several videos. The database is the representation whichgiven as follows.
Where n denotes the total number of videos in the database I (D), and each video is converted into some frames that denote the video’s frame i id . Each image has ’x’ rows and ‘y’ columns. After segmenting the video into several frames, each frame is converted to grey from RGB. Gaussian filtering is employed in all frames for image smoothening.
Gaussian filtering
Gaussian filter is employed to eliminate the Gaussian noise. The Gaussian Smoothing operator carries out a weighted average of surrounding pixels depending upon the Gaussian distribution. The weights offer high consequence to pixels close to the edge (which lessens blurring in the edges). The degree of smoothing is proportional to the term σ (high σ for more intensive smoothing). Sigma describes the degree of blurring. The radius slider is employed to manage the size of the template. More sigma values offer more blurring for large size of the template. Noise can be included by employing the sliders. Gaussian filtering is employed for image blurring and also to eliminate the noise and the details. The Gaussian function is described.
Where σ signifies the standard deviation of Gaussian distribution. The Gaussian distribution is considered to have a mean which is equal to 0. Gaussian smoothing is valuable for eliminating the Gaussian noise. The filtered image (I′ (x, y)) is then fed as input to the detection process.
Multi-object detection
The multi-object detection of our proposed technique includes the following three stages, Segmentation. Edge detection. Area Extraction.
Ontology-based multiple object segmentation
The smoothened image obtained after applying the Gaussian filter is subjected tothe segmentation process with modified ontology-based segmentation [28]. Here, the Dirichlet process mixture model is applied to the filtered image to transform the low-level visual space to intermediate semantic space to reduce the features’ dimensionality. After that, with the help of multiple C.R.F.s, the Dirichlet process features are weighed and learned separately within the context. After referencing to change the binary image to an RGB image, the segmentation technique looks like a classification technique. Finally, Modified k-means clustering technique is employed to get the segmented images accurately, and the segmented images are given as input for the edge detection process.
K-Means algorithm is an unsupervised clustering algorithm that classifies the input data points into multiple classes based on their inherent distance from each other. The algorithm assumes that the data features form a vector space and tries to find natural clustering. The points are clustered around centroids μ i , i = 1 . . . k which are obtained by minimizing the objective
Steps: Compute the intensity distribution of the intensities. Initialize the centroids μ
i
with k random intensities. Repeat the following steps until the cluster labels of the image do not change Cluster the points based on the distance of their intensities from the centroid intensities.
The computation μ
i
is modified as given in Equation (3).
Here m is the constant value. Compute the new centroid (μ
i
) for each of the clusters.
Finally, human, bat and ball objects are segmented from each frame individually and are subjected to process.
For attaining a better detection rate on every shot of a video frame, the detection plus tracking are pooled to acquire an entire tracking procedure. The two types of tracking are Forward Tracking and Backward Tracking.
The forward tracking procedure is implemented on every frame, starting from frames where the object has been identified. Backward Tracking is implemented on every frame for yielding an added group of objects being pursued. This tracking normally signifies the object tracking from the frame identified to the last the entire shot. In contrast, the backward tracking yields the unobserved consequence from the shot’s original frame to the frame where the final object detection is carried out. This tracking confirms to be effectual as the forward tracking does not place the object position in a specific frame. This occurs owing to occlusion, poor illumination or depending upon the tracker sticks to the background. If an object in frame1 is not traced properly and the similar object is traced in frame 5, the data are propagated back, offering object tracking in the initial frame. Finally, both the result from forwarding plus backward tracking is intersected to get the final tracking result.
Edge detection
An Edge in an image is a considerable local variation in the intensity of the image, generally related with a discontinuity in the image’s intensity. The edge description of an image considerably lessens the quantity of data to be handled. However, it preserves the vital information concerning the shapes of the objects in the image.
Area extraction
The area gets extorted from the edge detected frames for multi-object detection. The outcome is the multi-object detected frames. The area of the segmented image is computed through Equation (5).
Where, i (h), i (w) signifies the height and weight of the image.
Attributes such as perimeter circularity, homogeneity, energy, contrast, color, area, and correlation represent the imagecontent. The following are the attributes employed for proficient multi-object classification.
Multi objects classification using FFBNN classifier
The Extracted feature set is inputted to the Feed Forward Back Propagation Neural Network (FFBNN) classifier for training in the training phase. The FFBNN network gets admirably by the extracted features. The features extracted from the processed image are area (A), contrast (
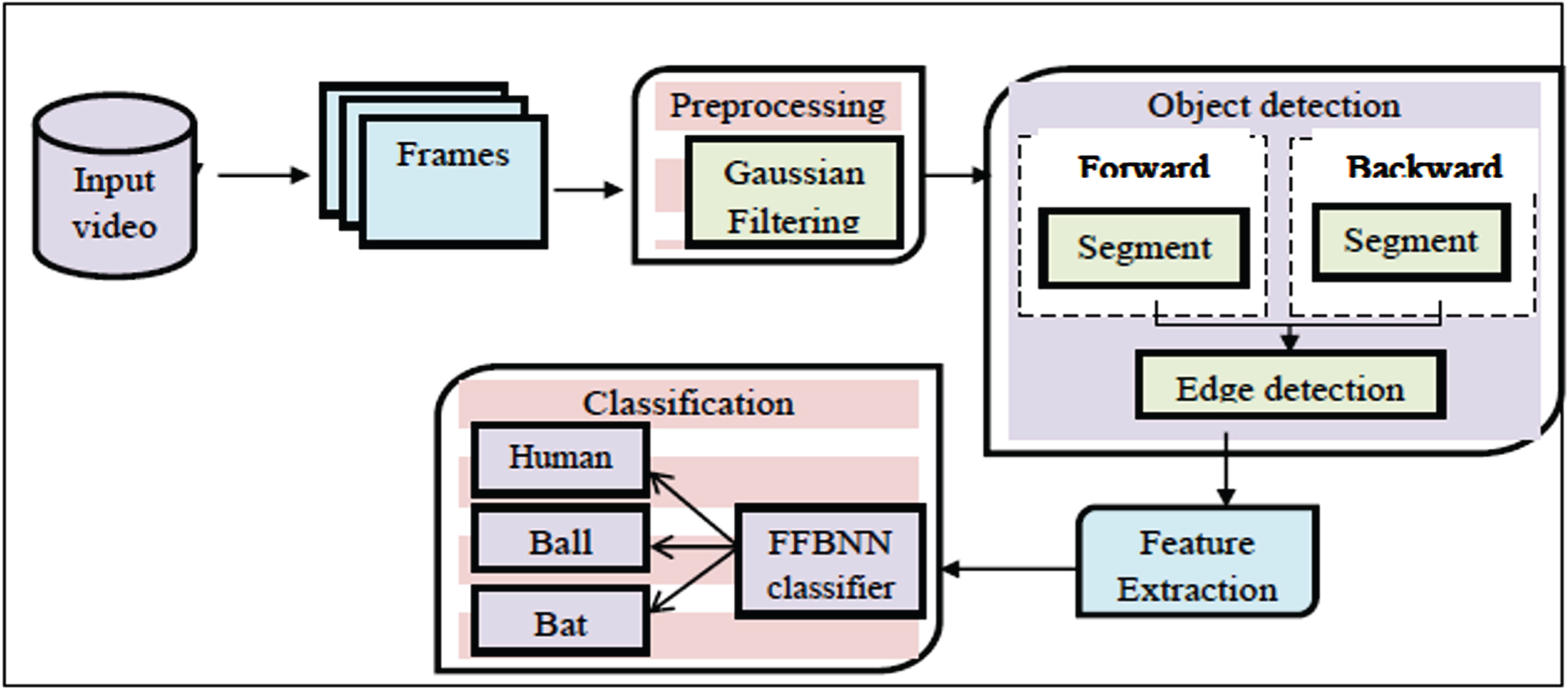
Block diagram of the intended multi-object detection and classification.

Properties of various Attributes.

Structure of FFBNN.
1. The bias function of the neural network.
The input weights are allotted to every neuron, excluding the neurons present in the input layer. The neural network’s planned bias function and activation function are expressed below: Bias function signifies the product of weights and inputs.
In the bias function A,
2. Activation functions for the neural network:
Activation function be a non-linear function which is expressed below
3. Calculation of learning error of the neural network obtained is given below:
The output of FFBNN r n andt n signifies the desired and the actual outputs and s be the total number of neurons present in the hidden layer. The error which arises at the training phase gets diminished through the back-propagation algorithm. The error minimization procedure using the backpropagation algorithm is discussed in [27]. The FFBNN network gets trained finely using the extracted features, and the network categorizes the specific value of the feature depending upon the feature types it belongs or not. Comparable FFBNN training procedure takes place for the entire feature set training.
In the testing stage, a fresh set of testing frames are acquired for the classification purpose. The testing frames get processed using our proposed approach, From the detected images, the features such as area (A), contrast (
In our projected object finding plus tracking approach, the input video obtained from the database is transformed into several frames. For accomplishing more precision in object detection, the noise is censored through Gaussian filter. Subsequently, objects are segmented with the assistance of graph cut with shape prior technique. The backward tracking process is performed, and the result of the forward tracking technique and the backward tracking technique is interconnected in the object tracking phase. After detecting every object in the frames, features are calculated to classify the objects into human and non-human. The intended object detection plus classification approach is executed in the effective MATLAB platform of version 14a. By employing the statistical measure, the performance of the intended object detection plus tracking method is scrutinized.
Snapshots of object detection plus tracking
The performance of the intended object tracking and classification method is evaluated using the conventional F.C.M. plus K-means methods. For assessing the performance of the intended approach, areutilized. Figure 3 (i), (ii) & (iii) illustrates the sample input frames, RGB to gray converted frames, noise-free frames obtained from video 1 and 2. Figure 5 (i), (ii), (iii), (iv) & (v) illustrates the segmented object obtained from the filtered images using F.C.M., K-Means, proposed technique, Edge image and tracking of the video1 and 2 respectively.

(i) Sample Input frames from video, (ii) RGB to Gray Converted Image, (iii) Filtered Image.
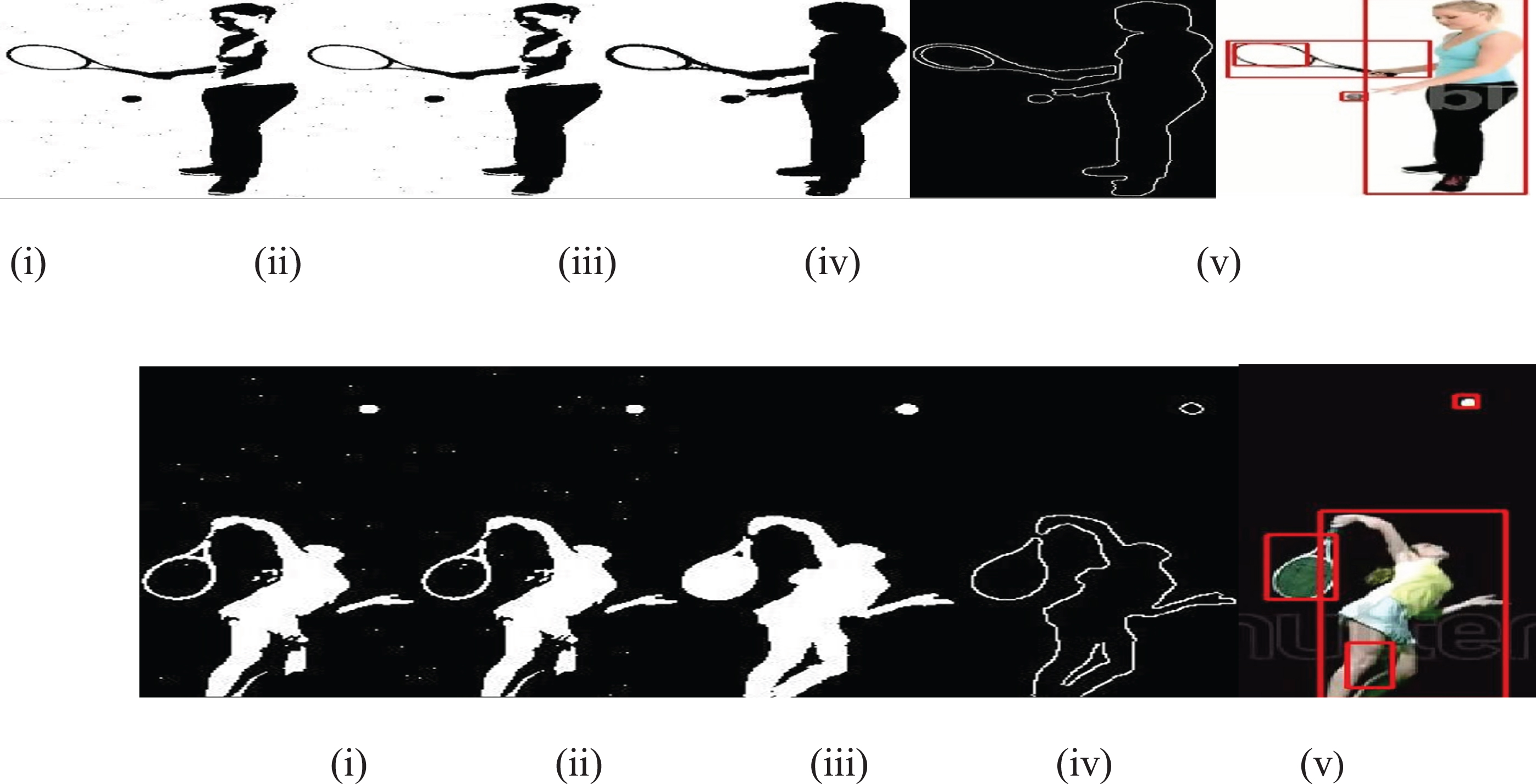
Segmentation via (i) FCM, (ii) K-Means, (iii) Proposed Technique, (iv) Edge Image (v) Detection.
The performance analysis of the intended object detection plus tracking approach is implemented through more images. The intended approach is assessed based upon precision, recall, F-measure, accuracy, specificity, sensitivity, F.D.R., F.P.R., F.N.R., and MCCto the conventional methods. The evaluation Table 1 of precision evokes the F-measures of the conventional and projected systems for video 1 and 2 mentioned below.
Evaluation of Segmentation of the suggested and prevailing technique in (a) video1, (b) video2
Evaluation of Segmentation of the suggested and prevailing technique in (a) video1, (b) video2
By examining the tables, In video1, the intended object segmentation system attained the utmost value of 98% when related to the accuracy of the conventional segmentation F.C.M. and K-Means techniques of 93.7% and 95.7%. In video 2, our system attains the utmost value of 99.6% when related to the accuracy of the conventional segmentation F.C.M. and K-Means techniques of 98.2% and 98.5%. Therefore, our intended system attains superior accuracy outcome when related to that of the conventional system. Similarly, the suggested technique offers better performance measures than the prevailing techniques. It is ascertained in the table. The comparison graph is illustrated below.
Figure 6 illustrates the proposed performance; the graph is built by considering the average accuracy, specificity, sensitivity, positive predictive value, negative predictive value, false discovery rate, false-positive rate, false-negative rate and MCC specified in the tables mentioned above. It is observedthrough the performance metrics of the suggested and existing techniques, the suggested technique shows better performance. Thus, it signifies that our intended approach outperforms the conventional approach.
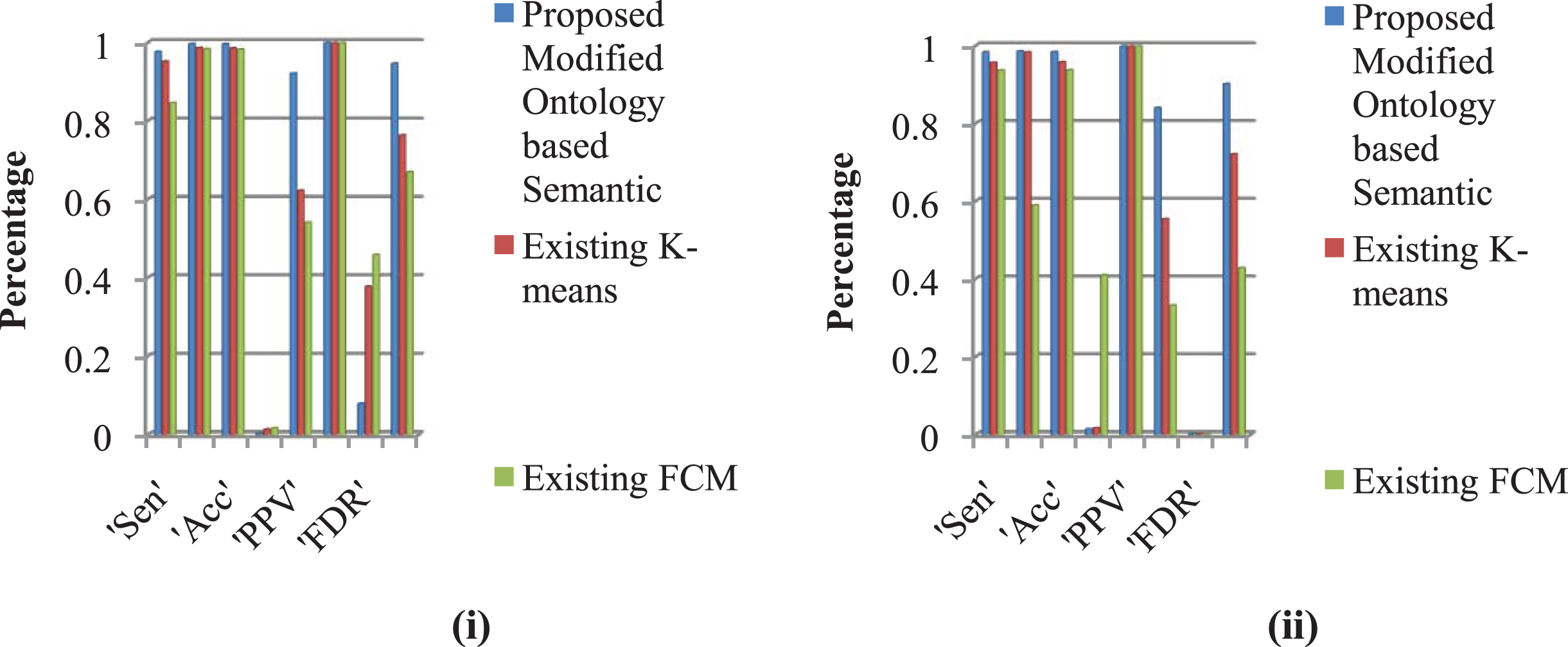
Performance Comparison of the suggested and prevailing segmentation techniques.
The performance consequences of three videos are tabularized in Table 2 based upon accuracy, specificity, sensitivity, F.D.R., F.N.R., F.P.R. and Mathew’s correlation coefficient (MCC). By examining the tables, in video1, the proposed classification attained the utmost value of 94% when related with that of the sensitivity of the conventional techniques K.N.N. and ANFIS possess 62% and 91% respectively. Thus, the proposed classification technique is 2-32% higher than the existing technique. When looking at the specificity and accuracy of the suggested and existing techniques, the proposed technique overtakes the prevailing techniques. In video 2, our system attains the utmost value of 96.8% when related to the accuracy of the conventional techniques K.N.N. and ANFIS possess 89% and 90% respectively. Thus, the suggested technique offers better classification performance, and it can be used for real-time purposes.
Performance Comparison of the proposed and existing classification technique
Our intended multiple object detection plus classification method uses forward and backward tracking based on modified ontology-based semantic and artificial intelligence approaches. The intended approach is executed in MATLAB platform. The intended method’s performance is assessed by means of two shadowing videos and it is compared by means of standard statistical measures like precision, F-measure, recall, accuracy, etc. Besides, the performance is evaluated with that of the conventional classifiers and segmentation system. The statistical measures exhibit that the projected method’s performance is superior compared to conventional methods. The projected technique yields superior performance outcomes, which shows that our intended approach implies performs better. It can be employed for actual time purposes.