
Abstract
The present paper proposes a fuzzy inference system for query-focused multi-document text summarization (MTS). The overall scheme is based on Mamdani Inferencing scheme which helps in designing Fuzzy Rule base for inferencing about the decision variable from a set of antecedent variables. The antecedent variables chosen for the task are from linguistic and positional heuristics, and similarity of the documents with the user-defined query. The decision variable is the rank of the sentences as decided by the rules. The final summary is generated by solving an Integer Linear Programming problem. For abstraction coreference resolution is applied on the input sentences in the pre-processing step. Although designed on the basis of a small set of antecedent variables the results are very promising.
Keywords
Introduction
Multi-document text summarization (MTS) has assumed huge importance in modern times due to the exponential growth of electronic text in different domains. The task of MTS is to create a gist of the contents present over several documents [1]. The task becomes even more challenging when the summary is to be made with respect to some specific user query. In the present work, the query contains a title and a description composed of one to four sentences as given in DUC 2006 dataset. The MTS system in such a case needs to produce a summary that is not generic, rather one that is pertinent from the query perspective. It is quite natural that the task involves dealing with ambiguities with respect to selection of the appropriate content from a collection of documents. This is because similar sentences may exist in more than one document. Straightforward selection of all of them based on some important keywords may make the summary repetitive [2].
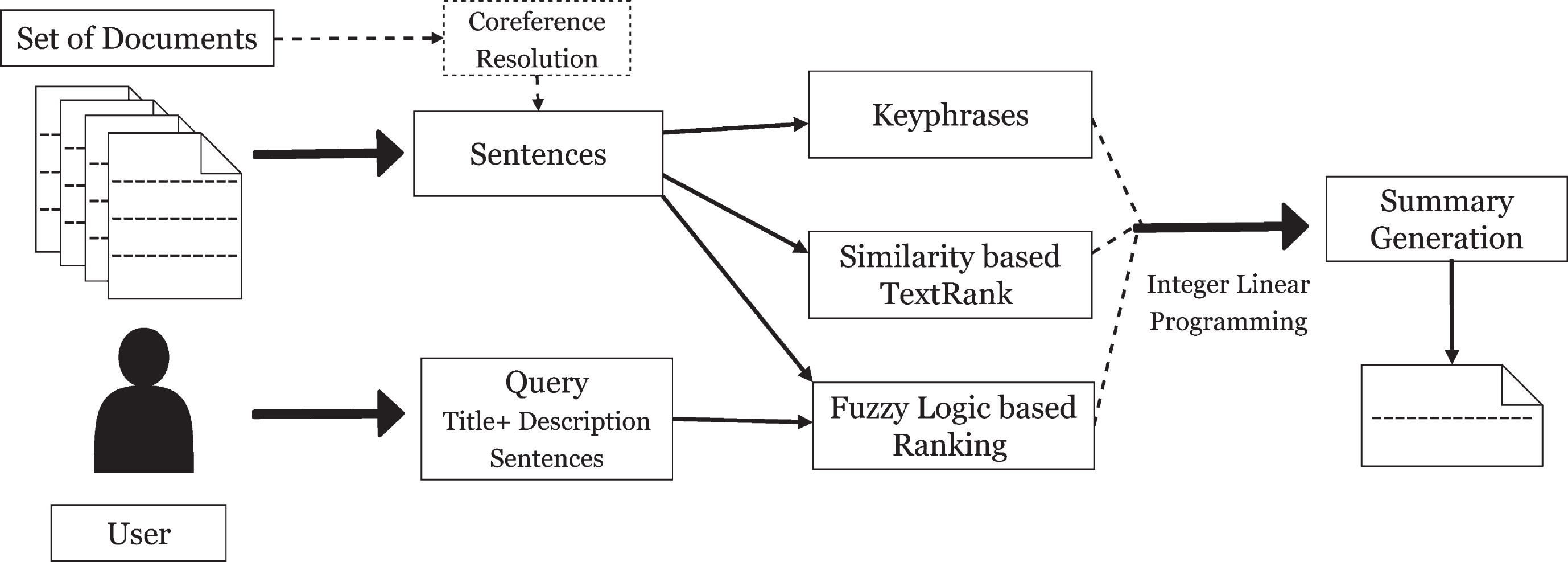
The Proposed Approach.
In order to deal with this uncertainty we propose a fuzzy rule-based inference system to achieve the intended goal. In particular, the proposed scheme uses Mamdani inferencing scheme [3] with Mean of Maxima defuzzification for deriving crisp ranks of the sentences from the entire set of sentences made out of the whole collection of documents. The antecedents of the rules are constructed by taking into account certain heuristics that are being practiced for several decades for the task of summarization. Additionally, it takes into account similarity of the document with the user query as well. Constrained Integer Linear Programming (ILP) has been used to maximize an objective function designed on the basis of the fuzzy rank of the sentences, TextRank [4] of the sentences and keyphrase scores. The summaries thus generated are evaluated and compared with past works using different ROUGE scores [5]. Furthermore, different automatic metrics based on lexical overlap as well as vector cosine similarity have also been reported in the present work. Coreference resolution [6] is employed as a pre-processing step for generation of abstractive summaries in addition to extractive ones. Ablation tests have been conducted to examine the importance of individual components and antecedent variables. The overall architecture of the system is given in Figure 1. The present work reports an initial version of the system which uses as few as only five antecedent variables. Even with this small set of variables the proposed system achieved performance better than the baseline systems. We plan to extend the scheme by considering additional antecedent variables.
The paper is organised as follows. Section 2 presents related works on existing fuzzy logic based summarization techniques. The proposed summarization scheme is described in Section 3. Section 4 contains experimental details and description of evaluation metrics. Section 5 presents results of different experiments. Section 6 concludes the paper.
Automatic Text summarization (ATS) has a long history of more than 60 years now [7]. However, application of fuzzy decision making in ATS is relatively recent. The first fuzzy logic based ATS system was developed by Kiani and Akbarzadeh [8]. Their system performed multi-document extractive summarization using a combination of Genetic Algorithm and Genetic Programming for optimization of the rule base and fuzzy sets. Nonstructural features, such as number of title words in the sentence, position of the sentence in the paragraph among others were used as input to the inference system. The fitness function used in their work was aimed at maximizing the presence of important words, such as title words, thematic words, emphasize words, in the summary and minimizing overlap of words between summary sentences. Their system achieved an average of 0.728 F1-score on a test set containing three document sets.
Witte and Bergler [9, 10] proposed a fuzzy clustering algorithm for generation of a context-sensitive summary from multiple input documents. In their work, topic clusters are generated using Noun Phrase (NP) chunks of the sentence and fuzzy coreference chains. For generation of generic summary the sentences belonging to the topic clusters having large size and spanning multiple documents were selected. Context-sensitive summary is generated by selecting sentences for the topic cluster which have high overlap with the given context.
Suanmali et al. [11] used features, such as sentence length, sentence location, number of words occurring in title, term frequency, number of proper nouns and number of numerical data for summarization of single input documents. A fuzzy inference engine with hand-crafted rules and Gaussian membership function has been used for sentence ranking. Kyoomarsi et al. [12] performed extraction of summary sentences from a single input document using fuzzy logic and WordNet. Their system incorporated nine input variables and four output variables for ranking sentences.
Megala et al. [13] performed summarization using fuzzy logic and artificial neural network. The neural network is used to identify important features and fuse common features. Megala et al. [14] also combined fuzzy logic and Conditional Random Field (CRF) for generation of extractive summaries. Important sentences are extracted based on their sentence features using fuzzy rules and membership functions. CRF is used to segment sentences based on the rhetorical roles present in the source document.
Jafari et al. [15] performed single-document summarization of 50 research articles using semantic and syntactic features of the text along with combination of these two aspects. The feature set included 13 features, such as TF-IDF, sentence length, sentence location, semantic similarity, word order similarity among others. In their work fuzzy logic is used to measure the degree of importance and correlation between sentences of the input documents.
Abbasi-ghalehtaki et al. [16] performed single-document ATS using Cellular Learning Automata (CLA), some evolutionary algorithm and fuzzy logic. CLA is used to optimize similarity between summary sentences in order to reduce redundancy in the summary. Importance of each sentence is taken as a linear combination of features, such as word features, similarity measure, position, length of the sentence.
Patel et al. [17] developed a sentence scoring technique using fuzzy logic for generation of extractive summaries in a multi-document setting with low redundancy. Similarity between sentences is calculated as the cosine similarity between TF-IDF vectors. Sentences are scored using fuzzy logic based on word features, e.g. title word, thematic word, proper noun words and sentence features, such as position and length. Top scoring sentences are added to the summary after deleting redundant sentences. The system achieved a ROUGE-2 score of 0.155 on DUC-2004 dataset.
All the above-mentioned systems except Witte and Bergler [10] used a fuzzy logic system for sentence scoring. Most of them produce generic extractive summaries and the features used as input to the logic system only considered the properties of the sentence.
The aim of the present work is to generate a query-focused multi-document summarization by incorporating query relevance in the features used for ranking the sentences. The proposed system performs both extractive and abstractive ATS. For generation of abstractive summaries coreference resolution is applied on the input sentences in the pre-processing step. This step replaces pronouns in the source sentences by its coreferent noun phrases.In a multi-document setting, the presence of similar sentences in the source documents poses a problem of redundancy in the summary. To address the issue of redundancy, similar sentences are grouped into clusters and only one sentence per cluster is selected in the final summary. While the fuzzy inference system ranks the sentences based on query relevance, keyphrases, position and rank, a mutual similarity based ranking of sentences is also performed using TextRank algorithm [4, 18]. Summary sentences are selected by solving an Integer Linear Program [19].
The proposed approach
Given a set of similar text documents and a relevant query, the proposed algorithms uses fuzzy inference system along with an ILP based sentence selection system for summary generation. The overall scheme works as follows: Ranking of source sentences using a Mamdani fuzzy inference scheme Summary generation using an Integer Linear Programming to maximize an objective function which in turn is a function of fuzzy rank of sentences, textrank of sentences and keyphrase scores.
Calculation of similarity between different sentences or phrases, and extraction of keyphrase along with their respective scores are applied in various steps of the algorithm. These are described in Section 3.1 and 3.2, respectively. The fuzzy sentence ranking algorithm is presented in Section 3.3.
Text similarity
The semantic similarity between different sentences/phrases are measured using cosine similarity between their embeddings. Let
Correlation between cosine similarity and relatedness score

Fuzzy inference system.
Text embedding can be obtained by averaging the individual word embeddings, such as pre-trained GloVe [20] or Word2Vec [21], a technique commonly used in literature. Alternatively, a fixed-size-vector representation of the text can also be obtained by processing the entire text using Transformer based Sentence-BERT [22] or Universal Sentence Encoder [23] architecture. In order to determine the best text vectorization scheme for measuring semantic similarity between texts, the SICK dataset [24] has been used. The SICK dataset contains 9840 pairs of sentences annotated with a relatedness score between 1 to 5, where a score of 1 indicates that the pair of sentences are least related (or unrelated) and 5 indicates that the sentences are extremely related. In order to assess different vectorization scheme the correlation between cosine similarity of the respective sentence vectors and relatedness score is studied. For all the embeddings maximum possible dimension has been considered. The results are presented in Table 1. Since vectors extracted using the pre-trained model en_stsb_roberta_large have the highest correlation between cosine similarity and relatedness score, this has been used in the present work for vectorization of sentences / phrases.
Keyphrases are the words or phrases that represent important topics mentioned in a given text. These can be one to ten words long [4]. A sentence containing multiple important (in terms of score) keyphrases will have a stronger candidature in the summary. From a given set of sentences, keyphrases along with its respective score (weight) is extracted using Rapid Automatic Keyword Extraction (RAKE) [25]. The score of each keyphrase is the sum of individual word scores calculated using a graph of word co-occurrences.
Fuzzy ranking
The source sentences are ranked using Mamdani Fuzzy Inference System [3] as described in Fig. 2. The proposed inference system incorporates five antecedent variables along with manually defined rules to derive a crisp value for the consequent variable Rank. The antecedent variables are named as QTitleSim, QDescriptionSim, KeyScore, RelPos and Length. The crisp inputs corresponding to the antecedent variables are fuzzified using Triangular Fuzzy Numbers as discussed in Section 3.3.2, the heuristics involved in creation of rules are described in Section 3.3.3. For defuzzification of consequent variable, Mean of Maxima is employed in the present work. Experiments with centroid / center of gravity defuzzification strategy yielded inferior results.
Antecedent variables
Let {S1, S2, …, S n } denote the set of source sentences, QT denote the query title, and {QD1, …, QD m } denote the m sentences present in the query description. Let SK = {sk1, …, sk r } denote the set of keyphrases extracted from the source sentences and QK = {qk1, …, qk t } denote the set of keyphrases extracted from the query description sentences. Table 2 illustrates these terms with a couple of examples taken from DUC 2006.
Examples of Queries from DUC-2006 dataset
Examples of Queries from DUC-2006 dataset
For each source sentence S
i
a crsip value for five antecedent variables are calculated as follows: QTitleSim (T
i
): Represents similarity between the source sentence and query title.
QDescriptionSim (D
i
): Represents the maximum of the similarity between the source sentence and each query description sentence.
KeyScore (K
i
): Represents the sum of scores of the keyphrases present in the source sentences. To incorporate query relevance in keyphrases a subset of SK is derived on the basis of similarity with query keyphrases. Each keyphrase sk
j
in SK is assigned a query similarity score calculated as max {Sim (sk
j
, qk1) , …, Sim (sk
j
, qk
t
)}, ∀j ∈ {1, … r} Top N keyphrases based on the query similarity score is collected in a set called SK
N
. KeyScore of S
i
is calculated as the sum of weights of the keyphrases belonging to SK
N
which are also present in S
i
.
RelPos (P
i
): Represents the relative position of the source sentence in the respective source document. Suppose S
i
belongs to document D such that total number of sentences in D is M
D
and S
i
is at m
th
position then,
Length (L
i
): Represents the length of the sentence in terms of number of words present in the sentence.
T
i
, D
i
and K
i
are normalised using min-max scaling such that the final values belong to [0,1].
In this section the fuzzy sets corresponding to antecedent and consequent variables are defined. In the present work, a Triangular Membership Function (TMF) is used for fuzzification of the crisp variable values described in Section 3.3.1. A TMF is characterized by three parameters a, b and c such that a and c denote the feet of the triangle and b denotes the peak.
Fuzzy Variable Modelling
Fuzzy Variable Modelling
The process of designing rules is an important part of any fuzzy inference engine. In the present work, if-then rules have been built manually using human knowledge. A set of 67 rules 1 were finalised by two experts. The rules are designed giving high priority to QTitleSim, QDescriptionSim and KeyScore. For the feature RelPos, the linguistic terms Begin and End are given higher preference in order to account for the fact that sentences appearing in the beginning and ending of a document contains salient information [26, 27]. Shorter sentences having higher KeyScore are preferred. The rules are of the form:
IF [QTitleSim is
Examples of fuzzy rules
Examples of fuzzy rules
A few examples of the rules that have been used in the present work are described in Table 4. For illustration the first row of the Table will be read as
IF [QTitleSim is High] AND [QDescriptionSim is High] AND [KeyScore is High] AND [RelPos is Begin] THEN [Rank is High]
The Fuzzy Ranking step measures the importance of a sentence based on its relevance to the query, presence of keyphrases, position and length. The importance of a sentence may also be analyzed using TextRank [18]. It is a graph based ranking algorithm, where vertices represent sentences and weighted edges are formed by connecting sentences by a similarity metric. TextRank determines the importance of each vertex based on global information extracted recursively from the entire graph. The Rank of each vertex is initialized as 1 and updated as described in Equation 6 until convergence. Here, 0 ≤ d ≤ 1 is the dampening factor which is set to 0.85 as suggested in [28] and N (S
i
) denotes the set of neighbours of S
i
. In Text Rank [18], only lexical overlap is used to determine similarity between sentences. In the present work the semantic similarity between sentences is measured using cosine similarity of vectors as described in Sec 3.1.
In a multi-document setting many similar sentences conveying the same information may be present in the source text. Selection of multiple similar sentences in the summary leads to redundancy. This step is aimed at grouping similar sentences. Selection of at most one sentence from each cluster helps to decrease redundancy in the summary. Moreover, selection of sentences from diverse clusters increases the information coverage in the summary.
Hierarchical Agglomerative Clustering [29] with complete linkage criterion is used for clustering. The clusters are created incrementally with each individual sentence considered as a cluster initially. Similar clusters are merged using a bottom up approach. In complete linkage the similarity between two clusters is measured as the minimum similarity between the sentences of two clusters. Clusters with similarity above a threshold λ are merged together. Similarity between sentences are measured as discussed in Sec 3.1.
Summary generation
The summary is generated by selecting the most important sentences relevant to the query while avoiding redundancy or selection of similar sentences. The sentence selection problem is formulated as a concept-based Integer Linear Programming (ILP) problem [19]. Let
subject to:
Equation 9 ensures that the sentences selected in the summary contains at least l words and Equation 10 limits the summary length to W words. Here, W is set to 250. Equation 11 prevents redundancy in the summary by allowing only one sentence per cluster, where each cluster of similar sentences are obtained as explained in Section 3.5. The constraints in Equation 12 and Equation 13 ensure compatibility between selection of the keyphrases and the sentences. The sentences selected using the above scheme are arranged on the basis of their relative position in the corresponding input document for generation of the summary.
In the present work, the sentences of the input source are ranked individually without taking into consideration its context. This leads to poor ranks for sentences having many coreferent terms. For illustration, consider the sentence It outlaws smoking in public and the workplace. The presence of pronoun ’it’ makes this sentence unsuitable for inclusion in the summary in spite of the presence of important information. A pre-processing step of coreference resolution [6] viz. replacement of pronouns by its coreferent head enables each sentence capable of communicating its relevant context by itself. The coreference resolved sentence for the above-mentioned example is, A drastic anti-smoking bill outlaws smoking in public and the workplace. The summary thus generated by applying the proposed summarization method is of abstractive form because the source sentences are modified using coreference resolution.
Experimental details
Experiments were conducted on the DUC-2006 dataset. It contains 50 document sets along with four manually written summaries. Every document set contains a user-specified query consisting of a title and one or more description sentences. The data statistics are presented in Table 5.
Data statistics for DUC 2006 dataset
Data statistics for DUC 2006 dataset
Sentence segmentation and tokenization are performed using spaCy 2 . The fuzzy ranking system has been implemented using Scikit-Fuzzy 3 . Coreference Resolution is performed using AllenNLP 4 .
Different automatic metrics based on lexical overlap as well as vector similarity have been used to evaluate the output summaries. The metrics used in the present work are the following: ROUGE (Recall-Oriented Understudy of Gisting Evaluation) [5] is a popular metric for evaluation of summaries. It computes the n-gram overlap between output summary and reference summaries. In the present work, ROUGE-n for n = 1, 2 and SU4 have been used for evaluating the summaries. ROUGE-SU4 allows skipping of at most 4 unigrams inside bigram components. These metrics have been shown to have high correlation with human evaluation [30]. BLEU Score (Bilingual Evaluation Understudy Score) [31] is a precision-based metric which is most commonly used for evaluation of machine translation systems. However, BLEU has demonstrated a high correlation with human judgment for paraphrase generation [32] and summarization [33] as well. In the present work n-grams up to n = 4 have been considered for calculation of BLEU. METEOR (Metric for Evaluation of Translation with Explicit ORdering) [34], which creates an explicit alignment between the system output and reference sentences. The alignment is based on exact token matching, followed by WordNet [35] synonyms, stemmed tokens, and paraphrases. Given a set of alignments, the METEOR score is the harmonic mean of precision and recall between the generated and the reference sentence. CIDEr (Consensus-based Image Description Evaluation) [36] computes n-gram co-occurrences (for n up to 4) between the reference and the generated sentences. It down-weighs the frequently occurring n-grams, and calculates the average cosine similarity between the n-grams of the reference and generated texts. VECS (Vector Extrema Cosine Similarity) [37] also computes the cosine similarity between the reference and generated sentences. However, in VECS the sentence embeddings are calculated by max-pooling the individual word embeddings [38]. Pre-trained GloVe embeddings
5
have been used to calculate the word embeddings. BERTScore [39] similarity is calculated as a weighted sum of cosine similarities between words of the sentences of the generated and the reference summaries. It correlates well with human judgment for evaluating different language generation tasks [40]. Let the system generated sentence be S = s1s2 … s
n
and the reference be R = r1r2 … r
m
then precison and recall for BERTScore are calculated as shown in Equation 14. Here,
The mean recall values of ROUGE-1, ROUGE-2 and ROUGE-SU4 are reported in Table 6 for the proposed system along with the NIST Baseline 7 and ERSS system [9]. Experiments were conducted for different values of parameter l ∈ {0, 2, 4, 6, 8, …, 20}, N ∈ {100, 500, 1000, 1500, all} and λ ∈ {0.1, 0.2, . . . .0.9}. The optimal parameter values were selected on the basis of the ROUGE score. The NIST Baseline corresponds to selection of lead sentences of the input document in the summary and ERSS generates query-focused multi-document summaries using fuzzy corefrence cluster graphs. It can be observed that both extractive and abstractive summarization strategies outperform the NIST baseline by a significant margin. The proposed system also outperforms the ERSS system in terms of ROUGE-2 and ROUGE-SU4 while ROUGE-1 scores are competitive.
Experimental results
Experimental results
Analysis of individual components for generation of extractive summary
Analysis of individual components for generation of abstractive summary
The efficacy of individual components of the proposed system are also studied, and results for extractive and abstractive summarization are presented in Tables 7 and 8, respectively. In these table TopRank selection strategy refers to selection of top ranking sentences in the summary such that total number of words is less than 250. Similarly One per Cluster refers to selection of sentences such that the sum of ranks of the summary sentences is maximized while selecting at most one sentence per sentence cluster. ILP refers to sentence selection process using Integer Linear Programming as discussed in Section 3.6. Here, the objective function contains only one sentence ranking term. The summaries generated using FuzzyRank outperforms TextRank across all selection strategies. ILP sentence selection also emerged superior to other selection strategies. The scores for extraction is marginally higher than abstraction for all the summarization methods.
Ablation results for analyzing the importance of individual antecedent variables for generation of extractive summary
Ablation results for analyzing the importance of individual antecedent variables for generation of abstractive summary
Summary generated for document set D0623E
In order to analyze the importance of individual antecedent variables ablation test was performed. Summaries were generated using the proposed method by removing one antecedent variables at a time. The values of different evaluation strategies for extractive and abstractive summaries are reported in Tables 9 and 10, respectively. It can be observed that for all the evaluation metrics except BLEU, removal of each antecedent variable decreases the system score. This indicates that each variable has a positive contribution towards the final performance of the summarizer. Removal of query relevant features, viz. QTitleSim, QDescriptionSim and KeyScore leads to higher decrease in score than RelPos and Length. QTitleSim emerged as the most important variable for both extractive and abstractive summarization as its removal lead to the highest decrease in scores. It can also be noticed that with respect to ROUGE scores and CIDEr the importance of KeyScore is higher than QDescriptionSim for extractive summarization; while it is the opposite for abstractive summarization. For BLEU metric the highest value is obtained upon removal of QDescriptionSim. The sub-optimality of BLEU score, which is a precision based metric, may be attributed to the fact that the parameter values l, N, and λ have been selected on the basis of highest ROUGE scores which are based on recall values. However, removal of all the other variables decreases the BLEU score of the system. Furthermore, it can be observed that for the metrics based on lexical overlap, viz. ROUGE, BLEU, METEOR and CIDEr, abstractive summary have lower values than extractive summary. In contrast, with respect to vector similarity metrics VECS and BERTScore, abstractive summaries have higher values than corresponding extractive ones. An example of the summary generated using the proposed system is presented in Table 11. It can be observed that the extractive summary contains sentences with unresolved coreferences.
The present work proposes a query-focused multi-document summarization scheme. Mamdani fuzzy inference with manually defined rules have been applied to rank the sentences on the basis of a small pool of five features. The features represent properties of the sentence, such as query relevance, position and length. The summary is generated by solving a constrained ILP problem. The objective function aims at selecting a subset of sentences in order to maximize the fuzzy logic based rank, TextRank and presence of important keyphrases in the summary. A constraint of the ILP problem allows the selection of atmost one sentence per cluster of similar sentences, and thereby reducing redundancy in the summary. Coreference resolution of input sentences is performed for generation of abstractive summaries. Automatic evaluation of the generated summaries in terms of ROUGE are particularly promising. While the proposed system outperforms baseline systems, Fuzzy ranking also outperforms graph-based TextRank scheme for different sentence selection methods. Extractive summaries have higher scores than abstractive summaries which indicates that replacement of pronouns increases the informativeness of a sentence at the cost of higher length and repetition of words. In future we would like to perform selective replacement of pronouns along with other abstractive techniques, such as lexical paraphrasing of complex words, sentence compression and fusion. We would also like to extend the current set of features used in the fuzzy ranking scheme to incorporate other aspects of the document, such as cohesion, readability, discourse analysis.