
Abstract
Sentiment classification is one of the major tasks of natural language processing (NLP) and has gained much attention by researchers and businesses in recent years. However, the semantics of the social networking language is becoming increasingly complex and unpredictable, affecting the accuracy of the associated NLP systems. In this paper, we propose a hybrid sentiment analysis (SA) framework that classifies the opinions of Vietnamese reviews into one of two types: positive or negative. The special feature of the proposed framework is that it is built on a combination of three different text representation models that focus on analyzing social media network language characteristics. Our system achieved an accuracy score of 81.54% on the test set, which is better than other strategies. Based on the experimental results, this work proves that the choice of text representation model determines the performance of the system.
Keywords
Introduction
The advent and development of the Internet and the explosion of Web 2.0 not only brought us a huge amount of digital data, but also gave us the opportunity to under-stand the emotional nuances of the online community through the analysis of these large-scale data. However, the larger the user-generated digital data, the more difficult it is to extract useful information. A recent report shows that every day, Facebook generates 4 petabytes of new data and 500 million tweets are sent by Twitter users. By the end of 2019, the world’s largest travel website, TripAdvisor, had 859 million reviews and opinions on more than 8 million hotels, restaurants, airlines, and yachts. Therefore, nowadays, many companies and organizations are facing problems of handling review data effectively. SA has been one of the most attractive areas of research in natural language processing since the early 2000 s.
The main task of SA is to automatically identify the value or semantic orientation (SO) of a given document [1]. SO, or the lexicon-based approach [2], refers to a measurement of subjective opinion, which denotes polarity (positive or negative) and the strength of a word, phrase, sentence, or text document. To this point, the research on SA has been approached in two main ways: the semantic approach, which involves calculation of the overall polarization through determination of the SOs of the words or phrases in text, and a machine-learning (ML) approach that implements the text classifications by choosing features and ML algorithms that match labeled text data.
Many works and tools for SA have been developed to exploit sentiments in user-generated content on weblogs. However, the complexity of natural languages, especially social media languages, makes these systems less efficient. In the words of Swiss linguist F. de Saussure, many regions will have many geographical dialects, and social linguists said that with many social groups, there will be social dialect meaning variations of the language used. For example, in a society where there are divisions of age, gender, occupation, status, etc., there will be corresponding dialects of age, gender, occupation, status, etc. In these dialects, along with the use of com-mon linguistic variations are language variations that reflect the individual style of each social group. Online communities with netizen members will exhibit language variations on the Internet. Language variations on the Internet can include phonetic-spelling variations of Vietnamese syllables online, word variations, and English lan-guage variations on Vietnamese social networks.
There are some remarkable publications on dealing with the SA problem, such as Yin et al. [3] for sentiment classification or Zhou et al. [4], who used a hierarchical attention mechanism with long- and short-term memory model [5]. At the fine-grained SA, [6] developed a model using both local and global attention, which outperforms the other state-of-the-art models. Systems based on deep learning always provide good results with sufficient training data, and these systems often have an efficient integrated language model. The language model is considered a key component of NLP-based tasks, including speech synthesis, question & answering, text analysis, and SA. However, state-of-the-art language models such as Word2Vec [7] and BERT [8], often are trained on standard datasets, cannot be used effectively for social media documents. For example, the PhoBERT [9] training dataset is a concatenation of two corpora, a 1 GB wiki and 19 GB Vietnamese news corpus (14,896,998 articles on the Internet). Furthermore, simple language models, such as bag-of-words (BoW), which is a statistical language model, are useful in some cases but require high-dimensional feature vectors.
This paper presents a sentiment classification framework based on a complementary combination of three language models to effectively represent data, aiming to improve the accuracy in the sentiment classification of social networking comments. When applying language models to the system, each document is modeled as a feature vector. We concatenate the feature vectors into an aggregate 1,200-dimensional vector. The system consists of three feature vectors as follows: BoW vector—Because the BoW method has a large feature vector dimension, affecting the performance of the system, we propose a strategy of considering the 400 sentiment words that are most prevalent in the dataset. BoW-base vector—First, each word in the corpus will be converted to its base form. Then, similarly to the BoW approach, we will take the 400 sentiment words that are most prevalent in the dataset. Word2Vec vector––Each word represented by Word2Vec has a dimension of 400. For each document, we will average the weights of each word within the document to create a 400-dimensional embeddings vector.
The main contributions of the paper are as follows: We propose a sentiment classification framework with improved accuracy when integrating an efficient text representation method. The feature vectors for the classifier are built through the characteristic combinations of words in social media language, frequency, and semantics.
The remainder of this paper is organized as follows. First, in Section 2, related work is presented. Then, in Section 3, natural language characteristics in social media are described. Next, in Section 4, the proposed framework is detailed. After that, in Section 5, we introduce the test results. Finally, in Section 6, conclusion is presented.
Related work
Our system is intended to combine social networks’ information and context with the original BoW model so as to achieve a strong and effective text representation model for documents through which to improve sentiment classifier’s accuracy. Therefore, the problems of text representation and sentiment analysis are all relevant to our work. The following part will briefly introduce the related work.
Text representation
Text representation is a critical component in NLP-based tasks. Most familiar NLP-based applications, such as Google Translate and Google’s chatbot Meena, are equipped with an effective text representation mechanism.
The BoW model is a simple text representation model that is commonly used but suffers from major disadvantages, such as sparsity, high dimensionality vectors, and the inability to capture semantics information. Since the 1990 s, the vector space models, including latent semantic analysis and topic models, have adopted distributional semantics [10–12]. These models were developed as an upgrade to the BoW model when transforming the BoW encode into low-dimensional representations to capture the implicit semantic information among the texts.
Recently, word embeddings have been proposed to express the semantics of words as real-valued, dense, and low-dimensional vectors. Basically, the word-embedding models i) use words in a dictionary as input, turning them into vectors of lower dimensions, ii) fine-tune the weights and parameters via a back-propagation process to form the embedding layer. Different from BoW model, word embeddings can present semantic information of a word into a low-dimensional and dense space and capture similarity more accurately. Furthermore, given a large-scale corpus, we can train word embeddings efficiently through neural language models without any annotations [13, 14]. Some state-of-the-art word-embedding models include Word2vec [7], Glove [15].
Sentiment analysis
SA studies the sentiments behind a text that helps businesses understand customers’ feelings expressed in their reviews. According to Liu [16], an opinion is defined by a set of five objects by (1):
In the above definition, s ijkl could be positive or negative, or it could be a measure that describes the degree of affection in comments, like the one- to five-star scaling in an Amazon.com review. The variable e i can be a product, a service, an event, or a topic. Based on the definition of opinion, SA (or opinion mining) aims to analyze the five objects of (1). For example, the document-level SA focuses on the fifth object (s ijkl ) without regard to the others. Meanwhile, the aspect-level SA is only con-cerned with the second (a ij ) and fifth object (s ijkl ).
With regards to the aspect-level SA problem, in recent years, the strong development of hybrid systems and deep learning models has yielded encouraging results. We can refer to works like [17] on mobile reviews, [18] on hotel reviews, or [19] and [20] with restaurant datasets. For the document-level SA issue, the top concerns of a document-level task are the mining of contextual information and the understanding of social media languages to help the system make accurate predictions. Notable works can be mentioned—[21] and [22] proposed ensemble learning models based on exploiting sentiment valence shifting and contextual information in Vietnamese re-views, [23] applied a self-attention mechanism to solve the sentiment classification on Spanish Twitter, and [24] built an effective language model based on part of speech and sentiment information to identify the emotional score of text.
Language is a social and interactive phenomenon that facilitates interpersonal communication within a society [25]. Social media languages involve the following elements [26]: Users have a habit of composing quick and short messages. The user is usually young. The social media environment is open and multicultural. In this environment, users can range from anonymous to named.
The factors that create the characteristics of the language on social networks include the following: Noise: Various words on social networks are nonsense. Abnormal vocabulary: The diversity of Vietnamese on social networks arises from the multicultural environment. Therefore, slang words are widely used. the multilingual environment often leads users to use their own words. many abbreviations are employed. Abnormal grammar: Weak grammar: The habit of composing quick and short messages causes users to ignore or misuse grammar rules: capitalizing proper nouns, employing the correct tense, using punctuation. Specific structures: Some sentences are ubiquitous on social networks, such as “Quên mSpecific structures: Some sentences are ubiquitous on social networks, such as Quên mâ. t kh u?” (Forgot your password?) Their aim is to be easy to remember; as a result, the structure is simplified but violates grammatical rules. Hashtags and emoticons such as “:)”, “(:”, “:b”, “:D”, etc.
Based on the language characteristics of social media networks, we defined four related dictionaries to form a text representation model, namely the BoW-base, which is described in detail in Section 4.2.
The proposed framework
In this paper, we propose a hybrid model for sentiment classification. The framework involves a combination of three language models: BoW, BoW-base, and word embeddings Word2Vec for data presentation. The main architecture of the proposed framework is illustrated in Fig. 1. In this framework, a document is preprocessed and then represented by three different feature vectors. The result is concatenated to obtain the final feature vector of the document. Then, a ML algorithm is chosen to classify a document as positive or negative.
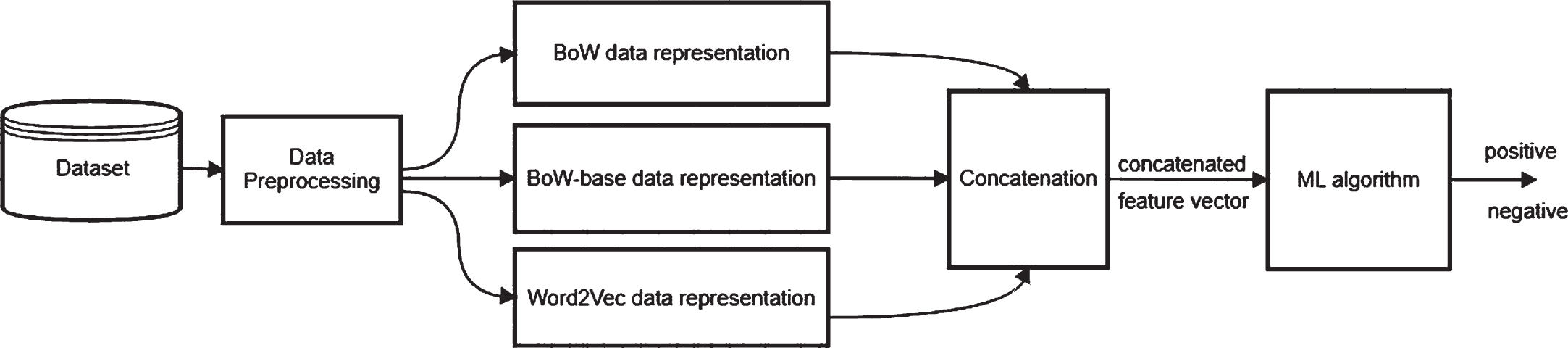
The proposed hybrid framework for sentiment classification.
The proposed hybrid classifier includes the following.
BoW is a language model for representing a document using the occurrences of each word in the document from a defined dictionary. The BoW model is simple but effective for text representation. If we have two documents: Document #1 is “X2 is a great band,” and document #2 is “King is a great band and Queen is a great band too!” The dictionary will contain 9 words {“X2”: 1, “is”: 2, “a”: 3, “great”: 4, “band”: 5, “King”: 6, “and”: 7, “Queen”: 8, “too”: 9}. Then, document #1 and document #2 are represented by the vectors [1,1,1,1,1,0,0,0,0] and [0,2,2,2,2,1,1,1,1], respectively. However, the more frequently a word appears in the document, the less important role that word plays. Therefore, the weight of a word t in a text vector d should be represented by both these factors, called the weight TF.IDF (Term Frequency - Inverse Document Frequency) [27] and calculated by formula (1).
where tf (t, d) is the frequency of occurrence of word t in document d; df (t) is the amount of text in the text set containing the vocabulary t; and n is the number of texts in the text set being considered. In formula (1), dividing tf (t, d) by the total frequency of all the words in d aims to normalize tf (t, d) according to the length of the text.
This paper uses the BoW model with weight calculated according to TF.IDF; this is considered the most classic text representation model [28]. To construct the BoW feature vectors we build a dictionary that consists of the 400 top sentiment words sort-ed by the occurrence of words among the corpus.
We propose the BoW-base model, which aims to improve robustness and comprise more social media information than the original BoW model. First, we construct four base word dictionaries which contain the base form of all words of the documents among the corpus. Then, all the words of each document are converted to their base form, and the document is presented with a BoW feature vector. We set up a dictionary of variations of words on Vietnamese social media, which contains 1,030 variations in all, the Table 1 describes a part of the dictionary.
A part of the dictionary of variations of words on Vietnamese social media
A part of the dictionary of variations of words on Vietnamese social media

Another dictionary of emotion icons is also created, in our database appear all the 36 emotion icons, some of which will be referred to on the Table 2.
A part of the dictionary of emotion icons

Popular acronyms are also combined to form the third dictionary, our database sums up 89 entries, we will see some of them in Table 3.
A part of the dictionary of popular acronyms

We also create a dictionary of English variations and abbreviations, the Table 4 will show a part of it.
A part of the dictionary of English variations and abbreviations

BoW and BoW-base model contain a number of defects such as i) word counts don’t consider synonyms ii) BoW representations lead to too large dimensions. For example, if a dictionary has 50,000 words, the dimension of a feature vector representing the document would be 50,000. In this paper, to construct the BoW-base feature vector we build a dictionary that consists of the 400 top sentiment words sorted by the occurrence of words in the training data.
Word2Vec is the best-known word-embedding technique. It is one of the NLP techniques that map semantic meaning onto a geometric space with smaller dimensionality compared with the BoW encoding. The new space is defined by the numerical output of an embedding layer in a deep neural network. With Word2Vec presentation, we can create features that group similar words, and these features have mathematical meaning. We use Word2Vec to generate a feature vector for the document based on the document’s semantic representation. In this paper, the word embeddings are averaged out for each word in a document. We use the pre-trained Word2Vec built by Son et al. [29]. Word2Vec feature representation with a one-hot vector dimension of 50,000, reduced to 400 after applying word embeddings.
Experiments
Datasets
We gathered 4,000 reviews from tinhte.vn. They are electronic product reviews with social media languages, symbols, abbreviations, and slang words. These reviews are divided into two classes: positive and negative. We divided the dataset into two parts, training and testing, with the ratio 70 : 30.
The models used in the experiments
We used four different ML algorithms and tested and evaluated our model over the dataset. We compare some different data representations, as follows: i) BoW+TF.IDF, ii) Word2Vec, and iii) the proposed model. Support Vector Machines (SVM) [30]: SVM is proposed in 1992 and is a strong baseline ML algorithm. Logistic Regression (LR) [31]: Despite the name regression, logistic regression is one of the most effective methods of text classification that has been proven in numerous publications. Multilayer perceptron (MLP) [32]: In neural network classification, feature vectors are integrated into a multilayer fully connected network. The last layer uses the softmax function to classify feature vectors. We built an MLP classifier that has one hidden layers with 100 neural units inside. AdaBoost [33]: AdaBoost is one of the ensemble booster classifiers proposed by Yoav et al. in 1996. It combines multiple classifiers to increase the classification performance. In this paper, we use the AdaBoost model in scikit-learn, for which the base estimator is LinearSVC.
Results
We measured accuracy for the experimental evaluation. Figure 2 and Table 5 present the results. The system using the LR classifier obtained the best result, with an 81.54% accuracy score. Furthermore, the proposed system outperforms in all four ML algorithms. The experimental results also show that the MLP classifier did not obtain adequate results with the small amount of training data. The SVM classifier yielded solid results but ultimately performed worse than the system using the LR algorithm with an accuracy score of two points les. Finally, the system based on the Word2vec language model gave poor results in all four classification algorithms. In our opinion, there are two main reasons—i) training data was not sufficient, and ii) Word2vec alone does not work well with data containing many social media words.
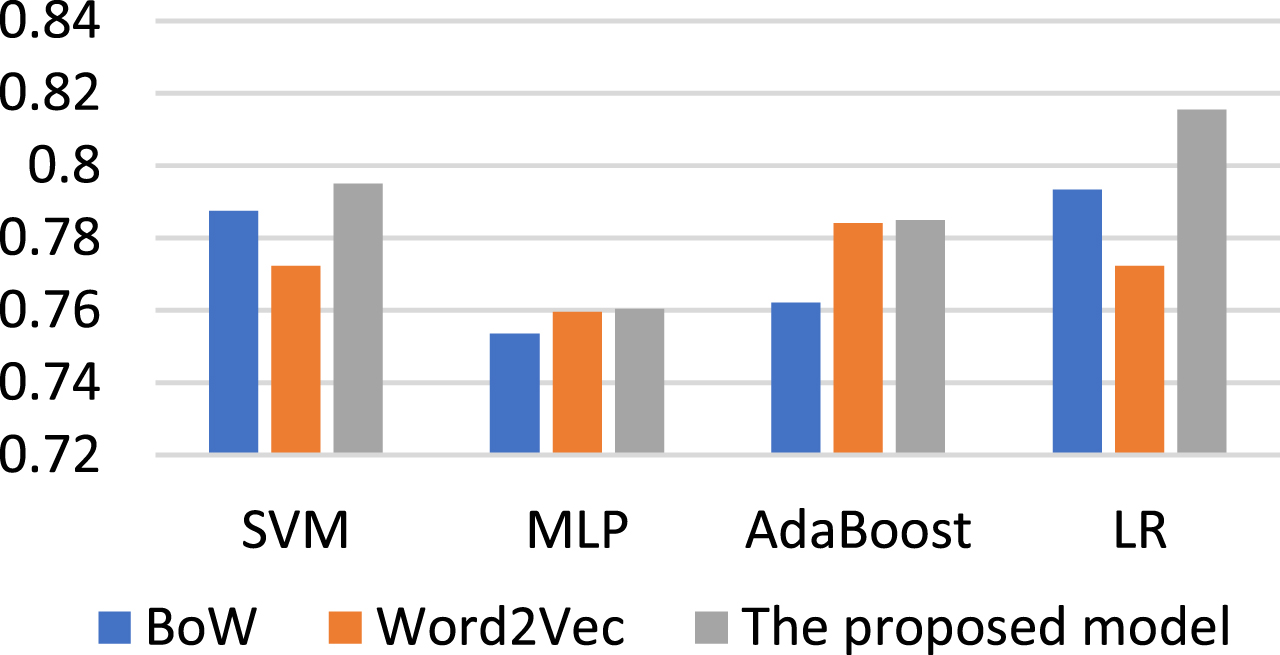
Experimental results.
Performance of four different ML algorithms
In this paper, we presented an effective sentiment classifier of comments on social media and weblogs. The analysis and extraction of social media-related information contributed to this framework’s success, unlike state-of-the-art language models like Word2vec, which proved ineffective when operating alone. We found that in this case, it is more important to analyze linguistic characteristics and recommend suitable text representation models than to choose a well-performing classification algorithm. In future work, we will continue to experiment with some different datasets, as well as adopt other modern language models such as Doc2Vec [34], BERT to the framework.
Footnotes
Acknowledgments
We acknowledge the support of time and facilities from Ho Chi Minh City University of Technology (HCMUT), VNU-HCM for this study.