
Abstract
Fire calamity is one of the worst adversarial events that can happen to the human race. Fire disaster can happen as a manmade disaster or even naturally, and it may cause environmental, social, and financial damages as well. In order to minimalize the unwanted fire calamity, early detection of fire eruptions coupled with immediate and effective response is extremely vital to disaster management systems. The classification of forest fire and non fire images using deep learning techniques has recently received popularity. Detection and prevention of forest fire have lot of significance from the perspective of the forest fire department, specially for the fire and arson investigators. There are shortcomings in the current mechanisms of forest fire detection in terms of accuracy. Hence, we propose a fire detection model using LeNet5 convolutional neural networks (CNN), which can spot fire in outdoor environments by classifying fire and non fire images. L2 regularization is critical technique that manipulates the complexity of the convolutional neural network model. In our work fire images have certain features that decide if the image is fire or non fire.A weight is assigned to every feature. Regularization used to help to reduce the over fitting that used to caused by plenty of weights. Our proposed provides the directiontowards developing a system that detects the early stages of forest fire.This model can further be utilized to prevent the damage caused by the fire. A CNN is a deep learning method, which has been adopted in order to detect the images of fire and non-fire. With the non sparse solution of L2 regularization we have obtained around 87% of train accuracy, 71% of validation accuracy and 70% of test accuracy after running 10 epochs.
Introduction
Disaster management aims at minimizing the harm to human lives and protect the property in the time of natural disaster. Various domains such as health and environmental disciplines have been constantly involved in the efficient detection and subsequent resolution of the disasters. Disasters can be broadly categorized into two parts, namely man-made disasters, such as nuclear power plants disaster, terrorism and man made disaster are natural disasters, such as volcanic eruptions, earth quakes, heat waves, wildfires and floods. However, fires may be exploded by the actions of human, alterations of weather and due to many other causes. A real time monitoring surveillance system has to be installed to tackle fire related disasters. Forest fires pose a threat to human mortality rates, ecological organizations, and groundwork. A lot of mainstream fire detection sensor systems are present, however fire detection in forests receive delayed response, it requires maintenance, extraordinary overheads, and other difficulties [1]. Application of fire detection in the form of an surveillance tool has intensified due to the repeated occurrence of extensive fire break out which has significantly impacted on human vigor and security. The latest detection methodologies, which were based on sensors, have been based on pressure and heat sensors. However, these prescribed systems have faults as they will only function when a specified condition is reached. Moreover, in the crisis, misconfigured sensors can lead to numerous fatalities in a situation [2]. Forest fires that are highly incidental, high in magnitude and unsafeness are more difficult to handle for disaster units. These are mostly spread across in a fasted manner and hence are most certainly hard to combat and tough to be located. In the recent years, feature based fire detection has received a lot of attention in fire monitoring research arena [3]. Forest fires can be caused either by natural or man-made incidents. The eruption of these fires can cause a widespread damage to life, property as well as to the wildlife and environment. In below, some fire related disasters are mentioned, 1) Arizona, USA fire disaster which destroyed at least hundred houses have been suffered. 2) The famous fire disaster of Siberian forest which has aggravated across an area of forty-seven millions acres of land, and burnt everything in the year 2014. 3) Forest fire of California (August 2013) that has burnt a land of 1042 km2 and dented around 111 buildings, leading to loss of $127.35 million [4]. Several researchers have highlighted mathematical models to throw some light upon the fire behavior such as the CMYK colour(Cyan, Magenta, Yellow, and Key) and the RGB(Red, Green, Blue) Colour model. These have been developed in accordance with diverse countries with the capability to combat forest fire and each model is dissimilar with respect to the input constraints and the environmental setup in terms of file indexing [5]. Our study has focused towards developing a system that detects the early stages of forest fire, which can further be utilized to prevent the damage caused by the fire. The primary aim of the proposed work is to use deep convolutional neural networks(CNNs) in order to detect the images which can be accumulated from the forestation areas that have been affected by fire (and will then be subjected to pre-processing techniques, i.e., data augmentation) and hence, classify them as fire or non-fire [36]. This study has focused on the following objectives: To study deep learning in depth and to propose an AI based fire detection software using deep convolutional neural networks for early forest fire detection using imagery to assist forest departments. To further integrates a complex and driven research into unstructured data of fire using data augmentation for effective surveillance based on imagery. To provide the classification of fire and non-fire states present in the ensemble of images with high accuracy of 87%. To propose an efficient implementation of deep learning technique(inspired by LeNet) with the use of dropout along with L2 regularization in order to overcome the issue of over-fitting. To adopt further as a tool to surveillance device in outdoor environment.
The remaining part of this manuscript has been organized as follows: related works has been discussed in Section 2. Materials and methods are presented in Section 3. Experimental set up, and simulation results with discussions have been provided in Section 4. Section 5 mentions the discussion part. Finally, Section 6 presents conclusion of the paper.
Related works
This section represents the various fire detection methods along with their pros and cons, from the previous works that are available in the literature such as neural network and image processing techniques.The strengths and weaknesses of the previous methods used for fire detection have been analyzed. Muhammad et al. (2018) have, projected a model for detecting fire equipped with surveillance using CNN [4]. However, such methodologies generally require high computational overheads and memory, restricting its subsequent application in the field of surveillance networks. Authors in [4] further proposed a comparatively cost-effective CNN architecture, which can be implemented with surveillance videos. Mahmoud et al. (2018) proposed a forest fire discovery procedure, which establishes the subtraction of background so that it can be applied to the apparent motion comprising area recognition [1]. Furthermore, translating the segmented sections from RGB to YCbCr space and retaining five fire discovery instructions for separating candidate pixel of fire have been tackled [1]. Lastly, temporal difference is applied to distinguish among objects of fire color. Wang et al. (2017) examined the robustness of the forest atmosphere, the accuracy of forest fire classification and discovered that the features are particularly low in their proposed feature mining model which was solely based on YCrCb color space and K-means clustering [3]. Hanamaraddi (2016) has introduced YCbCr model for the efficient detection of forest fires that is basically an image processing technique and it embraces rule-based color model pertaining to a reduced amount of complexity and effectiveness [5]. This procedure not just dissociates fire flame pixels but also splits high temperature fire center pixels by acknowledging the statistical parameters of fire image in YCbCr color space like mean and standard deviation [5]. Poobalan and Liew (2015) have put forward the collective subjects that occurs in Malays in which RGB colour model proposed to find fire’s colour that is primarily designed to realize by the intensity of red colour. Sobel edge detection has been implemented by the authors. Subsequently, in the final stage, a color-based segmentation technique is applied to the results from the first technique to locate the region of interest [2]. Zhang et al. (2016) have suggested a forest fire recognition based on a deep learning method.The number types of classes’ types in that classifiers was two and this was trained with the help of a convolution neural network (CNN) [6]. In addition, cascaded technique was implemented to detect fire. If the fire is detected in the entire image through the global image level classifier, then the model of the proposed work will use pulverized patch classifier to spot the exact position of fire patches. After the process, 97% and 90% accuracy on training and testing datasets was achieved, respectively. In addition, comparisons were made on support-vector machine (SVM) and CNN classifier for fire detection [6]. Frizzi et al. (2016) have developed a Convolutional Neural Network for recognizing fire in videos where they structured a network that was equipped to accomplish extraction of features along with classification and achieved superior performance on various formal audiovisual fire discovery methods [7]. Alongside, authors [7] also mentioned that using CNN to identify fire in videos proved to be highly accurate. The limitation in this network is that it only has detected red color fire in the video specimen [7]. Igor and Avramovic (2016) suggested that every day, enormous amounts of aerial and satellite images were generated, and such huge measures of insights can prove to be extremely helpful for multiple practical problems [8]. Sharma et al. (2017) advised to use deep CNN for fire detection in images and also proposed an enhancement with respect to the fully connected layer where the model used two pertained recent deep CNNs, VGG16(also called OxfordNet, named after the Visual Geometry Group) and Resnet to structure their network [9]. Authors in [9] utilized an unbalanced dataset to regenerate real world scenarios. Their result also showed that the fully coupled layers with fine tuning increases accuracy such that it also provides an increase in the training time [9]. Lee et al. (2017) have incorporated that for constant monitoring manned airplanes or helicopters are too expensive to operate and satellite images also cannot be used for early stage fire detection because of low temporal resolution and low spatial resolution [10]. Therefore, they suggested using unmanned aerial vehicles (UAV), which are cost effective and provide high resolution images. Bui et al. (2017) have computed the validation of a hybrid artificial intelligence approach based on particle swarm optimized neural fuzzy [11]. As the execution of the projected method was superior than two-benchmark representations, the conclusion was that particle swarm optimized neural fuzzy was an effective substitute tool for forest fire detection. This work is beneficial for development and administration of fire prone forest areas [11]. Muhammad et al. (2018) have provided a technique to detect an early fire detection mechanism by incorporating convolutional neural networks, and the input for this detection comes from CCTV cameras. This mechanism recognize fire in indoor and outdoor environments. In addition, authors have developed a techniques of an adaptive prioritization tool for cameras with the use of a surveillance scheme [12]. Other work also can be found in the literature such as Rao et al. (2016) who have cracked the difficulty of video-based flame recognition [13]. A dynamic tactic has been adopted here to look out the reliability factor of the method using Kalman Filter [13]. Here, feature extraction has been carried out from spatiotemporal flame modelling that claimed to have reduced computational cost as it requires dynamic texture analysis [13]. The features of the forest fire sometime becomes hard to extract as it may require long-distance and large-area features extraction of the outdoor forest fires as prescribed by Qiang et al.(2014) [14].The neural network model proposed by Qiang et al. (2014) exceeds with regards to the degree of recognition, rapidity, and the anti-congestion ability compared to the conventional fire detection strategy. Therefore, the outcomes demonstrated the soundness and the generalizability of the technique [14]. Author in [15] have proposed a method, which analyzed and compared different types of forest fire detection techniques. The possibility of enhancing the performance of this work is many fold.
In our proposed work, we have classified fire and non-fire images of forest area. The idea was to use CCTV camera to capture forest images and use them for prompt and effective analysis of classification of fire and non-fire images so that immediate surveillance mechanism can be initiated with the engagement of health care department and policing system. The proposed system can be worked as a warning mechanism for the forest nearby locality. The installation of such system needs sufficient power to recharge of batteries; and also, it is not easy to install as density of the large tree in the forest hinder the deployment of such of system. In this study, we could have incorporated geostationary satellite data with band number, width, wavelength, spatial resolution, land cover data and forest map. In addition to that attaching alarm based to detect various kinds of fire break out also is a good idea. Remote-controlled aircraft can assist firefighters to battle conflagrations by supplying surveillance in real time scenarios [20]. However, we have studied deep learning in depth and have proposed an AI based framework using deep convolutional neural networks inspired by LetNet architechture for early fire detection using imagery to assist forest departments. This study further integrates a complex and driven research into unstructured data of fire using data augmentation for effective surveillance based on imagery. Moreover, the proposed mechanism provides a classification strategy of fire and non-fire states present in the ensemble of images with high accuracy. In this proposed method we check the potential competence of deep convolutional neural network(inspired by LeNet) with the use of dropout along with L2 regularization in order to overcome the issue of over-fitting.
Materials and Methods
The dataset was collected from GitHub (https://github.com/cair/Fire-Detection-Image-Dataset). This dataset has 651 images, hence we used data augmentation technique to generate more images. In addition, the dataset is unbalanced so we balanced it manually and keep an equal set of images in the training set and validation set [9]. We have used Image Data Generator class to obtain data augmentation of fire and non fire images. The augmentation techniques have used horizontal and vertical shift augmentation, horizontal and vertical flip augmentation etc. Also rescaling the images of between a range of [0,1] & random rotation between [15, 15], some percentage of shifts in height width and brightness range also were enhanced. After data augmentation method total number of input images raised to 17631.The image dataset is partitioned into three sets, namely training, validation and test sets. The training set contains 14499 images in which 7252 images are of fire and 7247 images are of non-fire. The validation set contains 3132 images in which 1563 images are of fire and 1569 images are of non-fire. The test set contains 10 images in which each fire and non-fire have 5 images. This dataset does not only contain the fire in a forest but it also contains other types of images such as fire in a room, house with variant intensity and colors of red, yellow and orange; non-fire images include as a sunset or bright yellow light at night. The various steps that were implemented in the process of detecting forest fires in this proposed model are the elements of the convolutional neural networks. CNN is most commonly applied technique to scrutinizing visual imagery. CNNs, similar to neural networks, constitutes of neurons, which consist of learnable weights and biases. Each neuron receives multiple inputs, intakes a weighted sum over those inputs, passes it through an activation function and consequently reverts with an output. Therefore, in the following section, the entire process has been broken down into individual steps in order to provide detailed explanation of each of proposed model.
Proposed architecture
We have adopted LeNet architecture for this work. This architecture is constructed in Fig. 1. in order to show the convolutional layers, pooling layers,maxpooling layers and fully connected layers proposed LeNet architechture [36]. The initial convolutional layer is subjected to max-pooling iteratively, which eventually transforms the convolutional layers and hence, forms the dense layer. The proposed method has six convolution layers and has max-pooling which has three layers. In addition, it has two fully connected layers as provided in Fig. 1. The proposed model color input is of size 94 x 94 x 3. In the consecutive first and second convolution layer, 8 kernels of with the size 3 x 3 are employed through a stride of 2. This has generated 8 feature maps. The highest activations were selected by the first pooling of activation maps with size of 2 x 2 through a 2 pixels stride. So, feature or activation maps size is condensed by a divisor of 2. The third and fourth convolution layer involves of 16 kernels of magnitude 3 x 3, subsequently a max pooling layer analogous to the first one is attached. Afterwards, 2 successive convolution layers of 32 kernels, with sizes of 3 x 3 are placed. The layer of pooling stage at the end are exactly same in set-up to the initial two pooling layers. At the last stage, two fully connected layers with 16 and 2 neurons are placed. The yield of the last layer is served into the CNN classifier, which calculates two classes’ prior probabilities. We have used adam as an optimizer, taken 94 x 94 image size, 5 images per batch for both train and validation, learning rate used is 0.001 and decay is 0.9, loss functions used is categorical cross entropy and we have splitted total dataset into 82% train data and 18% of validation data to compute the model (Table 4).
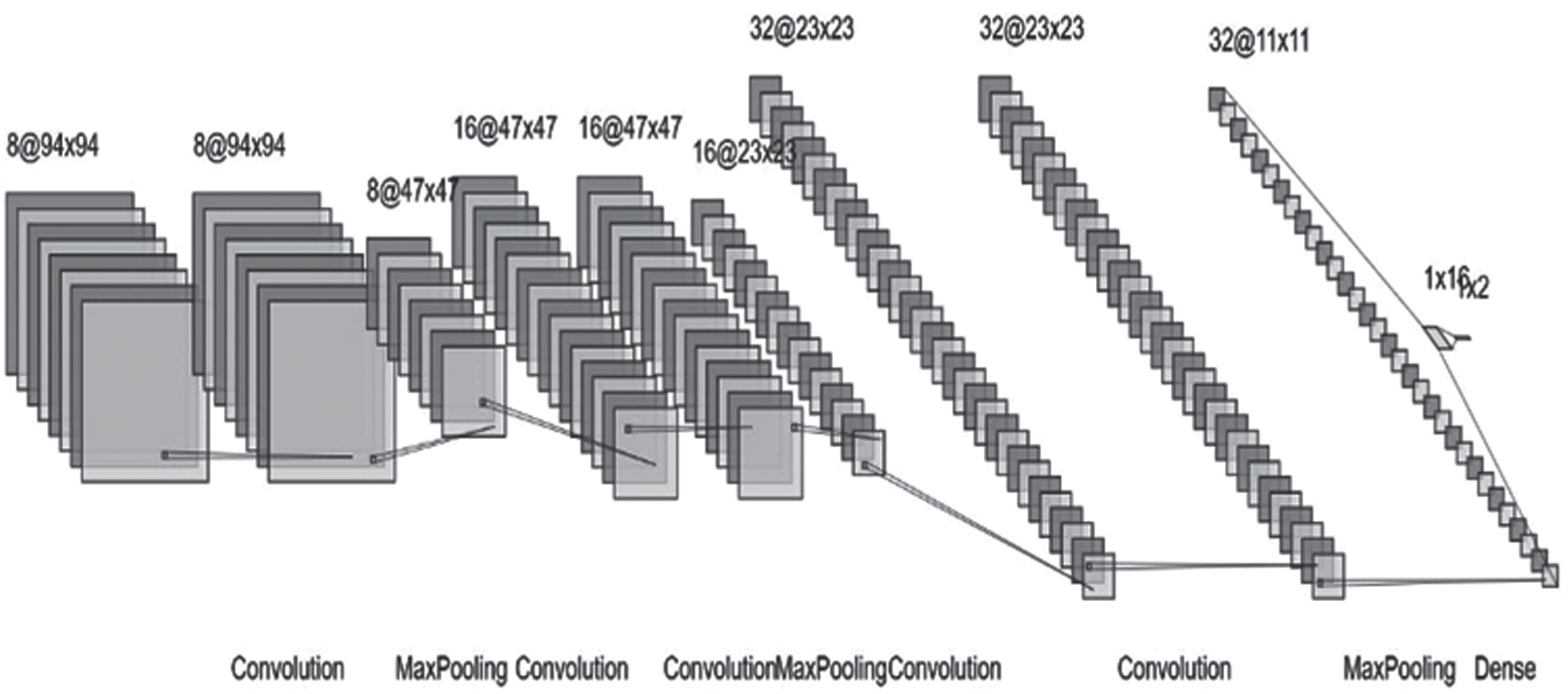
LeNet Architecture [36].
Hyperparameters used in proposed LeNet CNN and VGG16 Model computation
Convolutional neural network has been put to different uses, which includes image classification, retrieval, localization, object detection and image segmentation. Among all existing convolution neural network architectures LeNet [36] is the first of its kind and this has been shown in Fig. 1. Convolution, Pooling, Padding and Dense are different parts of a characteristics of CNN. The arrangement of these layers is conducted in such a manner that the fire and non fire image input of one layer is derived from the output of the preceding layer. Generation of feature maps takes place at the convolution layer where a number of kernels are employed on the input images. Pooling comes after convolution, which is used to shrink the feature map and to introduce translation and scale invariance. After simultaneous stacking of convolutional and pooling layers, comes the dense layer. Here, modelling of the high level image data is carried out which serves as a representation of the input image. During the training process, weights of all kernels and neurons in the hidden layers are learnt, which is then used to perform the classification
The flowchart of our proposed work has been presented in Fig. 2. This figure systematically explains our anticipated process of fire detection, in a step by step fashion. Figure 3 shows two sample images of fire and two sample images of non fire from our chosen data set.
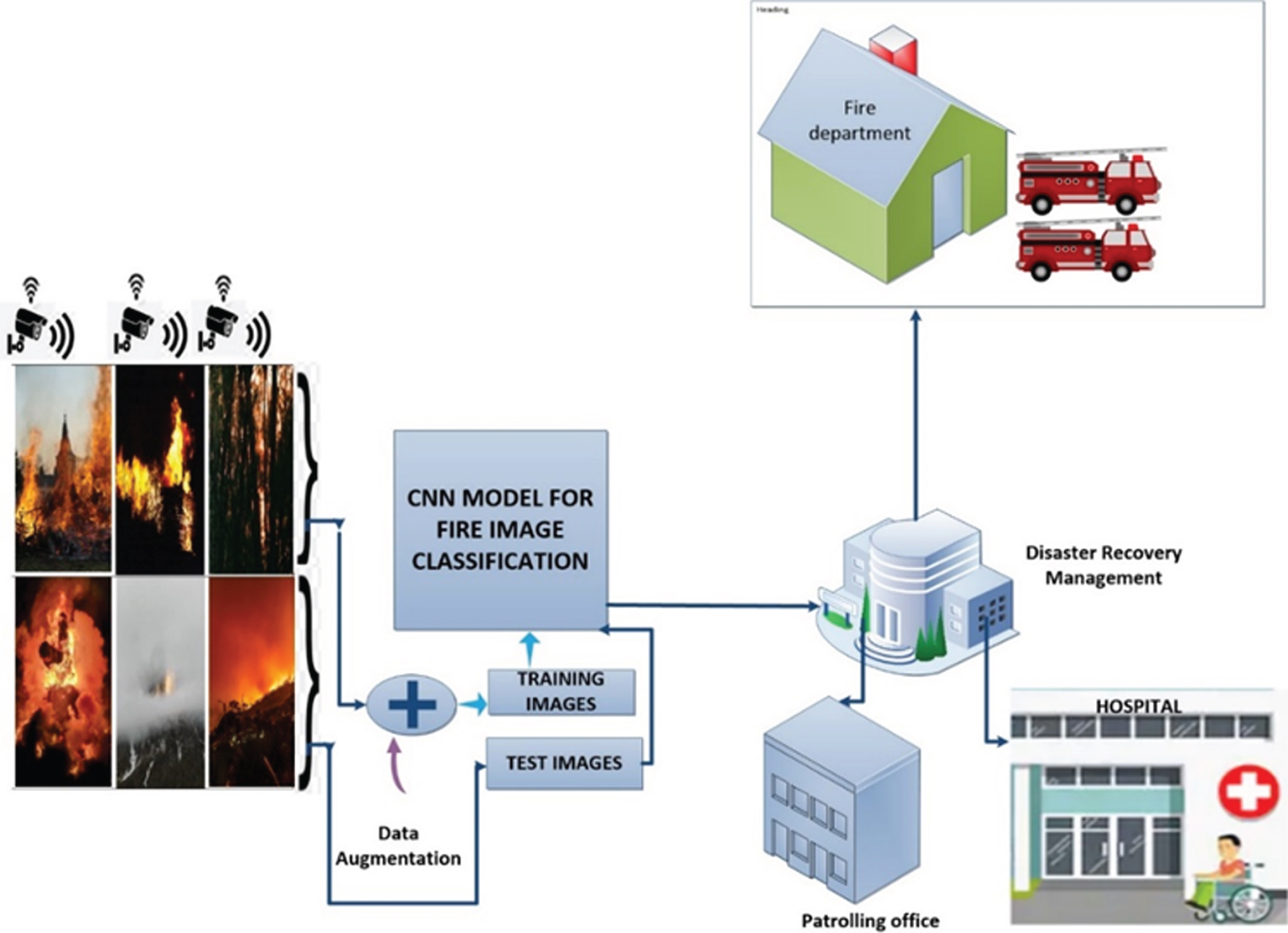
Overall System Architecture Diagram of Fire Detection using Deep CNN.

(a) Non fire image (b) Non fire image (c) Fire image (d) Fire image.
The flowchart of our proposed work has been presented in Fig. 2. This figure systematically explains our anticipated process of fire detection, in a step by step fashion.
There is a need of volumes of training data for convolutional neural network, as the requirement of tuning hyper-parameter is utmost important. The over-fitting usually happens in the last layer of the fully connected layers and is reduced by drop out technique. In this work, we fixed 70% dropout proportion after every convolution layer of size two: 50% dropout ratio after each layer of max pooling. In addition, L2 regularization has been used to further reduce over-fitting. This work implemented pre-trained VGG16 model with proper tuning of collection of images by improvising last fully connected layer with a learning rate of 0.0001. This fine tune was operated with 4 epochs. The convolution layer function takes four parameters, the initial one is the number of filters, the next parameter is the shape each filter, the next is the input shape and the type i.e., RGB or black and white of each image, the last i.e fourth parameter is the activation function that we want to use. To build a convolution concept, the theorem of convolution has to be incorporated that maps convolution in the domain of space and time. One can refer convolution as a fast Fourier transformation (FFT) [25]
Equation (1) depicts the convolution theorem, which is convolution of two continuous functions, h and g; f(x) is the final output hypothesis. Here h refers to the input images and g refers to the kernel function. Equation (2) refers to the 2D discrete convolution theorem related to discrete images. In CNN the feature map or activation map, refers to the output of one filter served to the previous layer. The definition of feature map (FM) can be given as,
The operation ⊕ refers to the operation of convolution. F stands for Fourier transform and F-1 is inverse Fourier transform, and F-1 is constant. The activation function given the input or set of inputs defines the output of the node or a neuron. Relu is one such activation function, what it does is, whenever the input is less than 0, it gives the output as 0 and it remains as it is whenever the value is greater than 0.
When we augment a boundary of pixels with all values zero round the edges of image is called zero padding. Padding can be of two categories; valid padding means no padding. Therefore, if anyone postulate valid padding that must indicate that the convolutional layer does not need to pad input images. On the contrary, the second category of padding is same padding; meaning that there is a need to pad before the convolution function works on input images to get same size of output image. The rule to calculate the size of the output to give any convolutional layer is
Where, M is the output height length, H is the input height or length, G is the size of the filter, P is the padding, and D is the stride. If normalizing the input layer gives us benefit, why leave the hidden layers, which can help improve the training speed. Dropout randomly knocks out units (both hidden and visible) of your network so a smaller neural network should have a regularizing effect. This technique is used to reduce overfitting in a neural network by preventing complex co-adaptations on training data. Max pooling is the method of shrinking the image stack. It is a sample-base discretization process. The main objective of using this technique is to reduce its dimensionality so that assumptions can be made about the features in the sub-regions of images. Window size and stride are the two parameters used for max pooling. Flattening is a process to convert the output of pooled feature map into a 1D vector. For further processing, it is then sent as a solo long feature vector to be cast-off by the dense layer for classification in the artificial neural network. Each image that the CNN processes, will always amount to a vote. The weights can consequently be adapted in order to reduce the error. Each value is adjusted bit higher and a bit smaller so that the newly attained error will be calculated every time. After doing the same process for each feature pixel in every convolutional layer and every weight in every fully connected layer, the newly calculated weights provide an answer that works marginally better for that particular image. This process is then repeated constantly with every following image in the entire collection of labelled images. If there are adequate labelled images, the values will alleviate to a bit that will perform efficiently across all the different scenarios. Given a neural network and an error function, the method calculates the gradient of the error function with respect to the neural network’s weights during the forward pass and the error contribution of each neuron is calculated when processing every batch of input images. Back-propagation iteratively computes error for every layer l, and the error term δ(l) at a particular layer l can be defined as:
ρ(l) term defines the error in layer l; W(l) denotes the weight in layer l; k(l) symbolizes the total weighted addition of inputs to in layer l. To calculate the gradient of the loss function and errors, back-propagation is used. Following the same convention, the gradients can be calculated in the below way:
In Equations (6), W, b are the parameters and m, n are the input image. The process of optimization thus will repeat these two steps, propagation and weight update. In the second phase, this gradient will be used to update the weights to minimize the loss function. The regularizers enable to implement the penalties on layered parameters or layered activity whilst the optimization is being carried out. The penalties are then integrated in the loss function that the network will further enhance. The ridge regression augments “squared magnitude” of measurement is used as the penalty block to the loss function.
In this work, L2 regularization has smoothed the distribution of all parameter. In addition, this work has combined L2 regularization with dropout, which further has lowered down the chance of overfitting. The importance of L2 regularization helps in training (Krizhevsky and Hinton 2012) alongside with dropout regularization [26]. The interesting fact is that the L2 regularization when combined with batch normalization, shows no regularizing effect (Acquarelli et al. 2017) [27, 35]. L2 regularization lowers down the values of the weights, however it does not make any weights to zero [35]. It helps to achieve non sparse solution. In addition, L2 penalizes the squared magnitude of hyper-parameters and parameters which helps to get better accuracy in terms of kernel regularization especially in the case of deep convolutional neural networks for recognizing visual things such as recognition of ethnicity of human, digits and object recognition (Yu, Xu, and Gong 2009) [28]. The significance phenomenon that matters to use to see that in our work L2 regularization behave more efficiently than L1 and hence we have incorporated this techniques while implementing deep CNN for forest fire detection. Over here, the emphasized portion represents the L2 regularization element. The formula to calculate the error excluding the Reguralization function can be given as, Loss = E(Y,
Here, in Equation (8) α represents weights (
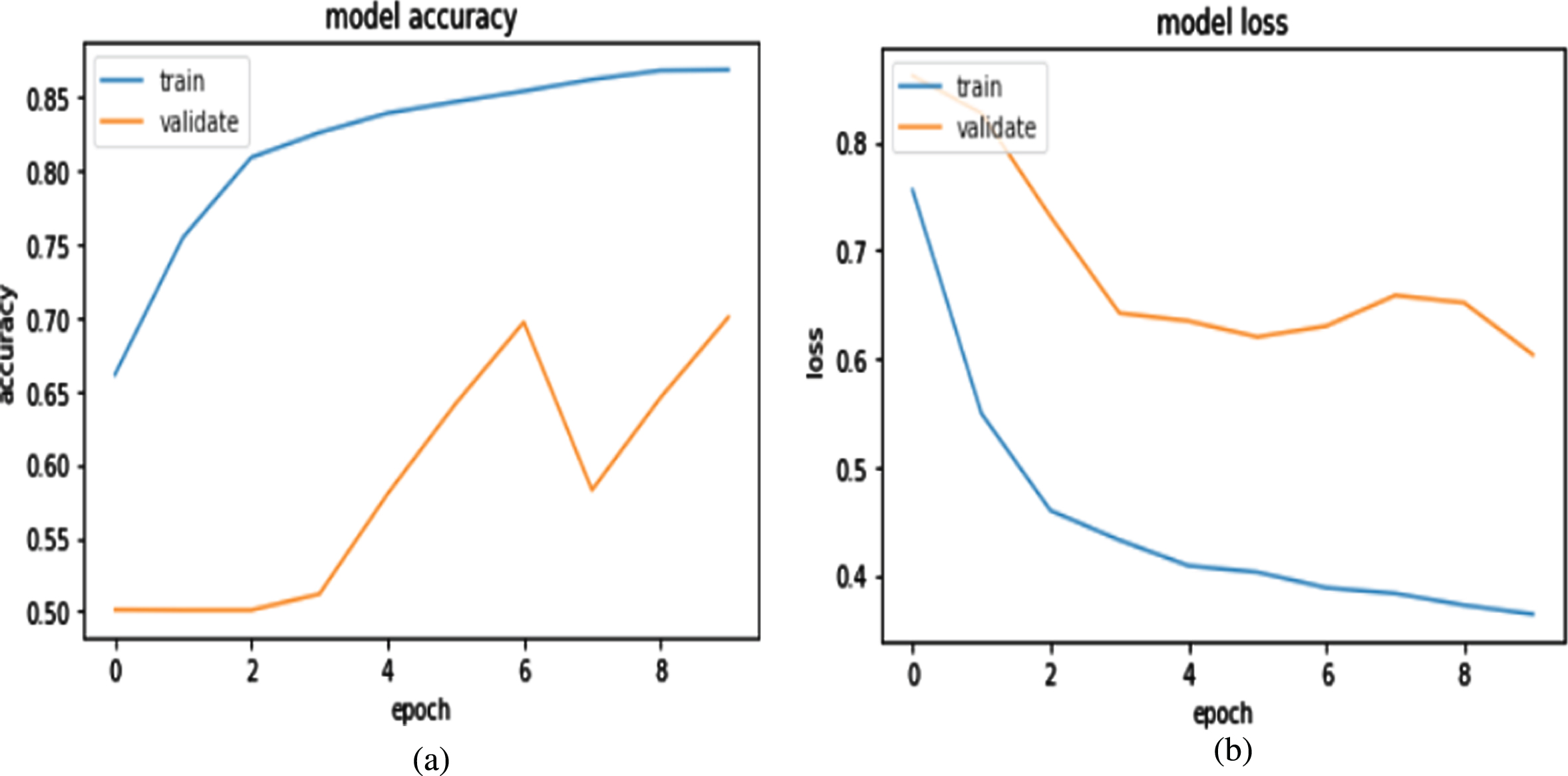
In this work, the image dataset was first classified using the basic CNN model of computation. Experimental results depicted the low training accuracy coupled with a high validation loss. To strengthen our model we used L2 regularization to penalize loss function and dropout to leave random nodes in the fully connected layer to enhance the back propagation method so that weight initialization process assigns a weight to hidden layers node magnificently. Here, our last layer of CNN contains two nodes, one for fire and one for non-fire. After training of our model, we get increasing order of accuracy for both train and validation data after every epoch and decreasing order of loss for both train and validation data as mentioned in Table 1 and its graphical representation in Fig. 4. We got the same type of result after using transfer learning method and it’s mentioned in Table 2 and its graphical representation in Fig. 5. After training, we test our model using 10 images, which consist of five images which has fire and rest are non-fire images. All the test images are collected from internet. We fed these images to our trained model and fine-tuned with Visual Geometry Group(VGG16) model to get the probabilities of test images. After getting probabilities of ten images we rounded probabilities to zero and one and compare this probability with one hot encoded values. We then form a confusion matrix as shown in Fig. 5. Here we clearly see that 70% of images are correctly classified as shown in Fig. 5(a) and for a fine-tuned model we get 60% correctly classified image. So the CNN model was subsequently fine-tuned with VGG16, a pre-existing model in order to increase the accuracy and lessen the validation loss. We also used F-measure to calculate our model’s performance. For calculating F-score we need precision and recall and that will be calculated using four parameter.
Model statistics obtained after running epochs on CNN Model
Model statistics obtained after running epochs on CNN Model
(a) Model accuracy of the VGG16 Model (b) Model loss of the VGG16 model.
Model statistics obtained after running epochs on VGG16 Model
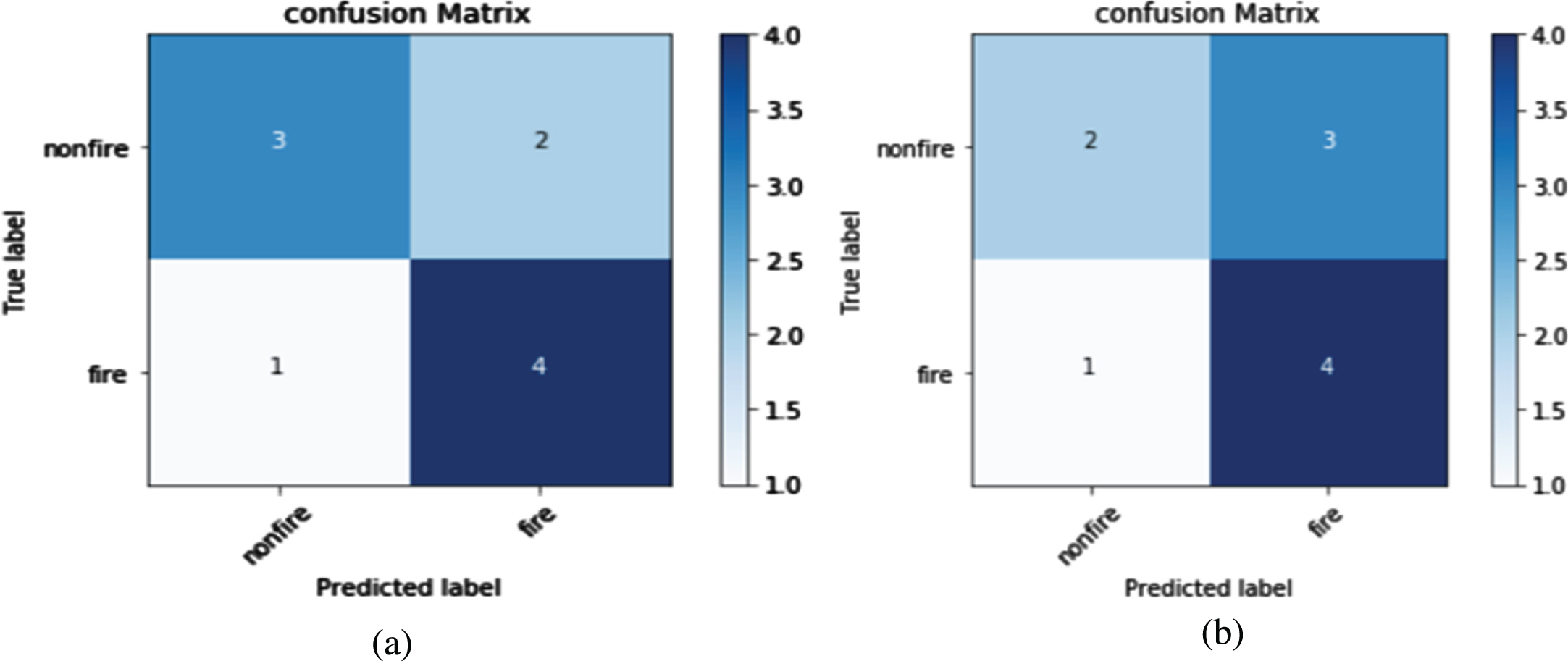
(a) Confusion matrix obtained for CNN model (b) Confusion matrix obtained for VGG16.
If an image contains the fire and it had been correctly classified by model as fire image then it is a true positive. If the same image was not classified correctly means it was classified as a non-fire image then it is a false negative. If an image has no fire pixel and it had been correctly classified as a non-fire image then it is a true negative(TP) and if the same image was not classified as non-fire then it is a false positive(FP).
Here, TP, FP, TN, and FN are true-positive, false-positive, true-negative(TN), false-negative(FN) respectively. A greater F-measure means better performance. Table 3 shows the F-measure of our model and comparison with other four model.
Precision, recall and F-Measure of our proposed model and other fire detection methods
This section discusses the performance of the proposed model used in accordance with the aforementioned graphs and confusion matrix. All the experiments were performed on a dataset of 17631 images, which were generated after data augmentation. To start with, the image dataset was first classified using the CNN LeNet-5 model of computation. Experimental results have depicted the low training accuracy coupled with a high validation loss, initially. In LeNet-5 there are 3 convolutional layers,2 sampling layers and 1 fully connected layer so to overcome overfitting and increase the accuracy we have added 3 more convolutional layers and added 1 sampling layers and also added dropout to lessen the overfitting and we got good accuracy and less validation loss. And then we want to increase our accuracy so our CNN model was subsequently fine-tuned with VGG16, a pre-existing model in order to increase the accuracy and lessen the validation loss. As we analyzed and compared the data from Table 1 2, we can conclude that the proposed CNN (inspired by LeNet) model has evidently resulted in the gradual increase of the training accuracy and a decent reduction in the validation loss, as compared to the fine-tuned model with the pre-existing VGG16. This change in the parameters makes our proposed CNN model comparatively more efficient and usable. Moreover, the ensemble of images created by us has augmented images which increase the volume of the data under computation. Hence, the dataset is stimulating and greater in size, so it is a more preferred alternative for various experiments. Hence, this particular model can be implemented on a larger scale by analyzing the various states of forest fires from where, the inputs can be received for detecting the fire-affected areas in the vegetation. Also, Table 3 depicts the values of precision, recall and F-measure for the acquired output after the computation of the ensemble of images. It also presents the subjective comparison of the method used in our proposed work (Deep CNN) to the other methods used for detecting forest fires. The most efficient results are reported by [17] among the existing methods by achieving an accuracy of about 70%. There still remains scope for improvement and hence we inculcate our proposed model mentioned in the table which therefore, achieves an even superior accuracy of 71%. Moreover, the values obtained for the recall and F-measure parameters [21] are also found to be higher than the existing works. The papers that have been utilized for the purpose of comparative assessment have been shortlisted depending on the factor of reliability, present dataset utilized for implementation and the year of publication [22–38].
Conclusion and future work
Initially, the dataset we obtained from online sources was very limited. For better results, we needed a bigger dataset. But since the dataset for fire was not readily available, we applied a pre-processing technique called data augmentation to increase the size of our dataset. Now, we have compared two models, one is our CNN model (inspired by LeNet) and the other one is VGG16 which is a pre trained model. Our model has better statistics than the pre-trained model in terms of training loss and validation loss. The same can be inferred from the confusion matrix that we obtained. The limitation encountered during the project is associated to the feasibility of the model to be developed. In order to monitor and capture real time images of forest areas, UAVs or drones have to be introduced which can increase the overall cost of the model. As the real time capturing of images makes the project less feasible, in future we plan to retrieve satellite images from tropical areas, which can subsequently be processed and classified as a fire or non-fire image. Henceforth, an alert can be broadcasted to the forest department for further safety measures at the early stage of the disaster and this can also be considered as future work.
Funding
This research received no external funding.
Conflicts of interest
The authors declare no conflict of interest.