
Abstract
Thousands of patients around the world affecting their health with various factor as age, body mass index, cholesterol levels, albumin levels and several other factor. Prediction of health outcome due to these factors at a proper time can be served as an early warning. Recent growth in machine learning algorithm inspired us to build a predictive model for better healthcare facilities. In our work we have focused on problem of noisy and imbalanced dataset in which majority class is favored over minority one that leads to false prediction. We have experimented with two publicly available medical imbalanced dataset which varies in its size as MIT’s GOSSIS death and PIMA Indians Diabetes Dataset based on binary class. In this model we have investigated 3 oversampling techniques (Synthetic Minority Oversampler, Random Oversampler and Adaptive Synthetic Sampler) along with two undersampling techniques (Random Undersampler and Near Miss) which were paired with 3 data reduction and cleaning methods namely Tomek Links, One Sided Selection and Edited Nearest Neighbors. At last, we found that combination of Adaptive Synthetic Sampler along with One Sided Selection perform better in case of large size dataset while combination of random oversampler along with Tomek Link showed better performance in case of low size data dataset. We have also analyzed that oversampling technique gives quite promising results in comparison to undersampling methods specifically when applied with machine learning classifiers as these classifiers are data hungry algorithms.
Keywords
Introduction
In the era of big data, working with imbalanced data patterns is quite a common problem. The performance of various data processing algorithms depends upon the balancing of data. Thus, to obtain better results we need to convert the imbalanced data into balanced data. In an imbalance dataset, there are two types of classes i.e. Majority classes which have more number of samples and Minority classes having less number of samples. Presence of majority and minority class in a dataset leads to increase the problem of biases as majority classes exist with a much higher composition percentage in comparison to the minority classes and in such case data belongs to minority class get ignored even though they are present which leads to model favoring one class over the another and increase the amount of false results [1, 24]. To overcome the limitation of biases in an imbalance dataset we have experimented multiple techniques of sampling along with feature scaling onto the two dataset which varies in its size also. Out of these dataset,One dataset belongs to patient health having records of a large number of patients and is comparatively bigger in size.This dataset consists of several factors as attributes which can affect health of patients like tumor, presence of diabetes, age etc. and another dataset named as PIMA dataset which is used to predict diabetes in patient and this dataset is small in size. Manually analyzing all the factors to predict health of a patient is not feasible hence to automatically recognize the associated pattern we have used machine learning algorithms along with sampling techniques to deal with the problem of imbalancing classes [2, 3]. In our work we have experimented with 5 sampling techniques in total out of which we have used 3 oversampling techniques as Synthetic Minority Oversampler (SMOTE) [5], Random Oversampler [6] and Adaptive Synthetic Sampler (ADASYN) [7] and 2 undersampling techniques as Random Undersampler [8] and Near Miss [9].
List of abbreviations
List of abbreviations
Further, to reduce noise, mentioned sampling techniques were paired with 3 data reduction and cleaning methods namely Tomek Links, One Sided Selection and Edited Nearest Neighbors. These reduction and cleaning methods helped in eliminating the noisy data or the irrelevant data. For example, if two samples of opposing classes in the balanced data were indistinguishable from the other [4], then one of them was removed. The two experimental datasets with varying size have been deliberately chosen to analyze the efficiency of the data reduction and cleaning techniques which had a significant impact on the results. We have shown in the result section that inclusion of data reduction techniques leads to improve results significantly as compared to not using them.
To analyze the effect of sampling and data reduction technique, we have used seven classifiers as Decision Tree using entropy using information gain and GINI, Logistic Regression, Gaussian Naïve Bayes, Random Forest, Linear Discriminant Analysis and a special amalgamation of Linear Discriminant Analysis+Random Forest [11].
In this analysis we have used 35 different pairs of sampling and cleaning techniques for each classifier. This has provided a deep insight about the performance of each classifier on both the datasets. At the last the performance analysis for each classifier is present in terms of accuracy, precision, recall, F-1 score and Matthews Correlation Coefficient [13].
This paper is organized into six sections. In section one we have explained the imbalanced data and brief about the various techniques to handle the same. In section two the detail of literature is elaborated. In section three and four we have discussed the methodology for handling imbalance data and different classification models. Lastly, we have concluded our work in section six.
This section describes the study related to data pre-processing and handling of imbalanced data. We first discussed about the sampling methods i.e. Oversampling and Undersampling along with data reduction techniques to handle the imbalance regarding the data [10, 12]. Further, we have discussed the seven popular classification techniques defined in the literature to study the impact of imbalanced data over the prepared machine learning model.
Sampling based methods
For sampling of imbalanced data there are two major techniques, which are described below: SMOTE: In this technique, to fill the gap between the classes, artificial samples are created for the minority class [14, 31]. For example: suppose we have two attributes from the minority class (x1, y1), then the k nearest neighbors are identified for (x1, y1) as (x2, y2). The artificial sample that will be created will be on the line joining the above two coordinates.
Here k is any random number from [0,1] (x
synthetic
, y
synthetic
) are new coordinates generated by the SMOTE technique as expressed in equations (2) where they represent an artificial sample. This process will continue until the number of samples in the minority class becomes equal to the majority class. The number of synthetic samples generated depends on the number of nearest neighbors used. ADASYN: This is an improved and refined version of SMOTE which focuses more on the samples that are closer to the class boundary and hence concentrates more on the complex and difficult examples [7]. ROS: In this technique, the samples in the minority class are increased by randomly replicating the samples originally present in that class till they reach the count of the majority class [32]. This method increases the chance of overfitting as the same data is used everywhere by the replication. Although it confirms its identity of being an oversampler, it does not create any new samples. RUS: In this method, it randomly eliminates data from the majority class or discards them [32]. The major problem with this sampler is that it can potentially remove or discard vital and essential information Near Miss: This is another undersampling technique where the sampler finds the distances between the samples of the minority class and the majority class and the samples which have smallest distances to the minority class are selected [34]. There are mainly three versions of Near Miss namely: Near Miss Version 1- It selects those samples from the majority class whose average distances to the closest instances of the minority class are smallest. Near Miss Version 2- It selects those samples from the majority class whose average distances to the farthest instances of the minority class are smallest. Near Miss Version 3- Firstly the nearest neighbors of the minority class will be stored and then those samples from the majority class are used or selected for which the average distance to the nearest neighbors is largest.
In our work, Near Miss Version 1 had been used for sampling and classification.
Even after performing the sampling methods over imbalanced data, the noisy data can still be present. Hence, to remove the noise from the sampled data three major data reduction methods have used. TL: This is an undersampling method [33]. To understand this, let us consider two samples Ac and Ad where the former belongs to the minority class and the latter to the majority class. Let d (A
c
, A
d
) be the distance between the two samples. If there is a sample A
f
, the pair(A
c
, A
d
) is called a Tomek Link where d(A
c
, A
d
)<d(A
c
, A
f
) or d(A
c
, A
d
)<d(A
d
, A
f
) then one sample is considered as noise as that would be indistinguishable and it would be hard for the classifier to classify them, so this is an undersampling technique and the sample from the majority class of the Tomek Links will be removed. OSS: In this method, a subset of all the minority class samples is created. After doing this a sample is randomly selected from the majority class. Using the 1NN rule (kNN rule with k = 1), that particular sample from the majority class is added to the subset of the minority class samples if it was misclassified. This technique helps in removing the misclassified samples of the majority class [33]. ENN: This technique is a modification of the kNN rule. Here the samples from the classes are sampled and their classification is checked by the kNN rule. The misclassified samples are removed from that class. The remaining samples can then proceed for the training [35].
To measure the efficacy of the classifiers and the sampling methods, the above discussed data reduction methods were paired with the sampling techniques (defined in Section 2.1) for the classifiers [15].
Classification techniques
Some of the popular classification techniques used for medical datasets are defined as:
Decision tree using information gain and entropy
Decision trees are a supervised method of learning where the dataset is broken into homogenous chunks. It begins at the root node and here each branch represents an outcome of a test and each leaf node represents the class label. The leaf node is also the terminal node. As the branches increase the tree gets more and more complex. If there are any binary decisions to be made, they are then sent in either direction of the tree. The main algorithm used for this type of decision tree is the Iterative Dichotomiser 3 or the ID3 [16]. It iterates through all the unused attributes of the set to calculate their entropy and information gain and that attribute is selected which has the smallest entropy or the largest information gain. After this the set is divided into smaller subsets by the selected attribute. By this method an entire decision tree is created using a top-down and greedy approach.
Information entropy [30] is defined as the variance of the data and calculated using Equation 3.
Where pi is the probability of picking an element of class i. Here since it was a dichotomous classification, the value of M was 2. That is why if there was only one class, then putting just i = 1 in the above formula, we get the entropy as zero.
Further in the Decision tree, Information gain determines the quality of the split and calculated using Equation 4:
Where j = 1 and n = number of splits were made and Entropy(p) is the entropy before the split. In the example above, two splits were present and hence n was 2.
The ID3 algorithm uses the above information gain and uses it for classification purposes.
This is another method to build a decision tree-based classifier, but instead of using information gain and entropy it uses the GINI impurity index [17, 29]. It is basically the measure of likelihood of the incorrect classification regarding a new instance of a random variable, if that sample were randomly classified based on the class labels available. To understand the GINI impurity index better, let us consider an example.
The formulaic version of the GINI impurity index ‘G’ is (Equation 5).
Where i starts from 1 and M are the number of classes, the same metrics as in the entropy version.
Just like information gain, there exists the GINI gain which is just the GINI index instead of the entropy. It is the subtraction of the index before the split and after the split.
As we know that GINI index is an impurity index, the smaller the index, the better the quality and because of which if the gain is high, the split was better as the index after the split would have been lower.
In regression techniques, there are two techniques namely linear regression and logistic regression. Regression analysis used to make predictions with the help of data from the past. It defines a relationship of several independent variables with a dependent variable. A very common form of linear regression can be expressed by Equation 6.
Equation (7) shows linear regression model with multiple variable where ‘Y’ is the dependent variable and the beta values are the coefficients of the independent variables. The values of the independent variables directly affect the dependent variable. For all regression models, a small amount of error can be considered as the values obtained are not always exact.
The main difference between Linear Regression and Logistic Regression is that output of linear regression is continuous in nature whereas the logistic regression model helps in categorization with a given input. Its categorization occurs with the estimation of value assumptions of the variables that are dependent in nature as a probability [18].
The logistic regression model makes use of the sigmoid function. It is a mathematical function having a ‘S’ shaped curve. The logistic model is a common example of the sigmoid function. It is represented by Equation 8.
Where e is the constant with a value of 2.71828 and x is the variable.
What the sigmoid function does in the logistic model is that it takes as input the value obtained from the linear regression model [28]. The probability ‘P’ obtained is defined by Equation 9.
Naïve Bayes is a probabilistic classifier based on the Bayes Theorem, it assumes independence between the features of the model [19]. Bayes theorem can simply be represented by Equation 10.
Where P(C|D) represents the probability of event ‘C’ occurring given that ‘D’ is true or has occurred, P(C) is the probability of event ‘C’ occurring, P(D|C) represents the probability of event ‘D’ occurring given that ‘C’ has occurred and P(D) represents the probability of ‘D’ occurring.
In this type of classifier, it is assumed that the data follows a Gaussian or normal distribution. The continuous values associated with the classes have to follow this distribution [27]. The general form of the probability density function ‘P’ is (Equation 11):
The random forest model is also a supervised learning algorithm. It is a collection of the decision trees as is in the name ‘forest’ [20, 26]. There is a connection between the number of trees used and the result. The more the number of trees the more precise it will be. In this algorithm the process of finding the root node and the splitting of feature nodes has no order. One benefit of using this model is that even if there are many trees present, it won’t overfit the model.
The features for the decision trees are selected from the bootstrap samples. and their root node is calculated. After this, the nodes are split into further nodes or the daughter nodes. The splitting process continued until the decision is reached. These steps are repeated for all the constituent decision trees. Thereafter, the outcome of each tree is stored, and the counts are made for each type of outcome. The outcome with the highest count is chosen and the model assigns it as the class.
Linear discriminant analysis
Linear Discriminant Analysis (LDA) is another type of classifier where a linear combination of features is found that separates two or more classes. LDA attempts to model the difference between the classes of the data. To understand this classifier better let us consider the variables that we were using to represent the data. Each class is treated as a Gaussian class which has its covariance matrix and a mean vector [21, 25]. The observations are then classified to the class of the mean vector that is closest. If the classes have a shared covariance matrix the decision surfaces between classes become linear. The procedure of constructing these decision surfaces which are the Fisher Discriminants is known as Linear Discriminant Analysis.This algorithm aims to maximize the distance between means of the two classes for better classification and minimize the variation within each class. To further use this classifier, it was also paired with random forest where LDA was used to transform the data and random forest was used as a classification tool. The new amalgamation of the two classifiers was renamed and used as LDA+Random Forest.
Methodology
This section elaborates the methodology used for finding the impact of imbalanced data over various popular classification techniques. In order to prepare the model, we have followed five steps:
Data Preparation and pre-processing
In this phase, first the missing values were filled with the means of that particular attribute and text entries were converted into numeric using one hot encoding. Next, the dataset was splitted into a testing and training set.
Data Resampling and further utilization
After pre-processing, different types of sampling techniques (SMOTE, ROS, ADASYN, RUS and Near Mi were applied on the training set. Further, these techniques were paired with the data reduction techniques (TL, OSS and ENN). This results in 35 combinations and 490 variations for both the datasets.
Standardization
Since there was data present of all magnitudes, it had to be first adjusted using standard scalar before being used in the classifier. The standard scaler works as follows (defined in Equation 12).
Here, the new value (x new ) is the old value (x i ) subtracted by the mean (x mean ) and then finally being divided by the standard deviation (σ).
For the classification purposes, several classifiers have been used. They were Decision Tree using entropy and information gain, Decision Tree GINI, Logistic Regression, Gaussian Naïve Bayes, Random Forest, Linear Discriminant Analysis and an amalgamation of Linear Discriminant Analysis+Random Forest.
Performance and evaluation measures
The model that was created by using the various classifiers and data reduction techniques was evaluated using performance metrics such as precision, recall, F-1 score and Matthews Correlation Coefficient. Precision (Percentage of true positives among all positives detected): True Positive/(True Positive+False Positive) Recall (Percentage of positives detected among all the true positives): True Positive/(True Positive+False Negative) F-1 Score (Harmonic Mean of Precision and Recall) defined by equation 13:
Matthews Correlation Coefficient (MCC) calculated using Equation 14.
Where TP- True Positive, TN-True Negative, FP-False Positive, FN-False Negative
The MCC gives a fairly strong idea about the correlation.
In order to achieve better understanding and to analyse the most accurate model and its dependency on the size of the dataset we have experimented with two different sized imbalanced datasets.
1. Patient Health Dataset (Death): MIT’s GOSSIS (Global Open Source Severity of Illness Score) community initiative, with privacy certification from the Harvard Privacy Lab, has provided a dataset of more than 90,000 hospital Intensive Care Unit (ICU) visits from patients, spanning a one-year timeframe which has 187 attributes or features to be considered [22].
As shown in Table 2 The dataset is imbalanced as data belongs to majority class is 10 times in count in comparison to minority class.
Composition of the dataset
Composition of the dataset
It is an annotated dataset having 91714 instances and each instance was annotated with target to be predicted as death(1) or Not (0).For experimentation, We have selected 15 of the 186 attributes as shown in Table 3 with the help of an expert.
Dataset attributes
Before the dataset could be split into separate sets for training and testing, it had to be preprocessed using following steps: The gaps in the categorical data were filled by replacing them with ‘No Type’ To remove the ‘NaN’ from the numerical columns, those gaps were filled by replacing them with the arithmetic mean of those particular columns.
The categorical data was converted into numerical data by using dummy variables which created new columns with the one hot encoded (0/1) data.
Table 4 shows oversampled and Table 5 shows under sampled data.
Composition of the training set after oversampling
Composition of the training set after undersampling
2. Patient Health Dataset (Pima Indians Diabetes Dataset): This dataset was also used for the binary classification [23]. The dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases.
As shown in (Table 6) the dataset is imbalanced as data belongs to majority class is 2 times in count in comparison to minority class. The attribute of dataset is shown in Table 7. In this dataset, each health record of 768 patients is annotated with target variable as diabetes (1) or Not(0). This dataset is clean in comparison to GOSSIS dataset hence requires no preprocessing.
Composition of the second dataset
Second dataset attributes
Table 8 mentioned undersampled and Table 9 mentioned oversampled data.
Second dataset composition of the training set after oversampling
Second dataset composition of the training set after undersampling
Further, for classification purpose, splitting of the dataset into training and test is required. Hence we used a 5 fold cross validation technique onto the above mentioned dataset to avoid occurrence of biases in accuracy.
Data resampling techniques
RUS: The seed used by the random number generator or the random state had been set to 42. ROS: The seed used by the random number generator or the random state had been set to 42. SMOTE: The seed used by the random number generator had been set to 2. If it was not specified, the random number generator is the ‘RandomState’ instance which is used by np.random. The default nearest neighbors chosen here for creating the synthetic samples were 5. ADASYN: Since this sampler is an improved and refined version of SMOTE, the parameters remained identical here. The seed used by the random number generator had been set to 2. If it was not specified, the random number generator is the ‘RandomState’ instance which is used by np.random. The default nearest neighbors chosen here for creating the synthetic samples were 5. Near Miss: The size of the neighborhood to be considered to compute the average distance to the samples from the minority class, or the nearest neighbors were chosen to be 3. Since there were three versions of Near Miss available to use, version 1 was used.
Classifiers
Decision Tree using Information Gain and Entropy: The max depth of the tree or the point till the nodes are expanded had been set to 400. The minimum number of samples for the leaf which were required to be present at the leaf were chosen to be 3. A split would be considered under this parameter. The seed used by the random number generator had been set to 100. Decision Tree using GINI index: The max depth of the tree or the point till the nodes are expanded had been set to 400. The minimum number of samples for the leaf which were required to be present at the leaf were chosen to be 5. A split would be considered under this parameter. The seed used by the random number generator had been set to 100. Logistic Regression: The seed of the pseudo random number generator to use when shuffling the data had been set to 0. The ‘fit_intercept’ that specifies if a constant should be added to the decision function was set to True by default. Gaussian Naïve Bayes: There were no prior probabilities of the classes. The features’ portion of the largest variance that is summed with the variances for the stability of calculations was by default set to 1 * 10-9 Random Forest: The number of estimators or the number of trees in the forest were set to 20. The minimum number of samples required to be at the leaf node was by default set to 1. The random state that controls the bootstrapping randomness of samples used to build trees and sampling features to be considered when looking for the best split at each node had been set to 0. Linear Discriminant Analysis: The value of number of components had been chosen as 1. LDA + RF: Here LDA was used as a data transformation technique where Random Forest was used as a classifier. The max depth of the tree or the point till the nodes are expanded had been chosen to be 300. The seed used by the random number generator was set to 0.
Data reduction techniques
TL: The ‘return_indices’ factor had been by default set to 0. The ‘random_state’ was also by default set to none. OSS: The ‘random_state’ factor which controls the randomization of the algorithm had been set to 42. Since this technique uses the 1NN rule, the number of neighbors was by default set to 1. ENN: The size of the neighborhood was taken as 3 to calculate the number of nearest neighbors. The ‘random_state’ factor was by default set to None.
Results
In this section we have elaborated the accuracies and confusion metrics obtained using the data reduction and cleaning techniques and pairing them with the sampling techniques to use with the classifiers. Afterward result is calculated using 5 fold cross validation technique. Further to simplify the results we have shown only top 10 performing combinations.
Patient health dataset (Death)
Decision tree using information gain and entropy
Table 10 shows the top 10 variations that were used for this classifier. The highest accuracy obtained was from Random Oversampler and One Sided Selection i.e. 88.611% whereas the lowest being by Near Miss and Tomek Links at 62.205%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 11 shows the top 10 variations that were used for this classifier. The highest accuracy obtained in this classifier was from Synthetic Minority Oversampling and Edited Nearest Neighbors at 88.802% and the lowest from Near Miss and OSS at 63.719%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 12 shows the top 10 variations that were used for this classifier. The highest accuracy obtained in this classifier was from the variation of Adaptive Synthetic Sampler and One Sided Selection at 92.748% and the lowest was from the variation of Near Miss at 76.72%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 13 shows the top 10 variations that were used for this classifier. This classifier achieved highest accuracy of 84.157% from Random Undersampler with One Sided Selection and Tomek Links. The lowest was 74.84% from Near Miss.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 14 shows the top 10 variations that were used for this classifier. Maximum accuracy here was 92.416% from Random Oversampler and One Sided Selection where the lowest was 74.955 from Near Miss and One Sided Selection with Tomek Links.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 15 shows the top 10 variations that were used for this classifier. The highest accuracy in this classifier was from the variation of Adaptive Synthetic Sampler being 92.138% ranging to the lowest 77.593% with Random oversampler along with One Sided Selection and Edited Nearest Neighbors.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 16 shows the top 10 variations that were used for this classifier. The highest accuracy in this classifier we achieved is 88.900% using the variation of Random Oversampler with Edited Nearest Neighbors and Tomek Links. The lowest accuracy obtained for this classifier was from the variation Near Miss at 68.505%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Figure 1 shows the accuracy level of each combination of sampling and data reduction method onto multiple classifiers and found that ADASYN along with OSS gives the highest accuracy of 92.73% when applied onto logistic regression.
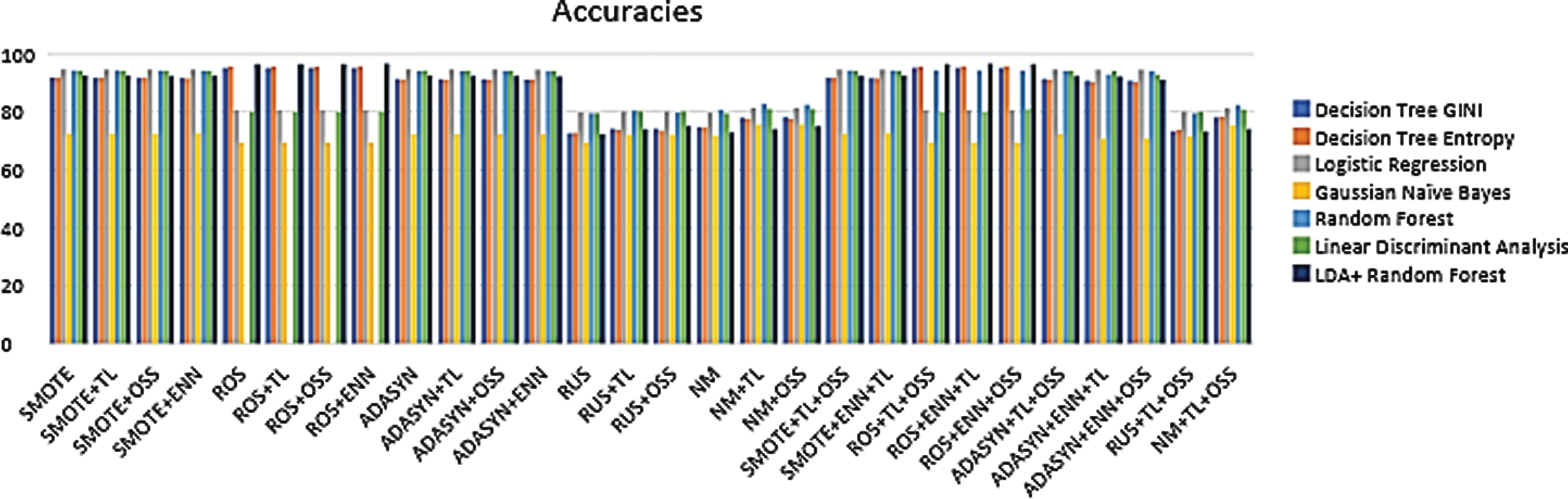
Comparison of accuracies for the patient death dataset.
Decision tree using information gain and entropy
Table 17 shows the top 10 variations that were used for this classifier. The highest accuracy obtained here was 75.974% by using Random Oversampler with Tomek Links with the lowest being 64.285% from Adaptive Synthetic Sampler with One Sided Selection and Tomek Links.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 18 shows the top 10 variations that were used for this classifierThe highest accuracy in this classifier was 74.675% by using the Synthetic Minority Oversampler and the lowest resulted from Near Miss at 63.636%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 19 shows the top 10 variations that were used for this classifier The highest accuracy in this classifier was 72.727% from Synthetic Minority Oversampler with Edited Nearest Neighbors with the lowest being 66.883% from Adaptive Synthetic Sampler with One Sided Selection and Tomek Links.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 20 shows the top 10 variations that were used for this classifier. Maximum accuracy in this classifier ranged at 70.779% using Adaptive Synthetic Sampler with One Sided Selection with the minimum being 66.233% by the Random Oversampler.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 21 shows the top 10 variations that were used for this classifier.The Highest accuracy achieved by this classifier is 74.025% from Synthetic Minority Oversampler using One Sided Selection and the lowest was 62.987% using Near Miss.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 22 shows the top 10 variations that were used for this classifier. The highest accuracy here was 73.376% by using Synthetic Minority Oversampling with Edited Nearest Neighbors with the lowest from Adaptive Synthetic Sampler with One Sided Selection and Tomek Links at 68.181%.
10 Highest accuracies among 35 in decreasing order
10 Highest accuracies among 35 in decreasing order
Table 23 shows the top 10 variations that were used for this classifier. The highest accuracy was 68.831% from Synthetic Minority Oversampler with Edited Nearest Neighbors with lowest at 61.038% from Random Undersampler with Tomek Links.
Highest accuracies among 35 in decreasing order
Highest accuracies among 35 in decreasing order
Figure 2 shows accuracy level of each combination of sampling and data reduction method onto multiple classifiers and found that ROS along with TL gives the highest accuracy of 75.97% when applied onto Decision Tree.
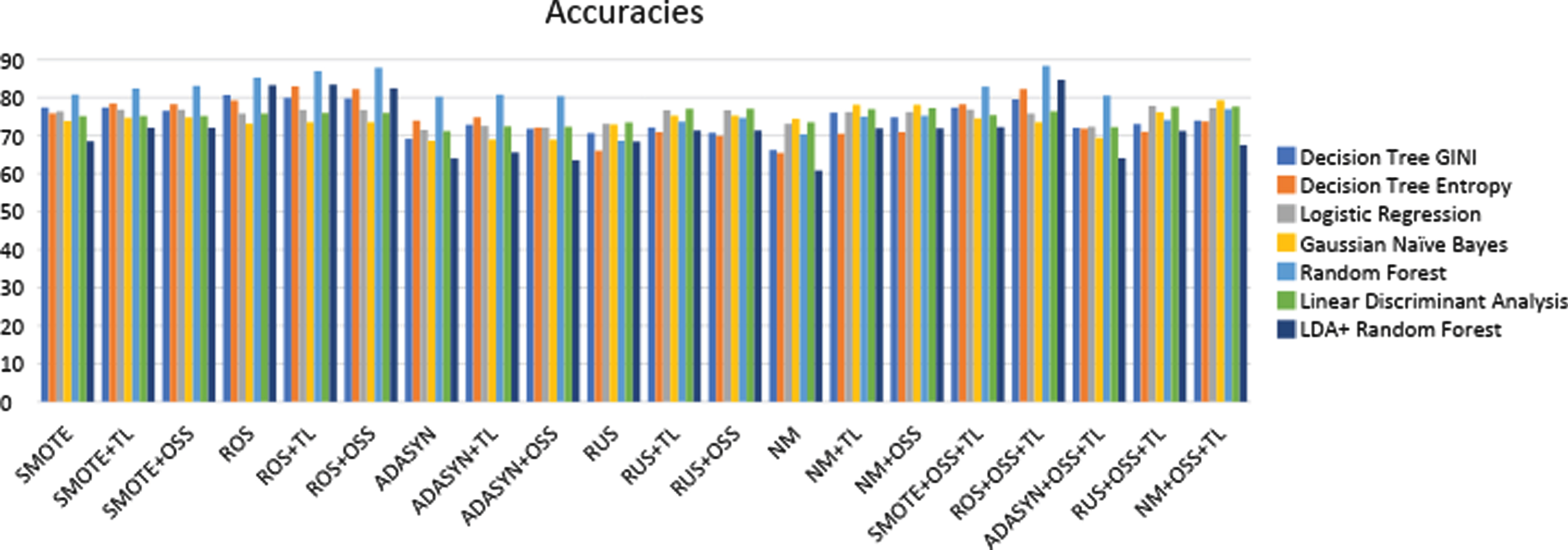
Comparison of accuracies for The Patient Diabetes Dataset.
Every step taken in constructing the model has imperative for accurate and precise calculations to obtain the results. If a dataset is not properly balanced, the minority class can be ignored by the algorithms and give an unfair result which is completely biased. That needs to be fixed when classifying the data.
In our work, we have experimented with two imbalanced datasets which varies in size in terms of number of instances.. One was highly complex and of a humongous level with 187 features and having over 90000 samples in total being considered for the predictions which was the patient death dataset and the other was completely opposite having just about 9 features for consideration and approximately 800 samples in total which was the diabetes dataset.
These highly variable datasets were chosen deliberately to observe the impact of sampling technique along with classifier performance. Further, for analyzing the performance seven classifiers were used. Instead of using raw data,we have focused on balancing the imbalanced dataset. For the same, three oversampling methods (SMOT, ROS and ADASYN) and two undersampling methods (RUS and Near Miss) were experimented. Extension of these sampling methods was also experimented by pairing the same with data cleaning and reduction methods (TL,ENN,OSS) and this has shown a significant improvement.
At last, we found that combination of ADASYN along with OSS perform better in case of large size dataset while combination of ROS along with TL showed better performance in case of low size data dataset. We have also analyzed that oversampling technique gives quite promising results in comparison to undersampling methods specifically when applied with machine learning classifiers.