
Abstract
Cloud computing in the current scenario comes with a large pool of resources, pay-per-use model and reliable infrastructure. Cloud optimization relies on resource optimization to improve the performance and reliability of the cloud. Fault in the cloud places an important role in defining the reliability of the cloud. The identification of fault is a challenging issue in a modular cloud environment. The researchers have developed various methods for the fault-aware scheduling of cloud resources. The fault-aware resource allocation includes static, dynamic, meta-heuristic, and learning-based approaches. In this article, we primarily focused on existing fault-aware resource allocation techniques and then we proposed a model that will primarily focus on fault forecast in tasks allocation. The projected model is based nature-inspired heuristic approach and intelligent artificial neural network. The fault-tolerant aware ANN-based proposed model focuses on performance improvement and reliability testing proactively. The proposed model surpasses the existing state of art methods for proactive and reactive fault-aware scheduling techniques in a large scale datacenter. The results and discussions section support the reliability assertion of the fault-tolerant aware human brain and nature-inspired model.
Introduction
In this world of growing online services cloud computing is plays an important role to provide an infrastructure with high reliability and cheaper services. The resource allocation in a cloud computing environment depends on resources used, cost of resources and scheduler policy to improve the performance of the system.
The local or global optimal point provides the solution. User requirements may test directly on a real cloud computing environment, but it increases the cost overhead, for example, Microsoft Azure, Amazon EC2 provides the real test environment. The scalable simulation reduces the cost. Cloud computing provides dynamic services using virtual resources over the Internet.
The fault and failure probability in a scalable cloud is handled by using fault-aware, reliable task scheduling in application execution. Failures handle using reactive or proactive techniques. The fault-tolerant aware reliable provisioning in cloud infrastructure is broadly categorized in two-class i.e. proactive and reactive. The proactive fault tolerance aware scheduling approach handles the failure of infrastructure service proactively.
The reliability of the system measures using the failure probability of the system [4–6]. In this article, we introduce the proactive, predictive power-aware fault-tolerant efficient scheduling technique which is based on a hybrid approach using Bat Algorithm and feed-forward Neural Network. This is also known as fault-tolerant power-efficient ANN-based scheduling (FTS-ANN). Results demonstrate that the proposed Fat-ANN technique improves the reliability of virtual machines. The paper is organized as follows. Segment 2, presents a brief literature review focusing on fault-tolerant scheduling in the cloud. Segment 3 illustrates the proposed FTS-ANN (fault-tolerant scheduling using an artificial neural network) technique. Segment 4 presents the experimental results of FTS-ANN compared with the other static, dynamic, and meta-heuristics techniques based on a proactive fault-tolerant aware scheduling mechanism. It also covers the detailed discussions of the outcomes using the FTS-ANN model. Finally, Segment 5 covers the conclusions & future extension of the work.
Related work
Cloud computing is a promising option for modern industries to achieve high performance at an affordable cost with a scalable and flexible environment In the real world the cloud is a heterogeneous combination of various services provides providing various storage, networking, processing services to the user on a pay-per-use model. Cloud computing is responsible to execute the user task with high computation and the least cost as promised to the user without compromising on either of one quality matrices. To manage these tasks scheduling places an important role to improve performance.
From the last one and a half-decade, a lot of research has been done in the field of fault-aware scheduling in the cloud [1, 2]. The authors have focused on proactive and reactive fault-aware scheduling in a modular cloud environment. In this section, we focused on numerous fault-tolerance-aware reliable resource provisioning methodologies. As we are familiar with that the scheduling is an NP-hard problem, so we proceed towards nature-inspired techniques, fault aware provisioning techniques which are discussed in this section.
The performance is improved in proactive fault-aware scheduling using failure rate.
The author’s Charity et al. presented a technique for the reliability of storage, computing, and network resources. The system setup measures the trust level of each virtual machine and then allocates the cloudlets on a more trusted virtual machine. The presented technique provided a stable and reliable allocation of the virtual machine [3]. There is a limitation that the author only focused on a proactive approach. The reactive techniques are not explored. Zhou et al. considered the reliability of the cloud services which include infrastructure, platform, and application as a service. The authors focused on virtual machine allocation on the host using datacenter network topology, K-fault tolerance guarantee using the key features of graph theory in a cloud environment. The authors considered the cloudlet’s allocation a reliable virtual machine [7]. The reliability will improve further focusing on cloudlets to virtual machine allocation.Monte Carlo’s failure measurement technique was experienced to probe the future trends of cloudlets allocation. The chance of the fault at virtual machines hosted on the datacenter is estimated using probabilistic Weibull failure distribution based on randomness feature. Rehani et al. bring out the cloudlet allocation on a reliable virtual machine, failure-aware resource reservation technique is presented which uses the reliability as a benchmark test parameter.
The authors presented a system of fault tolerance aware scheduling which reduces the scheduled time because the virtual machine having more trust level is allocated for the cloudlet scheduling [8]. Hence the researchers observed that reliability is still a challenging issue. The presented work will be helpful for us to propose a robust model having more level of significance and a level of trust. The scheduling issue in the cloud comes under the category of the NP-Hard problem. Hence this prominent issue is solved using nature-inspired heuristic and meta-heuristics techniques for reliable allocation in large population size. The selection of heuristic-based techniques relies on a problem statement Heuristic algorithm is developed to maximizing the reliability of cloud services to end-users across the globe [7].
The accuracy is measured under reliability threshold values for the allocation of the cloudlets on virtual machines. Resource allocation techniques differ from the centralized techniques where the primary host takes the decision, but in nature-inspired heuristic approaches, the datacenter distributed environment participates in deciding to achieve the performance metrics. The status of the failure rate is measured by the virtual machines running at hosts [9]. The reliability of the virtual machine is ascertained under the consideration of the end-to-end delay parameter. The authors only focused on workflow-based services in a heterogeneous environment. Attiya et al. expanded the simulated annealing algorithm for cloudlets allocation to a computing node. The objective and novelty of the work is the trust level of the methodology enhancement and calculated its efficiency in contrast with a branch & bound method [10]. The authors presented various multi-objective algorithms that depend on several performance evaluation metrics include reliability tests, power utilization, makespan, deadline constraint, and on-demand resource scalability. The authors also described the tradeoff between two performance metrics i.e. makespan and reliability of the presented system [11, 12]. Primarily author focused on optimization based on two performance metrics. Zhang et al. presented the two performance metric reliability and power consumption-based genetic algorithm. Nature-inspired population-based technique tested in a non-homogeneous environment. The schedules are generated randomly in a non-homogeneous environment [13]. The limitation of the proposed model i.e. solution may be converse at the local optimal point. Fard et al, experienced policy to minimize the Euclidean distance. Performance metrics included makespan, cost, power consumption, and reliability optimization [14]. The results are validated using only a nature-inspired meta-heuristic technique. The performance metrics may be improved using the neural computing base proposed model. The outcomes of the results may help for presenting the new proactive reliable scheduling technique.
Zhang et al. presented a novel technique for reliability improvement using power consumption constraints. The performance measurement parameters are estimated using infrastructure as a service delivery model [15]. The second category of fault aware provisioning includes the reactive fault tolerance policy which manages the cause to happen, not paying attention to cloudlet execution when the chance of failure increases. The chance of failure or failure rate increases at the datacenter level. Our objective includes suppress the failure rate and increase resource utilization. Several reactive approaches are claimed in the literature for handling the fault at the time of cloudlets execution and virtual machine reliability evaluation. Zhou et al. elaborated on an algorithm for optimal checkpointing [16]. The developed technique efficiently selects checkpoints of storage and recovery servers inside the datacenter. Zhou et al. developed a novel technique using a checkpoint. The authors covered two algorithms which include the datacenter topology, node communication feature and the second algorithm included the checkpoint image storage features. This systematic way of organizing the research helps in reducing the checkpoint overhead. The novelty is measured using the simulation process.
Author has proposed an evolutionary approach for using genetic algorithm and neural network to achieve optimal solution [17–20]. Nature-inspired population-based technique tested in a non-homogeneous environment. The schedules are generated randomly in a non-homogeneous environment [21]. The limitation of the proposed model i.e. solution may be converse at the local optimal point. Fard et al, experienced a policy to minimize the Euclidean distance. Performance metrics included makespan, cost, power consumption, and reliability optimization [22]. The results are validated using only a nature-inspired meta-heuristic technique. Zhou et al. elaborated on an algorithm for optimal checkpointing [23]. [24] author has proposed a hybrid approach using machine learning to improve QoS. In some recent works a hybrid approach using swarm intelligence and hybrid genetic approach with machine learning are proposed [25–27].
There is a gap to optimize the performance of the exiting proactive and reactive techniques using a hybrid type of model. The hybrid type of model includes the natural science base research designs for better performance of the data center network support service delivery model at infrastructure, platform, and application level.
Outcomes of the related works
The outcomes of the related work exhibit that researchers focused on the fault aware, checkpoint base, cost and power-aware provisioning techniques. The state of art methodologies works in overloaded, underloaded and average conditions. The proposed fault-aware power-efficient Bat-ANN model improves the performance of the state of art methods. The performance is evaluated using multiple schedules which provides the training data sets.
Proposed model
In the review section, we found that there are various challenging issues in fault aware and power efficient scheduling approaches. Our primary objective is to propose a reliable fault and power aware model which will consider multivariate objective parameters. The multi-variants parameters estimate the performance of the presented model and validate the results of the multilayer’s perceptron model using state of art methods. The multilayer perceptron model accuracy improves using multiple schedules for the training of the proposed Bat-ANN model. In this article a hybrid approach for resource optimization is proposed using Bat and deep neural network. In state of art methods, researchers presented the scheduling mechanism based on static, dynamic and meta-heuristic techniques. The state of art methods, genetic and particle swarm optimization technique provide the local optimal solution using various performance evaluation parameters. The performance metrics include specifically power and fault. The power and fault aware scheduling is introduced which focuses on power consumption, fault and efficiency using total execution time. The reliability of the power and fault-aware scheduling improves using the neural computing model. The hybrid Bat-ANN technique validates using GA-ANN base tasks scheduling technique. The sub-section exhibits the detailed deep neural model used for the quality of service improvement using fault-aware scheduling technique.
The model is devised into the following sections: Initialization Training Datasets Preparations Multi-Layer Perceptron Model Design Model Training Backpropagation and testing
Initialization
In the initialization phase, the output layer, input layer & hidden layers for features classifications & number of perceptron in each layer are defined. The associated parameters population size, learning rate, mutation rate, number of evolutions, and activation function used in the hidden layers and output layers are defined also. The efficiency of the multi-layer base proposed model defines using these initialized parameters.
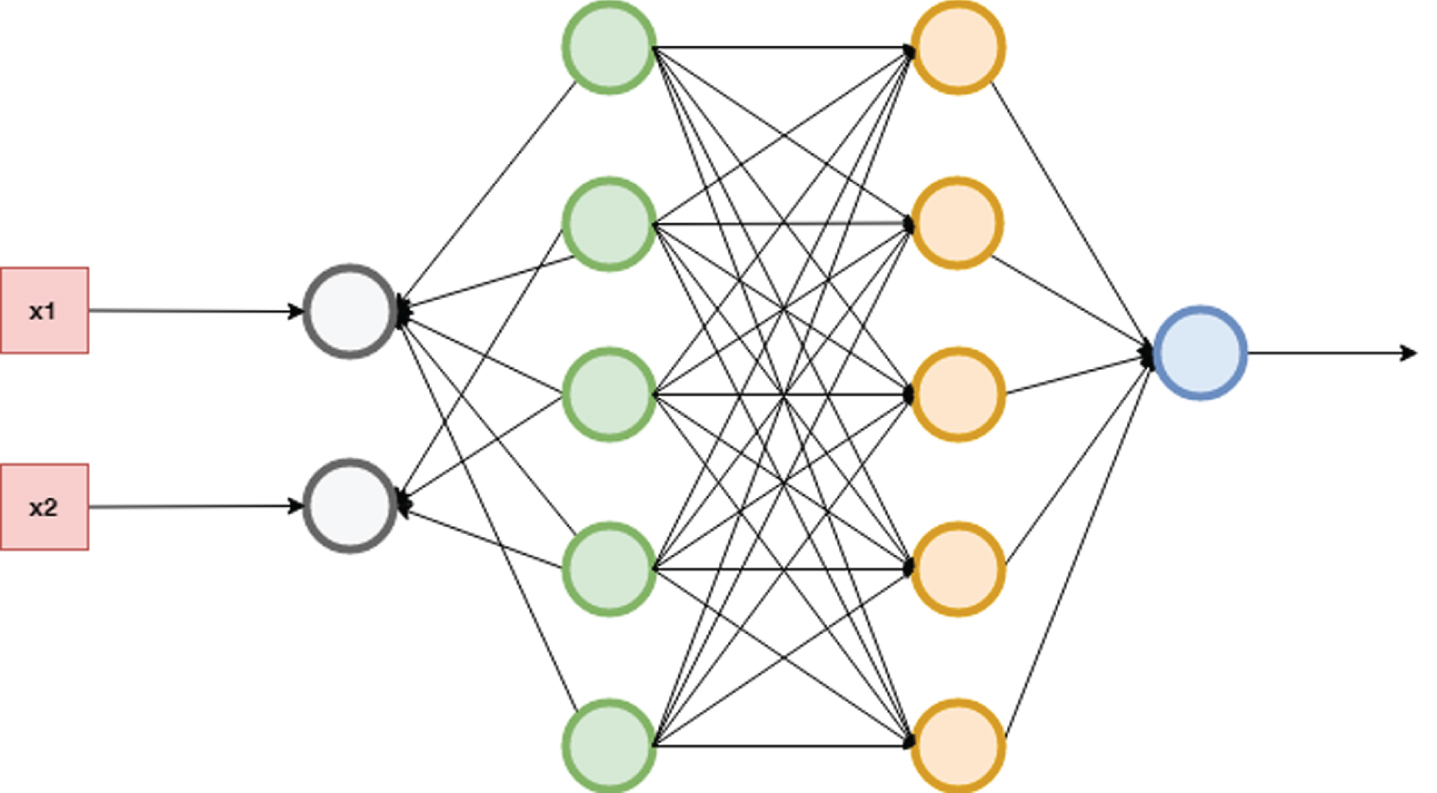
The architecture of the feedforward neural network for fault aware Scheduling in Cloud.
In this phase training data set is prepared using Bat optimization approach using the fitness function to enhance the performance metrics total execution time, fault rate, and power consumption.
The process of training aims to get the minimum fitness value defined and set the weight accordingly. The training dataset generated by the proposed algorithm aims to find the least cost and execution time at the same time, which is used to train the ANN model.
Where α+β=1
The output of the training datasets preparation is to find an optimal solution with the least execution time and power consumption and low fault rate.
In this phase, the ANN is defined using the factors defined in the setup phase. The model takes input as a number of neurons in input, output and hidden layer. The model also takes the number of hidden layers as input. The activation function is used to activate the neuron and is responsible for adjusting the further weights while error propagation. The activation function at the input layer is a sigmoidal function.
The proposed ANN model used a feed-forward network and backpropagation for adjusting weight to fit the model to the target dataset. The accuracy of the ANN model depends on the type of data with the number of hidden layers and number of neurons. Higher the dependency larger the count of hidden layer and count of neurons required. The state of art methods covered all the static, dynamic, and bio-inspired meta-heuristic techniques for the fault aware of efficient resource allocation on reliable virtual machines. The schedule sequences generate for the different evolution or iteration of the meta-heuristic technique. The trained neural network uses for the prediction of the appropriate virtual machine identity which executes the tasks without any fault. The strength of connection among the perceptron, and model trains using data sets in a cloud environment. Researches tried to solve the problem of fault awareness of job scheduling in cloud computing. The inspired trained model helps in the optimal distribution of cloud resources.
Model training
In the training phase, the dataset generated in phase 2 is divided into two parts i.e. training data set and testing dataset in a ratio of 80-20%. Where 80% of data is used for training the model and 20% of data is used for testing and error propagation to improve the accuracy. This phase defines the efficiency of the model by adjusting the weights of the neurons in each iteration. The process of training aims to get the minimum fitness value defined and set the weight accordingly.
The linear activation function Leaky ReLU is used at hidden layers and the non-linear sigmoidal activation function is used at the output layer. The activation function places an important role in dataset training that defines the accuracy of model fitting.
Here the objective of this phase is to improve the accuracy of the neural network by adjusting the weights of the neurons at the input layer and hidden layer to achieve the desired output. This phase plays an important role in weight adjustment to make the model more accurate and predict the value more accurately. This process improves the gap between the expected value and predicted output.
In Equations 4, and 5, the parameter d k (n) denotes the expected output, y k (n) denotes the exact output.
In this module, the trained neural model is used for predicting the suitable resource for a VM. The accuracy and efficiency of the multi-layer perceptron model depend on the training process. The training process depends on the frequency tuning Bat optimization technique which generates the training data set. The tasks scheduling phase generates an optimal schedule using performance metrics power and fault rate specifically.
Proposed Bat-ANN task scheduling
Bat optimization approach
The state of art methods includes meta-heuristic techniques which provide an optimal solution to scheduling problem in a cloud environment. The performance of the nature-inspired technique can be improved using artificial intelligence approaches. In this article, we proposed a hybrid technique i.e. Bat-ANN. The probability-based optimization technique is integrated with the artificial deep neural network. The proposed model follows the echolocation characteristics of microbats. The Bat-ANN hybrid technique improves the performance of the simple meta-heuristic optimization Bat algorithm for scheduling of tasks on cloud. The Bat algorithm is also known as a frequency tuning algorithm which provides an optimal solution of the combinatorial optimization and scheduling. Each bat is assigned a random frequency in a search space. The parameters associated with the Bat algorithm are obtained using Equations 6, 7, and 8 respectively.
Where βɛ [0, 1], Where min f
i
denotes the frequency of ith Bat,
Where
In Equation 8 x i shows the location of a Bat in the search space. The proposed algorithm has taken into use various parameters like frequency, position and velocity of the bats to find the optimal solution.
Define pulse frequency f
i
x
i
. The pulse rate emission r
i
and loudness parameter A
i
also initialize. In simple Bat algorithm following steps are used i.e. Initialize the Bat population, its position, velocity, frequency. Initialize echolocation parameters of all bats Initialize pulse frequency fi at xi Initialize pulse rate ri and loudness Ai
While (termination condition)
Generate new solutions by adjusting the frequency and updating the velocities and locations
End while
The proposed model is divided into following steps: Initialize Prepare Training data sets using a probability-based Bat optimization technique. Design a Deep Neural network and Train the model using Training data sets generated in step-2. Perform tasks scheduling on a virtual machine using the trained model. Generate an Optimal Schedule. Repeat the step 2–4 until the convergence condition is satisfied.
Configuration Parameters of user tasks
Configuration Parameters of user tasks
Figure 2 shows the flow of proposed model using hybrid bat and ANN models. The flow diagram denoted the various phases of the model from training to prediction.
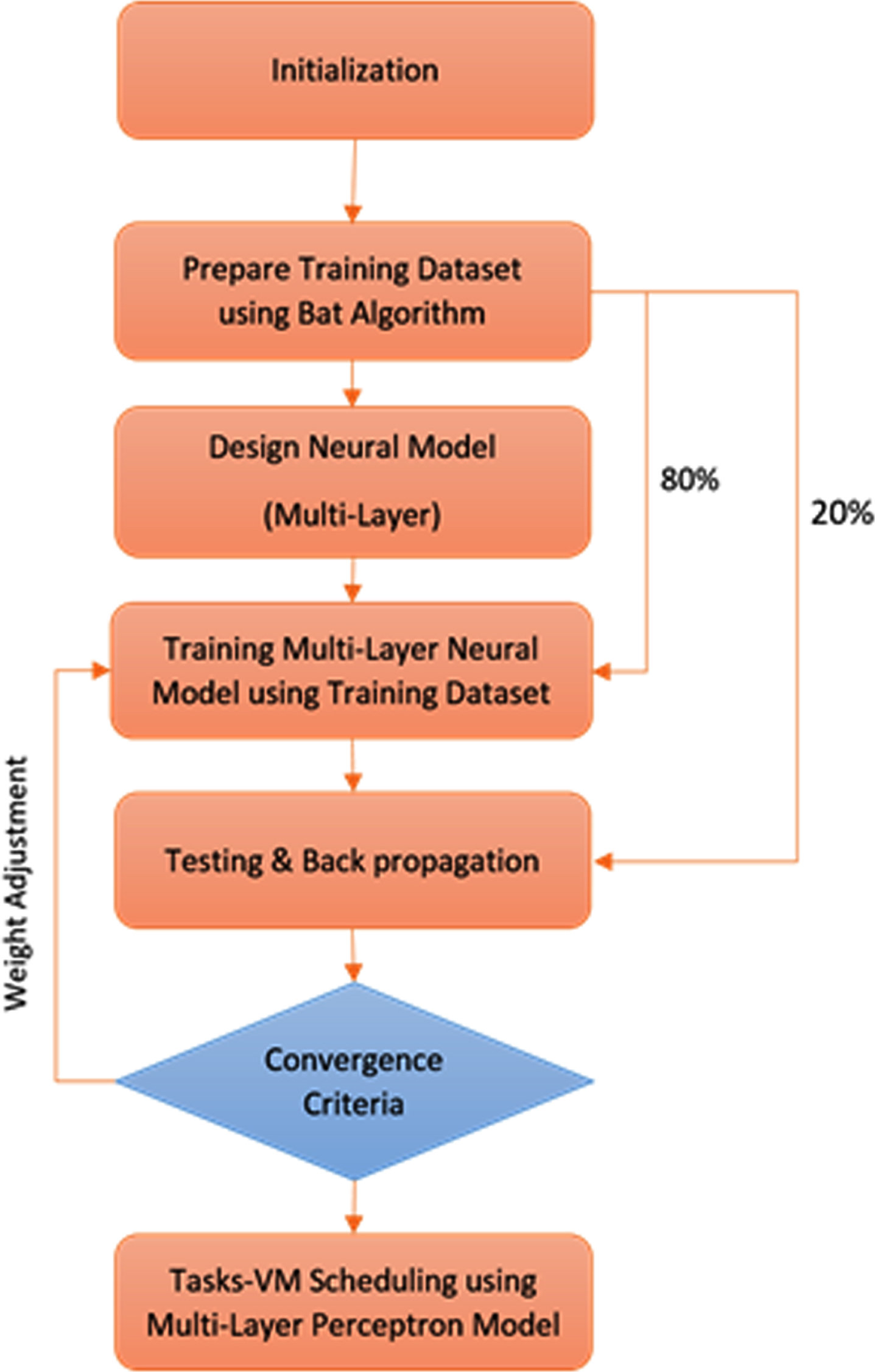
Flow diagram for Bat-ANN scheduling.
Simulation is performed using Cloudsim 3.0, The simulation uses workload traces for real-time task simulation which is an SWF format workload file from parallel workload, a free open source dataset from parallel workload repository.
The performance evaluation of the Bat-ANN model is performed using average start time, finish time, task failure count and task completion count as performance metrics.
Figures 3(a) and 3(b) show an analysis taking average start time as performance metrics for a set of tasks using the proposed algorithm and existing approaches using 5 VM and 10 virtual machines as resources. Figures 4(a) and 4(b) showcases an analysis of execution time for increasing of tasks load using the proposed algorithm and existing approaches using 5 VM and 10 virtual machines as resources. This experiment is performed to study the performance of the proposed algorithm in an underloaded and overloaded condition. Figures 5(a) and 5(b) show cases a comparison of finish time for a set of tasks using the proposed algorithm and existing approaches using 5 VM and 10 virtual machines as resources. Figures 6(a) and 6(b) showcases a study of completed tasks for a set of tasks using the proposed algorithm and existing approaches using 5 VM and 10 virtual machines as resources and increasing load over the data center. Similarly, the experiment is performed to find the improvement in the number tasks completed. The experiment results are shown in Figures 7(a) and 7(b) which shows improvement in performance with increasing load and resources.
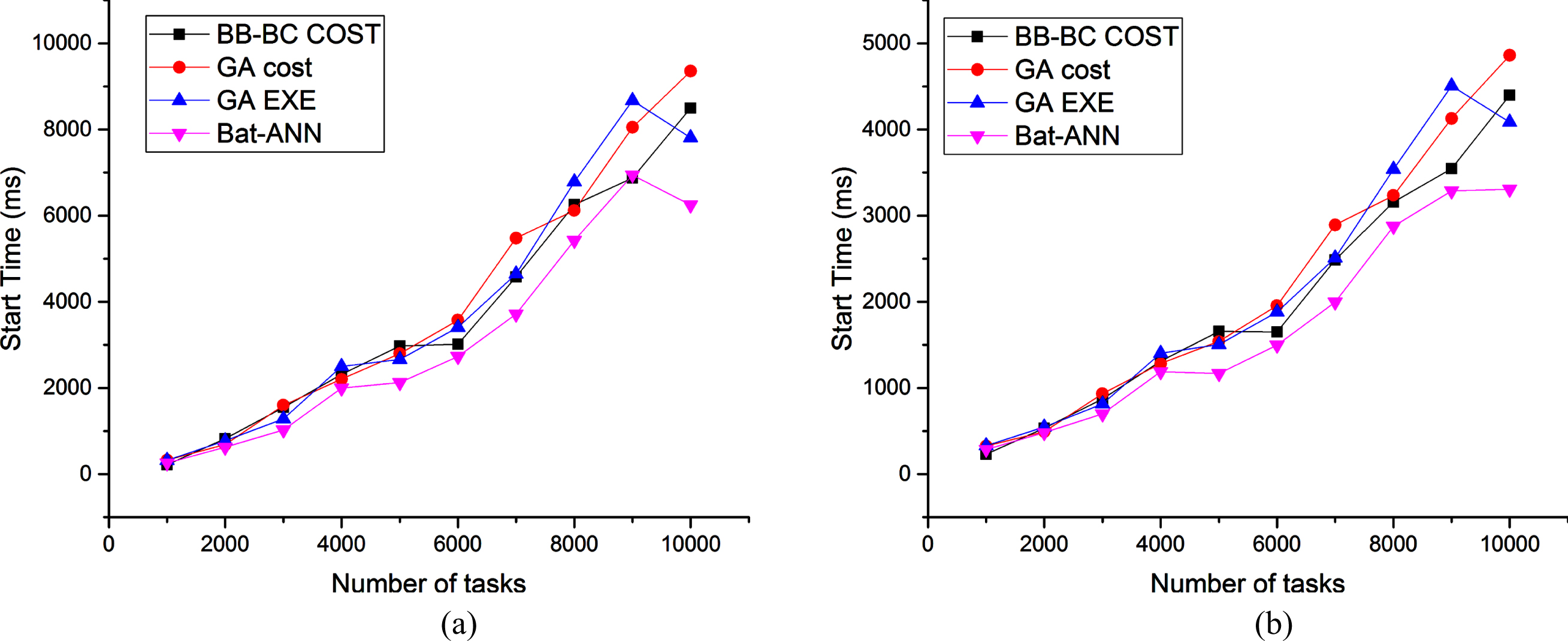
(a) Comparison start time for proposed and existing approaches. (b) Comparison start time for proposed and existing approaches.

(a) Analysis of execution time with 5 VM’s. (b) Analysis of execution time with 10 VM’s.
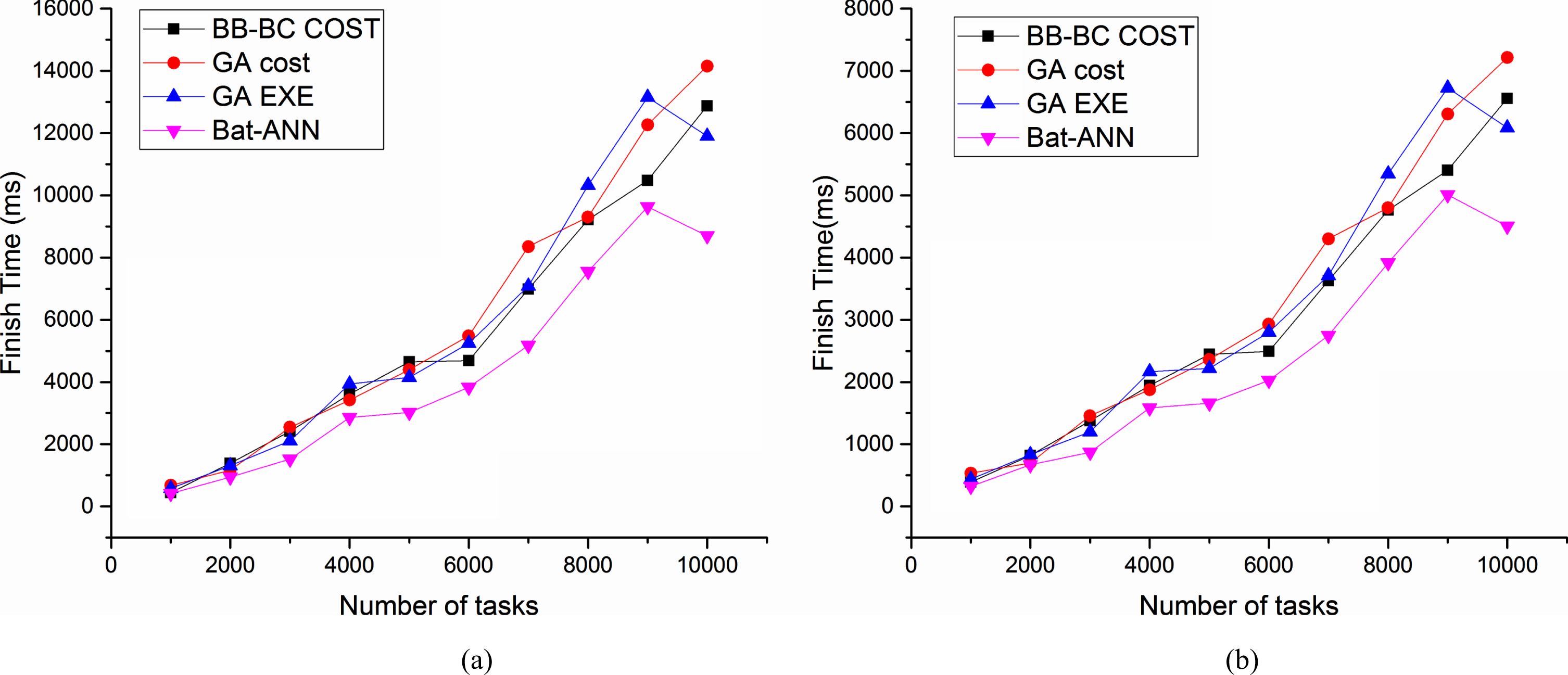
(a) Analysis of finish time with increasing task load using 5 VM’s. (b) Analysis of finish time with increasing task load and 10 VM’s.
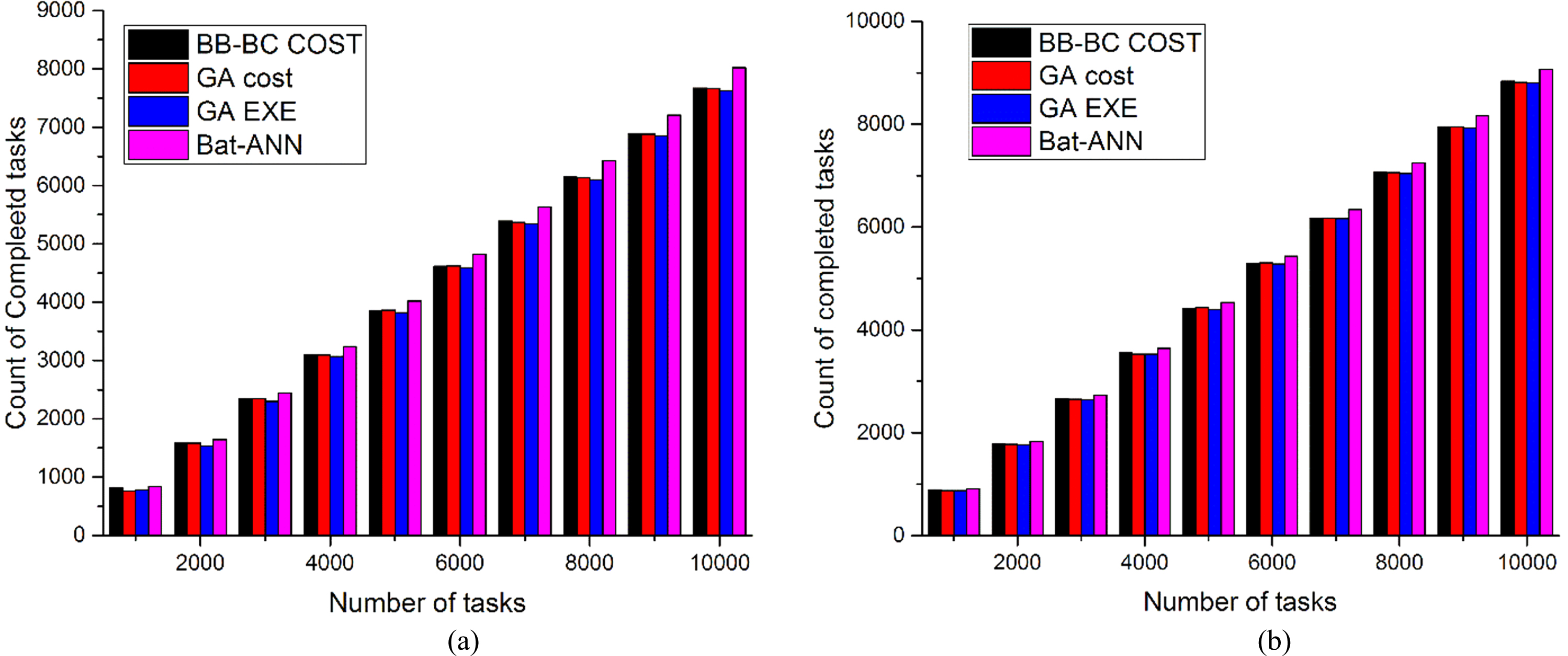
(a) Analysis of number of completed tasks with increasing task load using 5 VM’s. (b) Analysis of number of completed tasks with increasing task load using10 VM’s.
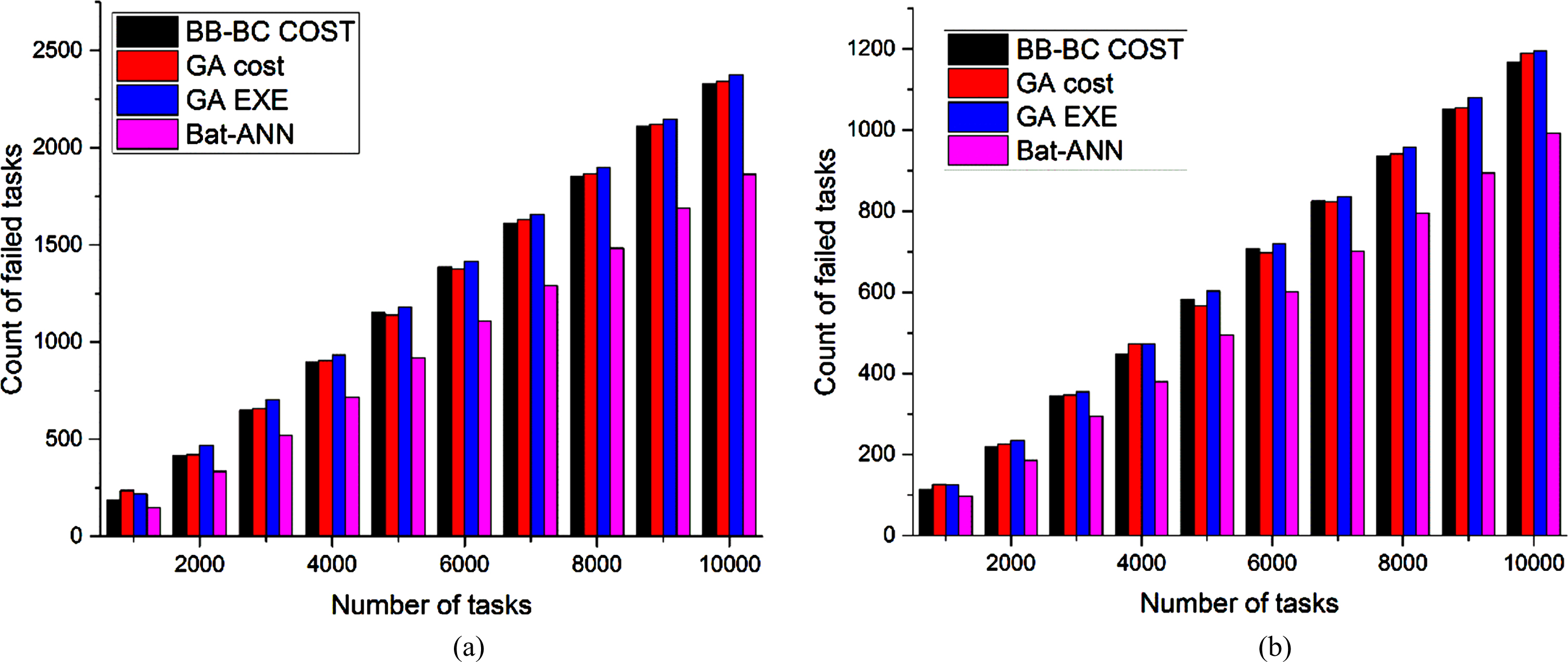
(a) Analysis of task failure count with increasing task load using 5 VM’s. (b) Analysis of task failure count with increasing task load and 10 VM’s.
In this paper, an efficient task scheduling scheme was presented for task scheduling in cloud infrastructure. The projected Bat-ANN model outperforms the genetic approach & existing techniques. The results section shows that proposed model performs better than the existing techniques for cloud IAAS. Performance is computed using the performance metrics: average finish time(ms), average start time (ms), the total execution time, fault rate, number of tasks completed and number of tasks failed. In this work focused only on task scheduling in the cloud using Bat algorithm. The work has proposed a fault-tolerant model with high quality of service. In future work, the model can be extended and tested for other deep learning models to study the performance of the model.