
Abstract
Mental and cognitive well-being is of paramount significance for human beings. Consequently, the early detection of issues that may culminate in conditions such as depression holds great importance in averting adverse outcomes for individuals. Depression, a prevalent mental health disorder, can severely impact an individual’s quality of life. Timely identification and intervention are critical to prevent its progression. Our research delves into the application of Machine Learning (ML) and Deep Learning (DL) techniques to potentially facilitate the early recognition of depressive tendencies. By leveraging the cognitive triad theory, which encapsulates negative self-perception, a pessimistic outlook on the world, and a bleak vision of the future, we aim to develop predictive models that can assist in identifying individuals at risk. In this regard, we selected The Cognitive Triad Dataset, which takes into account six different categories that encapsulate negative and positive postures about three different contexts: self context, future context and world context. Our proposal achieved great performance, by relying on a strict preprocessing analysis, which led to the models obtaining an accuracy value of 0.97 when classifying aspect contexts; 0.95 when classifying sentiment-aspects; and a value of 0.93 in accuracy was achieved under the aspect-sentiment paradigm. Our models outperformed those reported in the literature.
Keywords
Introduction
Depression is a potentially fatal mental disorder and is estimated to affect 3.8% of the world’s population according to World Health Organization (WHO) 1 . It has devastating effects on brain health as the dynamic state of the cognitive, emotional and mental domains, affecting the integrity of the structure and functionality of the brain [1, 2]. For this reason, it is important to identify factors that can help prevent depressive symptoms and serve as markers of some type of permanent brain damage [7, 12].
Cognitive therapy based on Beck’s Cognitive Triad has become an effective tool for treating depression by helping people identify, challenge and change their negative thought patterns. By challenging and replacing these cognitive distortions, people can experience a reduction in depressive symptoms and improve their emotional well-being.
Beck’s Cognitive Triad is a central concept of the cognitive theory of depression developed by Aaron T. Beck [8]. This theory is based on the idea that people suffering from depression tend to have distorted and negative thought patterns that influence their emotional state. Beck’s triad refers to three interrelated components of the following thought patterns:
It stems from his approach to cognitive therapy of depression, which focuses on identifying and changing the negative and distorted thought patterns that contribute to the depressive experience. Beck proposed that these negative thought patterns are unrealistic and inaccurate, and that they influence a person’s emotional state by maintaining and amplifying depression. It is of great importance because it provides a profound understanding of how thought patterns can influence a person’s emotional state and contribute to depression. This theory helped change the way depression is approached and treated by focusing on the active role that thoughts and beliefs play in the depressive experience.
Our approach is described in the following sections. This work is structured as follows. In Section 2 a brief description of the related works in depression detection is given. In Section 3, the preprocessing and feature extraction methods accompanied by the classification models implemented are given. Then, in Section 4 we describe the setup for the experiments and the results obtained. Finally, in Section 5 we discuss our results and some ideas about how to improve them for future work.
Jere et al. [6], presented a dataset for the purpose of modeling Beck’s Cognitive Triad (CTD) to model subjective symptoms of depression, such as negative view of self, future, and world. CTD is composed of 5,886 messages, which are divided into six categories: self-positive (spos), world-positive (wpos), future-positive (fpos), self-negative (sneg), world-negative (wneg), and future-negative (fneg). This set was evaluated in two subtasks: aspect detection and aspect-specific sentiment classification. The main purpose of creating the dataset is to aid the understanding of Beck’s Cognitive Triad Inventory (CTI) in people’s social network postings.
Jere and Patil [5], used their previously created dataset and propose the following classical ML models: Decision Tree (DT), Random Forest (RF), Nayve Bayes (NB) and SVMs. They also implemented the following DL models: Graph Neural Networks (GNN), Long Short-Term Memory (LSTM), Bilateral Long Short-Term Memory (BiLSTM) and a Recurrent Neural Network (RNN). Their best model for aspect-based sentiment classification was the single-layer RNN, with a precision and F1-score of 0.857 and 0.858 respectively. For the sentiment recognition subtask, they obtained an accuracy and F1-score of 0.89 and 0.892 respectively with a multilayer RNN model. Finally, for aspect detection they obtained an accuracy and F1-score 0.957 and 0.956 respectively and again with a multilayer RNN.
Gonzalez-Gomez et al. [4], analyzed data from two separate samples to assess associations between loneliness, social adjustment, depressive symptoms, and their neural correlates. This was achieved by contacting study participants by telephone or social networks to complete various tapping scales on depressive symptomatology, loneliness and social adjustment and these results were assessed with the CTI and the University of California (UCLA) Loneliness Scale and found that after controlling for age, gender, and years of education only loneliness emerged as a significant predictor of depressive symptomatology.
Methodology
In this paper we will make use of the dataset collected by Jere et al. [6], in which we will perform an approach with ML models such as: Support Vector Machines, Logistic Regression, Decision Trees and Random Forest with different configurations and finally, we will present an approach with DL, specifically with a Large Language Model (LLM). We will also make some adjustments to the documents of the original dataset by preprocessing them in order to obtain a better extraction of features for our models. Our final goal is to be able to compare our approach with the existing state-of-the-art results, we will perform the same subtasks that the state of the art has used to solve this problem, and we will also use the same evaluation metrics.
The evolution of the study, from the identification of the problem to the methodology employed, and the results obtained, is illustratively summarized in Fig. 2. This visual representation offers a global and enlightening vision of the research process developed in this work, providing an intuitive understanding of each stage of the study. Each of the modules shown in the figure are described in subsequent sections.
The dataset
A mentioned above, the data set used to perform the experiments was the Dataset for modeling Beck’s cognitive triad to understand depression [6]. Here, the main features of the data set are described. The corpus contains 5996 texts extracted from X (formerly Twitter), the blog Time-to-Change, and personal stories from the platform Beyond Blue. Those texts are divided into three subsets: train (4197 samples), development (899) and test (900). Texts could belong to six different classes: self negative (s-neg) self positive (s-pos), future negative (f-neg), future positive (f-pos), world negative (w-neg), and world positive (w-pos). We decided to merge the train and development subsets into a single train one, and then use the 15% of the train subset as validation. The distribution of the original dataset is shown in Fig. 1.

Corpus distribution.
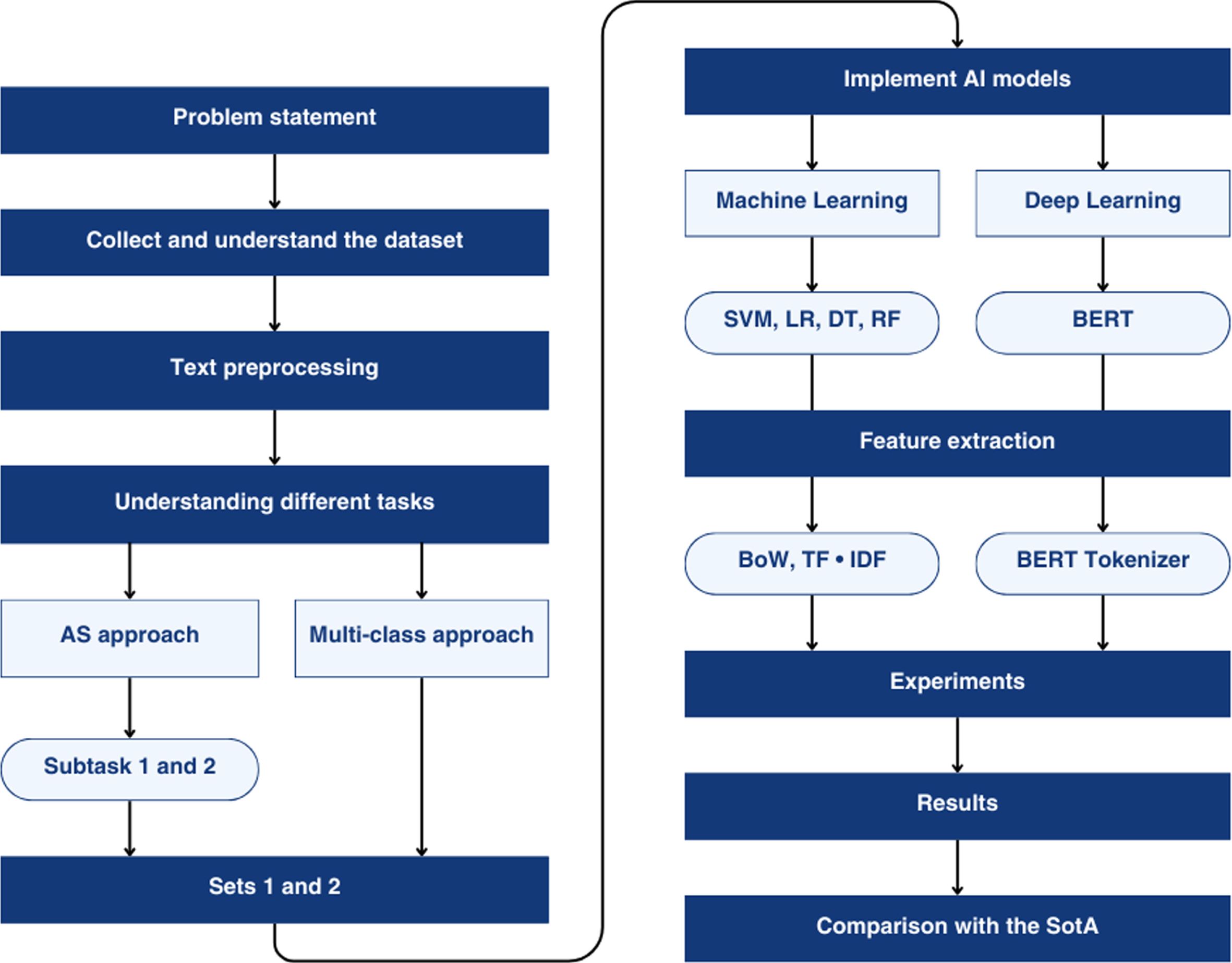
Visual representation of the development of the work presented.
Support vector machine (SVM)
They are a supervised learning algorithm used for both classification and regression problems. An SVM searches for a hyperplane that best separates two different classes in the feature space. The hyperplane is a geometric entity that is used to classify points into different categories. If the classes are not linearly separable in the original space, SVMs can use mathematical tricks to map the data to a higher dimensional space where they are linearly separable.
Logistic regression (LR)
It is a supervised learning algorithm used for classification and probability estimation in binary (two-class) or multi-class (more than two classes) problems. Logistic regression models the probability that an instance belongs to a particular class and uses the logistic function (also known as sigmoid function) to transform a linear combination of features into a value between 0 and 1, which is interpreted as the probability. Despite its name, it is mainly used for classification tasks rather than regression.
Decision trees (DT)
These are supervised learning algorithms used for classification and regression problems. They operate by recursively partitioning the feature space into smaller, more homogeneous subsets, with the objective of making decisions based on the hierarchical structure of the tree. At each node of the tree, a feature, and a threshold value are selected to split the data into two branches (subsets) based on that feature. The selection of the splitting feature is made based on some criterion, such as information gain in the case of classification or variance reduction in the case of regression.
Random Forest (RF)
It is a supervised learning algorithm used primarily for classification and regression tasks. They are a combination of multiple decision trees and are noted for their ability to handle both numerical and categorical data, as well as their ability to avoid overfitting and generate accurate predictions.
Bidirectional encoder representations from transformers (BERT)
BERT [3] is a language model, whose architecture is based on DL networks and is part of the LLM family. It uses a technique called “bidirectional attention” to process all the words in a sentence at the same time, allowing it to capture somewhat more complex relationships and greater context. BERT [3] was trained with large amounts of text obtained from the internet, allowing him to generate representations of words and phrases that capture a slightly deeper understanding of language.
Text preprocessing
Although the documents in the selected dataset are quite readable, there are some improvements that can be made to the text in order to improve the features that our ML model will be trained on. These enhancements include:
Bag of words
This model is a simplified representation of a text, where the bag represents the set of all words contained in a document collection. A single document is represented as a vector, where each dimension represents a word from the vocabulary obtained from the document collection and how many times the word appeared in a single document (TF).
TF·IDF
This method makes use of the term frequency (TF), and the inverse document frequency (IDF). For the TF calculation, a bag of words is generated with the vocabulary of the set of all documents that are to be analyzed, then the total number of occurrences of the word is obtained. IDF is calculated as the logarithm of the quotient of the number of documents in which the analyzed word appears and the number of documents in which it appears in the analyzed set. Finally, the product between TF and IDF is performed for each of the words in the analyzed text, generating a vector of characteristics.
BERT Tokenizer
As outlined in Devlin et al.‘s work [3], BERT Tokenizer serves as the standardized technique to segment and convert text into smaller units, usually words or sub-words. This process enables compatibility with various transformer-based models [11]. By breaking down text into coherent segments and assigning numerical embeddings to them, this tokenizer streamlines natural language processing tasks. Ultimately, it transforms textual data into a format comprehensible and manipulable by deep learning models.
Experiments and results
The solution proposed in this paper consists of two different approaches. The aspect-sentiment (AS) based classification and the multi-class scenario. These approaches are further described in their corresponding section.
Throughout our experiments, some changes will be seen in terms of modifying the inputs for the ML models, however, for our DL approach we will only change the training epochs parameter of the model in the different tasks. Therefore, the hyperparameters for our DL model are:
In order for these experiments to be replicable, it should be mentioned that for ML models we used the
AS approach
For this approach, the main classification task was divided into two subtasks, the first one was the aspect identification subtask. For this task, we trained our models to detect whether the text was describing the author’s thoughts about themselves (self), about future scenarios (future) or about the exterior (world). The second subtask was to detect the sentiment reflected by the author’s in the text, whether they were positive or negative. For both sets of experiments, the dataset was redistributed to adequate it for the subtasks aim. The redistribution is described below.
A ternary dataset was generated, the class division was the following and the distribution is shown in Fig. 3. {self-negative, self-positive} → {self} {future-negative, future-positive} → {future} {world-negative, world-positive} → {world}
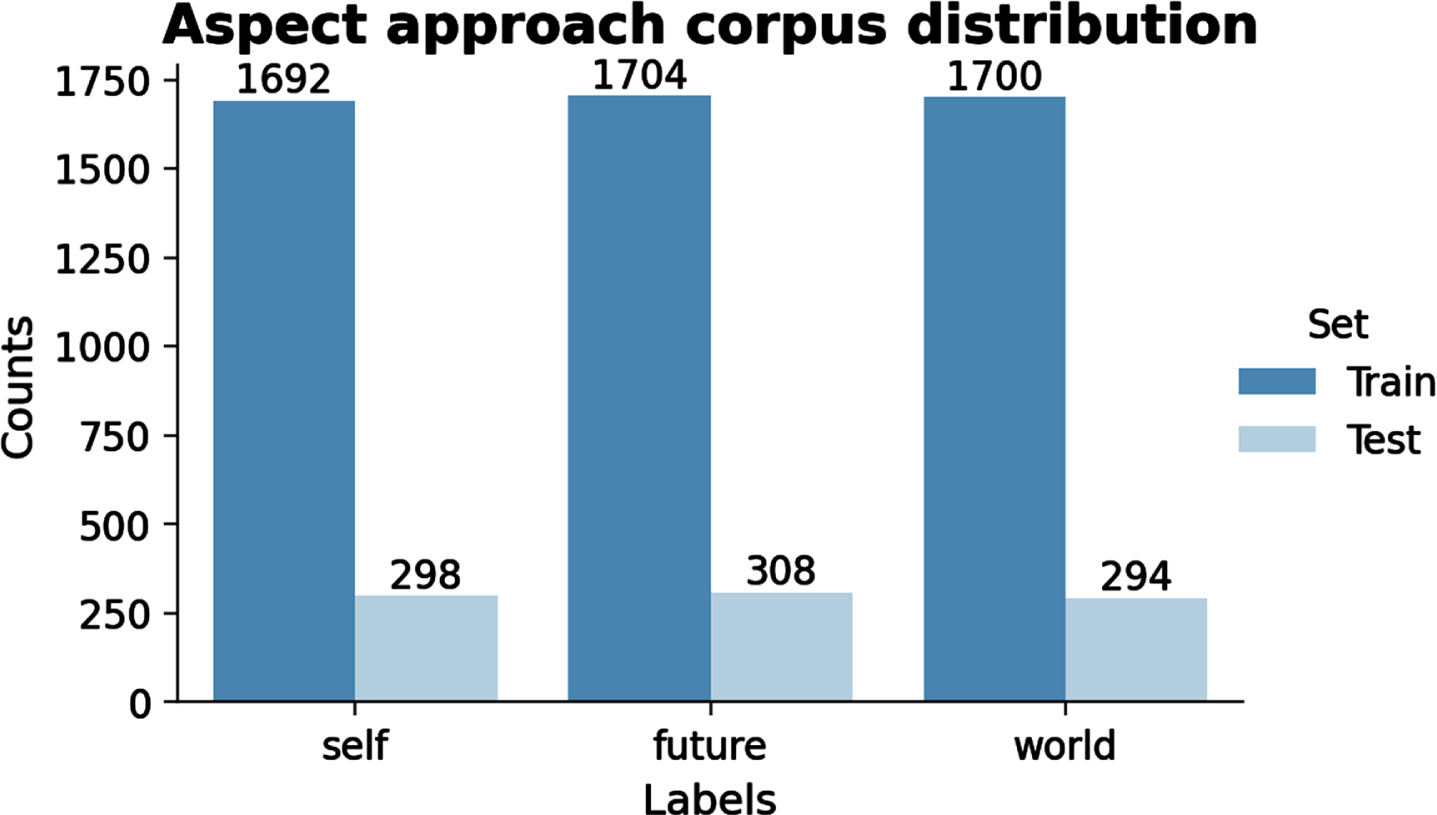
Aspect corpus distribution.
For this subtask, the redistribution of the classes of the dataset was performed as follows and is show in Fig. 4. {self-negative, future-negative, world-negative} → {negative} {self-positive, future-positive, world-positive} → {positive}
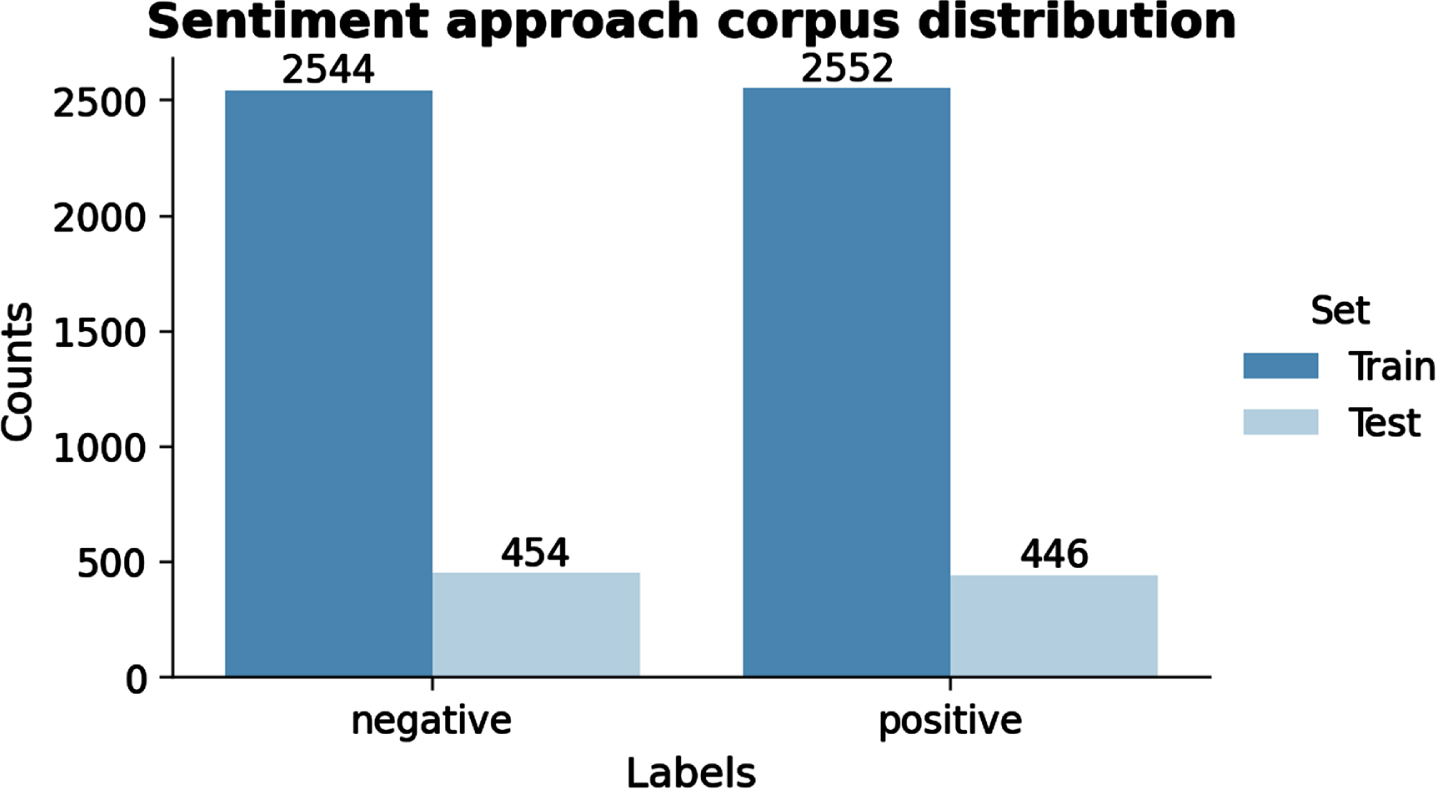
Sentiment corpus distribution.
For this first phase of experimentation, we will perform experiments with all the models described in section 3.2. The configuration to be used for these experiments will be the following: a) For ML approaches, as tokenizer we used TF·IDF, with a minimum word occurrence frequency of 3 and a range of n-grams of 3; b) For the DL approach, we used 3 and 5 epochs of training respectively for each subtask.
Subtask 1 In the Table 1, it can be seen that the best results for ML were LR and SVM with the specific feature that the text was preprocessed. However, they did not outperform our DL approach. In Fig. 5, we can observe the confusion matrices of our best results. Sub-figure 5a shows our ML approximation and Sub-figure 5b shows our DL approximation.
Setup and results for set 1, subtask 1 (macro avg.)
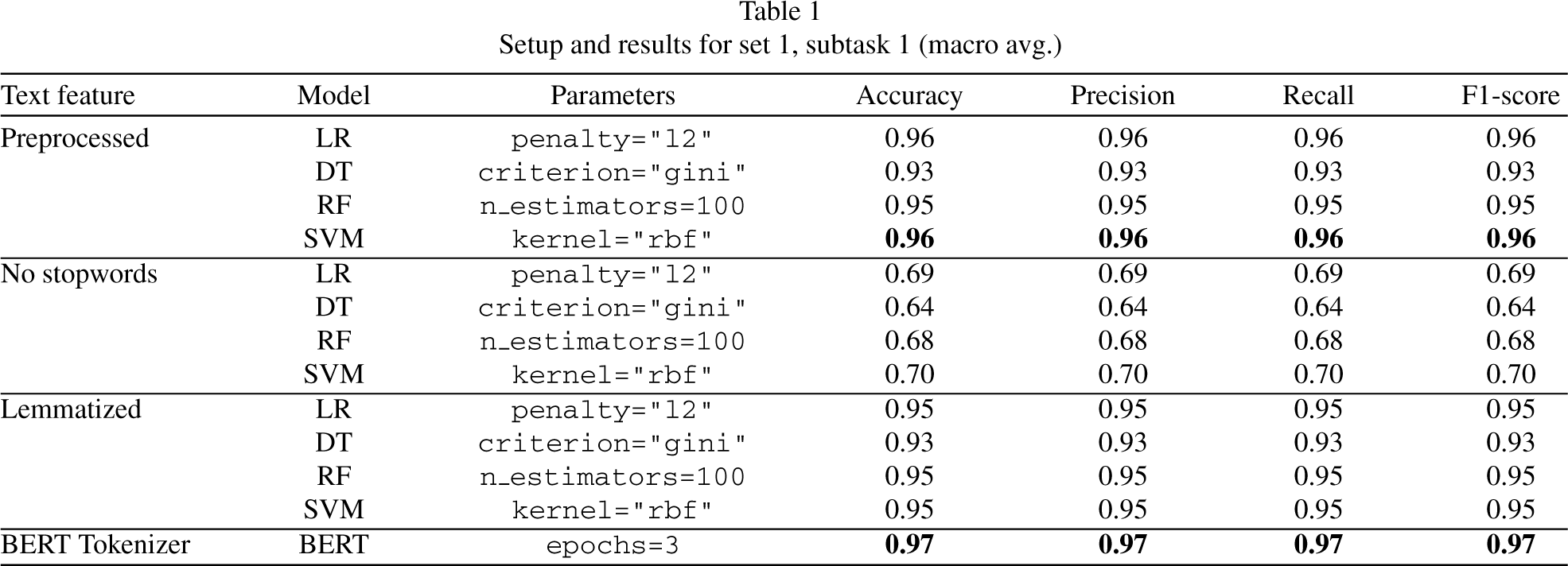
Setup and results for set 1, subtask 1 (macro avg.)

Confusion matrices for set 1, subtask 1: best models.
Subtask 2 The results for this subtask can be seen in the Table 2. For this second subtask, there are two models competing to be the best in the ML approach, however, both models are SVMs, with the difference being the treatment given to the text, one model was with preprocessed text and the other with lemmatized text. But, our approach with DL continues to perform better. The confusion matrices for our best models are shown in Fig. 6.
Setup and results for set 1, subtask 2 (macro avg.)


Confusion matrices for set 1, subtask 2: best models.
After the first stage of experiments in the AS approach, we performed a second trial to improve the performance of those obtained in the first set, the goal of this set of experiments was to reach the performance of the BERT model and to try to outperform it with the ML algorithms.
Subtask 1 The preprocessed texts were tokenized and as tokenizer we used TF·IDF, also we set a minimum word occurrence frequency of 2, maximum document frequency of 0.9 (to reduce the characteristic vector size), a range of n-grams of 2, and the seed was changed to 77.
Then, several models were trained and evaluated to test their performance. After the evaluation, two ML models draw, however we selected the SVM model as the best one. The best models setup and results are described in Table 3, their confusion matrices are shown in Fig. 7a.
Setup and results for set 2 (macro avg.)

Setup and results for set 2 (macro avg.)

Confusion matrices for set 2.
Subtask 2 As in the aspect identification subtask, preprocessed texts were tokenized and as tokenizer we will use TF·IDF, with a minimum word occurrence frequency of 2, maximum document frequency of 0.17 (the reduction to the characteristic vector size was huge) and a range of n-grams of 2.
In total, 3 models of ML were trained and evaluated for this subtask, the model configuration and their results are described in Table 3, their confusion matrices are shown in Fig. 7.
AS classification. Once both sets of experiments were completed, the cognitive triad of depression (CTD) classification task was performed. To accomplish it, the best models from the subtasks 1 and 2 were selected and put together. Subtask 1: ML: SVM with DL: BERT with 3 epochs (track 1). Subtask 2: ML: SVM with DL: BERT with 5 epochs (track 1).
The results for this approach are shown in Table 4, and the confusion matrix is shown in Fig. 8.
Results for AS CTD task (in macro avg.)
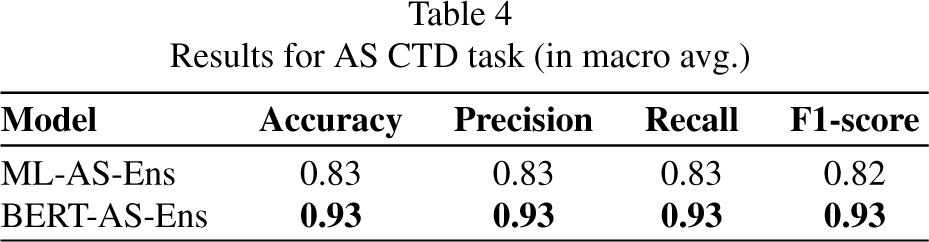

Confusion matrix for AS CTD task.
This set of experiments revealed interesting things about the features and the models. For the aspect identification subtask, words with high frequency (those that are present in 90% of the documents or less) and low frequency ones (those repeated in at least two documents) are relevant for the model performance, but for the sentiment classification subtask, the most frequent words are irrelevant (those words repeated in more than the 17% of the documents are ignored) and even with that feature reduction, the models were able to obtain promising results. For both subtasks, the best models were our DL approaches that in the CTD classification task performed very good.
Experiments, set 1
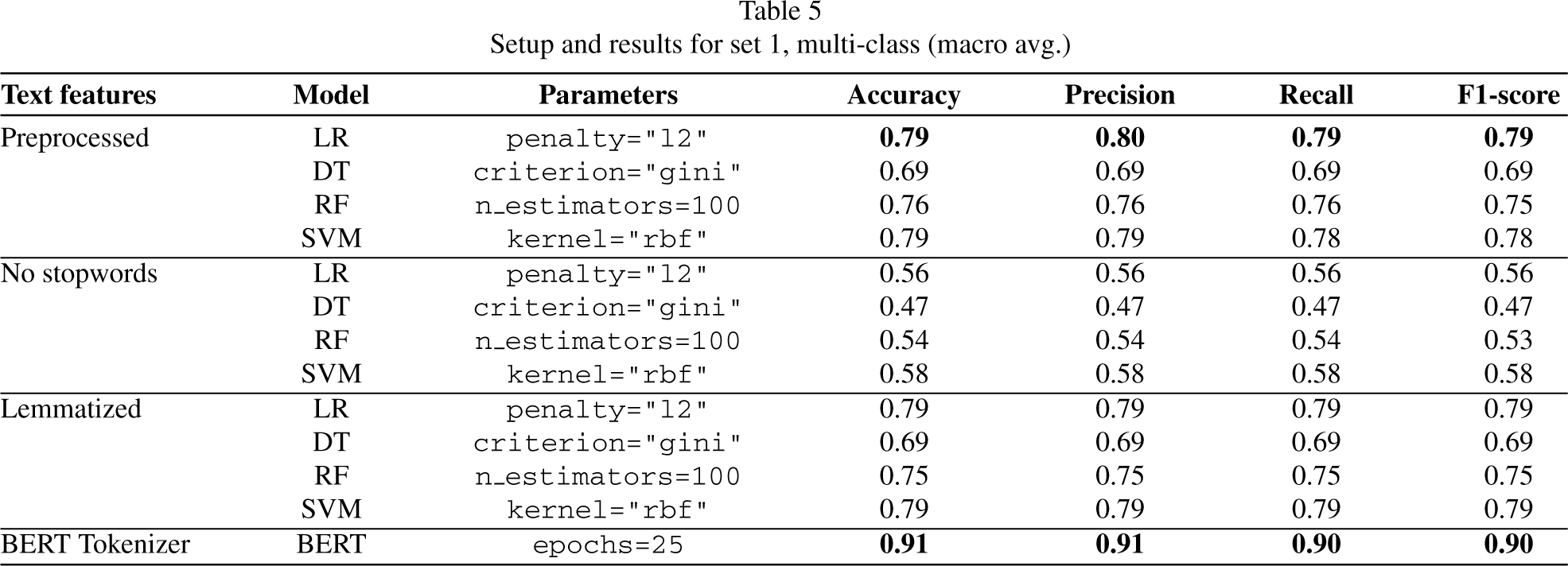
The first experimentation phase for this subtask was based on the first experimentation phase for subtask 1. Thus, the models used as well as their corresponding configurations were exactly the same, the only difference will be that this approach will be a multi-class one.
The results of this phase are shown in the Table 5, where we obtained three models with similar results: LR with preprocessed text, LR and SVM with lemmatized text. LR with the preprocessed text was chosen as the best model of all ML learning approaches since LR with the lemmatized text at the end of the experimentation did not end up converging with the predetermined number of iterations, on the other hand the SVM model with the lemmatized text has a lower precision value. Talking about our approach with DL, it continued to perform quite well, outperforming the ML models. The confusion matrix for the best model (BERT, multi-class) is shown in Fig. 9.

Confusion matrix for the best model in set 1 (multi-class).
Setup and results for set 1, multi-class (macro avg.)
After the first stage of experiments in the multi-class scenario, we performed a second experiment that consisted of a model ensemble. The ensemble consists of six SVMs trained to identify each of the six classes. To put the ensemble together, we first trained each of the models in a binary classification scenario. To achieve this, the main dataset was divided into subsets that contained all the samples of the class to train, then we balanced the subsets with random samples of data of the other five classes in the same proportion (approximately 20% of the size of the class to balance), obtaining six subsets to train and test the models of the ensemble. Similarly, we do the same for our DL model.
For each of the models a different tokenizer was fitted to tokenize the preprocessed text, the parameters used to fit the tokenizers were the same, a TF·IDF vectorizer from
The setup and results for each of the ensemble models is described in Table 6. To make the experiments replicable, the random generation seeds were set to 77.
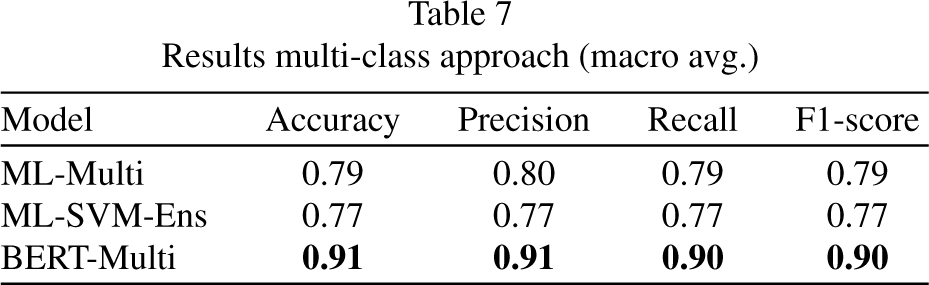
Finally, all the trained models for the multi-class approach were tested, and their results are shown in Table 7. The confusion matrix of the best model for this approach is displayed in Fig. 9.
Setup and results for set 2, multi-class ensemble model
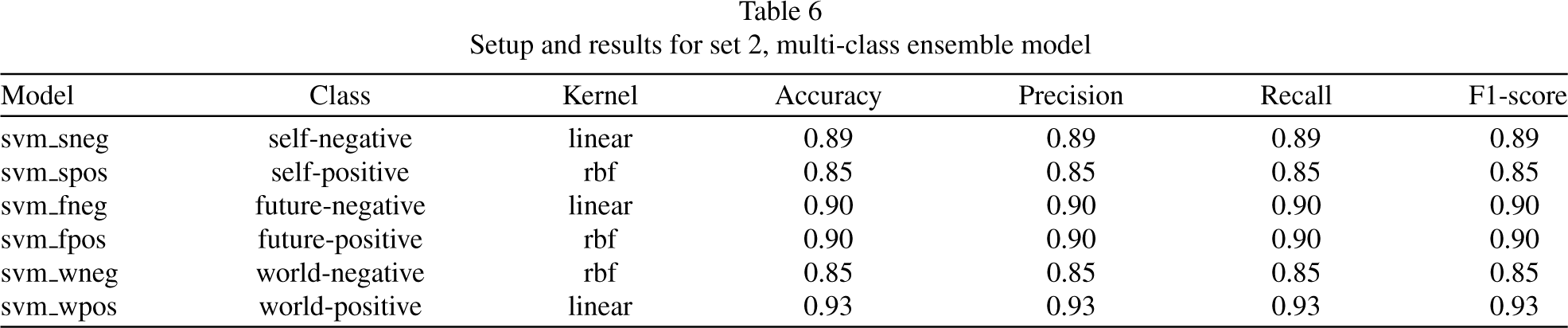
Setup and results for set 2, multi-class ensemble model
Results multi-class approach (macro avg.)
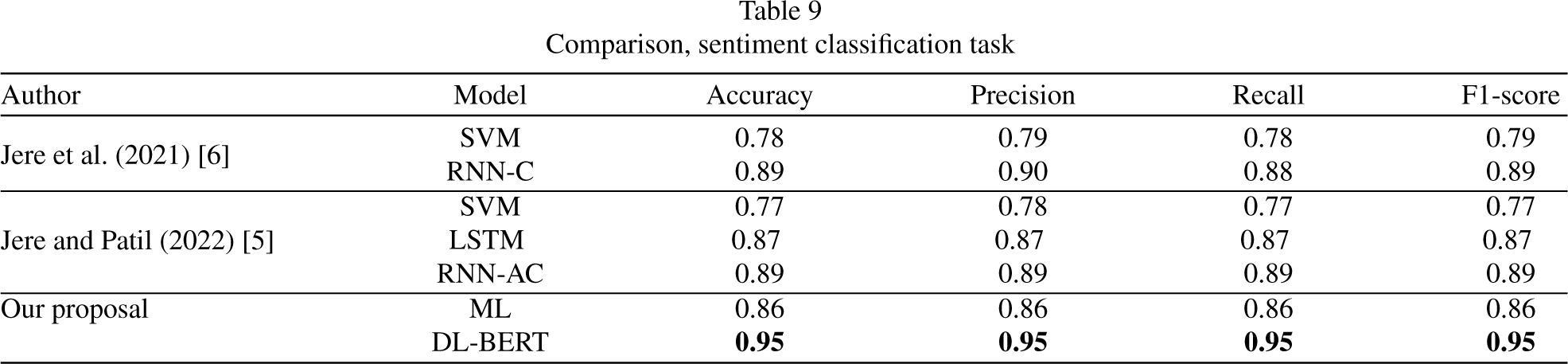
Here, a comparison between the results obtained from our proposals and those from the state of the art is provided. The results obtained from the aspect identification tasks are shown in Table 8, those obtained from the sentiment classification task in Table 9, and the CTD classification are shown in Table 10.
Comparison, aspect identification task
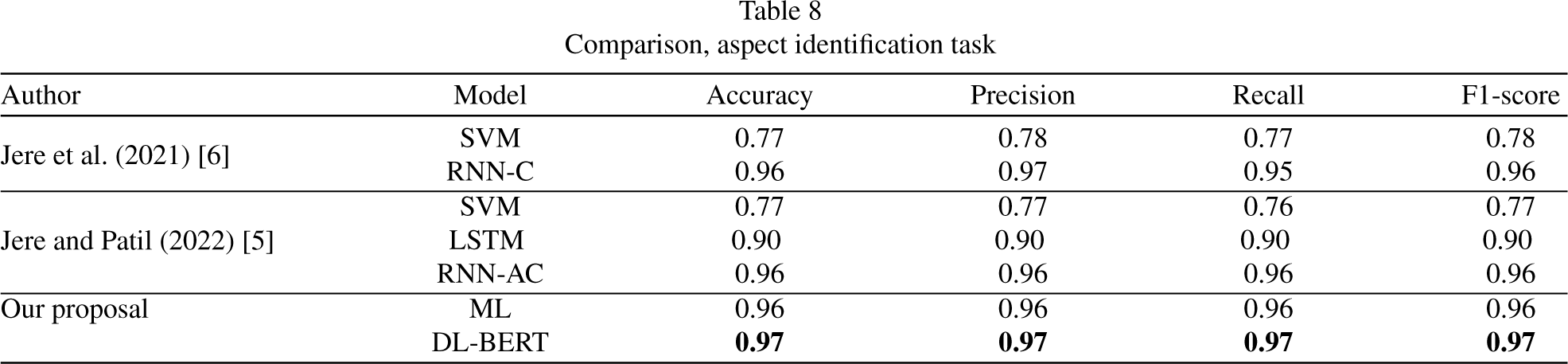
Comparison, aspect identification task
Comparison, sentiment classification task
Comparison, aspect-sentiment CTD classification task
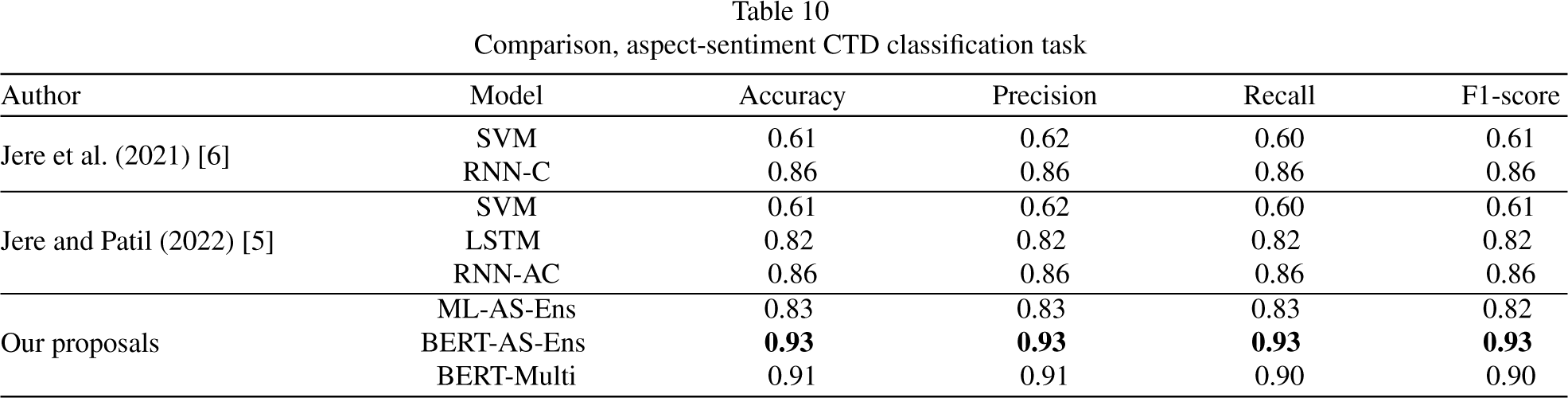
The comparison was made between ML and DL models on purpose, from the tables above, it can be inferred that although our ML proposals did not outperform the DL models are very competitive, overpassing the ML models proposed in the literature, and even reaching the DL models performance in some cases like the aspect identification task. The multi-class approach got some very good results, providing a new baseline for future proposals in this approach. Our BERT proposals for both approaches outperformed the models reported in the literature and our ML proposals, but the
sec:discussion The results obtained in this paper suggest that ML algorithms are suitable for classifying text sequences based on two different characteristics that are simultaneously present under the Beck’s Cognitive Triad, i.e., aspect analysis, whether it is self, world or future focused; and sentiment analysis, to determine if what was said is positive or negative with respect to the corresponding aspect. In this regard, our AS approach, which consists of two models, each one of them responsible for classifying either aspect or sentiments, to subsequently conjugate their results to deliver a final label, showed to be the most appropriate proposal for the task in question.
Additionally, we consider that these results are a consequence of the preprocessing pipeline applied to the data, which was based on our observations on the tasks after an in depth analysis. Therefore, we believe that data processing, even though lately, has received little to no attention, is still a procedure of vital importance, since it allows algorithms to learn on specific properties of the input data.
Furthermore, a new approach to this problem, the multi-class approach, was proposed. This approach trains directly on the corpus, without the need to divide the main task into subtasks. This new proposal obtained good results with ML algorithms which led us to experiment with more advanced algorithms such as DL, specifically the use of an LLM such as BERT, the results obtained by the
When analyzing the performance obtained by the best models in both perspectives, we can notice that both are able to cope with the problem, since the difference between their results is minimal (approximately 2%). Thus offering a new way to perform this task.
Expanding on these discoveries, future research possibilities may involve enhancing ML models by incorporating embeddings based on contextual cues and delving into more intricate linguistic characteristics. Exploring the fusion of diverse models through ensemble techniques could bolster the reliability and adaptability of classification. Moreover, broadening this study to encompass analysis across multiple languages could reveal captivating insights into the widespread nature of these cognitive elements in varied linguistic environments. Lastly, investigating how these algorithms perceive and prioritize different cognitive traits in text sequences could be achieved by assessing the interpretability of these models using attention mechanisms or visualization techniques.
Ethics
The results obtained in this work raise relevant ethical considerations in their practical application. Due to the lack of detailed information such as age, social status, country of origin of the data used, etc. the direct implementation of these results in real-life settings poses significant ethical challenges. The sample lacks representativeness for generalizing conclusions or applying the proposed solutions, which limits the validity and ethics of their implementation in wider contexts. Caution is therefore required when considering any practical applications based solely on the results of this study, given its limited scope and the lack of representative diversity in the data.
Footnotes
Acknowledgments
The authors wish to thank the support of the Instituto Politécnico Nacional (COFAA, SIP-IPN, Grant SIP 20240610) and the Mexican Government (CONAHCyT, SNI).