
Abstract
In today’s big data era, there are a large number of unstructured information resources on the web. Natural language processing researchers have been working hard to figure out how to extract useful information from them. Entity Relation Extraction is a crucial step in Information Extraction and provides technical support for Knowledge Graphs, Intelligent Q&A systems and Intelligent Retrieval. In this paper, we present a comprehensive history of entity relation extraction and introduce the relation extraction methods based on Machine Mearning, the relation extraction methods based on Deep Learning and the relation extraction methods for open domains. Then we summarize the characteristics and representative results of each type of method and introduce the common datasets and evaluation systems for entity relation extraction. Finally, we summarize current entity relation extraction methods and look forward to future technologies.
Keywords
Introduction
With the vigorous development of information technology, the information resources in the network are also showing an explosive growth trend. The rich and diverse forms of expression add different colors to the network data. The diversification of information has injected a lot of vitality into the information age, but it has also given rise to questions about how to retrieve and extract information data from this vast, diverse and rapidly growing body of information. At present, most of the data information is semi-structured or unstructured and cannot be directly understood by the computer, and there are various problems such as information overload and time-consuming filtering for users in accessing critical information. The extraction of critical and concise information from heterogeneous data in a cost-effective manner has become a hot topic of research. In this context, Information Extraction (IE) technology has emerged.
Information extraction refers to the structural processing of the information in the text so that it can take on a form (e.g., a table) that is conducive to computer recognition and use. It mainly includes three sub-tasks: Entity Extraction, Relation Extractio (RE) and Event Extraction. As one of them, RE has attracted extensive scholarly research in recent years. Its goal is to extract the semantic relation between named entity pairs in a sentence and form structured data for storage and access [1]. For example, the entity “rescue and relief workers” has an “arrived” relation with the entity “disaster area” in “The first batch of rescue and relief workers arrived in the disaster area on the morning of the 13th.”
RE has always been a challenging task in the field of Natural Language Processing (NLP). From early Pattern Matching to later Machine Learning [2] to Deep Learning, each technique has achieved good results in extraction performance. In addition, RE provides fundamental data for NLP tasks such as processing massive amounts of information, retrieving key information, building knowledge graphs and intelligent Q&A systems, and has important applications in many fields.
RE techniques are now well developed, providing theoretical support for other NLP tasks and driving the development of other NLP tasks. However, RE still faces different challenges.
First, datasets are a key component of model training. However, existing RE datasets are either undersized or contain large amounts of noisy data, which has a significant impact on model training and learning. How to effectively solve the dataset problem will motivate researchers to continuously improve the relevant algorithms and enhance the performance of the models.
Secondly, language is a complex discipline, and the semantic relations of texts in real environments are more diverse. The problems of entity nesting, multiple relations and overlapping entities pose challenges for the development of RE models. How to fully understand the semantic features of text, effectively fuse syntactic and semantic information, and improve the accuracy of model extraction is the focus of the research field of RE.
Thirdly, the Internet is an open and multi-source information repository containing information from various domains, but most of the existing extraction models are domain-specific. Although there are also open domain extraction models, there is still a gap between these approaches and domain-specific ones. How to improve the portability and scalability of the RE model is one of the challenges in the field of RE.
Through in-depth integration of academic research and market demand to further solve the above problems and constantly improve the reliability and execution efficiency of RE technology, it will inevitably be more widely used in semantic annotation, intelligent Q&A, human resource management and other fields [3], providing more convenience for people’s lives.
History of entity relation extraction
In the late 1980s, the Defense Advanced Research Projects Agency (DARPA) funded and held the Message Understanding Conference (MUC), which designated relevant tasks and evaluation systems for IE to encourage and develop new methods of IE and promote the development of IE research [4]. In 1998, the Seventh MUC put forward the task of Template Extraction for the first time, mainly focusing on three types of templates: Employee_of, Location_of and Product_of. The evaluation corpus mainly comes from the relevant news about aircraft crashes and space launches in the New York Times [5]. The Template Relation proposed in this conference is the earliest description of entity relations.
Main research conferences of relation extraction
Main research conferences of relation extraction
Due to the suspension of the MUC, the National Institute of Standards and Technology (NIST) held the Automatic Content Extraction (ACE) Conference in 1999 to continue the evaluation of IE in place of the MUC. In 2002, the ACE Conference added the task of Relation Detection and Recognition (RDR). In 2008, the ACE Conference divided the RE task into seven categories, including person (PER), organization (ORG), facility (FAC), location (LOC), geopolitical entities (GPE), vehicles (VEH), and weapons (WEA), and each category was further divided into multiple subcategories. In 2009, the ACE Conference was formally included in the Text Analysis Conference (TAC) and became an important part of the Knowledge Base Population (KBP) task [6].
The Semantic Evaluation (SemEval) Conference is another important evaluation conference in the field of IE after MUC and ACE [1]. It focuses on the relation between sentence-level entities and the natural language that people speak [7] and attracts many research institutions and colleges to participate in the evaluation. The SemEval-2007 evaluation task 4 set seven types of entity relations between common nouns and noun phrases, while the SemEval-2010 evaluation task 8 expanded the types of entity relations to nine and provided the SemEval-2010 Task8 dataset, allowing the SemEval Conference to develop into a highly influential evaluation conference.
The major research conferences on entity relation extraction are shown in Table 1, all of which have greatly advanced the task of RE and provided a large number of evaluation corpora for RE. These corpora, which were manually annotated and constructed by domain experts, are of high quality and have a recognised evaluation style [3], guiding the development of traditional RE research. However, as manual annotation is both time-consuming and laborious, and difficult to expand at a later stage, researchers have gradually turned their attention to RE methods for open domains. Large-scale knowledge bases such as Wikipedia, DBpedia and Freebase in the open domain of the Internet provide large and effective data support for annotating and expanding the corpus [1], which covers a wider range of domains and contains more comprehensive types, making RE in open domains possible.

The classfication of relation extraction methods.
Driven by various evaluation conferences, research on RE has been developing. From Binary Relation to N-ary Relation, from specific domains to open domains, researchers have learned from each other, made progress in competition, and proposed various models and methods to solve RE problems. In the early days, researchers used rule-based [76], dictionary-based [84–87], and other methods to deal with the extraction task of defining relation categories. After introducing feature vectors, researchers use traditional Machine Learning methods to train models on annotated corpora and then predict and extract relations. Later, in order to reduce the cost of annotated corpora and alleviate the difficulty of corpus expansion, researchers put forward the idea of automatic feature extraction and developed new methods based on Deep Learning.
This paper has summarised and collated the relevant literature on RE to classify the main techniques according to the evolution of relational extraction, as shown in Fig. 1. The following chapters will introduce these methods respectively.
Methods based on machine learning
Machine learning-based RE methods are based on statistical language models. These methods first analyze the text, select text features, and semantically express entity relations, then construct a relation classification model and predict the entity relations contained in the test text. It can be divided into Supervised, Semi-supervised and Unsupervised according to whether the adopted dataset is annotated.
Supervised methods
Supervised methods rely on manually annotated datasets. This method regards the RE as a classification problem. It uses Machine Learning to train a relation classifier on the training datasets, and then recognizes and predicts entity relations of candidate data or test data in specific fields with high precision. At present, the most popular supervised RE methods are mainly Feature-based methods and Kernel-based methods. Feature-based methods
The Feature-based methods need to extract some sentence feature information from the instances, such as lexical features, syntactic features, semantic features, etc., then represent this feature information as feature vectors. The RE model is trained by calculating the similarity between vectors. Finally, the trained Machine Learning model is used on unstructured text to achieve the task of RE.
In the Feature-based methods, Che et al. [8] selected the training data from ACE 2004 as the experimental data and used the Winnow algorithm and Support Vector Machine (SVM) algorithm to carry out the RE experiment. The experimental results show that when two words around each entity are selected as the features, the extraction performance is the best. Dong et al. [10] divided entity relations into contained entity relations and non-contained entity relations and proposed new syntactic features according to their respective characteristics. Using Conditional Random Field (CRF) model training, the experimental results in ACE 2007 evaluation data show that the new partition method and features effectively improve the performance of the Chinese entity relation extraction task.
Furthermore, some researchers have combined multiple feature information. Xu et al. [11] proposed a series of features for Chinese entity relations, including words, part of speech tagging, entity information, occurrence information, inclusion relations, and conceptual information provided by HowNet. They formed a context feature vector and used SVM on ACE 2004 corpus data to conduct experiments. The results show that the selection of feature sets has a great impact on the recognition effect. After fully considering the characteristics of the Chinese corpus, Huang et al. [13] combined lexical features, entity information, syntactic features and grammatical features in the way of feature combination and used SVM to conduct experiments on the Chinese corpus of ACE 2005. The results show that the feature combination of words and entities plays a greater role in Chinese RE.
In addition to the basic features, some researchers have also proposed new features. Zhou et al. [9] merged the base phrase chunking information into the feature vector and experimented with the SVM algorithm on the ACE corpus. The results show that chunking is very effective for RE and contributes to the improvement of most performances in syntax. Li et al. [12] clearly defined and explored nine kinds of positional relations between two entities in the newly proposed RE method. They fused these relations into entity features, context features, and word features. Combined with the proposed revision and reasoning mechanism based on relation hierarchy and co-referential information, they conducted experiments on the ACE 2005 Chinese corpus, and the results show that the method is effective. Guo et al. [14] added features such as dependent syntactic relations, core predicates, and semantic role annotation to the previous feature representations based on syntactic and semantic features. Then they used SVM for model training and experimented on a real news text corpus, and the results showed that the method had significant extraction effects. Kernel-based Methods
Although the Feature-based methods have achieved good results, they need to set basic features according to experience and cannot make full use of the structural information provided by the context, so people proposed the Kernel-based methods. The main idea of Kernel-based methods is to use invisible feature mapping instead of explicit feature mapping. Common Kernel-based methods include the word sequence kernel function method, dependency tree kernel function method, shortest path dependency tree kernel function method, convolution tree kernel function method and their combined kernel function method [1]. Kernel-based methods make full use of long-distance features and structural features in corpus data, then select appropriate sentence parsing structures (such as syntax trees) and calculate the similarity between trees, and finally use classifiers that support kernel functions to extract relations.
In the Kernel-based methods, Che et al. [15] proposed a kernel-based Chinese text RE method called Improved-Edit-Dependency Kernel (IED), which is used to calculate the similarity between two Chinese strings and uses Voted Perceptron and SVM as classifiers to extract personal relations from Chinese text. The experimental results show that the kernel-based method is better than the Feature-based method. Huang et al. [17] eliminated the strict requirement that the original shortest path dependency check should have the same length of dependent paths by building the shortest path dependency kernel on the Longest Common Subsequence (LCS) of the original shortest dependent path. The results on the ACE 2007 corpus show that the convolution kernel method is also effective for Chinese RE.
Some experiments show that the performance of RE can also be improved by using combined kernel functions. Li et al. [19] first carried out feature selection experiments for constructing plane kernels and then calculated the similarity of two SPTs containing entities using convolution tree kernels. Finally, they combined plane kernels with structure kernels and conducted experiments on the ACE 2005 Chinese corpus. The results show that the performance of the combined kernels was 4.36% and 17.27% higher than the F1 value of the single kernel method respectively. Chen et al. [21] proposed a method based on a convex combination kernel function that maps feature matrices into high-dimensional matrices using a convex combination kernel function composed of a radial basis function, a sigmoid kernel function, and a polynomial kernel function. They trained the model on the tourism corpus using the SVM method. The results show that the optimal convex combination kernel function can increase extraction performance. Guo et al. [22] improved the traditional radial basis kernel function and integrated it into the polynomial kernel function and convolution tree kernel function, and found the optimal composite kernel function parameters by enumerating. Tests on the corpus in the tourism field show that the RE’s performance is significantly improved compared with the single kernel method.
Semi-supervised relation extraction method.
In addition, researchers found that introducing new feature information into the kernel function can enhance the extraction performance. Liu et al. [16] integrated semantic sequence information into kernel functions, combined the KNN machine learning algorithm to construct classifiers to label relation types, and extracted the relations defined in ACE conferences. The experimental results show that this method is obviously superior to the method based on feature-based and traditional sequence kernel functions. Liu et al. [20] introduced two lexical-semantic similarity measurement methods based on the thesaurus and corpus into the convolution tree kernel. Experiments on the ACE 2005 Chinese corpus show that if the entity type is unknown, the introduction of vocabulary semantic similarity can significantly improve the performance of Chinese RE. Yu et al. [18] proposed a Chinese entity semantic RE method based on a convolution tree kernel function. They added the semantic information of entities to the SPT and conducted experiments on the ACE 2005 corpus. The results show that the method can significantly improve the performance of the extraction system.
In general, supervised methods have made great achievements in RE, but they must rely on an annotated corpus and need to do a lot of preprocessing work on the corpus, which is time-consuming and labor-intensive. They also cannot automatically expand the relation type and have poor expansion performance. Therefore, some researchers have turned their attention to the semi-supervised methods that can achieve RE with less annotated corpus.
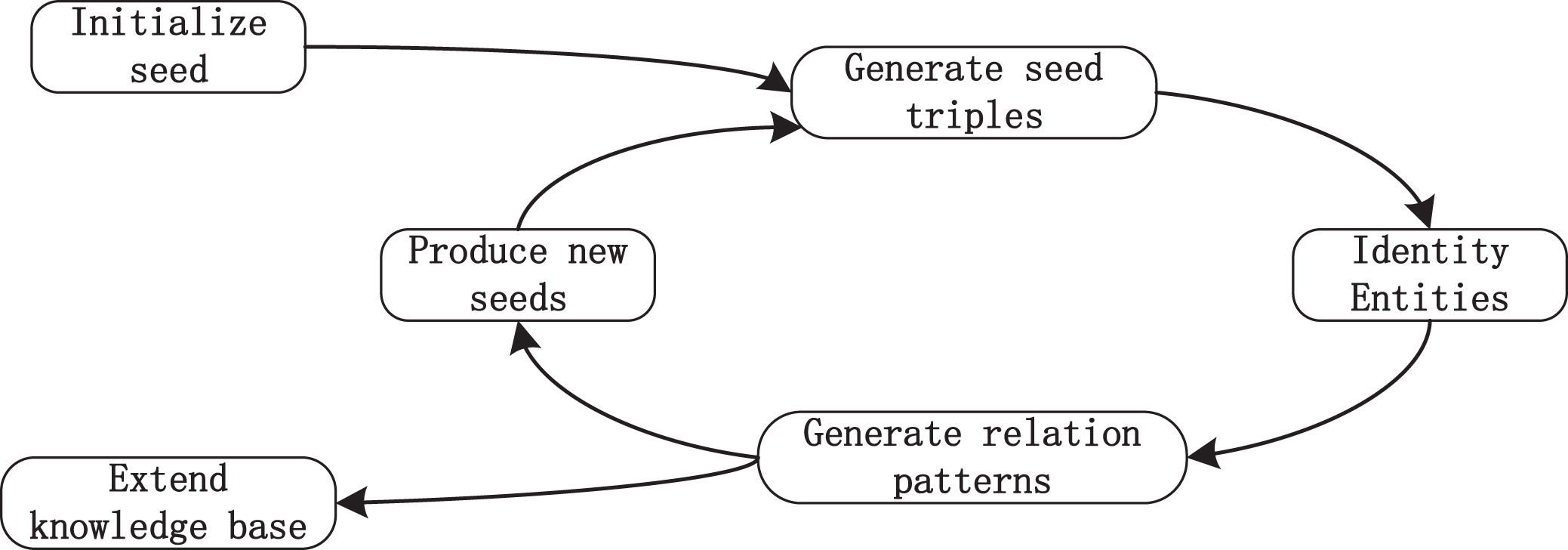
Semi-supervised methods address the high costs caused by supervised methods. The main idea of semi-supervised methods is to use a small amount of annotated seed data and some machine learning algorithms to extract new instances from a large number of unannotated instances in the iterative training process to expand the training corpus and finally generate a dataset and sequence patterns. Semi-supervised methods effectively reduce manual participation, and its expansion performance is good. The specific process of the semi-supervised methods is shown in Fig. 2. At present, the most commonly used semi-supervised methods are Bootstrapping, Co-training and Label Progression.
Comparison of relation extraction methods based on bootstrapping
Comparison of relation extraction methods based on bootstrapping
Bootstrapping Methods
Bootstrapping methods are derived from statistics, which refers to repeated sampling in a limited number of samples to re-establish a new sample that is sufficient to represent the distribution of the parent sample. In RE, the bootstrapping methods mainly use a small number of instances as the initial seed set, and then learn to obtain a new relation template. They then extract new relation triples based on the new and old templates, expand the seed set, and discover new potential relation triples from unstructured data through continuous iteration.
In 1998, Brin [23] first proposed to use a bootstrapping algorithm on RE and developed the RE system, DIPRE. He used a small number of book title and author entity pairs as seeds and found new relation pairs from documents and statements through constant adjustment and iteration. Later, Agichtein et al. [24] proposed the Snowball, which evaluated the new extracted entity pairs on the basis of Brin, and the extraction performance reached 96.0% under the best conditions. In addition, Liu et al. [25] proposed a new RE framework, MultiSnowball. This framework not only iteratively discovers new relation triples and extraction patterns but also shares extraction patterns in all types of extraction processes to obtain more relation triples. In addition to the above three classical methods, other researchers also use bootstrapping methods to extract triples. See Table 2 for a specific comparison. Co-training Methods
Co-training is a semi-supervised machine learning algorithm that uses two classifiers to classify relations from different perspectives for the same instance. The two classifiers learn from and reinforce each other to continuously improve the performance of relation extraction. Co-training is widely used in NLP and information retrieval [2].
Zhang [31] proposed the BootProject algorithm on the basis of co-training. This method is based on a random feature projection. It uses different vocabulary and syntax features to classify instances through a SVM classifier. On the one hand, it improves classification precision. On the other hand, it reduces the need for labeled training data. Cui et al. [32] used the SVM model based on word features and the SVM model based on dependency tree features to train according to the idea of co-training. The experimental results for protein-protein relation extraction show that co-training can use unannotated data more effectively than bootstrapping. Chen et al. [33] introduced N-gram features and focused on different collaboration strategies. Their experimental results show that the RE effect of co-training in a multilingual environment has been significantly improved. Zhang [34] proposed a co-training RE algorithm based on the kernel function and used SVM to train the classifier. The experimental results show that the extraction effect of this algorithm is improved by 0.05 compared with a single co-training algorithm and SVM classifier. Wang et al. [35] used the co-training method based on the Adaboost iterative algorithm to strengthen the model and conduct experiments on university domain texts. The results show that the proposed method has achieved good performance in Recall and F1. Zhang [36] improved the Tri-training method in the co-training algorithm and added the confidence measurement mechanism for unannotated data. The experimental results show that the extraction effect is better than the traditional Tri-training method. Label Propagation Algorithm
Label Propagation Algorithm (LPA) is a semi-supervised machine learning method based on graphs that abstracts the RE model into a graph. The nodes on the graph represent the entities, the edges on the graph represent the relations between entities, and the weight of the edges represents the distance between entities. Thus, the RE can be regarded as predicting the label information of unlabeled nodes from the labels of labeled nodes [2].
Chen et al. [37] proposed to establish a RE model using a graph strategy and use LPA to spread labels globally. Experiments show that the extraction performance of this method is significantly better than that of classification models based on SVM and bootstrapping when there are only a few annotated corpora. Hoffmann et al. [38] proposed a multi-instance, multi-label method, MULTIR, for overlapping relations. This method combines a sentence-level extraction model with a simple corpus-level component to achieve the aggregation of single facts. The experimental results show that MULTIR further improves the performance of RE. Pan et al. [39] introduced LPA to realize the relation matching of unlabeled person name pairs. The experiment shows that this method can make full use of the person relationships in the corpus for RE and has good portability. It can obtain nearly 70% precision. Liu et al. [40] proposed the LP-AL algorithm, which combines LPA with active learning. This algorithm uses LPA to predict unlabeled data. The experimental results show that LP-AL can achieve a better RE effect and can improve the precision of RE compared with the SVM algorithm.
Semi-supervised methods alleviate the high cost problem caused by manually annotated corpora to a certain extent, but they require high quality for the initial annotated corpus. In addition, semi-supervised methods are easy to introduce noise data into the iterative process and create semantic drift sites, so that the Recall of this type of method is generally low. Therefore, the current research focus of semi-supervised methods is on how to effectively remove noise data and improve classification performance.
Unsupervised methods get rid of the limitations of annotated corpora, do not need to define the relation type system in advance, and have good transferability. The methods mainly use the Clustering algorithm, which first extracts entities and relations from a large corpus from the bottom up, then clusters the entities with high contextual similarity into one class, and finally selects representative words to tag the relationships. It can be summarized in two parts: instance clustering and relation word selection. Unsupervised methods can avoid the problem of missing entity relations due to the incomplete establishment of relation patterns [4], so some researchers began to use unsupervised methods to extract entity relations.
Hasegawa et al. [41] first proposed an unsupervised method at the ACL Conference. Their main idea is to cluster named entities according to the similarity of context between named entities. The experimental results show that this method can not only detect the relations between named entities with high Recall and precision but also automatically provide appropriate labels for these relations. Zhang et al. [42] improved the previous relation tree kernel and grouped entity pairs into different clusters by using the similarity between parse trees. Their work proved the effectiveness of combining tree similarity measurement with unsupervised learning for RE. Chen et al. [43] divided the entities into a certain number of clusters according to their similarity to the context and then used Discriminative Category Matching (DCM) to find discriminant words representing different relations. The experimental results show the effectiveness of the algorithm.
Semi-supervised relation extraction method.
After that, Huang et al. [44] proposed an unsupervised method based on a convolution tree kernel. This method uses three hierarchical clustering algorithms—simple connected, full connected and average connected—to achieve RE. Experiments on the ACE 2005 Chinese benchmark corpus show that this method is effective for RE. Jia et al. [45] first used concept pairs and concept pair context patterns to build semantic models, and then used a collaborative clustering algorithm to cluster concept pairs with the same semantic relation and extract features to obtain part-whole relations. They extracted data from the interactive encyclopedia for experiments. The results show that this method is superior to traditional clustering methods and pattern matching methods.
Although the unsupervised methods can be easily transplanted to different fields, they still need to rely on the size and quality of the corpus, and there are still some problems with predefined clustering thresholds. At the same time, the unsupervised methods still lack an objective evaluation standard [7], and their Recall and Precision are generally about 10% lower than those of the supervised methods [2]. At the moment, the unsupervised methods research hotspot and difficulty is how to use a clustering algorithm to increase the confidence of the extraction template and then improve the precision of RE.
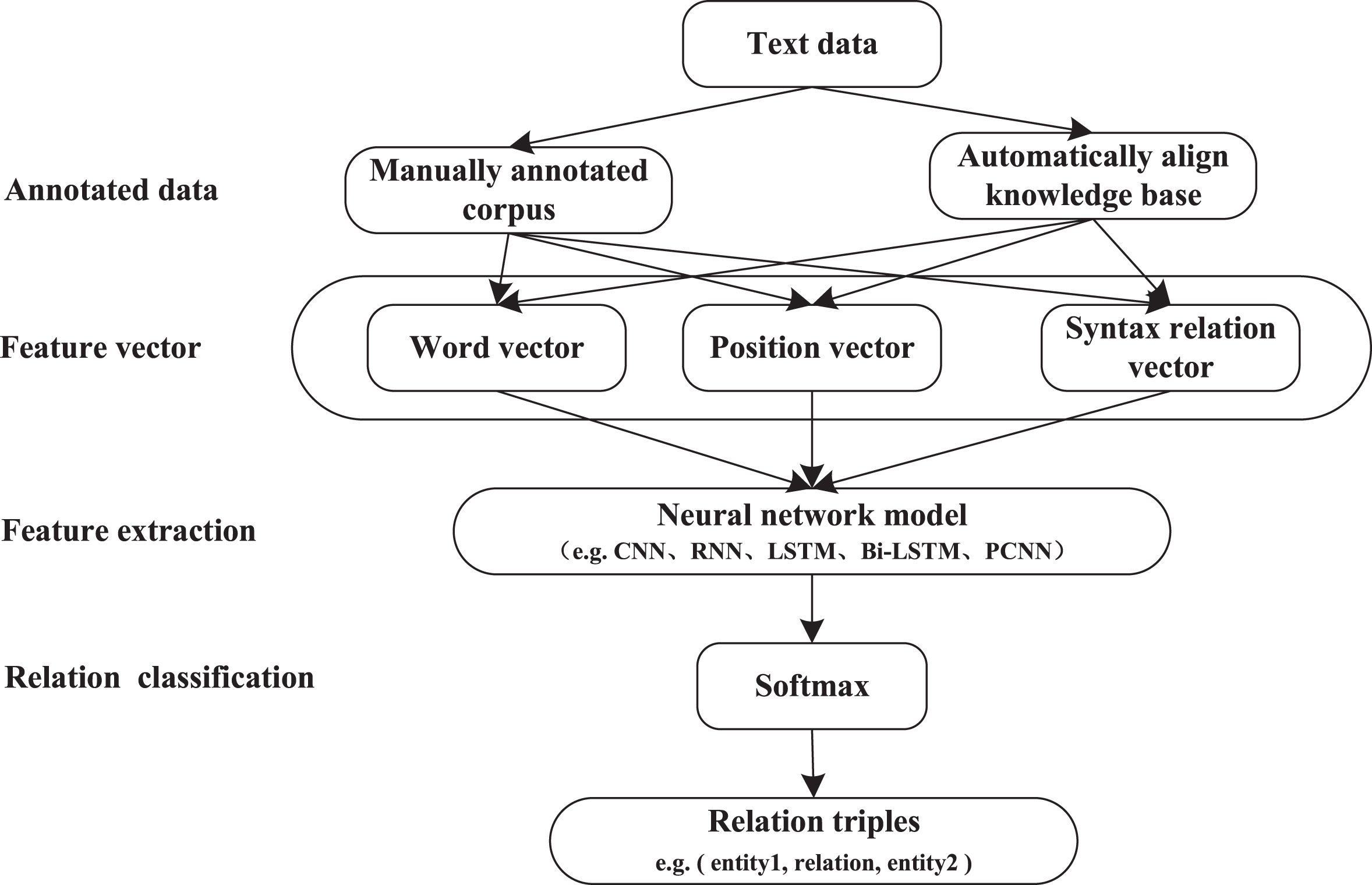
With the rise of deep learning technology, researchers have also applied this technology to the task of RE and achieved good results. The RE framework based on deep learning is shown in Fig. 3. After obtaining annotated data, feature vectors such as word vectors, position vectors, and syntax relation vectors are used to represent the semantic information of the text, and the feature vectors are used as input to a neural network model that extracts features. Finally, the output of the neural network model is transformed into probabilistic expressions to classify relations through a softmax function, and relation triples are output. At present, the methods based on Deep Learning can be divided into Pipeline methods, Joint Learning methods and Distant supervised methods.
Pipeline
Pipeline methods are to divide entity relation extraction into two subtasks, Named Entity Recognition (NER) and Relation Extraction(RE). This type of methods mainly uses Recursive Neural Network (RNN) and Convolutional Neural Networks (CNN). Among them, the memory function of RNN is conducive to processing sequence information of any time sequence. The diversity of CNN convolution kernels is conducive to identifying the structural features of the target [2]. Many new network models have emerged as a result of continuous improvement and perfection, such as long short-term memory (LSTM) and bidirectional long short-term memory (Bi-LSTM).
Comparison of relation extraction methods based on CNN and LSTM
Comparison of relation extraction methods based on CNN and LSTM
In 2012, Socher et al. [46] first proposed to use RNN for RE. Their model combines matrix vector representation with RNN, which can not only learn the meaning of words themselves but also modify other words. Experiments show that this model effectively solves the problem that the word vector space model cannot capture the meaning of long phrases. In 2013, Hashimoto et al. [47] proposed an RNN model based on the syntax tree. This model makes use of features like part of speech tags, phrase categories, and syntactic headers to display weighted important phrases from the target task. Compared with the model proposed by Socher et al., experiments show that this model further improves the performance of RE. In 2015, Ebrahimi et al. [48] proposed a RNN model based on the dependency tree for RE. The model uses the shortest dependency path to construct a binary tree and applies it to RNN. The experiment shows that the model has a faster classification speed and a better classification effect.
The internal structure of the RNN is complex, the training time is long, and it is difficult to deal with long-term dependence problems, which may lead to gradient disappearance, gradient explosion and other problems. Therefore, researchers propose to use CNN and LSTM for RE. The comparison of related research is shown in Table 3.
In the past two years, some new pipeline methods have achieved good results. In the process of exploring the simultaneous extraction of entities and relations, Zhong et al. [87] found that the context representation of entity models and relation models essentially restricted different information, and sharing their representation would affect the extraction performance. Therefore, they proposed a simple pipeline model PURE, which learned two independent encoders for NER and RE. Ye et al. [88] proposed a pipeline model PL-Marker, which is actually a neighborhood-oriented packaging strategy. Spans with the same starting token are packaged into a training instance as much as possible to better distinguish entity boundaries.
The pipeline methods have achieved good results, but they are easy to cause error propagation and ignore the connection between NER and RE. Joint learning, on the other hand, can closely link the interactive information between the two subtasks, that is, combine the models of the two subtasks to obtain the relation triple directly. According to different modeling objects, the joint learning methods can be divided into two categories: Parameter sharing and Sequence Labeling.
The parameter sharing method refers to modeling entities and relations respectively [55]. Miwa et al. [56] proposed a new end-to-end neural model for RE. The model divides the LSTM unit sequence representation of the encoding layer into two subtasks and extracts relations in the dependency tree based on the shortest path between target entities. The experimental F1 value on the SemEval2010 Task 8 dataset reached 84.4%. Katiyar et al. [57] proposed a RNN model based on the attention mechanism. The encoding layer representation is shared by two subtasks in this model. Different from the model proposed by Miwa et al., this model uses the attention mechanism to classify relations. Experiments show that this model performs well in RE. Li et al. [58] improved Miwa et al.’s model for error propagation. One is to use beam search in NER, and the other is to introduce a new relation “Invalid_Entity” in RE. The experimental results show that these two improvements significantly improve the performance of RE.
Sequence labeling methods refer to modeling entity-relation triples [55]. Gupta et al. [59] proposed a context-aware joint entity and word-level RE method based on semantic combination. This method simplified the task of NER and RE into a table filling problem and modeled the correlation between them. The experiment shows that this method is superior to the most advanced methods in both NER and RE. Zheng et al. [60] proposed a RE method based on a new labeling strategy. This method combines two subtasks into a sequence labeling problem. The end-to-end network model is used to extract relation triples, which improves the Recall and Precision of RE.
At present, the methods based on deep learning mainly focus on the research of joint learning methods. Most of the proposed models have achieved good results in the public dataset, providing new ideas for subsequent research. The comparison of related research is shown in Table 4.
Comparison of the joint learning relation extraction methods
Comparison of the joint learning relation extraction methods
Both pipeline methods and joint learning methods need annotated datasets and belong to supervised deep learning methods. To solve the problem of automatic annotation of large amounts of unlabeled data, some researchers have proposed diatant supervised methods [96]. This method has one more step than supervised to diatant align the knowledge base to label the unlabeled data [55]. However, the distant supervised methods will cause problems such as noise data and error propagation.
For the problem of noisy data, Zeng et al. [61] proposed a pulse-coupled neural network (PCNN) which combined multiple instances for distant supervised methods. Sentences are segmented according to entities, and the three segmented segments are pooled to obtain more information related to entities. Using multiple instance learning, the instance statement with the highest relation probability can be chosen as the representation of entity pairs. Qin et al. [62] proposed a distant supervised RE model based on deep reinforcement learning. Without any supervised information, this model automatically identifies false positives for each relation type. Unlike previous removal operations, this model reallocates them to negative examples. Experimental results show that this model significantly improves the performance of distant supervised methods. Mao et al. [63] proposed a distant supervised RE model based on the attention mechanism of a new relation representation. This model uses PCNN to obtain the semantic features of sentences and uses the transformation matrix to learn a new relation representation for each entity pair set, thus building sentence-level attention to further reduce noise.
For the problem of error propagation, Ren et al. [64] proposed a joint extraction model CoType, which combines training entities and relational vector space to better reduce the problem of error propagation. He et al. [65] proposed SE-LSTM that integrates multi-instance learning. To solve the problem of false positives, the model automatically learns and extracts features from the data itself, and it uses distant supervision as a multi-instance learning problem. The experimental results show that the model is effective and that its performance is better than that of traditional methods.
After years of development, deep learning has gradually become the main method used by researchers to solve problems. Compared with the classical RE method, the main advantage of the methods based on deep learning is that the deep learning neural network models can automatically learn sentence features without complex feature engineering [55].
Open relation extraction
According to whether the extraction domain and relation category are limited, RE methods can be divided into predefined extraction and open domain extraction. Both supervised and semi-supervised methods are based on specific fields, entities, and relations to automatically identify entity relations in the corpus. The portability of the methods and the scalability of the corpus are not high. Especially with the development of Internet technology, the scale of data is getting larger and larger, and the data types are becoming more and more complex. If researchers can successfully extract relations from large-scale open corpora without manual annotation, then RE will enter a new research stage.
Based on this background, the Open RE methods have gradually become the research focus of the current RE. This method first makes a deep analysis of a small-scale corpus, builds a relation representation model, and then uses the trained classifier to extract entity relations from large-scale domain-independent external entity knowledge bases (such as DBPedia, YAGO, OpenCyc, FreeBase, or other domain knowledge bases) to obtain candidate relation triples. Finally, this method uses a statistical method to calculate the reliability of each triple and establish an index. Currently, the Open RE methods can be divided into Binary relations and N-ary relations according to the complexity of the relation parameters.
In 2007, Yates et al. [68] proposed for the first time the concept of an “Open Information Extraction” (OIE) system, which transmits its corpus through a single data drive, extracts a large number of relation triples, and has a qualitative leap in operating efficiency compared to traditional IE systems. At the same time, they also designed the first OIE system, TextRunner. This design uses an unsupervised method to extract more diverse types of relation triples and assigns an index to the triples to support effective extraction and exploration through user queries, but the design is not ideal in terms of Precision and Recall.
In 2010, Wu et al. [69] designed a new RE system called WOE. The system uses Wikipedia as the knowledge base, uses heuristic rules to train and build entity relation sets, and runs the system with part of speech tagging or parsing dependency as the limiting condition. The experimental results show that WOE has greatly improved Precision and Recall, but the speed is much slower than TextRunner.
In 2011, Fader et al. [70] designed the ReVerb in view of the shortcomings of TextRunner and WOE. This system mainly focuses on the verb RE, uses shallow syntax to extract phrases, and uses the method of identifying relational words first and then identifying entities to extract long sentences. Experiments show that ReVerb effectively improves the Precision and performance of RE and promotes its development of RE.
In terms of Chinese Open RE, Tseng et al. [71] proposed a Chinese Open RE system CORE based on NLP technologies such as word segmentation, part of speech tagging, syntax analysis and extraction rules. This system can extract entity relation triples from Chinese free text, which effectively promotes the research and development of Open RE in Chinese. Qin et al. [72] proposed UnCore, an unguided, Chinese Open RE system for large-scale online texts. The system first uses distance constraints between entities and location constraints on relation indicators to obtain candidate relation triples. Then it uses global sorting and type sorting methods to mine relation indicators, and finally it uses relation indicators and sentence rules to filter relation triples. This method not only yields a large number of relation triples, but it also guarantees more than 80% micro-precision. Li et al. [73] proposed N-COIE for multiple entity relations. Based on dependency analysis, the system extracts entity sets from text sets by treating verbs as candidate relation words. Finally, it filters multiple entity relation groups using a trained logical regression classifier. The experimental results show that the proposed method achieves 81% on Precision.
Whether in terms of data size or data type, when dealing with massive heterogeneous Web data, the Open RE is obviously superior to the traditional RE method. But this new technology still has a lot of room for progress. For example, how to deeply mine the implicit relationship between entities, propose a unified evaluation standard, and improve Open RE’s precision and recall are critical to its future development.
Dataset and evaluation standard
Dataset for relation extraction
Common datasets for RE include ACE, SemEval2010 Task8, TACRED, NYT, WebNLG, etc. The details are as follows. ACE
The corpus for various tasks of the ACE evaluation conference is drawn from online special line news, radio news, newspaper articles, TV dialogues, network logs, etc. The ACE 2005 dataset contains 599 news and e-mail related documents, which can be divided into 7 categories and 25 subcategories of relations. Among them, the six main relation types contain an average of 700 instances each, which is sufficient for training and testing. SemEval2010 Task8
This dataset is provided by Hendrickx et al. [74], with a total of 10717 samples, including 8000 for training and 2717 for testing. It includes 9 relation types and Other, namely, Compoent-Whole, Instrument-Agency, Member-Collection, Cause-Effect, Entity-Destination, Content-Container, Message-Topic, Product-Producer and Entity-Origin. TACRED
The evaluation corpus from the TAC KBP challenge mainly uses Wikipedia snapshots as the existing knowledge base to obtain existing and updated information about entities from existing news or online texts, including 106264 instances and 42 relation types (including no_relation). NYT
NYT is the abbreviation for “New York Time.” This dataset is the most widely used distant supervised RE dataset. The training data obtained by Riedel et al. [75] by aligning the knowledge “triple” of the Freebase to the New York Times news. It contains 53 relation categories and 659059 instances, including 522611 training instances from the New York Times 2005–2006 corpus and 172448 test instances from the 2007 corpus. WebNLG
This dataset was originally created for the Natural Language Generation (NLG) task, using the triple in DBPedia and including 6 categories (astronauts, buildings, monuments, universities, sports teams, and works). Later, Zeng et al. [95] adapted it into a RE dataset.
Comparison of relation extraction methods
Comparison of relation extraction methods
The ACE conference developed evaluation indicators for the final effect of RE, which were measured by Precision and Recall, and introduced F1 to comprehensively measure the extraction results. Specifically, Precision is the ratio of the number of positive samples correctly classified by the classifier to the number of all positive samples for a given test dataset. Recall is the ratio of predicted correct positive class data to all positive class data for a given test dataset. F1 is the harmonic average of Precision and Recall, which can comprehensively evaluate the performance of the system [3]. The calculation formula is:
Among them, the prediction results of the test dataset can be divided into the following four categories: TP (True Positive): It was originally positive, and the prediction result was positive; FP (False Positive): It was originally negative, but the prediction result was positive; TN (True Negative): It was originally negative, but the prediction result was negative; FN (False Negative): It was originally positive, but the prediction result was negative.
Conclusion of relation extraction
During its more than 20-year development, RE has always been a research hotspot in NLP. The performance of RE models has been improved, and the processing methods have become more diverse. This paper introduces the development history, common datasets and evaluation standard of RE. It also studies different RE methods. The comparison of various methods is shown in Table 5.
Supervised methods are based on features and use machine learning methods to obtain high precision, but the methods need to rely on the quality and scale of manually annotated corpora. Semi-supervised methods only need a small amount of annotated corpus, but it is easy to introduce noise data into the iterative process, resulting in semantic drift. Unsupervised methods are mainly clustering, which has high portability, but Recall and Precision of such methods are generally low. The method based on deep learning has the characteristics of self-learning. It can automatically extract features, reduce the dependence on manual work, and extract large-scale text. It is a hot research topic of RE methods in recent years. The open RE method has stronger scalability compared with the specific domain, which attracts the attention of many researchers, but the performance of this type of model needs to be further improved.
No matter what kind of RE method is used, it is necessary to update and improve the technology. As long as we find a solution to the corresponding problem, RE will shine and further promote the development of NLP.
Future technology outlook
As a key step in IE, RE is an important supporting technology for NLP tasks such as knowledge graph and automatic question answering system. This paper summarizes the current research on RE methods and proposes the following development directions of RE. Multivariate relation extraction technology
At present, most of the RE focuses on binary relations, but there are still a lot of multivariate relations in reality, and the multivariate relations can reflect more information. Therefore, how to expand the binary extraction technology to the ternary or even multivariate level according to the context information will be a hot research direction for RE in the future. Document level relation extraction technology
A large number of relational facts are described in multiple sentences. At present, RE mainly focuses on sentence level. Generally speaking, when people read more paragraphs or chapters, they will get more detailed relational information. Therefore, how to combine existing knowledge to extract cross-sentence and cross-paragraph relations has more practical research value. Multilingual relation extraction technology
The Internet is a network that connects all of the world’s information. At present, the relatively advanced RE technologies are all tested on English datasets. The RE technologies in other languages, especially Chinese, are not mature enough. Therefore, how to successfully apply the existing technologies to other languages or design more optimized RE technologies based on language characteristics is of greater significance for language understanding. Multimodal relation extraction technology
There are various forms of data in the network, such as structured text, pictures, voice, natural language, etc. Each form can be called an existential mode of data. When building a dataset, using the complementarity between these multimodal data to propose the redundancy between modes will be more conducive to feature learning.
Acknowledgments
We thank the anonymous reviewers for their valuable comments. Our work has received significant help and support from the Natural Science Foundation of China (202204120017), the Autonomous Region Key R&D Task Special (2022B01008-2), and Major Science and Technology Special Projects in the Autonomous Region (2020A02001-1).