
Abstract
Learning Vector Quantization (LVQ) is a clustering method with supervised information, simple structures, and powerful functions. LVQ assumes that the data samples are labeled, and the learning process uses labels to assist clustering. However, the LVQ is sensitive to initial values, resulting in a poor clustering effect. To overcome these shortcomings, a granular LVQ clustering algorithm is proposed by adopting the neighborhood granulation technology and the LVQ. Firstly, the neighborhood granulation is carried out on some features of a sample of the data set, then a neighborhood granular vector is formed. Furthermore, the size and operations of neighborhood granular vectors are defined, and the relative and absolute granular distances between granular vectors are proposed. Finally, these granular distances are proved to be metrics, and a granular LVQ clustering algorithm is designed. Some experiments are tested on several UCI data sets, and the results show that the granular LVQ clustering is better than the traditional LVQ clustering under suitable neighborhood parameters and distance measurement.
Introduction
Granular computing is a branch of artificial intelligence, which covers fuzzy sets, rough sets, and quotient space theory. Zadeh, the founder of fuzzy sets, believes that there are information granules in many fields in the world [1], and information granules are distinct in different fields. In 1982, Pawlak proposed the rough set theory [2], describing the concepts of information granules and granular size [3]. Lin first proposed the concept of granular computing in 1996 [4] and applied it to data mining. Kang analyzed structures of granules from the views of sets and formal concept analysis [5]. Liu defined granular language and constructed a new model of logical reasoning based on the information granules [6]. Chen and Zhang designed a granular classifier based on convolution operations [7]. Chen proposed a granular computing-based classification method from an algebraic granule structure [8]. Miao studied the correlation between information entropy and granular computing, and innovatively introduced information entropy into the field of granular computing [9, 10]. To further develop rough set theory, many scholars introduced the neighborhood relation into rough sets and proposed neighborhood granular computing [11, 12]. Yao proposed a neighborhood rough set model [13, 14] and Hu proposed a neighborhood granulation method to construct neighborhood classifiers [15]. Wang analyzed the connection between rough sets and granular computing, to conduct some granular computing models and applications [16].
Clustering is one of the important researches in machine learning, data mining, pattern recognition, etc. And it plays an extremely important role in identifying the internal structure of data [17]. The goal of clustering is to classify similar samples and make diversities between data with different categories [18–20]. Cluster analysis involves three similarity measures: similarity between samples, the similarity between classes, and the similarity between different clustering results [21]. The LVQ is a clustering algorithm based on the prototype. The original LVQ is similar to most supervised learning algorithms that need to obtain class labels [22]. However, the LVQ clustering algorithm is severely sensitive to initial values. If the deviation of selected initial values is too large, then a good clustering effect will not be produced, resulting in insufficient clustering accuracy. Therefore, many scholars improved the LVQ algorithm. For example, Tapan proposed a variant of the LVQ algorithm as a data structure preserving LVQ [23]. Cruz-Vega proposed an LVQ-algorithm based on granular computing [24]. Shen proposed a novel OSSL method based on learning vector quantization (LVQ) [25]. Jatmiko proposed Adaptive Fuzzy-Neuro Generalized Learning Vector Quantization using the PI membership function (AFNGLVQ-PI) [26].
The relevant theories of granular computing are relatively perfect, and it is mainly used in the classification field of machine learning, while there is relevant literature on the combination of clustering and granular computing [27]. In this paper, the LVQ clustering algorithm is combined with neighborhood granulation technology, and Neighborhood Granular LVQ (NGLVQ) algorithm is proposed to improve the clustering effect of nonlinear fractal data. Meanwhile, this method can make each neighborhood granular vector global and improve the convergence rate of clustering. A neighborhood granule is constructed on a feature of a sample, and the neighborhood granular vector is formed on the multidimensional features after granulation. By defining the size and operation rules of neighborhood granular vectors, the granular distance measure is calculated. Based on the measure, the clustering algorithm of NGLVQ is further designed. Finally, clustering experiments are performed on several UCI datasets. Experimental results show that the NGLVQ is better than the traditional LVQ on some clustering indexes.
Neighborhood granulation and granular vectors
The neighborhood granulation technology refers to the neighborhood rough set model proposed by Yao [28] and the neighborhood classifier proposed by Hu [29]. To facilitate the measurement and calculation of neighborhood granules, the concept of neighborhood granular vector is proposed.
Set the information system as IS = (U, F), where the sample set is U = {x1, x2, . . . , x n } and the attribute set is F = {a1, a2, . . . , a m }. Given a sample x ∈ U, for any attribute a ∈ F, v (x, a) ∈ [0, 1] represents the normalized value of the sample x on the attribute a.
Set the information system as IS = (U, F), for samples x, y ∈ U, a single attribute a ∈ F, then the Manhattan distance between x and y on the single attribute a is:
Define 1. Set the information system as IS = (U, F), for samples x, y ∈ U, a single attribute a ∈ F, given a neighborhood parameter δ, the neighborhood discriminant function of samples x, y is defined as:
When φ (x, y) =1, x, y are neighbors. If φ (x, y) =0, it indicates that x, y are not adjacent.
Define 2. Given that the information system is IS = (U, F), for any sample x ∈ U and any attribute a ∈ F, then the x performs neighborhood granulation on the attribute a, and the neighborhood granules are defined as:
Define 3. Set the information system as IS = (U, F), for any sample x ∈ U, any attribute subset P ⊆ F, suppose P = {a1, a2, . . . , a
m
}, then the neighborhood granular vector of x on the attribute subset P is defined as:
Neighborhood granular vector is composed of neighborhood granules, which are composed of 0 or 1 and represent the neighborhood relationship between samples. Neighborhood granules are ordered sets of zeros or ones. Thus, the element of the neighborhood granular vector is an ordered set, unlike the traditional vector, where the element is a real number.
Define 4. Set the information system as IS = (U, F), for any sample x ∈ U, any attribute a ∈ F, the size of neighborhood granule g
a
(x) is defined as:
It is easy to know that the size of granules in the neighborhood satisfies: 1 ≤ | (g a (x) | ≤ n.
Define 5. Set the information system as IS = (U, F), for any sample x ∈ U, any attribute subset P ⊆ F, Suppose P = {a1, a2, . . . , a
m
}, then the size of neighborhood granular vector G
P
(x) of x is defined as:
The size of neighborhood granular vector G
P
(x) is also called the modulus of neighborhood granular vector, and it is easy to know that its size satisfies:
Example 1. An information system IS = (U, F) is shown in Table 1, U = {x1, x2, x3, x4} is a sample set,and F = {a, b, c} is an attribute set. Set the neighborhood granulation parameter as δ = 0.1.
The sample set is U = {x1, x2, x3, x4}. If neighborhood granulation is carried out according to attribute a, the neighborhood granules are: g1 = g a (x1) = {1, 1, 0, 0}, g2 = g a (x2) = {1, 1, 1, 0}, g3 = g a (x3) = {0, 1, 1, 0}, g4 = g a (x4) = {0, 0, 0, 1}.
If neighborhood granulation is carried out according to attribute b, the neighborhood granules are: g5 = g b (x1) = {1, 0, 1, 1}, g6 = g b (x2) = {0, 1, 0, 0}, g7 = g b (x3) = {1, 0, 1, 0}, g8 = g b (x4) = {1, 0, 0, 1}.
If neighborhood granulation is carried out according to attribute c, the neighborhood granules are: g9 = g c (x1) = {1, 1, 0, 0}, g10 = g c (x2) = {1, 1, 1, 1}, g11 = g c (x3) = {0, 1, 1, 1}, g12 = g c (x4) = {0, 1, 1, 1}.
An information system
If P = {a, b, c}, then the neighborhood granular vector of x1 on P is:
G
P
(x1) = (g
a
(x1) , g
b
(x1) , g
c
(x1))
T
= ({1, 1, 0, 0} , {1, 0, 1, 1} , {1, 1, 0, 0}). The size of the neighborhood granular vector is:
The neighborhood granular vector of x2 on P is:
G
P
(x2) = (g
a
(x2) , g
b
(x2) , g
c
(x2))
T
= ({1, 1, 1, 0} , {0, 1, 0, 0} , {1, 1, 1, 1}).The size of the neighborhood granular vector is:
The neighborhood granular vector of x3 on P is:
G
P
(x3) = (g
a
(x3) , g
b
(x3) , g
c
(x3))
T
= ({0, 1, 1, 0} , {1, 0, 1, 0} , {0, 1, 1, 1}).The size of the neighborhood granular vector is:
The neighborhood granular vector of x4 on P is:
G
P
(x4) = (g
a
(x4) , g
b
(x4) , g
c
(x4))
T
= ({0, 0, 0, 1} , {1, 0, 0, 1} , {0, 1, 1, 1}).The size of the neighborhood granular vector is:
Define 6. Set the information system as IS = (U, F), where the attribute set is F = {a1, a2, . . . , a
m
}. For ∀x, y ∈ U, there exists two neighborhood granular vectors G
F
(x) = (g1 (x) , g2 (x) , . . . , g
m
(x))
T
and G
F
(y) = (g1 (y) , g2 (y) , . . . , g
m
(y))
T
on F, then the intersection, union, subtraction and xor operations of the two neighborhood granular vectors are defined as:
Define 7. Set the information system as IS = (U, F), where the attribute set is F = {a1, a2, . . . , a
m
}. For ∀x, y ∈ U, there exists two neighborhood granular vectors G
F
(x) = (g1 (x) , g2 (x) , . . . , g
m
(x))
T
and G
F
(y) = (g1 (y) , g2 (y) , . . . , g
m
(y))
T
on F, then the relative distance of the two neighborhood granular vectors is defined as:
It is easy to know that the relative distance of neighborhood granular vector satisfies: 0 ≤ d ( G F (x) , G F (y)) ≤1.
Define 8. Set the information system as IS = (U, F), where the attribute set is F = {a1, a2, . . . , a
m
}. For ∀x, y ∈ U, there exists two neighborhood granular vectors G
F
(x) = (g1 (x) , g2 (x) , . . . , g
m
(x))
T
and G
F
(y) = (g1 (y) , g2 (y) , . . . , g
m
(y))
T
on F, then the absolute distance between the two neighborhood granular vectors is defined as:
It is easy to know that the absolute distance of the neighborhood granular vector satisfies: 0 ≤ h ( G F (x) , G F (y)) ≤1.
Theorem 1. The relative distance between two neighborhood granular vectors is a distance measure, which satisfies the following three properties:
(1) Non-negative, 0 ≤ d (G F (x) , G F (y)) ≤1;
(2) Symmetry, d (G F (x) , G F (y)) = d (G F (y) , G F (x));
(3) Triangle inequality, d (G
F
(x) , G
F
(y)) + d (G
F
(y) , G
F
(z)) ≥ d (G
F
(x) , G
F
(z)). Proof. (1) Suppose s = g
i
(x), t = g
i
(y), from g
i
(x) ⊕ g
i
(y) = g
i
(x) ∨ g
i
(y) - g
i
(x) ∧ g
i
(y), shows
(2) From g
i
(x) ∨ g
i
(y) = g
i
(y) ∨ g
i
(x), g
i
(x) ∧ g
i
(y) = g
i
(y) ∧ g
i
(x), shows
(3) From the literature [30],
Theorem 2. The absolute distance between two neighborhood granular vectors is a distance measure, which satisfies the following three properties:
(1) Non-negative, 0 ≤ h (G F (x) , G F (y)) ≤1;
(2) Symmetry, h (G F (x) , G F (y)) = h (G F (y) , G F (x));
(3) Triangle inequality, h (G F (x) , G F (y)) + h (G F (y) , G F (z)) ≥ h (G F (x) , G F (z)).
Proof. (1) Suppose s = g
i
(x), t = g
i
(y), from g
i
(x) ⊕ g
i
(y) = g
i
(x) ∨ g
i
(y) - g
i
(x) ∧ g
i
(y), 1 ≤ |g
i
(x) | ≤ n, shows 0 ≤ |g
i
(x) ⊕ g
i
(y) | ≤ n. From F = {a1, a2, . . . , a
m
}, shows |F| = m. Therefore,
(2) From g
i
(x) ∨ g
i
(y) = g
i
(y) ∨ g
i
(x), g
i
(x) ∧ g
i
(y) = g
i
(y) ∧ g
i
(x), shows
(3) From |g
i
(x) ⊕ g
i
(y) | + |g
i
(y) ⊕ g
i
(z) | ≥ |g
i
(x) ⊕ g
i
(z) |. Shows
The LVQ algorithm belongs to a prototype clustering, which usually initializes and iteratively updates the prototype and then obtains parameters of the prototype. Therefore, the LVQ algorithm tries to find a group of prototype vectors to describe data, but it assumes that samples have labels before training, and labels are used in the training process to assist clustering. The original LVQ algorithm is sensitive to the initial values, and even the clustering is not successful. Since a granule contains global information of a sample, introduce granular computing into the LVQ clustering to reduce sensitivity to initial values. According to the above neighborhood granular vector and its distance measurement, the Neighborhood Granular LVQ (NGLVQ) algorithm is further designed. It performs clustering with a granular vector as a unit, initializes the center points of q granular clusters first, and conducts iterative training to find new q clusters.
The cluster principle of NGLVQ
The data are granulated before the training of NGLVQ clustering algorithm. First, neighborhood granulation is carried out on the samples. After neighborhood granulation, each sample becomes a granular vector, and the label of each granular vector is the original category label. Assuming that the divided cluster is q, the learning objective is to find q prototype granular vectors P1, P2, . . . , P q . Initially, a labeled granular vector is randomly selected from the vectors. Then, the closest prototype granular vector P i is found according to the distance between granular vectors. The prototype granular vector is updated according to whether the labels between the two granular vectors are the same. After reaching the maximum number of iterations, the latest prototype granular vectors P1, P2, . . . , P q are obtained. Finally, the sample set is divided into q clusters by the distance measurement between granular vectors.
For a granular vector set GT = {G
F
(x1) , G
F
(x2) , . . . , G
F
(x
n
)}, the prototype granular vector is:
The prototype granular vector is a centroid of granular vectors in a same cluster. As for q clusters, they are q prototype granular vectors, represented as (μ1, μ2, . . . , μ q ).
Input: An information system is IS = (U, F, T), where the sample set is U = {x1, x2, . . . , x n },its corresponding label set is T = {y1, y2, . . . , y n }, and attribute set is F = {a1, a2, . . . , a m }; A class cluster parameter q, a neighborhood parameter δ, a maximum iteration N, a learning rate η ∈ [0, 1];
Process: (1) The sample set U is granulated by neighbors to become GT = {G F (x1) , G F (x2) , . . . , G F (x n )};
(2) q neighborhood granular vectors are randomly selected from GT as the initial prototype granular vectors (μ1, μ2, . . . , μ q ). Suppose their corresponding labels are (y1, y2, . . . , y q );
(3) For t = 1 to N
(3.1) A granulated sample (G F (x r ) , y r ) is randomly selected from GT and T;
(3.2) Calculate the granular distance of neighborhood granular vector G
F
(x
r
) and each prototype granular vector μ
j
(j = 1, 2, . . . , q) : d
rj
= d (G
F
(x
r
) , μ
j
) or d
rj
= h (G
F
(x
r
) , μ
j
); Find the prototype granular vector
(3.3) if y
r
= y
j
*
then
The prototype granular vector μ j * is updated by μ′;
(4) For i = 1, 2, . . . , n, calculate the granular distance of neighborhood granular vector G F (x i ) and each prototype granular vector μ j () : d ij = d (G F (x i ) , μ j ) or d ij = h (G F (x i ) , μ j ); Mark x i as the category λ j (j = 1, 2, . . . , q) corresponding to the smallest d ij ; Last update C λj = C λj ∪ x i ;
Output: A cluster partition C = (C1, C2, . . . , C q ).
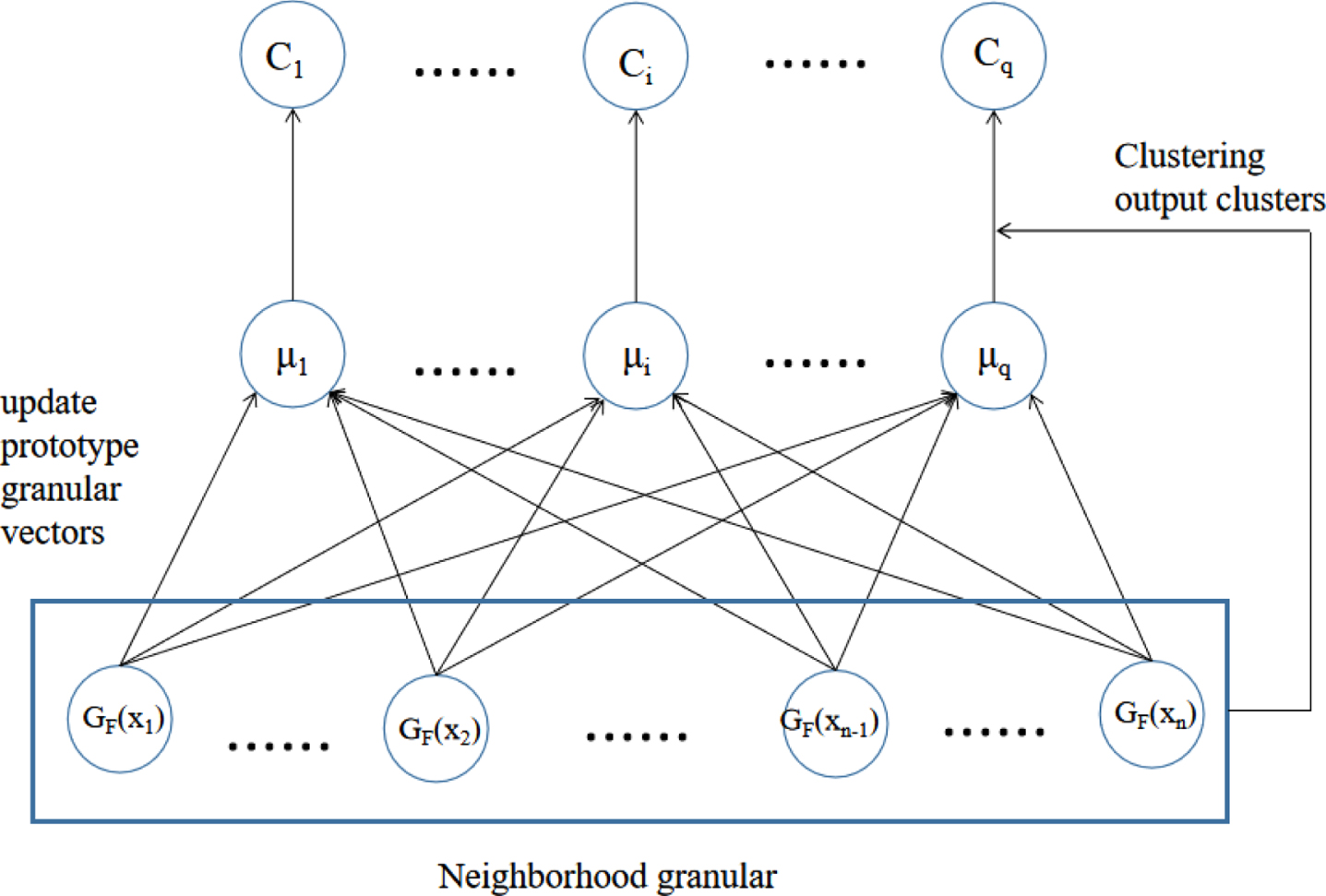
NGLVQ algorithm flow chart.
In some experiments, the NGLVQ algorithm is used to cluster on seven UCI datasets, and the dataset information is shown in Table 2.
Seven UCI datasets
Seven UCI datasets
Due to the different values among samples, a pre-processing of data is needed before clustering. For example, the numerical range of one feature may be [100,1000], and the numerical range of another feature may be [-0.1,0.1]. In distance calculation, a large difference in numerical values will lead to different results. Features with large numerical values will play a decisive role, while those with small numerical values may be ignored. To eliminate the influence of unit and scale differences between features, features need to be normalized. In this paper, maximum and minimum normalization is adopted to transform the range of each feature into within [0,1], and its formula is as follows:
After the normalization of the data, neighborhood granulation is performed on these data to construct neighborhood granular vectors. The relative distance and absolute distance between neighborhood granular vectors are used for distance calculation. The experiment compares our clustering method based on the relative and absolute distances with the traditional LVQ clustering algorithm to verify the actual effects.
TSNE was used for dimensionality reduction during the experiment, and the characteristics of each sample were reduced to 2 dimensions for visual comparison. In the experiment, the clustering of Original data, relative distance based NGLVQ, absolute distance based NGLVQ and traditional LVQ algorithm are compared. The data visualization is shown in Figs. 2–8.
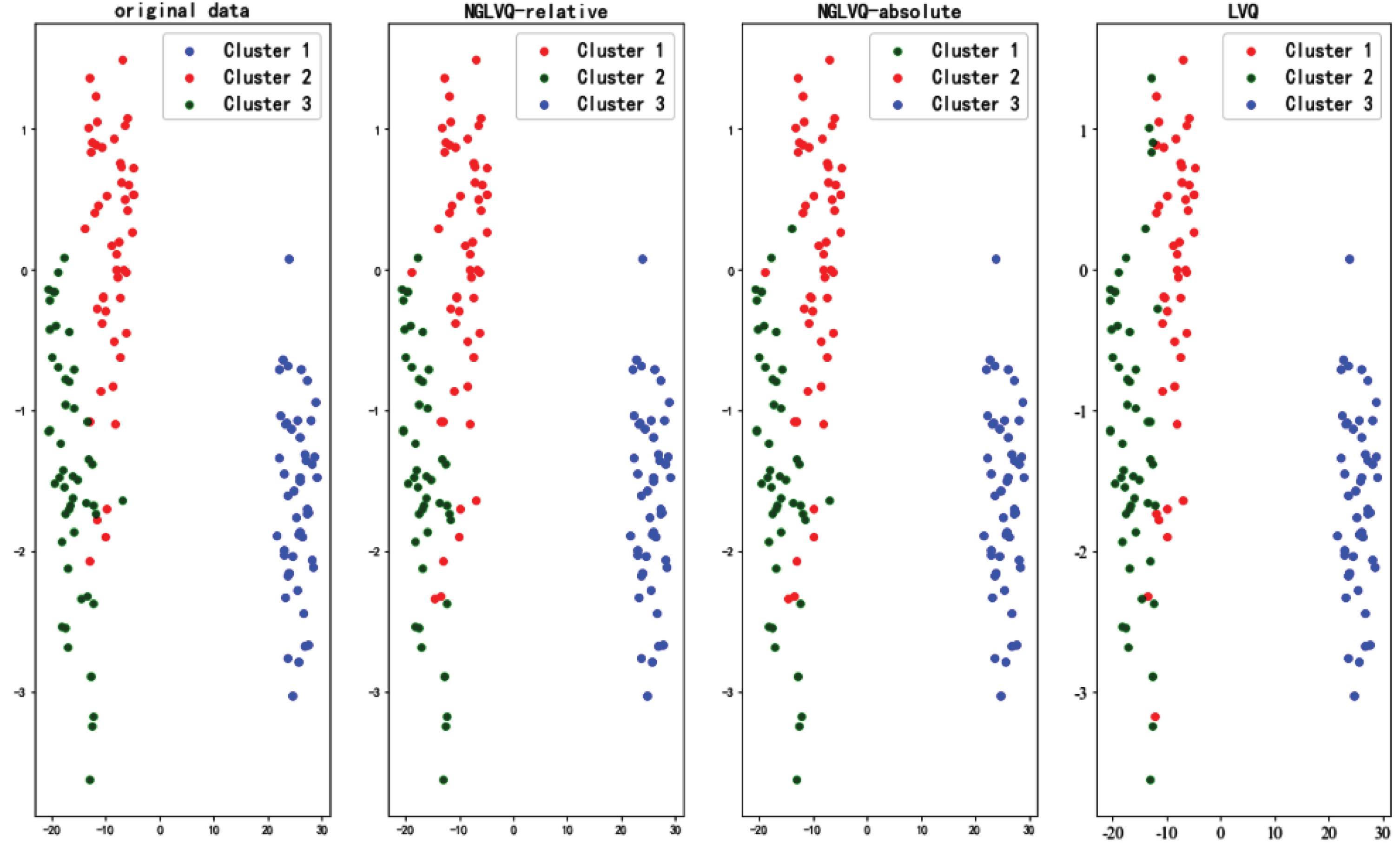
Iris data cluster results.
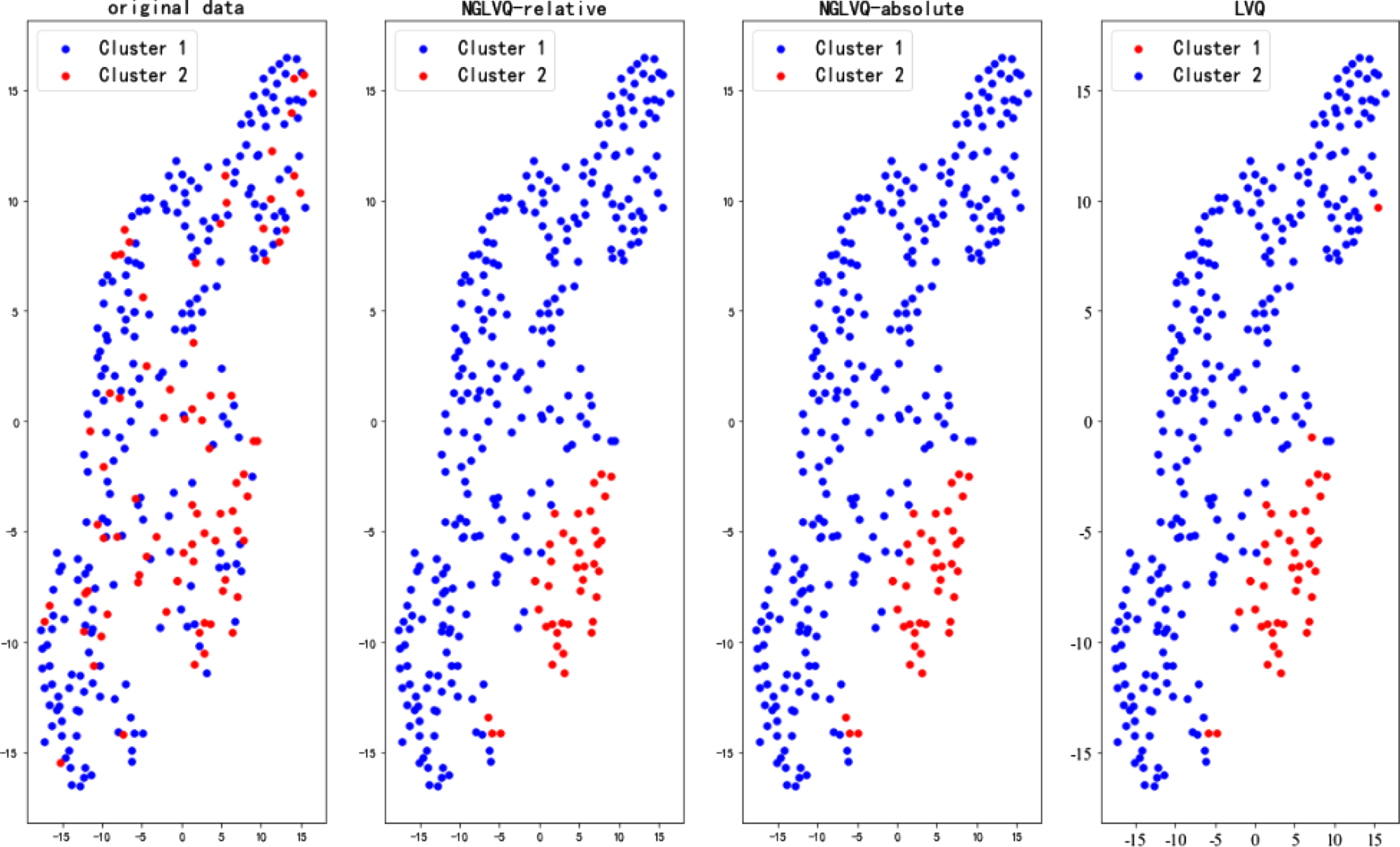
Haberman data cluster results.
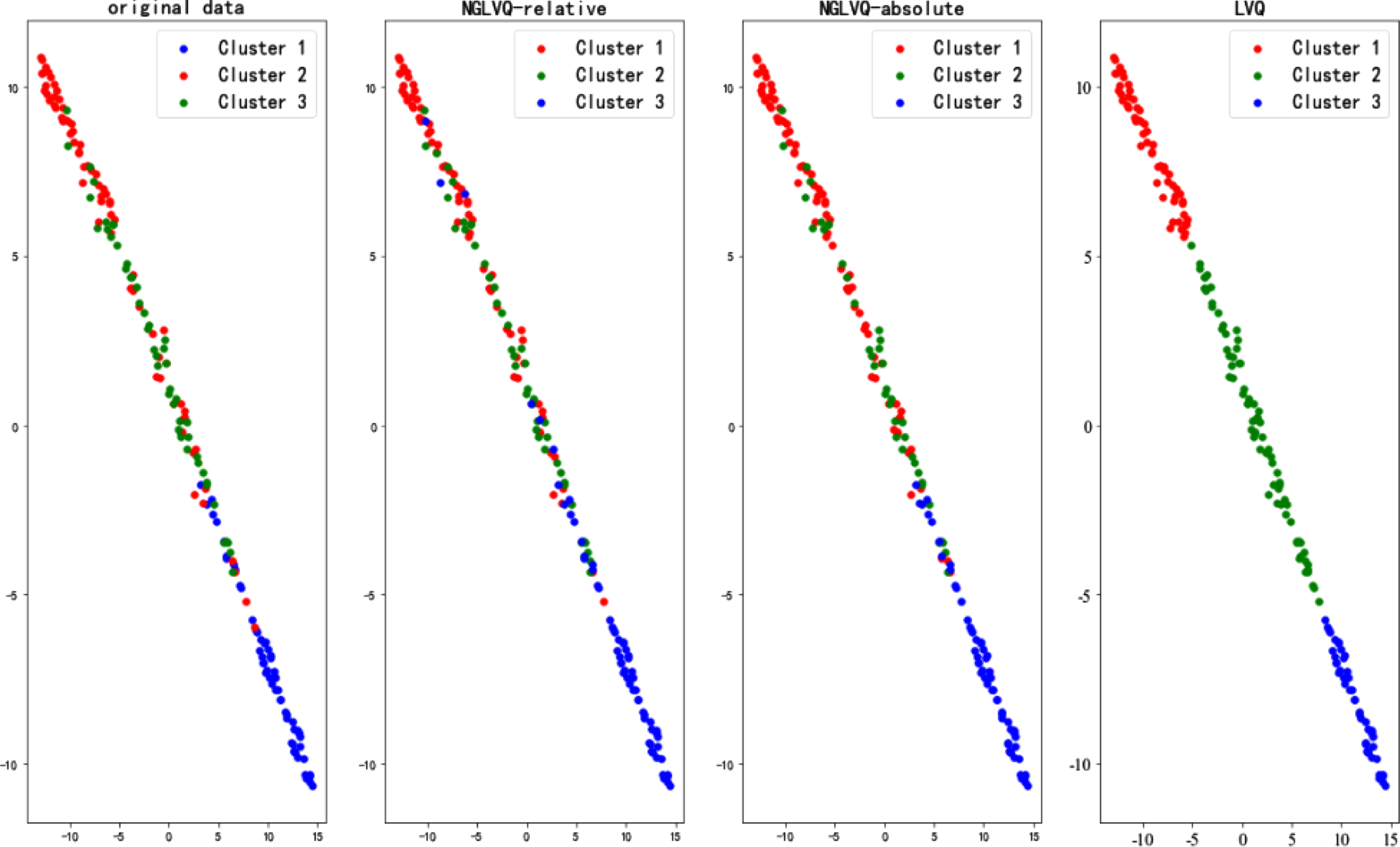
Wine data cluster results.
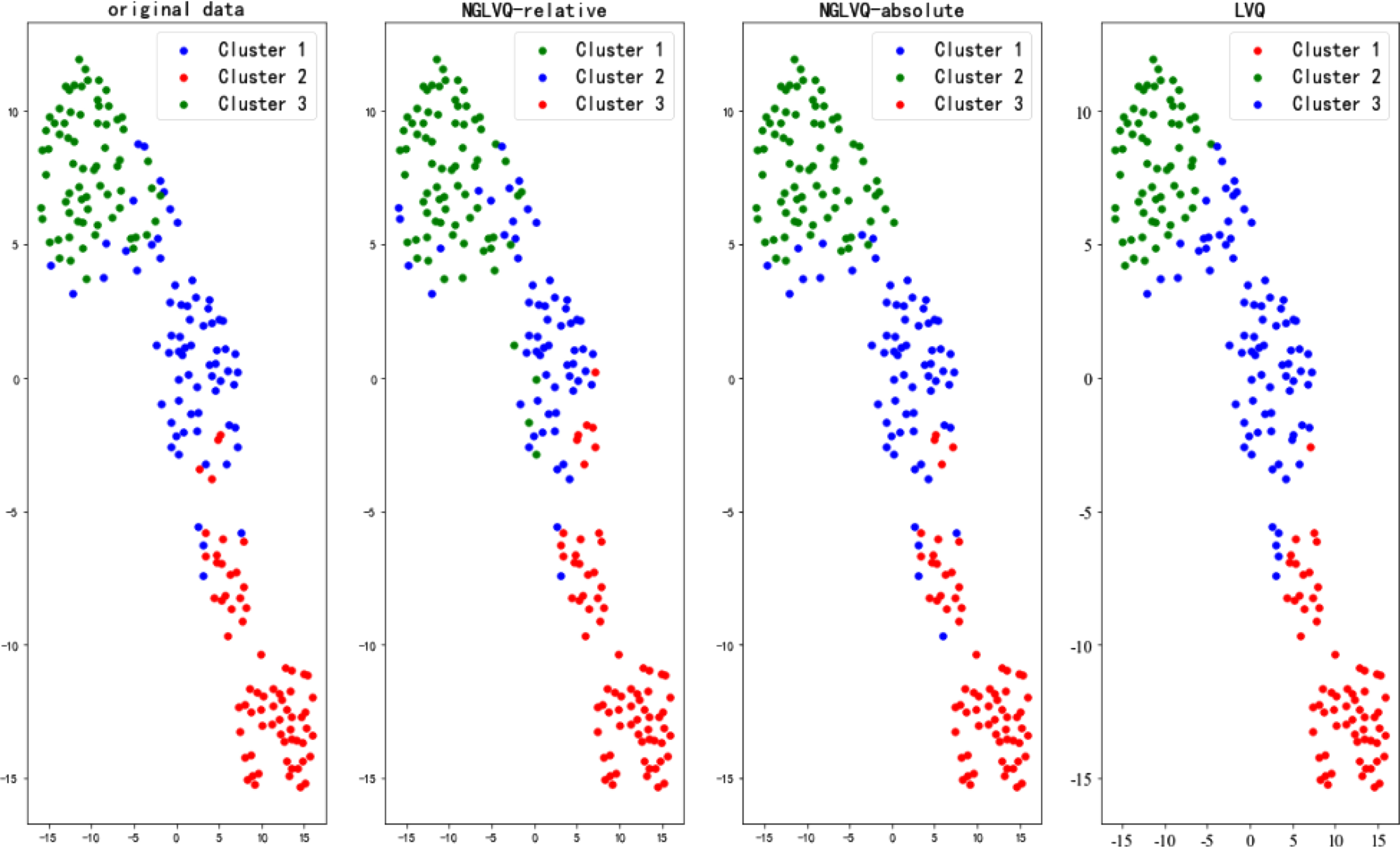
Seeds data cluster results.
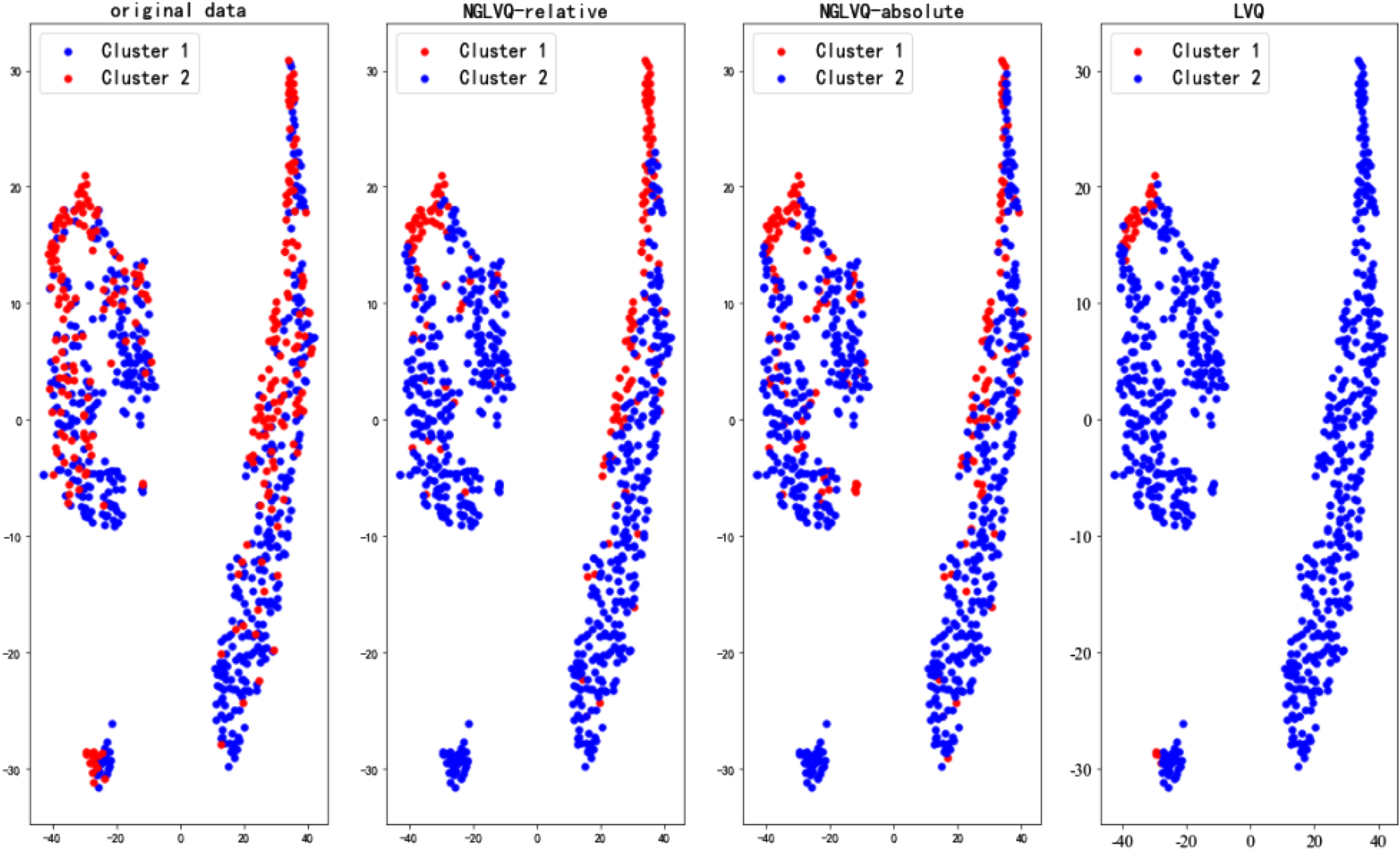
Pima-indians-diabetes data cluster results.
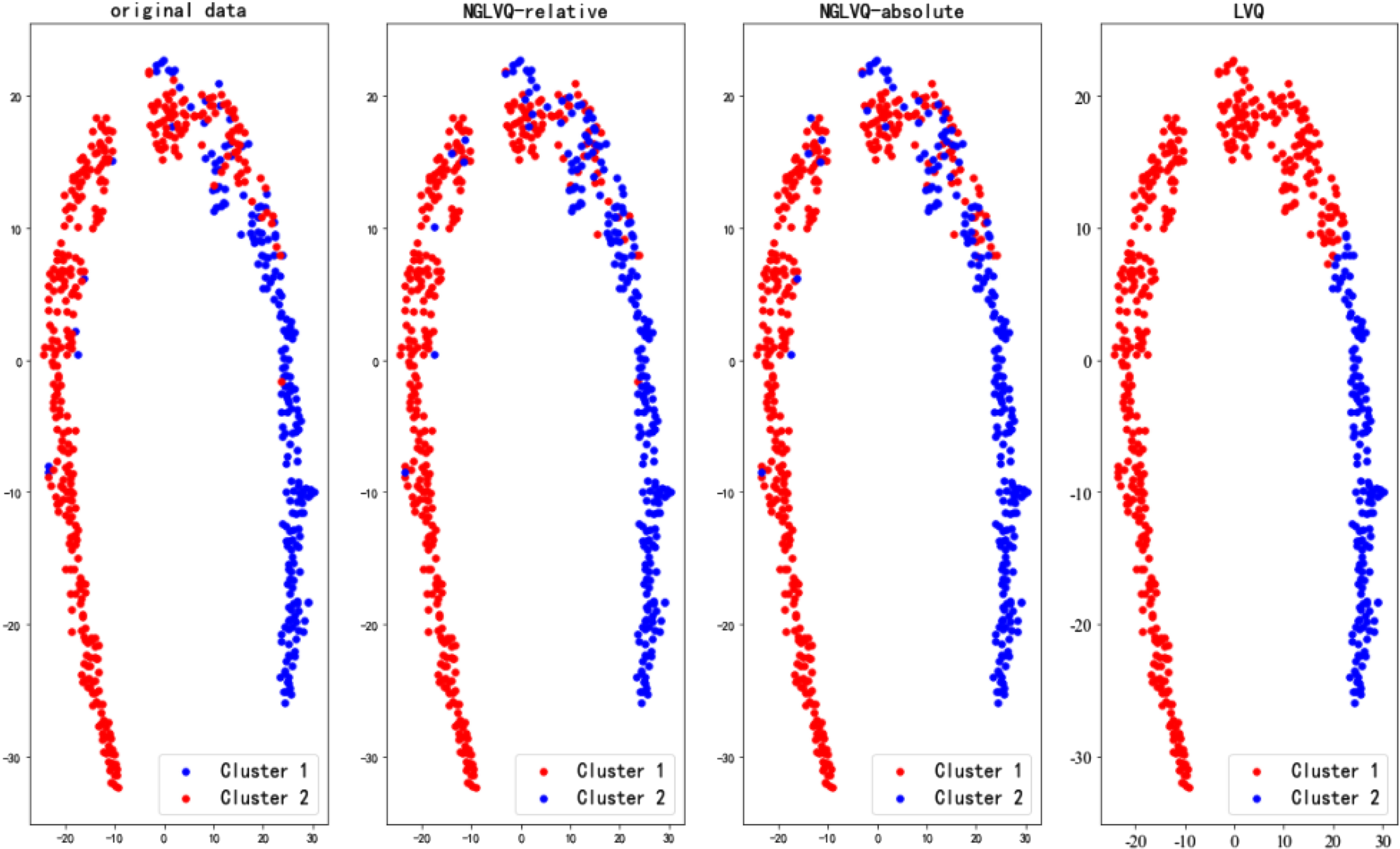
WDBC data cluster results.
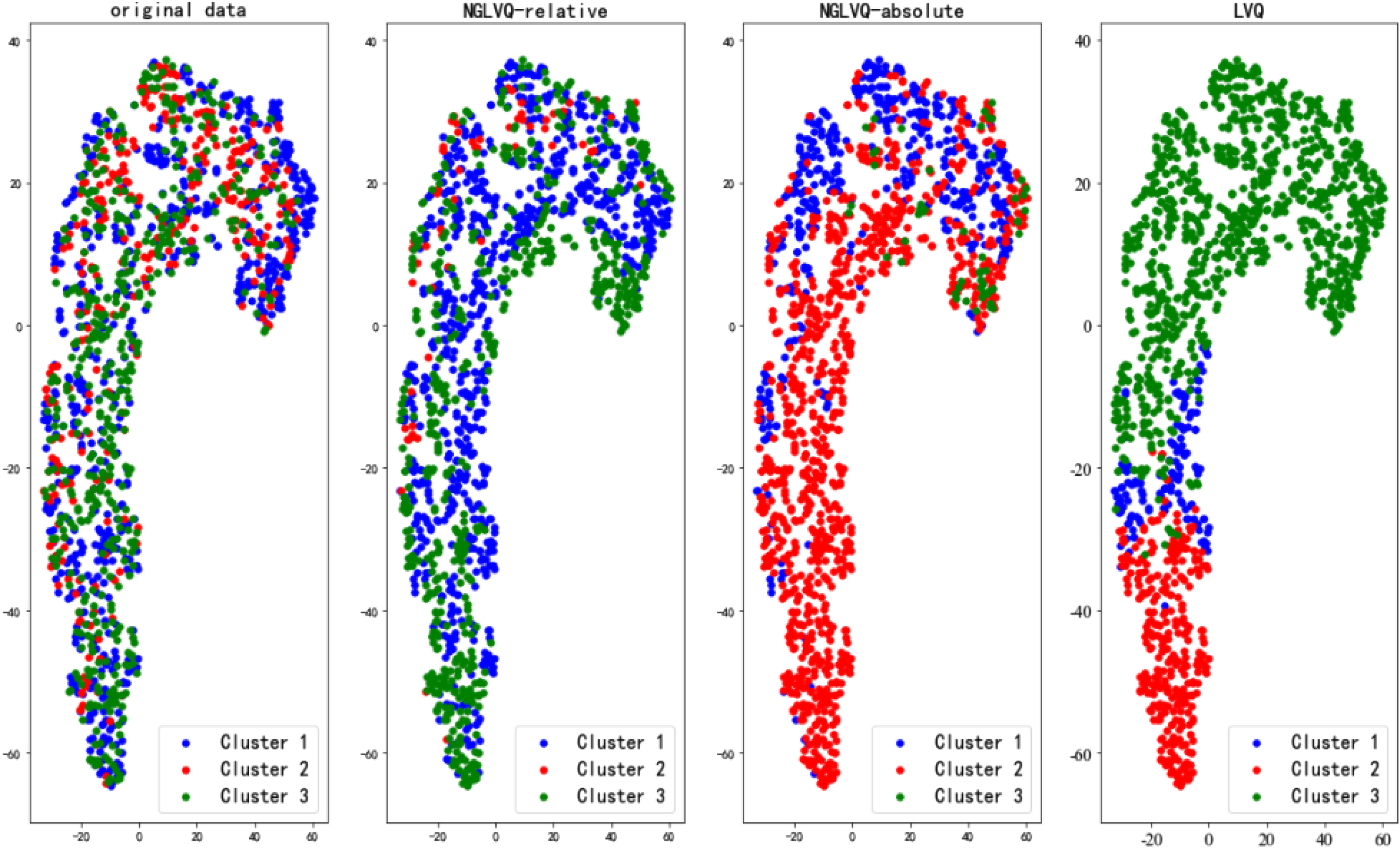
CMC data cluster results.
The experimental results of the Iris data set show that the clustering effects of NGLVQ based on relative distance and NGLVQ based on absolute distance are similar to the original data, while the traditional LVQ clustering algorithm is poor. The experimental results of the Haberman dataset and CMC dataset show that there are significant differences between NGLVQ and traditional LVQ clustering algorithm and original data. The experimental results of the Wine data set show that the clustering effect of NGLVQ based on relative distance and NGLVQ based on absolute distance roughly restores the original data, while the traditional LVQ clustering algorithm is poor. Experimental results of the Seeds data set showed that NGLVQ based on absolute distance had a better effect. The experimental results on Pima-Indians-Diabetes and WDBC data sets show that the cluster results of the NGLVQ algorithm are more consistent with the original data than the traditional LVQ algorithm, however, although the traditional LVQ clustering algorithm is divided into two categories, there is a huge gap between it and the original data.
This section analyzes the parameters of the neighborhood granulation and studies the influence of neighborhood parameters by the experimental results. The original data of the experiment are labeled, and the classification accuracy is obtained by comparing the original data labels with the clustering labels. In the experiment, neighborhood parameters ranging from 0 to 1 were used to carry out experiments. The learning rate was fixed at 0.2, and the number of iterations was 200. The experimental results of different data sets are shown in Figs. 9–15.
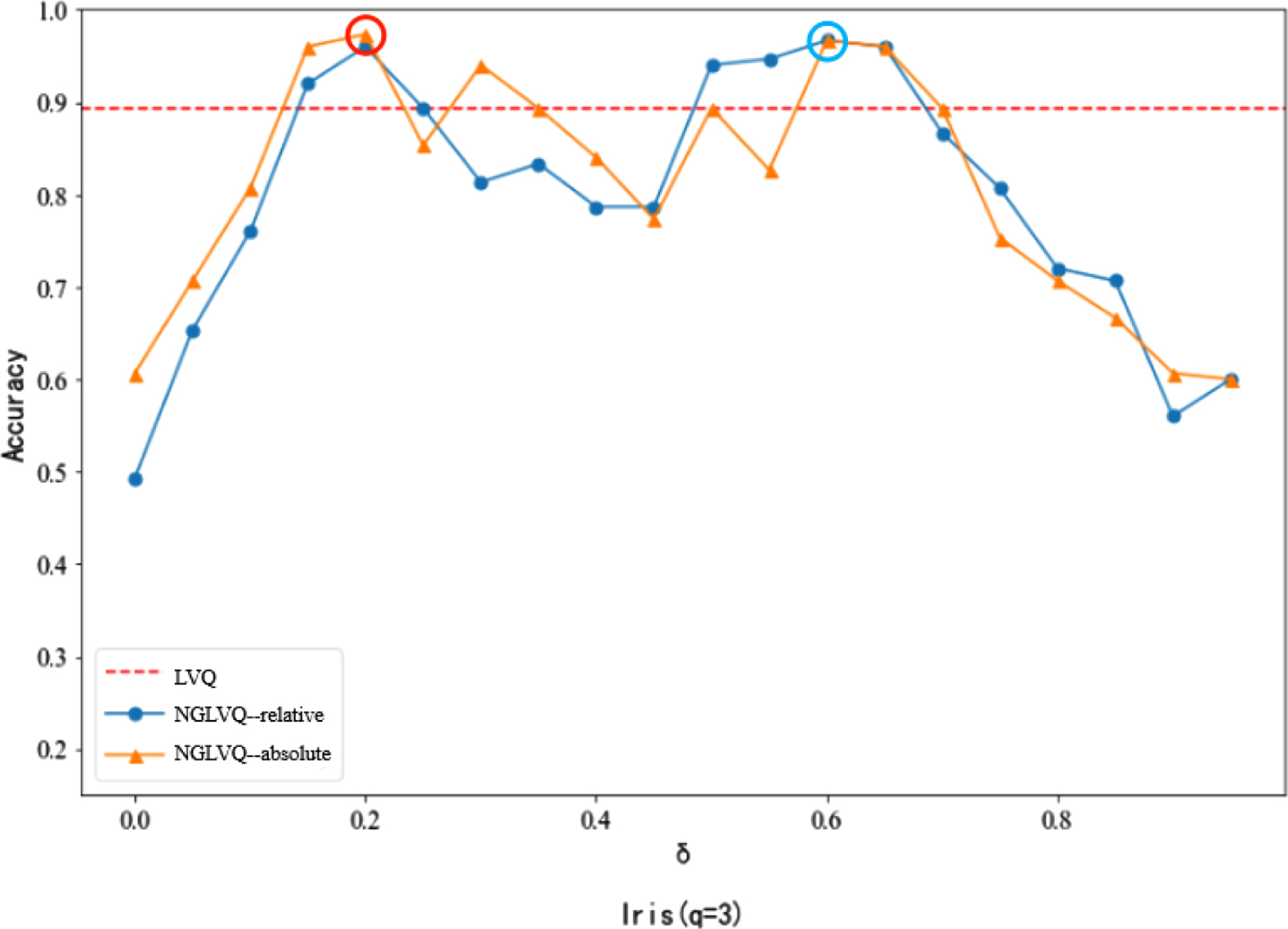
Classification accuracy of different neighborhood parameters in Iris dataset.
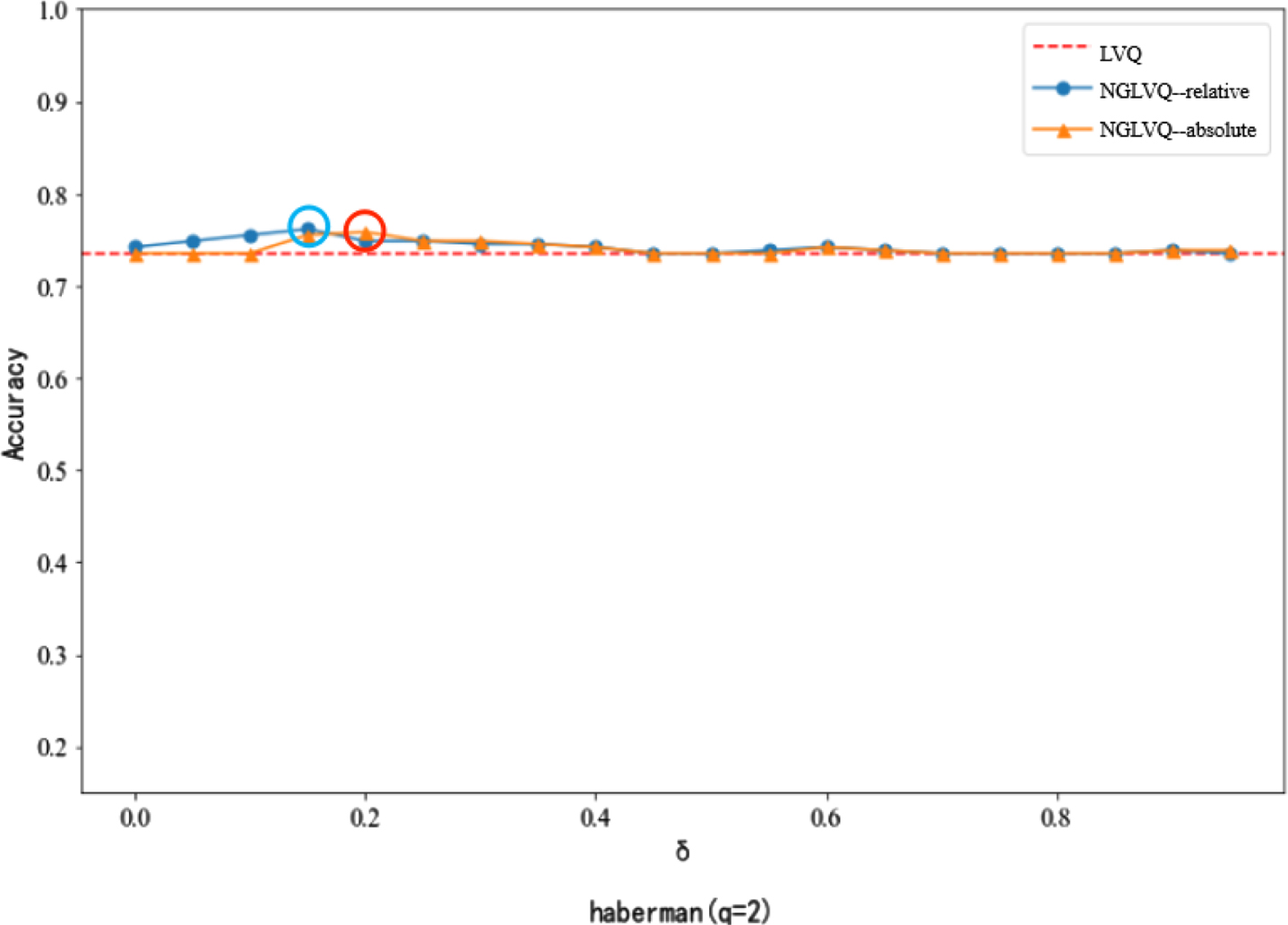
Classification accuracy of different neighborhood parameters in Haberman dataset.
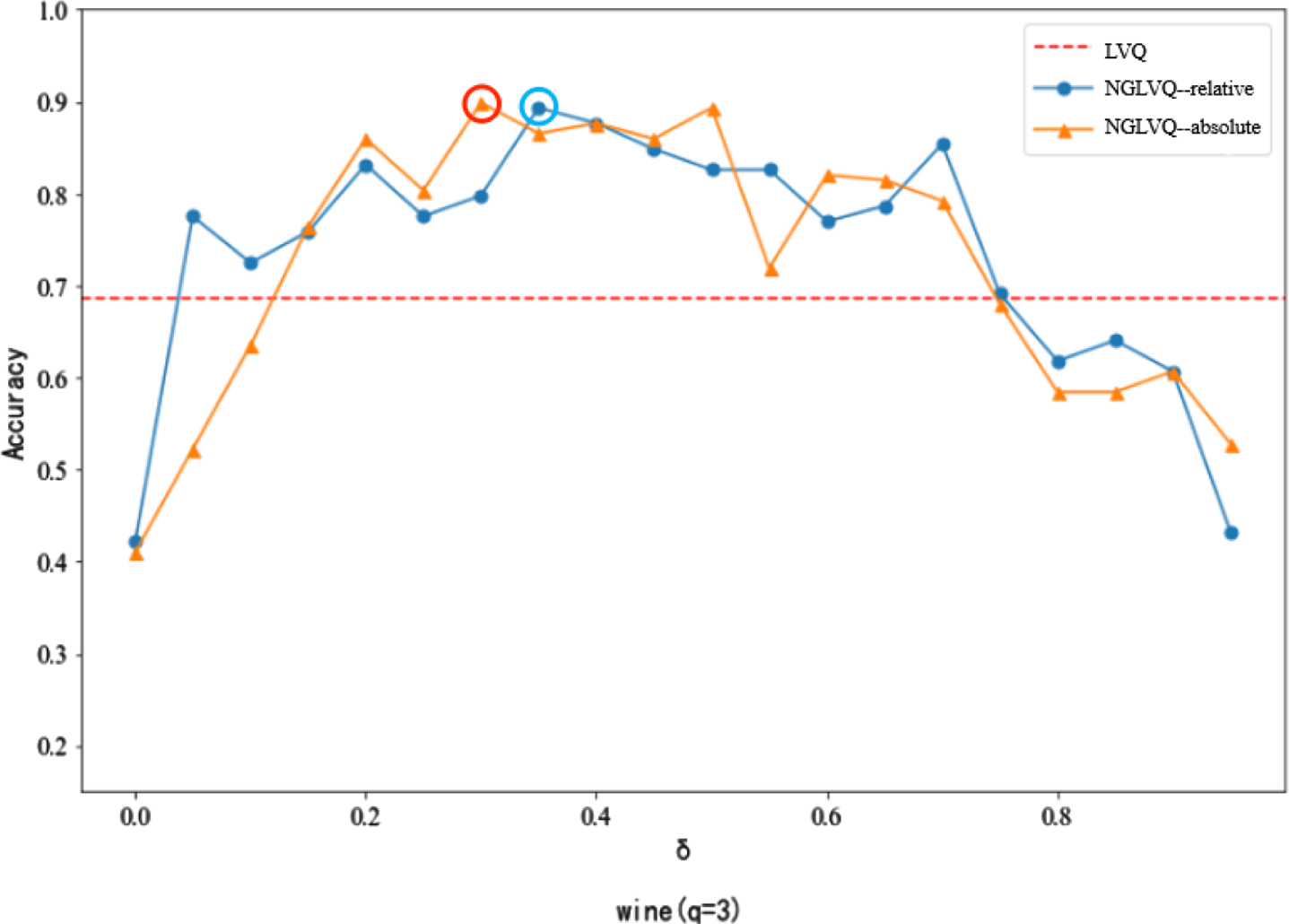
Classification accuracy of different neighborhood parameters in Wine dataset.
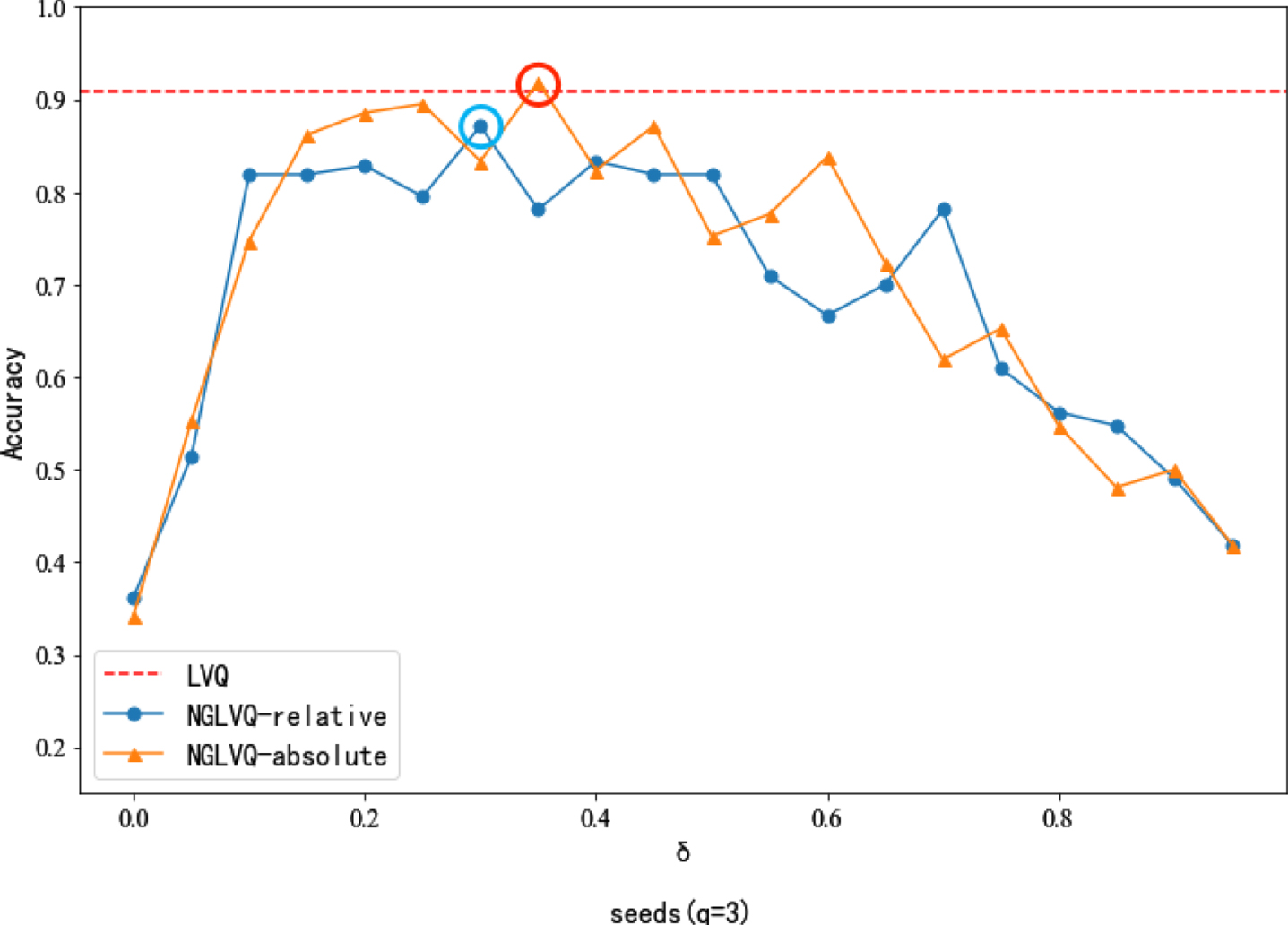
Classification accuracy of different neighborhood parameters in Seeds dataset.
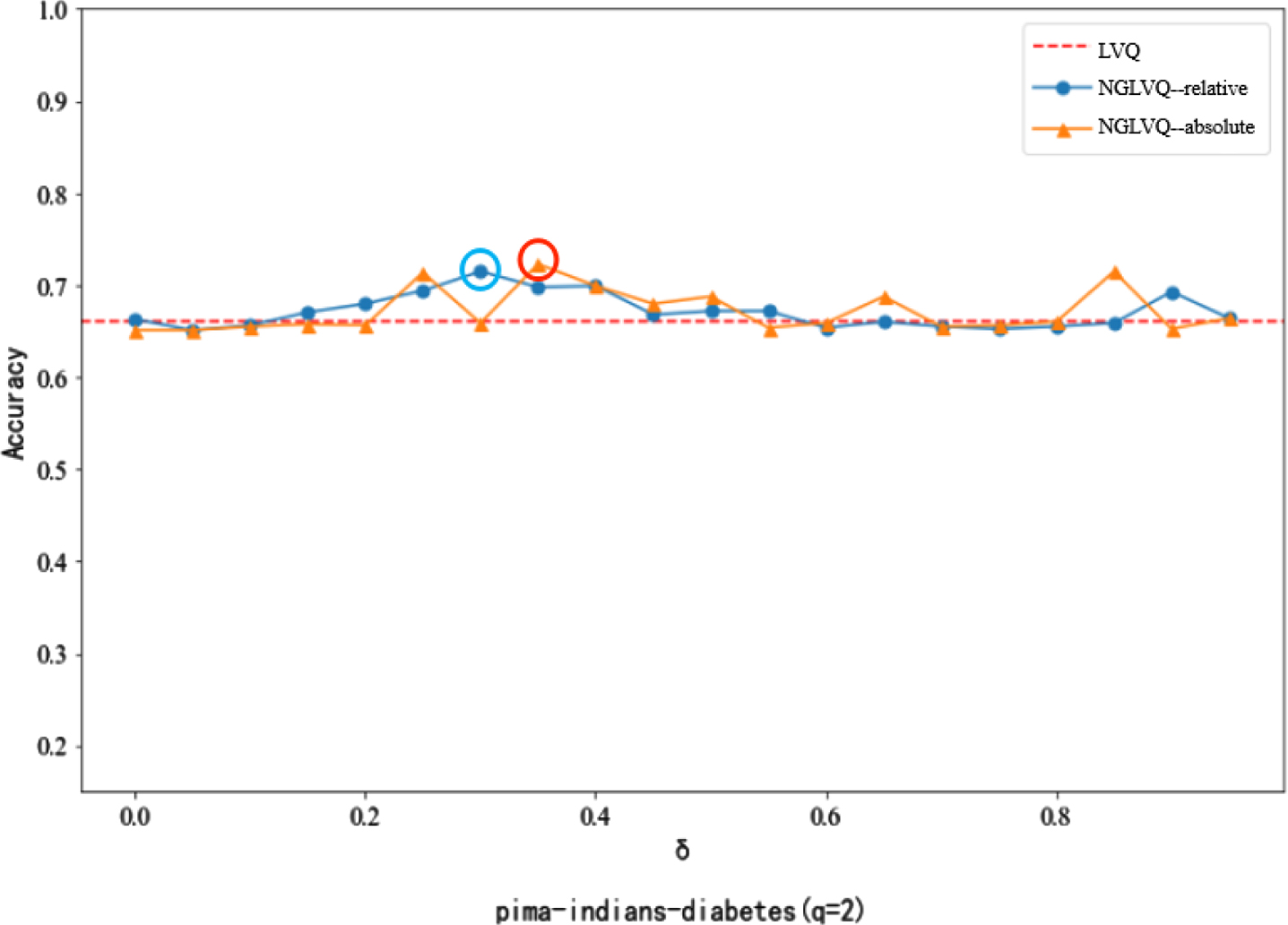
Classification accuracy of different neighborhood parameters in Pima-indians-diabetes dataset.
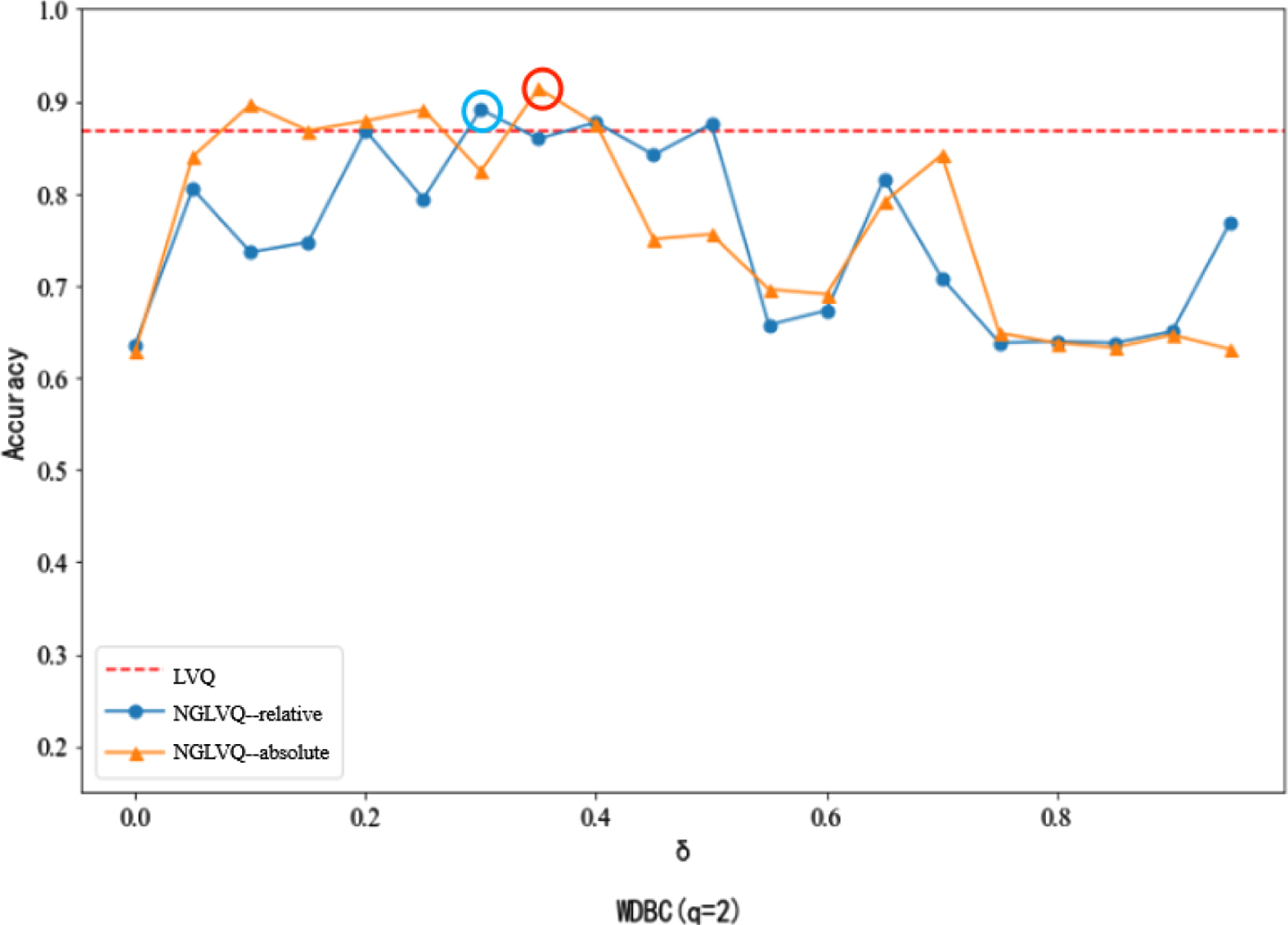
Classification accuracy of different neighborhood parameters in WDBC dataset.
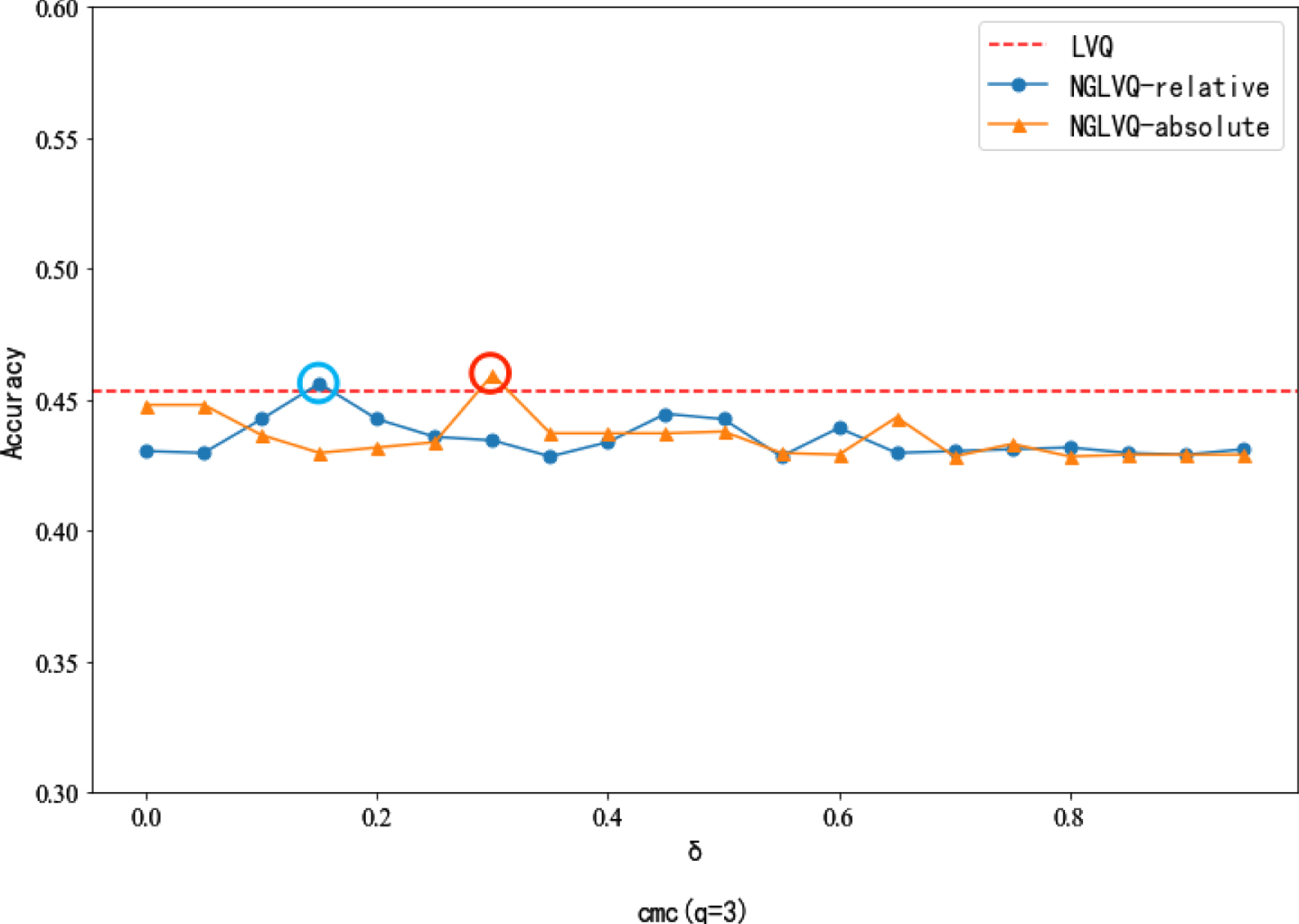
Classification accuracy of different neighborhood parameters in CMC dataset.
In the experiment of the Iris dataset, when the neighborhood parameter is 0.2, the classification accuracy of NGLVQ based on absolute distance reaches the maximum of 0.9733, and when the neighborhood parameter is 0.6, the classification accuracy of NGLVQ based on relative distance reaches the maximum of 0.9667. When the neighborhood parameters are 0.2 and 0.6, the NGLVQ performs better than the traditional LVQ.
In the experiment of the Haberman dataset, when the neighborhood parameter is 0 to 0.4, the classification accuracy of NGLVQ based on relative distance is slightly higher than that of traditional LVQ. When the neighborhood parameter is 0.15, the classification accuracy of NGLVQ based on relative distance reaches the maximum of 0.7614.
In the experiment of the Wine dataset, when the neighborhood parameters are between [0.05,0.75], the classification accuracy of the NGLVQ based on relative distance is higher than that of the traditional LVQ and the maximum value is 0.8933. The classification accuracy of NGLVQ based on absolute distance reaches the maximum of 0.8989 when the neighborhood parameter is 0.3, and the clustering effect is better than that of traditional LVQ when the neighborhood parameter is 0.15-0.7.
In the experiment of the Seeds dataset, when the neighborhood parameter is 0.35, the classification accuracy of NGLVQ based on absolute distance is slightly higher than that of traditional LVQ. The classification accuracy under other neighborhood parameter values is lower than that of traditional LVQ.
In the experiment of the Pima-Indians-Diabetes data set, when the neighborhood parameter is 0.35, the classification accuracy of NGLVQ based on absolute distance reaches the maximum of 0.7227, and when the neighborhood parameter is 0.3, the classification accuracy of NGLVQ based on relative distance reaches the maximum of 0.7148. NGLVQ is superior to traditional LVQ in most neighborhood parameters.
In the experiment of the WDBC data set, when the neighborhood parameter is 0.35, the classification accuracy of NGLVQ based on absolute distance reaches the maximum of 0.9139, and when the neighborhood parameter is 0.3, the classification accuracy of NGLVQ is based on the relative distance reaches the maximum of 0.891.NGLVQ based on absolute distance is superior to traditional LVQ when the neighborhood parameters are 0.1-0.4 (except 0.3).
In the experiment of the CMC dataset, when the neighborhood parameter is 0.3, the classification accuracy of NGLVQ based on absolute distance is slightly higher than that of traditional LVQ. When the neighborhood parameter is 0.15, the classification accuracy of NGLVQ based on relative distance is slightly higher than that of traditional LVQ. The classification accuracy under other neighborhood parameter values is lower than that of traditional LVQ.
As can be seen from Figs. 9–15, for different datasets and neighborhood parameters have a great influence on the classification accuracy. In each experimental data set, an appropriate neighborhood parameter can always be found, which makes the classification accuracy of NGLVQ superior to that of traditional LVQ. The maximum accuracy of NGLVQ based on absolute distance is generally greater than that of NGLVQ based on relative distance.
NGLVQ clustering algorithm based on relative distance and NGLVQ clustering algorithm based on absolute distance is compared with traditional LVQ clustering algorithm, Agglomerative clustering algorithm, and Gaussian mixture algorithm inaccuracy, ARI, and NMI of 7 data sets. The value range of ARI(Adjusted Rnd Index) is [-1,1], and the larger the value is, the more consistent the clustering result is with the real situation. NMI(Normalized Mutual Information) is commonly used in clustering to measure the similarity of two clustering results. The value range of NMI is [0,1]. The higher the value, the more accurate the partitioning.
According to Tables 3–5, under the three evaluation indexes, the score of the NGLVQ algorithm in Haberman, PIMA-Indians - Diabetes, and CMC data sets is higher than that of the other four algorithms. In Iris and Seeds data sets, the scores of the NGLVQ algorithm based on absolute distance were better than those of the other five algorithms. Although the score of the NGLVQ algorithm is higher than that of the LVQ clustering algorithm in the Wine data set, the score of the NGLVQ algorithm based on two kinds of distance is lower than that of Agglomerative Cluster, Gaussian Mixture, and K-means. Although the score of the NGLVQ algorithm is higher than the LVQ clustering algorithm in the WDBC data set, the score of the NGLVQ algorithm based on two kinds of distance is lower than Gaussian Mixture and K-means. It can be seen from the above experiments that the NGLVQ algorithm has better clustering performance on data sets with small feature numbers, and most of the experimental results are significantly better than the other four algorithms. The time complexity of the NGLVQ algorithm is O(N*Q), the granulation time complexity is O(m*n2), and the single cluster iteration time complexity is O(N). Where N is the number of iterations, Q is the number of clusters, m is the number of features and n is the number of samples. Meanwhile, for the NGLVQ algorithm, the clustering performance using absolute distance is higher than that using relative distance.
Comparison of accuracy of various data clustering algorithms
Comparison of accuracy of various data clustering algorithms
Comparison of ARI of various data clustering algorithms
Comparison of NMI of various data clustering algorithms
The clustering performance of the NGLVQ algorithm is inferior to that of the Agglomerative Cluster algorithm and Gaussian Mixture algorithm and K-means algorithm for data sets with a large number of features and categories (such as Wine and WDBC data sets). However, the NGLVQ algorithm is not much worse than the Agglomerative Cluster algorithm and Gaussian Mixture algorithm, and K-means algorithm in terms of performance evaluation index scores. Different from other clustering algorithms, the NGLVQ algorithm uses neighborhood granulation technology to make a breakthrough in structure, so that data can be processed in advance before running. The convergence speed and clustering performance of the NGLVQ algorithm are improved so that the algorithm has a good effect on different types of data sets.
In this paper, the LVQ clustering algorithm is improved by neighborhood granulation. A granule and a granular vector are constructed in the data set, and the size and operations of neighborhood granular vectors are defined. The relative distance and absolute distance measurement of neighborhood granular vectors is proposed, to design the NGLVQ clustering algorithm. The experimental results show that the NGLVQ clustering algorithm can achieve better performance and low prediction errors. The NGLVQ clustering algorithm clusters samples successfully, and also obtain good results under the condition of appropriate neighborhood parameters. NGLVQ clustering algorithm can get better clustering results compared with the traditional LVQ clustering algorithm. Compared with other clustering algorithms, the NGLVQ clustering algorithm has a better clustering performance on data sets with smaller feature numbers. In future work, try to study new granulation methods to improve performance and apply them to other research fields. And try to study the local granulation and the granular measurement to comprehensively improve the speed and performance of granular computing.
Footnotes
Acknowledgements
This research was supported by the National Natural Science Foundation of China under Grant 61976183; Major Project of Industry-university-research Innovation Fund of Chinese Universities at New Generation Information Technology Innovation of China (2019ITA01011).