
Abstract
Many websites are attempting to offer a platform for users or customers to leave their reviews and comments about the products or services in their native languages. The cross-domain adaptation (CDA) analyses sentiment across domains. The sentiment lexicon falls short resulting in issues like feature mismatch, sparsity, polarity mismatch and polysemy. In this research, an augmented sentiment dictionary is developed in our native regional language (Tamil) that intends to construct the contextual links between terms in multi-domain datasets to reduce problems like polarity mismatch, feature mismatch, and polysemy. Data from the source domain and target domain both labeled and unlabeled are used in the proposed dictionary. To be more specific, the initial dictionary uses normalised pointwise mutual information (nPMI) to derive contextual weight, whereas the final dictionary uses the value of terms across all reviews to compute the accurate rank score. Here, a deep learning model called BERT is used for sentiment classification. For cross-domain adaptation, a modified multi-layer fuzzy-based convolutional neural network (M-FCNN) is deployed. This work aims to build a single dictionary using large number of vocabularies for classifying the reviews in Tamil for several target domains. This extendible dictionary enhances the accuracy of CDA greatly when compared to existing baseline techniques and easily handles a large number of terms in different domains.
Keywords
Introduction
Nowadays, advancements in information and communication technologies enable online customers to read reviews before purchasing items. Customer reviews are used to evaluate the product’s quality. Customers provide feedback in the form of comments or reviews, which is what most companies use to improve their products. Sentiment analysis is used to analyze the reviews from the users based on positive polarity, negative polarity, and neutral [1]. Classifying the sentiments requires vast knowledge about the Natural Language Processing (NLP) methods for recognizing the sentiment polarity of reviews of the product. Typically, the NLP method extracts the customer’s response, thereby evaluating the expressed opinions [2]. The supervised, semi-supervised and unsupervised method of sentiment classification is practiced. A proper algorithm for machine learning is used for the prediction of the polarity of data. The datasets are in different domains, and if we use one sentiment classification model to predict other domains’ sentiment, it may fail due to the variation in the vocabulary. The vocabulary used for representing one product is not the same as the other. Furthermore, due to the large size of the dataset, manually labeling all of the reviews is not possible. To classify the polarities of the unlabeled reviews, the conventional sentiment classification algorithm must specify the marked reviews. The method that helps to receive the features from one labeled domain and adapt the same obtained knowledge to the other target unlabeled domain is said to be domain adaptation (DA) [3]. It is otherwise called Transfer Learning (TL). The sentiment classification contains all types of domain adaptation like supervised, semi-supervised, and unsupervised. Typically, the DA will be performed by machine learning (ML) algorithms or lexicon-based methods (LBM). Most probably the classification based on cross-domain involves the categories of opinion extracted from various directions [4]. Using ML methods to handle massive data is difficult, as it is expensive and time-consuming. Hence machine learning methods are not suitable for the unlabeled data. The domain adaptation performed in the exact domains will be known as Domain adaptation. The domain adaptation accomplished amongst various source domains along with single target domain is said to be Cross-Domain Adaptation (CDA). However, challenges like feature divergence, polarity divergence, polysemy, and sparsity may occur [5].
The various Dravidian languages which are emerged from the various comments are in a state of multilingualism [6] and it contains thousands of different comments which need to be translated into English languages. Mostly the annotators who were participating voluntarily are involved in this approach. Especially the mixed code terms are mostly used for the prediction of the sentiments. In recent research, the code mixed with Tamil languages is playing a crucial role in extracting the information [7] in an efficient manner. Mostly deep learning methods like BiLSTM are used for such code-mixed texts. The political parties are continuously delivering certain comments on Twitter regarding their manifestos and political stances. The support vector machine, random forest, and logistic regression are used for training the classifiers [8] in terms of TF-IDF. Some mixed texts make use of Naïve Bayes classifiers, especially for the Indian texts like Tamil, Malayalam, etc. For classifying the feelings from the tweets there occurs three important encounters [9]. Initially the contradiction with the informal texts, and then the local language-related issues like slang and mixed terms, and finally the morphological richness. Hence a proper rule-based approach is needed. Because most of the Indian peoples use multilingual languages and some patterns with mixed code for expressing their thoughts [10].Here also Bi-LSTM is used for analysing the sentiments by classifying the hated and non hated messages.Mostly the emotions of the persons are focused over here in consideration with the multiple languages [11]. This is specifically for multilingual Indian languages like Tamil other than English.
Sentiment analysis has been performed at several levels of texts. Usually, a sentence, a word, a paragraph, or the whole document may involve sentiment analysis [12]. For capturing the sentiment of words or sentences, the polarity strength is to be measured for judging the terms to be positive or negative. Probably the orientation of the words and the sentences [13] in the form of adverbs, adjectives, nouns, and phrases may be responsible for the fine-tuned sentiment analysis.
On the other hand, the variation in the domains may create difficulties in analyzing the sentiments. As each domain has its specific structure of information contents, and we cannot classify one domain by keeping a reference of the other. In this section, the overview of sentiment analysis done in different languages is discussed. In addition, the sentiment analysis using sentiment dictionary is discussed along with various classification methods and domain adaptation techniques.
Sentiment computation by sentiment dictionary
The computation of the sentiments by semantic sentiment dictionary will mostly depend on the open-source resources available. The obtained sentimental values might be combined with some of the semantic rules [14]. WordNet is the available English open-source dictionary where a sentiment analyzer is used to extract the sentiment from the online reviews. The computation of the sentiment dictionary based on lexicon processes some orientation in the semantic [15]. The usage of direction-dependent words may be responsible for the enhancement of the polarity classification while generating the sentiment dictionary. An efficient dictionary is proposed for social emotion detection, automatically determining the sentiments [16]. The semantic orientation of the word in correlation with the group of positive and negative polarities are determined by pointwise mutual information (PMI) in association with Latent semantic analysis (LSA). It focuses on sentiment scores in which the intensity of the words [17] are calculated and is compared. Thus, various sentiment analysis methods used the dictionary-based approach, but no suitable method is available for regional languages like Tamil. In this work, a sentiment dictionary is created for Tamil-translated texts using normalized pointwise mutual information(nPMI) and contextual representation methods.
In this work, we provided the solutions for feature mismatch, polarity mismatch, and polysemy-based problems. A sentiment dictionary is developed by adopting a lexicon-based approach for the Tamil language. Here the dictionary is developed for labeled datasets. Initially, the proposed method implies normalized point-wise mutual information(nPMI) [18] for constructing the dictionary. For making the system understandable, the contextual representation of the texts is calculated. An adaptive model-based contextual representation with hybrid modeling is proposed for solving the problem of ambiguity [19]. Here, the conceptualized contextual representation is used for extracting the sense of polarity correctly. Then the contextual weights are being calculated using the rank score. Sentiment classification is the central part of this research. For sentiment classification, the unified BERT model is used. BERT is a Bidirectional Representation for Transformers, and it is the most needed architecture for all-NLP related tasks. The trending classification model using BERT is designed by keeping word embedding and max-pooling layer at one section and dropout mechanism and softmax classification at other sections. The fully connected layer will combine these two outputs and classify the sentiments of the terms. Then the cross-domain adaptation was carried out with the help of modified multilayer fuzzy-based convolutional neural networks (M-FCNN) in connection with the fully connected layer.
The main objectives of this research include, A modified sentiment dictionary is created using a large number of vocabularies in the Tamil language by utilizing the contextual association between the words across all the domains which reduces the problems like feature mismatch, polarity mismatch, and polysemy. A multi-domain sentiment lexicon is being developed in the Tamil language for categorizing any target domain accurately. The cross-domain transfer is effectively done by using the multi-layer fuzzy-based convolutional neural networks(M-FCNN).
In this research, the sentiment dictionary is formed in the Tamil language for the datasets of six various domains. The construction of the dictionary provides a contextual link between the multidomain datasets for reducing the problems like polarity mismatch, feature mismatch, and polysemy. This makes the domain transfer process simple. In previous works, any one of the above problems is taken into account while transferring from the source domain to the target domain. The novelty involved in this research work is the implementation of modified multilayer fuzzy-based convolutional neural networks(M-FCNN) for cross-domain adaptation. The modification involves the combination of word2vec and doc2vec with the fuzzy-based convolutional neural networks for solving the issues like polarity mismatch, feature mismatch, and polysemy. This proposed approach provides better accuracy while transferring one source domain to different target domains.
Background knowledge and related work
Sentiment classification is the most significant part of data mining, and it is now becoming the blistering topic in the research area. The classification of polarity is improved by using standard machine learning algorithms, especially for multilingual and single-lingual texts [20]. Many researchers have contributed significantly to the sentiment classification from various perspectives. Table 1 summarises the contributions of various authors to sentiment analysis in various journals throughout a specific time period.
List of journals referred
List of journals referred
Sentiment Analysis is commonly used in the English language, while it is uncommon in Indian languages such as Tamil. The Recursive neural network-based models are used for the Tamil sentiment analysis. For capturing the meaning and detecting the sentiments from the Tamil language and adapting it to the English meaning, the Naïve Bayes approach is used in addition to the Hidden Markov algorithm [21]. On the other hand, a lexicon-based approach is used in sentiment prediction by using fastText word embeddings. Here word2vec tool is used along with SentiWordNet for dictionary creation. The SentiWordNet is alone a sentiment lexicon that is used to determine text sentiment [22]. The performance of Sentiment Analysis is limited by a large number of sentiment expressions which were not included in the SentiWordNet. A deep neural network with a bidirectional approach is used [23] for the extraction of the sentiments for the Tamil texts on the Twitter website is most common. The unigrams and bigram-based models are used in addition to the supervised machine learning method [24]. The feature is extracted from Lexical resources like Wordnets. However, the behavioral patterns are extracted for the persons who deliver posts, comments, and reviews [25]. This is the combination of English and Tamil language processing.
Thus, many approaches are developed for the sentiment analysis using the Tamil language, but the problem is with the polarity divergence and the prediction of polysemes words. In this work, the product reviews from six different domains are taken which is mentioned in English language and the same is translated to Tamil language using google translator toolkit to form a Tamil sentiment dictionary.
BERT (Bidirectional encoder representations from transformers)
Well-defined language models are used widely in many NLP tasks for training the texts [26]. The use of language models for sentiment classification will bring an effective mode of classification of sentiments. BERT (Bidirectional Encoder Representations from Transformers) is one such method and is used extensively for its accuracy and performance. It uses a Masked Language Model (MLM) for pre-training and the subsequent prediction mechanism for predicting the next word or sentiment. Primarily the deep learning models are used for analyzing the sentiments in a fine-grained manner [27]. The datasets are taken and processed using fine-tuned BERT model for some foreign languages like Chinese, Russian, and Arabic [28]. For Russian language datasets like news, Corp, and reviews, the deep learning-based model is used in addition to the multilingual BERT model. But for the fine-grained analysis for some datasets, the BERT model supports the syntax memory, which is label wise [29] and provides much better performance than state-of-the-art methods.
Moreover, in Arabic sentiment analysis, the word embedding is used along with the BERT model [30]. The language model used in the analysis of the Arabic language is transformer-based, providing better f-score values compared to the state of art methods. A sophisticated architecture is used here to demonstrate the effectiveness of NLP. The context-aware representation is another approach where the aspect-based terms use a word embedding mechanism [31]. This is a target-dependent mechanism that provides good accuracy in dealing with the target domain. There exist some restrictions in the NLP tasks while involving it in a multilingual approach. A specific model is developed with XQUAD [32] for providing options in the QA system. The document feature is constructed by embedding all the terms in the large documents [33] and obtaining multi-head attention in the transformer using the word embedding-based BERT model. The combination of BERT with BiLSTM-CRF [34] will provide better precision, recall, and F score. The sentiment classification using BERT models provides an effective result in handling the texts. The traditional approach using the word2vec model will not express the information contents, but the BERT model and convolutional neural networks [35] combine to achieve better results for all domains. When used for sentiment classification, this BERT model will provide better results in accuracy and performance. In this work, a BERT model with a softmax classifier and max-pooling layer is used in combination with the fully connected layer for sentiment classification.
Sentiment analysis using machine learning and deep learning algorithms
Considering user satisfaction, the accuracy of the analysis is needed to be taken into account. For this, a novel machine algorithm [36] is proposed, incorporating processes like collecting data, performing extraction methods, content weighting, and polarity prediction, etc. The scrapping algorithm is used here for the extraction of data from the datasets. The convolutional neural networks and LSTM are combined for classification purposes [37]. The accuracy of the system is better in comparison with all the previous methods. However, for some aspect prediction, the ontology-based method is used in addition to the neural network methods [38]. The complex nature of the words can be easily treated with the modified BERT model. The classification module used here is a two-dimensional CNN model. For Chinese texts, the fine-grained analysis is done with the help of a slang-based method [39]. The various slang expressions are collected, and the corresponding LSTM based method is used for the classification. The humorous type data are even categorized and distinguished.
Cross-domain adaptation and FCNN
Transfer learning or domain adaptation is the most popular method for solving target-dependent problems. The cross-domain sentiment classification methods are used for applying the labeled source domain that is already pre-processed directly to other unlabelled target domains. This method uses multilayer (three-layers) convolutional neural networks [40] for cross-domain transfer. This will reduce the inconsistency in the source domain while transferring to the target domain. Here retraining the network for the target domain is not necessary. For different domains, there is a lack of datasets available for training the models. Hence the cross-domain adaptation method is used for accuracy improvement in the sentiment analysis. In many sentiments’ analysis methods, the terms used for one domain are not applicable for other domains. Hence an aspect-based cross-domain adaptation [41] method combines the various features like labeled and unlabelled aspects. This is computed in a single network, and the domain transfer takes place from source to target in the same network. The differentiation of the attitudes of various groups of peoples involved for a discussion about the unified texts of Russian languages may involve some cyberslang aspects. In this, the machine learning classifier is built in addition to the BERT model [42]. Here instead of polarity classification, the attitudes of the texts are considered. The attitude includes the hating character and the non-hating character and is identified with the help of fine-tuned linguistic features. The human intervention of depression-related issues is analyzed with the help of microblog reviews extracted from the websites [43]. Here also the BERT model is used along with the LSTM. The average prediction of depression is much higher when compared to the previous works. The characteristics of misleading information from social media sites are disseminated with the flow of emotions predicted. The positive and the negative emotion [44] will strengthen the robustness of the obtained datasets in the mentioned languages. Normally the cross-domain algorithms are implemented for tackling the issues related to the sparsity [45] and feature mismatch problems. The ensemble used in the source domains is converted to the other target domains by enhancing its accuracy. The polarity determination is made possible with the help of collaborative filtering algorithms. The multimodal used in the representation of the semantic words provides and relationship among the language models graphically [46]. The graphical convolutional neural networks will outperform the language processing. It will combine the syntactic information with the phonetic information in the representation of the words and sentences. To add the missing features, the convolutional neural network is combined with fuzzy logic [47]. This will map the membership values and thus increase the accuracy better. Here in this research, the modified multilayer fuzzy-based convolutional neural network is used, which reduces the missing features while transferring to other domains thus improving the accuracy in domain adaptation (DA).
Work in context
Considering the reviews observed so far, the BERT model is used only for the English corpus, and here in this proposed approach, it is used for the Tamil corpus. Moreover, here BERT is used for sentiment classification. Mostly the cross-domain adaptation has some problems like feature mismatch, sparsity, polarity mismatch, and polysemy. Most of the research focuses on any one of the mentioned issues. However, in this proposed approach, we focus on three issues such as (polarity mismatch, feature mismatch, and polysemy). We used two dictionaries other than the previous works (i) initial and (ii) final. The initial dictionary uses normalized pointwise mutual information (nPMI) to derive contextual weight, whereas the final dictionary uses the value of terms across all reviews to compute the accurate rank score. For Cross-domain adaptation here, we used a modified multi-layer fuzzy-based convolutional neural network (M-FCNN) to handle many different domains, as it is lagging in previous works. The vocabularies considered in this approach are numerous compared to all other baseline methods.
Proposed method
The multi-domain dataset of “amazon.com”? is in the English language, and it is taken from the website and then first translated into the Tamil Language. The translated reviews are then pre-processed, and a dictionary is created using that review translation. The overall process involved in this proposed work is discussed as below, English Review Translation Pre-processing of Texts Classification using BERT Analysis Formation of Sentiment Dictionary Determination of frequency of Words Cross-domain adaptation using the sentiment dictionary
English review translation
The multidomain dataset for sentiment classification is taken from the database [50], which contains reviews of products like Books(B), DVDs(D), other electronic products(E) along with Kitchen related products(K). The collected reviews are in English, and all the English reviews in the dataset are interpreted into the Tamil language. The transformation of English reviews into Tamil is done with the help of the Google translator toolkit. The emoticons in the review are replaced with alternate sentiment words with the help of an online dictionary (application from google play store). While translating, the proper arrangement of words and sentences is taken care of to protect the whole connotation of the sentence. Some untraceable related words can be completed with the help of manual effort, specifically for emoticons and emojis. More than 5000 reviews (Both Positive and Negative) and 155 neutral reviews (which are manually included) are translated from each product review in this paper. This includes both labeled data and unlabelled data. The source of information used in this paper is shown in Table 2.
Datasets used in this research
Datasets used in this research
For analysis purposes, movie reviews and restaurant reviews are considered. The movie reviews are taken from the IMDB dataset [51], and the restaurant reviews are taken from the Zomato Bangalore dataset [52]. The obtained dataset is then translated into Tamil language using Google translator toolkit. 1680 reviews (both positive and negative) and 57 neutral manually framed reviews are collected from the movie review data set, and 1280 reviews are taken from the Zomato restaurant Bangalore data set. The reviews which are translated using the Google translator toolkit are shown in Table 3(sample data).
Sample translated data using Google translator Toolkit

The obtained data are not in the proper structure, and hence the pre-processing of data is done by implementing two steps. Basic Pre-processing Advanced pre-processing
In basic pre-processing methods, the extra information that is not needed for the analysis is being removed. For example, Punctuation marks removal and the removal of numeric data from the review. Then the advanced pre-processing might have control over the messages by removing the stop words. Predominantly the manual correction is needed for the translated reviews to correct the spelling. After lemmatization of the reviews, the translated reviews are then subjected to part of speech (POS) tagging for converting the sentence to a list of words [48]. After setting up the list of words, the repeated words are removed. The main problem that arises here is selecting suitable meaning for the original text in consideration of the translated text. Since many English words process the same meaning when converted to the Tamil language. Proper lemmatization is required instead of stemming for the effective gathering of data for analysis. After the pre-processing process, a set of words are obtained from the list, where the unigrams and bigrams are separated.
Sentiment classification using BERT analysis
Bidirectional Representation for Transformers (BERT) is used to understand the unique language sentiments better when translated. BERT model is used for binary classification tasks by utilizing the Corpus of Linguistic Acceptability. The contribution of BERT makes effective classification for both texts and sentences with the help of TensorFlow in python. Tensor flow is used for building neural networks. BERT interprets the exact meaning of the texts and sentences by considering the relationship between the words within the sentences, thus determining the words’ exact meaning. Typically, the BERT [49] framework consists of two processes named pretraining along with fine-tuning. Different tasks have pertained to the pretraining process in the case of unlabelled data. In the pretraining process, the considered parameters are fine-tuned using the already available labeled data. Usually, word2vec models are used to make the system understand the translated language, but the previous methods yield poor results when considering the polysemous words. However, BERT can effectively handle these kinds of polysemous words, especially the words with ambiguity. Using BERT models, the whole input sequence can be handled at the same time. It consists of two variants: BERTbase and BERTlarge. We must represent the first word of the sentence with a classification token (CLS) and separation token (SEP) for all the sequences for performing classification. Finally, the output is predicted to be the embedded sequence formed after classifying the whole sequence. The decoder’s end relates to a fully connected layer which is followed by a SoftMax layer and a dropout regulation unit. The SoftMax layer is nothing but a neural network layer.
The sentiment classification method we focused here is a target dependent classification method. In our approach, BERT is trained with the basic dictionary and then it is reconfigured to the proposed model. Here, the sentiment classification is based on a sentence, words and the target. The BERT model proposed here is of task specific. A word or pair of words and a sentence or pair of sentences is represented by BERT design.
Initially, the pre-processed text is used for computing the sequence embedding from the BERT. Then the dropout is applied for preventing the overfitting and regularisation process. Finally, the SoftMax classification layer is implied for identifying polarities of the sentiment based on the probability.
For example,
Here BERT uses the bidirectional transformer for training the language model in prior. Primarily the aspect-based design typically represents either a single term or a pair. BERT classification used here consists of two approaches. The pre-processed text is subjected to dropout and Softmax classifier to split the sentiments for dealing with word-based sentiment classification. However, for sentence-level sentiment classification, it has used a fully connected layer and max-pooling layer. For sentence-level classification, aspect-based terms are used, as it contains multiple words as shown in Table 4.
Extraction of aspect based terms
Extraction of aspect based terms

The sentence ‘s’ has some collection of words and is represented by W s , W s = [a1, a2, a3, ⋯, a i , ⋯ , a n ] and the selected aspect terms are represented by A s = [a i , ai+1, ⋯ ai+m-1]. The aspect-based terms are processed by the max pooling operation, as the polysemy words are selected from all the words, including the aspect terms. After selecting the words, it is then fed to the fully connected and softmax layers for further classification.
The domains that we use here in this research are entirely different. Four product domains, one movie review, and one restaurant review are taken for research. Care must be taken to avoid the repetition of the exact sentiment words representing different domains. Even some of the words are contradictory in their meaning while translating. Polysemy and sparsity are the common problems that occur while handling the data. The proper stemming method is applied to reduce the sparsity problem, and a contextual word embedding mechanism is implemented for dealing with polysemy, and thus, proper sentiment words are obtained in the dictionary.
Normalised PMI
Normalized Pointwise Mutual Information (nPMI) is used in between the words for the generation of sentiment dictionaries. It is the combination of mutual information and pointwise mutual information. The normalization range is in between [+1 and -1]. It is calculated within the obtained bigrams list, as the bigrams are labeled with positive and negative sentiments. It is appended to the unigrams in the dataset. Some of the words are direct words, and some are unpredictable because of the same meaning when translated. Let us consider |f1| be the frequency of unigram f1 and |f2| be the frequency of unigram f2. Hence the normalized PMI is obtained as,
Contextual representation (CR) is needed to form the dictionary, as it is mandatory for dictionaries that are machine-readable for gaining maximum knowledge acquisition. Primarily CR is described lexically or conceptually. In this research, the lexical-based contextual representation is applied for computation. The contextual representation is mentioned as "CR"("w,s" where ‘s’ denotes the sense of the word and ‘w’ denotes the polysemes word. Hence the lexical based CR(w,s) for sample words in each domain is represented as,
Sense-based Lexical contextual representations for various domains

Usually, the dictionaries for machines might use maximum pieces of information for the identification of translated meanings. This is achieved by designing a modified heuristic algorithm (MHA) for automatically tagging the bilingual sentences and sense labels based on translated words. For each instance of the polyseme word ‘w’ in the reference domains, the similarities in between the contextual information and its translation for Book (C
B
), DVD(C
D
), Kitchen (C
K
), Electronics (C
E
), Movie (C
M
) and Restaurant (C
R
) is obtained as
The contextual weights in between the words across various domains are calculated. The weights are calculated to tackle the situation of elements having similar sentiments. The contextual weights are calculated using the formula shown below.
The rank score is calculated depends on the frequency of words and the contextual weights. In some cases, the word ‘wx’ will get almost high whenever compared to the other words. Hence the rank score [x,y] is calculated for each word ‘wx’ in the review ‘y’. The average rank score for each word ‘wx’ is calculated using the formula given below.
Finalised sentiment dictionary

In this paper, six different domains (DVD, Electronics, Kitchen, Book, Movie, Restaurant) are taken for analysis. All six are different domains, and we need to keep track of one domain and apply it to other domains for analysis. The words used for representing DVD are not suited to the Kitchen, as both are mutually different. Hence, an adaptation method is used with modified multilayer fuzzy-based convolutional neural networks (M-FCNN) to solve cross domain-based problems. The modified multilayer fuzzy-based convolutional neural networks(M-FCNN) model is a specific type of deep neural network, that consists of an Embedding layer, a convolutional layer, a maximum pooling layer, fuzzy layer in addition with a fully connected layer. Here the convolution layer and the maximum pooling layer are used for representing different features by extracting and combining. Here in this work, a fuzzy-based convolutional neural network had used for solving the cross-domain analysis-related problems. The overall architecture is shown in Fig. 1.

Architecture of M-FCNN.
The proposed neural network model is trained by using the source domain data. The original information from the dataset is represented by SD (sentence in the source domain), where SD ∈ Y x mx1, where ‘m’ is the fixed length of the sequence and m=0, when L < m, where ‘L’ is the length of the sentence.
The embedding layer will transform the original source information to SD ∈ Y x mxn by using the modified sentiment dictionary. Here ‘n’ is considered as the word vector dimension.
If the SDi represents the ith word in the sentence, then
The next layer is the convolution layer which is used for extracting the features of the sentences. For obtaining the features, ’h x n’ convolution kernel Xs ∈ Y x hxn in the input layer from the top region to the bottom region for computing the convolution-based operation and hence the feature map column is obtained as 1 and the identified line m-h+1 is
The next layer is the pooling layer and the function of the pooling layer is to extract the most important and the relevant features. In this research the maximum pooling layer is used ie., the main feature contains the maximum value of the features, given as
The next layer is the fuzzification layer, which summarises the feature information from each fuzzy map using fuzzy neural networks. Individually all the feature maps will have ‘N’ fuzzy maps. Here ‘N’ is the number of fuzzy sets in the membership function. If there are four fuzzy sets ie., N=3, then four possibilities are there including positive, negative, neutral and zero. The fuzzification can be done by using the following formula
Where
Where fqp denotes the outputs of the inference from the feature maps. The next layer is the defuzzification layer and the defuzzification can be done by using the formula
The weights are adjusted by using the methods prescribed in the stochastic process. Here no activation function is used in the fuzzification layer. For avoiding the overfitting problem, the dropout mechanism is used. The same procedure is repeated for the target domain data set. For training the model, we have to extract some of the standard features and apply them to the modified transfer learning model. This model is used after creating the sentiment dictionary for the Tamil translated dataset as the obtained words might get classified as positive and negative. Hence the corresponding source domain will append the label and the obtained rank score to the target domains. Hence the test review is obtained by considering the overall score as either positive or negative.
The experiments are conducted in the python programming language. The proposed method uses the already available dataset in websites like Amazon (DVD, Electronics, Kitchen, Book) and Kaggle (IMDb movie reviews, Zomato restaurant). The translation was done with the help of google translator toolkit to the popular known Tamil language. Considering two such domains (Kitchen and Restaurant) as the source and any one of the other domains (Movie Review) as a target, the sentiment dictionary is developed with contextual weights and the Rank Score. Cross-domain adaptation was practiced for different combinations of the review. More than 5000 reviews were identified, and 3565 of such were taken for training.
Domain adaptation with the reviews
The domain adaptation was performed for all the combinations of the domains. Totally, 36 combinations of domains are available.
Same domain
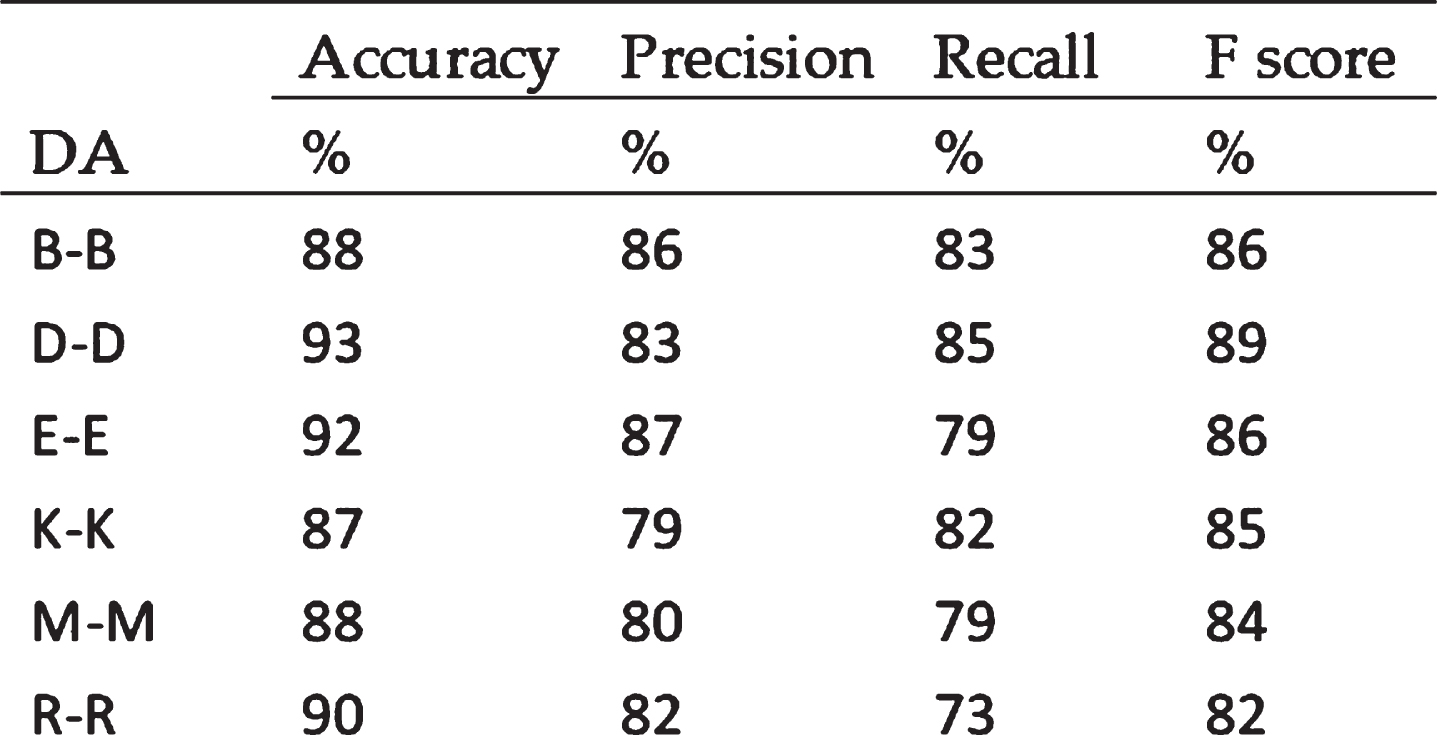
Domain adaptation is performed for exact domains and obtained good results when compared to the other domains. The performance metrics considered for the research are precision, accuracy, recall, F-score. Considering all the domains, the minimum accuracy (87%) is obtained for the Kitchen domain and maximum accuracy (93%) for the DVD domain. Similar domains combinations provide better accuracy when compared to the previous state of art methods. The obtained results are given in Table 7.
Cross-domain adaptation using sentiment dictionary of all domains
Cross-domain adaptation using sentiment dictionary of all domains
Considering other domains, the minimum accuracy is predicted to be 54% obtained for E-R, and the maximum accuracy is 82% obtained for K-R. The value of the accuracy depends on the similar terms used for the representations. Probably the Kitchen domain might match with the restaurant domain. Hence the accuracy for the combination (K-R) is obtained as 82%, and the precision is predicted to be 82%. However, for the combination (R-K), the accuracy is obtained as 81%, and the precision is obtained to be 80%. The similarities in the terms used may lead to better accuracy. Some of the transformations might produce the worst results because of the mismatch that exists in the usage of terms.
The various cross-domain adaptation results are shown in Table 8. The accuracy and precision value obtained for B-K, D-K, E-R are very low due to the feature mismatch problem. Many polysemy words occur in the combinations K-R, B-M, E-D, E-M, etc. It produces some better accuracy for some combinations, but for some, performance seems to be lacking. The occurrence of polysemy words for some combinations is shown in Table 9.
Cross-domain adaptation using sentiment dictionary of all domains
Cross-domain adaptation using sentiment dictionary of all domains
Polysemy words across each domain

The BERT model classifier is used for the classification of reviews in the dictionary. The three polarities determined in this approach are positive, negative, and neutral. Two modes of operations are performed, at one side, the word embedding followed by M-FCNN is used, and another part involves using the Softmax classifier. The indices used for the evaluation are accuracy, precision, F score, and Recall.

M-FCNN result producing accuracy for Different Target Domains.
Not like the English texts, the Tamil texts will be divided into single unigrams. Here the target domain data are fine-tuned, especially the labeled data. The value for M-FCNN is set to be k=100. For each labeled data of the target, the k values are adjusted for each iteration and set to be 100,200,300,400, and 500. The result is shown in Table 10.
Results for M-FCNN method at k=100
ByM-FCNN model, the highest accuracy 93% is achieved for movie Book review and the lowest accuracy 60% is achieved for Electronics Movie review. The whole analysis for k=100 is depicted in Fig. 2. The indication of values for each value of k is shown in Fig. 3.

M-FCNN result producing accuracy for Different Target Domains.
The results shown in Fig. 5 indicate the accuracy of the labelled data used for training. This shows that the application of M-FCNN brings better accuracy for transfer learning. The BERT model leads to the classification of sentiments for different domains in the multi-target operation. Even though the deliberation of the terms considered for analysis shows lower performance in the categorization of positive, negative, and neutral, BERT provides stable improvements in all aspects. Especially while using the dropout mechanism and Softmax classifier, the classification accuracy is predominantly increasing. The accuracy depends on the ratio of the correct prediction with the total prediction. The accuracy obtained using the BERT classifier is shown in Table 11.
Accuracy values using BERTBASE and BERTLARGE
While using the multiple domains, the accuracy values might get varied with the testing data and the training data. Normally for the labeled domains, the accuracy values will be in the range of 40% -93%.
The obtained results show that the terms considered in the sentiment dictionary provide better accuracy.
This is achieved by keeping one specific domain as a target and combining other domains as the source. The below Figs. 4 to 9 show the performance of the target domain and the source domain. All the five domains as multiple sources are considered and the electronic domain as a single target, the average accuracy is 54%, and keeping the DVD domain as a single target and other five domains as multiple sources is 59%. The different results are obtained by selecting one domain as the target and the other five domains as the source are shown in Table 12. The obtained results reveal the importance of considering the single target domain and multiple source domains.

Single Target domain (Electronic) vs Multiple Source domain (Other Five domains).

Single Target domain (DVD) vs Multiple Source domain (Other Five domains).

Single Target domain (Book) vs Multiple Source domain (Other Five domains).

Single Target domain (Kitchen) vs Multiple Source domain (Other Five domains).

Single Target domain (Movie) vs Multiple Source domain (Other Five domains).

Single Target domain (Restaurant) vs Multiple Source domain (Other Five domains).
Average accuracy of target domain vs source domain

The experimental results demonstrate that the well-enhanced proposed system highly reduces the polysemy-based problem and feature mismatch problem, thus increasing accuracy and performance even for multiple cross-domain datasets. The application using BERT classifier highly enhances the accuracy of sentiment polarity calculation. When compared with the previous methods, this proposed system provides better accuracy and the compared results are shown in Table 13.
From Table 13, it is clear that the modified fuzzy-based convolutional neural networks with BERT classifiers perform better for domain transfer when compared to the traditional methods. The value of k is fixed to be 300. The comparison is done by transferring all six domains between each other. The average accuracy is obtained to be 77% which is much better when compared to other methods. Hence based on the above results, it is clear that the transfer learning methods for different domains based on Fuzzy based Convolutional neural networks provide improved accuracy and better performance.
Comparison with other traditional methods

The cross-domain adaptation of any domain is carried out in the Tamil language by using the sentiment dictionary. Initially, the computation using the contextual representation and contextual weight is carried out for the labeled terms in the multi-source domain, and the same might be adapted to the target domain. The polysemy, polarity mismatch and feature mismatch problem are taken into consideration and is handled effectively in this work. Then the polarity of the unlabelled terms is identified by calculating the rank score. The novel modified BERT model equipped with the Max pooling layer and Softmax classifier has revealed some noticeable improvements in the polarity determination. In addition, the domain transfer method is adopted by means of modified multi-layer fuzzy-based CNN by training the data source that is not labeled and fine-tunes the target samples with the help of Fuzzy neural networks. The cross-domain adaptation between six different domains provides an accuracy of about 77.20%.
Declaration of interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Author contributions
K. Suresh Kumar: Conceptualization, Methodology, Writing-Original draft preparation, Visualization.
A. S. Radhamani: Supervision, Investigation.
T. Ananth kumar: Software, Validation.
Funding & financial disclosure
No Funding to declare. We certify that no party having a direct interest in the results of the research supporting this article has or will confer a benefit on me or on any organization with which I am associated.