
Abstract
The semantic query problem is commonly called the semantic gap and is one of the significant problems in multimedia data retrieval. In this study, we focus on multimedia data retrieval by combining semantic information with data content to solve the semantic gap problem effectively. The main idea behind the combination of low-level content descriptors and the concept of multimedia data is to represent the content information with the semantic information by adding a low-level content descriptor as a new dimension to the index structure. This new dimension is represented by constructing an array index structure that uses a fuzzy clustering algorithm. Thus, a new high-dimensional index structure, named MM-FOOD, supporting querying of multimedia data, including fuzzy querying, is presented in this paper. This proposed index structure’s construction and query algorithms are explained throughout this paper. Our experiments show that our indexing mechanism is considerably efficient compared to the basic indexing approach, which stores low-level content and semantic concept descriptors in separate structures when the data size is large.
Introduction
Multimedia retrieval has been a very active research topic for decades and includes many research areas: database management, computer vision, information retrieval, and search systems. It basically can be defined as the process of searching for complex objects in a multimedia object collection [1–3]. Indexing plays a critical role in effectively searching and retrieving multimedia objects since multimedia data has a very high number of attributes and features. These features can be divided into conceptual (or semantic) features and content features [2]. In general, multimedia data are indexed conceptually or using content information [4]. In concept-based indexing, objects are indexed by their semantic or metadata information. This information is extracted either manually or automatically. In [5], keywords are manually defined for videos. Users are expected to query the retrieval system by using linguistic terms or keywords. However, using keywords in queries is not representative most of the time since multimedia data contains complex objects and contents. Moreover, users are expected to have the domain knowledge to define the query. In [6], the authors claim that using conceptual attributes in multimedia retrieval requires the knowledge of places, societal class, etc. In [7], the authors explain that semantic similarity does not imply visual similarity and vice versa. Thus, content-based indexing techniques have been proposed to satisfy these requirements. This indexing approach has high expressive power [8] since contents are represented as features, and these features are directly extracted from the multimedia object itself automatically. Thus, this approach is easy and fast to represent objects in a machine under a stable format. Early systems used low-level features based on color or with, texture, and shape [9–12]. In [10], the authors used images to represent video clips and reduced the video retrieval task to an image retrieval task to improve the scalability of the system. Similarly, in [13], uses image queries for video retrieval by defining the similarity function between query and video clips. Due to the great advantages of deep learning technology in multimedia retrieval, deep neural networks are used in video retrieval task [14–16]. In [17], CNN is used to extract low-level features of videos. In [18], the authors propose the CNN model with SOM clustering for trademark image retrieval.
However, the computer has a different and low-level understanding of multimedia content than human understanding, content-based retrieval approach can have the semantic gap problem which simply can be defined as the gap between user queries and content features which are used in indexing phase [19]. Therefore, both approaches have some benefits and deficiencies. In order to develop an efficient retrieval system, these two approaches can be combined to form a hybrid retrieval system [20]. A multimodal or hybrid retrieval system can be defined as retrieving the relevant objects using any combination of concept and content retrieval model [21]. In [22], the authors propose a multimodal transformer for video retrieval to extract and use different modalities and features from the videos. However, they do not propose any access mechanism for the retrieval task. In [23], k-nearest neighbor mechanism is adapted for multimodal multimedia object retrieval. They used similarity matrix for finding relevant objects instead of using distance-based indexing.
Search speed is another important factor in retrieval systems. It is a challenging task to ensure that the system performance will not degrade even when the number of objects in the database is thousands or even millions. There are different solutions for this performance issue in the retrieval systems, such as applying distributed computing or using a multidimensional access mechanism. Moreover, since query performance is directly related to the size of the search space, pruning this space is very crucial for the performance of the system [24].
In this paper, we present a new indexing structure for the hybridization of content-based retrieval and concept-based retrieval to overcome each retrieval technique’s limitations. The first contribution of this study is the representation of multimedia data in low-dimensional space for fast retrieval. For embedding original high-dimensional features, we have adapted dimensionality reduction methods, including Principal Component Analysis (PCA) [25], Linear Discriminant Analysis (LDA) [25] and, a multidimensional scaling (MDS) approach, called Landmark-based Multidimensional Scaling using FastMap (LMDSFastMap) [26]. We further compared their effects on high-dimensional indexing and retrieval. The comparison results conclude that our approach reduces the problem of the multimedia data retrieval task to a spatial indexing task using LMDSFastMap. The accuracy of multimedia data is another important metric for the effectiveness of a retrieval system [1, 3]. Comprehensive experiments show that our dimensionality reduction approach achieves substantial improvements over the retrieval process performed in the original space up to an order of magnitude speed up and has a similar accuracy [27].
The following contribution of our study is the process of multimedia data retrieval by combining semantic information (high-level descriptors) with content information (low-level descriptors) to solve the semantic gap problem efficiently. We have developed an access method called MM-FOOD to index high-level and low-level descriptors together; hence, these descriptors can be accessed using the same index structure. MM-FOOD uses FOOD-Index [28], a fuzzy object-oriented index structure, with Array Index mechanism [29]. Construction of MM-FOOD involves two phases; semantic descriptor representation and content descriptor representation.
In semantic descriptor representation phase, the semantic information is extracted from objects [30] and the conceptual attributes are obtained. These attributes are stored as keys in MM-FOOD along with content descriptors. Moreover, efficient execution of fuzzy queries on multimedia data can be performed on these conceptual attributes. Using fuzzy logic in the retrieval system, we try to handle the uncertainty problem caused by describing multimedia objects using high-level semantics. As a result, the user can express her/his queries using fuzzy terms.
In content descriptor representation phase, first of all, several content descriptors [31, 32] are used in order to represent low-level features. After extracting these high-dimensional low-level features, to effectively represent the content of the multimedia data (visual and audio descriptors), we applied the LMDSFastMap embedding technique to reduce the dimensionality of the low-level features. The next stage is mapping low-dimensional content feature vectors to one-dimensional space so that each content vector can be presented in MM-FOOD using this one-dimensional representation. Content feature vectors are first clustered by using the Fuzzy C-Means [33] algorithm and these clusters are projected into a point in one-dimensional space using Array Index mechanism. The output of this one-dimensional mapping process is represented as a new key-value in MM-FOOD and combined with conceptual attributes’ keys. Therefore, the high-level semantic information and low-level content features are merged and indexed together in a single structure.
In this work, we also present another index structure called FOOD-X to compare and validate the effectiveness of MM-FOOD. In FOOD-X, we use FOOD-Index only for conceptual descriptors, and for content descriptors, we use a spatial indexing technique called X-Tree [34]. Then, we link these two structures to handle both content-based and concept-based queries by accessing these structures separately. The performance comparison of FOOD-X and MM-FOOD is conducted using response times of various complex queries and the retrieval accuracy of multimedia. The experiment results indicate that MM-FOOD considerably improves the performance of retrieving large multimedia objects regarding query response time and retrieval accuracy.
Contributions. In this work, we make the following three contributions: (i) First, we introduce a hybrid high dimensional indexing method for video retrieval to solve the semantic gap problem. A fuzzy object-oriented index structure is developed to support conceptual and content queries. (ii) We thoroughly investigate dimension reduction techniques to represent high-dimensional multimedia objects’ features in low-dimensional space without losing retrieval efficiency and show the superiority of LMDSFastMap. (iii) By leveraging our novel index structure, we reduce the retrieval task of multimedia objects to a spatial indexing task and, as a result, decrease the retrieval time.
The remaining of this paper is organized as follows: Section 2 introduces the multimedia retrieval task, the structures used in the retrieval process, and the multidimensional scaling algorithm and also includes related works in Section 2. In Section 3, our new index structure called MM-FOOD is represented. Section 4 contains experimental results about the performance of our index structure. Finally, we conclude the paper in Section 5.
Background
Retrieval systems
Multimedia retrieval techniques mainly can be classified into three categories: Text-Based Retrieval (TBR), Content-Based Retrieval (CBR), and Semantic-Based Retrieval (SBR), as shown in Fig. 1.

Multimedia retrieval categories.
TBR is the oldest method in this field and is generally used by manual annotation of multimedia objects [1]. Object descriptors or keywords are used to describe its content and other metadata related to the object, such as format, size, file name, etc. After this annotation step, the user formulates the query using pre-defined descriptors, keywords, or annotations to retrieve all the objects that meet the query conditions. This approach has some drawbacks [1–3]. First of all, the annotation is done manually, which is impractical for a vast number of objects. Second, most multimedia objects have rich content that cannot be described using simple annotations. Moreover, annotators can enter different keywords or descriptors for the same object. Another drawback of this technique is language dependency.
CBR has become popular in the early 1990s because of the drawbacks of TBR techniques and can be divided into two main steps: offline feature extraction and online querying [35]. In the offline stage, the system extracts low-level features of the multimedia object and stores them in a feature database. In the querying stage, the same feature extraction process is applied to query objects, and extracted features are compared to the other features in the database. The comparison is established by using a similarity/distance function. Then, the retrieval process is performed by using an indexing structure for efficient searching over the database, and the results that satisfy the query criteria are returned to the user.
One of the main drawbacks of CBR is that it narrows the semantic gap between human understanding and low-level features of multimedia data [1–3, 37]. While high-level semantic descriptors describe the human perception of the content of the multimedia objects, the computer has a different and low-level understanding of the same content. This problem is commonly referred to as the semantic gap. As a result, this gap between low-level features and high-level semantics has been one of the significant issues to better retrieval performance.
SBR systems try to solve this problem by defining and categorizing conceptual information using low-level features of multimedia objects [38, 39]. Similar to low-level features in CBR, SBR uses high-level features of objects, extracts the semantics description of objects, and stores them in a collection or database. Semantic descriptors can be extracted either by manual or automatic annotation or by using some advanced concept detection mechanism. Fuzzy logic is also used in semantic-based retrieval to deal with the uncertainty of extracted conceptual features [8, 40]. Consequently, in SBR, multimedia retrieval can be accomplished using high-level semantic information [19, 41]. The main drawback of SBR arises from extracting concept descriptors and annotations from low-level features.
As a result, both CBR and SBR techniques have advantages and disadvantages. Thus, CBR and SBR methods can be combined in a hybrid video retrieval system to develop a more effective video retrieval system. Hence, such hybridization of CBR and SBR techniques can eliminate the limitations of each approach and are more effective than either CBR or SBR systems in query accuracy. In addition to enhancing query result accuracy, using a hybrid approach may result in query response time advantage. Since multimedia objects are big-sized units and retrieving a multimedia object is time-consuming, retrieving fewer objects by search space reduction directly affects overall system performance. In addition, usability is another significant achievement in a retrieval system. In general, the user is expected to express her/his query by giving some example objects and/or defining some query terms. Crisp terms usually specify these query terms, whereas, for human beings, these terms can be expressed in terms of a natural language. Thus, adding some fuzziness to the query language may enhance the efficiency of our retrieval system.
In the literature, there are lots of studies in these categories, and some of them are summarized in Fig. 2. The figure categorizes the retrieval systems as feature-based (content) and annotation-based (concept) systems. In the feature-based category, multimedia data is used as input for offline low-level feature extraction [1, 42] and these features are used for comparing and retrieving the relevant data; whereas in the annotation-based category, semantic information is extracted or produced to define and describe the multimedia data and these descriptors are used as the conceptual data for the retrieval task [1, 35]. The annotation task is mostly evaluated manually. On the other hand, some image segmentation and/or object detection methods have been developed in order to perform automated annotation [43, 44]. The feature-based retrieval systems aims to find similar multimedia objects using low-level features [1, 35].
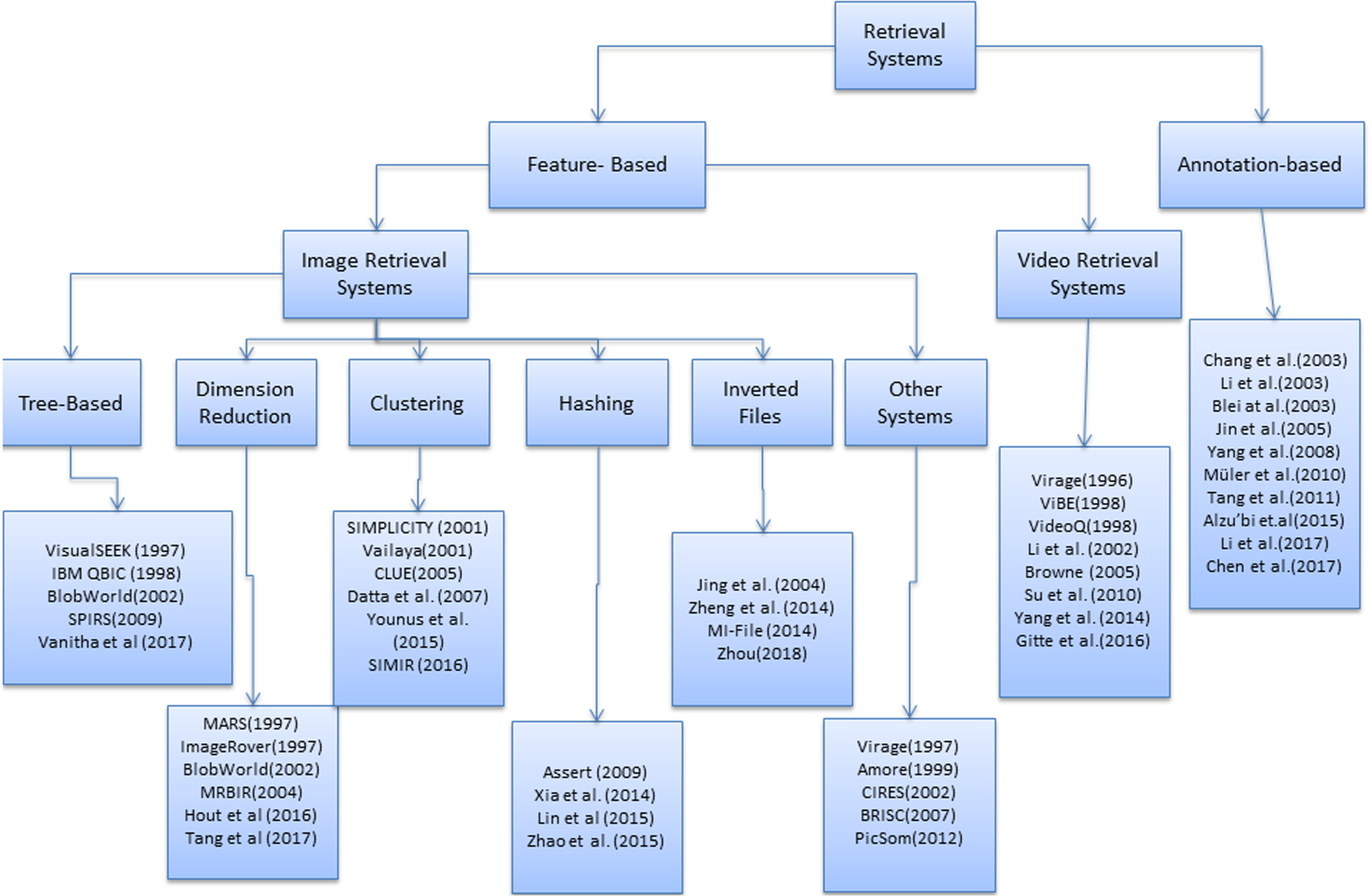
Retrieval systems proposed for accessing multimedia data.
For an efficient retrieval system, query performance is an essential factor, and it is the key metric that shows their application’s scaling to real-life applications. In order to meet these performance considerations of retrieval systems in high-dimensional space, there are several multidimensional access methods proposed in the literature [45, 46].
The first group of these access methods is Spatial Access Method (SAM) [47, 48]. SAM generally tries to index the multidimensional space rather than the points themselves. Data feature vectors construct this space. The structures in this category contain a tree data structure and store the data in leaf nodes. Moreover, this tree is formed as a cluster and built by the top-down approach [46]. The main drawback of spatial-access methods is the drastic decrease in the retrieval performance as the dimensionality of the feature vectors of data objects increases, a phenomenon known as the curse of dimensionality. Thus, even a sequential scan can outperform the SAMs in general [46].
In order to overcome this drawback of the SAMs, Point Access Methods (PAMs) are defined. In a simple way, a PAM tries to index objects or points rather than space itself by using either hashing or tree-based structures [45, 46]. For the hash-based approach, the Grid File [49] is the most commonly known and used index structure. Additionally, there are several tree-based PAMs such as k-d-B Tree [50, 51], LSD-Tree [52], and hB-Tree [53].
Dimension reduction techniques are used as another approach in multidimensional data retrieval. This approach is used to overcome the curse of dimensionality problem. There are a lot of methods and studies in this category, such as KPYR [54], Pyramid-Technique [55], iDistance [56], EHD-Tree [57], and Hilbert space-filling curve map [58]. Moreover, recently some machine learning and deep learning methods are proposed [59–62]. The dimension reduction increases the retrieval performance in terms of retrieval time. However, it decreases the query’s accuracy because it represents the objects in the low dimensional space rather than the original space.
Data Approximation Structures creates a representation of approximations which has small number of dimensions than the original data. VA-File [63], OVA-File [64], VQ-Index [65], BID/BID+[66], Hierarchical Bitmap Index [64], and BitMatrix [67] are the most known structures in this category. These structures use pruning algorithms to reduce the number of similarity or distance calculation in query phase.
The Metric Access Methods (MAMs), such as M-Tree [68], Slim-Tree [69, 70], MRKD-tree [71], and Hierarchical Cellular Tree [72], uses distances among objects and indexes these distances rather than space or points. MAMs uses a metric distance or similarity function in order to handle high-dimensional data. The structures in this category uses tree structure similar to SAMs [73].
Dimensionality reduction techniques
Dimensionality reduction techniques try to map original data in high-dimensional space into low-dimensional space. This mapping process should preserve original data representation in reduced space without loss of information. These techniques are widely used in pattern recognition, image segmentation and categorization, and multimedia retrieval [59]. There are several algorithms for dimensionality reduction in the literature such as Multidimensional scaling (MDS), Principal Component Analysis (PCA), Support Vector Machines (SVM), Singular Value Decomposition (SVD), Linear Discriminant Analysis (LDA) [74]. In this work, we have adapted a novel MDS algorithm for dimensionality reduction of multimedia objects’ feature vectors and compared this algorithm with PCA and LDA.
Multidimensional scaling (MDS)
Multidimensional scaling (MDS) [75] is a collection of statistical techniques that attempt to evaluate some set of patterns which uses similarity matrix, in order to embed objects from high-dimensional space into a low-dimensional space and tries to preserve their original pairwise interrelationships as closely as possible. MDS requires a distance matrix of the input points and outputs an array of low-dimensional coordinates for each input point. The main problem of the classical MDS algorithm that it is not appropriate for large number of points because it requires an entire N × N distance matrix. This distance matrix is usually stored in memory. The classical MDS algorithm has O(N3) complexity. Thus, several scalable MDS algorithms have been proposed to decrease this complexity.
One of the most popular dimensionality reduction algorithms is the Landmark Multidimensional Scaling (LMDS) [76] algorithm which requires a small subset of data to increase scalability of the classical MDS. The algorithm uses (dis)similarity matrix D of l landmark data points and embed these points in m-dimensional Euclidean space. While LMDS solves efficiency problem of classical MDS with the help of fast computation because of using small number of landmark points, it also preserves all properties of classical MDS. First of all, l landmark points are chosen by using some appropriate algorithm (random selection, farthest points etc . . .). Then the classical MDS algorithm is applied to these landmarks in order to find a mapping of the l landmark points into m-dimensional space. The remaining set of points are embedded to m-dimensional space by using distance function and a normalization algorithm is applied as final step. LMDS is much more efficient than classical MDS since it has O(nl + l 3 ) computational complexity.
FastMap [77] is another MDS method that construct a low-dimensional embedding by determining one dimension at a time. It uses two farthest pivot points and creates a transformation to n - 1 dimensions using distances to compute embedding coordinates. FastMap is an iterated form of LMDS with two landmarks.
Conventional MDS has many appealing features, but when the number of points increases, the efficiency of this algorithm decreases. Since the number of applications in the multimedia technology is growing very fast recently, the number of points and dimensions of these points are also increasing. Thus, this limitation has become more critical and the MDS algorithm should be scalable for these kinds of high-dimensional spaces and large databases. In order to solve scaling problem, we have adapted a very fast landmark based MDS technique; LMDSFastMap [26] to the multimedia data retrieval process.
Principal Component Analysis (PCA)
PCA is widely used an unsupervised dimensionality reduction technique which tries to reduce the dimension by projecting original data using the principal components so that the variance of the data in low-dimensional space is maximized. PCA tries to capture the direction of maximum variation in the feature vector [60, 62].
Suppose we have N numbers of n-dimensional vectors, X
i
, i = 1,2, . . . , N. First of all, mean vector is computed by using following formula;
After this step, eigenvectors and eigenvalues of the covariance matrix are computed. Then, eigenvectors φ i are ordered by eigenvalue λ i in order to represent significant components first. Thus, the eigenvector with highest eigenvalue is called the principal component of the input feature vector. Finally, most significant eigenvectors are used to form transform matrix in new low- dimensional space by taking the transpose of the vectors.
LDA is another popular dimensionality reduction technique similar to PCA but it is supervised and focuses on classification of the data. It tries to maximize the separation of known class of the original data. In LDA, the scatter matrix is used instead of covariance matrix which is used in PCA. The goal of LDA is maximizing the between-class measure while minimizing the within-class measure. In order to do this, first between-class scatter matrix S
b
and within-class scatter matrix S
w
are computed by following formulas;
Where
FOOD-Index is an index structure which supports fuzzy and crisp queries in a multidimensional approach [28]. FOOD-Index tree has two main parts; Routing nodes and data buckets. Routing nodes are responsible for accessing to the data bucket from the top of the tree using a key value. This key value is constructed using bits and called bit string. Data bucket records are created for each indexed key value and each data bucket record is linked to a path node by using a node pointer. This path node stores all paths related to the key value of that data bucket record. The details of the FOOD-Index can be found in [28].
X-Tree
X-tree [34] is a spatial indexing technique and can be seen as the modified version of R-tree. The X-tree has three different types of nodes-data nodes, normal directory nodes and supernodes. Supernodes are used to prevent overlapping bounding-boxes. Thus, these nodes have larger capacity than normal R-Tree nodes. This directly affects performance of the tree since R-Tree performance suffers from overlapping nodes which increases the probability of accessing multiple nodes for a single search. Thus, X-tree achieves a performance gain by using supernodes instead of overlapping nodes and for this kind of search, X-Tree is accessed sequentially. However, this performance gains yield much more complex I/O operations and thus, X-Tree also has longer index creation times.
Array index
More recent indexing algorithms that proposed in the literature is the Array Index [29]. It is a multidimensional data partitioning method which represents data partitions as array. Each data partition is converted to vector representation m i of relevant partition. After that, a reference data point called R is computed. Then, algorithm constructs a distance matrix for all m i and R pairs in order to use this matrix to map high dimensional data partitions into one-dimensional array space. In this one-dimensional space which is called array-index, data partitions are ordered by their distance to reference point R. Thus, the Array Index is a simple sorted array structure because the number of data partitions N c is very small compared to the number of points of the original space N p . In order to search the index efficiently, a pruning algorithm is used and, as a result, unnecessary access to points are eliminated. This results a fast and efficient search approach similar to binary search algorithm and has the computational complexity of O(logN c ). The details of the Array Index can be found in [29].
Proposed work
In this work, we have implemented two different index structures; MM-FOOD and FOOD-X, in order to satisfy both concept and content-based queries over multimedia data. M-FOOD tries to merge content and concept features in a single structure whereas FOOD-X uses two separate index structures for each feature. The details of each structure is explained in following sections. In order to validate these structures, a real world data set which contains Turkish news video is used [30].
MM-FOOD
MM-FOOD is constructed on hybrid representation of concept and content features, and the steps of construction MM-FOOD is shown in Fig. 3. The execution flows for creating index in offline stage and for each type of querying are shown in Figs. 4–8.
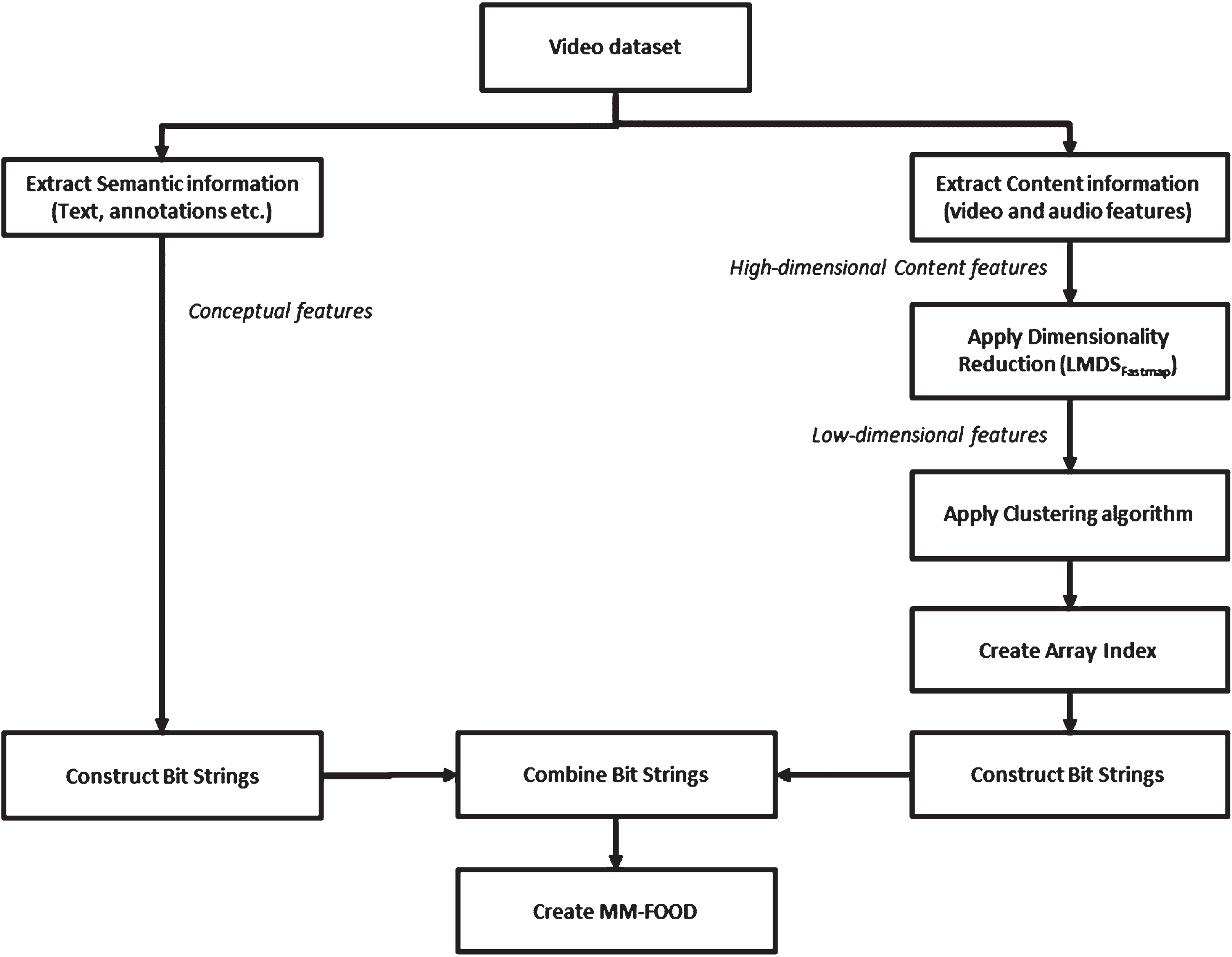
Execution flow of proposed work.
Execution flow of offline index construction.

Execution flow of content-based querying.
Execution flow of concept-based querying.
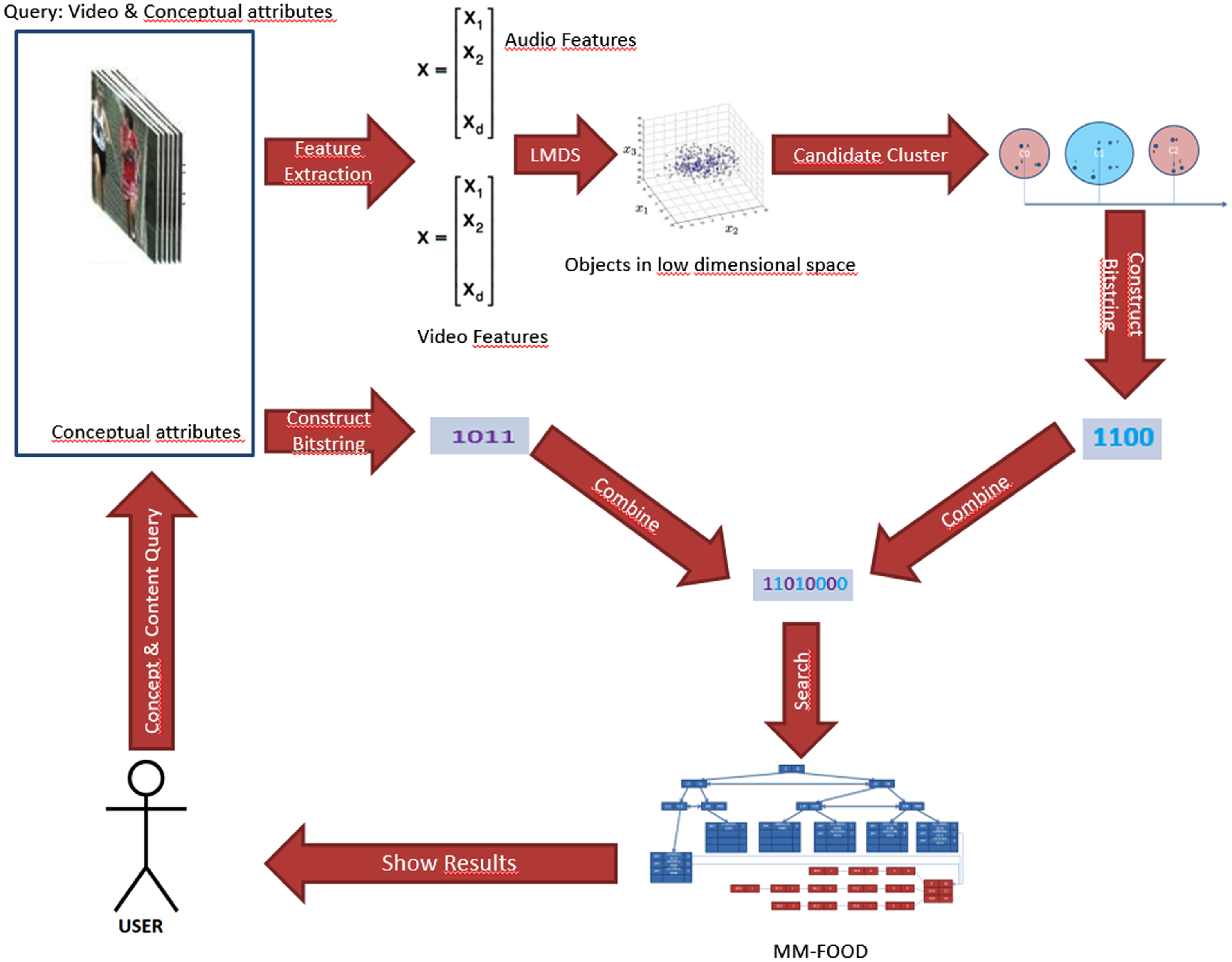
Execution flow of content and concept-based querying.
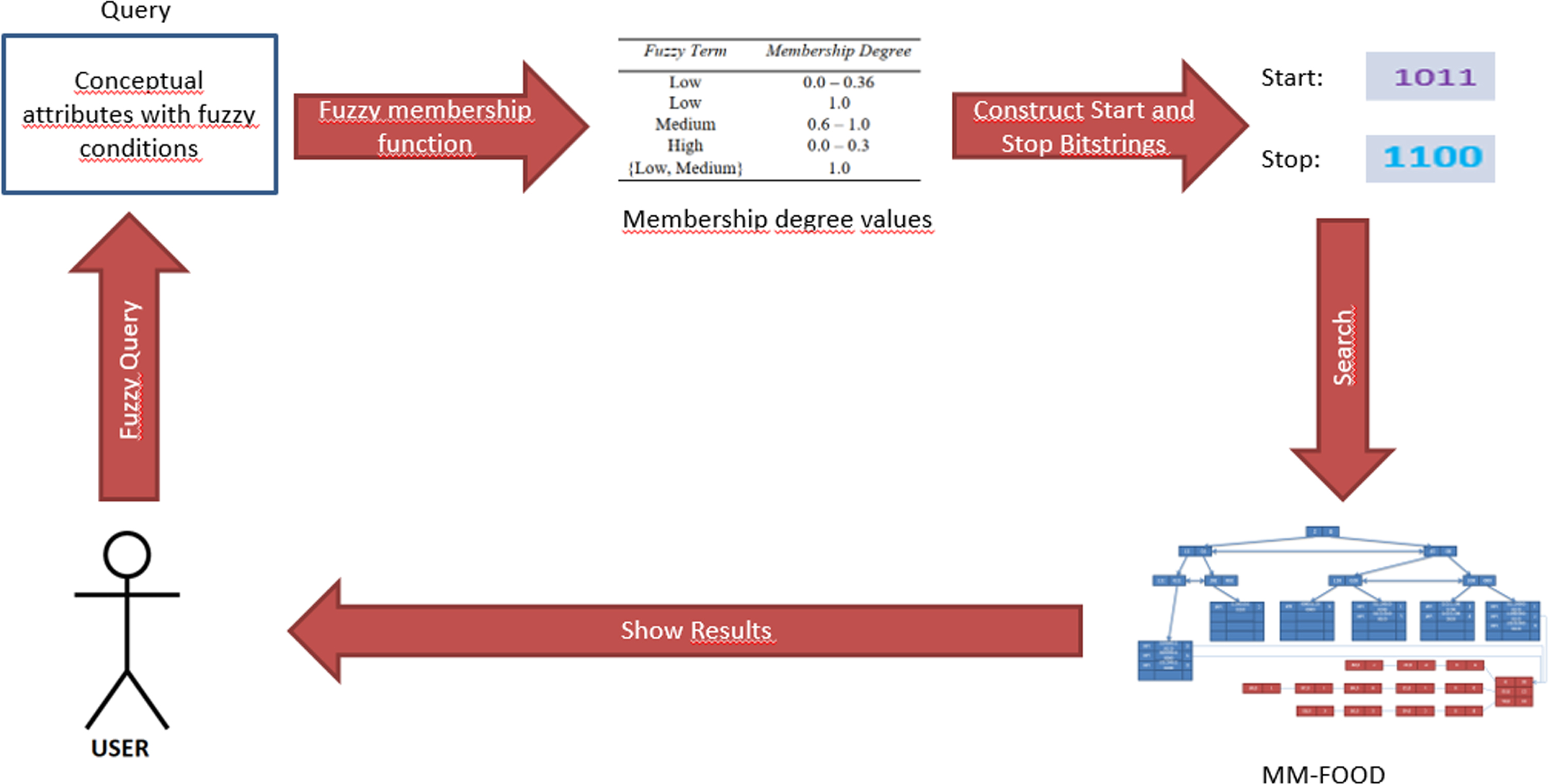
Execution flow of fuzzy querying.
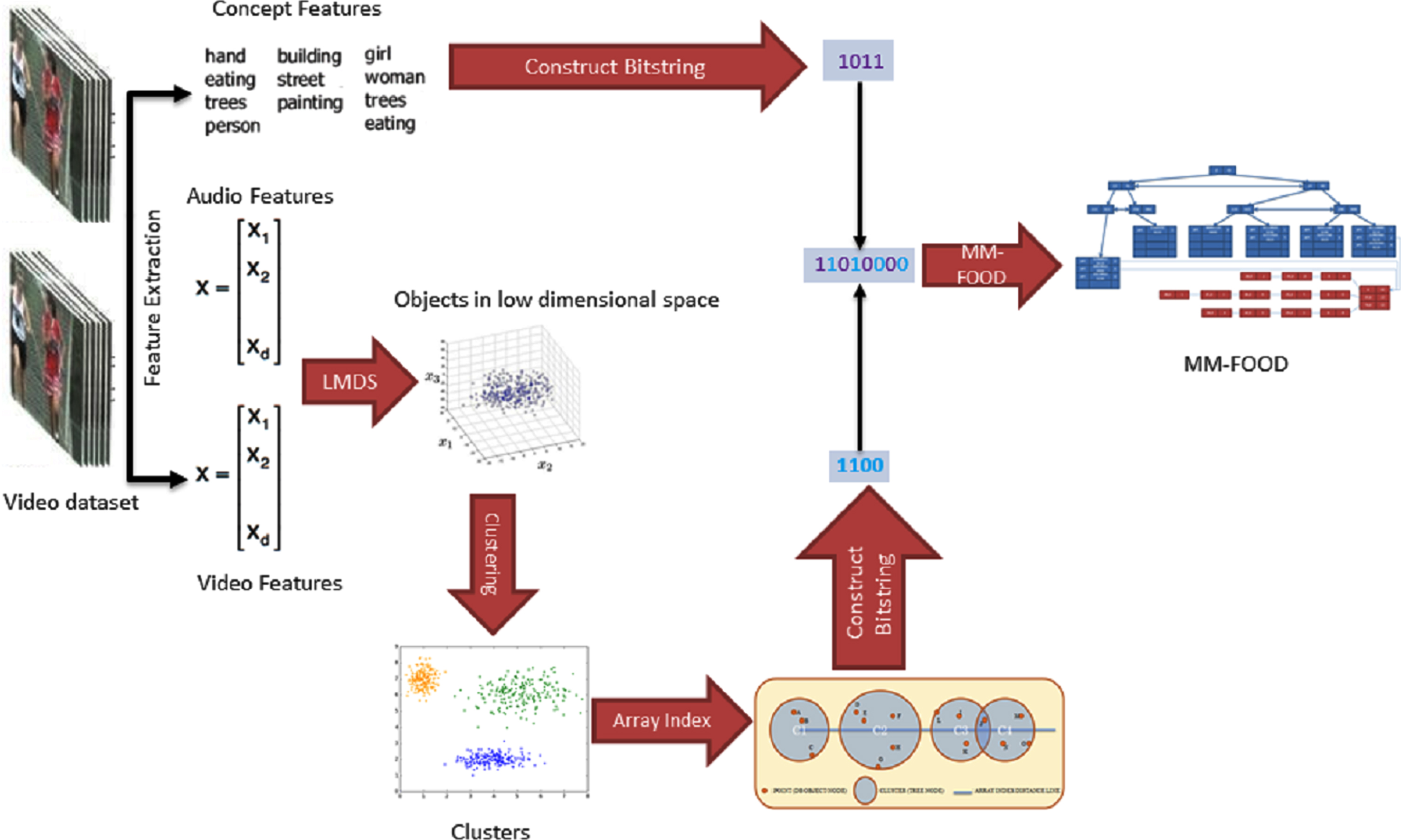
First of all, the semantic (conceptual) features and content features are extracted from the video data set by using the work proposed in [30]. The bit string representation of each conceptual information is constructed for conceptual features. Bit string construction is done as follows: if we have only one attribute, that means we have only one dimension to index, then we construct a bit representation of that attribute value. However, if there is more than one attribute, we simply merge bit strings of these attributes’ values because we need exactly a one-bit string representation of all attributes. Firstly, we take the first bits of each bit string and then concatenate them. After that, we take the second bits of each bit string and append them to the combined bit string and so on.
Extracted high-dimensional content features are first mapped into a representation of low-dimensional space by LMDS FastMap . LMDS FastMap is compared with state-of-art dimensionality reduction techniques, including LDA and PCA. The comparison results are discussed in the experiments section.
After embedding content features in low-dimensional space, a clustering algorithm is applied to form the input of Array Index structure. Array Index uses clustering techniques as a data partitioning method (DPM), and three different DPMs are adapted; K-means clustering [78, 79], Fuzzy C-means clustering [78] and X-Tree. The comparison of these DPMs is also discussed in the experiments section.
One of the main disadvantages of k-means is that the number of clusters must be present as an input. Thus, the user has to be similar to the data set and be able to specify an appropriate cluster number. Moreover, different distance functions produce different cluster centers. Thus, K-means is strictly dependent on the number of clusters and distance functions.
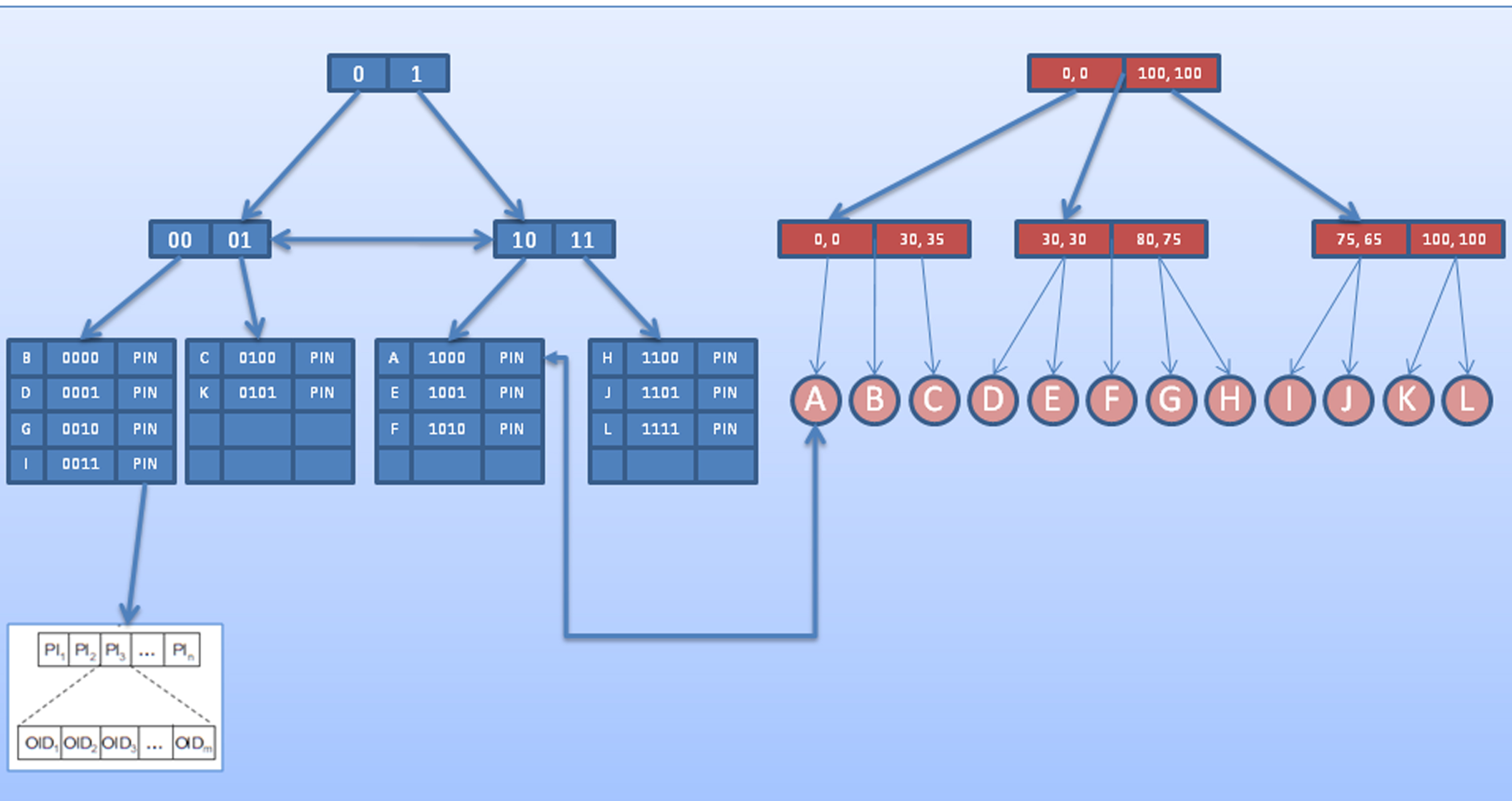
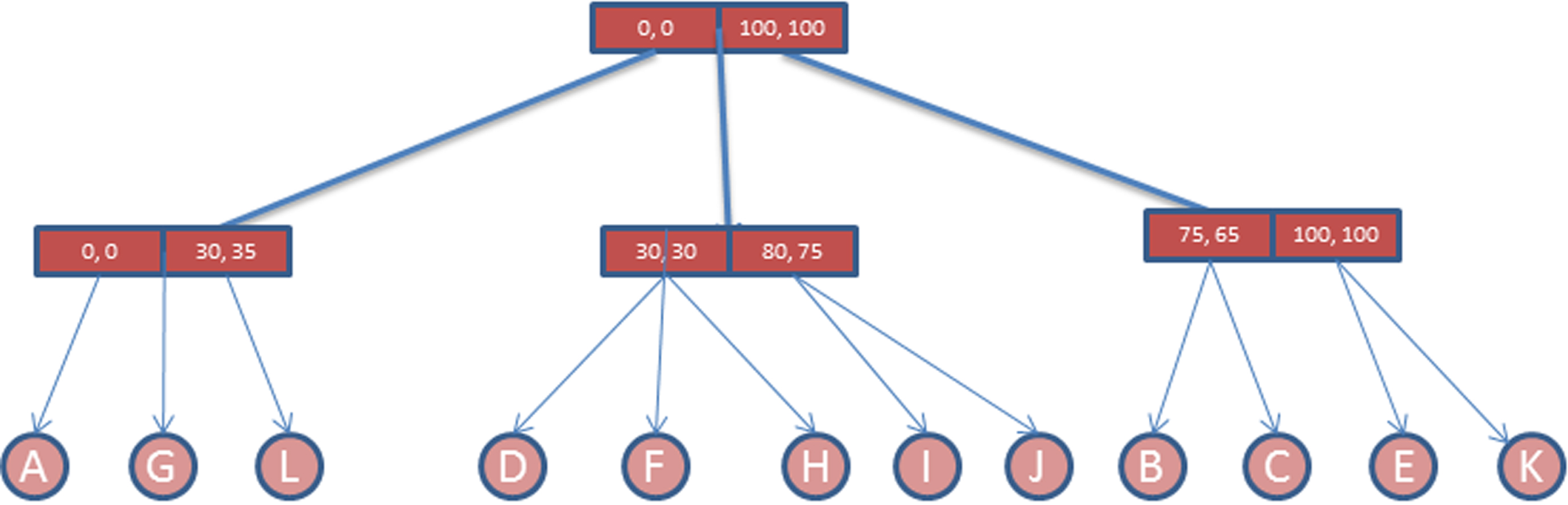
Because of this disadvantage, X-Tree is also adapted with LMDS FastMap as another DPM. Both approaches are shown in Figs. 9 and 10. After finding clusters and representing them in a single dimension as arrays of clusters, the distances of each cluster to the first (reference) cluster are calculated and stored in our new structure. Moreover, the objects in each cluster are listed by their distances to the center of the cluster they belong. Finally, Array Index is represented as a linked list in our new structure. Figure 13 shows an example representation of Array Index as linked list for the objects shown in Figs. 11 and 12.

Integration of FOOD-Index with Array Index and K-Means Clustering.
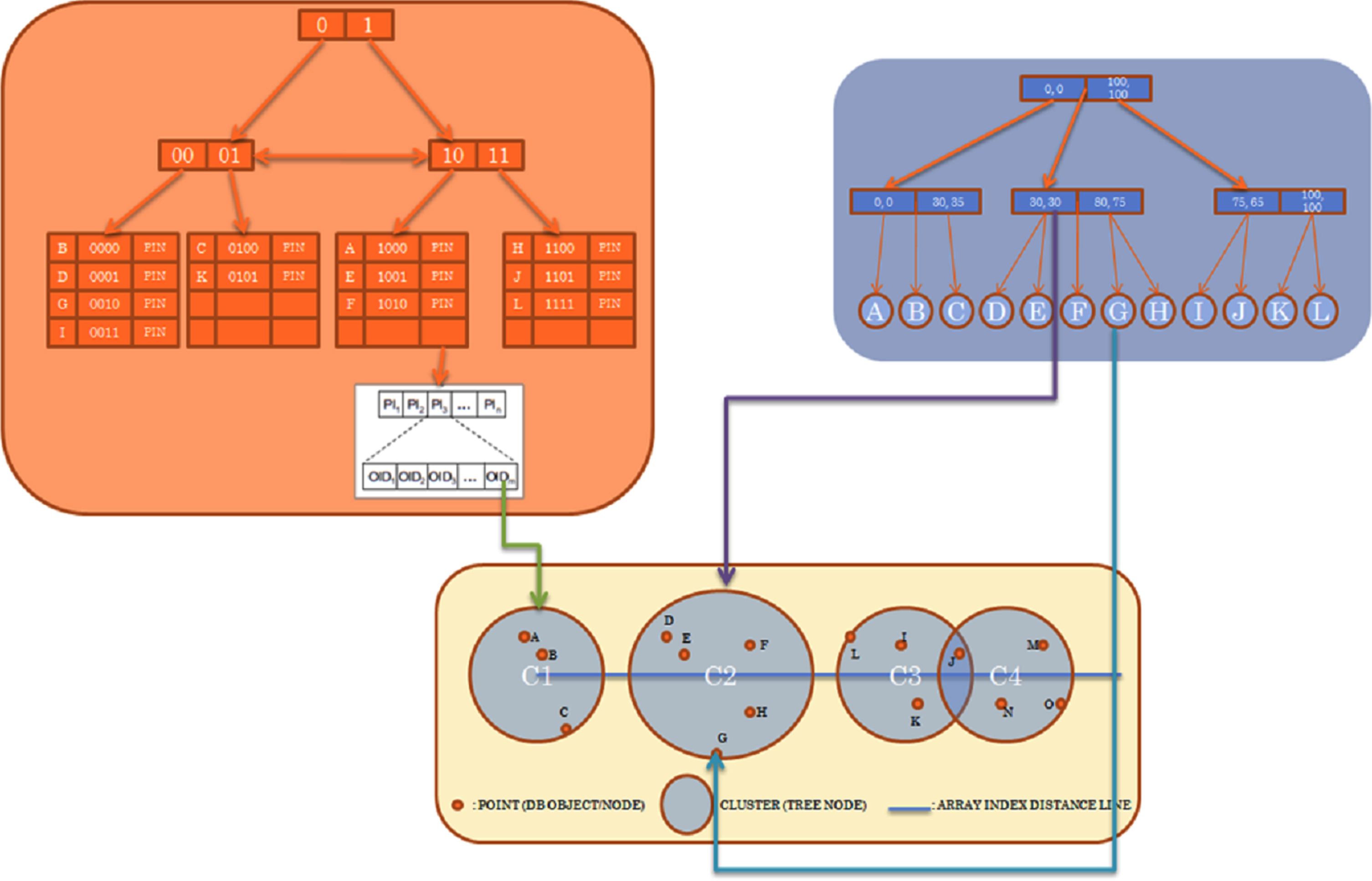
Integration of FOOD-Index with Array Index and and X-Tree.
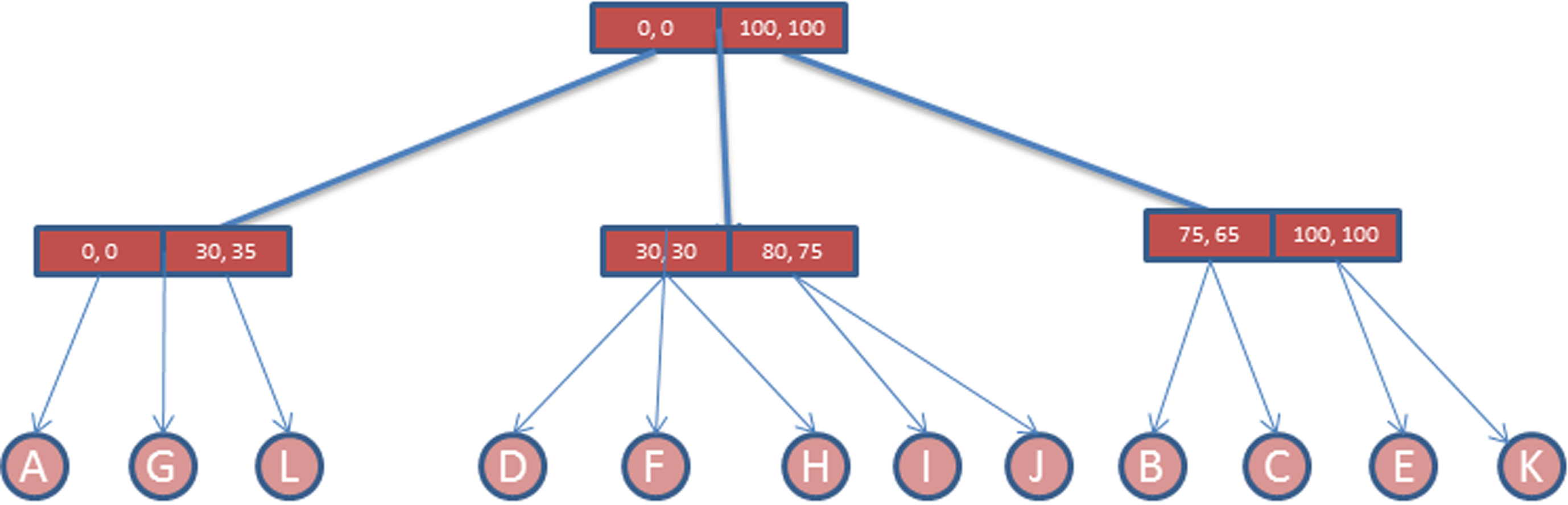
X-Tree of sample data.

Array-Index representation of X-Tree for sample data.

Linked list form of Array Index for sample data.
After creating Array Index, bit strings for the content cluster are constructed and merged with bit strings of conceptual information as cluster number to form the final bit string. This final bit string is used as a key for creating MM-FOOD. The overall execution flow for creating MM-FOOD structure is shown in Fig. 4.
Bulk loading algorithm is explained in Algorithm 1 and consists of the following steps; Firstly, low-level content features are extracted, and the distance matrix for the objects is calculated. LMDS FastMap algorithm is used this distance matrix as the original space, and the dimension values of objects in the reduced space are calculated.
Then, these dimension values are used in order to index the objects in DPM (X-Tree). Array Index is constructed by using X-Tree nodes. After finding cluster values for each object, these values are treated as new attributes similar to the conceptual attributes of the objects. The bit string representation for each attribute is now calculated, and the objects are inserted into the FOOD-Index using their final bit string form.
Using k-means/fuzzy C-means clustering instead of X-Tree in the creation of Array Index, only fourth and fifth steps change;
K-Means/Fuzzy C-means clustering is applied to the LMDS
FastMap
output. Array Index is constructed by using these cluster definitions.
For an example, let’s assume that we have 12 objects in our database as shown in Table 1. Similar to other conceptual attributes, the database contains a new attribute called cluster no as shown in Table 1. The cluster no is treated as another attribute for key value which is used in the FOOD-Index‘s construction phase. For instance, for the Object A, we have two conceptual attributes which have values 8(eight) and 12 (twelve) and also, we have now cluster number which is equal to 0 (zero). Now we construct bit strings for each attribute which are ‘1000’, ‘1100’ and ‘0000’ respectively. Finally, we construct a combined bit string for Object A as ‘110010000000’.
Sample data with cluster information
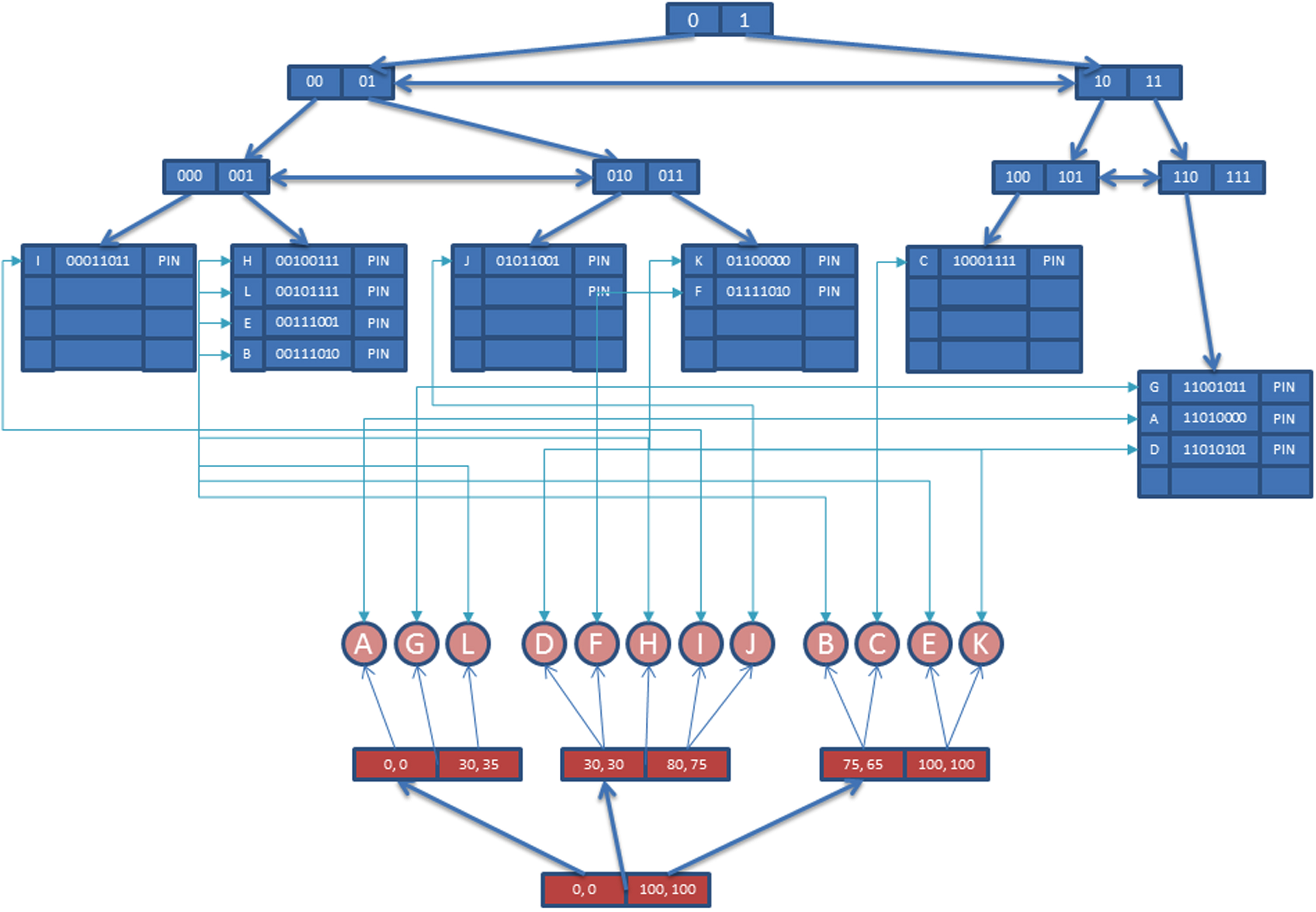
This combined bit string value is used as a key, and the object is inserted into FOOD-Index. A bidirectional link is created between Array Index and FOOD-Index to efficiently use the pruning algorithms of Array Index. The final structure is shown in Fig. 14. MM-FOOD index structure supports four different query methods and each one is explained in next sections.

MM-FOOD.
For the CBR systems, query by example (content) is the most common query strategy since the user can specify the query by giving an example object, such that “retrieve all objects similar to the given query object’. Thus, a good CBR system should meet the query by example requirement.
The algorithm for the content-based querying algorithm is shown in Algorithm 2 and the overall diagram is shown in Fig. 5. The content features of the query object are used as input. The high dimensional vectors of these features are mapped into low dimensional space using the LMDS FastMap algorithm. The output of the LMDS FastMap algorithm s used as input for locating the candidate cluster. The candidate cluster is located by calculating the distance of the query object to the reference cluster of the Array Index. After finding a candidate cluster, bit string is formed for the cluster number. The similarity function compares the query object with each object in the same cluster. If the object is similar to the query object, then it is added to the result set. This operation continues until the query condition is satisfied or there is no need to visit other objects and/or neighbor clusters. If the result set does not contain enough objects, the neighbor clusters are visited, and the algorithm tries to locate similar objects until the query conditions are satisfied.
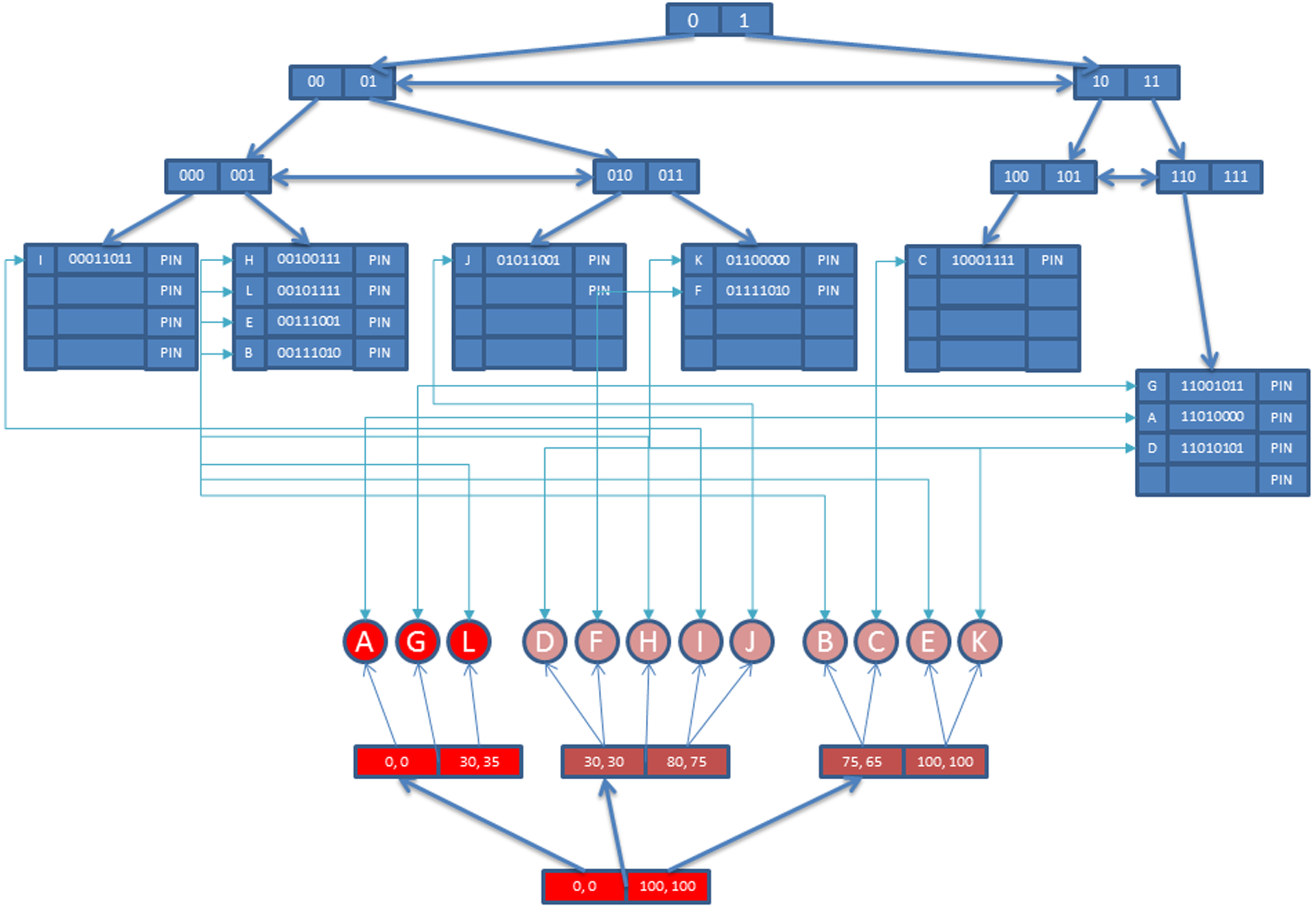
For an example, suppose the user wants to find first three (k = 3) objects similar to object A in our database. Content features of the query object is extracted. LMDS FastMap uses these features vector as input and calculate the object’s feature representation in low dimensional space. Here the number of dimensions for the embedding is 4 (four). Thus, the LMDS FastMap algorithm produces {8, 15, 25, 30} values as output. After this step, the candidate cluster should be located. In order to do this, the algorithm calculates the distance between the object of the query and the reference cluster of Array Index and locates the Candidate Cluster (C c ) which is C 0 in this example. The id number of C 0 is used to construct bit string and conceptual attributes are ignored since there is no query condition for these attributes. Finally, the bit string for the query is formed as ‘XX0XX0XX0XX0’. ‘X’ means ignore value (can be 0 or 1).
The final bit string is used as a key for MM-FOOD, and all the relevant objects in the same cluster are accessed using MM-FOOD. The similarity between these objects and the query object is calculated, and the appropriate objects are added to the result set. If k objects are not retrieved, then the algorithm seeks and retrieves other objects from the neighbor clusters by using Array Index pruning algorithms. The same steps are applied to the next candidate cluster, and this process continues until k objects are found. In this example, objects A, G, and L are returned to the user when k equals three (3).
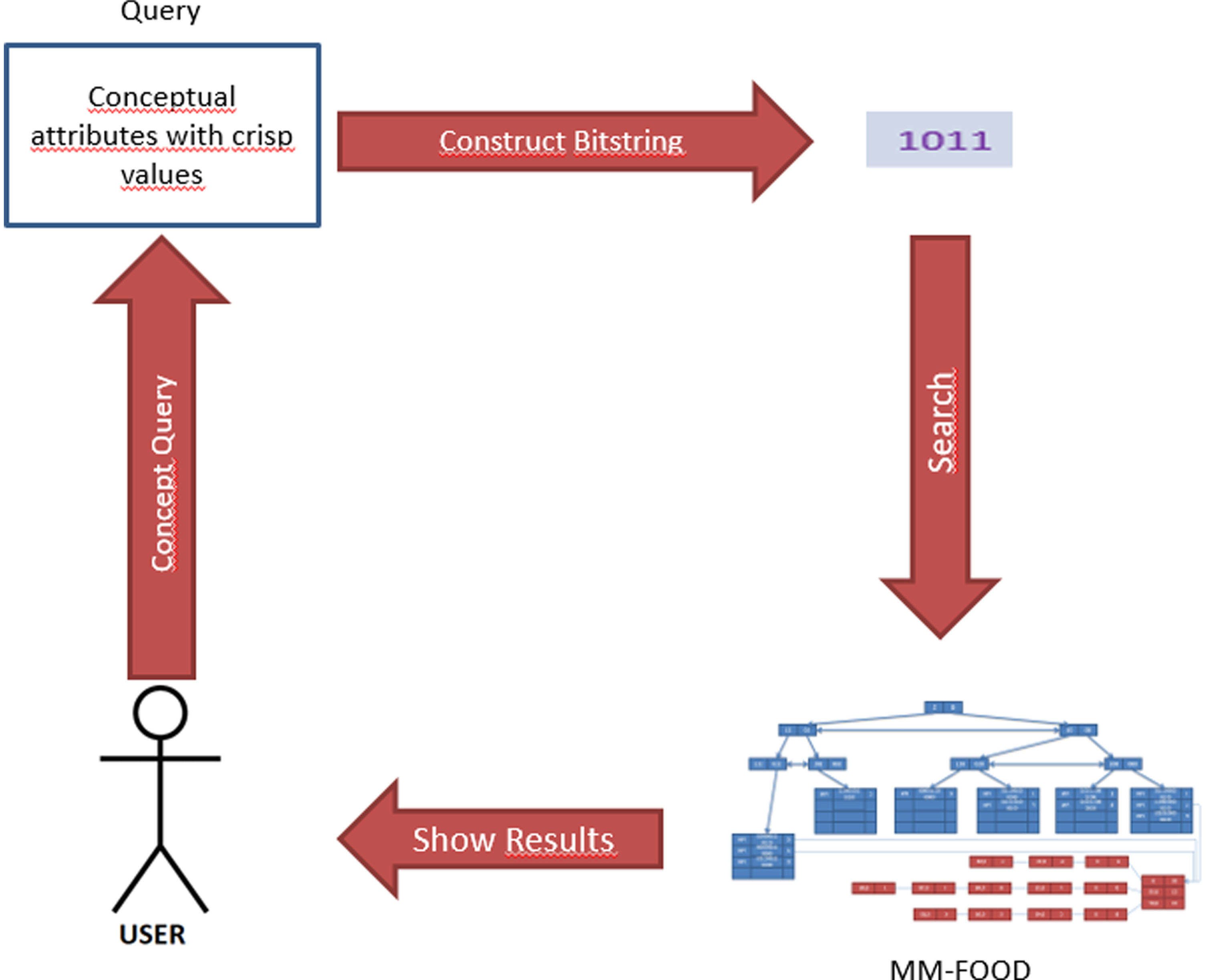
2- Query by concept
Semantic querying is performed by using only the conceptual part of MM-FOOD. First, we construct bit strings for query conditions that only include conceptual attributes. Then we use this bit string as a key to locate all objects in the database. The cluster information is never used in this type of query. The overall flow diagram for concept-based querying is shown in Fig. 6.
As an example, exact query, suppose that our query is as follows:
Retrieve all objects having first conceptual attribute equal to 7 and second conceptual attribute equal to 3
First of all, bit strings for both conceptual attributes are constructed, and these bit strings are combined, and final bit string is used to locate relevant objects from MM-FOOD. For the first conceptual attribute, bit string is formed as ‘0111’ and for the second attribute, the bit string is formed as ‘
The range query is also supported by the proposed structure. For an instance suppose that query is as follows;
Retrieve all objects having first conceptual attribute is less than 8 and second conceptual attribute is equal to 3.
We create start and stop bit strings for each condition in the range query. Therefore, the example will have two-bit strings for both conceptual attributes. For the first query condition (i.e., first conceptual attribute condition less than 8), the start bit string is formed as ‘0000’, and the stop bit string is formed as ‘0111’. Similarly, for the second query condition (second conceptual attribute is equal to 3), the start bit string is formed as ‘0011’, and the stop bit string is the same as the start bit string, which is ‘0011’ (because of the equality condition). Finally, each condition’s start and stop bit strings are merged to form the final start and stopping bit strings. For the example, the final start bit string is formed as ‘00000101’, and the stop bit string is formed as ‘00101111’. After using these bit strings as a search key for the FOOD-Index, all the nodes having the key value between these keys are added to the query result set.
3- Query by concept and content
One of the main contributions of this work is that MM-FOOD is capable of searching the objects using not only conceptual attributes but also content features in an efficient way. Contend and conceptual descriptors are formed together in a bit string formation and used as a key for MM-FOOD. Using this key(s), relevant objects to the query object are located by the conceptual part of MM-FOOD. Then, if there is a need to visit neighbor clusters, Array Index part of MM-FOOD is accessed. The overall flow diagram for concept and content-based querying is shown in Fig. 7. For example, suppose that the query is;
Retrieve objects having first conceptual attribute is equal to 7 and second conceptual attribute is equal to 3 and similar to the query content
Similar to content querying, content features of the query object are used and formed as input of LMDS FastMap to represent the object’s features in low dimensional space. For this example, the number of dimensions for the embedding is 4 (four). Thus, the LMDSFastMap algorithm produces {8, 15, 25, 30} values as output. After this step, the candidate cluster should be located. In order to do this, the algorithm calculates the distance between the object of the query and the reference cluster of Array Index. Therefore, it locates the Candidate Cluster (C c ) which is C 0 in this example. The id number of C 0 is used to construct bit string. Finally, a final bit string is constructed for all conceptual attributes and cluster information. For this example, the bit string for the first conceptual attribute is ‘0111’ and for the second conceptual attribute is ‘0011’. For the content part of the query, the bit string representation of cluster information (C 0 ) is ‘0000’. Therefore, the final bit string for the query is formed as ‘000100110110’. By using this bit string as a search key for MM-FOOD only the object L is returned to the user in this example.
MM-FOOD also supports range-based content and concept querying. For range querying, start and stop bits are constructed for the query condition(s) and these start bits and stop bits are combined separately. MM-FOOD returns the objects with key values between these start and stop bit strings.
4- Fuzzy Querying
MM-FOOD also supports the fuzzy querying method. This querying method can use fuzzy logic for searching the objects conceptually and also for content-based searches [63]. A fuzzy query is a kind of flexible query in which the user can define his/her requirements with fuzzy query conditions. For the conceptual part, fuzzy conditions in the query are expressed as a fuzzy term for the conceptual attribute and its threshold value. The fuzzy membership function is used for the evaluation of the fuzzy value of the query condition and its membership degree in the fuzzy term. Finally, these membership degree values are used to construct start and stop bit strings. Like range querying, start and stop bit strings are used as keys for the conceptual query conditions. The overall flow diagram for fuzzy querying is shown in Fig. 8.
For instance, suppose that our query is;
Retrieve all objects with content similar to a given image and a fuzzy condition where the conceptual attribute (noise) of the audio is average and the threshold value is 0.6 (conceptual attribute is equal to 0.6 medium)
First of all, Similarity matrix which is shown in Table 2, is used to calculate the following values which make it possible to search for the preceding and following fuzzy terms for the part (conceptual attribute is equal to 0.6 medium) of the query.
Similarity matrix for le fuzzy-valued attribute (noise)
Similarity matrix for le fuzzy-valued attribute (noise)
After this step, the similarity function presented in Table 2 is used to find the threshold values. These threshold values are used to calculate fuzzy values of the fuzzy term and for the example, these threshold values are;
Finally, we are interested in the search spaces of fuzzy terms which are shown in Table 3. Next, we construct bit strings for these space values and the corresponding bit strings are presented in Table 4.
The search space intervals for the condition “noise=medium 0.6’’
Constructed bit string for the fuzzy condition
In this part of the study X-Tree is integrated with FOOD-Index structure. Figure 15 shows an illustration of this structure for sample data. Conceptual indexing (FOOD-Index) and content indexing (X-Tree) are integrated by using a single directional pointer between the leaf nodes of each structure. For embedding high-dimension points into low dimensional points, LMDSFastMap is used. After the embedding process, the output points are indexed using the X-Tree spatial access method.
FOOD-Index with X-Tree for sample data.
LMDS FastMap algorithm enables low-level features with high dimensions to be represented in a low dimensional space which has 10 (ten) dimensions. Therefore, X-Tree can be easily used as spatial indexing structure for these points whereas semantic information of the objects is indexed using FOOD-Index as usual. LMDS FastMap corresponds to a reasonable retrieval time performance according to [80]. The Path instantiation structure of FOOD-Index is modified and a new pointer to the X-Tree leaf node is added in order to create a link between the two structures. Meanwhile, the X-Tree leaf node is also modified by adding a pointer to that leaf node for accessing the Path Instantiation node easily.
For construction of the proposed structure, the insertion algorithm shown in Algorithm 3 is used. Firstly, distance value between new object and the objects in the database are calculated. This distance values are used in order to evaluate new object‘s representation in spatial domain by applying LMDS FastMap algorithm. After embedding process, new object is inserted into X-Tree by using its new dimension values. For the conceptual attributes, bit strings are constructed for each attribute and final bit string is constructed. Finally, new object is inserted into the FOOD-Index.
Bulk loading of objects into this structure has similar algorithm to Algorithm 3. The similarities between each new object calculated and stored in a distance matrix as shown in Algorithm 4. This distance matrix is used as input of our LMDS FastMap algorithm and the new dimension values of each object in the embedded space are obtained. After embedding process, new object is inserted into X-Tree by using its new dimension values. For the conceptual attributes, bit strings are constructed for each attribute and final bit string is constructed. Then, new object is inserted into the FOOD-Index. Finally link between the FOOD-Index‘ PIN and X-Tree node are constructed.
For our example database shown in Table 1, we have two conceptual attributes for each object. However, we are not using cluster information for this structure thus it can be ignored. Each object has low level descriptors (content descriptors) for visual and audio features. First of all, distance matrix of whole database is evaluated by using Euclidian Distance Function. After evaluating all distances of each object, LMDS FastMap procedure is applied
The output of this procedure is used as input for X-Tree. Thus, each object is represented in two-dimensional space (i.e., coordinates in X-Y space) as shown in Content column of Table 1.
The next step is construction of X-Tree. The content data is used as coordinates of each object in the construction phase since X-Tree indexes the data in spatial domain (Fig. 16). There are two different X-Trees constructed: one for visual features and the other one for audio features.
X-Tree Structure for sample data.
While indexing content data, conceptual attributes are also indexed using FOOD-Index. In order to construct FOOD-Index, bit string representation of conceptual attributes is created. For instance, for the object A, we have two conceptual attributes. First one is equal to 8 (eight) and its bit string representation is ‘1000’. Second conceptual attribute is equal to 12 (twelve) and its bit string representation is ‘1100’. Now we combine these two-bit strings and form final bit string as ‘11010000’. This final bit string value is used as key for the FOOD-Index and the object is indexed according to this key. Finally, bidirectional link between X-Trees and the FOOD-Index is created. The final structure is shown in Fig. 17.
FOOD-Index with X-Tree Structure for sample data.
In order to delete an object from the structure, the object id must be known. First object is deleted from the FOOD-Index since it may result a reorganization process of the tree. If the FOOD-Index structure is reorganized, then links to the X-Tree nodes should also be organized. Otherwise, the node containing the deleted object is deleted easily from X-Tree. This structure can support three different query types. In the next sections, we introduce each query types with examples.
The proposed access structure is capable of satisfying the user’s visual query with the help of X-Tree. The main steps of the algorithm are shown in Algorithm 5.
Firstly, query object‘s embedded dimensions are computed by applying LMDS FastMap algorithm to low-level features. After that process, query object is searched over X-Tree by using its coordinates. Objects which satisfy the query conditions are added to result list.
Suppose that the user wants to run a nearest neighbor query (k-NN query) and expects k similar objects to objectA to be returned from our database. First of all, LMDS FastMap is applied to the query object (q)’s content descriptors in order to find its representation in low dimensional search and assume that LMDS FastMap produces an output containing the values {8,15,25,30} for only 4(four) dimensions. Then, only the X-Tree part of our structure is accessed, and first k objects are returned to the user. For example, if k value is three (3), then the result set contains A, G and L objects as shown in Fig. 18.
Sample content-based query.
In this type of query, only the FOOD-Index part of access mechanism is used. First, we construct the bit strings for query object attributes and then search over the FOOD-Index and retrieve all the PIs satisfying query conditions.
The X-Tree is never accessed in this type of querying because the user wants to retrieve objects by only their semantic attributes not by content descriptors.
As an example, exact query, suppose that our query is as follows:
Retrieve all objects having first conceptual attribute equal to 7 and second conceptual attribute equal to 3.
First of all, bit strings for both conceptual attributes are constructed, and these bit strings are combined, and final bit string is used to locate relevant objects from FOOD-Index. For the first conceptual attribute, bit string is formed as ‘0111’ and for the second attribute, the bit string is formed as ‘
In this type of query, only conceptual part of our structure is accessed as shown in Fig. 19. The range query is also supported by the proposed structure. For an instance suppose that query is as follows;
Retrieve all objects having first conceptual attribute is less than 8 and second conceptual attribute is equal to 3.
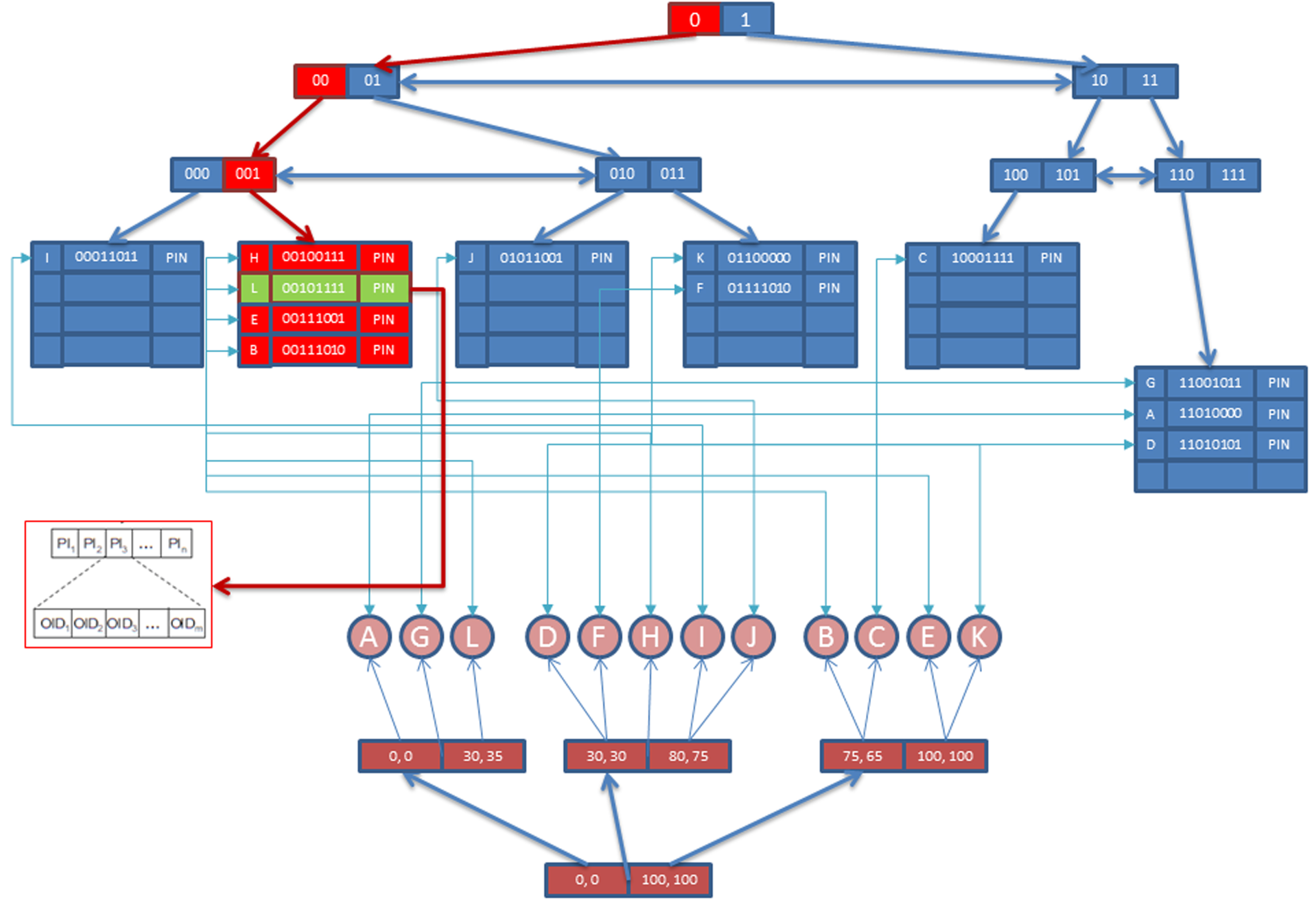
Sample concept-based query.
In range query, we create start and stop bit strings for each condition. Therefore, there will be two-bit strings for both conceptual attributes for the example. For the first query condition (i.e., first conceptual attribute condition less than 8), start bit string is formed as ‘0000’ and stop bit string is formed as ‘0111’. Similarly, for the second query condition (second conceptual attribute is equal to 3), start bit string is formed as ‘0011’ and stop bit string is the same as start bit string which is ‘0011’ (because of the equality condition). Finally start bit strings and stop bit strings of each condition are combined to have final start and stop bit strings. For the example, final start bit string is formed as ‘00000101’ and stop bit string is formed as ‘00101111’.
After using these bit strings as search key for the FOOD-X, all the nodes having the key value between these keys are added to the query result set. For this example, objects B, E and I are added to query result set as illustrated in Fig. 20.
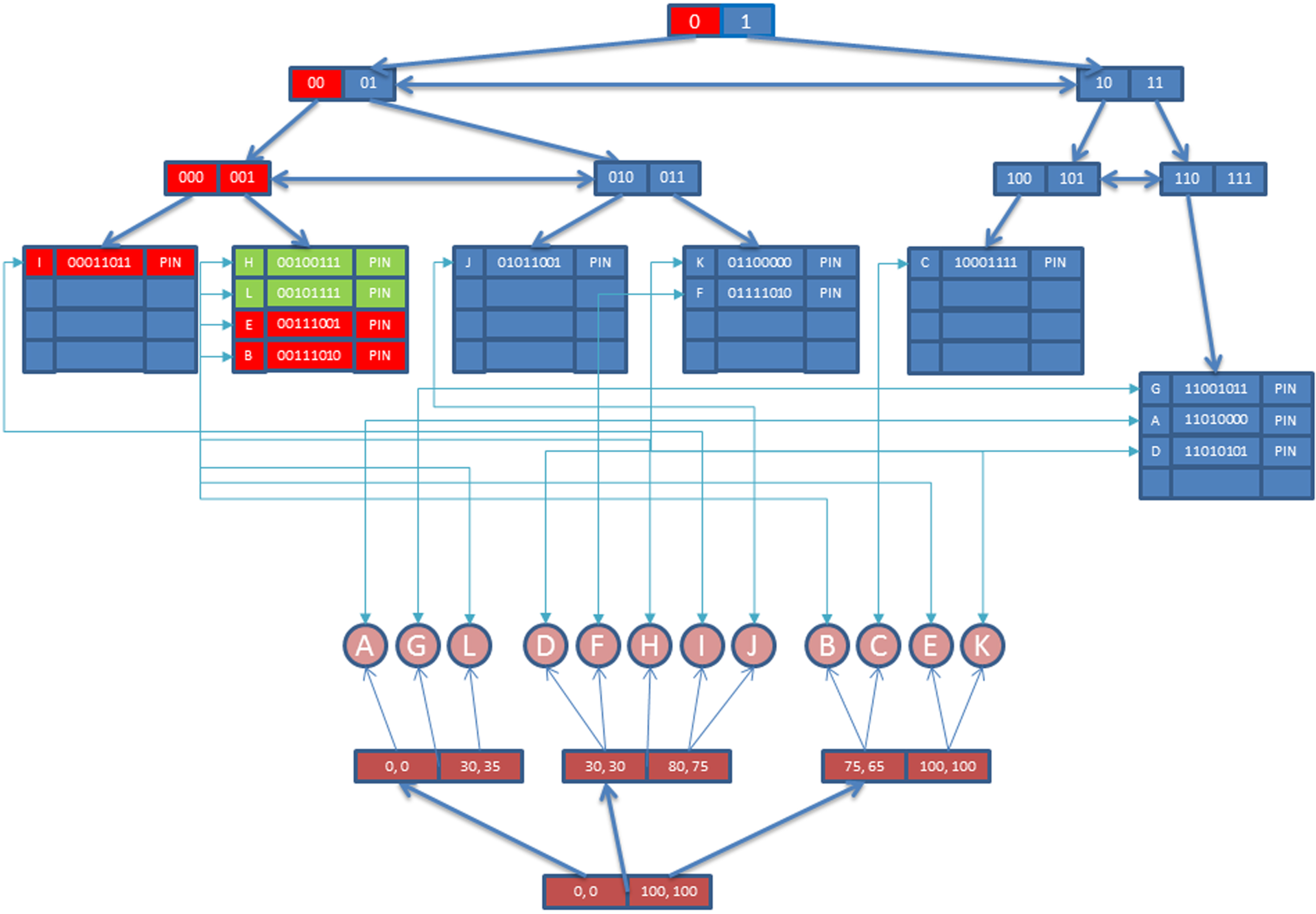
Sample concept-based range query.
The content and concept-based search mechanism is handled by accessing both structures simultaneously. In this query type, firstly the proposed structure is accessed by conceptually (i.e., using FOOD-Index part). At the same time, X-Tree part of the structure is accessed for content-based query and similarity degrees evaluated between X-Tree objects and the query object. If the similarity degree satisfies the query condition, the candidate object is added to the result list.
Finally, this result list is joined with FOOD-Index results and returned to the user. For example, suppose that the query is;
Retrieve objects having first conceptual attribute is equal to 7 and first conceptual attribute is equal to 3 and similar to the query content
First of all, query content features are extracted using MPEG-7 software. These features are mapped into low dimensional space using LMDS FastMap , and this algorithm produces output values such as {8,15,25,30} since embedded space has four dimensions. Finally, combined bit strings for conceptual part are constructed. Using both conceptual data (bit strings) and content data (space dimension values), the query is performed on our structure accessing both FOOD-Index and X-Tree parts respectively. The result objects are joined and returned to the user as final step. In this example FOOD-Index returns B, E, L and H objects while X-Tree returns A, G and L objects as shown in Fig. 21. Only object L is returned as query result to the user.
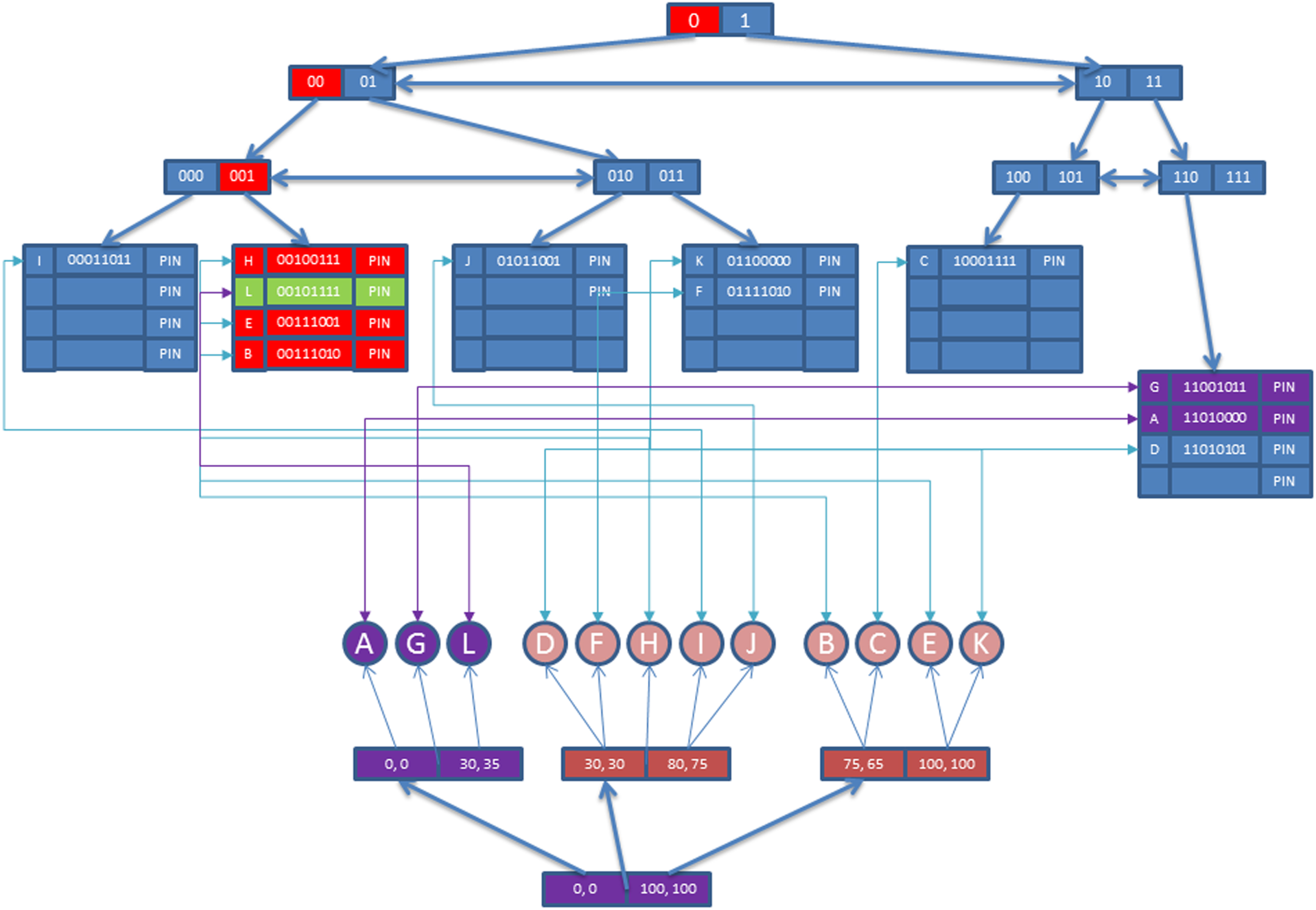
Sample concept and content-based range query.
In this section, we report the results of experiments performed by different types of queries. As explained in the previous section, MM-FOOD supports the following query types.
Content - basedquery: The user specifies an image or a video shot, and the system returns video segments which are similar to a specified query example. Concept - basedquery: The user specifies the query with either crisp or fuzzy terms corresponding to high-level semantics. Composite(contentandconcept - based) query: The user can specify his/her query by putting together an example of image or video segment with a crisp or a fuzzy query term.
These queries are conducted on a real-world news video dataset to demonstrate the effectiveness of index structures introduced throughout this paper. The query retrieval interface, developed in [30], is used in these experiments. The screenshots from this retrieval interface are shown in Figs. 23–25. This interface contains a video selection part to support the query by example paradigm. Moreover, the user can query the system by giving conceptual terms or combine conceptual terms with content-based querying by supplying an example image or video using this interface. The search results are listed in the lower part of the figures.
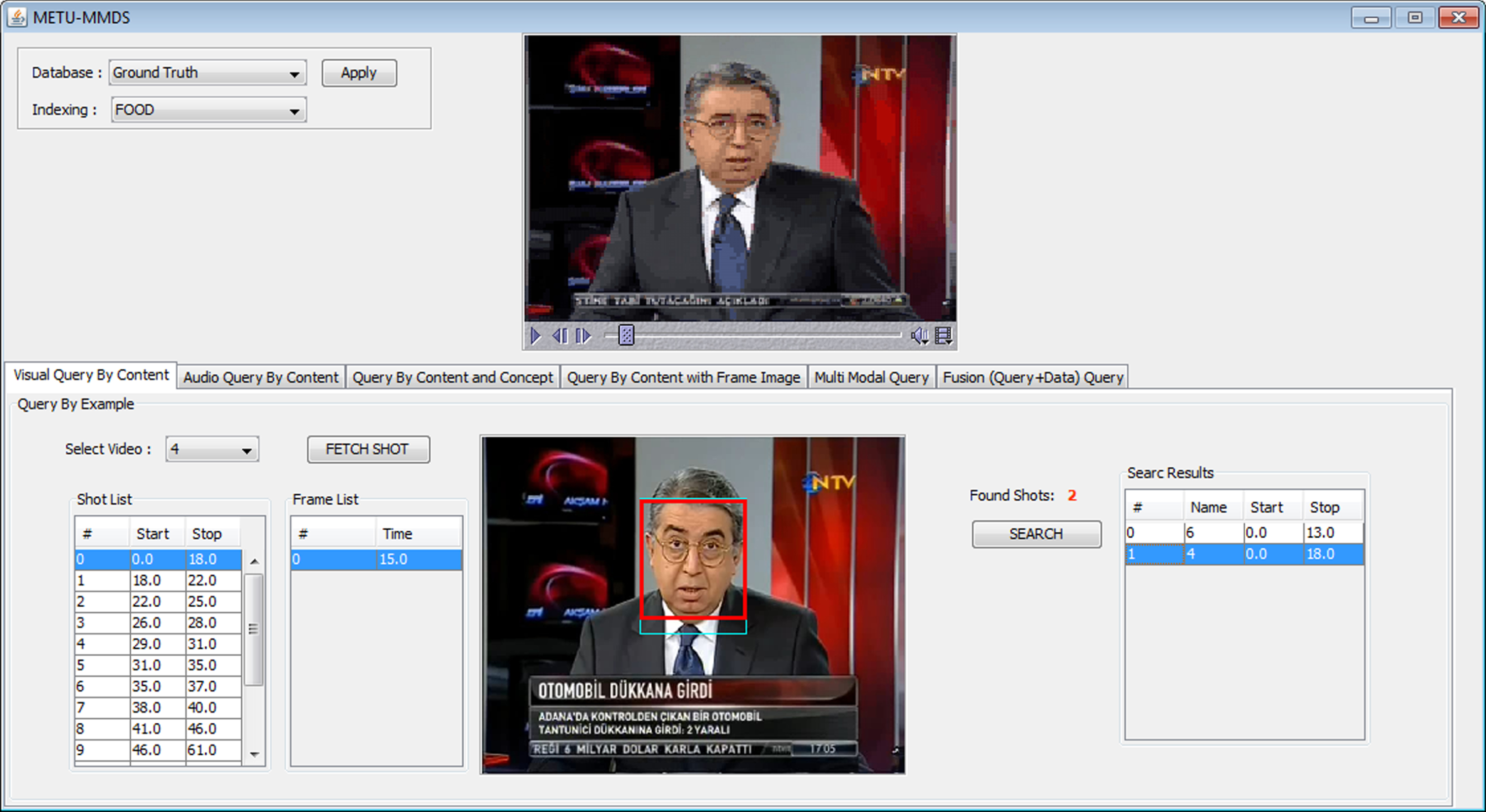
Query example for news video dataset.
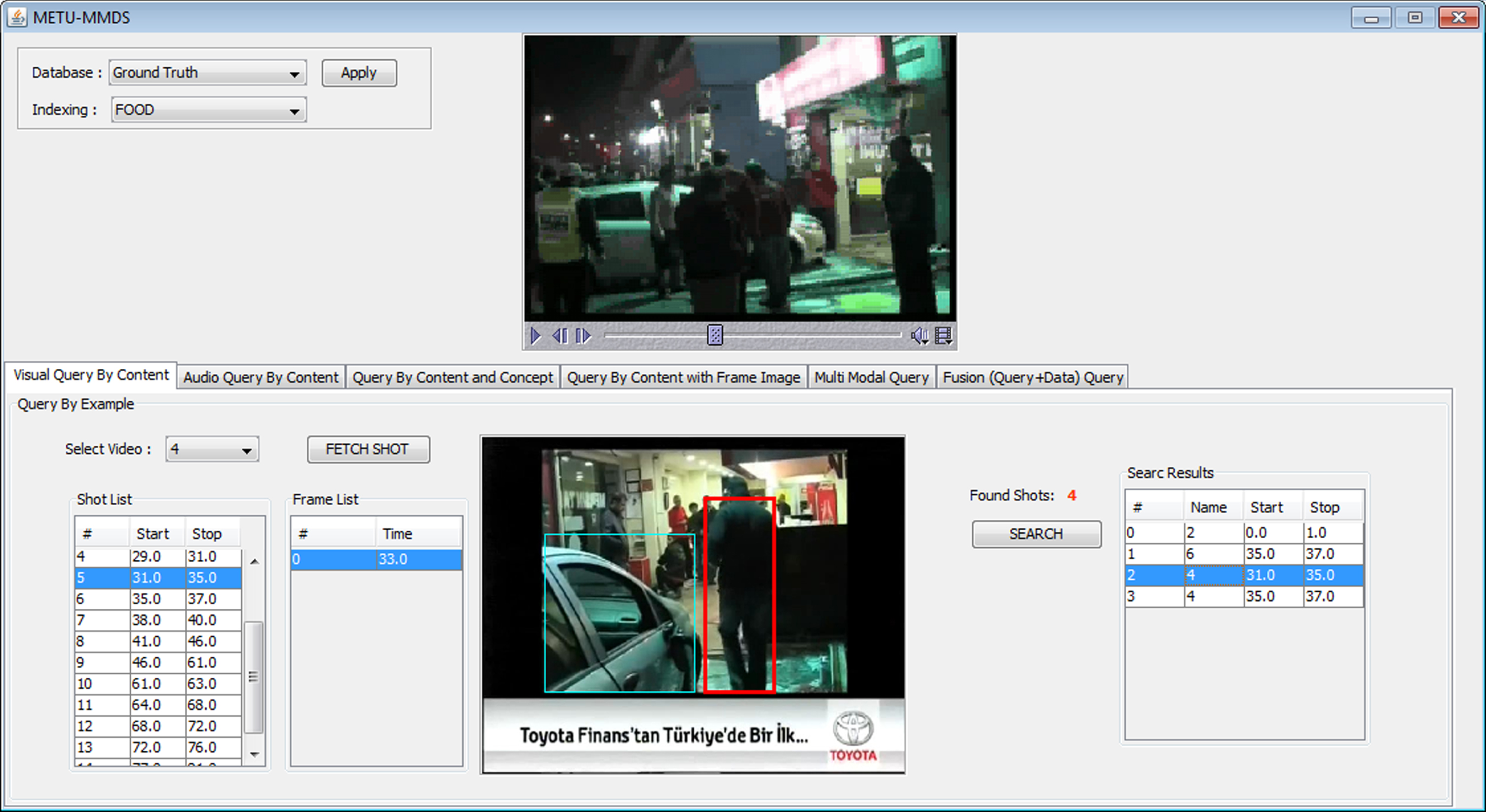
Query example for news video dataset.
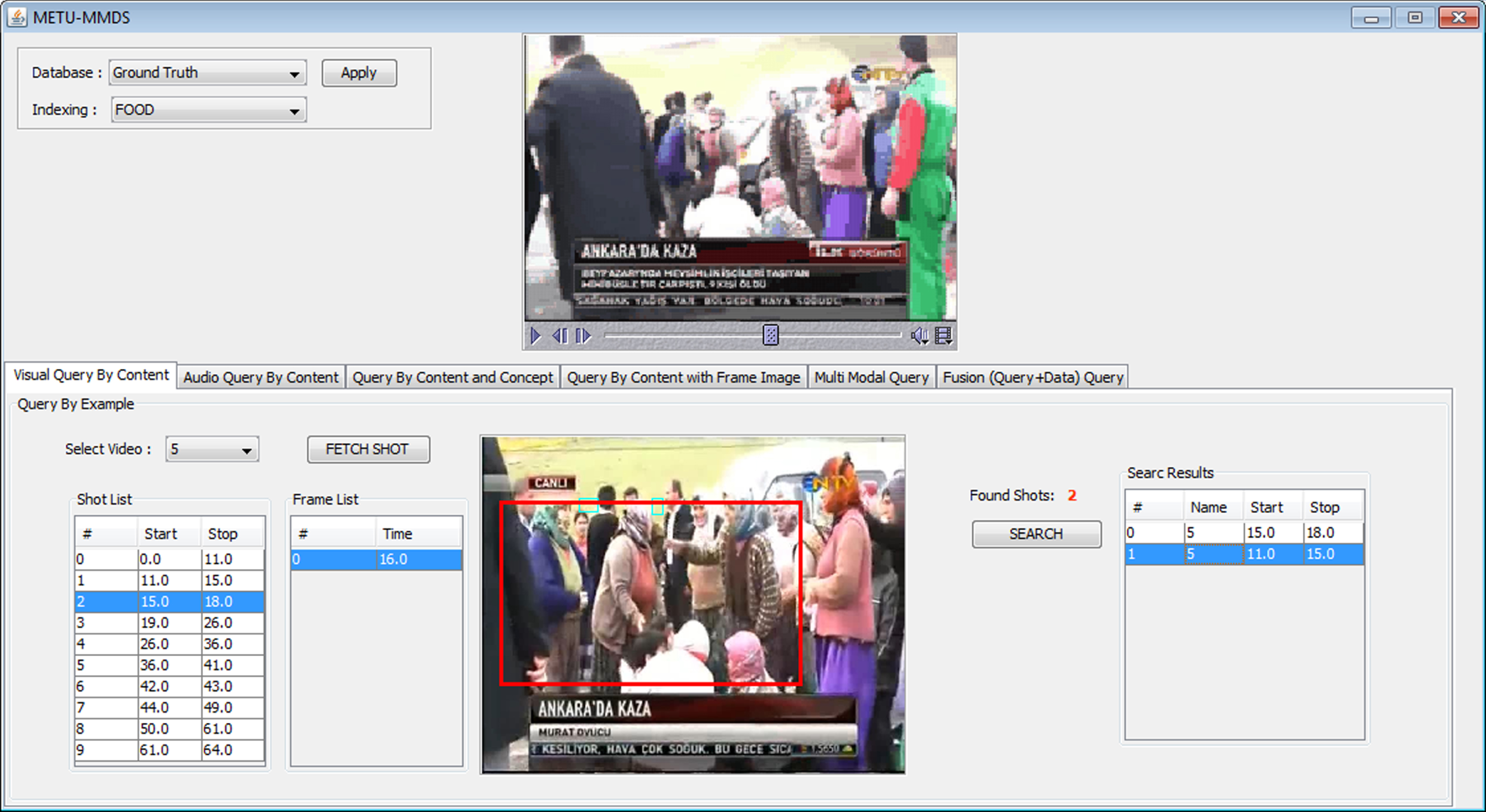
Query example for news video dataset.
In addition to this video data set, another large synthetic dataset is also used to validate our indexing structure.
The news video data set contains 76 videos. These videos are represented as shots, and there are 1571 shots stored. These shots contain different types of conceptual information, such as textual, visual, and audio concept. Furthermore, there may be a various number of objects in a single shot. In order to use these components, we have to create a new data structure to include all this information in a single object. The domain for news video is depicted in Fig. 22.
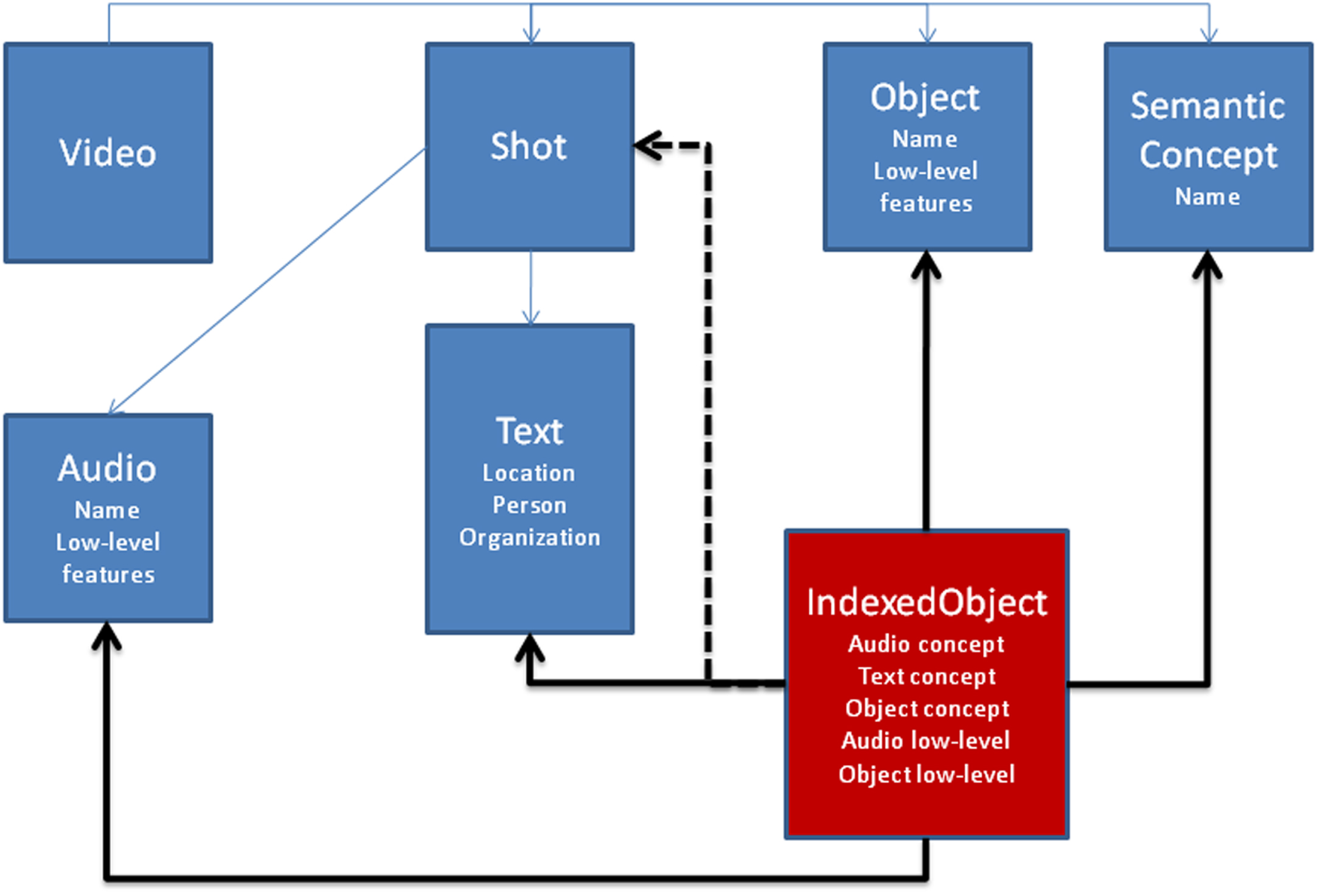
Overall domain for video data set.
Audio, Text, and Semantic classes store the concept (high-level) descriptors. On the other hand, Object and Audio classes are responsible for storing content features. There are 2796 Text objects, 7719 Semantic objects, 428 Visual Object objects, and 2428 Audio objects.
We created a new class for storing all concept (high-level) and content (low-level) information of a shot called IndexedObject. Storing content and concept in a single structure causes an increase in the number of indexed objects, and there are 57273 IndexedObject objects to be indexed. Our proposed index structures are built on this class.
First, each index structure’s construction time is evaluated and compared. The results shown in Fig. 26 indicate that FOOD-X has much more creation time than MM-FOOD since constructing X-Tree has a hefty cost and, in addition to this cost, FOOD-Index is separately constructed in this structure. Hence, the creation time for FOOD-X is the summation of the creation time of the X-Tree part and FOOD-Index part. However, using X-Tree in MM-FOOD as a data partitioning method (MM-FOODxtree) has the worst performance since it requires additional Array Index construction. On the other hand, the construction of MM-FOOD with Fuzzy-C-Means clustering (MM-FOODfuzzy) and MM-FOOD with k-Means clustering (MM-FOODkmeans) involves a simple clustering phase in addition to FOOD-Index construction phase.

Creation times of index structures.
The accuracy of the index structure is critical in traditional systems. However, since we are dealing with multimedia objects, the accuracy of queries on this data type is dependent on object representation [10]. Significantly, using low-level content features for the multimedia objects’ visual and audio information decreases the system’s accuracy [1]. Additionally, dimensionality reduction techniques and the similarity measurement function of multimedia objects directly affect the performance of the retrieval mechanism [80]. Thus, we have performed accuracy tests on selecting dimensionality reduction techniques first. The LMDS FastMap is adapted from [26] to show the effect of the embedding and compared with state-of-art dimensionality reduction techniques: PCA and LDA. The precision/recall graph of using different dimensionality techniques for MM-FOOD index structure for video data set is depicted in Fig. 27 for kNN queries where k is equal to ten (10). Average results of one hundred (100) queries are used in this test. The results show that LMDS FastMap has better accuracy performance for our data set. On the other hand, PCA and LDA show similar performance; however, they require a more extensive data set [44]. Hence, for our data set, we have used LMDS FastMap as a dimensionality reduction technique throughout the experiments.
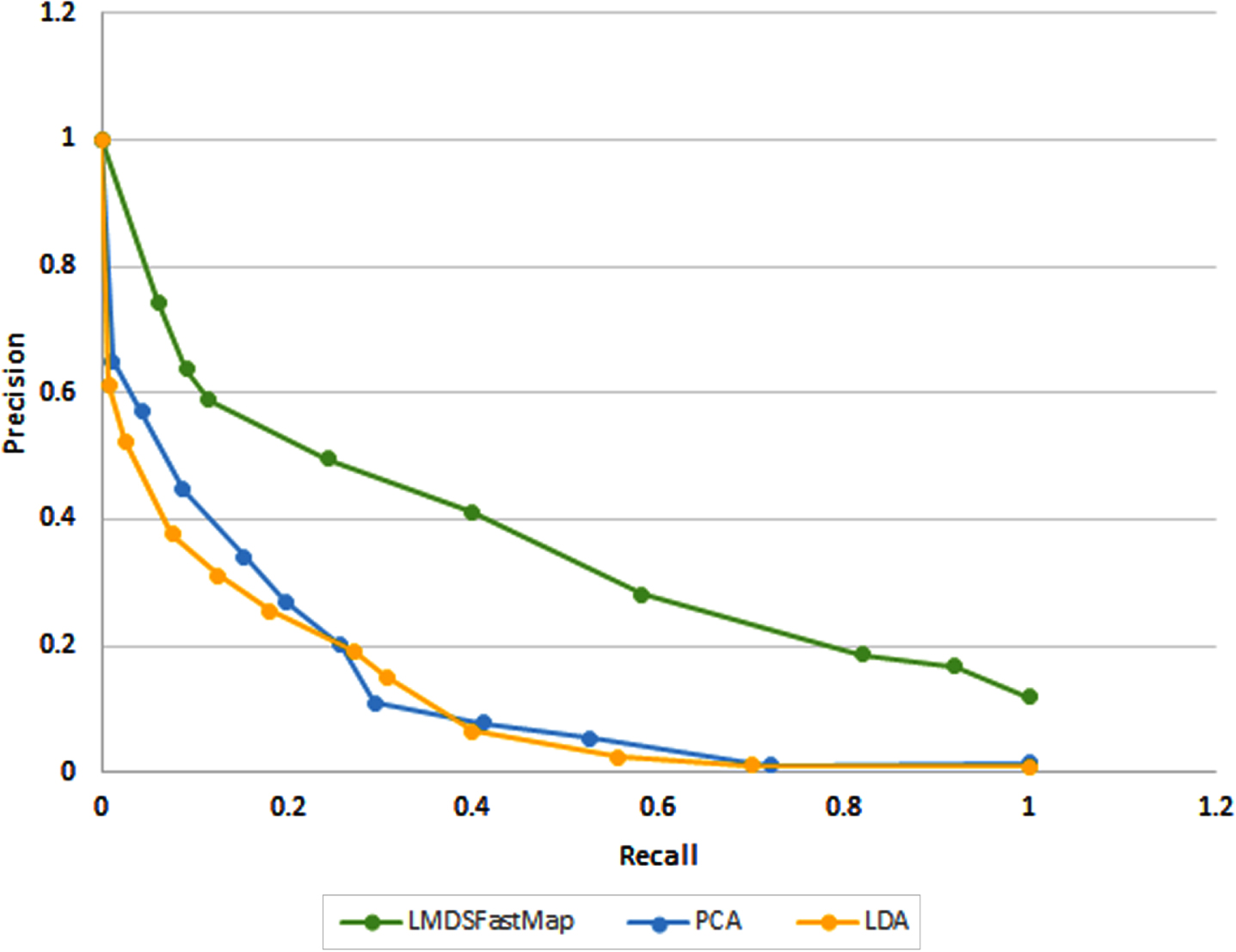
Precision/Recall graph of dimensionality reduction techniques for news video data set.
The similarity computation between visual objects for LMDS FastMap is carried out by the distance functions explained in [64]. L 1 distance function is used for audio similarity because of the simplicity and low calculation cost.
To evaluate retrieval performance of our index structure, (i) accuracy performance for each structure, (ii) query retrieval times of each query type using both video data set and an extensive synthetic data set, (iii) object access count and cluster access count are investigated and compared.
First of all, after choosing LMDS FastMap as our dimensionality reduction technique, we have performed more accuracy tests on the evaluation of MM-FOOD and FOOD-X using different DPMs for composite queries.
The Precision-Recall results are shown in Fig. 28 for k-NN queries (k = 10) for average values of one hundred (100) queries. As we can conclude from the figure, FOOD-X has the best performance, and MM-FOODxtree comes next since it uses X-Tree as clustering. If we use K-means clustering in MM-FOOD, the accuracy of the system decreases since k-means clustering is dependent on k value and requires the training process.
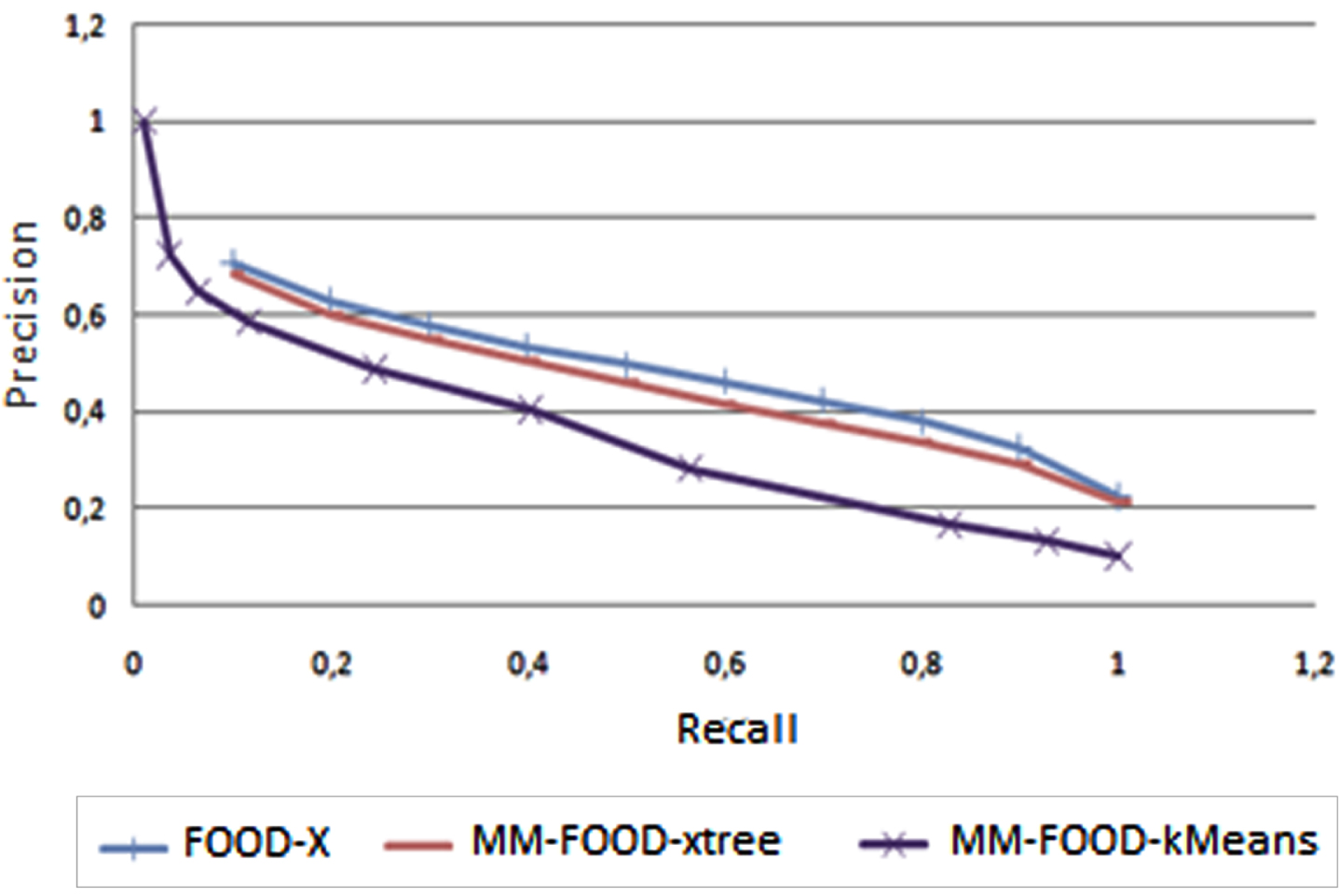
Precision/Recall graphs for k-NN queries for news video data set.
Another critical performance measure for the index structures is retrieval time. In order to evaluate this metric for the proposed structures, various numbers of queries have been conducted on each structure and the results are compared with sequential scan querying. The test database contains 57273 conceptual, 4428 visual, and 2428 audio objects. The results are depicted in Fig. 29. In this experiment, Fuzzy C-Means Clustering method, which is similar to K-Means Clustering method is applied in MM-FOOD. Cluster size (C) is set to 64. Again one hundred (100) queries have been tested and the average results are used.
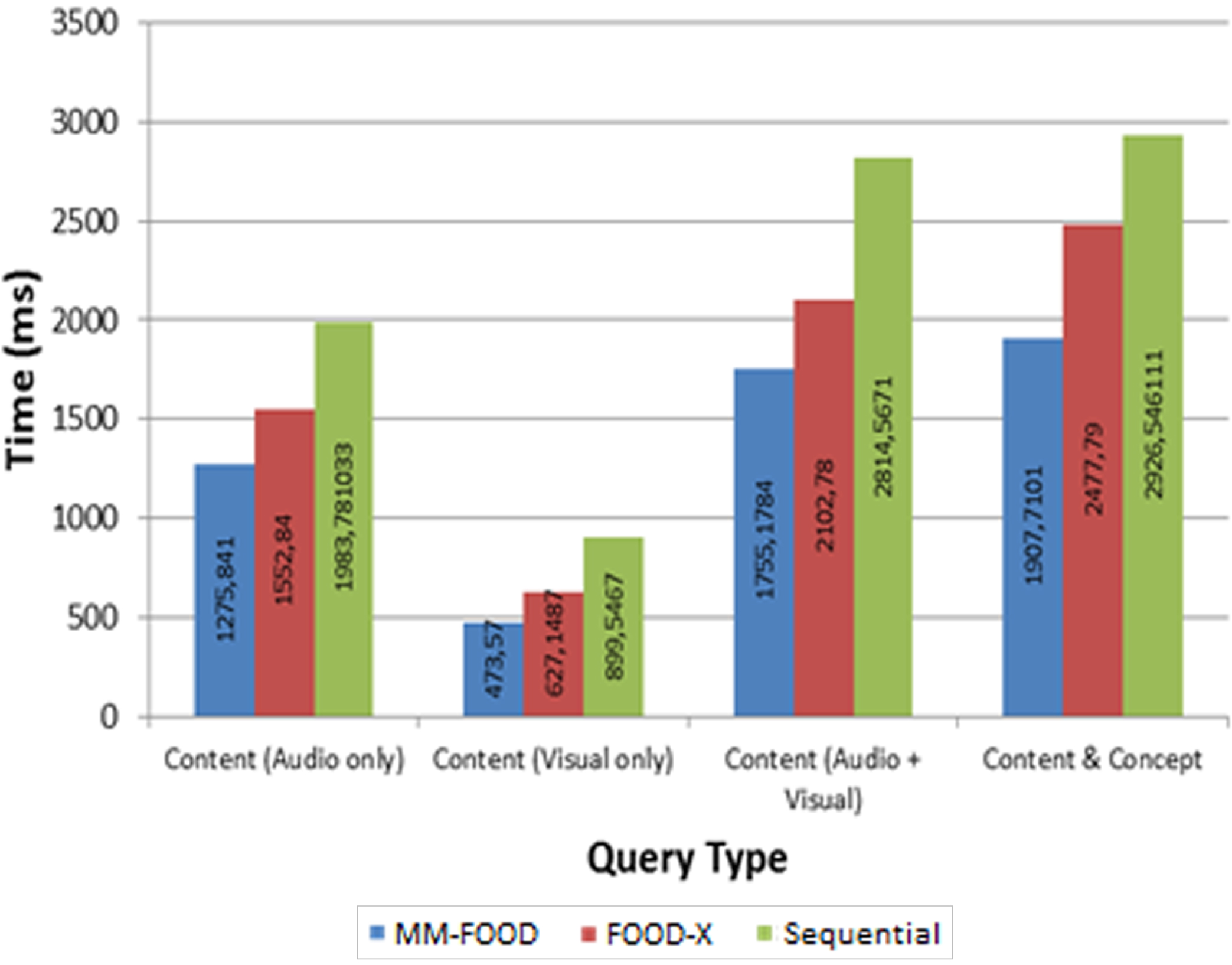
Query retrieval times for news video data set.
Figure 29 shows us that using MM-FOOD is faster for every type of query than for sequential scan and FOOD-X. Audio-based content querying is conducted on only audio objects, and content querying using visual descriptors is conducted on only visual objects. The figure indicates that visual-based querying has better results compared to audio-based querying. Audio descriptors used in this data set are much more complex than the visual descriptors. Consequently, the distance calculation for these descriptors also has much more complexity than visual descriptors’ distance calculation.
Since the number of objects in the database is an essential factor for the retrieval performance, we have created synthetic data to evaluate the effect of this value on query performance. We created one million objects and performed retrieval tests on both structures for composite queries. The conceptual attributes are created using actual values of the video data set, and embedding dimensions are created randomly. In order to have a baseline for comparison, we have also accessed these objects without using any indexing structure, and the results are depicted in Fig. 30. The results confirm the previous retrieval test results.
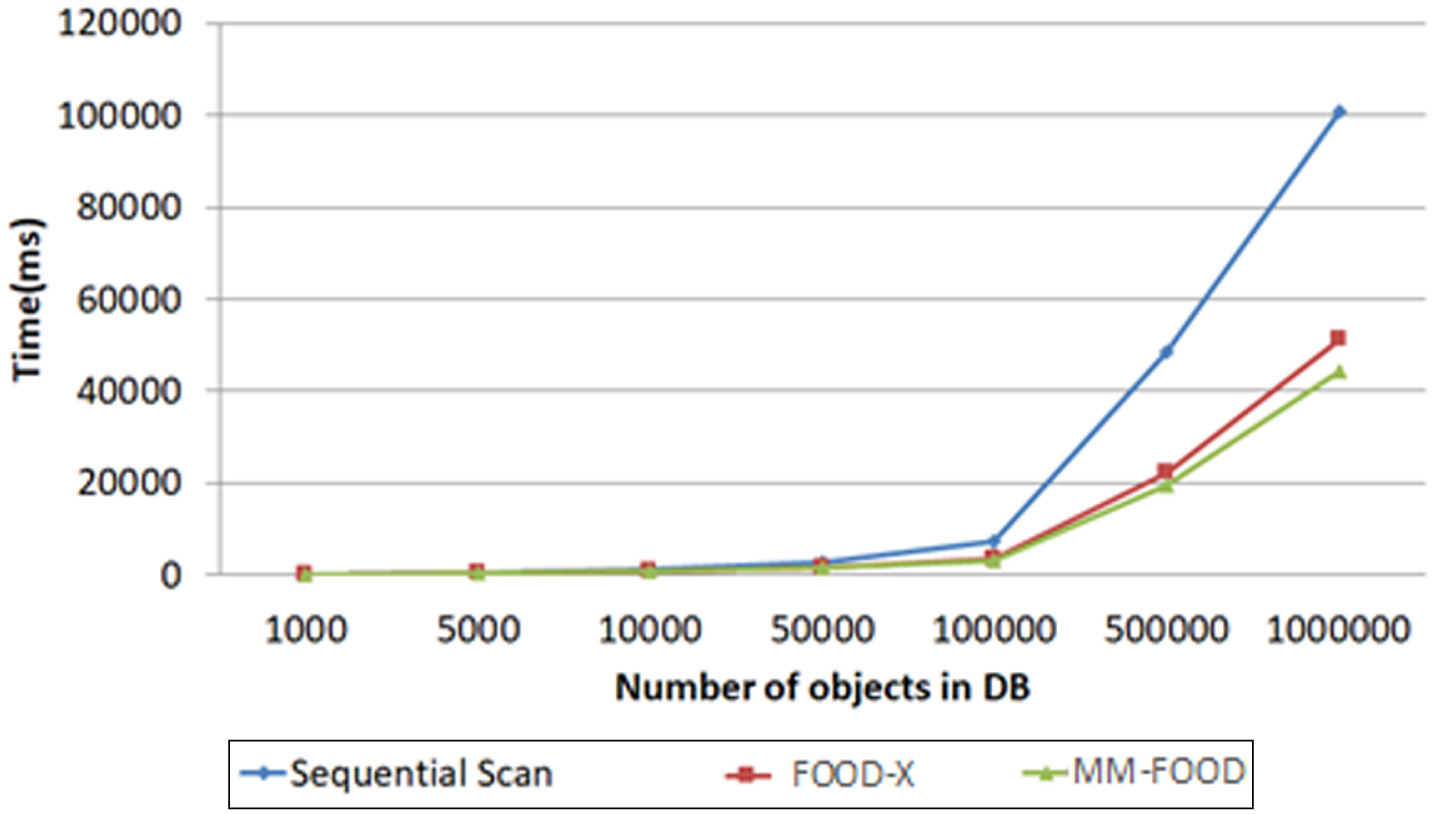
Query retrieval times for large synthetic data set.
Another query method tested through this study is fuzzy querying. We have evaluated query retrieval time tests for the sample fuzzy query defined as follows;
Retreive all objects which has similar content to given image and also has fuzzy condition where conceptual attribute for audio is medium and threshold value is equal to 0.6 (conceptual_attr1 = medium 0.6).
First of all, the similarity matrix shown in Table 2 is used in order to evaluate search spaces of the fuzzy terms. These search space intervals (Table 3) is used for construction of start and stop bit strings. The final start and stop bit strings are shown in Table 4.
Retrieval time results of fuzzy querying, depicted in Fig. 31 confirm the results illustrated in Fig. 30. In Fig. 32, we showed the retrieval times for fuzzy querying evaluated on a large synthetic dataset. As depicted in the figure, we can conclude that MM-FOOD has better retrieval times since the query is performed using only one single structure.

Query retrieval times of fuzzy querying for news video data set.

Fuzzy query retrieval times for large synthetic data set.
The number of accesses to the indexed objects is another performance metric. Figure 33 shows average number of object access for k-NN content-based querying for k = (1,5,10,20,50,100). For each k value, ten (10) queries have been evaluated and their average values are used. In this experiment, both audio and visual objects are searched and retrieved; thus, the total number of objects in our database is 6856. The results confirm retrieval time results since queries FOOD-X access much more objects than MM-FOOD. Thus, retrieval of objects by using the first structure requires much more time than MM-FOOD.

Number of object access results for news video data set.
We also performed object access count tests for varying database sizes. The results depicted in Fig. 34 show the effect of data set size over the access count for k-NN querying when k is equal to ten (10). MM-FOOD structure accesses fewer objects than other structures since it searches and locates possible result objects by selecting appropriate cluster(s). After accessing relevant cluster(s), this structure only accesses objects in that cluster(s). This efficient pruning mechanism of Array Index structure results in performance gain.

Number of object access results for varying data set sizes for news video data set.
However, there is a slight increase in retrieval time because of requirement of visiting the neighbor clusters in Array-Index. Thus, to evaluate cost of visiting clusters, we also performed average cluster access number tests on MM-FOOD structure and the results are shown in Fig. 35. The results show that choosing an efficient cluster number affects the query performance, specifically when k value increases.
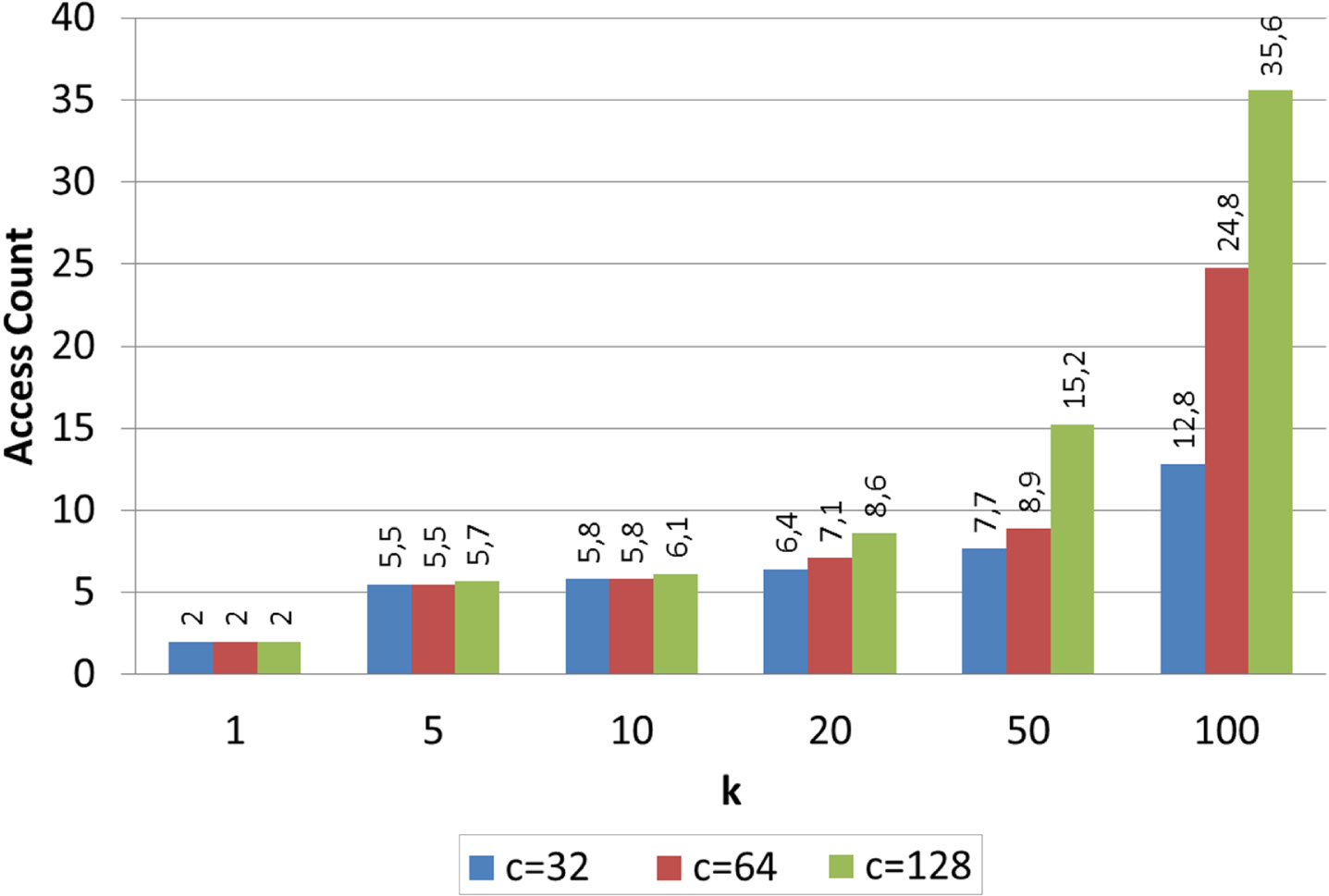
Number of cluster access results for news video data set.
Currently, many studies have been proposed for multimedia information retrieval. However, the semantic gap is still an open problem. Researchers have been developing new strategies and structures to close this gap between computer representation and human understanding of multimedia data. In this study, a new multimedia indexing mechanism called MM-FOOD is proposed in order to solve this semantic gap problem.
MM-FOOD represents the multimedia data’s concept and content descriptors in a single structure. In order to merge both these descriptors, a clustering algorithm is used for content features. The output clusters are represented in a one-dimensional space as arrays. Conceptual attributes are converted into bit strings and combined with a bit string representation of cluster information of this one-dimensional array enabling MM-FOOD to have a hybrid search key for different types of queries.
Several experiments have been carried out throughout this work, which indicates that using MM-FOOD in the retrieval process improves the retrieval performance in terms of query accuracy and response time. The experiment results also show that using the multidimensional scaling method for embedding high-dimensional multimedia data into low-dimensional space outperforms the model that uses objects in their original space. Moreover, defining clusters and using cluster information similar to conceptual information in our study as an index attribute result in query accuracy and efficiency.
Retrieval time is another crucial parameter for such a retrieval system. The retrieval time test results show that MM-FOOD performs much better than FOOD-X and sequential scan in terms of the number of accesses and, thereby, in terms of query execution time since it reduces the search space of the retrieval system.
In order to show the effect of the embedding, other dimension reduction techniques are used and compared with LMDSFastMap. The experiments confirm that LMDSFastMap outperforms state-of-art methods for the dataset we used in this study. In the future, clustering the data before applying the multidimensional scaling technique can be adapted to see its effect on performance on various queries.