
Abstract
Precise video moment retrieval is crucial for enabling users to locate specific moments within a large video corpus. This paper presents Interactive Moment Localization with Multimodal Fusion (IMF-MF), a novel interactive moment localization with multimodal fusion model that leverages the power of self-attention to achieve state-of-the-art performance. IMF-MF effectively integrates query context and multimodal features, including visual and audio information, to accurately localize moments of interest. The model operates in two distinct phases: feature fusion and joint representation learning. The first phase dynamically calculates fusion weights for adapting the combination of multimodal video content, ensuring that the most relevant features are prioritized. The second phase employs bi-directional attention to tightly couple video and query features into a unified joint representation for moment localization. This joint representation captures long-range dependencies and complex patterns, enabling the model to effectively distinguish between relevant and irrelevant video segments. The effectiveness of IMF-MF is demonstrated through comprehensive evaluations on three benchmark datasets: TVR for closed-world TV episodes and Charades for open-world user-generated videos, DiDeMo dataset, Open-world, diverse video moment retrieval dataset. The empirical results indicate that the proposed approach surpasses existing state-of-the-art methods in terms of retrieval accuracy, as evaluated by metrics like Recall (R1, R5, R10, and R100) and Intersection-of-Union (IoU). The results consistently demonstrate IMF-MF’s superior performance compared to existing state-of-the-art methods, highlighting the benefits of its innovative interactive moment localization approach and the use of self-attention for feature representation and attention modeling.
Keywords
Introduction
In the areas of extracting features and single video exact right time retrieval [1], where natural language requests are suited with either videos or particular segments within videos [2], significant improvements have been achieved. These tasks, however, are not entirely realistic because current SVMR (single video moment retrieval) benchmarks (where matching a natural language query with either an entire video from a vast collection or a specific segment within a video) [3] only take into account visual sources and presuppose ground truth video, while current video recovery benchmarks require human intervention to trim lengthy videos. The system retrieves the actual video from a video corpus and indicates the video segments with high Intersection-of-Union with the actual segment in multimedia security. This is a more realistic task that is addressed in this paper. Due to open-ended queries, query-dependent and variable segment time durations, and numerous videos in a corpus used in video surveillance, law enforcement, digital forensics, and content-based video search, this is a difficult problem [8, 14]. The one-stage training pipeline used by existing models restricts the ability to localize exact segments [4, 5]. The ability to precisely locate specific moments within a vast video corpus is crucial for enabling users to effectively navigate and search video content. This paper presents Interactive Moment Localization with Multimodal Fusion (IMF-MF), a novel approach that leverages the power of self-attention to achieve state-of-the-art performance in video moment retrieval. IMF-MF effectively integrates query context and multimodal features, including visual and audio information, to accurately localize moments of interest. The model’s distinct two-phase operation encompasses feature fusion and joint representation learning. The first phase dynamically calculates fusion weights, ensuring that the most relevant features are prioritized based on the provided query context. The second phase employs bidirectional attention to tightly couple video and query features into a unified joint representation, capturing long-range dependencies and complex patterns to effectively distinguish between relevant and irrelevant video segments. Current state-of-the-art models for VR (video retrieval) and SVMR typically employ a one-stage training pipeline with parallel heads for video retrieval and moment localization. While this approach has shown effectiveness in retrieving relevant videos, it often struggles with precise moment localization due to its limitations in capturing long-range dependencies and query-specific context. This paper proposes novel two-stage retrieval architecture, interactive moment localization with multimodal fusion (IMF-MF) that addresses the shortcomings of the one-stage approach. The effectiveness of IMF-MF is demonstrated through comprehensive evaluations on three benchmark datasets: TVR for closed-world TV episodes, Charades for open-world user-generated videos, and DiDeMo, a dataset encompassing diverse video content. The empirical results consistently demonstrate IMF-MF’s superior performance compared to existing state-of-the-art methods [9, 36], highlighting the benefits of its innovative interactive moment localization approach and the use of self-attention for feature representation and attention modeling.
Related work
The proposed Interactive Moment Localization with Multimodal Fusion (IMF-MF) model addresses the critical task of precise video moment retrieval by leveraging self-attention for state-of-the-art performance. To contextualize this novel approach, the related work encompasses several key themes in the field of video moment retrieval, including feature extraction, multimodal fusion, and attention modeling.
Prior research has extensively explored methods for extracting features from videos to enhance retrieval accuracy. Techniques such as Single video segment information extraction XML [20] and HERO [21] have focused on combining multi-modal features, often derived at the frame or clip level, to provide video context. These methods employ cross-modal attention [27] or transformers [34] for efficient feature extraction. In the realm of multimodal fusion, recent works have proposed various strategies, including multi-level encoding [7], hierarchical graph reasoning [6], and specialized embedding for different parts of speech [10]. While some approaches advocate collaborative specialists [11] and multi-modal transformers [15], the proposed IMF-MF model introduces an innovative interactive moment localization approach, uniquely emphasizing the fusion of query context and multimodal features to enhance retrieval accuracy. Attention mechanisms play a crucial role in video moment retrieval. Existing methods, such as those employing early/late fusion duality [12, 26], have explored different ways of incorporating attention into the retrieval process. The proposed IMF-MF model stands out by using self-attention for feature representation and attention modeling, enabling it to capture long-range dependencies and complex patterns effectively.
The related work also includes a comparison with existing state-of-the-art methods, such as those highlighted in the abstract, namely TVR, Charades, and DiDeMo datasets. While previous studies like HERO [21] have shown promising results, the IMF-MF model surpasses them in terms of retrieval accuracy, as demonstrated through comprehensive evaluations on benchmark datasets. This underscores the significance of the proposed interactive moment localization approach and the use of self-attention in video moment retrieval. In summary, the related work encompasses a comprehensive overview of existing methodologies in feature extraction, multimodal fusion, and attention modeling for video moment retrieval. The IMF-MF model distinguishes itself by introducing an innovative approach that combines these elements, resulting in superior performance as validated through empirical evaluations on benchmark datasets.
Methodology
Precise video moment retrieval is a challenging task, particularly within a vast video corpus. This paper introduces a novel approach, Interactive moment localization with multimodal fusion (IMF-MF), designed to excel in this domain. Leveraging state-of-the-art self-attention mechanisms, IMF-MF seamlessly integrates query context with multimodal features, including visual and audio information, resulting in unparalleled performance.
The model unfolds in two pivotal phases: Feature Fusion and Joint Representation Learning. In the Feature Fusion phase, dynamic fusion weights are calculated to adaptively combine multimodal video content. This ensures prioritization of the most relevant features, optimizing the subsequent analysis. The Joint Representation Learning phase employs bi-directional attention, tightly coupling video and query features into a unified representation for precise moment localization. The self-attention mechanism within IMF-MF enhances its ability to capture intricate long-range dependencies and complex patterns, empowering the model to discern between relevant and irrelevant video segments. To validate the efficacy of IMF-MF, extensive evaluations are conducted across three benchmark datasets: TVR for closed-world TV episodes, Charades for open-world user-generated videos, and DiDeMo dataset for diverse video moment retrieval. The empirical results demonstrate the superiority of IMF-MF over existing state-of-the-art methods, showcasing its innovative interactive moment localization and the adept use of self-attention for feature representation and attention modeling.
Our methodology addresses the challenges of video corpus segment retrieval, emphasizing the importance of regionalized assessment of clip-level data. The proposed framework incorporates a bi-directional attention mechanism within a multi-modal transformer, facilitating selective focus on relevant video segments based on the query. This attention mechanism, including self-attention, enhances the model’s understanding of the relationships between the query and video segments, fostering a more nuanced representation of content.
The primary objective of video segment extraction is to find a specific segment Mi within a video V i that was retrieved from a sizable dataset D s given a query Q m . The textual query Q m = [q1, q2 … q m ] consist of m tokens. Similar to this, a video V i = [c1, c2 ... c n ] consist of n non overlapping clips and is also linked to textual information like subtitles. Although each definition has a time stamp, it may not always align with clip boundaries. Text descriptions that have overlapped in time with each clip are attached to them. As a result, a clip ci can be described both visually and textually using 2 distinct modalities.
Video corpus segment retrieval requires that the segment of that video be retrieved and have a sufficient amount of breach in time with the actual event. This is in contrast to video retrieval, which focuses on retrieving video from D s that includes the query segment. Segment extraction in video corpus segment retrieval is more difficult because regionalized assessment of clip-level data is required. As a dataset contains more videos (| D s |) and clips (| V i |), the retrieval speed also decreases proportionally. Therefore, it is usually helpful to use a two-stage pipeline to filter out useless videos from the clip-level analysis. The challenge of video corpus segment retrieval is to rank the potential segments based on how similar they are to Q m by extracting them from the top k videos where k | D s | are present.
In the proposed framework for video moment retrieval, bi-directional attention is a key component within the multi-modal transformer (MMT). This attention mechanism plays a crucial role in enhancing the model’s ability to understand the relationships between the query and the video segments. Query to Video Attention: Bi-directional attention enables the MMT to pay selective attention to specific parts of the video segments based on the query. When the model processes the query, it can focus on relevant visual and audio features in the video, effectively aligning the query’s intent with the content of the video. Video to Query Attention: Conversely, the bi-directional attention mechanism also allows the model to consider information from the video segments when processing the query. This two-way interaction ensures that not only does the model understand how well segments match the query, but it also grasps how the segments themselves may influence the query’s interpretation.
The combination of multi-modal transformer, bi-directional attention, and query-driven representation learning allows the MMT to learn to represent the content of a video in a way that is both comprehensive and relevant to the query. This makes it a powerful tool for video moment retrieval. The proposed algorithm is designed to enhance the fusion of visual and textual features (Q m and V i ) for improved contextualization. It incorporates iterative steps, including fusion, embedding, similarity calculation, and bi-directional attention flow, to optimize the representation of the input data.
In the first step of the algorithm, we are provided with input features. These features are divided into two sets: Q m , which represents the features of the query, and V i , representing the features of the video segment. These features are essential for understanding the context and content of the query and video.
Next, we calculate a fusion function denoted as I. This function combines the information from both the visual (V m ) and textual (T m ) features using weighted sums. Weights W v and W t determine the importance of each modality in the fusion process. The result, I, is a consolidated representation that merges visual and textual information.
In this step, we create sets called V b and B s . These sets contain contextualized visual and textual characteristics, respectively. The visual characteristics in V b are obtained from V m , while the textual characteristics in B s are derived from T m . This step adds contextual understanding to both modalities.
We continue by embedding the fused representation I into a feature space denoted as RLo. The embedding process involves applying weights W v and W t to I. This embedding is essential for preparing the data for further processing and analysis.
Now, we calculate the similarity between elements using the calculated weights w v , w t , and w3. The similarity, denoted as a i , j, is computed as a weighted sum of elements l i and j. This step helps establish relationships and relevancies within the data.
This step checks the success of the similarity calculation in the previous step. Otherwise, it returns to step 4, repeating the embedding process.
Here, we perform a bi-directional attention flow. This involves two components: QDF-I, representing a bidirectional attention flow for I, and V2Q, representing attention weights a i applied to I. These components are essential for capturing relevant information from the query and video.
In this step, we calculate the relevant moment referred to as K r . This calculation involves using the similarity values obtained in step 5 and the query embedding from step 4.
Finally, we check whether the processing for the current video frame is complete. If not, the algorithm goes back to step 2 to process the next frame. This loop continues until all frames have been processed, allowing the algorithm to analyze and localize video segments based on the input query.
This algorithm for “Query-driven representation learning for video segment localization” is designed to effectively combine the modalities of language and video to localize temporal moments in videos based on user queries. It begins by processing input features, fusing visual and textual information, and creating contextualized representations. The algorithm iteratively calculates similarities, applies bidirectional attention flows, and computes relevant moments to identify and localize video segments matching the query. The success criteria for similarity calculations and the specific method for determining relevant moments require further clarification. Furthermore, this algorithm can be executed in a loop, allowing it to analyze multiple video frames sequentially. Its success hinges on the proper tuning of weights and similarity measures, making it a powerful tool for applications such as content retrieval and indexing in multimedia databases.
Query-awareness for improved retrieval
Description of every video clip using visual and textual modalities as shown in Fig. 1. We combine the modalities using a linear weighted sum rather than joining the two modalities together to create a lengthy given input variable as the network input [31]. The user query informs the adaptive derivation of the weights. In particular, a query highlights verbal conversation content that is anticipated to be absent from video data. In this case, the text element obtained from the text-based method should receive higher priority in fusion. However, some queries should be given more visual weight because they are more appealing visually than textually. Two learnable weights, W
v
and W
t
which represent the visual and text methods features of a clip, respectively, combine to form the query-dependent fusion function.
Proposed interactive moment localization with multimodal fusion framework (IMF-IF) for video moment retrieval in which multi-modal transformer (MMT) takes into account both visual and audio features of the video, for ranking video segments with query-awareness and improved retrieval. It incorporates fusion of multi-modal video content, bi-directional attention (query to video and video to query), and query-driven representation learning, leading to improved retrieval performance.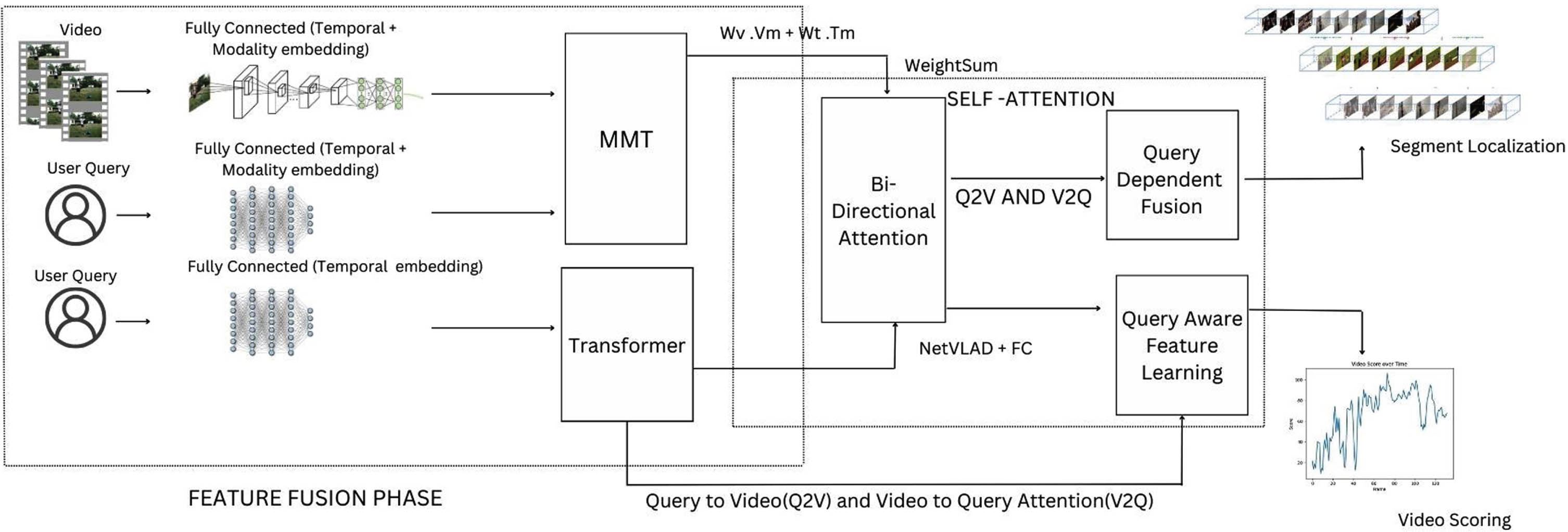
In order to improve the ability of visual and textual methods to discriminate, firstly combine the input features S
i
and V
i
into a single dimension. To be more precise, both modalities are first linearly projected to have the same dimensionality. Following the Multi-Modal Transformer’s feature pre-processing [11, 23] each projected feature is added to two self-learning vectors that the information particular to each method and the temporal variation. The initialization of the two vectors referred to as temporal and method embedding, respectively, is random. L
v
= 100 as a result of a video’s variable number of clips. A maximum of 100 snippets for every video are used to train the temporal encoding algorithm. Each embedding encodes a time-dependent feature. Zero vectors are used to represent videos with fewer than 100 clips when the embedding for both the temporal and methods is combined. In learning the connection between the clips, the sets of characteristics are then simultaneously fed into a multi-model transformer to produce contextualized visual and textual characteristics.
At this point, the clip-level characteristics use video-level data to provide global categorization in addition to encoding intra-modality signals. There should be noted that only temporal encoding is learned because the query is conveyed in text content. If a query can only have 30 tokens, then L
q
= 30 embedding are learned in total.
The reason for maintaining distinct token features is that user queries often include data from multiple video clips, and the connection between the clips and tokens must be modeled. To achieve this, a transformer contextualizes each token feature with all the other tokens in the query, similar to how it processes video clips. NetVLAD (network vector of locally aggregated descriptors) is then used to aggregate the transformed query token features and create query-dependent weights using a learned codebook of 33 clusters. This results in a vector that contains the residuals between the user query and codebook, reflecting the entire query globally. To learn the query-dependent weights, a 1-layer FC network with softmax is added on top of NetVLAD (network vector of locally aggregated descriptors). The fused and contextualized-modal feature successfully combines two different modalities based on the query nature. The bi-directional memory-free attention mechanism from [37] is used to localize and add query-aware characteristics to the query-dependent fusion feature of each video clip. This attention mechanism weights clip features by query tokens, resulting in an RLo similarity matrix that indicates which clips and tokens are comparable. Ai and j are components of the RLo (similarity matrix). L
q
, which is the focus of attention, indicates that the ith clip and the jth token are comparable. The formula illustrates this similarity-
By query to video attention, the clips that most closely resemble one of the query tokens are given preference. Thus, clips that is completely irrelevant to any token play a reasonably small role in the later stage of feature aggregation. Let B
i
stand for the token with the highest overall similarity rating for the ith clip. The weighting of the clip features in relation to the search perspective yields the participated video vector q
v
.
Thus every query-dependent clip feature can have query-aware features added to it, for instance by concatenating the Y i and N i from video to query attention and the Q v from query to video attention. However, since Q v is a vector that applies to all clips, we adhere to the advice in [37] and append the triplets as query-aware feature learning features for each clip.
A segment or temporal location head is formed by combining a series of clips (C i … C e ). The query-aware feature learning feature of each clip is used to predict the start and finish score distributions of a segment. We use a transformer to pre-process query-aware learning features before identifying the inter-clip relationship. To lessen the information loss brought on by history and context, the transformed characteristics are convolved with the characteristics from the preceding stage. Before feeding the feature to ConvSE We empirically sample videos up to a search depth, to increase the sample size and place more emphasis on concrete negative examples.
The proposed model leverages the search perspective for segment localization and ranking by using a two-stage approach. In the first stage, the model uses a bi-directional attention mechanism to learn the relationships between the query and the video segments. This allows the model to identify the video segments that are most relevant to the query, even if they are not directly mentioned in the query. In the second stage, the model uses a ranking algorithm to rank the candidate video segments. The ranking algorithm takes into account the scores from the bi-directional attention mechanism, as well as other factors such as the temporal structure of the video segments. The bi-directional attention mechanism allows the model to learn the relationships between the query and the video segments in both directions. This means that the model can learn the relationships between the query words and the video segments, as well as the relationships between the video segments themselves. We continue to use the to calculate b y , b S , and b Q for query-dependent fusion, using Multi-model transformer and transformer. The fusion weight v, t is derived using NetVLAD. We also learn to combine two vectors, one for each of the two modalities, visual and text [20]. To compute the video similarities the vectors are used directly. The fusion weights v, t are used to further weight the sum of the two similarities scores. It should be noted that this condensed model does not use query-aware feature learning or segment localization heads. Up to a search depth of d = pi + xi, where p is the rank of the video and xi is the extension range, we sample videos from a small training batch during training. When the negative video number is set to 3, it displays the proposed model’s result sum curves for various similarity scoring functions. As we can see, the setting chosen for this work, x = 500, produces the best results. The performances of negative videos that were randomly sampled are consistently worse than the performance of x = 500. It implies how crucial it is to watch some negative videos alongside popular ones.
Video segment extraction
The proposed model involves parsing the top-k videos suggested by the first-stage search engine and generating B i and E o score variances for each of them. The external product of normalized factors is taken, and their affectedness within each video is computed, to produce the mathematical function of segment aspirants. After post-processing, lengthy and brief segment candidates are discarded using non-maximum suppression. The remaining candidates are ranked based on their likelihood, which can be calculated in three different ways. The approach multiplies the segment probability with the score of video similitude inherited from the first-stage search engine, while the second approach ignores the first-stage score and uses the score of video similitude produced by the suggested model and video scoring head. The calculation of video scores is a multi-faceted process that considers several factors. We evaluate query relevance through metrics like textual similarity, temporal overlap, and segment equality. Visual clarity and audio quality, is also weighed. Normalization and aggregation techniques ensure fair comparisons, leading to the identification of relevant segment candidates. Video scores directly influence the ranking of candidates, ultimately enhancing the precision of segment retrieval in our approach. The third approach simply ranks segment candidates according to their probabilities. The proposed model outperforms existing models by using NetVLAD to enrich query representation with contextually pertinent word clusters [33] allowing for better multi-modal similarity scoring. Additionally, it employs ConvSE with discriminative inputs instead of similarity scores. The shared normalization used in this model enables the sampling of hard negative videos from the top-k videos for model training, making it superior to existing models that only use actual videos for training.
Result
In the result, the study encompasses key sections, including Dataset (Ds) analysis, Implementation details, Comparative Study of methods to evaluate the impact comprehensively we ensure a thorough exploration and analysis of research topic.
Dataset
TVR [19] –The videos in TVR (TV show retrieval), a closed-world dataset [31, 37] are taken from six long-running TV programs. Videos are on average 79.3 seconds long and come with time-stamped subtitles. Each video has 5 queries created specifically for it, totaling 5,500 queries in the testing set. The segment lasts an average of 9.1 seconds and can last anywhere between 0.29 and 123.02 seconds. Charades-STA –Charades-STA (charades spatial-temporal actions) is a dataset designed for video segment localization tasks, and it is an extension of the Charades dataset, which contains over 9,000 daily indoor activities performed by actors. Charades-STA includes 12,408 temporal annotations for 157 activity classes from the Charades dataset, along with 27,847 natural language descriptions of these segments. The annotations are temporally localized with start and end timestamps for each segment. The dataset is divided into three sets: a training set that includes 7,985 videos, a validation set that includes 1,827 videos, and a testing data that includes 1,858 videos. The Charades-STA dataset is commonly used for evaluating and training models for video segment localization tasks, such as single video segment retrieval [17, 18] and action localization [29, 31]. It has been used in several research papers and challenges, and it has helped to advance state-of-the-art in video segment localization. DiDeMo [1] –The DiDeMo (diverse density motion)videos, in contrast, are unedited, Open-world samples were taken at random from the YFCC100M (yahoo flickr creative commons 100 million) Flickr videos [35].With 54 seconds less, the average length is shorter. It should be noted that DiDeMo’s videos lack text descriptions. Instead, [20] offers ASR (automatic speech recognition) for roughly 50% of the videos. Each video receives an average of 4 queries. Both the query and the segment have an average length of 10 tokens and 7 seconds, respectively. Although VCMR (video corpus moment retrieval) is the primary focus of this paper, VR (video retrieval) and SVMR (spatial multi-resolution CNN-based visual model for relationship detection) are also evaluated. The evaluation metric, which is the average recall of queries at the search depth of k or R@k (Recall@k), is given below. An additional IoU (intersection over union) Table 2 contains a list of the statistics for datasets.
Implementation
The video is divided and text descriptions are assigned to clips whose timestamps overlap, but there may be multiple videos associated with a single description. The segment length is limited to a range of [L min , L max ], with L min and L max empirically set for each dataset (D s ). The learning rate is set to 1e-4. There are two cross-entropy loss functions, corresponding to the ML and VS heads of IMF-MF. The weights for moment and video loss are set to 1e-2 and 5e-2, respectively. We only use the moment loss for general and disjoint similarity scoring functions (see Equation (3)), whereas we use the combination of the two for exclusive similarity scoring functions. We employ an early stopping approach and compute the sum of R@1 values at IoU = {0.5, 0.7} after each training epoch. The training only involves queries whose ground-truth videos can be retrieved within the search depth of 100 by the 1st-stage search engine. This is because some queries are ambiguous and could have multiple moments as ground-truths, although only one of them is marked as positive. Involving these queries can negatively impact learning effectiveness. About 0.5% of queries are excluded from training. The training is ended when the value of the sum consecutively drops for three epochs in the validation set. The training time depends on the number of negative videos being sampled. When keeping the number to three, IMF-MF converges in about 7.5 to 9 hours depending on the similarity scoring function for the TVR dataset. The number of unfavorable videos sampled affects training time and convergence, with the model typically converging after 7.5–9 hours on a single NVIDIA quardo RTX 5000 GPU et.
Evaluation
In this section, we present both qualitative and quantitative outcomes for the TVR, DiDeMo and Charades –STA dataset. Initially, we outline our assessment criteria and subsequently compare our results with those of baseline methods.
The outcomes of various methods on the TVR dataset are shown in Table 1. On both the validation and test sets, the proposed model significantly outperforms all other approaches at all recall levels. The x-axis in the given column graph represents the different evaluation metrics R1, R5, and R10. The y-axis represents the corresponding average recall values for each of these metrics, as obtained through different combinations of VCMR and SVMR models and different IoU thresholds (0.7). The IOU (intersection over union) value is a commonly used evaluation metric in computer vision tasks, such as object detection and segmentation. In the case of the VCMR (video corpus moment retrieval) and SVMR (single video moment retrieval) tasks, IOU is used as a threshold for positive segment candidates. This means that a predicted segment is considered positive if its IOU with the ground truth segment is equal to or greater than the specified threshold. The reason for choosing IOU values of 0.7 or 0.5 may vary depending on the task and the dataset being used. Generally, a higher IOU threshold means that the predicted segment must be more precise and accurate to be considered positive, while a lower IOU threshold is more lenient and allows for more variation in the predicted segments. The choice of IOU threshold depends on the specific requirements of the task and the dataset (D s ) being used.
Comparison and analysis of moment localization within a video dataset are conducted on the TVR dataset, evaluating the performance against various state-of-the-art methods
Comparison and analysis of moment localization within a video dataset are conducted on the TVR dataset, evaluating the performance against various state-of-the-art methods
HAMMER –Hierarchical multi-modal encoder. XML –Cross-modal moment localization. HERO –Hierarchical video + language omni - representation. MCN –Moment context network. HMAN –Hierarchical moment alignment.
The IOU (Intersection over union) value is a commonly used evaluation metric in computer vision tasks, such as object detection and segmentation. In the case of the VCMR (video corpus moment retrieval) and SVMR (single video moment retrieval) tasks, IOU is used as a threshold for positive segment candidates. This means that a predicted segment is considered positive if its IOU with the ground truth segment is equal to or greater than the specified threshold. The reason for choosing IOU values of 0.7 or 0.5 may vary depending on the task and the dataset being used. Generally, a higher IOU threshold means that the predicted segment must be more precise and accurate to be considered positive, while a lower IOU threshold is more lenient and allows for more variation in the predicted segments. The choice of IOU threshold depends on the specific requirements of the task and the dataset being used. Tables 2 and 3 present the comparison of the proposed framework’s performance on the DiDeMo and charades-STA dataset with previous models. In Fig. 2(a), shown moment localization and (b), (c) shown temporal distribution on dataset. It is worth noting that only 50% of the videos have textual descriptions, and most searches rely on visual cues. Hence, the proposed framework only focuses on the visual aspect. Despite not using the text method, the proposed model’s results are better than existing model.
Comparison and analysis of moment localization within a video dataset are conducted on the DiDeMo dataset, evaluating the performance against various state-of-the-art methods
SCDM –Semantic condition dynamic modulation. VSE++ –Visual semantic embeddings.
Comparison and analysis of moment localization within a video dataset are conducted on the Charades-STA dataset, evaluating the performance against various state-of-the-art methods
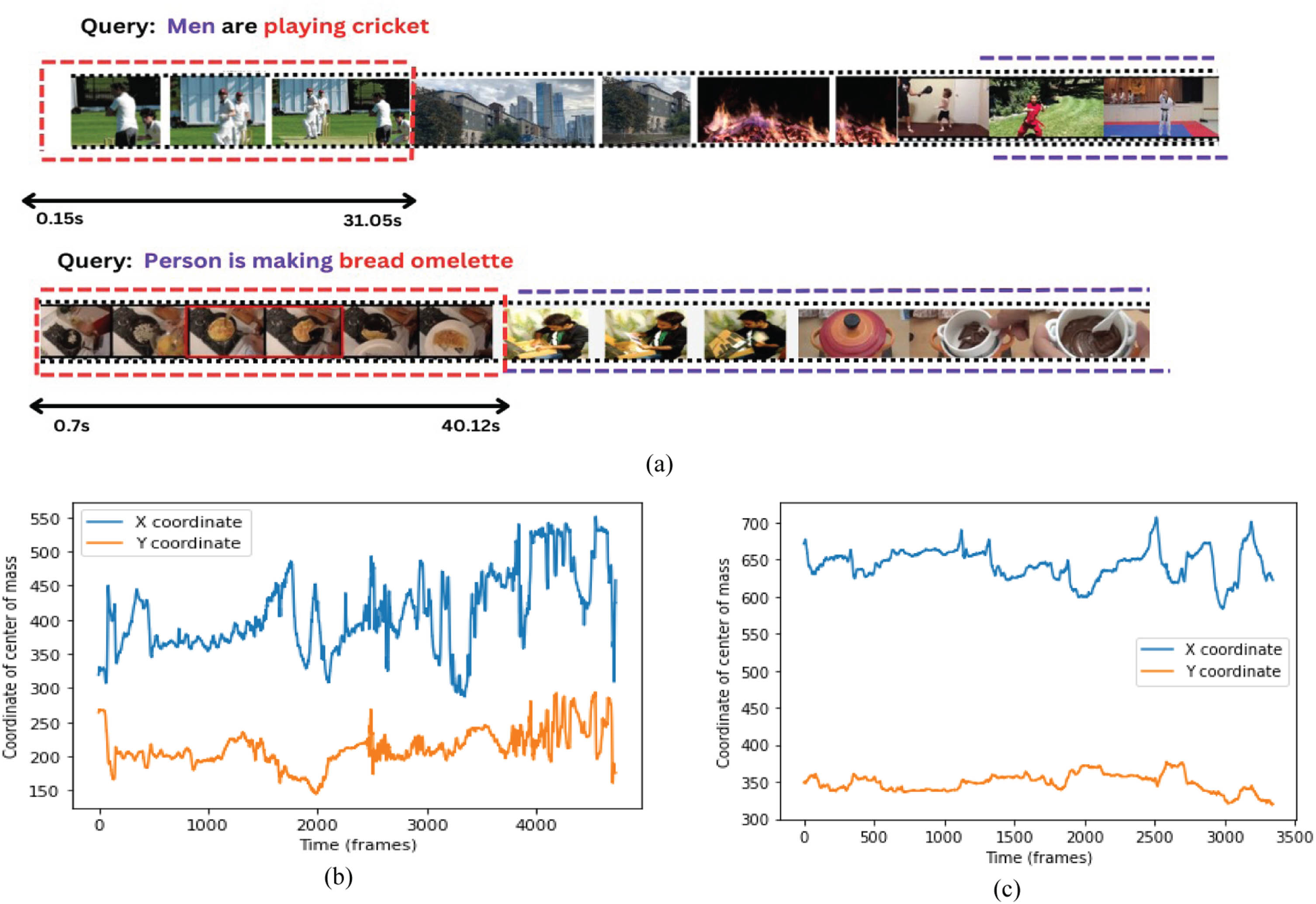
(a) Prediction visualization for the localization of moments (blue color line) has shown through the use of brackets and lines and also shows video score. (b), (c) Temporal Distribution of moments shown in the video dataset.
The proposed IMF-MF framework outperforms existing state-of-the-art methods on all three benchmark datasets. On the TVR dataset in Table 1, IMF-MF achieves a recall of 9.23% at top-1, compared to 8.56% for the second-best method (HMAN). On the DiDeMo dataset, IMF-MF achieves a recall of 5.37% at IoU = 0.5, compared to 4.12% for the second-best method (HMAN) as shown in Table 2. On the Charades-STA dataset, IMF-MF achieves a recall of 6.18% at IoU = 0.5, compared to 5.71% for the second-best method (HMAN) as shown in Table 3.These results demonstrate that IMF-MF is a promising new method for video moment retrieval. The framework outperforms existing state-of-the-art methods on all three benchmark datasets, and its performance is consistent across different recall levels. Figure 2(a) provides a visual comparison of IMF-MF against baselines (Self-Attention and Bi-directional Attention) for moment localization. The blue line representing IMF-MF exhibits superior localization accuracy, likely due to its effective integration of query context and multi-modal features. Figure 2(b) and (c) illustrate the temporal distribution of moments across the entire video corpus and individual videos, correspondingly, suggesting the model’s generalizability and applicability to diverse content. Overall, these figures demonstrate the efficacy of the proposed IMF-MF approach for accurate and robust video moment localization. The framework’s ability to effectively capture query-specific information, model relationships between query and video features, and fuse visual, audio, and textual information makes it a powerful tool for localizing relevant video segments.
Conclusion
The presented interactive moment localization with multimodal fusion (IMF-MF) model stands as a notable advancement in the field of video moment retrieval. The innovative two-phase approach, featuring dynamic feature fusion and joint representation learning, along with the incorporation of self-attention mechanisms, demonstrates superior performance across diverse datasets. IMF-MF outperforms existing state-of-the-art methods on all three benchmark datasets, achieving significant improvements in recall at top-1 and IoU = 0.5. Self-attention can be computationally expensive, especially for long videos. Future work should focus on developing more efficient and effective attention mechanisms, multimodal attention mechanisms, and models that better understand the semantic gap between natural language queries and video content. IMF-MF provides a strong foundation for future research in this area.
Disclosure
The authors have no relevant financial interests in the manuscript and no other potential conflicts of interest to disclose.
Acknowledgments
We would like to express our sincere gratitude to all those who supported and contributed to this research project. We extend our thanks to our supervisor who provided insightful comments and suggestions on our research. Their feedback and guidance helped to shape our analysis and interpretation of the results. Finally, we would like to express our appreciation to our families and friends for their encouragement and support throughout this project. Thank you all for your contributions and support.
Code, data, and materials availability
The datasets are publicly available. The codes that support the findings of this study are available from the corresponding author, upon request.